IV估计的最优工具变量选取方法
- 格式:pdf
- 大小:494.20 KB
- 文档页数:19



IV估计应用STATA实现IV估计是一种经济计量模型的估计方法,其基本思想是利用外生工具变量来处理内生性问题。
在许多经济学领域中,变量之间存在内生性问题,即自变量与误差项有相关性。
这会导致OLS估计结果的偏误和不一致性。
因此,为了获得一致且有效的估计结果,研究者常常采取IV估计方法。
在STATA中,进行IV估计通常需要执行以下步骤:1.数据准备:首先,需要准备好所需的数据集。
数据集通常包括内生变量、外生变量和工具变量。
确保数据集的准确性和完整性是非常重要的。
2. 检验变量内生性:在进行IV估计之前,需要检验变量之间是否存在内生性。
常用的内生性检验方法包括Hausman检验、Sargan检验和Anderson-Rubin检验等。
在STATA中,可以使用ivendog命令进行检验。
3. 选择合适的工具变量:选择合适的工具变量对于IV估计的成功至关重要。
工具变量应该与内生变量相关,但与误差项不相关。
在STATA中,可以使用ivregress命令来估计IV模型。
4. 进行IV估计:使用ivregress命令来估计IV模型。
该命令的基本语法为:ivregress 2sls 内生变量外生变量 (工具变量),其中2sls是估计方法之一,表示两阶段最小二乘估计方法。
5.评估结果:通过估计结果来评估IV估计的可行性和有效性。
常用的评估指标包括R方值、F统计量、工具变量的合理性等。
此外,还可以进行异方差性检验、序列相关性检验等。
总之,STATA提供了许多方便的命令来实现IV估计,但在实际应用中,研究人员需要仔细选择工具变量并进行内生性检验,以确保估计结果的可靠性。
同时,还应该注意IV估计的局限性和潜在偏误,以充分理解估计结果的影响。

IV估计应用STATA实现IV估计是一种具有统计学假设检验和参数估计功能的方法,常用于处理因果推断问题。
在实践中,STATA是一种广泛使用的统计软件,它提供了丰富的工具和功能来实现IV估计。
下面将介绍如何在STATA中进行IV估计,包括数据准备、IV模型估计、结果解释等。
1.数据准备首先,我们需要准备IV估计所需的数据。
通常,IV估计需要包含以下变量:-被解释变量(Y):需要估计的因果效应或处理效应。
-外生变量(X):存在内生性问题的变量,需要利用工具变量进行拟合。
-工具变量(Z):与内生变量相关,但不受因变量影响的变量。
它必须满足两个条件:与内生变量相关,但与误差项不相关。
-内生变量(W):直接影响被解释变量和内生变量的变量。
2.IV模型估计在STATA中,可以使用两步最小二乘法(2SLS)或广义矩估计(GMM)进行IV估计。
2.1两步最小二乘法(2SLS)估计首先,使用STATA的`regress`命令进行第一步OLS回归,将内生变量(W)作为解释变量,工具变量(Z)作为被解释变量。
例如:```regress W Z```然后,使用`predict`命令获取OLS预测值,并将其保存到新变量“W_hat”中。
例如:```predict W_hat```接下来,使用`regress`命令进行第二步OLS回归,将被解释变量(Y)作为解释变量,外生变量(X)和第一步OLS预测值(W_hat)作为解释变量。
例如:```regress Y X W_hat```通过查看回归结果,我们可以获取IV估计的系数和显著性水平。
2.2广义矩估计(GMM)估计广义矩估计(GMM)是一种更一般的方法,它使用工具变量进行估计。
在STATA中,可以使用`ivregress`命令进行GMM估计。
例如:```ivregress 2sls Y (X = Z) , gmm```其中,`2sls`表示使用两步最小二乘法估计,`(X = Z)`表示外生变量X使用工具变量Z进行估计,`gmm`表示使用广义矩估计进行估计。

政策效应评估的四种主流方法(Policyevaluation)来源:计量经济学#01工具变量法“标准的计量经济学提供了一种处理内生性问题的方法———IV 法。
”Ehrlich(1975,1977)运用时间序列数据和截面数据就美国执行死刑对降低谋杀率的影响进行的研究具有典型性。
Ehrlich 认识到谋杀率与死刑执行率之间的双向因果关系,并试图应用 IV 来解决其内生解释变量和遗漏解释变量的问题。
他选择了此项政策支出的滞后量、总的政府支出、人口、非白人比例等变量作为IV,但并没有解释为什么这些变量是好的 IV,所选出的这些 IV 与内生的解释变量之间又具有怎样的关联。
直至 Ehrlich(1987,1996)的研究出版,其选择 IV 的考虑及相关的因果识别问题才得到详细的阐述。
Angrist (1990)和 Angrist 等(1991)分别用 IV 研究了参加越战对老兵收入的影响和教育背景对收入的影响,从而充分显现了运用 IV 进行因果推断的价值。
Card 等(1992a,1992b)将学生的出生州与出生队列作为 IV,研究了教育投入对教育质量的影响,从而使得教育产出、教育质量领域的研究出现了重大转折。
Bound 等(1995)指出了 Angrist 等(1991)研究中存在的弱工具变量的问题,从而将IV 的效率问题以及IV 的选取准则引入研究。
此后,有关 IV 研究的理论问题都主要集中在如何寻找最优的工具变量上。
工具变量法是一个相对简单的估计方法,但是有两个重要的缺陷:(1) 工具变量的选择问题。
在政策评估问题中,要找出满足条件的工具变量并不容易。
在实践中,尤其是当纵向数据和政策实施前的数据可以获得时,研究者多使用因变量的滞后变量作为工具变量。
但是,这同样会引发相关性,并不能从根本上解决问题。
(2) 如果个体对于政策的反应不同,只有当个体对政策反应的异质性并不影响参与决策时,工具变量才能识别ATT、ATE。
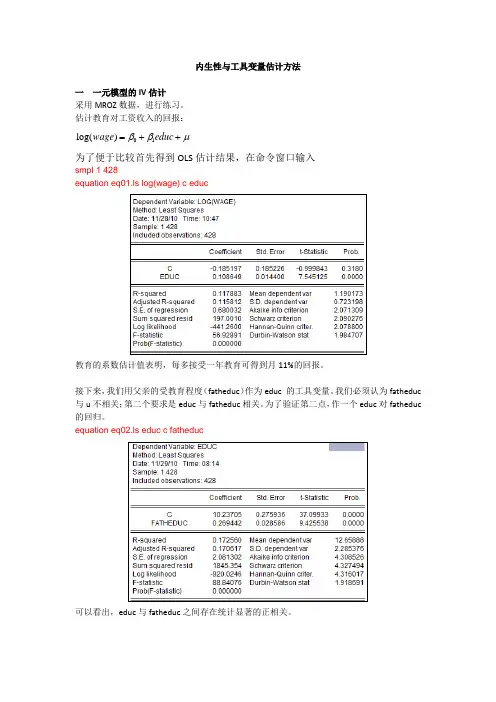
内生性与工具变量估计方法一 一元模型的IV 估计采用MROZ 数据,进行练习。
估计教育对工资收入的回报:01log()wage educ ββμ=++为了便于比较首先得到OLS 估计结果,在命令窗口输入smpl 1 428equation eq01.ls log(wage) c educ教育的系数估计值表明,每多接受一年教育可得到月11%的回报。
接下来,我们用父亲的受教育程度(fatheduc )作为educ 的工具变量。
我们必须认为fatheduc 与u 不相关;第二个要求是educ 与fatheduc 相关。
为了验证第二点,作一个educ 对fatheduc 的回归。
equation eq02.ls educ c fatheduc可以看出,educ 与fatheduc 之间存在统计显著的正相关。
采用fatheduc 作为educ 的工具变量,进行工具变量回归。
equation eq03.tsls log(wage) c educ @ fatheducIV 估计量的标准误是OLS 标准误的2.5倍,这在我们的意料之中。
二 多元模型的IV 估计 采用card 数据,进行练习。
估计教育对工资收入的回报:012log()var wage educ Control iables βββμ=+++为了便于对照,先做OLS 回归 Smpl 1 3010Equation eq01.ls log(wage) c educ exper expersq black smsa south smsa66 reg662 reg663 reg664 reg665 reg666 reg667 reg668 reg669在这个例子中,受教育程度的工具变量是标志着一个人是否在一所四年制大学附近成长的虚拟变量(nearc4)。
为了验证受教育程度与该虚拟变量的偏相关性,先做educ对nearc4以及其他所有外生变量的回归:Equation eq02.ls educ c nearc4 exper expersq black smsa south smsa66 reg662 reg663 reg664 reg665 reg666 reg667 reg668 reg669Nearc4的系数估计值意味着,在其他因素固定的情况下,曾住在大学附近的人所受的教育比不在大学附近长大的人平均多出约1/3年。


应用计量之一——工具变量(IV)本期推文来自首都经贸大学朱超的博客,关于上海对外经贸大学左翔老师暑期课上工具变量的介绍。
今年上海对外经贸大学李辉文老师和YES团队继续办暑期班(/thread-3742527-1-1.html),一个很好的福利,国内青年经济学者愿意分享的精神值得推广。
一个好的工具变量可以直接MIT博士毕业,可见找工具变量是一件有挑战性的事情。
在我看来,找工具变量是一项有趣的智力活动,除了需要一个人有经济学的素养和逻辑,还需要这个人知识面广,自然、地理、人文、世俗智慧和经验等,通常,这跟一个人熟悉的领域,由长期观察和思考产生的洞见有关。
当然还需要一点运气,学术不是苦思冥想,也许做一个梦,喝一杯下午茶,灵感就闪现了。
工具变量的原理最早出现在菲利普·莱特( Philip G.Wright) 1928年写的书《The Tariff on Animal and Vegetable Oils》里。
为了进一步解释这个原理,首先给出一个典型的线性回归模型:y = β0 + β1x1 + βX + ε (1)这里y为被解释变量,x1为自变量,或者解释变量,也即“因”。
大写的 X 为外生控制项向量( 也即一组假定为外生的其他控制变量,例如年龄、性别等等) ,ε则为误差项。
如果ε与x1不相关,那么我们可以利用OLS 模型对方程进行无偏估计。
然而,如果一个重要变量x2被模型(1) 遗漏了,且x1和x2也相关,那么对β1的OLS 估计值就必然是有偏的。
此时,x1被称作“内生”的解释变量,这就是“内生性”问题。
遇到“内生性”问题肿木办?有一个方法就是找工具变量Z。
工具变量(IV)可以用来解决1 )遗漏变量偏差2)经典的测量误差问题3)联立性(逆向因果)工具变量的条件·变量z可以作为变量x的有效工具变量,当满足:·工具变量必须外生·即, Cov(z,u) = 0·工具变量必须与内生变量x相关·即, Cov(z,x) ≠0 Cov(z,u) = 0无法验证,Cov(z,x) ≠0可以验证对工具变量的两个要求之间有一个非常重要的差别。

工具变量的标准工具变量在经济学和社会科学研究中起到至关重要的作用,它们用于处理内生性问题,即某种变量可能与因果变量以及其他自变量之间存在内在的相关性。
本文将从工具变量的定义、选择、标准以及使用等方面进行探讨。
工具变量(Instrumental Variables, IV)是一种经济学中用于解决内生性问题的技术手段。
内生性问题主要指的是观测数据中存在的内在的相关性,导致无法直接得到准确的因果关系。
例如,假设我们想研究教育对收入的影响,但由于教育与个体能力水平以及其他影响收入的因素存在共同决定因素,因此无法准确地测量教育对收入的独立影响。
在这种情况下,工具变量可以帮助我们解决内生性问题。
工具变量可以看作是对内生性问题的一个解决方案,它是一种可以从外部影响因果关系的变量。
通过使用工具变量,我们可以利用这种外部影响来估计原始因果效应,而不会受到内生性问题的影响。
工具变量的基本思想是通过利用这种外部影响,将原始内生性问题转化为一个外生性问题,进而得到更准确的因果关系估计。
在选择工具变量时,需要满足一些标准。
首先,工具变量与内生变量之间应该存在一定的相关性,即工具变量对内生变量有一定的影响。
如果工具变量与内生变量没有相关性,那么它就不能有效地解决内生性问题。
其次,工具变量与误差项之间应该不存在相关性。
如果工具变量与误差项之间存在相关性,那么工具变量就不能满足外生性的要求,从而无法有效地解决内生性问题。
此外,工具变量应该具有足够的异质性,即工具变量对不同个体的影响程度应该有所不同。
如果工具变量没有足够的异质性,那么它不能提供有效的“随机试验”条件,无法解决内生性问题。
在实际应用中,我们常常使用一些统计测量指标来评估工具变量是否符合标准。
例如,工具变量的相关性通常可以通过计算工具变量与内生变量之间的相关系数来衡量。
同时,我们可以使用所谓的第一阶段回归来检验工具变量与内生变量以及其他控制变量之间的相关性。
另外,工具变量也需要满足一些经济学上的合理性标准。

计量经济学工具变量IVSLS计量经济学中的工具变量(Instrumental Variable, IV)和两阶段最小二乘法(TwoStage Least Squares, 2SLS)是解决内生性问题的重要方法。
本文将从基本概念、理论依据、估计方法、应用实例和注意事项等方面,详细阐述IV和2SLS 的内容。
一、基本概念1. 内生性问题内生性问题是指模型中的解释变量与误差项存在相关性,导致普通最小二乘法(Ordinary Least Squares, OLS)估计结果有偏和不一致。
内生性问题的主要来源包括遗漏变量、双向因果关系和测量误差等。
2. 工具变量工具变量(IV)是指与内生解释变量具有相关性,但与误差项不相关的变量。
工具变量的选取应满足以下两个条件:(1)相关性:工具变量与内生解释变量具有相关性,即工具变量可以解释内生解释变量的变动。
(2)外生性:工具变量与误差项不相关,即工具变量不影响被解释变量的变动。
3. 两阶段最小二乘法(2SLS)两阶段最小二乘法(2SLS)是一种利用工具变量估计内生解释变量系数的方法。
2SLS估计过程分为两个阶段:第一阶段:用工具变量代替内生解释变量,对内生解释变量进行回归,得到拟合值。
第二阶段:将第一阶段得到的拟合值代入原模型,用OLS估计模型参数。
二、理论依据1. 内生性问题导致的估计偏误考虑一个简单的线性回归模型:Y = βX + ε其中,Y为被解释变量,X为解释变量,β为参数,ε为误差项。
如果X与ε相关,那么OLS估计的β将是有偏的。
2. 工具变量的有效性假设我们找到了一个工具变量Z,满足以下条件:(1)相关性:Cov(Z, X) ≠ 0(2)外生性:Cov(Z, ε) = 0那么,我们可以使用工具变量Z来估计β。
根据矩条件,我们有:E[(Z E(Z))ε] = 0这意味着Z与ε正交,可以用来消除ε对X的影响。
三、估计方法1. 第一阶段在第一阶段,我们将工具变量Z与内生解释变量X进行回归,得到拟合值X_hat:X_hat = Z (Z'Z)^(1)Z'X2. 第二阶段在第二阶段,我们将第一阶段得到的拟合值X_hat代入原模型,用OLS估计模型参数:Y = βX_hat + εβ_hat = (X_hat'X_hat)^(1)X_hat'Y四、应用实例以下是一个应用IV和2SLS估计的实例:考虑一个教育对收入影响的模型:Y = βX + ε其中,Y为收入,X为教育水平。

stata中工具变量法在Stata 中,工具变量法(Instrumental Variables, IV)是一种处理内生性(endogeneity)问题的方法,通常用于解决因果关系中的回归模型。
内生性问题指的是模型中的某些变量可能与误差项相关,从而导致OLS估计结果的偏误。
工具变量法通过引入一个或多个外生性足够相关但与误差项不相关的变量(称为工具变量)来解决这个问题。
以下是在Stata 中使用工具变量法的一般步骤:1. 确定内生性问题:确定模型中是否存在内生性问题,即某些解释变量与误差项相关。
2. 选择工具变量:选择足够相关但与误差项不相关的工具变量。
这些变量通常被认为是外生的,与误差项独立。
3. 估计工具变量模型:使用Stata 中的`ivregress` 命令估计工具变量模型。
语法如下:```stataivregress 2sls dependent_variable (endogenous_variable = instruments) other_exogenous_variables```其中,`dependent_variable` 是因变量,`endogenous_variable` 是内生变量,`instruments` 是工具变量,`other_exogenous_variables` 是其他外生变量。
例如:```stataivregress 2sls y (x = z) controls```4. 检验工具变量的有效性:使用`ivregress` 命令的`ivendog` 选项来检验工具变量的有效性。
```stataivregress 2sls y (x = z) controls, ivendog(x)```此命令将进行工具变量的内生性检验。
5. 诊断:进行模型诊断,检查模型的合理性和有效性。
工具变量法工具变量法具体步骤工具变量法目录概念某一个变量与模型随机解释变量高度相关,但却不与为丛藓科扭口藓项相关,那么就可以用此变量与模型中相应回归系数的一个一致估计量,这个变量就称为方法变量,这种估计方法就叫工具基本原理变量法。
缺点工具变量法的关键是选择一个有效的优先选择工具变量,由于工具自变量变量可以选择中的困难,工具变量法本身存在两方面不足:一是由于工具变量不是惟一的,因而工具变量估计量有一定的任意性;其二由于误差项实际上是不可观测的,因而要寻找严格意义上与误差项无关的与所替代而随机解释变量高度相关的变量总的来说事实上是困难的。
工具变量法与内生解释变量可持续性解释变量会造成解读严重的后果:不一致性inconstent 和有偏biased ,因为频域不满足误差以解释线性为条件的期望值为0。
产生解释变量招盛纯一般有三个原因:一、遗漏变量二、测量误差三、联立性第三种情况是无法逐步解决的,前两种可以采用工具变量(IV )法。
IV 会带来的唯一坏处是估计方差的增大,也就是说同时采用OLS 和IV 估计,则前者的方差小于后者。
但IV 的应用是有前提条件的:1.IV 与内生解释函数相关,2.IV 与u 不相关。
在小样本情况下,一般用内生解释变量对IV 进行回归,如果R -sq 值很小的话,一般t值也很小,所以对IV 质量的评价没有大的风险问题,但是当采用大样本时,情况则相反,往往是t 值很大,而R -sq 很小,这时如果采用t 值进行关键问题评价则可能出现出现问题。
这时IV 与内生解释变量之间的若干程度不是阐释太大,但是如果与u 之间有轻微的相关机构的话,则:1、导致很小的不一致性;2、有偏性,并且这种有偏性随着R -sq趋于0而趋于OLS 的有偏性。
所以现在在采用IV 时最好采用R -sq 或F -sta 作为评价标准,另外为了观测IV 与u 的关系,可以将IV 作为解释变量放入方程进行回归,如果没有其他的系数没有多的变化,则说明IV 满足第二个条件。