2015年软件水平考试程序员精选题
- 格式:pdf
- 大小:711.24 KB
- 文档页数:34

一、填空(10 *1分=10)(1)产品设想是产品用途和形式的概括描述,可以通过主要产品功能列表的形式详细阐明。
(2)项目范围是项目中要完成的工作。
风险承担者是受产品影响或参与。
影响产品开发的任何人。
(3)产品设计过程的特点可以概括为自顶向下和以用户为中心。
前者意味着设计人员首先要在高抽象级别上引出需要并生成、改进、评估和选择需求,然后再依次在更低的级别上引出需要并生成、改进、评估和选择需求。
后者意味着设计过程是以风险承担者为焦点,使用实验评估,而且高度重复。
(4)备选需求的思想可以来自设计团队的内部或外部。
前一种来源包括用户和其他风险承担者、专家、现实物品和比喻、竞争产品和相似产品。
后一种来源包括团队集体讨论、个人独立思考和建模。
(5)工程设计的第一步是工程设计分析。
这项活动的输入包括可能以各种模型和原型作为其补充的SRS,它们都是在产品设计过程中产生的。
从软件的生命周期的观点来说,工程设计发生在设计阶段。
在这项活动中分析问题的好方法是建模,这将产生该活动的主要输出。
(6)体系结构设计必须既考虑功能需求,又考虑非功能需求。
使程序能够满足其功能需求的体系结构可能有任意多个,但其中只有质量特性能够同时使程序满足其非功能需求。
软件体系结构设计者必须考虑多种程序以找出那些所能指定的程序既能满足功能需求,又能满足非功能需求的结构。
(7)设计模式出现在几个不同的抽象级别上,包括体系结构风格,它是处于体系结构级别的模式;中级设计模型它是设计类及其交互作用的模式;数据结构和算法它是实现抽象数据类型和有效操作的模式;编程惯用法,它是能够有效使用特定编程语言的模式。
(8)在应用树中,树根以utility加以标记,根的子树是概貌的名称,树叶表示场景。
这些树帮助生成用来评估体系结构方案的场景的集合。
(9)正确使用表示方法的SAD是结构良好的SAD,全部可以由一个程满足的一组设计说明是一致的。
所指定的程序能够满足其所有需求的软件体系结构是完整的。

计算机软考初级程序员试题及答案一、选择题(每题2分,共40分)1. 下列关于计算机硬件的描述,错误的是()A. CPU 是计算机的核心,负责解释和执行指令B. 内存用于存放计算机运行时的数据和程序C. 硬盘是外设,用于长期存放数据和程序D. 显卡负责将计算机的输出结果显示在屏幕上答案:C2. 下列关于操作系统的描述,错误的是()A. 操作系统是计算机系统的基础软件B. 操作系统负责管理计算机的硬件和软件资源C. 操作系统提供了用户与计算机之间的接口D. 操作系统可以同时运行多个程序答案:D3. 下列关于数据类型的描述,正确的是()A. 整型变量可以存储小数B. 字符型变量可以存储整数C. 浮点型变量可以存储整数和字符串D. 布尔型变量只有两个值:true 和 false答案:D(以下省略其他选择题)二、填空题(每题3分,共30分)11. 计算机网络的目的是实现信息的__________和共享。
答案:传输12. 在面向对象的程序设计中,一个类包含__________和__________。
答案:属性、方法13. 在计算机中,一个字节(Byte)由__________位二进制数组成。
答案:814. 在 SQL 语言中,用于创建表的语句是__________。
答案:CREATE TABLE15. 在计算机软件的生命周期中,__________阶段是软件开发的基础。
答案:需求分析(以下省略其他填空题)三、判断题(每题2分,共20分)21. 计算机的运算速度是指计算机每秒能执行的指令数。
()答案:正确22. 操作系统的任务管理功能包括进程管理和内存管理。
()答案:正确23. 在面向对象的程序设计中,继承是指子类从父类继承方法和属性。
()答案:正确24. 在数据库中,索引可以加快查询速度,但会降低插入和删除操作的速度。
()答案:正确25. 计算机网络的传输介质包括双绞线、同轴电缆、光纤和无线电波。
()答案:正确(以下省略其他判断题)四、问答题(每题10分,共30分)31. 请简述计算机软件的开发过程。

2015年下半年下午软件测评师考试试题-案例分析-答案与解析试题一(共15分)【说明】阅读下列java程序,回答问题1至问题3,将解答填入答题纸内对应栏内。
【Java程序】【问题1】请简述基本路径测试法的概念。
【参考答案】基本路径测试法是在程序控制流图的基础上,通过分析控制构造的环路复杂性,导出基本可执行路径集合,从而设计测试用例的方法。
【问题2】请画出上述程序的控制流图,并计算其控制流图的环图复杂度V(G)。
控制流图【参考答案】环路复杂度V(G)=5【问题3】请给出问题2中的控制流图的线性无关路径。
【参考答案】1. 1-2-4-5-6-8-9-102. 1-2-4-5-7-8-9-10(1-2-4-5-7-8-10)3. 1-2-4-5-6-8-10(1-2-4-5-7-8-10)4. 1-2-3-4-5-6-8-9-10(1-2-3-4-5-7-8-9-10,1-2-3-4-5-6-8-10,1-2-3-4-5-7-8-10)5. 1-2-3-8-9-10(1-2-3-8-10)本问题考査白盒测试用例设计方法:基本路径法。
涉及到的知识点包括:根据控制流图和环路复杂度给出线性无关路径。
线性无关路径是指包含一组以前没有处理的语句或条件的路径。
从控制流图上来看,一条线性无关路径是至少包含一条在其他线性无关路径中从未有过的边的路径。
程序的环路复杂度等于线性无关路径的条数,所以本题中应该有5条线性无关路径。
试题二阅读下列说明,回答问题1至问题3,将解答填入答题纸的对应栏内。
【说明】某商店的货品价格(P)都不大于20元(且为整数),假设顾客每次付款为20元且每次限购一件商品,现有一个软件能在每位顾客购物后给出找零钱的最佳组合(找给顾客货币张数最少)。
假定此商店的找零货币面值只包括:10元(N10)、5元(N5)、1元(N1)3种。
【问题1】请采用等价类划分法为该软件设计测试用例(不考虑P为非整数的情况)并填入到下表中。

2015年上半年软件水平考试(高级)系统分析师《案例分析》真题(总分100, 考试时间90分钟)1. 选答题(共4道大题,每道大题,本部分满分)从下列4道试题中任选2道解答,如果解答的试题数超过2道,则仅题号小的2道题解答有效。
1. 阅读以下关于软件项目进度管理的叙述回答问题。
某软件公司启动了一个中等规模的软件开发项目,其功能需求由5个用例描述。
项目采用增量开发模型,每一次迭代完成1个用例;共产生5个连续的软件版本,每个版本都比上一个版本实现的功能多。
每轮迭代都包含实现、测试、修正与集成4个活动,且前一个活动完成之后才能开始下一个活动。
不同迭代之间的活动可以并行。
例如,1个已经实现的用例在测试时,软件开发人员可以开始下一个用例的实现。
实现和修正活动不能并行。
每个活动所需的工作量估算如下:(1)实现1个用例所需的时间为10人天;(2)测试1个用例所需的时间为2人天;(3)修正1个用例所需的时间为1人天(平均估算);(4)集成1个用例所需的时间为0.5人天。
项目开发过程中能够使用的资源包括:5名开发人员共同完成实现和修正工作、2名测试人员完成测试工作和1名集成人员完成集成工作。
该项目的Gannt图(部分)如图1一1所示。
1. 根据题目描述中给出的工作量计算方法,计算1个用例的实现、测试、修正、集成4个活动分别所需的日历时间(单位:天)。
正确答案:(1)实现1个用例所需的时间:2天。
(2)测试1个用例所需的时间:1天。
(3)修正1个用例所需的时间:0.5天。
(4)集成1个用例所需的时间:0.5天。
解析:本题考查软件项目管理中进度管理的相关概念以及使用Gannt图进行进度规划的相关知识。
实现1个用例需要10人天,共有5个开发人员,也就是说实现1个用例花费的实际时间为2天。
测试1个用例需要2人天,共2个测试人员,完成1个用例的测试实际花费1天。
测试之后的修正/改错需要花费1人天,共5个开发人员。
修正用例的工作由开发人员兼任。

项可以查看他可以执行的命令_______?(A)A.-l B.-a C.-m D.-s2、一个文件的权限为“rwxr-----”,那么以下哪个说法是正确的_______?(B)A.所有用户都可以执行写操作B.只有所有者可以执行写操作C.所有者和所属组可以执行写操作 D.任何人都不能执行写操作3、IP地址是一个32位的二进制数,它通常采用点分________。
( C)A.二进制数表示 B.八进制数表示 C.十进制数表示D.十六进制数表示4、IP地址是一个32位的二进制数,它通常采用点分________。
( C)A.二进制数表示 B.八进制数表示 C.十进制数表示D.十六进制数表示5、以下哪种协议属于网络层协议的_______。
(B)A.HTTPS B.ICMP C.SSL D.SNMP6、在计算机名为huayu的Windows Server 2003服务器上利用IIS搭建好FTP服务器后,建立用户为jacky,密码为123,如何直接用IE来访问________。
(C)A.http://jacky:123@huayu B.ftp://123:jacky@huayuC.ftp://jacky:123@huayu D.http://123:jacky@huayu7、Windows 2003操作系统有多少个版本_______。
(C)A.2 B.3 C.4 D.58、如果你的umask设置为022,缺省的,你创建的文件的权限为:________。
(D)A.----w--w- B.-w--w---- C.r-xr-x---D.rw-r--r--9、以下配置默认路由的命令正确的是:________。
(A)A.ip route 0.0.0.0 0.0.0.0 172.16.2.1 B.ip route 0.0.0.0 255.255.255.255 172.16.2.1C.ip router 0.0.0.0 0.0.0.0 172.16.2.1 D.ip router 0.0.0.0 0.0.0.0 172.16.2.110、在Windows 2000 Advanced Server最多支持的处理器数量是______。

2015年下半年软件水平考试(高级)系统架构师上午(综合知识)真题试卷(总分:150.00,做题时间:90分钟)一、选择题(总题数:49,分数:150.00)1.选择题()下列各题A、B、C、D四个选项中,只有一个选项是正确的,请将此选项涂写在答题卡相应位置上,答在试卷上不得分。
__________________________________________________________________________________________ 解析:2.若系统中存在n个等待事务T i (i=0,1,2,…,n-1),其中:T 0正等待被T 1锁住的数据项A 1,T 1正等待被T 2锁住的数据项A 2,…,T i正等待被T i+1锁住的数据项A i+1,…,T n-1正等待被T 0锁住的数据项A 0,则系统处于___________状态。
(分数:2.00)A.封锁B.死锁√C.循环D.并发处理解析:解析:本题考查关系数据库事务处理方面的基础知识。
与操作系统一样,封锁的方法可能引起活锁和死锁。
例如事务T 1封锁了数据R,事务T 2请求封锁R,于是T 2等待。
T 3也请求封锁R,当T 1释放了R上的封锁之后系统首先批准了T 3的请求,T 2仍然等待。
然后T 4又请求封锁R,当T 3释放R上的封锁后系统又批准了T 4的请求,……。
T 2有可能长期等待,这就是活锁。
避免活锁的简单方法是采用先来先服务的策略。
即让封锁子系统按请求封锁的先后次序对事务排队。
数据尺上的锁一旦释放就批准申请队列中的第一个事务获得锁。
又如事务T 1封锁了数据R 1,T 2封锁了数据R 2,T 3封锁了数据R 3。
然后T 1又请求封锁R 2,T 2请求封锁R 3,T 3请求封锁R 1。
于是出现T 1等待T 2释放R 2上的封锁,T 2等待T 3释放R 3上的封锁,T 3等待T 1释放R 1上的封锁。
这就使得三个事务永远不能结束。

2015软件水平考试信息系统项目管理师真题及答案下半年案例第1部分:问答题,共12题,请在空白处填写正确答案。
1.[问答题]试题一:【说明】某信息系统集成公司决定采用项目管理办公室这样的组织形式来管理公司的所有项目,并任命了公司办公室主任王某来兼任项目管理办公室主任这一职务。
鉴于目前公司项目管理制度混乱。
各项目经理都是依照自己的经验来制定项目管理计划,存在计划制定不科学、不统一等情况,王某决定从培训入手来统一和改善公司项目管理计划的制定过程,并责成项目管理办公室的小张具体负责相关培训内容的组织。
小张接到任务后,仔细学习了项目管理的相关知识,并请教了专业人士。
小张觉得项目管理体系结构中,主要由输入、工具和技术、以及输出组成。
于是也按照项目管理编制计划的输入、项目管理编制计划的工具和技术,以及项目管理计划的输出内容三个方面来组织项目管理计划培训的相关课程内容。
但是在准备进一步的内容时,小张觉得目前公司的项目五花八门,有研发项目、系统集成项目、运维项目和纯粹的软件开发项目,还有部分弱点工程项目,既有规模大的项目,也有一些小项目,是不是能够用统一的标准来要求所有的项目管理计划规范制定过程?小张觉得很怀疑。
【问题1】(8分)项目管理计划制定的作用是什么?在以上案例中,是否能够用一个统一的标准来规范公司内部各种不同项目计划的制定过程?为什么?答案:【问题1】项目管理计划制定的作用:项目管理计划明确了如何执行、监督和控制,以及如何收尾项目,经过项目各有关干系人同意的项目管理计划就是项目的基准,为项目的执行、监督和变更提供了基础。
是否能够用一个统一的标准来规范公司内部各种不同项目计划的制定过程?为什么?可以用统一的标准来规范各种不同项目计划的制定过程。
因为虽然项目规格可能各有不同,但是站在项目管理的角度,都是分为五大过程组9大知识领域。
项目管理计划中包含的各子计划及基准,具体内容会因为项目有所不同,但是制定的过程和思路都是依据项目管理知识体系。

2015年上半年软件水平考试(高级)系统分析师下午(案例分析)真题试卷(题后含答案及解析)全部题型 2. 选答题选答题(共4道大题,每道大题25分,本部分满分50分)从下列4道试题中任选2道解答,如果解答的试题数超过2道,则仅题号小的2道题解答有效。
阅读以下关于软件项目进度管理的叙述回答问题。
某软件公司启动了一个中等规模的软件开发项目,其功能需求由5个用例描述。
项目采用增量开发模型,每一次迭代完成1个用例;共产生5个连续的软件版本,每个版本都比上一个版本实现的功能多。
每轮迭代都包含实现、测试、修正与集成4个活动,且前一个活动完成之后才能开始下一个活动。
不同迭代之间的活动可以并行。
例如,1个已经实现的用例在测试时,软件开发人员可以开始下一个用例的实现。
实现和修正活动不能并行。
每个活动所需的工作量估算如下:(1)实现1个用例所需的时间为10人天;(2)测试1个用例所需的时间为2人天;(3)修正1个用例所需的时间为1人天(平均估算);(4)集成1个用例所需的时间为0.5人天。
项目开发过程中能够使用的资源包括:5名开发人员共同完成实现和修正工作、2名测试人员完成测试工作和1名集成人员完成集成工作。
该项目的Gannt图(部分)如图1一1所示。
1.根据题目描述中给出的工作量计算方法,计算1个用例的实现、测试、修正、集成4个活动分别所需的日历时间(单位:天)。
正确答案:(1)实现1个用例所需的时间:2天。
(2)测试1个用例所需的时间:1天。
(3)修正1个用例所需的时间:0.5天。
(4)集成1个用例所需的时间:0.5天。
解析:本题考查软件项目管理中进度管理的相关概念以及使用Gannt图进行进度规划的相关知识。
实现1个用例需要10人天,共有5个开发人员,也就是说实现1个用例花费的实际时间为2天。
测试1个用例需要2人天,共2个测试人员,完成1个用例的测试实际花费1天。
测试之后的修正/改错需要花费1人天,共5个开发人员。
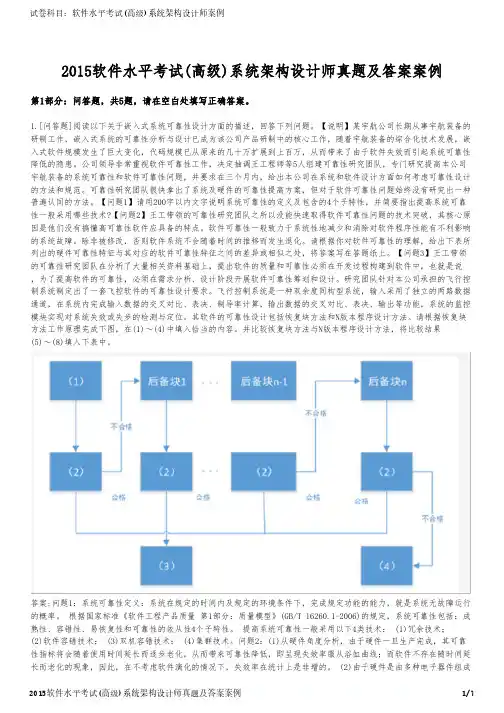
2015软件水平考试(高级)系统架构设计师真题及答案案例第1部分:问答题,共5题,请在空白处填写正确答案。
1.[问答题]阅读以下关于嵌入式系统可靠性设计方面的描述,回答下列问题。
【说明】某宇航公司长期从事宇航装备的研制工作,嵌入式系统的可靠性分析与设计已成为该公司产品研制中的核心工作,随着宇航装备的综合化技术发展,嵌入式软件规模发生了巨大变化,代码规模已从原来的几十万扩展到上百万,从而带来了由于软件失效而引起系统可靠性降低的隐患。
公司领导非常重视软件可靠性工作,决定抽调王工程师等5人组建可靠性研究团队,专门研究提高本公司宇航装备的系统可靠性和软件可靠性问题,并要求在三个月内,给出本公司在系统和软件设计方面如何考虑可靠性设计的方法和规范。
可靠性研究团队很快拿出了系统及硬件的可靠性提高方案,但对于软件可靠性问题始终没有研究出一种普遍认同的方法。
【问题1】请用200字以内文字说明系统可靠性的定义及包含的4个子特性,并简要指出提高系统可靠性一般采用哪些技术?【问题2】王工带领的可靠性研究团队之所以没能快速取得软件可靠性问题的技术突破,其核心原因是他们没有搞懂高可靠性软件应具备的特点。
软件可靠性一般致力于系统性地减少和消除对软件程序性能有不利影响的系统故障。
除非被修改,否则软件系统不会随着时间的推移而发生退化。
请根据你对软件可靠性的理解,给出下表所列出的硬件可靠性特征与其对应的软件可靠性特征之间的差异或相似之处,将答案写在答题纸上。
【问题3】王工带领的可靠性研究团队在分析了大量相关资料基础上,提出软件的质量和可靠性必须在开发过程构建到软件中,也就是说,为了提高软件的可靠性,必须在需求分析、设计阶段开展软件可靠性筹划和设计。
研究团队针对本公司承担的飞行控制系统制定出了一套飞控软件的可靠性设计要求。
飞行控制系统是一种双余度同构型系统,输入采用了独立的两路数据通道,在系统内完成输入数据的交叉对比、表决、制导率计算,输出数据的交叉对比、表决、输出等功能,系统的监控模块实现对系统失效或失步的检测与定位。

2015年下半年软件评测师真题+答案解析上午选择1、CPU响应DMA请求是在(1)结束时。
A. 一条指令执行B. 一段程序C. 一个时钟周期D. 一个总线周期答案:DDMA控制器在需要的时候代替CPU作为总线主设备,在不受CPU干预的情况下,控制I/O设备与系统主存之间的直接数据传输。
DMA 操作占用的资源是系统总线,而CPU并非在整个指令执行期间即指令周期内都会使用总线,故DMA请求的检测点设置在每个机器周期也即总线周期结束时执行,这样使得总线利用率最高2、虚拟存储体系是由(2)两线存储器构成。
A. 主存,辅存B. 寄存器,CacheC. 寄存器,主体D. Cache,主存答案:A计算机中不同容量、不同速度、不同访问形式、不同用途的各种存储器形成的是一种层次结构的存储系统。
所有的存储器设备按照一定的层次逻辑关系通过软硬件连接起来,并进行有效的管理,就形成了存储体系。
不同层次上的存储器发挥着不同的作用。
一般计算机系统中主要有两种存储体系:Cache存储体系是由Cache和主存储器构成,主要目的是提高存储器速度,对系统程序员以上均透明;虚拟存储体系是由主存储器和在线磁盘存储器等辅存构成,主要目的是扩大存储器容量,对应用程序员透明。
3、浮点数能够表示的数的范围是由其(3)的位数决定的。
A. 尾数B. 阶码C. 数符D. 阶符答案:B在计算机中使用了类似于十进制科学计数法的方法来表示二进制实数,因其表示不同的数时小数点位置的浮动不固定而取名浮点数表示法。
浮点数编码由两部分组成:阶码E(即指数,为带符号定点整数,常用移码表示,也有用补码的)和尾数(是定点纯小数,常用补码或原码表示)。
因此可以知道,浮点数的精度由尾数的位数决定,表示范围的大小则主要由阶码的位数决定。
4、在机器指令的地址段中,直接指出操作数本身的寻址方式称为(4)。
A. 隐含寻址B. 寄存器寻址C. 立即寻址D. 直接寻址答案:C随着主存增加,指令本身很难保证直接反映操作数的值或其地址,必须通过某种映射方式实现对所需操作数的获取。

计算机水平考试中级软件设计师2015年上半年下午真题(总分:90.00,做题时间:90分钟)一、下午试题(总题数:6,分数:90.00)试题一阅读下列说明和图,回答问题1至问题4,将解答填入答题纸的对应栏内。
【说明】某大学为进一步推进无纸化考试,欲开发一考试系统。
系统管理员能够创建包括专业方向、课程编号、任课教师等相关考试基础信息,教师和学生进行考试相关的工作。
系统与考试有关的主要功能如下。
(1)考试设置。
教师制定试题(题目和答案),制定考试说明、考试时间和提醒时间等考试信息,录入参加考试的学生信息,并分别进行存储。
(2)显示并接收解答。
根据教师设定的考试信息,在考试有效时间内向学生显示考试说明和题目,根据设定的考试提醒时间进行提醒,并接收学生的解答。
(3)处理解答。
根据答案对接收到的解答数据进行处理,然后将解答结果进行存储。
(4)生成成绩报告。
根据解答结果生成学生个人成绩报告,供学生查看。
(5)生成成绩单。
对解答结果进行核算后生成课程成绩单供教师查看。
(6)发送通知。
根据成绩报告数据,创建通知数据并将通知发送给学生;根据成绩单数据,创建通知数据并将通知发送给教师。
现采用结构化方法对考试系统进行分析与设计,获得如图1-1所示的上下文数据流图和图1-2所示的0层数据流图。
(分数:15.00)(1).问题:1.1 (2分)使用说明中的词语,给出图1-1中的实体E1~E2的名称。
(分数:3.75)__________________________________________________________________________________________ 正确答案:(E1:教师; E2:学生。
)解析:(2).问题:1.2 (4分)使用说明中的词语,给出图1-2中的数据存储D1~D4的名称。
(分数:3.75)__________________________________________________________________________________________ 正确答案:(D1:试题(表)或题目和答案(表) D2:学生信息(表) D3:考试信息(秦) D4:解答结果(表))解析:(3).问题:1.3 (4分)根据说明和图中词语,补充图1-2中缺失的数据流及其起点和终点。
2015软考软件设计师试题(4)13. 从静态角度看,进程由__(61)__ 、__(62)__ 和__(63)__ 三部分组成。
用户可通过__(64)__ 建立和撤消进程。
通常,用户进程被建立后,__(65)__ 。
供选择的答案(61)。
A.JCBB.DCBC.PCBD.PMT(62)。
A.程序段B.文件体C.I/OD.子程序(63)。
A.文件描述块B.数据空间C.EOFD.I/O缓冲区(64)。
A.函数调用B.宏指令C.系统调用D.过程调用(65)。
A.便一直存在于系统中,直到被操作人员撤消B.随着作业运行正常或不正常结束而撤消C.随着时间片轮转而撤消与建立D.随着进程的阻塞或唤醒而撤消与建立参考答案:(61)C (62)A (63)B (64)C (65)BD14. 设有关系模式W (C,P,S,G,T,R ),其中各属性的含义是:C--课程,P--教师,S--学生,G--成绩,T--时间,R--教室,根据语义有如下数据依赖集:D={ C→P,(S,C)→G,(T,R)→C,(T,P)→R,(T,S)→R }关系模式W 的一个码(关键字)是__(66)__ ,W的规范化程序达到__(67)__ 。
若将关系模式W 分解为3 个关系模式W1(C,P),W2(S,C,G),W3(S,T,R,C),则W1 的规范化程序达到__(68)__ ,W2 的规范化程度达到__(69)_ ,W3 的规范化程序达到__(70)__ 。
供选择的答案(66)A (S,C)B (T,R)C (T,P)D (T,S)(67)~(70)A.1NF B.2NF C.3NF D.BCNF E.4NF参考答案:(66)D (67)B (68)E (69)E (70)B14. 设有关系模式W (C,P,S,G,T,R ),其中各属性的含义是:C--课程,P--教师,S--学生,G--成绩,T--时间,R--教室,根据语义有如下数据依赖集:D={ C→P,(S,C)→G,(T,R)→C,(T,P)→R,(T,S)→R }关系模式W 的一个码(关键字)是__(66)__ ,W的规范化程序达到__(67)__ 。
2015年下半年下午软件测评师考试试题-案例分析-答案与解析试题一(共15分)【说明】阅读下列java程序,回答问题1至问题3,将解答填入答题纸内对应栏内。
【Java程序】【问题1】请简述基本路径测试法的概念。
【参考答案】基本路径测试法是在程序控制流图的基础上,通过分析控制构造的环路复杂性,导出基本可执行路径集合,从而设计测试用例的方法。
【问题2】请画出上述程序的控制流图,并计算其控制流图的环图复杂度V(G)。
控制流图【参考答案】环路复杂度V(G)=5【问题3】请给出问题2中的控制流图的线性无关路径。
【参考答案】1. 1-2-4-5-6-8-9-102. 1-2-4-5-7-8-9-10(1-2-4-5-7-8-10)3. 1-2-4-5-6-8-10(1-2-4-5-7-8-10)4. 1-2-3-4-5-6-8-9-10(1-2-3-4-5-7-8-9-10,1-2-3-4-5-6-8-10,1-2-3-4-5-7-8-10)5. 1-2-3-8-9-10(1-2-3-8-10)本问题考査白盒测试用例设计方法:基本路径法。
涉及到的知识点包括:根据控制流图和环路复杂度给出线性无关路径。
线性无关路径是指包含一组以前没有处理的语句或条件的路径。
从控制流图上来看,一条线性无关路径是至少包含一条在其他线性无关路径中从未有过的边的路径。
程序的环路复杂度等于线性无关路径的条数,所以本题中应该有5条线性无关路径。
试题二阅读下列说明,回答问题1至问题3,将解答填入答题纸的对应栏内。
【说明】某商店的货品价格(P)都不大于20元(且为整数),假设顾客每次付款为20元且每次限购一件商品,现有一个软件能在每位顾客购物后给出找零钱的最佳组合(找给顾客货币张数最少)。
假定此商店的找零货币面值只包括:10元(N10)、5元(N5)、1元(N1)3种。
【问题1】请采用等价类划分法为该软件设计测试用例(不考虑P为非整数的情况)并填入到下表中。
计算机软件水平考试/模拟试题2015软件水平考试《程序员》考前冲刺模拟题试题(1)在Word文字处理软件的界面上,单击工具栏上的按钮,其作用是 (1) 。
(1) A.打印当前页 B.打印文档全文C.打印预览D.弹出打印对话框进行设置试题(1)分析常用工具栏的图形按钮 (放大镜图形)是“打印预览”按钮,可以显示打印后文档的外观,可整体的浏览页面外观。
参考答案(1)C试题(2)关于计算机的使用和维护,下列叙述中错误的是 (2) 。
(2)A.计算机要经常使用,不要长期闲置不用B.在计算机附近应避免磁场干扰C.为了延长计算机的寿命,应避免频繁开关计算机D.为了省电,每次只打开一个程序窗口试题(2)分析计算机长期闲置不用,不利于发挥作用,也会像所有电器那样容易受潮锈蚀,电路板落尘短路等。
计算机附近的强磁场对显示器、磁记录设备等都有影响。
频繁开关机会造成强电压脉冲瞬间冲击,损害计算机设备。
打开多少个程序窗口是由软件决定的,并不会省电或费电。
参考答案(2)D试题(3)计算机内数据采用二进制表示是因为二进制数(3) 。
(3) A.最精确 B.最容易理解C.最便于硬件实现D.运算最快试题(3)分析二进制数只有“0”和“1”两个基本符号,易于用两种对立的物理状态表示。
例如,可用电灯开关的“闭合”状态表示“1”,用“断开”状态表示“0”;用晶体管的导通表示“1”,截止表示“0”;用电脉冲的有或无两种状态分别表示“1”或“0”;一切有两种对立稳定状态的器件都可以表示二进制的“0”和“1”。
而十进制数有10个基本符号(0,1,2,…,9),要用10种状态才能表示,在计算机内实现起来很困难。
一般来说,精确取决于小数点后的位数;数学语言、自然语言容易理解;运算速度与算法、时钟周期、物理器件等相关。
参考答案(3)C试题(4)以下计算机操作中,不正确的是 (4) 。
(4)A.各种汉字输入方法的切换操作是可以由用户设置的B.在文件夹中删除应用程序的方法往往不能彻底卸载软件产品C.用Del键删除的文件还可以从回收站中执行还原操作来恢复D.用Shift+Del键删除的文件还可以从回收站中执行还原操作来恢复试题(4)分析一般计算机系统可以安装多种汉字输入方法,各种汉字输入方法的切换操作是可以由用户设置的,即进行切换选择汉字输入方法;一个应用程序的各个文件不完全放在一个连续的存储空间中,或放在同一个文件夹中,不可能用删除的方法将一个应用程序的所有文件全部删除,而用卸载的方法可完成删除工作;在Windows 中删除文件或文件夹时,一般的操作方法是:先选定想删除的文件或文件夹,单击“文件”菜单,执行“删除”命令,或直接按Delete 键。
2015年下半年上午软件测评师考试试题-答案与解析一、单项选择题(共75分,每题1分。
每题备选项中,只有1个最符合题意)●CPU响应DMA请求是在(1)结束时。
(1)A.一条指令执行 B.一段程序 C.一个时钟周期 D.一个总线周期【参考答案】D【答案解析】DMA控制器在需要的时候代替CPU作为总线主设备,在不受CPU干预的情况下,控制I/O设备与系统主存之间的直接数据传输。
DMA操作占用的资源是系统总线,而CPU 并非在整个指令执行期间即指令周期内都会使用总线,故DMA请求的检测点设置在每个机器周期也即总线周期结束时执行,这样使得总线利用率最高。
●虚拟存储体系是由(2)两线存储器构成。
(2)A.主存,辅存 B.寄存器,Cache C.寄存器,主体 D.Cache,主存【参考答案】A【答案解析】计算机中不同容量、不同速度、不同访问形式、不同用途的各种存储器形成的是一种层次结构的存储系统。
所有的存储器设备按照一定的层次逻辑关系通过软硬件连接起来,并进行有效的管理,就形成了存储体系。
不同层次上的存储器发挥着不同的作用。
一般计算机系统中主要有两种存储体系:Cache存储体系是由Cache和主存储器构成,主要目的是提高存储器速度,对系统程序员以上均透明;虚拟存储体系是由主存储器和在线磁盘存储器等辅存构成,主要目的是扩大存储器容量,对应用程序员透明。
●浮点数能够表示的数的范围是由其(3)的位数决定的。
(3)A.尾数 B.阶码 C.数符 D.阶符【参考答案】B【答案解析】在计算机中使用了类似于十进制科学计数法的方法来表示二进制实数,因其表示不同的数时小数点位置的浮动不固定而取名浮点数表示法。
浮点数编码由两部分组成:阶码E(即指数,为带符号定点整数,常用移码表示,也有用补码的)和尾数(是定点纯小数,常用补码或原码表示)。
因此可以知道,浮点数的精度由尾数的位数决定,表示范围的大小则主要由阶码的位数决定。
●在机器指令的地址段中,直接指出操作数本身的寻址方式称为(4)。
2015年软件水平考试程序员精选题(1) -在排序数组中查找和为给定值的两个数字 题目:输入一个已经按升序排序过的数组和一个数字,在数组中查找两个数,使得它们的和正好是输入的那个数字。要求时间复杂度是O(n)。如果有多对数字的和等于输入的数字,输出任意一对即可。
例如输入数组1、2、4、7、11、15和数字15。由于4+11=15,因此输出4和11。
分析:如果我们不考虑时间复杂度,最简单想法的莫过去先在数组中固定一个数字,再依次判断数组中剩下的n-1个数字与它的和是不是等于输入的数字。可惜这种思路需要的时间复杂度是O(n2)。
我们假设现在随便在数组中找到两个数。如果它们的和等于输入的数字,那太好了,我们找到了要找的两个数字;如果小于输入的数字呢?我们希望两个数字的和再大一点。由于数组已经排好序了,我们是不是可以把较小的数字的往后面移动一个数字?因为排在后面的数字要大一些,那么两个数字的和也要大一些,就有可能等于输入的数字了;同样,当两个数字的和大于输入的数字的时候,我们把较大的数字往前移动,因为排在数组前面的数字要小一些,它们的和就有可能等于输入的数字了。
我们把前面的思路整理一下:最初我们找到数组的第一个数字和最后一个数字。当两个数字的和大于输入的数字时,把较大的数字往前移动;当两个数字的和小于数字时,把较小的数字往后移动;当相等时,打完收工。这样扫描的顺序是从数组的两端向数组的中间扫描。
问题是这样的思路是不是正确的呢?这需要严格的数学证明。感兴趣的读者可以自行证明一下。
参考代码: /////////////////////////////////////////////////////////////////////// // Find two numbers with a sum in a sorted array // Output: ture is found such two numbers, otherwise false
/////////////////////////////////////////////////////////////////////// bool FindTwoNumbersWithSum (
int data[], // a sorted array unsigned int length, // the length of the sorted array int sum, // the sum int& num1, // the first number, output int& num2 // the second number, output ) { bool found = false; if(length < 1) return found; int ahead = length - 1; int behind = 0; while(ahead > behind) { long long curSum = data[ahead] + data[behind]; // if the sum of two numbers is equal to the input // we have found them if(curSum == sum) { num1 = data[behind]; num2 = data[ahead]; found = true; break; } // if the sum of two numbers is greater than the input // decrease the greater number else if(curSum > sum) ahead --; // if the sum of two numbers is less than the input // increase the less number else behind ++; } return found; } -查找链表中倒数第k个结点 题目:输入一个单向链表,输出该链表中倒数第k个结点。链表的倒数第0个结点为链表的尾指针。链表结点定义如下: struct ListNode { int m_nKey; ListNode* m_pNext; }; 分析:为了得到倒数第k个结点,很自然的想法是先走到链表的尾端,再从尾端回溯k步。可是输入的是单向链表,只有从前往后的指针而没有从后往前的指针。因此我们需要打开我们的思路。 既然不能从尾结点开始遍历这个链表,我们还是把思路回到头结点上来。假设整个链表有n个结点,那么倒数第k个结点是从头结点开始的第n-k-1个结点(从0开始计数)。如果我们能够得到链表中结点的个数n,那我们只要从头结点开始往后走n-k-1步就可以了。如何得到结点数n?这个不难,只需要从头开始遍历链表,每经过一个结点,计数器加一就行了。 这种思路的时间复杂度是O(n),但需要遍历链表两次。第一次得到链表中结点个数n,第二次得到从头结点开始的第n-k-1个结点即倒数第k个结点。 如果链表的结点数不多,这是一种很好的方法。但如果输入的链表的结点个数很多,有可能不能一次性把整个链表都从硬盘读入物理内存,那么遍历两遍意味着一个结点需要两次从硬盘读入到物理内存。我们知道把数据从硬盘读入到内存是非常耗时间的操作。我们能不能把链表遍历的次数减少到1?如果可以,将能有效地提高代码执行的时间效率。
如果我们在遍历时维持两个指针,第一个指针从链表的头指针开始遍历,在第k-1步之前,第二个指针保持不动;在第k-1步开始,第二个指针也开始从链表的头指针开始遍历。由于两个指针的距离保持在k-1,当第一个(走在前面的)指针到达链表的尾结点时,第二个指针(走在后面的)指针正好是倒数第k个结点。
这种思路只需要遍历链表一次。对于很长的链表,只需要把每个结点从硬盘导入到内存一次。因此这一方法的时间效率前面的方法要高。
思路一的参考代码: /////////////////////////////////////////////////////////////////////// // Find the kth node from the tail of a list // Input: pListHead - the head of list // k - the distance to the tail // Output: the kth node from the tail of a list /////////////////////////////////////////////////////////////////////// ListNode* FindKthToTail_Solution1(ListNode* pListHead, unsigned int k)
{ if(pListHead == NULL) return NULL; // count the nodes number in the list ListNode *pCur = pListHead; unsigned int nNum = 0; while(pCur->m_pNext != NULL) { pCur = pCur->m_pNext; nNum ++; } // if the number of nodes in the list is less than k // do nothing if(nNum < k) return NULL; // the kth node from the tail of a list // is the (n - k)th node from the head pCur = pListHead; for(unsigned int i = 0; i < nNum - k; ++ i) pCur = pCur->m_pNext; return pCur; } 思路二的参考代码: /////////////////////////////////////////////////////////////////////// // Find the kth node from the tail of a list // Input: pListHead - the head of list // k - the distance to the tail // Output: the kth node from the tail of a list /////////////////////////////////////////////////////////////////////// ListNode* FindKthToTail_Solution2(ListNode* pListHead, unsigned int k) { if(pListHead == NULL) return NULL; ListNode *pAhead = pListHead; ListNode *pBehind = NULL; for(unsigned int i = 0; i < k; ++ i) { if(pAhead->m_pNext != NULL) pAhead = pAhead->m_pNext; else { // if the number of nodes in the list is less than k, // do nothing return NULL; } } pBehind = pListHead; // the distance between pAhead and pBehind is k // when pAhead arrives at the tail, p // Behind is at the kth node from the tail while(pAhead->m_pNext != NULL) { pAhead = pAhead->m_pNext; pBehind = pBehind->m_pNext; } return pBehind; } 讨论:这道题的代码有大量的指针操作。在软件开发中,错误的指针操作是大部分问题的根源。因此每个公司都希望程序员在操作指针时有良好的习惯,比如使用指针之前判断是不是空指针。这些都是编程的细节,但如果这些细节把握得不好,很有可能就会和心仪的公司失之交臂。
另外,这两种思路对应的代码都含有循环。含有循环的代码经常出的问题是在循环结束条件的判断。是该用小于还是小于等于?是该用k还是该用k-1?由于题目要求的是从0开始计数,而我们的习惯思维是从1开始计