
1. 数据类型、数据表示和数据结构之间是什么关系?在设计一个计算机系统
时,确定数据表示的原则主要有哪几个?
答:
略
2. 假设有A和B两种不同类型的处理机,A处理机中的数据不带标志位,其指令字长和
数据字长均为32位。B处理机的数据带有标志位,每个数据的字长增加至36位,其中有4位是标志符,它的指令条数由最多256条减少至不到64条。如果每执行一条指令平均要访问两个操作数,每个存放在存
储器中的操作数平均要被访问8次。对于一个由1000条指令组成的程序,分别计算这个程序在A处理机和B处理机中所占用的存储空间大小(包括指令和数据),从中得到什么启发?
答:
我们可以计算出数据的总数量:
???程序有1000条指令组成,且每条指令平均要访问两个操作数
???程序访问的数据总数为:1000x 2 = 2000个
???每个数据平均访问8次
???程序访问的不同数据个数为:2000-8 = 250
对于A处理机,所用的存储空间的大小为:
Mem A=Mem 咲渝n Mem data "00°32 - 250 32 =40000 bit 对于B处理机,指令字长由32位变为了30位(条数由256减少到64),这样,所用的存储空间的大小为:
Mem B - Mem instructio n ' Mem data =1000 30 ' 250 36 = 39000 bit 由此我们可以看出,由于数据的平均访问次数要大于指令,所以,采用带标
志符的数据表示不会增加总的存储空间大小。
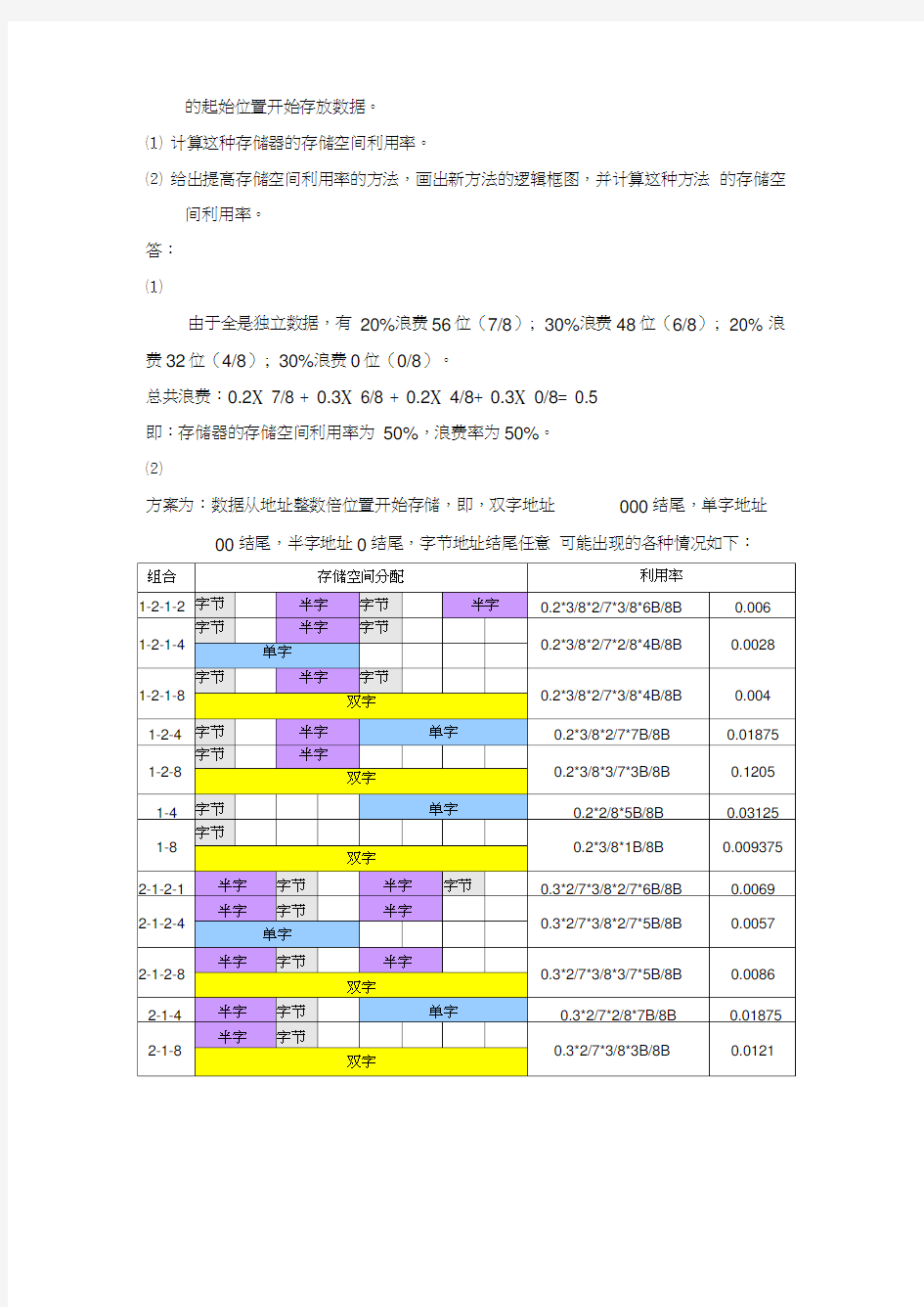
3. 对于一个字长为64位的存储器,访问这个存储器的地址按字节编址。假设存放在这
个存储器中的数据中有20 %是独立的字节数据(指与这个字节数据相邻的不是一个
字节数据),有30%是独立的16位数据,有20%是独立
的32位数据,另外30%是独立的64位数据;并且规定只能从一个存储字
的起始位置开始存放数据。
⑴ 计算这种存储器的存储空间利用率。
⑵ 给出提高存储空间利用率的方法,画出新方法的逻辑框图,并计算这种方法的存储空
间利用率。
答:
⑴
由于全是独立数据,有20%浪费56位(7/8); 30%浪费48位(6/8); 20% 浪费32位(4/8); 30%浪费0位(0/8)。
总共浪费:0.2X 7/8 + 0.3X 6/8 + 0.2X 4/8+ 0.3X 0/8= 0.5
即:存储器的存储空间利用率为50%,浪费率为50%。
⑵
方案为:数据从地址整数倍位置开始存储,即,双字地址000结尾,单字地址00结尾,半字地址0结尾,字节地址结尾任意可能出现的各种情况如下:
4. 一个处理机共有10条指令,各指令在程序中出现的概率如下表:
⑴采用最优Huffman编码法(信息熵)计算这10条指令的操作码最短平均长度。
(2) 采用Huffman编码法编写这10条指令的操作码,并计算操作码的平均长度, 计算与
最优Huffman编码法(信息熵)相比的操作码信息冗余量。将得到的操作码编码和计算的结果填入上面的表中。
(3) 采用2/8扩展编码法编写这10条指令的操作码,并计算操作码的平均长度, 计算与
最优Huffman编码法相比的操作码信息冗余量。把得到的操作码编
码和计算的结果填入上面的表中
(4) 采用3/7扩展编码法编写这10条指令的操作码,并计算操作码的平均长度, 计算与
最优Huffman编码法相比的操作码信息冗余量。把得到的操作码编码和计算的结果填入上面的表中。
答:
采用最优Huffman编码法(信息熵)的操作码最短平均长度为:
n
p i
H 二八P i log : 2.957
i丄
5. 一台模型机共有7条指令,各指令的使用频度分别是 35%、25%、20%、 10%、5%、
3%、2%,有8个通用数据寄存器,2个变址寄存器。
(1) 要求操作码的平均长度最短,请设计操作码的编码,并计算所设计操作码 的平均长
度。
(2) 设计8位字长的寄存器-寄存器型指令 3条,16位字长的寄存器-存储器 型变址寻址
方式指令4条,变址范围不小于正、负127。请设计指令格式, 并给出各字段的长度和操作码的编码。 答: ⑴
要使得到的操作码长度最短,应采用
Huffman 编码,
由此可以得到7
指令号
出现的频率
编码
1 35% 00
2 25% 01
3 20% 10
4 10% 110
5 5% 1110「
6 3% 11110 7
2%
11111
这样,Huffman 编码法得到的操作码的平均长度为:
I = 2 >(0.35+0.25+0.20) + 3 0.1C X + 4 0.05 + 5 ?03 + 0.02)
Huffman 树构造如下:
0.6
0.03
0.02
0 \/
尹 0.05
0.25
0.2
0.1
0.05
0.35
0.1
0.4
1.0
1
0.2
=1.6+0.3+0.2+0.25 = 2.35
⑵
设计8位字长的寄存器-寄存器型指令如下:
因为只有8个通用寄存器,所以寄存器地址需3位,操作码只有两位,设计格式如下:
2 3 3
三条指令的操作码分别为00、01、10。
设计16位字长的寄存器-存储器型变址寻址方式指令如下:
4 3 18
四条指令的操作码分别为1100 1101、1110、1111
6. 某处理机的指令字长为16位,有双地址指令、单地址指令和零地址指令三
类,并假设每个地址字段的长度均为6位。
(1) 如果双地址指令有15条,单地址指令和零地址指令的条数基本相同,问单地址指令
和零地址指令各有多少条?并且为这三类指令分配操作码。
(2) 如果要求三类指令的比例大致为1:9:9,问双地址指令、单地址指令和零地址指
令各有多少条?并且为这三类指令分配操作码。
答:
⑴
双地址指令格式为:
零地址指令格式为:
16
操作码
双地址指令15条,需要4位操作码来区分;单地址指令可以使用10-4=6位操作码来区分;零地址指令可以使用16-10=6位操作码来区分。这样,各类型指令的条数为:双地址指令15条,操作码为:0000~1110
单地址指令26-1=63条,操作码为:
1111000000-1111111110
零地址指令26=64条,操作码为:
1111 111111000000-1111 111111111111
⑵
假设双地址指令x条,则单地址、零地址分别为9x条:
4 6 6
[(2 ■ ■ x p- 2 ■ ■ 9x ]2 9x
解之即得:x =14
???双地址指令14条,操作码为:0000-1101;留出两个编码用于扩展。
单地址指令(26-1) X 2 = 126条,操作码为:
1110000000-1110 11111Q 1111000000-1111 111110 零地址指令126条,操作码为:
1110 111111000000-1110 11111111111Q 1111 11111000000-1111 111111111110
《计算机系统结构》题库 一.单项选择题(在下列每小题的四个备选答案中,只有一个答案是正确的,请把你认为是正确的答案填入题后的()内,每小题2分) 第一章: 1.计算机系统多级层次中,从下层到上层,各级相对顺序正确的应当是: A.汇编语言机器级---操作系统机器级---高级语言机器级 B.微程序机器级---传统机器语言机器级---汇编语言机器级 C.传统机器语言机器级---高级机器语言机器级---汇编语言机器级 D.汇编语言机器级---应用语言机器级---高级语言机器级 答案:B 分数:2 所属章节1—1 2.汇编语言源程序变成机器语言目标程序是经来实现的。 A. 编译程序解释 B. 汇编程序解释 C. 编译程序翻译 D. 汇编程序翻译 答案:D 分数:2 所属章节1—1 3.直接执行微指令的是: A. 汇编程序 B. 编译程序 C. 硬件 D. 微指令程序 答案:C 分数:2 所属章节1—1 4.对系统程序员不透明的是: A. Cache存储器 B. 系列机各档不同的数据通路宽度 C. 指令缓冲寄存器 D. 虚拟存储器 答案:D 分数:2 所属章节1—2 5.对应用程序员不透明的是: A. 先行进位链 B. 乘法器 C. 指令缓冲器 D. 条件码寄存器 答案:D 分数:2 所属章节1—2 6.对机器语言程序员透明的是: A. 中断字 B. 主存地址寄存器 C. 通用寄存器 D. 条件码 答案:B 分数:2 所属章节1—2 7.计算机系统结构不包括: A. 主存速度 B. 机器工作状态 C. 信息保护 D. 数据表示 答案:A 分数:2 所属章节1—2 8.对计算机系统结构透明的是: A. 字符行运算指令 B. 是否使用通道行I/O处理机 C. 虚拟存储器 D. VLSI技术 答案:D 分数:2 所属章节1—2 9.对汇编语言程序员透明的是: A.I/O方式中的DMA访问方式 B. 浮点数据表示 C. 访问方式保护 D 程序性中断. 答案:A 分数:2 所属章节1—2 10.属计算机系统结构考虑的应是:
实验二结构相关 一、实验目得: 通过本实验,加深对结构相关得理解,了解结构相关对CPU性能得影响。 二、实验内容: 1、用WinDLX模拟器运行程序structure_d、s 。 2、通过模拟,找出存在结构相关得指令对以及导致结构相关得部件。 3、记录由结构相关引起得暂停时钟周期数,计算暂停时钟周期数占总执行 周期数得百分比。 4、论述结构相关对CPU性能得影响,讨论解决结构相关得方法。 三、实验程序structure_d、s LHI R2, (A>>16)&0xFFFF 数据相关 ADDUI R2, R2, A&0xFFFF LHI R3, (B>>16)&0xFFFF ADDUI R3, R3, B&0xFFFF ADDU R4, R0, R3 loop: LD F0, 0(R2) LD F4, 0(R3) ADDD F0, F0, F4 ;浮点运算,两个周期,结构相关 ADDD F2, F0, F2 ; < A stall is found (an example of how to answer your questions) ADDI R2, R2, #8 ADDI R3, R3, #8 SUB R5, R4, R2 BNEZ R5, loop ;条件跳转 TRAP #0 ;; Exit < this is a ment !! A: 、double 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 B: 、double 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 四、实验过程 打开软件,load structure_d、s文件,进行单步运行。经过分析,此程序一 次循环中共有五次结构相关。(Rstall 数据相关Stall 结构相关) 1)第一个结构相关:addd f2,,f0,f2 由于前面得数据相关,导致上一条指令addd f0,f0,f4暂停在ID阶段,所以下一条指令addd f2,,f0,f2发生结构相关,导致相关得部件:译码部件。
实验二指令流水线相关性分析 ·实验目的 通过使用WINDLX模拟器,对程序中的三种相关现象进行观察,并对使用专用通路,增加运算部件等技术对性能的影响进行考察,加深对流水线和RISC处理器的特点的理解。 ·实验原理: 指令流水线中主要有结构相关、数据相关、控制相关。相关影响流水线性能。·实验步骤 一.使用WinDLX模拟器,对做如下分析: (1)观察程序中出现的数据/控制/结构相关。指出程序中出现上述现象的指令组合。 (2)考察增加浮点运算部件对性能的影响。 (3)考察增加forward部件对性能的影响。 (4)观察转移指令在转移成功和转移不成功时候的流水线开销。 ·实验过程 一.使用WinDLX模拟器,对做如下分析: } 浮点加、乘、除部件都设置为1,浮点数运算部件的延时都设置为4,如图1: 图1 初始设置 将和加载至WinDLX中,如图2示。
图2 加载程序 1.观察程序中出现的数据/控制/结构相关;指出程序中出现上述现象的指令组合。 1)数据相关 点击F7,使程序单步执行,当出现R-Stall时停止,运行过程中出现下图3所示,输入整数6。 图3 输入整数6 @ 打开Clock Diagram,可以清楚的看到指令执行的流水线如图4所示。 图4 指令流水线 双击第一次出现R-Stall的指令行,如图5所示。
图5 指令详细信息 对以上出现的情况分析如下: 程序发生了数据相关,R-Stall(R-暂停)表示引起暂停的原因是RAW。 lbu r3,0×0(r2) 要在WB周期写回r3中的数据;而下一条指令 & seqi r5,r3,0×a 要在intEX周期中读取r3中的数据。 上述过程发生了WR冲突,即写读相关。为了避免此类冲突, seq r5,r4,0×a的intEX指令延迟了一个周期进行。 由此,相关指令为: 2)控制相关 由图6可以看出,在第4时钟周期:第一条指令处于MEM段,第二条命令处于intEX段,第三条指令出于aborted状态,第四条命令处于IF段。 图 6 指令流水线 }
、填空题(20 每空 2 分) 1. 计数制中使用的数据个数被称为________ 。(基) 2. 移码常用来表示浮点数的_ 部分,移码和补码比较,它们除_外, 其他各位都相同。(阶码,符号位) 3. 码值80H: 若表示真值0, 则为_; 若表示-128 ,则为_ ; 若表示-127 ,则为____ ; 若表示-0, 则为 ____ 。(移码补码反 码原码) 4. 在浮点运算过程中,如果运算结果的尾数部分不是_ 形式,则需要进行规格化处理。设尾数采用补码表示形式,当运算结果—时, 需要进行右规操作;当运算结果________________________________ 时,需要进行左规操作。 (规格化溢出不是规格化数) 二、选择题(20 每题 2 分) 1. 以下给出的浮点数,_______ 规格化浮点数。(B ) A. 2 八-10 X 0.010101 B . 2 八-11 X 0.101010 C. 2 八-100 X 1.010100 D . 2 八-1 X 0.0010101 2. 常规乘除法器乘、除运算过程采用部分积、余数左移的做法,其好处是 。( C )
A. 提高运算速度 B. 提高运算精度 C.节省加法器的位数 D. 便于控制 3. 逻辑异运算10010011 和01011101 的结果是_____ 。(B) A.01001110 B.11001110 C.11011101 D.10001110 4. _________浮点数尾数基值rm=8, 尾数数值部分长 6 位,可表示的规 格化最小正尾数为。(Q 1. A.0.5 B.0.25 C.0.125 D.1/64 5?当浮点数尾数的基值rm=16, 除尾符之外的尾数机器位数为8 位时, 可表示的规格化最大尾数值是_____________ 。(D) A.1/2 B.15/16 C.1/256 D.255/256 6. 两个补码数相加,采用1 位符号位,当_时表示结果溢出。(D) A、符号位有进位 B、符号位进位和最高数位进位异或结果为0 C符号位为1D、符号位进位和最高数位进位异或结果为1 7. 运算器的主要功能时进行_ 。(0 A、逻辑运算 B、算术运算 C、逻辑运算和算术运算 D、只作加法 8. 运算器虽有许多部件组成,但核心部件是_______ 。(B) A、数据总线 B、算术逻辑运算单元 C、多路开关 D、累加寄存器9?在定
全国2010年4月自学考试计算机系统结构试题 课程代码:02325 一、单项选择题(本大题共10小题,每小题1分,共10分) 在每小题列出的四个备选项中只有一个是符合题目要求的,请将其代码填写在题后的括号内。错选、多选或未选均不得分。 1.在计算机系统结构设计中,提高软件功能实现的比例可( ) A.提高解题速度B.减少需要的存储器容量 C.提高系统的灵活性D.提高系统的性能价格比 2.浮点数表示的尾数的基r m=16,尾数长度p=8,可表示的规格化最大正尾数的值是( ) A.1/256 B.1/2 C.15/16 D.255/256 3.下列数据存储空间为隐含寻址方式的是( ) A.CPU中的通用寄存器B.主存储器 C.I/O接口中的寄存器D.堆栈 4.当计算机系统执行通道程序完成输入输出工作时,执行通道程序的是( ) A.CPU B.通道 C.CPU和通道D.指定的外设 5.下列有关中断的叙述正确的是( ) A.中断响应的次序是由硬件决定的B.中断处理的次序是由硬件决定的 C.中断处理的次序是不可改的D.中断响应的次序是可灵活改变的 6.与虚拟存储器的等效访问速度无关 ..的是( ) A.访存页地址流B.页面替换算法 C.主存的容量D.辅存的容量 7.非线性流水线的特征是( ) A.一次运算中使用流水线中的多个功能段 B.一次运算中多次使用流水线中的某些功能段 C.流水线中某些功能段在各次运算中的作用不同 D.流水线的各功能段在不同的运算中可以有不同的连接 8.属于集中式共享存储器结构的SIMD计算机是( ) A.ILLIAC IV B.BSP C.CM-2 D.MP-1 1
第二章计算机指令集结构 知识点汇总: 指令集设计、堆栈型机器、累加器型机器、通用寄存器型机器、CISC、RISC、寻址方式、数据表示 简答题 1.增强CISC机器的指令功能主要从哪几方面着手?(CISC) (1) 面向目标程序增强指令功能。 (2) 面向高级语言和编译程序改进指令系统。 (3) 面向操作系统的优化实现改进指令系统。 2.简述CISC存在的主要问题。(知识点:CISC) 答:(1)CISC结构的指令系统中,各种指令的使用频率相差悬殊。 (2)CISC结构指令系统的复杂性带来了计算机系统结构的复杂性,这不仅增加了研制时间和成本,而且还容易造成设计错误。 (3)CISC结构指令系统的复杂性给VLSI设计增加了很大负担,不利于单片集成。 (4)CISC结构的指令系统中,许多复杂指令需要很复杂的操作,因而运行速度慢。 (5)在CISC结构的指令系统中,由于各条指令的功能不均衡性,不利于采用先进的计算机系统结构技术来提高系统的性能。 3.简述RISC的优缺点及设计RISC机器的一般原则。(知识点:RISC) 答:(1)选取使用频率最高的指令,并补充一些最有用的指令。 (2)每条指令的功能应尽可能简单,并在一个机器周期内完成。 (3)所有指令长度均相同。 (4)只有load和store操作指令才访问存储器,其它指令操作均在寄存器之间进行。 (5)以简单、有效的方式支持高级语言。 4.根据CPU内部存储单元类型,可将指令集结构分为哪几类?(知识点:堆栈型机器、累加器型机器、通用寄存器型机器) 答:堆栈型指令集结构、累加器型指令集结构、通用寄存器型指令集结构。 5.常见的三种通用寄存器型指令集结构是什么?(知识点:通用寄存器型机器) 答:(1)寄存器-寄存器型。 (2)寄存器-存储器型。 (3)存储器-存储器型。
计算机系统结构 姓名:学号: 一、简答题(每小题10分,共20分) 1.简述使用物理地址进行DMA存在的问题,及其解决办法。 2.从目的、技术途径、组成、分工方式、工作方式等5个方面对同构型多处理机和异构型多处理机做一比较(列表)。 二、(60分)现有如下表达式: Y=a ×X 其中:X和Y是两个有64个元素的32位的整数的向量,a为32位的整数。假设在存储器中,X和Y的起始地址分别为1000和5000,a的起始地址为6000。 1.请写出实现该表达式的MIPS代码。 2.假设指令的平均执行时钟周期数为5,计算机的主频为500 MHz,请计算上述MIPS 代码(非流水化实现)的执行时间。 3.将上述MIPS代码在MIPS流水线上(有正常的定向路径、分支指令在译码段被解析出来)执行,请以最快执行方式调度该MIPS指令序列。注意:可以改变操作数,但不能改变操作码和指令条数。画出调度前和调度后的MIPS代码序列执行的流水线时空图,计算调度前和调度后的MIPS代码序列执行所需的时钟周期数,以及调度前后的MIPS流水线执行的加速比。 4.根据3的结果说明流水线相关对CPU性能的影响。 三、(20分)请分析I/O对于性能的影响有多大?假设: 1.I/O操作按照页面方式进行,每页大小为16 KB,Cache块大小为64 B;且对应新页的地址不在Cache中;而CPU不访问新调入页面中的任何数据。 2.Cache中95%被替换的块将再次被读取,并引起一次失效;Cache使用写回方法,平均50%的块被修改过;I/O系统缓冲能够存储一个完整的Cache块。 3.访问或失效在所有Cache块中均匀分布;在CPU和I/O之间,没有其他访问Cache 的干扰;无I/O时,每1百万个时钟周期中,有15,000次失效;失效开销是30个时钟周期。如果替换块被修改过,则再加上30个周期用于写回主存。计算机平均每1百万个周期处理一页。
计算机系统结构-第二章自考练习题答案
第二章数据表示与指令系统 历年真题精选 1. 计算机中优先使用的操作码编码方法是( C )。 A. BCD码 B. ASCII码 C. 扩展操作码 D. 哈夫曼编码 2.浮点数尾数基值r m=16,除尾符之外的尾数机器位数为8位时,可表示的规格化最大尾数值为( D )。 A. 1/2 B. 15/16 C. 1/256 D. 255/256 3. 自定义数据表示包括(标志符)数据表示和(数据描述符)两类。 4. 引入数据表示的两条基本原则是:一看系统 的效率是否有提高;二看数据表示的(通
用)性和(利用)率是否高。 5. 简述设计RISC的一般原则。 6. 简述程序的动态再定位的思想。 7. 浮点数表示,阶码用二进制表示,除阶符之外 的阶码位数p=3,尾数基值用十进制表示,除尾符外的尾数二进制位数m=8,计算非负阶、规格化、正尾数时, (1)可表示的最小尾数值;(2)可表示的最大值;(3)可表示的尾数个数。 8. (1)要将浮点数尾数下溢处理成K—1位结 果,则ROM表的单元数和字长各是多少? 并简述ROM表各单元所填的内容与其地址之间的规则。
(2)若3位数,其最低位为下溢处理前的附 加位,现将其下溢处理成2位结果,设 计使下溢处理平均误差接近于零的 ROM表,以表明地址单元与其内容的 关系。 同步强化练习 一.单项选择题。 1. 程序员编写程序时使用的地址是( D )。 A.主存地址B.有效地址C.辅存实地址D.逻辑地址 2. 在尾数下溢处理方法中,平均误差最大的是( B )。 A.舍入法B.截断法C.恒置“1”法
计算机系统结构复习题 单选及填空: 计算机系统设计的主要方法 1、由上往下的设计(top-down) 2、由下往上的设计(bottom-up) 3、从中间开始(middle-out) Flynn分类法把计算机系统的结构分为以下四类: (1)单指令流单数据流 (2)单指令流多数据流 (3)多指令流单数据流 (4) 多指令流多数据流 堆栈型机器:CPU 中存储操作数的单元是堆栈的机器。 累加器型机器:CPU 中存储操作数的单元是累加器的机器。 通用寄存器型机器:CPU 中存储操作数的单元是通用寄存器的机器。 名词解释: 虚拟机:用软件实现的机器叫做虚拟机,但虚拟机不一定完全由软件实现,有些操作可以由硬件或固件(固件是指具有软件功能的固件)实现。 系列机:由同一厂家生产的具有相同系统结构、但具有不同组成和实现的一系列不同型号的计算机。 兼容机:它是指由不同公司厂家生产的具有相同系统结构的计算机。 流水线技术:将一个重复的时序过程,分解成为若干个子过程,而每一个子过程都可有效地在其专用功能段上与其它子过程同时执行。 单功能流水线:指流水线的各段之间的连接固定不变、只能完成一种固定功能的流水线。 多功能流水线:指各段可以进行不同的连接,以实现不同的功能的流水线。 顺序流水线:流水线输出端任务流出的顺序与输入端任务流入的顺序完全相同。 乱序流水线:流水线输出端任务流出的顺序与输入端任务流入的顺序可以不同,允许后进入流水线的任务先完成。这种流水线又称为无序流水线、错序流水线、异步流水线。 吞吐率:在单位时间内流水线所完成的任务数量或输出结果的数量。 指令的动态调度:
是指在保持数据流和异常行为的情况下,通过硬件对指令执行顺序进行重新安排,以提高流水线的利用率且减少停顿现象。是由硬件在程序实际运行时实施的。 指令的静态调度: 是指依靠编译器对代码进行静态调度,以减少相关和冲突。它不是在程序执行的过程中、而是在编译期间进行代码调度和优化的。 超标量: 一种多指令流出技术。它在每个时钟周期流出的指令条数不固定,依代码的具体情况而定,但有个上限。 超流水:在一个时钟周期内分时流出多条指令。 多级存储层次: 采用不同的技术实现的存储器,处在离CPU不同距离的层次上,各存储器之间一般满足包容关系,即任何一层存储器中的内容都是其下一层(离CPU更远的一层)存储器中内容的子集。目标是达到离CPU最近的存储器的速度,最远的存储器的容量。 写直达法: 在执行写操作时,不仅把信息写入Cache中相应的块,而且也写入下一级存储器中相应的块。写回法: 只把信息写入Cache中相应块,该块只有被替换时,才被写回主存。 集中式共享多处理机: 也称为对称式共享存储器多处理SMP。它一般由几十个处理器构成,各处理器共享一个集中式的物理存储器,这个主存相对于各处理器的关系是对称的, 分布式共享多处理机: 它的共享存储器分布在各台处理机中,每台处理机都带有自己的本地存储器,组成一个“处理机-存储器”单元。但是这些分布在各台处理机中的实际存储器又合在一起统一编址,在逻辑上组成一个共享存储器。这些处理机存储器单元通过互连网络连接在一起,每台处理机除了能访问本地存储器外,还能通过互连网络直接访问在其他处理机存储器单元中的“远程存储器”。 多Cache一致性: 多处理机中,当共享数据进入Cache,就可能出现多个处理器的Cache中都有同一存储器块的副本,要保证多个副本数据是一致的。 写作废协议: 在处理器对某个数据项进行写入之前,它拥有对该数据项的唯一的访问权 。 写更新协议: 当一个处理器对某数据项进行写入时,它把该新数据广播给所有其它Cache。这些Cache用该新数据对其中的副本进行更新。 机群:是一种价格低廉、易于构建、可扩放性极强的并行计算机系统。它由多台同构或异构
计算机系统结构试题及答案 一、选择题(50分,每题2分,正确答案可能不只一个,可单选 或复选) 1.(CPU周期、机器周期)是内存读取一条指令字的最短时间。 2.(多线程、多核)技术体现了计算机并行处理中的空间并行。 3.(冯?诺伊曼、存储程序)体系结构的计算机把程序及其操作数 据一同存储在存储器里。 4.(计算机体系结构)是机器语言程序员所看到的传统机器级所具 有的属性,其实质是确定计算机系统中软硬件的界面。 5.(控制器)的基本任务是按照程序所排的指令序列,从存储器取 出指令操作码到控制器中,对指令操作码译码分析,执行指令操作。 6.(流水线)技术体现了计算机并行处理中的时间并行。 7.(数据流)是执行周期中从内存流向运算器的信息流。 8.(指令周期)是取出并执行一条指令的时间。 9.1958年开始出现的第二代计算机,使用(晶体管)作为电子器件。 10.1960年代中期开始出现的第三代计算机,使用(小规模集成电路、 中规模集成电路)作为电子器件。 11.1970年代开始出现的第四代计算机,使用(大规模集成电路、超 大规模集成电路)作为电子器件。 12.Cache存储器在产生替换时,可以采用以下替换算法:(LFU算法、 LRU算法、随机替换)。
13.Cache的功能由(硬件)实现,因而对程序员是透明的。 14.Cache是介于CPU和(主存、内存)之间的小容量存储器,能高 速地向CPU提供指令和数据,从而加快程序的执行速度。 15.Cache由高速的(SRAM)组成。 16.CPU的基本功能包括(程序控制、操作控制、时间控制、数据加 工)。 17.CPU的控制方式通常分为:(同步控制方式、异步控制方式、联合 控制方式)反映了时序信号的定时方式。 18.CPU的联合控制方式的设计思想是:(在功能部件内部采用同步控 制方式、在功能部件之间采用异步控制方式、在硬件实现允许的情况下,尽可能多地采用异步控制方式)。 19.CPU的同步控制方式有时又称为(固定时序控制方式、无应答控 制方式)。 20.CPU的异步控制方式有时又称为(可变时序控制方式、应答控制 方式)。 21.EPROM是指(光擦可编程只读存储器)。 22.MOS半导体存储器中,(DRAM)可大幅度提高集成度,但由于(刷 新)操作,外围电路复杂,速度慢。 23.MOS半导体存储器中,(SRAM)的外围电路简单,速度(快),但 其使用的器件多,集成度不高。 24.RISC的几个要素是(一个有限的简单的指令集、CPU配备大量的 通用寄存器、强调对指令流水线的优化)。
计算机系统结构实验报告 一.流水线中的相关 实验目的: 1. 熟练掌握WinDLX模拟器的操作和使用,熟悉DLX指令集结构及其特点; 2. 加深对计算机流水线基本概念的理解; 3. 进一步了解DLX基本流水线各段的功能以及基本操作; 4. 加深对数据相关、结构相关的理解,了解这两类相关对CPU性能的影响; 5. 了解解决数据相关的方法,掌握如何使用定向技术来减少数据相关带来的暂停。 实验平台: WinDLX模拟器 实验内容和步骤: 1.用WinDLX模拟器执行下列三个程序: 求阶乘程序fact.s 求最大公倍数程序gcm.s 求素数程序prim.s 分别以步进、连续、设置断点的方式运行程序,观察程序在流水线中的执行情况,观察 CPU中寄存器和存储器的内容。熟练掌握WinDLX的操作和使用。 2. 用WinDLX运行程序structure_d.s,通过模拟找出存在资源相关的指令对以及导致资源相 关的部件;记录由资源相关引起的暂停时钟周期数,计算暂停时钟周期数占总执行周期数的 百分比;论述资源相关对CPU性能的影响,讨论解决资源相关的方法。 3. 在不采用定向技术的情况下(去掉Configuration菜单中Enable Forwarding选项前的勾选符),用WinDLX运行程序data_d.s。记录数据相关引起的暂停时钟周期数以及程序执行的 总时钟周期数,计算暂停时钟周期数占总执行周期数的百分比。 在采用定向技术的情况下(勾选Enable Forwarding),用WinDLX再次运行程序data_d.s。重复上述3中的工作,并计算采用定向技术后性能提高的倍数。 1. 求阶乘程序 用WinDLX模拟器执行求阶乘程序fact.s。这个程序说明浮点指令的使用。该程序从标准 输入读入一个整数,求其阶乘,然后将结果输出。 该程序中调用了input.s中的输入子程序,这个子程序用于读入正整数。 实验结果: 在载入fact.s和input.s之后,不设置任何断点运行。 a.不采用重新定向技术,我们得到的结果
北京邮电大学 实验报告 课程名称计算机系统结构 计算机学院03班 王陈(11)
目录 实验一WINDLX模拟器安装及使用......................................... 错误!未定义书签。 ·实验准备................................................................................ 错误!未定义书签。 ·实验环境................................................................................ 错误!未定义书签。 ·实验步骤................................................................................ 错误!未定义书签。 ·实验内容及要求.................................................................... 错误!未定义书签。 ·实验过程............................................................................. 错误!未定义书签。 ·实验总结............................................................................. 错误!未定义书签。实验二指令流水线相关性分析 ............................................... 错误!未定义书签。 ·实验目的............................................................................. 错误!未定义书签。 ·实验环境................................................................................ 错误!未定义书签。 ·实验步骤................................................................................ 错误!未定义书签。 ·实验过程............................................................................. 错误!未定义书签。 ·实验总结............................................................................. 错误!未定义书签。实验三DLX处理器程序设计 .................................................... 错误!未定义书签。 ·实验目的............................................................................. 错误!未定义书签。 ·实验环境................................................................................ 错误!未定义书签。 ·实验步骤................................................................................ 错误!未定义书签。 ·实验过程............................................................................. 错误!未定义书签。 A.向量加法代码及性能分析 ................................................... 错误!未定义书签。 B.双精度浮点加法求和代码及结果分析 .............................. 错误!未定义书签。 ·实验总结............................................................................. 错误!未定义书签。实验四代码优化 ....................................................................... 错误!未定义书签。 ·实验目的............................................................................. 错误!未定义书签。 ·实验环境................................................................................ 错误!未定义书签。 ·实验原理................................................................................ 错误!未定义书签。 ·实验步骤................................................................................ 错误!未定义书签。 ·实验过程............................................................................. 错误!未定义书签。 ·实验总结+实习体会........................................................... 错误!未定义书签。实验五循环展开 ....................................................................... 错误!未定义书签。 ·实验目的............................................................................. 错误!未定义书签。 ·实验环境................................................................................ 错误!未定义书签。 ·实验原理................................................................................ 错误!未定义书签。 ·实验步骤................................................................................ 错误!未定义书签。 ·实验过程............................................................................. 错误!未定义书签。 矩阵乘程序代码清单及注释说明........................................... 错误!未定义书签。 相关性分析结果........................................................................... 错误!未定义书签。 增加浮点运算部件对性能的影响........................................... 错误!未定义书签。 增加forward部件对性能的影响 ............................................ 错误!未定义书签。 转移指令在转移成功和转移不成功时候的流水线开销 .. 错误!未定义书签。 ·实验总结+实习体会+课程建议......................................... 错误!未定义书签。
计算机系统结构第二章自考练习题答案
第二章数据表示与指令系统 历年真题精选 1. 计算机中优先使用的操作码编码方法是( C )。 A. BCD码 B. ASCII码 C. 扩展操作码 D. 哈夫曼编码 2.浮点数尾数基值r m=16,除尾符之外的尾数机器位数为8位时,可表示的规格化最大尾数值为( D )。 A. 1/2 B. 15/16 C. 1/256 D. 255/256 3. 自定义数据表示包括(标志符)数据表示和(数据描述符)两类。 4. 引入数据表示的两条基本原则是:一看系统 的效率是否有提高;二看数据表示的(通
用)性和(利用)率是否高。 5. 简述设计RISC的一般原则。 6. 简述程序的动态再定位的思想。 7. 浮点数表示,阶码用二进制表示,除阶符之外 的阶码位数p=3,尾数基值用十进制表示,除尾符外的尾数二进制位数m=8,计算非负阶、规格化、正尾数时, (1)可表示的最小尾数值;(2)可表示的最大值;(3)可表示的尾数个数。 8. (1)要将浮点数尾数下溢处理成K—1位结 果,则ROM表的单元数和字长各是多少? 并简述ROM表各单元所填的内容与其地址之间的规则。 (2)若3位数,其最低位为下溢处理前的附 加位,现将其下溢处理成2位结果,设
计使下溢处理平均误差接近于零的 ROM表,以表明地址单元与其内容的 关系。 同步强化练习 一.单项选择题。 1. 程序员编写程序时使用的地址是( D )。 A.主存地址B.有效地址C.辅存实地址D.逻辑地址 2. 在尾数下溢处理方法中,平均误差最大的是( B )。 A.舍入法B.截断法C.恒置“1”法D.ROM查表法 3. 数据表示指的是( C )。A.应用中要用到的数据元素之间的结构关系
计算机系统结构实验 实验1:MIPS指令系统和MIPS体系结构 (预习报告) 姓名: 学号: 班级:
大连理工大学实验预习报告 学院:______________________专业:_______________________班级:_____________________ 姓名:______________________学号:_______________________ 实验时间:__________________实验室:__________________实验台:__________________ 指导老师签字:_________________________________________成绩:____________________ 实验目的: 了解熟悉MIPSsim模拟器; 熟悉MIPS指令系统及其特点; 熟悉MIPS体系结构 实验平台: 指令级和流水线操作级模拟器MIPSsim 资料准备: MIPS64指令系统介绍 1.MIPS的寄存器 32个64位通用寄存器(GPRs整数寄存器):R0-R31。R0的值永远是0。 32个64位浮点数寄存器FPRs:F0-F31。它们可以存放32个单精度浮点数(32位),也可以存放32个双精度浮点数(64位)。 MIPS提供了单精度和双精度操作的指令,而且还提供了在FPRs和GPRs之间传送数据的指令。2.MIPS的数据表示
整数:字节(8位)、半字(16位)、字(32位)和双字(64位)。 浮点数:单精度浮点数(32位)和双精度浮点数(64位)。 MIPS64的操作是针对64位整数以及32位或64位浮点数进行的。字节、半字或字在装入64位寄存器时,用零扩展或者用符号位扩展来填充该寄存器的剩余部分。装入以后,对它们按照64位整数的方式进行运算。 3.MIPS的数据寻址方式 MIPS的数据寻址方式只有立即数寻址和偏移量寻址两种,立即数字段和偏移量字段都是16位。 寄存器间接寻址是通过把0作为偏移量来实现的,16位绝对寻址是通过把R0作为基址寄存器来完成的。 MIPS的存储器是按字节寻址的,地址是64位。由于MIPS是load-store结构,寄存器和存储器之间的数据传送都是通过load指令和store指令来完成的。所有存储器访问都必须边界对齐。 4.MIPS的指令格式 指令格式简单,其中操作码6位。按不同类型的指令设置不同的格式,共有3种格式,分别对应I指令、R指令和J指令。在这3种格式中,同名字段的位置固定不变。 I类指令 包括所有的load和store指令、立即数指令、分支指令、寄存器跳转指令、寄存器链接跳转指令。其中立即数字段位16位,用于提供立即数或偏移量。 1)load指令 2)store指令 3)立即数指令 4)分支指令 5)寄存器跳转、寄存器跳转并链接
第二章指令系统 ?指令系统是计算机系统结构的主要组成部分 ?指令系统是软件与硬件分界面的一个主要标志 ?指令系统软件与硬件之间互相沟通的桥梁 ?指令系统与软件之间的语义差距越来越大 2.1 数据表示 2.2 寻址技术 2.3 指令格式的优化设计 2.4 指令系统的功能设计 2.5 RISC指令系统 2.1 数据表示 ?新的研究成果,如浮点数基值的选择 ?新的数据表示方法,如自定义数据表示 2.1.1 数据表示与数据类型 2.1.2 浮点数的设计方法 2.1.3 自定义数据表示 2.1.1 数据表示与数据类型 ?数据的类型:文件、图、表、树、阵列、队列、链表、栈、向量、串、实数、整数、布尔数、字符 ?数据表示的定义:数据表示研究的是计算机硬件能够直接识别,可以被指令系统直接调用的那些数据类型。 例如:定点、逻辑、浮点、十进制、字符、字符串、堆栈和向量 ?确定哪些数据类型用数据表示实现,是软件与硬件的取舍问题 ?确定数据表示的原则: 一是缩短程序的运行时间, 二是减少CPU与主存储器之间的通信量, 三是这种数据表示的通用性和利用率。 例2.1:实现A=A+B,A和B均为200×200的矩阵。分析向量指令的作用解:如果在没有向量数据表示的计算机系统上实现,一般需要6条指令,其中有4条指令要循环4万次。因此,CPU与主存储器之间的通信量:取指令2+4×40,000条, 读或写数据3×40,000个, 共要访问主存储器7×40,000次以上 如果有向量数据表示,只需要一条指令 减少访问主存(取指令)次数:4×40,000次 缩短程序执行时间一倍以上
N m m e r =?? 数据表示在不断扩大,如字符串、向量、堆栈、图、表 ? 用软件和硬件相结合的方法实现新的数据表示 例如:用字节编址和字节运算指令来支持字符串数据表示 用变址寻址方式来支持向量数据表示 2.1.2 浮点数的设计方法 1、浮点数的表示方式 ? 一个浮点数N 可以用如下方式表示: 需要有6个参数来定义。 两个数值: m :尾数的值,包括尾数的码制(原码或补码)和数制(小数或整数) e :阶码的值,移码(偏码、增码、译码、余码等)或补码,整数 两个基值: r m :尾数的基值,2进制、4进制、8进制、16进制和10进制等 r e :阶码的基值,通常为2 两个字长: p :尾数长度,当r m =16时,每4个二进制位表示一位尾数 q :阶码长度,阶码部分的二进制位数 p 和q 均不包括符号位 ? 浮点数的存储式 注:m f 为尾数的符号位,e f 为阶码的符号位,e 为阶码的值,m 为尾数的值。 2、浮点数的表数范围 ? 尾数为原码 尾数用原码、纯小数,阶码用移码、整数时,规格化浮点数N 的表数范围: ---?≤≤-?-111r r N r r m m p m m q e q e r r () ? 尾数为补码 尾数用补码表示时,正数区间的表数范围与尾数采用原码时完全相同,而负数区间的表数范围为: q e q e r r r N r r r m m p m m ----≤≤-+?-11() ? 浮点数在数轴上的分布情况 min max min max 例2.2:设p =23,q =7,r m =r e =2,尾数用原码、纯小数表示,阶码用移码、整数表示,求规格化浮点数N 的表数范围。 解:规格化浮点数N 的表数范围是:
实验二结构相关 一、实验目的: 通过本实验,加深对结构相关的理解,了解结构相关对CPU性能的影响。 二、实验内容: 1. 用WinDLX模拟器运行程序structure_d.s 。 2. 通过模拟,找出存在结构相关的指令对以及导致结构相关的部件。 3. 记录由结构相关引起的暂停时钟周期数,计算暂停时钟周期数占总执行 周期数的百分比。 4. 论述结构相关对CPU性能的影响,讨论解决结构相关的方法。 三、实验程序structure_d.s LHI R2, (A>>16)&0xFFFF 数据相关 ADDUI R2, R2, A&0xFFFF LHI R3, (B>>16)&0xFFFF ADDUI R3, R3, B&0xFFFF ADDU R4, R0, R3 loop: LD F0, 0(R2) LD F4, 0(R3) ADDD F0, F0, F4 ;浮点运算,两个周期,结构相关 ADDD F2, F0, F2 ; <- A stall is found (an example of how to answer your questions) ADDI R2, R2, #8 ADDI R3, R3, #8 SUB R5, R4, R2 BNEZ R5, loop ;条件跳转 TRAP #0 ;; Exit <- this is a comment !! A: .double 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 B: .double 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
四、实验过程 打开软件,load structure_d.s文件,进行单步运行。经过分析,此程序一 次循环中共有五次结构相关。(R-stall 数据相关Stall- 结构相关) 1)第一个结构相关:addd f2,,f0,f2 由于前面的数据相关,导致上一条指令addd f0,f0,f4暂停在ID阶段,所以下一条指令addd f2,,f0,f2发生结构相关,导致相关的部件:译码部件。 2)第二个结构相关:ADDI R2, R2, #8,与第一个结构相关类似。由于数据相关, 上一条指令暂停在ID阶段,所以导致下一条指令发生结构相关。