《编译原理(实验部分)》实验1_程序预处理
- 格式:docx
- 大小:15.33 KB
- 文档页数:3

实验一词法分析程序设计(6学时)一、实验目的设计并实现一个包含预处理功能的词法分析程序,加深对编译中词法分析过程的理解。
二、实验要求1、实现词法分析功能输入:所给文法的源程序字符串。
输出:二元组(syn,token)构成的序列。
其中,syn为单词种别码。
Token为存放的单词自身字符串。
具体实现时,可以将单词的二元组用结构进行处理。
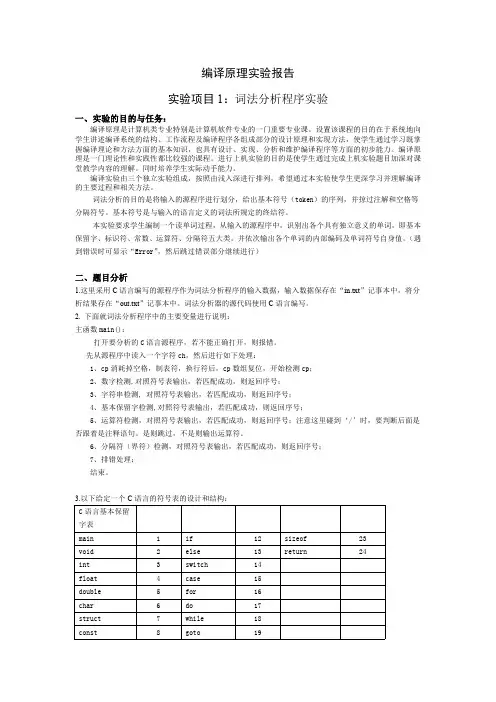
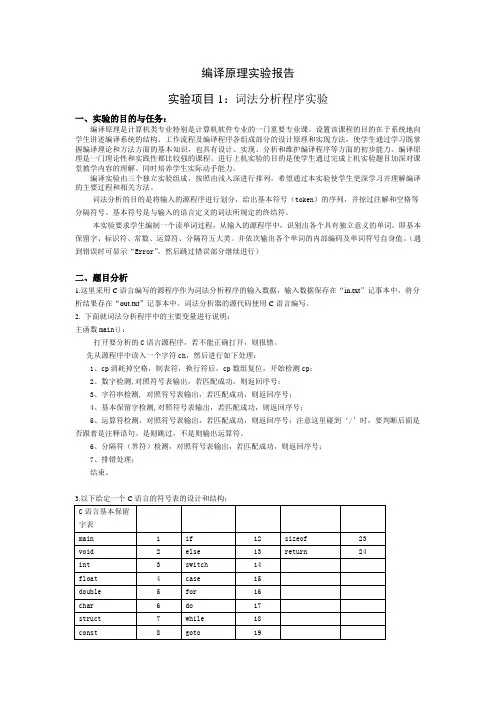
2、待分析的C语言子集的词法1)关键字main if then while do static int double struct break else long switch case typedef char return const float shortcontinue for void default sizeof do所有的关键字都是小写。
2)运算符和界符+ - * / < <= > >= = ; ( )3)其他标记ID和NUM通过以下正规式定义其他标记:标识符 ID→letter(letter|digit)*无符号整数 NUM→digit digit*字母 letter→a|…|z|A|…|Z数字 digit→0|…|9…4)空格由空白、制表符和换行符组成空格一般用来分隔ID、NUM、专用符号和关键字,词法分析阶段通常被忽略。
4、各种单词符号对应的种别码表1 各种单词符号的种别码单词符号种别码单词符号种别码main 1 ; 41if 2 ( 42else 3 ) 43while 4 int 7do 5 double 8static 6 struct 9ID (标识符)25 break 10NUM (整数) 26 else 11+ 27 long 12- 28 switch 13* 29 case 14/ 30 typedef 15: 31 char 16:= 32 return 17< 33 const 18<> 34 float 19<= 35 short 20> 36 continue 21>= 37 for 22= 38 void 23default 39 sizeof 24do 405、词法分析程序的主要算法思想算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到的单词符号的第一个字符的种类,拼出相应的单词符号。
编译原理实验报告实验项目1:词法分析程序实验一、实验的目的与任务:编译原理是计算机类专业特别是计算机软件专业的一门重要专业课。
设置该课程的目的在于系统地向学生讲述编译系统的结构、工作流程及编译程序各组成部分的设计原理和实现方法,使学生通过学习既掌握编译理论和方法方面的基本知识,也具有设计、实现、分析和维护编译程序等方面的初步能力。
编译原理是一门理论性和实践性都比较强的课程。
进行上机实验的目的是使学生通过完成上机实验题目加深对课堂教学内容的理解。
同时培养学生实际动手能力。
编译实验由三个独立实验组成,按照由浅入深进行排列,希望通过本实验使学生更深学习并理解编译的主要过程和相关方法。
词法分析的目的是将输入的源程序进行划分,给出基本符号(token)的序列,并掠过注解和空格等分隔符号。
基本符号是与输入的语言定义的词法所规定的终结符。
本实验要求学生编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(遇到错误时可显示“Error”,然后跳过错误部分继续进行)二、题目分析1.这里采用C语言编写的源程序作为词法分析程序的输入数据,输入数据保存在“in.txt”记事本中,将分析结果存在“out.txt”记事本中。
词法分析器的源代码使用C语言编写。
2.下面就词法分析程序中的主要变量进行说明:主函数main():打开要分析的C语言源程序,若不能正确打开,则报错。
先从源程序中读入一个字符ch,然后进行如下处理:1、cp消耗掉空格,制表符,换行符后,cp数组复位,开始检测cp;2、数字检测,对照符号表输出,若匹配成功,则返回序号;3、字符串检测, 对照符号表输出,若匹配成功,则返回序号;4、基本保留字检测,对照符号表输出,若匹配成功,则返回序号;5、运算符检测,对照符号表输出,若匹配成功,则返回序号;注意这里碰到‘/’时,要判断后面是否跟着是注释语句。

编译原理实验报告一、实验目的编译原理是计算机科学中的重要学科,它涉及到将高级编程语言转换为计算机能够理解和执行的机器语言。
本次实验的目的是通过实际操作和编程实践,深入理解编译原理中的词法分析、语法分析、语义分析以及中间代码生成等关键环节,提高我们对编译过程的认识和编程能力。
二、实验环境本次实验使用的编程语言为C++,开发环境为Visual Studio 2019。
此外,还使用了一些相关的编译工具和调试工具,如 GDB 等。
三、实验内容(一)词法分析器的实现词法分析是编译过程的第一步,其任务是将输入的源程序分解为一个个单词符号。
在本次实验中,我们使用有限自动机的理论来设计和实现词法分析器。
首先,定义了各种单词符号的类别,如标识符、关键字、常量、运算符等。
然后,根据这些类别设计了相应的状态转换图,并将其转换为代码实现。
在实现过程中,使用了正则表达式来匹配输入字符串中的单词符号。
对于标识符和常量等需要进一步处理的单词符号,使用了相应的规则进行解析和转换。
(二)语法分析器的实现语法分析是编译过程的核心环节之一,其任务是根据给定的语法规则,分析输入的单词符号序列是否符合语法结构。
在本次实验中,我们使用了递归下降的语法分析方法。
首先,根据实验要求定义了语法规则,并将其转换为相应的递归函数。
在递归函数中,通过对输入单词符号的判断和处理,逐步分析语法结构。
为了处理语法错误,在分析过程中添加了错误检测和处理机制。
当遇到不符合语法规则的输入时,能够输出相应的错误信息,并尝试进行恢复。
(三)语义分析及中间代码生成语义分析的目的是对语法分析得到的语法树进行语义检查和语义处理,生成中间代码。
在本次实验中,我们使用了三地址码作为中间代码的表示形式。
在语义分析过程中,对变量的定义和使用、表达式的计算、控制流语句等进行了语义检查和处理。
对于符合语义规则的语法结构,生成相应的三地址码指令。
四、实验步骤(一)词法分析器的实现步骤1、定义单词符号的类别和对应的正则表达式。

《编译原理》实验指导书编译⽅法实验指导书柴本成赵晨编写浙江万⾥学院2010.01⽬录实验⼀有限⾃动机的构造与实现 (1)实验⼆词法分析器的设计 (3)实验三语法分析-递归下降分析器 (5)实验四LL(1)⽂法预测分析表的实现 (6)附录 (9)附录⼀实验结果的提交与检查 (9)附录⼆实验报告参考格式 (9)附录三Visual C++上机环境简介 (10)附录四参考程序 (13)实验⼀有限⾃动机的构造与实现⼀、实验⽬的1、正确理解正规式和正规集以及有限⾃动机的定义;2、熟练掌握⽤状态转换图表⽰有限⾃动机的⽅法。
⼆、实验预习提⽰1、正规表达式就是⼀种形式化的表⽰法,它可以表⽰单词符号的结构,从⽽精确地定义单词符号集。
正规表达式简称为正规式,它表⽰的集合即为正规集。
2、状态转换图是⼀张当输⼊不同内容时选择不同分析路径的有向图。
⼀个状态转换图可⽤于识别⼀定的字符串。
3、有限⾃动机(FA)是更⼀般化的状态转换图,可⽤来识别正规集;分为DFA和NFA 两种。
三、实验内容构造识别如下字符串的状态转换图,并将其编程实现。
1、识别标识符(以字母开始由字母和数字构成的字符串,要求长度不超过10);参考程序:#include#include //字符串处理的头⽂件//判断⼀个字符是不是字母bool Isletter(char ch){if(ch>='a' && ch<='z' || ch>='A' && ch<='Z') return true;return false;}//判断⼀个字符是不是数字bool IsDigit(char ch){if(ch>='0' && ch<='9') return true;return false;}//判断⼀个字符串是不是标识符bool IsId(char *str){if(!Isletter(str[0]) ) return false;int l=strlen(str); //计算字符串的长度for(int i=1;iif(Isletter(str[i]) || IsDigit(str[i])) continue; //如果是字母或数字就继续循环else return false; //否则,返回不是字符串return true;}void main(){char *str="1abc"; //初始化字符串,也可键盘输⼊if(IsId(str)) cout<<"accept!"<else cout<<" not accept!"<}2、识别实数(要求正负号可有可⽆,长度不超过20,不要求识别⽤科学记数法表⽰的实数)。

《编译原理》实验指导书编著陈志刚中南大学信息科学与工程学院2006年11月第一部分词法分析(实验一必作)实验一词法分析程序设计与实现一、实验目的加深对词法分析器的工作过程的理解;加强对词法分析方法的掌握;能够采用一种编程语言实现简单的词法分析程序;能够使用自己编写的分析程序对简单的程序段进行词法分析。
二、实验内容自定义一种程序设计语言,或者选择已有的一种高级语言,编制它的词法分析程序。
词法分析程序的实现可以采用任何一种编程语言和编程工具。
从输入的源程序中,识别出各个具有独立意义的单词,即关键字、标识符、常数、运算符、界符。
并依次输出各个单词的内部编码及单词符号自身值。
(遇到错误时可显示“Error”,然后跳过错误部分继续显示)三、实验要求:1.对单词的构词规则有明确的定义;2.编写的分析程序能够正确识别源程序中的单词符号;3.识别出的单词以<种别码,值>的形式保存在符号表中,正确设计和维护符号表;4.对于源程序中的词法错误,能够做出简单的错误处理,给出简单的错误提示,保证顺利完成整个源程序的词法分析;四、实验步骤1.定义目标语言的可用符号表和构词规则;2.依次读入源程序符号,对源程序进行单词切分和识别,直到源程序结束;3.对正确的单词,按照它的种别以<种别码,值>的形式保存在符号表中;4.对不正确的单词,做出错误处理。
五、实验报告要求详细说明你的程序的设计思路和实现过程。
用有限自动机或者文法的形式对词法定义做出详细说明,说明词法分析程序的工作过程,说明错误处理的实现。
参考资料一、程序要求1、以下面一段程序为例main() {int a,b;a = 10;b = a + 20;}2、需要识别的词1.关键字:if、int、for、while、do、return、break、continue;单词种别码为1。
2.标识符;单词种别码为2。
3.常数为无符号整形数;单词种别码为3。
4.运算符包括:+、-、*、/、=、、<、=、<=、!= ;单词种别码为4。


《编译原理》(实验部分)实验1_程序预处理一、实验目的明确预处理子程序的任务,构造一个简单的预处理子程序,对源程序进行相应的预处理。
二、实验设备1、PC 兼容机一台;操作系统为WindowsWindowsXP。
2、Visual C++ 6.0 或以上版本, Windows 2000 或以上版本,汇编工具(在Software 子目录下)。
三、实验原理定义模拟的简单语言的词法构成,编制读入源程序和进行预处理的程序,要求将源程序读入到文件或存入数组中,再从文件或数组中逐个读取字符进行预处理,包括去掉注释、Tab、Enter和续行符等操作,并显示预处理后的程序。
四、实验步骤1、从键盘读入源程序存放到输入缓冲区中。
2、对源程序进行预处理,预处理后的程序存放到扫描缓冲区中。
3、显示预处理后的程序。
参考源程序(C++语言编写)//源程序的输入及预处理#include <fstream.h>#include <iostream.h>void pro_process(char *);void main( ) //测试驱动程序{//定义扫描缓冲区char buf[4048]={'\0'}; //缓冲区清0//调用预处理程序pro_process(buf); //在屏幕上显示扫描缓冲区的内容cout<<buf<<endl;}void pro_process(char *buf) //预处理程序{ifstream cinf("source.txt",ios::in);int i=0; //计数器char old_c='\0',cur_c; //前一个字符,当前字符。
bool in_comment=false; //false表示当前字符未处于注释中。
while(cinf.read(&cur_c,sizeof(char))){ //从文件读一个字符switch(in_comment){case false:if(old_c=='/' && cur_c=='*'){ //进入注释i--; //去除已存入扫描缓冲区的字符'/'in_comment=true;}else {if(old_c=='\\' && cur_c=='\n') //发现续行i--; //去除已存入扫描缓冲区的字符'\'else {if(cur_c>='A' && cur_c<='Z') //大写变小写cur_c+=32;if(cur_c =='\t' || cur_c =='\n')//空格取代TAB换行cur_c=' ';buf[i++]=cur_c ;}}break;case true:if(old_c=='*' && cur_c=='/') //离开注释in_comment=false;}//end of switchold_c= cur_c; //保留前一个字符}//end of whilebuf[i++]='#'; //在源程序尾部添加字符'#' }。

编译原理实验教程课程设计背景编译原理是计算机科学专业的一门重要课程,它研究如何将高级语言翻译成低级语言,以便计算机执行。
编译器是实现这一过程的关键工具。
然而,对于很多学生来说,编译原理的理论知识学习起来比较抽象,难以掌握。
因此,本文旨在为编译原理的学习提供一些实验教程的设计思路。
实验一:词法分析器词法分析器是编译器的第一个模块,它的作用是将输入的字符流转化为一个个单词符号。
本实验的目的是设计并实现一个简单的词法分析器,实现以下功能:1.识别输入的程序中所包含的各个单词符号。
2.输出所有单词符号及其对应的单词类型。
3.当遇到不合法单词符号时,给出相应的错误提示。
具体实现可以采用有限自动机的思想,使用正则表达式或者手写代码,实现对于不同的单词类型的识别,并对于不合法单词进行识别和报错处理。
实验二:语法分析器语法分析器是编译器的第二个模块,它的作用是将词法分析器输出的单词序列转换成语法树或者语法分析表,以便后续进行语义分析和目标代码生成。
本实验的目的是设计并实现一个简单的语法分析器,实现以下功能:1.识别输入的程序是否符合所设计的文法规则。
2.输出语法树或语法分析表。
具体实现可以采用自上而下的递归下降分析法或自下而上的移进-规约分析法,实现对于不同的句型的识别,并生成语法树或语法分析表。
实验三:语义分析器语义分析器是编译器的第三个模块,它的作用是对语法分析器输出的语法树或语法分析表进行语义分析,并生成中间代码。
本实验的目的是设计并实现一个简单的语义分析器,实现以下功能:1.对语法树或语法分析表进行遍历,识别语法错误和语义错误,给出相应的错误提示。
2.生成中间代码。
具体实现可以采用语义规则和符号表的检查方式,识别语法错误和语义错误,并在生成中间代码时,根据中间代码语言的规则进行实现。
实验四:目标代码生成器目标代码生成器是编译器的第四个模块,它的作用是将中间代码转换成机器语言,以便计算机执行。
本实验的目的是设计并实现一个简单的目标代码生成器,实现以下功能:1.将中间代码转换成机器语言。

编译原理实验报告某某:班级:学号:自评:中实验一词法分析程序实现一、实验目的与要求通过编写和调试一个词法分析程序,掌握在对程序设计语言的源程序进行扫描的过程中,将字符形式的源程序流转化为一个由各类单词符号组成的流的词法分析方法。
二、实验内容根据教学要求并结合学生自己的兴趣和具体情况,从具有代表性的高级程序设计语言的各类典型单词中,选取一个适当大小的子集。
例如,可以完成无符号常数这一类典型单词的识别后,再完成一个尽可能兼顾到各种常数、关键字、标识符和各种运算符的扫描器的设计和实现。
输入:由符合或不符合所规定的单词类别结构的各类单词组成的源程序。
输出:把单词的字符形式的表示翻译成编译器的内部表示,即确定单词串的输出形式。
例如,所输出的每一单词均按形如(CLASS,V ALUE)的二元式编码。
对于变量和常数,CLASS字段为相应的类别码;V ALUE字段则是该标识符、常数的具体值或在其符号表中登记项的序号(要求在变量名表登记项中存放该标识符的字符串;常数表登记项中则存放该常数的二进制形式)。
对于关键字和运算符,采用一词一类的编码形式;由于采用一词一类的编码方式,所以仅需在二元式的CLASS字段上放置相应的单词的类别码,V ALUE字段则为“空”。
另外,为便于查看由词法分析程序所输出的单词串,要求在CLASS字段上放置单词类别的助记符。
三、实现方法与环境词法分析是编译程序的第一个处理阶段,本次试验用手工的方式(C语言)构造词法分析程序。
根据文法和状态转换图直接编写词法分析程序。
四、基本实验题目1)题目1:试用手工编码方式构造识别以下给定单词的某一语言的词法分析程序。
语言中具有的单词包括五个有代表性的关键字begin、end、if、then、else;标识符;整型常数;六种关系运算符;一个赋值符和四个算术运算符。
参考实现方法简述如下。
单词的分类:构造上述语言中的各类单词符号及其分类码表。
表I 语言中的各类单词符号及其分类码表+ 15 PL- 16 MI* 17 MU/ 18 DI处理过程:在一个程序设计语言中,一般都含有若干类单词符号,为此首先为每类单词建立一X状态转换图,然后将这些状态转换图合并成一X统一的状态图,即得到了一个有限自动机,再进行必要的确定化和状态数最小化处理,最后据此构造词法分析程序。

编译原理实验大纲1.实验简介-介绍编译原理实验的目的和意义。
-解释编译原理实验的基本原理和流程。
2.实验环境搭建-说明实验所需的软件工具和开发环境。
-指导学生安装和设置实验环境。
3.实验一:词法分析器设计-介绍词法分析器的作用和原理。
-分析需求,设计词法分析器的数据结构和算法。
-实现基于所设计算法的词法分析器。
-编写测试用例,验证词法分析器的功能和正确性。
4.实验二:语法分析器设计-介绍语法分析器的作用和原理。
-分析需求,设计语法分析器的数据结构和算法。
-实现基于所设计算法的语法分析器。
-编写测试用例,验证语法分析器的功能和正确性。
5.实验三:语义分析器设计-介绍语义分析器的作用和原理。
-分析需求,设计语义分析器的数据结构和算法。
-实现基于所设计算法的语义分析器。
-编写测试用例,验证语义分析器的功能和正确性。
6.实验四:中间代码生成-介绍中间代码生成的作用和原理。
-分析需求,设计中间代码生成的数据结构和算法。
-实现基于所设计算法的中间代码生成器。
-编写测试用例,验证中间代码生成器的功能和正确性。
7.实验五:目标代码生成-介绍目标代码生成的作用和原理。
-分析需求,设计目标代码生成的数据结构和算法。
-实现基于所设计算法的目标代码生成器。
-编写测试用例,验证目标代码生成器的功能和正确性。
8.实验六:优化与调试-介绍编译优化和调试的基本概念。
-分析已实现的编译器的性能和问题。
-提出优化方案,并实现相应的优化功能。
-进行性能测试和调试,验证优化效果和解决问题。
9.实验七:实验报告撰写-分析实验过程和结果,总结经验和收获。
-撰写实验报告,包括实验目的、原理、实现过程、结果分析等内容。
-提交实验报告并进行评分评比。
10.总结与展望-对实验进行总结,回顾实验目标和实现情况。
-展望未来的发展方向和对编译原理的深入研究。
以上为编译原理实验的大纲,通过完成这些实验,学生可以深入理解编译原理的基本原理和算法,并掌握编译器的设计与实现方法。
《编译原理》实验教学大纲一、实验目的和任务编译原理是计算机科学与技术专业的一门重要课程,它主要研究的是将高级语言程序翻译成机器语言程序的方法和技术。
通过本实验课程的学习,旨在使学生掌握编译原理的基本原理和方法,培养学生对编译器结构与构造技术的专门知识和技能,为学生今后进行编译器设计与实现打下基础。
二、实验设备和工具1.计算机和相关硬件设备2. 编程语言的开发环境,如C/C++或Java三、实验内容1.实验一:词法分析器设计与实现a)实验目的:学习词法分析器的原理和设计方法,掌握正则表达式、DFA和NFA的转换方法。
b)实验任务:i.设计并实现一个词法分析器的原型,能够正确地识别出给定的程序中的词法单元。
ii. 使用给定的正则表达式设计并实现识别给定程序中的关键字、标识符、常量等的词法分析器。
2.实验二:语法分析器设计与实现a)实验目的:学习语法分析器的原理和设计方法,掌握上下文无关文法和LR分析表的构造方法。
b)实验任务:i.学习并理解上下文无关文法和LR分析表的构造方法。
ii. 设计并实现一个简单的递归下降语法分析器。
3.实验三:语义分析器设计与实现a)实验目的:学习语义分析器的原理和设计方法,掌握语义动作的定义和处理方法。
b)实验任务:i.学习并理解语义分析器的原理和设计方法。
ii. 设计并实现一个简单的语义分析器,能够对给定的程序进行语义分析和语义动作的处理。
4.实验四:中间代码生成器设计与实现a)实验目的:学习中间代码生成器的原理和设计方法,掌握中间代码的生成和优化方法。
b)实验任务:i.学习并理解中间代码生成器的原理和设计方法。
ii. 设计并实现一个简单的中间代码生成器,能够将给定的程序翻译成中间代码。
5.实验五:目标代码生成器设计与实现a)实验目的:学习目标代码生成器的原理和设计方法,掌握目标代码的生成和优化方法。
b)实验任务:i.学习并理解目标代码生成器的原理和设计方法。
ii. 设计并实现一个简单的目标代码生成器,能够将中间代码翻译成目标代码。
一、实验目的与任务编制一个源程序的输入过程,从键盘、文件或文本框输入若干行语句,依次存入输入缓冲区(字符型数据);并编制一个扫描子程序,该子程序中每次调用能依次从存放源程序的输入缓冲区中读出一个有效字符。
二、实验涉及的相关知识点1、VC++中微软基础类库MFC的使用,包括控件、菜单的使用以及消息映射。
2、原程序的扫描,分析及处理。
三、实验内容与过程1、创建一个单文档应用程序,添加控件,关联变量,结果如下:2、为控件添加消息映射,代码如下:void CMainFrame::OnBYYuChuLi(){// TODO: Add your command handler code herechar strWrite[1024];char strTmp[32];int i;if (!bFileOk){MessageBox("请先打开一个源程序文件!","预处理",MB_OK|MB_ICONINFORMATION);return;}GetAppPath();strcpy(strWrite,strAppPath);strcat(strWrite,"yuchuli.txt");//定义输入文件及输出文件/*///////////////////////////////方法(1)CFile//缺点:文件结束的判断CFile fpIn,fpOut;char ch;UINT nfLen;if (!fpIn.Open(strFile,CFile::modeRead,NULL))MessageBox("Open Error!");if(!fpOut.Open(strWrite,CFile::modeWrite|CFile::modeCreate,NULL)) MessageBox("Write Error!");fpIn.Read(&ch,1);//读一个字节nfLen=fpIn.GetLength();//取得文件长度fpOut.Write(&ch,1); //写一个字节/////////////////*//*///////////////////////////////方法(2)fstreamchar ch;fstream fpIn(strFile,ios::in);//定义文件用于输入fstream fpOut(strWrite,ios::out);//定义文件用于输出fpIn>>ch;//读入一个字节或使用fpIn.read();fpout<<ch;///写一个字节到文件或使用fpOut.write();fpIn.close();//关闭文件fpOut.close();/////////////////////////////*////////////////////////////////方法(3)FILEchar ch=' ',ch1;FILE *fpIn,*fpOut;//打开文件用于读入数据if ((fpIn=fopen(strFile,"rt"))==NULL){MessageBox("无法读入文件数据!","预处理",MB_OK|MB_ICONEXCLAMATION);return;}//打开文件用于写入数据if ((fpOut=fopen(strWrite,"wt"))==NULL){MessageBox("无法写数据到文件!","预处理",MB_OK|MB_ICONEXCLAMATION);return;}//去掉程序最前面的空格while (ch==' ')ch=fgetc(fpIn);//开始对程序进行扫描i=0;while(!feof(fpIn)){if (islower(ch) || ch=='#'){strTmp[i++]=ch;fprintf(fpOut,"%c",ch);ch=fgetc(fpIn);}else{if (!(isalpha(ch) || isdigit(ch))){//不是字母和数字strTmp[i]='\0';if (i!=0)if (isKeyWord(strTmp))fprintf(fpOut,"%c",' ');i=0;switch(ch){case ' ':while (ch==' ' &&!feof(fpIn))ch=fgetc(fpIn);break;case '/':ch1='/';ch=fgetc(fpIn);if ( ch=='*'){while ((ch1!='*' || ch!='/')&&!feof(fpIn)){ch1=ch;ch=fgetc(fpIn);}if (!feof(fpIn)){ch=fgetc(fpIn);while (ch=='\n' &&!feof(fpIn))ch=fgetc(fpIn);}}elsefprintf(fpOut,"%c",'/');break;default:fprintf(fpOut,"%c",ch);ch=fgetc(fpIn);if (ch=='\n'){fprintf(fpOut,"%c",'\n');ch=fgetc(fpIn);}while (ch=='\n' && !feof(fpIn))ch=fgetc(fpIn);}}else{fprintf(fpOut,"%c",ch);ch=fgetc(fpIn);}}}fclose(fpIn);fclose(fpOut);//打开处理的结果CByylApp *pApp=(CByylApp *)AfxGetApp();POSITION curTemplatePos=pApp->GetFirstDocTemplatePosition();CDocTemplate*curTemplate=pApp->GetNextDocTemplate(curTemplatePos);curTemplate->OpenDocumentFile(strWrite);}void CMainFrame::OnByOpen(){// TODO: Add your command handler code herestatic TCHAR szFilter[]=_T("C Source Files(*.c)|*.c|Text Files(*.txt)|*.txt|C++ Source Files(*.cpp)|*.cpp|");CString strOpen;CByylApp *pApp=(CByylApp *)AfxGetApp();CFileDialogdlg(TRUE,"",NULL,OFN_HIDEREADONLY|OFN_PATHMUSTEXIST,szFilter,NULL);dlg.m_ofn.lpstrTitle="打开文件";if (dlg.DoModal()==IDOK){POSITION curTemplatePos=pApp->GetFirstDocTemplatePosition();CDocTemplate*curTemplate=pApp->GetNextDocTemplate(curTemplatePos);curTemplate->OpenDocumentFile(dlg.GetPathName());strOpen=dlg.GetPathName();strcpy(strFile,LPCTSTR(strOpen));bFileOk=TRUE;}}void CMainFrame::GetAppPath(){CString strName;GetModuleFileName(NULL,strAppPath,1024);strName=strAppPath;int x=strName.ReverseFind('\\');strAppPath[x+1]='\0';return;}BOOL CMainFrame::isKeyWord(char* word){char*keyWords[]={"#include","#define","int","char","short","long", "unsigned","signed","float","double","FILE","struct","enum","static","return"};int i,n=15;for(i=0;i<n;i++)if (strcmp(word,keyWords[i])==0)return TRUE;return FALSE;}四、实验结果及分析1、打开一个CPP文件:处理前:处理后:五、实验相关说明文中利用了单文档应用程序的菜单和工具栏进行数据的处理。
《编译原理》实验指导书实验一词法分析器的设计一、实验目的和要求加深对状态转换图的实现及词法分析器的理解。
熟悉词法分析器的主要算法及实现过程。
要求学生掌握词法分析器的设计过程,并实现词法分析。
二、实验基本内容给出一个简单语言的词法规则,画出状态转换图,并依据状态转换图编制出词法分析程序,能从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单Error”,然后跳过错误部分继续显示)词法规则如下:三、实验时间:上机三次。
第一次按照自己的思路设计一个程序。
第二、三次在理论课学习后修改程序,使得程序结构更加合理。
四、实验过程和指导:(一)准备:1.阅读课本有关章节(c/c++,数据结构),花一周时间明确语言的语法,写出基本算法以及采用的数据结构和要测试的程序例。
2.初步编制好程序。
3.准备好多组测试数据。
(二)上课上机:将源代码拷贝到机上调试,发现错误,再修改完善。
(三)程序要求:程序输入/输出示例:输入如下一段:main(){/*一个简单的c++程序*/int a,b; //定义变量a = 10;b = a + 20;}要求输出如右图。
要求:(1) 剔除注解符(2) 常数为无符号整数(可增加实型数,字符型数等)(四)练习该实验的目的和思路:程序开始变得复杂起来,可能是大家以前编过的程序中最复杂的,但相对于以后的程序来说还是简单的。
因此要认真把握这个过渡期的练习。
程序规模大概为200行及以上。
通过练习,掌握对字符进行灵活处理的方法。
(五)为了能设计好程序,注意以下事情:1.模块设计:将程序分成合理的多个模块(函数/类),每个模块(类)做具体的同一事情。
2.写出(画出)设计方案:模块关系简图、流程图、全局变量、函数接口等。
3.编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。
4.程序设计语言不限,建议使用面向对象技术及可视化编程语言,如C++,VC,JA V A,VJ++等。
实验一词法分析程序
一、实验目的
设计、编写、调试一个具体的词法分析程序,实现从源程序中识别出各种单词符号的功能,加深对词法分析原理的理解,并掌握对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
二、实验教学基本要求
1.掌握从源程序文件中读取有效字符的方法和并结合单词符号构词方法生成相应的单词符号,并将识别出的单词符号输出到文件中。
2.掌握词法分析的实现方法。
3.上机调试词法分析程序。
三、实验教学的内容或要求
1.编制一个词法分析程序,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。
2.并依次输出各个单词的内部编码(种别)及单词符号自身值。
广州大学实验课程建设项目《编译原理实验》实验指导书广州大学信息与机电工程学院计算机系2006年10月目录实验1 Pascal 语言的编译器的使用 3 实验2 词法分析(一) 13 (调试一个词法分析程序)实验3 词法分析(二) 16 (设计、编制并调试一个词法分析程序)实验4 语法分析(一) 19 (调试一个语法分析程序,了解编译程序中LR分析表的作用)实验5 语法分析(二) 22(设计、编制并调试一个语法分析程序)实验6 语义分析 24实验7 编译原理综合实验 26 实验报告示例:词法分析程序 47考试考核方式 53实验一:Pascal 语言的编译器的使用实验目的:调试一个Pascal 语言的编译器,加深对语言编译器的理解实验内容:此程序为Pascal 语言的编译器,支持Proc ,Repeat,If,While,For,Fun函数结构代码的编译,能生成变量表、常量表和汇编程序。
界面如下:图1 Pascal 语言的编译器的使用界面下面给出软件所能编译的代码和编译出的结果。
―――――――――――――――――――――――――――――――――――Proc函数结构代码:vara, b, i: integer;procedure p1(arg1: integer; arg2: integer);begina := arg1 * arg2;end;beginb := 123;p1(3, b);――――――――――――――――――――――――――――――――――-编译状态下:变量[0]str = unsigned[参], OffPos = 0[1]a = unsigned[静], OffPos = 0[2]b = unsigned[静], OffPos = 0[3]i = unsigned[静], OffPos = 0[4]arg1 = unsigned[参], OffPos = 0[5]arg2 = unsigned[参], OffPos = 1常量[0]Number = 123[静], OffPos = 0[1]Number = 3[静], OffPos = 0方法ID = 1, Name = p1, MethodType = 过程, ParamList = (4, 5), DynaV arList = (), Addr = 2 ++++++++++++++++++++++++++++++++++++运行状态下:变量[0]str = unsigned[参], OffPos = 0[1]a = 369[静], OffPos = 0[2]b = 123[静], OffPos = 0[3]i = unsigned[静], OffPos = 0[4]arg1 = unsigned[参], OffPos = 0[5]arg2 = unsigned[参], OffPos = 1汇编语句:0:Goto 0, 71:Return 0, 02:Mov 0, 43:Mov 0, 54:Mul 0, 05:Sto 1, 16:Return 0, 07:LoadConst 0, 08:Sto 0, 29:LoadConst 0, 110:Mov 0, 211:Call 0, 1 ―――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――For结构代码:vara, b, i: integer;a := 0;for i := 0 to 100 dobegina := a + i;end;end;――――――――――――――――――――――――――――――――――-编译状态下:变量[0]str = unsigned[参], OffPos = 0[1]a = unsigned[静], OffPos = 0[2]b = unsigned[静], OffPos = 0[3]i = unsigned[静], OffPos = 0常量[0]Number = 0[静], OffPos = 0[1]Number = 0[静], OffPos = 0[2]Number = 100[静], OffPos = 0方法ID = 0, Name = ShowMessage, MethodType = 过程, ParamList = (0), DynaV arList = (), Addr = 1++++++++++++++++++++++++++++++++++++运行状态下:变量[0]str = unsigned[参], OffPos = 0[1]a = 5050[静], OffPos = 0[2]b = unsigned[静], OffPos = 0[3]i = 101[静], OffPos = 0汇编语句:0:Goto 0, 21:Return 0, 02:LoadConst 0, 03:Sto 0, 14:LoadConst 0, 15:Sto 0, 36:LoadConst 0, 27:Mov 0, 38:>=? 0, 09:IfFalseGoto 0, 1810:Mov 0, 111:Mov 0, 312:Add 0, 013:Sto 0, 114:Mov 0, 315:IncV ar 0, 116:Sto 0, 317:Goto 0, 6 ―――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――While函数结构代码:vara, i: integer;begini := 0;a := 0;while i <= 100 dobegina := a +i;i := i +1;end;end;――――――――――――――――――――――――――――――――――-编译状态下:变量[0]str = unsigned[参], OffPos = 0[1]a = unsigned[静], OffPos = 0[2]i = unsigned[静], OffPos = 0常量[0]Number = 0[静], OffPos = 0[1]Number = 0[静], OffPos = 0[2]Number = 100[静], OffPos = 0[3]Number = 1[静], OffPos = 0方法ID = 0, Name = ShowMessage, MethodType = 过程, ParamList = (0), DynaV arList = (), Addr = 1++++++++++++++++++++++++++++++++++++运行状态下:变量[0]str = unsigned[参], OffPos = 0[1]a = 5050[静], OffPos = 0[2]i = 101[静], OffPos = 0汇编语句:0:Goto 0, 21:Return 0, 02:LoadConst 0, 03:Sto 0, 24:LoadConst 0, 15:Sto 0, 16:Mov 0, 27:LoadConst 0, 28:<=? 0, 09:IfFalseGoto 0, 1910:Mov 0, 111:Mov 0, 212:Add 0, 013:Sto 0, 114:Mov 0, 215:LoadConst 0, 316:Add 0, 017:Sto 0, 218:Goto 0, 6 ―――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――Repeat函数结构代码:vara, i: integer;begina := 0;i := 0;repeata := a + i;i := i + 1;until i > 100;end; ――――――――――――――――――――――――――――――――――-编译状态下:变量[0]str = unsigned[参], OffPos = 0[1]a = unsigned[静], OffPos = 0[2]i = unsigned[静], OffPos = 0常量[0]Number = 0[静], OffPos = 0[1]Number = 0[静], OffPos = 0[2]Number = 1[静], OffPos = 0[3]Number = 100[静], OffPos = 0方法ID = 0, Name = ShowMessage, MethodType = 过程, ParamList = (0), DynaV arList = (), Addr = 1++++++++++++++++++++++++++++++++++++运行状态下:变量[0]str = unsigned[参], OffPos = 0[1]a = 5050[静], OffPos = 0[2]i = 101[静], OffPos = 0汇编语句:0:Goto 0, 21:Return 0, 02:LoadConst 0, 03:Sto 0, 14:LoadConst 0, 15:Sto 0, 26:Mov 0, 17:Mov 0, 28:Add 0, 09:Sto 0, 110:Mov 0, 211:LoadConst 0, 212:Add 0, 013:Sto 0, 214:Mov 0, 215:LoadConst 0, 316:>? 0, 017:IfFalseGoto 0, 6 ―――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――Fun函数结构代码:vara, i: integer;function fun1(arg1, arg2: integer): integer;beginResult := arg1 + arg2;end;begina := 0;for i := 1 to 100 dobegina := fun1(a, i);end;end;――――――――――――――――――――――――――――――――――-编译状态下:变量[0]str = unsigned[参], OffPos = 0[1]a = unsigned[静], OffPos = 0[2]i = unsigned[静], OffPos = 0[3]arg1 = unsigned[参], OffPos = 0[4]arg2 = unsigned[参], OffPos = 1[5]Result = unsigned[动], OffPos = 2常量[0]Number = 0[静], OffPos = 0[1]Number = 1[静], OffPos = 0[2]Number = 100[静], OffPos = 0方法ID = 1, Name = fun1, MethodType = 函数, ParamList = (3, 4), DynaV arList = (5), Addr = 2 ++++++++++++++++++++++++++++++++++++运行状态下:变量[0]str = unsigned[参], OffPos = 0[1]a = 5050[静], OffPos = 0[2]i = 101[静], OffPos = 0[3]arg1 = unsigned[参], OffPos = 0[4]arg2 = unsigned[参], OffPos = 1[5]Result = unsigned[动], OffPos = 2汇编语句:0:Goto 0, 71:Return 0, 02:Mov 0, 33:Mov 0, 44:Add 0, 05:Sto 0, 56:Return 0, 07:LoadConst 0, 08:Sto 0, 19:LoadConst 0, 110:Sto 0, 211:LoadConst 0, 212:Mov 0, 213:>=? 0, 014:IfFalseGoto 0, 2315:Mov 0, 116:Mov 0, 217:Call 0, 118:Sto 0, 119:Mov 0, 220:IncV ar 0, 121:Sto 0, 222:Goto 0, 11 ―――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――If 结构代码:vara, i: integer;begina := 2;if a = 1 thenbegini := 10;endelse begini := 100;end;end;――――――――――――――――――――――――――――――――――-编译状态下:变量[0]str = unsigned[参], OffPos = 0[1]a = unsigned[静], OffPos = 0[2]i = unsigned[静], OffPos = 0常量[0]Number = 2[静], OffPos = 0[1]Number = 1[静], OffPos = 0[2]Number = 10[静], OffPos = 0[3]Number = 100[静], OffPos = 0方法ID = 0, Name = ShowMessage, MethodType = 过程, ParamList = (0), DynaV arList = (), Addr = 1 ++++++++++++++++++++++++++++++++++++运行状态下:变量[0]str = unsigned[参], OffPos = 0[1]a = 2[静], OffPos = 0[2]i = 100[静], OffPos = 0汇编语句:0:Goto 0, 21:Return 0, 02:LoadConst 0, 03:Sto 0, 14:Mov 0, 15:LoadConst 0, 16:=? 0, 07:IfFalseGoto 0, 118:LoadConst 0, 29:Sto 0, 210:Goto 0, 1311:LoadConst 0, 312:Sto 0, 2 ―――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――递归结构代码:vara, b: integer;function f1(arg: integer): integer;beginif arg <= 1 thenbeginResult := 1;endelse beginResult := arg * f1(arg - 1);end;end;begina := 10;b := f1(a);ShowMessage(b);end; ――――――――――――――――――――――――――――――――――-编译状态下:变量[0]str = unsigned[参], OffPos = 0[1]a = unsigned[静], OffPos = 0[2]b = unsigned[静], OffPos = 0[3]arg = unsigned[参], OffPos = 0[4]Result = unsigned[动], OffPos = 1常量[0]Number = 1[静], OffPos = 0[1]Number = 1[静], OffPos = 0[2]Number = 1[静], OffPos = 0[3]Number = 10[静], OffPos = 0方法ID = 1, Name = f1, MethodType = 函数, ParamList = (3), DynaV arList = (4), Addr = 2 ++++++++++++++++++++++++++++++++++++运行状态下:变量:无汇编语句:Goto 0, 171:Return 0, 02:Mov 0, 33:LoadConst 0, 04:<=? 0, 05:IfFalseGoto 0, 96:LoadConst 0, 17:Sto 0, 48:Goto 0, 169:Mov 0, 310:Mov 0, 311:LoadConst 0, 212:Sub 0, 013:Call 0, 114:Mul 0, 015:Sto 0, 416:Return 0, 017:LoadConst 0, 318:Sto 0, 119:Mov 0, 120:Call 0, 121:Sto 0, 222:Mov 0, 223:Call 0, 0 ―――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――实验二:词法分析(一)实验目的:调试一个词法分析程序,加深对词法分析原理的理解实验内容:(1)设一小型编译程序关于高级语言有如下的规定:高级语言程序具有四种基本结构:顺序结构﹑选择结构﹑循环结构和过程。
《编译原理》(实验部分)
实验1_程序预处理
一、实验目的
明确预处理子程序的任务,构造一个简单的预处理子程序,对源程序进行相应的预处理。
二、实验设备
1、PC 兼容机一台;操作系统为WindowsWindowsXP。
2、Visual C++ 6.0 或以上版本, Windows 2000 或以上版本,汇编工具(在Software 子目录下)。
三、实验原理
定义模拟的简单语言的词法构成,编制读入源程序和进行预处理的程序,要求将源程序读入到文件或存入数组中,再从文件或数组中逐个读取字符进行预处理,包括去掉注释、Tab、Enter和续行符等操作,并显示预处理后的程序。
四、实验步骤
1、从键盘读入源程序存放到输入缓冲区中。
2、对源程序进行预处理,预处理后的程序存放到扫描缓冲区中。
3、显示预处理后的程序。
参考源程序(C++语言编写)
//源程序的输入及预处理
#include <fstream.h>
#include <iostream.h>
void pro_process(char *);
void main( ) //测试驱动程序
{
//定义扫描缓冲区
char buf[4048]={'\0'}; //缓冲区清0
//调用预处理程序
pro_process(buf); //在屏幕上显示扫描缓冲区的内容cout<<buf<<endl;
}
void pro_process(char *buf) //预处理程序{
ifstream cinf("source.txt",ios::in);
int i=0; //计数器
char old_c='\0',cur_c; //前一个字符,当前字符。
bool in_comment=false; //false表示当前字符未处于注释中。
while(cinf.read(&cur_c,sizeof(char))){ //从文件读一个字符switch(in_comment){
case false:
if(old_c=='/' && cur_c=='*'){ //进入注释
i--; //去除已存入扫描缓冲区的字符'/'
in_comment=true;
}
else {
if(old_c=='\\' && cur_c=='\n') //发现续行
i--; //去除已存入扫描缓冲区的字符'\'
else {
if(cur_c>='A' && cur_c<='Z') //大写变小写
cur_c+=32;
if(cur_c =='\t' || cur_c =='\n')
//空格取代TAB换行
cur_c=' ';
buf[i++]=cur_c ;
}
}
break;
case true:
if(old_c=='*' && cur_c=='/') //离开注释
in_comment=false;
}//end of switch
old_c= cur_c; //保留前一个字符}//end of while
buf[i++]='#'; //在源程序尾部添加字符'#' }。