
《统计分析与SPSS的应用(第五版)》(薛薇)
课后练习答案
第5章SPSS的参数检验
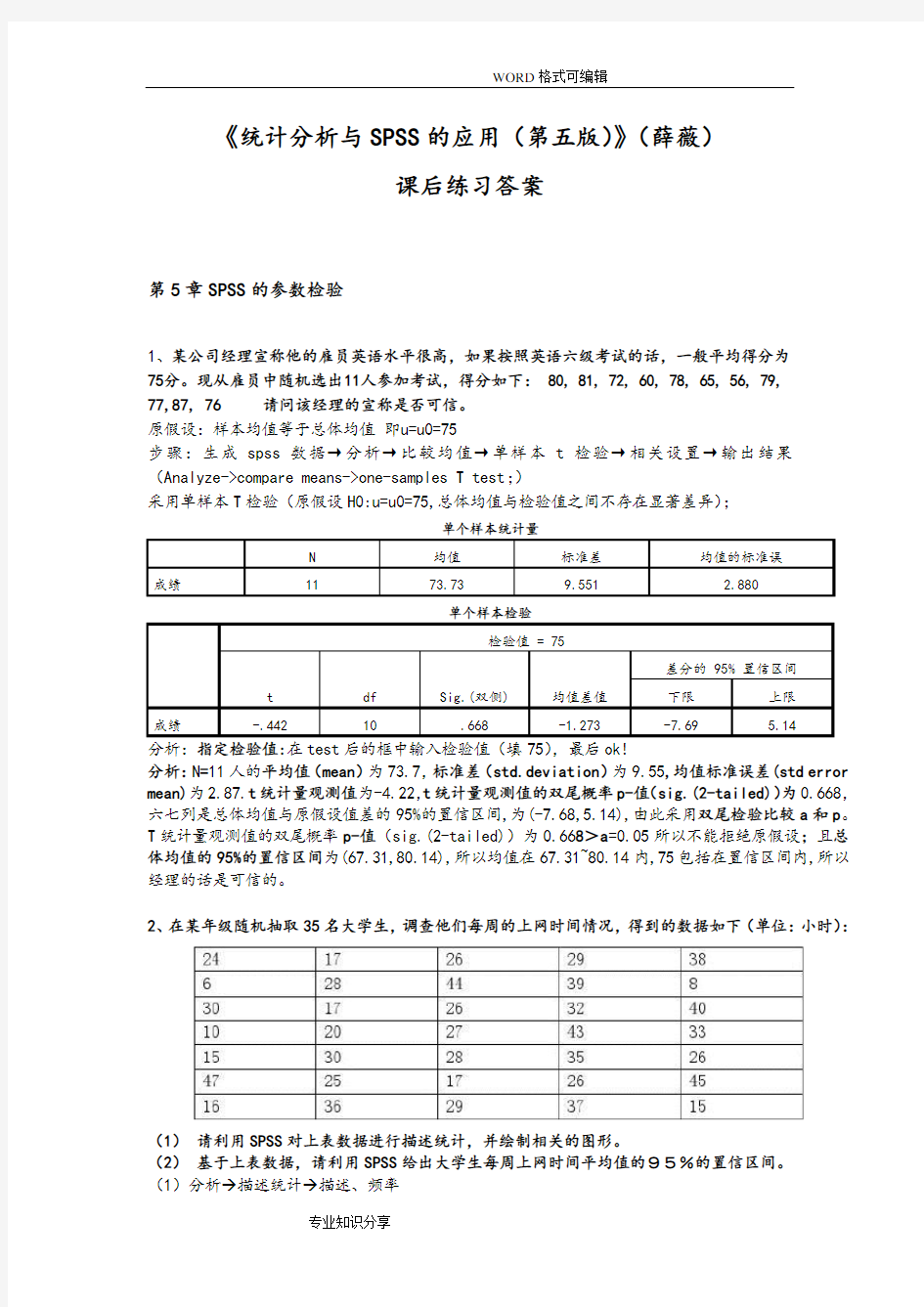
1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为
75分。现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75
步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;)
采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异);
单个样本统计量
N 均值标准差均值的标准误
成绩11 73.73 9.551 2.880
单个样本检验
检验值 = 75
t df Sig.(双侧) 均值差值差分的 95% 置信区间下限上限
成绩-.442 10 .668 -1.273 -7.69 5.14
分析:指定检验值:在test后的框中输入检验值(填75),最后ok!
分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):
(1)请利用SPSS对上表数据进行描述统计,并绘制相关的图形。
(2)基于上表数据,请利用SPSS给出大学生每周上网时间平均值的95%的置信区间。
(1)分析→描述统计→描述、频率
(2)分析→比较均值→单样本T检验
每周上网时间的样本平均值为27.5,标准差为10.7,总体均值95%的置信区间为23.8-31.2.
3、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。然而心理学家则倾向于认为提出事实的方式是有关系的。为验证哪种观点更站得住脚,调查者分别以下面两种不同的方式随机访问了足球球迷。
原假设:决策与提问方式无关,即u-u0=0
步骤:生成spss数据→分析→比较均值→两独立样本t检验→相关设置→输出结果
表5-3
组统计量
提问方式N 均值标准差均值的标准误决策丢票再买200 .46 .500 .035 丢钱再买183 .88 .326 .024
表5-4
独立样本检验
方差方程的 Levene
检验均值方程的 t 检验
F Sig. t df Sig.(双
侧)
均值差
值
标准误差
值
差分的 95% 置信
区间
下限上限
决策假设方差相等257.985 .000 -9.640 381 .000 -.420 .044 -.505 -.334 假设方差不相
等
-9.815 345.536 .000 -.420 .043 -.504 -.336
分析:由表5-3可以看出,提问方式不同所做的相同决策的平均比例是46%和88%,认为决策者的决策与提问方式有关。由表5-4看出,独立样本在0.05的检验值为0,小于0.05,故拒绝原假设,认为决策者对事实所作出的反应与提问方式有关,心理学家的观点更站得住脚。
分析:
从上表可以看出票丢仍买的人数比例为46%,钱丢仍买的人数比例为88%,两种方式的样本比例有较大差距。
1.两总体方差是否相等F检验:F的统计量的观察值为257.98,对应的
P值为0.00,;如果显著性水平为0.05,由于概率P值小于0.05,两种方式的方差有显著差异。
看假设方差不相等行的结果。2.两总体均值(比例)差的检验:.T统计量的观测值为-9.815,
对应的双尾概率为0.00,T统计量对应的概率P值<0.05,故推翻原假设,表明两总体比例有显
著差异.更倾向心理学家的说法。
4、一种植物只开兰花和白花。按照某权威建立的遗传模型,该植物杂交的后代有75%的几
率开兰花,25%的几率开白花。现从杂交种子中随机挑选200颗,种植后发现142株开了兰花,
请利用SPSS进行分析,说明这与遗传模型是否一致?
原假设:开蓝花的比例是75%,即u=u0=0.75
步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果
表5-5
单个样本统计量
N 均值标准差均值的标准误
开花种类200 1.29 .455 .032
表5-6
单个样本检验
检验值 = 0.75
t df Sig.(双侧) 均值差值差分的 95% 置信区间下限上限
开花种类16.788 199 .000 .540 .48 .60
分析:由于检验的结果sig值为0,小于0.05,故拒绝原假设,由于检验区间为(1.23,1.35),0.75不在此区间内,进一步说明原假设不成立,故认为与遗传模型不一致。
5、给幼鼠喂以不同的饲料,用以下两种方法设计实验:方式1:同一鼠喂不同的饲料所测得的体内钙留存量数据如下:
鼠号 1 2 3 4 5 6 7 8 9
饲料1 33.1 33.1 26.8 36.3 39.5 30.9 33.4 31.5 28.6
饲料2 36.7 28.8 35.1 35.2 43.8 25.7 36.5 37.9 28.7
方式2:甲组有12只喂饲料1,乙组有9只喂饲料2所测得的钙留存量数据如下:
甲组饲料1:29.7 26.7 28.9 31.1 31.1 26.8 26.3 39.5 30.9 33.4 33.1 28.6
乙组饲料2:28.7 28.3 29.3 32.2 31.1 30.0 36.2 36.8 30.0
请选用恰当方法对上述两种方式所获得的数据进行分析,研究不同饲料是否使幼鼠体内钙的留存量有显著不同。
原假设:不同饲料使幼鼠体内钙的留存量无显著不同。
方式1步骤:生成spss数据→分析→比较均值→配对样本t检验→相关设置→输出结果
表5-7
成对样本统计量
均值N 标准差均值的标准误对 1 饲料1钙存量32.578 9 3.8108 1.2703 饲料2钙存量34.267 9 5.5993 1.8664 表5-8
成对样本相关系数
N 相关系数Sig. 对 1 饲料1钙存量 & 饲料2钙存量9 .571 .108 表5-9
成对样本检验
成对差分
t df Sig.(双侧)
均值标准差均值的标准
误
差分的 95% 置信
区间
下限上限
对 1 饲料1钙存量 - 饲料2
钙存量
-1.6889 4.6367 1.5456 -5.2529 1.8752 -1.093 8 .306 方式2步骤:生成spss数据→分析→比较均值→独立样本t检验→相关设置→输出结果
表5-10
组统计量
饲料类型N 均值标准差均值的标准误
钙存量
dimensio n1
饲料1 12 30.508 3.6882 1.0647
饲料2 9 31.400 3.1257 1.0419
表5-11
独立样本检验
方差方程的 Levene
检验均值方程的 t 检验
F Sig. t df Sig.(双
侧)
均值差
值
标准误差
值
差分的 95% 置信
区间
下限上限
钙存量假设方差相
等
.059 .811 -.584 19 .566 -.8917 1.5268 -4.087
3
2.3040
假设方差不
相等
-.599 18.645 .557 -.8917 1.4897 -4.013
6
2.2303
分析:采用配对样本t检验法所得结果如表5-7,5-8,5-9所示,配对样本的分析结果可以看出两组的平均差是1.789在置信区间内(-5.2529,1.8752)同时sig值为0.153>0.05 不应该拒绝原假设。采用独立样本t检验法所得结果如表5-10,5-11所示,可以看出均值差为0.892在置信区间内 sig值为0.405,大于0.05 ,故不能拒绝原假设。所以,两种饲料使用后的钙存量无显著差异。
6、如果将第2章第9题的数据看作是来自总体的样本,试分析男生和女生的课程平均分是否存在显著差异?
原假设:男女生课程平均分无显著差异
步骤:分析→比较均值→单因素分析→因变量选择课程,因子选择性别进行→输出结果:表5-12
描述
poli
N 均值标准差标准误均值的 95% 置信区间
极小值极大值下限上限
female 30 78.8667 10.41793 1.90205 74.9765 82.7568 56.00 94.00 male 30 76.7667 18.73901 3.42126 69.7694 83.7639 .00 96.00 总数60 77.8167 15.06876 1.94537 73.9240 81.7093 .00 96.00 表5-13
ANOVA
poli
平方和df 均方 F 显著性组间66.150 1 66.150 .288 .594 组内13330.833 58 229.842
总数13396.983 59
分析:由表5-12和5-13可以看,出男生和女生成绩平均差为1.4021在置信区间内 sig值为
0.307,大于0.05,故不能拒绝原假设,即认为男生和女生的平均成绩没有显著差异
7、如果将第2章第9题的数据看作是来自总体的样本,试分析哪些课程的平均分差异不显著。
步骤:计算出各科的平均分:转换→计算变量→相关的设置
表5-14
组统计量
sex N 均值标准差均值的标准误average female 30 67.5208 9.08385 1.65848
male 30 68.9229 9.85179 1.79868
重新建立SPSS数据→分析→比较均值→单因素→进行方差齐性检验→选择Tukey方法进行检验。
利用配对样本T检验,逐对检验
8、以下是对促销人员进行培训前后的促销数据:试分析该培训是否产生了显著效果。
培训前440 500 580 460 490 480 600 590 430 510 320 470
培训后620 520 550 500 440 540 500 640 580 620 590 620
原假设:培训前后效果无显著差异
步骤:生成spss数据→分析→比较均值→配对样本t检验→相关设置→输出结果
表5-15
成对样本统计量
均值 N 标准差 均值的标准误 对 1
培训前 489.17 12 78.098 22.545 培训后
560.00
12
61.938
17.880
表5-16
成对样本相关系数
N 相关系数 Sig. 对 1
培训前 & 培训后
12
-.135
.675
表5-17
成对样本检验
成对差分
t
df Sig.(双侧) 均值
标准差
均值的标准
误 差分的 95% 置信区
间 下限
上限
对 1 培训前 - 培
训后
-70.833 106.041 30.611
-138.209 -3.458 -2.314
11
0.41
分析:由表5-15,5-16,5-17可以看出,培训前与培训后的均值差为70.83 ,由sig 值为0.041,小于0.05,故拒绝原假设,认为培训前后有显著差异 即培训产生了显著效果
成对样本检验
成对差分
t df Sig.(双侧) 均值
标准差
均值的标准
误 差分的 95% 置信区
间 下限 上限 对 1 培训前 - 培
训后
-70.833 106.041
30.611
-138.209
-3.458
-2.314
11
.041
社会统计学课程期末复习题 一、填空题(计算结果一般保留两位小数) 1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。 2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。 3、在回归分析中,各实际观测值y 与估计值y ?的离差平方和称为 剩余 变差。 4、平均增长速度= 平均发展速度 —1(或100%)。 5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。 6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。 7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。 8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为 100%7% A 100% 1.06%100%6% -=-=-产品单位成本计划超额完成程度 ;若某厂计划规定B 产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为 100%10% 100% 4.76%100%5% +=-=+B 产品产量计划超额完成程度 。 9、按照标志表现划分,学生的民族、性别、籍贯属于 品质 标志;学生的体重、年龄、成绩属于 数量 标志。 10、从内容上看,统计表由 主词 和 宾词 两个部分组成;从格式上看,统计表由 总标题 、 横行标题 、 纵栏标题 和 指标数值(或统计数值); 四个部分组成。 11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于 正 相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于 负 相关。 12、按指标所反映的数量性质不同划分,国民生产总值属于 数量 指标;单位成本属于 质量 指标。 13、如果相关系数r=0,则表明两个变量之间 不存在线性相关关系 。 二、判断题
《应用统计学》习题解答 第一章绪论 【1.1】指出下列变量的类型: (1)汽车销售量; (2)产品等级; (3)到某地出差乘坐的交通工具(汽车、轮船、飞机); (4)年龄; (5)性别; (6)对某种社会现象的看法(赞成、中立、反对)。 【解】(1)数值型变量 (2)顺序变量 (3)分类变量 (4)数值型变量 (5)分类变量 (6)顺序变量 【1.2】某机构从某大学抽取200个大学生推断该校大学生的月平均消费水平。 要求: (1)描述总体和样本。 (2)指出参数和统计量。 (3)这里涉及到的统计指标是什么? 【解】(1)总体:某大学所有的大学生 样本:从某大学抽取的200名大学生 (2)参数:某大学大学生的月平均消费水平 统计量:从某大学抽取的200名大学生的月平均消费水平 (3)200名大学生的总消费,平均消费水平 【1.3】下面是社会经济生活中常用的统计指标: ①轿车生产总量,②旅游收入,③经济发展速度,④人口出生率,⑤安置再就业人数,⑥全国第三产业发展速度,⑦城镇居民人均可支配收入,⑧恩格尔系数。 在这些指标中,哪些是数量指标,哪些是质量指标?如何区分质量指标与数量指标?【解】数量指标有:①、②、⑤ 质量指标有:③、④、⑥、⑦、⑧ 数量指标是说明事物的总规模、总水平或工作总量的指标,表现为绝对数的形式,并附有计量单位。而质量指标是说明总体相对规模、相对水平、工作质量和一般水平的统计指标,通常是两个有联系的统计指标对比的结果。 【1.4】某调查机构从某小区随机地抽取了50为居民作为样本进行调查,其中60%的居民对自己的居住环境表示满意,70%的居民回答他们的月收入在6000元以下,生活压力大。 回答以下问题: (1)这一研究的总体是什么? (2)月收入是分类变量、顺序变量还是数值型变量? (3)对居住环境的满意程度是什么变量? 【解】(1)这一研究的总体是某小区的所有居民。
第三章节:数据的图表展示 (1) 第四章节:数据的概括性度量 (15) 第六章节:统计量及其抽样分布 (26) 第七章节:参数估计....................................................... (28) 第八章节:假设检验........................................................ (38) 第九章节:列联分析........................................................ (41) 第十章节:方差分析........................................................ (43) 3.1 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。调查结果如下: B E C C A D C B A E D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C E E A B D D C A D B C C A E D C B C B C E D B C C B C 要求: (1)指出上面的数据属于什么类型。 顺序数据 (2)用Excel制作一张频数分布表。 用数据分析——直方图制作: 接收频率 E16 D17 C32 B21 A14 (3)绘制一张条形图,反映评价等级的分布。 用数据分析——直方图制作: (4)绘制评价等级的帕累托图。 逆序排序后,制作累计频数分布表:
第五章 习题 5—2 试用力法计算下列结构,并会出弯矩图。 解:1.判断超静定次数:n=1 2. 确定(选择)基本结构。 3.写出变形(位移)条件: (a ) 根据叠加原理,式(a )可写成 (a) 基本体系 M P 图 F P l 0 1=?
(b ) 4 .建立力法基本方程 将?11=δ11x 1代入(b)得 (c ) 5. 计算系数和常数项 EI l l l l EI 332)21(1311= ???=δ 6. 将d11、 ?11代入力法方程式(c ) 1111=?+?=?P 0 1111=?+P X δEI l F l F l l l F l l EI P P P P 485)2322212312221(131=???+????=?) (16 511 11↑=?- =P P F X δp M X M M +=1
7.作弯矩图 3FP P l /16 (b) 基本体系 M P 图 F P (l -a ) 16 32165l F l F l F M P P P A = -?=
解:1.判断超静定次数:n=1 2. 确定(选择)基本结构。 3.写出变形(位移)条件: (a ) 根据叠加原理,式(a )可写成 (b ) 4 .建立力法基本方程 将?11=δ11x 1代入(b)得 (c ) 5. 计算系数和常数项 1=?0 1111=?+?=?P 0 1111=?+P X δ
1 33)3 221(1)]332()(21)332()(21[13 2331211EI a EI a l a a a EI a l a a l l a a a l EI + -=???++??-?++??-?= δ2 2216)2()(]3 )(2)(213)()(21 [1EI a l a l F a l F a a l a l F a a l EI P P P P +--= -??-?+-??-?=? 6. 将d11、 ?11代入力法方程式(c ) 31 23 3 231)1(322a I I l a al l F X P --+-= 7.作弯矩图 (d )解: 超静定次数为2 选择基本结构如图 (1)所示力法 p M X M M +=1 1(a)
第1章绪论 1.什么是统计学怎样理解统计学与统计数据的关系 2.试举出日常生活或工作中统计数据及其规律性的例子。 3..一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。因此,他们开始检查供货商的集装箱,有问题的将其退回。最近的一个集装箱装的是2 440加仑的油漆罐。这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。装满的油漆罐应为4.536 kg。要求: (1)描述总体; (2)描述研究变量; (3)描述样本; (4)描述推断。 答:(1)总体:最近的一个集装箱内的全部油漆; (2)研究变量:装满的油漆罐的质量; (3)样本:最近的一个集装箱内的50罐油漆; (4)推断:50罐油漆的质量应为×50=226.8 kg。 4.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。这场战役因影视明星、运动员的参与以及消费者对品尝试验优先权的抱怨而颇具特色。假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝试验(即在品尝试验中,两个品牌不做外观标记),请每一名被测试者说出A品牌或B品牌中哪个口味更好。要求: (1)描述总体; (2)描述研究变量; (3)描述样本; (4)一描述推断。 答:(1)总体:市场上的“可口可乐”与“百事可乐” (2)研究变量:更好口味的品牌名称; (3)样本:1000名消费者品尝的两个品牌 (4)推断:两个品牌中哪个口味更好。 第2章统计数据的描述——练习题 ●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。调查结果如下: B E C C A D C B A E D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C D E A B D D C A D B C C A E D C B C B C E D B C C B C (1) 指出上面的数据属于什么类型; (2)用Excel制作一张频数分布表;
统计学各章练习题答案第1章绪论(略) 第2章统计数据的描述 2.1 (1)属于顺序数据。 (2)频数分布表如下: 服务质量等级评价的频数分布 服务质量等级家庭数(频率)频率% A1414 B2121 C3232 D1818 E1515 合计100100 (3)条形图(略) 2.2 (1)频数分布表如下: (2)某管理局下属40个企分组表 按销售收入分组(万元)企业数(个)频率(%) 先进企业良好企业一般企业落后企业11 11 9 9 27.5 27.5 22.5 22.5 合计40 100.0 2.3 频数分布表如下: 某百货公司日商品销售额分组表 按销售额分组(万元)频数(天)频率(%) 25~30 30~35 35~40 40~45 45~50 4 6 15 9 6 10.0 15.0 37.5 22.5 15.0 合计40 100.0 直方图(略)。
2.4 (1)排序略。 (2)频数分布表如下: 100只灯泡使用寿命非频数分布 按使用寿命分组(小时)灯泡个数(只)频率(%)650~660 2 2 660~670 5 5 670~680 6 6 680~690 14 14 690~700 26 26 700~710 18 18 710~720 13 13 720~730 10 10 730~740 3 3 740~750 3 3 合计100 100 直方图(略)。 2.5 (1)属于数值型数据。 (2)分组结果如下: 分组天数(天) -25~-20 6 -20~-15 8 -15~-10 10 -10~-5 13 -5~0 12 0~5 4 5~10 7 合计60 (3)直方图(略)。 2.6 (1)直方图(略)。 (2)自学考试人员年龄的分布为右偏。 2.7 (1
5-1 已知某承受均布荷载的矩形截面梁截面尺寸b ×h =250mm ×600mm (取a s =35mm ),采用C25混凝土,箍筋为HPB235钢筋。若已知剪力设计值V =150kN ,试采用Φ8双肢箍的箍筋间距s ? 『解』 (1)已知条件: a s =35mm 0h =h —a s =600—35=565mm SV A =1012mm 查附表1—2、2—3得: c β=1.0 , c f =11.9 N/2mm , t f =1.27 N/2mm ,yv f =210N/2mm (2)复合截面尺寸: w h =0h =565mm w h b =565 250=2.26<4 属一般梁。 00.25c c f bh β=0.25?1.0?11.9?250?565=420.2 kN>150 kN 截面满足要求。 (3)验算是否可构造配箍: 00.7 t f b h =0.7?1.27?250?565=125.6 kN<150 kN 应按计算配箍 (4)计算箍筋间距: V ≤00.7t f bh +01.25sv yv A f h s s ≤001.250.7sv yv t A f h s V f bh -=()3 1.25210101565150125.610???-?=613.2mm 查表5—2 ,取s=200 mm (5)验算最小配箍率: sv A bs =101250200?=0.202﹪>0.24t yv f f =0.24 1.27 210?=0.145﹪ 满足要求。
(6)绘配筋图: 5-2 图5-51所示的钢筋混凝土简支粱,集中荷载设计值F =120kN ,均布荷载设计值(包括梁自重)q=10kN/m 。选用C30混凝土,箍筋为HPB235钢筋。试选择该梁的箍筋(注:途中跨度为净跨度,l n =4000mm )。 『解』 (1)已知条件: a s =40mm 0h =h —a s =600—40=560mm 查附表1—2、2—3得: c β=1.0 , c f =14.3N/2mm , t f =1.43N/2mm ,yv f =210N/2mm (2)确定计算截面及剪力设计值: 对于简支梁,支座处剪力最大,选该截面为设计截面。 剪力设计值: V=12n ql +F=1 2?10?4+120=140 kN 120 140=85.7﹪>75﹪
第十二章 相关与回归分析 第一节 变量之间的相关关系 相关程度与方向·因果关系与对称关系 第二节 定类变量的相关 双变量交互分类(列联表)·削减误差比例(PRE )·λ系数与τ系数 第三节 定序变量的相关分析 同序对、异序对和同分对·Gamma 系数·肯德尔等级相关系数(τa 系数、τb 与τc 系数)·萨默斯系数(d 系数)·斯皮尔曼等级相关(ρ相关)·肯德尔和谐系数 第四节 定距变量的相关分析 相关表和相关图·积差系数的导出和计算·积差系数的性质 第五节 回归分析 线性回归·积差系数的PRE 性质·相关指数R 第六节 曲线相关与回归 可线性化的非线性函数·实例分析(二次曲线指数曲线) 一、填空 1.对于表现为因果关系的相关关系来说,自变量一般都是确定性变量,依变量则一般是( 随机性 )变量。 2.变量间的相关程度,可以用不知Y 与X 有关系时预测Y 的全部误差E 1,减去知道Y 与X 有关系时预测Y 的联系误差E 2,再将其化为比例来度量,这就是( 削减误差比例 )。 3.依据数理统计原理,在样本容量较大的情况下,可以作出以下两个假定:(1)实际观察值Y 围绕每个估计值c Y 是服从( );(2)分布中围绕每个可能的c Y 值的( )是相同的。 4.在数量上表现为现象依存关系的两个变量,通常称为自变量和因变量。自变量是作为( 变化根据 )的变量,因变量是随( 自变量 )的变化而发生相应变化的变量。 5.根据资料,分析现象之间是否存在相关关系,其表现形式或类型如何,并对具有相关关系的现象之间数量变化的议案关系进行测定,即建立一个相关的数学表达式,称为( 回归方程 ),并据以进行估计和预测。这种分析方法,通常又称为( 回归分析 )。 6.积差系数r 是( 协方差 )与X 和Y 的标准差的乘积之比。 二、单项选择 1.当x 按一定数额增加时,y 也近似地按一定数额随之增加,那么可以说x 与y 之间 存在( A )关系。 A 直线正相关 B 直线负相关 C 曲线正相关 D 曲线负相关
统计课后思考题答案 第一章思考题 1.1什么是统计学 统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。 1.2解释描述统计和推断统计 描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。 推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。 1.3统计学的类型和不同类型的特点 统计数据;按所采用的计量尺度不同分; (定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述; (定性数据)顺序数据:只能归于某一有序类别的非数字型数据。它也是有类别的,但这些类别是有序的。 (定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。 统计数据;按统计数据都收集方法分; 观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。 实验数据:在实验中控制实验对象而收集到的数据。 统计数据;按被描述的现象与实践的关系分; 截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。 时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。 1.4解释分类数据,顺序数据和数值型数据 答案同1.3 1.5举例说明总体,样本,参数,统计量,变量这几个概念 对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。 1.6变量的分类
统计学课后习题答案(袁卫、庞皓、曾五一、贾俊平)第三版 第1章绪论 1.什么是统计学?怎样理解统计学与统计数据的关系? 2.试举出日常生活或工作中统计数据及其规律性的例子。 3..一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。因此,他们开始检查供货商的集装箱,有问题的将其退回。最近的一个集装箱装的是2 440加仑的油漆罐。这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。装满的油漆罐应为4.536 kg。要求: (1)描述总体; (2)描述研究变量; (3)描述样本; (4)描述推断。 答:(1)总体:最近的一个集装箱内的全部油漆; (2)研究变量:装满的油漆罐的质量; (3)样本:最近的一个集装箱内的50罐油漆; (4)推断:50罐油漆的质量应为4.536×50=226.8 kg。 4.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。这场战役因影视明星、运动员的参与以及消费者对品尝试验优先权的抱怨而颇具特色。假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝试验(即在品尝试验中,两个品牌不做外观标记),请每一名被测试者说出A品牌或B品牌中哪个口味更好。要求: (1)描述总体; (2)描述研究变量; (3)描述样本; (4)一描述推断。 答:(1)总体:市场上的“可口可乐”与“百事可乐” (2)研究变量:更好口味的品牌名称; (3)样本:1000名消费者品尝的两个品牌 (4)推断:两个品牌中哪个口味更好。 第2章统计数据的描述——练习题 ●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。调查结果如下: B E C C A D C B A E D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C D E A B D D C A D B C C A E D C B C B C E D B C C B C (1) 指出上面的数据属于什么类型;
第二章 3.某公司下属40个销售点2012年的商品销售收入数据如下:单位:万元152 124 129 116 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 108 97 88 123 115 119 138 112 146 113 126 要求:(1)根据上面的数据进行适当分组,编制频数分布表,绘制直方图。 (2)制作茎叶图,并与直方图进行比较。 解:(1)频数分布表
或: (2)茎叶图
第三章 1. 已知下表资料: 试根据频数和频率资料,分别计算工人平均日产量。解:计算表
根据频数计算工人平均日产量:6870 34.35200 xf x f = = =∑∑(件) 根据频率计算工人平均日产量:34.35f x x f = = ∑∑ g (件) 结论:对同一资料,采用频数和频率资料计算的变量值的平均数是一致的。 2.某企业集团将其所属的生产同种产品的9个下属单位按其生产该产品平均单位成本的分组资料如下表: 试计算这9个企业的平均单位成本。 解:
这9个企业的平均单位成本=f x x f = ∑∑ =13.74(元) 3.某专业统计学考试成绩资料如下: 试计算众数、中位数。 解:众数的计算: 根据资料知众数在80~90这一组,故L=80,d=90-80=10,fm=20,fm-1=14,fm+1=9, ()() 1 11m m o m m m m f f M L d f f f f --+-=+ ?-+-
思考题与练习题 参考答案 【友情提示】请各位同学完成思考题与练习题后再对照参考答案。回答正确,值得肯定;回答错误,请找出原因更正,这样使用参考答案,能力会越来越高,智慧会越来越多。学而不思则罔,如果直接抄答案,对学习无益,危害甚大。想抄答案者,请三思而后行! 第一章绪论 思考题参考答案 1.不能,英军所有战机=英军被击毁的战机+英军返航的战机+英军没有弹孔的战机,因为英军被击毁的战机有的掉入海里、敌军占领区,或因堕毁而无形等,不能找回;没有弹孔的战机也不可能自己拿来射击后进行弹孔位置的调查。即便被击毁的战机找回或没有弹孔的战机自己拿来射击进行实验,也不能从多个弹孔中确认那个弹孔就是危险的。 2.问题:飞机上什么区域应该加强钢板?瓦尔德解决问题的思想:在她的飞机模型上逐个不重不漏地标示返航军机受敌军创伤的弹孔位置,找出几乎布满弹孔的区域;发现:没有弹孔区域就是军机的危险区域。 3.能,拯救与发展自己的参考路径为:①找出自己的优点,②明确自己大学阶段的最佳目标,③拟出一个发扬自己优点,实现自己大学阶段最佳目标的可行计划。 练习题参考答案 一、填空题 1.调查。
2.探索、调查、发现。 3、目的。 二、简答题 1.瓦尔德;把剩下少数几个没有弹孔的区域加强钢板。 2.统计学解决实际问题的基本思路,即基本步骤就是:①提出与统计有关的实际问题;②建立有效的指标体系;③收集数据;④选用或创造有效的统计方法整理、显示所收集数据的特征;⑤根据所收集数据的特征、结合定性、定量的知识作出合理推断;⑥根据合理推断给出更好决策的建议。不解决问题时,重复第②-⑥步。 3.在结合实质性学科的过程中,统计学就是能发现客观世界规律,更好决策,改变世界与培养相应领域领袖的一门学科。 三、案例分析题 1.总体:我班所有学生;单位:我班每个学生;样本:我班部分学生;品质标志:姓名;数量标志:每个学生课程的成绩;指标:全班学生课程的平均成绩 ;指标体系:上学期全班同学学习的科目 ;统计量:我班部分同学课程的平均成绩 ;定性数据:姓名 ;定量数据: 课程成绩 ;离散型变量:学习课程数;连续性变量:学生的学习时间;确定性变量:全班学生课程的平均成绩;随机变量:我班部分同学课程的平均成绩,每个同学进入教室的时间;横截面数据:我班学生月门课程的出勤率;时间序列数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;面板数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;选用描述统计。 2.(1)总体:广州市大学生;单位:广州市的每个大学生。(2)如果调查中了解的就是价格高低,为定序尺度;如果调查中了解的就是商品丰富、价格合适、节约时间,为定类尺度。(3)广州市大学生在网上购物的平均花费。(4)就是用统计量作为参数的估计。(5)推断统计。 3.(1)10。(2)6。(3)定类尺度:汽车名称,燃油类型;定序尺度:车型大小;定距尺度:引擎的汽缸数;定比尺度:市区驾车的油耗,公路驾车的油耗。(4)定性变量:汽车名称,车型大小,燃油类型;定量变量:引擎的汽缸数,市区驾车的油耗,公路驾车的油耗。(5)40%;(6)30%。 第二章收集数据 思考题参考答案
第五章企业所得税、个人所得税法律制度 一、单项选择题 1、张先生为一名工程师,2012年1月为一企业做产品设计,当月预付报酬30000元,3月设计完成又取得50000元,该工程师共纳个人所得税为()元。 A、16000 B、18600 C、22000 D、25000 2、2012年10月,某中国居民因出租自有的一套检测设备,取得租金收入为5000元。设备原值10万元。根据规定,其应纳个人所得税为()。(不考虑其他税费) A、400元 B、420元 C、800元 D、1000元 3、郝某系某大型企业职工,2012年12月取得国债利息收入2000元,从所在企业取得企业集资利息收入1000元。本月郝某利息收入应缴纳的个人所得税为()元。 A、50 B、0 C、200 D、600 4、根据最新税法的相关规定,个人所得税工资、薪金的计算适用()。 A、适用3%-45%的超额累进税率 B、适用5%-35%的超额累进税率 C、20%的比例税率 D、适用5%-45%的超率累进税率 5、下列所得中,“次”的使用错误的是()。 A、为房地产企业设计图纸的收入以每次提供劳务取得的收入作为一次 B、同一作品再版取得的所得,按照一次征收计征个人所得税 C、租赁房屋以一个月的收入作为一次 D、偶然所得,以每次收入作为一次 6、张某2012年12月取得全年一次性奖金30000元,当月工资1800元,张某取得的全年一次性奖金应缴纳个人所得税()。 A、3600元 B、4345元 C、2725元 D、5245元 7、某个人独资企业2012年的销售收入为5000万元,实际支出的业务招待费为40万元,根据个人所得税法律的规定,在计算应纳税所得额时允许扣除的业务招待费是()万元。 A、18 B、24 C、25 D、30 8、公司职工取得的用于购买企业国有股权的劳动分红,适用的税目为()。 A、工资薪金所得 B、特许权使用费所得 C、个体工商户的生产经营所得 D、利息股息红利所得 9、个人所得税的纳税义务人不包括()。 A、国有独资公司 B、个人独资企业投资者 C、港澳台同胞 D、股份有限公司总经理 10、关于个人独资企业和合伙企业征收个人所得税的管理办法,下列表述正确的是() A、投资者兴办的企业中含有合伙性质的,投资者应向经常居住地主管税务机关申报纳税,办理汇算清缴
社会统计学复习题有答 案 集团标准化工作小组 #Q8QGGQT-GX8G08Q8-GNQGJ8-MHHGN#
社会统计学课程期末复习题 一、填空题(计算结果一般保留两位小数) 1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。 2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。 3、在回归分析中,各实际观测值y 与估计值y ?的离差平方和称为 剩余 变差。 4、平均增长速度= 平均发展速度 —1(或100%)。 5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。 6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。 7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。 8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为 100%7% A 100% 1.06%100%6% -=- =-产品单位成本计划超额完成程度 ;若某厂计划规定B 产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为 100%10% 100% 4.76%100%5% += -=+B 产品产量计划超额完成程度 。
9、按照标志表现划分,学生的民族、性别、籍贯属于品质标志;学生的体重、年龄、成绩属于数量标志。 10、从内容上看,统计表由主词和宾词两个部分组成;从格式上看,统计表由 总标题、横行标题、纵栏标题和指标数值(或统计数值); 四个部分组成。 11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于正相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于负相关。 12、按指标所反映的数量性质不同划分,国民生产总值属于数量指标;单位成本属于质量指标。 13、如果相关系数r=0,则表明两个变量之间不存在线性相关关系。 二、判断题 1、在季节变动分析中,若季节比率大于100%,说明现象处在淡季;若季节比率小于100%,说明现象处在旺季。(×;答案提示:在季节变动分析中,若季节比率大于100%,说明现象处在旺季;若季节比率小于100%,说明现象处在淡季。 ) 2、工业产值属于离散变量;设备数量属于连续变量。(×;答案提示:工业产值属于连续变量;设备数量属于离散变量) 3、中位数与众数不容易受到原始数据中极值的影响。(√;) 4、有意识地选择十个具有代表性的城市调查居民消费情况,这种调查方式属于典型调查。(√)
附录:教材各章习题答案 第1章统计与统计数据 1.1(1)数值型数据;(2)分类数据;(3)数值型数据;(4)顺序数据;(5) 分类数据。 1.2(1)总体是“该城市所有的职工家庭”,样本是“抽取的2000个职工家 庭”;(2)城市所有职工家庭的年人均收入,抽取的“2000个家庭计算出的年人均收入。 1.3(1)所有IT从业者;(2)数值型变量;(3)分类变量;(4)观察数据。 1.4(1)总体是“所有的网上购物者”;(2)分类变量;(3)所有的网上购物 者的月平均花费;(4)统计量;(5)推断统计方法。 1.5(略)。 1.6(略)。 第2章数据的图表展示 2.1(1)属于顺序数据。 (2)频数分布表如下 (4)帕累托图(略)。 2.2(1)频数分布表如下
2.5(1)排序略。 (2)频数分布表如下 (4)茎叶图如下
2.6 (3)食品重量的分布基本上是对称的。 2.7 2.8(1)属于数值型数据。
2.9 (1)直方图(略)。 (2)自学考试人员年龄的分布为右偏。 比A 班分散, 且平均成绩较A 班低。 2.11 (略)。 2.12 (略)。 2.13 (略)。 2.14 (略)。 2.15 箱线图如下:(特征请读者自己分析) 第3章 数据的概括性度量 3.1 (1)100=M ;10=e M ;6.9=x 。
(2)5.5=L Q ;12=U Q 。 (3)2.4=s 。 (4)左偏分布。 3.2 (1) 19 0=M ; 23 =e M 。 (2)5.5=L Q ;12=U Q 。 (3)24=x ;65.6=s 。 (4)08.1=SK ;77.0=K 。 (5)略。 3.3 (1)略。 (2)7=x ;71.0=s 。 (3)102.01=v ;274.02=v 。 (4)选方法一,因为离散程度小。 3.4 (1)x =274.1(万元);M e=272.5 。 (2)Q L =260.25;Q U =291.25。 (3)17.21=s (万元)。 3.5 甲企业平均成本=19.41(元),乙企业平均成本=18.29(元);原 因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。 3.6 (1)x =426.67(万元);48.116=s (万元)。 (2)203.0=SK ;688.0-=K 。 3.7 (1)(2)两位调查人员所得到的平均身高和标准差应该差不多相 同,因为均值和标准差的大小基本上不受样本大小的影响。 (3)具有较大样本的调查人员有更大的机会取到最高或最低者,因为样本越大,变化的围就可能越大。 3.8 (1)女生的体重差异大,因为女生其中的离散系数为0.1大于男 生体重的离散系数0.08。 (2) 男生:x =27.27(磅),27.2=s (磅); 女生:x =22.73(磅),27.2=s (磅); (3)68%; (4)95%。 3.9 通过计算标准化值来判断,1=A z ,5.0=B z ,说明在A项测试中 该应试者比平均分数高 出1个标准差,而在B 项测试中只高出平均分数0.5个标准差,由于A 项测试的标准化值高于B 项测试,所以A 项测试比较理想。 3.10 通过标准化值来判断,各天的标准化值如下表 日期 周一 周二 周三 周四 周五 周六 周日 标准化值Z 3 -0.6 -0.2 0.4 -1.8 -2.2 0 周一和周六两天失去了控制。
第五章练习题答案 5.1网络互连有何实际意义?进行网络互连时,有哪些共同的问题需要解决? 答:网络互连使得相互连接的网络中的计算机之间可以进行通信,也就是说从功能上和 逻辑上看,这些相互连接的计算机网络组成了一个大型的计算机网络。网络互连可以使处于 不同地理位置的计算机进行通信,方便了信息交流,促成了当今的信息世界。 需要解决的问题有:不同的寻址方案;不同的最大分组长度;不同的网络介入机制;不 同的超时控制;不同的差错恢复方法;不同的状态报告方法;不同的路由选择技术;不同的 用户接入控制;不同的服务(面向连接服务和无连接服务);不同的管理与控制方式;等等。 注:网络互连使不同结构的网络、不同类型的机器之间互相连通,实现更大范围和更广 泛意义上的资源共享。 5.2转发器、网桥和路由器都有何区别? 答:1)转发器、网桥、路由器、和网关所在的层次不同。转发器是物理层的中继系统。网桥是数据链路层的中继系统。路由器是网络层的中继系统。在网络层以上的中继系统为网关。 2)当中继系统是转发器或网桥时,一般并不称之为网络互连,因为仍然是一个网络。路由器其实是一台专用计算机,用来在互连网中进行路由选择。一般讨论的互连网都是指用 路由器进行互连的互连网络。 5.3试简单说明IP、ARR RARP口ICMP协议的作用。 答:IP :网际协议,TCP/IP体系中两个最重要的协议之一,IP使互连起来的许多计算 机网络能够进行通信。无连接的数据报传输?数据报路由。 ARP(地址解析协议)实现地址转换,将IP地址映射成物理地址。RARP(逆向地址解析协议)将物理地址映射成IP地址。 ICMP: Internet 控制消息协议,进行差错控制和传输控制,减少分组的丢失。 注:ICMP协议帮助主机完成某些网络参数测试,允许主机或路由器报告差错和提供有关异常情况报告,但它没有办法减少分组丢失,这是高层协议应该完成的事情。IP协议只 是尽最大可能交付,至于交付是否成功,它自己无法控制。 5.4分类IP地址共分几类?各如何表示?单播分类IP地址如何使用? 答:IP地址共分5类,分类情况如下所示: A 类0 Netid Hostid (24 比特) B 类10 Netid Hostid (16 比特) C 类110 Netid Hostid (8 比特) D类1110组播地址 E类11110保留为今后使用 IP地址是32位地址,其中分为netid (网络号),和hostid (主机号)。根据IP地址第一个字
第十二章 相关与回归分析 第一节 变量之间的相关关系 相关程度与方向·因果关系与对称关系 第二节 定类变量的相关 双变量交互分类(列联表)·削减误差比例(PRE)·λ系数与τ系数 第三节 定序变量的相关分析 同序对、异序对与同分对·Gamma 系数·肯德尔等级相关系数(τa 系数、τb 与τc 系数)·萨默斯系数(d 系数)·斯皮尔曼等级相关(ρ相关)·肯德尔与谐系数 第四节 定距变量的相关分析 相关表与相关图·积差系数的导出与计算·积差系数的性质 第五节 回归分析 线性回归·积差系数的PRE 性质·相关指数R 第六节 曲线相关与回归 可线性化的非线性函数·实例分析(二次曲线指数曲线) 一、填空 1.对于表现为因果关系的相关关系来说,自变量一般都就是确定性变量,依变量则一般就是( 随机性 )变量。 2.变量间的相关程度,可以用不知Y 与X 有关系时预测Y 的全部误差E 1,减去知道Y 与X 有关系时预测Y 的联系误差E 2,再将其化为比例来度量,这就就是( 削减误差比例 )。 3.依据数理统计原理,在样本容量较大的情况下,可以作出以下两个假定:(1)实际观察值Y 围绕每个估计值c Y 就是服从( );(2)分布中围绕每个可能的c Y 值的( )就是相同的。 4.在数量上表现为现象依存关系的两个变量,通常称为自变量与因变量。自变量就是作为( 变化根据 )的变量,因变量就是随( 自变量 )的变化而发生相应变化的变量。 5.根据资料,分析现象之间就是否存在相关关系,其表现形式或类型如何,并对具有相关关系的现象之间数量变化的议案关系进行测定,即建立一个相关的数学表达式,称为( 回归方程 ),并据以进行估计与预测。这种分析方法,通常又称为( 回归分析 )。 6.积差系数r 就是( 协方差 )与X 与Y 的标准差的乘积之比。 二、单项选择 1.当x 按一定数额增加时,y 也近似地按一定数额随之增加,那么可以说x 与y 之间 存在( A )关系。 A 直线正相关 B 直线负相关 C 曲线正相关 D 曲线负相关 2.评价直线相关关系的密切程度,当r 在0、5~0、8之间时,表示( C )。 A 无相关 B 低度相关 C 中等相关 D 高度相关 3.相关分析与回归分析相辅相成,又各有特点,下面正确的描述有( D )。 A 在相关分析中,相关的两变量都不就是随机的;
统计学课后习题答案 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】
第四章 统计描述 【】某企业生产铝合金钢,计划年产量40万吨,实际年产量45万吨;计划降低成本5%,实际降低成本8%;计划劳动生产率提高8%,实际提高10%。试分别计算产量、成本、劳动生产率的计划完成程度。 【解】产量的计划完成程度=%5.112100%40 45 100%=?=?计划产量实际产量 即产量超额完成%。 成本的计划完成程=84%.96100%5%-18% -1100%-1-1≈?=?计划降低百分比实际降低百分比 即成本超额完成%。 劳动生产率计划完= 85%.101100%8%110% 1100%11≈?++=?++计划提高百分比实际提高百分比 即劳动生产率超额完成%。 【】某煤矿可采储量为200亿吨,计划在1991~1995年五年中开采全部储量的%, 试计算该煤矿原煤开采量五年计划完成程度及提前完成任务的时间。 【解】本题采用累计法: (1)该煤矿原煤开采量五年计划完成=100% ?数 计划期间计划规定累计数 计划期间实际完成累计 = 75%.1261021025357 4 =?? 即:该煤矿原煤开采量的五年计划超额完成%。 (2)将1991年的实际开采量一直加到1995年上半年的实际开采量,结果为2000万吨,此时恰好等于五年的计划开采量,所以可知,提前半年完成计划。 【】我国1991年和1994年工业总产值资料如下表:
要求: (1)计算我国1991年和1994年轻工业总产值占工业总产值的比重,填入表中; (2)1991年、1994年轻工业与重工业之间是什么比例(用系数表示)? (3)假如工业总产值1994年计划比1991年增长45%,实际比计划多增长百分之几? 1991年轻工业与重工业之间的比例=96.01.144479 .13800≈; 1994年轻工业与重工业之间的比例=73.04.296826 .21670≈ (3) %37.25 1%) 451(2824851353 ≈-+ 即,94年实际比计划增长%。 【】某乡三个村2000年小麦播种面积与亩产量资料如下表: 要求:(1)填上表中所缺数字; (2)用播种面积作权数,计算三个村小麦平均亩产量; (3)用比重作权数,计算三个村小麦平均亩产量。
《统计学概论》第八章课后练习答案 一、思考题 1.什么是相关系数?它与函数关系有什么不同?P237- P238 2.什么是正相关、负相关、无线性相关?试举例说明。P238- P239 3.相关系数r的意义是什么?如何根据相关系数来判定变量之间的相关系数?P245 4.简述等级相关系数的含义及其作用?P250 5.配合回归直线方程有什么要求?回归方程中参数a、b的经济含义是什么?P256 6.回归系数b与相关系数r之间有何关系?P258 7.回归分析与相关分析有什么联系与区别?P254 8.什么是估计标准误差?这个指标有什么作用?P261 9.估计标准误差与相关系数的关系如何?P258-P264 10.解释判定系数的意义和作用。P261 二、单项选择题 1.从变量之间相互关系的方向来看,相关关系可以分为()。A.正相关和负相关B.直线关系与曲线关系 C.单相关和复相关D.完全相关和不完全相关 2.相关分析和回归分析相比较,对变量的要求是不同的。回归分析中要求()。
A.因变量是随机的,自变量是给定的B.两个变量都是随机的 C.两个变量都不是随机的D.以上三个答案都不对 3.如果变量x与变量y之间的相关系数为-1,这说明两个变量之间是()。 A.低度相关关系B.完全相关关系 C.高度相关关系D.完全不相关 4.初学打字时练习的次数越多,出现错误的量就越少,这里“练习次数”与“错误量”之间的相关关系为()。 A.正相关B.高相关 C.负相关D.低相关 5.假设两变量呈线性关系,且两变量均为顺序变量,那么表现两变量相关关系时应选用()。 A.简单相关系数r B.等级相关系数r s C.回归系数b D.估计标准误差S yx 6.变量之间的相关程度越低,则相关系数的数值()。A.越大B.越接近0 C.越接近-1 D.越接近1 7.下列各组中,两个变量之间的相关程度最高的是()。A.商品销售额和商品销售量的相关系数是0.9