
课程代码:3112161 成绩:
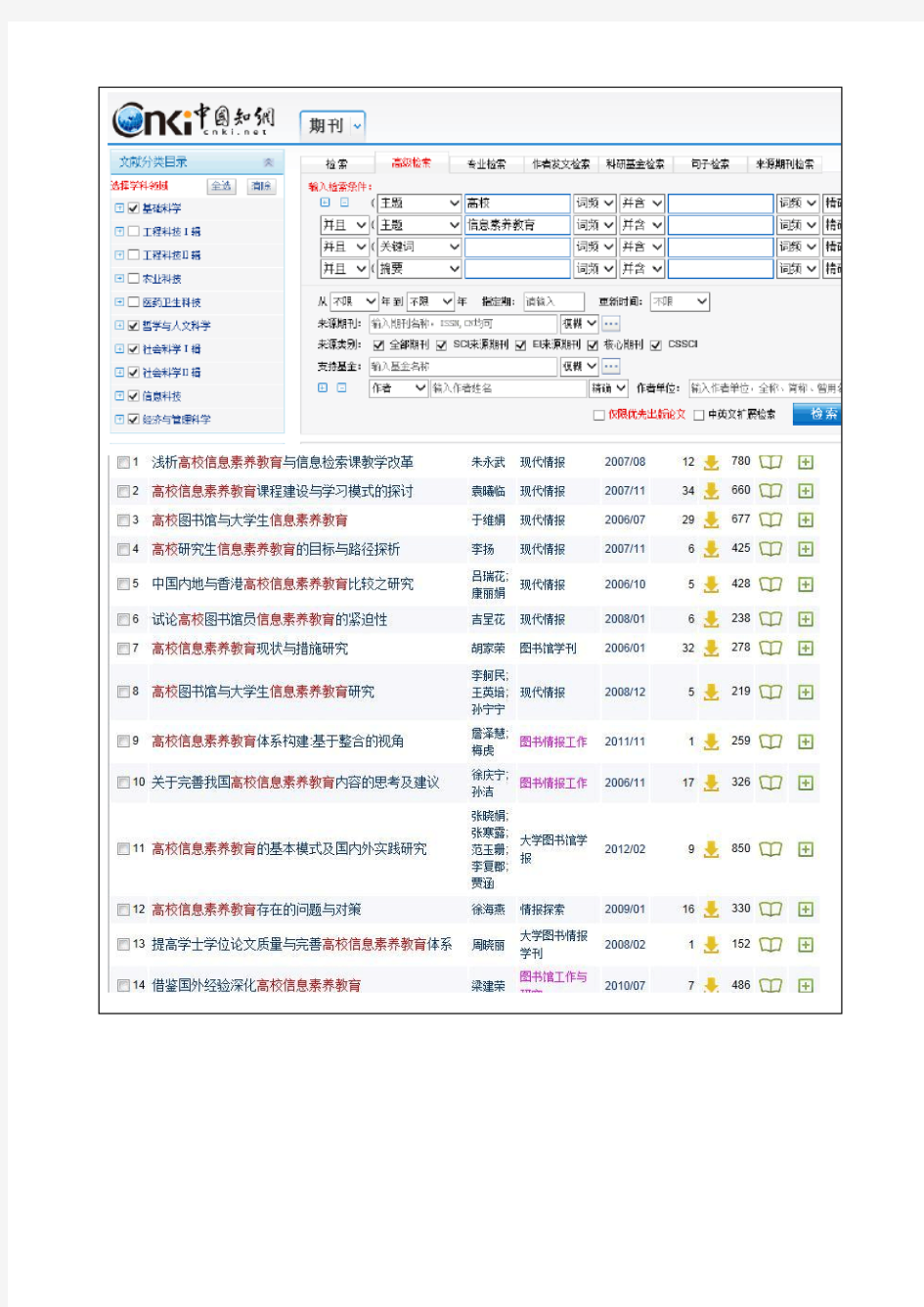
5 利用CNKI期刊论文数据库:选择与自己所学专业相关的一种中文核心期刊,并在其中选择专业文献报道的某一方面,介绍该方面近两年的报道情况(同班同专业不得重复);工商管理专业:
研究报道情况:普遍报道了工商管理专业人才的培养与教学的研究。
Google搜索引擎检索性能评价 2012/12/9
Google搜索引擎检索性能评价 摘要: 网络信息和信息检索技术的发展推动了搜索引擎实践的发展,使得搜索引擎评价研究成为信息检索领域的研究热点之一。本文以搜索引擎检索结果的相关性为核心指标,对Google搜索引擎的检索性能进行了评价,旨在帮助用户在利用搜索引擎时选取恰当的检索策略。 关键词:搜索引擎信息检索评价相关性 Abstract: The development of Internet information and technologies of information retrieval accelerates the development of search engine. It has made the study of evaluation of search engine to be one of the popular issues in the field of information retrieval. This paper takes relevance of retrieval results as index to evaluate the performance of Google. The finding can be used to assist users in formulating an appropriate search strategy. Keywords:search engine; information retrieval; evaluation; relevance 前言 研究背景: 根据2012年7月由中国互联网络信息中心(CNNIC)公布的中国互联网络发展状况统计报告显示截至2012年6月底,中国网民数量达到5.38亿,互联网普及率为39.9%。伴随着如此巨大规模的网络用户而来的是海量的互联网信息,面对这些信息,用户们不免迷失于此,网络信息资源的无限增长与用户有限的效用信息需求之间的矛盾便日益凸显[1]。因此用户利用搜索引擎辅助,以尽可能得到自己所需信息也就是很自然的了。据上述报告,截至2012年6月底,搜索引擎用户规模达到4.29亿,较2011年底增长2121万人,半年增长率为5.2%;在网民中的渗透率为79.7%,使用比例与2011年6月、12月基本持平,是仅次于即时通信的第二大网络应用。但是,即使使用搜索引擎,也难免不能获取所需信息,研究表明,公认最好的搜索引擎,其检索结果中的相关信息也不会超过50%。[2]所以如何使搜索引擎用户能够获取所需信息,在信息研究领域便显得尤为重要。而这则一定离不开搜索引擎的评价研究,通过调查搜索引擎的检索性能并进行评价研究,对搜索引擎的改进将起到很大帮助。 研究目的 从上个世纪90年代初到现在,短短的20余年间搜素引擎的发展发生了巨大的变化,不断地有新的搜素引擎出现,同时也有一些搜素引擎退出了历史舞台。因此搜索引擎市场千变万化,要对它们全部进行评价研究还不现实。经过综合考虑搜素引擎的流行度与所占市场份额,笔者选取Google作为典型案例加以分析。Google当前以83.33%的搜索量占据搜素引擎
word 查找的通配符高级篇 我们在进行查找、替换文档内容时,再配合通配符这一有利武器,将使我们很好的完成Wo rd查找替换操作,从而提高工作效率。下面我们将以实际列子配合讲解Word查找替换中通配符的使用。 1、“>”通配符 该通配符代表查找以××结尾的目标对象。用来指定要查找对象的结尾字符串,比如说要是记不清所要查找对象的完整内容,但记得要查找对象的结尾字符串是某个特定的字符,就可以用“>”来将这个特定字符表达出来,这样word程序就自动去查找以这个特定字符结尾的相关内容了。 例如:将文件中以“en”结尾的所有目标对象找出来。 方法是:按CTRL+F,点击“高级”,勾选“使用通配符”。然后在查找框中输入“en>”,就可以查找到“ten”、“pen”、“men”等等。 注:在结合“使用通配符”进行查找替换时,都必须先勾选“使用通配符”,才能正确查找替换。 2、“<” 通配符 它与“>”正好是相对的一组通配符,所以,我们可以用它来查找以某字母开头的对象。 3、“?” 通配符 该通配符是用来代表任意单个字符,当大家不清楚查找目标中指定位置的内容是什么的时候,就可以用“?”来代替,几个“?”就代表几个未知字符。 例一:比方说,要是大家在查找对话框中输入“?家”的话,word程序就可以找到类似“大家”、“国家”、“全家”之类的目标内容。 例二:输入“???家”的话,就能找到“保卫国家”之类的内容。 例三:输入“?土”的话,Word查找工具就可以找到类似“黑土”、“黄土”之类的目标内容。
例四:输入“??土”的话,就能找到“五色土”之类的内容。 4、“ *” 通配符 “*”可以用来代替任意多个字符。 实例:比如我们输入“*国”,就可以找到“大国”、“法兰西国”、“中华人民共和国”等字符串内容。 5、“ @” 通配符 该通配符可以用来查找字符中包含一个以上的前一字符。 实例:例如,如果输入“me@n”的话,Word查找工具就可以找到“men”、“meen”之类的字符内容了。 6、“ []” 通配符 表示查找中括号指定的字符中的任意一个。 例一:输入“th[iu]g”,就可查找到“thigh”和“thug”。 例二:输入“[高矮]个”的话,Word查找工具就可以找到“高个”、“矮个”等内容。 例三:输入“[学硕博]士”,查找到的将会是学士、硕士、博士。 例四:输入“[大中小]学”可以查找到“大学”、“中学”或“小学”,但不查找“求学”、“开学”等。 7、“ [!]” 通配符 用来查找指定字符以外的任意字符。 例一:输入“m[!a]st”,用来查找“mist”和“most”不会查找“mast”。 例二:输入“[!a]n”,查到的将会是除an以外的所有可能组合如:in、on等。 8、“[!-]” 通配符 这个通配符的作用就是用来排除指定范围内的任意单个字符。
第14章索引与查询性能 索引中文词典解释根据一定需要,把书刊中的主要内容或各种题名摘录下来,标明出处、页码,按一定次序分条排列,以供人查阅的资料。如果一本书籍没有目录,要想快速检索出想要查询的资料,就只有逐页查找,这种方式效率极其底下。数据库中的索引也类似于书籍目录相同的功能。 索引是有效使用数据库系统的基础,当表中的数据量较小时,使用索引和不使用索引带来的性能差异不大;但当表中的数据量极大时,就一定需要索引的辅助才能有效的存取数据。 一般索引建立的是否适当,是决定性能好坏的关键。并由于更改索引结构不会影响数据字段的定义,也就是前端程序可以照常存取,因此当上线后的应用程序使用效率比较低的时候,可以尝试建立或优化所以,从而提高应用软件的性能。 SCMDB示例数据库中表的数据量较小,无法演示使用索引带来的效率提升。本章采用微软示例数据库AdventureWorks作为演示数据库。希望通过以下的测试,给读者一个感性认识。 【演示】查询表SalesOrderDetail中销售订单编号在48077-48080范围内的订单编号、产品ID以及订单数量。 【分析】表SalesOrderDetail的记录数为121317,其中Sales前缀为架构名称。通过参数set statistics time on开启统计时间。图14-1所示为在表SalesOrderDetail使用聚集索引后的演示效果,时间执行时间仅仅为1毫秒。图14-2所示为删除聚集索引后的运行时间为27毫秒。表中的数据量越大,使用索引与不使用索引带来的性能上的差异性越大。 图14-1 使用索引进行查询 图14-2 没有使用索引进行查询 14.1 索引的分类 SQL Server中索引分为两种类型:聚集索引(Clustered Index)和非聚集索引(Non Clustered Index),也可称为聚簇索引和非聚簇索引。
这里面讲到的方法对于经常进行word编辑的人员来说,非常实用。功能强大。当文档的段落间有两个换行符时,可以通过查找:“^p^p”的方法替换为一个换行符:“^p”。在这里,^p就是word中的换行符。 Word中查找/替换通配符和代码 一、使用通配符搜索 要查找和替换的项目的通配符 如果要查找: 任意单个字符 键入? 例如,s?t可查找“sat”和“set”。 任意字符串 键入* 例如,s*d可查找“sad”和“started”。 单词的开头 键入< 例如,<(inter)查找“interesting”和“intercept”,但不查找“splintered”。 单词的结尾 键入> 例如,(in)>查找“in”和“within”,但不查找“interesting”。 指定字符之一 键入[ ]
例如,w[io]n查找“win”和“won”。 指定范围内任意单个字符 键入[-] 例如,[r-t]ight查找“right”和“sight”。必须用升序来表示该范围。 中括号内指定字符范围以外的任意单个字符 键入[!x-z] 例如,t[!a-m]ck查找“tock”和“tuck”,但不查找“tack”和“tick”。 n个重复的前一字符或表达式 键入{n} 例如,fe{2}d查找“feed”,但不查找“fed”。 至少n个前一字符或表达式 键入{n,} 例如,fe{1,}d查找“fed”和“feed”。 n到m个前一字符或表达式 键入{n,m} 例如,10{1,3}查找“10”、“100”和“1000”。 一个以上的前一字符或表达式 键入@ 例如,lo@t查找“lot”和“loot”。 注释
百度搜索引擎查询外部链接命令 百度搜索引擎是没有查询外部链接的命令,只能使用“domain”命令来查询含有当前网址的结果页面。有的朋友会说查询外链可以使用雅虎搜索引擎就可以了,不过大家应该都知道,相关域的数量和质量对网站权重的提升也有作用,而domain命令返回的结果是否是真实的相关域数量呢? 曾经看到过很多网站收录一百万,查询其网站相关域的时候会发现数量远远超过一百万,这是什么情况呢?DOMAIN查询出来的结果中只是显示了包含有您查询的网址的页面,不管这个页面来自哪里,这样查询出来的结果中肯定会包含很多自己的页面,甚至是所有site查询出来的所有结果都在domain查询中出来了,因为域名也是被搜索的对象。而“-”的命令是减去的意思,意思很容易理解,但如何更好的利用才是关键,就比如刚刚的情况,想要得到网站在百度的相关域的准确数据可以使用这个组合命令,命令解释为查询当前域名在百度的相关域的数量并减去当前域名在百度收录的数量,那么得到的结果自然就是当前域名的百度的相关域数量的准确值了。 还有一个问题给大家解释一下,那就是很多站长在DOMAIN自己网站的时候会发现本来查询数量为几千,但是翻页后却发现只有几百个了,这种情况其实很好解释,那就是你在发外链的时候网址局限性比较大,很多查询结果都源自固定的几个或十几个网站,百度为了节省资源而省略了一个网站下的多个查询结果,所以一般在结果的最后一页都有提示:为了提供最相关的结果,我们省略了一些内容相似的条目,点击这里可以看到所有搜索结果。再细心点的网友还发现即使点了那个链接后再来看,翻到后面也不一定会显示跟原来一样的结果,甚至当你翻到最后一页的时候你算下页数计算出总数后跟百度提供的数据还是对不上,我的理解是这样的,因为百度数据库非常大,可能其中一样数据都被分在很多服务器上,所以查询时不同的服务器给出的结果会对不上。
Word和Excel中查找替换通配符使用方法详解 通配符是一些特殊的语句,主要作用是用来模糊搜索和替换使用。在Word、Excel中使用通配符可以查找和替换文字、格式、段落标记、回车符、分页符(分页符:上一页结束以及下一页开始的位置。可以使用通配符和代码来扩展搜索。 Word、Excel中清除使用通配符复选框 任意单个字符^? 任意数字:^# 任意英文字母:^$ 段落标记:^p 手动换行符:^l 图形:^g or ^1 1/4长划线:^+ 长划线:^j 短划线:^q 制表符:^t 脱字号:^ 分栏符:^v 分节符:^b 省略号:^n 全角省略号:^i 无宽非分隔符:^z 无宽可选分隔符:^x 不间断空格:^s 不间断连字符:^~ ?段落符号:^% §分节符:^ 脚注标记:^f or ^2 可选连字符:^- 空白区域:^w 手动分页符:^m 尾注标记:^e 域:^d Unicode 字符:^Unnnn 全角空格:^u8195 半角空格:^32 or ^u8194 批注:^a or ^5 手动换行符↓:^l 查找的容:^& 剪贴板容:^c 省略号:^i 全角省略号:^j 制表符:^t 长划线:^+ 1/4长划线( —):^q
短划线( –):^= 脱字号:^^ 手动分页符:^m or ^12 可选连字符(_):^- 不间断连字符(-):^~ 不间断空格:^s 无宽非分隔符:^z 无宽可选分隔符:^x 分栏符:^n §分节符:^% ?段落符号:^v Word、Excel中勾选使用通配符复选框任意单个字符:? 任意字符串:* 任意数字(单个):[0-9] 任意英文字母:[a-zA-Z] 指定围外任意单个字符:[!x-z] 指定围任意单个字符:[ - ] 段落标记:^13 手动换行符:^l or ^11 图形:^g 1/4长划线:^q 长划线:^+ 短划线:^= 制表符:^t 脱字号:^^ 分栏符:^n or ^14 分节符/分页符:^m 省略号:^i 全角省略号:^j 无宽非分隔符:^z 无宽可选分隔符:^x 不间断空格:^s 不间断连字符:^~ 表达式:( ) 单词结尾:< 单词开头:> 1个以上前一字符或表达式: n 个前一字符或表达式:{ n } n个以上前一字符或表达式:{ n, } n 到m 个前一字符或表达式:{ n,m } 所有小写英文字母:[a-z] 所有大写英文字母:[A-Z] 所有西文字符:[^1-^127]
网上搜索的方法和技巧 我们已经知道网上有多种多样的教育资源,从技术上讲,它们是在Internet的多种服务功能的支持下实现的,包含WWW、e-mail、Usenet、FTP、BBS等,其中发展最快,也是最为流行的是WWW。因此我们着重介绍WWW信息的检索方法。 据1999年底的统计,网上大约有15亿个网页,并且以每天增加190万个网页的速度在增长,到2002年已达到80亿个网页。要想在这么大的一个资源库中查找一条具体 的信息,犹如大海捞针一般。因此,有人发出这样的感叹:"我们淹没在数据资料的的海 洋中,却又在忍受着知识的饥渴"。 现在出现了许多种在网上查找信息的方法。这些方法可以分为两类:一类是有既定目标的查找,一类是没有目标的查找,而后者往往是指一种网上"冲浪"游戏。在具有既定目标的情况下,如果已有信息线索,可以用浏览器航行的办法寻找信息对象;如果信息线索未定,则需要利用搜索工具首先获得信息线索。 搜索工具又有传统工具和现代工具之分。传统工具是在索引数据库中进行主题树/目录检索或KWDSEs(关键词搜索引擎)进行建设而索引库的建设是一个极其繁重的任 务,现在已经可以利用"机器人"程序来帮忙,它们通过跟踪最新建立的HTML网页的URL对整个网络进行浏览,可以在网上从这一个网站爬到另一个网站,并记录下它们访问过的网页的各自特征(这种只有十来年历史的搜索技术就被称为传统工具了,你觉得 奇怪吗?)。而现代搜索工具是利用智能代理来工作,它们不是对整个网络进行索引,而 是在接到一个新任务时就出发,去搜索网上资源并提取有价值的信息。因此,智能代理 是利用神经网络技术进行搜索,它试图去发现自然语言与样本网页的模式及它们之间的 相互关系,这些将与新近发现的网上资源相匹配,最后以一串网址的形式供用户访问。 图2_3_10显示了网上信息检索工具的选择方法。
WORD通配符全攻略 (1) 通配符主要有 (2) word 查找的通配符高级篇 (7) Word查找替换高级用法五例 (9) Word查找栏代码?通配符一览表 (10) Word查找栏代码?通配符示例 (12) Word替换栏代码?通配符一览表 (12) Word查找与替换.ASCII字符集代码 (13) Word中通配符用法全攻略! (14) WORD通配符全攻略 作者:逍遥赵2006-01-17 11:44分类:默认分类标签: 什么是WORD通配符?通配符是配合WORD查找、替换文档内容的有利武器。打开WORD,按CTRL+F,点击“高级”,勾选“使用通配符”,再点击“特殊字符”,就看到以下通配符: 1、“>”:使用该通配符的话,可以用来指定要查找对象的结尾字符串,比方说要是大家记不清所要查找对象的完整内容了,但记得要查找对象的结尾字符串是某个特定的字符,此时大家就可以用“>”来将这个特定字符表达出来,这样word程序就自动去查找以这个特定字符结尾的相关内容了。 实例一:输入“en>”的话,word程序就会在当前文档中查找到以“en”结尾的所有目标对象,例如可能找到“ten”、“pen”、“men”等等。 实例二:在查找对话框中输入“up>”的话,Word查找工具就会在当前文档中查找到以“up”结尾的所有目标对象,例如会找到“setup”、“cup”等等对象。 实例三:如果查找的是汉字目标,我们要注意的是,查找的汉字应该是结尾字词(后面应该有标点符号分隔)。 2、“<”:它与“>”正好是相对的一组通配符,所以,我们可以用它来查找以某字母开头的对象。 实例:输入“ 使用通配符搜索 使用通配符查找和替换 例如,可用星号 (*) 通配符搜索字符串(使用“s*d”将找到“sad”和“started”)。 1.单击“编辑”菜单中的“查找”或“替换”命令。 2.如果看不到“使用通配符”复选框,请单击“高级”按钮。 3.选中“使用通配符”复选框。 4.在“查找内容”框中输入通配符,请执行下列操作之一: o若要从列表中选择通配符,请单击“特殊字符”按钮,再单击所需通配符,然后在“查找内容”框键入要查找的其他文字。 o在“查找内容”框中直接键入通配符。 5.如果要替换该项,请在“替换为”框键入替换内容。 6.单击“查找下一处”、“替换”或者“全部替换”按钮。 按 Esc 可取消正在执行的搜索。 注释 ?选中“使用通配符”复选框后,Word 只查找与指定文本精确匹配的文本(请注意,“区分大小写”和“全字匹配”复选框会变灰而不可用,表明这些选项已自动选中,您不能关闭这些选项)。 ?要查找已被定义为通配符的字符,请在该字符前键入反斜扛 (\),例如,要查找问号,可键入“\?”。 要查找和替换的项目的通配符 如果要查找: 任意单个字符 键入? 例如,s?t 可查找“sat”和“set”。 任意字符串 键入* 例如,s*d 可查找“sad”和“started”。 单词的开头 键入< 例如,<(inter) 查找“interesting”和“intercept”,但不查找 “splintered”。 单词的结尾 键入> 例如,(in)> 查找“in”和“within”,但不查找“interesting”。 指定字符之一 键入[ ] 例如,w[io]n 查找“win”和“won”。 指定范围内任意单个字符 键入[-] 例如,[r-t]ight 查找“right”和“sight”。必须用升序来表示该范围。中括号内指定字符范围以外的任意单个字符 键入[!x-z] 例如,t[!a-m]ck 查找“tock”和“tuck”,但不查找“tack”和 “tick”。 n 个重复的前一字符或表达式 键入{n} 例如,fe{2}d 查找“feed”,但不查找“fed”。 至少 n 个前一字符或表达式 键入{n,} 例如,fe{1,}d 查找“fed”和“feed”。 n 到 m 个前一字符或表达式 键入{n,m} 例如,10{1,3} 查找“10”、“100”和“1000”。 一个以上的前一字符或表达式 键入@ 例如,lo@t 查找“lot”和“loot”。 注释 化学结构式检索 第一部分:学习数据库 Dialog系统可以进行结构式检索的数据库: Beilstein Facts (File 390) Derwent Chemistry Resource (File 355) IMS Patent Focus (File 447,947) IMS R&D Focus (File 445,955) Index Chemicus (File 302) Pharmaprojects (Files 128,928) Prous Science Drug Data Report (File 452) Prous Science Drugs of the Future (File 453) 390: Beilstein Facts 389: (ONTAP Beilstein Facts) Beilstein 贝尔斯坦化学文摘(390,391,393号文档) 是世界上最大的关于有机化学事实的数据库,数据来源于175种期刊,已收录9百多万个化合物和9百多万个反应。作为最基本的化学文献数据库,Beilstein能帮助有机化学研究人员形成新思路、设计合成路径(包括起始原料和中间体)、确定生物活性和物理性质、了解外界环境对化合物的影响,等等。主要数据的索引分为3部分:其中390 Beilstein Facts即化学物质部分收集了结构信息及相关的事实和参考文献,包括化学、物理和生物活性数据;391 Beilstein Reactions反应部分提供化学物质制备的详细资料,帮助研究人员用反应式检索特定的反应路径;393 Beilstein Abstracts文献部分包括引用、文献标题和文摘,化学物质部分和反应部分的条目与文献部分有超链接。1771至今,季度更新。 355: Derwent Chemistry Resource Derwent Chemistry Resource 德温特化学资源(355号文档) 可对Derwent世界专利索引(Derwent World Patent Index,DWPI)和Derwent药学文档(Derwent Drug File,DDF)中的化学内容进行结构检索。DWPI含有全球40多个专利发布权威机构的一千一百万篇专利文献,并且每年新增一百五十万。本库提供专利中的化学信息,包括化学结构、分子式、化学名称等信息,通过它可以直接用化学结构绘图检索DWPI和DDF中的专利信息,并掌握相关的化学信息。每周更新2次。 445: IMS R & D Focus IMS R&D Focus ,IMS医药研发聚焦(445号文档) 该库侧重企业和健康研究机构新药的研发过程。提供23300种处于R&D阶段的药物,9400种表现活跃的药物,4800种生物制品,关注3000家业内公司及国际药品市场从研发到商业等一系列进展。每条记录包括药品从研发到推向市场的全部信息。信息来源于IMS HEALTH 公司出版的R&D Focus和R&D Focus Drugs News。1991至今,每周更新。 447: IMS Patent Focus IMS Patent Focus (IMS药物专利数据库) 法律检索——方法和技巧 一、学习法律检索的重要性 第一,无论你在律师行业中是什么身份处于何等地位,是初出茅庐还是经验老道,法律检索都贯穿你的执业生涯全程。这里的法律检索,是一个相对广义的概念,不仅仅包括在数据库里找具体法条。在座的每一位,可能都曾经有过这样的时候:资深律师或者合伙人交给你一沓材料,或者你刚刚听客户滔滔不绝讲了三个小时还拿到一大堆文件,你看来看去就是发现不了其中需要研究的地方,哪些是会引起争议的点。而当你们成长为资深律师或者合伙人,本身仍然要参与案件或者项目,也需要自己去进行法律研究。在合伙人与助理磨合还没有非常默契的时候,在合伙人对助理的工作能力、检索能力、认真程度尚不能完全确信的时候,他势必要亲自验证或者说核查你搜索到的是否就已经穷尽了所有正确的答案。所以,我说法律检索是做律师一辈子的工作内容之一。 第二,无论你擅长的是什么业务类型,是做诉讼还是非诉讼业务,法律检索都是必备技能之一。以诉讼业务为例,无非就是“接案子”和“做案子”。大家都有个最基本的常识,那就是法院判案要“以事实为基础,以法律为准绳”。这里的事实和法律,都需要我们通过法律检索或者说法律研究来协助法官完成,以使得判决更加有利于你这一方。在这我来说说法律检索在接案过程中的重要作用。在梳理事实现状与了解客户要求的基础上,只有做好法律检索才能制定出更加完备的策略报告,才能提供更加充实、可行、准确的诉讼方案,甚至于通过完整的法律检索得到的答案决定你主观是否要接这个案子。我曾经听过大成所张健律师“诉讼策略报告如何写作”的讲座,他谈到“在你不具备经验的时候,你只能靠逻辑”。我想这里还可以补充一点,即便是“经验”也是可以通过法律检索去获得的,比如说某种案情的案件原告如何起诉被告如何答辩,你完全可以通过在数据库中搜索同类型案件裁判文书来学习、观摩与模仿。前阵子听说律师代理案件的政府指导价要取消了,律师的价值将会由市场决定,那么你如何才能脱颖而出或者说不被远远甩在后面,让客户认可你的价值,就需要你能拿出比别人更多更好的方案,取决于你发现了哪些问题以及就这些问题你找到了什么样的答案。 第三,无论社会发展到什么程度,变幻莫测的交易模式、产品以及专业术语怎样层出不穷,法律检索仍然是每位律师必须掌握的基本功之一。我每天都会关注行业新闻,几乎几天就会出现一个新的产品或者交易架构,但是我认为从根本上讲,暂时还没有脱离民商法的基本法律概念或者说基本的法律关系。在座的助理们来自不同的合伙人团队,大家平时接触的业务也都不尽相同。我就举两个金融方面的例子来印证我刚才的观点。第一个某银行计划操作一个“信贷资产证券化项目”,考虑选用“债权转让+权利完善措施”的模式,需要律师帮他们做一个完整的法律论证。第二个互联网金融方面的争议解决,李某通过 检索效果的评价指标 克兰弗登(Cranfield)在分析用户基本要求的基础上,提出了6项检索系统性能的评价指标,它们是收录范围、查全率、查准率、响应时间、用户负担和输出形式。 (1)查全率 查全率(recall factor)是指检出的相关文献量与检索系统中相关文献总量的百分比,是衡量信息检索系统检出相关文献能力的尺度,可用下式表示: 查全率=检出的相关文献总量/系统中的相关文献总量×100%即R=b/a * 100% 设R为查全率,P查准率,M表示漏检率、N表示误检率,m为检出文献总量,a为检索系统中的相关文献总量,b为检出的相关文献总量。 例如,要利用某个检索系统查某课题。假设在该系统数据库中共有相关文献为40篇,而只检索出来30篇,那么查全率就等于75%。 (2)查准率 查准率(Pertinency factor)是指检出的相关文献量与检出文献总量的百分比,是衡量信息检索系统精确度的尺度,可用下式表示: 查准率=检出的相关文献总量/检出文献总量×100% 即P=b/m*100% 例如,如果检出的文献总篇数为50篇,经审查确定其中与课题相关的文献只有40篇,另外10篇与该课题无关。那么,这次检索的查准率就等于80%。 检索效果2 检索系统的响应时间是指从发出检索提问到获得检索结果平均消耗的时间。主要包括: ①用户请求到服务器的传送时间;②服务器处理请求的时间;②服务器的答复到用户端的传送时间;④用户端计算机处理服务器传来信息的时间。 提高检索效果的措施 1."提高用户信息素质 2."选择好的检索工具和系统 3."优选检索词 4."合理调整查全率和查准率 不同的检索课题对文献信息的需求不同,用户应根据课题的需要,适当调整查全率和查准率,优化检索策略,以达到最佳检索效果。 (1)提高查全率 提高查全率时,调整检索式的主要方法有: ①降低检索词的专指度,从词表或检出文献中选一些上位词或相关词。 ②减少AND组配,如删除某个不甚重要的概念组面(检索词)。 ③多用OR组配,如选同义词、近义词等并以“OR”方式加入到检索式中。 ④族性检索,如采用分类号检索。 ⑤截词检索。 ⑥放宽限制运算,如取消字段限制符,调松位置算符等。 (2)提高查准率 提高查准率时,调整检索式的主要方法有: ①提高检索词的专指度,增加或采用下位词和专指性较强的检索词。 word扔掉键盘的神技能 W or d查找栏代码·通配符一览表 清除使用通配符复选框勾选使用通配符复选框 代码or通配序号 特殊字符代码特殊字符 符 1任意单个字符^?任意单个字符? 2任意数字^#任意数字(单个)[0-9] 3任意英文字母^$任意英文字母[a-zA-Z] 4段落标记^p段落标记^13 5手动换行符^l手动换行符^l or ^11 6图形^g or ^1图形^g 71/4长划线^+1/4长划线^q 8长划线^j长划线^+ 9短划线^q短划线^= 10制表符^t制表符^t 11脱字号^脱字号^^ 12分栏符^v分栏符^n or ^14 13分节符^b分节符/分页符^m 14省略号^n省略号^i 15全角省略号^i全角省略号^j 16无宽非分隔符^z无宽非分隔符^z 17 无宽可选分隔 符^x 无宽可选分隔符 ^x 18不间断空格^s不间断空格^s 19不间断连字符^~不间断连字符^~ 20?段落符号^%表达式( ) 21§分节符^单词结尾< 22脚注标记^f or ^2单词开头> 23可选连字符^-任意字符串* 24空白区域 ^w 指定范围外任意单个字 符 [!x-z] 25手动分页符 ^m 指定范围内任意单个字 符 [ - ] 26尾注标记 ^e 1个以上前一字符或表 达式 @ 27域^d n 个前一字符或表达式{ n } 28Unicode 字符 ^Unnnn n个以上前一字符或表 达式 { n, } 29全角空格 ^u8195 n 到 m 个前一字符或表 达式 { n,m } 30 半角空格^32 or ^u81 94所有小写英文字母 [a-z] 31批注^a or ^5所有大写英文字母[A-Z] Find and Replace using wildcards This tutorial pre-supposes that the user will have some basic experience of Word's 'replace' function. The secret of using wildcard searches is to identify the unique string of text that you wish to find. Wildcards are combined with regular text and formatting options to represent the characters or sequences of characters in that string. Because different combinations of characters can be represented by a variety of wildcard combinations, there is often more than one way of identifying a particular string of text within a document. How you choose to represent that group of characters is therefore a matter of individual preference; and the context of the text within the document will to a great extent dictate the most suitable combination to use on a particular occasion. Start by identifying the string you wish to replace and then pop up the replace function (CTRL+H) or select Advanced Find from the Editing group on the Home tab of the ribbon (see below); or in earlier Word versions Edit > Replace. Google 学术搜索及其检索技巧 1 Google 学术搜索简介 2 Google 学术搜索的功能 3 Google 学术搜索检索技巧及其实例 3.1 关键词检索 3.2 作者检索 3.3 组合检索 3.4 高级检索 4 与其他检索系统的对比分析 5 结论 6 现场交流 1 Google 学术搜索简介 Google Scholar (https://www.doczj.com/doc/f65956834.html,/)Google学术搜索, 是网络搜索领域的领头羊Google公司于2004 年11 月18 日推出 的一项新的搜索服务,它能帮助用户查找包括期刊论文、学位论文、书籍、预印本、摘要和科技报告等在内的学术文献,内容涉 及诸多学科,并且经过了业内专家的评审,具有一定的权威性。 它以“站在巨人的肩膀上” (Stand on the shoulders of giants) 为服务理念, 重点提供医学、物理、经济、计算机等学科文献的 检索, 还通过知识链接功能提供了文章的引用次数及链接, 人们 可以利用它查找文献的被引用情况, 这是目前为止除 web of science 外的另一个可以检索英文文献被引情况的检索工具。 2006 年1 月11 日Google推出了Google 中文学术搜索Beta 版(https://www.doczj.com/doc/f65956834.html,/intl/zh-CN/ ),用于搜索网上的中文学术文献,同时它还具有检索中文文献被引情况的功能,为科学研究与学术共同体学术评价工作的开展提供了新的工具和途径。笔者通过对Google 学术搜索的分析、使用,以及与其它商业性跨库检索系统的比较,对Google 学术搜索的检索功能进行了评价,以便大家更好的使用。 实验:搜索引擎性能评价 小组成员:黄婷苏亮肖方定山 一、实验目的: 依据MAP,P@10,MRR等评价指标对各个搜索引擎(百度、搜狗、必应)的查询性能进行评测,对搜索引擎满足不同信息需求的情况加以比较。 二、实验方案: 1.构建查询样例集合: (1)构建查询样例集合 规模:100个查询 热门程度:冷门/热门 类型:导航类/信息类/事务类(2:5:3) (2)根据个人经验,撰写每个查询样例的信息需求内容 2.构建Pooling: (1)抓取各个搜索引擎对步骤一查询词的查询结果 抓取的搜索引擎:五个中文搜索引擎(百度、搜狗、必应) 抓取范围:查询结果的前30位结果 注:pooling method的大概意思是查询结果去重 3.构造标准答案集合: (1)根据步骤1中撰写好的信息需求,对Pooling里的结果进行标注,标注为“答案”和“非答案”两类即可 4.查询性能评价: (1)根据标注结果,依据MAP,P@10,MRR等评价指标对各个搜索引擎的查询性能进行评价 (2)对搜索引擎满足不同信息需求的情况加以比较 5.扩展内容: (1)可以尝试对搜索引擎处引擎处理非中文查询、有错别字查询等情况的不同策略进行分析、比较 三、实验结果及分析: 根据实验结果及目的,详细分析实验结果。 1.实验结果: 百度:https://https://www.doczj.com/doc/f65956834.html, 搜狗:https://https://www.doczj.com/doc/f65956834.html, Bing国内版:https://https://www.doczj.com/doc/f65956834.html, 综合比较: 2.结果分析: (1)导航类搜索词 对于导航类搜索关键词,RR一般用作评价导航类的查询需求,用于表示用户在知道目标前需要浏览的结果数目,可以看到,搜狗事务类的MRR指标偏高,可以发现,当用户想要搜索的信息为已知资源,主页,资源等信息时,搜索引擎可能会更倾向于返回给用户一些官方的主页信息,以使用户能够尽快找到目标,对于导航类信息的其他指标,相差也不大,但是P@10的指标值差异有些明显,搜狗和百度的P@10值是较好的,而必应的结果则稍差,查看原始搜索结果标记, 课程设计III 设计说明书 网页中超链检测程序设计 学生姓名 学号 班级 成绩 指导教师 数学与计算机科学学院 2014 年 3 月 7 日 课程设计任务书 2013 —2014 学年第一学期 课程设计名称:课程设计三课程设计 课程设计题目:网页中超链检测程序设计 完成期限:自2014 年9 月2日至2014 年9 月13日共 2 周 设计内容: 1. 任务说明 设计一个程序,给一个指定URL,分析该URL所在域中所有网页中的超链接情况:本域内链接、外域链接、页内链接、死链(链接目标不存在)等情况。 2.要求 (1)了解网络爬虫的架构和工作原理,实现网络爬虫的基本框架; (2)开发平台采用JDK 1.60 eclipse集成开发环境。 (3)要求按时按量完成所规定的实验内容; (4)界面设计要求通用性强、具有实用性; 指导教师:教研室负责人: 课程设计评阅 摘要 设计了一个基于宽度优先的爬虫程序,本程序采用java编程语言,开发平台采用JDK 1.60 eclipse集成开发环境。可实现检测网页中超链接,是一种自动搜集互联网信息的程序,可以搜集某一站点的URL,并将搜集到的URL存入文件。 关键词:网络爬虫;JAVA;超链接 目录 1 绪论 (1) 2 网络爬虫 (2) 3 对URL的认识 (4) 4 通过URL抓取网页 (5) 5 算法分析及程序实现 (7) 6 总结 (14) 1 绪论 随着网络的迅速发展,万维网成为大量信息的载体,万维网已经成为人们获取信息的重要渠道,如何高效地提取并利用这些信息成为一个巨大的挑战。搜索引擎(Search Engine),例如传统的通过搜索引擎百度,Yahoo和Google等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。但是,这些通用性搜索引擎也存在着一定的局限性,如: (1)统一的返回不能满足不同用户的检索需求。 (2)搜索引擎提高覆盖面的目标与膨胀的网络信息之间的矛盾日益加深。 (3)搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。 为了解决上述问题,定向抓取相关网页资源的主题爬虫应运而生。主题爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。 本文通过JAVA语言实现了一个基于宽度优先遍历算法的爬虫程序。通过实现此爬虫程序可以定点搜集某一站点的URL,可以分析出网页中的超链接情况:本域内链接、外域链接、页内链接、死链(链接目标不存在)等情况 检索效果的评价指标 克兰弗登( Cranfield)在分析用户基本要求的基础上,提出了 6 项检索系统 性能的评价指标,它们是收录范围、查全率、查准率、响应时间、用户负担和 输出形式。 ( 1)查全率 查全率 (recall factor)是指检出的相关文献量与检索系统中相关文献总量 的百分比,是衡量信息检索系统检出相关文献能力的尺度,可用下式表示: 查全率 =检出的相关文献总量 / 系统中的相关文献总量×100% 即 R=b/a * 100% 设 R 为查全率, P 查准率, M 表示漏检率、 N 表示误检率, m 为检出文献总量, a 为检索系统中的相关文献总量, b 为检出的相关文献总量。 例如,要利用某个检索系统查某课题。假设在该系统数据库中共有相关 文献为 40 篇,而只检索出来 30 篇,那么查全率就等于 75%。 ( 2)查准率 查准率 (Pertinency factor)是指检出的相关文献量与检出文献总量的百 分比,是衡量信息检索系统精确度的尺度,可用下式表示: 查准率 =检出的相关文献总量 / 检出文献总量×100% 即 P=b/m*100% 例如,如果检出的文献总篇数为 50 篇,经审查确定其中与课题相关的文 献只有 40 篇,另外 10 篇与该课题无关。那么,这次检索的查准率就等于80%。 检索效果 2 检索系统的响应时间是指从发出检索提问到获得检索结果平均消耗的时 间。主要包括: ① 用户请求到服务器的传送时间;② 服务器处理请求的时间;② 服务器的答复到用户端的传送时间;④用户端计算机处理服务器传来信息的时间。 提高检索效果的措施 1."提高用户信息素质 2."选择好的检索工具和系统 3."优选检索词 4."合理调整查全率和查准率 不同的检索课题对文献信息的需求不同,用户应根据课题的需要,适当调 整查全率和查准率,优化检索策略,以达到最佳检索效果。 (1)提高查全率 提高查全率时,调整检索式的主要方法有: ① 降低检索词的专指度,从词表或检出文献中选一些上位词或相关词。 ②减少 AND 组配,如删除某个不甚重要的概念组面(检索词)。 ③多用 OR组配,如选同义词、近义词等并以“ OR方”式加入到检索式中。 ④ 族性检索,如采用分类号检索。 ⑤ 截词检索。 ⑥ 放宽限制运算,如取消字段限制符,调松位置算符等。 (2)提高查准率 提高查准率时,调整检索式的主要方法有: ① 提高检索词的专指度,增加或采用下位词和专指性较强的检索词。使用通配符搜索
化学结构式检索
法律检索方法和技巧
检索效果的评价指标
扔掉键盘的神技能---word通配符和查找符
使用通配符在word中实现高级查找和替换
学术检索技巧
搜索引擎性能评价报告
超链接检测
检索效果的评价指标.doc
相关主题
文本预览