均数的抽样误差和标准误
- 格式:ppt
- 大小:616.50 KB
- 文档页数:26



1、计量资料的标准差和标准误有何区别与联系标准差和标准误都是变异指标,但它们之间有区别,也有联系。
区别: ①概念不同;标准差是描述观察值(个体值)之间的变异程度;标准误是描述样本均数的抽样误差;②用途不同;标准差与均数结合估计参考值范围,计算变异系数,计算标准误等。
标准误用于估计参数的可信区间,进行假设检验等。
③它们与样本含量的关系不同: 当样本含量n 足够大时,标准差趋向稳定;而标准误随n的增大而减小,甚至趋于0 。
联系: 标准差,标准误均为变异指标,当样本含量不变时,标准误与标准差成正比。
2、二项分布、Poission分布的应用条件二项分布的应用条件:医学领域有许多二分类记数资料都符合二项分布(传染病和遗传病除外),但应用时仍应注意考察是否满足以下应用条件:(1) 每次实验只有两类对立的结果;(2) n次事件相互独立;(3) 每次实验某类结果的发生的概率是一个常数。
Poisson分布的应用条件:医学领域中有很多稀有疾病(如肿瘤,交通事故等)资料都符合Poisson分布,但应用中仍应注意要满足以下条件:(1) 两类结果要相互对立;(2) n次试验相互独立;(3) n应很大, P应很小。
3、极差、四分位数间距、标准差、变异系数的适用范围有何异同?答:这四个指标的相同点在于均用于描述计量资料的离散程度。
其不同点为:极差可用于各种分布的资料,一般常用于描述单峰对称分布小样本资料的变异程度,或用于初步了解资料的变异程度。
若样本含量相差较大,不宜用极差来比较资料的离散程度。
四分位数间距适用于描述偏态分布资料、两端无确切值或分布不明确资料的离散程度。
标准差常用于描述对称分布,特别是正态分布或近似正态分布资料的离散程度。
变异系数适用于比较计量单位不同或均数相差悬殊的几组资料的离散程度。
4.中位数、均数、几何均数的适用条件有何异同。
(1)均数适用于描述对称分布,特别是正态分布的数值变量资料的平均水平;(2)几何均数适用于描述原始数据呈偏态分布,但经过对数变换后呈正态分布或近似正态分布的数值变量资料的平均水平;(3)中位数适用于描述呈明显偏态分布(正偏态或负偏态),或分布情况不明,或分布的末端有不确切数值的数值变量资料的平均水平。

第三章总体均数的区间估计和假设检验第一节均数的抽样误差与标准误一、标准误的意义及计算标准误是反映均数抽样误差大小的指标;同类性质的资料,标准误越小,表示样本均数与总体均数越接近,也就是抽样误差越小,说明样本均数推论总体均数的可靠性越大;反之,标准误越大,说明抽样误差越大,表示样本均数推论总体均数的可靠性越小。
数理统计已证明:标准误的大小与总体标准差成正比,而与样本含量的平方根成反比,即,当总体中各变量值都相等时,即σ=0,则抽取的各样本均数与总体均数必然相同,即抽样误差为零;而当总体中变量值间的变异度越大时,即σ越大,则抽取的各样本均数间离散度也越大,即抽样误差也越大;同时,当样本含量n越大时,则样本均数与总体均数越接近,抽样误差越小;反之,抽样误差越大。
因此可以适当增加样本例数来缩小抽样误差。
实际工作中总体标准差σ往往是不知道的,而只知道样本标准差S,所以只能用S代替,求得标准误的估计值,即二、标准误的应用▲表示抽样误差的大小,从而说明样本均数的可靠性。
(在医学文献上常用样本均数加减标准误的形式表示资料的均数及可靠程度)进行总体均数的区间估计进行均数的t检验第二节t分布一、t分布的概念如果从一个正态总体中,抽取样本含量为n的许多样本,分别计算其和,然后求出每一个t值,这样可有许多t值。
这些t值有大有小,有正有负,其频数分布是一种连续性分布,这就是统计上著名的t分布。
二、t分布曲线的特征▲特征:①t分布曲线是单峰分布,以0为中心,左右两侧对称,曲线的中间比标准正态曲线(u分布曲线)低,两侧翘得比标准曲线略高。
②当样本含量越小(严格地说是自由度v=n-1越小),t分布与u分布差别越大;当v逐渐增大时,t分布逐渐逼近u分布,当v=∞时,t分布就完全成为u分布。
所以t分布曲线的形状随v的变动而变化。
在自由度为v的t分布曲线下双侧尾部合计面积或单侧尾部面积为指定值α时,常把横轴上相应的t界值记为tα,v。



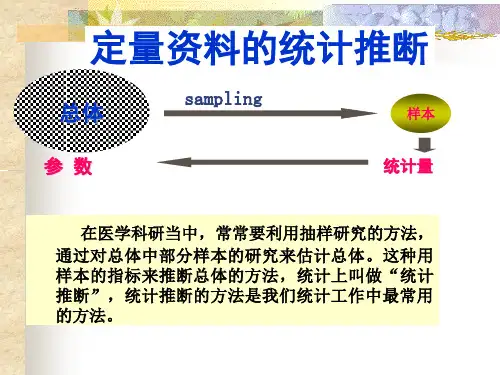
医学统计学计量资料的统计推断主要内容:标准误t 分布总体均数的估计假设检验均数的 t检验、u 检验、方差分析几个重要概念的回顾:计量资料:总体:样本:统计量:参数:统计推断:参数估计、假设检验第一节均数的抽样误差与总体均数的估计欲了解某地2000年正常成年男性血清总胆固醇的平均水平,随机抽取该地200名正常成年男性作为样本。
由于存在个体差异,抽得的样本均数不太可能恰好等于总体均数。
一、均数的抽样误差与标准误一、均数的抽样误差与标准误抽样误差:由于抽样引起的样本统计量与总体参数之间的差异X数理统计推理和中心极限定理表明:1、从正态总体N(??,??2)中,随机抽取例数为n的样本,样本均数??X 也服从正态分布;即使从偏态总体抽样,当n足够大时??X也近似正态分布。
2、从均数为??,标准差为??的正态或偏态总体中抽取例数为n的样本,样本均数??X的总体均数也为??,标准差为X标准误含义:样本均数的标准差计算:(标准误的估计值)注意: X 、S??X均为样本均数的标准误标准误意义:反映抽样误差的大小。
标准误越小,抽样误差越小,用样本均数估计总体均数的可靠性越大。
标准误用途:衡量抽样误差大小估计总体均数可信区间用于假设检验二 t 分布对正态变量样本均数??X做正态变换(u变换):X 常未知而用S??X估计,则为t变换:二、 t 分布t值的分布即为t分布t 分布的曲线:与??有关t分布与标准正态分布的比较1、二者都是单峰分布,以0为中心左右对称2、t分布的峰部较矮而尾部翘得较高说明远侧的t值个数相对较多即尾部面积(概率P值)较大。
当ν逐渐增大时,t分布逐渐逼近标准正态分布,当ν→??时,t分布完全成为标准正态分布t 界值表(附表9-1 )t??/2,??:表示自由度为??,双侧概率P为??时t的界值t分布曲线下面积的规律:中间95%的t值:- t0.05/2,?? ?? t0.05/2,??中间99%的t值:- t0.01/2,?? ?? t0.01/2,??单尾概率:一侧尾部面积双尾概率:双侧尾部面积(1) 自由度(ν)一定时,p与t成反比;(2) 概率(p)一定时,ν与t成反比;三总体均数的估计统计推断:用样本信息推论总体特征。


标准误和标准差的区别
标准偏差反映的是个体观察值的变异,标准误反映的是样本均数之间的变异(即样本均数的标准差,是描述均数抽样分布的离散程度及衡量均数抽样误差大小的尺度),标准误不是标准差。
标准差也被称为标准偏差,或者实验标准差。
简单来说,标准差是一组数据平均值分散程度的一种度量。
一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
标准误用来衡量抽样误差。
标准误越小,表明样本统计量与总体参数的值越接近,样本对总体越有代表性,用样本统计量推断总体参数的可靠度越大。
因此,标准误是统计推断可靠性的指标。
std.error:标准误差std.deviation:标准差标准误:是样本统计量的标准差,如样本均数的标准差也称为均数的标准误,它反映了样本均数间的离散程度,也反映了样本均数与总体均数的差异,说明均数抽样误差的大小。
在实际工作中,我们无法直接了解研究对象的总体情况,经常采用随机抽样的方法,取得所需要的指标,即样本指标。
样本指标与总体指标之间存在的差别,称为抽样误差,其大小通常用均数的标准误来表示。
标准差:是方差的算术平方根,是描述数据分布的离散程度的指标。
实际应用中,总体标准差一般未知,常用样本标准差来估计。
用来反映变异程度,当两组观察值在单位相同、均数相近的情况下,标准差越大,说明观察值间的变异程度越大。
即观察值围绕均数的分布较离散,均数的代表性较差。
反之,标准差越小,表明观察值间的变异较小。
标准差与标准误有何区别和联系?标准差和标准误都是变异指标,但它们之间有区别,也有联系。
区别:①概念不同;标准差是描述观察值(个体值)之间的变异程度;标准误是描述样本均数的抽样误差;②用途不同;标准差与均数结合估计参考值范围,计算变异系数,计算标准误等。
标准误用于估计参数的可信区间,进行假设检验等。
③它们与样本含量的关系不同: 当样本含量n 足够大时,标准差趋向稳定;而标准误随n 的增大而减小,甚至趋于0 。
联系: 标准差,标准误均为变异指标,当样本含量不变时,标准误与标准差成正比。
标准差是表示个体间变异大小的指标,反映了整个样本对样本平均数的离散程度,是数据精密度的衡量指标;而标准误反映样本平均数对总体平均数的变异程度,从而反映抽样误差的大小,是量度结果精密度的指标。
标准误其实就是标准差的一种,不过二者的含义有所区别:标准差计算的是一组数据偏离其均值的波动幅度,不管这组数是总体数据还是样本数据。
你看standard deviation,说的就是“偏离”,只是在翻译为中文时,失去了其英文涵义。
而标准误,衡量的是我们在用样本统计量去推断相应的总体参数(常见如均值、方差等)的时候,一种估计的精度。