
复制
Oracle订阅服务器
Microsoft? SQL Server? 2000 包含 ODBC 驱动程序及 OLE DB 提供程序,它们在 Intel 计算机上支持Oracle对 SQL Server 发布的订阅。SQL Server 2000 安装程序自动地安装该驱动程序。
说明为了复制到Oracle ODBC 及 OLE DB 订阅服务器,您必须还要从
Oracle或您的软件厂商那里获取合适的Oracle SQL*Net 驱动程序。然后您还必须将该驱动程序安装在发布服务器及分发服务器上。
Oracle订阅服务器的复制限制
当复制到Oracle ODBC 订阅服务器时,会有如下限制:
?如果表的名称带有空格,那么将不会在Oracle订阅服务器上创建这些表的复制。复制将会因Oracle错误 ORA-00903 而失败:无效的表名称。
?date数据类型为小datetime(范围从 4712 B.C. 到 4712 A.D.)。
如果准备复制到Oracle,请验证在复制的列中,SQL Server datetime条目在上述范围之内。
?复制表只能有一个text或image数据类型的列,该数据类型被映射为long raw。
?datetime数据类型被映射为 char4。
?对于float及real数据类型,SQL Server 2000 范围与Oracle范围不同。
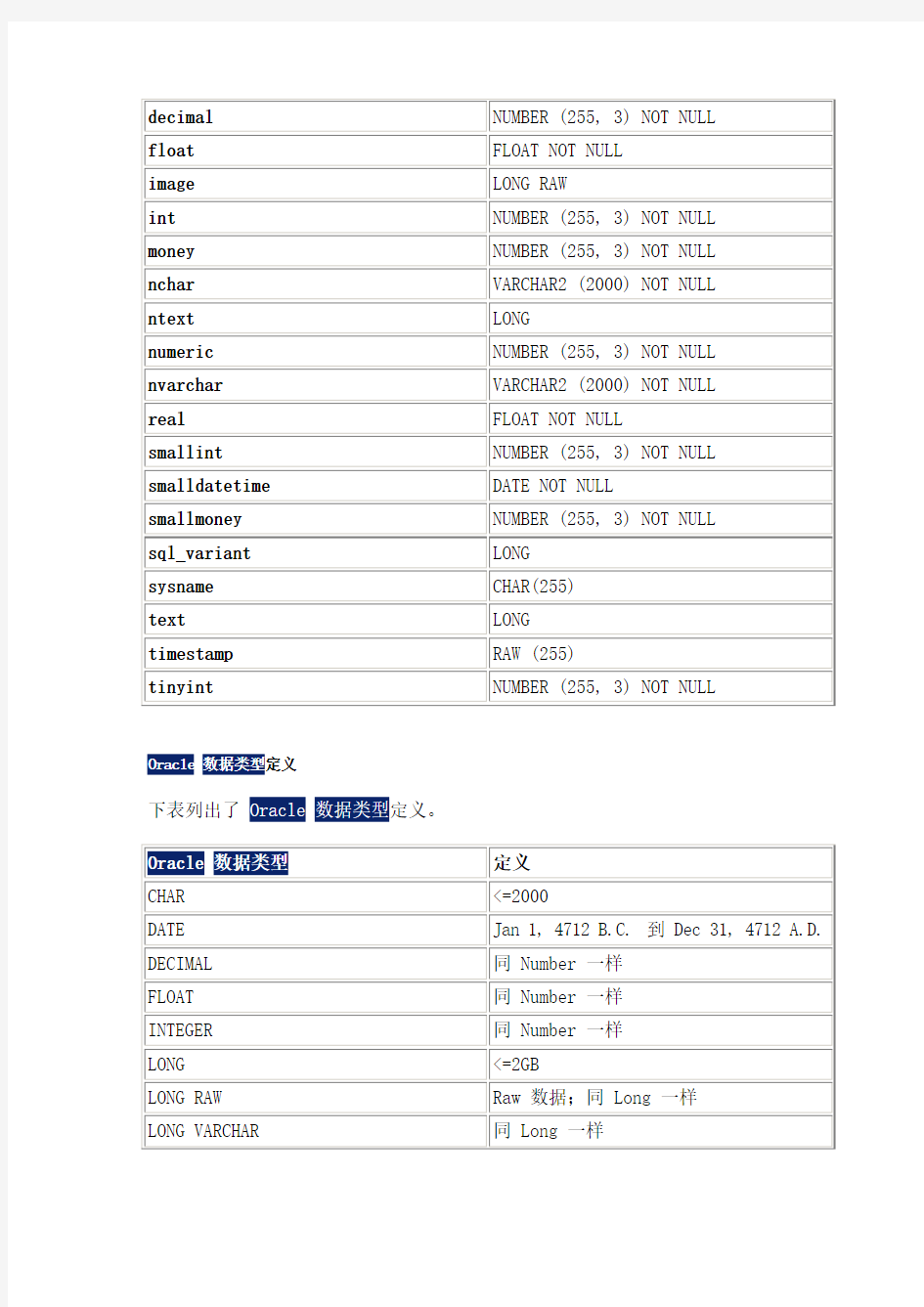
下表将复制的数据类型映射到Oracle订阅服务器。
Oracle数据类型定义
下表列出了Oracle数据类型定义。
?1988-2000 Microsoft Corporation。保留所有权利。
ORACLE数据库与实例的关系 1 数据库名 1.1 数据库名的概念 数据库名(db_name)就是一个数据库的标识,就像人的身份证号一样。如果一台机 器上装了多个数据库,那么每一个数据库都有一个数据库名。在数据库安装或创建完成之后,参数DB_NAME被写入参数文件之中。 数据库名在$Oracle_HOME/admin/db_name/pfile/init.ora(或 $ORACLE_BASE/admin/db_name/pfile/init.ora或$ORACLE_HOME/dbs/SPFILE<实 例名>.ORA)文件中 ########################################### # Database Identification ########################################### db_domain="" db_name=orcl 在创建数据库时就应考虑好数据库名,并且在创建完数据库之后,数据库名不宜修改,即使要修改也会很麻烦。因为,数据库名还被写入控制文件中,控制文件是 以二进制型式存储的,用户无法修改控制文件的内容。假设用户修改了参数文件中的数据库名,即修改DB_NAME的值。但是在Oracle启动时,由于参数文件中的DB_NAME与控制文件中的数据库名不一致,导致数据库启动失败,将返回ORA-01103错误。 1.2 数据库名的作用 数据库名是在安装数据库、创建新的数据库、创建数据库控制文件、修改数据结构、备份与恢复数据库时都需要使用到的(注意这些时候不能使用sid,还有alter database时都是使用数据库名)。 有很多Oracle安装文件目录是与数据库名相关的,如: winnt: F:\oracle\product\10.2.0\oradata\DB_NAME\...
Oracle 数据库基础 数据库是我们安装完产品后建立的,可以在同一台主机上存在8i,9i,10g,11g等多个数据库产品,一套产品可以建立多个数据库,每个数据库是独立的。每个数据库都有自己的全套相关文件,有各自的控制文件、数据文件、重做日志文件、参数文件、归档文件、口令文件等等。 其中控制文件、数据文件、重做日志文件、跟踪文件及警告日志(trace files,alert files)属于数据库文件; 参数文件(parameter file)口令文件(password file)是非数据库文件 我们的表存储在数据库中 数据库不能直接读取 我们通过实例(instance)来访问数据库 数据库实例 实例由内存和后台进程组成 实例是访问数据库的方法 初始化参数控制实例的行为 一个实例只能连接一个数据库
启动实例不需要数据库 产品安装好 有初始化参数文件 就可以启动实例 与是否存在数据库无关 实例内存分为SGA 和PGA SGA:是用于存储数据库信息的内存区,该信息为数据库进程所共享。它包含Oracle 服务器的数据和控制信息,它是在Oracle 服务器所驻留的计算机的实际内存中得以分配,如果实际内存不够再往虚拟内存中写。 PGA:包含单个服务器进程或单个后台进程的数据和控制信息,与几个进程共享的SGA正相反,PGA 是只被一个进程使用的区域,PGA 在创建进程时分配,在终止进程时回收. 后台进程是实例和数据库的联系纽带 分为核心进程和非核心进程 当前后台进程的查看 SQL> select name,description from v$bgprocess where paddr<>'00'; NAME DESCRIPTION
ORACLE常用SQL语句大全 一、基础 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的 device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:/mssql7backup/MyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not nul l],..) 根据已有的表创建新表: A:select * into table_new from table_old (使用旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only<仅适用于Oracle> 5、说明:删除表 drop table tablename
6、说明:增加一个列,删除一个列 A:alter table tabname add column col type B:alter table tabname drop column colname 注:DB2DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、添加主键: Alter table tabname add primary key(col) 删除主键: Alter table tabname drop primary key(col) 8、创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、创建视图:create view viewname as select statement 删除视图:drop view viewname 10、几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count as totalcount from table1 求和:select sum(field1) as sumvalue from table1 平均:select avg(field1) as avgvalue from table1 最大:select max(field1) as maxvalue from table1 最小:select min(field1) as minvalue from table1 11、几个高级查询运算词 A:UNION 运算符 UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2。 B:EXCEPT 运算符 EXCEPT 运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当ALL 随 EXCEPT 一起使用时 (EXCEPT ALL),不消除重复行。 C:INTERSECT 运算符 INTERSECT 运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL 随 INTERSECT 一起使用时 (INTERSECT ALL),不消除重复行。 注:使用运算词的几个查询结果行必须是一致的。 12、使用外连接
Oracle SQL的优化 标签:oraclesql优化date数据库subquery 2009-10-14 21:18 18149人阅读评论(21) 收藏举报分类: Oracle Basic Knowledge(208) SQL的优化应该从5个方面进行调整: 1.去掉不必要的大型表的全表扫描 2.缓存小型表的全表扫描 3.检验优化索引的使用 4.检验优化的连接技术 5.尽可能减少执行计划的Cost SQL语句: 是对数据库(数据)进行操作的惟一途径; 消耗了70%~90%的数据库资源;独立于程序设计逻辑,相对于对程序源代码的优化,对SQL语句的优化在时间成本和风险上的代价都很低; 可以有不同的写法;易学,难精通。 SQL优化: 固定的SQL书写习惯,相同的查询尽量保持相同,存储过程的效率较高。 应该编写与其格式一致的语句,包括字母的大小写、标点符号、换行的位置等都要一致 ORACLE优化器: 在任何可能的时候都会对表达式进行评估,并且把特定的语法结构转换成等价的结构,这么做的原因是 要么结果表达式能够比源表达式具有更快的速度 要么源表达式只是结果表达式的一个等价语义结构 不同的SQL结构有时具有同样的操作(例如: = ANY (subquery) and IN (subquery)),ORACLE会把他们映射到一个单一的语义结构。 1 常量优化: 常量的计算是在语句被优化时一次性完成,而不是在每次执行时。下面是检索月薪大于2000的的表达式: sal > 24000/12
sal > 2000 sal*12 > 24000 如果SQL语句包括第一种情况,优化器会简单地把它转变成第二种。 优化器不会简化跨越比较符的表达式,例如第三条语句,鉴于此,应尽量写用常量跟字段比较检索的表达式,而不要将字段置于表达式当中。否则没有办法优化,比如如果sal上有索引,第一和第二就可以使用,第三就难以使用。 2 操作符优化: 优化器把使用LIKE操作符和一个没有通配符的表达式组成的检索表达式转换为一个“=”操作符表达式。 例如:优化器会把表达式ename LIKE 'SMITH'转换为ename = 'SMITH' 优化器只能转换涉及到可变长数据类型的表达式,前一个例子中,如果ENAME 字段的类型是CHAR(10),那么优化器将不做任何转换。 一般来讲LIKE比较难以优化。 其中: ~~IN 操作符优化: 优化器把使用IN比较符的检索表达式替换为等价的使用“=”和“OR”操作符的检索表达式。 例如,优化器会把表达式ename IN ('SMITH','KING','JONES')替换为 ename = 'SMITH' OR ename = 'KING' OR ename = 'JONES‘ oracle 会将 in 后面的东西生成一存中的临时表。然后进行查询。 如何编写高效的SQL: 当然要考虑sql常量的优化和操作符的优化啦,另外,还需要: 1 合理的索引设计: 例:表record有620000行,试看在不同的索引下,下面几个SQL的运行情况:语句A SELECT count(*) FROM record WHERE date >'19991201' and date <'19991214‘and amount >2000 语句B
SQLServer的数据类型 第一大类:整数数据 bit:bit数据类型代表0,1或NULL,就是表示true,false.占用1byte. int:以4个字节来存储正负数.可存储范围为:-2^31至2^31-1. smallint:以2个字节来存储正负数.存储范围为:-2^15至2^15-1 tinyint: 是最小的整数类型,仅用1字节,范围:0至此^8-1 第二大类:精确数值数据 numeric:表示的数字可以达到38位,存储数据时所用的字节数目会随着使用权用位数的多少变化. decimal:和numeric差不多 第三大类:近似浮点数值数据 float:用8个字节来存储数据.最多可为53位.范围为:-1.79E+308至1.79E+308. real:位数为24,用4个字节,数字范围:-3.04E+38至3.04E+38 第四大类:日期时间数据 datatime:表示时间范围可以表示从1753/1/1至9999/12/31,时间可以表示到3.33/1000秒.使用8个字节. smalldatetime:表示时间范围可以表示从1900/1/1至2079/12/31.使用4个字节. 第五大类:字符串数据 char:长度是设定的,最短为1字节,最长为8000个字节.不足的长度会用空白补上. varchar:长度也是设定的,最短为1字节,最长为8000个字节,尾部的空白会去掉. text:长宽也是设定的,最长可以存放2G的数据. 第六大类:Unincode字符串数据 nchar:长度是设定的,最短为1字节,最长为4000个字节.不足的长度会用空白补上.储存一个字符需要2个字节. nvarchar:长度是设定的,最短为1字节,最长为4000个字节.尾部的空白会去掉.储存一个字符需要2个字节. ntext:长度是设定的,最短为1字节,最长为2G.尾部的空白会去掉,储存一个字符需要2个字节.
(Oracle管理)如何优化SQL语句以提高Oracle执 行效率
(1)选择最有效率的表名顺序(只在基于规则的优化器中有效): Oracle的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表drivingtable)将被最先处理,在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。如果有3个以上的表连接查询,那就需要选择交叉表(intersectiontable)作为基础表,交叉表是指那个被其他表所引用的表。 (2)WHERE子句中的连接顺序: Oracle采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前,那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。(3)SELECT子句中避免使用‘*’: Oracle在解析的过程中,会将‘*’依次转换成所有的列名,这个工作是通过查询数据字典完成的,这意味着将耗费更多的时间。 (4)减少访问数据库的次数: Oracle在内部执行了许多工作:解析SQL语句,估算索引的利用率,绑定变量,读数据块等。(5)在SQL*Plus,SQL*Forms和Pro*C中重新设置ARRAYSIZE参数,可以增加每次数据库访问的检索数据量,建议值为200。 (6)使用DECODE函数来减少处理时间: 使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表。 (7)整合简单,无关联的数据库访问: 如果你有几个简单的数据库查询语句,你可以把它们整合到一个查询中(即使它们之间没有关系)。 (8)删除重复记录: 最高效的删除重复记录方法(因为使用了ROWID)例子:DELETEFROMEMPEWHEREE.ROWID>(SELECTMIN(X.ROWID)
配置oracle连接 怎么在windows环境下配置连接oracle数据库? 步骤如下: 一、安装PL/SQL: 1、获取PL/SQL安装包;(PL/SQL是连接oracle的客户端) 2、安装PL/SQL; (1)双击PL/SQL安装程序,安装PL/SQL; (2)选择“I Agree”进行安装;
(3)选择安装路径(一般选择默认路径);点击【Next】按钮; (4)默认选择,点击【Next】按钮; (5)默认选择,点击【Finish】按钮,开始安装;
(6)安装进度显示 (7)窗口提示“PL/SQL Developer installed successfully”,安装完成,点击【Close】按钮。
二、配置连接 1、获取oci.dll文件(该文件是用来连接数据库的文件),将该文件及其所在的文件夹放置在一个不含有中文的路径下(如:F:\instantclient); 2、双击打开PL/SQL客户端,点击【Cancel】按钮; 3、跳转到PL/SQL页面,如下图所示。选择【Tool】—>Preferences; 4、按下图进行选择,在“Oracle Home(enpty is autodetect)”栏中选择oci.dll文件所在的目录;在“OCI library(enpty is autodetect)”栏中选择oci.dll文件
5、点击【OK】按钮即可完成 6、退出PL/SQL页面,重新登录。双击PL/SQL客户端,在Oracle Logon窗口中填写数据库的用户名、密码、数据库名和连接方式;点击【OK】按钮即可查询数据库。 完毕!谢谢!
SQL Server 数据库基本知识点一、数据类型
二、常用语句 (用到的数据库Northwind) 查询语句 简单的Transact-SQL查询只包括选择列表、FROM子句和WHERE子句。它们分别说明所查询列、查询的 表或视图、以及搜索条件等。例如,下面的语句查询Customers 表中公司名称为“Alfreds Futterkiste”的ContactName字段和Address字段。 SELECT ContactName, Address FROM Customers WHERE CompanyName='Alfreds Futterkiste' (一) 选择列表 选择列表(select_list)指出所查询列,它可以是一组列名列表、星号、表达式、变量(包括局部变量和全局变量)等构成。 1、选择所有列 例如,下面语句显示Customers表中所有列的数据: SELECT * FROM Customers 2、选择部分列并指定它们的显示次序查询结果集合中数据的排列顺序与选择列表中所指定的列名排列顺序相同。 例如: SELECT ContactName, Address FROM Customers 3、更改列标题 在选择列表中,可重新指定列标题。定义格式为: 列标题 as 列名 列名列标题如果指定的列标题不是标准的标识符格式时,应使用引号定界符,例如,下列语句使用汉字显示列标题: SELECT ContactName as 联系人名称, Address as地址 FROM Customers 4、删除重复行
SELECT语句中使用ALL或DISTINCT选项来显示表中符合条件的所有行或删除其中重复的数据行,默认 为ALL。使用DISTINCT选项时,对于所有重复的数据行在SELECT返回的结果集合中只保留一行。 SELECT DISTINCT(Country) FROM Customers 5、限制返回的行数 使用TOP n [PERCENT]选项限制返回的数据行数,TOP n说明返回n行,而TOP n PERCENT 时,说明n是 表示一百分数,指定返回的行数等于总行数的百分之几。 例如: SELECT TOP 2 * FROM Customers SELECT TOP 20 PERCENT * FROM Customers (二)FROM子句 FROM子句指定SELECT语句查询及与查询相关的表或视图。在FROM子句中最多可指定256个表或视图,它们之间用逗号分隔。在FROM子句同时指定多个表或视图时,如果选择列表中存在同名列,这时应使用对象名限定这些列 所属的表或视图。例如在Orders和Customers表中同时存在CustomerID列,在查询两个表中的CustomerID时应 使用下面语句格式加以限定: select * from Orders,Customers where Orders.CustomerID =Customers.CustomerID 在FROM子句中可用以下两种格式为表或视图指定别名: 表名 as 别名 表名别名 select * from Orders as a,Customers as b where a.CustomerID =b.CustomerID SELECT不仅能从表或视图中检索数据,它还能够从其它查询语句所返回的结果集合中查询数据。 例如: select * from Customers where CustomerID in (select CustomerID from Orders where EmployeeID=4) 此例中,将SELECT返回的结果集合给予一别名CustomerID,然后再从中检索数据。 (三) 使用WHERE子句设置查询条件 WHERE子句设置查询条件,过滤掉不需要的数据行。例如下面语句查询年龄大于20的数据:select CustomerID from Orders where EmployeeID=4
1、数据库基本语句 (1)表结构处理 创建一个表:cteate table 表名(列1 类型,列2 类型); 修改表的名字 alter table 旧表名 rename to 新表名 查看表结构 desc 表名(cmd) 添加一个字段 alter table 表名 add(列类型); 修改字段类型 alter table 表名 modify(列类型); 删除一个字段 alter table 表名 drop column列名; 删除表 drop table 表名 修改列名 alter table 表名 rename column 旧列名 to 新列名; (2)表数据处理 增加数据:insert into 表名 values(所有列的值); insert into 表名(列)values(对应的值); 更新语句:update 表 set 列=新的值,…[where 条件] 删除数据:delete from 表名 where 条件 删除所有数据,不会影响表结构,不会记录日志, 数据不能恢复--》删除很快: truncate table 表名 删除所有数据,包括表结构一并删除: drop table 表名 去除重复的显示:select distinct 列 from 表名 日期类型:to_date(字符串1,字符串2)字符串1是日期的字 符串,字符串2是格式 to_date('1990-1-1','yyyy-mm-dd')-->返回日期的 类型是1990-1-1 (3)查询语句 1)内连接 select a.*,b.* from a inner join b on a.id=b.parent_id
MySql Oracle SqlServer三大数据库的数据类型列表MySql数据类型
Oracle数据类型 一、概述 在ORACLE8中定义了:标量(SCALAR)、复合(COMPOSITE)、引用(REFERENCE)和LOB四种数据类型,下面详细介绍它们的特性。 二、标量(SCALAR) 合法的标量类型与数据库的列所使用的类型相同,此外它还有一些扩展。它又分为七个组:数字、字符、行、日期、行标识、布尔和可信。 数字,它有三种基本类型--NUMBER、PLS_INTEGER和BINARY_INTENER。NUMBER可以描述整数或实数,而PLS_INTEGER和BINARY_INTENER只能描述整数。 NUMBER,是以十进制格式进行存储的,它便于存储,但是在计算上,系统会自动的将它转换成为二进制进行运算的。它的定义方式是NUMBER(P,S),P是精度,最大38位,S是刻度范围,可在-84...127间取值。例如:NUMBER(5,2)可以用来存储表示-999.99...999.99间的数值。P、S可以在定义是省略,例如:NUMBER(5)、NUMBER 等; BINARY_INTENER用来描述不存储在数据库中,但是需要用来计算的带符号的整数值。它以2的补码二进制形式表述。循环计数器经常使用这种类型。 PLS_INTEGER和BINARY_INTENER唯一区别是在计算当中发生溢出时,BINARY_INTENER型的变量会被自动指派给一个NUMBER型而不会出错,PLS_INTEGER型的变量将会发生错误。 字符,包括CHAR、VARCHAR2(VARCHAR)、LONG、NCHAR和NVARCHAR2几种类型。 CHAR,描述定长的字符串,如果实际值不够定义的长度,系统将以空格填充。它的声明方式如下CHAR(L),L 为字符串长度,缺省为1,作为变量最大32767个字符,作为数据存储在ORACLE8中最大为2000。 VARCHAR2(VARCHAR),描述变长字符串。它的声明方式如下VARCHAR2(L),L为字符串长度,没有缺省值,作为变量最大32767个字节,作为数据存储在ORACLE8中最大为4000。在多字节语言环境中,实际存储的字符个数可能小于L值,例如:当语言环境为中文(SIMPLIFIED CHINESE_CHINA.ZHS16GBK)时,一个VARCHAR2(200)的数据列可以保存200个英文字符或者100个汉字字符。 LONG,在数据库存储中可以用来保存高达2G的数据,作为变量,可以表示一个最大长度为32760字节的可变字符串。 NCHAR、NVARCHAR2,国家字符集,与环境变量NLS指定的语言集密切相关,使用方法和CHAR、VARCHAR2相同。 行,包括RAW和LONG RAW两种类型。用来存储二进制数据,不会在字符集间转换。 RAW,类似于CHAR,声明方式RAW(L),L为长度,以字节为单位,作为数据库列最大2000,作为变量最大32767字节。 LONG RAW,类似于LONG,作为数据库列最大存储2G字节的数据,作为变量最大32760字节。 日期,只有一种类型--DATE,用来存储时间信息,站用7个字节(从世纪到秒),绝对没有“千年虫”问题。 行标识,只有一种类型--ROWID,用来存储“行标识符”,可以利用ROWIDTOCHAR函数来将行标识转换成为字符。 布尔,只有一种类型--BOOLEAN,仅仅可以表示TRUE、FALSE或者NULL。 可信,只有一种类型--MLSLABEL,可以在TRUSTED ORACLE中用来保存可变长度的二进制标签。在标准ORACLE 中,只能存储NULL值。 三、复合(COMPOSITE) 标量类型是经过预定义的,利用这些类型可以衍生出一些复合类型。主要有记录、表。 记录,可以看作是一组标量的组合结构,它的声明方式如下: TYPE record_type_name IS RECORD ( filed1 type1 [NOT NULL] [:=expr1] ....... filedn typen [NOT NULL] [:=exprn] ) 其中,record_type_name是记录类型的名字。(是不是看着象CREATE TABLE?......)引用时必须定义相关的变量,记录只是TYPE,不是VARIABLE。 表,不是物理存储数据的表,在这里是一种变量类型,也称为PL/SQL表,它类似于C语言中的数组,在处理方式上也相似。它的声明方式如下:
大型ORACLE数据库优化设计方案 摘要主要从大型数据库ORACLE环境四个不同级别的调整分析入手,分析ORACLE的系统结构和工作机理,从九个不同方面较全面地总结了ORACLE数据库的优化调整方案。 关键词ORACLE数据库环境调整优化设计方案 对于ORACLE数据库的数据存取,主要有四个不同的调整级别,第一级调整是操作系统级包括硬件平台,第二级调整是ORACLERDBMS级的调整,第三级是数据库设计级的调整,最后一个调整级是SQL级。通常依此四级调整级别对数据库进行调整、优化,数据库的整体性能会得到很大的改善。下面从九个不同
方面介绍ORACLE数据库优化设计方案。 一.数据库优化自由结构OFA(OptimalflexibleArchitecture) 数据库的逻辑配置对数据库性能有很大的影响,为此,ORACLE公司对表空间设计提出了一种优化结构OFA。使用这种结构进行设计会大大简化物理设计中的数据管理。优化自由结构OFA,简单地讲就是在数据库中可以高效自由地分布逻辑数据对象,因此首先要对数据库中的逻辑对象根据他们的使用方式和物理结构对数据库的影响来进行分类,这种分类包括将系统数据和用户数据分开、一般数据和索引数据分开、低活动表和高活动表分开等等。 二、充分利用系统全局区域SGA (SYSTEMGLOBALAREA) SGA是oracle数据库的心脏。用户的进程对这个内存区发送事务,并且以这里作为高速缓存读取命中的数据,以实现加速的目的。正确的SGA大小对数据库
的性能至关重要。SGA包括以下几个部分: 2、字典缓冲区。该缓冲区内的信息包括用户账号数据、数据文件名、段名、盘区位置、表说明和权限,它也采用LRU 方式管理。 3、重做日志缓冲区。该缓冲区保存为数据库恢复过程中用于前滚操作。 4、SQL共享池。保存执行计划和运行数据库的SQL语句的语法分析树。也采用LRU算法管理。如果设置过小,语句将被连续不断地再装入到库缓存,影响系统性能。 另外,SGA还包括大池、JA V A池、多缓冲池。但是主要是由上面4种缓冲区构成。对这些内存缓冲区的合理设置,可以大大加快数据查询速度,一个足够大的内存区可以把绝大多数数据存储在内存中,只有那些不怎么频繁使用的数据,才从磁盘读取,这样就可以大大提高内存区的命中率。三、规范与反规范设计数据库
一、基础 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的 device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1. dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only 5、说明:删除新表 drop table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、说明:添加主键:Alter table tabname add primary key(col) 说明:删除主键: Alter table tabname drop primary key(col) 8、说明:创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、说明:创建视图:create view viewname as select statement 删除视图:drop view viewname 10、说明:几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count as totalcount from table1
OracleSQL性能优化方法 Oracle性能优化方法(SQL篇) (1) 1综述 (2) 2表分区的应用 (2) 3访咨询Table的方式 (3) 4共享SQL语句 (3) 5选择最有效率的表名顺序 (5) 6WHERE子句中的连接顺序. (6) 7SELECT子句中幸免使用’*’ (6) 8减少访咨询数据库的次数 (6) 9使用DECODE函数来减少处理时刻 (7) 10整合简单,无关联的数据库访咨询 (8) 11删除重复记录 (8) 12用TRUNCATE替代DELETE (9) 13尽量多使用COMMIT (9) 14运算记录条数 (9) 15用Where子句替换HA VING子句 (9) 16减少对表的查询 (10) 17通过内部函数提高SQL效率 (11) 18使用表的不名(Alias) (12) 19用EXISTS替代IN (12) 20用NOT EXISTS替代NOT IN (13) 21识不低效执行的SQL语句 (13) 22使用TKPROF 工具来查询SQL性能状态 (14) 23用EXPLAIN PLAN 分析SQL语句 (14) 24实时批量的处理 (16)
1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要通过反反复复的过程。在数据库建立时,就能依照顾用的需要合理设计分配表空间以及储备参数、内存使用初始化参数,对以后的数据库性能有专门大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积存体会,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用咨询题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来讲明对数据库性能如何进行优化。 2表分区的应用 关于海量数据的表,能够考虑建立分区以提高操作效率。建立分区一样以关键字为分区的标志,也能够以其他字段作为分区的标志,但效率不如关键字高。建立分区的语句在建表时能够进行讲明: create table TABLENAME(
共享和专用操作模式的工作过程有什么区别? 在专用服务器操作模式中,Oracle为每个连接到数据库实例的用户进程启动一个专门的服务进程,其用户进程数与服务器进程数的比例为1:1因为在用户进程空闲期间,对应的服务器进程始终存在,数据库的效率比较低。共享服务器操作模式可以实现只运行少量的服务器进程,由少量的服务器进程为大量用户提供服务。在此模式下,数据库实例启动的同时也将启动一定数量的服务进程,在调度进程Dnnn 的调度下位任意数量的用户进程提供服务。 简述oracle的初始化参数文件? 答:在传统上,Oracle在启动实例时将读取本地的一个文本文件,并利用从中获取初始化参数对实例和数据库进行设置,这个文本文件称为初始化参数文件(简称为PFILE)。 简述如何修改初始化参数文件? 答:如果要对初始化参数进行修改,必须先关闭数据库,然后在初始化参数文件中进行编辑,再重新启动数据库使修改生效。 简述启动数据库时的状态。 答:开启数据库分成4种状态。SHUTDOWN状态:数据库是关闭的。NOMOUNT状态:Instance被开启的状态,会去读取初始化参数文件。MOUNT状态:会去读取控制文件。数据库被装载。OPEN状态:读取数据文件、在线重做日志文件等,数据库开启。 简述数据库的各种关闭方式。 答:(1)正常关闭(SHUTDOWN NORMAL):不允许新的USER连进来。(2)事务关闭(SHUTDOWN TRANSACTIONAL):等待所有未提交的事务完成后再关闭数据库(3)立即关闭(SHUTDOWN IMMEDIATE):任何未提交的事务均被回退。(4)终止关闭(SHUTDOWN ABORT):立即终止当前正在执行的SQL语句,任何未提交的事务 页脚内容1
1、判断题,正确请写写"T",错误请写写"F", 1、oracle数据库系统中,启动数据库的第一步是启动一个数据库实例。( T ) 2、Oracle服务器端的监听程序是驻留在服务器上的单独进程,专门负责响应客户机的连接请求。( F) 3、oracle数据库中实例和数据库是一一对应的(非ORACLE并行服务,非集群)。( T) 4、系统全局区SGA 是针对某一服务器进程而保留的内存区域,它是不可以共享的。( F ) 5、数据库字典视图ALL_***视图只包含当前用户拥有的数据库对象信息。( F ) 8、数据字典中的内容都被保存在SYSTEM表空间中。( T ) 9、HAVING后面的条件中可以有聚集函数,比如SUM(),AVG()等, WHERE 后面的条件中也可以有聚集函数。( F ) 10、"上海西北京" 可以通过like ‘%上海_’查出来。( F ) 11、表空间是oracle 最大的逻辑组成部分。Oracle数据库由一个或多个表空间组成。一个表空间由一个或多个数据文件组成,但一个数据文件只能属于一个表空间。( T ) 12、表空间分为永久表空间和临时表空间两种类型。( T ) 13、truncate是DDL操作,不能 rollback。( T ) 14、如果需要向表中插入一批已经存在的数据,可以在INSERT语句中使用WHERE语句。( F ) 15、Oracle数据库中字符串和日期必须使用双引号标识。( F ) 16、Oracle数据库中字符串数据是区分大小写的。( T ) 17、Oracle数据库中可以对约束进行禁用,禁用约束可以在执行一些特殊操作时候保证操作能正常进行。( F ) 18、为了节省存储空间,定义表时应该将可能包含NULL值的字段放在字段列表的末尾。( T ) 20、在连接操作中,如果左表和右表中不满足连接条件的数据都出现在结果中,那么这种连接是全外连接。( T ) 21、自然连接是根据两个表中同名的列而进行连接的,当列不同名时,自然连接将失去意义。( T ) 23、PL/SQL代码块声明区可有可无。( T ) 24、隐式游标与显式游标的不同在于显式游标仅仅访问一行,隐式的可以访问多行。( F )
二、在Windows下创建数据库 Oracle实例在Windows下表现为操作系统服务。在windows下,使用命令行方式创建数据的方法有所不同,差别在于在Windows下,需要先创建数据库服务和实例。 1.确定数据库名、数据库实例名和服务名并创建目录(DBCA创建的脚本不包含建立目录命令,须自己创建) 建立目录命令(下面以 db_name=eygle为例): mkdir D:\oracle\ora90\cfgtoollogs\dbca\eygle mkdir D:\oracle\ora90\database mkdir d:\oracle\admin\eygle\adump mkdir d:\oracle\admin\eygle\bdump mkdir d:\oracle\admin\eygle\cdump mkdir d:\oracle\admin\eygle\dpdump mkdir d:\oracle\admin\eygle\pfile mkdir d:\oracle\admin\eygle\udump mkdir d:\oracle\flash_recovery_area mkdir d:\oracle\oradata mkdir d:\oracle\oradata\eygle 2.创建参数文件 在Windows下的参数文件名称及路径如下: d:\oracle\product\10.1.0\admin\DB_NAME\pfile\init.ora(oracle10g) d:\orant\database\iniORACLE_SID.ora(oracle7,oracle8) 参数据文件内容与前述一致。这里不再说明。 3.选择数据库实例 设置环境变量ORACLE_SID c:\>set ORACLE_SID=数据库实例名 4.创建数据库实例 在Windows中创建数据库实例的命令为Oradim.exe,是一个可执行文件,可以在操作系统符号下直接运行。直接输入oradim显示此命令的帮助。 c:\>Oradim 下面对Oradim命令的参数进行一个说明 ------------------------------- -NEW 表示新建一个实例 -EDIT 表示修改一个实例 -DELETE 表示删除一个实例 -SID sid 指定要启动的实例名称 -SRVC service 指定要启动的服务名称 -INTPWD password 以Internal方式连接数据库时的口令字 -MAXUSERS count 该实例可以连接的最大用户数 -USRPWD password 指定内部用户的口令,如是作为Windows管理登录,不用此参数 -PFILE pfile 该实例所使用的参数文件名及路径 -STARTTYPE srvc|inst|srvc,inst 启动选项(srvc:只启动服务,inst:启动实例,服务必须先启动,srvc,inst:服务和实例同时启动) -SHUTTYPE srvc|linst|srvc,inst 关闭选项(srvc:只关闭服务,实例必须已关闭,inst:只关闭实例,srvc,inst:服务和实例同时关闭)
oracle数据库 优化报告
目录 1、概述 (3) 2、数据库优化部分 (3) 2.1、环境优化 (3) 2.1.1 统计信息收集被关闭 (3) 2.1.2 部分索引失效 (4) 2.2、设计优化 (4) 2.2.1 设计类问题概述 (4) 2.2.2 设计类问题优化建议 (5) 2.3、SQL优化 (5) 2.3.1 SQL_ID= 7gf3typgc469a (5) 2.3.2 SQL_ID= bdcfdz26x5hm9 (6) 3、数据库优化总结 (7)
1、概述 随着应用软件用户负载的增加和愈来愈复杂的应用环境,操作系统的各项性能参数、数据库的使用效率、用户的响应速度、系统的安全运行等性能问题逐渐成为系统必须考虑的指标之一。性能测试以及优化通常通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试,用来检测系统是否达到用户提出的性能指标,及时发现系统中存在的瓶颈,最后起到优化系统的目的。 随着需求不断增加,特别是复杂逻辑的需求,一旦出现高并发量时,也将可能导致数据库主机无法承载,因此数据库优化亟待解决。 2、数据库优化部分 从2018年1月份开始跟踪及分析,发现托管区数据库在环境、设计及SQL三方面,都存在不少问题。在SQL类优化中,本地化代码编写和设计不良,是比较明显的问题。下面将分成环境、设计、SQL优化三类进行持续分析,并给出相关建议、整改方案、整改进度。 2.1、环境优化 2.1.1 被关闭 zonghe托管区数据库统计信息未自动收集,如果未打开收集,会对系统性能造成较大的影响。
需要开启统计信息 开启方法如下: --执行 BEGIN dbms_auto_task_admin.enable(client_name => 'auto optimizer statscollection', operation => NULL, window_name =>NULL); END; 2.1.2 部分索引失效 需要将索引进行删除。删除命令参考如下: drop index index_name; 2.2、设计优化 2.2.1 设计类问题概述 序号 类型 问题描述 1 表 ZJ_KZH_DATE 、ZJ_CRM_S_ORDER_GATHER 等本 地表,设计了大量的V1,V2,需要开发人员核对需 求 2 索引 索引定义较混乱,常与其他表进行连接的表,在连接