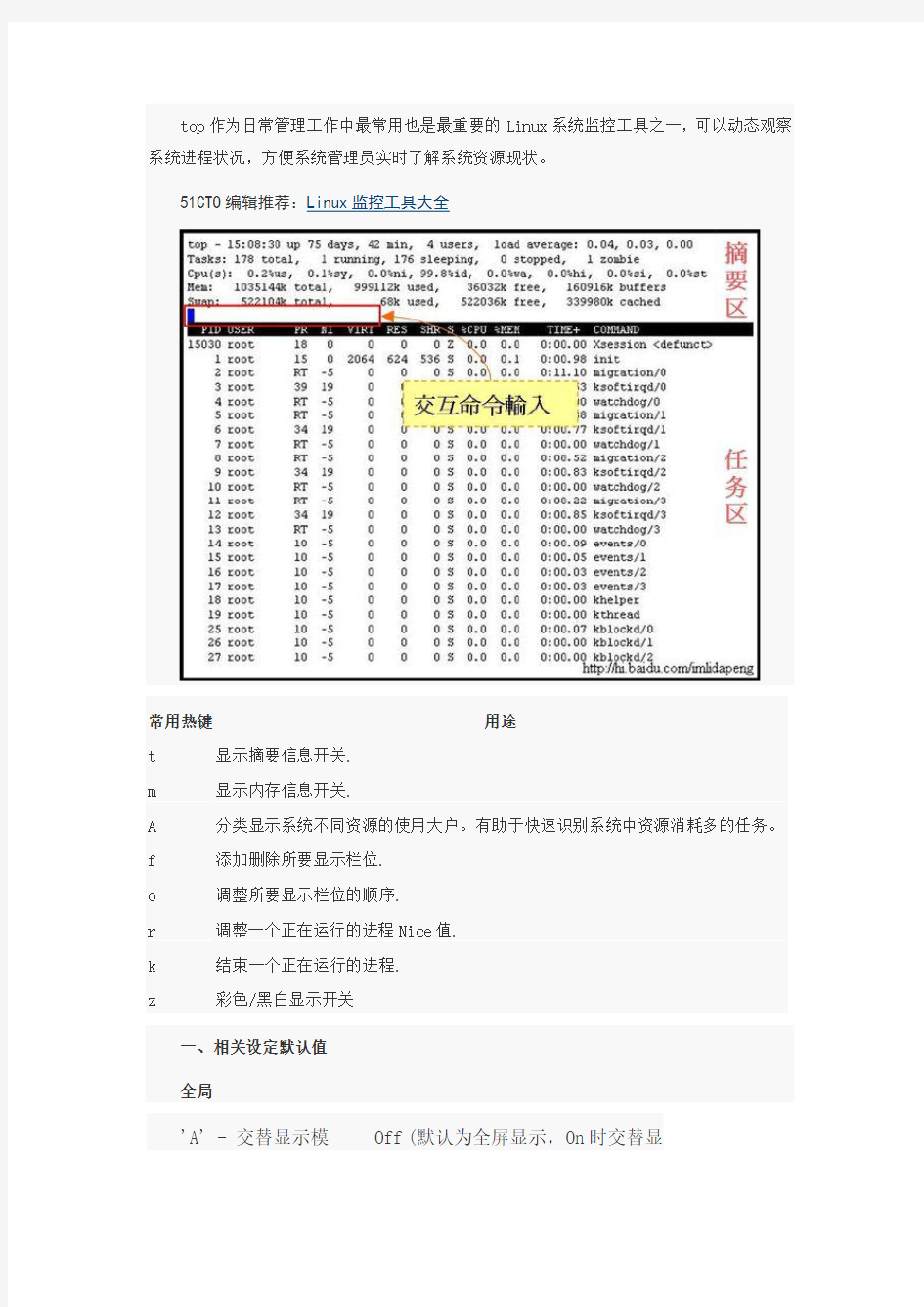

top作为日常管理工作中最常用也是最重要的Linux系统监控工具之一,可以动态观察系统进程状况,方便系统管理员实时了解系统资源现状。
51CTO编辑推荐:Linux监控工具大全
一、相关设定默认值
全局
式
* 'd' - 刷新时间间隔
'I' - Irix mode
* 'p' - 监控特定PID
* 's' - 安全模式
'B' - 粗体显示示)
3.0秒
On
Off
Off
Off
摘要区
'l'- 平均负载及系统运行时间
't'- 任务及CPU状态
'm'- 内存及交换空间状态
'1'- 单CPU显示
On
On
On
On (如果为系统包含多处理器,只显示在一行中)
任务区域
'b'- 黑体/反色显示高亮的行/列
* 'c'- 任务执行的命令行
* 'H'- 显示线程
* 'i'- 空闲任务显示
'R'- 反序显示
* 'S'- 累计时间
'x'- 高亮显示排序的列
'y'- 高亮显示正在运行的任务
'z'- 彩色/黑白显示
On (off)
Off (只显示任务名称,不显示任务全格式信息)
Off
On
On
Off
Off
On
Off
注:*标示的设定,可以在启动top时,使用命令行参数覆盖指定参数值。
二、命令行启动参数:
用法: top -hv | -bcisSHM -d delay -n iterations [-u user | -U user] -p pid [,pid ...]
-b : 批次模式运行。通常用作来将top的输出的结果传送给其他程式或储存成文件。
-c : 显示执行任务的命令行。
-d : 设定延迟时间
-h : 帮助
-H : 显示线程。当这个设定开启时,将显示所有进程产生的线程。
-i : 显示空闲的进程。
-n : 执行次数。一般与-b搭配使用
-u : 监控指定用户相关进程
-U : 监控指定用户相关进程
-p : 监控指定的进程。当监控多个进程时,进程ID以逗号分隔。这个选项只能在命令行下使用。
-s : 安全模式操作
-S : 累计时间模式
-v : 显示top版本,然后退出。
-M : 自动显示内存单位(k/M/G)
三、栏位信息
在top中,分别使用26个英文字母对应进程相关信息栏位。可已通过f来添加或移除指定的栏位,通过o来调整对栏位显示顺序。下面我们针对这些栏位进行说明。
a: PID (Process Id):任务的进程ID
b: PPID (Parent Process Pid):父任务的进程ID
c: RUSER (Real User Name):任务的所有者真实名称
d: UID (User Id):任务所有者ID
e: USER (User Name):任务所有者名称
f: GROUP (Group Name):任务所有者群组名
g: TTY (Controlling Tty):终端
h: PR (Priority):优先级
i: NI (Nice value):Nice值
j: P (Last used CPU (SMP)):
k: %CPU (CPU usage):CPU使用率
l: TIME (CPU Time):CPU时间
m: TIME+ (CPU Time, hundredths):CPU时间,精确到秒
n: %MEM (Memory usage (RES)):内存使用率
o: VIRT (Virtual Image (kb)):虚拟内存。VIRT = SWAP + RES p: SWAP (Swapped size (kb)):交换空间
q: RES (Resident size (kb)):常驻内存。RES = CODE + DATA r: CODE (Code size (kb)):
s: DATA (Data+Stack size (kb)):
t: SHR (Shared Mem size (kb)):共享内存。
u: nFLT (Page Fault count):
v: nDRT (Dirty Pages count):
w: S (Process Status):进程状态
分别有以下几种:
D = uninterruptible sleep = 不可被唤醒睡眠
R = running = 正在运行中
S = sleeping = 睡眠状态
T = traced or stopped = 出错或停止状态
Z = zombie = 僵尸状态
x: Command (Command line or Program name):进程名或命令行y: WCHAN (Sleeping in Function):
z: Flags (Task Flags):
示例1:增加和移除进程信息栏位(输入f)
示例2:调整进程信息栏位显示顺序(输入o)
四、交互命令
1.全局命令
回车、空格 : 刷新显示信息?、h : 帮助
= : 移除所有任务显示的限制
A : 交替显示模式切换
B : 粗体显示切换
d、s : 更改界面刷新时间间隔G : 选择其它窗口/栏位组
I : Irix或Solaris模式切换u、U : 监控指定用户相关进程k : 结束进程
q : 退出top
r : 重新设定进程的nice值
W : 存储当前设定
Z : 改变颜色模板
2.摘要区命令
l : 平均负载及系统运行时间显示开关
m : 内存及交换空间使用率显示开关
t : 当前任务及CPU状态显示开关
1 : 汇总显示CPU状态或分开显示每个CPU状态
3.任务区命令
外观样式
b : 黑体/反色显示高亮的行/列。控制x和y交互命令的顯示樣式。x : 高亮显示排序的列
y : 高亮显示正在运行的任务
z : 彩色/黑白显示。
显示内容
c : 任务执行的命令行或进程名称
f、o : 增加和移除进程信息栏位及调整进程信息栏位显示顺序
H : 显示线程
S : 时间累计模式
u : 监控指定用户相关进程
任务显示的数量
i : 显示空闲的进程
n或# : 设置任务显示最大数量
任务排序
M : 按内存使用率排序
N : 按PID排序
P : 按CPU使用率排序
T : 按Time+排序
< : 按当前排序栏位左边相邻栏位排序> : 按当前排序栏位右边相邻栏位排序F 或 O : 选择排序栏位
R : 反向排序
查询相关 find 按规则查找某个文件或文件夹,包括子目录 ?find . -name '*.sh' -- 以.sh结尾的文件 ?find . -name '*channel*' -- 包含channel字符的文件 ?find . -name 'build*' -- 以build开头的文件 ?find . -name 'abc??' -- abc后面有两个字符的文件 grep 查找内容包含指定的范本样式的文件,Global Regular Expression Print ?grep -n pattern files -- 规则-n表示显示行号 ?grep -n 'PostsActivity' AndroidManifest.xml ?grep -n '\d' AndroidManifest.xml ?grep 'aapt' build-channel.xml -- 文件中包含字符串的所有地方 ?grep -n 'aapt' build-channel.xml -- 文件中包含字符串的所有地方,并显示行号 ?ps -e | grep java -- 所有java进程 ?ps -e | grep -i qq --所有qq进程,不区分大小写 ?find . -name '*channel.xml' | xargs grep -n 'aapt' -- 在以channel.xml 结尾的文件中查找包含‘aapt’关键字的地方 ?ls | grep 'channel' -- 包含channel关键字的文件 which 在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果?which zip ?which grep 查看命令 tail tail [-f] [-c Number | -n Number | -m Number | -b Number | -k Number] [File] 从指定点开始将文件写到标准输出。使用tail命令的-f选项可以方便的查阅正在改变的日志文件,tail -f filename会把filename里最尾部的内容显示在屏幕上,并且不断刷新,使你看到最新的文件内容。 ?tail -f test.log,循环查看文件内容,Ctrl+c来终止 ?tail -n 5 test.log,显示文件最后5行内容
1.1 CPU消耗 在文件"/proc/stat"里面就包含了CPU的信息。 #cat /proc/stat 可通过mpstat系统性能检测工具对当前cpu使用情况进行查看,如下: 语法:mpstat [ options... ] [
目录: Linux硬件基础 CPU:就像人的大脑,主要负责相关事情的判断以及实际处理的机制。 CPU:CPU的性能主要体现在其运行程序的速度上。影响运行速度的性能指标包括CPU的工作频率、Cache容量、指令系统和逻辑结构等参数。 查询指令:cat /proc/cpuinfo 内存:大脑中的记忆区块,将皮肤、眼睛等所收集到的信息记录起来的地方,以供CPU 进行判断。 内存:影响内存的性能主要是内存主频、内容容量。 查询指令:cat /proc/meminfo 硬盘:大脑中的记忆区块,将重要的数据记录起来,以便未来再次使用这些数据。 硬盘:容量、转速、平均访问时间、传输速率、缓存。 查询指令:fdisk -l (需要root权限) Linux监控命令 linux性能监控分析命令 vmstat vmstat使用说明 vmstat可以对操作系统的内存信息、进程状态、CPU活动、磁盘等信息进行监控,不足之处是无法对某个进程进行深入分析。 vmstat [-a] [-n] [-S unit] [delay [ count]] -a:显示活跃和非活跃内存 -m:显示slabinfo -n:只在开始时显示一次各字段名称。 -s:显示内存相关统计信息及多种系统活动数量。 delay:刷新时间间隔。如果不指定,只显示一条结果。 count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。-d:显示各个磁盘相关统计信息。 Sar sar是非常强大性能分析命令,通过sar命令可以全面的获取系统的CPU、运行队列、磁盘I/O、交换区、内存、cpu中断、网络等性能数据。 sar 命 令行
Linux top 命令详解 top命令经常用来监控linux的系统状况,比如cpu、内存的使用,程序员基本都知道这个命令,但比较奇怪的是能用好它的人却很少,例如top监控视图中内存数值的含义就有不少的曲解。 本文通过一个运行中的WEB服务器的top监控截图,讲述top视图中的各种数据的含义,还包括视图中各进程(任务)的字段的排序。 top进入视图 top视图01 【top视图01】是刚进入top的基本视图,我们来结合这个视图讲解各个数据的含义。 第一行: 10:01:23 —当前系统时间 126 days, 14:29 —系统已经运行了126天14小时29分钟(在这期间没有重启过) 2 users —当前有2个用户登录系统 load average: 1.15, 1.42, 1.44 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。 load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。 第二行: Tasks —任务(进程),系统现在共有183个进程,其中处于运行中的有1个,182个在休眠(sleep),stoped 状态的有0个,zombie状态(僵尸)的有0个。
第三行:cpu状态 6.7% us —用户空间占用CPU的百分比。 0.4% sy —内核空间占用CPU的百分比。 0.0% ni —改变过优先级的进程占用CPU的百分比 92.9% id —空闲CPU百分比 0.0% wa — IO等待占用CPU的百分比 0.0% hi —硬中断(Hardware IRQ)占用CPU的百分比 0.0% si —软中断(Software Interrupts)占用CPU的百分比 在这里CPU的使用比率和windows概念不同,如果你不理解用户空间和内核空间,需要充充电了。 第四行:内存状态 8306544k total —物理内存总量(8GB) 7775876k used —使用中的内存总量(7.7GB) 530668k free —空闲内存总量(530M) 79236k buffers —缓存的内存量(79M) 第五行:swap交换分区 2031608k total —交换区总量(2GB) 2556k used —使用的交换区总量(2.5M) 2029052k free —空闲交换区总量(2GB) 4231276k cached —缓冲的交换区总量(4GB) 这里要说明的是不能用windows的内存概念理解这些数据,如果按windows的方式此台服务器“危矣”:8G的内存总量只剩下530M的可用内存。Linux的内存管理有其特殊性,复杂点需要一本书来说明,这里只是简单说点和我们传统概念(windows)的不同。 第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。 如果出于习惯去计算可用内存数,这里有个近似的计算公式:第四行的free + 第四行的buffers + 第五行的cached,按这个公式此台服务器的可用内存:530668+79236+4231276 = 4.7GB。 对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。 第六行是空行 第七行以下:各进程(任务)的状态监控 PID —进程id USER —进程所有者 PR —进程优先级 NI — nice值。负值表示高优先级,正值表示低优先级 VIRT —进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES RES —进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA SHR —共享内存大小,单位kb
Linux终端下使用ifconfig命令出错“bash ifconfig command not found “解决方法 ?平台信息:FAQ适用于linux环境。 ?适用对象:爱数技术人员/客户/代理商技术人员。 ?文档类型:FAQ。 问题描述 打开linux终端,输入ifconfig,显示ifconfig:command not found ,su root,还是不可以。如下图所示: 分析问题 主要是一些用在系统管理上的命令,例如ifconfig, route等等,他们位于/sbin, 或/usr/sbin/下。其实这些命令本身就没有任何问题,软件包早已安装完毕,路径设置也没有丝毫问题。而出现Command not found的原因在于:在终端使用su变成超级用户的时候没有将root的路径(环境)一起切换过来,从而导致身份虽然已经是root,但是工作的环境和路径依旧是普通用户的。 解决方案 方案一:最直接的办法是使用su - ,root的路径会一起跟着变过来,就可以运用ifconfig进行网络配置等操作。如下图所示:
方案二:在root用户下按照下面的操作进行修改文件,重新启动或者注销系统,再输入ifconfig就可以直接配置网络了。操作如下: [oracle@rhel4ora10g ~]$ su [root@rhel4ora10g oracle]# vi /etc/profile 把下面if语句注释掉: #path Manipulation if [`id -u` = 0]; then pathmunge /sbin pathmunge /usr/sbin pathmunge /usr/local/sbin fi 修改为: #path Manipulation #if [`id -u` = 0]; then pathmunge /sbin pathmunge /usr/sbin pathmunge /usr/local/sbin #fi
总控服务器性能: 一、Cpu性能评估 Vmstat命令的参数解释: 对上面每项的输出解释如下: procs r列表示运行和等待cpu时间片的进程数,这个值如果长期大于系统CPU的个数,说明CPU 不足,需要增加CPU。? b列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。 Memory swpd列表示切换到内存交换区的内存数量(以k为单位)。如果swpd的值不为0,或者比较大,只要si、so的值长期为0,这种情况下一般不用担心,不会影响系统性能。 free列表示当前空闲的物理内存数量(以k为单位)? buff列表示buffers cache的内存数量,一般对块设备的读写才需要缓冲。 cache列表示page cached的内存数量,一般作为文件系统cached,频繁访问的文件都会被cached,如果cache值较大,说明cached的文件数较多,如果此时IO中bi比较小,说明文件系统效率比较好。 swap si列表示由磁盘调入内存,也就是内存进入内存交换区的数量。 so列表示由内存调入磁盘,也就是内存交换区进入内存的数量。 一般情况下,si、so的值都为0,如果si、so的值长期不为0,则表示系统内存不足。需要增加系统内存。? IO项显示磁盘读写状况? Bi列表示从块设备读入数据的总量(即读磁盘)(每秒kb)。 Bo列表示写入到块设备的数据总量(即写磁盘)(每秒kb) 这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大,则表示系统磁盘IO有问题,应该考虑提高磁盘的读写性能。 system 显示采集间隔内发生的中断数 in列表示在某一时间间隔中观测到的每秒设备中断数。 cs列表示每秒产生的上下文切换次数。 上面这2个值越大,会看到由内核消耗的CPU时间会越多。 CPU项显示了CPU的使用状态,此列是我们关注的重点。 us列显示了用户进程消耗的CPU 时间百分比。us的值比较高时,说明用户进程消耗的cpu 时间多,但是如果长期大于50%,就需要考虑优化程序或算法。 sy列显示了内核进程消耗的CPU时间百分比。Sy的值较高时,说明内核消耗的CPU资源很多。 根据经验,us+sy的参考值为80%,如果us+sy大于 80%说明可能存在CPU资源不足。 id 列显示了CPU处在空闲状态的时间百分比。 wa列显示了IO等待所占用的CPU时间百分比。 wa值越高,说明IO等待越严重,根据经验,wa的参考值为20%,如果wa超过20%,说明IO等待严重,引起IO等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者磁盘控制器的带宽瓶颈造成的(主要是块操作)。综上所述,在对CPU的评估中,需要重点注意
https://www.doczj.com/doc/f9776765.html,下面是我常用的几个Linux系统监控的脚本,大家可以根据自己的情况在进行修改,希望能给大家一点帮助。 1、查看主机网卡流量 1.#!/bin/bash 2. 3.#network 4. 5.#Mike.Xu 6. 7.while : ; do 8. 9.time=’date +%m”-”%d” “%k”:”%M’ 10. 11.day=’date +%m”-”%d’ 12. 13.rx_before=’ifconfig eth0|sed -n “8″p|awk ‘{print $2}’|cut -c7-’ 14. 15.tx_before=’ifconfig eth0|sed -n “8″p|awk ‘{print $6}’|cut -c7-’ 16. 17.sleep 2 18. 19.rx_after=’ifconfig eth0|sed -n “8″p|awk ‘{print $2}’|cut -c7-’ 20. 21.tx_after=’ifconfig eth0|sed -n “8″p|awk ‘{print $6}’|cut -c7-’ 22. 23.rx_result=$[(rx_after-rx_before)/256] 24. 25.tx_result=$[(tx_after-tx_before)/256] 26. 27.echo “$time Now_In_Speed: “$rx_result”kbps Now_OUt_Speed: “$tx_result”kbps” 28. 29.sleep 2 30. 31.done 2、系统状况监控 1.#!/bin/sh 2. 3.#systemstat.sh
shell是用户和Linux操作系统之间的接口。Linux中有多种shell,其中缺省使用的是Bash。本章讲述了shell的工作原理,shell的种类,shell的一般操作及Bash的特性。 什么是shell Linux系统的shell作为操作系统的外壳,为用户提供使用操作系统的接口。它是命令语言、命令解释程序及程序设计语言的统称。 shell是用户和Linux内核之间的接口程序,如果把Linux内核想象成一个球体的中心,shell 就是围绕内核的外层。当从shell或其他程序向Linux传递命令时,内核会做出相应的反应。 shell是一个命令语言解释器,它拥有自己内建的shell命令集,shell也能被系统中其他应用程序所调用。用户在提示符下输入的命令都由shell先解释然后传给Linux核心。 有一些命令,比如改变工作目录命令cd,是包含在shell内部的。还有一些命令,例如拷贝命令cp和移动命令rm,是存在于文件系统中某个目录下的单独的程序。对用户而言,不必关心一个命令是建立在shell内部还是一个单独的程序。 shell首先检查命令是否是内部命令,若不是再检查是否是一个应用程序(这里的应用程序可以是Linux本身的实用程序,如ls和rm,也可以是购买的商业程序,如xv,或者是自由软件,如emacs)。然后shell在搜索路径里寻找这些应用程序(搜索路径就是一个能找到可执行程序的目录列表)。如果键入的命令不是一个内部命令并且在路径里没有找到这个可执行文件,将会显示一条错误信息。如果能够成功找到命令,该内部命令或应用程序将被分解为系统调用并传给Linux内核。 shell的另一个重要特性是它自身就是一个解释型的程序设计语言,shell程序设计语言支持绝大多数在高级语言中能见到的程序元素,如函数、变量、数组和程序控制结构。shell编程语言简单易学,任何在提示符中能键入的命令都能放到一个可执行的shell程序中。 当普通用户成功登录,系统将执行一个称为shell的程序。正是shell进程提供了命令行提示符。作为默认值(TurboLinux系统默认的shell是BASH),对普通用户用―$‖作提示符,对超级用户(root)用―#‖作提示符。 一旦出现了shell提示符,就可以键入命令名称及命令所需要的参数。shell将执行这些命令。如果一条命令花费了很长的时间来运行,或者在屏幕上产生了大量的输出,可以从键盘上按ctrl+c发出中断信号来中断它(在正常结束之前,中止它的执行)。
一、命令:ifconfig eth6 Link encap:EthernetHWaddr 00:E0:ED:29:91:02 inet addr:192.168.53.206 Bcast:192.168.53.207 Mask:255.255.255.252 inet6addr: fe80::2e0:edff:fe29:9102/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:730143989490 errors:0 dropped:0 overruns:53397868 frame:0 TX packets:738432898210 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:78921752346272 (71.7 TiB) TX bytes:275903597565877 (250.9 TiB) Memory:df8a0000-df8c0000 Link encap 接口的概要描述。 HWaddr 网卡的硬件MCA地址。 inetaddr 网卡的IP地址。 Bcast 广播地址。 Mask 网络掩码。 UP 表示“接口已启用”。 BROADCAST 表示“主机支持广播”。 RUNNING 表示“接口在工作中”。 MULTICAST 表示“主机支持多播”。 MTU 见上上表。 Metric 见上上表。(同“Met”) RX packets 接收时,正确的数据包数。 RX errors 接收时,产生错误的数据包数。 RX dropped 接收时,丢弃的数据包数。 RX overruns 接收时,由于过速而丢失的数据包数。 RX frame 接收时,发生frame错误而丢失的数据包数。 (以太网是一种共享媒体(shared medium),所以必须要有机制来决定由谁来使用传输媒体,在以太网中所采用的是CSMA/CD(Carrier Sense Multiple Access with Collision Detection)方式,步骤如下: 1 将要传输的数据切割成Frame,作为传输单位。 2 要传输时先侦测电缆上是否有设备送Frame(Carrier Sense)。 3 若沒有设备使用,才准备发送Frame,并侦测是否有另外的设备发送Frame(Collision
这30个Linux系统监控工具,每个系统管理员都应该知道 是否需要监控Linux服务器的性能?试试这些内置的命令和附加工具。大多数发行版都附带了大量的Linux监控工具,这些工具提供了可以用来获取系统活动信息的指标。你可以使用这些工具来查找性能问题的可能原因。下面讨论的命令是关于系统分析和调试Linux服务器问题的一些最基本的命令,例如:1、找出系统的瓶颈2、磁盘(存储)瓶颈3、CPU 和内存瓶颈4、网络瓶颈。01top—进程活动监视命令top命令显示Linux进程。它提供了一个运行系统的动态实时视图,即实际的流程活动。默认情况下,它显示在服务器上运行的cpu密集型任务,并每5秒钟更新一次列表。图01:Linux top命令常用热键和top Linux监视工具下面是一些有用的热键:热键使用t显示摘要信息m显示内存信息A对不同系统资源的顶级用户进行排序。能快速识别系统里的性能需求。f进入一个交互式配置屏幕。有助于为特定的任务置顶。o优先进行交互式地选择r发布renice命令。k问题终止命令。z打开或关闭color/mono02vmstat—虚拟内存统计vmstat命令报告有关进程、内存、分页、阻塞IO、陷阱和cpu活动的信息。示例输出:显示内存使用的slab信息获取关于活动/非活动内存页的信息。03w—找出谁在登录,他们在做什么w命令显示当前机器上的用户及其进程的信息。示
例输出:04uptime—Linux系统运行了多长时间可以使用uptime命令查看服务器运行了多长时间。当前时间,系统运行的时间,当前登录的用户数量,以及过去1、5和15分钟的系统负载平均值。输出:1可视为最优荷载值。负载可以从系统切换到系统。对于单个CPU系统,1 - 3和SMP系统6-10的负载值是可以接受的。05ps—显示Linux进程ps命令将报告当前进程的快照。要选择所有进程,请使用A或E 选项:示例输出: ps和top一样,但是提供了更多的信息。显示长格式输出打开额外的全模式(它将显示传递到过程的命令行参数):显示线程(LWP和NLWP)观察进程后的线程在服务器上打印所有进程。想要打印一个进程树?#pstree获取Linux进程的安全信息。打印每一个作为用户Vivek运行的进程。将ps命令以用户定义的格式配置输出。尝试只显示Lighttpd的进程id。或者或者打印PID 55977的名称。10大内存消耗过程。显示10个CPU消耗过程。06free—Linux 服务器内存使用情况free命令显示系统中空闲和使用的物 理和交换内存的总量,以及内核使用的缓冲区。示例输出:07iostat—Montor Linux平均CPU负载和磁盘活动iostat命令报告中央处理单元(CPU)统计数据和设备、分区和网络文件系统(NFS)的输入/输出统计数据。示例输出:08sar –Monitor,收集和报告Linux系统活动sar命令用于收集、报告和保存系统活动信息。要查看网络计数器,请输入:网络计
Linux必学的60个命令 Linux必学的60个命令 Linux提供了大量的命令,利用它可以有效地完成大量的工作,如磁盘操作、文件存取、目录操作、进程管理、文件权限设定等。所以,在Linux系统上工作离不开使用系统提供的命令。要想真正理解Linux系统,就必须从Linux命令学起,通过基础的命令学习可以进一步理解Linux系统。不同Linux发行版的命令数量不一样,但Linux发行版本最少的命令也有200多个。这里笔者把比较重要和使用频率最多的命令,按照它们在系统中的作用分成下面六个部分一一介绍。 ◆安装和登录命令:login、shutdown、halt、reboot、install、mount、umount、chsh、exit、last; ◆文件处理命令:file、mkdir、grep、dd、find、mv、ls、diff、cat、ln; ◆系统管理相关命令:df、top、free、quota、at、lp、adduser、groupadd、kill、crontab; ◆网络操作命令:ifconfig、ip、ping、netstat、telnet、ftp、route、rlogin、rcp、finger、mail、nslookup; ◆系统安全相关命令:passwd、su、umask、chgrp、chmod、chown、chattr、sudo ps、who; ◆其它命令:tar、unzip、gunzip、unarj、mtools、man、unendcode、uudecode。 本文以Mandrake Linux 9.1(Kenrel 2.4.21)为例,介绍Linux下的安装和登录命令。immortality按:请用ctrl+f在本页中查找某一部分的内容或某一命令的用法。
即用即查L i n u x命令行实例参考手册代码 第13章基本网络配置命令 配置或显示网络设备——ifconfig ifconfig命令语法: ifconfig [网络设备] [IP地址] [参数] 实例1:显示安装在本地主机的第一块以太网卡eth0的状态,执行命令: [root@localhost ~]# ifconfig eth0 实例2:配置本地主机回送接口。执行命令: 实例3:显示本地主机上所有网络接口的信息,包括激活和非激活的,执行命令: [root@localhost ~]# ifconfig 在设置eth0网络接口之前,首先显示本地主机上所有网络接口的信息。执行命令: [root@localhost ~]# ifconfig 实例5:启动/关闭eth0网络接口。 在eth0网络接口禁用之前,首先显示本地主机上所有网络接口的信息。执行命令: [root@localhost ~]# ifconfig 然后执行禁用eth0网络接口命令: [root@localhost ~]# ifconfig eth0 down [root@localhost ~]# ifconfig 再次显示本地主机上所有网络接口的信息,以便比较分析禁用eth0网络接口命令的作用。 为了进一步深入了解,可以测试ping该网络接口。执行命令: 命令重新启动该网络接口。 [root@localhost ~]# ifconfig eth0 up 实例6:为eth0网络接口添加一个IPv6地址fe80::20c::29ff:fe5f:ba3f/64。 在为eth0网络接口添加IPv6地址之前,首先显示本地主机上所有网络接口的信息。执行命令:[root@localhost ~]# ifconfig 然后执行ping6命令检测未添加IPv6地址fe80::20c::29ff:fe5f:ba3f/64之前eth0网络接口的状况:[root@localhost ~]# ping6 –I eth0 –c 4 fe80::20c::29ff:fe5f:ba3f 接下来为eth0网络接口添加一个IPv6地址fe80::20c::29ff:fe5f:ba3f/64,执行命令: [root@localhost ~]# ifconfig eth0 add fe80::20c:29ff:fe5f:ba3f 再次执行ping6命令检测IPv6地址fe80::20c::29ff:fe5f:ba3f : [root@localhost ~]# ping6 –I eth0 –c 4 fe80::20c:29ff:fe5f:ba3f 再次显示本地主机上所有网络接口的信息,以便比较分析eth0网络接口添加IPv6地址前后发生的变化。 [root@localhost ~]# ifconfig 查看或设置网络接口——ifup、ifdown ifup、ifdown命令语法: ifup [网络设备] ifdown [网络设备] 实例1:关闭eth0网络接口。
Linux命令大全完整版 目录 目录........................................................................................................................................... I 1. linux系统管理命令 (1) adduser (1) chfn(change finger information) (1) chsh(change shell) (1) date (2) exit (3) finger (4) free (5) fwhois (5) gitps(gnu interactive tools process status) (5) groupdel(group delete) (6) groupmod(group modify) (6) halt (7) id (7) kill (8) last (8) lastb (8) login (9) logname (9) logout (9) logrotate (9) newgrp (10) nice (10) procinfo(process information) (11) ps(process status) (11) pstree(process status tree) (14) reboot (15)
rlogin(remote login) (16) rsh(remote shell) (16) rwho (16) screen (17) shutdown (17) sliplogin (18) su(super user) (18) sudo (19) suspend (19) swatch(simple watcher) (20) tload (20) top (21) uname (21) useradd (22) userconf (22) userdel (23) usermod (23) vlock(virtual console lock) (24) w (24) who (25) whoami (25) whois (25) 2. linux系统设置命令 (27) alias (27) apmd(advanced power management BIOS daemon) (27) aumix(audio mixer) (27) bind (29) chkconfig(check config) (29) chroot(change root) (30)
四、服务器主板工作状况监测: 服务器主板以及CPU工作温度是否正常是服务器稳定的核心。迄今为止还没有一种CPU散热系统能保证永不失效。失去了散热系统保护伞的“芯”,往往会在几秒钟内永远停止“跳动”。值得庆幸的是,聪明的工程师们早已开发出有效的处理器温度监控、保护技术。以特殊而敏锐的“嗅觉”随时监测CPU的温度变化,并提供必要的保护措施,使CPU免受高温下的灭顶之灾。lm_sensors可以有效监控主板和CPU的工作电压、风扇转速、温度等核心数据。软件安装: #mv lm_sensors-2.8.8.tar.gz /usr/lo ca l/src/ #cd /usr/local/src/ #tar zxvf lm_sensors-2.8.8.tar.gz #cd /usr/local/src/lm_sensors-2.8.8 #tar xzf i2c-2.8.8.tar.gz #make clean ;make dep ;make all ;make install #/sbin/depmod -a 修改配置文件:“/etc/ld.so.conf”加入一行:/usr/local/lib #ldconfig #sensors-detect #扫描主板所有芯片,选择缺省选项即可(按会车)# 加载模块,注意主板不一定相同。 #modprobe i2c-isa #modprobe lm78 #modprobe sis5595 开始检测,见图-8:
#sensors 图 8 lm_sensors 工作界面 可以看到主板温度、CPU温度电压以及风扇转速等信息非常清晰。 高级应用:定时检测主板运行情况: 这里可以使用Linux组合命令: #watch --interval=450 “sensors ” 这样每隔450秒运行因此sensors 令,就可以得知主板运行情况。 五、P2P通信监测 P2P(Peer-to-Peer)是一种用于文件交换的新技术,通过Internet允许建立分散的、动态的、匿名的逻辑网络。P2P为对等连接或对等网络,点对点网络技术,可应用于文件共享交换,深度搜索、分布计算等领域。它允许个体的PC通过Internet共享文
IT运维之Linux服务器监控方案 随着Linux应用日益广泛,绝大部分的网络服务器都使用Linux操作系统。为了全面掌握网络服务器的运行状况和趋势,需要对服务器进行全面的监控。 利用Linux发行版搭建一个网络服务器可能对于许多人都是一件很容易的事情,但网络服务器正式上线后,服务器数据流动、连接数、网络流量、系统负荷等各方面都会增加,安全问题也随之而来,再考虑到日志、数据库的重要性,我想无论是哪一位系统管理员,都应该迫不及待地想把服务器上线的前期工作做好吧。 那我们究竟需要做好哪些工作准备呢?之前有看过一篇文章说到系统管理员应该定期完成的九件事情,我分析过后,认为有几件事情是必须得做的。首先是备份,做好定时备份策略,备份所有你认为重要的数据,并且定期检查你的备份是否有效、全面;日志轮换,无论你想用哪种轮换方式,控制日志增长避免驱动器已满是你的目的;做一定的安全措施,如防火墙iptables的访问控制,用denyhosts防止黑客远程暴力破解,mysql远程登录权限等等;最后就是服务器监控,也是我主要想讲述的内容。 对于服务器的硬件资源、性能、带宽、端口、进程、服务等都必须有一个可靠和持续的监测,统计分析每天的各种数据,从而能及时反映出服务器哪里存在性能瓶颈、安全隐患等。另外是要有危机意识,就是了解服务器有可能出现哪些严重的问题,出现这些问题后该如何去迅速处理。比如数据库的数据丢失,日志容量过大,被黑客入侵等等。说到底,预防是关键。 监控,是预防的其中的一项重要工作。这里先说说我需要监控的内容。系统负载、cpu 使用率、内存占用、磁盘空间、网络流量、端口、进程、apache或tomcat的连接数、mysql 的运行状态这些都是我想要监控的东西,但又能做到多少呢,我只能尽力而为了。要了解服务器每时每刻的整体运行状态,单靠几个Linux自带的性能监测命令是很难实现的。所以,利用shell脚本和开源监控工具进行服务器监控成为了我的两个主要的选择。 利用shell脚本监控能够很好把握的监控的内容,时间,警告峰值,以及方便地进行告警通知,自定义监控日志内容等等;而许多开源的监控工具都十分方便和实用,比如有zabbix、cacti、nagios等,而且能够针对不同的监控内容,生成好看的便于观察的曲线图,多数的开源监控工具都比较成熟,至于哪个好用就得用过才知道。由于这些监控工具都有许多热血人士写了安装和使用的文档,我这里就不写进来了。想了解下的朋友也可以到我的博客上走走,在这里我主要是把自己写的一些shell监控脚本分享一下,希望大家能给点意见。 我这里写了四个脚本(performance.sh 性能监控,process.sh 进程监控,network.sh 流量监控,tongji.sh流量分析统计),并使用crontab定时执行脚本进行监控数据的记录,形成每天的监控日志放在如下相应的文件夹,并且超过自己设定的告警值后发邮件通知,如果是腾讯企业邮箱,163邮箱那些有免费短信通知功能的可以尝试一下,收到邮件告警后很快就能收到短信了,十分方便。 性能监控脚本 ############################################################################## #!/bin/bash #监控cpu系统负载 IP=`ifconfig eth0 | grep "inet addr" | cut -f 2 -d ":" | cut -f 1 -d " "` cpu_num=`grep -c 'model name' /proc/cpuinfo`
Ifconfig ⑴基础知识 ifconfig 命令被用来: ①为一个网卡分配一个IP地址 ②设置本地环路界面 ③分配一个子网掩码(可选) 这个命令在系统启动的时候通过/sbin/init.d/net脚本自动执行的。也可以在任何时候以命令行的方式执行。 Usage: ifconfig interface addr_family [address] [ parameters] Options: interface 一个最大四位的字符串,最后一个字符是数字,例如lan0。这个字符串代表网卡。数字表示网卡的instance。对有的系统来说,网卡的instance是自动分配的。首先配置的网卡是lan0。而lo0指明这是本地回路。 add_family 对DARPA Internet协议来说,唯一支持的是inet(默认的)。 address 数字形式的IP地址 parameters 最重要的参数是up,down,arp,-arp,和netmask。 up 激活这个网卡 down 关闭这个网卡 [-] arp 在OSI模型的第二层和第三层(链路层和网络层)之间禁用/使用地址解析协议netmask subnet 子网位掩盖网络部分。并指明了在将网络分割为子网的时候所保留地址的数量,一般也用数字形式。 -a 详细显示所有接口 -u 显示目前使用中的装置 ⑵实例 ①检查网络接口 例如: *检查所有网络接口的状态: # ifconfig –a lo0: flags=849
即用即查Linux命令行实例参考手册代码 第13章基本网络配置命令 配置或显示网络设备——ifconfig ifconfig命令语法: ifconfig [网络设备] [IP地址] [参数] 实例1:显示安装在本地主机的第一块以太网卡eth0的状态,执行命令: [root@localhost ~]# ifconfig eth0 实例2:配置本地主机回送接口。执行命令: [root@localhost ~]# ifconfig lo inet 127.0.0.1 up 实例3:显示本地主机上所有网络接口的信息,包括激活和非激活的,执行命令: [root@localhost ~]# ifconfig 实例4:配置eth0网络接口的IP为192.168.1.108。 在设置eth0网络接口之前,首先显示本地主机上所有网络接口的信息。执行命令:[root@localhost ~]# ifconfig 然后设置eth0网络接口,ip为192.168.1.108,netmask为255.255.255.0,broadcast为192.168.1.255。执行命令: [root@localhost ~]# ifconfig eth0 192.168.1.108 netmask 255.255.255.0 broadcast 192.168.1.255 实例5:启动/关闭eth0网络接口。 在eth0网络接口禁用之前,首先显示本地主机上所有网络接口的信息。执行命令:[root@localhost ~]# ifconfig 然后执行禁用eth0网络接口命令: [root@localhost ~]# ifconfig eth0 down [root@localhost ~]# ifconfig 再次显示本地主机上所有网络接口的信息,以便比较分析禁用eth0网络接口命令的作用。 为了进一步深入了解,可以测试ping该网络接口。执行命令: [root@localhost ~]# ping 192.168.1.108 此时应该ping不通主机192.168.1.108。接下来可以执行如下命令重新启动该网络接口。 [root@localhost ~]# ifconfig eth0 up 实例6:为eth0网络接口添加一个IPv6地址fe80::20c::29ff:fe5f:ba3f/64。 在为eth0网络接口添加IPv6地址之前,首先显示本地主机上所有网络接口的信息。执行命令: [root@localhost ~]# ifconfig 然后执行ping6命令检测未添加IPv6地址fe80::20c::29ff:fe5f:ba3f/64之前eth0网络接口的状况: [root@localhost ~]# ping6 –I eth0 –c 4 fe80::20c::29ff:fe5f:ba3f 接下来为eth0网络接口添加一个IPv6地址fe80::20c::29ff:fe5f:ba3f/64,执行命令:[root@localhost ~]# ifconfig eth0 add fe80::20c:29ff:fe5f:ba3f