
之前介绍过的基于线性模型的方差分析,虽然扩展了方差分析的领域,但是并没有突破方差分析三个原有的假设条件,即正态性、方差齐性和独立性,这其中独立性要求较严格,我们知道方差分析的基本思想其实就是细分,将所有对因变量产生影响的因素逐一摘出,但是如果各观测值之间相互影响,这样在细分影响因素的时候,是很难分出到底是自变量的影响还是观测值之间自己的影响。虽然随机抽样会最大程度的使数据满足独立性,但是有时候这种方法并不奏效,比如随机抽取受访者分析其消费特征,这里就假定所有受访者的之间是相互独立的,然而仔细想想,这其中存在问题,如果某些受访者来自同一个城市或地区,从个体角度讲,他们确实是独立的人,之间没有任何联系,但是如果从分析目的角度讲,由于区域因素他们之间的消费特征是趋于相似的,而产生这种相似性,正是由于相互作用导致,这些人是存在相互影响关系的,也就类以于相关样本,与此同时,这种相互作用也使得不同城市间的消费特征产生差异,我们称这种数据为具有层次聚集性的数据。数据的聚集性除了表现在聚集因素间指标的均值水平不同外,还表现在不同城市间的指标离散度上。
从层次聚集性数据也可以看出,随机抽样只能保证数据被抽到的概率相同,但是对于抽到的是什么样的数据,却无法控制了。对于这种具有层次结构的数据,如果分析目的仅限于这几种层次,比如就分析这几个城市,那么可以把它当做一种固定因子,只分析固定效应而不用考虑这种聚集性,但是如果想把结果推广到所有城市,那就不能忽略这种特征,否则会降低结果的准确性,因此还要加入随机效应。
混合线性模型就是同时包含固定效应和随机效应的线性模型,是解决此类层次聚集性数据的方法之一,我们需要将使观测值之间产生相互影响的层次因素也摘出来,比如上述中的城市因素,传统的方差分析模型中,将所有无法解释的因素都归在随机误差中,而随着我们对传统方差模型的不断拓展,对随机误差的分解也越来越精细,结果也越来越准确。
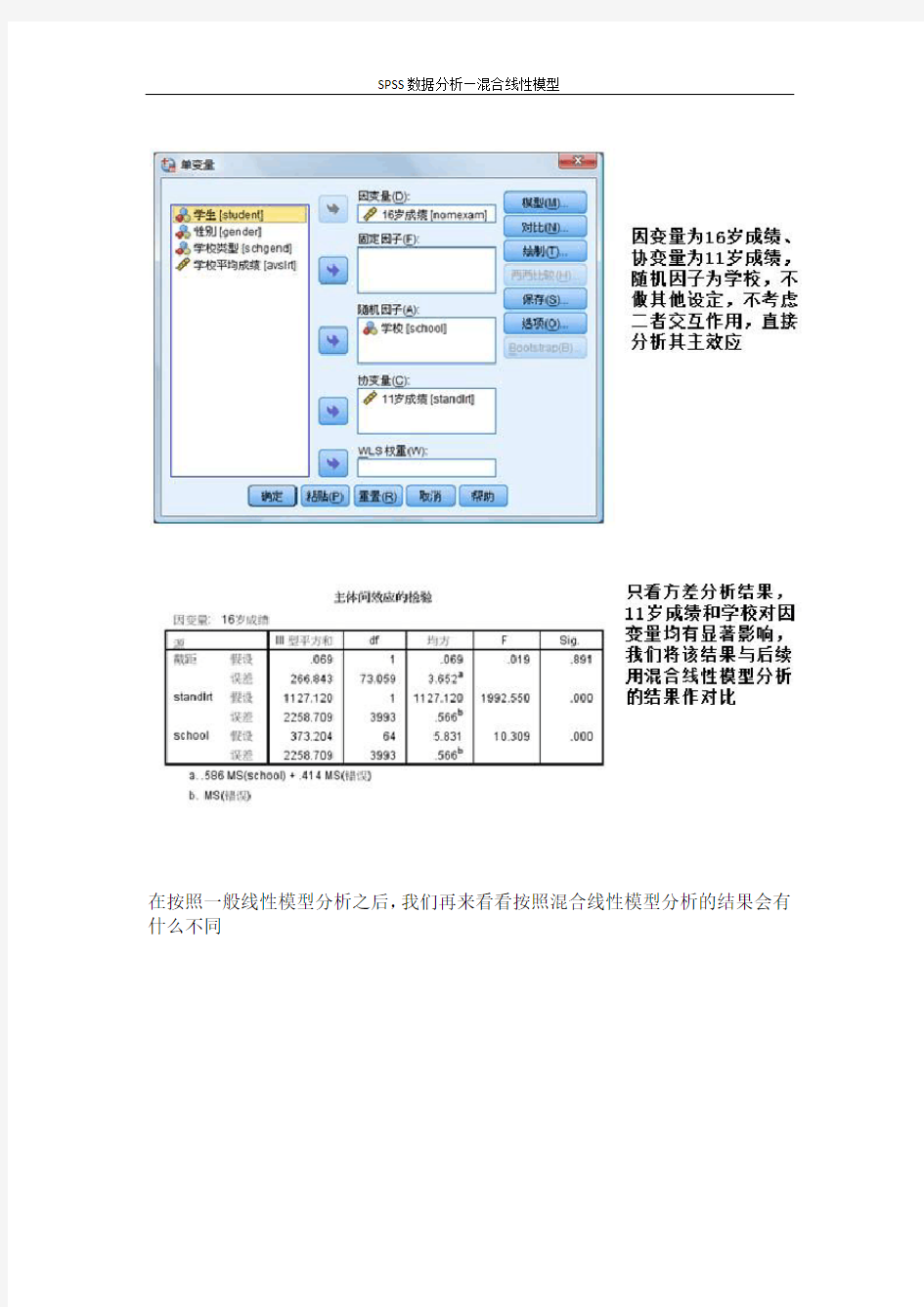
【例】我们想分析哪些因素会对16岁时毕业成绩的影响,显然毕业成绩和学校有关,好学校的学生成绩会好一些,而差学校的学生成绩会差一些,那么学校这个因素就是上述的层次因素,它使得因变量产生相关性,而且我们是想把结果推广到所有学校,因此学校这个变量应该被定为随机变量,我们首先按照一般线性模型来分析,不考虑层次因素
分析—一般线性模型—单变量
在按照一般线性模型分析之后,我们再来看看按照混合线性模型分析的结果会有什么不同
分析—混合模型—线性
经过以上分析,我们知道学校确实是一个层次聚集因素,不能按照一般线性模型进行分析,那么影响16岁考试成绩的原因有很多,我们继续加入变量进行分析。首先加入11岁时的入学成绩,先将其加入固定因素,并观测和之前不加人任何因子相比有何变化
通过以上分析,我们看到,在固定因素中加入入学成绩这个变量以后,对于层次聚集性起到了减弱的效果,但是该影响仍然存在,说明还需要引入其他变量以完
善模型,之前讲过,数据聚集性除了表现在聚集因素间指标的均值水平不同外,还表现在不同聚集因素间的指标离散度上,我们现在将11岁时的入学成绩这个变量加入随机因素中。
在将11岁毕业成绩引入到随机效应之后,层次聚集性又进一步减弱了,实际上我们可以不断的引入变量,这样最终层次聚集性就会消失,下面我们再来引入性别、学校类型、各学校学生在11岁入学时的平均成这三个变量。
根据以上思路,我们可以继续将变量引入随机效应、或者分析变量间的交互作用等,对数据进行更进一步的分析。