四、统计分析
(一)不同性别的外企中青年白领工作投入比较研究
针对不同性别的外企中青年白领的工作投入3个维度水平进行了独立样本T 检验,结果如表3-1所示:
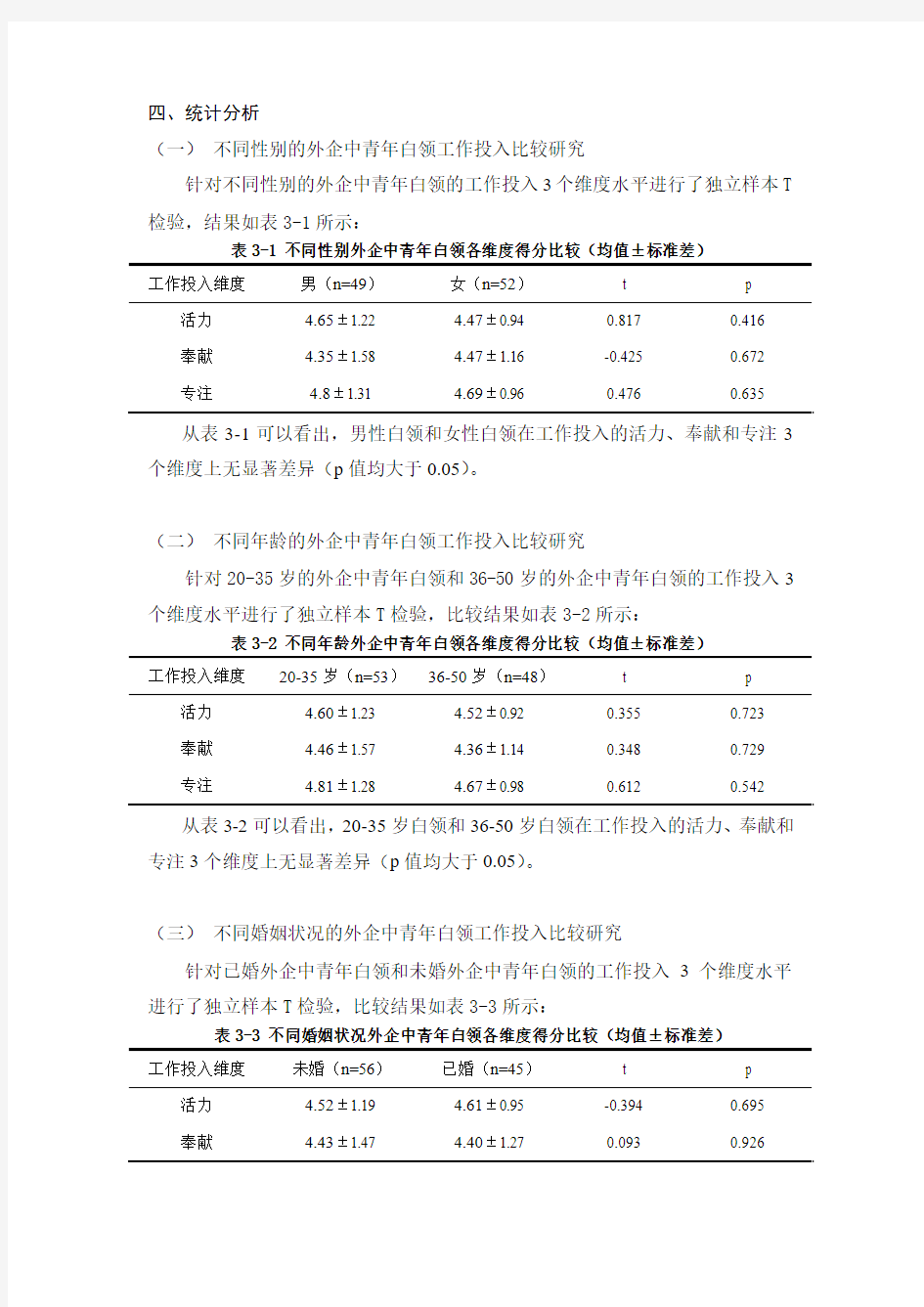
表3-1 不同性别外企中青年白领各维度得分比较(均值±标准差)
工作投入维度男(n=49)女(n=52)t p 活力 4.65±1.22 4.47±0.94 0.817 0.416 奉献 4.35±1.58 4.47±1.16 -0.425 0.672 专注 4.8±1.31 4.69±0.96 0.476 0.635 从表3-1可以看出,男性白领和女性白领在工作投入的活力、奉献和专注3个维度上无显著差异(p值均大于0.05)。
(二)不同年龄的外企中青年白领工作投入比较研究
针对20-35岁的外企中青年白领和36-50岁的外企中青年白领的工作投入3个维度水平进行了独立样本T检验,比较结果如表3-2所示:
表3-2 不同年龄外企中青年白领各维度得分比较(均值±标准差)
工作投入维度20-35岁(n=53)36-50岁(n=48)t p 活力 4.60±1.23 4.52±0.92 0.355 0.723 奉献 4.46±1.57 4.36±1.14 0.348 0.729 专注 4.81±1.28 4.67±0.98 0.612 0.542 从表3-2可以看出,20-35岁白领和36-50岁白领在工作投入的活力、奉献和专注3个维度上无显著差异(p值均大于0.05)。
(三)不同婚姻状况的外企中青年白领工作投入比较研究
针对已婚外企中青年白领和未婚外企中青年白领的工作投入3个维度水平进行了独立样本T检验,比较结果如表3-3所示:
表3-3 不同婚姻状况外企中青年白领各维度得分比较(均值±标准差)
工作投入维度未婚(n=56)已婚(n=45)t p 活力 4.52±1.19 4.61±0.95 -0.394 0.695 奉献 4.43±1.47 4.40±1.27 0.093 0.926
专注 4.75±1.24 4.73±1.03 0.104 0.917 从表3-3中可以看出,未婚白领和已婚白领在工作投入的活力、奉献和专注3个维度上无显著差异(p值均大于0.05)。
(四)不同受教育程度的外企中青年白领工作投入比较研究
针对大专、高中及以下学历的外企中青年白领和本科及以上的中青年白领的工作投入3个维度水平进行了独立样本T检验,比较结果如表3-4所示:表3-4 不同受教育程度外企中青年白领各维度得分比较(均值±标准差)
工作投入维度大专、高中及以下学历
(n=42)本科及以上学历
(n=59)
t p
活力 4.28±1.28 4.76±0.88 -2.223 0.028 奉献 4.18±1.51 4.58±1.26 -1.417 0.160 专注 4.44±1.31 4.96±0.96 -2.288 0.024 从表3-4中可以看出,不同受教育程度的外企中青年白领在活力维度上存在显著差异(t=-2.223,p=0.028<0.05),在奉献维度上无显著差异(t=-1.417,p=0.160>0.05),在专注维度上存在显著差异(t=-2.288,p=0.024<0.05)。
(五)不同职位层级的外企中青年白领工作投入比较研究
针对不同职位层级,即管理类(如:基层和中高层管理者)与非管理类(一般职员或技术类人员)的外企中青年白领的工作投入3个维度水平进行了独立样本T检验,比较结果如表3-5所示:
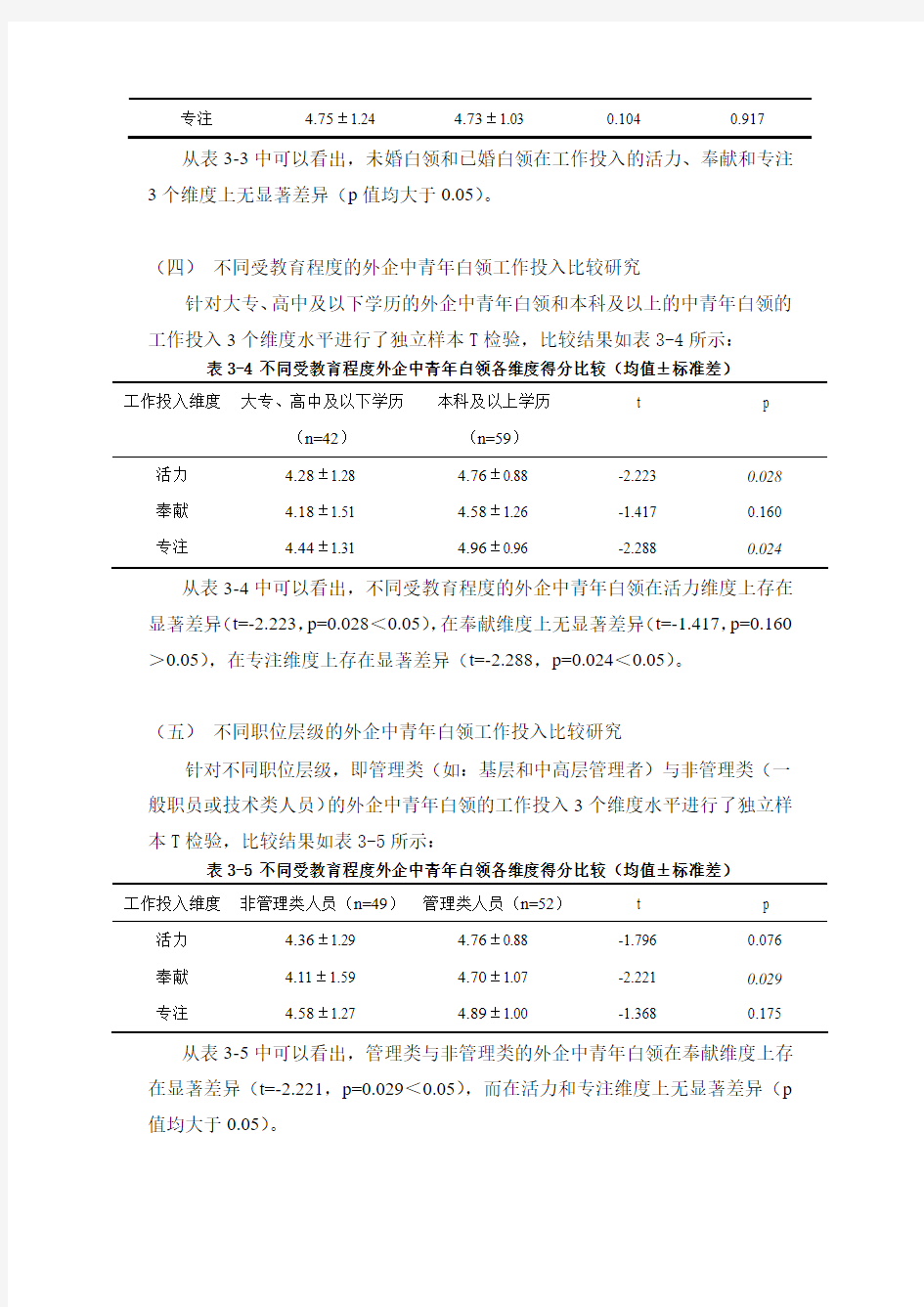
表3-5 不同受教育程度外企中青年白领各维度得分比较(均值±标准差)
工作投入维度非管理类人员(n=49)管理类人员(n=52)t p 活力 4.36±1.29 4.76±0.88 -1.796 0.076 奉献 4.11±1.59 4.70±1.07 -2.221 0.029 专注 4.58±1.27 4.89±1.00 -1.368 0.175 从表3-5中可以看出,管理类与非管理类的外企中青年白领在奉献维度上存在显著差异(t=-2.221,p=0.029<0.05),而在活力和专注维度上无显著差异(p 值均大于0.05)。
(六)不同工作年限的外企中青年白领工作投入比较研究
针对在同一企业工作年限的不同,将外企中青年白领分为6类:1.工作年限在半年之内;2.工作年限在半年到1年内;3.工作年限在1到3年;4.工作年限在3到5年;5.工作年限在5到10年;6.工作年限在10年以上。
对此6类被访者采用单因素方差分析方法检验工作投入3个维度水平,结果如表3-6所示:
表3-6 不同工作年限外企中青年白领工作投入比较分析维度工作年限均值±标准差 F P
活力
<0.5年 5.40±0.75 1.635 0.158 0.5~1年 4.41±1.16
1~3年 4.35±1.10
3~5年 4.04±1.22
5~10年 4.26±1.40
10年以上 4.43±1.09
奉献
<0.5年 5.34±1.23 2.676 0.026 0.5~1年 4.60±1.48
1~3年 4.29±1.34
3~5年 3.86±1.47
5~10年 4.20±1.11
10年以上 2.90±0.84
专注
<0.5年 5.48±0.72 1.389 0.235
0.5~1年 4.96±1.16
1~3年 4.61±1.15
3~5年 4.40±1.32
5~10年 4.60±1.04
10年以上 4.37±0.78
从表3-6中可以看出,在活力、奉献和专注三个维度上,刚进入外企工作不
满半年的中青年白领平均分均明显高于半年以上的中青年白领。尤其是不同工作年限的外企中青年白领在奉献维度上存在显著差异(F=2.676,P=0.026<0.05),
而在活力维度上(F=1.635,P=0.158>0.05)和专注维度上(F=1.389,P=0.235>0.05)均没有显著差异。
从奉献得分上来看,得分最高的是工作不满半年的中青年白领,其次是工作半年到一年者,1-3年和5-10年的中青年白领在得分上不相伯仲,而得分最低的是工作10年以上的中青年白领,统计结果如图3-1:
图3-1 外企中青年白领奉献得分均值统计分布图
从图3-1中我们可以清晰看出,外企中青年白领工作投入的奉献程度自刚进入公司时的最高点在工作的3-5年间呈现逐年下降趋势,而在5-10年间又会反弹上升,直至工作满10年以上奉献程度跌至最低点。
学海无涯苦作舟! 毕业设计说明书(论文) 题目: 大数据的时代商业模式的创新分析 学生姓名: \ 学 号: \ 系 部: \ 专业班级: \ 指导教师: \
大数据的时代商业模式的创新分析 摘要 大数据对商业模式具有创造性破坏的潜能。将大数据与商业模式有效结合,从商业模式的经济、运营和战略3个视角指出大数据能提升竞争优势。基于创新目标和机制分析了大数据时代商业模式创新的框架,围绕商业模式的4个界面分析了大数据背景下商业模式构成要素和构成结构的变革。 大数据的核心是建立在相关关系分析法基础上的预测。在诸多领域,大数据浪潮正引致颠覆性创新,也必将带来制度变迁。供应商和自身运营状况数以亿计字节的信息。大数据大量可被获取、交流、集聚、存储和分析的数据,现在已是全球经济活动中每个部门和每一功能的核心,已成为与实物资产人力资本同样重要的生产要素。 大数据作为一个很好的视角和工具。从资本角度来看,从其拥有的数据规模、数据的活性和这家公司能运用、解释数据的能力,就可以看出这家公司的核心竞争力。而这几个能力正是资本关注的点。移动互联网与社交网络兴起将大数据带入新的征程,互联网营销将在行为分析的基础上向个性化时代过渡。 关键词:大数据,商业模式,价值创造,创新机制
目录 1 大数据的概述 (1) 1.1 大数据的概念 (1) 1.1.1 大数据的发展 (2) 1.1.2 大数据的分类 (3) 1.2 大数据的四大特点 (4) 1.2.1 海量性 (4) 1.2.2易变性 (4) 1.2.3多样性 (4) 1.2.4高速性 (4) 1.3大数据时代对生活、工作的影响 (5) 1.4大数据时代的发展方向、趋势 (5) 1.4.1发展方向 (5) 1.4.2发展趋势 (6) 1.5企业应如何应对大数据时代 (7) 2 我国外贸型企业发展所面临的困难 (8) 2.1我国外贸型企业面临的困境 (8) 2.1.1 外贸型企业发展历程 (9) 2.1.2 外贸型企业的困境 (10) 2.2商业模式创新对我国外贸型企业发展的机遇 (11) 2.2.1 商业模式的创新概念 (11) 2.2.2 商业模式的创新特点 (11) 2.2.3商业模式创新可以为外贸型企业带来什么 (12) 3 基于大数据的分析,商业模式创新 (14) 3.1 加大数据处理分析能力 (14) 3.2 提高专业技术人员的技术水平 (14) 3.3 理论与实践相结合促进商业模式的创新 (15) 结论 (21) 致谢 (22) 参考文献 (22)
浅谈实验设计与数据分析的应用 摘要:本文主要为针对四篇论文做的一个评述性论文,主要围绕实验设计与数据分析这一主旨进行分析,针对论文的实验目标及假设、实验设计方法、实验数据汇报方法、实验结果分析方法等方面指出了作者在设计实验和进行数据分析时的合理与不足之处,并为今后在进行实验设计与数据分析时提供经验和借鉴。 关键词:实验设计;数据分析;评述 Discussion on experimental design and data analysis applications Abstract:This is mainly for a critical review of four papers, mainly around the experimental design and data analysis of this subject for analysis, the experimental targets for paper and assumptions, experimental design, the experimental data reporting methods, analytical methods, experimental results that the author in the design of experiments and data analysis, and shortcomings of the rational, and for the future during the experimental design and data analysis to provide experience and learn. Keywords: experimental design;analysis of experimental data;a critical review 1 引言(Introduction) 实验设计直接影响着实验结果的准确性、可靠性、严密性和代表性,是实验数据的前提,决定着科学研究的成败。在科学研究和工农业生产中.往往要通过实验来寻找所研究对象的变化规律.并通过对规律的研究达到各种实用的目的,比如提高产量、降低消耗等,特别是对新产品的实验,未知的东两很多,要通过大量的实验来摸索工艺条件和配方;另外,随着实验的进行,必然会得到大量的实验数据.要对数据进行分析处理才能找到其中的规律。在这个实践过程中,要想提高效率和降低成本,就必须科学合理的设计安排实验和用科学的手段分析处
SPSS数据分析论文 一、主要研究日用百货零售业 股票代码流动比率净资产负每股收益净利润(百万元) 增长率股价1 债比率 0.3279 52.5695 24.1948 22.65 002264 0.9673 68.635 142.8697 19.5732 18.7575 19.98 002277 1.3561 45.3962 75.6168 44.4275 62.6644 17.01 000861 1.14 65.3274 201.7301 21.8301 72.9039 20.35 002419 1.3538 54.0314 43.2128 17.6622 11.8946 5.09 000516 0.9526 59.3387 65.7971 19.4052 30.0738 14.69 002187 1.0129 48.6491 63.824 28.5704 26.1524 14.95 002561 3.7229 16.2211 11.8655 18.7297 -2.0984 7.11 000416 3.8607 20.4735 26.4492 19.7197 5.6478 8.76 600361 1.1268 73.0423 -11.5851 23.6777 2.0428 6.88 600515 0.1508 95.3196
相关分析 二、宏观分析:百货零售行业受宏观经济影响较大,但具体到每个细分行业的 影响程度是不同的。超市出售的主要是必须消费品,人们只要活着就会买,所以受经济波动较小。专业连锁要看它具体卖的产品是什么,有的是家电连锁,比如苏宁电器和国美电器,它们的销售金额就与房地产市场紧密相关。有的是珠宝首饰,比如老凤祥、潮宏基、蒂芙尼,它们的销售金额就与金价走势相关。但总体来看,有一些综合类的宏观经济指标会对整个百货零售大行业产生影响。消费占GDP的比重:中国政府要鼓励消费,促进内需,如果该比重较低,那么就意味着有较大的增长空
成绩评定表 课程设计任务书
摘要 汇率是在商品交易和货币运动越出国界时产生的,是一国货币价值在国际的又一表现。因为一国货币汇率受制于经济、政治、军事和心理等因素的影响,这些因素彼此之间既相互联系又相互制约,而且在不同时间,各因素产生作用的强度也会出现交替变化,所以很难准确地找出究竟哪些因素影响着一国货币汇率的变化,在开放经济中,汇率是一种重要的资源配置价格。汇率的失衡或错估,不仅会破坏经济的外部平衡,而且会给国内宏观经济稳定和经济可持续增长带来一系列不利影响。 另外,汇率的变化还能对人们的日常生活和企业的生产销售生产较大的影响。所以,对影响汇率的因素进行分析和探讨,对于指导汇率政策的制定、预测汇率变化趋势、优化投资策略,以及研究与汇率有关的生活消费等问题都有重要的应用价值。spss在经济、管理、医学及心理学等方面的研究起着很重要的作用,在我国的国民经济问题中,增加农民收入是我国扩大内需的关键,通过运用SPSS分析方法对我国人民币及其影响因素的相关分析以便能够更好地了解我国的汇率的情况。 关键词:spss;汇率;影响因素;回归
目录 1问题分析 (1) 2数据来源 (1) 3数据定义 (2) 4数据输入 (2) 5变量的标准化处理 (2) 5.1描述性分析选入变量及参数设置 (2) 5.2描述性分析 (2) 5.3描述性分析结果输出 (2) 6.1描述性分析选入变量及参数设置 (3) 6.2线性回归分析 (4) 7进一步的分析和应用 (11) 总结 (14) 参考文献 (14)
汇率影响因素分析 1问题分析 汇率是在商品交易和货币运动越出国界时产生的,是一国货币价值在国际上的又一表现。因为一国货币汇率受制于经济、政治、军事和心理等因素的影响,这些因素彼此之间既相互联系又相互制约,而且在不同时间,各种因素产生作用的强度也会出现交替变化,所以很准确地找出究竟哪些因素影响着一国货币汇率的变化。 在开放经济中,汇率是一种重要的资源配置价格。汇率的失衡或错估,不仅会破坏经济的外部平衡,而且会给国内宏观经济稳定和经济可持续增长带来一系列不利影响。另外,汇率的变化还能对人们的日常生活和企业的生产销售产生较大的影响。所以,对影响汇率的因素进行分析和探讨,对于指导汇率政策的制定、预测汇率变化趋势、优化投资策略,以及研究与汇率有关的生产消费等问题都有重要的应用价值。 2数据来源 所用数据参考自“人民币汇率研究”(陈瑨,CENET网刊,2005)、“汇率决定模型与中国汇率总分析”(孙煜,复旦大学<经济学人>,2004)和“人民币汇率的影响因素与走势分析”(徐晨,对外经济贸易大学硕士论文,2002),其中通货膨胀率、一年期名义利率、美元利率和汇率4个指标的数据来自于<中国统计年鉴>(2001,中国统计出版社);2000年的部分数据来自于国家统计局官方网站。
论文 题目大数据下人均消费支出及影响因素姓名xxx 学号xxxxxxxx 院、系经济与管理学院、财税系 专业财政学 指导教师袁新宇 2016年10月20日 云南师范大学教务处制
大数据下人均消费支出及影响因素 摘要:随着互联网事业的不断发展,“互联网+大数据”的时代也随之而来,从而可以让我们通过大数据来分析更多的市场前景和人们的需要,然后可以把事业做得更好,更加适合社会发展的需要。本文将通过简述基本的概念和简单的模型分析,来说明大数据下我国人均消费支出与人均收入存在的关系,更好的说明我国影响居民人均消费的因素有哪些,希望可以通过一些数据来说明这些影响因素中能有多少是可以改进和努力然后更好地改进居民的生活水平,从而增加我国的居民收入,增加国家的GDP。只有不断提高居民的收入水平,才能刺激国内消费的增长。党的十八大也明确提出,到2020年要实现城乡居民收入比2010年增长一倍的目标。本文就如何运用宏观调控中财政政策和货币政策以及政府的一些其它政策提高居民收入水平,提出合理化方法。 关键词:居民收入水平;财政政策;人均消费支出;货币政策 一、引言 根据国家统计局调查数据,2014年全国城镇居民人均可支配收入28844元,比上年增长9.0%,扣除价格因素实际增长6.8%。文章将通过简述基本的概念和简单的模型分析,来说明大数据下我国人均消费支出与人均收入存在的关系,更好的说明我国影响居民人均消费的因素有哪些,希望可以通过一些数据来说明这些影响因素中能有多少是可以改进和努力然后更好地改进居民的生活水平,从而让人民的生活水平有所提高。 二、正文 (一)研究的目的
本案例分析根据1995年~2008年城镇居民人均可支配收入和人均消费性支出的基本数据,应用一元线性回归分析的方法研究了城镇居民人均可支配收入和人均消费性支出之间数量关系的基本规律,并在预测2010年人均消费性支出的发展趋势。从理论上说,居民人均消费性支出应随着人均可支配收入的增长而提高。随着消费更新换代的节奏加快,消费日益多样化,从追求物质消费向追求精神消费和服务消费转变。因此,政府在制定当前的宏观经济政策时,考虑通过增加居民收入来鼓励消费,以保持经济的稳定增长。近年来,我国经济的主要特征从供给不足进入了供给相对过剩、需求约束为主的发展阶段,内需不足的问题凸显。如何扩大消费需求、拉动经济增长,已经成为关键问题。党的十七大报告中提出了提高居民消费率、形成合理居民消费率的关于全面建设小康社会奋斗目标的具体要求。面对当前美国金融危机所引发的经济困境,如何深入考察我国居民消费行为、采取有效政策来振兴消费,将成为我们的研究主题。本文通过计量经济学的相关研究方法,从影响城乡居民的消费因素入手,分析了这些因素对消费的影响,以期获得解决问题和改善情况的新思路。 (二)研究背景 目前,国内学者对于我国居民消费问题主要是以城镇居民、农村居民或全体居民为研究对象,分别对其消费特征、影响因素和对策等问题进行深入研究,并在我国经济学界形成了相对盛行的四种代表性观点:居民收入分配不公说、居民消费行为说、福利制度改革说和居民消费结构升级换代说。国内学者通过建立自己的理论框架和经济计量模型以及根据理论假设运用中国的经验数据进行实证检验,或多或少都存在一定的局限,尤其是将城乡居民消费问题分开进行研究的现象十分普遍。本文建立误差修正模型的同时,建立城乡居民消费和诸多主要经济影响因素之间的经济计量模型,探讨经济影响因素对我国城乡居民消费的影响效应。近几年来,中国经济保持了快速发展势头,投资、出口、消费形成了拉动经济发展的“三架马车”,这已为各界所取得共识。通过建立计量模型,运用计量分析方法对影响城镇居民人均消费支出的各因素进行相关分析,找出其中关键影响因素,以为政策制定者提供一定参考,最终促使消费需求这架“马车”能成为引领中国经济健康、快速、持续发展的基石。 (三)理论分析 1、影响我国居民的消费的因素分析 (1)政府支出 根据凯恩斯的收入决定模型,政府支出对消费的影响主要是通过政府支出的收入效应来实现。政府支出分为购买性支出和转移性支出,这两种支出对居民消费的作用和手段等方面都有不同。购买性支出主要是作用于生产环节,在直接增加社会总需求的同时,通过间接增加居民收入水平,改善居民消费环境来减少对消费的约束,增加消费量。转移性支出作为一种资金单方面的、无偿的转移,主要是在分配环节发挥作用,通过直接增加接受者的收入水平对居民消费需求产生 影响:一是通过社会保障支出、财政补贴和税式支出等手段调整收入分配结构,直接增加居民收入从而增强其消费能力。二是通过建立健全的社会保障制度以及大力发展社会事业来改变居民消费的支出预期,从而间接提高其消费意愿和边际消费倾向。
修订日:2010.12.8实证论文数据分析方法详解 (周健敏整理) 名称变量类型在SPSS软件中的简称(自己设定的代号) 变革型领导自变量1 zbl1 交易型领导自变量2 zbl2 回避型领导自变量3 zbl3 认同和内部化调节变量 TJ 领导成员交换中介变量 ZJ 工作绩效因变量 YB 调节变量:如果自变量与因变量的关系是变量M的函数,称变量M为调节变量。也就是, 领 导风格(自变量)与工作绩效(因变量)的关系受到组织认同(调节变量)的影 响,或组织认同(调节变量)在领导风格(自变量)对工作绩效(因变量)影响 关系中起到调节作用。具体来说,对于组织认同高的员工,变革型领导对工作绩 效的影响力,要高于组织认同低的员工。 中介变量:如果自变量通过影响变量N 来实现对因变量的影响,则称N 为中介变量。也就 是,领导风格(自变量)对工作绩效(因变量)影响作用是通过领导成员交换(中 介变量)的中介而产生的。 研究思路及三个主要部分组成: (1)领导风格对于员工工作绩效的主效应(Main Effects)研究。 (2)组织认同对于不同领导风格与员工工作绩效之间关系的调节效应(Moderating Effects)研究。
(3)领导成员交换对于不同领导风格与员工工作绩效之间关系的中介效应(Mediator Effects)研究。 目录 1.《调查问卷表》中数据预先处理~~~~~~~~~~~~~~ 3 1.1 剔除无效问卷~~~~~~~~~~~~~~~~~~~~ 3 1.2 重新定义控制变量~~~~~~~~~~~~~~~~~~ 3 2. 把Excel数据导入到SPSS软件中的方法~~~~~~~~~~ 4 3. 确认所有的变量中有无“反向计分”项~~~~~~~~~~~4 3.1 无“反向计分”题~~~~~~~~~~~~~~~~~~ 5 3.2 有“反向计分”题~~~~~~~~~~~~~~~~~~ 5 4. 效度分析~~~~~~~~~~~~~~~~~~~~~~~~6 5. 信度分析~~~~~~~~~~~~~~~~~~~~~~~~8 6. 描述统计~~~~~~~~~~~~~~~~~~~~~~~~9 7. 各变量相关系数~~~~~~~~~~~~~~~~~~~~ 12 7.1 求均值~~~~~~~~~~~~~~~~~~~~~~~12 7.2 相关性~~~~~~~~~~~~~~~~~~~~~~~12 8. 回归分析~~~~~~~~~~~~~~~~~~~~~~~13 8.1 使用各均值来分别求Z值~~~~~~~~~~~~~~~13 8.2 自变量Z值与调节变量Z值的乘积~~~~~~~~~~~13 8.3 进行回归运算~~~~~~~~~~~~~~~~~~~~14 8.3.1 调节作用分析~~~~~~~~~~~~~~~~~~14 8.3.2 中介作用分析~~~~~~~~~~~~~~~~~~18
大数据论文 摘要数据发展到今天,已不再是一个新的概念,基于大数据技术的应用也层出不穷,但作为一项发展前景广阔的技术,其很多作用还有待挖掘,比如为人们的生活带来方便,为企业带来更多利益等。现今,互联网上每日产生的数据已由曾经的TB级发展到了今天的PB级、EB级甚至ZB级。如此爆炸性的数据怎样去使用它,又怎样使它拥有不可估量的价值呢?这就需要不断去研究开发,让每天的数据“砂砾”变为“黄金”。那么如何才能将大量的数据存储起来,并加以分析利用呢,大数据技术应运而生。大数据是指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合。大数据的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化的处理。本文就大数据技术进行了深入探讨,从大数据的定义、特征以及目前的应用情况引入,简述了大数据分析的统计方法、挖掘方法、神经网络方法和基于深度学习框架的方法,并对大数据分析流程和框架、大数据存储模式和服务机制、大数据分析中的多源数据融合技术、高维数据的降维技术、子空间分析、集成分析的处理方法等做了概述。最后,以网络信息安全为例,阐述了该领域的大数据分析过程和方法。 关键词大数据;数据挖掘;深度学习;大数据分析;网络信息安全一、大数据概述
1.1大数据的定义和特征 目前,虽然大数据的重要性得到了大家的一致认同,但是关于大数据的定义却众说纷纭。大数据是一个抽象的概念,除去数据量庞大,大数据还有一些其他的特征,这些特征决定了大数据与“海量数据”和“非常大的数据”这些概念之间的不同。一般意义上,大数据是指无法在有限时间内用传统IT技术和软硬件工具对其进行感知、获取、管理、处理和服务的数据集合。科技企业、研究学者、数据分析师和技术顾问们,由于各自的关注点不同,对于大数据有着不同的定义。通过以下定义,或许可以帮助我们更好地理解大数据在社会、经济和技术等方而的深刻内涵。2010年Apache Hadoop组织将大数据定义为,“普通的计算机软件无法在可接受的时间范围内捕捉、管理、处理的规模庞大的数据集”。在此定义的基础上,2011年5月,全球著名咨询机构麦肯锡公司发布了名为“大数据:下一个创新、竞争和生产力的前沿”的报 告,在报告中对大数据的定义进行了扩充。大数据是指其大小超出了典型数据库软件的采集、存储、管理和分析等能力的数据集。该定义有两方而内涵:(1)符合大数据标准的数据集大小是变化的,会随着时间推移、技术进步而增长;(2)不同部门符合大数据标准的数据集大小会存在差别。目前,大数据的一般范围是从几个TB到数个PB(数千TB)[2]。根据麦肯锡的定义可以看出,数据集的大小并不是大数据的唯一标准,数据规模不断增长,以及无法依靠传统的数据库技术进行管理,也是大数据的两个重要特征。大数据价值链可分为4个阶段:数据生成、数据采集、数据储存以及数据分析。数据分析是大数据价值链的最后也是最重要的阶段,是大数据价值的实现,是大数据应用的基础,其目的在于提取有用的值,提供论断建议或支持决策,通过对不同领域数据集的分析可能会产生不同级别的潜在价值。 在日新月异的IT业界,各个企业对大数据都有着自己不同的解读.大数据的主要特征5个,即5" V”特征:Volume(容量大)、Variety(种类多)、Velocity(速度快)、难辨识(veracity)和最重要的Value(价值密度低)。 Volume(容量大)是指大数据巨大的数据量与数据完整性。可指大数据集合中包含的数据多,也可指组成大数据的网络包含的子数据个数多。 Variety(种类多)意味着要在海量、种类繁多的数据间发现其内在关联。大数据中包含的各种数据类型很多,既可包含各种结构化数据类型,又可包含各种非结构化数据类型,乃至其他数据类型。 Velocity(速度快)可以理解为更快地满足实时性需求。大数据的结构和内容等都可动态变化,而且变化频率高、速度快、范围广,数据形态具有极大的动态性,处理需要极快的实时性。 Veracity (难辨识)可以体现在数据的内容、结构、处理、以及所含子数据间的关联等多方面。大数据中可以包含众多具有不同概率分布的随机数和众多具有不同定义域的模糊数。数间关联模糊不清、并且可能随时随机变化。
离心泵特性曲线特性研究 吕秋芸 (郑州大学化工与能源学院2011级环境科学二班) 摘要:泵是输送液体常用的机械。在选用一台离心泵时,既要满足一定工艺要求的流量、压头,还要有较高的效率。要正确地选择和使用离心泵,就必须掌握离心泵送液能力(q)变化时,泵的压头(H)、有效功率(P)、效率(η)的变化规律,也就是要查明离心泵的特性曲线。 关键词:扬程,转速,功率,最高效率 一、概述 离心泵的特性曲线取决于泵的结构、尺寸和转速。对于一定的离心泵,在一定的转速下,泵的扬程H与流量q之间存在一定的关系。此外,离心泵的轴功率和效率亦随泵的流量而改变。因此H-q,P-q 和η-q三条关系曲线反应了离心泵的特性,称为离心泵的特性曲线。 二、实验设计: 1.实验目的:测定一定条件(一定大气压、一定水温、一定转速)下离心泵的特性曲线。 2、实验指标:当转速一定时 H、N、P与Q的关系曲线,最高效率点为工作点。 3、实验流程: 循环槽进口阀真空表离心泵压力表出口阀孔板流量计上弯摆管计量槽循环槽
离心泵性能测定实验装置流程图 三.实验结果 1、按实验设计方案实施后,所得的实验结果如表1所示 2、实验结果图 表1 离心泵性能测定 水箱面积A=0.1718 管内径d1=48 孔内经d0=30.36 β=0.4 水温t ρ μ[CP] A d1[mm] d0[mm] 18 998.5 1.0510416 0.1718 48.0 30.36 流量测量 扬程测量 转速 功率 压差 中间 泵性能曲线 No h1[mm] h2[mm] t[s] P1[-MPa] P2[MPa] n[r/min] P[Kw] ΔP[Pa] q'[l/s] q [l/s] H[m] P[Kw] η 1 53.0 53.0 1.0 0.0100 0.2050 2957 0.880 0 0.000 0.000 21.11 0.830 0.000 2 53.0 108.0 20.0 0.0100 0.2050 2949 0.940 70 0.472 0.465 21.23 0.894 0.108 3 112.0 220.0 19.8 0.0120 0.2000 2945 1.010 180 0.937 0.923 20.99 0.964 0.197 4 218.0 400.0 20.0 0.0180 0.1950 2935 1.140 480 1.563 1.545 21.23 1.100 0.292 5 62.0 314.0 20.0 0.0238 0.1850 2925 1.260 950 2.165 2.146 20.95 1.228 0.359 6 69.0 442.0 20.0 0.0380 0.1650 2910 1.440 2000 3.204 3.193 20.58 1.425 0.452 7 47.0 386.0 14.5 0.0500 0.1450 2898 1.580 3040 4.017 4.019 19.93 1.583 0.496 8 82.0 376.0 11.0 0.0640 0.1250 2885 1.690 4170 4.592 4.616 19.50 1.716 0.514 9 63.0 382.0 11.0 0.0760 0.1050 2875 1.770 4990 4.982 5.026 18.80 1.817 0.509 10 63.0 366.0 10.1 0.0900 0.0700 2869 1.780 5300 5.154 5.210 16.69 1.838 0.463 14-真空表 15-压力表 16-泵出口阀 17-转速传感器 18-转速表 20-支架8-摆头式出水管口 9-孔板流量计 10-U型管压差计 11-计量槽 12-排水阀 13-液位计1,3-40CQ-32型离心泵 2-压差计平衡阀 4-进口闸阀 5-水槽 6-功率表 7-回水管 20
论文的数据分析 大家现在都要写论文的数据分析了……很多同学都一点不会……所以把我知道的跟大家分享一下……下面以PASW18.0为例,也就是SPSS18.0…………什么?不是18.0,好吧……差不多的,凑合着看吧……要不去装个……= =……下面图片看不清的请右键查看图片…… 首先,要把问卷中的答案都输进SPSS中,强烈建议直接在SPSS中输入,不要在EXCEL中输入,再导入SPSS,这样可能会出问题……在输数据之前先要到变量视图中定义变量……如下图 所有类型都是数值,宽度默认,小数点看个人喜好,标签自定,其他默认……除了值…… 讲讲值的设定…… 点一下有三点的蓝色小框框……会跳出一个对话框,如果你的变量是性别,学历,那么就如下图
如果是五点维度的量表,那么就是 记住,每一题都是一个变量,可以取名Q1,Q2……设定好所有问卷上有的变量之后,就可以到数据视图中输入数据啦……如下图
都输完后……还有要做的就是计算你的每个维度的平均得分……如果你的问卷Q1-Q8是一个维度,那么就把Q1-Q8的得分加起来除以题目数8……那么得到的维度1分数会显示在数据视图中的最后……具体操作如下…… 转换——计算变量
点确定,就会在数据视图的最后一列出现计算后的变量……如果你的满意度有3个维度,那么就要计算3个维度,外加满意度这个总维度,满意度=3个维度的平均分=满意度量表的所有题目的平均分…………把你所有的维度变量都计算好之后就可以分析数据啦…… 1.描述性统计 将你要统计的变量都放到变量栏中,直接点确定……
如果你要统计男女的人数比例,各个学历或者各个年级的比例,就要用描述统计中的频率……如果要统计男女中的年级分布,比如大一男的有几个,大二女的有几个,就用交叉表……不细说了……地球人都懂的………… 2.差异性分析 差异性分析主要做的就是人口学变量的差异影响,男女是否有差异,年级是否有差异,不做的就跳过…… 对于性别来说,差异分析采用独立样本T检验,也可以采用单因素ANOVA分析,下面以T检验为例……
计算机系统结构(论文) 题目大数据的分析 院系信息工程系专业计算机科学与技术 年级2014级班级1471 姓名杜航学号201442051029 指导教师: 孙杨 2015 年12 月22 日
目录 1 绪论 (3) 2 大数据概述 (3) 2.1 什么是大数据 (3) 2.2 大数据的三个层次 (4) 2.3 云存储对大数据的促进作用 (5) 2.4 大数据未来的行业应用 (6) 3 大数据时代的机遇与挑战 (7) 3.1 机遇与挑战并存 (7) 3.2 大数据时代如何抓住机遇并应对挑战 (7) 4 国内外有关大数据以及信息资源共享的研究现状 (9) 4.1 境外的大数据发展 (9) 4.2 国内外有关"政府数据信息共享"研究与比较…………………………………………………… 10 5 参考文献…………………………………………………………………………………………………
11 1 绪论 说起大数据,估计大家都觉得只听过概念,但是具体是什么东西,怎么定义,没有一个标准的东西,因为在我们的印象中好像很多公司都叫大数据公司,业务形态则有几百种,感觉不是很好理解,所以我建议还是从字面上来理解大数据,在维克托?迈尔?舍恩伯格及肯尼斯?库克耶编写的《大数据时代》提到了大数据的4个特征,一个是数量大,一个是价值大,一个是速度快,一个是多样性。 关于大数据的概念其实在1998年已经就有人提出了,但是到了现在才开始有所发展,这些其实都是和当下移动互联网的快速发展分不开的,移动互联网的高速发展,为大数据的产生提供了更多的产生大数据的硬件前提,比如说智能手机,智能硬件,车联网,Pad等数据的产生终端。这些智能通过移动通信技术和人们的生活紧密的结合在一起,在人流、车流的背后产生了信息流,也就产生了大量的数据。 其次就是移动通信技术的快速发展,在2G时代,无线网速慢,数据产生也非常慢,数据体量也不够,所以还是无法形成大数据,而到了4G时代,终端数据的增加,使得任何的移动终端都在无时无刻的产生着大量的数据,这个也是大数据到来的一个条件之一。 第三个方面的就是大数据相关技术的飞速发展,如云计算,云存储技术,他们的快速发展,是大数据诞生的温床,如果没有这些技术,即使有大量的数据也只能望洋兴叹。传统的存储技术相对落后,根据不同数据实行单一存储,这个显然满足不了大数据的需求,而云时代的存储系统需要的不仅仅是容量的提升,对于性能的要求同样迫切,与以往只面向有限的用户不同,在云时代,存储系统将面向更为广阔的用户群体,用户数量级的增加使得存储系统也必须在吞吐性能上有飞速的提升,只有这样才能对请求作出快速的反应,云储存技术的成熟为大数据的快速发展奠定了基础。
《数据分析方法》课程设计 成绩评定表 学生姓名严震班级学号1109010114 专业信息与计算课程设计题目NBA球员技科学术统计分析报告 评 语 组长签字: 成绩 日期 20年月日
《数据分析方法》课程设计 课程设计任务书 学院理学院专业信息与计算科学学生姓名严震班级学号1109010114 课程设计题目NBA 球员技术统计分析报告实践教学要求与 任务 : 设计要求(技术参数): 1、熟练掌握SPSS 软件的操作方法; 2、根据所选题目及调研所得数据,运用数据分析知识,建立适当的数学模型; 3、运用 SPSS 软件,对模型进行求解,对结果进行分析并得出结论; 4、掌握利用数据分析理论知识解决实际问题的一般步骤。 设计任务: 1、查阅相关资料,找到NBA 球员技术的相关指标,获得相关数据; 2、利用数据分析的理论,建立线性回归模型,以及对其进行主成分分析; 3、利用 SPSS软件求解 , 并给出正确的结论。 工作计划与进度安排 : 第一天——第二天学习使用SPSS 软件并选题 第三天——第四天查阅资料 第五天——第六天建立数学模型 第七天——第九天上机求解并完成论文 第十天答辩 指导教师:专业负责人:学院教学副院长: 201年月日201年月日201年月日
II
摘要 数据分析析的主要应用有两方面,一是寻求基本结构,简化观测系统,将具有错综复杂关系的对象(变量或样品)综合为少数几个因子(不可观测的,相互独立的随机变 量),以再现因子与原变量之间的内在联系;二是用于分类,对p 个变量或 n 个样品进 行分类。聚类分析一般有两种类型,即按样品聚类或按变量(指标)聚类,其基本思想是通过定义样品或变量间“接近程度”的度量,将“相近”的样品或变量归为一类。本文 利用利用数据分析中的因子分析和聚类分析对多个变量数据进行了分析。就是分析和处理 数据的理论与方法,数据分析中提出了广泛的多元数据分析的统计方法,包括线性回归分析、方差分析、因子分析、主成分分析、典型相关分析、判别分析、聚类分析等。 关键词: spss 软件 ; 聚类分析 ; 因子分析 ; 线性规划
精选范文、公文、论文、和其他应用文档,希望能帮助到你们! SPSS简单数据分析报告
目录 一、数据样本描述 (4) 二、要解决的问题描述 (4) 1 数据管理与软件入门部分 (4) 1.1 分类汇总 (4) 1.2 个案排秩 (5) 1.3 连续变量变分组变量 (5) 2 统计描述与统计图表部分 (5) 2.1 频数分析 (5) 2.2 描述统计分析 (5) 3 假设检验方法部分 (5)
3.1 分布类型检验 (5) 3.1.1 正态分布 (5) 3.1.2 二项分布 (6) 3.1.3 游程检验 (6) 3.2 单因素方差分析 (6) 3.3 卡方检验 (6) 3.4 相关与线性回归的分析方法 (6) 3.4.1 相关分析(双变量相关分析&偏相关分析) (6) 3.4.2 线性回归模型 (6) 4 高级阶段方法部分 (6) 三、具体步骤描述 (7) 1 数据管理与软件入门部分 (7) 1.1 分类汇总 (7) 1.2 个案排秩 (8) 1.3 连续变量变分组变量 (10) 2 统计描述与统计图表部分 (11) 2.1 频数分析 (11) 2.2 描述统计分析 (14) 3 假设检验方法部分 (16) 3.1 分布类型检验 (16) 3.1.1 正态分布 (16) 3.1.2 二项分布 (17)
3.1.3 游程检验 (18) 3.2 单因素方差分析 (22) 3.3 卡方检验 (24) 3.4 相关与线性回归的分析方法 (26) 3.4.1 相关分析 (26) 3.4.2 线性回归模型 (28) 4 高级阶段方法部分 (32) 4.1 信度 (32) 一、数据样本描述 本次分析的数据为某公司474名职工状况统计表,其中共包含11个变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用SPSS统计软件,对变量进行统计分析,以了解该公司职工总体状况,并分析职工受教育程度、起始工资、现工资的分布特点及相互间的关系。 二、要解决的问题描述 1 数据管理与软件入门部分 1.1 分类汇总 以受教育水平程度为分组依据,对职工的起始工资和现工资进行数据
Google关于大数据处理的论文简述7 2013年4月
目录 一、简述 (3) 二、Google经典三篇大数据论文介绍 (3) 2.1、GFS (3) 2.2、MapReduce (5) 2.3、BigTable一个分布式的结构化数据存储系统 (6) 三、Google新大数据论文介绍 (6) 3.1、Caffeine:处理个体修改 (7) 3.2、Pregel:可扩展的图计算 (8) 3.3、Dremel:在线可视化 (8) 四、总结 (12)
一、简述 Google在2003年开始陆续公布了关于GFS、MapReduce和BigTable三篇技术论文,这也成为后来云计算发展的重要基石,为数据领域工作者开启了大数据算法之门。然而Google的大数据脚步显然不止于此,其后公布了Percolator、Pregel、Dremel、Spanner等多篇论文。没有止步的不仅是Google,很多公司也跟随其脚步开发了很多优秀的产品,虽然其中不乏模仿。主流的大数据基本都是MapReduce的衍生,然而把目光聚焦到实时上就会发现:MapReuce 的局限性已经渐渐浮现。下面将讨论一下自大数据开始,Google公布的大数据相关技术,以及这些技术的现状。 从2010年之后Google在后Hadoop时代的新“三驾马车”——Caffeine、Pregel、Dremel再一次影响着全球大数据技术的发展潮流。但这还远远不够,目前Google内部使用的大数据软件Dremel使大数据处理起来更加智能。 二、Google经典三篇大数据论文介绍 Google在2003年到2006年公布了关于GFS、MapReduce和BigTable 三篇技术论文。 三篇论文主要阐述: 2.1、GFS 公布时间:2003年。 GFS阐述了Google File System的设计原理,GFS是一个面向大规模数据密集型应用的、可伸缩的分布式文件系统。GFS虽然运行在廉价的普遍硬件设备上,但是它依然了提供灾难冗余的能力,为大量客户机提供了高性能的服务。 虽然GFS的设计目标与许多传统的分布式文件系统有很多相同之处,但是,我们设计还是以我们对自己的应用的负载情况和技术环境的分析为基础的,不管现在还是将来,GFS和早期的分布式文件系统的设想都有明显的不同。所
课 程 论 文 课程名称试验设计与数据处理 专业2012级网络工程 学生姓名孙贵凡 学号201210420136 指导教师潘声旺职称副教授
成绩 科学研究与数据处理 学院信息科学与技术学院专业网络工程姓名孙贵凡学号:201210420136 摘要:《实验设计与数据处理》这门课程列举典型实例介绍了一些常用的实验设计及实验数据处理方法在科学研究和工业生产中的实际应用,重点介绍了多因素优化实验设计——正交设计、回归分析方法以对目标函数进行模型化处理。其适于工艺、工程类本科生使用,尤其适用于化学化工、矿物加工、医学和环境学等学科的本科生使用。其对行实验设计可提供很大的帮助,也可供广大分析化学工作者应用。关键字:优化实验设计; 标函数进行模型化处理; 正交设计; 回归分析方法 1 引言 实验是一切自然科学的基础,科学界中大多数公式定理是由试验反复验证而推导出来的。只有经得起试验验证的定理规律才具有普遍实用性。而科学的试验设计是利用自己已有的专业学科知识,以大量的实践经验为基础而得出的既能减少试验次数,又能缩短试验周期,从而迅速找到优化方案的一种科学计算方法,就必然涉及到数据处理,也只有对试验得出的数据做出科学合理的选择,才能使实验结果更具说服力。实验设计与数据处理在水处理中发挥着不可估量的作用,通过科学合理的实验设计过程加上严谨规范的数据处理方法,可以使水处理原理,内在规律性被很好的发现,从而更好的应用于生产实践。 2 材料与方法 2.1 供试材料 1. 论文所围绕的目标和假设 研究的目标就是实验的目的,我们设计了这个实验是想来做什么以及想得到什么样的结论。要正确的识别问题和陈述问题,这些需要专业知识和大量的阅读文献综述等方法来获得我们所要提出的问题。需要对某一个具体的问题,并且对这个具体的问题提出假设。如水处理中混凝剂的最佳投加量,混凝剂的最佳投加量有一个适宜的PH值范围。
2011-2012学年度第二学期数据分析课程论文 院系数学与计算科学学院专业数学与应用数学 姓名xxx 学号xxxxxxxxxx 论文题目聚类分析和因子分析在就业人数案例中的应用 完成日期2012-6-26 评语: (评阅成绩:) 评定教师签名: 日期:2012 年月日
聚类分析和因子分析在就业人数案例中的应用 摘要:中国的就业问题是一个备受关注的热点问题。了解中国各地区各行业的就业情况,有利于更好地调整各地区更行业的就业情况,加快产业结构的转型。本文利用2011年《中国统计年鉴》的统计数据资料,在研究各地区各行业就业人数的现状及主要问题的基础上,运用聚类分析和因子分析方法发现全国就业情况分三个类型,东南部沿海地区就业情况最好,中东部就业一般,西部、北部和中部一些地区就业情况较差。针对这些情况对优化各地区各行业就业结构提出一些对策和建议。 关键词:就业人数;聚类分析;因子分析 一、引言 1、1 背景知识 中国是世界上人口最多的国家,就业问题成为中国政府面临的一个十分严峻的社会问题。就业情况的好与差与当地的经济发展水平有很大关系。了解中国各地区各行业的就业情况,有利于更好地调整各地区更行业的就业情况,加快产业结构的转型。在高等教育大众化的今天,就业难已经成为一个不争的事实,越来越引起社会的关注。作为当代大学生,我们很有必要了解当前的各地区各行业的就业就业情况。 1、2 聚类分析法 系统聚类法是聚类分析诸方法中用得最多的一种,其基本思想是:开始将n个样品各自作为一类,并规定样品之间的距离和类与类之间的距离,然后将距离最近的两类合并成一个新类,计算新类与其他类的距离;重复进行两个最近类的合并,每次减少一类,直至所有的样品合成一类。[1] 1、3 因子分析法 因子分析是主成分分析的推广和发展,它也是将具有错综复杂关系的变量(或样品)综合为数量较少的几个因子,以再现原始变量与因子之间的相互关系,同时根据不同因子还可以对变量进行分类,它也是属于多元分析中处理降维的一种统计方法。因子分析法是从研究变量内部相关的依赖关系出发,把一些具有错综复杂关系的变量归结为少数几个综合因子的一种多变量统计分析方法。它的基本思想是将观测变量进行分类,将相关性较高,即联系比较紧密的分在同一类中,而不同类变量之间的相关性则较低,那么每一类变量实际上就代表了一个基本结构,即公共因子。对于所研究的问题就是试图用最少个数的不可测的所谓公共因子的线性函数与特殊因子之和来描述原来观测的每一分量。[2]
成绩评定表
课程设计任务书
汇率是在商品交易和货币运动越出国界时产生的,是一国货币价值在国际的又一表现。因为一国货币汇率受制于经济、政治、军事和心理等因素的影响,这些因素彼此之间既相互联系又相互制约,而且在不同时间,各因素产生作用的强度也会出现交替变化,所以很难准确地找出究竟哪些因素影响着一国货币汇率的变化,在开放经济中,汇率是一种重要的资源配置价格。汇率的失衡或错估,不仅会破坏经济的外部平衡,而且会给国内宏观经济稳定和经济可持续增长带来一系列不利影响。 另外,汇率的变化还能对人们的日常生活和企业的生产销售生产较大的影响。所以,对影响汇率的因素进行分析和探讨,对于指导汇率政策的制定、预测汇率变化趋势、优化投资策略,以及研究与汇率有关的生活消费等问题都有重要的应用价值。spss在经济、管理、医学及心理学等方面的研究起着很重要的作用,在我国的国民经济问题中,增加农民收入是我国扩大内需的关键,通过运用SPSS分析方法对我国人民币及其影响因素的相关分析以便能够更好地了解我国的汇率的情况。 关键词:spss;汇率;影响因素;回归
1问题分析 (1) 2数据来源 (1) 3数据定义 (2) 4数据输入 (2) 5变量的标准化处理 (3) 5.1描述性分析选入变量及参数设置 (3) 5.2描述性分析 (4) 5.3描述性分析结果输出 (5) 6.1描述性分析选入变量及参数设置 (5) 6.2线性回归分析 (7) 7进一步的分析和应用 (17) 总结 (22) 参考文献 (23)
汇率影响因素分析 1问题分析 汇率是在商品交易和货币运动越出国界时产生的,是一国货币价值在国际上的又一表现。因为一国货币汇率受制于经济、政治、军事和心理等因素的影响,这些因素彼此之间既相互联系又相互制约,而且在不同时间,各种因素产生作用的强度也会出现交替变化,所以很准确地找出究竟哪些因素影响着一国货币汇率的变化。 在开放经济中,汇率是一种重要的资源配置价格。汇率的失衡或错估,不仅会破坏经济的外部平衡,而且会给国内宏观经济稳定和经济可持续增长带来一系列不利影响。另外,汇率的变化还能对人们的日常生活和企业的生产销售产生较大的影响。所以,对影响汇率的因素进行分析和探讨,对于指导汇率政策的制定、预测汇率变化趋势、优化投资策略,以及研究与汇率有关的生产消费等问题都有重要的应用价值。 2数据来源 所用数据参考自“人民币汇率研究”(陈瑨,CENET网刊,2005)、“汇率决定模型与中国汇率总分析”(孙煜,复旦大学<经济学人>,2004)和“人民币汇率的影响因素与走势分析”(徐晨,对外经济贸易大学硕士论文,2002),其中通货膨胀率、一年期名义利率、美元利率和汇率4个指标的数据来自于<中国统计年鉴>(2001,中国统计出版社);2000年的部分数据来自于国家统计局官方网站。