序列提交软件sequin使用方法
- 格式:doc
- 大小:316.00 KB
- 文档页数:8
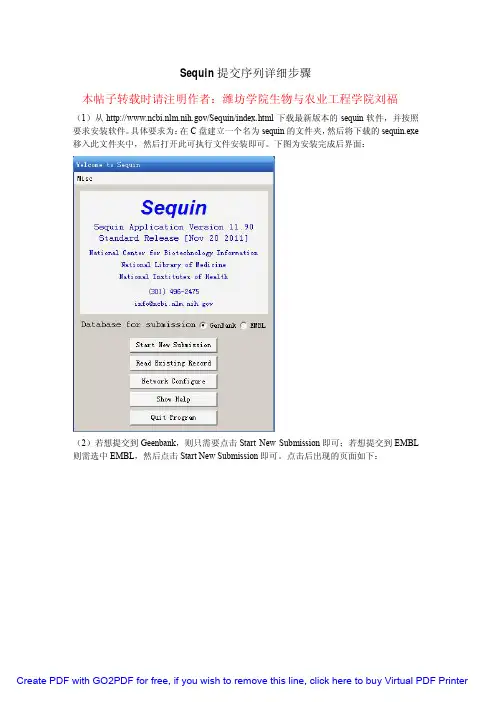
Sequin提交序列详细步骤本帖子转载时请注明作者:潍坊学院生物与农业工程学院刘福(1)从/Sequin/index.html下载最新版本的sequin软件,并按照要求安装软件。
具体要求为:在C盘建立一个名为sequin的文件夹,然后将下载的sequin.exe 移入此文件夹中,然后打开此可执行文件安装即可。
下图为安装完成后界面:(2)若想提交到Geenbank,则只需要点击Start New Submission即可;若想提交到EMBL 则需选中EMBL,然后点击Start New Submission即可。
点击后出现的页面如下:(3)第一个标签Submission:什么时候发表你的序列?可以选择①Immediately After Processing即Geenbank工作人员处理完毕你的序列后就将其发表到Geenbank内。
②Release Date即选择让Geenbank工作人员发表到Geenbank内的时间。
Tentative title for manuscript 这一项一般填写你将发表论文的暂定题目或已发表论文的题目。
(4)完成后点击Next Page,出现以下界面:此处填发见图内,需要解释的是Sfx是别命的意思,中国人一般不需要填写;M.I为中间名,中国人也不需要填;邮箱地址是负责最终提交序列者的,不一定是序列的作者的,如你导师是作者,你是负责给他提交者,则这里就填写你的邮箱,其他信息填写你导师的。
注:0086为中国国际代号,必须加上。
(5)完成后,点击Next Page,出现以下界面:为填写序列作者的界面,前一步填写的联系人被自动列为第一作者,然后往下继续填写其他作者,此处只显示三行,当你填写完第三个后,通过拖动滚动条后面将会还出现填写的表格,直到将所有作者填写完毕。
另外Consortium 为参与序列获取的机构名,当以此机构名义发表序列时可以填写,上面的作者也一并填写。
(6)完成后,点击Next Page。

向GenBank批量上传序列的方法Qin1.利用DNAstar的editSeq制作待序列的FASTA文档:待上传序列删减至合适长度后,将待上传序列全部打开随后点击File - export as one,保存文件格式为:*.fas ,将待上传序列全部归至一个FASTA 文档。
注意序列命名:2.在GenBank的Submission Tools里,下载序列信息编辑软件Sequin。
:// /Sequin/〔下列图中点击Instructions下载软件〕注意打开安装文件后,程序会自动安装在安装包所在的文件夹。
3.打开Sequin,点击Start New Submission。
4.随后选择序列发布日期,输入论文题目。
假设之前保存有模板,可以点击下面的“Click here to import a template”导入。
模板导出在下文的第五点提到。
5.联系人、作者信息、机构或者学校信息建议导出模板,之后修改信息时可以直接导入模板而不需重新输入。
6.选择上传的序列类型。
7.导入之前准备好的FASTA文件:导入之后,输入序列ID〔序号ID相当于编号,可以自由命名,只要各个序列的ID不一致即可。
在这里以病人编号作为序列ID〕:导入序列成功后,显示各个序列信息如下:点击Sequencing Method,将测序方法输入:选择上传序列的用途:病毒类型:8.编辑每条序列的信息:点击Import Source T able可以导入模板,点击Export This Table 可以输出模板备用。
9.选择核酸类型,序列内容后,点击Open Record Viewer。
10.添加每条序列的信息,包括编码区重复区RNA结构等等。
双击相关信息可进行修改,点击Annotate添加相关信息。
11.检查信息是否有误〔也可以点击Search里的Validate检测是否有明显错误〕:有些错误是可以忽略的,如上传的序列为CDS序列,那么软件报错”序列无终止子”时可忽略。
Sequin提交序列详细步骤本帖子转载时请注明作者:潍坊学院生物与农业工程学院刘福(1)从/Sequin/index.html下载最新版本的sequin软件,并按照要求安装软件。
具体要求为:在C盘建立一个名为sequin的文件夹,然后将下载的sequin.exe 移入此文件夹中,然后打开此可执行文件安装即可。
下图为安装完成后界面:(2)若想提交到Geenbank,则只需要点击Start New Submission即可;若想提交到EMBL 则需选中EMBL,然后点击Start New Submission即可。
点击后出现的页面如下:(3)第一个标签Submission:什么时候发表你的序列?可以选择①Immediately After Processing即Geenbank工作人员处理完毕你的序列后就将其发表到Geenbank内。
②Release Date即选择让Geenbank工作人员发表到Geenbank内的时间。
Tentative title for manuscript 这一项一般填写你将发表论文的暂定题目或已发表论文的题目。
(4)完成后点击Next Page,出现以下界面:此处填发见图内,需要解释的是Sfx是别命的意思,中国人一般不需要填写;M.I为中间名,中国人也不需要填;邮箱地址是负责最终提交序列者的,不一定是序列的作者的,如你导师是作者,你是负责给他提交者,则这里就填写你的邮箱,其他信息填写你导师的。
注:0086为中国国际代号,必须加上。
(5)完成后,点击Next Page,出现以下界面:为填写序列作者的界面,前一步填写的联系人被自动列为第一作者,然后往下继续填写其他作者,此处只显示三行,当你填写完第三个后,通过拖动滚动条后面将会还出现填写的表格,直到将所有作者填写完毕。
另外Consortium 为参与序列获取的机构名,当以此机构名义发表序列时可以填写,上面的作者也一并填写。
(6)完成后,点击Next Page。


SEQUENCE函数用法SEQUENCE函数是Excel2021新增函数中的一个,这个函数提供的转换能力令人惊讶!今天和大家一起来认识这个函数。
SEQUENCE函数的语法为:=SEQUENCE(rows,[columns],[start],[step])其中,rows:行数。
columns:可选的,列数。
start:可选的,序列的起始值,默认值是1。
step:可选的,序列的步长,默认值是1。
基本用法示例三个例子你就懂了在工作表中输入公式:=SEQUENCE(10),会得到一列十行的数组。
ps:如果你的版本不支持数组自动扩展,就需要先选中10个单元格,输入公式后三键结束。
在工工作表中输入公式:=SEQUENCE(5,3),会得到三列五行的数组。
调整两个参数的位置,公式=SEQUENCE(3,5)则会得到五列三行的数组。
注意,到序列填充的顺序是从左至右、由上至下。
如果想首先填充列,则使用TRANSPOSE函数进行转置:=TRANSPOSE(SEQUENCE(10,3))日期函数和SEQUENCE函数有点意思吧还可以使用SEQUENCE函数和日期函数进行组合,得到日、月、季度或年的序列。
例如,公式=SEQUENCE(10,,TODAY())可以生成10个日期序列。
ps:需要修改单元格格式为日期。
公式=DATE(2022,SEQUENCE(12),1)可以得到一年中每个月的第一天。
使用公式=DATE(2022,SEQUENCE(1,MONTH(TODAY())),1)可以得到当前日期之前的每个月的第一天,并且在一行显示。
值得一提的是,使用TODAY函数使公式具有了动态性,因此它会随着时间的推移而扩展。
当10月来临的时候,将会显示到10月!SEQUENCE函数在数据排列方面的应用以后再也不用烧脑了如下图所示,原数据都在一列中,我们可以使用SEQUENCE函数将其快速转换成行列排列的表。
使用公式=INDEX(A2:A16,SEQUENCE(5,3))得到的效果。


SEQUIN3.0Sequin3.0是NCBI为了方便各国参与测序工作的分子生物学研究人员将序列输入到由Genbank,EMBL,DDBJ联合组成的国际协作核酸序列数据库(International Nucleotide Sequence Database Collaboration)而设计的一个客户端软件,使用户可以不需要上网就能够实现序列输入,格式的定制,和在序列数据库中的注册、修改、更新。
与其他的输入方法,如NCBI提供的另外一种在线序列注册工具Bankit相比,Sequin提供许多自动处理功能对序列进行格式定制,避免了手工输入的麻烦和格式不统一,并且,在大量相关数据输入时,Sequin可以方便的直接根据各个序列前的数据行读入各个序列的注释信息。
Sequin3.0是该程序的最新版本,与上一个版本2.9相比,3.0修改了程序的网络配置功能,解决了位于防火墙后的一些用户无法用该程序联网的问题。
另外对在2.9版本中发现的一些小的BUG也作了修正。
该程序具体的序列输入操作包括简单模式和复杂模式两种:一.简单模式:打开Sequin3.0可进入如下开始界面,然后选择了需要进行数据注入的数据库后就可以开始序列输入,对各个数据库序列输入的过程中信息填写都是一样的,只是最终生成的数据格式互不相同。
序列的具体输入过程是下面几个界面,按照要求填写即可:这一页是填写序列引用信息,包括文章(稿件)名,通讯作者联系方式,前三个作者列表,和作者所属机构。
这一页是选择所注入的序列的格式,程序会根据不通格式直接自动读入生成一些序列注释信息。
最后这页是输入序列,在上一页中选择不通格式,页面会有所不同,主要是表明序列的来源,包括来源物种的种属名,菌株号或克隆系列号等,对多序列还要进行注释,输入序列时是使用FASTA格式进行导入,即将各序列按照如下的FASTA格式加上序列头信息后保存成文本格式的文件再导入到Sequin中。
核酸:>ID [org=scientific name] [strain=name][clone=name] title蛋白:>ID [gene=symbol] [prot=name] title这样就完成了序列的简单输入,进入到以下的提交界面:这时可以利用程序提供的自动检查功能(Search菜单中的Validate命令)对输入的序列格式进行检查,之后向数据库提交可以通过三种方式:1.用File菜单中的Prepare submission将输入的序列及注册信息合成为提交文件,之后再用Email发给各个数据库的收件信箱Genbank: gb-sub@EMBL: datasub@DDBJ: ddbjsub@ddbj.nig.ac.jp2.用File菜单中Submit to NCBI来发送。

Excel中sequence函数的序列生成技巧Excel中sequence函数是一种强大的工具,能够方便地生成序列。
在Excel中,使用sequence函数可以快速生成指定的数值序列,并且可以按照一定的步长和规则进行调整。
本文将介绍一些使用sequence函数的技巧和示例,帮助读者更好地运用这一函数。
1. 生成基本序列通过sequence函数,可以轻松生成基本的数值序列。
该函数需要三个参数:序列的长度、起始值和步长。
例如,若想生成1到100的整数序列,可以使用如下公式:=SEQUENCE(100,1,1)这个公式的意思是生成一个长度为100的序列,起始值为1,步长为1。
通过填写不同的参数,我们可以生成不同的序列。
2. 递增/递减的序列sequence函数可以根据设置的步长生成递增或递减的序列。
例如,若想生成从1到100,步长为2的整数序列,可以使用如下公式:=SEQUENCE(50,1,2)这个公式的意思是生成一个长度为50的序列,起始值为1,步长为2。
通过修改步长,我们可以得到递增或递减的序列。
3. 生成日期序列sequence函数还可以生成日期序列。
在Excel中,日期被表示为序列号,起始日期为1900年1月1日。
例如,若想生成从2022年1月1日开始的连续7天的日期序列,可以使用如下公式:=SEQUENCE(7,1,DATE(2022,1,1),1)这个公式的意思是生成一个长度为7的日期序列,起始日期为2022年1月1日,步长为1天。
通过填写不同的参数,我们可以生成指定日期范围内的日期序列。
4. 生成自定义序列除了基本的数值和日期序列外,sequence函数还可以生成自定义的序列。
例如,若想生成一个由字符串组成的序列,可以使用如下公式:=SEQUENCE(5,1,"A",1)这个公式的意思是生成一个长度为5的序列,起始值为"A",步长为1。
通过修改起始值和步长,我们可以生成不同的自定义序列。

sequence函数sequence函数是一种数学工具,它可以用来生成不断增加或减少的序列。
序列由公式或算法定义,它们可以是固定长度或持续增长或减少的序列。
它们的功能是,给出一组数字或其它序列元素,根据指定的算法,通过每个元素的增加或减少,生成不断增加或减少的序列。
序列函数能够产生一系列特定的数字,允许用户更加细致地控制变量和参数,以及它们之间的关系。
它们也可以用来推算出其他变量的影响,从而了解更多信息。
它们还可以用来预测不断变化的趋势,也可以用来检测时间变化和空间变化。
使用sequence函数时,首先要定义序列的种类。
可以决定是生成持续增长的序列,还是持续减少的序列。
然后计算序列的首项,填入初始值,即序列的第一个元素,再给出每一项的公式,以及步长的数值,即每一项和前一项之间的差值。
这样,就可以通过既定的公式,逐项推算出序列的每一项。
sequence函数可用于不同的应用领域。
它可以用于线性代数,用来求解特定方程的根,也可以用于图像图形学,确定图像中每个像素点的坐标,甚至可以计算空间曲线的参数。
数学的一般运用,如计算面积、计算体积、计算某种函数的积分、求解不定积分等,均可以用sequence函数来实现。
随着计算机技术的发展,序列函数也推广到很多其他领域,可以应用于生物学、药学、心理学、物理学、机械工程、计算机科学和多媒体等领域。
例如在机器学习及人工智能方面,也可以用序列函数来建立相应的模型,从而更加准确地预测出实际数据的趋势。
总之,sequence函数不仅可以帮助用户生成不断增长或减少的序列,还可以用来更加精准地预测变化趋势,解决实际问题等。
它的价值就在于可以将复杂的数学问题简化,并有效地求解出精确的结果。

MySQL的sequence用法1.简介M y SQ L是一种流行的关系型数据库管理系统,广泛用于各种应用程序中。
在M yS QL中,se q ue nc e是一种非常有用的特性,可以轻松生成递增的序列值。
本文将详细介绍M yS QL中s eq u en ce的用法。
2.什么是s equence在数据库中,se qu en c e是一种生成递增序列值的对象。
它可以用于自动生成唯一的主键或其他需要递增值的列。
通常情况下,se q ue nc e是与表格关联的,每次向表格中插入一行数据时,s eq ue nc e会自动生成一个序列值。
3.创建seq uence在M yS QL中,可以通过以下语法创建se q ue nc e:C R EA TE SE QU EN CE seq u en ce_n am e;在创建s eq ue nc e时,可以定义其起始值、步长和最大值等属性。
例如,以下语法创建一个名为s eq ue nc e_na m e的se qu en ce,起始值为1,步长为1,最大值为100:C R EA TE SE QU EN CE seq u en ce_n am eS T AR TW IT H1I N CR EM EN TB Y1M A XV AL UE100;4.使用seq uence创建了s eq ue nc e后,可以通过以下方式获取s eq ue nc e的下一个值:N E XT VA LU EF OR se que n ce_n am e;通过这个语法,可以在插入数据时使用se q ue nc e的下一个值作为列的值。
例如,以下语句向名为ta bl e_nam e的表格中插入一行数据,其中i d列使用se qu en c e的下一个值:I N SE RT IN TO ta bl e_n a me(i d,na me)V A LU ES(N EX TV AL UEF O Rs eq ue nc e_na me,'Jo hn');5.修改seq uence在某些情况下,可能需要修改已创建的se q ue nc e的属性。

PostgreSQLSequence序列的使⽤详解PostgreSQL是⼀种关系型数据库,和Oracle、MySQL⼀样被⼴泛使⽤。
平时⼯作主要使⽤的是PostgreSQL,所以有必要对其相关知识做⼀下总结和掌握,先总结下序列。
⼀、 Sequence序列Sequence是⼀种⾃动增加的数字序列,⼀般作为⾏或者表的唯⼀标识,⽤作代理主键。
1、Sequence的创建例⼦:创建⼀个seq_commodity,最⼩值为1,最⼤值为9223372036854775807,从1开始,增量的步长为1,缓存为1的循环排序Sequence。
SQL语句如下:CREATE SEQUENCE seq_commodityINCREMENT 1MINVALUE 1MAXVALUE 9223372036854775807START 1CACHE 1CYCLE; // 循环,表⽰到最⼤值后从头开始2、查找Sequence中的值SELECT nextval('seq_commodity');这⾥nextval表⽰下⼀个值3、修改 Sequence⽤alter sequence来修改,除了start以外的所有sequence参数都可以被修改,alter sequence 的例⼦(SQL语句)ALTER SEQUENCE seq_commodityINCREMENT 10MAXVALUE 10000CYCLENOCACHE ;当然如果想要修改start的值,可以先⽤ drop sequence删掉,然后再重新创建。
4、删除Drop SequenceDROP SEQUENCE seq_commodity;5、Sequence分配策略调⽤select nextval(seq_ commodity);返回下⼀个序列号后,系统优先给⽤户分配⼀个序号,接着系统的次Sequence⽴刻加上设置的步长(increment 1),不论此序号⽤户是否使⽤;调⽤select currval(seq_ commodity);返回当前的序列号,该序列号只要没有被使⽤,就不会变化,如果当前请求⼀直使⽤,那么不会再分配给其他的请求,因为该序列号已经分配给当前请求。
mysql sequence 用法MySQL Sequence 是一种用于生成自增值的对象。
它是在MySQL 8.0 中引入的,可以用于生成唯一的,连续递增的数字序列,以用于创作主键或其他需要连续自增值的列。
在本文中,我们将一步一步地介绍MySQL Sequence 的用法及其在数据库中的应用。
第一步:了解MySQL Sequence的概念MySQL Sequence 是一个特殊的对象,用于生成连续递增的数字序列。
它类似于自动增量列(AUTO_INCREMENT),但更加灵活和可控。
通过使用Sequence,可以在不插入或删除记录的情况下生成自增值。
它可以为表提供一个全局唯一的连续自增序列,不受任何其他操作的影响。
第二步:创建Sequence对象在MySQL 中,可以使用`CREATE SEQUENCE`语句来创建Sequence 对象。
语法如下:CREATE SEQUENCE sequence_name START WITH 1 INCREMENT BY 1;其中,`sequence_name`是Sequence 对象的名称,`START WITH`定义了序列的起始值,`INCREMENT BY`定义了每次递增的步长。
在上述示例中,我们定义了一个从1开始,步长为1的Sequence 对象。
第三步:使用Sequence生成自增值要使用Sequence 生成自增值,可以使用`NEXT VALUE FOR`语句。
语法如下:NEXT VALUE FOR sequence_name;这将返回Sequence 生成的下一个值。
例如,如果我们使用上一步创建的Sequence 对象,可以执行以下语句来获取下一个自增值:SELECT NEXT VALUE FOR sequence_name;可以将该语句嵌入到插入语句中,以将自增值插入表中的相应列。
第四步:修改Sequence对象的属性要修改Sequence 对象的属性,可以使用`ALTER SEQUENCE`语句。
怎样向NCBI提交基因序列PublicLibraryofBioinformatics当克隆得到一个基因后,就需要对基因信息向NCBI提交,获得一个登录号,以后写文章就可以直接引用登录号,而不需要在文章中列出序列信息,这里主要介绍比较常见的提交DNA和cDNA信息。
1、打开NCBI的数据提交页面,DNA和cDNA就是第一个,有两种方式,Banklt是网页在线形式,Sequin是本地批量形式,网页形式的话应先点右上角的NCBI注册,注册好后再返回到这个页面点击Banklt,NCBI将保存你提交的数据在你的帐户,如果一次没完成,下次登录后可以继续提交,介而网络的原因,不推荐这种方式。
第二种是用Sequin软件在本地生成提交信息文件,然后将文件通过邮件的形式发送给NCBI,这里主要介绍这种方式,Banklt注册的程序内容也和Sequin一样。
2、下载sequin,如果是windows系统就下载”sequin.win.exe“。
3、双击打开程序”sequin”,如果打不开的话,按“win+R”,输入”cmd”,进入sequin存放的位置。
如放这个文件夹中“D:\Program Files\”,首先在刚打开的命令符窗口中输入”D:”,进入D盘后,输入”cd Program Files”,进入这个文件夹后,输入“sequin.exe”就可以了。
4、打开软件后,点第一行的”Start New Submission”,提交新的序列。
5、在文本域中输入序列的题目,如果是多序列的话就概括一下,这个关系不是很大,文章发表后可以修改这个题目为文章题目,但不填不行;上面有两个单选按钮,”Immediately After Processing”是提交后马上公布,”Release Date”是在规定的时间之后发布,如果你提交的序列还没有写文章,建议还是选”Release Date”,然后点”Next Page”进行下一步。
6、下一步填写通讯作者信息,注意中国人的名称的话,姓是“First Name”,名是”Last Name”,不填”M.I.”,电话和传真前面加上中国的区号”+0086″,填好后”Next Page”。
Fujian Agriculture and Forestry UniversitySequin 批量提交序列A graphic guide for Sequin to submit sequence2012.12Raindyok@生信系列课件(内部交流)•序列文件•序列信息•联系信息准备工作序列文件•格式必须是FASTA,扩展名不限;•序列内容只有含有常见的五种碱基字母(A/C/T/G/U)序列信息SeqId Organism Isolate Country Collection-date HostXQ2Potato virus Y XQ2China30-Mar-2011Solanum tuberosum XQ3Potato virus Y XQ3China30-Mar-2011Solanum tuberosum XQ4Potato virus Y XQ4China30-Mar-2011Solanum tuberosum XQ5Potato virus Y XQ5China30-Mar-2011Solanum tuberosum XQ8Potato virus Y XQ8China30-Mar-2011Solanum tuberosum XQ9Potato virus Y XQ9China30-Mar-2011Solanum tuberosum XQ10Potato virus Y XQ10China30-Mar-2011Solanum tuberosum XQ11Potato virus Y XQ11China30-Mar-2011Solanum tuberosum 相关信息(Organism、Isolate、Country、Collection-date、Host )注意:列(column)之间的界定符号是Tab符,不是空格。
联系信息联系方式联系信息(续上)完整填写后,可以导出为模板单位通讯地址启动Sequin开始操作…1启动序列提交读取保存的已有提交记录23设置序列发布日期,默认是接收后立即发布导入联系方式模板4使用常规的提交向导5批量提交6导入预先准备的序列文件(FASTA格式)7导入预先准备的序列信息8 91011序列注释CDS为编码区信息批量添加序列的定义行,并添加前缀16修改编码区信息,双击即可弹出窗口,修改相关信息全部修改完成,点此12修改编码区位置131415接受修改提交前,最好验证一下提交序列是否有重要错误,并根据提示修改!验证提交文件是否存在明显错误?1718主要检查Error 、Reject是否有明显错误19准备提交20提示保存*.sqn文件,作为附件提交正式提交,将生成*.sqn文件作为附件,并简要说明一下所提交的序列的简要信息,发到gb-sub@《Sequin 批量提交序列》/raindy E-mail: raindy@or raindyok@ Net disk: 。
1. 填写作者、联系方式等,可以将这一部分存为模板,以后修改时可以省去大量时间。
2. 选择序列准备方法”use the normal submission dialog”3. 选择序列格式Submission type:single sequence(单条序列)Batch submission(批量提交,适用于相似的多条序列)4. 载入DNA序列:将DNA 序列保存为FASTA格式(注意序列内不要有“—”,尤其是多条序列时,较短的序列末端可能会用“—”补齐,可以用记事本打开文件,删除)。
序列名称不要超过32个字符,可以用简单的编号。
5. 选择测序、拼接方法6. 添加物种名称7. 补充蛋白信息(如果序列是编码序列,则要提交蛋白序列信息)若为ITS序列见后用MEGA或BioEdit将DNA序列翻译成蛋白序列,如果有内含子,则先要找出内含子并切除,否则不能翻译成功。
(确定内含子位置方法:先从GenBank上下载一条该基因已经提交并注释好的序列,跟自己的序列比对一下,然后根据下载序列的注释确定自己序列的内含子位置)8. 注释9. 添加分类地位10. mRNA 添加“Name = 基因全称”CDS添加“product = 基因全称”11. 更改序列标题(编号);Source 添加“strain = ”:Modifiers > organism12. 保存若点击Done之后可以保存,则说明序列修改成功,可以提交了;若有错误则会提示,修改好之后再保存。
ITS序列7. 以下信息无需填写8.9. 此时进入预览页面会有错误提示,可以忽略。
10. 添加miscRNA11.。
CREATE SEQUENCE名称CREATE SEQUENCE —创建一个新的序列号生成器语法CREATE SEQUENCE seqname [ INCREMENT increment ][ MINVALUE minvalue ] [ MAXVALUE maxvalue ][ START start ] [ CACHE cache ] [ CYCLE ]输入seqname将要创建的序列号名.incrementINCREMENT increment子句是可选的.一个正数将生成一个递增的序列,一个负数将生成一个递减的序列.缺省值是一(1).minvalue可选的子句MINVALUE minvalue决定一个序列可生成的最小值.缺省分别是递增序列为1递减为-2147483647.maxvalue使用可选子句MAXVALUE maxvalue决定序列的最大值.缺省的分别是递增为2147483647,递减为-1.start可选的START start子句使序列可以从任意位置开始.缺省初始值是递增序列为minvalue递减序列为maxvalue.cacheCACHE cache选项使序列号预分配并且为快速访问存储在内存里面.最小值(也是缺省值)是1(一次只能生成一个值, 也就是说没有缓存).CYCLE可选的 CYCLE 关键字可用于使序列到达最大值(maxvalue)或最小值(minvalue)时可复位并继续下去.如果达到极限,生成的下一个数据将分别是最小值(minvalue)或最大值(maxvalue).输出CREATE命令成功执行的返回信息.ERROR: Relation 'seqname' already exists如果声明的序列已经存在.ERROR: DefineSequence: MINVALUE (start) can't be >= MAXVALUE (max) 如果声明的初始值超出范围(最大值),返回此信息.ERROR: DefineSequence: START value (start) can't be < MINVALUE (min) 如果声明的初始值超出范围(最小值),返回此信息.ERROR: DefineSequence: MINVALUE (min) can't be >= MAXVALUE (max)如果最小值和最大值不连贯.描述CREATE SEQUENCE将向当前数据库里增加一个新的序列号生成器.包括创建和初始化一个新的名为seqname 的单行表.生成器将为使用此命令的用户"所有".在序列创建后,你可以使用函数 nextval(seqname) 从序列中获得新的数字.函数 currval('seqname') 可用于获取对当前会话中指定序列的上一次nextval(seqname) 调用返回的数字.函数 setval('seqname', newvalue) 可用于设置指定的序列的当前值.下一次 nextval(seqname) 调用将返回所给的值加上序列增值.使用象SELECT * FROM sequence_name;这样的查询可以获得序列的参数.除了获取最初的参数外,你可以用SELECT last_value FROM sequence_name;获得后端分配的最后一个值.你可以使用底层的锁定用于令多个请求同时调用生成器成为可能.注意请参考DROP SEQUENCE语句来删除序列.每个后端使用其自身的缓存来存储分配的数字.已分配但当前会话没有使用的数字将丢失,导致序列里面出现"空洞".用法创建一个叫 serial 的递增序列,从101开始:CREATE SEQUENCE serial START 101;从此序列中选出下一个数字SELECT NEXTVAL ('serial');nextval-------114在一个 INSERT 中使用此序列:INSERT INTO distributors VALUES (NEXTVAL('serial'),'nothing');在一个 COPY FROM 后设置序列:CREATE FUNCTION distributors_id_max() RETURNS INT4AS 'SELECT max(id) FROM distributors'LANGUAGE 'sql';BEGIN;COPY distributors FROM 'input_file';SELECT setval('serial', distributors_id_max());END;兼容性SQL92CREATE SEQUENCE是Postgres 语言扩展.在SQL92 里没有CREATE SEQUENCE语句.1、Create Sequence你首先要有CREATE SEQUENCE或者CREATE ANY SEQUENCE权限,CREATE SEQUENCE emp_sequenceINCREMENT BY 1 -- 每次加几个START WITH 1 -- 从1开始计数NOMAXVALUE -- 不设置最大值NOCYCLE -- 一直累加,不循环CACHE 10;一旦定义了emp_sequence,你就可以用CURRVAL,NEXTVALCURRVAL=返回 sequence的当前值NEXTVAL=增加sequence的值,然后返回 sequence 值比如:emp_sequence.CURRVALemp_sequence.NEXTVAL可以使用sequence的地方:- 不包含子查询、snapshot、VIEW的 SELECT 语句- INSERT语句的子查询中- NSERT语句的VALUES中- UPDATE 的 SET中可以看如下例子:INSERT INTO emp VALUES(empseq.nextval, 'LEWIS', 'CLERK',7902, SYSDATE, 1200, NULL, 20);SELECT empseq.currval FROM DUAL;但是要注意的是:- 第一次NEXTVAL返回的是初始值;随后的NEXTVAL会自动增加你定义的INCREMENT BY值,然后返回增加后的值。
用BankIt向NCBI在线提交序列向NCBI提交序列常用的方法有两种,其一是在线提交的BankIt,其二是用软件Sequin。
在此结合网络牛人实际操作经验来总结下如何通过BankIt在线提交DNA 或RNA序列,供参考。
1.整理序列信息:包括病原采集地、病原的寄主、寄主症状、采集人等基本信息;还有序列分析结果,包括序列全长大小,开放阅读框(ORF)的长度、位置及特定ORF序列翻译的氨基酸序列等基因水平的信息,这对于接下来的快速准确提交序列及提交成功后为全世界其他作者准确全面分享此类信息很重要;2.登陆BackIt站点,注意到页面右边的“Sign in to use BankIt”标签,点击登录进入。
如果没有账号就注册一个(注意,此账号与ncbi 账号不通用)。
附注册账号步骤,需要填写的项目为:Title:你的职位或头衔First name:名last name:姓login:登陆名Affiliation:所属机构地址,一般填写自己学校地址E-mail Address:通信电邮,填完后会发随机密码到此电邮地址,使用随机密码进行登陆,当然登陆后可对密码进行重置;3.登陆BankIt,看到如下图所示界面,此时NCBI会自动分配一个SubmissionID,但不是最终的提交序列ID:接下来共有九个步骤(好事多磨):3.1 Contact Information填写个人姓名、机构、电邮等资料集联系方式,如果错误该页会有ERROR提示直到正确填写,填写完毕点击CONTINUE;3.2 Reference填写参考作者信息(Reference author)及序列相关信息,比如该序列是否对应有文章,如单纯提交序列则只需选择Unpublished即可(Reference title项可以填入“Direct Submission”),有的话就填写已发表文章的信息(卷、期等),接下来会问你该序列的提交者是否是序列的发现者等信息,填写完毕点击CONTINUE;※提示:新版的BankIt中,接下来会有“Sequencing Technology”一项,呈现有454、Illumina、SOLiD 及Other等测序方法选择,目前为“Sanger dideoxy sequencing”即一代测序方法测序,并且所提交的序列均为“assembled sequences”,目前的“assembly program”为“Lasergene,version 7.0”。
1. 填写作者、联系方式等,可以将这一部分存为模板,以后修改时可以省去大量时间。
2. 选择序列准备方法”use the normal submission dialog”
3. 选择序列格式
Submission type:single sequence(单条序列)
Batch submission(批量提交,适用于相似的多条序列)
4. 载入DNA序列:
将DNA 序列保存为FASTA格式(注意序列不要有“—”,尤其是多条序列时,较短的序列末端可能会用“—”补齐,可以用记事本打开文件,删除)。
序列名称不要超过32个字符,可以用简单的编号。
5. 选择测序、拼接方法
6. 添加物种名称
7. 补充蛋白信息(如果序列是编码序列,则要提交蛋白序列信息)若为ITS序列见后
用MEGA或BioEdit将DNA序列翻译成蛋白序列,如果有含子,则先要找出含子并切除,否则不能翻译成功。
(确定含子位置方法:先从GenBank上下载一条该基因已经提交并注释好的序列,跟自己的序列比对一下,然后根据下载序列的注释确定自己序列的含子位置)
8. 注释
9. 添加分类地位
10. mRNA 添加“Name = 基因全称”CDS添加“product = 基因全称”
11. 更改序列标题(编号);Source 添加“strain = ”:
Modifiers > organism
12. 保存
若点击Done之后可以保存,则说明序列修改成功,可以提交了;若有错误则会提示,修改好之后再保存。
ITS序列
7. 以下信息无需填写
8.
9. 此时进入预览页面会有错误提示,可以忽略。
10. 添加miscRNA
11.。