GraphSearch:搜索颠覆者?
- 格式:pdf
- 大小:650.03 KB
- 文档页数:2

机器学习领域的知名人物和论文机器学习作为人工智能领域的重要分支及研究方向,不断涌现出许多杰出的知名人物以及具有重要影响力的论文。
这些人物和论文在推动机器学习技术发展和应用方面起到了重要的作用。
本文将介绍几位机器学习领域的知名人物以及他们的重要论文,带领读者了解机器学习领域的发展脉络和重要思想。
1. Andrew Ng(吴恩达)在机器学习领域,Andrew Ng无疑是一个家喻户晓的人物。
他是斯坦福大学的教授,并且曾经是谷歌的首席科学家。
他的重要贡献之一是创建了Coursera上非常著名的机器学习课程,该课程使得机器学习技术的学习变得更加便捷和可普及。
他的学术研究涉及深度学习、神经网络以及数据挖掘等领域。
他的论文《Deep Learning》被广泛引用,对深度学习领域的发展起到了重要推动作用。
2. Geoffrey Hinton(杰弗里·辛顿)Geoffrey Hinton被誉为“深度学习之父”,他是深度学习领域的杰出研究者和学者。
他的重要贡献之一是开发了BP(Backpropagation)算法,该算法为神经网络的训练提供了有效的方法。
他还提出了“Dropout”技术,通过随机丢弃一些神经元的方式来防止神经网络的过拟合问题。
他的论文《Deep Neural Networks for Acoustic Modeling in Speech Recognition》对语音识别等领域产生了巨大的影响。
3. Yoshua BengioYoshua Bengio是加拿大蒙特利尔大学教授,也是深度学习领域的重要人物之一。
他在深度学习领域的贡献源远流长。
他的论文《Learning Deep Architectures for AI》介绍了深度学习的概念和技术,并提出了一种深度置信网络(Deep Belief Networks)的训练方法。
这篇论文的发表引发了深度学习的研究和应用的热潮。
4. Ian GoodfellowIan Goodfellow是深度学习领域的年轻研究者,其主要贡献是提出了生成对抗网络(GAN)的概念。

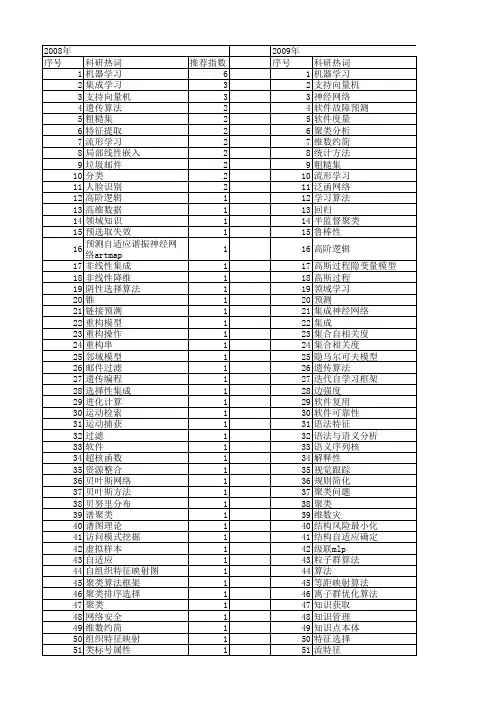
名词解释中英文对比<using_information_sources> social networks 社会网络abductive reasoning 溯因推理action recognition(行为识别)active learning(主动学习)adaptive systems 自适应系统adverse drugs reactions(药物不良反应)algorithm design and analysis(算法设计与分析) algorithm(算法)artificial intelligence 人工智能association rule(关联规则)attribute value taxonomy 属性分类规范automomous agent 自动代理automomous systems 自动系统background knowledge 背景知识bayes methods(贝叶斯方法)bayesian inference(贝叶斯推断)bayesian methods(bayes 方法)belief propagation(置信传播)better understanding 内涵理解big data 大数据big data(大数据)biological network(生物网络)biological sciences(生物科学)biomedical domain 生物医学领域biomedical research(生物医学研究)biomedical text(生物医学文本)boltzmann machine(玻尔兹曼机)bootstrapping method 拔靴法case based reasoning 实例推理causual models 因果模型citation matching (引文匹配)classification (分类)classification algorithms(分类算法)clistering algorithms 聚类算法cloud computing(云计算)cluster-based retrieval (聚类检索)clustering (聚类)clustering algorithms(聚类算法)clustering 聚类cognitive science 认知科学collaborative filtering (协同过滤)collaborative filtering(协同过滤)collabrative ontology development 联合本体开发collabrative ontology engineering 联合本体工程commonsense knowledge 常识communication networks(通讯网络)community detection(社区发现)complex data(复杂数据)complex dynamical networks(复杂动态网络)complex network(复杂网络)complex network(复杂网络)computational biology 计算生物学computational biology(计算生物学)computational complexity(计算复杂性) computational intelligence 智能计算computational modeling(计算模型)computer animation(计算机动画)computer networks(计算机网络)computer science 计算机科学concept clustering 概念聚类concept formation 概念形成concept learning 概念学习concept map 概念图concept model 概念模型concept modelling 概念模型conceptual model 概念模型conditional random field(条件随机场模型) conjunctive quries 合取查询constrained least squares (约束最小二乘) convex programming(凸规划)convolutional neural networks(卷积神经网络) customer relationship management(客户关系管理) data analysis(数据分析)data analysis(数据分析)data center(数据中心)data clustering (数据聚类)data compression(数据压缩)data envelopment analysis (数据包络分析)data fusion 数据融合data generation(数据生成)data handling(数据处理)data hierarchy (数据层次)data integration(数据整合)data integrity 数据完整性data intensive computing(数据密集型计算)data management 数据管理data management(数据管理)data management(数据管理)data miningdata mining 数据挖掘data model 数据模型data models(数据模型)data partitioning 数据划分data point(数据点)data privacy(数据隐私)data security(数据安全)data stream(数据流)data streams(数据流)data structure( 数据结构)data structure(数据结构)data visualisation(数据可视化)data visualization 数据可视化data visualization(数据可视化)data warehouse(数据仓库)data warehouses(数据仓库)data warehousing(数据仓库)database management systems(数据库管理系统)database management(数据库管理)date interlinking 日期互联date linking 日期链接Decision analysis(决策分析)decision maker 决策者decision making (决策)decision models 决策模型decision models 决策模型decision rule 决策规则decision support system 决策支持系统decision support systems (决策支持系统) decision tree(决策树)decission tree 决策树deep belief network(深度信念网络)deep learning(深度学习)defult reasoning 默认推理density estimation(密度估计)design methodology 设计方法论dimension reduction(降维) dimensionality reduction(降维)directed graph(有向图)disaster management 灾害管理disastrous event(灾难性事件)discovery(知识发现)dissimilarity (相异性)distributed databases 分布式数据库distributed databases(分布式数据库) distributed query 分布式查询document clustering (文档聚类)domain experts 领域专家domain knowledge 领域知识domain specific language 领域专用语言dynamic databases(动态数据库)dynamic logic 动态逻辑dynamic network(动态网络)dynamic system(动态系统)earth mover's distance(EMD 距离) education 教育efficient algorithm(有效算法)electric commerce 电子商务electronic health records(电子健康档案) entity disambiguation 实体消歧entity recognition 实体识别entity recognition(实体识别)entity resolution 实体解析event detection 事件检测event detection(事件检测)event extraction 事件抽取event identificaton 事件识别exhaustive indexing 完整索引expert system 专家系统expert systems(专家系统)explanation based learning 解释学习factor graph(因子图)feature extraction 特征提取feature extraction(特征提取)feature extraction(特征提取)feature selection (特征选择)feature selection 特征选择feature selection(特征选择)feature space 特征空间first order logic 一阶逻辑formal logic 形式逻辑formal meaning prepresentation 形式意义表示formal semantics 形式语义formal specification 形式描述frame based system 框为本的系统frequent itemsets(频繁项目集)frequent pattern(频繁模式)fuzzy clustering (模糊聚类)fuzzy clustering (模糊聚类)fuzzy clustering (模糊聚类)fuzzy data mining(模糊数据挖掘)fuzzy logic 模糊逻辑fuzzy set theory(模糊集合论)fuzzy set(模糊集)fuzzy sets 模糊集合fuzzy systems 模糊系统gaussian processes(高斯过程)gene expression data 基因表达数据gene expression(基因表达)generative model(生成模型)generative model(生成模型)genetic algorithm 遗传算法genome wide association study(全基因组关联分析) graph classification(图分类)graph classification(图分类)graph clustering(图聚类)graph data(图数据)graph data(图形数据)graph database 图数据库graph database(图数据库)graph mining(图挖掘)graph mining(图挖掘)graph partitioning 图划分graph query 图查询graph structure(图结构)graph theory(图论)graph theory(图论)graph theory(图论)graph theroy 图论graph visualization(图形可视化)graphical user interface 图形用户界面graphical user interfaces(图形用户界面)health care 卫生保健health care(卫生保健)heterogeneous data source 异构数据源heterogeneous data(异构数据)heterogeneous database 异构数据库heterogeneous information network(异构信息网络) heterogeneous network(异构网络)heterogenous ontology 异构本体heuristic rule 启发式规则hidden markov model(隐马尔可夫模型)hidden markov model(隐马尔可夫模型)hidden markov models(隐马尔可夫模型) hierarchical clustering (层次聚类) homogeneous network(同构网络)human centered computing 人机交互技术human computer interaction 人机交互human interaction 人机交互human robot interaction 人机交互image classification(图像分类)image clustering (图像聚类)image mining( 图像挖掘)image reconstruction(图像重建)image retrieval (图像检索)image segmentation(图像分割)inconsistent ontology 本体不一致incremental learning(增量学习)inductive learning (归纳学习)inference mechanisms 推理机制inference mechanisms(推理机制)inference rule 推理规则information cascades(信息追随)information diffusion(信息扩散)information extraction 信息提取information filtering(信息过滤)information filtering(信息过滤)information integration(信息集成)information network analysis(信息网络分析) information network mining(信息网络挖掘) information network(信息网络)information processing 信息处理information processing 信息处理information resource management (信息资源管理) information retrieval models(信息检索模型) information retrieval 信息检索information retrieval(信息检索)information retrieval(信息检索)information science 情报科学information sources 信息源information system( 信息系统)information system(信息系统)information technology(信息技术)information visualization(信息可视化)instance matching 实例匹配intelligent assistant 智能辅助intelligent systems 智能系统interaction network(交互网络)interactive visualization(交互式可视化)kernel function(核函数)kernel operator (核算子)keyword search(关键字检索)knowledege reuse 知识再利用knowledgeknowledgeknowledge acquisitionknowledge base 知识库knowledge based system 知识系统knowledge building 知识建构knowledge capture 知识获取knowledge construction 知识建构knowledge discovery(知识发现)knowledge extraction 知识提取knowledge fusion 知识融合knowledge integrationknowledge management systems 知识管理系统knowledge management 知识管理knowledge management(知识管理)knowledge model 知识模型knowledge reasoningknowledge representationknowledge representation(知识表达) knowledge sharing 知识共享knowledge storageknowledge technology 知识技术knowledge verification 知识验证language model(语言模型)language modeling approach(语言模型方法) large graph(大图)large graph(大图)learning(无监督学习)life science 生命科学linear programming(线性规划)link analysis (链接分析)link prediction(链接预测)link prediction(链接预测)link prediction(链接预测)linked data(关联数据)location based service(基于位置的服务) loclation based services(基于位置的服务) logic programming 逻辑编程logical implication 逻辑蕴涵logistic regression(logistic 回归)machine learning 机器学习machine translation(机器翻译)management system(管理系统)management( 知识管理)manifold learning(流形学习)markov chains 马尔可夫链markov processes(马尔可夫过程)matching function 匹配函数matrix decomposition(矩阵分解)matrix decomposition(矩阵分解)maximum likelihood estimation(最大似然估计)medical research(医学研究)mixture of gaussians(混合高斯模型)mobile computing(移动计算)multi agnet systems 多智能体系统multiagent systems 多智能体系统multimedia 多媒体natural language processing 自然语言处理natural language processing(自然语言处理) nearest neighbor (近邻)network analysis( 网络分析)network analysis(网络分析)network analysis(网络分析)network formation(组网)network structure(网络结构)network theory(网络理论)network topology(网络拓扑)network visualization(网络可视化)neural network(神经网络)neural networks (神经网络)neural networks(神经网络)nonlinear dynamics(非线性动力学)nonmonotonic reasoning 非单调推理nonnegative matrix factorization (非负矩阵分解) nonnegative matrix factorization(非负矩阵分解) object detection(目标检测)object oriented 面向对象object recognition(目标识别)object recognition(目标识别)online community(网络社区)online social network(在线社交网络)online social networks(在线社交网络)ontology alignment 本体映射ontology development 本体开发ontology engineering 本体工程ontology evolution 本体演化ontology extraction 本体抽取ontology interoperablity 互用性本体ontology language 本体语言ontology mapping 本体映射ontology matching 本体匹配ontology versioning 本体版本ontology 本体论open government data 政府公开数据opinion analysis(舆情分析)opinion mining(意见挖掘)opinion mining(意见挖掘)outlier detection(孤立点检测)parallel processing(并行处理)patient care(病人医疗护理)pattern classification(模式分类)pattern matching(模式匹配)pattern mining(模式挖掘)pattern recognition 模式识别pattern recognition(模式识别)pattern recognition(模式识别)personal data(个人数据)prediction algorithms(预测算法)predictive model 预测模型predictive models(预测模型)privacy preservation(隐私保护)probabilistic logic(概率逻辑)probabilistic logic(概率逻辑)probabilistic model(概率模型)probabilistic model(概率模型)probability distribution(概率分布)probability distribution(概率分布)project management(项目管理)pruning technique(修剪技术)quality management 质量管理query expansion(查询扩展)query language 查询语言query language(查询语言)query processing(查询处理)query rewrite 查询重写question answering system 问答系统random forest(随机森林)random graph(随机图)random processes(随机过程)random walk(随机游走)range query(范围查询)RDF database 资源描述框架数据库RDF query 资源描述框架查询RDF repository 资源描述框架存储库RDF storge 资源描述框架存储real time(实时)recommender system(推荐系统)recommender system(推荐系统)recommender systems 推荐系统recommender systems(推荐系统)record linkage 记录链接recurrent neural network(递归神经网络) regression(回归)reinforcement learning 强化学习reinforcement learning(强化学习)relation extraction 关系抽取relational database 关系数据库relational learning 关系学习relevance feedback (相关反馈)resource description framework 资源描述框架restricted boltzmann machines(受限玻尔兹曼机) retrieval models(检索模型)rough set theroy 粗糙集理论rough set 粗糙集rule based system 基于规则系统rule based 基于规则rule induction (规则归纳)rule learning (规则学习)rule learning 规则学习schema mapping 模式映射schema matching 模式匹配scientific domain 科学域search problems(搜索问题)semantic (web) technology 语义技术semantic analysis 语义分析semantic annotation 语义标注semantic computing 语义计算semantic integration 语义集成semantic interpretation 语义解释semantic model 语义模型semantic network 语义网络semantic relatedness 语义相关性semantic relation learning 语义关系学习semantic search 语义检索semantic similarity 语义相似度semantic similarity(语义相似度)semantic web rule language 语义网规则语言semantic web 语义网semantic web(语义网)semantic workflow 语义工作流semi supervised learning(半监督学习)sensor data(传感器数据)sensor networks(传感器网络)sentiment analysis(情感分析)sentiment analysis(情感分析)sequential pattern(序列模式)service oriented architecture 面向服务的体系结构shortest path(最短路径)similar kernel function(相似核函数)similarity measure(相似性度量)similarity relationship (相似关系)similarity search(相似搜索)similarity(相似性)situation aware 情境感知social behavior(社交行为)social influence(社会影响)social interaction(社交互动)social interaction(社交互动)social learning(社会学习)social life networks(社交生活网络)social machine 社交机器social media(社交媒体)social media(社交媒体)social media(社交媒体)social network analysis 社会网络分析social network analysis(社交网络分析)social network(社交网络)social network(社交网络)social science(社会科学)social tagging system(社交标签系统)social tagging(社交标签)social web(社交网页)sparse coding(稀疏编码)sparse matrices(稀疏矩阵)sparse representation(稀疏表示)spatial database(空间数据库)spatial reasoning 空间推理statistical analysis(统计分析)statistical model 统计模型string matching(串匹配)structural risk minimization (结构风险最小化) structured data 结构化数据subgraph matching 子图匹配subspace clustering(子空间聚类)supervised learning( 有support vector machine 支持向量机support vector machines(支持向量机)system dynamics(系统动力学)tag recommendation(标签推荐)taxonmy induction 感应规范temporal logic 时态逻辑temporal reasoning 时序推理text analysis(文本分析)text anaylsis 文本分析text classification (文本分类)text data(文本数据)text mining technique(文本挖掘技术)text mining 文本挖掘text mining(文本挖掘)text summarization(文本摘要)thesaurus alignment 同义对齐time frequency analysis(时频分析)time series analysis( 时time series data(时间序列数据)time series data(时间序列数据)time series(时间序列)topic model(主题模型)topic modeling(主题模型)transfer learning 迁移学习triple store 三元组存储uncertainty reasoning 不精确推理undirected graph(无向图)unified modeling language 统一建模语言unsupervisedupper bound(上界)user behavior(用户行为)user generated content(用户生成内容)utility mining(效用挖掘)visual analytics(可视化分析)visual content(视觉内容)visual representation(视觉表征)visualisation(可视化)visualization technique(可视化技术) visualization tool(可视化工具)web 2.0(网络2.0)web forum(web 论坛)web mining(网络挖掘)web of data 数据网web ontology lanuage 网络本体语言web pages(web 页面)web resource 网络资源web science 万维科学web search (网络检索)web usage mining(web 使用挖掘)wireless networks 无线网络world knowledge 世界知识world wide web 万维网world wide web(万维网)xml database 可扩展标志语言数据库附录 2 Data Mining 知识图谱(共包含二级节点15 个,三级节点93 个)间序列分析)监督学习)领域 二级分类 三级分类。


谷歌知识图谱功能带来的是什么?果壳包果核 2012-05-29 17:18:59近日,谷歌正式推出被称为知识图谱的新搜索功能。
只要在谷歌搜索相关信息,在搜索结果的右侧就会多 出一个栏目显示该词条的相关信息,这些信息来自维基百科与其他提供信息服务的网站。
这给用户提供了 便捷,但可能也会造成网络信息的流失。
近日,谷歌(暂限于英文版谷歌)正式推出被称为知识图谱(Knowledge Graph)的新搜索 功能。
只要在谷歌搜索引擎里键入单词或短语, 在传统搜索结果的右侧就会多出一个栏目直 接显示该词条的相关信息, 这些信息来自维基百科与其他提供信息服务的网站。
与之前的浏 览方式相比, 用户免去了自己访问信息出处网站这一过程——谷歌直接把信息呈现在搜索页 面中。
站在用户的角度, 谷歌的创新的确提供了更加快捷的搜索体验——只需轻轻一敲, 信息尽在 眼前。
不过需要点击量的网站们听到这个消息肯定开心不起来了。
知识图谱的出现给他们的 生存带来了威胁,甚至对现存互联网产业的商业模式造成了冲击。
可以预测,知识图谱将导 致一系列网站关门,而网站的减少又将造成网络信息的流失。
信息是网络的基石,谷歌此举 究竟会带来什么呢?技术进步知识图谱仅作为一项新功能,就已经收录了约 5 亿个词条,信息量也已达到 35 亿条,而且 这个数据还在不断地膨胀。
对于一个语义搜索引擎而言它的确足够强大, 老牌语义搜索引擎 维基百科只有 3000 万个页面,相比于谷歌足足少了一位数。
功能推出后的谷歌搜索搜索结 果分为左右两个部分,左侧是传统的搜索结果,右侧是知识图谱功能提供的语义信息。
谷歌搜索布朗克斯动物园,在右侧会出现动物园的相关信息 上图为对美国布朗克斯动物园(Bronx Zoo)的搜索结果。
在搜索结果新增的右侧,谷歌给 出了一张布朗克斯动物园的地理位置图, 地图下方是对动物园的基本描述。
描述的右下角标 注了维基百科的链接, 表示此条信息选取自维基百科。

国内外主要大模型梳理1. ResNet(深度残差网络)- 由微软提出,是目前最流行的深度学习模型之一,包含几十层的网络结构,并使用残差块(Residual Blocks)来降低梯度消失和梯度爆炸问题。
在ImageNet分类任务中曾创下最高的精确度记录。
2. Transformer(转换器)- 由谷歌提出,主要应用于自然语言处理任务中,是一个基于注意力机制(Self-Attention)的模型。
它在解决长序列处理、短语或句子表示等问题方面具有很好的效果,并被广泛应用于机器翻译、语言模型等领域。
3. GPT(生成式预训练模型)- 由OpenAI提出,也是一种自然语言处理模型。
它采用预训练+微调(Pre-training + Fine-tuning)的方式,先在大规模文本数据上进行自监督学习,再在特定任务上进行微调,取得了很好的效果。
GPT系列模型已成为自然语言处理领域的重要研究方向。
4. BERT(双向编码器表示的Transformer)- 由谷歌提出,也是一种预训练模型。
它采用了双向编码器(Bidirectional Encoder)和Transformer结构,并在多个自然语言处理任务上取得了最新的最佳性能。
BERT的出现使得自然语言处理领域的相关任务大幅提升。
5. YOLO(You Only Look Once)- 由美国华盛顿大学提出,是一种实时目标检测算法。
它采用了单个卷积神经网络来同时预测目标的类别和位置,速度非常快并且效果不错。
YOLO系列模型已经应用于无人车、智能交通、智能安防等领域。
6. Faster R-CNN(Region-based Convolutional Neural Network)- 是目前最成功的目标检测模型之一,由谷歌提出。
它采用了两个子网络:区域提议网络(Region Proposal Network)和目标检测网络(Detection Network),能够高效准确地检测目标物体的位置和类别。

稀疏向量检索一、引言在大数据时代,稀疏向量检索已成为一个重要的研究领域。
稀疏向量检索是指在大型数据集中gao效地查找与给定稀疏向量相似的向量。
这种技术在推荐系统、信息检索、机器学习等领域有着广泛的应用。
本文将探讨稀疏向量检索的方法、应用和面临的挑战。
二、稀疏向量检索的方法1. 近似最近邻搜索(Approximate Nearest Neighbor Search,ANN):这种方法通过计算向量的近似距离来找到相似的向量。
常见的近似算法包括基于哈希的方法(如LSH)和基于树的方法(如Annoy)。
2. 基于密度的聚类(Density-Based Clustering):通过将高维数据聚类成多个簇,然后在每个簇内查找与给定向量相似的向量。
这种方法对于处理非线性数据和异常值具有较好的效果。
3. 基于核的方法(Kernel-Based Methods):利用核函数将高维数据映射到低维空间,然后在低维空间中计算向量间的相似度。
这种方法在处理高维数据时具有较好的性能。
三、稀疏向量检索的应用1. 推荐系统:稀疏向量检索技术可以用于推荐系统中,根据用户的历史行为和偏好,为其推荐相似的内容或产品。
2. 信息检索:在搜索引擎中,稀疏向量检索技术可以用于快速查找与查询相关的文档或网页。
3. 机器学习:稀疏向量检索技术可以用于特征降维、异常值检测等机器学习任务中,提高算法的效率和准确性。
四、面临的挑战1. 高维数据的处理:高维数据的处理是稀疏向量检索面临的一个重要挑战。
高维空间中的数据通常具有高度稀疏的特点,如何有效地表示和处理这些数据是一个难题。
2. 数据规模和效率的平衡:在大数据环境下,稀疏向量检索需要在大规模数据集中快速找到相似的向量。
如何在保证效率的同时处理大规模数据集是一个挑战。
3. 语义相似度的计算:在某些应用中,我们需要计算向量间的语义相似度,而不仅仅是基于距离的相似度。
如何有效地计算语义相似度是一个具有挑战性的问题。

Google 构建面向未来的搜索引擎什么是完美的搜索引擎?拉里·佩奇(Larry Page)曾经这样形容:它能够理解你的真正意图,并为你提供最想要的答案。
这与我曾经梦想过的计算机非常像。
我在印度长大,小时候经常守在家里的黑白电视机旁,每一集《星际迷航》都不愿错过,在我的想象中,未来会有一台“星际迷航”式的计算机:它能够即刻回答我可能会提出的任何问题。
今天,我们离这个梦想又近了一些,而且比我在自己工作生涯中曾经预想过的还要近——以下是我们目前在提升搜索智慧方面取得的一些进展:理解现实世界今年五月份,我们推出了Knowledge Graph; 这是Google的一个数据库,里面包含超过5亿条关于现实世界中人物、地点、事实的信息,以及超过35亿条不同事物的属性和它们之间的关系。
用户对这个功能的反馈很好,所以我们想要把这项功能呈现给美国以外的用户。
从今天开始,您将可以在世界上每一个英语国家使用Knowledge Graph。
如果你在澳大利亚搜索[chiefs],会得到关于这支橄榄球队的所有信息——包括其队员、战绩以及历史。
此外,当您的搜索请求可能具有不同含义时,我们还将使用这一功能,帮助您更迅速地找到准确结果。
例如,当您搜索[rio]时,说明您感兴趣的可能是巴西的这座著名城市,或者是最近上映的那部动画电影,又或者是拉斯维加斯的一家叫“Rio”的赌场。
现在,有了Knowledge Graph,当您键入搜索内容时,我们可以在搜索框中给您提供下面这些关于现实世界实体的不同建议:最后,您所提问题的最佳答案,不一定是某个单独实体,有时候会是一个互相联系的事实的列表或组合。
自动从网络上获取这些列表是一项相当具有挑战性的工作。
但我们现在将开始接受这一挑战。
因此,现在当您搜索[california lighthouses](加州灯塔)、[hurricanes in 2008](2008年飓风)或[famous female astronomers](著名女天文学家)时,我们将在页面顶端向您显示关于这些事实的一个列表。

A Survey of Clustering Data Mining TechniquesPavel BerkhinYahoo!,Inc.pberkhin@Summary.Clustering is the division of data into groups of similar objects.It dis-regards some details in exchange for data simplifirmally,clustering can be viewed as data modeling concisely summarizing the data,and,therefore,it re-lates to many disciplines from statistics to numerical analysis.Clustering plays an important role in a broad range of applications,from information retrieval to CRM. Such applications usually deal with large datasets and many attributes.Exploration of such data is a subject of data mining.This survey concentrates on clustering algorithms from a data mining perspective.1IntroductionThe goal of this survey is to provide a comprehensive review of different clus-tering techniques in data mining.Clustering is a division of data into groups of similar objects.Each group,called a cluster,consists of objects that are similar to one another and dissimilar to objects of other groups.When repre-senting data with fewer clusters necessarily loses certainfine details(akin to lossy data compression),but achieves simplification.It represents many data objects by few clusters,and hence,it models data by its clusters.Data mod-eling puts clustering in a historical perspective rooted in mathematics,sta-tistics,and numerical analysis.From a machine learning perspective clusters correspond to hidden patterns,the search for clusters is unsupervised learn-ing,and the resulting system represents a data concept.Therefore,clustering is unsupervised learning of a hidden data concept.Data mining applications add to a general picture three complications:(a)large databases,(b)many attributes,(c)attributes of different types.This imposes on a data analysis se-vere computational requirements.Data mining applications include scientific data exploration,information retrieval,text mining,spatial databases,Web analysis,CRM,marketing,medical diagnostics,computational biology,and many others.They present real challenges to classic clustering algorithms. These challenges led to the emergence of powerful broadly applicable data2Pavel Berkhinmining clustering methods developed on the foundation of classic techniques.They are subject of this survey.1.1NotationsTo fix the context and clarify terminology,consider a dataset X consisting of data points (i.e.,objects ,instances ,cases ,patterns ,tuples ,transactions )x i =(x i 1,···,x id ),i =1:N ,in attribute space A ,where each component x il ∈A l ,l =1:d ,is a numerical or nominal categorical attribute (i.e.,feature ,variable ,dimension ,component ,field ).For a discussion of attribute data types see [106].Such point-by-attribute data format conceptually corresponds to a N ×d matrix and is used by a majority of algorithms reviewed below.However,data of other formats,such as variable length sequences and heterogeneous data,are not uncommon.The simplest subset in an attribute space is a direct Cartesian product of sub-ranges C = C l ⊂A ,C l ⊂A l ,called a segment (i.e.,cube ,cell ,region ).A unit is an elementary segment whose sub-ranges consist of a single category value,or of a small numerical bin.Describing the numbers of data points per every unit represents an extreme case of clustering,a histogram .This is a very expensive representation,and not a very revealing er driven segmentation is another commonly used practice in data exploration that utilizes expert knowledge regarding the importance of certain sub-domains.Unlike segmentation,clustering is assumed to be automatic,and so it is a machine learning technique.The ultimate goal of clustering is to assign points to a finite system of k subsets (clusters).Usually (but not always)subsets do not intersect,and their union is equal to a full dataset with the possible exception of outliersX =C 1 ··· C k C outliers ,C i C j =0,i =j.1.2Clustering Bibliography at GlanceGeneral references regarding clustering include [110],[205],[116],[131],[63],[72],[165],[119],[75],[141],[107],[91].A very good introduction to contem-porary data mining clustering techniques can be found in the textbook [106].There is a close relationship between clustering and many other fields.Clustering has always been used in statistics [10]and science [158].The clas-sic introduction into pattern recognition framework is given in [64].Typical applications include speech and character recognition.Machine learning clus-tering algorithms were applied to image segmentation and computer vision[117].For statistical approaches to pattern recognition see [56]and [85].Clus-tering can be viewed as a density estimation problem.This is the subject of traditional multivariate statistical estimation [197].Clustering is also widelyA Survey of Clustering Data Mining Techniques3 used for data compression in image processing,which is also known as vec-tor quantization[89].Datafitting in numerical analysis provides still another venue in data modeling[53].This survey’s emphasis is on clustering in data mining.Such clustering is characterized by large datasets with many attributes of different types. Though we do not even try to review particular applications,many important ideas are related to the specificfields.Clustering in data mining was brought to life by intense developments in information retrieval and text mining[52], [206],[58],spatial database applications,for example,GIS or astronomical data,[223],[189],[68],sequence and heterogeneous data analysis[43],Web applications[48],[111],[81],DNA analysis in computational biology[23],and many others.They resulted in a large amount of application-specific devel-opments,but also in some general techniques.These techniques and classic clustering algorithms that relate to them are surveyed below.1.3Plan of Further PresentationClassification of clustering algorithms is neither straightforward,nor canoni-cal.In reality,different classes of algorithms overlap.Traditionally clustering techniques are broadly divided in hierarchical and partitioning.Hierarchical clustering is further subdivided into agglomerative and divisive.The basics of hierarchical clustering include Lance-Williams formula,idea of conceptual clustering,now classic algorithms SLINK,COBWEB,as well as newer algo-rithms CURE and CHAMELEON.We survey these algorithms in the section Hierarchical Clustering.While hierarchical algorithms gradually(dis)assemble points into clusters (as crystals grow),partitioning algorithms learn clusters directly.In doing so they try to discover clusters either by iteratively relocating points between subsets,or by identifying areas heavily populated with data.Algorithms of thefirst kind are called Partitioning Relocation Clustering. They are further classified into probabilistic clustering(EM framework,al-gorithms SNOB,AUTOCLASS,MCLUST),k-medoids methods(algorithms PAM,CLARA,CLARANS,and its extension),and k-means methods(differ-ent schemes,initialization,optimization,harmonic means,extensions).Such methods concentrate on how well pointsfit into their clusters and tend to build clusters of proper convex shapes.Partitioning algorithms of the second type are surveyed in the section Density-Based Partitioning.They attempt to discover dense connected com-ponents of data,which areflexible in terms of their shape.Density-based connectivity is used in the algorithms DBSCAN,OPTICS,DBCLASD,while the algorithm DENCLUE exploits space density functions.These algorithms are less sensitive to outliers and can discover clusters of irregular shape.They usually work with low-dimensional numerical data,known as spatial data. Spatial objects could include not only points,but also geometrically extended objects(algorithm GDBSCAN).4Pavel BerkhinSome algorithms work with data indirectly by constructing summaries of data over the attribute space subsets.They perform space segmentation and then aggregate appropriate segments.We discuss them in the section Grid-Based Methods.They frequently use hierarchical agglomeration as one phase of processing.Algorithms BANG,STING,WaveCluster,and FC are discussed in this section.Grid-based methods are fast and handle outliers well.Grid-based methodology is also used as an intermediate step in many other algorithms (for example,CLIQUE,MAFIA).Categorical data is intimately connected with transactional databases.The concept of a similarity alone is not sufficient for clustering such data.The idea of categorical data co-occurrence comes to the rescue.The algorithms ROCK,SNN,and CACTUS are surveyed in the section Co-Occurrence of Categorical Data.The situation gets even more aggravated with the growth of the number of items involved.To help with this problem the effort is shifted from data clustering to pre-clustering of items or categorical attribute values. Development based on hyper-graph partitioning and the algorithm STIRR exemplify this approach.Many other clustering techniques are developed,primarily in machine learning,that either have theoretical significance,are used traditionally out-side the data mining community,or do notfit in previously outlined categories. The boundary is blurred.In the section Other Developments we discuss the emerging direction of constraint-based clustering,the important researchfield of graph partitioning,and the relationship of clustering to supervised learning, gradient descent,artificial neural networks,and evolutionary methods.Data Mining primarily works with large databases.Clustering large datasets presents scalability problems reviewed in the section Scalability and VLDB Extensions.Here we talk about algorithms like DIGNET,about BIRCH and other data squashing techniques,and about Hoffding or Chernoffbounds.Another trait of real-life data is high dimensionality.Corresponding de-velopments are surveyed in the section Clustering High Dimensional Data. The trouble comes from a decrease in metric separation when the dimension grows.One approach to dimensionality reduction uses attributes transforma-tions(DFT,PCA,wavelets).Another way to address the problem is through subspace clustering(algorithms CLIQUE,MAFIA,ENCLUS,OPTIGRID, PROCLUS,ORCLUS).Still another approach clusters attributes in groups and uses their derived proxies to cluster objects.This double clustering is known as co-clustering.Issues common to different clustering methods are overviewed in the sec-tion General Algorithmic Issues.We talk about assessment of results,de-termination of appropriate number of clusters to build,data preprocessing, proximity measures,and handling of outliers.For reader’s convenience we provide a classification of clustering algorithms closely followed by this survey:•Hierarchical MethodsA Survey of Clustering Data Mining Techniques5Agglomerative AlgorithmsDivisive Algorithms•Partitioning Relocation MethodsProbabilistic ClusteringK-medoids MethodsK-means Methods•Density-Based Partitioning MethodsDensity-Based Connectivity ClusteringDensity Functions Clustering•Grid-Based Methods•Methods Based on Co-Occurrence of Categorical Data•Other Clustering TechniquesConstraint-Based ClusteringGraph PartitioningClustering Algorithms and Supervised LearningClustering Algorithms in Machine Learning•Scalable Clustering Algorithms•Algorithms For High Dimensional DataSubspace ClusteringCo-Clustering Techniques1.4Important IssuesThe properties of clustering algorithms we are primarily concerned with in data mining include:•Type of attributes algorithm can handle•Scalability to large datasets•Ability to work with high dimensional data•Ability tofind clusters of irregular shape•Handling outliers•Time complexity(we frequently simply use the term complexity)•Data order dependency•Labeling or assignment(hard or strict vs.soft or fuzzy)•Reliance on a priori knowledge and user defined parameters •Interpretability of resultsRealistically,with every algorithm we discuss only some of these properties. The list is in no way exhaustive.For example,as appropriate,we also discuss algorithms ability to work in pre-defined memory buffer,to restart,and to provide an intermediate solution.6Pavel Berkhin2Hierarchical ClusteringHierarchical clustering builds a cluster hierarchy or a tree of clusters,also known as a dendrogram.Every cluster node contains child clusters;sibling clusters partition the points covered by their common parent.Such an ap-proach allows exploring data on different levels of granularity.Hierarchical clustering methods are categorized into agglomerative(bottom-up)and divi-sive(top-down)[116],[131].An agglomerative clustering starts with one-point (singleton)clusters and recursively merges two or more of the most similar clusters.A divisive clustering starts with a single cluster containing all data points and recursively splits the most appropriate cluster.The process contin-ues until a stopping criterion(frequently,the requested number k of clusters) is achieved.Advantages of hierarchical clustering include:•Flexibility regarding the level of granularity•Ease of handling any form of similarity or distance•Applicability to any attribute typesDisadvantages of hierarchical clustering are related to:•Vagueness of termination criteria•Most hierarchical algorithms do not revisit(intermediate)clusters once constructed.The classic approaches to hierarchical clustering are presented in the sub-section Linkage Metrics.Hierarchical clustering based on linkage metrics re-sults in clusters of proper(convex)shapes.Active contemporary efforts to build cluster systems that incorporate our intuitive concept of clusters as con-nected components of arbitrary shape,including the algorithms CURE and CHAMELEON,are surveyed in the subsection Hierarchical Clusters of Arbi-trary Shapes.Divisive techniques based on binary taxonomies are presented in the subsection Binary Divisive Partitioning.The subsection Other Devel-opments contains information related to incremental learning,model-based clustering,and cluster refinement.In hierarchical clustering our regular point-by-attribute data representa-tion frequently is of secondary importance.Instead,hierarchical clustering frequently deals with the N×N matrix of distances(dissimilarities)or sim-ilarities between training points sometimes called a connectivity matrix.So-called linkage metrics are constructed from elements of this matrix.The re-quirement of keeping a connectivity matrix in memory is unrealistic.To relax this limitation different techniques are used to sparsify(introduce zeros into) the connectivity matrix.This can be done by omitting entries smaller than a certain threshold,by using only a certain subset of data representatives,or by keeping with each point only a certain number of its nearest neighbors(for nearest neighbor chains see[177]).Notice that the way we process the original (dis)similarity matrix and construct a linkage metric reflects our a priori ideas about the data model.A Survey of Clustering Data Mining Techniques7With the(sparsified)connectivity matrix we can associate the weighted connectivity graph G(X,E)whose vertices X are data points,and edges E and their weights are defined by the connectivity matrix.This establishes a connection between hierarchical clustering and graph partitioning.One of the most striking developments in hierarchical clustering is the algorithm BIRCH.It is discussed in the section Scalable VLDB Extensions.Hierarchical clustering initializes a cluster system as a set of singleton clusters(agglomerative case)or a single cluster of all points(divisive case) and proceeds iteratively merging or splitting the most appropriate cluster(s) until the stopping criterion is achieved.The appropriateness of a cluster(s) for merging or splitting depends on the(dis)similarity of cluster(s)elements. This reflects a general presumption that clusters consist of similar points.An important example of dissimilarity between two points is the distance between them.To merge or split subsets of points rather than individual points,the dis-tance between individual points has to be generalized to the distance between subsets.Such a derived proximity measure is called a linkage metric.The type of a linkage metric significantly affects hierarchical algorithms,because it re-flects a particular concept of closeness and connectivity.Major inter-cluster linkage metrics[171],[177]include single link,average link,and complete link. The underlying dissimilarity measure(usually,distance)is computed for every pair of nodes with one node in thefirst set and another node in the second set.A specific operation such as minimum(single link),average(average link),or maximum(complete link)is applied to pair-wise dissimilarity measures:d(C1,C2)=Op{d(x,y),x∈C1,y∈C2}Early examples include the algorithm SLINK[199],which implements single link(Op=min),Voorhees’method[215],which implements average link (Op=Avr),and the algorithm CLINK[55],which implements complete link (Op=max).It is related to the problem offinding the Euclidean minimal spanning tree[224]and has O(N2)complexity.The methods using inter-cluster distances defined in terms of pairs of nodes(one in each respective cluster)are called graph methods.They do not use any cluster representation other than a set of points.This name naturally relates to the connectivity graph G(X,E)introduced above,because every data partition corresponds to a graph partition.Such methods can be augmented by so-called geometric methods in which a cluster is represented by its central point.Under the assumption of numerical attributes,the center point is defined as a centroid or an average of two cluster centroids subject to agglomeration.It results in centroid,median,and minimum variance linkage metrics.All of the above linkage metrics can be derived from the Lance-Williams updating formula[145],d(C iC j,C k)=a(i)d(C i,C k)+a(j)d(C j,C k)+b·d(C i,C j)+c|d(C i,C k)−d(C j,C k)|.8Pavel BerkhinHere a,b,c are coefficients corresponding to a particular linkage.This formula expresses a linkage metric between a union of the two clusters and the third cluster in terms of underlying nodes.The Lance-Williams formula is crucial to making the dis(similarity)computations feasible.Surveys of linkage metrics can be found in [170][54].When distance is used as a base measure,linkage metrics capture inter-cluster proximity.However,a similarity-based view that results in intra-cluster connectivity considerations is also used,for example,in the original average link agglomeration (Group-Average Method)[116].Under reasonable assumptions,such as reducibility condition (graph meth-ods satisfy this condition),linkage metrics methods suffer from O N 2 time complexity [177].Despite the unfavorable time complexity,these algorithms are widely used.As an example,the algorithm AGNES (AGlomerative NESt-ing)[131]is used in S-Plus.When the connectivity N ×N matrix is sparsified,graph methods directly dealing with the connectivity graph G can be used.In particular,hierarchical divisive MST (Minimum Spanning Tree)algorithm is based on graph parti-tioning [116].2.1Hierarchical Clusters of Arbitrary ShapesFor spatial data,linkage metrics based on Euclidean distance naturally gener-ate clusters of convex shapes.Meanwhile,visual inspection of spatial images frequently discovers clusters with curvy appearance.Guha et al.[99]introduced the hierarchical agglomerative clustering algo-rithm CURE (Clustering Using REpresentatives).This algorithm has a num-ber of novel features of general importance.It takes special steps to handle outliers and to provide labeling in assignment stage.It also uses two techniques to achieve scalability:data sampling (section 8),and data partitioning.CURE creates p partitions,so that fine granularity clusters are constructed in parti-tions first.A major feature of CURE is that it represents a cluster by a fixed number,c ,of points scattered around it.The distance between two clusters used in the agglomerative process is the minimum of distances between two scattered representatives.Therefore,CURE takes a middle approach between the graph (all-points)methods and the geometric (one centroid)methods.Single and average link closeness are replaced by representatives’aggregate closeness.Selecting representatives scattered around a cluster makes it pos-sible to cover non-spherical shapes.As before,agglomeration continues until the requested number k of clusters is achieved.CURE employs one additional trick:originally selected scattered points are shrunk to the geometric centroid of the cluster by a user-specified factor α.Shrinkage suppresses the affect of outliers;outliers happen to be located further from the cluster centroid than the other scattered representatives.CURE is capable of finding clusters of different shapes and sizes,and it is insensitive to outliers.Because CURE uses sampling,estimation of its complexity is not straightforward.For low-dimensional data authors provide a complexity estimate of O (N 2sample )definedA Survey of Clustering Data Mining Techniques9 in terms of a sample size.More exact bounds depend on input parameters: shrink factorα,number of representative points c,number of partitions p,and a sample size.Figure1(a)illustrates agglomeration in CURE.Three clusters, each with three representatives,are shown before and after the merge and shrinkage.Two closest representatives are connected.While the algorithm CURE works with numerical attributes(particularly low dimensional spatial data),the algorithm ROCK developed by the same researchers[100]targets hierarchical agglomerative clustering for categorical attributes.It is reviewed in the section Co-Occurrence of Categorical Data.The hierarchical agglomerative algorithm CHAMELEON[127]uses the connectivity graph G corresponding to the K-nearest neighbor model spar-sification of the connectivity matrix:the edges of K most similar points to any given point are preserved,the rest are pruned.CHAMELEON has two stages.In thefirst stage small tight clusters are built to ignite the second stage.This involves a graph partitioning[129].In the second stage agglomer-ative process is performed.It utilizes measures of relative inter-connectivity RI(C i,C j)and relative closeness RC(C i,C j);both are locally normalized by internal interconnectivity and closeness of clusters C i and C j.In this sense the modeling is dynamic:it depends on data locally.Normalization involves certain non-obvious graph operations[129].CHAMELEON relies heavily on graph partitioning implemented in the library HMETIS(see the section6). Agglomerative process depends on user provided thresholds.A decision to merge is made based on the combinationRI(C i,C j)·RC(C i,C j)αof local measures.The algorithm does not depend on assumptions about the data model.It has been proven tofind clusters of different shapes,densities, and sizes in2D(two-dimensional)space.It has a complexity of O(Nm+ Nlog(N)+m2log(m),where m is the number of sub-clusters built during the first initialization phase.Figure1(b)(analogous to the one in[127])clarifies the difference with CURE.It presents a choice of four clusters(a)-(d)for a merge.While CURE would merge clusters(a)and(b),CHAMELEON makes intuitively better choice of merging(c)and(d).2.2Binary Divisive PartitioningIn linguistics,information retrieval,and document clustering applications bi-nary taxonomies are very useful.Linear algebra methods,based on singular value decomposition(SVD)are used for this purpose in collaborativefilter-ing and information retrieval[26].Application of SVD to hierarchical divisive clustering of document collections resulted in the PDDP(Principal Direction Divisive Partitioning)algorithm[31].In our notations,object x is a docu-ment,l th attribute corresponds to a word(index term),and a matrix X entry x il is a measure(e.g.TF-IDF)of l-term frequency in a document x.PDDP constructs SVD decomposition of the matrix10Pavel Berkhin(a)Algorithm CURE (b)Algorithm CHAMELEONFig.1.Agglomeration in Clusters of Arbitrary Shapes(X −e ¯x ),¯x =1Ni =1:N x i ,e =(1,...,1)T .This algorithm bisects data in Euclidean space by a hyperplane that passes through data centroid orthogonal to the eigenvector with the largest singular value.A k -way split is also possible if the k largest singular values are consid-ered.Bisecting is a good way to categorize documents and it yields a binary tree.When k -means (2-means)is used for bisecting,the dividing hyperplane is orthogonal to the line connecting the two centroids.The comparative study of SVD vs.k -means approaches [191]can be used for further references.Hier-archical divisive bisecting k -means was proven [206]to be preferable to PDDP for document clustering.While PDDP or 2-means are concerned with how to split a cluster,the problem of which cluster to split is also important.Simple strategies are:(1)split each node at a given level,(2)split the cluster with highest cardinality,and,(3)split the cluster with the largest intra-cluster variance.All three strategies have problems.For a more detailed analysis of this subject and better strategies,see [192].2.3Other DevelopmentsOne of early agglomerative clustering algorithms,Ward’s method [222],is based not on linkage metric,but on an objective function used in k -means.The merger decision is viewed in terms of its effect on the objective function.The popular hierarchical clustering algorithm for categorical data COB-WEB [77]has two very important qualities.First,it utilizes incremental learn-ing.Instead of following divisive or agglomerative approaches,it dynamically builds a dendrogram by processing one data point at a time.Second,COB-WEB is an example of conceptual or model-based learning.This means that each cluster is considered as a model that can be described intrinsically,rather than as a collection of points assigned to it.COBWEB’s dendrogram is calleda classification tree.Each tree node(cluster)C is associated with the condi-tional probabilities for categorical attribute-values pairs,P r(x l=νlp|C),l=1:d,p=1:|A l|.This easily can be recognized as a C-specific Na¨ıve Bayes classifier.During the classification tree construction,every new point is descended along the tree and the tree is potentially updated(by an insert/split/merge/create op-eration).Decisions are based on the category utility[49]CU{C1,...,C k}=1j=1:kCU(C j)CU(C j)=l,p(P r(x l=νlp|C j)2−(P r(x l=νlp)2.Category utility is similar to the GINI index.It rewards clusters C j for in-creases in predictability of the categorical attribute valuesνlp.Being incre-mental,COBWEB is fast with a complexity of O(tN),though it depends non-linearly on tree characteristics packed into a constant t.There is a similar incremental hierarchical algorithm for all numerical attributes called CLAS-SIT[88].CLASSIT associates normal distributions with cluster nodes.Both algorithms can result in highly unbalanced trees.Chiu et al.[47]proposed another conceptual or model-based approach to hierarchical clustering.This development contains several different use-ful features,such as the extension of scalability preprocessing to categori-cal attributes,outliers handling,and a two-step strategy for monitoring the number of clusters including BIC(defined below).A model associated with a cluster covers both numerical and categorical attributes and constitutes a blend of Gaussian and multinomial models.Denote corresponding multivari-ate parameters byθ.With every cluster C we associate a logarithm of its (classification)likelihoodl C=x i∈Clog(p(x i|θ))The algorithm uses maximum likelihood estimates for parameterθ.The dis-tance between two clusters is defined(instead of linkage metric)as a decrease in log-likelihoodd(C1,C2)=l C1+l C2−l C1∪C2caused by merging of the two clusters under consideration.The agglomerative process continues until the stopping criterion is satisfied.As such,determina-tion of the best k is automatic.This algorithm has the commercial implemen-tation(in SPSS Clementine).The complexity of the algorithm is linear in N for the summarization phase.Traditional hierarchical clustering does not change points membership in once assigned clusters due to its greedy approach:after a merge or a split is selected it is not refined.Though COBWEB does reconsider its decisions,its。

AI训练中的超参数搜索自动化与最佳实践引言:在人工智能领域,超参数搜索是一项重要任务,它对于模型的性能和效果具有决定性的影响。
然而,由于超参数搜索空间庞大,传统的手动搜索方法往往是耗时且低效的。
因此,自动化超参数搜索成为了研究和实践中的一个热门话题。
一、超参数与其搜索的重要性超参数是指在机器学习算法中需要手动设置的参数,与模型的学习无关,通常用来控制学习算法的行为和性能。
典型的超参数包括学习率、正则化参数、隐藏层节点数等。
不同的超参数组合可以导致完全不同的模型效果。
由于超参数搜索空间庞大,对于大型深度神经网络,超参数数量可达数十个甚至上百个。
手动搜索超参数往往需要经验和时间,并且结果往往难以保证最佳性能。
自动化超参数搜索的目标是通过算法或技术手段自动地在给定搜索空间内寻找到最佳的超参数组合,以提升模型性能。
二、超参数搜索方法与技术1.网格搜索(Grid Search)最基本和直观的超参数搜索方法是网格搜索,即穷举搜索给定的超参数组合,并通过交叉验证方法评估模型效果。
该方法的优点是简单易懂,适用于超参数较少的情况。
然而,对于超参数空间较大的问题,网格搜索的计算量会非常大,低效且耗时。
2.随机搜索(Random Search)随机搜索通过在给定超参数范围内随机采样并进行评估,以获得最佳的超参数组合。
随机搜索相对于网格搜索而言,具有更好的效率和扩展性。
尤其是对于超参数之间的依赖关系不明确的情况下,随机搜索往往能够找到更好的超参数组合。
3.贝叶斯优化(Bayesian Optimization)贝叶斯优化利用贝叶斯统计理论和高斯过程回归等方法,在每次选择超参数进行评估后,根据得到的结果更新先验分布,从而引导下一次选择更优的超参数组合。
相比于传统的网格搜索和随机搜索方法,贝叶斯优化能够更快地收敛到最佳超参数组合,并且能够应用于连续型和离散型超参数搜索。
4.遗传算法(Genetic Algorithms)遗传算法是一种通过模拟生物进化机制进行全局优化的方法,通过选择、交叉和变异等操作,生成新的超参数组合,并根据评估结果进行迭代优化。
高级检索增强生成技术全面指南全文共四篇示例,供读者参考第一篇示例:高级检索增强生成技术全面指南随着互联网的发展,信息的获取变得越来越容易,但由此带来的信息超载也成为了一个问题。
在这个信息时代,如何从海量的信息中准确快速地找到所需的信息变得愈发重要。
高级检索增强生成技术应运而生,为用户提供了更智能、更个性化的信息检索体验。
本文将全面介绍高级检索增强生成技术的原理、应用及未来发展趋势。
高级检索增强生成技术是一种结合了检索技术和生成技术的新型信息检索方法。
其基本原理是通过智能算法对用户所提供的查询条件进行分析和理解,从而精准地定位用户需求,再通过生成技术生成相关的信息或建议。
这种方法的核心在于提供更精准、更个性化的搜索结果,大大提高了用户的搜索效率和满意度。
在实际应用中,高级检索增强生成技术主要依靠以下几种关键技术:1. 自然语言处理技术(NLP):NLP技术是高级检索增强生成技术的基础之一。
通过自然语言处理技术,系统可以理解用户的查询意图、分析文本内容,并根据用户需求生成相应的搜索结果。
2. 机器学习技术:机器学习技术可以帮助系统不断学习用户的搜索习惯和偏好,从而提高搜索结果的精准度和个性化程度。
3. 文本生成技术:文本生成技术可以帮助系统根据用户的查询条件和需求生成相关的文本内容,帮助用户更快地获取所需信息。
高级检索增强生成技术在各个领域都有着广泛的应用。
以下是几个常见的应用场景:1. 搜索引擎:搜索引擎是高级检索增强生成技术应用最为广泛的领域之一。
通过智能算法的分析和处理,搜索引擎可以为用户提供更加精准和个性化的搜索结果,大大提高了信息检索的效率和准确性。
2. 智能助手:智能助手是高级检索增强生成技术在个人助手领域的应用。
通过NLP技术和机器学习技术,智能助手可以帮助用户更快地获取所需信息,提供个性化的服务和建议。
3. 内容推荐:内容推荐是高级检索增强生成技术在内容推荐系统中的应用。
通过分析用户的浏览历史和偏好,系统可以为用户推荐相关的内容,提高用户的浏览体验。
新类别发现综述新类别发现(New Category Discovery)是机器学习领域中的一个重要问题,旨在从给定的数据集中自动发现新的、先前未知的类别。
这一任务在现实世界中具有广泛的应用,例如在图像分类、文本挖掘、生物信息学等领域中,新的类别可能代表着新的概念、实体或现象。
近年来,随着深度学习技术的发展,新类别发现领域取得了显著的进展。
基于深度学习的新类别发现方法通常利用神经网络强大的特征提取能力,从原始数据中学习有效的表示,并基于这些表示来识别新的类别。
以下是一些基于深度学习的新类别发现方法的综述:1. 基于自编码器的方法:自编码器是一种无监督的神经网络模型,它通过学习将输入数据编码为低维表示,并从这些表示中重建原始数据。
在新类别发现中,自编码器可以用于学习数据的压缩表示,然后基于这些表示使用聚类算法来识别新的类别。
2. 基于生成对抗网络(GAN)的方法:GAN是一种生成模型,由生成器和判别器两个神经网络组成。
生成器的目标是生成与真实数据相似的假数据,而判别器的目标是区分真实数据和假数据。
在新类别发现中,GAN可以用于生成与已知类别不同的新数据,从而揭示潜在的新类别。
3. 基于深度聚类的方法:深度聚类方法结合了深度学习和聚类算法的优势,通过学习数据的深度表示和聚类分配来同时优化表示学习和聚类目标。
这些方法通常使用神经网络来学习数据的表示,并使用聚类损失来鼓励模型将相似的样本分组到同一类别中。
4. 基于对比学习的方法:对比学习是一种自监督学习方法,它通过比较正样本对(相似的样本)和负样本对(不相似的样本)来学习数据的表示。
在新类别发现中,对比学习可以用于学习区分不同类别的表示,从而识别新的类别。
5. 基于增量学习的方法:增量学习方法旨在逐步学习新的知识和概念,而不会忘记之前学习的内容。
在新类别发现中,增量学习方法可以用于逐步识别新的类别,同时保持对已知类别的识别能力。
总之,基于深度学习的新类别发现方法已经取得了显著的进展,并在各种应用中展现出了强大的潜力。
搜索的“理”性进化作者:暂无来源:《计算机世界》 2012年第32期■ 本报记者王哲玮在很多人眼里,互联网搜索已经是一个非常成熟的产业了,人们已经对目前的信息检索方式习以为常。
多年来,搜索的本质就是字符串的匹配。
比如“taj mahal”,对于搜索引擎来说,它们只不过是两个单词而已,但用户可能会想到世界上最美丽的纪念遗址之一、一位荣获格莱美奖的音乐家,甚至上次去的一家印度餐厅。
“很显然,搜索还应该变得更好。
”Google 科学家兼高级副总裁阿米特·辛格哈尔在搜索领域积累了20多年的工作经验,对于他来说,搜索不仅是工具,更是梦想。
知识图谱今年5 月推出的“KnowledgeGraph” 是阿米特以及Google对于改变信息检索和认知的又一次努力。
“Knowledge Graph 的目标在于准确解读现实世界,而不仅仅提供网页链接。
通过庞大的Knowledge Graph,可提供关于国家、城市、篮球队、摩天大楼、灯塔等任何事物的信息,以及不同事物之间的属性和它们之间的关系。
这是计算机首次通过搜索引擎理解现实世界中的实体,为用户提供最想要的信息,而非简单的字符串匹配。
”阿米特兴奋地将其形容为“一首信息与人类世界的交响曲”。
理解引擎在搜索领域,机器和人的差别在于: 机器检索更快,人类理解更深。
让机器像人类一样“理解”现实世界,是一项极具挑战性的工作,但同时也足够酷,它能让未来的搜索更加智慧。
“ 一般情况下,KnowledgeGraph 会处于页面的右侧,上面提供的信息是对页面左侧搜索结果所提供内容的补充,这是我们的首要设计原则。
第二个设计原则是,在用户提问之前就可以回答他的下一个问题。
例如一提到“过山车”,你可能会询问乘坐一次需要多少时间,然后KnowledgeGraph 就会给出答案:3 分钟。
”阿米特表示,Knowledge Graph甚至可以关联到用户Gmail 中的相关信息。
这一切都建立在庞大的数据资源挖掘和整合上。
•Creating a reference list or bibliographyA numbered list of references must be provided at the end of thepaper. The list should be arranged in the order of citation in the text of the assignment or essay, not in alphabetical order. List only one reference per reference number. Footnotes or otherinformation that are not part of the referencing format should not be included in the reference list.The following examples demonstrate the format for a variety of types of references. Included are some examples of citing electronic documents. Such items come in many forms, so only some examples have been listed here.Print DocumentsBooksNote: Every (important) word in the title of a book or conference must be capitalised. Only the first word of a subtitle should be capitalised. Capitalise the "v" in Volume for a book title.Punctuation goes inside the quotation marks.Standard formatSingle author[1] W.-K. Chen, Linear Networks and Systems. Belmont, CA: Wadsworth,1993, pp. 123-135.[2] S. M. Hemmington, Soft Science. Saskatoon: University ofSaskatchewan Press, 1997.Edited work[3] D. Sarunyagate, Ed., Lasers. New York: McGraw-Hill, 1996.Later edition[4] K. Schwalbe, Information Technology Project Management, 3rd ed.Boston: Course Technology, 2004.[5] M. N. DeMers, Fundamentals of Geographic Information Systems,3rd ed. New York : John Wiley, 2005.More than one author[6] T. Jordan and P. A. Taylor, Hacktivism and Cyberwars: Rebelswith a cause? London: Routledge, 2004.[7] U. J. Gelinas, Jr., S. G. Sutton, and J. Fedorowicz, Businessprocesses and information technology. Cincinnati:South-Western/Thomson Learning, 2004.Three or more authorsNote: The names of all authors should be given in the references unless the number of authors is greater than six. If there are more than six authors, you may use et al. after the name of the first author.[8] R. Hayes, G. Pisano, D. Upton, and S. Wheelwright, Operations,Strategy, and Technology: Pursuing the competitive edge.Hoboken, NJ : Wiley, 2005.Series[9] M. Bell, et al., Universities Online: A survey of onlineeducation and services in Australia, Occasional Paper Series 02-A. Canberra: Department of Education, Science andTraining, 2002.Corporate author (ie: a company or organisation)[10] World Bank, Information and Communication Technologies: AWorld Bank group strategy. Washington, DC : World Bank, 2002.Conference (complete conference proceedings)[11] T. J. van Weert and R. K. Munro, Eds., Informatics and theDigital Society: Social, ethical and cognitive issues: IFIP TC3/WG3.1&3.2 Open Conference on Social, Ethical andCognitive Issues of Informatics and ICT, July 22-26, 2002, Dortmund, Germany. Boston: Kluwer Academic, 2003.Government publication[12] Australia. Attorney-Generals Department. Digital AgendaReview, 4 Vols. Canberra: Attorney- General's Department,2003.Manual[13] Bell Telephone Laboratories Technical Staff, TransmissionSystem for Communications, Bell Telephone Laboratories,1995.Catalogue[14] Catalog No. MWM-1, Microwave Components, M. W. Microwave Corp.,Brooklyn, NY.Application notes[15] Hewlett-Packard, Appl. Note 935, pp. 25-29.Note:Titles of unpublished works are not italicised or capitalised. Capitalise only the first word of a paper or thesis.Technical report[16] K. E. Elliott and C.M. Greene, "A local adaptive protocol,"Argonne National Laboratory, Argonne, France, Tech. Rep.916-1010-BB, 1997.Patent / Standard[17] K. Kimura and A. Lipeles, "Fuzzy controller component, " U.S. Patent 14,860,040, December 14, 1996.Papers presented at conferences (unpublished)[18] H. A. Nimr, "Defuzzification of the outputs of fuzzycontrollers," presented at 5th International Conference onFuzzy Systems, Cairo, Egypt, 1996.Thesis or dissertation[19] H. Zhang, "Delay-insensitive networks," M.S. thesis,University of Waterloo, Waterloo, ON, Canada, 1997.[20] M. W. Dixon, "Application of neural networks to solve therouting problem in communication networks," Ph.D.dissertation, Murdoch University, Murdoch, WA, Australia, 1999.Parts of a BookNote: These examples are for chapters or parts of edited works in which the chapters or parts have individual title and author/s, but are included in collections or textbooks edited by others. If the editors of a work are also the authors of all of the included chapters then it should be cited as a whole book using the examples given above (Books).Capitalise only the first word of a paper or book chapter.Single chapter from an edited work[1] A. Rezi and M. Allam, "Techniques in array processing by meansof transformations, " in Control and Dynamic Systems, Vol.69, Multidemsional Systems, C. T. Leondes, Ed. San Diego: Academic Press, 1995, pp. 133-180.[2] G. O. Young, "Synthetic structure of industrial plastics," inPlastics, 2nd ed., vol. 3, J. Peters, Ed. New York:McGraw-Hill, 1964, pp. 15-64.Conference or seminar paper (one paper from a published conference proceedings)[3] N. Osifchin and G. Vau, "Power considerations for themodernization of telecommunications in Central and Eastern European and former Soviet Union (CEE/FSU) countries," in Second International Telecommunications Energy SpecialConference, 1997, pp. 9-16.[4] S. Al Kuran, "The prospects for GaAs MESFET technology in dc-acvoltage conversion," in Proceedings of the Fourth AnnualPortable Design Conference, 1997, pp. 137-142.Article in an encyclopaedia, signed[5] O. B. R. Strimpel, "Computer graphics," in McGraw-HillEncyclopedia of Science and Technology, 8th ed., Vol. 4. New York: McGraw-Hill, 1997, pp. 279-283.Study Guides and Unit ReadersNote: You should not cite from Unit Readers, Study Guides, or lecture notes, but where possible you should go to the original source of the information. If you do need to cite articles from the Unit Reader, treat the Reader articles as if they were book or journal articles. In the reference list or bibliography use the bibliographical details as quoted in the Reader and refer to the page numbers from the Reader, not the original page numbers (unless you have independently consulted the original).[6] L. Vertelney, M. Arent, and H. Lieberman, "Two disciplines insearch of an interface: Reflections on a design problem," in The Art of Human-Computer Interface Design, B. Laurel, Ed.Reading, MA: Addison-Wesley, 1990. Reprinted inHuman-Computer Interaction (ICT 235) Readings and Lecture Notes, Vol. 1. Murdoch: Murdoch University, 2005, pp. 32-37. Journal ArticlesNote: Capitalise only the first word of an article title, except for proper nouns or acronyms. Every (important) word in the title of a journal must be capitalised. Do not capitalise the "v" in volume for a journal article.You must either spell out the entire name of each journal that you reference or use accepted abbreviations. You must consistently do one or the other. Staff at the Reference Desk can suggest sources of accepted journal abbreviations.You may spell out words such as volume or December, but you must either spell out all such occurrences or abbreviate all. You do not need to abbreviate March, April, May, June or July.To indicate a page range use pp. 111-222. If you refer to only one page, use only p. 111.Standard formatJournal articles[1] E. P. Wigner, "Theory of traveling wave optical laser," Phys.Rev., vol. 134, pp. A635-A646, Dec. 1965.[2] J. U. Duncombe, "Infrared navigation - Part I: An assessmentof feasability," IEEE Trans. Electron. Devices, vol. ED-11, pp. 34-39, Jan. 1959.[3] G. Liu, K. Y. Lee, and H. F. Jordan, "TDM and TWDM de Bruijnnetworks and shufflenets for optical communications," IEEE Trans. Comp., vol. 46, pp. 695-701, June 1997.OR[4] J. R. Beveridge and E. M. Riseman, "How easy is matching 2D linemodels using local search?" IEEE Transactions on PatternAnalysis and Machine Intelligence, vol. 19, pp. 564-579, June 1997.[5] I. S. Qamber, "Flow graph development method," MicroelectronicsReliability, vol. 33, no. 9, pp. 1387-1395, Dec. 1993.[6] E. H. Miller, "A note on reflector arrays," IEEE Transactionson Antennas and Propagation, to be published.Electronic documentsNote:When you cite an electronic source try to describe it in the same way you would describe a similar printed publication. If possible, give sufficient information for your readers to retrieve the source themselves.If only the first page number is given, a plus sign indicates following pages, eg. 26+. If page numbers are not given, use paragraph or other section numbers if you need to be specific. An electronic source may not always contain clear author or publisher details.The access information will usually be just the URL of the source. As well as a publication/revision date (if there is one), the date of access is included since an electronic source may change between the time you cite it and the time it is accessed by a reader.E-BooksStandard format[1] L. Bass, P. Clements, and R. Kazman. Software Architecture inPractice, 2nd ed. Reading, MA: Addison Wesley, 2003. [E-book] Available: Safari e-book.[2] T. Eckes, The Developmental Social Psychology of Gender. MahwahNJ: Lawrence Erlbaum, 2000. [E-book] Available: netLibrary e-book.Article in online encyclopaedia[3] D. Ince, "Acoustic coupler," in A Dictionary of the Internet.Oxford: Oxford University Press, 2001. [Online]. Available: Oxford Reference Online, .[Accessed: May 24, 2005].[4] W. D. Nance, "Management information system," in The BlackwellEncyclopedic Dictionary of Management Information Systems,G.B. Davis, Ed. Malden MA: Blackwell, 1999, pp. 138-144.[E-book]. Available: NetLibrary e-book.E-JournalsStandard formatJournal article abstract accessed from online database[1] M. T. Kimour and D. Meslati, "Deriving objects from use casesin real-time embedded systems," Information and SoftwareTechnology, vol. 47, no. 8, p. 533, June 2005. [Abstract].Available: ProQuest, /proquest/.[Accessed May 12, 2005].Note: Abstract citations are only included in a reference list if the abstract is substantial or if the full-text of the article could not be accessed.Journal article from online full-text databaseNote: When including the internet address of articles retrieved from searches in full-text databases, please use the Recommended URLs for Full-text Databases, which are the URLs for the main entrance to the service and are easier to reproduce.[2] H. K. Edwards and V. Sridhar, "Analysis of software requirementsengineering exercises in a global virtual team setup,"Journal of Global Information Management, vol. 13, no. 2, p.21+, April-June 2005. [Online]. Available: Academic OneFile, . [Accessed May 31, 2005].[3] A. Holub, "Is software engineering an oxymoron?" SoftwareDevelopment Times, p. 28+, March 2005. [Online]. Available: ProQuest, . [Accessed May 23, 2005].Journal article in a scholarly journal (published free of charge on the internet)[4] A. Altun, "Understanding hypertext in the context of readingon the web: Language learners' experience," Current Issues in Education, vol. 6, no. 12, July 2003. [Online]. Available: /volume6/number12/. [Accessed Dec. 2, 2004].Journal article in electronic journal subscription[5] P. H. C. Eilers and J. J. Goeman, "Enhancing scatterplots withsmoothed densities," Bioinformatics, vol. 20, no. 5, pp.623-628, March 2004. [Online]. Available:. [Accessed Sept. 18, 2004].Newspaper article from online database[6] J. Riley, "Call for new look at skilled migrants," TheAustralian, p. 35, May 31, 2005. Available: Factiva,. [Accessed May 31, 2005].Newspaper article from the Internet[7] C. Wilson-Clark, "Computers ranked as key literacy," The WestAustralian, para. 3, March 29, 2004. [Online]. Available:.au. [Accessed Sept. 18, 2004].Internet DocumentsStandard formatProfessional Internet site[1] European Telecommunications Standards Institute, 揇igitalVideo Broadcasting (DVB): Implementation guidelines for DVBterrestrial services; transmission aspects,?EuropeanTelecommunications Standards Institute, ETSI TR-101-190,1997. [Online]. Available: . [Accessed:Aug. 17, 1998].Personal Internet site[2] G. Sussman, "Home page - Dr. Gerald Sussman," July 2002.[Online]. Available:/faculty/Sussman/sussmanpage.htm[Accessed: Sept. 12, 2004].General Internet site[3] J. Geralds, "Sega Ends Production of Dreamcast," ,para. 2, Jan. 31, 2001. [Online]. Available:/news/1116995. [Accessed: Sept. 12,2004].Internet document, no author given[4] 揂憀ayman抯?explanation of Ultra Narrow Band technology,?Oct.3, 2003. [Online]. Available:/Layman.pdf. [Accessed: Dec. 3, 2003].Non-Book FormatsPodcasts[1] W. Brown and K. Brodie, Presenters, and P. George, Producer, 揊rom Lake Baikal to the Halfway Mark, Yekaterinburg? Peking to Paris: Episode 3, Jun. 4, 2007. [Podcast television programme]. Sydney: ABC Television. Available:.au/tv/pekingtoparis/podcast/pekingtoparis.xm l. [Accessed Feb. 4, 2008].[2] S. Gary, Presenter, 揃lack Hole Death Ray? StarStuff, Dec. 23, 2007. [Podcast radio programme]. Sydney: ABC News Radio. Available: .au/newsradio/podcast/STARSTUFF.xml. [Accessed Feb. 4, 2008].Other FormatsMicroform[3] W. D. Scott & Co, Information Technology in Australia:Capacities and opportunities: A report to the Department ofScience and Technology. [Microform]. W. D. Scott & CompanyPty. Ltd. in association with Arthur D. Little Inc. Canberra:Department of Science and Technology, 1984.Computer game[4] The Hobbit: The prelude to the Lord of the Rings. [CD-ROM].United Kingdom: Vivendi Universal Games, 2003.Software[5] Thomson ISI, EndNote 7. [CD-ROM]. Berkeley, Ca.: ISIResearchSoft, 2003.Video recording[6] C. Rogers, Writer and Director, Grrls in IT. [Videorecording].Bendigo, Vic. : Video Education Australasia, 1999.A reference list: what should it look like?The reference list should appear at the end of your paper. Begin the list on a new page. The title References should be either left justified or centered on the page. The entries should appear as one numerical sequence in the order that the material is cited in the text of your assignment.Note: The hanging indent for each reference makes the numerical sequence more obvious.[1] A. Rezi and M. Allam, "Techniques in array processing by meansof transformations, " in Control and Dynamic Systems, Vol.69, Multidemsional Systems, C. T. Leondes, Ed. San Diego: Academic Press, 1995, pp. 133-180.[2] G. O. Young, "Synthetic structure of industrial plastics," inPlastics, 2nd ed., vol. 3, J. Peters, Ed. New York:McGraw-Hill, 1964, pp. 15-64.[3] S. M. Hemmington, Soft Science. Saskatoon: University ofSaskatchewan Press, 1997.[4] N. Osifchin and G. Vau, "Power considerations for themodernization of telecommunications in Central and Eastern European and former Soviet Union (CEE/FSU) countries," in Second International Telecommunications Energy SpecialConference, 1997, pp. 9-16.[5] D. Sarunyagate, Ed., Lasers. New York: McGraw-Hill, 1996.[8] O. B. R. Strimpel, "Computer graphics," in McGraw-HillEncyclopedia of Science and Technology, 8th ed., Vol. 4. New York: McGraw-Hill, 1997, pp. 279-283.[9] K. Schwalbe, Information Technology Project Management, 3rd ed.Boston: Course Technology, 2004.[10] M. N. DeMers, Fundamentals of Geographic Information Systems,3rd ed. New York: John Wiley, 2005.[11] L. Vertelney, M. Arent, and H. Lieberman, "Two disciplines insearch of an interface: Reflections on a design problem," in The Art of Human-Computer Interface Design, B. Laurel, Ed.Reading, MA: Addison-Wesley, 1990. Reprinted inHuman-Computer Interaction (ICT 235) Readings and Lecture Notes, Vol. 1. Murdoch: Murdoch University, 2005, pp. 32-37.[12] E. P. Wigner, "Theory of traveling wave optical laser,"Physical Review, vol.134, pp. A635-A646, Dec. 1965.[13] J. U. Duncombe, "Infrared navigation - Part I: An assessmentof feasibility," IEEE Transactions on Electron Devices, vol.ED-11, pp. 34-39, Jan. 1959.[14] M. Bell, et al., Universities Online: A survey of onlineeducation and services in Australia, Occasional Paper Series 02-A. Canberra: Department of Education, Science andTraining, 2002.[15] T. J. van Weert and R. K. Munro, Eds., Informatics and theDigital Society: Social, ethical and cognitive issues: IFIP TC3/WG3.1&3.2 Open Conference on Social, Ethical andCognitive Issues of Informatics and ICT, July 22-26, 2002, Dortmund, Germany. Boston: Kluwer Academic, 2003.[16] I. S. Qamber, "Flow graph development method,"Microelectronics Reliability, vol. 33, no. 9, pp. 1387-1395, Dec. 1993.[17] Australia. Attorney-Generals Department. Digital AgendaReview, 4 Vols. Canberra: Attorney- General's Department, 2003.[18] C. Rogers, Writer and Director, Grrls in IT. [Videorecording].Bendigo, Vic.: Video Education Australasia, 1999.[19] L. Bass, P. Clements, and R. Kazman. Software Architecture inPractice, 2nd ed. Reading, MA: Addison Wesley, 2003. [E-book] Available: Safari e-book.[20] D. Ince, "Acoustic coupler," in A Dictionary of the Internet.Oxford: Oxford University Press, 2001. [Online]. Available: Oxford Reference Online, .[Accessed: May 24, 2005].[21] H. K. Edwards and V. Sridhar, "Analysis of softwarerequirements engineering exercises in a global virtual team setup," Journal of Global Information Management, vol. 13, no. 2, p. 21+, April-June 2005. [Online]. Available: AcademicOneFile, . [Accessed May 31,2005].[22] A. Holub, "Is software engineering an oxymoron?" SoftwareDevelopment Times, p. 28+, March 2005. [Online]. Available: ProQuest, . [Accessed May 23, 2005].[23] H. Zhang, "Delay-insensitive networks," M.S. thesis,University of Waterloo, Waterloo, ON, Canada, 1997.[24] P. H. C. Eilers and J. J. Goeman, "Enhancing scatterplots withsmoothed densities," Bioinformatics, vol. 20, no. 5, pp.623-628, March 2004. [Online]. Available:. [Accessed Sept. 18, 2004].[25] J. Riley, "Call for new look at skilled migrants," TheAustralian, p. 35, May 31, 2005. Available: Factiva,. [Accessed May 31, 2005].[26] European Telecommunications Standards Institute, 揇igitalVideo Broadcasting (DVB): Implementation guidelines for DVB terrestrial services; transmission aspects,?EuropeanTelecommunications Standards Institute, ETSI TR-101-190,1997. [Online]. Available: . [Accessed: Aug. 17, 1998].[27] J. Geralds, "Sega Ends Production of Dreamcast," ,para. 2, Jan. 31, 2001. [Online]. Available:/news/1116995. [Accessed Sept. 12,2004].[28] W. D. Scott & Co, Information Technology in Australia:Capacities and opportunities: A report to the Department of Science and Technology. [Microform]. W. D. Scott & Company Pty. Ltd. in association with Arthur D. Little Inc. Canberra: Department of Science and Technology, 1984.AbbreviationsStandard abbreviations may be used in your citations. A list of appropriate abbreviations can be found below:。
rag检索增强技术在知识库智能检索场景下的应用实践-回复题目:Knowledge Base Intelligent Retrieval: Application and Practice of RAG-based Enhanced Retrieval TechniquesIntroduction:In the era of big data, knowledge bases have become crucial tools for storing and organizing vast amounts of information. However, the effectiveness of knowledge base retrieval systems heavily relies on their ability to accurately and efficiently retrieve relevant information. To address this challenge, the use of enhanced retrieval techniques, such as RAG (Retrieval-Augmented Generation), has gained attention. This article aims to provide a step-by-step explanation of RAG-based enhanced retrieval techniques and their application in knowledge base intelligent retrieval.I. Understanding RAG-based Enhanced Retrieval Techniques:1. Overview of RAG:- RAG combines machine reading comprehension and language generation to improve traditional information retrieval systems.- It extends the capabilities of retrieval systems by generatingdetailed responses instead of traditional short suggestions.- RAG utilizes pre-trained models and fine-tuning on specific domains to enhance retrieval performance.2. Core Components of RAG:a. Retriever:- The initial step in the RAG pipeline.- Utilizes traditional information retrieval techniques, such as TF-IDF or BM25, to retrieve relevant documents from the knowledge base.b. Reader:- Performs machine reading comprehension on the retrieved documents.- Applies advanced techniques, such as BERT (Bidirectional Encoder Representations from Transformers), to understand the context and extract relevant information.c. Generator:- Uses the output from the reader to generate detailed responses.- Can employ techniques like T5 (Text-to-Text TransferTransformer) or GPT (Generative Pre-trained Transformer) models for effective response generation.II. Application of RAG-based Enhanced Retrieval Techniques in Knowledge Base Intelligent Retrieval:1. Query Expansion and Reformulation:- RAG can expand and reformulate user queries to improve retrieval accuracy.- By leveraging the reader component, RAG understands user queries and generates alternative query formulations to capture the full user intent.2. Context-aware Response Generation:- RAG can generate contextually relevant and informative responses.- The generator component utilizes the information extracted by the reader to craft detailed and accurate responses to user queries.3. Intelligent Knowledge Base Navigation:- RAG enables users to navigate the knowledge base more efficiently.- By utilizing the reader component, RAG can provide precise suggestions for related topics or sections within the knowledge base, improving user navigation experience.III. Practical Considerations and Challenges:1. Training Data and Knowledge Base:- Adequate training data, including high-quality documents and relevant user queries, is essential for RAG model training.- A well-structured and comprehensive knowledge base is needed for efficient retrieval and generation.2. Fine-Tuning and Model Selection:- RAG models need to be fine-tuned on specific domains to maximize their retrieval effectiveness.- Model selection consideration should include factors like available computing resources, the size of the knowledge base, and desired response generation quality.3. Ethical and Privacy Concerns:- Knowledge bases may contain sensitive information, so ensuring the ethical and privacy considerations of the retrieved content is crucial.- Regular audits and safeguards can help prevent potential data leakage or misuse.IV. Conclusion:RAG-based enhanced retrieval techniques offer significant potential in improving knowledge base intelligent retrieval. By combining retrieval and generation, RAG empowers retrieval systems to provide contextually relevant and informative responses to user queries. However, practical considerations and challenges, such as training data and model selection, need to be carefully addressed to realize the full potential of RAG in knowledge base intelligent retrieval. With further research and development,RAG-based techniques are expected to revolutionize the efficiency and effectiveness of knowledge base retrieval systems, ultimately enhancing our ability to access and utilize vast amounts of information.。