Oracle instr、substr、translate 函数使用介绍
- 格式:doc
- 大小:29.00 KB
- 文档页数:3

oracle中substring的用法在Oracle数据库中,SUBSTRING函数是一个非常有用的字符串函数,它可用于提取字符串的一部分。
虽然Oracle中没有直接的SUBSTRING函数,但是可以使用以下两种方法实现子字符串的提取。
方法一:使用SUBSTR函数SUBSTR函数是Oracle中最常用的子字符串提取函数,它使用下面的语法:`SUBSTR(string, start_position, [length])`其中,string是要提取子字符串的字符串,start_position是开始提取的位置。
可以选择一个可选的参数length来指定要提取的子串长度。
如果没有指定length,则将提取从start_position到字符串的末尾的所有字符。
如果start_position为负数,则表示从字符串的末尾开始计数。
例如,要在字符串'this is a test'中提取“is a “字串,可以使用以下语句:`SELECT SUBSTR('this is a test', 6, 4) FROM DUAL;`上述语句将返回 'is a'。
方法二:使用INSTR和SUBSTR函数如果想要提取一个字符串中的子字符串,但是无法确定子字符串的完整长度,可以使用INSTR函数来确定要提取的子字符串的开始位置,然后再使用SUBSTR函数来提取子字符串。
INSTR函数的语法为:`INSTR(string, substring, [start_position], [occurrence])`其中,string是要从中查找子串的字符串,substring是要搜索的子串,start_position是在哪个位置开始搜索,而occurrence是要搜索的子串在字符串中出现的次数。
这个函数将返回子串在关联字符串中第一次出现的位置。
可以将这个位置传递给SUBSTR函数,以提取子字符串。

instr在oracle中用法Oracle数据库中,instr函数是一种用于在字符串中查找子字符串的函数,它返回子字符串第一次出现的位置。
这个功能在实际应用中非常实用,可以用在很多情景中。
一、函数的格式和参数函数的格式如下:instr(str,substr,[start,[th]])参数解释:str:在该字符串中查找子字符串substr:要查找的子字符串start:查找的起始位置,可以不填,默认从字符串开头开始查找th:指定要查找的次数,可以不填,默认查找所有二、函数的返回值instr函数的返回值是一个数字,表示子字符串在原字符串中第一次出现的位置。
如果子字符串未出现,则返回0。
如果某参数非法,将会抛出异常。
例如,在以下代码中,'e'是子字符串,返回值为2:select instr('hello', 'e') from dual;三、使用场景instr函数在实际应用中非常广泛,在开发和运维中都可以看到它的身影。
下面是一些具体的使用场景。
1. 字符串分割instr函数可以通过子字符串的位置来实现字符串分割。
例如,以下代码可以将字符串以','为分隔符来进行分割:select substr('A,B,C,D,E', 1, instr('A,B,C,D,E', ',')-1) from dualunion allselect substr('A,B,C,D,E', instr('A,B,C,D,E', ',')+1,instr('A,B,C,D,E', ',', 1, 2)-instr('A,B,C,D,E', ',')-1) from dualunion allselect substr('A,B,C,D,E', instr('A,B,C,D,E', ',', 1, 2)+1, instr('A,B,C,D,E', ',', 1, 3)-instr('A,B,C,D,E', ',', 1, 2)-1) from dualunion allselect substr('A,B,C,D,E', instr('A,B,C,D,E', ',', 1, 3)+1) from dual;输出结果如下:ABCD,E2. 替换字符串instr函数可以通过指定查找次数来实现替换指定位置的字符串。

oracle的instr函数用法Oracle数据库中的INSTR函数是一个用于返回一个字符串在另一个字符串中第一次出现的位置的函数。
它的基本语法是:INSTR(str1, str2, start_position, nth_appearance)参数解释如下:- str1: 要的字符串,即目标字符串。
- str2: 要的子字符串,即要在目标字符串中查找的字符串。
- start_position: 的起始位置。
如果省略此参数,则默认从第一个字符开始。
- nth_appearance: 要的子字符串在目标字符串中出现的顺序。
如果省略此参数,则默认为1INSTR函数返回一个整数值,表示子字符串第一次出现的位置。
如果未找到子字符串,则返回0。
下面是一些使用INSTR函数的示例:1.返回子字符串第一次出现的位置:SELECT INSTR('Hello, World', 'o') AS position FROM dual;输出:5解释:子字符串 'o' 第一次出现在字符串 'Hello, World' 的位置是第5个字符。
2.返回子字符串在目标字符串中第二次出现的位置:SELECT INSTR('Hello, World', 'o', 1, 2) AS position FROM dual;输出:8解释:子字符串 'o' 在字符串 'Hello, World' 中第二次出现的位置是第8个字符。
3.返回子字符串在目标字符串中的位置,从指定位置开始:SELECT INSTR('Hello, World', 'l', 4) AS position FROM dual;输出:4解释:子字符串 'l' 在字符串 'Hello, World' 中第一次出现的位置是第4个字符,从第4个字符开始。

orcal的instr函数Oracle的instr函数是一种非常强大和常用的函数,它可以帮助我们在字符串中查找指定子字符串的位置。
本文将详细介绍instr函数的用法和示例,以帮助读者更好地理解和应用此函数。
一、instr函数的基本语法和参数instr函数的基本语法如下所示:instr(待搜索字符串, 子字符串, 开始位置, 第n次出现)其中,各参数的含义如下:- 待搜索字符串:需要进行搜索的字符串。
- 子字符串:要查找的子字符串。
- 开始位置:指定搜索的起始位置,如果省略,则默认从第一个字符开始搜索。
- 第n次出现:指定查找子字符串的第几次出现,如果省略,则默认为第一次出现。
二、instr函数的应用示例下面通过一些实际的例子来演示instr函数的用法。
例1:查找子字符串的位置假设我们有一个字符串"Hello World",我们想要查找字符串中字母"o"的位置,可以使用如下代码:SELECT instr('Hello World', 'o') FROM dual;运行结果为5,表示字母"o"在字符串中的位置是第5个字符。
例2:查找子字符串的第二次出现的位置如果我们想要查找子字符串的第二次出现的位置,可以使用如下代码:SELECT instr('Hello World', 'o', 1, 2) FROM dual;运行结果为9,表示字母"o"在字符串中的第二次出现的位置是第9个字符。
例3:查找子字符串的位置并计算长度如果我们想要同时获取子字符串的位置和长度,可以使用如下代码:SELECT instr('Hello World', 'o'), length('Hello World') FROM dual;运行结果为5和11,分别表示字母"o"在字符串中的位置和字符串的长度。

oracle 函数的用法Oracle 是一个非常强大的数据库管理系统,它提供了丰富的函数库,可以让我们在SQL 语句中使用各种函数来实现数据处理、计算和查询。
本文将给大家介绍一些常用的Oracle 函数及其用法。
一、字符串函数1. UPPER 函数:将字符串转换为大写字母。
SELECT UPPER('hello world!') FROM DUAL;结果为:HELLO WORLD!结果为:hello world!3. INSTR 函数:查找子字符串在字符串中第一次出现的位置。
结果为:54. SUBSTR 函数:截取字符串的一部分。
5. REPLACE 函数:将字符串中的某个子串替换为另一个子串。
二、数值函数1. ROUND 函数:将指定的数字四舍五入到指定的小数位数。
3. ABS 函数:计算数字的绝对值。
4. SIGN 函数:返回数字的符号,如果为正数返回 1,为负数返回 -1,为零返回 0。
SELECT SIGN(-10), SIGN(10), SIGN(0) FROM DUAL;结果为:-1 1 05. POWER 函数:计算一个数的指定次幂。
三、日期函数1. SYSDATE 函数:返回当前系统日期和时间。
SELECT SYSDATE FROM DUAL;2. MONTHS_BETWEEN 函数:计算两个日期之间相差的月数。
SELECT MONTHS_BETWEEN('2022-01-01', '2021-01-01') FROM DUAL;3. ADD_MONTHS 函数:对指定日期增加指定的月数。
4. TRUNC 函数:截取日期到指定的精度,例如截取到月份。
5. TO_CHAR 函数:将日期类型转换为字符串类型。
SELECT TO_CHAR(SYSDATE, 'yyyy-mm-dd hh24:mi:ss') FROM DUAL;结果为:2021-08-01 14:00:00四、聚合函数1. COUNT 函数:计算查询结果集中的行数。

instr用法oracle -回复[instr用法Oracle]Oracle是一种关系型数据库管理系统,广泛应用于企业级应用和数据管理中。
在Oracle中,使用函数和操作符来处理和查询数据库中存储的数据。
其中,INSTR函数是一种非常常用的函数,用于查找一个字符串在另一个字符串中第一次出现的位置。
本文将详细介绍INSTR函数的使用方法及应用场景。
1. INSTR函数的基本语法INSTR函数有多个参数和返回值,其中最常用的形式为:INSTR(source_string, search_string, [start_position],[nth_appearance])其中,source_string是待查找的字符串,search_string是要查找的子字符串。
start_position参数可选,代表要开始搜索的位置,默认为1。
nth_appearance参数可选,代表要查找的第几个出现位置,默认为1。
返回值为所找到的子字符串在源字符串中第一次出现的位置。
2. INSTR函数的使用示例下面是几个实际使用INSTR函数的示例,帮助理解其用法。
2.1 查找子字符串在源字符串中出现的位置例如,有一个表格名为employees,其中有一列名为last_name,我们需要查找出last_name列中包含“Smith”子字符串的员工的位置。
可以使用以下代码:SELECT last_name, INSTR(last_name, 'Smith') as positionFROM employeesWHERE INSTR(last_name, 'Smith') > 0;这将返回包含“Smith”子字符串的员工的last_name列的值和其在字符串中的位置。
2.2 查找第N个出现位置有时候,我们需要查找一个子字符串在源字符串中的第N个出现位置。
例如,我们需要查找last_name列中包含“Smith”子字符串的员工的第二个出现位置。

oracle中instr用法
在Oracle数据库中,INSTR函数用于返回一个字符串中某个子字符串第一次出现的位置。
INSTR函数的基本语法如下:
INSTR(str1, str2 [, start_position [, occurrence]])
其中,
- str1为要搜索的字符串;
- str2为要查找的子字符串;
- start_position为开始搜索的位置,默认为1;
- occurrence为要查找的子字符串在str1中的第几次出现,默认为1。
返回值为一个整数,表示子字符串在字符串中的位置。
示例1:查找子字符串在字符串中第一次出现的位置
SELECT INSTR('Hello World', 'World') AS position FROM dual;
执行结果为:
POSITION
----------
7
示例2:在特定位置开始搜索子字符串
SELECT INSTR('Hello Hello World', 'Hello', 6) AS position FROM dual;
执行结果为:
POSITION
----------
6
示例3:查找子字符串在字符串中第二次出现的位置SELECT INSTR('Hello Hello World', 'Hello', 1, 2) AS position FROM dual;
执行结果为:
POSITION
----------
7
这些示例演示了INSTR函数的基本用法,它是在Oracle中用于搜索子字符串的常用函数之一。

Oracle函数Translate的⽤法⼀、语法:TRANSLATE(string,from_str,to_str)⼆、⽬的返回将(所有出现的)from_str中的每个字符替换为to_str中的相应字符以后的string。
TRANSLATE 是 REPLACE 所提供的功能的⼀个超集。
如果 from_str ⽐to_str 长,那么在 from_str 中⽽不在 to_str 中的额外字符将从 string 中被删除,因为它们没有相应的替换字符。
to_str 不能为空。
Oracle 将空字符串解释为 NULL,并且如果TRANSLATE 中的任何参数为NULL,那么结果也是 NULL。
三、允许使⽤的位置过程性语句和SQL语句。
四、⽰例Sql代码1. SELECT TRANSLATE('abcdefghij','abcdef','123456') FROM dual;2. TRANSLATE (3. --------------4. 123456ghij5.6. SELECT TRANSLATE('abcdefghij','abcdefghij','123456') FROM dual;7. TRANSL8. ----------9. 123456语法:TRANSLATE(expr,from,to)expr: 代表⼀串字符,from 与 to 是从左到右⼀⼀对应的关系,如果不能对应,则视为空值。
举例:select translate('abcbbaadef','ba','#@') from dual (b将被#替代,a将被@替代)select translate('abcbbaadef','bad','#@') from dual (b将被#替代,a将被@替代,d对应的值是空值,将被移⾛)因此:结果依次为:@#c##@@def 和@#c##@@ef语法:TRANSLATE(expr,from,to)expr: 代表⼀串字符,from 与 to 是从左到右⼀⼀对应的关系,如果不能对应,则视为空值。
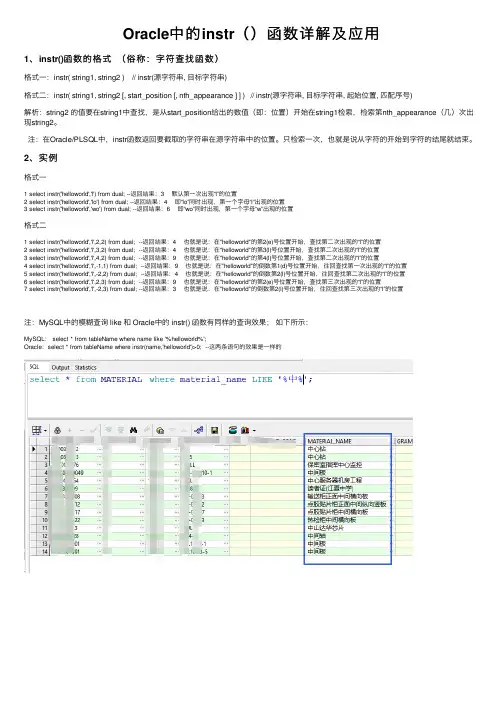
Oracle中的instr()函数详解及应⽤1、instr()函数的格式(俗称:字符查找函数)格式⼀:instr( string1, string2 ) // instr(源字符串, ⽬标字符串)格式⼆:instr( string1, string2 [, start_position [, nth_appearance ] ] ) // instr(源字符串, ⽬标字符串, 起始位置, 匹配序号)解析:string2 的值要在string1中查找,是从start_position给出的数值(即:位置)开始在string1检索,检索第nth_appearance(⼏)次出现string2。
注:在Oracle/PLSQL中,instr函数返回要截取的字符串在源字符串中的位置。
只检索⼀次,也就是说从字符的开始到字符的结尾就结束。
2、实例格式⼀1 select instr('helloworld','l') from dual; --返回结果:3 默认第⼀次出现“l”的位置2 select instr('helloworld','lo') from dual; --返回结果:4 即“lo”同时出现,第⼀个字母“l”出现的位置3 select instr('helloworld','wo') from dual; --返回结果:6 即“wo”同时出现,第⼀个字母“w”出现的位置格式⼆1 select instr('helloworld','l',2,2) from dual; --返回结果:4 也就是说:在"helloworld"的第2(e)号位置开始,查找第⼆次出现的“l”的位置2 select instr('helloworld','l',3,2) from dual; --返回结果:4 也就是说:在"helloworld"的第3(l)号位置开始,查找第⼆次出现的“l”的位置3 select instr('helloworld','l',4,2) from dual; --返回结果:9 也就是说:在"helloworld"的第4(l)号位置开始,查找第⼆次出现的“l”的位置4 select instr('helloworld','l',-1,1) from dual; --返回结果:9 也就是说:在"helloworld"的倒数第1(d)号位置开始,往回查找第⼀次出现的“l”的位置5 select instr('helloworld','l',-2,2) from dual; --返回结果:4 也就是说:在"helloworld"的倒数第2(l)号位置开始,往回查找第⼆次出现的“l”的位置6 select instr('helloworld','l',2,3) from dual; --返回结果:9 也就是说:在"helloworld"的第2(e)号位置开始,查找第三次出现的“l”的位置7 select instr('helloworld','l',-2,3) from dual; --返回结果:3 也就是说:在"helloworld"的倒数第2(l)号位置开始,往回查找第三次出现的“l”的位置注:MySQL中的模糊查询 like 和 Oracle中的 instr() 函数有同样的查询效果;如下所⽰:MySQL: select * from tableName where name like '%helloworld%';Oracle:select * from tableName where instr(name,'helloworld')>0; --这两条语句的效果是⼀样的3、实例截图1、2、3、4、5、6、7、8、9、原创作者:作者主页:原⽂出⾃:版权声明:欢迎转载,转载务必说明出处。

Oracle中translate 函数的使用实例:select lmark3, translate( t.lmark3, '9876543210' ||t.lmark3, '9876543210')from line_data_all_t t在实际的业务中,可以用来删除一些异常数据,比如表a中的一个字段t_no表示电话号码,而电话号码本身应该是一个由数字组成的字符串,为了删除那些含有非数字的异常数据,就用到了translate函数:SQL> delete from a,where length(translate(trim(a.t_no),'0123456789' || a.t_no,'0123456789')) <>length(trim(a.t_no));2.replace语法:REPLACE(char, search_string,replacement_string)用法:将char中的字符串search_string全部转换为字符串replacement_string。
举例:SQL> select REPLACE('fgsgswsgs', 'fk' ,'j') 返回值 from dual;返回值---------fgsgswsgsSQL> select REPLACE('fgsgswsgs', 'sg' ,'eeerrrttt') 返回值 from dual;返回值-----------------------fgeeerrrtttsweeerrrttts分析:第一个例子中由于'fgsgswsgs'中没有与'fk'匹配的字符串,故返回值仍然是'fgsgswsgs';第二个例子中将'fgsgswsgs'中的字符串'sg'全部转换为'eeerrrttt'。

Oracle中instr和substr存储过程详解instr和substr存储过程,分析内部⼤对象的内容instr函数instr函数⽤于从指定的位置开始,从⼤型对象中查找第N个与模式匹配的字符串。
⽤于查找内部⼤对象中的字符串的instr函数语法如下:dbms_lob.instr(lob_loc in blob,pattern in raw,offset in integer := 1;nth in integer := 1)return integer;dbms_lob.instr(lob_loc in clob character set any_cs,pattern in varchar2 character set lob_loc%charset,offset in integer:=1,nth in integer := 1)return integer;lob_loc为内部⼤对象的定位器pattern是要匹配的模式offset是要搜索匹配⽂件的开始位置nth是要进⾏的第N次匹配substr函数substr函数⽤于从⼤对象中抽取指定数码的字节。
当我们只需要⼤对象的⼀部分时,通常使⽤这个函数。
操作内部⼤对象的substr函数语法如下:dbms_lob.substr(lob_loc in blob,amount in integer := 32767,offset in integer := 1)return raw;dbms_lob.substr(lob_loc in clob character set any_cs,amount in integer := 32767,offset in integer := 1)return varchar2 character set lob_loc%charset;其中各个参数的含义如下:lob_loc是substr函数要操作的⼤型对象定位器amount是要从⼤型对象中抽取的字节数offset是指从⼤型对象的什么位置开始抽取数据。
oracle substring()用法Oracle SQL中的substring()函数用于从字符串中提取子字符串。
它提供了方便的方法来处理数据库中的字符串数据。
本篇文章将详细介绍substring()函数的用法,包括其语法、参数和常见应用。
一、语法```scssSUBSTRING(string, start_position, [length])```其中:* string:要提取子字符串的原始字符串。
* start_position:子字符串的起始位置,以1为单位。
负值表示从字符串末尾开始计数的位置。
* length(可选):要提取的子字符串的长度。
如果省略,将提取从起始位置到字符串末尾的所有字符。
二、参数说明1. 起始位置:允许指定子字符串的起始位置,从而可以按特定方式切割字符串。
负值表示从字符串末尾开始计数。
2. 长度:可选参数,用于指定要提取的子字符串的长度。
如果没有指定长度,将提取从起始位置到字符串末尾的所有字符。
3. 结果:substring()函数返回提取的子字符串。
三、常见应用1. 提取指定位置的字符:使用substring()函数可以从字符串中提取特定位置的字符。
例如,要从字符串中提取第5个字符,可以使用以下表达式:`SUBSTRING(string, 5)`。
2. 分割字符串:通过指定起始位置和长度,可以使用substring()函数将字符串分割成多个子字符串。
例如,要将字符串按空格分割成单词,可以使用以下表达式:`SUBSTRING(string, 1, INSTR(string, ' ') - 1)`。
3. 去除空格和特殊字符:可以使用substring()函数去除字符串开头和结尾的空格以及特殊字符。
例如,要将字符串中的空格和标点符号删除,可以使用以下表达式:`SUBSTRING(REPLACE(string, ' ', ''), 1, LENGTH(string))`。
Oracle数据库函数之SUBSTR函数的详解1. 定义SUBSTR函数是Oracle数据库中的一个字符串函数,主要用于截取指定字符串的子字符串。
它根据给定的参数,从字符串中返回一个指定长度的部分子字符串。
2. 用途SUBSTR函数的主要用途是提取一个字符串的一部分,可以根据实际需求截取字符串的任意位置和长度,以满足各种数据处理和分析的需要。
它可以用于实现以下功能:•截取子字符串:可以根据指定的位置和长度截取出一个字符串的子字符串。
•替换部分字符:可以将指定位置的字符串替换为其他字符串。
•字符串截断:可以将一个较长的字符串截断为指定长度的字符串。
•数据过滤:可以根据指定的条件,截取出符合条件的子字符串。
3. 语法SUBSTR函数的语法如下所示:SUBSTR(string, position, [length])其中,参数的含义如下:•string:要截取的字符串。
•position:截取的起始位置。
如果为正数,则从左侧开始计算索引;如果为负数,则从右侧开始计算索引。
•length:可选参数,指定截取的长度。
如果省略该参数,则截取从起始位置到字符串末尾的所有字符。
4. 示例下面是一些使用SUBSTR函数的示例,以说明其具体用法和工作方式。
示例一:截取指定长度的子字符串假设有一个表格employees,其中包含员工的姓名和电话号码。
现在需要从电话号码中截取区号和手机号码,并将其分别存入两个不同的列中。
CREATE TABLE employees (id NUMBER,name VARCHAR2(50),phone VARCHAR2(20),area_code VARCHAR2(10),phone_number VARCHAR2(20));INSERT INTO employees (id, name, phone)VALUES (1, 'John Smith', '+1 (123) 456-7890');UPDATE employeesSET area_code = SUBSTR(phone, 5, 3),phone_number = SUBSTR(phone, 10)WHERE id = 1;执行以上代码后,employees表的数据将如下所示:id name phone area_code phone_number1 John Smith +1 (123) 456-7890 123 456-7890在上述示例中,使用SUBSTR函数分别从电话号码中截取了区号和手机号码,然后将它们存储到了area_code和phone_number两个列中。
oracle translate函数用法Introduction:Oracle Translate函数是Oracle SQL语言中的一个强大的字符串函数,用于将一个字符串中的一个字符集替换为另一个字符集。
该函数在Oracle数据库中使用通常需要用到,特别是在数据清洗,数据替换等业务场景下会大量使用。
基本语法:Oracle Translate函数的基本语法如下:`TRANSLATE(string, from_string, to_string)`参数说明:1. string:需要执行替换操作的字符串2.from_string:需要被替换的字符串子集 3. to_string:需要替换成的字符串子集返回值说明:函数返回一个按参照to_string替换过后的结果字符串。
用法示例:`SELECT TRANSLATE('ABCDEFG','ABCD','ZYXW') FROM DUAL;`结果输出:EFGZYXW在上面的示例代码中,我们将字符串ABCDE替换为ZYXW,所以结果字符串变成了EFGZYXW。
注意:当to_string长度小于from_string长度的时候,to_string中的最后一个字符将被用于填充from_string中剩余的字符。
例如:`SELECT TRANSLATE('ABCDEFG','ABCD','ZYXWVU') FROM DUAL;`结果输出:EFGZYXWV在上面的示例代码中,当to_string字符串长度比from_string长度要短时,to_string字符串的最后一个字符将重复使用进行向右的字符填充。
用法案例:通常情况下,Oracle Translate函数应用于字符串替换的场景中,较为常见的应用场景如下:1. 数据清洗:在数据导入系统的过程中,很多时候由于导入数据源的不确定性,会出现一些不规范的字符串数据作为到的数据,如特殊字符、空格、换行符等等对数据的影响,导致数据分析不稳定和不准确。
oracle的translate函数
Oracle的translate函数是一种用于在字符串中进行字符替换的函数。
它可以将一个字符串中的一组字符替换为另外一组字符,并返回替换后的字符串。
该函数的语法如下:
TRANSLATE(string, from_string, to_string)
其中,string是要进行字符替换的字符串,from_string是要被替换的字符集,to_string是替换后的字符集。
举个例子,假设有一个字符串“abc”,我们要将其中的“a”替换为“x”,“b”替换为“y”,“c”替换为“z”,那么可以使用如下的SQL语句:
SELECT TRANSLATE('abc', 'abc', 'xyz') FROM dual;
执行以上语句后,将返回字符串“xyz”。
需要注意的是,如果from_string和to_string的长度不相等,则to_string中多余的字符将被忽略。
如果to_string中的字符数少于from_string中的字符数,则from_string中多余的字符将被删除。
另外,如果在to_string中指定了一个转义字符,它将被忽略。
因此,如果要替换一个字符为一个转义字符,应该先用一个转义字符替换它,然后再把这个转义字符替换为目标字符。
总的来说,Oracle的translate函数是一种很有用的字符串处理函数,它可以帮助我们在SQL语句中进行字符替换,实现更加灵
活的数据处理。
oracle存储过程常用字符串处理函数在Oracle中,常用的字符串处理函数有:
1.CONCAT:用于连接两个或多个字符串。
2.SUBSTR:用于提取字符串的一部分。
3.INSTR:用于查找字符串中特定子串的位置。
4.REPLACE:用于替换字符串中的指定子串。
5.UPPER:用于将字符串转换为大写。
6.LOWER:用于将字符串转换为小写。
7.INITCAP:用于将字符串的首字母转换为大写,其余字母转换为小写。
8.TRIM:用于删除字符串首尾的空格或指定字符。
9.LENGTH:用于返回字符串的长度。
10.LPAD:用于在字符串的左侧填充指定字符,使字符串达到指定长度。
11.RPAD:用于在字符串的右侧填充指定字符,使字符串达到指定长度。
12.TO_CHAR:用于将其他数据类型转换为字符类型。
13.TO_NUMBER:用于将字符类型转换为数字类型。
14.TO_DATE:用于将字符类型转换为日期类型。
15.REGEXP_REPLACE:用于使用正则表达式替换字符串中的指定内容。
以上是一些常用的字符串处理函数,在实际的存储过程中可以根据具
体的需求,选择合适的函数来进行字符串处理。
oracle中的替换函数replace和translate函数1.translate语法:TRANSLATE(char, from, to)⽤法:返回将出现在from中的每个字符替换为to中的相应字符以后的字符串。
若from⽐to字符串长,那么在from中⽐to中多出的字符将会被删除。
三个参数中有⼀个是空,返回值也将是空值。
举例:SQL> select translate('abcdefga','abc','wo') 返回值from dual;返回值-------wodefgw分析:该语句要将'abcdefga'中的'abc'转换为'wo',由于'abc'中'a'对应'wo'中的'w',故将'abcdefga'中的'a'全部转换成'w';⽽'abc'中'b'对应'wo'中的'o',故将'abcdefga'中的'b'全部转换成'o';'abc'中的'c'在'wo'中没有与之对应的字符,故将'abcdefga'中的'c'全部删除;简单说来,就是将from中的字符转换为to中与之位置对应的字符,若to中找不到与之对应的字符,返回值中的该字符将会被删除。
在实际的业务中,可以⽤来删除⼀些异常数据,⽐如表a中的⼀个字段t_no表⽰电话号码,⽽电话号码本⾝应该是⼀个由数字组成的字符串,为了删除那些含有⾮数字的异常数据,就⽤到了translate函数:SQL> delete from a,where length(translate(trim(a.t_no),'0123456789' || a.t_no,'0123456789')) <> length(trim(a.t_no));2.replace语法:REPLACE(char, search_string,replacement_string)⽤法:将char中的字符串search_string全部转换为字符串replacement_string。
Oracle substr/instr/translate 函数使用介绍
substr 函数:
Sql代码
substr('This is a test', 6, 2) would return 'is'
substr('This is a test', 6) would return 'is a test'
substr('TechOnTheNet', 1, 4) would return 'Tech'
substr('TechOnTheNet', -3, 3) would return 'Net'
substr('TechOnTheNet', -6, 3) would return 'The'
substr('TechOnTheNet', -8, 2) would return 'On'
instr 函数:
INSTR方法的格式为:
INSTR(源字符串, 目标字符串, 起始位置, 匹配序号)
例如:
INSTR('CORPORATE FLOOR','OR', 3, 2)中,源字符串为'CORPORATE FLOOR', 目标字
符串为'OR',起始位置为3,取第2个匹配项的位置。
默认查找顺序为从左到右。当起始位置为负数的时候,从右边开始查找。
所以SELECT INSTR('CORPORATE FLOOR', 'OR', -1, 1) "Instring" FROM DUAL的显示
结果是
Instring
——————
14
select t.*, t.rowid from os_currentstep t where instr(t.owner,'wgc',-1,1)>0
在sql语句中可以判断这个字符串是否存在记录 判断出自己要筛选的记录
translate 函数:
Translate主要是用来做字符串的替换的,对于字母和数字来说,是一个字符替换一个字
符
如:
下面的语句会把 'f' 替换成 'v','a' 替换成 'g'
Sql代码
select Translate('fasdbfasegafs','fa','vg' ) value from dual;
VALUE
-------------
vgsdbvgseggvs
但是对于汉字来说,则会根据不同的情况而有点不同
如
Sql代码
select Translate('fasdbfasegas','fa','我' ) value from dual;
VALUE
-----------
我sdb我segs
Sql代码
select Translate('fasdbfasegafs','fa','你' ) value from dual;
VALUE
-------------
你sdb你seg你s
第一个语句的fa替换成'我',由于最后面的a对应不到而用空代替
现在看第二个语句,前面的fa替换成了'你'没有问题,但是后面的af居然也是一样的替换?!
另外:
Sql代码
select Translate('fasdbfasegafs','fa','你我' ) value from dual;
VALUE
-------------------
你我sdb你我seg我你s
f被替换成'你'而a被替换成了'我'
可见oracle会根据替换字符串的不同而进行'自适应'
另外Translate还有一个小功能:
Sql代码
select trim(Translate('fasdbfa12vr2segas','abcdefghijklmnopqrstuvwxyz','
')) value from dual;
VALUE
-----
122
最后综合使用:
Sql代码
update gd_stru_pole set name=
substr(name,1,instr(translate(name,'1234567890','1111111111'),'1')-1)||'你
要添加的字母
'||substr(name,instr(translate(name,'1234567890','1111111111'),'1'))