排序算法的比较及时间
- 格式:doc
- 大小:72.50 KB
- 文档页数:11

数字的顺序比较和排序数字在我们的日常生活中,数字无处不在。
无论是购物、工作、学习还是娱乐,我们都需要对数字进行比较和排序。
了解如何进行数字的顺序比较和排序是非常重要的,因为它有助于我们更好地组织和管理数据。
本文将介绍数字的顺序比较和排序的方法。
一、顺序比较数字顺序比较数字是指根据数字的大小进行比较,判断它们的先后顺序。
比较数字的方法有以下几种:1. 使用不等式进行比较:最常见的方法是使用大于(>)、小于(<)、大于等于(≥)和小于等于(≤)等符号进行比较。
例如,如果有两个数字a和b,我们可以通过比较a和b的大小来确定它们的顺序关系。
如果a大于b,则a排在b的后面;如果a小于b,则a排在b的前面。
2. 使用计数方法进行比较:另一种比较数字的方法是使用计数方法,将数字转化为计数单位,然后根据计数单位的大小进行比较。
例如,如果有两个数字a和b,我们可以将它们转化为相应的计数单位,如百、千或万,然后比较它们的大小。
例如,如果a表示100,b表示1000,那么b排在a的后面。
3. 使用排序算法进行比较:如果有多个数字需要比较,我们可以使用排序算法将它们按照一定的规则进行排序。
常见的排序算法有冒泡排序、插入排序、选择排序和快速排序等。
这些排序算法会根据定义的排序规则对数字进行比较和交换,最终将数字按照顺序排列。
二、排序数字排序数字是指将一组数字按照一定的规则进行排列,以便更好地组织和管理数据。
常见的排序方法有以下几种:1. 冒泡排序:冒泡排序是一种简单而常用的排序方法。
它通过重复比较相邻的两个数字,并根据定义的排序规则交换它们的位置,从而逐渐将最大(或最小)的数字“冒泡”到序列的末尾(或开头)。
冒泡排序的时间复杂度为O(n^2),其中n为待排序数字的个数。
2. 插入排序:插入排序是一种适用于小型数据集的排序方法。
它通过将数字逐个插入到已经排好序的序列中,从而逐步构建有序序列。
插入排序的时间复杂度为O(n^2)。

各种排序算法的总结和比较1 快速排序(QuickSort)快速排序是一个就地排序,分而治之,大规模递归的算法。
从本质上来说,它是归并排序的就地版本。
快速排序可以由下面四步组成。
(1)如果不多于1个数据,直接返回。
(2)一般选择序列最左边的值作为支点数据。
(3)将序列分成2部分,一部分都大于支点数据,另外一部分都小于支点数据。
(4)对两边利用递归排序数列。
快速排序比大部分排序算法都要快。
尽管我们可以在某些特殊的情况下写出比快速排序快的算法,但是就通常情况而言,没有比它更快的了。
快速排序是递归的,对于内存非常有限的机器来说,它不是一个好的选择。
2 归并排序(MergeSort)归并排序先分解要排序的序列,从1分成2,2分成4,依次分解,当分解到只有1个一组的时候,就可以排序这些分组,然后依次合并回原来的序列中,这样就可以排序所有数据。
合并排序比堆排序稍微快一点,但是需要比堆排序多一倍的内存空间,因为它需要一个额外的数组。
3 堆排序(HeapSort)堆排序适合于数据量非常大的场合(百万数据)。
堆排序不需要大量的递归或者多维的暂存数组。
这对于数据量非常巨大的序列是合适的。
比如超过数百万条记录,因为快速排序,归并排序都使用递归来设计算法,在数据量非常大的时候,可能会发生堆栈溢出错误。
堆排序会将所有的数据建成一个堆,最大的数据在堆顶,然后将堆顶数据和序列的最后一个数据交换。
接下来再次重建堆,交换数据,依次下去,就可以排序所有的数据。
Shell排序通过将数据分成不同的组,先对每一组进行排序,然后再对所有的元素进行一次插入排序,以减少数据交换和移动的次数。
平均效率是O(nlogn)。
其中分组的合理性会对算法产生重要的影响。
现在多用D.E.Knuth的分组方法。
Shell排序比冒泡排序快5倍,比插入排序大致快2倍。
Shell排序比起QuickSort,MergeSort,HeapSort慢很多。
但是它相对比较简单,它适合于数据量在5000以下并且速度并不是特别重要的场合。

所有排序的原理排序是将一组数据按照某种特定顺序进行排列的过程。
在计算机科学中,排序是一种基本的算法问题,涉及到许多常见的排序算法。
排序算法根据其基本原理和实现方式的不同,可以分为多种类型,如比较排序、非比较排序、稳定排序和非稳定排序等。
下面将详细介绍排序的原理和各种排序算法。
一、比较排序的原理比较排序是指通过比较数据之间的大小关系来确定数据的相对顺序。
所有常见的比较排序算法都基于这种原理,包括冒泡排序、插入排序、选择排序、归并排序、快速排序、堆排序等。
比较排序算法的时间复杂度一般为O(n^2)或O(nlogn),其中n是待排序元素的数量。
1. 冒泡排序原理冒泡排序是一种简单的比较排序算法,其基本思想是从待排序的元素中两两比较相邻元素的大小,并依次将较大的元素往后移,最终将最大的元素冒泡到序列的尾部。
重复这个过程,直到所有元素都有序。
2. 插入排序原理插入排序是一种简单直观的比较排序算法,其基本思想是将待排序序列分成已排序和未排序两部分,初始状态下已排序部分只包含第一个元素。
然后,依次将未排序部分的元素插入到已排序部分的正确位置,直到所有元素都有序。
3. 选择排序原理选择排序是一种简单直观的比较排序算法,其基本思想是每次从待排序的元素中选择最小(或最大)的元素,将其放到已排序部分的末尾。
重复这个过程,直到所有元素都有序。
4. 归并排序原理归并排序是一种典型的分治策略下的比较排序算法,其基本思想是将待排序的元素不断地二分,直到每个子序列只包含一个元素,然后将相邻的子序列两两归并,直到所有元素都有序。
5. 快速排序原理快速排序是一种常用的比较排序算法,其基本思想是通过一趟排序将待排序的元素分割成两部分,其中一部分的元素均比另一部分的元素小。
然后,对这两部分元素分别进行快速排序,最终将整个序列排序完成。
6. 堆排序原理堆排序是一种常用的比较排序算法,其基本思想是利用堆这种数据结构对待排序的元素进行排序。

一、设计思想排序是数据处理中使用频率很高的一种操作,是数据查询之前需要进行的一项基础操作。
它是将任意序列的数据元素(或记录)按关键字有序(升序或降序)重新排列的过程。
排序的过程中有两种基本操作:一是比较两个关键字的值;二是根据比较结果移动记录位置。
排序的算法有很多种,这里仅对插入排序、选择排序、希尔排序、归并排序和快速排序作了比较。
直接插入排序算法基本思路:直接插入排序时将一个元素插入已排好的有序数组中,从而得到一个元素个数增加1的新的有序数组。
其具体实现过程是,将第i个元素与已经排好序的i-1个元素依次进行比较,再将所有大于第i个元素的元素后移一个位置,直到遇到小于或等于第i个元素,此时该元素的后面一个位置为空,将i元素插入此空位即可。
选择排序算法基本思路:定义两个数组sela[]和temp[],sela[]用来存放待排序数组,temp[]用来存放排好序的数组。
第一趟,将sela[]数组中n个元素进行比较,找出其中最小的元素放入temp[]的第一个位置,同时将sela[]中将该元素位置设置为无穷大。
第二趟,将sela[]数组中n个元素进行比较,找出其中最小的元素放入temp[]的第二个位置,同时将sela[]中将该元素位置设置为无穷大。
以此类推,n趟后将sela[]中所有元素都已排好序放入temp[]数组中。
希尔排序算法基本思路:希尔排序又称为变长步径排序,它也是一种基于插入排序的思想。
其基本思路是,定义一个步长数组gaps[1,5,13,43……],先选取合适的大步长gap将整个待排序的元素按步长gap分成若干子序列,第一个子序列的元素为a[0]、a[0+gap]、a[0+2gap]……a[0+k*gap];第二列为a[1]、a[1+gap]、a[1+2gap]……a[1+k*gap];……。
然后,对这些子序列分别进行插入排序,然后将gap按gaps[]数组中的步长缩小,按缩小后的步长再进行子序列划分排序,再减小步长直到步长为1为止。

几种排序的算法时间复杂度比较1.选择排序:不稳定,时间复杂度 O(n^2)选择排序的基本思想是对待排序的记录序列进行n-1遍的处理,第i遍处理是将L[i..n]中最小者与L[i]交换位置。
这样,经过i遍处理之后,前i个记录的位置已经是正确的了。
2.插入排序:稳定,时间复杂度 O(n^2)插入排序的基本思想是,经过i-1遍处理后,L[1..i-1]己排好序。
第i遍处理仅将L[i]插入L[1..i-1]的适当位置,使得L[1..i] 又是排好序的序列。
要达到这个目的,我们可以用顺序比较的方法。
首先比较L[i]和L[i-1],如果L[i-1]≤ L[i],则L[1..i]已排好序,第i遍处理就结束了;否则交换L[i]与L[i-1]的位置,继续比较L[i-1]和L[i-2],直到找到某一个位置j(1≤j≤i-1),使得L[j] ≤L[j+1]时为止。
图1演示了对4个元素进行插入排序的过程,共需要(a),(b),(c)三次插入。
3.冒泡排序:稳定,时间复杂度 O(n^2)冒泡排序方法是最简单的排序方法。
这种方法的基本思想是,将待排序的元素看作是竖着排列的“气泡”,较小的元素比较轻,从而要往上浮。
在冒泡排序算法中我们要对这个“气泡”序列处理若干遍。
所谓一遍处理,就是自底向上检查一遍这个序列,并时刻注意两个相邻的元素的顺序是否正确。
如果发现两个相邻元素的顺序不对,即“轻”的元素在下面,就交换它们的位置。
显然,处理一遍之后,“最轻”的元素就浮到了最高位置;处理二遍之后,“次轻”的元素就浮到了次高位置。
在作第二遍处理时,由于最高位置上的元素已是“最轻”元素,所以不必检查。
一般地,第i遍处理时,不必检查第i高位置以上的元素,因为经过前面i-1遍的处理,它们已正确地排好序。
4.堆排序:不稳定,时间复杂度 O(nlog n)堆排序是一种树形选择排序,在排序过程中,将A[n]看成是完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系来选择最小的元素。

经典⼗⼤排序算法前⾔排序种类繁多,⼤致可以分为两⼤类:⽐较类排序:属于⾮线性时间排序,时间复杂度不能突破下界O(nlogn);⾮⽐较类排序:能达到线性时间O(n),不是通过⽐较来排序,有基数排序、计数排序、桶排序。
了解⼀个概念:排序的稳定性稳定是指相同⼤⼩的元素多次排序能保证其先后顺序保持不变。
假设有⼀些学⽣的信息,我们先根据他们的姓名进⾏排序,然后我们还想根据班级再进⾏排序,如果这时使⽤的时不稳定的排序算法,那么第⼀次的排序结果可能会被打乱,这样的场景需要使⽤稳定的算法。
堆排序、快速排序、希尔排序、选择排序是不稳定的排序算法,⽽冒泡排序、插⼊排序、归并排序、基数排序是稳定的排序算法。
1、冒泡排序⼤多数⼈学编程接触的第⼀种排序,名称很形象。
每次遍历排出⼀个最⼤的元素,将⼀个最⼤的⽓泡冒出⽔⾯。
时间复杂度:平均:O(n2);最好:O(n);最坏:O(n2)空间复杂度:O(1)public static void bubbleSort(int[] arr) {/*** 总共⾛len-1趟即可,每趟排出⼀个最⼤值放在最后*/for (int i = 0; i < arr.length - 1; i++) {for (int j = 0; j < arr.length - i - 1; j++) {if (arr[j] > arr[j + 1]) {int tp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tp;}}}}2、选择排序最直观易理解的排序算法,每次排出⼀个最⼩的元素。
也是最稳定的算法,时间复杂度稳定为O(n^2)。
需要⼀个变量记录每次遍历最⼩元素的位置。
时间复杂度:O(n2)空间复杂度:O(1)public static void selectSort(int[] arr){int n = arr.length;for (int i = 0; i < n; i++) {int maxIdx = 0;for(int j = 1; j < n - i; j++){if(arr[maxIdx] < arr[j]){maxIdx = j;}}int tp = arr[maxIdx];arr[maxIdx] = arr[n - 1 - i];arr[n - 1 - i] = tp;}}3、插⼊排序⼀种直观的排序算法,从第⼆个元素开始,每次往前⾯遍历找到⾃⼰该在的位置。

常见排序算法的时间复杂度比较和应用场景排序算法是计算机科学中最基本的算法之一。
在数据结构和算法中,排序算法的研究一直是热门话题。
这篇文章将会介绍一些最基本的排序算法,探讨它们的时间复杂度和一些应用场景。
1. 冒泡排序冒泡排序是最基本的排序算法之一。
其主要思想是循环遍历待排序的序列多次,每次比较相邻的两个元素的大小,如果前面的元素大于后面的元素,则交换这两个元素。
一个简单的例子如下:```pythondef bubble_sort(arr):n = len(arr)for i in range(n):for j in range(n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j]return arr```冒泡排序的时间复杂度为 $O(n^2)$,其中 $n$ 是待排序序列的长度。
由于其时间复杂度较高,冒泡排序只适用于小规模的排序任务。
2. 快速排序快速排序是一种高效的排序算法。
其主要思想是选取序列中的一个元素作为基准值,将序列中小于基准值的元素放在基准值左边,大于基准值的元素放在右边,然后递归地对左右两部分进行排序。
一个简单的例子如下:```pythondef quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr)//2]left = [x for x in arr if x < pivot]right = [x for x in arr if x > pivot]middle = [x for x in arr if x == pivot]return quick_sort(left) + middle + quick_sort(right)```快速排序的时间复杂度为 $O(n\log n)$,其中 $n$ 是待排序序列的长度。

时间的大小比较与排序时间的大小比较与排序在日常生活中经常出现,无论是安排日程、记录事件还是进行时间线推演,准确理解时间的先后关系对我们的工作生活有着重要的影响。
本文将从时间的大小比较和排序两个方面进行探讨和解析。
一、时间的大小比较时间的大小比较通常依据的是时间的先后关系,我们可以通过以下几种方式进行比较:1. 时间戳比较:时间戳是指从1970年1月1日00:00:00 Coordinated Universal Time(UTC)开始所经过的秒数。
通过比较两个时间戳的数值大小,可以得出时间的先后顺序,较大的时间戳表示较晚的时间。
2. 时刻比较:时刻比较是指比较两个具体的时间点,例如"2022年1月1日12:00"和"2022年1月2日10:00"这两个时刻,由于第二个时刻的日期较大,因此可以判断第二个时刻为较晚的时间。
3. 时段比较:时段比较是指比较两个时间段的长度,例如"上午"和"下午","2022年1月"和"2022年2月"等。
通常采用时间段的起始时间进行比较,起始时间较早的时间段被认为是较早的时间。
二、时间的排序时间的排序是指将一系列时间按照从早到晚(或从晚到早)的顺序排列。
根据需要的排序模式不同,我们可以采用以下几种方式进行排序:1. 数字排序:将时间转换为数字格式,例如时间戳或者将时间进行数值化转换,然后按照数字大小进行排序。
通过数字排序可以快速得到排序结果,但可能失去时间的具体意义。
2. 字符串排序:将时间以字符串形式表示,按照字符串的字典序进行排序。
字符串排序可以保留时间的具体信息,适合用于人工阅读和理解。
3. 列表排序:将时间按照时间戳、时刻、时段等格式组成列表,然后通过编程语言的排序算法进行排序。
列表排序可以灵活处理不同形式的时间数据,可以根据实际需求进行调整和扩展。

数组排序算法与时间复杂度分析在计算机科学中,数组排序是一项基本的操作。
排序算法的目的是将一个无序的数组按照一定的规则重新排列,使得数组中的元素按照升序或降序排列。
在实际应用中,排序算法被广泛应用于数据处理、搜索和数据库等领域。
本文将介绍几种常见的数组排序算法,并分析它们的时间复杂度。
一、冒泡排序(Bubble Sort)冒泡排序是一种简单直观的排序算法,它重复地遍历数组,每次比较相邻的两个元素,如果顺序错误就交换它们。
通过多次遍历,将最大(或最小)的元素逐渐“冒泡”到数组的末尾。
冒泡排序的时间复杂度为O(n^2),其中n是数组的长度。
这是因为冒泡排序需要遍历n次数组,并且每次遍历需要比较n-1次相邻元素。
二、选择排序(Selection Sort)选择排序是一种简单直观的排序算法,它重复地从未排序的部分选择最小(或最大)的元素,将其放到已排序部分的末尾。
选择排序的时间复杂度也为O(n^2),因为它需要遍历n次数组,并且每次遍历需要比较n-1次未排序元素。
三、插入排序(Insertion Sort)插入排序是一种简单直观的排序算法,它将数组分为已排序和未排序两部分,每次从未排序部分选择一个元素插入到已排序部分的正确位置。
插入排序的时间复杂度为O(n^2),因为它需要遍历n次数组,并且每次遍历需要比较最多n-1次已排序元素。
四、快速排序(Quick Sort)快速排序是一种高效的排序算法,它采用分治法的思想。
首先选择一个基准元素,然后将数组分成两部分,使得左边的元素都小于基准元素,右边的元素都大于基准元素。
然后递归地对左右两部分进行快速排序。
快速排序的平均时间复杂度为O(nlogn),最坏情况下为O(n^2)。
这是因为在最坏情况下,每次选择的基准元素都是数组中的最大或最小元素,导致分割不均匀。
五、归并排序(Merge Sort)归并排序是一种稳定的排序算法,它采用分治法的思想。
将数组分成两部分,分别对左右两部分进行归并排序,然后将排序好的两个部分合并成一个有序的数组。

123456987排序最快的算法-回复题目:123456987排序最快的算法摘要:排序是计算机科学中最基本的操作之一,常用的排序算法有很多种。
本文将以题目中的数字序列123456987为例,探讨其中最快的排序算法。
首先,我们将介绍目前常见的几种排序算法,然后通过比较它们的时间复杂度、空间复杂度和实际应用情况,分析并选择最合适的算法。
最后,我们将详细说明选定算法的具体实施步骤,并对结果进行评估。
第一部分:介绍几种常见排序算法1. 冒泡排序:每次比较相邻元素,如果顺序错误则交换位置,直到整个序列有序为止。
2. 插入排序:将序列分成已排序和未排序两部分,每次将未排序部分的第一个元素插入到已排序部分的正确位置。
3. 选择排序:每次从未排序部分选择一个最小(或最大)元素,放到已排序部分的末尾,直到整个序列有序为止。
4. 快速排序:选择一个基准元素,将序列分成小于基准和大于基准两部分,递归地对两部分进行排序。
第二部分:比较排序算法的时间复杂度、空间复杂度和实际应用情况1. 时间复杂度:- 冒泡排序:最好情况O(n),最坏情况O(n^2),平均情况O(n^2)。
- 插入排序:最好情况O(n),最坏情况O(n^2),平均情况O(n^2)。
- 选择排序:最好情况O(n^2),最坏情况O(n^2),平均情况O(n^2)。
- 快速排序:最好情况O(nlogn),最坏情况O(n^2),平均情况O(nlogn)。
2. 空间复杂度:- 冒泡排序:O(1)。
- 插入排序:O(1)。
- 选择排序:O(1)。
- 快速排序:最好情况O(logn),最坏情况O(n)。
3. 实际应用情况:- 冒泡排序:适用于数据量较小、基本有序的情况。
- 插入排序:适用于数据量较小、基本有序的情况。
- 选择排序:不适用于大规模数据排序。
- 快速排序:适用于大规模数据排序,目前是最常用的排序算法之一。
第三部分:选择最合适的排序算法综合考虑时间复杂度、空间复杂度和实际应用情况,我们可以得出最适合此题目的排序算法是快速排序算法。
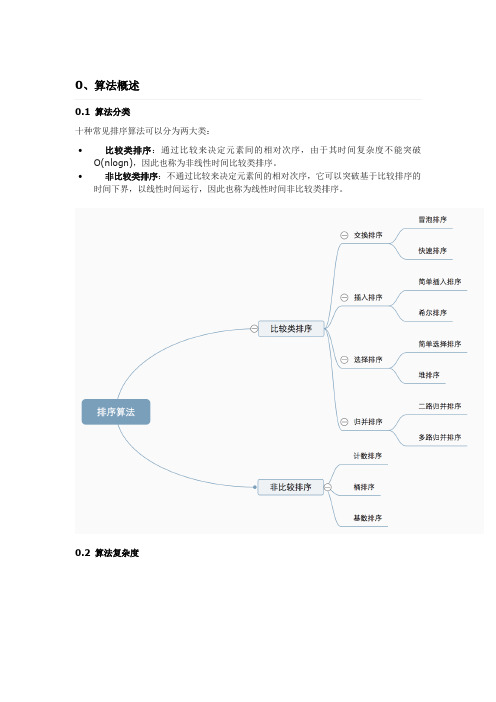
0、算法概述0.1 算法分类十种常见排序算法可以分为两大类:∙比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。
∙非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
0.2 算法复杂度0.3 相关概念∙稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
∙不稳定:如果a原本在b的前面,而a=b,排序之后a 可能会出现在b 的后面。
∙时间复杂度:对排序数据的总的操作次数。
反映当n变化时,操作次数呈现什么规律。
∙空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
1、冒泡排序(Bubble Sort)冒泡排序是一种简单的排序算法。
它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。
走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
1.1 算法描述∙比较相邻的元素。
如果第一个比第二个大,就交换它们两个;∙对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;∙针对所有的元素重复以上的步骤,除了最后一个;∙ 重复步骤1~3,直到排序完成。
1.2 代码实现 12 345678 910111213 function bubbleSort(arr) { var len = arr.length; for (var i = 0; i < len - 1; i++) { for (var j = 0; j < len - 1 - i; j++) { if (arr[j] > arr[j+1]) { // 相邻元素两两对比 var temp = arr[j+1]; // 元素交换 arr[j+1] = arr[j]; arr[j] = temp; } } } return arr; }2、选择排序(Selection Sort )选择排序(Selection-sort)是一种简单直观的排序算法。

各种排序算法的稳定性和时间复杂度小结选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法,冒泡排序、插入排序、归并排序和基数排序是稳定的排序算法。
冒泡法:这是最原始,也是众所周知的最慢的算法了。
他的名字的由来因为它的工作看来象是冒泡:复杂度为O(n*n)。
当数据为正序,将不会有交换。
复杂度为O(0)。
直接插入排序:O(n*n)选择排序:O(n*n)快速排序:平均时间复杂度log2(n)*n,所有内部排序方法中最高好的,大多数情况下总是最好的。
归并排序:log2(n)*n堆排序:log2(n)*n希尔排序:算法的复杂度为n的1.2次幂关于快速排序分析这里我没有给出行为的分析,因为这个很简单,我们直接来分析算法:首先我们考虑最理想的情况1.数组的大小是2的幂,这样分下去始终可以被2整除。
假设为2的k次方,即k=log2(n)。
2.每次我们选择的值刚好是中间值,这样,数组才可以被等分。
第一层递归,循环n次,第二层循环2*(n/2)......所以共有n+2(n/2)+4(n/4)+...+n*(n/n) = n+n+n+...+n=k*n=log2(n)*n所以算法复杂度为O(log2(n)*n)其他的情况只会比这种情况差,最差的情况是每次选择到的middle都是最小值或最大值,那么他将变成交换法(由于使用了递归,情况更糟)。
但是你认为这种情况发生的几率有多大??呵呵,你完全不必担心这个问题。
实践证明,大多数的情况,快速排序总是最好的。
如果你担心这个问题,你可以使用堆排序,这是一种稳定的O(log2(n)*n)算法,但是通常情况下速度要慢于快速排序(因为要重组堆)。
本文是针对老是记不住这个或者想真正明白到底为什么是稳定或者不稳定的人准备的。
首先,排序算法的稳定性大家应该都知道,通俗地讲就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。
在简单形式化一下,如果Ai = Aj, Ai原来在位置前,排序后Ai还是要在Aj位置前。

排序算法的时间复杂度分析排序算法是计算机科学领域中的重要问题之一,用于将一组未排序的数据按照一定规则重新排列。
排序算法的时间复杂度是评估算法执行效率的一个指标,它表示对于特定输入规模的数据,算法执行所需的计算时间与数据量增加的关系。
在实际应用中,时间复杂度是衡量算法效率的重要标准之一,因为它决定算法在处理大规模数据时的速度。
不同的排序算法具有不同的时间复杂度,根据复杂度不同,其执行时间也不同。
在具体应用场景中,我们需要根据不同的数据规模和数据特征选择合适的排序算法,以确保算法具有高效性和可扩展性。
下面具体介绍几种常见的排序算法及其时间复杂度分析。
1. 冒泡排序算法冒泡排序算法是一种简单的排序算法,其基本思想是通过比较相邻两个数据的大小,将较大的数据往后移,最终实现数据升序或降序排列的目的。
其时间复杂度为O(n^2),即当数据量增加一倍时,执行时间将增加4倍,算法效率较低。
2. 快速排序算法快速排序算法是一种经典的排序算法,在实际应用中广泛使用。
该算法通过定义基准值,将待排序数据分成两个子序列,并递归地对子序列进行排序,最终实现数据排序的目的。
其时间复杂度为O(n log n),效率较高,在对大规模数据进行排序时表现出色。
3. 直接插入排序算法直接插入排序算法是一种简单但效率较低的排序算法,其基本思想是将数据依次插入已排序的有序序列中,最终实现数据排序的目的。
该算法的时间复杂度为O(n^2),随着数据量的增加,算法执行时间增加较快。
4. 堆排序算法堆排序算法是一种基于堆数据结构的排序算法,其基本思想是通过维护一个堆,不断取出堆中最大或最小元素,最终实现数据排序的目的。
其时间复杂度为O(n log n),执行效率较高,在处理大规模数据时表现出色。
综上所述,排序算法的时间复杂度对算法的效率和可扩展性具有重要影响。
在具体应用场景中,我们需要根据数据特征和数据规模选择合适的排序算法,并结合算法的时间复杂度进行评估,以确保算法具有高效性和可扩展性。

时分的比较与排序时间,作为我们生活中不可或缺的一部分,时刻影响着我们的日常安排与生活节奏。
怎样准确地比较和排序时间,对于我们合理安排时间、高效管理生活至关重要。
本文将探讨时分的比较与排序方法,以帮助读者更好地管理时间。
一、比较时间的方式1. 相对时间比较:我们常常会用到相对时间表达方式,如“早上”、“中午”、“下午”、“晚上”等。
这种比较方式主要是针对每天的不同时间段进行排序。
例如,早上通常是指6点到9点之间,中午是指11点到13点之间,下午是14点到18点之间,晚上则是19点到24点之间。
2. 精确时间比较:在某些场合下,我们需要对时间进行更精确的比较,例如在制定行程或会议安排时。
这时,常常会用到“点”、“分”、“秒”等时间单位进行比较,如“8点30分”、“12点15分”等。
3. 日期比较:在处理更长时间跨度的事件时,我们需要进行日期的比较。
可以通过年、月、日的顺序进行排序,例如“2019年5月15日”、“2020年1月1日”等。
二、排序时间的方法1. 数字排序法:这是最常见的一种时间排序方法。
我们可以将时间按照先后顺序,从小到大或从大到小进行排序。
比如,我们可以将一天的24小时按照时间顺序从0点至24点进行排序。
2. 时分秒排序法:在需要更精确的时间排序时,我们可以将时间按照小时、分钟、秒的顺序进行排序。
例如,我们可以将各个时间点按照小时、分钟、秒的大小进行排序,以便更好地了解事件发生的顺序。
3. 日期排序法:对于需要比较日期先后的场合,可以按照先后顺序对日期进行排序。
这种排序方法常用于旅行计划、会议安排等需要按照日期先后顺序进行排序的情况。
三、时间排序的实际应用1. 日程安排:在我们的日常生活中,合理安排时间是非常重要的。
通过对时间进行比较和排序,我们可以更好地安排每天的行程,合理利用时间,提高工作效率和生活质量。
比如,在制定每日的时间表时,我们可以按照先后顺序排列每个时间段的任务,以确保按计划完成任务。

常见排序算法及对应的时间复杂度和空间复杂度转载请注明出处:(浏览效果更好)排序算法经过了很长时间的演变,产⽣了很多种不同的⽅法。
对于初学者来说,对它们进⾏整理便于理解记忆显得很重要。
每种算法都有它特定的使⽤场合,很难通⽤。
因此,我们很有必要对所有常见的排序算法进⾏归纳。
排序⼤的分类可以分为两种:内排序和外排序。
在排序过程中,全部记录存放在内存,则称为内排序,如果排序过程中需要使⽤外存,则称为外排序。
下⾯讲的排序都是属于内排序。
内排序有可以分为以下⼏类: (1)、插⼊排序:直接插⼊排序、⼆分法插⼊排序、希尔排序。
(2)、选择排序:直接选择排序、堆排序。
(3)、交换排序:冒泡排序、快速排序。
(4)、归并排序 (5)、基数排序表格版排序⽅法时间复杂度(平均)时间复杂度(最坏)时间复杂度(最好)空间复杂度稳定性复杂性直接插⼊排序O(n2)O(n2)O(n2)O(n2)O(n)O(n)O(1)O(1)稳定简单希尔排序O(nlog2n)O(nlog2n)O(n2)O(n2)O(n)O(n)O(1)O(1)不稳定较复杂直接选择排序O(n2)O(n2)O(n2)O(n2)O(n2)O(n2)O(1)O(1)不稳定简单堆排序O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)O(1)O(1)不稳定较复杂冒泡排序O(n2)O(n2)O(n2)O(n2)O(n)O(n)O(1)O(1)稳定简单快速排序O(nlog2n)O(nlog2n)O(n2)O(n2)O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)不稳定较复杂归并排序O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)O(n)O(n)稳定较复杂基数排序O(d(n+r))O(d(n+r))O(d(n+r))O(d(n+r))O(d(n+r))O(d(n+r))O(n+r)O(n+r)稳定较复杂图⽚版①插⼊排序•思想:每步将⼀个待排序的记录,按其顺序码⼤⼩插⼊到前⾯已经排序的字序列的合适位置,直到全部插⼊排序完为⽌。

三大常规语句运行时间排序
排序算法的运行时间:
可以发现:
归并排序最快,而希尔排序与快速排序也比较快。
1.冒泡排序(Bubble sort)
冒泡排序是最直觉的比较算法了,它的思想是:
将相邻的元素两两比较,若顺序不对则交换顺序,直到没有需要交换的数对为止。
算法复杂度O(n2)O(n2),举例:排序(5 1 4 2)
2.插入排序
基本思想类似于扑克牌的起牌,总是将后一个元素插入到前面有序的数组中。
算法复杂度:O(n2)O(n2)
3.希尔排序
该排序是插入排序的扩展,基本思想是:使数组中任意间隔为hh的元素都是有序的。
算法复杂度为:O(n3/2)O(n3/2)或O(n4/3)O(n4/3),算法复杂度的证明比较复杂,与数列hh的选择有关。
4.归并排序
归并排序的思想是:利用二分法,将一个数组分成两个子数组,对每个子数组分别排序,然后将排序好的子数组合并。
注意:该算法需要一个辅助数组,为了加快运算速度,在分治之前就应该定义初始化好辅助数组,否则在子数组中频繁初始化辅助数组,就会大大增加计算时间。
算法复杂度:O(nlgn)O(nlgn)
注:将一个数组用二分法,共有lgnlgn层,没一层有nn次比较,因此得出该算法复杂度。
5.快速排序
快速排序是java默认的排序算法,其基本思想是:
1.从数列中调出一个元素作为基准;
2.对基准元素左侧与右侧分别扫描,将比基准元素小的放在基准元素左侧,大的放在右侧;
3.基准元素左右两端得到了两个子数列,对子数列重复以上步骤。
其算法复杂度为O(nlg(n))。

排序算法比较主要内容:1)利用随机函数产生10000个随机整数,对这些数进行多种方法排序。
2)至少采用4种方法实现上述问题求解(可采用的方法有插入排序、希尔排序、起泡排序、快速排序、选择排序、堆排序、归并排序),并把排序后的结功能果保存在不同的文件里。
3)给出该排序算法统计每一种排序方法的性能(以运行程序所花费的时间为准进行对比),找出其中两种较快的方法。
程序的主要功能:1.随机数在排序函数作用下进行排序2.程序给出随机数排序所用的时间。
算法及时间复杂度(一)各个排序是算法思想:(1)直接插入排序:将一个记录插入到已排好的有序表中,从而得到一个新的,记录数增加1的有序表。
(2)冒泡排序:首先将第一个记录的关键字和第二个记录的关键字进行比较,若为逆序,则将两个记录交换,然后比较第二个记录和第三个记录的关键字。
依此类推,直到第N-1和第N个记录的关键字进行过比较为止。
上述为第一趟排序,其结果使得关键字的最大纪录被安排到最后一个记录的位置上。
然后进行第二趟起泡排序,对前N-1个记录进行同样操作。
一共要进行N-1趟起泡排序。
(3)快速排序:通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,已达到整个序列有序。
(4)选择排序:通过N-I次关键字间的比较,从N-I+1个记录中选出关键字最小的记录,并和第I(1<=I<=N)个记录交换。
时间复杂度分析排序算法最差时间时间复杂度是否稳定?插入排序O(n2) O(n2) 稳定冒泡排序O(n2) O(n2) 稳定快速排序O(n2) O(n*logn) 不稳定2选择排序O(n2) O(n2) 稳定10000个数据的时间比较:算法名称用时插入排序122冒泡排序343快速排序7选择排序116程序源代码:/********************************************************************************************** package test;public class SortArray {private static final int Min = 1;//生成随机数最小值private static final int Max = 10000;//生成随机数最大值private static final int Length = 10000;//生成随机数组长度(测试的朋友建议不要超过40000,不然你要等很久,如果你电脑配置绝对高的情况下你可以再加个0试试)public static void main(String[] args) {System.out.println("数组长度:"+Length+", Min:"+Min+", Max:"+Max);long begin;long end;int arr[] = getArray(Length);begin = System.currentTimeMillis();insertSort(arr.clone());end = System.currentTimeMillis();System.out.println("插入法排序法消耗时间:"+(end-begin)+"毫秒");begin = System.currentTimeMillis();bubbleSort(arr.clone());end = System.currentTimeMillis();System.out.println("冒泡发排序法消耗时间:"+(end-begin)+"毫秒");begin = System.currentTimeMillis();fastSort(arr.clone(),0,arr.length-1);end = System.currentTimeMillis();System.out.println("快速排序法消耗时间:"+(end-begin)+"毫秒");begin = System.currentTimeMillis();choiceSort(arr.clone());end = System.currentTimeMillis();System.out.println("选择排序法消耗时间:"+(end-begin)+"毫秒");}/**生成随机数数组* @param length 数组长度* @return int[]*/private static int[] getArray(int length){if(length<=0)return null;int arr[] = new int[length];for (int i = 0; i < arr.length; i++) {int temp = (int)(Min+Math.random()*(Max-Min-1)); arr[i] = temp;}return arr;}/**快速发排序* @param arr 需要排序的数组* @param left 数组最小下标(一般是0)* @param right 数组最大下标(一般是Length-1)* @return int[]*/private static int[] fastSort(int[] arr,int left,int right){ if(left < right){int s = arr[left];int i = left;int j = right + 1;while(true){//向右找大于s的元素的索引while(i+1 < arr.length && arr[++i] < s);//向左找小于s的元素的索引while(j-1 > -1 && arr[--j] > s);//如果i >= j 推出循环if(i >= j){break;}else{//教化i和j位置的元素int t = arr[i];arr[i] = arr[j];arr[j] = t;}}arr[left] = arr[j];arr[j] = s;//对左面进行递归fastSort(arr,left,j-1);//对右面进行递归fastSort(arr,j+1,right);}return arr;}/**插入法排序* @param arr 需要排序的数组* @return int[]*/private static int[] insertSort(int[] arr){ for(int i = 1;i < arr.length;i++){ int temp = arr[i];int j = i - 1;while(temp < arr[j]){arr[j+1] = arr[j];j--;if(j == -1){break;}}arr[j+1] = temp;}return arr;}/**冒泡发排序* @param arr 需要排序的数组* @return int[]*/private static int[] bubbleSort(int[] arr){for(int i = 0;i < arr.length;i++){//比较两个相邻的元素for(int j = 0;j < arr.length-i-1;j++){ if(arr[j] > arr[j+1]){int t = arr[j];arr[j] = arr[j+1];arr[j+1] = t;}}}return arr;}/**选择法排序* @param arr* @return*/private static int[] choiceSort(int[] arr){for(int i = 0;i < arr.length;i++){int m = i;for(int j = i + 1;j < arr.length;j++){//如果第j个元素比第m个元素小,将j赋值给mif(arr[j] < arr[m]){m = j;}}//交换m和i两个元素的位置if(i != m){int t = arr[i];arr[i] = arr[m];arr[m] = t;}}return arr; }/**打印数组* @param arr 需要打印的数组*/private static void print(int[] arr){ if(arr==null||arr.length==0)return;for (int i = 0; i < arr.length; i++) { System.out.print(arr[i]+",");}}}测试结果:11总结:好的算法+编程技巧+高效率=好的程序。

排序的时间复杂度
1、插入排序
插入排序时间复杂度:
最好:
所有元素已经排好序,只需遍历一遍,无需交换位置;
最坏:
所有元素逆序排列,遍历一次需要比较的元素个数每次+1,所以时间复杂度是O(n^2);
平均时间复杂度就是O(n^2)喽。
2、快速排序
有关快速排序时间复杂度:
最好的时间复杂度和平均时间复杂度就是O(nlogn);
正常情况下是递归log2n次,每次遍历的最坏时间复杂度是n,所以平均时间复杂度是O(nlogn);
最好的时间复杂度就是每次都划分的很均匀;时间复杂度就是O(nlogn);
最坏的时间复杂度是O(n^2),这种情况就是原先的数据就是排序好,这样每次只能位移一个数据,
每次划分的子序列只比上一次划分少一个记录,注意两一个为空。
3、归并排序
归并排序时间复杂度:
归并排序无论在什么情况下,将数组拆分都需要log(n)次;
在归并时,也需要遍历比较两个数组的大小,平均时间复杂度O(n);所以归并排序最好最坏时间复杂度都是nlogn;
空间复杂度是O(n);
4、堆排序
堆排序每次都要将一个元素上升到堆顶,然后放回最后,需要n轮,固定不变
每一轮堆调整的时间复杂度是log(n),n依次递减
所以堆排序的时间复杂度是O(nlogn)。
题目:排序算法比较设计目的:1.掌握各种排序的基本思想。
2.掌握各种排序方法的算法实现。
3.掌握各种排序方法的优劣分析及花费的时间的计算。
4.掌握各种排序方法所适应的不同场合。
二、设计内容和要求利用随机函数产生30000个随机整数,利用插入排序、起泡排序、选择排序、快速排序、堆排序、归并排序等排序方法进行排序,并统计每一种排序上机所花费的时间。
函数说明cha_ru_sort(int nData[], unsigned int nNum) 插入排序maopao_sort(int maopao_data[],int maopao_n) 起泡排序select_sort(int *Data,int nLen) 选择排序QuickSort(int* pData,int nLen) 快速排序HeapSort(int array[],int length) 堆排序MergeSort(int sourceArr[], int targetArr[], int startIndex, int endIndex) 归并排序无参数返回**************************************************************/#include<stdio.h>#include<stdlib.h>//#include"stdlib.h"??//随机函数头文件#include<time.h>#define rand_number 30000 //产生随机数的个数int rand_numbers_30000_0[rand_number]={0},rand_numbers_30000_1[rand_number]={0}; int min,max; //随机数的范围//***************************************************************//功能:产生随机数//无参数返回void produce_rand_num(){int i;for(i=0;i<rand_number;i++){rand_numbers_30000_0[i]=min+rand()%max;}}/****************************************************************************** ***///函数名:插入排序////功能描述:插入排序从下到大,nData为要排序的数据,nNum为数据的个数,该排序是稳定的排序//一个数就是已经排列好的了,所以从数组第二个数开始进行插入排序////无参数返回/****************************************************************************** ***/void cha_ru_sort(int nData[], unsigned int nNum){unsigned int i,j,k;for( i = 1 ; i < nNum; i++){int nTemp = nData[i]; //从数组中的第二个数开始获取数据for( j = 0 ; j < i; j++)//对该数,寻找他要插入的位置{if(nData[j]>nTemp)//找到位置,然后插入该位置,之后的数据后移{for( k = i; k > j ;--k)//数据后移{nData[k]=nData[k-1];}nData[j]=nTemp;//将数据插入到指定位置break;}}}}/****************************************************************************** ***///函数名:冒泡排序////功能描述:/****************************************************************************** ***///冒泡排序,maopao_data要排序的数据,maopao_n数据的个数void maopao_sort(int maopao_data[],int maopao_n){unsigned char flag=0;//flag为1表示排序结束,初始化为0int i,j;int nTemp;//i从[0,maopao_n-1)开始冒泡,确定第i个元素for( i=0 ; i<maopao_n-1 ; i++)//比较maopao_n-1次{//从[maopao_n - 1, i)检查是否比上面一个小,把小的冒泡浮上去for(j=0;j<maopao_n- 1 -i ; j++){if( maopao_data[j] > maopao_data[j+1]) //如果下面的比上面小,交换{nTemp=maopao_data[j];maopao_data[j] = maopao_data[j+1];maopao_data[j+1]=nTemp;}}}}///****************************************************************************** ***///函数名:选择排序////功能描述:/****************************************************************************** ***///选择排序//选择排序,pnData要排序的数据,nLen数据的个数void select_sort(int *Data,int nLen){int nIndex,i,j,nTemp;//i从[0,nLen-1)开始选择,确定第i个元素for(i=0;i<nLen-1;i++){nIndex=i;//遍历剩余数据,选择出当前最小的数据for(j=i+1;j<nLen;j++){if(Data[j]<Data[nIndex]){nIndex=j;}}//如果当前最小数据索引不是i,也就是说排在i位置的数据不在nIndex处if(nIndex!=i){//交换数据,确定i位置的数据。
nTemp=Data[i];Data[i]=Data[nIndex];Data[nIndex]=nTemp;}}}/****************************************************************************** ***///函数描述:快速排序///////****************************************************************************** ***///化分区间,找到最后元素的排序位置。
并返回分隔的点(即最后一数据排序的位置)。
//划分的区间是[nBegin,nEnd) .pData是保存数据的指针int position(int *pData, int nBeging, int nEnd){int j,i,nD,nTemp;nEnd--;i=nBeging-1;//分隔符号,最后nD保存在这里nD=pData[nEnd];//比较的数据。
//遍历数据比较,找到nD的位置,这里注意,比较结果是,//如果i的左边是小于等于nD的,i的右边是大于nD的for(j=nBeging;j<nEnd;++j){if(pData[j]<=nD)//如果数据比要比较的小,则在该数据的左边,与i+1交换{i++;//小于nD的数据多一个,所以要加1,i的左边数据都比nD小nTemp=pData[i];//交换数据pData[i]=pData[j];pData[j]=nTemp;}}//最后不要忘了吧nD和i+1交换,因为这里就是nD的位置咯。
++i;pData[nEnd]=pData[i];pData[i]=nD;return i;//返回nD的位置,就是分割的位置。
}//排序的递归调用。
int QuickSortRecursion(int *pData,int nBeging,int nEnd){int i;if(nBeging>=nEnd-1)//如果区域不存在或只有一个数据则不递归排序{return 1;}//这里因为分割的时候,分割点处的数据就是排序中他的位置。
//也就是说他的左边的数据都小于等于他,他右边的数据都大于他。
//所以他不在递归调用的数据中。
i=position(pData,nBeging,nEnd);//找到分割点QuickSortRecursion(pData,nBeging,i);//递归左边的排序QuickSortRecursion(pData,i+1,nEnd);//递归右边的排序return 1;}//快速排序void QuickSort(int* pData,int nLen){//递归调用,快速排序。
QuickSortRecursion(pData,0,nLen);}/****************************************************************************** ***///函数名:堆排序////功能描述:/****************************************************************************** ***/void HeapAdjust(int array[], int i, int nLength)int nChild;int nTemp;for (nTemp = array[i]; 2 * i + 1 < nLength; i = nChild){// 子结点的位置=2*(父结点位置)+ 1nChild = 2 * i + 1;// 得到子结点中较大的结点if ( nChild < nLength-1 && array[nChild + 1] > array[nChild])++nChild;// 如果较大的子结点大于父结点那么把较大的子结点往上移动,替换它的父结点if (nTemp < array[nChild]){array[i] = array[nChild];array[nChild]= nTemp;}else// 否则退出循环break;}}// 堆排序算法void HeapSort(int array[],int length){int tmp,i;// 调整序列的前半部分元素,调整完之后第一个元素是序列的最大的元素//length/2-1是第一个非叶节点,此处"/"为整除for (i = floor(length -1)/ 2 ; i >= 0; --i)HeapAdjust(array, i, length);// 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素for (i = length - 1; i > 0; --i){// 把第一个元素和当前的最后一个元素交换,// 保证当前的最后一个位置的元素都是在现在的这个序列之中最大的/// Swap(&array[0], &array[i]);tmp = array[i];array[i] = array[0];array[0] = tmp;// 不断缩小调整heap的范围,每一次调整完毕保证第一个元素是当前序列的最大值HeapAdjust(array, 0, i);}}/****************************************************************************** ***///函数名:归并排序////功能描述:将sourceArr[]中的数据排序,按顺序存入targetArr[]数组中,排序的个数从// startIndex开始到endIndex/****************************************************************************** ***/void Merge(int sourceArr[], int targetArr[], int startIndex, int midIndex, int endIndex){int i, j, k;for(i = midIndex+1, j = startIndex; startIndex <= midIndex && i <= endIndex; j++) {if(sourceArr[startIndex] < sourceArr[i]){targetArr[j] = sourceArr[startIndex++];}else{targetArr[j] = sourceArr[i++];}}if(startIndex <= midIndex){for(k = 0; k <= midIndex-startIndex; k++){targetArr[j+k] = sourceArr[startIndex+k];}}if(i <= endIndex){for(k = 0; k <= endIndex- i; k++){targetArr[j+k] = sourceArr[i+k];}}//内部使用递归,空间复杂度为n+lognvoid MergeSort(int sourceArr[], int targetArr[], int startIndex, int endIndex){int midIndex;int tempArr[100]; //此处大小依需求更改if(startIndex == endIndex){targetArr[startIndex] = sourceArr[startIndex];}else{midIndex = (startIndex + endIndex)/2;MergeSort(sourceArr, tempArr, startIndex, midIndex);MergeSort(sourceArr, tempArr, midIndex+1, endIndex);Merge(tempArr, targetArr,startIndex, midIndex, endIndex);}}/****************************************************************************** ***/void main(){long int go_time; //所用时间time_t t1,t2;//time_t是表示时间的结构体,t1为开始时间。