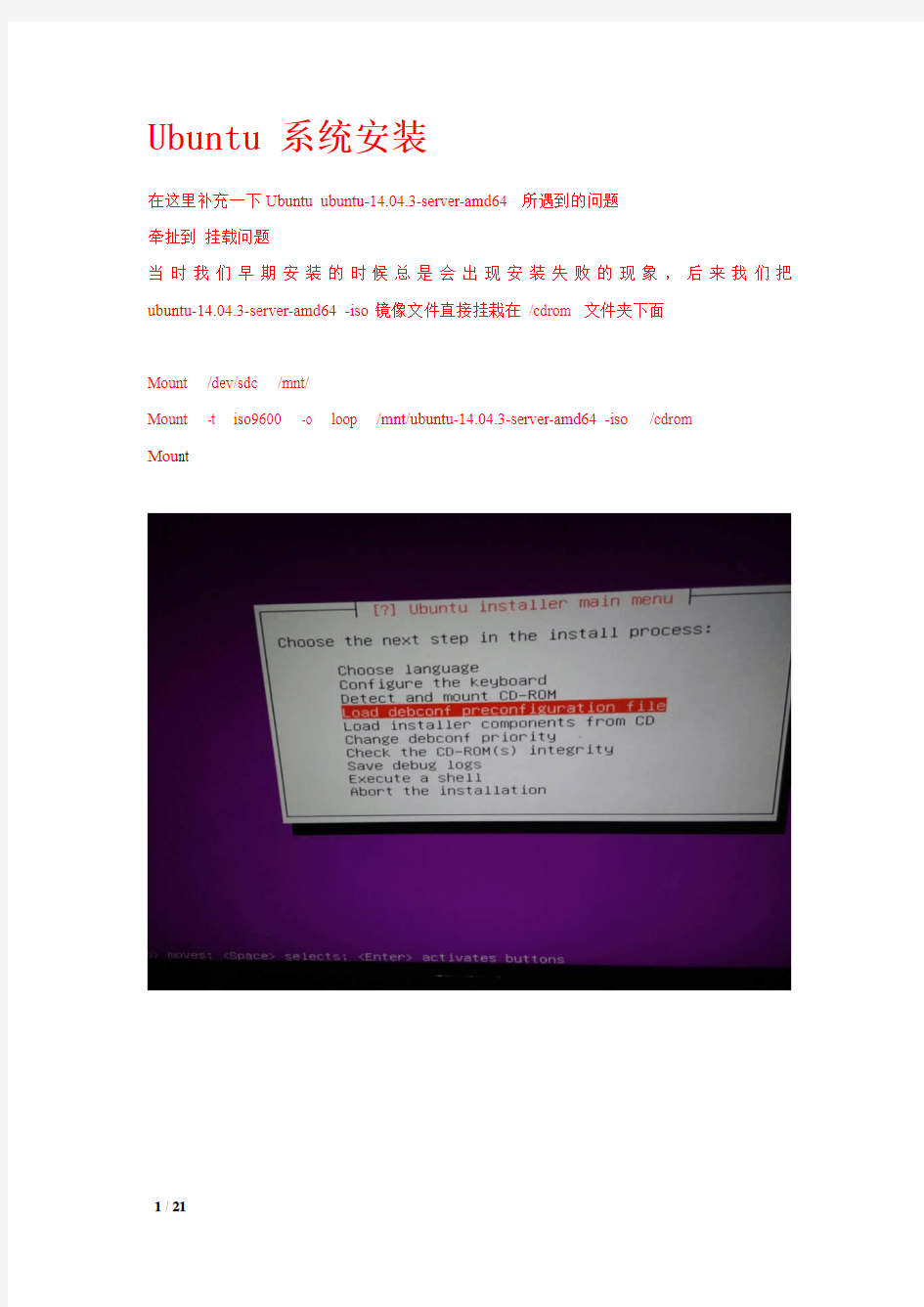
Ubuntu 系统安装
在这里补充一下Ubuntu ubuntu-14.04.3-server-amd64 所遇到的问题
牵扯到挂载问题
当时我们早期安装的时候总是会出现安装失败的现象,后来我们把ubuntu-14.04.3-server-amd64 -iso镜像文件直接挂栽在/cdrom 文件夹下面
Mount /dev/sdc /mnt/
Mount -t iso9600 -o loop /mnt/ubuntu-14.04.3-server-amd64 -iso /cdrom
Mou nt
基于Ubuntu的Hadoop集群安装与配置
一、实验目的
1、掌握Hadoop原理机制,熟悉Hadoop集群体系结构、核心技术。
2、安装和配置Hadoop集群。
二、实验原理
Hadoop分布式计算平台是由Apache软件基金会开发的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
Hadoop 中的分布式文件系统 HDFS 由一个管理结点 ( NameNode )和N个数据结点( DataNode )组成,每个结点均是一台普通的计算机。在使用上同我们熟悉的单机上的文件系统非常类似,一样可以建目录,创建,复制,删除文件,查看文件内容等。但其底层实现上是把文件切割成 Block,然后这些 Block 分散地存储于不同的 DataNode 上,每个 Block 还可以复制数份存储于不同的 DataNode 上,达到容错容灾之目的。NameNode 则是整个HDFS 的核心,它通过维护一些数据结构,记录了每一个文件被切割成了多少个 Block,这些 Block 可以从哪些 DataNode 中获得,各个 DataNode 的状态等重要信息。
MapReduce 是 Google 公司的核心计算模型,它将复杂的运行于大规模集群上的并行计算过程高度的抽象到了两个函数,Map 和 Reduce, 这是一个令人惊讶的简单却又威力巨大的模型。适合用 MapReduce 来处理的数据集(或任务)有一个基本要求: 待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。基于它写出来的程序能够运行在由上千台商用机器组成的大型集群上,并以一种可靠容错的方式并行处理T级别的数据集,实现了Haddoop在集群上的数据和任务的并行计算与处理。
个人认为,从HDFS(分布式文件系统)观点分析,集群中的服务器各尽其责,通力合作,共同提供了整个文件系统的服务。从职责上集群服务器以各自任务分为namenode、datanode服务器.其中namenode为主控服务器,datanode为数据服务器。Namenode管理所有的datanode数据存储、备份、组织记录分配逻辑上的处理。说明白点namenode就是运筹帷幄、负责布局指挥将军,具体的存储、备份是由datanode这样的战士执行完成的。故此很多资料将HDFS分布式文件系统的组织结构分为master(主人)和slaver(奴隶)的关系。其实和namenode、datanode划分道理是一样的。
从MapReduce计算模型观点分析,Map/Reduce框架和分布式文件系统是运行在一组相同的节点上的,也就是说计算节点和存储节点在一起。这种配置允许在那些已经存好数据的节点上高效的调度任务,这样可以使整个集群的网络宽带得到非常高效的利用。另外,在Hadoop中,用于执行MapReduce任务的机器有两个角色:JobTracker,TaskTracker。JobTracker(一个集群中只能有一台)是用于管理和调度工作的,TaskTracker是用于执行工作的。
在技术方面Hadoop体系具体包含了以下技术:
Common:在0.20及以前的版本中,包含HDFS、MapReduce和其他项目公共内容,从0.21开始HDFS和MapReduce被分离为独立的子项目,其余内容为Hadoop Common。
Avro:新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
MapReduce:并行计算框架,0.20前使用org.apache.hadoop.mapred旧接口,0.20版本开始引入org.apache.hadoop.mapreduce的新API。
HDFS:Hadoop分布式文件系统(Hadoop Distributed File System)。
Pig:大数据分析平台,为用户提供多种接口。
Hive:数据仓库工具,由Facebook贡献。
Hbase:类似Google BigTable的分布式NoSQL列数据库。(HBase和Avro已经于2010年5月成为顶级Apache项目)。
ZooKeeper:分布式锁设施,提供类似Google Chubby的功能,由Facebook贡献。
Sqoop:Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如:MySQL, Oracle, Postgres等)中的数据导入到Hadoop的HDFS 中,也可以将HDFS的数据导入到关系型数据库中。
Oozie:负责MapReduce作业调度。
以上对Hadoop体系框架和相应技术做了相应分析,并从HDFS、MapReduce的角度分析了集群中的角色扮演,这既是我们实验的理论基础,也是实验研究Hadoop深层次系统知识体系结构的意义所在。
三、实验内容
实验的主要内容有如下几点:
1、Jdk安装:Hadoop是用Java编写的程序,Hadoop的编译及MapReduce的运行都需要JDK,
因此在安装Hadoop之前,必须安装JDK1.6或更高版本。
2、SSH免密登录安装设置:Hadoop需要通过ssh(安全外壳协议)远程无密码登录,来启动
Slave列表中各台机器的守护进程,因此ssh也是必须安装的。
3、Hadoop完全分布式集群的安装配置和启动验证。
四、实验步骤
为方便阐述,本实验只搭建一个有三台主机的小集群。
三台机器的具体分工命名如下:
IP 主机名功能角色
10.31.44.117 master(主人) namenode(控制节点)、JobTracker(工作分配) 10.31.44.200 slaver1(奴隶)datanode(数据节点)、TaskTracker(任务执行) 10.31.44.201 slaver2(奴隶)datanode(数据节点)、TaskTracker(任务执行)
主机网络结构图如下:
实验环境:Ubuntu14.04,hadoop-2.2.0,java-1.7.0-openjdk-i386,ssh。
综述:Hadoop完全分布式的安装需要以下几个过程:
(1)为防止权限不够,三台机器均开启root登录。
(2)为三台机器分配IP地址及相应的角色。
(3)对三台机器进行jdk安装并配置环境变量。
(4)对三台机器进行ssh(安全外壳协议)远程无密码登录安装配置。
(5)进行Hadoop集群完全分布式的安装配置。
下面对以上过程进行详细叙述。
1、三台机器开启root登录。
针对ubuntu-14.04默认是不开启root用户登录的,在这里开启root登录,只需要修改50-ubuntu.conf即可,命令如下
添加内容如下:
配置完成后开启root账号命令如下:
sudo passwd root
根据提示输入root账号密码。
重启ubuntu,登录窗口会有“登录”选项,这时候我们就可以通过root登录了。
2、在三台主机上分别设置/etc/hosts及/etc/hostname
hosts文件用于定义主机名与IP地址之间的对应关系(三台主机配置相同)。
命令如下:
配置结果如下:
hostname这个文件用于定义Ubuntu的主机名(不同ip对应的名字不同10.31.44.117对应master,10.31.44.200对应slaver1,10.31.44.201对应slaver2)。
命令:vim /etc/hostname
“你的主机名”(master,slaver1,slaver2)
重启
3、在三台主机上安装openjdk-7-jdk
更新软件源:
配置Ubuntu Server高速apt-get源
今天刚装上Ubuntu Server 12,默认的apt-get源比较慢。更改一下源地址。
方法:
1、修改源地址:
cp /etc/apt/sources.list /etc/apt/sources.list.bak
vim /etc/apt/sources.list
加入如下内容(中科大的):
deb https://www.doczj.com/doc/f55843802.html,/ubuntu/ precise-updates main restricted deb-src https://www.doczj.com/doc/f55843802.html,/ubuntu/ precise-updates main restricted
deb https://www.doczj.com/doc/f55843802.html,/ubuntu/ precise universe
deb-src https://www.doczj.com/doc/f55843802.html,/ubuntu/ precise universe
deb https://www.doczj.com/doc/f55843802.html,/ubuntu/ precise-updates universe
deb-src https://www.doczj.com/doc/f55843802.html,/ubuntu/ precise-updates universe deb https://www.doczj.com/doc/f55843802.html,/ubuntu/ precise multiverse
deb-src https://www.doczj.com/doc/f55843802.html,/ubuntu/ precise multiverse
deb https://www.doczj.com/doc/f55843802.html,/ubuntu/ precise-updates multiverse
deb-src https://www.doczj.com/doc/f55843802.html,/ubuntu/ precise-updates multiverse deb https://www.doczj.com/doc/f55843802.html,/ubuntu/ precise-backports main
restricted universe multiverse
deb-src https://www.doczj.com/doc/f55843802.html,/ubuntu/ precise-backports main restricted universe multiverse
deb https://www.doczj.com/doc/f55843802.html,/ubuntu precise-security main restricted deb-src https://www.doczj.com/doc/f55843802.html,/ubuntu precise-security main restricted
deb https://www.doczj.com/doc/f55843802.html,/ubuntu precise-security universe
deb-src https://www.doczj.com/doc/f55843802.html,/ubuntu precise-security universe
deb https://www.doczj.com/doc/f55843802.html,/ubuntu precise-security multiverse deb-src https://www.doczj.com/doc/f55843802.html,/ubuntu precise-security multiverse
查询资料:
https://www.doczj.com/doc/f55843802.html,/lyp3314/archive/2012/07/18/2597973.html
以上信息是为了安装软件更新软件源,我在做的时候用的就是服务器里面虚拟出来的三台虚拟机,在自动更新软件源这方面有很大问题,故而自己在网上查找软件源手动输入(此时我的内心是奔溃的,但这并不是最坑的)
使用命令apt-get install openjdk-7-jdk 进行安装JA V A环境。
具体操作命令如图1-1java安装。
按照以上命令安装完成后可以查看jdk安装目录
配置系统环境变量命令如下:
添加环境变量内容如下:
在/etc/profile文件末尾添加java用户环境变量如下:
至此JDK安装配置完成。
配置jdk环境变量,并不算是麻烦事,但我在配置过程中出错了,导致的问题就是,在命令框输入任何命令都是无效的,最后只能找到/usr/bin/vi 来启动vi编辑器,重新配置环境变量。按以上的步骤配置不会有问题的
4、安装ssh配置免密登录
ssh及ssh-agent注意事项
(2012-06-27 17:24:30) service ssh start
转载▼
标签:
杂谈
注意:一定要给.ssh文件夹和authorized_keys文件赋予权限,分别为711和644
ssh连接的用户信息保存在know_hosts文件夹下,如果想要删除某个机器的连接,命令为
ssh-keygen -R 机器名
清除私钥密码
1.在终端下输入ssh-keygen -p。
2.系统会提示选择需要修改的私钥,默认是/home/username/.ssh/id_rsa。
3.选好文件后按回车,会提示你输入旧密码。
4.输入好后会提示输入新密码。
5.直接回车,提示确认新密码再直接回车,此时指定的私钥的密码就被清除了
查看所连机器的公钥,用ssh-keygen -F
OpenSSH在4.0p1引入了 Hash Known Hosts功能,在known_hosts中把访问过的计算机名称或IP地址以hash方式存放,令入侵都不能直接知道你到访过那些计算机。这项新项功能缺省是关闭的,要你手动地在ssh_config加上\"HashKnownHosts yes\"才会被开启
/etc/ssh/ssh_config 文件是ssh的配置文件
"ssh-keygen -F 计算机名称\"找出相关机器的公钥
启用ssh-agent:
$eval `ssh-agent ` (反引号)
查询资料:
https://www.doczj.com/doc/f55843802.html,/s/blog_72827fb101018wtx.html
以上信息就是百度得来的关于ssh问题
关于ssh配置,我只想说直接使用命令安装ssh是可以的,在开启ssh的时候可能会没有ssh-gent ,我的就是这样,后来按了卸再按结果依然如初,通过百度才发现没有打开于是乎又学会了一个命令:eval ssh-agent 执行后会再查看ssh-agent 就会出现了。为什么会这样呢,自己猜吧
安装ssh命令如下:
安装完成后查看是否安装成功,如果有如下两个进程说明安装成功。
如果缺少以上任意一进程,需要重新安装对应如下ssh版本。
如果需要重新安装,使用命令:
apt-get install openssh-client
apt-get install openssh-server
安装成功后,需要更改sshd_config文件
命令:vim /etc/ssh/sshd_config
修改为如下图内容:
这个修改问题在我竟如文件后发现就是yes
生成密钥并配置SSH免密码登录本机
执行以下命令,生成密钥对,并把公钥文件写入授权文件中
生成密钥对及授权文件,公钥在/root/.ssh/下
然后将授权文件复制到slaver1主机中,输入命令:
scp authorized_keys slaver1:~/.ssh
然后在slave1机器中,使用同样命令生成密钥对,将公钥写入授权文件中。让后将slaver1主机中的授权文件复制到slaver2中,使用同样命令生成密钥对,将公钥写入授权文件中。这样就完成了同一个授权文件拥有三个公钥。最后将此时的授权文件分别复制到master主机、slaver1主机中,这样就完成了,ssh免密登录验证工作。
为了防止防火墙禁止一些端口号,三台机器应使用
关闭防火墙命令:ufw disable
重启三台机器,防火墙关闭命令才能生效,重启后后查看是否可以从master主机免密码登录slaver,输入命令:
ssh slaver1
ssh slaver2
关于开机自启动项目,我是把命令写在/etc/rc.local 里面,等到开机的时候,写在里面的命令会自动启动运行的
5、进行Hadoop集群完全分布式的安装配置
在这里我想说一下编译问题,由于我使用的是ubuntu-14.04.3-server-amd64
hadoop-2.6.0
下载的hadoop解压后还要重新编译,编译好的hadoop-2.6.0 才能用,直接根据下列步骤做就行了,我说一下我遇到的问题
1.编译失败hadoop 原因----------------------maven环境变量配置出错,因为在本文件指导安装配置hadoop的文件中是没有maven环境变量配置的(我同学没配也成功编译了,每个人遇到的问题可能不一样,主要是独立解决问题)我的环境变量写在/etc/profile(这是针对所有用户的)
2.每个hadoop的版本不同,发生的情况也不同,只能应对了
将下载的hadoop-2.2.0解压至/root下,并更改名字为u
三台hadoop文件配置相同,所以配置完一台后,可以把整个hadoop复制过去就行了,现在开始配置master主机的hadoop文件。
需要配置的文件涉及到的有7个(标示有A的除外)如下图标示部分:
以上文件默认不存在的,可以复制相应的template文件获得(如mapred-site.xml文件)。
配置文件1:hadoop-env.sh
修改JA V A_HOME值如下图:
配置文件2:yarn-env.sh
修改JA V A_HOME值如下图:
配置文件3:slaves(保存所有slave节点)写入以下内容:
配置文件4:core-site.xml
添加配置内容如下图:
配置文件5:hdfs-site.xml
配置文件6:mapred-site.xml
配置文件7:yarn-site.xml
上面配置完毕后,基本上完成了90%的工作,剩下的就是复制。我们可以把整个hadoop复制过去使用命令如下:
scp -r /root/u slaver1:/root/
scp -r /root/u slaver2:/root/
为方便用户和系统管理使用hadoop、hdfs相关命令,需要在/etc/environment配置系统环境变量,使用命令:vim /etc/environment
配置内容为hadoop目录下的bin、sbin路径,具体如下
添加完后执行生效命令:source /etc/environment
下面要做的就是启动验证,建议在验证前,把以上三台机器重启,使其相关配置生效。6、启动验证
这个步骤有的问题就是:
1.上一步骤文件没有配置好,不过格式化的时候会出现ERROR,并且提示你你配置文件出错的地方,这点要注意。
2.hadoop的环境变量没有配好,具体表现在start-all.sh 这个命令上面,就是找不到start-all.sh 这就是环境变量没有配好的原因,顺便说一下start-all.sh这个文件在sbin这个目录里面,所以个人建议把/bin 和/sbin的环境变量都配上
在master节点上进行格式化namenode:
命令:hadoop namenode -format
在master节点上进行启动hdfs:
start-all.sh
使用Jps命令master有如下进程,说明ok
使用jps命令slaver1、slaver2有如下进程,说明ok
查看集群状态,命令:hadoop dfsadmin -report
查看分布式文件系统:http://master:50070
查看MapReduce:http://master:8088
使用以上命令,当你看到如下图所示的效果图时,恭喜你完成了Hadoop完全分布式的安装设置,其实这些部署还是比较基本的,对于Hadoop高深的体系结构和强大技术应用,这仅
仅是一个小小的开始。
集群的关闭在master节点上执行命令如下:
stop-all.sh
五、附录hadoop基本操作实践
基本命令
1. 格式化工作空间
进入bin目录,运行hadoop namenode –format
2. 启动hdfs
进入hadoop目录,在bin/下面有很多启动脚本,可以根据自己的需要来启动。
* start-all.sh 启动所有的Hadoop守护。包括namenode, datanode, jobtracker, tasktrack
* stop-all.sh 停止所有的Hadoop
* start-dfs.sh 启动Hadoop DFS守护Namenode和Datanode
* stop-dfs.sh 停止DFS守护
HDFS文件操作
Hadoop使用的是HDFS,能够实现的功能和我们使用的磁盘系统类似。并且支持通配符,如*。
1. 查看文件列表
Hadoop配置参数建议 流量三期程序和Hive脚本需要运行在Hadoop集群上,本文档用于对Hadoop的参数提出建议。如果Hadoop集群是我们自己管理的,可以参考文档里建议的参数进行配置;如果Hadoop集群不由我们管理,我们只是集群资源的用户,可以通过给流量三期Job或者Hive 脚本指定Hadoop参数来调整程序的运行方式。 需要注意的是,通过编辑配置文件来设置Hadoop参数的方式,只适用于独立安装的Hadoop2.X、CDH4.X和CDH5.X,不适用于通过Athena大数据管理平台安装的CDH,因为Athena要求必须使用Web界面修改Hadoop的配置,不允许直接编辑Hadoop的配置文件。 Hadoop的参数有数百个,其中绝大多数都应该使用默认值,本文档只对可能需要修改的参数进行说明。对于文档没有列出的参数,如果没有特殊需要,不建议修改,避免出现难以定位的问题。 Hadoop参数可以分成三类,分别是Linux环境变量、集群配置变量和作业配置变量,下面对各类变量分别说明。 一、Linux环境变量 Linux环境变量用来配置各个Hadoop守护进程的行为,包括Yarn的ResourceManager 进程、Yarn的NodeManager进程、HDFS的NameNode进程、HDFS的Secondary NameNode 进程、HDFS的DataNode进程和Hadoop Job History Server进程等。 Hadoop在启动各个守护进程时会通过环境变量的值来确定进程的行为,所以环境变量一般在启动Hadoop前设置才有意义。 设置方式是在Hadoop启动或者重启前,编辑Hadoop配置文件目录下的hadoop-env.sh、mapred-env.sh和yarn-env.sh文件。这三个文件是shell脚本,并且mapred-env.sh和yarn-env.sh 的优先级高于hadoop-env.sh,也就是说如果在mapred-env.sh和hadoop-env.sh中设置了同一个环境变量,Hadoop会使用mapred-env.sh中的变量值。 下面是Hadoop比较重要的环境变量:
1.HDFS:HADOOP的分布式文件系统 HDFS:是一个分布式文件系统(整个系统中有多种角色
5、重启linux服务器:reboot 6、在windows上配置这几台linux服务器的域名映射: 改好后,同步scp给所有其他机器 7、用crt软件试连接 8、对每一台linux服务器关闭防火墙 8、对每一台linux机器配置域名映射 scp /etc/hosts hdp20-02:/etc/ scp /etc/hosts hdp20-03:/etc/ scp /etc/hosts hdp20-04:/etc/ 验证:比如在hdp20-01上, ping hdp20-02 ###看是否能ping通 9、在每台linux服务器上安装jdk 上传jdk安装包 解压 然后,将安装好的目录scp到其他所有机器的相同路径 然后,将改好的/etc/profile 拷贝scp到其他所有机器的对应路径下
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS 本教程讲述如何配置Hadoop 集群,默认读者已经掌握了Hadoop 的单机伪分布式配置,否则请先查看Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置。 本教程由厦门大学数据库实验室出品,转载请注明。本教程适合于原生Hadoop 2,包括Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,保证按照步骤来,都能顺利安装并运行Hadoop。另外有Hadoop安装配置简略版方便有基础的读者快速完成安装。 为了方便新手入门,我们准备了两篇不同系统的Hadoop 伪分布式配置教程。但其他Hadoop 教程我们将不再区分,可同时适用于Ubuntu 和CentOS/RedHat 系统。例如本教程以Ubuntu 系统为主要演示环境,但对Ubuntu/CentOS 的不同配置之处、CentOS 6.x 与CentOS 7 的操作区别等都会尽量给出注明。 环境 本教程使用Ubuntu 14.04 64位作为系统环境,基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1,Hadoop 2.4.1 等。 本教程简单的使用两个节点作为集群环境: 一个作为Master 节点,局域网IP 为192.168.1.121;另一个作为Slave 节点,局域网IP 为192.168.1.122。 准备工作 Hadoop 集群的安装配置大致为如下流程: 1.选定一台机器作为Master 2.在Master 节点上配置hadoop 用户、安装SSH server、安装Java 环境 3.在Master 节点上安装Hadoop,并完成配置 4.在其他Slave 节点上配置hadoop 用户、安装SSH server、安装Java 环境 5.将Master 节点上的/usr/local/hadoop 目录复制到其他Slave 节点上 6.在Master 节点上开启Hadoop 配置hadoop 用户、安装SSH server、安装Java 环境、安装Hadoop 等过程已经在Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置中有详细介绍,请前往查看,不再重复叙述。 继续下一步配置前,请先完成上述流程的前 4 个步骤。 网络配置 假设集群所用的节点都位于同一个局域网。 如果使用的是虚拟机安装的系统,那么需要更改网络连接方式为桥接(Bridge)模式,才能实现多个节点互连,例如在VirturalBox 中的设置如下图。此外,如果节点的系统是在虚拟机中直接复制的,要确保各个节点的Mac 地址不同(可以点右边的按钮随机生成MAC 地址,否则IP 会冲突):
本文为笔者安装配置过程中详细记录的笔记 1.下载hadoop hadoop-2.7.1.tar.gz hadoop-2.7.1-src.tar.gz 64位linux需要重新编译本地库 2.准备环境 Centos6.4 64位,3台 hadoop0 192.168.1.151namenode hadoop1 192.168.1.152 datanode1 Hadoop2 192.168.1.153 datanode2 1)安装虚拟机: vmware WorkStation 10,创建三台虚拟机,创建时,直接建立用户ha,密码111111.同时为root密码。网卡使用桥接方式。 安装盘 、 2). 配置IP.创建完成后,设置IP,可以直接进入桌面,在如下菜单下配置IP,配置好后,PING 确认好用。 3)更改三台机器主机名 切换到root用户,更改主机名。 [ha@hadoop0 ~]$ su - root Password: [root@hadoop0 ~]# hostname hadoop0 [root@hadoop0 ~]# vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=hadoop0 以上两步后重启服务器。三台机器都需要修改。 4)创建hadoop用户 由于在创建虚拟机时,已自动创建,可以省略。否则用命令创建。
5)修改hosts文件 [root@hadoop0 ~]# vi /etc/hosts 127.0.0.1 localhostlocalhost.localdomain localhost4 localhost4.localdomain4 ::1localhostlocalhost.localdomain localhost6 localhost6.localdomain6 192.168.1.151 hadoop0 192.168.1.152 hadoop1 192.168.1.153 hadoop2 此步骤需要三台机器都修改。 3.建立三台机器间,无密码SSH登录。 1)三台机器生成密钥,使用hadoop用户操作 [root@hadoop0 ~]# su– ha [ha@hadoop0 ~]$ ssh -keygen -t rsa 所有选项直接回车,完成。 以上步骤三台机器上都做。 2)在namenode机器上,导入公钥到本机认证文件 [ha@hadoop0 ~]$ cat ~/.ssh/id_rsa.pub>>~/.ssh/authorized_keys 3)将hadoop1和hadoop2打开/home/ha/.ssh/ id_rsa.pub文件中的内容都拷贝到hadoop0的/home/ha /.ssh/authorized_keys文件中。如下: 4)将namenode上的/home/ha /.ssh/authorized_keys文件拷贝到hadoop1和hadoop2的/home/ha/.ssh文件夹下。同时在三台机器上将authorized_keys授予600权限。 [ha@hadoop1 .ssh]$ chmod 600 authorized_keys 5)验证任意两台机器是否可以无密码登录,如下状态说明成功,第一次访问时需要输入密码。此后即不再需要。 [ha@hadoop0 ~]$ ssh hadoop1 Last login: Tue Aug 11 00:58:10 2015 from hadoop2 4.安装JDK1.7 1)下载JDK(32或64位),解压 [ha@hadoop0 tools]$ tar -zxvf jdk-7u67-linux-x64.tar.gz 2)设置环境变量(修改/etx/profile文件), export JAVA_HOME=/usr/jdk1.7.0_67 export CLASSPATH=:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin 3)使环境变量生效,然后验证JDK是否安装成功。
hadoop:建立一个单节点集群伪分布式操作 安装路径为:/opt/hadoop-2.7.2.tar.gz 解压hadoop: tar -zxvf hadoop-2.7.2.tar.gz 配置文件 1. etc/hadoop/hadoop-env.sh export JAVA_HOME=/opt/jdk1.8 2. etc/hadoop/core-site.xml
Hadoop集群在linux下配置 第一部分Hadoop 2.2 下载 Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。 下载地址:https://www.doczj.com/doc/f55843802.html,/hadoop/common/hadoop-2.2.0/ 如下图所示,下载红色标记部分即可。 第二部分集群环境搭建 1、这里我们搭建一个由两台机器组成的集群: 10.11.1.67 tan/123456 yang 10.11.1.57 tan/123456 ubuntu 1.1 上面各列分别为IP、user/passwd、hostname 1.2 Hostname可以在/etc/hostname中修改 1.3 这里我们为每台机器新建了一个账户tan.这里需要给每个账户分配sudo的权限。 (切换到root账户,修改/etc/sudoers文件,增加:tan ALL=(ALL) ALL ) 2、修改/etc/hosts 文件,增加两台机器的ip和hostname的映射关系 10.11.1.67 yang 10.11.1.57 ubuntu 3、打通yang到ubuntu的SSH无密码登陆 3.1 安装ssh 一般系统是默认安装了ssh命令的。如果没有,或者版本比较老,则可以重新安 装: sudo apt-get install ssh 3.2设置local无密码登陆
安装完成后会在~目录(当前用户主目录,即这里的/home/tan)下产生一个隐藏文 件夹.ssh(ls -a 可以查看隐藏文件)。如果没有这个文件,自己新建即可 (mkdir .ssh)。 具体步骤如下: 1、进入.ssh文件夹 2、 ssh-keygen -t rsa 之后一路回车(产生秘钥) 3、把id_rsa.pub 追加到授权的key 里面去(cat id_rsa.pub >> authorized_keys) 4、重启SSH 服务命令使其生效:service ssh restart 此时已经可以进行ssh localhost的无密码登陆 【注意】:以上操作在每台机器上面都要进行。 3.3设置远程无密码登陆 这里只有yang是master,如果有多个namenode,或者rm的话则需要打通所有master 都其他剩余节点的免密码登陆。(将yang的authorized_keys追加到ubuntu的authorized_keys) 进入yang的.ssh目录 scp authorized_keys tan@ubuntu:~/.ssh/ authorized_keys_from_yang 进入ubuntu的.ssh目录 cat authorized_keys_from_yang >> authorized_keys 至此,可以在yang上面ssh tan@ubuntu进行无密码登陆了。 4、安装jdk 注意:这里选择下载jdk并自行安装,而不是通过源直接安装(apt-get install) 4.1、下载jdk(https://www.doczj.com/doc/f55843802.html,/technetwork/java/javase/downloads/index.html) 4.1.1 对于32位的系统可以下载以下两个Linux x86版本(uname -a 查看系统版 本) 4.1.2 64位系统下载Linux x64版本(即x64.rpm和x64.tar.gz) 4.2、安装jdk(这里以.tar.gz版本,32位系统为例) 安装方法参https://www.doczj.com/doc/f55843802.html,/javase/7/docs/webnotes/install/linux/linux-jdk.html 4.2.1 选择要安装java的位置,如/usr/目录下,新建文件夹java(mkdir java) 4.2.2 将文件jdk-7u40-linux-i586.tar.gz移动到/usr/java 4.2.3 解压:tar -zxvf jdk-7u40-linux-i586.tar.gz 4.2.4 删除jdk-7u40-linux-i586.tar.gz(为了节省空间)
前言 本篇主要介绍在大数据应用中比较常用的一款软件Mysql,我相信这款软件不紧紧在大数据分析的时候会用到,现在作为开源系统中的比较优秀的一款关系型开源数据库已经被很多互联网公司所使用,而且现在正慢慢的壮大中。 在大数据分析的系统中作为离线分析计算中比较普遍的两种处理思路就是:1、写程序利用 mapper-Reducer的算法平台进行分析;2、利用Hive组件进行书写Hive SQL进行分析。 第二种方法用到的Hive组件存储元数据最常用的关系型数据库最常用的就是开源的MySQL了,这也是本篇最主要讲解的。 技术准备 VMware虚拟机、CentOS 6.8 64 bit、SecureCRT、VSFTP、Notepad++ 软件下载 我们需要从Mysql官网上选择相应版本的安装介质,官网地址如下: MySQL下载地址:https://www.doczj.com/doc/f55843802.html,/downloads/
默认进入的页面是企业版,这个是要收费的,这里一般建议选择社区开源版本,土豪公司除外。
然后选择相应的版本,这里我们选择通用的Server版本,点击Download下载按钮,将安装包下载到本地。 下载完成,上传至我们要安装的系统目录。 这里,需要提示下,一般在Linux系统中大型公用的软件安装在/opt目录中,比如上图我已经安装了Sql Server On linux,默认就安装在这个目录中,这里我手动创建了mysql目录。 将我们下载的MySQL安装介质,上传至该目录下。
安装流程 1、首先解压当前压缩包,进入目录 cd /opt/mysql/ tar -xf mysql-5.7.16-1.el7.x86_64.rpm-bundle.tar 这样,我们就完成了这个安装包的解压。 2、创建MySql超级管理用户 这里我们需要单独创建一个mySQL的用户,作为MySQL的超级管理员用户,这里也方便我们以后的管理。 groupaddmysql 添加用户组 useradd -g mysqlmysql 添加用户 id mysql 查看用户信息。
hadoop学习之hadoop完全分布式集群安装 注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流。转载请注明来自: https://www.doczj.com/doc/f55843802.html,/ab198604/article/details/8250461 要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个hadoop分布式集群了。 说来简单,但是应该怎么做呢?不急,本文的主要目的就是让新手看了之后也能够亲自动手实施这些过程。由于本人资金不充裕,只能通过虚拟机来实施模拟集群环境,虽然说是虚机模拟,但是在虚机上的hadoop的集群搭建过程也可以使用在实际的物理节点中,思想是一样的。也如果你有充裕的资金,自己不介意烧钱买诸多电脑设备,这是最好不过的了。 也许有人想知道安装hadoop集群需要什么样的电脑配置,这里只针对虚拟机环境,下面介绍下我自己的情况: CPU:Intel酷睿双核 2.2Ghz 内存: 4G 硬盘: 320G 系统:xp 老实说,我的本本配置显然不够好,原配只有2G内存,但是安装hadoop集群时实在是很让人崩溃,本人亲身体验过后实在无法容忍,所以后来再扩了2G,虽然说性能还是不够好,但是学习嘛,目前这种配置还勉强可以满足学习要求,如果你的硬件配置比这要高是最好不过的了,如果能达到8G,甚至16G内存,学习hadoop表示无任何压力。 说完电脑的硬件配置,下面说说本人安装hadoop的准备条件: 1 安装Vmware WorkStation软件 有些人会问,为何要安装这个软件,这是一个VM公司提供的虚拟机工作平台,后面需要在这个平台上安装linux操作系统。具体安装过程网上有很多资料,这里不作过多的说明。 2 在虚拟机上安装linux操作系统 在前一步的基础之上安装linux操作系统,因为hadoop一般是运行在linux平台之上的,虽然现在也有windows版本,但是在linux上实施比较稳定,也不易出错,如果在windows安装hadoop集群,估计在安装过程中面对的各种问题会让人更加崩溃,其实我还没在windows 上安装过,呵呵~ 在虚拟机上安装的linux操作系统为ubuntu10.04,这是我安装的系统版本,为什么我会使用这个版本呢,很简单,因为我用的熟^_^其实用哪个linux系统都是可以的,比如,你可以用centos, redhat, fedora等均可,完全没有问题。在虚拟机上安装linux的过程也在此略过,如果不了解可以在网上搜搜,有许多这方面的资料。 3 准备3个虚拟机节点 其实这一步骤非常简单,如果你已经完成了第2步,此时你已经准备好了第一个虚拟节点,那第二个和第三个虚拟机节点如何准备?可能你已经想明白了,你可以按第2步的方法,再分别安装两遍linux系统,就分别实现了第二、三个虚拟机节点。不过这个过程估计会让你很崩溃,其实还有一个更简单的方法,就是复制和粘贴,没错,就是在你刚安装好的第一个虚拟机节点,将整个系统目录进行复制,形成第二和第三个虚拟机节点。简单吧!~~ 很多人也许会问,这三个结点有什么用,原理很简单,按照hadoop集群的基本要求,其中一个是master结点,主要是用于运行hadoop 程序中的namenode、secondorynamenode和jobtracker任务。用外两个结点均为slave结点,其中一个是用于冗余目的,如果没有冗余,就不能称之为hadoop了,所以模拟hadoop集群至少要有3个结点,如果电脑配置非常高,可以考虑增加一些其它的结点。slave结点主要将运行hadoop程序中的datanode和tasktracker任务。 所以,在准备好这3个结点之后,需要分别将linux系统的主机名重命名(因为前面是复制和粘帖操作产生另两上结点,此时这3个结点的主机名是一样的),重命名主机名的方法:
hadoop集群安装 要想深入的学习hadoop集群数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个hadoop分布式集群了。 说来简单,但是应该怎么做呢?不急,本文的主要目的就是让新手看了之后也能够亲自动手实施这些过程。由于本人资金不充裕,只能通过虚拟机来实施模拟集群环境,虽然说是虚机模拟,但是在虚机上的hadoop的集群搭建过程也可以使用在实际的物理节点中,思想是一样的。也如果你有充裕的资金,自己不介意烧钱买诸多电脑设备,这是最好不过的了。 也许有人想知道安装hadoop集群需要什么样的电脑配置,这里只针对虚拟机环境,下面介绍下我自己的情况: CPU:Intel酷睿双核2.2Ghz 内存: 4G 硬盘: 320G 系统:xp 老实说,我的本本配置显然不够好,原配只有2G内存,但是安装hadoop集群时实在是很让人崩溃,本人亲身体验过后实在无法容忍,所以后来再扩了2G,虽然说性能还是不够好,但是学习嘛,目前这种配置还勉强可以满足学习要求,如果你的硬件配置比这要高是最好不过的了,如果能达到8G,甚至16G内存,学习hadoop表示无任何压力。 说完电脑的硬件配置,下面说说本人安装hadoop的准备条件: 1安装Vmware WorkStation软件 有些人会问,为何要安装这个软件,这是一个VM公司提供的虚拟机工作平台,后面需要在这个平台上安装linux操作系统。具体安装过程网上有很多资料,这里不作过多的说明。 2在虚拟机上安装linux操作系统 在前一步的基础之上安装linux操作系统,因为hadoop一般是运行在linux平台之上的,虽然现在也有windows版本,但是在linux上实施比较稳定,也不易出错,如果在windows安装hadoop集群,估计在安装过程中面对的各种问题会让人更加崩溃,其实我还没在windows 上安装过,呵呵~ 在虚拟机上安装的linux操作系统为ubuntu10.04,这是我安装的系统版本,为什么我会使用这个版本呢,很简单,因为我用的熟^_^其实用哪个linux系统都是可以的,比如,你可以用
1、采用一台机器开两个虚拟机的方式构成两台电脑的环境,用root登录。 分别查看其IP地址:输入# ifconfig,可得主机IP:192.168.1.99;分机为:192.168.1.100。 2、在两台机器上的/etc/hosts均添加相应的主机名和IP地址: 这里主机名命名为shenghao,分机名命名为slave: 保存后重启网络: 3、两台机器上均创立hadoop用户(注意是用root登陆) # useradd hadoop # passwd hadoop 输入111111做为密码 登录hadoop用户: 注意,登录用户名为hadoop,而不是自己命名的shenghao。 4、ssh的配置 进入centos的“系统→管理→服务器设置→服务,查看sshd服务是否运行。 在所有的机器上生成密码对: # ssh-keygen -t rsa 这时hadoop目录下生成一个.ssh的文件夹, 可以通过# ls .ssh/来查看里面产生的私钥和公钥:id_rsa和id_rsa.pub。 更改.ssh的读写权限: # chmod 755 .ssh 在namenode上(即主机上)
进入.ssh,将id_rsa.pub直接复制为authorized_keys(namenode的公钥): # cp id_rsa.pub authorized_keys 更改authorized_keys的读写权限: # chmod 644 authorized_keys 【这个不必须,但保险起见,推荐使用】 然后上传到datanode上(即分机上): # scp authorized_keys hadoop@slave:/home/hadoop/.ssh # cd .. 退出.ssh文件夹 这样shenghao就可以免密码登录slave了: 然后输入exit就可以退出去。 然后在datanode上(即分机上): 将datanode上之前产生的公钥id_rsa.pub复制到namenode上的.ssh目录中,并重命名为slave.id_rsa.pub,这是为了区分从各个datanode上传过来的公钥,这里就一个datanode,简单标记下就可。 # scp -r id_rsa.pub hadoop@shenghao:/home/hadoop/.ssh/slave.id_rsa.pub 复制完毕,此时,由于namenode中已经存在authorized_keys文件,所以这里是追加,不是复制。在namenode上执行以下命令,将每个datanode的公钥信息追加: # cat slave.id_rsa.pub >> authorized_keys 这样,namenode和datanode之间便可以相互ssh上并不需要密码: 然后输入exit就可以退出去。 5、hadoop的集群部署 配置hadoop前一定要配置JDK,请参考相关资料,这里就不赘述了。 将下载好的hadoop-0.19.0.tar.gz文件上传到namenode的/home/hadoop/hadoopinstall 解压文件: # tar zxvf hadoop-0.19.0.tar.gz 在/erc/profile的最后添加hadoop的路径: # set hadoop path export HADOOP_HOME=/home/hadoop/hadoopinstall/hadoop-0.20.2 export PATH=$HADOOP_HOME/bin:$PATH 之后配置hadoop/conf中的4个文件:
腾讯大规模Hadoop集群实践 发表于2014-02-19 21:26| 21878次阅读| 来源《程序员》| 45条评论| 作者翟艳堂 《程序员》杂志2014年2月刊hadoop集群腾讯分布式计算数据存储云计算大数据TDW 摘要:TDW是腾讯最大的离线数据处理平台。本文主要从需求、挑战、方案和未来计划等方面,介绍了TDW 在建设单个大规模集群中采取的JobTracker分散化和NameNode高可用两个优化方案。 TDW(Tencent distributed Data Warehouse,腾讯分布式数据仓库)基于开源软件Hadoop和Hive进行构建,打破了传统数据仓库不能线性扩展、可控性差的局限,并且根据腾讯数据量大、计算复杂等特定情况进行了大量优化和改造。 TDW服务覆盖了腾讯绝大部分业务产品,单集群规模达到4400台,CPU总核数达到10万左右,存储容量达到100PB;每日作业数100多万,每日计算量4PB,作业并发数2000左右;实际存储数据量80PB,文件数和块数达到6亿多;存储利用率83%左右,CPU利用率85%左右。经过四年多的持续投入和建设,TDW已经成为腾讯最大的离线数据处理平台。 TDW的功能模块主要包括:Hive、MapReduce、HDFS、TDBank、Lhotse等,如图1所示。TDW Core 主要包括存储引擎HDFS、计算引擎MapReduce、查询引擎Hive,分别提供底层的存储、计算、查询服务,并且根据公司业务产品的应用情况进行了很多深度订制。TDBank负责数据采集,旨在统一数据接入入口,提供多样的数据接入方式。Lhotse任务调度系统是整个数据仓库的总管,提供一站式任务调度与管理。
Hadoop云计算平台及相关组件搭建安装过程详细教程 ——Hbase+Pig+Hive+Zookeeper+Ganglia+Chukwa+Eclipse等 一.安装环境简介 根据官网,Hadoop已在linux主机组成的集群系统上得到验证,而windows平台是作为开发平台支持的,由于分布式操作尚未在windows平台上充分测试,所以还不作为一个生产平台。Windows下还需要安装Cygwin,Cygwin是在windows平台上运行的UNIX模拟环境,提供上述软件之外的shell支持。 实际条件下在windows系统下进行Hadoop伪分布式安装时,出现了许多未知问题。在linux系统下安装,以伪分布式进行测试,然后再进行完全分布式的实验环境部署。Hadoop完全分布模式的网络拓补图如图六所示: (1)网络拓补图如六所示: 图六完全分布式网络拓补图 (2)硬件要求:搭建完全分布式环境需要若干计算机集群,Master和Slaves 处理器、内存、硬盘等参数要求根据情况而定。 (3)软件要求 操作系统64位版本:
并且所有机器均需配置SSH免密码登录。 二. Hadoop集群安装部署 目前,这里只搭建了一个由三台机器组成的小集群,在一个hadoop集群中有以下角色:Master和Slave、JobTracker和TaskTracker、NameNode和DataNode。下面为这三台机器分配IP地址以及相应的角色: ——master,namenode,jobtracker——master(主机名) ——slave,datanode,tasktracker——slave1(主机名) ——slave,datanode,tasktracker——slave2(主机名) 实验环境搭建平台如图七所示:
Hadoop集群搭建(二)HDFS HDFS只是Hadoop最基本的一个服务,很多其他服务,都是基于HDFS 展开的。所以部署一个HDFS集群,是很核心的一个动作,也是大数据平台的开始。 安装Hadoop集群,首先需要有Zookeeper才可以完成安装。如果没有Zookeeper,请先部署一套Zookeeper。另外,JDK以及物理主机的一些设置等。都请参考下文: Hadoop集群搭建(一) Zookeeper 下面开始HDFS的安装 HDFS主机分配 1.19 2.168.67.101 c6701 --Namenode+datanode 2.192.168.67.102 c6702 --datanode 3.192.168.67.103 c6703 --datanode 1. 安装HDFS,解压hadoop- 2.6.0-EDH-0u2.tar.gz 我同时下载2.6和2.7版本的软件,先安装2.6,然后在执行2.6到2.7的升级步骤 https://www.doczj.com/doc/f55843802.html,eradd hdfs 2.echo "hdfs:hdfs"| chpasswd 3.su - hdfs
4.cd /tmp/software 5.tar -zxvf hadoop-2. 6.0-EDH-0u2.tar.gz -C /home/hdfs/ 6.mkdir -p /data/hadoop/temp 7.mkdir -p /data/hadoop/journal 8.mkdir -p /data/hadoop/hdfs/name 9.mkdir -p /data/hadoop/hdfs/data 10.chown -R hdfs:hdfs /data/hadoop 11.chown -R hdfs:hdfs /data/hadoop/temp 12.chown -R hdfs:hdfs /data/hadoop/journal 13.chown -R hdfs:hdfs /data/hadoop/hdfs/name 14.chown -R hdfs:hdfs /data/hadoop/hdfs/data 15.$ pwd 16./home/hdfs/hadoop-2.6.0-EDH-0u2/etc/hadoop 2. 修改core-site.xml对应的参数 1.$ cat core-site.xml 2.<configuration> 3.<!--指定hdfs的nameservice为ns --> 4.<property> 5.<name>fs.defaultFS</name> 6.<value>hdfs://ns</value> 7.</property> 8.<!--指定hadoop数据临时存放目录-->
Hadoop集群部署方案
目录 1.网络拓扑 (1) 2.软件安装 (1) 2.1.修改主机名 (1) 2.2.修改host文件 (1) 2.3.创建Hadoop 用户 (2) 2.4.禁用防火墙 (2) 2.5.设置ssh登录免密码 (2) 2.6.安装hadoop (4) 3.集群配置 (5) 3.1.修改脚本 (5) 3.1.1................................................ hadoop-env.sh 5 3.1.2................................................... y arn-env.sh 5 3.2.配置文件 (5) 3.2.1................................................ core-site.xml 5 3.2.2................................................ hdfs-site.xml 7 3.2.3.............................................. mapred-site.xml 10 3.2. 4................................................ yarn-site.xml 11 3.2.5.配置datanode 14 3.3.创建目录 (14)
4.启动zk集群 (14) 5.启动hadoop (14) 5.1.启动所有节点journalnode (14) 5.2.格式化h1 namenode (15) 5.3.在h1上格式化ZK (15) 5.4.启动h1的namenode,zkfc (16) 5.5.启动h2上namenode (16) 5.6.同步h1上的格式化数据到h2 (16) 5.7.启动 HDFS (17) 5.8.启动 YARN (18) 5.9.启动h2 ResourceManager (18) 5.10........................................ h4上启动 JobHistoryServer 19 5.11.......................................... 查看ResourceManager状态19 6.浏览器访问 (19) https://www.doczj.com/doc/f55843802.html,node管理界面 (19) 6.1.1............................... http://192.168.121.167:50070 19 6.1.2............................... http://192.168.121.168:50070 20 6.2.ResourceManager管理界面 (20) 6.2.1............................... http://192.168.121.167:8088/ 21 6.2.2............................... http://192.168.121.168:8088/ 21 6.3.JournalNode HTTP 服务 (21) 6.3.1............................... http://192.168.121.167:8480/ 21 6.4.Datanode HTTP服务 (22)
如何基于Docker快速搭建多节点Hadoop集群 Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中。这篇教程介绍了利用Docker在单机上快速搭建多节点 Hadoop集群的详细步骤。作者在发现目前的Hadoop on Docker项目所存在的问题之后,开发了接近最小化的Hadoop镜像,并且支持快速搭建任意节点数的Hadoop集群。 Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中。这篇教程介绍了利用Docker在单机上快速搭建多节点 Hadoop集群的详细步骤。作者在发现目前的Hadoop on Docker项目所存在的问题之后,开发了接近最小化的Hadoop镜像,并且支持快速搭建任意节点数的Hadoop集群。 一. 项目简介 GitHub: kiwanlau/hadoop-cluster-docker 直接用机器搭建Hadoop集群是一个相当痛苦的过程,尤其对初学者来说。他们还没开始跑wordcount,可能就被这个问题折腾的体无完肤了。而且也不是每个人都有好几台机器对吧。你可以尝试用多个虚拟机搭建,前提是你有个性能杠杠的机器。 我的目标是将Hadoop集群运行在Docker容器中,使Hadoop开发者能够快速便捷地在本机搭建多节点的Hadoop集群。其实这个想法已经有了不少实现,但是都不是很理想,他们或者镜像太大,或者使用太慢,或者使用了第三方工具使得使用起来过于复杂。下表为一些已知的Hadoop on Docker项目以及其存在的问题。 我的项目参考了alvinhenrick/hadoop-mutinode项目,不过我做了大量的优化和重构。alvinhenrick/hadoop-mutinode项目的GitHub主页以及作者所写的博客地址如下: GitHub:Hadoop (YARN) Multinode Cluster with Docker
Hadoop集群安装详细步骤|Hadoop安装配置 文章分类:综合技术 Hadoop集群安装 首先我们统一一下定义,在这里所提到的Hadoop是指Hadoop Common,主要提供DFS(分布式文件存储)与Map/Reduce的核心功能。 Hadoop在windows下还未经过很好的测试,所以笔者推荐大家在linux(cent os 5.X)下安装使用。 准备安装Hadoop集群之前我们得先检验系统是否安装了如下的必备软件:ssh、rsync和Jdk1.6(因为Hadoop需要使用到Jdk中的编译工具,所以一般不直接使用Jre)。可以使用yum install rsync来安装rsync。一般来说ssh是默认安装到系统中的。Jdk1.6的安装方法这里就不多介绍了。 确保以上准备工作完了之后我们就开始安装Hadoop软件,假设我们用三台机器做Hadoop集群,分别是:192.168.1.111、192.168.1.112和192.168.1.113(下文简称111,112和113),且都使用root用户。 下面是在linux平台下安装Hadoop的过程: 在所有服务器的同一路径下都进行这几步,就完成了集群Hadoop软件的安装,是不是很简单?没错安装是很简单的,下面就是比较困难的工作了。 集群配置
根据Hadoop文档的描述“The Hadoop daemons are N ameNode/DataNode and JobTracker/TaskTracker.”可以看出Hadoop核心守护程序就是由 NameNode/DataNode 和JobTracker/TaskTracker这几个角色构成。 Hadoop的DFS需要确立NameNode与DataNode角色,一般NameNode会部署到一台单独的服务器上而不与DataNode共同同一机器。另外Map/Reduce服务也需要确立JobTracker和TaskTracker的角色,一般JobTracker与NameNode共用一台机器作为master,而TaskTracker与DataNode同属于slave。至于NameNode/DataNode和JobTracker/TaskTracker的概念这里就不多讲了,需要了解的可以参看相关文档。 在这里我们使用111作为NameNode与JobTracker,其它两台机器作为DataNode和TaskTracker,具体的配置如下: 环境的配置 在$HADOOP_HOME/conf/hadoop-env.sh中定义了Hadoop启动时需要的环境变量设置,其中我们至少需要配置JAVA_HOME(Jdk的路径)变量;另外我们一般还需要更改HADOOP_LOG_DIR(Hadoop的日志路径)这个变量,默认的设置是“export HADOOP_LOG_DIR=${HADOOP_HOME}/logs”,一般需要将其配置到一个磁盘空间比较大的目录下。 Hadoop核心程序配置 Hadoop 包括一组默认配置文件($HADOOP_HOME/src目录下的 core/core-default.xml, hdfs/hdfs-default.xml 和 mapred/mapred-default.xml),大家可以先好好看看并理解默认配置文件中的那些属性。虽然默认配置文件能让Hadoop核心程序顺利启动,但对于开发人员来说一般需要自己的来设置一些常规配置以满足开发和业务的需求,所以我们需要对默认配置文件的值进行覆盖,具体方法如下。 $HADOOP_HOME/conf/core-site.xml是Hadoop的核心配置文件,对应并覆盖core-default.xml中的配置项。我们一般在这个文件中增加如下配置: Core-site.xml代码 1.