LINQ to XML
- 格式:doc
- 大小:999.50 KB
- 文档页数:25

xmllint 参数
XMllint参数是在使用xmllint工具时需要指定的选项和参数。
xmllint是一个命令行工具,用于验证和格式化 XML 文件。
以下是xmllint 常用的参数:
1. --noout:不输出任何信息。
2. --format:将 XML 文件格式化为易读的格式。
3. --encode:指定输出编码格式。
4. --xpath:使用 XPath 表达式来选择 XML 文件中的元素。
5. --schema:指定一个 XML Schema 文件,用于验证 XML 文件。
6. --valid:验证 XML 文件是否符合规范。
7. --dtdvalid:指定一个 DTD 文件,用于验证 XML 文件。
8. --html:将输入文件视为 HTML 文档进行解析。
9. --xmlout:将解析后的结果输出为 XML 文件。
10. --stream:启用流模式来处理大型 XML 文件。
这些参数可以通过在命令行中指定来使用。
例如,要将 XML 文件格式化为易读格式,可以使用以下命令:
```
xmllint --format input.xml > output.xml
```
这将读取名为 input.xml 的文件,并将格式化后的结果写入名为 output.xml 的文件中。
- 1 -。

linux xmllint用法摘要:1.概述2.Linux 和xmllint 的关系3.xmllint 的基本用法4.xmllint 的选项和参数5.xmllint 的实例6.总结正文:1.概述xmllint 是一个用于解析XML 文档的轻量级命令行工具,它可以在Linux 系统上使用。
xmllint 可以解析XML 文档,并输出解析后的结果,方便用户进行进一步的处理。
2.Linux 和xmllint 的关系Linux 是一个开源的操作系统,它提供了许多命令行工具,以便用户在终端上进行各种操作。
xmllint 是Linux 系统中的一个命令行工具,用户可以在终端中使用它来解析XML 文档。
3.xmllint 的基本用法xmllint 的基本用法如下:```xmllint [options] xmlfile```其中,`xmlfile`是用户要解析的XML 文档的路径,`options`是xmllint 的选项和参数。
4.xmllint 的选项和参数xmllint 有许多选项和参数,它们可以帮助用户对XML 文档进行各种操作。
例如,`-i`选项可以让xmllint 忽略XML 文档的注释,`-s`选项可以让xmllint 将XML 文档解析为脚本,`-p`选项可以让xmllint 打印XML 文档的解析树等。
5.xmllint 的实例例如,如果用户想要解析一个名为`example.xml`的XML 文档,并忽略其中的注释,可以使用如下命令:```xmllint -i example.xml```如果用户想要将一个名为`example.xml`的XML 文档解析为脚本,可以使用如下命令:```xmllint -s example.xml```如果用户想要打印一个名为`example.xml`的XML 文档的解析树,可以使用如下命令:```xmllint -p example.xml```6.总结xmllint 是Linux 系统中的一个命令行工具,它可以用于解析XML 文档。

lxml 是一个用于处理XML 和HTML 的Python 库,它基于libxml2 和libxslt 库,提供了高性能和易用的API。
以下是一些基本的lxml 使用方法:
1. 安装:
2. 解析XML 文档:
python代码:
3. 解析HTML 文档:
python代码:
4. XPath 查询:
XPath 是一种在XML 文档中查找信息的语言。
以下是如何使用XPath 在lxml 中查询元素:
python代码:
5. 修改元素:
python代码:
6. 保存修改后的文档:
python代码:
7. 属性访问与修改:
python代码:
8. 遍历元素树:
python代码:
这些是lxml 库的一些基本用法。
根据具体需求,还可以进行更复杂的操作,如使用CSS Selectors、处理命名空间、进行XML 转换等。
在处理不规范或复杂的HTML 文档时,可能需要结合使用BeautifulSoup 或其他库来提高数据
提取的准确性。
如果遇到问题,可以使用etree.tostring() 方法来查看解析后的HTML 字符串,以便更好地理解其结构并进行调试。

linux xmllint用法摘要:一、Linux 简介二、XMLLint 工具介绍三、XMLLint 的基本用法1.安装和配置2.验证XML 文档3.格式化XML 文档4.查询XML 文档5.修改XML 文档四、XMLLint 在实际应用中的案例五、总结正文:一、Linux 简介Linux 是一个免费、开源的类Unix 操作系统。
它具有良好的稳定性、高度可定制性和强大的功能,广泛应用于服务器、嵌入式设备和超级计算机等领域。
Linux 系统中有许多实用的工具,可以帮助用户更高效地处理各种任务。
二、XMLLint 工具介绍XMLLint 是一个用于验证和处理XML 文档的命令行工具。
它基于libxml2 库,支持XML 1.0 标准,可以检查XML 文档的语法正确性、结构完整性以及遵循的规范。
通过XMLLint,用户可以轻松地识别和纠正XML 文档中的错误,从而保证数据的准确性和一致性。
三、XMLLint 的基本用法1.安装和配置在Linux 系统中,可以通过包管理器(如apt、yum 等)安装XMLLint。
以Ubuntu 系统为例,可以使用以下命令进行安装:```sudo apt-get install libxml2-utils```2.验证XML 文档XMLLint 的最基本用法是验证XML 文档的语法正确性。
使用如下命令:```xmllint --valid file.xml```其中,`file.xml`是需要验证的XML 文档。
如果文档没有错误,XMLLint 会输出“OK”,否则会显示错误信息。
3.格式化XML 文档XMLLint 还可以对XML 文档进行格式化,使其更易读。
使用如下命令:```xmllint --format file.xml```同样,`file.xml`是需要格式化的XML 文档。
4.查询XML 文档XMLLint 支持XPath 表达式,可以用来查询XML 文档中的数据。

linuxxmllint用法xmllint是一个功能强大的命令行工具,用于验证和解析XML文档。
它是libxml库的一部分,可在Linux系统上使用。
本文将详细介绍xmllint的用法,包括验证XML文档、格式化XML文档、查询XML文档等方面。
1.验证XML文档xmllint可以用于验证XML文档的有效性,即验证它们是否符合XML语法规则。
使用它的--valid选项可以执行验证操作。
示例命令如下:```xmllint --valid example.xml```这将验证example.xml文档是否有效。
如果文档有效,则不会有输出。
如果文档无效,则会显示一条错误消息。
2.格式化XML文档xmllint还可以用来格式化XML文档,使其易于阅读和理解。
使用--format选项可以对XML文档进行格式化。
示例命令如下:```xmllint --format example.xml```这将格式化example.xml文档,并在标准输出中显示格式化后的结果。
3.查询XML文档使用xmllint的--xpath选项可以执行XPath查询操作,从XML文档中提取所需的数据。
以下是一个示例命令:```xmllint --xpath "//book[price>10]/title" example.xml```这将执行一个XPath查询,提取example.xml文档中价格大于10的书籍的标题。
输出结果将显示在标准输出中。
4.修改XML文档xmllint还可以用来修改XML文档。
使用--shell选项可以进入一个交互式shell环境,以执行各种XML修改操作。
以下是一个示例命令:```xmllint --shell example.xml```这将打开一个交互式shell环境,您可以在其中执行各种shell命令来修改XML文档。
例如,您可以使用cat命令查看文档内容,使用set命令更改元素的文本内容,使用write命令保存修改后的文档等等。

xml 解决单引号和双引号的方法1. 什么是 XML?XML 是一种可扩展标记语言,用于存储和传输数据。
XML 标签用于定义数据元素,并以树形结构来组织数据。
XML 的格式非常灵活,易于解析和读取。
2. 单引号和双引号在 XML 中的问题在 XML 中,常常需要使用单引号或双引号来引用属性值或字符串。
然而,这两种引号在 XML 中是有歧义的,如果不加以区别,可能会导致 XML 解析错误。
例如,以下代码中使用了单引号和双引号混合的方式定义了一个属性:```xml<book author="Jane Austen" title='Pride & Prejudice'/> ```这段代码中,& 是一个特殊字符,用于表示 & 符号。
该属性使用了单引号和双引号混合的方式来定义,虽然在这个例子中不会出现问题,但是当属性值中本身包含单引号或双引号时,就会出现 XML解析错误问题。
3. 解决办法为了避免这种问题,XML 规范中规定,双引号用于在 XML 属性中引用字符串,单引号用于在 XML 文本中引用字符串。
以下是正确的写法:```xml<book author="Jane Austen" title="Pride & Prejudice"/> ```在 XML 文本中引用字符串时,使用 CDATA 块可以避免问题。
CDATA 块中的数据不会被 XML 解析器解析,而是直接作为文本输出。
例如:```xml<description><![CDATA[This is a "quote" from Jane's book.]]></description>```在上面的例子中,双引号和单引号都不会出现问题,因为它们都是作为文本输出的。

关于tinyxml在LINUX环境下的使用TinyXML是一个跨平台的C++库,用于读取、解析和生成XML文件。
它提供了一个简单、易用的API,可以用于在Linux环境下进行XML文件的处理。
要在Linux环境下使用TinyXML,首先需要在系统上安装该库。
可以通过源码安装或使用包管理工具进行安装。
以下是在Ubuntu上使用apt包管理器安装的示例命令:```shellsudo apt-get install libtinyxml2-dev```安装完成后,就可以在项目中使用TinyXML库了。
下面是一个简单的示例代码,演示了如何使用TinyXML在Linux环境下解析和生成XML文件:```cpp#include <iostream>#include <tinyxml2.h>using namespace tinyxml2;int main//解析XML文件XMLDocument doc;doc.LoadFile("test.xml");if (doc.Error()std::cout << "Failed to load XML file." << std::endl; return 1;}//获取根元素XMLElement* root = doc.RootElement(;if (root == nullptr)std::cout << "Failed to get root element." << std::endl; return 1;}//遍历子元素XMLElement* child = root->FirstChildElement(;while (child != nullptr)const char* value = child->Value(;std::cout << "Element: " << value << std::endl;//获取元素属性const XMLAttribute* attribute = child->FirstAttribute(; while (attribute != nullptr)const char* attributeName = attribute->Name(;const char* attributeValue = attribute->Value(;std::cout << "Attribute: " << attributeName << " = " << attributeValue << std::endl;attribute = attribute->Next(;}child = child->NextSiblingElement(;}//生成XML文件XMLDocument newDoc;XMLNode* newRoot = newDoc.NewElement("Root");newDoc.InsertFirstChild(newRoot);XMLElement* newElement = newDoc.NewElement("Element");newElement->SetAttribute("Attribute", "Value");newRoot->InsertEndChild(newElement);newDoc.SaveFile("new_test.xml");return 0;```这个例子中,首先通过`XMLDocument::LoadFile`函数载入一个XML 文件(test.xml)。
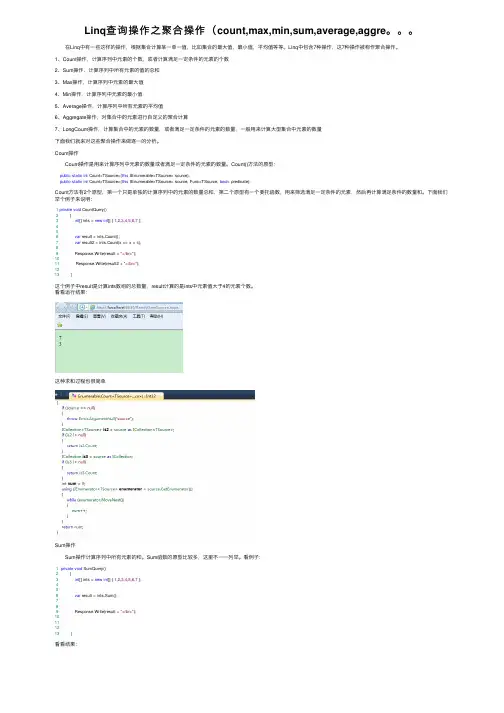
Linq查询操作之聚合操作(count,max,min,sum,average,aggre。
在Linq中有⼀些这样的操作,根据集合计算某⼀单⼀值,⽐如集合的最⼤值,最⼩值,平均值等等。
Linq中包含7种操作,这7种操作被称作聚合操作。
1、Count操作,计算序列中元素的个数,或者计算满⾜⼀定条件的元素的个数2、Sum操作,计算序列中所有元素的值的总和3、Max操作,计算序列中元素的最⼤值4、Min操作,计算序列中元素的最⼩值5、Average操作,计算序列中所有元素的平均值6、Aggregate操作,对集合中的元素进⾏⾃定义的聚合计算7、LongCount操作,计算集合中的元素的数量,或者满⾜⼀定条件的元素的数量,⼀般⽤来计算⼤型集合中元素的数量下⾯我们就来对这些聚合操作来做逐⼀的分析。
Count操作 Count操作是⽤来计算序列中元素的数量或者满⾜⼀定条件的元素的数量。
Count()⽅法的原型:public static int Count<TSource>(this IEnumerable<TSource> source);public static int Count<TSource>(this IEnumerable<TSource> source, Func<TSource, bool> predicate);Count⽅法有2个原型,第⼀个只是单独的计算序列中的元素的数量总和,第⼆个原型有⼀个委托函数,⽤来筛选满⾜⼀定条件的元素,然后再计算满⾜条件的数量和。
下⾯我们举个例⼦来说明:1private void CountQuery()2 {3int[] ints = new int[] { 1,2,3,4,5,6,7 };456var result = ints.Count();7var result2 = ints.Count(x => x > 4);89 Response.Write(result + "</br>");1011 Response.Write(result2 + "</br>");1213 }这个例⼦中result是计算ints数组的总数量,result计算的是ints中元素值⼤于4的元素个数。

unity3d 列表的linq用法LINQ是Language-Integrated Query(语言集成查询)的缩写,它是一种强大的查询语言,用于在数据集合中检索、过滤和操作数据。
在Unity3D中,LINQ可用于操作游戏对象列表、组件列表、组件属性等。
下面将介绍Unity3D中列表的LINQ用法。
在Unity3D中,可以使用LINQ查询游戏对象列表、组件列表等。
以下是一些常见的LINQ用法示例:1. 查询游戏对象列表:```c# GameObject[] gameObjects =GameObject.FindObjectsOfType<GameObject>();IEnumerable<GameObject> filteredObjects =gameObjects.Where(obj => == "MyGameObject"); ```上述代码中,使用`FindObjectsOfType<GameObject>()`方法获取所有游戏对象,并使用LINQ查询过滤出名称等于"MyGameObject"的游戏对象。
2. 查询组件列表:```c# Component[] components =gameObject.GetComponentsInChildren<Component>(); IEnumerable<Component> filteredComponents =components.Where(comp => == "MyComponent"); ```上述代码中,使用`GetComponentsInChildren<Component>()`方法获取指定游戏对象子对象下的所有组件,并使用LINQ查询过滤出名称等于"MyComponent"的组件。

linq中in的用法-回复Linq中in的用法在Linq中,"in" 是一个关键词,用于在一个给定的集合中查找某个属性或值是否存在。
它可以与条件或查询表达式一起使用,以更有效和简洁的方式进行数据检索和过滤。
本文将逐步回答有关Linq中"in"的用法以及相关的概念和示例。
第一步:了解Linq在深入探讨Linq中"in"的用法之前,我们需要先了解Linq是什么。
Linq (Language Integrated Query)是一种编程范式,它允许开发人员在.NET平台上使用类似于SQL的查询语句来对各种数据源进行查询和操作。
无论是查询数据库,XML文档,集合或任何其他数据源,Linq都提供了一种统一的方式来执行这些操作。
第二步:掌握"in"的语法Linq中的"in"运算符使用非常简单直观。
它使用以下语法:var result = from item in collectionwhere item.Property in [value1, value2, ...]select item;上述代码示例中的`collection`可以是一个集合,数组或任何实现了`IEnumerable`接口的数据源。
`item`是集合中的每个元素,它的属性(`Property`)将被用于与给定的值(`value1, value2`等)进行比较。
使用"in"运算符,我们可以轻松地检查集合中的每个元素是否满足给定的条件。
第三步:使用"in"进行简单过滤现在,我们将通过一个简单的示例来演示如何使用"in"运算符进行过滤。
假设我们有一个包含学生信息的集合,我们想要从中找出年龄在18到21岁之间的学生。
csharpclass Student{public string Name { get; set; }public int Age { get; set; }}...List<Student> students = new List<Student>(){new Student() { Name = "Alice", Age = 17 },new Student() { Name = "Bob", Age = 20 },new Student() { Name = "Carol", Age = 22 },new Student() { Name = "Dave", Age = 19 }};var result = from student in studentswhere student.Age in [18, 19, 20, 21]select student;在上述示例中,我们创建了一个名为`students`的学生列表,并使用"in"运算符筛选出了年龄在18到21岁之间的学生。
C#集合与Linq总结序列化与反序列化1. 将DataTable 转换List <T> 1)要求DataTable中的列名称必须和实体的属性名称相同public static List<TResult> DataTableToList<TResult>(DataTable dt) where TResult : class,new(){//创建⼀个属性的列表List<PropertyInfo> prlist = new List<PropertyInfo>();//获取TResult的类型实例反射的⼊⼝Type t = typeof(TResult);//获得TResult 的所有的Public 属性并找出TResult属性和DataTable的列名称相同的属性(PropertyInfo) 并加⼊到属性列表Array.ForEach<PropertyInfo>(t.GetProperties(), p => { if (dt.Columns.IndexOf() != -1) prlist.Add(p); });//创建返回的集合List<TResult> oblist = new List<TResult>();foreach (DataRow row in dt.Rows){//创建TResult的实例TResult ob = new TResult();//找到对应的数据并赋值prlist.ForEach(p =>{if (row[] != DBNull.Value){Type type = p.PropertyType;if ( == "String"){t.GetProperty().SetValue(ob, row[].ToString(), null);p.SetValue(ob, row[], null);}else{var value = Activator.CreateInstance(type);if (type.IsEnum){string str = row[].ToString();value = Enum.Parse(type, str, true);}else{value = Convert.ChangeType(row[], type);}p.SetValue(ob, value, null);}}});//放⼊到返回的集合中.oblist.Add(ob);}return oblist;} 2)要求实体的属性名称的顺序跟DataTable中的列名对应的顺序相同public static List<TResult> DataTableToList<TResult>(DataTable dt) where TResult : class,new(){//创建⼀个属性的列表List<string> columNamelist = new List<string>();foreach (DataColumn dc in dt.Columns){if (!columNamelist.Contains(dc.ColumnName))columNamelist.Add(dc.ColumnName);}//创建⼀个属性的列表List<PropertyInfo> prlist = new List<PropertyInfo>();//获取TResult的类型实例反射的⼊⼝Type t = typeof(TResult);//获得TResult 的所有的Public 属性并找出TResult属性和DataTable的列名称相同的属性(PropertyInfo) 并加⼊到属性列表Array.ForEach<PropertyInfo>(t.GetProperties(), p => { prlist.Add(p); });//创建返回的集合//创建返回的集合List<TResult> oblist = new List<TResult>();foreach (DataRow row in dt.Rows){//创建TResult的实例TResult ob = new TResult();//找到对应的数据并赋值for (int i = 0; i < columNamelist.Count; i++){string columName = columNamelist[i];if (row[columName] != DBNull.Value){PropertyInfo p = prlist[i];Type type = p.PropertyType;if ( == "String"){t.GetProperty().SetValue(ob, row[columName].ToString(), null);}else{var value = Activator.CreateInstance(type);if (type.IsEnum){string str = row[columName].ToString();value = Enum.Parse(type, str, true);}else{value = Convert.ChangeType(row[columName], type);}t.GetProperty().SetValue(ob, value, null);}}}//放⼊到返回的集合中.oblist.Add(ob);}return oblist;}2.将IEnumerable接⼝对象转换成DataTablepublic static DataTable ToDataTable<TResult>(this IEnumerable<TResult> value) where TResult : class{//创建属性的集合List<PropertyInfo> pList = new List<PropertyInfo>();//获得反射的⼊⼝Type type = typeof(TResult);DataTable dt = new DataTable();//把所有的public属性加⼊到集合并添加DataTable的列Array.ForEach<PropertyInfo>(type.GetProperties(), p =>{ pList.Add(p);dt.Columns.Add(, p.PropertyType);});foreach (var item in value){//创建⼀个DataRow实例DataRow row = dt.NewRow();//给row 赋值pList.ForEach(p => row[] = p.GetValue(item, null));//加⼊到DataTabledt.Rows.Add(row);}return dt;} 3.对象的克隆1)通过序列化与反序列化得到⼀个对象的克隆(注意该对象必须声明为可序列化,⽽且他的所有属性的类型都是可序列化的)public static object Clone(object obj){MemoryStream memoryStream = new MemoryStream();BinaryFormatter formatter = new BinaryFormatter();formatter.Serialize(memoryStream, obj);memoryStream.Position = 0;return formatter.Deserialize(memoryStream);}2)通过实现ICloneable接⼝实现克隆public class T : ICloneable{public object Clone(){//如果实体中含有引⽤类型,则需要对每个引⽤类型进⾏深度拷贝return this.MemberwiseClone(); //这⾥可以通过Object中的⽅法实现浅拷贝}}4.常⽤的⼀些LINQ 1)把DataTable转换成Dictionary、Array、List等等var dic = (from row in dt.AsEnumerable()select (new { PowerRoomID = row["PowerRoomID"].ToString(), PowerRoomName = row["PowerRoomName"].ToString() })).Distinct().ToDictionary(k => k.PowerRoomName, v => v.PowerRoomID);dic = dt.AsEnumerable().Select(row => new { PowerRoomID = row["PowerRoomID"].ToString(), PowerRoomName = row["PowerRoomName"].ToString() }).Distinct().ToDictionary(k => k.PowerRoomName, v => v.PowerRoomID);2.过滤数据源并且可以创建临时实体类型的数据源1)⽣成局部的临时实体类型的数据源(这⾥的局部是指下⾯的source是局部,不能⽣成全局变量)var source = (from row in devModel.Source where row.Type =="类型" && row.IsChecked == true select new { DevNo = row.DevNo, DevName = row.DevName }).ToList();source = devModel.Source.Where(row => row.Type == "类型" && row.IsChecked == true).Select(row => new { DevNo = row.DevNo, DevName = row.DevName }).ToList(); 2)全局的临时实体类型数据源List<Tuple<int,string>> source = (from row in devModel.Source where row.Type == "类型" && row.IsChecked == true select new Tuple<int, string>(row.Id, row.DevName)).ToList();source = devModel.Source.Where(row => row.Type == "类型" && row.IsChecked == true).Select(row => new Tuple<int, string>(row.Id, row.DevName)).ToList();3 序列化与反序列化操作 将对象序列化成字符串 View Code将对象序列化成字符串public static string Serialize<T>(T obj){if (obj == null){return null;}string ret = "";using (MemoryStream stream = new MemoryStream()){DataContractSerializer serializer = new DataContractSerializer(obj.GetType());using (XmlDictionaryWriter binaryDictionaryWriter = XmlDictionaryWriter.CreateTextWriter(stream, Encoding.UTF8)){serializer.WriteObject(binaryDictionaryWriter, obj);binaryDictionaryWriter.Flush();}ret = Encoding.UTF8.GetString(stream.ToArray());}return ret;}将对象序列化成配置xml⽂件 (保存)View Codepublic static void DataContractSerializeToFile<T>(T t, string fileName){if (t == null){return;}using (FileStream fileStream = new FileStream(fileName, FileMode.Create)){XmlWriterSettings xmlWriterSettings = new XmlWriterSettings { Indent = true, Encoding = Encoding.Default };using (XmlWriter xmlWriter = XmlWriter.Create(fileStream, xmlWriterSettings)){DataContractSerializer dataContractSerializer = new DataContractSerializer(typeof(T));dataContractSerializer.WriteObject(xmlWriter, t);xmlWriter.Flush();}}}public static void XmlSerializeToFile<T>(T t, string fileName){if (t == null){return;}using (FileStream fileStream = new FileStream(fileName, FileMode.Create)){XmlWriterSettings xmlWriterSettings = new XmlWriterSettings { Indent = true, Encoding = Encoding.Default };using (XmlWriter xmlWriter = XmlWriter.Create(fileStream, xmlWriterSettings)){XmlSerializer xmlSerializer = new XmlSerializer(typeof(T));xmlSerializer.Serialize(xmlWriter, t);xmlWriter.Flush();}}}将字符串反序列化为对象View Codepublic static T DataContractDeserialize<T>(string xml){T ret = default(T);if (string.IsNullOrEmpty(xml)){return ret;}using (MemoryStream stream = new MemoryStream()){byte[] bytes = Encoding.UTF8.GetBytes(xml);stream.Write(bytes, 0, bytes.Length);stream.Position = 0L;DataContractSerializer serializer = new DataContractSerializer(typeof(T));using (XmlDictionaryReader binaryDictionaryReader = XmlDictionaryReader.CreateTextReader(stream, XmlDictionaryReaderQuotas.Max)) {ret = (T)serializer.ReadObject(binaryDictionaryReader);}}return ret;}将xml配置⽂件反序列化为对象(实体初始化)View Codepublic static T DataContractDeserializeByFile<T>(string fileName){T result = default(T);if (string.IsNullOrEmpty(fileName) || !File.Exists(fileName)){return result;}using (FileStream fileStream = new FileStream(fileName, FileMode.Open)){DataContractSerializer dataContractSerializer = new DataContractSerializer(typeof(T));using (XmlDictionaryReader xmlDictionaryReader = XmlDictionaryReader.CreateTextReader(fileStream, XmlDictionaryReaderQuotas.Max)) {result = (T)dataContractSerializer.ReadObject(xmlDictionaryReader);}}return result;}public static T XmlDeserializeByFile<T>(string fileName){T result = default(T);if (string.IsNullOrEmpty(fileName) || !File.Exists(fileName)){return result;}using (FileStream fileStream = new FileStream(fileName, FileMode.Open)){XmlSerializer xmlSerializer = new XmlSerializer(typeof(T));result = (T)xmlSerializer.Deserialize(fileStream);}return result;}总结:以上纯属个⼈的理解,对于有些地⽅觉得还是理解不是很深,有不⾜之处和错误的地⽅希望⼤家帮我指出。
asqueryable的用法"asqueryable"的用法指的是在LINQ(Language-Integrated Query)查询中的一种方法。
LINQ是一种在.NET框架中用于查询数据的技术,它允许开发人员使用类似于SQL的语法来查询各种数据源,包括集合、数据库和XML。
在LINQ中,有一个名为"asqueryable"的方法,它用于将泛型集合转换为实现IQueryable接口的查询对象。
通过调用"asqueryable"方法,可以将普通的集合转换为可查询的集合,从而可以在查询中应用更多的操作和条件。
例如,假设有一个名为"students"的List<Student>集合,我们可以使用"asqueryable"方法将其转换为可查询的集合,然后在查询中应用各种条件和操作符,如Where、OrderBy、Select等。
下面是一个简单的示例:csharp.List<Student> students = GetStudents(); // 从某个数据源获取学生列表。
// 将集合转换为可查询的集合。
IQueryable<Student> queryableStudents =students.AsQueryable();// 在查询中应用条件。
var result = queryableStudents.Where(s => s.Age > 18).OrderBy(s => stName).Select(s => new { s.FirstName, stName });// 执行查询。
foreach (var student in result)。
{。
Console.WriteLine($"{student.FirstName}{stName}");}。
Linq查询数据集取得排序后的序列号(⾏号)今天群⾥有同学问如何⽤linq取结果集的⾏号,查了⼀下资料,发现linq有很简单的⽅法可以实现,花了⼏分钟写了⼀个测试⽤例,现记录下来,以备参考:/// <summary>/// 测试类/// </summary>public class models{public int id { set; get; }public string Name { set; get; }public string Phone { set; get; }public string Address { set; get; }public DateTime Birthday { set; get; }private static int idx { set; get; } = 0;public models(){id = idx++;Name = "testName" + id.ToString();Phone = "testPhone" + id.ToString();Address = "testAddress" + id.ToString();Birthday = DateTime.Now.AddHours(id);}}下⾯是实现⽅法:var list = new List<models>();list.Add(new models());list.Add(new models());list.Add(new models());list.Add(new models());list.Add(new models());list.Add(new models());var tt = list.OrderBy(p => ).OrderByDescending(p =>p.Birthday).OrderByDescending(p => p.id).Select((p, idx) => new {row = idx,name = ,phone = p.Phone});。
LINT TO SQL增删改protected IQueryable<Products> GetQuery(decimal pId) //定制一个查询方法,返回产品id大于指定id的对象集{pdc = new LINQtoSQLDataContext();var query = from product in pdc.Productswhere product.pId > pIdselect product;return query;}protected void btnSelect_Click(object sender, EventArgs e) //查找{int id = 0;if (TextBox1.Text.Length == 0){this.TextBox1.Text = "请输入整数!";this.TextBox1.Focus();}else{id = Convert.ToInt32(TextBox1.Text);var query = GetQuery(id);if (query.Count() > 0){GridView_Show.DataSource = query;GridView_Show.DataBind();lblInfo.T ext = "查询id号大于" + id + "的记录成功";}else{lblInfo.T ext = "不存在满足条件的记录";}}}protected void btnUpdate_Click(object sender, EventArgs e) //更新{try{int id = 0;if (this.TextBox2.Text.Length == 0){this.TextBox2.Text = "请输入数字!将增大productId字段";this.TextBox2.Focus();}else{id = Convert.ToInt32(TextBox2.Text);foreach (Products prod in GetQuery(1)){prod.ProductId += (int)id;}pdc.SubmitChanges();GridView_Show.DataSource = GetQuery(0);GridView_Show.DataBind();lblInfo.T ext = "把ProductId增加了" + id;}}catch{lblInfo.T ext = "执行失败!";}}protected void btnInsert_Click(object sender, EventArgs e) //插入{pdc = new LINQtoSQLDataContext();Products newproduct = new Products();//int id = Convert.ToInt32(TextBox3.Text);//newproduct.pId = id; 不能给主键赋值,赋值无效newproduct.ProductId = 1;newproduct.ProductName = "橙子";newproduct.ProductSupplierId = 1;pdc.Products.InsertOnSubmit(newproduct); //插入一条记录pdc.SubmitChanges();GridView_Show.DataSource = GetQuery(0);GridView_Show.DataBind();lblInfo.T ext = "插入一条记录成功!";}protected void btnDelete_Click(object sender, EventArgs e) //删除{pdc = new LINQtoSQLDataContext();int id = Convert.ToInt32(this.T extBox4.Text);IEnumerable<Products> query = from product in pdc.Products //查询数据库中满足条件的数据集where product.ProductSupplierId == idselect product;pdc.Products.DeleteAllOnSubmit(query); //一次删除一批记录pdc.SubmitChanges(); //提交与正式执行更改申请//Single()和SingleOrDefault()都只返回一条记录,前者在没有记录的情况下会抛出一个InvalidOperationnException的异常,//后者只是简单地返回一个默认值//Products pro = pdc.Products.SingleOrDefault(t => t.pId == id);//pdc.Products.DeleteOnSubmit(pro); //一次只能删除一条记录//lblInfo.Text = "删除id号为" + id + "的记录成功!";//重新绑定到GridView_Show中GridView_Show.DataSource = from product in pdc.Productsselect product;GridView_Show.DataBind();}。
linq to entities does not recognize the method 这个错误通常出现在使用LINQ查询时,你调用了一个无法被Entity Framework转换为SQL语句的方法。
可能原因是该方法没有被实现或不支持LINQ to Entities。
要解决这个问题,你可以尝试以下几种方法:
1. 将数据加载到内存中再进行操作,即使用ToList()方法将查询结果加载到内存中,然后再执行其他操作。
2. 使用LINQ to Objects而不是LINQ to Entities,将需要过滤或排序的数据从数据库中读入,然后使用LINQ to Objects进行操作。
3. 重新编写查询,使用SQL Server中的函数代替自定义函数。
希望以上信息能够对你有所帮助!。
LINQ to XML LINQ to XML是LINQ系列技术中的一种,它主要用来处理XML结构的数据。LINQ to XML提供了修改文档对象模型的内存文档和支持LINQ查询表达式等功能,以及处理XML文档的全新的编程接口。本章节介绍LINQ to XML提供的基础类,以及使用LINQ to XML查询、创建、修改和删除XML文档的方法。
1 LINQ to XML概述
LINQ to XML是一种启用了LINQ的内存XML编程接口。使用LINQ to XML可以在.NET Framework编程语言中处理XML结构的数据。LINQ to XML可以将XML文档保存在内存中,并对内存中的XML文档进行查询、修改操作,以及将内存中的XML文档另存为XML文件。LINQ to XML与传统的DOM的最大不同之处在于:LINQ to XML提供了一种新的轻量级的对象模型。 正是因为LINQ to XML集成了LINQ,才使得LINQ to XML查询、检索、操作XML文档变得更加简单。LINQ to XML查询XML文档的查询表达式与XPath在语法上不相同,但是,它们提供相似的功能。下面的实例代码使用LINQ演示了查询Book.xml文件中的根节点“Books”的方法。 XDocument doc = ///…省略了初始化代码 ///查询根元素 IEnumerable elements = from e in doc.Elements("Books") select e; 使用LINQ to XML可以对XML文档(或片段)实现以下功能或操作: 从文件或流加载XML文档,即读取XML文档的内容。 将XML文件序列化为文件或流,即XML文档的序列化操作。 使用函数构造更加简单、方便地从头开始创建一个新的XML文档。 使用LINQ更加简单、方便地查询XML文档。 添加、修改和删除XML文档中的元素、属性等信息。 使用XSD验证XML文档。
1.1 LINQ to XML基础类 LINQ to XML提供了多个支持查询和操作XML文档的基础类,具体说明如下。 XElement类,表示XML文件中的元素。 XAttribute类,表示XML文件中的元素的属性(名称/值对)。 XDocument类,表示一个XML文档。 XDeclaration类,表示XML文件中XML声明。 XComment类,表示XML文件中一个XML注释,一般使用“”格式表示。 XNamespace类,表示XML文件中的一个XML命名空间。 XDocumentType类,表示XML文件的文档类型定义(DTD)。 XName类,表示XML元素或属性的名称。 XCData类,表示包含CDATA的文本节点。 XNode类,表示XML文件中的一个节点,可以为元素、注释、文本、XML处理指令等。 XText类,表示一个文本节点。 XContainer类,表示可以包含子节点的节点,即充当一个节点“容器”。 XProcessingInstruction类,表示XML处理指令。 XObject类,表示XML文件中的节点或属性。 XObjectChange枚举,指定XObject对象引发的事件的事件类型。 XObjectChangeEventArgs类,为XObject对象引发的事件提供相关数据。 XNodeEqualityComparer类,用来比较两个节点是否相等。 XNodeDocumentOrderComparer类,提供用于比较节点的文档顺序
1.2 使用函数构造方法创建XML LINQ to XML提供了一种被称为“函数构造”的方式来创建XML元素(或文档或属性等)。其中,函数构造是指在单个语句中创建XML元素(或文档或属性等)的能力。LINQ to XML中的XElement函数构造具有以下2个特点: XElement函数的参数的数据类型为Object的params数组。因此,该函数可以使用任意数量的对象(参数的值)。 XElement构造函数可以使用采用多种类型的参数。 下面的实例代码使用LINQ to XML调用XDocument函数构造了一个XML文档,并在该文档中添加了XML声明、根元素Books、一级子元素Book及其ID属性、二级子元素(NO、Name、Price和Remark)等内容。 XDocument doc = new XDocument( new XDeclaration("1.0","utf-8","yes"), new XElement("Books", new XElement("Book", new XAttribute("ID","104"), ///添加属性ID new XElement("No","0004"), ///添加元素No new XElement("Name","Book 0004"), ///添加元素Name new XElement("Price","300"), ///添加元素Price new XElement("Remark","This is a book 0004.") ///添加元素Remark ) ) );
2 LINQ to XML基础类
本小节主要介绍了LINQ to XML提供查询和操作XML文档的基础类,如XElement、XAttribute、XDocument、XDeclaration、XComment、XNamespace等。
2.1 XElement类 XElement类表示XML文件中的一个元素(XML文件的基本组成部分)。一般情况下,每一个元素都必须包含其名称。它还可以包含以下4个组成内容: 元素(由XElement类表示),作为元素的子元素。 文本(由XText类表示)。 注释(由XComment类表示),将注释作为元素的一个子元素。 XML处理指令(由XProcessingInstruction类表示),用来指定处理该XML文件的处理器。 XElement类提供了多个属性获取或操作XML文件中的元素,如获取元素名称的Name属性、获取元素的值的Value属性等。XElement类的属性如表所示。
表 XElement类的属性 属 性 说 明 Name 元素的名称。
Value 元素的值。
FirstAttribute 元素的第一个属性。
LastAttribute 元素的最后一个属性。
HasAttributes 表示元素是否包含属性。
HasElements 表示元素是否包含元素。
IsEmpty 表示是否为一个空元素。
EmptySequence 空的元素集合。
另外,XElement类还提供了多个方法操作XML文件中的元素,如设置元素的值的SetValue()方法、移除元素的所有节点和属性的RemoveAll()方法等。XElement类的方法如表所示。
表 XElement类的方法 方 法 说 明 AncestorsAndSelf() 自身及其上级元素的集合。
DescendantsAndSelf() 自身及其子元素元素的集合。
DescendantNodesAndSelf() 自身及其子节点的集合。
Load() 导入XML文件或片段,并创建为XElement类实例。
Parse() 解释XML文件或片段,。
Save() 将XElement实例保存为XML文件。
Attribute() 获取指定的属性。
Attributes() 获取该元素的所有属性。
GetDefaultNamespace() 元素的默认命名空间。
GetNamespaceOfPrefix() 与元素相关的命名空间的。
GetPrefixOfNamespace() 获取与元素的命名控件的前缀。
ReplaceAll() 替换该元素自动的属性。
RemoveAll() 移除该元素的所有内容。
ReplaceAttributes() 替换该元素的所有属性。
RemoveAttributes() 移除元素的属性。
SetValue() 设置该元素的值。
SetAttributeValue() 设置该元素的属性的值。
SetElementValue() 设置该元素的子元素的值。
下面的实例代码创建了名称为Advertisements的元素,并添加了两个子元素Ad。同时,Ad元素也包含Name和Url元素及其值。具体步骤如下。 (1)创建Advertisements元素及其子元素和值。 (2)使用网页显示Advertisements元素的内容。 (3)设置网页的输出格式为“text/xml”,并中止网页的输出操作。 private void XElementClass() {///创建一个XML元素 XElement element = new XElement("Advertisements", new XElement("Ad", new XElement("Name","w3c"), ///添加元素Name new XElement("Url","http://www.w3c.com") ///添加元素Url ), new XElement("Ad",