
表1.常用的元字符
表2.常用的限定符
表3.常用的反义代码
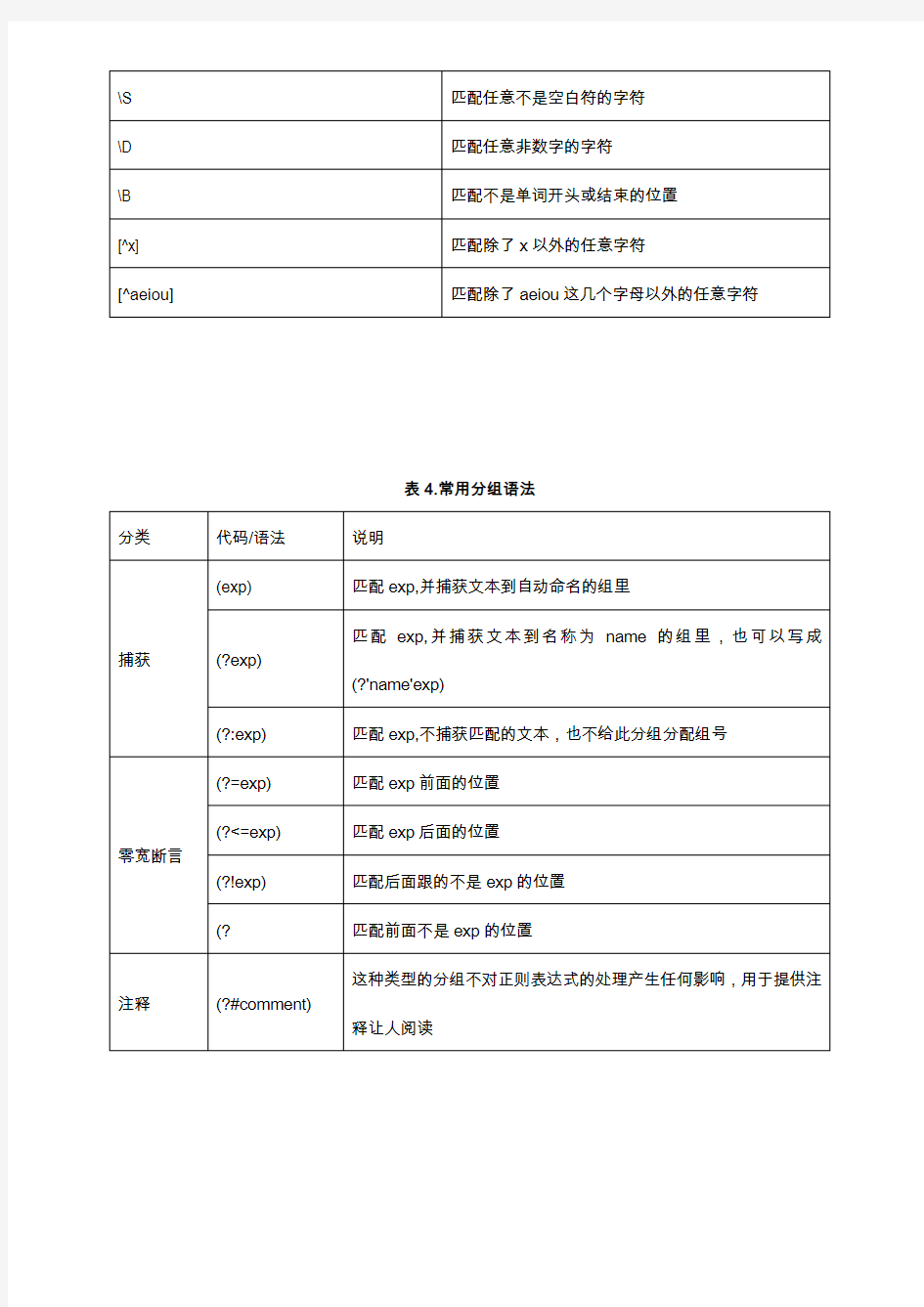
表4.常用分组语法
表5.懒惰限定符
表6.常用的处理选项
表7.尚未详细讨论的语法
正则 正则:一个规则,它是用来处理字符串的,验证字符串是否符合某个规则(正则匹配),或者是把字符串中符合规则的内容取出来(正则捕获) 一个正则是由元字符组成的。 创建正则有两种方式(有一些区别) var reg1=/\d/;//字面量方式,代表包含0-9之间的任意一个数字即可var reg2=new RegExp("\\d");//实例创建方式 区别在于: 1.实例创建方式需要多转译一次,把具有特殊意思,并且带\的都要多转译一次。 2.字面量方式无法识别变量,而实例创建方式可以,也就是说实例创建可以进行我们的字符串拼接(把一个变量代表的值放到正则中作为规则)。 var reg1=/\d/; var reg2=new RegExp("\\d"); varreg=/zhufeng/; console.log(reg.test("welcome zhufeng student"));//true console.log(reg.test("welcome zhufeng student"));//false var c="w100"; varreg=/^"+c+"$/;//以"开头,出现一到多次,然后是c出现一到多次,最后以"结尾,而不是我们认为的字符串拼接 varreg=new RegExp("^"+c+"$");//此时只能包含w100的 正则中还包含修饰符:i(ignoreCase忽略大小写), m(multiline 匹配换行), g(global 全局匹配) varreg=/^[a-z]$/i; varreg=new RegExp("^[a-z]$","i"); console.log(reg.test("Z")); 具有特殊意义的元字符 \d :0-9之间任意一个数字 \ :转译字符 ^ :以某一个元字符开始 $ :以某一个元字符结束 \n :一个换行符 . :匹配除了\n以为的任何字符 x|y :x或者y [xyz] :x y z 三个中一个 [^xyz] :除三个中的任一个 [a-z] :a--z之间任意一个 [^a-z] :除了a--z之间任意一个
学习笔记:正则表达式 2011-8-29 一.正则表达式 正则表达式(Regex)是用来进行文本处理的技术,是语言无关的,在几乎所有语言中都有实现。 一个正则表达式就是由普通的字符及特殊字符(称为元字符符)组成的文字模式。该模式秒杀在查找文章主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。 正则表达式的常用元字符(全为英文状态,注意可以代表的字符种类和个数): 元字符含义 .(点) 可以匹配除”\n”外的任意一个字符 [](中括号) 可以匹配中括号内的任意一个字符 例如,"[abc]" 匹配"plain"中的"a" |(或符号) 可以匹配或符号两边的任意一个字符,优先级比较低 匹配x 或y。例如"z|food" 可匹配"z" 或"food"。 正则表达式的常用限定符(全为英文状态): 元字符含义 *(星号) 其限定的表达式出现次数等于或大于0次 例如,"zo*"可以匹配"z"、"zoo" +(加号) 其限定的表达式至少出现1次 例如,"zo+"可以匹配"zoo",但不匹配"z" ?(问号) 其限定的表达式出现1次或0次 例如,"a?ve?"可以匹配"never"中的"ve" {n} 其限定的表达式出现次数确定n次(n≥0) {n,} 其限定的表达式至少出现n次 {n,m} 其限定的表达式出现的次数为≥n次,≤m次(m>n) 还有几个重要的符号: 符号含义 ^ (Shift+6)匹配输入的开始位置 非的意思。例如[^a-z],匹配非a-z的一个字符。 $ (Shift+4)匹配输入的结尾 \将下一个字符标记为特殊字符或字面值 例如:想匹配”.”时或其他特殊字符时,需写为的”\.” ()(小括号) 1.改变优先级 2.分组,提取信息 需要熟记一些简写: \d = [0-9]
正则表达式中常用符号 符号含义举例或说明 .任何字符或非字符 2.4匹配204, 214, 2t4, 2 4, 2.4, 2-4 *重复0次或更多BA*匹配B,BA,BAA,BAAA等 .* 某个字符重复0次或更多R.* 表示R后面有0个过多个字符,不同类副词 的赋码包括RR,RG,PGQ,RGQV等, 所以R.*表示, 不分类笼统地指所有副词, 类似的所有名词 N.*,所有形容词J.* +重复1次或多次A+匹配A,AA,AAA等 ?有或者无BA?匹配B和BA .*?任何字符串 |或者(|号在回车键上面)(analyze|analyse) 检索analyse 或者 analyze [ ] 方括号中的任意字符或单词[abc]匹配a、b或c [abc]+匹配 [ ]* n个单词。 () 组合,使得括号中的部分可以当作 一个符号处理 act(ing)可以匹配act和acting (cat|dog),把dog 和cat 两个词一块检索出来, ([pos="R.*"][pos="J.*"]) 前面一个词的词性为副词, 后面一个词的词性为形容词,把副词和形容词作 为一个整体检索 {} { }表示选择范围,{0,3}表示0~3个 范围内[pos="J.*"]{0,2} 表示其前的形容词有0个,1个或者2个 [ ] {0,}中,[ ]表示任意单词,{0,2}表示这个单词有0个,1个,或者无穷个,后面一个数字不写表示无穷个。 & 和,并且
段首标记, “however|However”表示句首为However或 however 开头的句子 !不等于[word!=","] "which"表示which 前没有逗号 [pos!="JJ.*|N.*|I.*"] 词性不是形容词、名词、介词 的词 N.*名词、V.* 动词、J.*形容词、R.* 副词、AT.* 冠词、I.* 介词、P.*代词 VB.*表示be动词、VH*有动词、VV.*实意动词及其各种变形、VM*情态动词
正则表达式 一、什么是这则表达式 正则表达式(regular expressions)是一种描述字符串集的方法,它是以字符串集中各字符串的共有特征为依据的。正则表达式可以用于搜索、编辑或者是操作文本和数据。它超出了java程序设计语言的标准语法,因此有必要去学习特定的语法来构建正则表达式。一般使用的java.util.regex API所支持的正则表达式语法。 二、测试用具 import java.io.BufferedReader; import java.io.InputStreamReader; import java.util.Scanner; import java.util.regex.Matcher; import java.util.regex.Pattern; public class Regex{ public static void main(String[]args)throws Exception{ BufferedReader br=new BufferedReader(new InputStreamReader(System.in)); if(br==null){ System.out.println("没有输入任何数据"); System.exit(1); } while(true){ System.out.print("输入表达式:"); Pattern pattern=https://www.doczj.com/doc/fb1330723.html,pile(br.readLine()); System.out.print("输入字符串:"); Matcher matcher=pattern.matcher(br.readLine()); boolean found=false; while(matcher.find()){ System.out.println("找到子字符串"+matcher.group()+" 开始于索引"+matcher.start()+"结束于索引"+matcher.end()+"\n") found=true; } if(!found){ System.out.println("没有找到子字符串\n"); } } } }
JS正则表达式大全 JS正则表达式大全【1】 正则表达式中的特殊字符【留着以后查用】字符含意 \ 做为转意,即通常在"\"后面的字符不按原来意义解释,如/b/匹配字符"b",当b前面加了反斜杆后/\b/,转意为匹配一个单词的边界。 -或- 对正则表达式功能字符的还原,如"*"匹配它前面元字符0次或多次,/a*/将匹配a,aa,aaa,加了"\"后,/a\*/将只匹配"a*"。 ^ 匹配一个输入或一行的开头,/^a/匹配"an A",而不匹配"An a" $ 匹配一个输入或一行的结尾,/a$/匹配"An a",而不匹配"an A" * 匹配前面元字符0次或多次,/ba*/将匹配b,ba,baa,baaa + 匹配前面元字符1次或多次,/ba*/将匹配ba,baa,baaa ? 匹配前面元字符0次或1次,/ba*/将匹配b,ba (x) 匹配x保存x在名为$1...$9的变量中 x|y 匹配x或y {n} 精确匹配n次 {n,} 匹配n次以上 {n,m} 匹配n-m次 [xyz] 字符集(character set),匹配这个集合中的任一一个字符(或元字符) [^xyz] 不匹配这个集合中的任何一个字符 [\b] 匹配一个退格符 \b 匹配一个单词的边界 \B 匹配一个单词的非边界 \cX 这儿,X是一个控制符,/\cM/匹配Ctrl-M \d 匹配一个字数字符,/\d/ = /[0-9]/ \D 匹配一个非字数字符,/\D/ = /[^0-9]/ \n 匹配一个换行符 \r 匹配一个回车符 \s 匹配一个空白字符,包括\n,\r,\f,\t,\v等 \S 匹配一个非空白字符,等于/[^\n\f\r\t\v]/ \t 匹配一个制表符 \v 匹配一个重直制表符 \w 匹配一个可以组成单词的字符(alphanumeric,这是我的意译,含数字),包括下划线,如[\w]匹配
要想真正的用好正则表达式,正确的理解元字符是最重要的事情。下表列出了所有的元字符和对它们的一个简短的描述。 字符描述 \ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,“\n”匹配字符“n”。“\\n”匹配一个换行符。序列“\\”匹配“\”而“\(”则匹配“(”。 ^ 匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 $ 匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 * 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”以及“zoo”。*等价于{0,}。 + 匹配前面的子表达式一次或多次。例如,“z o+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 ? 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“does”或“does”中的“d o”。?等价于{0,1}。 {n} n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 {n,} n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“fo o o ood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 {n,m} m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 ? 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o?”将匹配单个“o”,而“o+”将匹配所有“o”。 点匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字符,请使用像“[\s\S]”的模式。
js正则表达式使用 一,概述 1,正则表达式,可以说是任何一种编程语言都提供的机制,它主要是提供了对字符串的处理能力。 2,正则表达式在页面处理中的使用场景: 1)表单验证。验证某些域符合某种规则,例如邮件输入框必须输入的是邮件、联系电话输入框输入的必须是数字等等 2)处理DOM模型。例如通过表达式定位DOM中的一个对象或一系列对象,一个例子就是定位id属性中含有某个特殊字符的div对象。 3)纯编程逻辑。直接用于编程的逻辑之中。 3,说明:本部分所举的正则表达式的代码片断,都是经过测试的,但有一点需要注意,对于换行的字符串的定义,我们在表述时使用的是类似如下的形式: var str=“It?s is a beautiful city”; 这种形式直接写在JS代码中是错误的,那如何获取具有换行的字符串呢?简单的办法:在textarea中输入文本并换行,然后将该值赋给JS变量即可。例如: var str=document.forms[0].mytextarea.value; 二,语法与使用 1,定义正则表达式 1)定义正则表达式有两种形式,一种是普通方式,一种是构造函数方式。 2)普通方式:var reg=/表达式/附加参数 表达式:一个字符串,代表了某种规则,其中可以使用某些特殊字符,来代表特殊的规则,后面会详细说明。 附加参数:用来扩展表达式的含义,目前主要有三个参数: g:代表可以进行全局匹配。 i:代表不区分大小写匹配。 m:代表可以进行多行匹配。 上面三个参数,可以任意组合,代表复合含义,当然也可以不加参数。 例子: var reg=/a*b/; var reg=/abc+f/g; 3)构造函数方式:var reg=new RegExp(“表达式”,”附加参数”); 其中“表达式”与“附加参数”的含义与上面那种定义方式中的含义相同。 例子: var reg=new RegExp(“a*b”); var reg=new RegExp(“abc+f”,”g”); 4)普通方式与构造函数方式的区别 普通方式中的表达式必须是一个常量字符串,而构造函数中的表达式可以是常量字符串,也可以是一个js变量,例如根据用户的输入来作为表达式参数等等: var reg=new RegExp(document.forms[0].exprfiled.value,”g”);
1. 平时做网站经常要用正则表达式,下面是一些讲解和例子,仅供大家参考和修改使用: 2. "^\d+$"//非负整数(正整数+ 0) 3. "^[0-9]*[1-9][0-9]*$"//正整数 4. "^((-\d+)|(0+))$"//非正整数(负整数+ 0) 5. "^-[0-9]*[1-9][0-9]*$"//负整数 6. "^-?\d+$"//整数 7. "^\d+(\.\d+)?$"//非负浮点数(正浮点数+ 0) 8. "^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$"//正浮点数 9. "^((-\d+(\.\d+)?)|(0+(\.0+)?))$"//非正浮点数(负浮点数+ 0) 10. "^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$"//负浮点数 11. "^(-?\d+)(\.\d+)?$"//浮点数 12. "^[A-Za-z]+$"//由26个英文字母组成的字符串 13. "^[A-Z]+$"//由26个英文字母的大写组成的字符串 14. "^[a-z]+$"//由26个英文字母的小写组成的字符串 15. "^[A-Za-z0-9]+$"//由数字和26个英文字母组成的字符串 16. "^\w+$"//由数字、26个英文字母或者下划线组成的字符串 17. "^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$"//email地址 18. "^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$"//url 19. /^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日 20. /^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年 21. "^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$" //Emil 22. /^((\+?[0-9]{2,4}\-[0-9]{3,4}\-)|([0-9]{3,4}\-))?([0-9]{7,8})(\-[0-9]+)?$/ //电话号码 23. "^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}| 1dd|2[0-4]d|25[0-5])$" //IP地址 24. 25. 匹配中文字符的正则表达式:[\u4e00-\u9fa5] 26. 匹配双字节字符(包括汉字在内):[^\x00-\xff] 27. 匹配空行的正则表达式:\n[\s| ]*\r 28. 匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/ 29. 匹配首尾空格的正则表达式:(^\s*)|(\s*$) 30. 匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* 31. 匹配网址URL的正则表达式:^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$ 32. 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$ 33. 匹配国内电话号码:(\d{3}-|\d{4}-)?(\d{8}|\d{7})? 34. 匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$ 35. 36. 37. 元字符及其在正则表达式上下文中的行为:
JavaScript code: