
第十二章 简介定性资料的统计分析
本章不是全面的介绍这方面的理论、方法和应用,而是初步反映一下这方面的主要内容,目的是展示进一步可学的知识,以便更好地解决实际问题。
§12.1 定性变量数量化
前面几章所介绍的各种统计方法,主要是研究与定量变量(或称间隔尺度变量)有关的问题,但在实际应用中,往往不可避免地要涉及到定性变量(或称名义尺度变量),例如人的性别、职业、天气状态,经济工作中选择的政策以及地层的构成类型等等,这些变量都只有各种状态的区别,而没有数量之区别。若定性变量不进入数学关系式,则会丢失信息,若要进入,又难于直接参加运算,于是从20世纪五十年代起开始发展了数量化理论,首先应用于“计量社会学”,六十年代后,逐步应用于各种学科,随着电子计算机的普及和发展,数量化理论将会在自然科学和社会科学的许多方面发挥出更大的作用。
如何对定性变量给以相应的数值描述,从而进行有关的统计分析,这就是数量化理论所研究的主要内容。
数量化理论已有专著出版,本节为了应用上的需要,仅介绍常用的0-1赋值法。 例如定性变量是性别,记为X ,如此赋值:
??
?=???=当性别为男
当性别为女或当性别为女当性别为男 ,0
,1X ,0 ,1X 如此赋值的理由是简单,并没有任何数量大小的意义,它仅仅用来说明观察单位的特征
或属性,因此不同特性或属性的观察单位应取不同的值。
例如:天气可取晴、阴、雨三类,则用两个变量(X 1,X 2)表示天气,如此赋值:
??
?
??=当天气雨当天气阴当天气晴 ),1,0( ),0,1(
),0,0(),(21X X
例如:有多种有害物污染了大气,由于有害物的结构不同,将污染物分为五类地区;甲、
乙、丙、丁、成戊将地区用4个变量(X 1, X 2, X 3, X 4)来表示,如此赋值:
?????
??
??=戊类地区丁类地区丙类地区乙类地区甲类地区
),1,0,0,0( ),0,1,0,0( ),0,0,1,0(
),0,0,0,1(
),0,0,0,0(),,,(4321X X X X
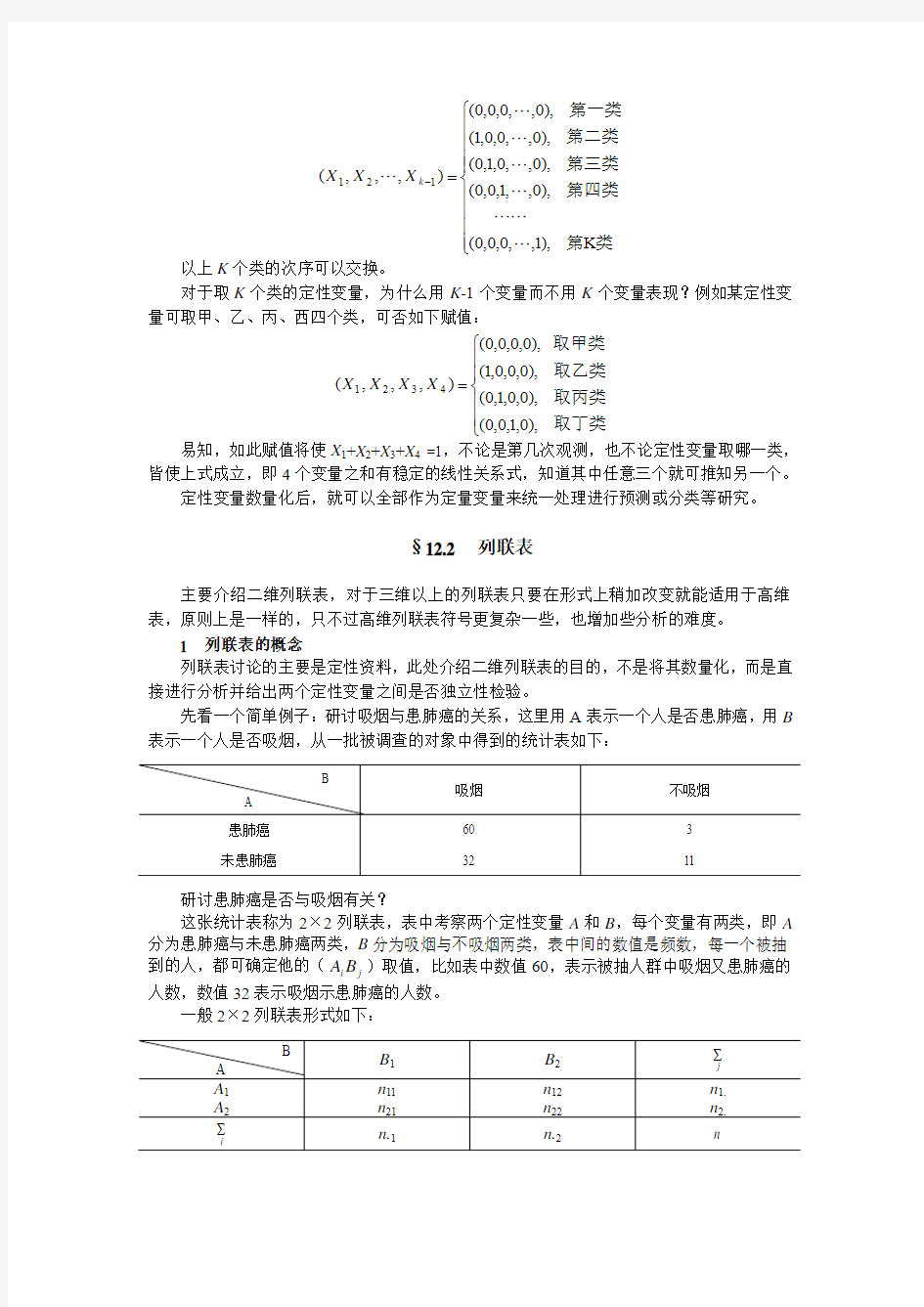
综上所述,推广为一般的赋值法如下:若某定性变量可取K 类,则用K -1个变量表示,
如此赋值:
?????????
?
?=-类第第四类第三类第二类第一类K
),1,,0,0,0(
),0,,1,0,0(
),0,,0,1,0(
),0,,0,0,1( ),0,,0,0,0(),,,(121 k X X X 以上K 个类的次序可以交换。
对于取K 个类的定性变量,为什么用K -1个变量而不用K 个变量表现?例如某定性变量可取甲、乙、丙、西四个类,可否如下赋值:
???
??
?
?=取丁类取丙类取乙类取甲类 ),0,1,0,0(
),0,0,1,0(
),0,0,0,1( ),0,0,0,0(),,,(4321X X X X 易知,如此赋值将使X 1+X 2+X 3+X 4 =1,不论是第几次观测,也不论定性变量取哪一类,皆使上式成立,即4个变量之和有稳定的线性关系式,知道其中任意三个就可推知另一个。
定性变量数量化后,就可以全部作为定量变量来统一处理进行预测或分类等研究。
§12.2 列联表
主要介绍二维列联表,对于三维以上的列联表只要在形式上稍加改变就能适用于高维表,原则上是一样的,只不过高维列联表符号更复杂一些,也增加些分析的难度。
1 列联表的概念
列联表讨论的主要是定性资料,此处介绍二维列联表的目的,不是将其数量化,而是直接进行分析并给出两个定性变量之间是否独立性检验。
先看一个简单例子:研讨吸烟与患肺癌的关系,这里用A 表示一个人是否患肺癌,用B 表示一个人是否吸烟,从一批被调查的对象中得到的统计表如下:
研讨患肺癌是否与吸烟有关?
这张统计表称为2×2列联表,表中考察两个定性变量A 和B ,每个变量有两类,即A 分为患肺癌与未患肺癌两类,B 分为吸烟与不吸烟两类,表中间的数值是频数,每一个被抽到的人,都可确定他的(j i B A )取值,比如表中数值60,表示被抽人群中吸烟又患肺癌的人数,数值32表示吸烟示患肺癌的人数。
一般2×2列联表形式如下:
其中)2,1,(=j i n ij 表示第i 行A i 和第j 列B j 的样品出现的频数,一般ij n 可取任意非负整数。
这是一个最简单的列联表,如果两个定性变量分别考察r 和c 类,则相应的列联表为c r ?表(r 和c 可以不等)有如下形式:
如果一个问题涉及到很多的定性变量,相应的频数表就是一个高维列联表。
在概率统计中描述两个随机变量的相关程度是用线性相关系数,为了避免术语上的混淆,描述两个一性随机变量之间的相关性是指广义的相关性,称为关联性,两个定性随机变量之间的关联程度在某种意义上就是指的“不独立性”,它与独立的情形差距越大,就表明彼此的关系越密切,这种关系不一定是线性关系,然而在实际问题中,重要的是判断变量之间是否独立,因为不独立就意味着是关联的。如何判断是否独立有很多方法,这里仅介绍一种常用的皮尔逊拟合优度x 2检验。
2×2列联表,对应一个多项分布,检验A 与B 是否独立,等价于检验:
j i ij p p p H ..0:=
其中ij p 表示A 为i 、B 为j 的样品概率,.i p 和j p .是相应的边缘概率,当独立性成立时, 理论频数为:∑∑===
=2
1i 2
1
..n j ij
j i ij n
p np np 其中
实际频数为:n ij
运用x 2检验作判定,需要知道列联表中实际频数与相应的理论频数。用估计量
n
n n n
p
j i i ..j ..p ? ,?==代替j i p p ..和。基实际频数与理论频数有差异,这时可用其差值的大小来度量两个变量相关程度。相差愈大,表明0H 为真的可能性愈小,即A 与B 无关的可能性愈小。相反差值愈小,即二愈接近,0H 为真的可能性愈大,A 与B 之间相关的可能性愈小。为避免实际频数与理论频数的差值出现正负抵消,可采用差值的加权平方和来检验,于是给
出皮尔逊的拟合优度x 2
统计量为:
∑∑
==???? ??-=
2
1
21
..
2
..2
i j j i j i ij n
n n n n n n n n n n x
()
∑∑
==-=
2
1
21
..2
..i j j i j
i ij n nn n n nn
它的极限分布是自由度为1的2x 分布,根据给定的显著性水平a ,查x 2分布表得到临界值a λ。若a x λ≥2则拒绝H 0,表示A 与B 之间不独立,存在相关,若a x λ<2则不能拒绝
H 0,表明A 与B 之间独立,不存在相关。
将前面的例子作x 2检验:
计算
9243106)924332106(9263106)926360106(2
22
???-?+???-?=x
1443106)144311106(1463106)14633106(22???-?+???-?+
419336)39563392(614376)57966360(22-+-=
63812
)6021166(93492)882318(22-+-+
66360.940239.398489.45775.075857.0=+++=
取显著性水平a =0.05,自由度为1,查x 2分布表,临界值84.3=a λ。显然84.366360.92>=x ,表明在5%的显著性水平上,拒绝H 0即说明吸烟与肺癌不独立,而是存在相关的。
如果列联表中变量间存在相关,那么如何度量变量间的相关程度?又如何从一个变量去预测另一变量呢?解决这类总是还有很多方法,已超出本书范围,不再详述,有兴趣的读者可查阅这方面的参考书。
§12.3 对数线性模型
如前所述,列联表能够反映定性变量之间的关系,但能否像定量变量那样建立起数学模型如方差分析模型、回归分析模型等以便进一步描述定性变量之间的复杂关系呢?对数线性模型和Logistic 回归模型就是解决这一问题的极为有效的方法,它们从不同角度出发导出不同的处理方法。
对数线性模型,近十年来是国外实际工作者常用的方法,它的主要优点是可以把方差分析和线性模型的一些方法系数地移植过来,在概念和理解上均可进行对比,对数线性模型能够估计模型中各个参数,而这些参数值使各个变量的效应和变量间的交互作用效应得以数量化。下面即将看到这些结论。
1 模型
对数线性模型又分为很多种类型,常用的模型有:饱和模型(当变量间相互不独立时),非饱和型(变量间相互独立),谱系模型(包含高阶效应)等。
下面从2×2的频数表与概率表出发,推导对数线性模型: (频数表)(概率表)
将概率取对数后进行分解处理,使处理后的变量有较好的数学、统计的性质。
???
? ??==j i ij j i ij ij p p p p p p ....ln ln μ j
i ij
j i p p p p p ....ln
ln ln ++= 记j
i ij j i i p p p p p A ..ij .j .ln (AB) ,ln B ,ln ===
由上式可写成
1.2j i, )(=++=ij j i ij AB B A μ
显然上式的结构类似于两因子有交互作用,各因子均为二水平的方差分析模型,于是令
∑∑∑∑=======21
21i 2
1
.j 21
. , ,i j ij ij j ij i μμμμμμ
然后再进行平均,对i, j =1,2
..2
1 21 ,21
......μμμμμμ===j j i i
记
...μμα-=i i
...μμβ-=j j
....μλ+--=j i ij ij
则有关系式:
?????
?
???
??=====+++=∑∑
∑
∑====21212121
01,2j i,
,0 ,0..i j ij ij j j i i ij j i ij λλβαλβαμμ且 可见通过上边分解处理,可以完全化成与方差分析模型有同样的结构,因此借助于方差分析的术语,上式中..μ表示“总平均效益”,i α表示A 属性的“主效应”,j β表示B 属性
的“主效应”,ij λ表示,A , B 的 “交互作用效应”,直观可以理解当交互作用效应为0,即等价于A 、B 独立。上式模型称为对数线性模型的饱和模型,当ij λ=0时,称为非饱和模型。
在实际应用时概率可用其估计量代替,即n n p
n n p
i i ij
ij .
.?,?==,n
n p j j ..?=,这时就可以看
到对数线性模型是将列联表上每个单元的频数作为因变量,表上所有变量作为自变量,建立各个自变量的效应与每个单元频数的对应之间的函数关系。因而可以用它分析列联表上的各个变量的关系。主效应i α或j β若大于0,表明效应为正;若小于0,表明效应为负。i α是
第一个变量的第i 个水平对总平均效应..μ的增减量;j β是第二个变量的第j 个水平对总平均效应..μ的增减量,ij λ代表变量1和变量2在各自的第i 个水平和第j 个水平之间交互作用效应,是其交互作用对总平均效应的增减量。若0 ∑ ∑ === = 2 1 1 .)(ln 212 1 j ij n j ij i n n μμ … 第i 行频数对数的平均 ∑ ∑ === = 2 1 1 .)(ln 212 1i ij n i ij j n n μμ … 第j 列频数对数的平均 ∑∑∑∑ === = =n i i j ij j ij n n 1 22 2 1 ..)(ln 41 4 1 ..41μμμ … 各个观测值对数的总平均即总平均效 应对本章前面的例子,按上述模型估计各效应参数。 各单元的频数对数表: 计算: 0823.05141.25964.2...11=-=-=μμα 0823.05141.24318.2...22-=-=-=α 765.05141.22800.3..1.1=-=-=μμβ9 7659.05141.27482.1..2.2-=-=-=β 主效应估计值: 计算: 7482.15964.20986.1..2..11212--=+--=μλ +2.5141=3.6127-4.3426=-0.7319 2800.34318.24657.2..1..22121--=+--=μμμμλ +2.5141=4.9798-5.7188=-0.7320 2800.35964.20943.4..1..11111--=+--=μμμμλ +2.5141=6.6083-0.8319=0.8319 7482.14318.23979.2..2..22222--=+--=μμμμλ 7320.01800.9120.45141.2==+ 变量间交互作用效应估计值: 8319.011=λ 7399.012-=λ 7317.021-=λ 7320.022=λ 主效应大于0,表明效应为正,如00832.01>=α是因为患肺癌比未患肺癌的人多;主效应小于0,表明效应为负,如076599.02<-=β,是因为不吸烟的比吸烟的人少。交互作用大于0,表明交互作用效应为正,如08319.011≥=x ,表明患肺癌与吸烟之间存在着相关;并互作用小于0,表明交互作用效应为负,如07317.012<-=λ,表明患肺癌与不吸烟之间存在负相关。 §12.4 Logistic 回归 对数线性模型是将列联表中每格的概率(或理论频数)取对数后分解参数获得的,Logistic 回归模型是将概率比取对数后,再时行参数化而获得的。研究概率比这样的量在不少问题中是常常遇到的,当列联表中因变量是一个多级分类的变量时,就需要考虑两两比较的情况。 Logistic 回归要解决的问题,类似于普通回归所要解决的很大一类问题。比如在医药行业中,因变量y 取0, 1, …, g 这g+1个不同的值,y=0表示正常情况类型,y=1….,g 表示不同用药后的反应,显然它与药的剂量x 1 ,性别x 2,年龄x 3,体重x 4,血压x 5,…等等自然变量有关,这里因变量是定性的,自变量有定性的也有定量的,问这些自变量对一个定性变量的关系是否独立?不独立又会具有什么形式的联系?是线性的还是非线性的等等。 1 Logit 变换 为了给出Logistic 回归模型,先介绍Logit 变换。在现实问题中,人们常常要研究某一事件A 发生的概率p 以及p 值的大小与某些因素的关系,但由于p 对x 的变化在p = 0或p =1的的附近是很敏感的,或说是缓慢的比如像可靠系统,可靠度p 已经是0.988了,即使再改善条件和系统结构,它的可靠度增长只能在小数点后面的第三位或第四位,于是自然希望寻找一个p 的函数)(p θ,使它在p = 0或p =1附近变化幅度较大,而且函数的形式也不要太复杂,根据数学上导数的意义,提出用dp p d ) (θ来反映)(p θ在p 附近的变化是很合适的,同时希望p = 0或p =1, dp p d ) (θ有较大的值,因此取 p p p p dp p d -+=-=11 1)1(1)(θ 即 p p p -=1ln )(θ 称上式为Logit 变换。 由于p p p -=1ln )(θ,因此p 也可用θ表示: θ θ e e p +=1 如果θ是某些自变量x 1, …, x k ,的线性函数 ∑=k i i k x a 1 ,则p 就x 1, …, x k 的下述函数: ∑+∑= ==k i i i k i i i x a x a e p 1 1 1 显然,如果如果p 对x 不是线性关系,则θ对x 就可以是线性关系了,这就是Logit 变换带来的方便。 2 Logistic 回归模型 设因变量y 为二值定性变量,用0,1表示取两个不同的状态,y =1的概率p=P(y=1)是我们要研究的对象。如果有很多因素影响y 的取值,这些因素就是自变量,记为x 1,…, x k ,这其中既有定性变量也有定量变量,最重要的一个条件是 k k x a x a a p p +++=- 1101ln 适合于上式线性函数称为Logistic 线性回归。如果有已知函数),,(1k x x g ,其中含有若干待定的参数,且 ),,(1ln 1k x x g p p =- 称上式为非线性Logistic 回归。 Logistic 线性模型相当于广义线性模型,因此可以系统地应用线性模型的方法,在处理时就比较方便。 如果某一事件A 发生的概率p 依赖于一些自变量k x x ,,1 (定性定量均可),对),,(1'=k x x x 观测了m 组结果,在第a 组中,共试验了n a 次,A 发生了r a 次,于是A 发 生的概率p a 可用a a a n r p =?来估计。假定a p 适合于Logistic 线性回归关系式,即 m ,1,a 1ln 110 =+++=-ak k a a a x x p p βββ 其中ai x 表示x i 在第a 组所取的值。用a p ?代入上式中a p 就有关系式: m ,1,a ?1?ln 110 =++++=-a ak k a a a x x p p εβββ 其中a ε是随机误差项。记 a a mk ml k k k m p p x x x x x x X ?1?ln y ,111a 221111)1(-=????? ? ??????=+? ),,(1'=m y y y ,假定m a a a v V E εεεε,,,)(,0)(1 ==相互独立,于是就有 ??????????==??? ?? ? ? ??????=m k v X X Ey 00v V Var(y) 110 ββββ 这就是典型的线性模型,因此β的最小二乘估计(因V 不是单位阵,应该相应地加权)β ? 有公式: y V X X V X 111)(?---''=β 这样就求得了β的估计值。要讨论某些x i 是否对A 发生的概率有无影响,也即要检验x i 相应的回归系数0=i β这一假设是否成立,这时要搬用线性模型中已知的结论时,必须知道y 是否服从正态分布以及V 的估计,数学上可以证明: a a p p ?1?ln -的渐近分布为正态的,即???? ? ?--)1(1 ,1ln a a a a a p p n p p N V 是的v a 的估计值为) ?1(?1 1?a a a a p p n v -= 如果在m 组试验结果中,有的0=a r 或a a n r =,此时 a a a a a r n r p p -=-ln ?1?ln 会取∞-或∞的值,y a 就不是一个有限的值,上述方法就会行不通,于是要进行修正,修正 的目的是使a a a r n r -ln 尽可能接近a a p p -1ln ,可以证明下面的修正是合理的。 m ,1,a 5.05 .0ln =+-+=a a a a r n r Z m ,1,a )1)(1() 2)(1(? =+-+++=a a a a a a a r n r n n n v 上式Z a 称为经验的Logistic 变换,相应的线性模型也称为经验的Logistic 回归模型: ?? ?? ? ????? ???????????==???? ??????=m m v v Z Var X EZ EZ EZ ?00?)(11 β 其中a a v Z ?,为修正后的表达式,β?的估计值如下: 2 1 2112 121)(?-- ---''=V V X X V V X β 用加权最小二乘估计回归系数时,第a 组的权系数是2 1 ~- a v 。 引入经验Logistic 变换后,Logistic 回归就和普通的回归一样了,而且用的是加权最小 二乘,在普通回归中遇到的一些检验的问题,如回归系数的显著性检验、共线性问题、……等等,在这里都有同样的意义,而且处理方法也相似,经验的Logistic 回归是Logistic 回归中最常用的方法。 3 实例 对本章所例举的实例,讨论吸烟与肺癌的关系,作经验的Logistic 变换并再次检验吸烟与肺癌是否相关。 将吸烟人作为一类,不吸烟人作为一类,此时m =2, n 1=92, n 2=14, r 1=60, r 2=3。 作经验Logistic 变换: 6214.05 .325 .60ln 5.05.0ln 1111==+-+=r n r Z 1896.15.115 .3ln 5.05.0ln 2222-==+-+=r n r Z 047204.01851968742336192)292)(192()1)(1()2)(1(?1111111==??++=+-+++=r n r n n n v 3571428.0672 240 12414)214)(114()1)(1()2)(1(?2222222==??++=+-+++=r n r n n n v 为了作假设检验,设吸烟人患肺癌的概率是p 1,未患肺癌的概率就是1-p 1,不吸烟的人 患肺癌的概率是p 2,未患肺癌的概率就是1-p 2,作Logit 变换: 2221111ln ,1ln p p p p -=-=θθ 设θθ=2,则 ?+=-+=θθθθθ)(2121 因此患肺癌是否与吸烟有关,就归结为检验 0:0=?H 是否成立。 由于21,Z Z 可以看成是相互独立的正态变量。因此,H 0成立时,)??,0(~2121v v N Z Z +-,即 )1,0(~??2121N v v Z Z +- 计算 8483.26358 .08110 .14043 .08110.1357 .00472.08110.1??2121== = += +-v v Z Z 取05.0=a ,查N (0,1)表得临界值834.0=a λ。 2.8483>0.834,应拒绝H 0,即认为吸烟与不吸烟对于患肺癌是有影响的。 综上所述,对于列联表,既可以用对数线性模型也可以用Logistic 模型,要根据实际问题的需要来选择模型。 定性资料统计分析的内容是很丰富的,这里不再详述,有兴趣的读者可查有关资料。 附录:矩阵代数 矩阵和行列式是研究多元统计分析的重要工具,这里针对本书的需要,对有关矩阵的知识作复习,同时再简单的补充矩阵的分块和矩阵的微商。(因为在部分章节中要用到)。 §1 矩阵及基本运算 1 矩阵的定义 将n ×p 个实数,a 11, a 12, …, a 1p , a 21, a 22, …, a 2p , …, a n1, a n2, …, a np 排成如下形式的矩形表,记为A ?????? ????????=np n n p p a a a a a a a a a A 212222111211 则称A 为p n ?阶矩阵,一般记为p n ij a A ?=)(,其中ij a 是A 中元素,它也可以是复数,但本书的ij a 均为实数。当n = p 时,称A 为n 阶方阵;若p =1,A 只有一列,称A 为列向量, 记为 ????? ???????=12111n a a a a 当n =1时,A 只有一行,称A 为行向量,记为 ),,,(11211p a a a a =' 当A 为n 阶方阵,称nn a a a ,,,2211 为A 的对角线元素,其它元素称为非对角元素,若方阵A 的非对角元素全为0,称A 为对角阵,记为 ),,,(22112211 nn nn a a a diag a a a A =??????????? ?O O = 进一步若a 11 = a 22 =…= a nn =1,称 ????? ???????O O =111 A 为n 阶单位阵,记为I n 或A =I (I 的阶数从上下文可明确)。 若A 为n×p 阶矩阵,它的转置A ′是阶p×n 阶矩阵,即 ?????? ????????='np p p n n a a a a a a a a a A 212221212111 若A 是方阵,且A ′=A ,则称A 为对称阵;若方阵A =(a ij )的元素a ij = 0,对一切i <j 成立,则称 ? ???? ???????O =nn n n a a a a a a A 2 1 2221 11 为下三角阵;若A ′为下三角阵,则称A 为上三角阵。 2 矩阵的运算 若A 与B 是n×m 阶阵,则A 与B 的和定义为: m n ij ij b a B A ?+=+)( 若a 为一常数,它与A 的积定义为 m n aa aA ij ?=)( 若r q kj q p ik b B a A ??==)(,)(,则A 与B 的积定义为: AB=r p q k kj ik b a ?=∑)( 1 在一般情况下AB ≠BA 。 容易验证上述运算符合下面运算规律: A+(-1)A=0 (AB)′=B ′A ′ (A ′)′=A (A+B)′=A ′+B ′ A(BC)=(AB)C A(B+C)=AB+AC (A+B)C=AC+BC AI=IA=A a(A+B)=aA+aB a(AB)=(aA)B=A(aB) 若A 为方阵,满足A ′A=AA ′=I ,则称A 为正交阵。 §2 行列式、逆矩阵和矩阵的秩 1 行列式 一个p 阶方阵p p ij a A ?=)(对应一个数,记为|A| ?? ? ??? ? ???? ???=pp p p p p a a a a a a a a a A 21 22221 11211 ∑-= p p p j j j pj j j j j a a a 21211,,,) 1(21) (τ 称|A|为A 的行列式或记为detA 。这里p j j 1∑表示对所有p 元排列求和。)(1p j j τ表示p j j 1的逆序数(在一个排列p s t j j j j j ,,,21),若s t j j >,则称这两个数组成一个逆序。一个排列中逆序的总数称为此排列的逆序数)。 不难证明: ∑=+-= p j ij ij j i M a A 1 ,) 1( 其中M ij 是在A 中去掉第i 行、第j 列而形成的p -1阶方阵。称ij j i M +-)1(为ij a 的代数余子式,通常记为A ij 。 直接由行列式的定义来计算行列式是很麻烦的,通常利用行列式的如下一些性质可以简化行列式的计算: (1)若A 的某行(或列)为零,则|A |=0; (2)|A |=|A ′|; (3)将A 的某行(或列)乘以数a 所得矩阵的行列式等于a |A |; (4)若A 的两行(或列)相同,则|A |=0; (5)若将A 的两行(两列)互换所得矩阵的行列式等于-|A |; (6)若将A 的某一行(或列)乘上一个常数后加到另一行相应的元素上,所得矩阵的行列式不变,仍等于|A |。 2 逆矩阵 设A 为p 阶方阵,若|A |≠0,则称A 是非退化阵或称非奇异阵,若|A |=0,则称A 是退化阵或称奇异阵。 若A 是p 阶非退化阵,则存在唯一的矩阵B ,使得AB =I p ,B 称为A 的逆矩阵,记为B =A -1,不难证明: ??? ???? ??? ? ???????????=-A A A A A A A A A A A A A A A A A A A pp p p p p 2122212121 111 其中ij A 是ij a 的代数余子式。 一般情况,这个求逆公式只有理论的价值,在多元分析中求逆矩阵是通过消去变换来实现的,并且同时可求得该矩阵的行列式。消去变换在后面介绍。 逆矩阵的基本性质如下: (1)I A A AA ==--11 (2))()(11'='--A A (3)若A 和C 均为p 阶非退化阵,则 111)(---=A C AC (4)设A 为p 阶非退化阵,b 和a 为p 维列向量,则方程: Ab=a 的解为 a A b 1 -= (5)1 1--=A A (6)若A 是正交阵,由于I A A ='推知A A '=-1;若A 是对角阵,A=diag(a 11,a 22,…,a pp ) 且p i a ij ,,1,0 =≠,则),,,(1 1221111----=pp a a a diag A 。 3 矩阵的秩 设A 为p×q 阶阵,若存在它的一个r 阶子方阵的行列式不为零,而A 的一切(r +1)阶子方阵的行列式均为零,则称A 的秩为r ,记作r A rk =)(。它有如下基本性质: (1)rk (A)=0,当且仅当A=0; (2)若A 为p×q 阶阵,则),min()(0q p A rk ≤≤; (3))()(A rk A rk '=; (4)))(),(min()(B rk A rk AB rk ≤; (5))()()(B rk A rk B A rk +≤+; (6)若A 和C 为非退化阵,则)()(B rk ABC rk =。 §3 特征根、特征向量和矩阵的迹 1 特征根和特征向量 设A 为p 阶方阵,则方程0=-p I A λ是λ的p 次多项式,由多项式理论知道必有p 个根(可以有重根),记为p λλλ,,,21 ,称为A 的特征根或称特征值。 若存在一个p 维向量l i ,使得0)(=-i p i l I A λ,则称l i 为对应于i λ的A 的特征向量。今后总假设1 ='i i l l 。 特征根有如下性质: (1)若A 为实对称阵,则A 的特征根全为实数,故可按大小次序排列成p λλλ≥≥≥ 21,若j i λλ≠,则相应的特征向量i l 与j l 必正交。 (2)A 和A ′有相同的特征根。 (3)若A 与B 分别是p×q 与q×p 阶阵,则AB 与BA 有相同的非零特征根。 (4)若A 为三角阵(上三角或下三角),则A 的特征根为其对角元素。 (5)若p λλλ,,,21 是A 的特征根,A 可逆,则A -1的特征根为11211,,,---p λλλ 。 2 矩阵的迹 若A 是p 阶方阵,它的对角元素之和称为A 的迹,记为∑==p i ii a A tr 1 )(; 若A 是p 阶方阵,它的特征根为p λλλ ,,21,则∑==p i i A tr 1 )(λ 。 特征根和迹有如下关系: (1)tr(AB)=tr(BA) (2)tr(A)=tr(A ′) (3)tr(A+B)=tr(A)+tr(B) (4)tr(aA)=atr(A) §4 二次型与正定阵 称表达式 ∑∑=== p i p j j i ij x x a Q 11 为二次型,其中ji ij a a =是实常数;p x x x ,,,21 是p 个实变量。 若p p ij a A ?=)(为对称阵,),,(1'=p x x X 则 ∑∑=='== p i p j j i ij AX X x x a Q 11 若方阵A 对一切0≠X ,都有0>'A X X ,则称A 与其相应的二次型是正定的,记为0>A ;若对一切0≠X ,都有0≥'A X X ,则称A 与二次型是非负定的,记为0≥A 。 记B A ≥,表示0≥-B A ;记B A >,表示0>-B A 。 正定阵和非负定阵有如下性质: (1)一个对称阵是正(非负)定的当且仅当它的特征根为正(非负); (2)若0>A ,则01>-A ; (3)若0>A ,则0>CA ,其中C 为正数; (4)若0≥A ,因它是对称阵,则必存在一个正交阵Γ,使Λ==ΓΓ'),,,(21p d i a g A λλλ 其中p λλ,,1 为A 的特征根,Γ的列向量为相应的特征向量,于是 Γ'ΓΛ=A (5)由性质1,p λλ,,1 均非负,即0≥Λ。记)),(,),(()(1p f f diag f λλ =Λ=)(A f Γ'ΛΓ)(f 特别), ,(212 112 1 p diag λ λ =Λ Γ' ΓΛ= 212 1A 称2 1A 为A 的平方根; (6)若),0( 0>≥A 则存在 )0( 02 1>≥A ,使得2 121A A A = 。 §5 消去变换 在多元分析中经常要解线性方程组,求矩阵的逆和行列式,或进行某种逆推运算,通过消去变换可以达到目的。 设)(ij a A =是n×p 阶阵,若0≠ij a ,将A 变换为)(* *ij a A =,使得 ????? ? ?===≠=≠-≠≠-=j i a a a a a a a a a a a ij ij i ij aj ij j i βαββββαβαβαβ , 1i j, j i,a j i,a * 当当当当 即*A 阵为如下形式: ??? ??? ???? ? ???????????----=++--ij nj ij j i ij im ij ij ij ij ij ij i ij j i ij j a a a a a a a a a a a a a a a a a A **** 1****111111* 其中**部分第(βα,)位置的元素是ij i j a a a a βααβ-。这个变换称为以(i, j )为枢轴 的消去变换,记作)(*A T A ij =。 消去交换具有如下性质: (1)A A T T ij ij =)(,即对A 连续施行两次(i,j )消去交换,其结果仍是A 不变。 (2)若l j k i ≠≠,,则)()(A T T A T T ij kl kl ij =,它表明T ij 在某种意义下的可交换性。 §6 矩阵的分块和矩阵的微商 1 矩阵的分块 对于任意一个p×q 阶矩阵A ,可以用纵线和横线按某种需要将它们划分成若干块低阶的矩阵,也可以看作是以所分成的子块为元素的矩阵,称为分块矩阵,即: ?????? ????????=pq p p q q a a a a a a a a a A 212222111211 写成 ??????=2221 1211A A A A A 其中 n ,1,j m;,1,i ][11 ===ij a A q ,1,j m;,1,i ][12 +===n a A ij n ,1,j p;,1,i ][21 =+==m a A ij q ,1,j p;,1,i ][22 +=+==n m a A ij 矩阵的分块是相当任意的,同一个矩阵可以根据不同的需要,划分成不同的子块,构成 不同的分块矩阵。 值得注意的是,在分块矩阵中,每行(列)上各元素(指原矩阵的子块)具有相同的行(列)数(指在原矩阵中的行(列)数)。 分块矩阵也满足平常矩阵的加法、乘法等运算规律。 不难证明: 若???? ??''''='???? ??=22 1221 11 22212111 ,A A A A A A A A A A 则。 若A 11, A 22是 方阵且是非退化阵,则 211 2212112212111212211A A A A A A A A A A A ---=-= 2 矩阵的微商 设),,(1'=p x x x 为实向量,)(x f y =为x 的实函数。 则)(x f 关于x 的微商定义为: ??? ?? ?? ?????? ??????????p x f x f x x f 1)( 若 ??? ? ??????=np n p x x x x X 1111 则定义 ?? ????????? ??????????????np n p x f x f x f x f X X f 1 111)( 由上述定义不难推出以下公式: (1)若)a ,,(a A ,),,(p 11'='= p x x x 则 A X A x =?'?) ( (2)若x x x x x p 2x) x ( ,),,(1=?'?'=则 (3)若p p ij 1)(b B ,),,(?='=p x x x 对称阵 则 Bx x 2Bx) x (=?'? (4)若)(AX X tr y '=,式中X 为n×p 阶阵,A 为n×n 阶阵,则 则 X A A X tr )(AX) X ('+=?'? 若A 为对称阵,则 AX X tr 2AX) X (=?'? 参 考 文 献 [1] 张尧庭,方开泰(1982):《多元统计分析引论》,科学出版社。 [2] 王学仁(1982):《地质数据的多变量统计分析》,科学出版社。 [3] 方开泰,潘恩沛(1982):《聚类分析》,地质出版社。 [4] [英]M. 肯德尔(1983):《多元分析》,科学出版社。 [5] Morris L. Eaton(1983), Multivariate Statistical A Vactor Space Approach. [6] Anderson, T. W. (1984), An Introduction to Multivariate Statistical Analysis (2nd Edition), Wiley. [7] 田中丰·垂水共之·胁本和昌编(1984):《 卜2统计解 II 多变量解析编》,共立出版株式会社。 [8] 余金生、李裕伟(1985):《地质因子分析》,地质出版社。 [9] 陈希孺,王松桂(1987):《近代回归分析—原理方法及应用》,安徽教育出版社。 [10] 罗积玉、邢瑛(1987):《经济统计分析方法及预测—附实用计算机程序》,清华大学出版社。 [11] 周光亚等(1988):《多元统计分析》,吉林大学出版社。 [12] 方开泰(1989):《实用多元统计分析》,华东师范大学出版社。 [13] 孙尚拱(1990):《实用多变量统计方法与计算程序》,北京医科大学、中国协和医科大学联合出版社。 [14] 孙尚拱、潘恩沛(1990):《实用判别分析》,科学出版社。 [15] 王学仁、王松桂(1990):《实用多元统计分析》,上海科学出版社。 [16] 胡国定、张润楚(1990):《多元数据分析方法》,南开大学出版社。 [17] 张明立、于秀林(1991):《多元统计分析方法及程序——在体育科学中的应用》,北京体育学院出版社。 [18] 张尧庭等(1991):《定性资料的统计分析》,广西师范大学出版社。 [19] 于秀林(1993):《多元统计分析及程序》,中国统计出版社。 [20] 王国梁、何晓群(1993):《多变量经济数据统计分析》,陕西科学技术出版社。 [21] Alvin C.Rencher (1995), Methods of Multivariate Analysis. [22] [美]David Freedman 等著,魏宗舒等译(1997):《统计学》,中国统计出版社。 一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。 第六章 分类资料的统计描述 一、教学大纲要求 (一)掌握内容 1. 绝对数。 2. 相对数常用指标:率、构成比、比。 3. 应用相对数的注意事项。 4. 率的标准化和动态数列常用指标:标准化率、标准化法、时点动态数列、时期动态数列、绝对增长量、发展速度、增长速度、定基比、环比、平均发展速度和平均增长速度。 (二)熟悉内容 1. 标准化率的计算。 2. 动态数列及其分析指标。 二、教学内容精要 (一) 绝对数 绝对数是各分类结果的合计频数,反映总量和规模。如某地的人口数、发病人数、死亡人数等。绝对数通常不能相互比较,如两地人口数不等时,不能比较两地的发病人数,而应比较两地的发病率。 (二)常用相对数的意义及计算 相对数是两个有联系的指标之比,是分类变量常用的描述性统计指标,常用两个分类的绝对数之比表示相对数大小,如率、构成比、比等。 常用相对数的意义及计算见表6-1。 表6-1 常用相对数的意义及计算 常用相对数 概念 表示方式 计算公式 举例 率 (rate ) 又称频率指标,说明一定时期内某现象发生的频率或强度 百分率(%)、千分率 (‰)等 单位时间内的发病率、患病 率,如年(季)发病率、时 点患病率等 构成比 (proportion ) 又称构成指标,说明某一事物内部各组成 部分所占的比重或分布 百分数 疾病或死亡的顺位、位次或所占比重 比 (ratio ) 又称相对比,是A 、B 两个有关指标之 比,说明A 是B 的若干倍或百分之几 倍数或分数 ①对比指标,如男:女 =106.04:100 ②关系指标,如医护人员:病床数=1.64 ③计划完成指标,如完成计划的130.5% (三) 应用相对数时应注意的问题 1. 计算相对数的分母一般不宜过小。 2. 分析时不能以构成比代替率 容易产生的错误有 (1)指标的选择错误如住院病人只能计算某病的病死率,不能认为是某病的死亡率; (2)若用构成指标下频率指标的结论将导致错误结论,如 某部队医院收治胃炎的门诊人数中军人的构成比最高,但不一定军人的胃炎发病率最高。 %100?=单位总数 可能发生某现象的观察数 发生某现象的观察单位率%100?= 观察单位总数 同一事物各组成部分的位数某一组成部分的观察单构成比B A = 比 第十章分类资料的统计分析 A型选择题 1、下列指标不属于相对数的是() A、率 B、构成比 C、相对比 D、百分位数 E、比 2、表示某现象发生的频率或强度用 A 构成比 B 观察单位 C 相对比 D 率 E 百分比 3、下列哪种说法是错误的() A、计算相对数尤其是率时应有足够数量的观察单位数或观察次数 B、分析大样本数据时可以构在比代替率 C、应分别将分子和分母合计求合计率或平均率 D、相对数的比较应注意其可比性 E、样本率或构成比的比较应作假设检验 4、以下哪项指标不属于相对数指标( ) A.出生率 B.某病发病率 C.某病潜伏期的百分位数 D.死因构成比 E.女婴与男婴的性别比 5、计算麻疹疫苗接种后血清检查的阳转率,分母为( ). A.麻疹易感人群 B.麻疹患者数 C.麻疹疫苗接种人数 D.麻疹疫苗接种后的阳转人数 E.年均人口数 6、某病患者120人,其中男性114人,女性6人,分别占95%与5%,则结论为( ). A.该病男性易得 B.该病女性易得 C.该病男性、女性易患率相等 D.尚不能得出结论 E.以上均不对 7、某地区某重疾病在某年的发病人数为0α,以后历年为1α,2α,…,n α,则该疾病发病人数的年平均增长速度为( )。 A.1...10+++n n ααα B. 110+??n n ααα C.n n 0 α α D.n n 0 α α -1 E. 10 -a a n 8、按目前实际应用的计算公式,婴儿死亡率属于( )。 A. 相对比(比,ratio ) B. 构成比(比例,proportion ) C. 标准化率(standardized rate ) D. 率(rate ) E 、以上都不对 9、某年某地乙肝发病人数占同年传染病人数的9.8%,这种指标是 A .集中趋势 B .时点患病率 C .发病率 D .构成比 E .相对比 10、构成比: A.反映事物发生的强度 B 、反映了某一事物内部各部分与全部构成的比重 C 、既反映A 也反映B D 、表示两个同类指标的比 E 、表示某一事物在时间顺序上的排列 第一章总论 1、统计数据有哪些分类?不同类型的数据有什么不同特点?试举例说明。 (一)统计数据按照所采用的计量尺度不同,可以分为定性数据与定量数据两类。 一、定性数据是指只能用文字或数字代码来表现事物的品质特征或属性特征的数据,具体又分为定类 数据与定序数据两种。 (1)定类数据:按照事物的某种属性对其进行平行的分类或分组所形成的数据。特点:①定类数据只测度了事物之间的类别差,而对各类之间的其他差别却无法从中得知,因此各类地位相同, 顺序可以任意改变②对定类数据,可以且只能计算每一类别中各元素个体出现的频数。 人口的性别(男、女),为了便于统计处理,用数字代码来表示各个类别,例如分别用1、0表示男性与 女性,要注意的是,这时的数字没有任何程度上的差别或大小多少之分,只是符号而已。 (2)定序数据:对事物之间等级或顺序差别测度所形成的数据。特点:①不仅可以测度类别差(分类),还可以测度次序差(比较优劣或排序)②无法测出类别之间的准确差值,因此该尺度的 计量结果只能排序,不能进行算术运算。产品等级(一等品、二等品…)考试成绩(优、良、差) 二、定量数据是指用数值来表现事物数量特征的数据,具体又分为定距数据与定比数据两种。 (1)定距数据:对事物类别或次序之间间距的测度所形成的数据。特点:①不仅能将事物区分为不同类型并进行排序而且可准确指出类别之间的差距是多少②定距尺度通常以自然或物理单位为计量尺度,因此测量结果往往表现为数值③计量结果可以进行加减运算(加减运算有意义)④“0”是测量尺度上的一个测量点,并不代表“没有”。100分制考试成绩;摄氏温度对不同地区温度的测量。 (2)定比数据(比率尺度):是能够测算两个测度值之间比值的数据。特点:①与定距尺度属于同一层次,计量结果也表现为数值②除了具有其他三种计量尺度的全部特点外,还具有可计算两个测度值之间比值的特点③“0”表示“没有”,即它有一固定的绝对“零点”,因此它可进行加、减、乘、除运算(而定距尺度只可进行加减运算)职工月收入、企业产值、企业销售收入3亿元,人的身高176厘米、体重65公斤,物体的长度30厘米、面积600平方厘米、容积9000立方厘米,水稻的平均亩产400 公斤/亩,某地区的人均国内生产总值25000元/人、第三产业比重48%等,都是定比数据。 (二)统计数据按照其表现形式不同,可以分为绝对数、相对数和平均数三类 绝对数:反映现象或事物绝对数量特征的数据,它以最直观、最基本的形式体现现象或事物的外在数量特征,有明确的计量单位。 相对数:反映现象或事物相对数量特征的数据,它通过另外两个相关统计数据的对比来体现现象(事物)内部或现象(事物)之间的联系关系,其结果主要表现为没有明确计量单位的无名数,少部分表现为有明确计量单位的有名数(限于强度相对数)。 1.结构相对数。将同一总体内的部分数值与全部数值对比求得比重,用以说明事物的性质、结构或质量。居民食品支出 额占消费支出总额比重、产品合格率等。 2.比例相对数。将同一总体内不同部分的数值对比,表明总体内各部分的比例关系,如,人口性别比例、投资与消费比例等。 3.比较相对数。将同一时期两个性质相同的指标数值对比,说明同类现象在不同空间条件下的数量对比关系。如,不同地区 商品价格对比,不同行业、不同企业间某项指标对比等。 4.强度相对数,将两个性质不同但有一定联系的总量指标对比,用以说明现象的强度、密度和普遍程度。如,人均国内生产 总值用“元/人”表示,人口密度用“人/平方公里”表示,也有用百分数或千分数表示的,如,人口出生率用‰表示。 5.计划完成程度相对数,是某一时期实际完成数与计划数对比,用以说明计划完成程度。 6.动态相对数,将同一现象在不同时期的指标数值对比,用以说明发展方向和变化的速度。如,发展速度、增长速度等。平均数:反映现象或事物平均数量特征的数据,体现现象某一方面的一般数量水平。 (三)统计数据按照其来源不同,可以分为观测数据与实验数据两类。 (四)统计数据按照其加工程度不同,可以分为原始数据与次级数据两类。 (五)统计数据按照其时间或空间状态不同,可以分为时序数据与截面数据两类。 2、总体、样本、个体三者关系如何?试举例说明。 总体:统计研究的客观对象的全体,是具有某种共同性质的事物所组成的集合体(也称为母体) 个体:构成统计总体的个别事物称为个体(也称总体单位) 定性数据分析第五章课后答案 定性数据分析第五章课后作业 1、为了解男性和女性对两种类型的饮料的偏好有没有差异,分别在年青人和老年人中作调查。调查数据如下: 试分析这批数据,关于男性和女性对这两种类型的饮料的偏好有没有差异的问题,你有什么看法?为什么?解:(1)数据压缩分析首先将上表中不同年龄段的数据合并在一起压缩成二维2X2列联表1.1,合起来看,分析男性和女性对这两种类型的饮料的偏好有没有差异? 表1.1 “性别X偏好饮料”列联表 二维2X2列联表独立检验的似然比检验统计量-2ln A的值为0.7032, P值为p=P(x2⑴m0.7032)=0.4017>0.05,不应拒绝原假设,即认为“偏好类型”与“性别”无关。(2)数据分层分析 其次,按年龄段分层,得到如下三维2X2X2列联表1.2,分开来看,男性和女性对这两种类型的饮料的偏好有没有差异? 表1.2三维2X2X2列联表 在上述数据中,分别对两个年龄段(即年青人和老年人)进行饮料偏好的调查,在“年青人”年龄段,男性中偏好饮料A占58. 73%,偏好饮料B占41.27%;女性中偏好饮料A占58. 73%,偏好饮料B占41.27%, 我们可以得出在这个年龄段,男性和女性对这两种类型的饮料的偏好有一定的差异。同理,在“老年人”年龄段,也有一定的差异。 (3)条件独立性检验 为验证上述得出的结果是否可靠,我们可以做以下的条件独立性检验。即由题意,可令C表示年龄段,C1表示年青人,C2表示老年人;D表示性别,D1表示男性,D2表示女性;E表示偏好饮料的类型,E1表示偏好饮料A,E2表示偏好饮料B。欲检验的原假设为:C给定后D和E条件独立。 按年龄段分层后得到的两个四格表,以及它们的似然比检验统计量-2ln A的值如下: C1层 C2层 -2ln A=6.248 -2ln A =11.822 条件独立性 检验问题的似然比检验统计量是这两个似然比检验统计量的和,其值为-2lnA=6.248+11.822=18.07 由于r=c=t=2,所以条件独立性检验的似然比检验统计量的渐近x 2分布的自由度为r(c-l)(t-l)=2,也就是上面这2个四格表的渐近x 2分布的自由度的和。由于p值P(x 2(2)318.07)=0.000119165很小,所以认为条件独立性不成立,即在年龄段给定的条件下,男性和女性对两种类型的饮料的偏好是有差异的。 (4)产生偏差的原因 a、在(1)中,将不同年龄段的数据压缩在一起合起来后分析发现男性和女性在对两种类型的饮料的偏好上是没有差异的。但将数据以不同的年龄段 定性数据的统计分析理论与应用研究 刘 洋 西安财经学院 摘 要:定性数据的统计研究一直以来在统计研究方法中都起着十分重要的作用,尤其近几年更是成为统计学研究的重点之一。由于统计方法的逐步发展,定性数据的研究也正不断有新的突破和新的方法,以求找到更适合自身的理论方法。相应分析方法和结构方程模型方法都是较新的定性数据分析应用中的方法。 关键词:定型数据 相应分析 统计分析 一、定性数据的背景及发展 1.研究背景及意义。随着实际问题中愈来愈多定性数据的出现,学会使用定性数据来处理实际问题便成为了必要的技能之一,定性数据的统计方法也成为统计学研究的重点之一。定性研究方法是根据社会现象或事物所具有的属性和在运动中的矛盾变化,从事物的内在规律性来研究事物的一种方法或角度。它以普遍承认的公理、一套演绎逻辑和大量的历史事实为分析基础,从事物的矛盾性出发,描述、阐述所研究的事物。定性数据的性质间接决定了定性数据成为了统计研究中不可小觑的一部分,也为统计研究方法在实际中遇到的困难扫清了很多障碍。 2.定性数据的发展。定性研究起于19世纪,早期的定性研究是从社会调查运动中的实际问题引发的,但是很少有人能意识到它的价值所在。Pearson(1904)首次提出了列联表的概念,也就意味着开始了定性数据的研究。Bartlett(1935)定义了三维列联表三变量的交互作用,但仍不能进行结构复杂的大量数据的研究。随着科技的不断发展,统计学运用计算机处理数字的能力越来越强,使定性数据的研究更是有大幅的提高,现在对定性数据的研究方法更是多样的,例如相应分析、结构方程模型等。 二、定性数据相关的统计分析理论 1.定性数据。在统计学中,数据按照其取值分为四种类型,即计量数据、计数数据、名义数据和有序数据。其中,计量数据和计数数据称为定量数据。名义数据和有序数据称为定性数据,定性变量中包含了名义定性变量和有序定性变量。 2.相应分析。相应分析(correspondence analysis)也叫对应分析,其特点是它所研究的变量可以是定性的,通过分析由定性变量构成的交互汇总表来揭示变量间的联系。通常意义下的相应分析,是指对两个定性变量(因素)的多种水平进行相应性研究,因而它的应用越来越广泛,现在这种方法已经成为常用的多元分析方法之一。相应分析的思想首先由Richardson和Kuder于1933年提出,后来法国统计学家Benzecri等对该方法进行了详细的论述而使其得到了发展。 3.结构方程模型。结构方程模型(Structural Equation Modeling)在20世纪80年代以来迅速发展,是可以处理多个原因、多个结果关系,或者处理不可直接观测变量即潜变量的好方法,解决了一些传统的统计方法不能很好解决的问题。结构方程模型可以假设潜变量的存在,即潜变量可以在结构方程模型中使用,而不是作为观测变量。使定性数据得到了更好更全面的分析,适用于新的统计方法。主要适用于数据较多的定性数据的调查问卷。 三、定性数据统计分析的实证研究 1.数据处理。 1.1数据来源。本文所采用数据来自于由朱建平主编的《应用多元统计分析》一书中相应分析章节举例。应用spss17.0做相关分析。 1.2定性数据数字化。每个定性数据都含有不可量化成分,所以,在分析定性数据之前需要把定性数据中所代表的不同含义或不同范围用简单整数表示,一种含义或范围只能用一个整数表示,这样就使得定性数据数字化。 2.定性数据的相应分析。 2.1相应分析原理。相应分析是在列联表的基础上通过交互汇总数据来解释变量之间的内在联系,用相同的因子轴同时描述两个因素各个水平的情况,把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上。一般情形,取两个公共因子,在一张二维平面图上绘出两个因素各个水平的情况,即可以直观地描述两个因素A和因素B以及各个水平之间的相关关系。同时揭示了同一变量的各个类别之间的差异以及不同变量各个类别之间的对应关系。 2.2相应分析实证。研究数据为1992年美国总统大选的部分数据。对1847位选民的最高学历与所支持总统候选人进行相应分析。由于该分析通过了卡方检验,所以相应分析的分析结果是有效的。 从图1中可以发现大学本科(bachelor)层次的选民最支持Bush,其次是高中(high school)层次的选民。Clinton更受研究生(graduate degree)层次的选民的青睐,而Perot的支持者更多是专科学历者(junior college)。大学本科和高中学历的选民是普通选民所拥有的最普遍学历,也就是说得到的支持中这部分学历的选民最多的话,也就可以说明这个人得到了相对大多说人的支持。 相应的对选民的年龄与所支持的总统候选人间进行相应分析的结果可以看出,年龄在45-64岁之间的选民最支持Clinton,35-44岁的选民其次,这部分选民相对而言更多的选择了支持Bush。Clinton与Bush更多的赢得的是中年人的支持,其中Clinton赢得了相对较多的老年群体的票数支持。Perot与两名竞争对手在支持选民年龄上显示了很大不同,支持他的选民相对年轻化,且选民随之年龄的增长逐渐减少,超过65岁的选民几乎没有支持者。 3.模型结果分析。以上模型分析了该定性数据的显著特点与有趣的分类,知道了选民在最高学历与年龄的不同上对所支持政客不同的相对应分析,让我们从新认识了这组定性数据。通过以上实证分析模型证实利用相关分析的方法可以对定性数据进行有效合理的分析,使得我们更好的对定性数据进行理解。由于定性数据本身的特点,使得我们不能很好的直接通过定性数据本身观测、理解和使用定性数据,但是借助于相关分析,我们可以透过定性数据难以分析的数据特点来理解定性数据,使数据为研究服务。 四、结论与建议 1.结论。定性数据不应只通过数据表面的观测进行分析,由于定性数据自身性质会给相关研究带来误导性信息且不准确。所以定性数据的统计研究方法为统计研究做出了重要贡献。虽然定性数据在问卷调查的应用中还是相对突出的,但是了解和学会定性数据的分析方法可以使你在任何数据的面前不再担心它的种类,都能做到游刃有余。 定性数据的分析理论正在迅速发展,一些相关理论已经相当成熟,但要深入分析,仍需不断探索新理论与新方法。分析定性数据的对数线性模型、结构方程模型和相应分析方法都已相对成熟,而非线性主成分分析方法仍在起步,需要更多的研究与实证支持。 2.建议。由于定性数据的多样性,可以在分析定性数据时使用多种分析方法,以便正确数据所包含信息。定性数据和定量数据一般都是相互结合使用,互相融合,共同发展的,定性数据在数量化之后也属于定量数据,所以在发展定性数据统计研究方法的同时,定量数据的统计研究方法也会相应进步,相互取长补短。定性数据的分析方法仍然满足不了数字化的发展,对新方法的创新仍是耽误之急。希望完善以前好用的方法,不断创新新方法。 参考文献: [1]葛新锋.有序数据的多元分析模型及实证研究[D].山西财经大学,2009. [2]王静龙、梁小筠.定性数据统计分析[M].中国统计出版社,2008. [3]朱建平.应用多元统计分析[M].科学出版社,2013. [4]王济川,王小倩,姜宝法.结构方程模型:方法与应用[M].高等教育出版社,2011. [5]Donald J. Treiman.量化数据分析:通过社会研究检验想法[M].社会科学文献出版社,2012. 作者简介:刘洋(1989—),女,吉林东丰人,西安财经学院2013级统计学专业研究生,研究方向:经济统计。 2014年·8月·中期经营管理者 学 术 理 论 经营管理者 Manager' Journal 207 第五章定性资料的统计描述 【思考与练习】 一、思考题 1.应用相对数时需要注意哪些问题? 2. 为什么不能以构成比代替率? 3. 标准化率计算的直接法和间接法的应用有何区别? 4. 常用动态数列分析指标有哪几种?各有何用途? 5. 率的标准化需要注意哪些问题? 二、案例辨析题 某医生对98例女性生殖器溃疡患者的血清进行检测,发现杜克雷氏链杆菌、梅毒螺旋体和人类单纯疱疹病毒2型病原体感染患者分别是30、51、17例,于是该医生得出结论:女性生殖器溃疡患者3种病原体的感染率分别为30.6%(30/98)、52.0%(51/98)和17.4%(17/98)。该结论是否正确?为什么? 三、最佳选择题 1. 某地2006年肝炎发病人数占当年传染病发病人数的10.1%,该指标为B A. 率 B. 构成比 C. 发病率 D. 相对比 E. 时点患病率 2. 标准化死亡比SMR是指A A. 实际死亡数/预期死亡数 B. 预期死亡数/实际死亡数 C. 实际发病数/预期发病数 D. 预期发病数/实际发病数 E. 预期发病数/预期死亡数 3. 某地人口数:男性13,697,600人,女性13,194,142人;五种心血管疾病的死 亡人数:男性16774人,女性23334人;其中肺心病死亡人数:男性13952人,女性19369人。可计算出这样一些相对数: 11395283.18%16774 p ==, 21395219369 83.08%1677423334p +==+, 313952 101.86/1013697600 p = =万, 416774122.46/1013697600p = =万,523334 176.85/1013194142 p = =万, 645p p p =+ 71395219369 123.91/101369760013194142 p += =+万 81677423334 149.15/101369760013194142 p += =+万 该地男性居民五种心血管疾病的死亡率为D A. 1p B. 2p C. 3p D. 4p E. 5p 4. 根据第3题资料,该地居民五种心血管病的总死亡率为E A. 1p B. 2p C. 5p D. 6p E. 8p 5. 根据第3题资料,该地男、女性居民肺心病的合计死亡率为D A. 2p B. 5p [模拟] 计数资料的统计学分析 A型题题干在前,选项在后。有A、B、C、D、E五个备选答案其中只有一个为最佳答案。 第1题: 计数资料又称如下哪一种资料 A.数量资料 B.抽样资料 C.普查资料 D.调查资料 E.定性资料 参考答案:E 答案解析: 第2题: 计数资料是指将观察单位按下列哪一种分组计数所得的资料 A.数量 B.体重 C.含量 D.属性或类型或品质 E.放射性计数 参考答案:D 答案解析: 第3题: 计数资料的初步分析常常要用下列哪些相对数 A.频数 B.频数和频率指标 C.率、构成比和相对比 D.构成指标和相对比 E.比和构成比 参考答案:C 答案解析: 第4题: 频率指标,它说明某现象发生的如下哪一种 B.强度 C.比重大小 D.例数 E.各组的单位数 参考答案:B 答案解析: 第5题: 构成指标,它说明一事内部各组成部分所占的如下哪一种大小 A.比重 B.强度 C.频数 D.频率 E.例数 参考答案:A 答案解析: 第6题: 对480人进行老年性白内障普查,分60岁一、70岁一和80岁一三个年龄组受检人数分别为300、150和30人,白内障例数分别为150、90和24人。回答70岁一年龄组的患病率(%)是多少 A.5 B.50 C.60 D.80 E.20 参考答案:C 答案解析: 第7题: 对1000人进行老年性白内障普查,分50岁一和60岁一两个年龄组,受检人数分别为480人和520人,白内障例数分别为120人和280人。回答患者50岁一年龄构成比(%)是多少 A.53.9 B.12 C.30 D.28 参考答案:C 答案解析: 第8题: 在计数资料计算相对数时,应注意如下哪些问题 A.分母不宜过大 B.可比性 C.随机性 D.分母不宜过小 E.分母宜中 参考答案:D 答案解析: 第9题: 在计数资料进行相对数间比较时,应注意如下哪些问题 A.分母不宜太小 B.可比性 C.可用频率指标代替构成指标 D.随机性和正态分布 E.其可比性和遵循随机抽样 参考答案:E 答案解析: 第10题: X2检验是要计算检验统计量X2值、X2值是反应如下哪种情况 A.实际频数大于理论频数 B.理论频数大于实际频数 C.实际频率和理论频率的吻合程度 D.实际频数和理论频数的吻合程度 E.实际频率大于理论频率 参考答案:D 答案解析: 第11题: X2值愈大,则X2值的概率P值如下哪种情况 统计学》期末重点 1. 统计学的类型和不同类型的特点 统计数据;按所采用的计量尺度不同分; (1)(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述; (2)(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。它也是有类别的,但这些类别是有序的。 (3)(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。统计数据;按统计 数据都收集方法分; (4)观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。 (5)实验数据:在实验中控制实验对象而收集到的数据。统计数据;按被描述的现象与实践的关系分; (6)截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。 (7)时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。 2. 变量的题型 第10 页,习题1.1 (1)年龄:数值型变量 (2)性别:分类变量 (3)汽车产量:离散型变量 (4)员工对企业某项改革措施的态度(赞成、中立、反对):顺序变量 (5)购买商品时的支付方式(现金、信用卡、支票):分类变量 3.随机抽样(概率抽样)的抽样方式。 (1)简单随机抽样 (2)分层抽样:就是抽样单位按某种特征或者某种规则划分为不同的层,然后从不同的层中独立、随机地 抽取样本。将各层的样本结合起来,对总体目标量进行估计。 (3)整群抽样: (4)系统抽样 (5)多阶段抽样 分层抽样与整群抽样的区别: 分层抽样的层数就是样本容量;整群抽样的群中单位的个数就是样本容量 4.非概率抽样的几种类型 (1)方便抽样 (2)判断抽样 (3)自愿样本 (4)滚雪球抽样 滚雪球抽样往往用于对稀少群体的调查。在滚雪球抽样中,首先选择一组调查单位,对其实施调查后,再请他们提供另外一些属于研究总特的调查对象,调查人员根据调查线索,进行此后的调查。这个过程持续下去,就会形成滚雪球效应。 优点:容易找到那些属于特定群体的被调查者,调查成本也比较低。 (5)配额抽样 比较概率抽样和非概率抽样的特点,指出各自适用情况概率抽样:抽样时按一定的概率以随机原则抽取样本。每个单位别抽中的概率已知或可以计算,当用样本对总体目标量进行估计时,要考虑到每个单位样本被抽到的概率。技术含量和成本都比较高。如果调查目的在于掌握和研究对象总体的数量特征,得到总体参数的置信区间,就使用概率抽样。 非概率抽样:操作简单,时效快,成本低,而且对于抽样中的统计学专业技术要求不是很高。它适合探索性的研究,调查结果用于发现问题,为更深入的数量分析提供准备。它同样使用市场调查中的概念测试(不需要调查结果投影到总体的情况)。 5.数据预处理内容 数据审核(完整性和准确性;适用性和实效性),数据筛选和数据排序。 6.数据型数据的分组方法和步骤 分组方法:单变量值分组和组距分组,组距分组又分为等距分组和异距分组。分组步骤:(1)确定组数 (2)确定各组组距 3)根据分组整理成频数分布表 7.散点图与饼图的主要用途 饼图是用圆形及圆内扇形的角度来表示数值大小的图形,它主要用于表示一个样本(或总体)中各组成部分的数据占全部数据的比例,对于研究结构性问题十分有用。 散点图是描述变量之间关系的一种直观方法,从中可以大体上看出变量之间的关系形态及关系强度。 定性数据分析第五章课后作业 1、为了解男性和女性对两种类型的饮料的偏好有没有差异,分别在年青人和老 试分析这批数据,关于男性和女性对这两种类型的饮料的偏好有没有差异的问 题,你有什么看法?为什么? 解:(1)数据压缩分析 首先将上表中不同年龄段的数据合并在一起压缩成二维 2X 2列联表1.1 ,合 起来看,分析男性和女性对这两种类型的饮料的偏好有没有差异? 表 1.1 “性别偏好饮料”列联表 二维2X 2列联表独立检验的似然比检验统计量 - 21 n 上的值为0.7032,p 值 为p =P( 2(1) -0.7032) =0.4017 ■ 0.05,不应拒绝原假设,即认为“偏好类型” 与“性别”无关。 (2) 数据分层分析 其次,按年龄段分层,得到如下三维 2X 2X 2列联表1.2,分开来看,男性 和女性对这两种类型的饮料的偏好有没有差异? 表1.2 三维2X 2X 2列联表 在上述数据中,分别对两个年龄段(即年青人和老年人)进行饮料偏好的调 查,在“年青人”年龄段,男性中偏好饮料A 占58. 73%偏好饮料B 占41.27%; 女性中偏好饮料A 占58. 73%偏好饮料B 占41.27%,我们可以得出在这个年 龄段,男性和女性对这两种类型的饮料的偏好有一定的差异。 同理,在“老年人” 年龄段,也有一定的差异。 (3) 条件独立性检验 为验证上述得出的结果是否可靠,我们可以做以下的条件独立性检验。 即由题意,可令C 表示年龄段,0表示年青人,C 2表示老年人;D 表示性别,D ! 表示男性,D 2表示女性;E 表示偏好饮料的类型,E !表示偏好饮料A, E 2表示 偏好饮料B 。欲检验的原假设为:C 给定后D 和E 条件独立 按年龄段分层后得到的两个四格表,以及它们的似然比检验统计量 -21 n 上的值 如下: 条件独立性检验问题的似然比检验统计量是这两个似然比检验统计量的和, 其值 -2ln 上=6.248 11.822 =18.07 由于r = c = t = 2,所以条件独立性检验的似然比检验统计量的渐近 2分布的自 由度为r(c-1)(t-1) =2,也就是上面这 2个四格表的渐近 2分布的自由 G 层 -2ln 上=6.248 C 2层 -2ln 上=11.822 第五章定性资料的统计描述 欧阳光明(2021.03.07) 【思考与练习】 一、思考题 1.应用相对数时需要注意哪些问题? 2. 为什么不能以构成比代替率? 3. 标准化率计算的直接法和间接法的应用有何区别? 4. 常用动态数列分析指标有哪几种?各有何用途? 5. 率的标准化需要注意哪些问题? 二、案例辨析题 某医生对98例女性生殖器溃疡患者的血清进行检测,发现杜克雷氏链杆菌、梅毒螺旋体和人类单纯疱疹病毒2型病原体感染患者分别是30、51、17例,于是该医生得出结论:女性生殖器溃疡患者3种病原体的感染率分别为30.6%(30/98)、52.0%(51/98)和 17.4%(17/98)。该结论是否正确?为什么? 三、最佳选择题 1. 某地2006年肝炎发病人数占当年传染病发病人数的10.1%,该指标为B A. 率 B. 构成比 C. 发病率 D. 相对比 E. 时点患病率 2. 标准化死亡比SMR 是指A A. 实际死亡数/预期死亡数 B. 预期死亡数/实际死亡数 C. 实际发病数/预期发病数 D. 预期发病数/实际发病数 E. 预期发病数/预期死亡数 3. 某地人口数:男性13,697,600人,女性13,194,142人;五种心血管疾病的死亡人数:男性16774人,女性23334人;其中肺心病死亡人数:男性13952人,女性19369人。可计算出这样一些相对数: 11395283.18%16774p = =, 21395219369 83.08% 1677423334p +==+, 313952 101.86/1013697600p ==万 , 416774122.46/1013697600p ==万, 523334 176.85/1013194142p = =万 , 645p p p =+ 该地男性居民五种心血管疾病的死亡率为D A.1p B. 2p C.3p D.4p E. 5p 4. 根据第3题资料,该地居民五种心血管病的总死亡率为E 定性数据的图表描述分析 内容摘要:数据的整理是为下一步对数据描述和分析打好基础。实际上在企业管理中有很多问题和现象无法通过数值直接表示出来,因此人们经常使用定性数据来反映对应的定类或定序变量的值。下面我们介绍如何用图表对定类和定序变量的定性数据值进行整理和描述。本文通过对单变量和多变量定型数据的图形描述来实现对定性数据图表的全面分析。首先,我们简单介绍一下定性数据的整理;其次我们从单变量定性数据的图标描述着眼,具体可分为条形图、饼图、累积频数分布表和帕累托图。最后我们从多变量定性数据的图形描述着眼,具体可分为环形图、交叉表和多重条形图。这就是本文的全部内容介绍。 关键词:定性数据;单变量;多变量;图表描述 Content abstract: the data of the data for the next step is described and analyzed. Actually has a lot of problems and phenomena in the enterprise management can't directly by numerical representation, so people often use qualitative data to reflect the corresponding nominal or ordinal variable's value. We introduce how to use the chart below for nominal and ordinal variables in order and description about the qualitative data values. Based on univariate and multivariate finalize the design of the data graph description to achieve comprehensive analysis of the qualitative data chart. First, we make a brief introduction of qualitative data sorting; Secondly we from single variable on the basis of the icon description of qualitative data, the concrete can be divided into bar chart, pie chart, cumulative frequency distribution table and pareto chart. We finally on the basis of the graph description of qualitative data from multiple variables, concrete can be divided into circular diagram, cross table and multiple bar chart. This is the entire contents of the introduced in this paper. Keywords: qualitative data; Single variable; Many variables; The chart description 第五章 定性资料的统计描述 在医学研究与实践中,大量资料都是按照事物的特征或属性进行分类的,这类资料称为定性资料,也称分类资料或计数资料。如性别、HIV 感染情况、病情轻重等都属于分类资料。对于这类资料,其绝对数往往不便于进行相互比较。例如甲医院某年因某病死亡105人,同年乙医院因该病死亡185人。但不能据此认为乙医院该病的死亡情况比甲医院严重,因为两医院因该病住院的人数不一定相等,此时需要采用相对数指标进行统计描述。 第一节 常用相对数及其应用 相对数是两个有关联的数值之比,常用的相对数指标有率、构成比和相对比三种。 一、率 率是指某现象实际发生数与某时间点或某时间段可能发生该现象的观察单位总数之比,用以说明该现象发生的频率或强度。根据计算公式中分母的观察单位总数是否引入时间因素,率包括频率和速率两类指标。 频率(frequency)计算中,分母没有引入时间因素,无时间量纲,分子是分母的一部分,其取值在0~1之间,如常见的发病率、患病率、病死率、治愈率等指标,都属于频率型指标,其实质是比例,在流行病学中也常称为累积发生率。其计算公式可表达为: K = ?同时期实际发生某现象的观察单位数 频率某时期可能发生某现象的观察单位总数 (5.1) 式中,K 为比例基数,可以是100%、1000‰、100000/10万等。比例基数的选择主要根据习惯用法或使计算结果保留1~2位整数,以便阅读。 例5.1 为研究吸烟与肺癌的关系,某医生收集了2003~2005年286例住院肺癌患者的吸烟史,吸烟的肺癌患者有166例,而同时期同年龄段的1855名非肺癌患者中,吸烟的有407例。试计算该资料中肺癌患者与非肺癌患者的吸烟率。 由式(5.1),肺癌患者的吸烟率=166/286100%=58.04%?,非肺癌患者吸烟率=407/1855100%=21.94%?,肺癌患者的吸烟率比非肺癌患者的吸烟率高36.1%。 速率(rate)是带有时间因素的频率,根据数理统计的定义是指随时间变化而 浅谈统计分析中的定量与定性 随着现代社会的发展,统计分析在具体的实践工作中得到广泛的应用,但将统计分析应用于工作实践中时,必须对定量分析与定性分析的关系问题有一个系统的认识和正确的把握,这样才能使统计分析在具体的工作中发挥其良好的作用,取得最佳的工作效果。 一、定量分析与定性分析的起源 作为社会实践发展产物的定量分析与定性分析是人们在认识事物过程中的两种理性思维分析方式。 定性分析的概念最早起源于古希腊,古希腊时代的一批著名的学者对定性分析的理念进行了很好的展开研究。早期古希腊的学者们在自己的研究领域中,都是给予自己所研究的自然世界以物理解释。例如著名的学者亚里士多德,在他的一生中研究过许许多多的自然现象,但在他的著作中对其发现的每个自然定理都是给出了一些性质定义,而没有用一个明确的数学公式,所进行的都是一些定性的研究。虽然这些定性分析的认识对人们认识感官世界发挥了极其重要的作用,但是这种认识只是感性的停留于事物表象的缺乏深入思考基础的一种认识方法。 在历史实践的发展过程中,定量分析出现于定性分析之后,其较之定性分析的优势是很明显的,它把事物定义在了人类能理解的范围,由量而定性。第一个将定量分析作为一种分析问题的基础思维方式的学者是伽利略,伽利略第一次在自己的研究领域中全面展开使用了定量分析的思维方法。在他研究的方方面面之中,他以实验、数学符号、公式等准确定量的东西取代了以前人们对事物原因和结果进行主观臆测成分居多的分析。可以这样说,“伽利略追求描述的决定是关于科学方法论的最深刻最有成效的变革。它的重要性,就在于把科学置于科学的保护之下。”数学本身是一门关于量的科学,只有当科学在成功地运用了数学的时候,才能称得上是一门科学。从整个理性发展的过程来看,伽利略提出的以定量代替定性的科学方法,是一个使人类的认识对象由模糊变得清晰起来,由抽象变得具体的过程,使得人类的理性在定性之上又增加了定量的特征,使得如空间、时间、重量、速度、加速度、能量等一些全新的量化概念,在一定的领域和范围内替代了那些与定量无关的概念,使理性思维进行了深刻的变革,上升到了另一个理性高度。 二、定量分析与定性分析的整体统一性 要想合理地运用定量分析与定性分析,就要准确全面地认识定量分析与定性 第十二章 简介定性资料的统计分析 本章不是全面的介绍这方面的理论、方法和应用,而是初步反映一下这方面的主要内容,目的是展示进一步可学的知识,以便更好地解决实际问题。 §12.1 定性变量数量化 前面几章所介绍的各种统计方法,主要是研究与定量变量(或称间隔尺度变量)有关的问题,但在实际应用中,往往不可避免地要涉及到定性变量(或称名义尺度变量),例如人的性别、职业、天气状态,经济工作中选择的政策以及地层的构成类型等等,这些变量都只有各种状态的区别,而没有数量之区别。若定性变量不进入数学关系式,则会丢失信息,若要进入,又难于直接参加运算,于是从20世纪五十年代起开始发展了数量化理论,首先应用于“计量社会学”,六十年代后,逐步应用于各种学科,随着电子计算机的普及和发展,数量化理论将会在自然科学和社会科学的许多方面发挥出更大的作用。 如何对定性变量给以相应的数值描述,从而进行有关的统计分析,这就是数量化理论所研究的主要内容。 数量化理论已有专著出版,本节为了应用上的需要,仅介绍常用的0-1赋值法。 例如定性变量是性别,记为X ,如此赋值: ?? ?=???=当性别为男 当性别为女或当性别为女当性别为男 ,0 ,1X ,0 ,1X 如此赋值的理由是简单,并没有任何数量大小的意义,它仅仅用来说明观察单位的特征 或属性,因此不同特性或属性的观察单位应取不同的值。 例如:天气可取晴、阴、雨三类,则用两个变量(X 1,X 2)表示天气,如此赋值: ?? ? ??=当天气雨当天气阴当天气晴 ),1,0( ),0,1( ),0,0(),(21X X 例如:有多种有害物污染了大气,由于有害物的结构不同,将污染物分为五类地区;甲、 乙、丙、丁、成戊将地区用4个变量(X 1, X 2, X 3, X 4)来表示,如此赋值: ????? ?? ??=戊类地区丁类地区丙类地区乙类地区甲类地区 ),1,0,0,0( ),0,1,0,0( ),0,0,1,0( ),0,0,0,1( ),0,0,0,0(),,,(4321X X X X 综上所述,推广为一般的赋值法如下:若某定性变量可取K 类,则用K -1个变量表示, 如此赋值:16种常用的数据分析方法汇总
统计学教案习题06分类资料的统计描述
分类资料的统计分析(doc 24页)
统计学
定性数据分析第五章课后答案.doc
定性数据的统计分析理论与应用研究_刘洋
医学统计学定性资料统计描述思考与练习带答案
计数资料的统计学分析 (1)
《统计学》重点归纳(20200625174335)
最新定性数据分析第五章课后答案
2021年医学统计学定性资料统计描述思考与练习带答案
定性数据的图表描述分析
定性资料的统计描述
浅谈统计分析中的定量与定性
简介定性资料的统计分析
相关主题
文本预览