
Hadoop配置部署
每个节点上的Hadoop配置基本相同,在Master节点操作,然后完成复制到其他所有的从节点。
下面所有的操作都使用waibao用户,切换waibao用户的命令是:
su waibao
密码是:waibao
将软件包中的Hadoop生态系统包复制到相应waibao用户的主目录下(直接拖拽方式即可拷贝)
3.3.1 Hadoop安装包解压
进入Hadoop软件包,命令如下:
cd /home/waibao/resources/
复制并解压Hadoop安装包命令如下:
cp hadoop-2.5.2.tar.gz ~/
cd
tar -xvf hadoop-2.5.2.tar.gz
mv hadoop-2.5.2 hadoop
cd hadoop
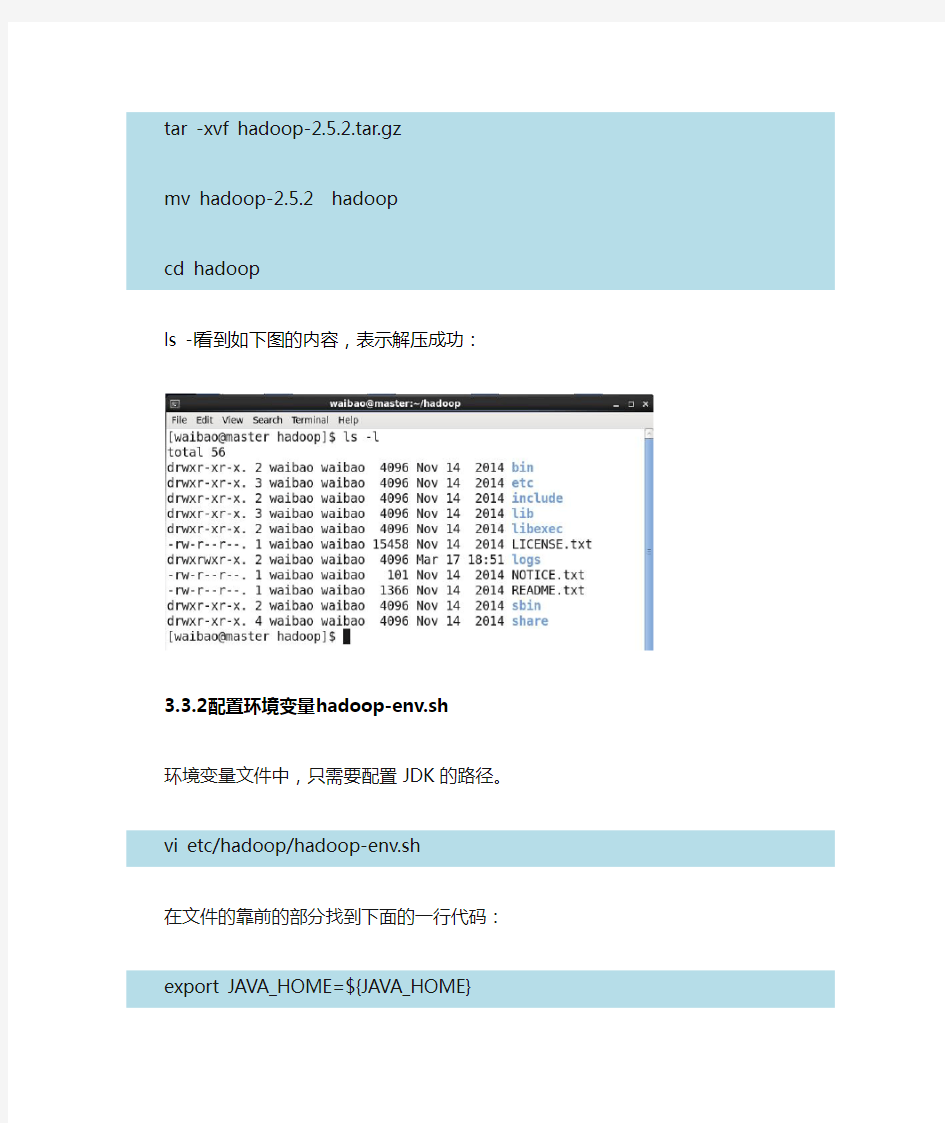
ls -l看到如下图的内容,表示解压成功:
3.3.2配置环境变量hadoop-env.sh
环境变量文件中,只需要配置JDK的路径。
vi etc/hadoop/hadoop-env.sh
在文件的靠前的部分找到下面的一行代码:
export JAVA_HOME=${JAVA_HOME}
将这行代码修改为下面的代码:
export JAVA_HOME=/usr/java/jdk7
然后保存文件。
3.3.3配置环境变量yarn-env.sh
环境变量文件中,只需要配置JDK的路径。
vi etc/hadoop/yarn-env.sh
在文件的靠前的部分找到下面的一行代码:
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
将这行代码修改为下面的代码(将#号去掉):
export JAVA_HOME=/usr/java/jdk7
然后保存文件。
3.3.4配置核心组件core-site.xml
vi etc/hadoop/core-site.xml
用下面的代码替换core-site.xml中的内容:
href="configuration.xsl"?>
3.3.5配置文件系统hdfs-site.xml
vi etc/hadoop/hdfs-site.xml
用下面的代码替换hdfs-site.xml中的内容:
href="configuration.xsl"?>
3.3.6配置文件系统yarn-site.xml
vi etc/hadoop/yarn-site.xml
用下面的代码替换yarn-site.xml中的内容:
3.3.7配置计算框架mapred-site.xml
复制mapred-site-template.xml文件:
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
vi etc/hadoop/mapred-site.xml
用下面的代码替换mapred-site.xml中的内容
href="configuration.xsl"?>
3.3.8 在master节点配置slaves文件
vi etc/hadoop/slaves
用下面的代码替换slaves中的内容:
slave01
slave02
slave03
3.3.9 复制到从节点
使用下面的命令将已经配置完成的Hadoop复制到从节点Slave上:
cd
scp -r hadoop slave01:~/
scp -r hadoop slave02:~/
scp -r hadoop slave03:~/
注意:因为之前已经配置了免密钥登录,这里可以直接远程复制。
3.4 启动Hadoop集群
下面所有的操作都使用waibao用户,切换waibao用户的命令是:
su waibao
密码是:waibao
3.4.1 配置Hadoop启动的系统环境变量
该节的配置需要同时在所有主从节点(Master和各Slave)上进行操作,操作命令如下:
cd
vi ~/.bash_profile
将下面的代码追加到.bash_profile末尾:
#HADOOP
export HADOOP_HOME=/home/waibao/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
然后执行命令:
source .bash_profile
3.4.2 创建数据目录
该节的配置需要同时在所有主从节点(master和各Slave)上进行操作。
在外包的用户主目录下,创建数据目录,命令如下:
mkdir /home/waibao/hadoopdata
3.4.3启动Hadoop集群
1、格式化文件系统
格式化命令如下,该操作需要在Master节点上执行:
hdfs namenode -format
如果出现Exception/Error,表示出问题
2、启动Hadoop
使用start-all.sh启动Hadoop集群,首先进入Hadoop安装主目录,然后执行启动命令:
cd ~/hadoop
sbin/start-all.sh
执行命令后,提示出入yes/no时,输入yes。
3、查看进程是否启动
在Master的终端执行jps命令,在打印结果中会看到4个进程,分别是ResourceManager、Jps、NameNode和SecondaryNameNode,如下图所示。如果出现了这4个进程表示主节点进程启动成功。
在各个slave的终端执行jps命令,在打印结果中会看到3个进程,分别是NodeManager、DataNode和Jps,如下图所示。如果出现了这3个进程表示从节点进程启动成功。
4、Web UI查看集群是否成功启动
在Master上启动Firefox浏览器,在浏览器地址栏中输入输入http://master:50070/,检查namenode 和datanode 是否正常。UI页面如下图所示。
在Master上启动Firefox浏览器,在浏览器地址栏中输入输入http://master:18088/,检查Yarn是否正常,页面如下图所示。
第一章 一、单选题 1、下面哪个选项不属于Google的三驾马车?(C ) A、GFS B、MapReduce C、HDFS D、BigTable 2、大数据的数据量现在已经达到了哪个级别?(C ) A、GB B、TB C、PB D、ZB 3、2003年,Google公司发表了主要讲解海量数据的可靠存储方法的论文是?( A ) A、“The Google File System” B、“MapReduce: Simplified Data Processing on Large Clusters” C、“Bigtable: A Distributed Storage System for Structured Data” D、“The Hadoop File System” 4、下面哪个选项不是HDFS架构的组成部分?( C ) A、NameNode B、DataNode C、Jps D、SecondaryNameNode 5、Hadoop能够使用户轻松开发和运行处理大数据的应用程序,下面不属于Hadoop特性的是(C ) A、高可靠性、高容错性 B、高扩展性 C、高实时性 D、高效性 6、2004年,Google公司发表了主要讲解海量数据的高效计算方法的论文是?( B ) A、“The Google File System” B、“MapReduce: Simplified Data Processing on Large Clusters” C、“Bigtable: A Distributed Storage System for Structured Data” D、“The Hadoop File System” 7、建立在Hadoop文件系统之上的分布式的列式数据库?(A )
Hadoop大数据平台架构与实践--基础篇 大数据时代已经到来,越来越多的行业面临着大量数据需要存储以及分析的挑战。Hadoop,作为一个开源的分布式并行处理平台,以其高扩展、高效率、高可靠等优点,得到越来越广泛的应用。 本课旨在培养理解Hadoop的架构设计以及掌握Hadoop的运用能力。 导师简介 Kit_Ren,博士,某高校副教授,实战经验丰富,曾担任过大型互联网公司的技术顾问,目前与几位志同道合的好友共同创业,开发大数据平台。 课程须知 本课程需要童鞋们提前掌握Linux的操作以及Java开发的相关知识。对相关内容不熟悉的童鞋,可以先去《Linux达人养成计划Ⅰ》以及《Java入门第一季》进行修炼~~ 你能学到什么? 1、Google的大数据技术 2、Hadoop的架构设计 3、Hadoop的使用 4、Hadoop的配置与管理 大纲一览 第1章初识Hadoop 本章讲述课程大纲,授课内容,授课目标、预备知识等等,介绍Hadoop的前世今生,功能与优势 第2章 Hadoop安装 本章通过案例的方式,介绍Hadoop的安装过程,以及如何管理和配置Hadoop 第3章 Hadoop的核心-HDFS简介 本章重点讲解Hadoop的组成部分HDFS的体系结构、读写流程,系统特点和HDFS
的使用。 第4章 Hadoop的核心-MapReduce原理与实现 本章介绍MapReduce的原理,MapReduce的运行流程,最后介绍一个经典的示例WordCount 第5章开发Hadoop应用程序 本章介绍在Hadoop下开发应用程序,涉及多个典型应用,包括数据去重,数据排序和字符串查找。 课程地址:https://www.doczj.com/doc/f810615429.html,/view/391
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS 本教程讲述如何配置Hadoop 集群,默认读者已经掌握了Hadoop 的单机伪分布式配置,否则请先查看Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置。 本教程由厦门大学数据库实验室出品,转载请注明。本教程适合于原生Hadoop 2,包括Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,保证按照步骤来,都能顺利安装并运行Hadoop。另外有Hadoop安装配置简略版方便有基础的读者快速完成安装。 为了方便新手入门,我们准备了两篇不同系统的Hadoop 伪分布式配置教程。但其他Hadoop 教程我们将不再区分,可同时适用于Ubuntu 和CentOS/RedHat 系统。例如本教程以Ubuntu 系统为主要演示环境,但对Ubuntu/CentOS 的不同配置之处、CentOS 6.x 与CentOS 7 的操作区别等都会尽量给出注明。 环境 本教程使用Ubuntu 14.04 64位作为系统环境,基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1,Hadoop 2.4.1 等。 本教程简单的使用两个节点作为集群环境: 一个作为Master 节点,局域网IP 为192.168.1.121;另一个作为Slave 节点,局域网IP 为192.168.1.122。 准备工作 Hadoop 集群的安装配置大致为如下流程: 1.选定一台机器作为Master 2.在Master 节点上配置hadoop 用户、安装SSH server、安装Java 环境 3.在Master 节点上安装Hadoop,并完成配置 4.在其他Slave 节点上配置hadoop 用户、安装SSH server、安装Java 环境 5.将Master 节点上的/usr/local/hadoop 目录复制到其他Slave 节点上 6.在Master 节点上开启Hadoop 配置hadoop 用户、安装SSH server、安装Java 环境、安装Hadoop 等过程已经在Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置中有详细介绍,请前往查看,不再重复叙述。 继续下一步配置前,请先完成上述流程的前 4 个步骤。 网络配置 假设集群所用的节点都位于同一个局域网。 如果使用的是虚拟机安装的系统,那么需要更改网络连接方式为桥接(Bridge)模式,才能实现多个节点互连,例如在VirturalBox 中的设置如下图。此外,如果节点的系统是在虚拟机中直接复制的,要确保各个节点的Mac 地址不同(可以点右边的按钮随机生成MAC 地址,否则IP 会冲突):
单选题 1、以下选项哪个是YARN的组成部分?(A) A、Container、ResourceManager、NodeManager、ApplicationMaster B、Container、ResourceManager、NodeManager、ApplicationManager C、Container、ResourceManager、Scheduler、ApplicationMaster D、Container、ApplicationManager、NodeManager、ApplicationMaster 2、下列关于YARN的描述错误的是?(C) A、ResourceManager负责整个系统的资源分配和管理,是一个全局的资源管理器 B、NodeManager是每个节点上的资源和任务管理器 C、ApplicationManager是一个详细的框架库,它结合从ResourceManager 获得的资源和 NodeManager协同工作来运行和监控任务 D、调度器根据资源情况为应用程序分配封装在Container中的资源 3、下列关于调度器的描述不正确的是?(A) A、先进先出调度器可以是多队列 B、容器调度器其实是多个FIFO队列 C、公平调度器不允许管理员为每个队列单独设置调度策略 D、先进先出调度器以集群资源独占的方式运行作业 4、YARN哪种调度器采用的是单队列?(A) A、FIFO Scheduler B、Capacity Scheduler C、Fair Scheduler D、ResourceManager
1、YARN不仅支持MapReduce,还支持Spark,Strom等框架。 ( √ ) 2、Container是YARN中资源的抽象,它封装了某个节点上的多维度资源。 ( √ ) 3、YARN的三种调度器只有FIFO是属于单队列的。 ( √ ) 4、在YARN的整个工作过程中,Container是属于动态分配的。 ( √ )
Hadoop是什么 Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Hadoop名字的由来 Hadoop was created by Doug Cutting and Mike Cafarella in 2005 Named the project after son's toy elephant
从移动数据到移动算法
Hadoop的核心设计理念?可扩展性 ?可靠性
相对于传统的BI 架构转变 数据仓库电子表格 视觉化工 具 数据挖掘集成开发工具 数据集市 企业应用工具 传统文件日志社交& 网络遗留系 统结构化 非结构化 音视频数据应用非关系型数据库内存数据库NO SQL 应用 Nod e Nod e Nod e Hadoop * Web Apps MashUps 导出/导入INSIGHTS 消费Create Map 存储/计算实时数据处理通道(Spark,Storm)数据交换平台数据存储计算平台数据访问 层Kafka Flume Goldengat e Shareplex ..传感器传感器
hadoop 的适用场景 小数据+ 小计算量OLTP 业务系统:ERP/CRM/EDA 大数据+ 小计算量如全文检索,传统的ETL 小数据+大计算量D a t a Compute 数据 计算 实时性
安装 2011年4月4日 10:13 Hadoop-0.20.2安装使用 1、Cygwin 安装 ssh 2、按照以下的文档配置ssh 在Windows上安装Ha doop教程.pdf 3、几个配置文件的配置 3.1、conf/core-site.xml
你想了解大数据,却对生涩的术语毫不知情?你想了解大数据的市场和应用,却又没有好的案例和解说?别担心,这本来自Wikibon社区的小书想要帮你。 是的,这是一本小书而不是一篇文章,因为它详实细致的让你从一个完全不了解大数据技术及相关应用的门外汉,变成一个熟知其概念和意义的“内行人”,所以它很棒! 主要内容 目录 1.来自Wikibon社区的大数据宣言 (1) 2.数据处理和分析:传统方式 (2) 3.大数据性质的变化 (3) 4.大数据处理和分析的新方法 (5) 4.1 Hadoop (5) 4.1.1 Hadoop如何工作 (6) 4.1.2 Hadoop的技术组件 (7) 4.1.3 Hadoop:优点和缺点 (8) 4.2 NoSQL (8) 4.3 大规模并行分析数据库 (9) 5.大数据方法的互补 (10) 6.大数据供应商发展状况 (12) 7.大数据:实际使用案例 (13) 8.大数据技能差距 (14) 9.大数据:企业和供应商的后续动作 (15) 1.来自Wikibon社区的大数据宣言 为公司提供有效的业务分析工具和技术是首席信息官的首要任务。有效的业务分析(从基本报告到高级的数据挖掘和预测分析)使得数据分析人员和业务人员都可以从数据中获得见解,当这些见解转化为行动,会给公司带来更高的效率和盈利能力。 所有业务分析都是基于数据的。传统意义上,这意味着企业自己创建和存储的结构化数据,如CRM系统中的客户数据,ERP系统中的运营数据,以及会计数据库
中的财务数据。得益于社交媒体和网络服务(如Facebook,Twitter),数据传感器以及网络设备,机器和人类产生的网上交易,以及其他来源的非结构化和半结构化的数据的普及,企业现有数据的体积和类型以及为追求最大商业价值而产生的近实时分析的需求正在迅速增加。我们称这些为大数据。 传统的数据管理和业务分析工具及技术都面临大数据的压力,与此同时帮助企业获得来自大数据分析见解的新方法不断涌现。这些新方法采取一种完全不同于传统工具和技术的方式进行数据处理、分析和应用。这些新方法包括开源框架Hadoop,NoSQL数据库(如Cassandra和Accumulo)以及大规模并行分析数据库(如EMC的Greenplum,惠普的Vertica和TeradataASTERData)。这意味着,企业也需要从技术和文化两个角度重新思考他们对待业务分析的方式。 对于大多数企业而言,这种转变并不容易,但对于接受转变并将大数据作为业务分析实践基石的企业来说,他们会拥有远远超过胆小对手的显著竞争优势。大数据助力复杂的业务分析可能为企业带来前所未有的关于客户行为以及动荡的市 场环境的深入洞察,使得他们能够更快速的做出数据驱动业务的决策,从而比竞争对手更有效率。 从存储及支持大数据处理的服务器端技术到为终端用户带来鲜活的新见解的前 端数据可视化工具,大数据的出现也为硬件、软件和服务供应商提供了显著的机会。这些帮助企业过渡到大数据实践者的供应商,无论是提供增加商业价值的大数据用例,还是发展让大数据变为现实的技术和服务,都将得到茁壮成长。 大数据是所有行业新的权威的竞争优势。认为大数据是昙花一现的企业和技术供应商很快就会发现自己需要很辛苦才能跟上那些提前思考的竞争对手的步伐。在我们看来,他们是非常危险的。对于那些理解并拥抱大数据现实的企业,新创新,高灵活性,以及高盈利能力的可能性几乎是无止境的。 2.数据处理和分析:传统方式 传统上,为了特定分析目的进行的数据处理都是基于相当静态的蓝图。通过常规的业务流程,企业通过CRM、ERP和财务系统等应用程序,创建基于稳定数据模型的结构化数据。数据集成工具用于从企业应用程序和事务型数据库中提取、转换和加载数据到一个临时区域,在这个临时区域进行数据质量检查和数据标准化,
Hadoop大数据平台测试报告及成功案例
目录 1技术规范书应答书 ................................. 错误!未定义书签。2技术方案建议 ......................................... 错误!未定义书签。3测试及验收 ............................................. 错误!未定义书签。4项目实施与管理 ..................................... 错误!未定义书签。5人员资质与管理 ..................................... 错误!未定义书签。6技术支持及保修 ..................................... 错误!未定义书签。7附录 ......................................................... 错误!未定义书签。
1.1 大数据平台测试报告 1.1.1某银行Cloudera CDH 性能测试测试 某银行现有HODS在支撑行内业务方面已经遇到瓶颈。希望通过搭建基于Hadoop 的历史数据平台(新HODS),以提升平台运行效率及数据覆盖面,支撑未来大数据应用,满足未来业务发展需求。本次POC测试的主要目的是验证Hadoop商业发行版(EDH) 是否可以满足某银行HODS应用特点,主要考察点包括: ?验证产品本身的易用性、可扩展性,主要涉及集群的部署、运维、监控、升级等; ?验证产品对安全性的支持,包括认证、授权、审计三大方面; ?验证产品对资源分配的控制与调度; ?验证Hadoop基本功能,包括可靠性、稳定性、故障恢复等; ?验证Hadoop子系统(包括HDFS、HBase、Hive、Impala等) 的性能、使用模式、设计思想、迁移代价等。 1.1.1.1基础设施描述 1.1.1.1.1硬件配置 硬件配置分为两类:管理节点(master node) 与计算节点(worker node)。 管理节点配置(2) CPU Intel? Xeon? E5-2650 v3 2.3GHz,25M Cache,9.60GT/s QPI,Turbo,HT,10C/20T (105W) Max Mem 2133MHz (40 vcore) 内存16GB RDIMM, 2133MT/s, Dual Rank, x4 Data Width (128GB) 网络Intel X520 DP 10Gb DA/SFP+ Server Adapter, with SR Optics
Hadoop-2.6.0配置 前面的部分跟配置Hadoop-1.2.1的一样就可以,什么都不用变,完全参考文档1即可。下面的部分就按照下面的做就可以了。 hadoop-2.6.0的版本用张老师的。 下面的配置Hadoop hadoop-2.6.0的部分 1.修改hadoop- 2.6.0/etc/hadoop/hadoop-env.sh,添加JDK支持: export JAVA_HOME=/usr/java/jdk1.6.0_45 如果不知道你的JDK目录,使用命令echo $JAVA_HOME查看。 2.修改hadoop-2.6.0/etc/hadoop/core-site.xml 注意:必须加在
第1章 初识Hadoop大数据技术 本章主要介绍大数据的时代背景,给出了大数据的概念、特征,还介绍了大数据相关问题的解决方案、Hadoop大数据技术以及Hadoop的应用案例。 本章的主要内容如下。 (1)大数据技术概述。 (2)Google的三篇论文及其思想。 (3)Hadoop概述。 (4)Hadoop生态圈。 (5)Hadoop的典型应用场景和应用架构。 1.1 大数据技术概述 1.1.1 大数据产生的背景 1946年,计算机诞生,当时的数据与应用紧密捆绑在文件中,彼此不分。19世纪60年代,IT系统规模和复杂度变大,数据与应用分离的需求开始产生,数据库技术开始萌芽并蓬勃发展,并在1990年后逐步统一到以关系型数据库为主导,具体发展阶段如图1-1所示。
Hadoop 大数据技术与应用 图1-1 数据管理技术在2001年前的两个发展阶段 2001年后,互联网迅速发展,数据量成倍递增。据统计,目前,超过150亿个设备连接到互联网,全球每秒钟发送290万封电子邮件,每天有2.88万小时视频上传到YouTube 网站,Facebook 网站每日评论达32亿条,每天上传照片近3亿张,每月处理数据总量约130万TB 。2016年全球产生数据量16.1ZB ,预计2020年将增长到35ZB (1ZB = 1百万,PB = 10亿TB ),如图1-2所示。 图1-2 IDC 数据量增长预测报告 2011年5月,EMC World 2011大会主题是“云计算相遇大数据”,会议除了聚焦EMC 公司一直倡导的云计算概念外,还抛出了“大数据”(BigData )的概念。2011年6月底,IBM 、麦肯锡等众多国外机构发布“大数据”相关研究报告,并予以积极的跟进。 19世纪60年代,IT 系统规模和复杂度变大,数据与应 用分离的需求开始产生,数据库技术开始萌芽并蓬勃发 展,并在1990年后逐步统一到以关系型数据库为主导 1946年,计算机诞生, 数据与应用紧密捆绑 在文件中,彼此不分 1946 1951 1956 1961 1970 1974 1979 1991 2001 … 网络型 E-R SQL 关系型数据库 数据仓库 第一台 计算机 ENIAC 面世 磁带+ 卡片 人工 管理 磁盘被发明,进入文件管理时代 GE 公司发明第一个网络模型数据库,但仅限于GE 自己 的主机 IBM E. F.Dodd 提出关系模型 SQL 语言被发明 ORACLE 发布第一个商用SQL 关系数据库,后续快速发展 数据仓库开始涌现,关系数据库开始全面普及且与平台无关,数据管理技术进入成熟期 0.8ZB :将一堆 DVD 堆起来够 地球到月亮一 个来回 35ZB :将一堆DVD 堆起来是地球到火星距离的一半 IDC 报告“Data Universe Study ” 预测:全世界数据量将从2009 年的0.8ZB 增长到2020年的 35ZB ,增长44倍!年均增 长率>40%!
Hadoop2.6配置详解 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。 这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop-2.6解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调 hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM(由cloudra提出,原理类似zookeeper)。这里我使用QJM完成。主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode 1安装前准备 1.1示例机器 192.168.0.10 hadoop1 192.168.0.20 hadoop2 192.168.0.30 hadoop3 192.168.0.40 hadoop4 每台机器都有一个hadoop用户,密码是hadoop 所有机器上安装jdk1.7。 在hadoop2,hadoop3,hadoop4上安装Zookeeper3.4集群。 1.2配置ip与hostname 用root用户修改每台机器的hosts
大数据技术Hadoop面试题,看看你能答对多少? 单项选择题 1. 下面哪个程序负责HDFS 数据存储。 a)NameNode b)Jobtracker c)Datanode d)secondaryNameNode e)tasktracker 2. HDfS 中的block 默认保存几份? a)3 份 b)2 份 c)1 份 d)不确定 3. 下列哪个程序通常与NameNode 在一个节点启动? a)SecondaryNameNode b)DataNode c)TaskTracker d)Jobtracker 4. Hadoop 作者 a)Martin Fowler b)Kent Beck c)Doug cutting 5. HDFS 默认Block Size a)32MB b)64MB c)128MB 6. 下列哪项通常是集群的最主要瓶颈 a)CPU b)网络 c)磁盘 d)内存 7. 关于SecondaryNameNode 哪项是正确的? a)它是NameNode 的热备 b)它对内存没有要求 c)它的目的是帮助NameNode 合并编辑日志,减少NameNode 启动时间 d)SecondaryNameNode 应与NameNode 部署到一个节点 多选题: 8. 下列哪项可以作为集群的管理工具 a)Puppet b)Pdsh c)Cloudera Manager d)d)Zookeeper
9. 配置机架感知的下面哪项正确 a)如果一个机架出问题,不会影响数据读写 b)写入数据的时候会写到不同机架的DataNode 中 c)MapReduce 会根据机架获取离自己比较近的网络数据 10. Client 端上传文件的时候下列哪项正确 a)数据经过NameNode 传递给DataNode b)Client 端将文件切分为Block,依次上传 c)Client 只上传数据到一台DataNode,然后由NameNode 负责Block 复制工作 11. 下列哪个是Hadoop 运行的模式 a)单机版 b)伪分布式 c)分布式 12. Cloudera 提供哪几种安装CDH 的方法 a)Cloudera manager b)Tar ball c)Yum d)Rpm 判断题: 13. Ganglia 不仅可以进行监控,也可以进行告警。() 14. Block Size 是不可以修改的。() 15. Nagios 不可以监控Hadoop 集群,因为它不提供Hadoop 支持。() 16. 如果NameNode 意外终止,SecondaryNameNode 会接替它使集群继续工作。() 17. Cloudera CDH 是需要付费使用的。() 18. Hadoop 是Java 开发的,所以MapReduce 只支持Java 语言编写。() 19. Hadoop 支持数据的随机读写。() 20. NameNode 负责管理metadata,client 端每次读写请求,它都会从磁盘中读取或则会写入metadata 信息并反馈client 端。() 21. NameNode 本地磁盘保存了Block 的位置信息。() 22. DataNode 通过长连接与NameNode 保持通信。() 23. Hadoop 自身具有严格的权限管理和安全措施保障集群正常运行。() 24. Slave 节点要存储数据,所以它的磁盘越大越好。() 25. hadoop dfsadmin –report 命令用于检测HDFS 损坏块。() 26. Hadoop 默认调度器策略为FIFO() 27. 集群内每个节点都应该配RAID,这样避免单磁盘损坏,影响整个节点运行。() 28. 因为HDFS 有多个副本,所以NameNode 是不存在单点问题的。() 29. 每个map 槽就是一个线程。() 30. Mapreduce 的input split 就是一个block。() 31. NameNode 的Web UI 端口是50030,它通过jetty 启动的Web 服务。() 32. Hadoop 环境变量中的HADOOP_HEAPSIZE 用于设置所有Hadoop 守护线程的内存。它默认是200 GB。() 33. DataNode 首次加入cluster 的时候,如果log 中报告不兼容文件版本,那需要NameNode执行“Hadoop namenode -format”操作格式化磁盘。() 【编辑推荐】 没有数据分析大数据什么也不是...... 大数据告诉你,真正的白富美的生活是怎样的呢?
基于Hadoop的大数据平台实施——整体架构设计大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星。我们暂不去讨论大数据到底是否适用于您的公司或组织,至少在互联网上已经被吹嘘成无所不能的超级战舰。好像一夜之间我们就从互联网时代跳跃进了大数据时代!关于到底什么是大数据,说真的,到目前为止就和云计算一样,让我总觉得像是在看电影《云图》——云里雾里的感觉。或许那些正在向你推销大数据产品的公司会对您描绘一幅乌托邦似的美丽画面,但是您至少要保持清醒的头脑,认真仔细的慎问一下自己,我们公司真的需要大数据吗? 做为一家第三方支付公司,数据的确是公司最最重要的核心资产。由于公司成立不久,随着业务的迅速发展,交易数据呈几何级增加,随之而来的是系统的不堪重负。业务部门、领导、甚至是集团老总整天嚷嚷的要报表、要分析、要提升竞争力。而研发部门能做的唯一事情就是执行一条一条复杂到自己都难以想象的SQL语句,紧接着系统开始罢工,内存溢出,宕机........简直就是噩梦。OMG!please release me!!! 其实数据部门的压力可以说是常人难以想象的,为了把所有离散的数据汇总成有价值的报告,可能会需要几个星期的时间或是更长。这显然和业务部门要求的快速响应理念是格格不入的。俗话说,工欲善其事,必先利其器。我们也该鸟枪换炮了......。 网上有一大堆文章描述着大数据的种种好处,也有一大群人不厌其烦的说着自己对大数据的种种体验,不过我想问一句,到底有多少人多少组织真的在做大数据?实际的效果又如何?真的给公司带来价值了?是否可以将价值量化?关于这些问题,好像没看到有多少评论会涉及,可能是大数据太新了(其实底层的概念并非新事物,老酒装新瓶罢了),以至于人们还沉浸在各种美妙的YY中。 做为一名严谨的技术人员,在经过短暂盲目的崇拜之后,应该快速的进入落地应用的研究中,这也是踩着“云彩”的架构师和骑着自行车的架构师的本质区别。说了一些牢骚话,
Hadoop大数据平台建设要求及应答方案
目录 2技术规范书应答书 (2) 2.1业务功能需求 (4) 2.1.1系统管理架构 (4) 2.1.2数据管理 (12) 2.1.3数据管控 (26) 2.1.4数据分析与挖掘 (27) 2.2技术要求 (30) 2.2.1总体要求 (30) 2.2.2总体架构 (31) 2.2.3运行环境要求 (32) 2.2.4客户端要求 (35) 2.2.5数据要求 (36) 2.2.6集成要求 (36) 2.2.7运维要求 (37) 2.2.8性能要求 (49) 2.2.9扩展性要求 (50) 2.2.10可靠性和可用性要求 (52) 2.2.11开放性和兼容性要求 (57) 2.2.12安全性要求 (59)
1大数据平台技术规范要求 高度集成的Hadoop平台:一个整体的数据存储和计算平台,无缝集成了基于Hadoop 的大量生态工具,不同业务可以集中在一个平台内完成,而不需要在处理系统间移动数据;用廉价的PC服务器架构统一的存储平台,能存储PB级海量数据。并且数据种类可以是结构化,半结构化及非结构化数据。存储的技术有SQL及NoSQL,并且NoSQL能提供企业级的安全方案。CDH提供统一的资源调度平台,能够利用最新的资源调度平台YARN分配集群中CPU,内存等资源的调度,充分利用集群资源; 多样的数据分析平台–能够针对不用的业务类型提供不同的计算框架,比如针对批处理的MapReduce计算框架;针对交互式查询的Impala MPP查询引擎;针对内存及流计算的Spark框架;针对机器学习,数据挖掘等业务的训练测试模型;针对全文检索的Solr搜索引擎 项目中所涉及的软件包括: ?Hadoop软件(包括而不限于Hadoop核心) ?数据采集层:Apache Flume, Apache Sqoop ?平台管理:Zookeeper, YARN ?安全管理:Apache Sentry ?数据存储:HDFS, HBase, Parquet ?数据处理:MapReduce, Impala, Spark ?开发套件:Apache Hue, Kite SDK ?关系型数据库系统:SAP HANA企业版 ?ETL工具:SAP Data Services 数据管控系统的二次开发量如下: ?主数据管理功能 通过二次开发的方式实现主数据管理功能,并集成甲方已有的主数据管理系统。
hadoop3.0.0安装和配置1.安装环境 硬件:虚拟机 操作系统:Centos 7 64位 IP:192.168.0.101 主机名:dbp JDK:jdk-8u144-linux-x64.tar.gz Hadoop:hadoop-3.0.0-beta1.tar.gz 2.关闭防火墙并配置主机名 [root@dbp]#systemctl stop firewalld #临时关闭防火墙 [root@dbp]#systemctl disable firewalld #关闭防火墙开机自启动 [root@dbp]#hostnamectl set-hostname dbp 同时修改/etc/hosts和/etc/sysconfig/network配置信息 3.配置SSH无密码登陆 [root@dbp]# ssh-keygen -t rsa #直接回车 [root@dbp]# ll ~/.ssh [root@dbp .ssh]# cp id_rsa.pub authorized_keys [root@dbp .ssh]# ssh localhost #验证不需要输入密码即可登录
4.安装JDK 1、准备jdk到指定目录 2、解压 [root@dbp software]# tar–xzvf jdk-8u144-linux-x64.tar.gz [root@dbp software]# mv jdk1.8.0_144/usr/local/jdk #重命名4、设置环境变量 [root@dbp software]# vim ~/.bash_profile 5、使环境变量生效并验证 5.安装Hadoop3.0.0 1、准备hadoop到指定目录 2、解压
1、VMware安装 我们使用Vmware 14的版本,傻瓜式安装即可。(只要) 双击 如过 2.安装xshell 双击 3.安装镜像: 解压centos6.5-empty解压 双击打开CentOS6.5.vmx 如果打不开,在cmd窗口中输入:netsh winsock reset 然后重启电脑。 进入登录界面,点击other 用户名:root 密码:root 然后右键open in terminal 输入ifconfig 回车 查看ip地址
打开xshell
点击链接 如果有提示,则接受 输入用户名:root 输入密码:root 4.xshell连接虚拟机 打开虚拟机,通过ifconfig查看ip
5.安装jkd 1.解压Linux版本的JDK压缩包 mkdir:创建目录的命令 rm -rf 目录/文件删除目录命令 cd 目录进入指定目录 rz 可以上传本地文件到当前的linux目录中(也可以直接将安装包拖到xshell窗口) ls 可以查看当前目录中的所有文件 tar 解压压缩包(Tab键可以自动补齐文件名)
pwd 可以查看当前路径 文档编辑命令: vim 文件编辑命令 i:进入编辑状态 Esc(左上角):退出编辑状态 :wq 保存并退出 :q! 不保存退出 mkdir /home/software #按习惯用户自己安装的软件存放到/home/software目录下 cd /home/software #进入刚刚创建的目录 rz 上传jdk tar包 #利用xshell的rz命令上传文件(如果rz命令不能用,先执行yum install lrzsz -y ,需要联网) tar -xvf jdk-7u51-linux-x64.tar.gz #解压压缩包 2.配置环境变量 1)vim /etc/profile 2)在尾行添加 #set java environment JAVA_HOME=/home/software/jdk1.8.0_65 JAVA_BIN=/home/software/jdk1.8.0_65/bin PATH=$JAVA_HOME/bin:$PATH CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME JAVA_BIN PATH CLASSPATH Esc 退出编辑状态 :wq #保存退出 注意JAVA_HOME要和自己系统中的jdk目录保持一致,如果是使用的rpm包安
Hadoop安装简要过程及配置文件 1、机器准备 ①、Linux版操作系统centos 6.x ②、修改主机名,方便配置过程中记忆。修改文件为: /etc/sysconfig/network 修改其中的HOSTNAME即可 ③、配置局域网内,主机名与对应ip,并且其中集群中所有的机器的文件相同,修改文件为 /etc/hosts 格式为: 10.1.20.241 namenode 10.1.20.242 datanode1 10.1.20.243 datanode2 2、环境准备 ①、配置ssh免密码登陆,将集群中master节点生成ssh密码文件。具体方法: 1)、ssh-keygen -t rsa 一直回车即可,将会生成一份 ~/.ssh/ 文件夹,其中id_rsa为私钥文件 id_rsa.pub公钥文件。 2)、将公钥文件追加到authorized_keys中然后再上传到其他slave节点上 追加文件: cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 上传文件: scp ~/.ssh/authorized_keys root@dananode:~/.ssh/ 3)、测试是否可以免密码登陆:ssh 主机名或局域网ip ②、配置JDK ③、创建hadoop用户 groupadd hadoop useradd hadoop -g hadoop 4)、同步时间 ntpdate https://www.doczj.com/doc/f810615429.html, 5)、关闭防火墙 service iptables stop 3、安装cdh5 进入目录/data/tools/ (个人习惯的软件存储目录,你可以自己随便选择); wget "https://www.doczj.com/doc/f810615429.html,/cdh5/one-click-install/redhat/ 6/x86_64/cloudera-cdh-5-0.x86_64.rpm" yum --nogpgcheck localinstall cloudera-cdh-5-0.x86_64.rpm 添加cloudera仓库验证: rpm --importhttps://www.doczj.com/doc/f810615429.html,/cdh5/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera