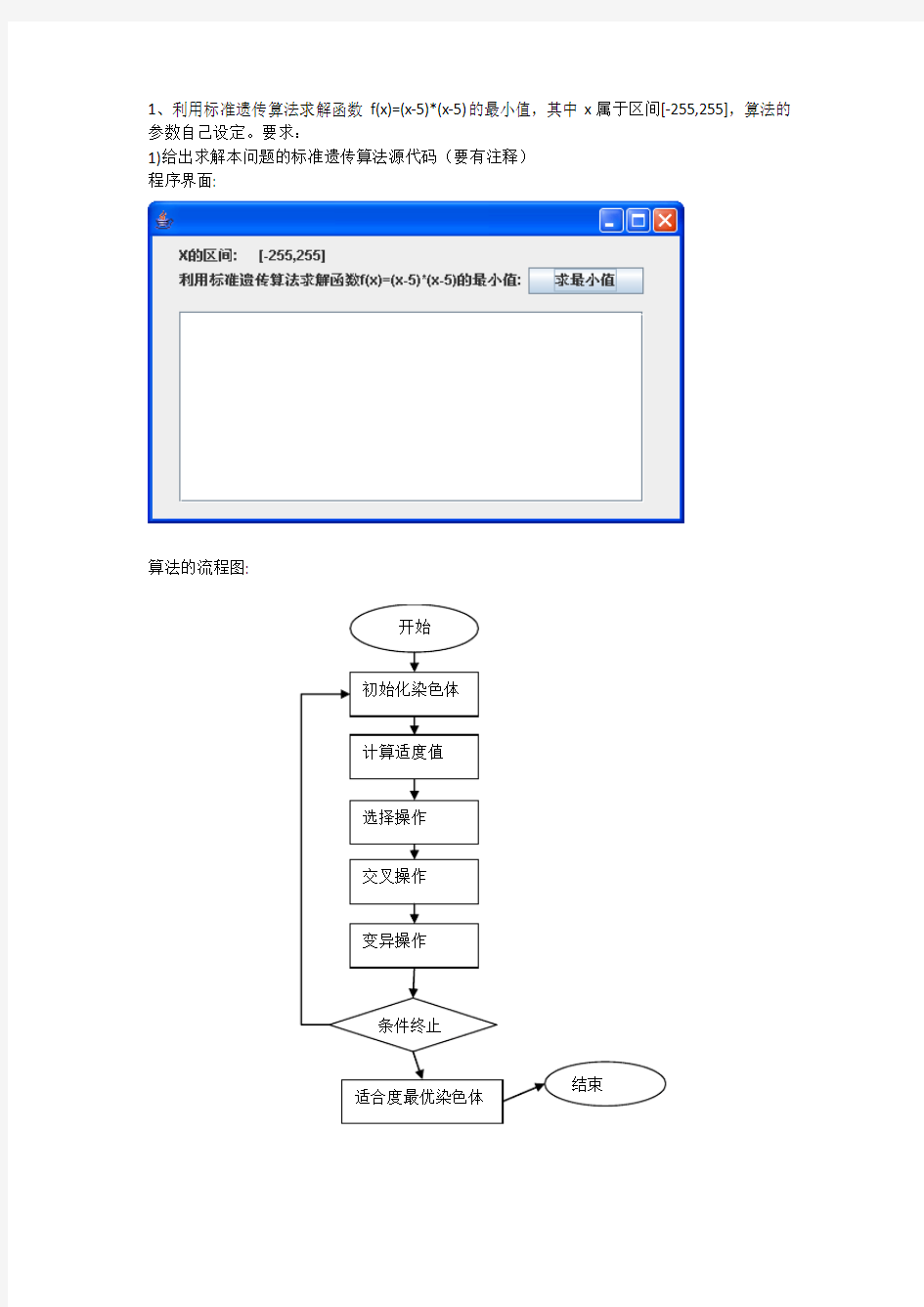

1、利用标准遗传算法求解函数f(x)=(x-5)*(x-5)的最小值,其中x属于区间[-255,255],算法的参数自己设定。要求:
1)给出求解本问题的标准遗传算法源代码(要有注释)
:
程序界面
源程序:
import java.awt.BorderLayout;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JPanel;
import javax.swing.JScrollPane;
import javax.swing.JTextArea;
import javax.swing.JTextField;
class Best {
public int generations; //最佳适应值代号
public String str; //最佳染色体
public double fitness; //最佳适应值
}
public class SGAFrame extends JFrame {
private JTextArea textArea;
private String str = "";
private Best best = null; //最佳染色体private String[] ipop = new String[10]; //染色体private int gernation = 0; //染色体代号public static final int GENE = 22; //基因数
/**
*Launch the application
*@param args
*/
public static void main(String args[]) {
try {
SGAFrame frame = new SGAFrame();
frame.setVisible(true);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
*Create the frame
*/
public SGAFrame() {
super();
this.ipop = inialPops();
getContentPane().setLayout(null);
setBounds(100, 100, 461, 277);
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
final JLabel label = new JLabel();
label.setText("X的区间:");
label.setBounds(23, 10, 88, 15);
getContentPane().add(label);
final JLabel label_1 = new JLabel();
label_1.setText("[-255,255]");
label_1.setBounds(92, 10, 84, 15);
getContentPane().add(label_1);
final JButton button = new JButton();
button.addActionListener(new ActionListener() {
public void actionPerformed(final ActionEvent e) {
SGAFrame s = new SGAFrame();
str = str + s.process() + "\n";
textArea.setText(str);
}
});
button.setText("求最小值");
button.setBounds(323, 27, 99, 23);
getContentPane().add(button);
final JLabel label_2 = new JLabel();
label_2.setText("利用标准遗传算法求解函数f(x)=(x-5)*(x-5)的最小值:");
label_2.setBounds(23, 31, 318, 15);
getContentPane().add(label_2);
final JPanel panel = new JPanel();
panel.setLayout(new BorderLayout());
panel.setBounds(23, 65, 399, 164);
getContentPane().add(panel);
final JScrollPane scrollPane = new JScrollPane();
panel.add(scrollPane, BorderLayout.CENTER);
textArea = new JTextArea();
scrollPane.setViewportView(textArea);
//
}
/**
*初始化一条染色体(用二进制字符串表示)
*@return一条染色体
*/
private String inialPop() {
String res = "";
for (int i = 0; i < GENE; i++) {
if (Math.random() > 0.5) {
res += "0";
} else {
res += "1";
}
}
return res;
}
/**
*初始化一组染色体
*@return染色体组
*/
private String[] inialPops() {
String[] ipop = new String[10];
for (int i = 0; i < 10; i++) {
ipop[i] = inialPop();
}
return ipop;
}
/**
*将染色体转换成x的值
*@param str染色体
*@return染色体的适应值
*/
private double calculatefitnessvalue(String str) {
int b = Integer.parseInt(str, 2);
//String str1 = "" + "/n";
double x = -255 + b * (255 - (-255)) / (Math.pow(2, GENE) - 1);
//System.out.println("X = " + x);
double fitness = -(x - 5) * (x - 5);
//System.out.println("f(x)=" + fitness);
//str1 = str1 + "X=" + x + "/n"
//+ "f(x)=" + "fitness" + "/n";
//textArea.setText(str1);
return fitness;
}
/**
*计算群体上每个个体的适应度值;
*按由个体适应度值所决定的某个规则选择将进入下一代的个体;
*/
private void select() {
double evals[] = new double[10]; // 所有染色体适应值
double p[] = new double[10]; // 各染色体选择概率
double q[] = new double[10]; // 累计概率
double F = 0; // 累计适应值总和
for (int i = 0; i < 10; i++) {
evals[i] = calculatefitnessvalue(ipop[i]);
if (best == null) {
best = new Best();
best.fitness = evals[i];
best.generations = 0;
best.str = ipop[i];
} else {
if (evals[i] > best.fitness) // 最好的记录下来
{
best.fitness = evals[i];
best.generations = gernation;
best.str = ipop[i];
}
}
F = F + evals[i]; // 所有染色体适应值总和
}
for (int i = 0; i < 10; i++) {
p[i] = evals[i] / F;
if (i == 0)
q[i] = p[i];
else {
q[i] = q[i - 1] + p[i];
}
}
for (int i = 0; i < 10; i++) {
double r = Math.random();
if (r <= q[0]) {
ipop[i] = ipop[0];
} else {
for (int j = 1; j < 10; j++) {
if (r < q[j]) {
ipop[i] = ipop[j];
break;
}
}
}
}
}
/**
*交叉操作
*交叉率为25%,平均为25%的染色体进行交叉
*/
private void cross() {
String temp1, temp2;
for (int i = 0; i < 10; i++) {
if (Math.random() < 0.25) {
double r = Math.random();
int pos = (int) (Math.round(r * 1000)) % GENE;
if (pos == 0) {
pos = 1;
}
temp1 = ipop[i].substring(0, pos)
+ ipop[(i + 1) % 10].substring(pos);
temp2 = ipop[(i + 1) % 10].substring(0, pos)
+ ipop[i].substring(pos);
ipop[i] = temp1;
ipop[(i + 1) / 10] = temp2;
}
}
}
/**
*基因突变操作
*1%基因变异m*pop_size共180个基因,为了使每个基因都有相同机会发生变异,
*需要产生[1--180]上均匀分布的
*/
private void mutation() {
for (int i = 0; i < 4; i++) {
int num = (int) (Math.random() * GENE * 10 + 1);
int chromosomeNum = (int) (num / GENE) + 1; // 染色体号
int mutationNum = num - (chromosomeNum - 1) * GENE; // 基因号
if (mutationNum == 0)
mutationNum = 1;
chromosomeNum = chromosomeNum - 1;
if (chromosomeNum >= 10)
chromosomeNum = 9;
//System.out.println("变异前" + ipop[chromosomeNum]);
String temp;
if (ipop[chromosomeNum].charAt(mutationNum - 1) == '0') { if (mutationNum == 1) {
temp = "1" + ipop[chromosomeNum].substring
(mutationNum);
} else {
if (mutationNum != GENE) {
temp = ipop[chromosomeNum].substring(0, mutationNum -
1) + "1" + ipop
[chromosomeNum].substring(mutationNum);
} else {
temp = ipop[chromosomeNum].substring(0, mutationNum -
1) + "1";
}
}
} else {
if (mutationNum == 1) {
temp = "0" + ipop[chromosomeNum].substring
(mutationNum);
} else {
if (mutationNum != GENE) {
temp = ipop[chromosomeNum].substring(0, mutationNum -
1) + "0" + ipop
[chromosomeNum].substring(mutationNum);
} else {
temp = ipop[chromosomeNum].substring(0, mutationNum -
1) + "1";
}
}
}
ipop[chromosomeNum] = temp;
//System.out.println("变异后" + ipop[chromosomeNum]);
}
}
/**
*执行遗传算法
*/
public String process() {
String str = "";
for (int i = 0; i < 10000; i++) {
this.select();
this.cross();
this.mutation();
gernation = i;
}
str = "最小值" + best.fitness + ",第" + best.generations + "个染色体";
return str;
}
}
2)多次运行程序,观察运行结果,给出你对标准遗传算法优缺点的判断(可以从是否收敛、收敛速度,参数设置等方面考虑)。
答:运行程序的结果:
求四次最小值的结果:
本算法优缺点的判断:
1.优点:
●本算法是基于面向对象语言Java 开发,而遗传算法本身的思想也是存在继承等面
向对象概念;
●算法执行速度快。
2.缺点:
●参数设置方面的缺点(循环次数)本算法循环10000次,求解f(x)的最小值,理论上,
循环的次数越大,其最小结果会越接近于0。
标准遗传算法优缺点的判断:
标准遗传算法的优点:
(1). 将搜索过程作用在编码后的字符串上,不直接作用在优化问题的具体变量上,在搜索中用到的是随机的变换规则,而不是确定的规则。它在搜索时采用启发式的搜索,而不是盲目的穷举,因而具有更高所搜索效率。
(2). 现行的大多数优化算法都是基于线性、凸性、可微性等要求,而遗传算法只需要适合度信息,不需要导数等其他辅助信息,对问题的依赖性较小,因而具有高度的非线性,适用范围更广。此外还可以写出一个通用算法,以求解许多不同的优化问题。
(3). 遗传算法从一组初始点开始搜索,而不是从某一个单一的初始点开始搜索。而且给出的是一组优化解,而不是一个优化解,这样可以给设计者更大的选择余地。它能在解空间内充分搜索,具有全局优化能力。
(4). 遗传算法具有很强的易修改性。即使对原问题进行很小的改动( 比如目标函数的改进),现行的大多数算法就有可能完全不能使用,而遗传算法则只需作很小的修改就完全可以适应新的问题。
(5). 遗传算法具有很强的可并行性,可通过并行计算来提高计算速度,因而更适用于大规模复杂问题的优化。
标准遗传算法的缺点:
(1). 遗传算法的理论研究比较滞后。由于遗传算法本身也是一种仿生的思想,尽管实践效果很好,但理论证明比较困难。而且这种算法提出来的时间还不是很长,因此其理论和实践的研究几乎是平行进行的。
(2). GA 算法本身的参数还缺乏定量的标准,目前采用的都是经验数值,而且不同的编码、不同的遗传技术都会影响到遗传参数的选取,因而会影响到算法的通用性。
(3). GA 对处理约束化问题还缺乏有效的手段,传统的罚函数法中对惩罚因子的选取还是一个比较困难的技术问题。
遗传算法参数调整实验报告 算法设计: 编码方案:遍历序列 适应度函数:遍历路程 遗传算子设计: 选择算子:精英保留+轮盘赌 交叉算子:Pxover ,顺序交叉、双亲双子, 变异算子:Pmutation ,随机选择序列中一个染色体(城市)与其相邻染色体交换 首先,我们改编了我们的程序,将主函数嵌套在多层迭代之内,从外到内依此为: 过程中,我们的程序将记录每一次运行时种群逐代进化(收敛)的情况,并另外记录总体测试结果。 测试环境: AMD Athlon64 3000+ (Overclock to 2.4GHz)
目标:寻求最优Px 、Pm 组合 方式:popsize = 50 maxgen = 500 \ 10000 \ 15000 Px = 0.1~0.9(0.05) Pm = 0.01~0.1(0.01) count = 50 测试情况:运行近2万次,时间约30小时,产生数据文件总共5.8GB 测试结果:Px, Pm 对收敛结果的影响,用灰度表示结果适应度,黑色为适应度最低 结论:Px = 0.1 ,Pm = 0.01为最优,并刷新最优结果19912(之前以为是20310),但20000次测试中最优解只出现4次,程序需要改进。 Maxgen = 5000 Pm=0.01 Px = 0.1 Maxgen = 10000 0.1 0.9 Px = 0.1 0.9 0.1
目标:改进程序,再寻求最优参数 方式:1、改进变异函数,只保留积极变异; 2、扩大测试范围,增大参数步进 popsize = 100 \ 200 \ 400 \ 800 maxgen = 10000 Px = 0.1 \ 0.5 \ 0.9 Pm = 0.01 \ 0.04 \ 0.07 \ 0.1 count = 30 测试情况:运行1200次,时间8小时,产生数据文件600MB 测试结果: 结论:Px = 0.1,Pm = 0.01仍为最优,收敛情况大有改善,10000代基本收敛到22000附近,并多次达到最优解19912。变异函数的修改加快了整体收敛速度。 但是收敛情况对Pm并不敏感。另外,单个种群在遗传过程中收敛速度的统计,将是下一步的目标。
第四章遗传算法与函数优化 4.1 研究函数优化的必要性: 首先,对很多实际问题进行数学建模后,可将其抽象为一个数值函数的优化问题。由于问题种类的繁多,影响因素的复杂,这些数学函数会呈现出不同的数学特征。除了在函数是连续、可求导、低阶的简单情况下可解析地求出其最优解外,大部分情况下需要通过数值计算的方法来进行近似优化计算。 其次,如何评价一个遗传算法的性能优劣程度一直是一个比较难的问题。这主要是因为现实问题种类繁多,影响因素复杂,若对各种情况都加以考虑进行试算,其计算工作量势必太大。由于纯数值函数优化问题不包含有某一具体应用领域中的专门知识,它们便于不同应用领域中的研究人员能够进行相互理解和相互交流,并且能够较好地反映算法本身所具有的本质特征和实际应用能力。所以人们专门设计了一些具有复杂数学特征的纯数学函数,通过遗传算法对这些函数的优化计算情况来测试各种遗传算法的性能。 4.2 评价遗传算法性能的常用测试函数 在设计用于评价遗传算法性能的测试函数时,必须考虑实际应用问题的数学模型中所可能呈现出的各种数学特性,以及可能遇到的各种情况和影响因素。这里所说的数学特性主要包括: ●连续函数或离散函数; ●凹函数或凸函数; ●二次函数或非二次函数; ●低维函数或高维函数; ●确定性函数或随机性函数; ●单峰值函数或多峰值函数,等等。 下面是一些在评价遗传算法性能时经常用到的测试函数: (1)De Jong函数F1: 这是一个简单的平方和函数,只有一个极小点f1(0, 0, 0)=0。
(2)De Jong 函数F2: 这是一个二维函数,它具有一个全局极小点f 2(1,1) = 0。该函数虽然是单峰值的函数,但它却是病态的,难以进行全局极小化。 (3)De Jong 函数F3: 这是一个不连续函数,对于]0.5,12.5[--∈i x 区域内的每一个点,它都取全局极小值 30),,,,(543213-=x x x x x f 。
计算机系统结构发展历程及未来展望 一、计算机体系结构 什么是体系结构 经典的关于“计算机体系结构(computer Architecture)”的定义是1964年C.M.Amdahl在介绍IBM360系统时提出的,其具体描述为“计算机体系结构是程序员所看到的计算机的属性,即概念性结构与功能特性” 。 按照计算机系统的多级层次结构,不同级程序员所看到的计算机具有不同的属性。一般来说,低级机器的属性对于高层机器程序员基本是透明的,通常所说的计算机体系结构主要指机器语言级机器的系统结构。计算机体系结构就是适当地组织在一起的一系列系统元素的集合,这些系统元素互相配合、相互协作,通过对信息的处理而完成预先定义的目标。通常包含的系统元素有:计算机软件、计算机硬件、人员、数据库、文档和过程。其中,软件是程序、数据库和相关文档的集合,用于实现所需要的逻辑方法、过程或控制;硬件是提供计算能力的电子设备和提供外部世界功能的电子机械设备(例如传感器、马达、水泵等);人员是硬件和软件的用户和操作者;数据库是通过软件访问的大型的、有组织的信息集合;文档是描述系统使用方法的手册、表格、图形及其他描述性信息;过程是一系列步骤,它们定义了每个系统元素的特定使用方法或系统驻留的过程性语境。 体系结构原理 计算机体系结构解决的是计算机系统在总体上、功能上需要解决的问题,它和计算机组成、计算机实现是不同的概念。一种体系结构可能有多种组成,一种组成也可能有多种物理实现。 计算机系统结构的逻辑实现,包括机器内部数据流和控制流的组成以及逻辑设计等。其目标是合理地把各种部件、设备组成计算机,以实现特定的系统结构,同时满足所希望达到的性能价格比。一般而言,计算机组成研究的范围包括:确定数据通路的宽度、确定各种操作对功能部件的共享程度、确定专用的功能部件、确定功能部件的并行度、设计缓冲和排队策略、设计控制机构和确定采用何种可靠技术等。计算机组成的物理实现。包括处理机、主存等部件的物理结构,器件的集成度和速度,器件、模块、插件、底板的划分与连接,专用器件的设计,信号传输技术,电源、冷却及装配等技术以及相关的制造工艺和技术。 主要研究内容 1·机内数据表示:硬件能直接辨识和操作的数据类型和格式 2·寻址方式:最小可寻址单位、寻址方式的种类、地址运算 3·寄存器组织:操作寄存器、变址寄存器、控制寄存器及专用寄存器的定义、数量和使用规则 4·指令系统:机器指令的操作类型、格式、指令间排序和控制机构 5·存储系统:最小编址单位、编址方式、主存容量、最大可编址空间 6·中断机构:中断类型、中断级别,以及中断响应方式等
遗传算法 遗传算法(Genetic Algorithm)是基于进化论的原理发展起来的一种广为应用,高效的随机搜索与优化的方法。它从一组随机产生的初始解称为“种群”,开始搜索过程。种群中的每个个体是问题的一个解,成为“染色体”是一串符号。这些染色体在每一代中用“适应度”来测量染色体的好坏, 通过选择、交叉、变异运算形成下一代。选择的原则是适应度越高,被选中的概率越大。适应度越低,被淘汰的概率越大。每一代都保持种群大小是常数。经过若干代之后,算法收敛于最好的染色体,它很可能是问题的最优解或次优解。这一系列过程正好体现了生物界优胜劣汰的自然规律。 比如有编号为1到10的特征,现在要选取其中的5个,基于遗传算法的特征选择可以如下这样直观的理解: 下续(表格) 下续……
即设有4个不同的初始特征组合,分别计算判别值,然后取最大的2个组合([1,2,3,4,9]和[1,3,5,7,8])进行杂交,即互换部分相异的特征(4和7),得到新的两个特征组合([1,2,3,7,9]和[1,3,4,5,8]),然后再计算这两个新的组合的判别值,和原来的放在一起,再从中选择2个具有最大判别值的组合进行杂交。如此循环下去,在某一代的时候就得到了一个最好的特征组合(比如第2代的[1,3,5,7,9]的特征组合)。当然,在实际中每代的个体和杂交的数量是比较大的。 遗传算法的具体的步骤如下:
1.编码:把所需要选择的特征进行编号,每一个特征就是一个基因,一个解就是一串基因的组合。为了减少组合数量,在图像中进行分块(比如5*5大小的块),然后再把每一块看成一个基因进行组合优化的计算。每个解的基因数量是要通过实验确定的。 2.初始群体(population)的生成:随机产生N个初始串结构数据,每个串结构数据称为一个个体。N个个体,构成了一个群体。GA以这N个串结构数据作为初始点开始迭代。这个参数N需要根据问题的规模而确定。 3.交换(crossover):交换(也叫杂交)操作是遗传算法中最主要的遗传操作。由交换概率( P)挑选的每两个父代 c 通过将相异的部分基因进行交换(如果交换全部相异的就变成了对方而没什么意义),从而产生新的个体。可以得到新一代个体,新个体组合了其父辈个体的特性。交换体现了信息交换的思想。 4.适应度值(fitness)评估检测:计算交换产生的新个体的适应度。适应度用来度量种群中个体优劣(符合条件的程度)的指标值,这里的适应度就是特征组合的判据的值。这个判据的选取是GA的关键所在。
实验十遗传算法与优化问题 一、问题背景与实验目的 遗传算法(Genetic Algorithm—GA),是模拟达尔文的遗传选择和自然淘汰的生物进化过程的计算模型,它是由美国Michigan大学的J.Holland教授于1975年首先提出的.遗传算法作为一种新的全局优化搜索算法,以其简单通用、鲁棒性强、适于并行处理及应用范围广等显着特点,奠定了它作为21世纪关键智能计算之一的地位. 本实验将首先介绍一下遗传算法的基本理论,然后用其解决几个简单的函数最值问题,使读者能够学会利用遗传算法进行初步的优化计算. 1.遗传算法的基本原理 遗传算法的基本思想正是基于模仿生物界遗传学的遗传过程.它把问题的参数用基因代表,把问题的解用染色体代表(在计算机里用二进制码表示),从而得到一个由具有不同染色体的个体组成的群体.这个群体在问题特定的环境里生存竞争,适者有最好的机会生存和产生后代.后代随机化地继承了父代的最好特征,并也在生存环境的控制支配下继续这一过程.群体的染色体都将逐渐适应环境,不断进化,最后收敛到一族最适应环境的类似个体,即得到问题最优的解.值得注意的一点是,现在的遗传算法是受生物进化论学说的启发提出的,这种学说对我们用计算机解决复杂问题很有用,而它本身是否完全正确并不重要(目前生物界对此学说尚有争议). (1)遗传算法中的生物遗传学概念
由于遗传算法是由进化论和遗传学机理而产生的直接搜索优化方法;故而在这个算法中要用到各种进化和遗传学的概念. 首先给出遗传学概念、遗传算法概念和相应的数学概念三者之间的对应关系.这些概念如下:
(2)遗传算法的步骤 遗传算法计算优化的操作过程就如同生物学上生物遗传进化的过程,主要有三个基本操作(或称为算子):选择(Selection)、交叉(Crossover)、变异(Mutation). 遗传算法基本步骤主要是:先把问题的解表示成“染色体”,在算法中也就是以二进制
一需求分析 1.本程序演示的是用简单遗传算法随机一个种群,然后根据所给的交叉率,变异率,世代数计算最大适应度所在的代数 2.演示程序以用户和计算机的对话方式执行,即在计算机终端上显示“提示信息”之后,由用户在键盘上输入演示程序中规定的命令;相应的输入数据和运算结果显示在其后。3.测试数据 输入初始变量后用y=100*(x1*x1-x2)*(x1*x2-x2)+(1-x1)*(1-x1)其中-2.048<=x1,x2<=2.048作适应度函数求最大适应度即为函数的最大值 二概要设计 1.程序流程图 2.类型定义 int popsize; //种群大小 int maxgeneration; //最大世代数 double pc; //交叉率 double pm; //变异率 struct individual
{ char chrom[chromlength+1]; double value; double fitness; //适应度 }; int generation; //世代数 int best_index; int worst_index; struct individual bestindividual; //最佳个体 struct individual worstindividual; //最差个体 struct individual currentbest; struct individual population[POPSIZE]; 3.函数声明 void generateinitialpopulation(); void generatenextpopulation(); void evaluatepopulation(); long decodechromosome(char *,int,int); void calculateobjectvalue(); void calculatefitnessvalue(); void findbestandworstindividual(); void performevolution(); void selectoperator(); void crossoveroperator(); void mutationoperator(); void input(); void outputtextreport(); 4.程序的各函数的简单算法说明如下: (1).void generateinitialpopulation ()和void input ()初始化种群和遗传算法参数。 input() 函数输入种群大小,染色体长度,最大世代数,交叉率,变异率等参数。 (2)void calculateobjectvalue();计算适应度函数值。 根据给定的变量用适应度函数计算然后返回适度值。 (3)选择函数selectoperator() 在函数selectoperator()中首先用rand ()函数产生0~1间的选择算子,当适度累计值不为零时,比较各个体所占总的适应度百分比的累计和与选择算子,直到达到选择算子的值那个个体就被选出,即适应度为fi的个体以fi/∑fk的概率继续存在; 显然,个体适应度愈高,被选中的概率愈大。但是,适应度小的个体也有可能被选中,以便增加下一代群体的多样性。 (4)染色体交叉函数crossoveroperator() 这是遗传算法中的最重要的函数之一,它是对个体两个变量所合成的染色体进行交叉,而不是变量染色体的交叉,这要搞清楚。首先用rand ()函数产生随机概率,若小于交叉概率,则进行染色体交叉,同时交叉次数加1。这时又要用rand()函数随机产生一位交叉位,把染色
遗传算法发展前景概况 (华北电力大学电气与电子工程学院,北京102206) 摘要:遗传算法是一种基于生物进化自然选择和群体遗传机理的,适合于复杂系统优化的自适应概率优化技术,近年来,因为遗传算法求解复杂优化问题的巨大潜力和在工业工程领域的成功应用,这种算法受到了国内外学者的广泛关注,本文介绍了遗传算法研究现状和发展的前景,概述了它的理论和技术,并对遗传算法的发展情况发表了自己的看法。 关键词:遗传算法; 遗传算子;进化计算;编码 GENERAL GENETIC ALGORITHM DEVELOPMENT PROSPECT (North China Electric Power University Electrical And Electronic Engineering Institute,Beijing102206) ABSTRACT: Genetic algorithm is a kind of natural selection and based on biological evolution of genetic mechanism, group suitable for complex system optimization adaptive probability optimization technique, in recent years, because genetic algorithm for solving complex optimization problem in the huge potential and the successful application of industrial engineering, this algorithm was wide attention of scholars at home and abroad, this paper introduces the current research status and development of genetic algorithm, summarizes the prospect of its theory and technology of genetic algorithm and the development of published opinions of his own. KEY WORD: Genetic algorithm; Genetic operator; Evolutionary computation; coding 1.引言 现在,遗传算法正在迅速发展,遗传算法与其很强的解决问题能力和适合于复杂系统的自适应优化技术渗透到研究和工业工程领域,在电力系统,系统辨识,最优控制,模式识别等领域有了很广泛的应用,取得了很好的效果。 2.遗传算法基本思想 遗传算法是建立在自然选择和群体遗传学基础上的随机,迭代和进化,具有广泛适用性的搜索方法,所有的自然种类都是适应环境而生存,这一自然适用性是遗传算法的主要思想。 遗传算法是从代表问题可能潜在解集的一个种群开始的,而一个种群则经过基因编码的一定数目的个体组成。每个个体实际上是染色体带有特征的实体。染色体作为遗传物质的主要载体,其内部基因决定了个体的外部表现。因此,在一开始就要实现外部表现到内部基因的映射,即编码工作,通常采用二进制码。初始种群产生之后,按照适者生存和优胜劣汰的原则,逐代演化产生出越来越好的近似解。在每一代,根据问题域中个体的适应度大小选择个体,并借助自然遗传学的遗传算子进行组合交叉和变异,产生出代表新的解集和种群,这种过程将导致种群像自然进化那样产生比前代更适应于环境的后代种群,末代种群中的最有个体经过解码,可以作为问题近似最优解。 遗传算法采纳了自然进化模型,如选择,交叉,变异等,计算开始时,种群随机初始化产生一定数目的N个个体,并计算每个个体的适应度函数,如果不满足优化准则,就开始新一代的计算。为了产生下一代,按照适应度选择个体父代进行基因重组二产生子代。所有的子代按一定的概率进行变异,子代取代父代构成新一代,然后重新计算子代的适应度。这一过程循环执行,直到满足优化准则为止。 3.遗传算法基本操作
基于遗传算法的PID控制器参数整定报告 一、遗传算法。 遗传算法(GAs)是基于自然界生物进化机制的搜索寻优技术。用遗传算法来整定PID参数,可以提高优化性能,对控制系统有良好的控制精度、动态性能和鲁棒性。 一般的,Gas包括三个基本要素:复制、交叉和突变。 二、PID Optimal-Tuning PID控制:对偏差信号e(t)进行比例、积分和微分运算变换后形成的一种控制规律。 (1) 可调参数:比例度δ(P)、积分时间Ti(I)、微分时间Td(D)。 通常,PID控制准则可以写成下面传递函数的形式: ) 1( ) (s T T s K s G d i p + + =(2) Kp、Ti和Td分别是比例放大率、积分时间常量和微分时间常量。 1)比例控制(P):是一种最简单的控制方式。其控制器的输出与输入误差信号成比例关系。当仅有比例控制时系统输出存在稳态误 差(Steady state error),比例度减小,稳态误差减小; 2)积分(I)控制:在积分控制中,控制器的输出与输入误差信号的积分成正比关系。 3)微分(D)控制:在微分控制中,控制器的输出与输入误差信号()()()()? ? ? ? ? ? + + =?t e dt d T d e T t e K t u d t i p0 1 τ τ
的微分(即误差的变化率)成正比关系。 文中,性能指标是误差平方的时间加权积分,表示为: ),,1,0(,0 2n k dt e t J i t k ==? (3) 其中n 是非负整数,i t 是积分周期。此外,其他标准项如超调量、上升时间和稳定时间也被一个合成性能指标选择: ))(1(s s r r c t c t c os J ++= (4) s r os t t 、、分别代表超调量、上升时间和稳定时间。s r c 、c 两个系数有用户定义或决定。预期的性能指标的最下化可以认为是小的超调量、短的上升时间和稳定时间。 三个PID 参数的编码方式如下: 10101011:S 1010100011100111 p K i K d K p K 、i K 和d K 都是八位二进制字符格式。 自适应函数的选择关系到性能指标,如: 101)(J J F F == (5) 实际上,)(J F 可以是任何一个能切实表达F 和J 关系的非线性函数。 遗传操作是模拟生物基因遗传的操作,从优化搜索的角度而言,遗传操作可使问题的解一代一代地优化,并逼近最优解,主要包括三个遗传算子:选择、交叉和变异。关于他们的具体方法这里不在赘述。 三、 计算机实现 作者编程使用的事TURBO C 。程序包括两个部分:一个是仿真PID 控制系统的闭环阶跃响应;另一个是实施对一代所有成员的遗传算法的仿真,这里遗传算法将一代作为一个整体。在第一代生物的二进制代码随机产生之后,这个过程重复直至迭代次数达到预选的次数。 步长、PID 参数X 围、性能指标、自适应函数和方法得时间延迟都是从一个文件中读取。而遗传算法的的参数,诸如世代数、交叉概率、变异概率、选择概率等通过菜单选择。 整个闭环系统仿真的完成可以用四阶龙格库塔法或直接时域计算。在程序中,复制的实现是通过轮盘赌博法的线性搜索,面积加权于上一代成员的适应值。交叉发生在每一对复制产生的成员。 交叉操作是将一个随机产生的一个在0到1之间数与交叉概率比较决定是否需要交叉。如果需要交叉,则在1到47之间随机产生一个交叉位置代码。变异,对新一代所有成员都随机产生一个0到1之间的数与变异概率比较,然后再决定是否改变代码的一位。同理,反转也是这样判定和操作的。另一需要说明的事,两个反转位置代码是在1~48之间随机选择的。同样,
介绍遗传算法的发展历程 遗传算法起源于对生物系统进行的计算机模拟研究。早在20世纪40年代,就有学者开始研究利用计算机进行生物模拟的技术,他们从生物学的角度进行了生物的进化过程模拟、遗传过程模拟等研究工作。 早期的研究特点是侧重于对一些复杂操作的研究。最早意识到自然遗传算法可以转化为人工智能算法的是J.H.Hnllaad教授。1965年,Holland教授首次提出了人工智能操作的重要性,并将其应用到自然系统和人工系统中。1967年,Holland教授的学生.J.D.Bagley在其博士论文中首次提出了“遗传算法”一词,并发表了遗传算法应用方面的第一篇论文,从而创立了自适应遗传算法的概念e J.D.Bagley发展了复制、交叉、变异、显性、倒位等遗传算子,在个体编码上使用了双倍体的编码方法。1970年,Cavicchio把遗传算法应用于模式识别。Holistien最早把遗传算法应用于函数优化。20世纪70年代初,Holland 教授提出了遗传算法的基本定理—模式定理,从而奠定了遗传算法的理论基础。模式定理揭示出种群中优良个体(较好的模式)的样本数将以指数级规律增长,因而从理论上保证了遗传算法是一个可以用来寻求最优可行解的优化过程。1975年,Holland教授出版了第一本系统论述遗传算法和人工自适应系统的专著《自然系统和人工系统的自适应性》。同年,K.A.De Song在博士论文《遗传自适应系统的行为分析》‘护结合模式定理进行了大量的纯数值函数优化计算实验,建立了遗传算法的工作框架,为遗传算法及其应用打下了坚实的基础,他所得
出的许多结论迄今仍具有普遍的指导意义。20世纪80年代,Hntland 教授实现了第一个基于遗传算法的机器学习系统—分类器系统(Classifier Systems,简称CS),提出了基于遗传算法的机器学习的新概念,为分类器系统构造出了一个完整的框架。1989年,D.J.Goldberg 出版了专著—《搜索、优化和机器学习中的遗传算法》。该书系统总结了遗传算法的主要研究成果,全面而完整地论述了遗传算法的基本原理及其应用。可以说这本书奠定了现代遗传算法的科学基础,为众多研究和发展遗传算法的学者所瞩目。1991年,L,Davis编辑出版了《遗传算法手册》一书,书中包括了遗传算法在科学计算、工程技术和社会经济中的大量应用样本,为推广和普及遗传算法的应用起到了重要的指导作用。1992年,J.R.Koza将遗传算法应用于计算机程序的优化设计及自动生成,提出了遗传规划(Genetic Programming,简称GP)的概念。
最新最全的遗传算法工具箱Gaot_v5及说明 Gaot_v5下载地址:https://www.doczj.com/doc/f618649362.html,/mirage/GAToolBox/gaot/gaotv5.zip 添加遗传算法路径: 1、 matlab的file下面的set path把它加上,把路径加进去后在 2、 file→Preferences→General的Toolbox Path Caching里点击update Toolbox Path Cache更新一下,就OK了
遗传算法工具箱Gaot_v5包括许多实用的函数,各种算子函数,各种类型的选择方式,交叉、变异方式。这些函数按照功能可以分成以下几类:
主程序 ga.m提供了 GAOT 与外部的接口。它的函数格式如下: [x endPop bPop traceInfo]=ga(bounds,evalFN,evalOps,startPop,opts,termFN,termOps, selectFn,selectOps,xOverFNs,xOverOps,mutFNs,mutOps) 输出参数及其定义如表 1 所示。输入参数及其定义如表 2 所示。 表1 ga.m的输出参数 输出参数 定义 x 求得的最好的解,包括染色体和适应度 endPop 最后一代染色体(可选择的) bPop 最好染色体的轨迹(可选择的) traceInfo 每一代染色体中最好的个体和平均适应度(可选择的) 表2 ga.m的输入参数 表3 GAOT核心函数及其它函数
核心函数: (1)function [pop]=initializega(num,bounds,eevalFN,eevalOps,options)--初始种群的生成函数 【输出参数】 pop--生成的初始种群 【输入参数】 num--种群中的个体数目 bounds--代表变量的上下界的矩阵 eevalFN--适应度函数 eevalOps--传递给适应度函数的参数 options--选择编码形式(浮点编码或是二进制编码)[precision F_or_B],如 precision--变量进行二进制编码时指定的精度 F_or_B--为1时选择浮点编码,否则为二进制编码,由precision指定精度) (2)function [x,endPop,bPop,traceInfo] = ga(bounds,evalFN,evalOps,startPop,opts,... termFN,termOps,selectFN,selectOps,xOverFNs,xOverOps,mutFNs,mutOps)--遗传算法函数 【输出参数】 x--求得的最优解 endPop--最终得到的种群 bPop--最优种群的一个搜索轨迹 【输入参数】
第32卷 第12期2009年12月 计 算 机 学 报 CH INESE JOURNA L OF COMPU TERS Vol.32No.12 Dec.2009 收稿日期:2008210219;最终修改稿收到日期:2009209227.本课题得到国家自然科学基金(60774084)资助.岳 嵚,男,1977年生,博士研究生,主要研究方向为进化算法.E 2mail:yueqqin@si https://www.doczj.com/doc/f618649362.html,.冯 珊,女,1933年生,教授,博士生导师,主要研究领域为智能决策支持系统. 遗传算法的计算性能的统计分析 岳 嵚 冯 珊 (华中科技大学控制科学与工程系 武汉 430074) 摘 要 通过对多维解析函数的多次重复计算并对计算结果进行统计分析来讨论遗传算法的可靠性和可信度,结果表明:遗传算法的计算结果具有一定的稳定性,可以通过采用多次重复计算的方法提高计算结果的可信度,并用以评价算法及其改进的实际效果.关键词 遗传算法;计算可靠性;置信区间 中图法分类号TP 18 DOI 号:10.3724/SP.J.1016.2009.02389 The Statistical Analyses for Computational Performance of the Genetic Algorithms YU E Qin FENG Shan (Dep artment of Contr ol Science and Eng ineering ,H uazhong University of Science and T ech nology ,W u han 430074) Abstr act In this paper,the author s discuss the reliability of the GAs by reiteratively computing the multi 2dimensional analytic functions and statistical analysis of the results.The analysis re 2sults show that the GAs have certain stability;it could improve the reliability by reiteratively computation and estimates the effects of improvements. Keywor ds genetic algorithms;computational stability;confidence interval 1 遗传算法的随机性 遗传算法是将生物学中的遗传进化原理和随机优化理论相结合的产物,是一种随机性的全局优化算法[1].遗传算法作为一种启发式搜索算法,其计算结果具有不稳定性和不可重现性;遗传算法的进化过程具有有向随机性,整体上使种群的平均适应度不断提高.现在学术界对遗传算法中的某些遗传操作的作用机制还不十分清楚,遗传算法的许多性能特点无法在数学上严格证明.遗传算法的计算过程会受到各种随机因素的影响,如随机产生的初始种群和随机进行的变异操作等,尤其初始种群对计算结果影响较大.但另一方面,大量的实算结果表明,遗传算法的计算结果具有一定的规律性,在统计意义上具有一定的可靠性,这样就可以对待求解问题 进行多次重复计算后取平均值的方法,提高遗传算 法在实际计算中的准确性和可信度. 包括遗传算法在内的启发式搜索算法主要用于解决大型的复杂优化问题,这些问题一般难以使用传统的优化算法解决.遗传算法对这类问题的计算结果也难达到精确的最优解.这给对用遗传算法解决实际工程优化问题的计算结果的评价带来了困难,在实际工程计算中也难以评价遗传算法及其改进型的计算效果的优劣. 为了分析遗传算法的计算性能,本文采用的计算对象是一个复杂的多维解析函数.使用这类函数评价遗传算法计算性能的好处是可以事先通过其他方法求得最优解,这样便于评价遗传算法及其改进型的计算效果.本文从统计学角度对多次重复计算的结果进行分析,试图得到遗传算法的稳定性和可信度方面的相关结论,通过分析遗传算法及其改进
遗传算法及对于过早收敛的改进 摘要遗传算法是模拟达尔文生物进化论中的自然选择与遗传学机理的生物过程的一种计算模型。该模型通过模拟自然进化过程来搜索最优解,其应用非常广泛。但是在运用遗传算法的过程之中经常遇到过早收敛的问题,为了改进该问题,在文中对遗传算法进行了介绍,并在此基础上就如何改进过早收敛进行探讨。 关键词遗传算法;过早收敛;改进 中图分类号TP18 文献标识码 A 文章编号2095-6363(2017)15-0023-01 遗传算法(Genetic Algorithm,GA)是自然科学与工程科学互相结合的产物,是一类借鉴达尔文自然选择机理(适者生存,优胜劣汰遗传机制)演化而来的随机化搜索方法。 遗传算法求解优化问题的性能与交叉概率(Pc)、变异概率(Pm)等参数的选择有着很大的联系。本文基于传统思路,对GA的交叉概率和变异概率参数进行自适应控制,对过早收敛问题进行了适当优化。 1 遗传算法综述 1.1 遗传算法思想 通常来说,遗传算法包括三个算子,即选择、交叉和变
异。选择算子的作用是为了提升整个群体的平均适度值,在整个群体中选择那些评价值高的个体组成交配池的主要群体:交叉算子的主要作用是选择交配池中的优良基因遗传给下一代,先将交配池中个体进行两两配对,再有目的的交换部分基因,生成基因性状更加复杂的个体;变异算子是对个体某一个或是几个按照某一较小的概率进行反转二进制字符。从而实现对自然界中基因突变现象的模拟。 1.2 遗传算法的思想流程 1)初始化群体;2)计算群体上每个个体的适应度值;3)针对于个体适应度值,依据某个规则选择将进入下一代的个体;4)通过概率Pc进行交叉操作;5)通过概率Pm进行突变操作;6)未达到终止条件,则返回2)步,否则进入下一步;7)输出群体中适应度值最大的个体作为问题的满意解或最优解。 2 过早收敛及其特点 过早收敛在早期的选择过程,种群中就出现了“完美”个体,该类个体的适应度值特别大,然而选择压力很大,后期变异概率比较小。继而在后期的繁殖中占主体地位,种群的多样性会很快的降低进而导致种群多样化的丧失。 过早收敛对于整个种群来说弊大于利,因为结果并非是全局最优,仅仅是局部最优。特别是到了算法进行的后期,进过算法的多代进化,完美的个体已经在种群中占据绝大多
认知无线电的发展历程与现状 认知无线电的发展历程与现状 摘要:认知无线电是一种通过与其运行环境交互而改变其发射参数从而提高频谱利用率的新的智能技术,其核心思想是CR具有学习能力,能与周围环境交互 信息,以感知和利用在该空间的可用频谱,并限制和降低冲突的发生,认知无线电就是通过频谱感知(Spectrum Sensing )和系统的智能学习能力,实现动态频谱分配(DSA dynamic spectrum allocation )和频谱共享(Spectrum Shari ng )。本文主要分析认知无线电的起源,认知无线电的关键技术概要,认知无线电的相关标准化进程以及认知无线电的应用场景等多个方面,对认知无线电进行一个概述,从而加深对无线电的认知与了解。关键字:认知无线电、起源、关键技术、标准化、应用 随着无线通信需求的不断增长,对无线通信技术支持的数据传输速率的要求越来越高。根据香农信息理论,这些通信系统对无线频谱资源的需求也相应增长,从而导致适用于无线通信的频谱资源变得日益紧张,成为制约无线通信发展的新瓶颈。另一方面,已经分配给现有很多无线系统的频谱资源却在时间和空间上存在不同程度的闲置。为解决无线频谱资源紧张的问题,出现了许多先进的无线通信理论与技术,如链路自适应技术、多天线技术等。这些技术虽然能提高频谱效率,但仍受限于Sha nnon理论。 美国联邦通信委员会的大量研究表明:ISM频段以及适用于陆地移动通信的2GHz 左右授权频段过于拥挤,而有些授权频段却经常空闲。因而提出了认知无线电。认知无线电是一种智能频谱共享技术。它通过感知频谱环境、智能学习并实时调整其传输参数,实现频谱的再利用,进而显著地提高频谱的利用率,通过从时间和空间上充分利用那些空闲的频谱资源,从而有效解决上述难题。 1. 认知无线电的发展历程
matlab遗传算法工具箱函数及实例讲解(转引) 核心函数:? (1)function [pop]=initializega(num,bounds,eevalFN,eevalOps,options)--初始种群的生成函数?【输出参数】? ?pop--生成的初始种群?【输入参数】? ?num--种群中的个体数目? ?bounds--代表变量的上下界的矩阵? ?eevalFN--适应度函数? ?eevalOps--传递给适应度函数的参数? ?options--选择编码形式(浮点编码或是二进制编码)[precision F_or_B],如? precision--变量进行二进制编码时指定的精度? F_or_B--为1时选择浮点编码,否则为二进制编码,由precision指定精度)? (2)function [x,endPop,bPop,traceInfo] = ga(bounds,evalFN,evalOps,startPop,opts.? ?termFN,termOps,selectFN,selectOps,xOverFNs,xOverOps,mutFNs ,mutOps)--遗传算法函数?【输出参数】? x--求得的最优解? endPop--最终得到的种群?
bPop--最优种群的一个搜索轨迹?【输入参数】? bounds--代表变量上下界的矩阵? evalFN--适应度函数? evalOps--传递给适应度函数的参数? startPop-初始种群? opts[epsilon prob_ops display]--opts(1:2)等同于initializega 的options参数,第三个参数控制是否输出,一般为0。如[1e-6 termFN--终止函数的名称,如['maxGenTerm']? termOps--传递个终止函数的参数,如[100]? selectFN--选择函数的名称,如['normGeomSelect']? selectOps--传递个选择函数的参数,如[0.08]? xOverFNs--交叉函数名称表,以空格分开,如['arithXover heuristicXover simpleXover']? xOverOps--传递给交叉函数的参数表,如[2 0;2 3;2 0]? mutFNs--变异函数表,如['boundaryMutation multiNonUnifMutation nonUnifMutation unifMutation']? mutOps--传递给交叉函数的参数表,如[4 0 0;6 100 3;4 100 3;4 0 0]?注意】matlab工具箱函数必须放在工作目录下?【问题】求f(x)=x+10*sin(5x)+7*cos(4x)的最大值,其中0=x=9?【分析】选择二进制编码,种群中的个体数目为10,二进制编码长度为20,交叉概率为0.95,变异概率为0.08?【程序清单】?
遗传算法遗传算法的计算性能的统计分析 岳嵚冯珊 (华中科技大学控制科学与工程系) 摘要:本文通过对多维解析函数的多次重复计算并对计算结果的进行统计分析来讨论遗传算法的可靠性和可信度,结果表明:遗传算法的计算结果具有一定的稳定性,可以通过采用多次重复计算的方法提高计算结果的可信度,并用以评价算法及其改进的实际效果。 关键词:遗传算法;计算可靠性;置信区间 分类号:TP18 1遗传算法的随机性 遗传算法是将生物学中的遗传进化原理和随机优化理论相结合的产物,是一种随机性的全局优化算法[1]。遗传算法作为一种启发式搜索算法,其计算结果具有不稳定性和不可重现性;遗传算法的进化过程具有有向随机性,整体上使种群的平均适应度不断提高。现在学术界对遗传算法中的某些遗传操作的作用机制还不十分清楚,遗传算法的许多性能特点无法在数学上严格证明。遗传算法的计算过程会受到各种随机因素的影响,如随机产生的初始种群和随机进行的变异操作等,尤其初是始种群对计算结果影响较大。但另一方面,大量的实算结果表明,遗传算法的计算结果具有一定的规律性,在统计意义上具有一定的可靠性,这样就可以对待求解问题进行多次重复计算后取平均值的方法,提高遗传算法在实际计算中的准确性和可信度。 包括遗传算法在内的启发式搜索算法主要用于解决大型的复杂优化问题,这些问题一般难以使用传统的优化算法解决。遗传算法对这类问题的计算结果也难达到精确的最优解。这给对用遗传算法解决实际工程优化问题的计算结果的评价带来了困难,在实际工程计算中也难以评价遗传算法及其改进型的计算效果的优劣。 为了分析遗传算法的计算性能,本文采用的计算对象是一个复杂的多维解析函数。使用这类函数评价遗传算法计算性能的好处是可以事先通过其他方法求得最优解,这样便于评价遗传算法及其改进型的计算效果。本文从统计学角度对多次重复计算的结果进行分析,试图得到遗传算法的稳定性和可信度方面的相关结论,通过分析遗传算法及其改进型求解解析问题的计算效果,再把所得到的相关结论推广应用到复杂的工程实际问题中去。 遗传算法在实际使用中有多种形式的变型,经典遗传算法是遗传算法的最简单的形式,但是经典遗传算法并不理想。本文使用的是粗粒度并行遗传算法。粗粒度并行遗传算法是遗传算法的一个重要改进型。它具有比经典遗传算法更好的计算性能。 2算例、实验方法和实验结果 2.1算例 本文所使用的算例是Deb 函数: ]10,10[,)]4cos(10[10)(12?∈??+=∑=i n i i i Deb x n x x x f i π(1) Deb 函数是一个高维的非凸函数,该函数在点(9.7624,9.7624,…,9.7624)上取得最大
基于遗传算法的参数优化估算模型 【摘要】支持向量机中参数的设置是模型是否精确和稳定的关键。固定的参数设置往往不能满足优化模型的要求,同时使得学习算法过于死板,不能体现出来算法的智能化优点,因此利用遗传算法(Genetic Algorithm,简称GA)对估算模型的参数进行优化,使得估算模型灵活、智能,更加符合实际工程建模的需求。 【关键词】遗传算法;参数优化;估算模型 1.引言 随着支持向量机估算模型在工程应用的不断深入。研究发现,支持向量机算法(包括LS-SVM算法)存在着一些本身不可避免的缺陷,最为突出的是参数的选取和优化问题,以往在参数选取方面,一般依靠专家系统或者设定初始值盲目搜寻等等,在实际应用必然会影响模型的精准度,造成一定影响。如何选取合理的参数成为支持向量机算法应用过程中应用中关注的问题,同时也是目前应用研究的重点。而常用的交叉验证试算的方法,不仅耗时,且搜索目的不清,使得资源浪费,耗时耗力。不能有效的对参数进行优化。 针对参选取的问题,本文使用GA算法对模型中的参数设置进行优化。 2.遗传算法 2.1 遗传算法的实施过程 遗传算法的实施过程中包括了编码、产生群体、计算适应度、复制、交换、变异等操作。图1详细的描述了遗传算法的流程。 其中,变量GEN是当前进化代数;N是群体规模;M是算法执行的最大次数。 遗传算法在参数寻优过程中,基于生物遗传学的基本原理,模拟自然界生物种群的“物竞天则,适者生存”的自然规律。把自变量看作生物体,把它转化成由基因构成的染色体(个体),把寻优的目标函数定义为适应度,未知函数视为生存环境,通过基因操作(如复制、交换和变异等),最终求出全局最优解。 2.2 GA算法的基本步骤 遗传算法操作的实施过程就是对群体的个体按照自然进化原则(适应度评估)施加一定的操作,从而实现模型中数据的优胜劣汰,使得进化过程趋于完美。从优化搜索角度出发,遗传算法可使问题的解,一代一代地进行优化,并逼近最优解。 通常采用的遗传算法的工作流程和结果形式有Goldberg提出的,常用的GA 算法基本步骤如下: ①选择编码策略,把参数集合X和域转换为位串结构空间S。常用的编码方法有二进制编码和浮点数编码。 ②定义合适的适应度函数,保证适应度函数非负。 ③确定遗传策略,包括选择群体大小,选择、交叉、变异方法,以及确定交叉概率、变异概率等其它参数。 ④随机初始化生成群体N,常用的群体规模:N=20~200。 ⑤计算群体中个体位串解码后的适应值。 ⑥按照遗传策略,运用选择、交叉和变异算子作用于群体,形成下一代群体。 ⑦判断群体性能是否满足某一个指标,或者以完成预订迭代次数,若满足则