
空间数据分析方法
一、绪论
1、空间分析的概念
空间分析( Spatial Analysis):包括空间数据操作、空间数据分析、空间统计分析、空间建模。
1)空间分析是对数据的空间信息、属性信息或二者共同信息的统计描述或说明。
2)空间分析是对于地理空间现象的定量研究,其常规能力是操纵空间数据成为不同的形式,并且提取潜在信息。
3)空间分析是结果随着分析对象位置变化而改变的一系列方法。4)空间分析是基于地理对象的位置和形态特征的空间数据分析技术,其目的在于提取和传输空间信息。
2、空间数据的类型
空间点数据、空间线数据、空间面数据、地统计数据
3、属性数据的类型
属性:与空间数据库中一个独立对象(记录)关联的数据项。属性已成为描述一个位置任何可记录特征或性质的术语。又分为一下几种:1)名义属性:最简单的属性类型,即对地理实体的测度,本质上是对地球实体的分类。包括数字、文字、颜色,即名义属性是数值。其作用只是区分特定的实体类。可以用众数和频率分布进行概括和比较。2)序数属性:其定义的类型之间存在等级关系,属性值具有逻辑顺序,本质上是一种分类等级数据,即类型必须分为不同的等级。可以
进行优先级的比较运算,对名义和序数数据能够进行分类计数,所以常被称为离散变量,或定性变量。其可以用中位数和箱线图进行概括和比较。
3)间距属性:是一种对地理实体或现象的数量测度方法。其测度的是一个值对另一个值差异的幅度,但不是该值和真实零点之间的差值。由于间距属性的数值测度不是基于自然的或绝对的零点,因此数量关系的运算收到限制。间距属性之间的加减算术运算时有效的,但是乘除运算时无效的。其还可以使用均值、标准差等进行描述。
4)比率属性:是数值和其真实零点之间的差异幅度的测度。对于比率属性的数据可以实施各种数学运算。
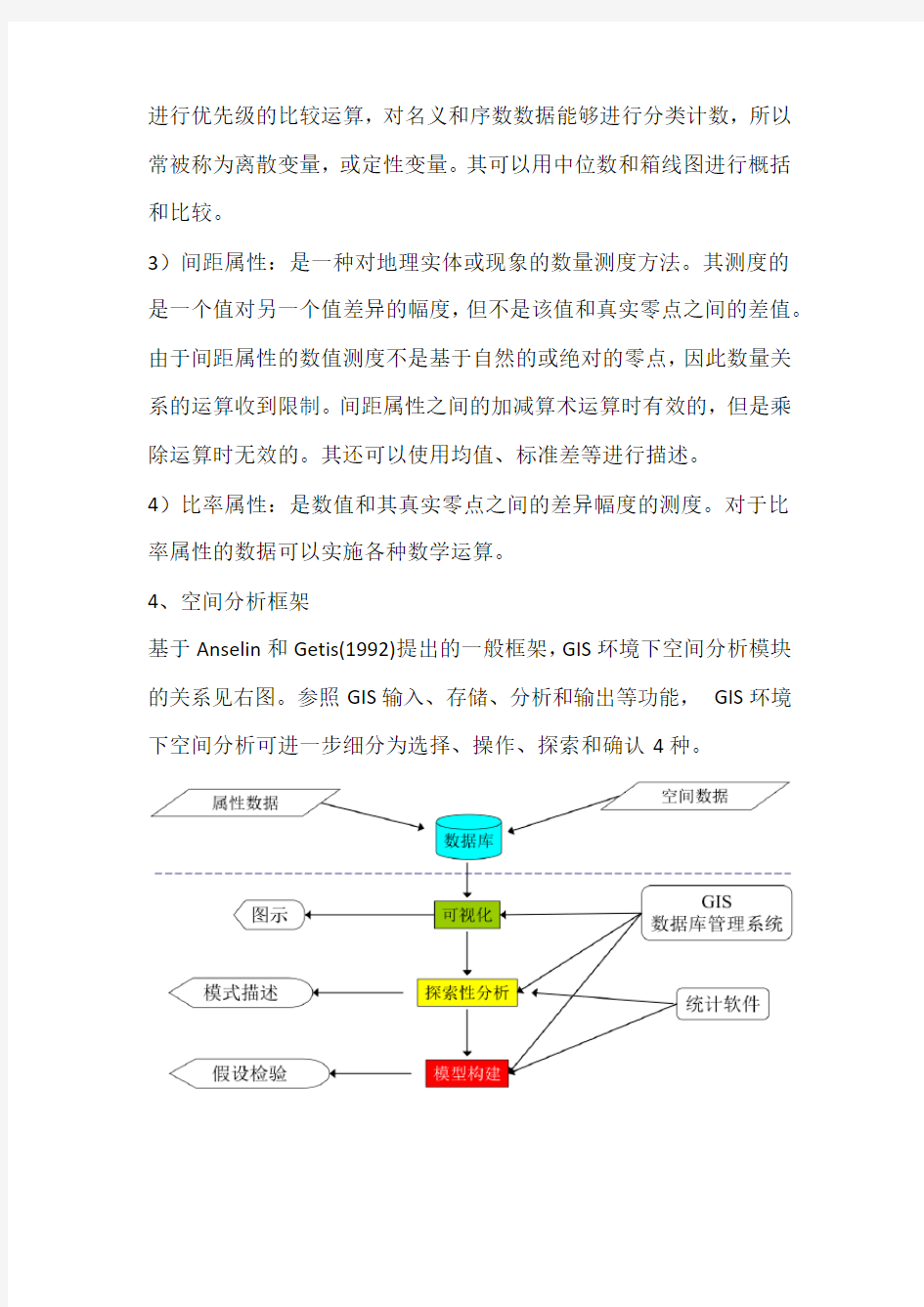
4、空间分析框架
基于Anselin和Getis(1992)提出的一般框架,GIS环境下空间分析模块的关系见右图。参照GIS输入、存储、分析和输出等功能,GIS环境下空间分析可进一步细分为选择、操作、探索和确认4种。
5、空间统计分析陷阱
1)空间自相关:“地理学第一定律”—任何事物都是空间相关的,距离近的空间相关性大。空间自相关破坏了经典统计当中的样本独立性假设。避免空间自相关所用的方法称为空间回归模型。
2)可变面元问题:随面积单元定义的不同而变化的问题,就是可变面元问题。古老但依然没有很好,简称MAUP。其类型分为:①尺度效应(Scale effect):当空间数据经聚合而改变其单元面积的大小、形状和方向时,分析结果也随之变化的现象。
②区划效应(Zoning effect):给定尺度下不同的单元组合方式导致分析结果产生变化的现象。
尺度效应
区划效应
3)边界效应:边界效应(edge effect)指分析中由于实体向一个或多个边界近似时出现的误差
二、空间基础和量测
1、地理空间数据的特征:1)时空特征,地理数据区别于其他数据的根本性标志。2)多维结构:空间方面,描述地理对象所处的位置和空间范围,一般需要2~3个变量;属性方面,描述地理对象产生、发展和存在的时间范围,需要1个变量。如在一个坐标位置上,既包括地理位置、海拔高度、气候、地貌和土壤等自然地理特征,也具有相应的社会经济信息如人口、交通灯数据。3)多尺度性:地理数据的重要特征。分为空间多尺度、时间多尺度。4)不确定性:主要指介于清楚和模糊之间或清楚和模糊并存的现象。数据不确定性是数据“真实值”不能被肯定的程度。5)海量特征:更新速度快、分辨率提高。随着对地观测技术的发展,每天可以获得上万亿兆的数据。由于样本数量庞大,地理数据统计必须进行适当方式的抽样,或者采用非统计方式进行数据分析。6)空间相关性:地理学第一定律,随距离增加,影响力越来越小,即存在距离衰减。随距离增加,某地理现象对周围的影响力逐渐变小;随距离增加,两个地理实体间的相互作用逐渐减弱。
2、地理空间问题
在进行空间分析时,一般主要从以下几个方面入手:
1)空间位置:是借助于空间坐标系来传递空间物体的个体定位信息。GIS中,利用地图投影和坐标转换。
2)空间分布与格局:空间分布是从总体的、全局的角度来描述空间变量和空间物体的特性。在GIS中通常采用分布密度、均值、分布中心、离散度等指标进行描述;通过空间分布检验来确定地理对象的聚
集、分散、随机等。
3)资源配置与规划
4)空间关系与影响:当考察两个或多个对象的时候,空间对象之间的关系就必然成为考察内容。空间对象类型和层次的多样性,决定了空间关系的多样性。一般空间关系可分成3种:一是由空间对象的几何特性引起的空间关系,二是由空间物体的几何和非几何特性共同产生的空间关系,三是由空间物体的非几何特性所导出的空间关系。空间相似是空间关系分析中的一种,一种是指空间对象形态上的相似,另一种是指空间对象结构上的相似。
5)空间动态与过程
三、探索性空间数据分析
1、茎叶图:单变量、小数据集数据分布的图示方法。
优点是容易制作,让阅览者能很快抓住变量分布形状。缺点是无法指定图形组距,对大型资料不适用。
示例:
55 49 37 57 46 40 64 35 73 62 61 43 72 48 54 69 45 78 46 59 40 58 56 52 49 42 62 53 46 81
茎叶图
3 | 5 7
4 | 0 0 2 3
5
6 6 6 8 9 9
5 | 2 3 4 5
6
7
8 9
6 | 1 2 2 4 9
7 | 2 3 8
8 | 1
茎叶图制作方法:①选择适当的数字为茎,通常是起首数字,茎之间的间距相等;②每列标出所有可能叶的数字,叶子按数值大小依次排列; ③由第一行数据,在对应的茎之列,顺序记录茎后的一位数字为叶,直到最后一行数据,需排列整齐(叶之间的间隔相等)。 茎叶图行数的确定,主要有三个公式L=[10log 10n ] L=[2√n ] L=[1+log 2n ] 其中,L 为行数,[]表示取整数。
2、箱线图&五数总结
箱线图(boxplot )也称箱须图(box-whisker plot )需要五个数,称为五数总结:①最小值②下四分位数:Q1③中位数(median)④上四分位数:Q3⑤最大值。分位数差:IQR = Q3 - Q1
3密度估计是一个随机变量概率密度函数(pdf )的非参数方法。 应用不同带宽生成的100个服从正态分布随机数的核密度估计。
四、空间点模式分析
1、空间点模式:一般来说,点模式分析可以用来描述任何类型的事件数据(incident data )。因为每一事件都可以抽象化为空间上的一个位置点。
空间模式的三种基本分布:1)随机分布:任何一点在任何一个位置发生的概率相同,某点的存在不影响其它点的分布。又称泊松分布 11?()n i i x x f x K nh h =-??= ???
∑
2)均匀分布:个体间保持一定的距离,每一个点尽量地远离其周围的邻近点。在单位(样方)中个体出现与不出现的概率完全或几乎相等。3)聚集分布:许多点集中在一个或少数几个区域,大面积的区域没有或仅有少量点。总体中一个或多个点的存在影响其它点在同一取样单位中的出现概率。
2、怎样描述点模式?1)一阶效应:事件间的绝对位置具有决定作用,单位面积的事件数量在空间上有比较清楚的变化,如空间上平均值/密度的变化。2)二阶效应:事件间的相对位置和距离具有决定作用,如空间相互作用。
3、空间点模式分析方法
1)基于密度的方法:测度一阶效应
①样方分析,包括选取所有点和随机取样法。步骤:a)研究区域中打上网格,建议方格大小为OuadratSize=2A/n A:研究区域面积,n:点的个数。
b)确定每个网格中点的个数。c)计算均值(Mean)、方差(Var)和方差均值比:VMR=Var/Mean {对于均与分布,方差=0,因此VMR 的期望值=0;对于随机分布,方差=均值,因此VMR的期望值=1;对于聚集分布,方差大于均值。因此VME的期望值>1.}
样方分析的缺点:结果依赖于样方的大小和方向;样方分析主要依据点密度,而不是点之间的相互关系,所以不能区别图示的两种情况。
②样方分析的统计检验,包括K-S检验和方差均值比的X2检验。
③核密度估计
基本思想:在研究区域内的任一点都有一个密度,而不仅仅是在事件点上。
该密度通过计数一定区域内的事件点数量,或核(Kernel)进行估计。核以估计点为中心,一定距离为半径。
C (s ,r )是以点s 为圆心、r 为半径的圆域,#表示事件S 落在圆域C 中的数量。
核密度估计(KDE)用途:
a ) 可视化点模式进行热点 (hot spot)探测;
b ) 离散 连续。 如,疾病与污染。
2)基于距离的方法:测度二阶效应
①最近邻距离
计算每个点到其最近邻点之间的距离, 然后计算所有点最近邻距离的平均值。对每一个点,根据其欧几里德距离最小确定其最近邻点。 平均最近邻距离的大小,反映点在空间的分布特征。最近邻距离越小,说明点在空间分布越密集,反之,越离散。
②最近邻距离的方法
G 函数:欧几里德距离
F 函数:与
G 函数仅仅基于事件间最近邻距离的频率分布不同,F 函数基于区域内任意位置点与事件间最近邻距离的频率分布。
2
)]
,(#.[r r p C S p ?∈=πλ 2
2)()(),(j i j i j i y y x x s s d -+-=)(min )(&),1(min ij i j n j i d s d ≠∈=n s d d n
i i ∑==1min min )
(
K 函数 :与G 函数、F 函数只使用事件或点的最近邻距离不同,K 函数基于事件间的所有距离。因此,K 函数不仅能探测空间模式,而且可以给出空间模式和尺度的关系。
定义 经验K 函数估计的四个步骤: 1) 对于每一个事件s i ,以s i 为圆心、d 为半径画圆C (s i ,d )
2) 计算圆内其他事件点的数量 3) 3) 计算同一半径下所有事件的均值 4) 4) 均值除以研究区内事件密度 得:
五、空间格数据分析
1、空间权重矩阵
为了测度一组地理对象的空间自相关性,必须讨论识别多边形之间关系的方法。空间自相关衡量的是邻接区域内各单元属性值的相似程度,但首先必须定量地界定“邻接区域”的概念。即,在计算这些统计量之前,必须定量地界定区域单元之间的邻接关系,即,空间权重矩阵。 邻居的类型:两种规则
– 邻接 (公共边):二值或标准
– 距离 (距离带,K -近邻)
2、连接数统计量 连接数统计量(Join Count Statistics):一般用于名义量(nominal )数据,尤其是二值变量数据。
(#())
()d K d λ
=E 距任一事件距离小于的事件)]
,([#d s C S i ∈n d s C S n
i i ∑=∈1)]
,([#121#[(,)]?()#[(,)]?n n
i i i
i S C s d A K d S C s d n n λ==∈==∈∑∑
3. 全局空间自相关指标
Moran’s I 指数及其统计检验 、 Geary’s C 指数、
Getis’s G 指数。
三个指标计算方法相似,一般用于间隔量(interval )和比率量(ratio )数据,最常用的是Moran’s I 。
4. 局部空间自相关指标
● 局部空间自相关指标: Local Indicators of Spatial Association (LISA)
● Proposed in Getis & Ord (1992) and Anselin (1995).
● 全局自相关:不能给出局部变化。
● LISA :全局自相关的分解,描述一个面元在多大程度上与其邻居相似,或不同。
● 局部 Moran’s I i 指数
● 局部 Geary’s C i 指数
● 局部 Getis’s G i 指数
六、 空间插值与地统计
1、倒距离权重差值、趋势面分析
倒距离加权 (IDW) 插值方法假定每个输入点都有着局部影响,这种2
()()
()ij i j i j ij i i j i w z z z z n I w z z --=-∑∑∑∑∑2112111()1()2n n ij i j i j n n n i ij i i j w y y n C y y w =====--=-∑∑∑∑∑()(), ij i j i j i j
i j w d z z G d i j
z z =≠∑∑∑∑
影响随着距离增加而减弱。步骤:
a)计算未知点到所有点的距离;
2、
当一个变量的取值与其空间位置有关时,就称为区域化变量(regionalized variable)。区域化变量具有两个最显著,也是最重要的特征:随机性和结构性。
地统计学是以区域化变量理论为基础,以变异函数为主要工具,研究那些在空间分布上既有随机性又有结构性,或空间相关和依赖性现象的学科。
克里金方法(Kriging)就是建立在变异函数理论和结构分析基础之上的。
区域化变量的组成部分:结构性,可以用均值和常数趋势表示;空间相关,数据通常呈现正空间相关性;随机性,测量误差,其他误差。
经验半变异函数(semi-variogram):区域化变量的基本研究工具,半
变异函数就是区域化变量增量平方的 数学期望之半。
理论变异函数图模型:
3、 理解不同的克立金模型
克立金方法的基本形式:
对误差项的假设:期望值为0,并且 和 之间的自相()s ε()s h ε+
关不取决于s 点的位置,而取决于位移量h 。为确保自相关方差有解,必须允许某两点间的自相关可以相等。如,下面有箭头相连的两对位置点假设具有相同的自相关性。
趋势值 可以被简单地赋予一个常量,即,在任何位置处 如果
未知,就是普通克里金模型。 如果在任何时候趋势 已知,无论趋势是否是常量,都形成简单克里金模型。
趋势也可以表示为: 若趋势中的系数未知,就是泛克里金模型。
七、 空间回归
1、 空间自回归模型的形式 式中,y 是因变量,为n ×1向量;X 表示解释变量的n ×k 阶矩阵;m 是随空间变化的误差项;e 是白噪声。W 1,W 2是空间权重矩阵。
如果对式(1)施加某些限定,可导出多种不同形式的空间自回归模型。
① 设X =0,W 2=0,则由式(1)推出一阶空间自回归模型(SAR ):
意义:y 的变化是邻接空间单元的因变量的线性组合,解释变量X 对于y 的变化没有贡献。
包含空间效应的方法:通过因变量自身
② 设W 2=0,则由式(1)推出回归-空间自回归组合模型(MAR ):
()s μ()s μμ=μμμ
22012345x y x y xy
μββββββ=+++++122~(0,)y y N I ρβμ
μλμε
εσ=++=+W X W 12~(0,)
y y N I ρε
εσ=+W
意义:y 的变化不仅和邻接空间单元的因变量有关,而且解释变量X 对y 的变化也有贡献。 y 是因变量,经过空间加权 (W 1); r 为系数。
③ 设W 1=0,则由式(1)推出空间误差模型(Spatial error model):
m 是空间加权的(W 2) 误差项; l 系数; e 不相关的、同方差的误差
向量。 包含空间效应的方法:通过误差项。
④空间Durbin 模型(SDM ):将因变量的空间延迟(spatial lag )和自变量的空间延迟项加在模型中便得到空间Durbin 模型。
八、 地图代数&GIS 空间建模
1. 栅格数据结构为空间分析提供了最强的建模环境及空间运算,法
很多。
12~(0,)
y y N I ρβε
εσ=++W X 22~(0,)
y N I βμμλμε
εσ=+=+X W 11122~(0,)y y N I ρββεε
σ=+++W X W X
2.地图代数中的函数与类型
1)GIS空间分析的能力体现在回答“Where, What, When”等各类空间问题,即能够描述地理要素的空间分布特征、空间关系、
动态过程等,需要定量刻画分布是否聚集、距离对于相互之间
的影响、分布的高低趋势等。
2)函数是建立在基本运算符基础上的对栅格数据的高级操作,主要包括:局部函数、焦点函数、类区函数、块函数。
①局部函数
函数运算:栅格数据以某种函数关系作为分析依据进行逐网格运算,从而得到新的栅格数据。又分为数学函数、选择函数、重分类函数、统计函数。
②焦点函数,又称邻域函数
邻域分析也称窗口分析,主要应用于栅格数据模型。邻域函数计算出的栅格数据每个象元位置上的值都是输入数据中相应位置下指定的一些邻域单元的函数. 计算出的邻域统计值是一个移动窗口,它可以对数据进行扫描。
窗口分析:对于栅格数据系统中的一个、多个栅格点或全部数据,开辟一个有固定分析半径的分析窗口,并在该窗口内进行诸如极值、均值等一系列统计计算,或与其它层面的信息进行必要的复合分析,从
而实现栅格数据水平方向上的扩展分析。
分析窗口的类型
按窗口的形状可分为:
1)矩形窗口:以目标栅格为中心,分别向周围八个方向扩展一
层或多层栅格,从而形成矩形分析区域,矩形区域的大小,比
如3×3、5×5、7×7的窗口。
2)圆型窗口:以目标栅格为中心,向周围作一等距离搜索区,构成一圆型分析窗口。
3)环型窗口:以目标栅格为中心,按指定的内、外半径构成环
型分析窗口。
4)扇型窗口:以目标栅格为起点,按指定的起始、终止角度构
成扇型分析窗口。
③类区函数
类区函数(zonal function)非常类似于邻域函数,特别是二者都基于邻域的思想,但类区函数中的邻域是定义在地理空间的类型区上的。类区是栅格中所有具有相同值的单元格而不考虑它们在空间上是否相邻,栅格和图像数据集都能用作类型的数据集。
九、域系统模型的层次和体系
1、论述区域系统模型体系。
区域系统模型体系是区域系统问题结构与方法结构的一种指向实用的耦合。其耦合的结果取决于区域系统的问题结构和方法结构两个方面,而这两个侧面则从根本上取决于区域发展的性质。
由此可见,区域开发问题从研究的角度来看实际上就包括了四个基本内容:区域系统结构(S )、区域系统过程(E)、区域发展设计(D)和区域发展管理(M),并且这些内容还有着明显的层次性。
显然,区域系统的结构和过程是基础层,属于认识客观世界的问题,区域发展设计和管理则是上一个层次,属于改造客观世界的问题。从研究方法来说,顺序采用的是分析(A )、预测(F)、规划(P )和决策
(D)方法。上述四类基本问题与方法在不同层次上的耦合就构成了区域系统模型体系上的四大基本模块。
区域系统模型体系的耦合
将区域系统模型用集合映射的形式表示为:
式中:Re 和Me 分别为区域开发问题集和方法集;f 是两集合之间的一种对应和耦合,包括已知的和未知的两种。通常已知的耦合是常见的现有区域系统模型,
而未知的则是尚待进一步创造和发展的那些潜()
D P F A Me M D
E S f RSM Me ,,,:/,,,:Re Re ?=()()(),,,,,(,)SA s p E
F t DP s t MD s t ????=??????
过程设计管理结构预测规划决策分析
在的模型。已知耦合主要是:区域系统结构分析模型(SA)、区域系统演化预测模型(EF)、区域发展设计规划模型(DP)和区域发展管理决策模型(MD)。下标s, p和t则分别表示空间型、部门型和时间型的模型。区域系统模型体系研究应当集中在对耦合f的探讨上。
2、简述区域开发的理论模式。
梯度开发模式
增长极模式
点轴开发模式
网络开发模式
十、可持续发展评价模型
1、国际上几种可持续发展能力测度指标
①经济测度:绿色国民生产净值
②经济测度:真实储蓄
③社会-政治测度:可持续经济福利指数和真实进步
指标
④生态测度:净初级生产力和承载力
⑤生态测度:生态占用
⑥生态测度:环境空间
2、构建指标体系的基础
区域可持续发展的实质是区域社会、经济、资源、环境四大子系统的动态协调发展。因此,确切的把握区域人口、经济、资源、环境之间的相互作用关系就成为构建区域可持续发展评价指标体系的基础。对
于人口、经济、资源、环境之间的关系,可以归纳出两条主线,一个枢纽。两条主线是:
(1)人口-经济-资源;
(2)人口-经济-环境
经济发展在这两条主线中处于枢纽地位。
其它关系如:人口-资源、人口-环境、资源-环境等关系在区域可持续发展中的重要性则相对降低,或均可以通过经济发展这个枢纽得到体现。所以两个主线、一个枢纽就构成了人口、资源、环境与经济发展之间的核心。区域可持续发展在人口、经济、环境、资源层次上需要协调好经济与资源、经济与环境、经济与人口三组主要关系。十一、区域投入、产出结构模型
1.简述区域投入产出平衡表、平衡式的基本结构。
2.区域投入产出模型有哪些主要参数?如何表达?
3.区域投入产出模型有何作用?
一、第4题方差分析 1.1 建立数据文件 由题意可知,在同一浓度和温度下各做两次实验,将每一次的实验结果看作一个样本量,共342=24 ??个样本量。 (1) 在“变量视图”下,名称分别输入“factor1”、“factor1”、“result”,类型设为“数值”,小数均为“0”,标签分别为“浓度”、“温度”、“收率”,factor1的值“1=A1,2=A2,3=A3”,factor2的值“1=B1,2=B2,3=B3,4=B4”,对齐选择“居中”。 (2) 在“数据视图”下,根据表中数据输入对应的数据。 数据文件如图1所示,其中“factor1”表示浓度,“factor2”表示温度,“result”表示收率。三种不同浓度分别用1、2、3表示,四种不同温度分别用1、2、3、4表示。 图1.1 SPSS数据文件格式 1.2 基本思路 ,利用单因素方差分析,对 (1) 设“浓度对收率的影响不显著”为零假设H 该假设进行判定。 ,则可 (2) 设“它们间的交互作用对收率没有显著影响”分别依次为假设H 是否成立。 以通过多因素方差分析工具,利用得出的结果即能证明假设H 1.3 操作步骤 (1) 单因素的方差分析操作 ①分析—比较均值—单因素;因变量列表:收率;因子:浓度; ②两两比较:选中“LSD”复选框,定义用LSD法进行多重比较检验;显著性水平:0.05,单击“继续”; ③选项:选中“方差齐次性检验”,单击“继续”; ④单击“确定”。 (2) 有交互作用的两因素方差分析操作
①分析—一般线性模型—单变量;因变量:收率;固定因子:温度、浓度; ②绘制。水平轴:factor1,选择浓度作为均值曲线的横坐标,单图:factor2,选择温度作为曲线的分组变量;单击添加—继续。 ③选项。显示均值:factor1,定义估计因素1的均值;显著性水平:0.05;单击“继续”; ④单击“确定”。 1.4 结果分析 (1) “浓度对收率有无显著影响”结果分析 执行上述操作后,生成下表。 表1.1 方差齐性检验 表1中Levene统计量的取值为0.352,Sig.的值为0.708,大于0.05,所以认为各组的方差齐次。 表1.2 单因素方差分析 从表2可以看出,观测变量收率的总离差平方和为119.58;如果仅考虑浓度单因素的影响,则收率总变差中,浓度可解释的变差为39.083,抽样误差引起的变差为80.875,它们的方差分别为19.542、3.851,相除所得的F统计量的观测值为5.074,对应的概率P值为0.016,小于显著性水平0.05,则应拒绝原假设,认为不同浓度对收率产生了显著影响,它对收率的影响效应不全为0。
数据分析方法及软件应用 (作业) 题目:4、8、13、16题 指导教师: 学院:交通运输学院 姓名: 学号:
4、在某化工生产中为了提高收率,选了三种不同浓度,四种不同温度做试验。在同一浓度与温度组合下各做两次试验,其收率数据如下面计算表所列。试在α=0.05显著性水平下分析 (1)给出SPSS数据集的格式(列举前3个样本即可); (2)分析浓度对收率有无显著影响; (3)分析浓度、温度以及它们间的交互作用对收率有无显著影响。 解答:(1)分别定义分组变量浓度、温度、收率,在变量视图与数据视图中输入表格数据,具体如下图。 (2)思路:本问是研究一个控制变量即浓度的不同水平是否对观测变量收率产生了显著影响,因而应用单因素方差分析。假设:浓度对收率无显著影响。 步骤:【分析-比较均值-单因素】,将收率选入到因变量列表中,将浓度选入到因子框中,确定。 输出: 變異數分析 收率 平方和df 平均值平方 F 顯著性 群組之間39.083 2 19.542 5.074 .016 在群組內80.875 21 3.851 總計119.958 23 显著性水平α为0.05,由于概率p值小于显著性水平α,则应拒绝原假设,认为浓度对收率有显著影响。
(3)思路:本问首先是研究两个控制变量浓度及温度的不同水平对观测变量收率的独立影响,然后分析两个这控制变量的交互作用能否对收率产生显著影响,因而应该采用多因素方差分析。假设,H01:浓度对收率无显著影响;H02:温度对收率无显著影响;H03:浓度与温度的交互作用对收率无显著影响。 步骤:【分析-一般线性模型-单变量】,把收率制定到因变量中,把浓度与温度制定到固定因子框中,确定。 输出: 主旨間效果檢定 因變數: 收率 來源第 III 類平方 和df 平均值平方 F 顯著性 修正的模型70.458a11 6.405 1.553 .230 截距2667.042 1 2667.042 646.556 .000 浓度39.083 2 19.542 4.737 .030 温度13.792 3 4.597 1.114 .382 浓度 * 温度17.583 6 2.931 .710 .648 錯誤49.500 12 4.125 總計2787.000 24 校正後總數119.958 23 a. R 平方 = .587(調整的 R 平方 = .209) 第一列是对观测变量总变差分解的说明;第二列是观测变量变差分解的结果;第三列是自由度;第四列是均方;第五列是F检验统计量的观测值;第六列是检验统计量的概率p值。可以看到观测变量收率的总变差为119.958,由浓度不同引起的变差是39.083,由温度不同引起的变差为13.792,由浓度和温度的交互作用引起的变差为17.583,由随机因素引起的变差为49.500。浓度,温度和浓度*温度的概率p值分别为0.030,0.382和0.648。 浓度:显著性<0.05说明拒绝原假设(浓度对收率无显著影响),证明浓度对收率有显著影响;温度:显著性>0.05说明不拒绝原假设(温度对收率无显著影响),证明温度对收率无显著影响;浓度与温度: 显著性>0.05说明不拒绝原假设(浓度与温度的交互作用对收率无显著影响),证明温浓度与温度的交互作用对收率无显著影响。 8、以高校科研研究数据为例:以课题总数X5为被解释变量,解释变量为投入人年数X2、投入科研事业费X4、专著数X6、获奖数X8;建立多元线性回归模型,
最新初中数学数据分析解析 一、选择题 1.在一次数学答题比赛中,五位同学答对题目的个数分别为7,5,3,5,10,则关于这组数据的说法不正确的是() A.众数是5 B.中位数是5 C.平均数是6 D.方差是3.6 【答案】D 【解析】 【分析】 根据平均数、中位数、众数以及方差的定义判断各选项正误即可. 【详解】 A、数据中5出现2次,所以众数为5,此选项正确; B、数据重新排列为3、5、5、7、10,则中位数为5,此选项正确; C、平均数为(7+5+3+5+10)÷5=6,此选项正确; D、方差为1 5 ×[(7﹣6)2+(5﹣6)2×2+(3﹣6)2+(10﹣6)2]=5.6,此选项错误; 故选:D. 【点睛】 本题主要考查了方差、平均数、中位数以及众数的知识,解答本题的关键是熟练掌握各个知识点的定义以及计算公式,此题难度不大. 2.某校组织“国学经典”诵读比赛,参赛10名选手的得分情况如表所示: 那么,这10名选手得分的中位数和众数分别是() A.85.5和80 B.85.5和85 C.85和82.5 D.85和85 【答案】D 【解析】 【分析】 众数是一组数据中出现次数最多的数据,注意众数可以不只一个; 找中位数要把数据按从小到大的顺序排列,位于最中间的一个数(或两个数的平均数)为中位数. 【详解】 数据85出现了4次,最多,故为众数; 按大小排列第5和第6个数均是85,所以中位数是85. 故选:D. 【点睛】 本题主要考查了确定一组数据的中位数和众数的能力.一些学生往往对这个概念掌握不清
楚,计算方法不明确而误选其它选项.注意找中位数的时候一定要先排好顺序,然后再根据奇数和偶数个来确定中位数,如果数据有奇数个,则正中间的数字即为所求.如果是偶数个则找中间两位数的平均数. 3.在只有15人参加的演讲比赛中,参赛选手的成绩各不相同,若选手要想知道自己是否进入前8名,只需要了解自己的成绩以及全部成绩的( ) A.平均数B.中位数C.众数D.以上都不对 【答案】B 【解析】 【分析】 此题是中位数在生活中的运用,知道自己的成绩以及全部成绩的中位数就可知道自己是否进入前8名. 【详解】 15名参赛选手的成绩各不相同,第8名的成绩就是这组数据的中位数, 所以选手知道自己的成绩和中位数就可知道自己是否进入前8名. 故选B. 【点睛】 理解平均数,中位数,众数的意义. 4.某校四个绿化小组一天植树的棵数如下:10,x,10,8,已知这组数据的众数与平均数相等,则这组数据的中位数是( ) A.8 B.9 C.10 D.12 【答案】C 【解析】 【分析】 根据这组数据的众数与平均数相等,可知这组数据的众数(因10出现了2次)与平均数都是10;再根据平均数是10,可求出这四个数的和是40,进而求出x的数值;然后把这四个数据按照从大到小的顺序排列,由于是偶数个数据,则中间两个数的平均数就是中位数. 【详解】 当x=8时,有两个众数,而平均数只有一个,不合题意舍去. 当众数为10,根据题意得(10+10+x+8)÷4=10,解得x=12, 将这组数据按从小到大的顺序排列为8,10,10,12, 处于中间位置的是10,10, 所以这组数据的中位数是(10+10)÷2=10. 故选C. 【点睛】 本题为统计题,考查平均数、众数与中位数的意义,解题时需要理解题意,分类讨论.
¥ 数值分析思考题1 1、讨论绝对误差(限)、相对误差(限)与有效数字之间的关系。 2、相对误差在什么情况下可以用下式代替 3、查阅何谓问题的“病态性”,并区分与“数值稳定性”的不同点。 4、取 ,计算 ,下列方法中哪种最好为什么(1)(3 3-,(2)(2 7-,(3) ()3 1 3+ ,(4) ()6 1 1 ,(5)99- , 数值实验 数值实验综述:线性代数方程组的解法是一切科学计算的基础与核心问题。求解方法大致可分为直接法和迭代法两大类。直接法——指在没有舍入误差的情况下经过有限次运算可求得方程组的精确解的方法,因此也称为精确法。当系数矩阵是方的、稠密的、无任何特殊结构的中小规模线性方程组时,Gauss消去法是目前最基本和常用的方法。如若系数矩阵具有某种特殊形式,则为了尽可能地减少计算量与存储量,需采用其他专门的方法来求解。 Gauss消去等同于矩阵的三角分解,但它存在潜在的不稳定性,故需要选主元素。对正定对称矩阵,采用平方根方法无需选主元。方程组的性态与方程组的条件数有关,对于病态的方程组必须采用特殊的方法进行求解。 数值计算方法上机题目1 1、实验1. 病态问题 实验目的: 算法有“优”与“劣”之分,问题也有“好”和“坏”之别。所谓坏问题就是问题本身的解对数据变化的比较敏感,反之属于好问题。希望读者通过本实验对此有一个初步的体会。 数值分析的大部分研究课题中,如线性代数方程组、矩阵特征值问题、非线性方程及方程组等都存在病态的问题。病态问题要通过研究和构造特殊的算法来解决,当然一般要付出一些代价(如耗用更多的机器时间、占用更多的存储空间等)。 $ r e x x e x x ** * ** - == 141 . ≈)61
空间分析的概念空间分析:是基于地理对象的位置和形态特征的空间数据分析技术,其目的在于提取和传输空间信息。包括空间数据操作、空间数据分析、空间统计分析、空间建模。 空间数据的类型空间点数据、空间线数据、空间面数据、地统计数据 属性数据的类型名义量、次序量、间隔量、比率量 属性:与空间数据库中一个独立对象(记录)关联的数据项。属性已成为描述一个位置任何可记录特征或性质的术语。 空间统计分析陷阱1)空间自相关:“地理学第一定律”—任何事物都是空间相关的,距离近的空间相关性大。空间自相关破坏了经典统计当中的样本独立性假设。避免空间自相关所用的方法称为空间回归模型。2)可变面元问题MAUP:随面积单元定义的不同而变化的问题,就是可变面元问题。其类型分为:①尺度效应:当空间数据经聚合而改变其单元面积的大小、形状和方向时,分析结果也随之变化的现象。②区划效应:给定尺度下不同的单元组合方式导致分析结果产生变化的现象。3)边界效应:边界效应指分析中由于实体向一个或多个边界近似时出现的误差。生态谬误在同一粒度或聚合水平上,由于聚合方式的不同或划区方案的不同导致的分析结果的变化。(给定尺度下不同的单元组合方式) 空间数据的性质空间数据与一般的属性数据相比具有特殊的性质如空间相关性,空间异质性,以及有尺度变化等引起的MAUP效应等。一阶效应:大尺度的趋势,描述某个参数的总体变化性;二阶效应:局部效应,描述空间上邻近位置上的数值相互趋同的倾向。 空间依赖性:空间上距离相近的地理事物的相似性比距离远的事物的相似性大。 空间异质性:也叫空间非稳定性,意味着功能形式和参数在所研究的区域的不同地方是不一样的,但是在区域的局部,其变化是一致的。 ESDA是在一组数据中寻求重要信息的过程,利用EDA技术,分析人员无须借助于先验理论或假设,直接探索隐藏在数据中的关系、模式和趋势等,获得对问题的理解和相关知识。 常见EDA方法:直方图、茎叶图、箱线图、散点图、平行坐标图 主题地图的数据分类问题等间隔分类;分位数分类:自然分割分类。 空间点模式:根据地理实体或者时间的空间位置研究其分布模式的方法。 茎叶图:单变量、小数据集数据分布的图示方法。 优点是容易制作,让阅览者能很快抓住变量分布形状。缺点是无法指定图形组距,对大型资料不适用。 茎叶图制作方法:①选择适当的数字为茎,通常是起首数字,茎之间的间距相等;②每列标出所有可能叶的数字,叶子按数值大小依次排列;③由第一行数据,在对应的茎之列,顺序记录茎后的一位数字为叶,直到最后一行数据,需排列整齐(叶之间的间隔相等)。 箱线图&五数总结 箱线图也称箱须图需要五个数,称为五数总结:①最小值②下四分位数:Q1③中位数④上四分位数:Q3⑤最大值。分位数差:IQR = Q3 - Q1 3密度估计是一个随机变量概率密度函数的非参数方法。 应用不同带宽生成的100个服从正态分布随机数的核密度估计。 空间点模式:一般来说,点模式分析可以用来描述任何类型的事件数据。因为每一事件都可以抽象化为空间上的一个位置点。 空间模式的三种基本分布:1)随机分布:任何一点在任何一个位置发生的概率相同,某点的存在不影响其它点的分布。又称泊松分布
第7 章空间数据分析模型 7.1 空间数据 按照空间数据的维数划分,空间数据有四种基本类型:点数据、线数据、面数据和体数据。 点是零维的。从理论上讲,点数据可以是以单独地物目标的抽象表达,也可以是地理单元的抽象表达。这类点数据种类很多,如水深点、高程点、道路交叉点、一座城市、一个区域。 线数据是一维的。某些地物可能具有一定宽度,例如道路或河流,但其路线和相对长度是主要特征,也可以把它抽象为线。其他的线数据,有不可见的行政区划界,水陆分界的岸线,或物质运输或思想传播的路线等。 面数据是二维的,指的是某种类型的地理实体或现象的区域范围。国家、气候类型和植被特征等,均属于面数据之列。 真实的地物通常是三维的,体数据更能表现出地理实体的特征。一般而言,体数据被想象为从某一基准展开的向上下延伸的数,如相对于海水面的陆地或水域。在理论上,体数据可以是相当抽象的,如地理上的密度系指单位面积上某种现象的许多单元分布。 在实际工作中常常根据研究的需要,将同一数据置于不同类别中。例如,北京市可以看作一个点(区别于天津),或者看作一个面(特殊行政区,区别于相邻地区),或者看作包括了人口的“体”。 7.2 空间数据分析 空间数据分析涉及到空间数据的各个方面,与此有关的内容至少包括四个领域。 1)空间数据处理。空间数据处理的概念常出现在地理信息系统中,通常指的是空间分析。就涉及的内容而言,空间数据处理更多的偏重于空间位置及其关系的分析和管理。 2)空间数据分析。空间数据分析是描述性和探索性的,通过对大量的复杂数据的处理来实现。在各种空间分析中,空间数据分析是重要的组成部分。空间数据分析更多的偏重于具有空间信息的属性数据的分析。 3)空间统计分析。使用统计方法解释空间数据,分析数据在统计上是否是“典型”的,或“期望”的。与统计学类似,空间统计分析与空间数据分析的内容往往是交叉的。 4)空间模型。空间模型涉及到模型构建和空间预测。在人文地理中,模型用来预测不同地方的人流和物流,以便进行区位的优化。在自然地理学中,模型可能是模拟自然过程的空间分异与随时间的变化过程。空间数据分析和空间统计分析是建立空间模型的基础。 7.3 空间数据分析的一些基本问题 空间数据不仅有其空间的定位特性,而且具有空间关系的连接属性。这些属性主要表现为空间自相关特点和与之相伴随的可变区域单位问题、尺度和边界效应。传统的统计学方法在对数据进行处理时有一些基本的假设,大多都要求“样本是随机的”,但空间数据可能不一定能满足有关假设,因此,空间数据的分析就有其特殊性(David,2003)。
数据分析经典测试题含答案解析 一、选择题 1.某校九年级数学模拟测试中,六名学生的数学成绩如下表所示,下列关于这组数据描述正确的是() A.众数是110 B.方差是16 C.平均数是109.5 D.中位数是109 【答案】A 【解析】 【分析】 根据众数、中位数的概念求出众数和中位数,根据平均数和方差的计算公式求出平均数和方差. 【详解】 解:这组数据的众数是110,A正确; 1 6 x=×(110+106+109+111+108+110)=109,C错误; 21 S 6 = [(110﹣109)2+(106﹣109)2+(109﹣109)2+(111﹣109)2+(108﹣109)2+ (110﹣109)2]=8 3 ,B错误; 中位数是109.5,D错误; 故选A. 【点睛】 本题考查的是众数、平均数、方差、中位数,掌握它们的概念和计算公式是解题的关键. 2.一组数据2,x,6,3,3,5的众数是3和5,则这组数据的中位数是() A.3 B.4 C.5 D.6 【答案】B 【解析】 【分析】 由众数的定义求出x=5,再根据中位数的定义即可解答. 【详解】 解:∵数据2,x,3,3,5的众数是3和5, ∴x=5,
则数据为2、3、3、5、5、6,这组数据为35 2 =4. 故答案为B. 【点睛】 本题主要考查众数和中位数,根据题意确定x的值以及求中位数的方法是解答本题的关键. 3.如图,是根据九年级某班50名同学一周的锻炼情况绘制的条形统计图,下面关于该班50名同学一周锻炼时间的说法错误的是() A.平均数是6 B.中位数是6.5 C.众数是7 D.平均每周锻炼超过6小时的人数占该班人数的一半 【答案】A 【解析】 【分析】 根据中位数、众数和平均数的概念分别求得这组数据的中位数、众数和平均数,由图可知锻炼时间超过6小时的有20+5=25人.即可判断四个选项的正确与否. 【详解】 A、平均数为1 50 ×(5×7+18×6+20×7+5×8)=6.46,故本选项错误,符合题意; B、∵一共有50个数据, ∴按从小到大排列,第25,26个数据的平均值是中位数, ∴中位数是6.5,故此选项正确,不合题意; C、因为7出现了20次,出现的次数最多,所以众数为:7,故此选项正确,不合题意; D、由图可知锻炼时间超过6小时的有20+5=25人,故平均每周锻炼超过6小时的人占总数的一半,故此选项正确,不合题意; 故选A. 【点睛】 此题考查了中位数、众数和平均数的概念等知识,中位数是将一组数据从小到大(或从大到小)重新排列后,最中间的那个数(最中间两个数的平均数),叫做这组数据的中位数,如果中位数的概念掌握得不好,不把数据按要求重新排列,就会错误地将这组数据最中间的那个数当作中位数.
《统计与数据分析》 数据分析实验作业 数据来源于大肠杆菌Escherichia coli K-12 MG1655注释的4289个编码蛋白基因的长度l(单位:核苷酸,NT)及其GC含量r(%)。其中,第1列为基因序号,第2列为基因的长度l(单位:核苷酸,NT),第3列为基因的GC含量r(%)。试针对这一组数据完成下列数据分析工作: 一. 将全部4289个基因视为总体Y,请完成如下工作: 1. 严格按照要求(注意:软件自动生成的结果视为无效作业),分别画出基因长度l和基因GC含量r的频率直方图和箱线图,并对这两类数据的异常值进行分析; 2. 分别求出基因长度l和基因GC含量r的均值、标准差、极差、中位数、众数、变异系数,并在k≤10范围内依次、完整地检验Chebyshev定理; 3. 基于总体Y,考察l与GC含量r比值l/r,请设计抽样对l/r进行比值估计与单随机变量估计的抽样效率的比较分析,并以合适的图示表示比较结果; 4. 基于总体Y,根据中心极限定理构造一个基于GC含量r值的模拟总体数据X,并以合适的图示表示,要求总体X为经过显著性水平α=0.01下的K-S检验的标准正态分布,且X的个体数目也为4289,取值可表示为R。(提示:简单随机抽样的样本均值R近似服从正态分布,样本容量n自定。) 二. 基于服从标准正态分布的总体X,请完成如下工作: 1. 从中进行1次简单随机抽样(容量n=277),求出样本均值和样本标准差,并画出这一样本的频率直方图和箱线图;由此估计总体X的正态分布参数(方法不限,需写出具体求解过程),并分别采用自举法(Bootstrap)重复抽样1000次,分别确定该样本均值和该样本标准差是否处于90%的置信区间(以上下5%分位数来定义90%的置信区间),并以合适的图示表示自举法重复抽样1000次以及该置信区间的结果; 2. 进一步地,进行100次容量为n=61的简单随机抽样,分别画出样本均值、样本标准差的频率直方图,考察同样参数估计方法所估计参数的90%置信区间的情况,并以合适的图示表示(提示:(1)相关分布的分位数表可参考本课程讲义;(2)请参考本课程讲义的表示方式。)。 三. 对于总体Y,将全部4289个基因视为从某一总体中进行1次简单随机抽样的样本(容量n=4289),给定显著性水平为10%,试考察基因长度l与GC含量r是否相互独立。要求写出具体的分析过程。(提示:相关分布的分位数表可参考本课程讲义。) 要求: (1)本次数据分析以实验报告形式打印、装订提交,请在第一页注明学号、姓名; (2)请保证独立完成本作业,鼓励自行编程完成上述数据分析,也可使用相关软件(不限);(3)本作业占课程总成绩15%。
空间数据分析报告 —使用Moran's I统计法实现空间自相关的测度1、实验目的 (1)理解空间自相关的概念和测度方法。 (2)熟悉ArcGIS的基本操作,用Moran's I统计法实现空间自相关的测度。2、实验原理 2.1空间自相关 空间自相关的概念来自于时间序列的自相关,所描述的是在空间域中位置S 上的变量与其邻近位置Sj上同一变量的相关性。对于任何空间变量(属性)Z,空间自相关测度的是Z的近邻值对于Z相似或不相似的程度。如果紧邻位置上相互间的数值接近,我们说空间模式表现出的是正空间自相关;如果相互间的数值不接近,我们说空间模式表现出的是负空间自相关。 2.2空间随机性 如果任意位置上观测的属性值不依赖于近邻位置上的属性值,我们说空间过程是随机的。 Hanning则从完全独立性的角度提出更为严格的定义,对于连续空间变量Y,若下式成立,则是空间独立的: 式中,n为研究区域中面积单元的数量。若变量时类型数据,则空间独立性的定义改写成 式中,a,b是变量的两个可能的类型,i≠j。 2.3Moran's I统计 Moran's I统计量是基于邻近面积单元上变量值的比较。如果研究区域中邻近面积单元具有相似的值,统计指示正的空间自相关;若邻近面积单元具有不相似的值,则表示可能存在强的负空间相关。
设研究区域中存在n 个面积单元,第i 个单位上的观测值记为y i ,观测变量在n 个单位中的均值记为y ,则Moran's I 定义为 ∑∑∑∑∑======n i n j ij n i n j ij n i W W n I 11 11j i 1 2i ) y -)(y y -(y )y -(y 式中,等号右边第二项∑∑==n 1i n 1j j i ij )y -)(y y -(y W 类似于方差,是最重要的项,事 实上这是一个协方差,邻接矩阵W 和) y -)(y y -(y j i 的乘积相当于规定)y -)(y y -(y j i 对邻接的单元进行计算,于是I 值的大小决定于i 和j 单元中的变量值对于均值的偏离符号,若在相邻的位置上,y i 和y j 是同号的,则I 为正;y i 和y j 是异号的, 则I 为负。在形式上Moran's I 与协变异图 {}{}u ?-)Z(s u ?-)Z(s N(h)1(h)C ?j i ∑=相联系。 Moran's I 指数的变化范围为(-1,1)。如果空间过程是不相关的,则I 的期望接近于0,当I 取负值时,一般表示负自相关,I 取正值,则表示正的自相关。用I 指数推断空间模式还必须与随机模式中的I 指数作比较。 通过使用Moran's I 工具,会返回Moran's I Index 值以及Z Score 值。如果Z score 值小于-1.96获大于1.96,那么返回的统计结果就是可采信值。如果Z score 为正且大于1.96,则分布为聚集的;如果Z score 为负且小于-1.96,则分布为离散的;其他情况可以看作随机分布。 3、实验准备 3.1实验环境 本实验在Windows 7的操作系统环境中进行,使用ArcGis 9.3软件。 3.2实验数据 此次实习提供的数据为以湖北省为目标区域的bount.dbf 文件。.dbf 数据中包括第一产业增加值,第二产业增加值万元,小学在校学生数,医院、卫生院床位数,乡村人口万人,油料产量,城乡居民储蓄存款余额,棉花产量,地方财政一般预算收入,年末总人口(万人),粮食产量,普通中学在校生数,肉类总产量,规模以上工业总产值现价(万元)等属性,作为分析的对象。
初中数学数据分析知识点总复习含解析 一、选择题 1.在创建平安校园活动中,九年级一班举行了一次“安全知识竞赛”活动,第一小组6名同学的成绩(单位:分)分别是:87,91,93,87,97,96,下列关于这组数据说正确的是() A.中位数是90 B.平均数是90 C.众数是87 D.极差是9 【答案】C 【解析】 【分析】 根据中位数、平均数、众数、极差的概念求解. 【详解】 解:这组数据按照从小到大的顺序排列为:87,87,91,93,96,97, 则中位数是(91+93)÷2=92, 平均数是(87+87+91+93+96+97)÷6=915 6 , 众数是87, 极差是97﹣87=10. 故选C. 【点睛】 本题考查了中位数、平均数、众数、极差的知识,掌握各知识点的概念是解答本题的关键. 2.一组数据2,x,6,3,3,5的众数是3和5,则这组数据的中位数是() A.3 B.4 C.5 D.6 【答案】B 【解析】 【分析】 由众数的定义求出x=5,再根据中位数的定义即可解答. 【详解】 解:∵数据2,x,3,3,5的众数是3和5, ∴x=5, 则数据为2、3、3、5、5、6,这组数据为35 2 =4. 故答案为B. 【点睛】 本题主要考查众数和中位数,根据题意确定x的值以及求中位数的方法是解答本题的关键. 3.已知一组数据a、b、c的平均数为5,方差为4,那么数据a+2、b+2、c+2的平均数和
方差分别为() A.7,6 B.7,4 C.5,4 D.以上都不对【答案】B 【解析】 【分析】 根据数据a,b,c的平均数为5可知a+b+c=5×3,据此可得出1 3 (-2+b-2+c-2)的值;再由 方差为4可得出数据a-2,b-2,c-2的方差. 【详解】 解:∵数据a,b,c的平均数为5,∴a+b+c=5×3=15, ∴1 3 (a-2+b-2+c-2)=3, ∴数据a-2,b-2,c-2的平均数是3;∵数据a,b,c的方差为4, ∴1 3 [(a-5)2+(b-5)2+(c-5)2]=4, ∴a-2,b-2,c-2的方差=1 3 [(a-2-3)2+(b-2-3)2+(c--2-3)2] = 1 3 [(a-5)2+(b-5)2+(c-5)2]=4, 故选B. 【点睛】 本题考查了平均数、方差,熟练掌握平均数以及方差的计算公式是解题的关键. 4.2022年将在北京﹣﹣张家口举办冬季奥运会,很多学校为此开设了相关的课程,下表记录了某校4名同学短道速滑成绩的平均数x和方差S2,根据表中数据,要选一名成绩好又发挥稳定的运动员参加比赛,应选择() A.队员1 B.队员2 C.队员3 D.队员4 【答案】B 【解析】 【分析】
枣果皮中酚类物质提取工艺优化及抗氧化活性分析 1.实验数据背景叙述。 一:实验关于枣果皮中酚类物质提取工艺优化及抗氧化活性分析。酚类物质是植物体内重要的次生代谢产物,主要通过莽草酸和丙二酸途径合成,广泛分布于植物界。许多的酚类物质具有营养保健功效。现代流行病学研究证明,经常食用富含酚类物质的果蔬能够预防由活性氧导致的相关疾病如癌症、糖尿病、肥胖症等的发生。 二:实验问题:为提高枣果皮中的酚类物质的提取效率,该文以马牙枣为试验材料,对枣果皮中酚类物质提取条件进行了优化。同时分析枣果皮提取物中酚类物质的抗氧化活性。 三:实验目的:要通过实验得到枣果皮中酚类物质提取的最优条件。并对提取物中酚类物质清除DPPH,2,2'-连氮基双(3-乙基苯并噻唑啉)-6-磺酸(ABTS)自由基及铁还原能力进行探讨,同时与合成抗氧化剂2,6-二叔丁基对甲酚(BHT)的抗氧化能力进行比较。 2. 实验数据处理方法选择及论述。 一:单因素试验(获得数据,将数据输入excel中,使用excel绘制图表,以便直观感受影响因素对实验的影响趋势。)
以冻干枣果皮为材料,分别以甲醇浓度、提取温度、提取料液比和提取时 间作为因素,分析不同的提取条件对枣果皮中酚类物质提取效果的影响,检测 指标为提取物中总酚含量。 二:正交试验(设计正交试验以便获得到枣果皮中酚类物质提取的最优条件, 用excel进行结果直观分析,见表2。) 以冻干枣果皮为材料,以提取溶剂浓度(A)、提取温度(B)、料液比(C)、和浸提时间(D)作4 因素3水平的L9(34)正交设计(见表1),检测指标为 提取物中总酚含量。 表1 枣果皮中酚类物质提取因素水平表 三:统计分析 所有提取试验均重复3 次,每次提取液的测定均重复3 次。结果表示为平 均值±标准偏差。应用excel软件对所有数据进行方差分析。 3. 实验数据的处理的过程叙述。 一:在单因素试验中,将每次试验结果输入excel中,选中表格,点击“插入”柱形图。
空间分析实习报告 学院遥感信息工程学院班级 学号 姓名 日期
一、实习内容简介 1.实验目的: (1)通过实习了解ArcGIS的发展,以及10.1系列软件的构成体系 (2)熟练掌握ArcMap的基本操作及应用 (3)了解及应用ArcGIS的分析功能模块ArcToolbox (4)加深对地理信息系统的了解 2.实验内容: 首先是对ArcGIS有初步的了解。了解ArcGIS的发展,以及10.1系列软件的构成体系,了解桌面产品部分ArcMap、ArcCatalog和ArcToolbox的相关基础知识。 实习一是栅格数据空间分析,ArcGIS软件的Spatial Analyst模块提供了强大的空间分析工具,可以帮助用户解决各种空间分析问题。利用老师所给的数据可以创建数据(如山体阴影),识别数据集之间的空间关系,确定适宜地址,最后寻找一个区域的最佳路径。 实习二是矢量数据空间分析,ArcToolbox软件中的Analysis Tools和Network Analyst Tools提供了强大的矢量数据处理与分析工具,可以帮助用户解决各种空间分析问题。利用老师所给的数据可以通过缓冲区分析得到矢量面数据,通过与其它矢量数据的叠置分析、临近分析来辅助选址决策过程;可以构建道路平面网络模型,进而通过网络分析探索最优路径,从而服务于公交选线、智能导航等领域。 实习三是三维空间分析,学会用ArcCatalog查找、预览三维数据;在ArcScene中添加数据;查看数据的三维属性;从二维要素与表面中创建新的三维要素;从点数据源中创建新的栅格表面;从现有要素数据中创建TIN表面。 实习四是空间数据统计分析,利用地统计分析模块,你可以根据一个点要素层中已测定采样点、栅格层或者利用多边形质心,轻而易举地生成一个连续表面。这些采样点的值可以是海拔高度、地下水位的深度或者污染值的浓度等。当与ArcMap一起使用时,地统计分析模块提供了一整套创建表面的工具,这些表面能够用来可视化、分析及理解各种空间现象。 实习五是空间分析建模,空间分析建模就是运用GIS空间分析方法建立数学模型的过程。按照建模的目的,可分为以特征为主的描述模型(descriptive model)和提供辅助决策信息和解决方案为目的的过程模型(process model)两类。本次实习主要是通过使用ArcGIS的模型生成器(Model Builder)来建立模型,从而处理涉及到许多步骤的空间分析问题。 二、实习成果及分析 实习一: 练习1:显示和浏览空间数据。利用ArcMap和空间分析模块显示和浏览数据。添加和显示各类空间数据集、在地图上高亮显示数值、查询指定位置的属性值、分析一张直方图和创建一幅山体阴影图。
常用数据分析方法详解 目录 1、历史分析法 2、全店框架分析法 3、价格带分析法 4、三维分析法 5、增长率分析法 6、销售预测方法 1、历史分析法的概念及分类 历史分析法指将与分析期间相对应的历史同期或上期数据进行收集并对比,目的是通过数据的共性查找目前问题并确定将来变化的趋势。 *同期比较法:月度比较、季度比较、年度比较 *上期比较法:时段比较、日别对比、周间比较、 月度比较、季度比较、年度比较 历史分析法的指标 *指标名称: 销售数量、销售额、销售毛利、毛利率、贡献度、交叉比率、销售占比、客单价、客流量、经营品数动销率、无销售单品数、库存数量、库存金额、人效、坪效 *指标分类: 时间分类 ——时段、单日、周间、月度、季度、年度、任意 多个时段期间 性质分类 ——大类、中类、小类、单品 图例 2框架分析法 又叫全店诊断分析法 销量排序后,如出现50/50、40/60等情况,就是什么都能卖一点但什么都不 好卖的状况,这个时候就要对品类设置进行增加或删减,因为你的门店缺少 重点,缺少吸引顾客的东西。 如果达到10/90,也是品类出了问题。 如果是20/80或30/70、30/80,则需要改变的是商品的单品。 *单品ABC分析(PSI值的概念) 销售额权重(0.4)×单品销售额占类别比+销售数量权重(0.3) × 单品销售数量占类别比+毛利额权重(0.3)单品毛利额占类别比 *类别占比分析(大类、中类、小类) 类别销售额占比、类别毛利额占比、 类别库存数量占比、类别库存金额占比、
类别来客数占比、类别货架列占比 表格例 3价格带及销售二维分析法 首先对分析的商品按价格由低到高进行排序,然后 *指标类型:单品价格、销售额、销售数量、毛利额 *价格带曲线分布图 *价格带与销售对数图 价格带及销售数据表格 价格带分析法 4商品结构三维分析法 *一种分析商品结构是否健康、平衡的方法叫做三维分析图。在三维空间坐标上以X、Y、Z 三个坐标轴分别表示品类销售占有率、销售成长率及利润率,每个坐标又分为高、低两段,这样就得到了8种可能的位置。 *如果卖场大多数商品处于1、2、3、4的位置上,就可以认为商品结构已经达到最佳状态。以为任何一个商品的品类销售占比率、销售成长率及利润率随着其商品生命周期的变化都会有一个由低到高又转低的过程,不可能要求所有的商品同时达到最好的状态,即使达到也不可能持久。因此卖场要求的商品结构必然包括:目前虽不能获利但具有发展潜力以后将成为销售主力的新商品、目前已经达到高占有率、高成长率及高利润率的商品、目前虽保持较高利润率但成长率、占有率趋于下降的维持性商品,以及已经决定淘汰、逐步收缩的衰退型商品。 *指标值高低的分界可以用平均值或者计划值。 图例 5商品周期增长率分析法 就是将一段时期的销售增长率与时间增长率的比值来判断商品所处生命周期阶段的方法。不同比值下商品所处的生命周期阶段(表示) 如何利用商品生命周期理论指导营运(图示) 6销售预测方法[/hide] 1.jpg (67.5 KB) 1、历史分析法
第三章 误差和分析数据的处理 作业及答案 一、选择题(每题只有1个正确答案) 1. 用加热挥发法测定BaCl 2·2H 2O 中结晶水的质量分数时,使用万分之一的分析天平称样0.5000g ,问测定结果应以几位有效数字报出?( D ) [ D ] A. 一位 B. 二位 C .三位 D. 四位 2. 按照有效数字修约规则25.4507保留三位有效数字应为( B )。 [ B ] A. 25.4 B. 25.5 C. 25.0 D. 25.6 3. 在定量分析中,精密度与准确度之间的关系是( C )。 [ C ] A. 精密度高,准确度必然高 B. 准确度高,精密度不一定高 C. 精密度是保证准确度的前提 D. 准确度是保证精密度的前提 4. 以下关于随机误差的叙述正确的是( B )。 [ B ] A. 大小误差出现的概率相等 B. 正负误差出现的概率相等 C. 正误差出现的概率大于负误差 D. 负误差出现的概率大于正误差 5. 可用下列何种方法减免分析测试中的随机误差( D )。 [ D ] A. 对照实验 B. 空白实验 C. 仪器校正 D. 增加平行实验的次数 6. 在进行样品称量时,由于汽车经过天平室附近引起天平震动产生的误差属于( B )。 [ B ] A. 系统误差 B. 随机误差 C. 过失误差 D. 操作误差 7. 下列表述中,最能说明随机误差小的是( A )。 [ A ] A. 高精密度 B. 与已知含量的试样多次分析结果的平均值一致 C. 标准偏差大 D. 仔细校正所用砝码和容量仪器 8. 对置信区间的正确理解是( B )。 [ B ] A. 一定置信度下以真值为中心包括测定平均值的区间 B. 一定置信度下以测定平均值为中心包括真值的范围 C. 真值落在某一可靠区间的概率 D. 一定置信度下以真值为中心的可靠范围 9. 有一组测定数据,其总体标准偏差σ未知,要检验得到这组分析数据的分析方法是否准确可靠,应该用( C )。 [ C ] A. Q 检验法 B. G(格鲁布斯)检验法 C. t 检验法 D. F 检验法 答:t 检验法用于测量平均值与标准值之间是否存在显著性差异的检验------准确度检验 F 检验法用于两组测量内部是否存在显著性差异的检验-----精密度检验 10 某组分的质量分数按下式计算:10 ???= m M V c w 样,若c =0.1020±0.0001,V=30.02±0.02, M=50.00±0.01,m =0.2020±0.0001,则对w 样的误差来说( A )。 [ A ] A. 由“c ”项引入的最大 B. 由“V ”项引入的最大
Answer of Homework 2 1.6 计算下列各式的卷积: (a )()e (),()e (),at bt x t u t h t u t a b --==≠ Answer: (a )通过卷积定义()0()()()d e e d ,0t at b t y t x h t t τττττ∞----∞=-=≥??,因此 ()[(e e )/(b )]()at bt y t a u t --=-- 1.7 计算下列各式的卷积,并画出结果曲线。 (b )21()(2),()(2)2n x n u n h n u n -??=-=+ ??? Answer: 定义信号11()()2n x n u n ??= ??? 和1()()h n u n = ,可以发现1()(2)x n x n =-,1()(2)h n h n =+,因此, 1111()()()(2)(2)(2)(2)k y n x n h n x n h n x k h n k ∞ =-∞=*=-*+=--+∑ 用2m + 代替k 得到: 111011()()()21()22m n n m m y n x m h n m u n +∞=-∞=??????=-==-?? ? ?????????∑∑ 2n 1.9 一因果LTI 系统,其输入输出关系由1()(1)()4 y n y n x n = -+给出,若()(1)x n n δ=-,试求()y n 。 Answer: 由于该系统为一因果系统,因而()0,1y n n =<从而得到 1 1(1)(0)(1)0114 111(2)(1)(2)0444 111(3)(2)(3)0416161()()4 m y y x y y x y y x y m -= +=+==+=+==+=+== 因此, 11()()(1)4 n y n u n -=- 1.12 给定()(2),()e (1)t x t u t h t u t =-=--。试计算卷积()()()y t x t h t =*。 Answer:
实验4-1、空间分析基本操作 一、实验目的 1. 了解基于矢量数据和栅格数据基本空间分析的原理和操作。 2. 掌握矢量数据与栅格数据间的相互转换、 栅格重分类(Raster Reclassify)、 栅格计算-查询符合条件的栅格(Raster Calculator)、 面积制表(Tabulate Area)、 分区统计(Zonal Statistic)、 缓冲区分析(Buffer) 、采样数据的空间内插(Interpolate)、 栅格单元统计(Cell Statistic)、 邻域统计(Neighborhood)等空间分析基本操作和用途。 3. 为选择合适的空间分析工具求解复杂的实际问题打下基础。 二、实验准备 预备知识: 空间数据及其表达 空间数据(也称地理数据)是地理信息系统的一个主要组成部分 。空间数据是指以地球表面空间位置为参照的自然、社会和人文经济景观数据,可以是图形、图像、文字、表格和数字等。它是GIS 所表达的现实世界经过模型抽象后的内容,一般通过扫描仪、键盘、光盘或其它通讯系统输入GIS。 在某一尺度下,可以用点、线、面、体来表示各类地理空间要素。有两种基本方法来表示空间数据:一是栅格表达; 一是矢量表达。两种数据格式间可以进行转换。 空间分析 空间分析是基于地理对象的位置和形态的空间数据的分析技术,其目的在于提取空间信息或者从现有的数据派生出新的数据,是将空间数据转变为信息的过程。 空间分析是地理信息系统的主要特征。空间分析能力(特别是对空间隐含信息的提取和传输能力)是地理信息系统区别与一般信息系统的主要方面,也是评价一个地理信息系统的主要指标。 空间分析赖以进行的基础是地理空间数据库。空间分析运用的手段包括各种几何的逻辑运算、数理统计分析,代数运算等数学手段。空间分析可以基于矢量数据或栅格数据进行,具体是情况要根据实际需要确定。 空间分析步骤 根据要进行的空间分析类型的不同, 空间分析的步骤会有所不同。通常,所有 的空间分析都涉及以下的基本步骤,具体 在某个分析中,可以作相应的变化。 空间分析的基本步骤: a) 确定问题并建立分析的目标和要满足 的条件 b) 针对空间问题选择合适的分析工具 c) 准备空间操作中要用到的数据。 d) 定制一个分析计划然后执行分析操作。 e) 显示并评价分析结果