hadoop_0_20_3_完全分布式配置
- 格式:doc
- 大小:899.50 KB
- 文档页数:74

使用Hadoop进行分布式数据处理的基本步骤随着大数据时代的到来,数据处理变得越来越重要。
在处理海量数据时,传统的单机处理方式已经无法满足需求。
分布式数据处理技术应运而生,而Hadoop作为目前最流行的分布式数据处理框架之一,被广泛应用于各行各业。
本文将介绍使用Hadoop进行分布式数据处理的基本步骤。
1. 数据准备在使用Hadoop进行分布式数据处理之前,首先需要准备好要处理的数据。
这些数据可以是结构化的,也可以是半结构化或非结构化的。
数据可以来自各种来源,如数据库、文本文件、日志文件等。
在准备数据时,需要考虑数据的规模和格式,以便在后续的处理过程中能够顺利进行。
2. Hadoop环境搭建在开始使用Hadoop进行分布式数据处理之前,需要先搭建Hadoop的运行环境。
Hadoop是一个开源的分布式计算框架,可以在多台机器上进行并行计算。
在搭建Hadoop环境时,需要安装Hadoop的核心组件,如Hadoop Distributed File System(HDFS)和MapReduce。
同时,还需要配置Hadoop的相关参数,以适应实际的数据处理需求。
3. 数据上传在搭建好Hadoop环境后,需要将准备好的数据上传到Hadoop集群中。
可以使用Hadoop提供的命令行工具,如Hadoop命令行界面(Hadoop CLI)或Hadoop文件系统(Hadoop File System,HDFS),将数据上传到Hadoop集群的分布式文件系统中。
上传数据时,可以选择将数据分割成多个小文件,以便在后续的并行计算中更高效地处理。
4. 数据分析与处理一旦数据上传到Hadoop集群中,就可以开始进行数据分析与处理了。
Hadoop的核心组件MapReduce提供了一种分布式计算模型,可以将数据分成多个小任务,分配给集群中的不同节点进行并行计算。
在进行数据分析与处理时,可以根据实际需求编写MapReduce程序,定义数据的输入、输出和处理逻辑。


Hadoop集群的三种⽅式1,Local(Standalone) Mode 单机模式$ mkdir input$ cp etc/hadoop/*.xml input$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar grep input output 'dfs[a-z.]+'$ cat output/*解析$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar grep input output 'dfs[a-z.]+'input 夹下⾯的⽂件:capacity-scheduler.xml core-site.xml hadoop-policy.xml hdfs-site.xml httpfs-site.xml yarn-site.xml bin/hadoop hadoop 命令jar 这个命令在jar包⾥⾯share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar 具体位置grep grep 函数input grep 函数的⽬标⽂件夹output grep 函数结果的输出⽂件夹'dfs[a-z.]+' grep 函数的匹配正则条件直译:将input⽂件下⾯的⽂件中包含 'dfs[a-z.]+' 的字符串给输出到output ⽂件夹中输出结果:part-r-00000 _SUCCESScat part-r-00000:1 dfsadmin在hadoop-policy.xml 存在此字符串2,Pseudo-Distributed Operation 伪分布式在 etc/hadoop/core.site.xml 添加以下属性<configuration><property><name>fs.defaultFS</name><value>hdfs://:8020</value> 是主机名,已经和ip相互映射</property>还需要覆盖默认的设定,mkdir -p data/tmp<property><name>hadoop.tmp.dir</name><value>/opt/modules/hadoop-2.5.0/data/tmp</value> 是主机名,已经和ip相互映射</property>垃圾箱设置删除⽂件保留时间(分钟)<property><name>fs.trash.interval</name><value>10080</value></property></configuration>etc/hadoop/hdfs-site.xml: 伪分布式1个备份<configuration><property><name>dfs.replication</name><value>1</value></property>配置从节点<property><name>node.secondary.http-address</name><value>主机名:50090</value></property></configuration>格式化元数据,进⼊到安装⽬录下bin/hdfs namenode -format启动namenode,所有的命令都在sbin下,通过ls sbin/ 可以查看sbin/hadoop-daemon.sh start namenode hadoop 的守护线程启动(主数据)sbin/hadoop-daemon.sh start datanode 启动datanode(从数据)nameNode都有个web⽹页,端⼝50070创建hdfs ⽂件夹,创建在⽤户名下⾯bin/hdfs dfs -mkdir -p /user/chris查看⽂件夹bin/hdfs dfs -ls -R / 回调查询本地新建⽂件夹mkdir wcinput mkdir wcoutput vi wc.input创建wc.input⽂件,并写⼊内容hdfs⽂件系统新建⽂件夹bin/hdfs dfs -mkdir -p /user/chris/mapreduce/wordcount/input本地⽂件上传hdfs⽂件系统bin/hdfs dfs -put wcinput/wc.input /user/chris/mapreduce/wordcount/input/在hdfs⽂件系统上使⽤mapreduce$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /user/chris/mapreduce/wordcount/input /user/chris/mapreduce/wordcount/output红⾊代表:读取路径蓝⾊代表:输出路径所以mapreduce的结果已经写到了hdfs的输出⽂件⾥⾯去了Yarn on a Single Node/opt/modules/hadoop-2.5.0/etc/hadoop/yarn-site.xml 在hadoop的安装路径下<configuration><property><name>yarn.resourcemanager.hostname</name><value></value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>yarn 的配置已经完成在同⼀⽬录下slave⽂件上添加主机名或者主机ip,默认是localhostyarn-env.sh 和 mapred-env.sh把JAVA_HOME 更改下,防⽌出错export JAVA_HOME=/home/chris/software/jdk1.8.0_201将mapred-site.xml.template 重命名为mapred-site.xml,同时添加以下配置<configuration><property><name></name><value>yarn</name></property></configuration>先将/user/chris/mapreduce/wordcount/output/删除再次执⾏$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jarwordcount /user/chris/mapreduce/wordcount/input /user/chris/mapreduce/wordcount/output伪分布式执⾏完毕,mapreduce 执⾏在了yarn 上3,完全分布式基于伪分布式,配置好⼀台机器后,分发⾄其它机器step1: 配置ip 和 hostname 映射vi /etc/hosts192.168.178.110 hella-hadoop192.168.178.111 hella-hadoop02192.168.178.112 hella-hadoop03同时在window以下路径也得设置C:\Windows\System32\drivers\etc\hosts192.168.178.110 hella-hadoop192.168.178.111 hella-hadoop02192.168.178.112 hella-hadoop03具体可参考linux ip hostname 映射step2:部署(假设三台机器)不同机器配置不同的节点部署:hella-hadoop hella-hadoop02 hella-hadoop03HDFS:NameNodeDataNode DataNode DataNodeSecondaryNameNodeYARN:ResourceManagerNodeManager NodeManager NodeManager MapReduce:JobHistoryServer配置:* hdfshadoop-env.shcore.site.xmlhdfs-site.xmlslaves*yarnyarn-env.shyarn-site.xmlslaves*mapreducemapred-env.shmapred-site.xmlstep3:修改配置⽂件core.xml<configuration><property><name>fs.defaultFS</name><value>hdfs://:8020</value></property><property><name>hadoop.tmp.dir</name><value>/opt/app/hadoop-2.5.0/data/tmp</value></property><property><name>fs.trash.interval</name><value>10080</value></property></configuration>hdfs-site.xml<configuration><property><name>node.secondary.http-address</name><value>:50090</value></property></configuration>slavesyarn-site.xml<configuration><property><name>yarn.resourcemanager.hostname</name><value></value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--NodeManager Resouce --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>4</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation-retain-seconds</name><value>640800</value></property></configuration>mapred-site.xml<configuration><property><name></name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>:19888</value></property></configurationstep4:集群的配置路径在各个机器上要⼀样,⽤户名⼀样step5: 分发hadoop 安装包⾄各个机器节点scp -p 源节点⽬标节点使⽤scp 命令需要配置ssh ⽆密钥登陆,博⽂如下:step6:启动并且test mapreduce可能会有问题No route to Host 的Error,查看hostname 以及 ip 配置,或者是防⽕墙有没有关闭防⽕墙关闭,打开,状态查询,请参考以下博⽂:4,完全分布式+ HAHA全称:HDFS High Availability Using the Quorum Journal Manager 即 HDFS⾼可⽤性通过配置分布式⽇志管理HDFS集群中存在单点故障(SPOF),对于只有⼀个NameNode 的集群,若是NameNode 出现故障,则整个集群⽆法使⽤,知道NameNode 重新启动。

Hadoop中常用端口说明和相关配置文件Hadoop是一个开源的分布式处理系统,可以对大规模数据进行高效的存储和处理。
在Hadoop中,有许多常用的端口和相关配置文件,这些端口和文件对于Hadoop集群的运行非常重要。
本文将详细介绍Hadoop中常用的端口说明和相关配置文件。
一、Hadoop常用端口说明1. Namenode端口:默认端口为8020,是Hadoop集群中的主节点,存储有HDFS的元数据信息,命令行中通过hdfs://<namenode-ip>:8020/访问HDFS。
Namenode的端口负责管理整个集群中文件块的元数据信息,由于这些信息比较重要,建议使用安全的方式进行访问和管理。
2. Datanode端口:默认端口为50010,是Hadoop集群中的从节点,存储有HDFS的数据块。
Datanode的端口用于管理数据块,当文件需要进行读写操作时,客户端会向Namenode请求相应数据块的位置信息,然后直接通过Datanode端口进行读写操作。
3. Secondary Namenode端口:默认端口为50090,是Hadoop集群中的辅助节点,不存储实际数据,但能够定期备份主节点的元数据信息,避免因Namenode节点失效而导致Hadoop集群无法访问。
4. JobTracker端口:默认端口为8021,是Hadoop中的工作节点,负责处理MapReduce任务。
JobTracker的端口负责监控整个Hadoop集群中的运行情况,以及处理MapReduce任务的分配和管理。
5. TaskTracker端口:默认端口为50060,是Hadoop中的工作节点,负责处理MapReduce任务。
TaskTracker的端口负责处理实际的MapReduce任务,将计算结果返回给JobTracker进行处理。
二、Hadoop相关配置文件1. core-site.xml:这个配置文件是Hadoop的核心配置文件之一,主要用于配置Hadoop集群的全局属性。

hadoop核⼼组件概述及hadoop集群的搭建什么是hadoop? Hadoop 是 Apache 旗下的⼀个⽤ java 语⾔实现开源软件框架,是⼀个开发和运⾏处理⼤规模数据的软件平台。
允许使⽤简单的编程模型在⼤量计算机集群上对⼤型数据集进⾏分布式处理。
hadoop提供的功能:利⽤服务器集群,根据⽤户的⾃定义业务逻辑,对海量数据进⾏分布式处理。
狭义上来说hadoop 指 Apache 这款开源框架,它的核⼼组件有:1. hdfs(分布式⽂件系统)(负责⽂件读写)2. yarn(运算资源调度系统)(负责为MapReduce程序分配运算硬件资源)3. MapReduce(分布式运算编程框架)扩展:关于hdfs集群: hdfs集群有⼀个name node(名称节点),类似zookeeper的leader(领导者),namenode记录了⽤户上传的⼀些⽂件分别在哪些DataNode上,记录了⽂件的源信息(就是记录了⽂件的名称和实际对应的物理地址),name node有⼀个公共端⼝默认是9000,这个端⼝是针对客户端访问的时候的,其他的⼩弟(跟随者)叫data node,namenode和datanode会通过rpc进⾏远程通讯。
Yarn集群: yarn集群⾥的⼩弟叫做node manager,MapReduce程序发给node manager来启动,MapReduce读数据的时候去找hdfs(datanode)去读。
(注:hdfs集群和yarn集群最好放在同⼀台机器⾥),yarn集群的⽼⼤主节点resource manager负责资源调度,应(最好)单独放在⼀台机器。
⼴义上来说,hadoop通常指更⼴泛的概念--------hadoop⽣态圈。
当下的 Hadoop 已经成长为⼀个庞⼤的体系,随着⽣态系统的成长,新出现的项⽬越来越多,其中不乏⼀些⾮ Apache 主管的项⽬,这些项⽬对 HADOOP 是很好的补充或者更⾼层的抽象。

1.1软件环境1)CentOS6.5x642)Jdk1.7x643)Hadoop2.6.2x644)Hbase-0.98.95)Zookeeper-3.4.61.2集群环境集群中包括 3个节点:1个Master, 2个Slave2安装前的准备2.1下载JDK2.2下载Hadoop2.3下载Zookeeper2.4下载Hbase3开始安装3.1 CentOS安装配置1)安装3台CentOS6.5x64 (使用BasicServer模式,其他使用默认配置,安装过程略)2)Master.Hadoop 配置a)配置网络修改为:保存,退出(esc+:wq+enter ),使配置生效b) 配置主机名修改为:c)配置 hosts修改为:修改为:在最后增加如下内容以上调整,需要重启系统才能生效g) 配置用户新建hadoop用户和组,设置 hadoop用户密码id_rsa.pub ,默认存储在"/home/hadoop/.ssh" 目录下。
a) 把id_rsa.pub 追加到授权的 key 里面去b) 修改.ssh 目录的权限以及 authorized_keys 的权限c) 用root 用户登录服务器修改SSH 配置文件"/etc/ssh/sshd_config"的下列内容3) Slavel.Hadoop 、Slavel.Hadoop 配置及用户密码等等操作3.2无密码登陆配置1)配置Master 无密码登录所有 Slave a)使用 hadoop 用户登陆 Master.Hadoopb)把公钥复制所有的 Slave 机器上。
使用下面的命令格式进行复制公钥2) 配置Slave 无密码登录Mastera) 使用hadoop 用户登陆Slaveb)把公钥复制Master 机器上。
使用下面的命令格式进行复制公钥id_rsa 和相同的方式配置 Slavel 和Slave2的IP 地址,主机名和 hosts 文件,新建hadoop 用户和组c) 在Master机器上将公钥追加到authorized_keys 中3.3安装JDK所有的机器上都要安装 JDK ,先在Master服务器安装,然后其他服务器按照步骤重复进行即可。

Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册前言: (3)一. Hadoop安装(伪分布式) (4)1. 操作系统 (4)2. 安装JDK (4)1> 下载并解压JDK (4)2> 配置环境变量 (4)3> 检测JDK环境 (5)3. 安装SSH (5)1> 检验ssh是否已经安装 (5)2> 安装ssh (5)3> 配置ssh免密码登录 (5)4. 安装Hadoop (6)1> 下载并解压 (6)2> 配置环境变量 (6)3> 配置Hadoop (6)4> 启动并验证 (8)前言:网络上充斥着大量Hadoop1的教程,版本老旧,Hadoop2的中文资料相对较少,本教程的宗旨在于从Hadoop2出发,结合作者在实际工作中的经验,提供一套最新版本的Hadoop2相关教程。
为什么是Hadoop2.2.0,而不是Hadoop2.4.0本文写作时,Hadoop的最新版本已经是2.4.0,但是最新版本的Hbase0.98.1仅支持到Hadoop2.2.0,且Hadoop2.2.0已经相对稳定,所以我们依然采用2.2.0版本。
一. Hadoop安装(伪分布式)1. 操作系统Hadoop一定要运行在Linux系统环境下,网上有windows下模拟linux环境部署的教程,放弃这个吧,莫名其妙的问题多如牛毛。
2. 安装JDK1> 下载并解压JDK我的目录为:/home/apple/jdk1.82> 配置环境变量打开/etc/profile,添加以下内容:export JAVA_HOME=/home/apple/jdk1.8export PATH=$PATH:$JAVA_HOME/binexport CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar执行source /etc/profile ,使更改后的profile生效。
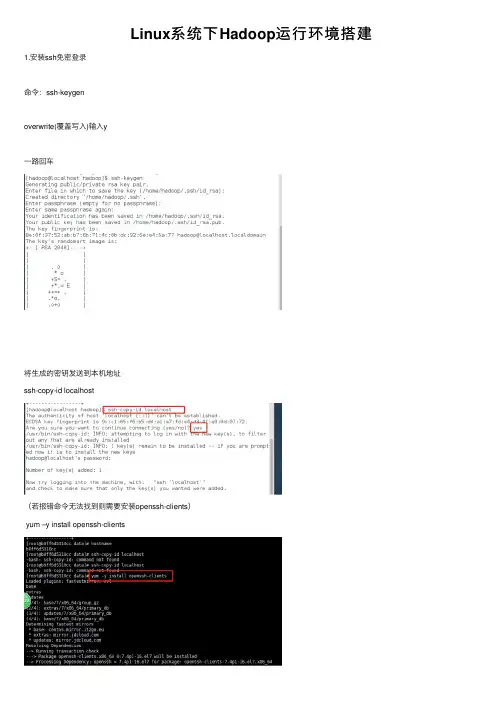
Linux系统下Hadoop运⾏环境搭建1.安装ssh免密登录命令:ssh-keygenoverwrite(覆盖写⼊)输⼊y⼀路回车将⽣成的密钥发送到本机地址ssh-copy-id localhost(若报错命令⽆法找到则需要安装openssh-clients)yum –y install openssh-clients测试免密设置是否成功ssh localhost2.卸载已有java确定JDK版本rpm –qa | grep jdkrpm –qa | grep gcj切换到root⽤户,根据结果卸载javayum -y remove java-1.8.0-openjdk-headless.x86_64 yum -y remove java-1.7.0-openjdk-headless.x86_64卸载后输⼊java –version查看3.安装java切换回hadoop⽤户,命令:su hadoop查看下当前⽬标⽂件,命令:ls新建⼀个app⽂件夹,命令:mkdir app将桌⾯的hadoop⽂件夹中的java及hadoop安装包移动到app⽂件夹中命令:mv /home/hadoop/Desktop/hadoop/jdk-8u141-linux-x64.gz /home/hadoop/app mv /home/hadoop/Desktop/hadoop/hadoop-2.7.0.tar.gz /home/hadoop/app解压java程序包,命令:tar –zxvf jdk-7u79-linux-x64.tar.gz创建软连接ln –s jdk1.8.0_141 jdk配置jdk环境变量切换到root⽤户再输⼊vi /etc/profile输⼊export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141export JAVA_JRE=JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/libexport PATH=$PATH:$JAVA_HOME/bin保存退出,并使/etc/profile⽂件⽣效source /etc/profile能查询jdk版本号,说明jdk安装成功java -version4.安装hadoop切换回hadoop⽤户,解压缩hadoop-2.6.0.tar.gz安装包创建软连接,命令:ln -s hadoop-2.7.0 hadoop验证单机模式的Hadoop是否安装成功,命令:hadoop/bin/hadoop version此时可以查看到Hadoop安装版本为Hadoop2.7.0,说明单机版安装成功。
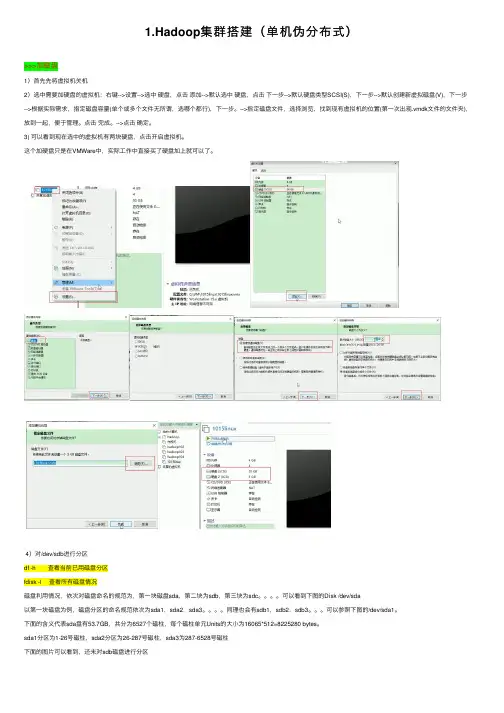
1.Hadoop集群搭建(单机伪分布式)>>>加磁盘1)⾸先先将虚拟机关机2)选中需要加硬盘的虚拟机:右键-->设置-->选中硬盘,点击添加-->默认选中硬盘,点击下⼀步-->默认硬盘类型SCSI(S),下⼀步-->默认创建新虚拟磁盘(V),下⼀步-->根据实际需求,指定磁盘容量(单个或多个⽂件⽆所谓,选哪个都⾏),下⼀步。
-->指定磁盘⽂件,选择浏览,找到现有虚拟机的位置(第⼀次出现.vmdk⽂件的⽂件夹),放到⼀起,便于管理。
点击完成。
-->点击确定。
3) 可以看到现在选中的虚拟机有两块硬盘,点击开启虚拟机。
这个加硬盘只是在VMWare中,实际⼯作中直接买了硬盘加上就可以了。
4)对/dev/sdb进⾏分区df -h 查看当前已⽤磁盘分区fdisk -l 查看所有磁盘情况磁盘利⽤情况,依次对磁盘命名的规范为,第⼀块磁盘sda,第⼆块为sdb,第三块为sdc。
可以看到下图的Disk /dev/sda以第⼀块磁盘为例,磁盘分区的命名规范依次为sda1,sda2,sda3。
同理也会有sdb1,sdb2,sdb3。
可以参照下图的/dev/sda1。
下⾯的含义代表sda盘有53.7GB,共分为6527个磁柱,每个磁柱单元Units的⼤⼩为16065*512=8225280 bytes。
sda1分区为1-26号磁柱,sda2分区为26-287号磁柱,sda3为287-6528号磁柱下⾯的图⽚可以看到,还未对sdb磁盘进⾏分区fdisk /dev/sdb 分区命令可以选择m查看帮助,显⽰命令列表p 显⽰磁盘分区,同fdisk -ln 新增分区d 删除分区w 写⼊并退出选w直接将分区表写⼊保存,并退出。
mkfs -t ext4 /dev/sdb1 格式化分区,ext4是⼀种格式mkdir /newdisk 在根⽬录下创建⼀个⽤于挂载的⽂件mount /dev/sdb1 /newdisk 挂载sdb1到/newdisk⽂件(这只是临时挂载的解决⽅案,重启机器就会发现失去挂载)blkid /dev/sdb1 通过blkid命令⽣成UUIDvi /etc/fstab 编辑fstab挂载⽂件,新建⼀⾏挂载记录,将上⾯⽣成的UUID替换muount -a 执⾏后⽴即⽣效,不然的话是重启以后才⽣效。

Hadoop集群搭建步骤1.先建⽴⼀台虚拟机,分配内存2G,硬盘20G,⽹络为nat 模式,设置⼀个静态的ip 地址: 例如设定3台机器的ip 为192.168.63.167(master) 192.16863.168(slave1) 192.168.63.169 (slave2)2.修改第⼀台主机的⽤户名3.复制master⽂件两次,重命名为slave1和slave2,打开虚拟机⽂件,然后按照同样的⽅法设置两个节点的ip和主机名4.建⽴主机名和ip的映射5.查看是否能ping通,关闭防⽕墙和selinux 配置6.配置ssh免密码登录在root⽤户下输⼊ssh-keygen -t rsa ⼀路回车秘钥⽣成后在~/.ssh/⽬录下,有两个⽂件id_rsa(私钥)和id_rsa.pub(公钥),将公钥复制到authorized_keys并赋予authorized_keys600权限同理在slave1和slave2节点上进⾏相同的操作,然后将公钥复制到master节点上的authoized_keys检查是否免密登录(第⼀次登录会有提⽰)7..安装JDK(省去)三个节点安装java并配置java环境变量8.安装MySQL(master 节点省去)9.安装SecureCRT或者xshell 客户端⼯具,然后分别链接上 3台服务器12.搭建集群12.1 集群结构三个结点:⼀个主节点master两个从节点内存2GB 磁盘20GB12.2 新建hadoop⽤户及其⽤户组⽤adduser新建⽤户并设置密码将新建的hadoop⽤户添加到hadoop⽤户组前⾯hadoop指的是⽤户组名,后⼀个指的是⽤户名赋予hadoop⽤户root权限12.3 安装hadoop并配置环境变量由于hadoop集群需要在每⼀个节点上进⾏相同的配置,因此先在master节点上配置,然后再复制到其他节点上即可。
将hadoop包放在/usr/⽬录下并解压配置环境变量在/etc/profile⽂件中添加如下命令12.4 搭建集群的准备⼯作在master节点上创建以下⽂件夹/usr/hadoop-2.6.5/dfs/name/usr/hadoop-2.6.5/dfs/data/usr/hadoop-2.6.5/temp12.5 配置hadoop⽂件接下来配置/usr/hadoop-2.6.5/etc//hadoop/⽬录下的七个⽂件slaves core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml hadoop-env.sh yarn-env.sh配置hadoop-env.sh配置yarn-env.sh配置slaves⽂件,删除localhost配置core-site.xml配置hdfs-site.xml配置mapred-site.xml配置yarn-site.xml将配置好的hadoop⽂件复制到其他节点上12.6 运⾏hadoop格式化Namenodesource /etc/profile13. 启动集群。
Hadoop使用常见问题以及解决方法1:Shuffle Error: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out Answer:程序里面需要打开多个文件,进行分析,系统一般默认数量是1024,(用ulimit -a可以看到)对于正常使用是够了,但是对于程序来讲,就太少了。
修改办法:修改2个文件。
/etc/security/limits.confvi /etc/security/limits.conf加上:* soft nofile 102400* hard nofile 409600$cd /etc/pam.d/$sudo vi login添加 session required /lib/security/pam_limits.so针对第一个问题我纠正下答案:这是reduce 预处理阶段shuffle时获取已完成的map的输出失败次数超过上限造成的,上限默认为5。
引起此问题的方式可能会有很多种,比如网络连接不正常,连接超时,带宽较差以及端口阻塞等。
通常框架内网络情况较好是不会出现此错误的。
2:Too many fetch-failuresAnswer:出现这个问题主要是结点间的连通不够全面。
1) 检查、/etc/hosts要求本机ip对应服务器名要求要包含所有的服务器ip + 服务器名2) 检查 .ssh/authorized_keys要求包含所有服务器(包括其自身)的public key3:处理速度特别的慢出现map很快但是reduce很慢而且反复出现reduce=0% Answer:结合第二点,然后修改conf/hadoop-env.sh 中的export HADOOP_HEAPSIZE=40004:能够启动 datanode ,但无法访问,也无法结束的错误在重新格式化一个新的分布式文件时,需要将你NameNode上所配置的.dir 这一namenode用来存放NameNode持久存储名字空间及事务日志的本地文件系统路径删除,同时将各DataNode上的dfs.data .dir的路径DataNode存放块数据的本地文件系统路径的目录也删除。
Hadoop集群环境搭建1、准备资料虚拟机、Redhat6.5、hadoop-1.0.3、jdk1.62、基础环境设置2.1配置机器时间同步#配置时间自动同步crontab -e#手动同步时间/usr/sbin/ntpdate 1、安装JDK安装cd /home/wzq/dev./jdk-*****.bin设置环境变量Vi /etc/profile/java.sh2.2配置机器网络环境#配置主机名(hostname)vi /etc/sysconfig/network#修第一台hostname 为masterhostname master#检测hostname#使用setup 命令配置系统环境setup#检查ip配置cat /etc/sysconfig/network-scripts/ifcfg-eth0#重新启动网络服务/sbin/service network restart#检查网络ip配置/sbin/ifconfig2.3关闭防火墙2.4配置集群hosts列表vi /etc/hosts#添加一下内容到vi 中2.5创建用户账号和Hadoop部署目录和数据目录#创建hadoop 用户/usr/sbin/groupadd hadoop#分配hadoop 到hadoop 组中/usr/sbin/useradd hadoop -g hadoop#修改hadoop用户密码Passwd hadoop#创建hadoop 代码目录结构mkdir -p /opt/modules/hadoop/#修改目录结构权限拥有者为为hadoopchown -R hadoop:hadoop /opt/modules/hadoop/2.6生成登陆密钥#切换到Hadoop 用户下su hadoopcd /home/hadoop/#在master、node1、node2三台机器上都执行下面命令,生成公钥和私钥ssh-keygen -q -t rsa -N "" -f /home/hadoop/.ssh/id_rsacd /home/hadoop/.ssh#把node1、node2上的公钥拷贝到master上scp /home/hadoop/.ssh/ id_rsa.pub hadoop@master:/home/hadoop/.ssh/node1_pubkey scp /home/hadoop/.ssh/ id_rsa.pub hadoop@master:/home/hadoop/.ssh/node2_pubkey#在master上生成三台机器的共钥cp id_rsa.pub authorized_keyscat node1_pubkey >> authorized_keyscat node2_pubkey >> authorized_keysrm node1_pubkey node2_pubkey#吧master上的共钥拷贝到其他两个节点上scp authorized_keys node1: /home/hadoop/.ssh/scp authorized_keys node1: /home/hadoop/.ssh/#验证ssh masterssh node1ssh node2没有要求输入密码登陆,表示免密码登陆成功3、伪分布式环境搭建3.1下载并安装JAVA JDK系统软件#下载jdkwget http://60.28.110.228/source/package/jdk-6u21-linux-i586-rpm.bin#安装jdkchmod +x jdk-6u21-linux-i586-rpm.bin./jdk-6u21-linux-i586-rpm.bin#配置环境变量vi /etc/profile.d/java.sh#手动立即生效source /etc/profile3.2 Hadoop 文件下载和安装#切到hadoop 安装路径下cd /opt/modules/hadoop/#从 下载Hadoop 安装文件wget /apache-mirror/hadoop/common/hadoop-1.0.3/hadoop-1.0.3.tar.gz#如果已经下载,请复制文件到安装hadoop 文件夹cp hadoop-1.0.3.tar.gz /opt/modules/hadoop/#解压hadoop-1.0.3.tar.gzcd /opt/modules/hadoop/tar -xvf hadoop-1.0.3.tar.gz#配置环境变量vi /etc/profile.d/java.sh#手动立即生效source /etc/profile3.3配置hadoop-env.sh 环境变量#配置jdk。
Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程历时一周多,终于搭建好最新版本Hadoop2.2集群,期间遇到各种问题,作为菜鸟真心被各种折磨,不过当wordcount给出结果的那一刻,兴奋的不得了~~(文当中若有错误之处或疑问欢迎指正,互相学习)另外:欢迎配置过程中遇到问题的朋友留言,相互讨论,并且能够把解决方法共享给大家。
下面评论中有几个朋友遇到的问题和解决方法,欢迎参考!第一部分Hadoop 2.2 下载Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。
官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译(10楼评论中提供了一个解决方法链接)。
下载地址:/hadoop/common/hadoop-2.2.0/如下图所示,下载红色标记部分即可。
如果要自行编译则下载src.tar.gz.第二部分集群环境搭建1、这里我们搭建一个由三台机器组成的集群:192.168.0.1 hduser/passwd cloud001 nn/snn/rm CentOS6 64bit192.168.0.2 hduser/passwd cloud002 dn/nm Ubuntu13.04 32bit192.168.0.3 hduser/passwd cloud003 dn/nm Ubuntu13.0432bit1.1 上面各列分别为IP、user/passwd、hostname、在cluster中充当的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager)1.2 Hostname可以在/etc/hostname中修改(ubuntu是在这个路径下,RedHat稍有不同)1.3 这里我们为每台机器新建了一个账户hduser.这里需要给每个账户分配sudo的权限。
⼤数据--Hadoop集群环境搭建⾸先我们来认识⼀下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式⽂件系统。
它其实是将⼀个⼤⽂件分成若⼲块保存在不同服务器的多个节点中。
通过联⽹让⽤户感觉像是在本地⼀样查看⽂件,为了降低⽂件丢失造成的错误,它会为每个⼩⽂件复制多个副本(默认为三个),以此来实现多机器上的多⽤户分享⽂件和存储空间。
Hadoop主要包含三个模块:HDFS模块:HDFS负责⼤数据的存储,通过将⼤⽂件分块后进⾏分布式存储⽅式,突破了服务器硬盘⼤⼩的限制,解决了单台机器⽆法存储⼤⽂件的问题,HDFS是个相对独⽴的模块,可以为YARN提供服务,也可以为HBase等其他模块提供服务。
YARN模块:YARN是⼀个通⽤的资源协同和任务调度框架,是为了解决Hadoop中MapReduce⾥NameNode负载太⼤和其他问题⽽创建的⼀个框架。
YARN是个通⽤框架,不⽌可以运⾏MapReduce,还可以运⾏Spark、Storm等其他计算框架。
MapReduce模块:MapReduce是⼀个计算框架,它给出了⼀种数据处理的⽅式,即通过Map阶段、Reduce阶段来分布式地流式处理数据。
它只适⽤于⼤数据的离线处理,对实时性要求很⾼的应⽤不适⽤。
多相关信息可以参考博客:。
本节将会介绍Hadoop集群的配置,⽬标主机我们可以选择虚拟机中的多台主机或者多台阿⾥云服务器。
注意:以下所有操作都是在root⽤户下执⾏的,因此基本不会出现权限错误问题。
⼀、Vmware安装VMware虚拟机有三种⽹络模式,分别是Bridged(桥接模式)、NAT(⽹络地址转换模式)、Host-only(主机模式):桥接:选择桥接模式的话虚拟机和宿主机在⽹络上就是平级的关系,相当于连接在同⼀交换机上;NAT:NAT模式就是虚拟机要联⽹得先通过宿主机才能和外⾯进⾏通信;仅主机:虚拟机与宿主机直接连起来。
➢3.10.2.进程➢JpsMaster节点:namenode/tasktracker(如果Master不兼做Slave, 不会出现datanode/TasktrackerSlave节点:datanode/Tasktracker说明:JobTracker 对应于NameNodeTaskTracker 对应于DataNodeDataNode 和NameNode 是针对数据存放来而言的JobTracker和TaskTracker是对于MapReduce执行而言的mapreduce中几个主要概念,mapreduce整体上可以分为这么几条执行线索:jobclient,JobTracker与TaskTracker。
1、JobClient会在用户端通过JobClient类将应用已经配置参数打包成jar文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker创建每个Task(即MapTask和ReduceTask)并将它们分发到各个TaskTracker服务中去执行2、JobTracker是一个master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。
一般情况应该把JobTracker部署在单独的机器上。
3、TaskTracker是运行在多个节点上的slaver服务。
TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。
TaskTracker都需要运行在HDFS的DataNode上3.10.3.文件系统HDFS⏹查看文件系统根目录:Hadoop fs–ls /。
《大数据Hadoop基础》课程标准一、课程说明课程编码〔37601〕承担单位〔计算机信息学院〕制定〔〕制定日期〔2022年11月16日〕审核〔专业指导委员会〕审核日期〔2022年11月26日〕批准〔二级学院(部)院长〕批准日期〔2022年11月28日〕(1)课程性质:《大数据应用技术基础》由Hadoop开发基础、分布式存储HDFS开发基础和分布式计算Map Reduce开发基础三部分组成,它是由Apache基金会所开发的分布式系统基础架构,一个能够对大量数据进行分布式处理的软件框架;Hadoop以一种可靠、高效、可伸缩的方式进行数据处理,能够处理PB级数据。
从学科性质上讲,它既是大数据技术与应用专业的基础课程,又是大数据技术与应用专业的专业核心课程,它为大数据技术与应用专业后继课程的学习提供必要的理论与实践基础。
(2)课程任务:通过本门课程的学习,使学生知道Hadoop框架最核心的设计是:HDFS和Map Reduce;HDFS是部署在Hadoop集群的底层为海量的数据提供了存储,而Map Reduce为海量的数据提供了计算;而且能够理解并掌握HDFS文件系统的存储原理、两种访问HDFS文件系统的模式以及理解Hadoop集群的计算框架Map Reduce的工作原理,为《Hadoop基础实战》、《数据的可视化》和《Spark数据计算》等课程的学习提供理论依据和实战基础。
(3)课程衔接:《大数据应用技术基础》的先修课程为《Java程序设计》、《Linux系统管理》等,这些课程的学习将为本课程的学习奠定了理论基础。
《大数据应用技术基础》的后续课程是《Hadoop基础实战》、《数据的可视化》和《Spark 数据计算》等,通过该课程的学习可为这些课程内容的学习奠定良好的理论和实战基础,在教学中起到承上启下的作用。
二、学习目标通过本门课程的学习,首先,使学生知道Hadoop集群的基本架构,理解并掌握Hadoop 集群搭建的三种模式;其次,知道HDFS是部署在Hadoop集群的一个分布式文件存储系统,理解并掌握HDFS文件系统的存储原理以及两种访问HDFS文件系统的模式;最后,理解Hadoop集群的计算框架Map Reduce的工作原理,并且掌握map Reduce分析年气象数据和英语单词统计,从而提高学生的发现问题、分析问题和解决问题的能力。
2.1.3 Hadoop版本变迁 到2012年5月为止,Apache Hadoop已经出现四个大的分支,如图2-1所示。 Apache Hadoop的四大分支构成了四个系列的Hadoop版本。 1. 0.20.X系列 0.20.2版本发布后,几个重要的特性没有基于trunk而是在0.20.2基础上继续研发。值得一提的主要有两个特性:Append与Security。其中,含Security特性的分支以0.20.203版本发布,而后续的0.20.205版本综合了这两个特性。需要注意的是,之后的1.0.0版本仅是0.20.205版本的重命名。0.20.X系列版本是最令用户感到疑惑的,因为它们具有的一些特性,trunk上没有;反之,trunk上有的一些特性,0.20.X系列版本却没有。
2. 0.21.0/0.22.X系列 这一系列版本将整个Hadoop项目分割成三个独立的模块,分别是 Common、HDFS和MapReduce。HDFS和MapReduce都对Common模块有依赖性,但是MapReduce对HDFS并没有依赖性。这样,MapReduce可以更容易地运行其他分布式文件系统,同时,模块间可以独立开发。具体各个模块的改进如下。
Common模块:最大的新特性是在测试方面添加了Large-Scale Automated Test Framework和Fault Injection Framework。
HDFS模块:主要增加的新特性包括支持追加操作与建立符号连接、Secondary NameNode改进(Secondary NameNode被剔除,取而代之的是Checkpoint Node,同时添加一个Backup Node的角色,作为NameNode的冷备)、允许用户自定义block放置算法等。
MapReduce模块:在作业API方面,开始启动新MapReduce API,但老的API仍然兼容。 0.22.0在0.21.0的基础上修复了一些bug并进行了部分优化。
3. 0.23.X系列 0.23.X是为了克服Hadoop在扩展性和框架通用性方面的不足而提出来的。它实际上是一个全新的平台,包括分布式文件系统HDFS Federation和资源管理框架YARN两部分,可对接入的各种计算框架(如MapReduce、Spark等)进行统一管理。它的发行版自带MapReduce库,而该库集成了迄今为止所有的MapReduce新特性。
4. 2.X系列 同0.23.X系列一样,2.X系列也属于下一代Hadoop。与0.23.X系列相比,2.X系列增加了NameNode HA和Wire-compatibility等新特性。
表2-1总结了Hadoop各个发布版的特性以及稳定性。 表2-1 Hadoop各个发布版的特性以及稳定性
本书之所以以分析Apache Hadoop 1.0.0为主,主要是因为这是一个稳定的版本,再有其为1.0.0,具有里程碑意义。Apache发布这个版本,也是希望该版本成为业界的规范。需要注意的是,尽管本书以分析Apache Hadoop 1.0.0版本为主,但本书内容适用于所有Apache Hadoop 1.X版本。
一、需要的设备 1.虚拟机VM和 ) 2.jdk(Linux版本) 3.完全分布式 4.hadoop安装包(0.20.2),配置core-site.xml,hdfs-site.xml,mapred-site.xml 5.ssh,生成密钥,免密码连接 二、安装和配置 1.配置hosts文件 如果ip较多,可使用DNS来配置。 所有的节点都修改etc/hosts,使得彼此都能被解析 **************************************************** 127.0.0.1 localhost.localdomain localhost ::1 localhost6.localdomain6 localhost6 192.168.1.102 h1 192.168.1.103 h2 192.168.1.163 cat 192.168.1.162 dog **************************************************** 2.建立hadoop运行账号 先用root进入,建立用户xxx(用户名),在root下使用命令passwd xxx(用户名),
3.配置ssh免密码连入 使用xxx(用户名)登录,使用命令ssh-keygen -t rsa 命令cd .ssh(进入.ssh) 命令ls,cp id_rsa_pub authorized_keys
4.下载并解压hadoop安装包 5.配置namenode,修改site文件 6.配置hadoop-env.sh 7.配置master和salves文件 8.向各节点复制hadoop 9.格式化namenode 10.启动hadoop 11.用jps验证 大家可以尝试下Ambari来配置Hadoop的相关环境 快速的部署Hadoop,Hbase和Hive等并提供Ganglia和Nagios的监控功能,强烈推荐使用.
http://www.cnblogs.com/scotoma/archive/2013/05/18/3085248.html
Hadoop 2.0集群配置详细教程 前言 Hadoop2.0介绍 Hadoop是 apache 的开源 项目,开发的主要目的是为了构建可靠,可拓展 scalable ,分布式的系 统, hadoop 是一系列的子工程的 总和,其中包含 1. hadoop common : 为其他项目提供基础设施 2. HDFS :分布式的文件系 统 3. MapReduce : A software framework for distributed processing of large data sets on compute clusters 。一个 简化分布式编程的框架。 4. 其他工程包含: Avro( 序列化系 统 ) , Cassandra( 数据 库项目 ) 等
Hadoop,以 Hadoop 分布式文件系统( HDFS ,Hadoop Distributed Filesystem )和 MapReduce ( Google MapReduce 的开源实现)为核心的 Hadoop 为用户提供了系统底层细节透明的分布式基础架构。 对于 Hadoop 的集群来讲,可以分成两大类角色: Master 和 Salve 。一个 HDFS 集群是由一个 NameNode 和若干个 DataNode 组成的。其中 NameNode 作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的 DataNode 管理存 储的数据。 MapReduce 框架是由一个 单独运行在主节点上的 JobTracker 和 运行在每个集群从节点的 TaskTracker 共同 组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个 Job 被提交 时, JobTracker 接收到提交作 业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控 TaskTracker 的 执行。 从上面的介 绍可以看出, HDFS 和 MapReduce 共同 组成了 Hadoop 分布式系 统体系结构的核心。 HDFS 在集群上 实现分布式文件系统, MapReduce 在集群上 实现了分布式计算和任务处理。 HDFS 在 MapReduce 任 务处理过程中提供了文件操作和存储等支持, MapReduce 在 HDFS 的基 础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了 Hadoop 分布式集群的主要任 务。
为什么要使用2.0版本(来自董的博客) 该版本提供了一些新的、重要的功能,包括: • HDFS HA ,当前只能 实现人工切换。 Hadoop HA 分支 merge 进了该版本,并支持热切,主要特性包括: ( 1 ) NN 配置文件有改变,使得配置更加简单 ( 2 ) NameNode 分 为两种角色: active NN 与 standby NN , active NN 对外提供读写服务,一旦出现故障,便切换到 standby NN 。 ( 3 ) 支持 Client 端重定向,也就是 说,当 active NN 切 换到 standby NN 过程中, Client 端所有的 进行时操作都可以无缝透明重定向到 standby NN 上, Client 自己感 觉不到切换过程。 ( 4 ) DN 同 时向 active NN 和 standby NN 汇报 block 信息。 具体 设计文档参考: https://issues.apache.org/jira/browse/HDFS-1623 当前 Hadoop HA 只能 实现人工切换,该功能在某些情况下非常有用,比如,对 NN 进行升级时,先将 NN 切 换到 standby NN ,并 对之前的 active NN 进行升级,升级完成后,再将 NN 切 换至升级后的 NN 上,然后 对 standby NN 进行升级。
• YARN ,下一代 MapReduce 这是一套资源统一管理和调度平台,可管理各种计算框架,包括 MapReduce 、 Spark 、 MPI 等。 YARN 是一套 资源统一管理和调度平台,可管理各种计算框架,包括 MapReduce , Spark , MPI 等。尽管它是完全重写而成,但其思想是从 MapReduce 衍化而来的,并克服了它在 扩展性和容错性等方面的众多不足。具体参考: http://hadoop.apache.org/common/docs/r0.23.0/hadoop-yarn/hadoop-yarn-site/YARN.html • HDFS Federation ,允 许 HDFS 中存在多个 NameNode ,且每个 NameNode 分管一部分目 录,而 DataNode 不 变,进而缩小了故障带来的影响范围,并起到一定的隔离作用。 传统 HDFS 是 master/slave 结构,其中, master (也就是 NameNode )需要存 储所有文件系统的元数据信息,且所有文件存储操作均需要访问多次 NameNode ,因而 NameNode 成 为制约扩展性的主要瓶颈所在。为了解决该问题,引入了 HDFS Federation ,允 许 HDFS 中存在多个 NameNode ,且每个 NameNode 分管一部分目 录,而 DataNode 不 变,也就是 “ 从中央集权 专政变为各个地方自治 ” , 进而缩小了故障带来的影响范围,并起到一定的隔离作用。具体参考: http://dongxicheng.org/mapreduce-nextgen/nextgen-mapreduce-introduction/ • 基准性能测试 该版本中为 HDFS 和 YARN 添加了性能的基准 测试集,其中 HDFS 测试包括: ( 1 ) dfsio 基准 测试 HDFS I/O 读写性能 ( 2 ) slive 基准 测试 NameNode 内部操作的性能 ( 3 ) scan 基准 测试 MapReduce 作 业访问 HDFS 的 I/O 性能 ( 4 ) shuffle 基准 测试 shuffle 阶段性能 ( 5 ) compression 基准 测试 MapReduce 作 业中间结果和最终结果的压缩性能 ( 6 ) gridmix-V3 基准 测试集群吞吐率 YARN 测试包括 : ( 1 ) ApplicationMaster 扩展性基准测试 主要 测试调度 task/container 的性能。与 1.0 版本比 较,大约快 2 倍。 ( 2 ) ApplicationMaster 恢复性基准 测试 测试 YARN 重 启后,作业恢复速度。稍微解释一下 ApplicationMaster 恢复作 业的功能:在作业执行过程中, Application Master 会不断地将作 业运行状态保存到磁盘上,比如哪些任务运行完成,哪些未完成等,这样,一旦集群重启或者 master 挂掉,重 启后,可复原各个作业的状态,并只需重新运行未运行完成的哪些任务。 ( 3 ) ResourceManager 扩展性基准测试 通 过不断向 Hadoop 集群中添加 节点测试 RM 的 扩展性。