
第四节 自相关的诊断与处理
数据来源: 《计量经济学》于俊年 编著 对外经济贸易大学出版社 2000.6 p156
4.1 自相关的诊断 4.1.1图解法
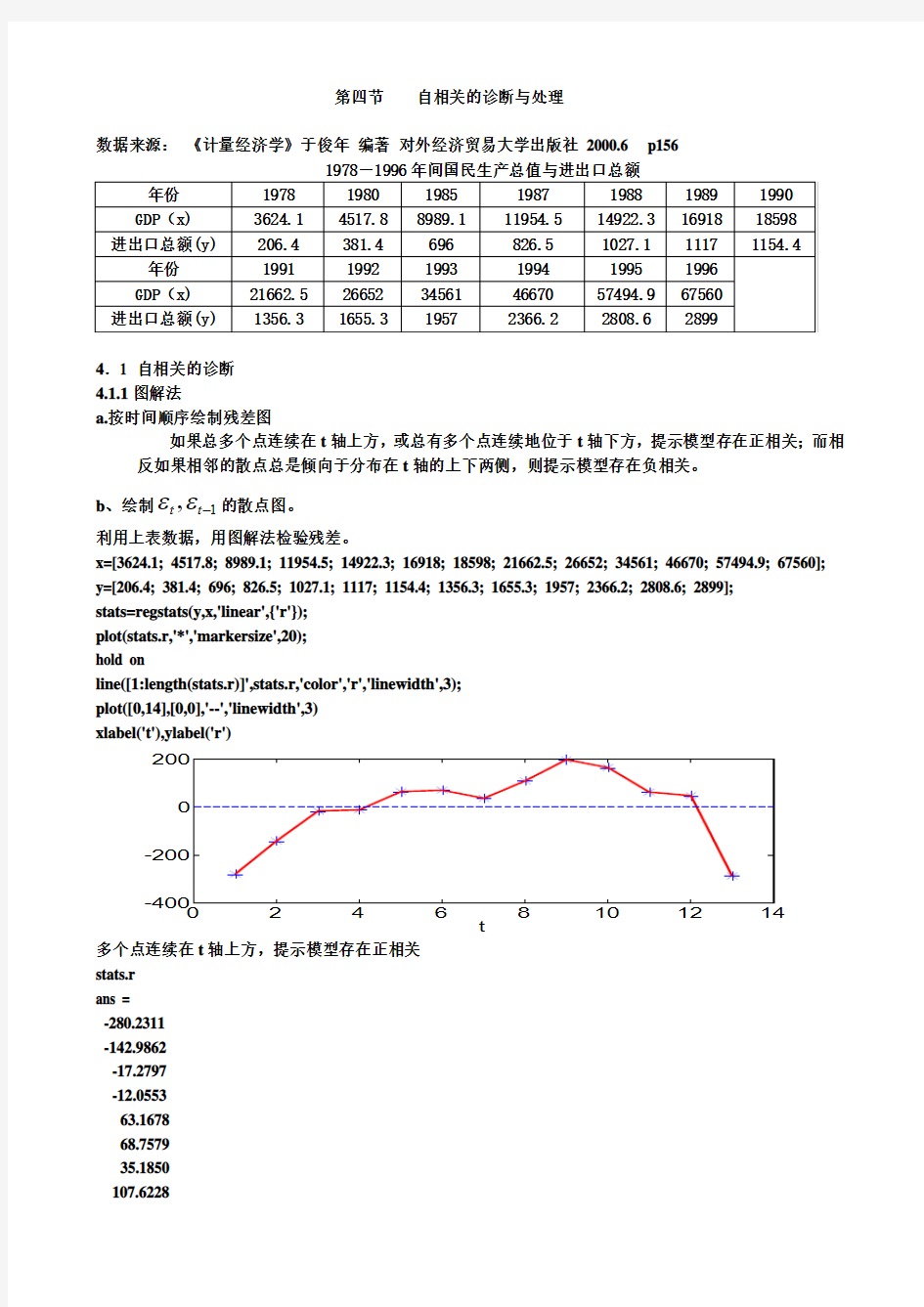
a.按时间顺序绘制残差图
如果总多个点连续在t 轴上方,或总有多个点连续地位于t 轴下方,提示模型存在正相关;而相反如果相邻的散点总是倾向于分布在t 轴的上下两侧,则提示模型存在负相关。 b 、绘制1,-t t ε
ε的散点图。
利用上表数据,用图解法检验残差。
x=[3624.1; 4517.8; 8989.1; 11954.5; 14922.3; 16918; 18598; 21662.5; 26652; 34561; 46670; 57494.9; 67560]; y=[206.4; 381.4; 696; 826.5; 1027.1; 1117; 1154.4; 1356.3; 1655.3; 1957; 2366.2; 2808.6; 2899]; stats=regstats(y,x,'linear',{'r'}); plot(stats.r,'*','markersize',20); hold on
line([1:length(stats.r)]',stats.r,'color','r','linewidth',3); plot([0,14],[0,0],'--','linewidth',3) xlabel('t'),ylabel('r')
t
r
多个点连续在t 轴上方,提示模型存在正相关 stats.r ans =
-280.2311 -142.9862 -17.2797 -12.0553 63.1678 68.7579 35.1850 107.6228
195.8376
163.4158
61.0619
46.1557
-288.6522
lr=lagmatrix(stats.r,1) lr =
NaN
-280.2311
-142.9862
-17.2797
-12.0553
63.1678
68.7579
35.1850
107.6228
195.8376
163.4158
61.0619
46.1557
plot(lr,stats.r,'*','markersize',20); xlabel('lr'),ylabel('r')
lr
r
从图形可知,残差存在正相关。
4.1.2 D-W 检验
dw= (norm(diff(stats.r))).^2/(norm(stats.r)).^2 dw =
0.64811814206819
可知模型存在一阶正相关。
注意:当模型把滞后因变量Y t-1作为一个自变量,D-W 此时失效。可用D-W-h 检验,大样本情形
。
一阶序列相关的估计值为系数的方差,为滞后- Y )
1,0(~)var(11t 33∧
∧∧
∧
??
????
-=ρββρ
N n n
h
当h 的绝对值大于1.96,表明存在一阶自相关。
4.1.3 BG 检验或LM 检验
t
p t p t t t t p t p t p t t t t t t t u u X X u H u u u u u X X Y ερραααρρρερρρβββ++++++==++++=+++=-∧
∧
-∧
∧∧
--- 112312112102211231210
:0
H 不全为===:其中从这个方程得R 2
当样本容量很大时:
()
在自相
时,拒绝原假设,即存大于等于当)()(~)(2
2
22p R p n p R p n αχχ--
BG 检验可检验含有Y t-1、Y t-2等可能作为自变量的模型。BG 检验可以检验高阶自相关,而DW 只能检验一阶自相关。 在本例中,
[bb,bbint,br,rint,stats2]=regress(stats.r,[ones(13,1) lr x]) stats2 =
1.0e+003 *
0.00068209425988 0.00965513918801 0.00000575894145
6.71556078464737 R 2=0.00068209425988
(n-p) R 2=(13-1) R 2=8.185******** p=1-chi2cdf(8.185********,1) p =
0.00422351257693
小于显著性水平0.05,故存在一阶自相关。
同理,也可检验模型是否存在二阶、三阶等高阶自相关。
4.2 自相关的处理 4.2.1 广义差分法
2
2)
1(1)1()21(n
k n k d +-++-=∧
ρ k 为自变量个数,例子中只有一个自变量,k=1 由于做了一次差分,y 和x 的第一个观察值转换为
2
12111ρρ--x y 、
r1=((1-dw/2)+(2/13)^2)/(1-(2/13)^2) r1 =
0.7166
yd=y-lagmatrix(y,1)*r1; xd=x-lagmatrix(x,1)*r1;
y1=[y(1)*sqrt(1-r1^2);yd(2:13,:)]; x1=[x(1)*sqrt(1-r1^2);xd(2:13,:)];
[bx,bxint,rx,rxint,stats1]=regress(y1,[ones(13,1) x1]) bx =
181.3190
0.0344
stats1 =
1.0e+003 *
0.0009 0.1113 0.0000 8.8190
stats2=regstats(y1,x1,'linear',{'tstat','beta','r'}); stats2.tstat.se ans =
44.1375
0.0033
stats2.tstat.pval
ans =
0.0017
0.0000
红色的命令是检验回归系数是否显著。结果表明回归系数显著。
dw1=(norm(diff(rx)))^2/(norm(rx))^2
dw1=1.5718
n=13,d u=1.340,不存在自相关。
181.3190/(1-r1)=639.7307
因此,经过处理自相关的模型为:
y=639.7307+0.0344x
4.2.2 杜宾两步法
b=regress(y,[ones(13,1) lagmatrix(y,1) x lagmatrix(x,1)])
b =
147.0043
0.9444
0.0508
-0.0562
stats3=regstats(y-b(2)*lagmatrix(y,1),x-b(2)*lagmatrix(x,1),'linear',{'tstat','beta','r'}); stats3.tstat.se
ans =
49.1835
0.0062
>> stats3.tstat.pval
ans =
0.0202
0.0027
stats3.tstat.beta
ans =
135.6720
0.0245
rr=stats3.r(2:13,:);dw=(norm(diff(rr)))^2/(norm(rr))^2
dw =
1.8233
查表,d u=1.331,不存在自相关。
135.6720/(1-b(2))=2440.4
因此,最后处理自相关的模型为:
y=2440.4+0.0245x
4.2.3 广义最小平方法
y1=y-0.7166*lagmatrix(y,1);
y1b=[sqrt(1-0.7166^2)*y(1);y1([2:13],:)];
x1=x-0.7166*lagmatrix(x,1);
x1b=[sqrt(1-0.7166^2)*x(1);x1([2:13],:)];
x0b=[sqrt(1-0.7166^2);ones(12,1)*(1-0.7166)];
[b,bint,r,rint,stats]=regress(y1b,[x0b,x1b])
b =
1.0e+002 *
3.33671155944042
0.00039442818880
stats =
1.0e+004 *
0.00011323890666 0.00818603568660 0.00000000019905
1.49196944111691
检验回归系数的显著性:
t=b./sqrt((diag(inv([x0b,x1b]'*[x0b,x1b]))*14919.6944))
t =
2.34021409915385
11.20657679636486
p1= 2*(1-tcdf(t(1),11))
p1 =
0.03915750386630
p2= 2*(1-tcdf(t(2),11))
p2 =
2.342261409271629e-007
在显著水平水平0.01,两回归系数均显著。
由于模型不含有截距项,用BG检验
[bb,bbint,br,rint,stats2]=regress(r,[ones(13,1) lagmatrix(r,1) x])
stats2 =
1.0e+003 *
0.00036112152153 0.00254359303322 0.00013316256851
7.85573887079230
p=1-chi2cdf(0.36112152153*12,1)
p =
0.03737024575375
在显著性水平0.01下,经处理后模型不存在一阶自相关。
4.2.4 Cochrane-Orcutt迭代法
x=[3624.1; 4517.8; 8989.1; 11954.5; 14922.3; 16918; 18598; 21662.5; 26652; 34561; 46670; 57494.9; 67560];
y=[206.4; 381.4; 696; 826.5; 1027.1; 1117; 1154.4; 1356.3; 1655.3; 1957; 2366.2; 2808.6; 2899];
[b,beta,r,rint,stats]=regress(y,[ones(13,1) x]);
dw=(norm(diff(r)))^2/(norm(r))^2
dw =
0.64811814206819
存在自相关。
r1=corr(r,lagmatrix(r,1),'row','complete');
r1 =
0.52450786278612
[bb,bbint,rr,rint,stats]=regress(y-r1*lagmatrix(y,1),[ones(13,1) x-r1*lagmatrix(x,1)])
bb =
1.0e+002 *
2.61202927714807
0.00036463857798
stats =
1.0e+003 *
0.00095470328100 0.21076654159006 0.00000000004784
9.00863292898721
rx=rr(2:13,:);
dw=(norm(diff(rx)))^2/(norm(rx))^2
dw =
1.46703056442554
d u=1.331,不存在自相关。
261.202927714807/(1-0.52450786278612)=5.493317497221115e+002
所以,y=549.33+0.03646x
如果上面的模型还存在自相关,则用y=549.33+0.03646x计算得残差,再估计一阶自相关系数,重复上面的步骤,直到不出出自相关为止。
白噪声的测试MATLAB程序 学术篇 2009-11-13 22:18:03 阅读232 评论0 字号:大中小订阅 clear; clc; %生成各种分布的随机数 x1=unifrnd(-1,1,1,1024);%生成长度为1024的均匀分布 x2=normrnd(0,1,1,1024);%生成长度为1024的正态分布 x3=exprnd(1,1,1024);%生成长度为1024的指数分布均值为零 x4=raylrnd(1,1,1024);%生成长度为1024的瑞利分布 x5=chi2rnd(1,1,1024);%生成长度为1024的kaifang分布%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %求各种分布的均值 m1=mean(x1),m2=mean(x2),m3=mean(x3),m4=mean(x4),m5=mean(x5) %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %求各种分布的方差 v1=var(x1),v2=var(x2),v3=var(x3),v4=var(x4),v5=var(x5) %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %求各种分布的自相关函数 figure(1);title('自相关函数图'); cor1=xcorr(x1);cor2=xcorr(x2);cor3=xcorr(x3);cor4=xcorr(x4);cor5=xcorr(x5); subplot(3,2,1),plot(1:2047,cor1);title('均匀分布自相关函数图'); subplot(3,2,2),plot(1:2047,cor2);title('正态分布'); subplot(3,2,3),plot(1:2047,cor3);title('指数分布'); subplot(3,2,4),plot(1:2047,cor4);title('瑞利分布'); subplot(3,2,5),plot(1:2047,cor5);title('K方分布'); %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %求各种分布的概率密度函数 y1=unifpdf(x1,-1,1); y2=normpdf(x2,0,1); y3=exppdf(x3,1); y4=raylpdf(x4,1); y5=chi2pdf(x5,1); %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %各种分布的频数直方图 figure(2); subplot(3,2,1),hist(x1);title('均匀分布频数直方图'); subplot(3,2,2),hist(x2,[-4:0.1:4]);title('正态分布'); subplot(3,2,3),hist(x3,[0:.1:20]);title('指数分布'); subplot(3,2,4),hist(x4,[0:0.1:4]);title('瑞利分布'); subplot(3,2,5),hist(x5,[0:0.1:10]);title('K方分布'); %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %各种分布的概率密度估计 figure(3);
经济计量分析实验报告 一、实验项目 自相关性的检验及修正 二、实验日期 2015.12.13 三、实验目的 对于国内旅游总花费的有关影响因素建立多元线性回归模型,对变量进行多重共线性的检验及修正后,对随机误差项进行异方差的检验和补救及自相关性的检验和修正。 四、实验内容 建立模型,对模型进行参数估计,对样本回归函数进行统计检验,以判定估计的可靠程度,包括拟合优度检验、方程总体线性的显著性检验、变量的显著性检验,以及参数的置信区间估计。 检验变量是否具有多重共线性并修正。 检验是否存在异方差并补救。 检验是否存在相关性并修正。 五、实验步骤 1、建立模型。 以国内旅游总花费Y 作为被解释变量,以年底总人口表示人口增长水平,以旅行社数量表示旅行社的发展情况,以城市公共交通运营数表示城市公共交通运行状况,以城乡居民储蓄存款年末增加值表示城乡居民储蓄存款增长水平。 2、模型设定为: t t t t t μβββββ+X +X +X +X +=Y 443322110t 其中:t Y — 国内旅游总花费(亿元) t 1X — 年底总人口(万人) t 2X — 旅行社数量(个) t 3X — 城市公共交通运营数(辆) t 4X — 城乡居民储蓄存款年末增加值(亿元) 3、对模型进行多重共线性检验。 4、检验异方差是否存在并补救。 5、检验自相关性是否存在并修正。 六、实验结果
消除多重共线性及排除异方差性之后的回归模型为:2382963.08388.301?X Y +-= 检验 I 、图示法 1、1-t e ,t e 散点图 -1,500 -1,000 -500 500 1,000 1,500 -2,000 -1,00001,0002,000 ET(-1) E T 大部分落在第Ⅰ,Ⅲ象限,表明随机误差项存在正自相关。 2、t e 折线图 -1,500 -1,000 -500 500 1,000 1,500 86 88 90 92 94 96 98 00 02 04 06 08 10 RESID Ⅱ、解析法 1、D-W 检验
1.excel与MATLAB链接: Excel: 选项——加载项——COM加载项——转到——没有勾选项 2. MATLAB安装目录中寻找toolbox——exlink——点击,启用宏 E:\MATLAB\toolbox\exlink 然后,Excel中就出现MATLAB工具 (注意Excel中的数据:)
3.启动matlab (1)点击start MATLAB (2)senddata to matlab ,并对变量矩阵变量进行命名(注意:选取变量为数值,不包括各变量) (data表中数据进行命名) (空间权重进行命名) (3)导入MATLAB中的两个矩阵变量就可以看见
4.将elhorst和jplv7两个程序文件夹复制到MATLAB安装目录的toolbox文件夹 5.设置路径:
6.输入程序,得出结果 T=30; N=46; W=normw(W1); y=A(:,3); x=A(:,[4,6]); xconstant=ones(N*T,1); [nobs K]=size(x);
results=ols(y,[xconstant x]); vnames=strvcat('logcit','intercept','logp','logy'); prt_reg(results,vnames,1); sige=results.sige*((nobs-K)/nobs); loglikols=-nobs/2*log(2*pi*sige)-1/(2*sige)*results.resid'*results.resid % The (robust)LM tests developed by Elhorst LMsarsem_panel(results,W,y,[xconstant x]); % (Robust) LM tests 解释 附录: 静态面板空间计量经济学 一、OLS静态面板编程 1、普通面板编程 T=30; N=46; W=normw(W1); y=A(:,3); x=A(:,[4,6]);
相关分析:主要研究随机变量间的相关形式及相关程度。 回归分析:研究一个变量关于另一个变量的依赖关系的计算方法和理论。 高斯马尔科夫定理:普通最小二乘估计量具有线性性、无偏性和有效性等优良性质,是最佳线性无偏估计量。 高斯马尔科夫假定:(1)模型设立正确 (2)无完全共线性 (3)可识别性 (4) 零均值、同方差。无序列相关假定(5) 解释变量与随机项不相关 计量经济学模型:揭示经济活动中各种因素之间的定量关系,用随机性的数学方程加以描述。广义计量经济学:利用经济理论、统计学和数学定量研究经济现象的经济计量方法的统称,包括回归分析方法、投入产出分析方法、时间序列分析方法等。 狭义计量经济学:以揭示经济现象中的因果关系为目的,在数学上主要应用回归分析方法。计量经济学: 是经济学的一个分支学科,是以揭示经济活动中的客观存在的数量关系为内容的分支学科。 计量经济学模型成功的三要素:理论、方法和数据。 滞后变量模型:把过去时期的,具有滞后作用的变量叫做滞后变量,含有滞后变量的模型称为滞后变量模型。 多重共线性:如果某两个或多个解释变量之间出现了相关性,则称为存在多重共线性。 多重共线性的后果:(1)完全共线性下参数估计量不存在(2)近似共线性下普通最小二乘法参数估计量的方差变大(3)参数估计量经济含义不合理(4)变量的显著性检验和模型的预测功能失去意义。 多重共线性的检验:(1)检验多重共线性是否存在(2)判明存在多重共线性的范围。 克服多重共线性的方法:(1)排出引起共线性的变量(2)差分法(3)减小参数估计量的方差。完全共线性:对于多元线性回归模型,其基本假设之一是解释变量,,…,是相互独立的,如果存在,i=1,2,…,n,其中c不全为0,即某一个解释变量可以用其他解释变量的线性组合表示,则称为完全共线性。 异方差性:对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同,则认为出现了异方差性。 异方差性的后果:(1)参数估计量非有效(2)变量的显著性检验失去意义(3)模型的预测失效异方差性的检验方法:(1)图示检验法(2)帕克检验和戈里瑟检验(3)G-Q检验(4)怀特检验。异方差性的修正:最常用的方法是加权最小二乘法,即对原模型加权,使之变成一个新的不存在异方差的模型,然后采用OLS法估计其参数。 序列相关性:多元线形回归模型的基本假设之一是模型的随机干扰项相互独立或不相关。如果模型的随机干扰项违背了相互独立的基本假设,称为存在序列相关性。 序列相关性的后果:(1)参数估计量非有效(2)变量的显著性检验失去意义(3)模型的预测失败。 序列相关性的检验方法:(1)图示法(2)回归检验法(3)杜宾—瓦森检验法(4)拉格朗日乘法检验。 序列相关性的补救:(1)广义最小二乘法(2)广义差分法(3)随机干扰项相关系数的估计(4)广义差分法在计量经济学软件中的实现。 最小二乘估计量的性质:(1)线形性(2)无偏性(3)有效性(4)渐近无偏性(5)一致性(6)渐进有效性。 最小样本容量:即从最小二乘原理和最大似然原理出发,欲得到参数估计量,不管其质量如何,所要求的样本容量的下限。 随机干扰项:即随机误差项,是一个随机变量,是针对总体回归函数而言的。 无偏性:是指参数估计量的均值(期望)等于模型的参数值。
计量经济学所有检验方法 一、拟合优度检验 可决系数 TSS RSS TSS ESS R - ==12 TSS 为总离差平方和,ESS 为回归平方和,RSS 为残差平方和 该统计量用来测量样本回归线对样本观测值的拟合优度。 该统计量越接近于1,模型的拟合优度越高。 调整的可决系数)1/() 1/(12---- =n TSS k n RSS R 其中:n-k-1为残差平方和的自由度,n-1为总体平方 和的自由度。将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。 二、方程的显著性检验(F 检验) 方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。 原假设与备择假设:H 0:β1=β2=β3=…βk =0 H 1: βj 不全为0 统计量 )1/(/--= k n RSS k ESS F 服从自由度为(k , n-k-1)的F 分布,给定显著性水平α,可得到临 界值F α(k,n-k-1),由样本求出统计量F 的数值,通过F>F α(k,n-k-1)或F ≤F α(k,n-k-1)来拒绝或接受原假设H 0,以判定原方程总体上的线性关系是否显著成立。 三、变量的显著性检验(t 检验) 对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。 原假设与备择假设:H0:βi =0 (i=1,2…k );H1:βi ≠0 给定显著性水平α,可得到临界值t α/2(n-k-1),由样本求出统计量t 的数值,通过 |t|> t α/2(n-k-1) 或 |t|≤t α/2(n-k-1) 来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。 四、参数的置信区间 参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。 统计量 )1(~1??? ----'--= k n t k n c S t ii i i i i i e e βββββ 在(1-α)的置信水平下βi 的置信区间是 ( , ) ββααββ i i t s t s i i -?+?2 2 ,其中,t α/2为显著性 水平为α、自由度为n-k-1的临界值。 五、异方差检验 1. 帕克(Park)检验与戈里瑟(Gleiser)检验 试建立方程: i ji i X f e ε+=)(~2 或 i ji i X f e ε+=)(|~|
我学习了半年的计量经济学,我的起点是零,现在也是略有小成吧。我想如果你想学好计量经济学,根据我的心得,我想应该做到以下几点吧: 第一、我觉得应该好好看看概率论与数理统计部分,因为计量的好多知识,与这部分有关,如果你有那部分还不太熟悉,应该尽量补牢。第二,就是选一本教材,比较主流的就是古扎拉蒂的和伍德里奇的书。我看的是前者的。感觉前者的书写的还是挺通俗易懂的,一些例子还是挺典型的。很适合初学者自学或者跟着老师学习 第三、就是计量和实践是紧密不分的,所以在学习过程中最好做一下题,尤其是课后题。 第四、就是学会一到两种统计学软件,比如SPSS等 如果打好基础的话,想象高级方向学习,可以学习时间序列的知识。总之,计量经济学是一门实用的学科,有时候不必深究为什么这样。就像你只要知道1+1=2就行了,不必追问1+1为什么等于2 看下高铁梅、张晓峒、李子奈的书。他们编的还是不错的。 个人认为只有wooldridge那本书是值得反复读的(是那个初级本,国内译本也很好),古扎拉弟就算了,很多理论上的原因大家学到后来就明白了。古的书我读了两遍,现在早就扔了。但现在依然常常翻阅
WOO.对于开始的人,woo书上的海量例子太宝贵了,而且绝大多数取材于著名论文,值得仔细品味。 学习方法:用随便那个软件(我用SAS)把书中的例子几乎全部做一遍,知道你用的软件所报告的结果中那些重要的东西是怎么来的(不用知道的太精确),该怎么解释。―――书上后来那几章不懂也没关系。数学要求:基础数理统计学(就是一般初级书上附录那些内容),不用懂大样本理论,知道有一致性这个概念就行了,并且记住它是计量经济学中几乎唯一重要的评价统计量的标准。什么无偏啊有效啊都几乎是空中楼阁,达不到的标准。 本人数学稀烂,理解力和记忆力又不好,所以对于学习计量经济学很是吃力,经过半年把书狂啃,终于有点进步,感觉有点进步,回过头来看自己的学习之路,感到有好多地方走弯路了。现把自己学习的经验传上来,以供初学者分享。 第一,不要开始去就看国外的计量经济学,看国内的。国外的教材基本上都是难以短时间看完的大部头书籍,看完要很长时间,无论拿着还是看在眼里都是压力。而且对于翻译过来的东西,不一定翻译
实验6.美国股票价格指数与经济增长的关系 ——自相关性的判定和修正 一、实验内容:研究美国股票价格指数与经济增长的关系。 1、实验目的: 练习并熟练线性回归方程的建立和基本的经济检验和统计检验;学会判别自相关的存在,并能够熟练使用学过的方法对模型进行修正。 2、实验要求: (1)分析数据,建立适当的计量经济学模型 (2)对所建立的模型进行自相关分析 (3)对存在自相关性的模型进行调整与修正 二、实验报告 1、问题提出 通过对全球经济形势的观察,我们发现在经济发达的国家,其证券市场通常也发展的较好,因此我们会自然地产生以下问题,即股票价格指数与经济增长是否具有相关关系? GDP是一国经济成就的根本反映。从长期看,在上市公司的行业结构与国家产业结构基本一致的情况下,股票平均价格的变动跟GDP的变化趋势是吻合的,但不能简单地认为GDP增长,股票价格就随之上涨,实际走势有时恰恰相反。必须将GDP与经济形势结合起来考虑。在持续、稳定、高速的GDP增长下,社会总需求与总供给协调增长,上市公司利润持续上升,股息不断增加,老百姓收入增加,投资需求膨胀,闲散资金得到充分利用,股票的内在含金量增加,促使股票价格上涨,股市走牛。 本次试验研究的1970-1987年的美国正处在经济持续高速发展的状态下,据此笔者利用这一时期美国SPI与GDP的数据建立计量经济学模型,并对其进行分析。 2、指标选择: 指标数据为美国1970—1987年美国股票价格指数与美国GDP数据。 3、数据来源: 实验数据来自《总统经济报告》(1989年),如表1所示:
表1 4、数据处理 将两组数据利用Eviews绘图,如图1、2所示: 图1 GDP数据简图图2 SPI数据简图
< 序列相关实验报告> <1>第一问 D.W.检验 命令: Data y c x Genr lny=log(y) Genr lnx=log(x) Ls lny c lnx
Dependent Variable: LNY Method: Least Squares Date: 12/10/12 Time: 15:39 Sample: 1980 2007 Included observations: 28 Variable Coefficient Std. Error t-Statistic Prob. C 1.588478 0.134220 11.83492 0.0000 LNX 0.854415 0.014219 60.09058 0.0000 R-squared 0.992851 Mean dependent var 9.552256 Adjusted R-squared 0.992576 S.D. dependent var 1.303948 S.E. of regression 0.112351 Akaike info criterion -1.465625 Sum squared resid 0.328192 Schwarz criterion -1.370468 Log likelihood 22.51875 Hannan-Quinn criter. -1.436535 F-statistic 3610.878 Durbin-Watson stat 0.379323 Prob(F-statistic) 0.000000 D.W.检验结果表明,在5%显著性水平下,n=28,k=2(包含常数项),查表得,dl=1.33,du=1.48,由于D.W.=0.379 1.编辑输入某市1991-2011年国内生产总值X 和出口总额Y 、通过OLS 估计法进行回归分析得到线性回归结果 线性回归方程:i X ?0.288354-3398.045i Y ?+= (-1.0118467) (17.5565) --t 统计量 R 2 =0.9419 F=308.2308 2.自相关检验 (1)图示法(e 与e(-1)的散点图、残差序列图、相关图和Q 统计量检验) (2)D .W .检验:给定显著水平a=0.05,得到临界水平值d L =1.22、d U =1.42。从回归分析中查得DW=0.5235 (3)LM 检验 给定显著水平a=0.05,得临界值X2 0.05 (1)=3.84,根据回归结果知n*R2=11.578, 与临界值比较得n*R2>X2 0.05 (1)故认为存在一阶序列相关。 3.序列相关修正 (1)广义差分法 ○1DW =0.5235估计p值为0.74做广义差分,创建新序列DY DX、进行线性回归 对结果做DW 2检验,存在自相关。○2再次做差分p估计值为1-DW 2 /2,创建新序 列LY LX、对回归结果做DW 3 检验,从而得到不存在自相关。○3检验最终结果序列相关性,可得不存在序列相关。 (2)科克栏内-奥克特迭代法 在用OLS估参时同时选择c和X,AR(p)作为解释变量可得参数β 0,β 1, p p 的估计 值,AR(p)即为随即干扰项的p阶自回归。根据DW统计量逐次引入AR(p)直到满意。所以引入AR(1),AR(2)对迭代一次与迭代二次的回归结果分别检验,得迭代二次回归结果不存在自相关。 第一章 1.Econometrics(计量经济学): the social science in which the tools of economic theory, mathematics, and statistical inference are applied to the analysis of economic phenomena. the result of a certain outlook on the role of economics, consists of the application of mathematical statistics to economic data to lend empirical support to the models constructed by mathematical economics and to obtain numerical results. 2.Econometric analysis proceeds along the following lines计量经济学 分析步骤 1)Creating a statement of theory or hypothesis.建立一个理论假说 2)Collecting data.收集数据 3)Specifying the mathematical model of theory.设定数学模型 4)Specifying the statistical, or econometric, model of theory.设立统计或经济计量模型 5)Estimating the parameters of the chosen econometric model.估计经济计量模型参数 6)Checking for model adequacy : Model specification testing.核查模型的适用性:模型设定检验 7)Testing the hypothesis derived from the model.检验自模型的假设 8)Using the model for prediction or forecasting.利用模型进行预测 Step2:收集数据 Three types of data三类可用于分析的数据 1)Time series(时间序列数据):Collected over a period of time, are collected at regular intervals.按时间跨度收集得到 第六章 自相关性 本章教学要求:本章是违背古典假定情况下线性回归描写的参数估计的又一问题。通过本章的学习应达到:掌握自相关的基本概念,产生自相关的背景;自相关出现对模型影响的后果;诊断自相关存在的方法和修正自相关的方法。能够运用本章的知识独立解决模型中的自相关问题。经过第四、五、六章的学习,要求自行选择一个实际经济问题,建立模型,并判断和解决上述可能存在的问题。 第一节 自相关性的概念 一、一个例子 研究中国城镇居民消费函数,其中选取了两个变量,城镇家庭商品性支出(现价)和城镇家庭可支配收入(现价),分别记为CSJTZC 和CSJTSR ,时间从1978年到1997年,n=20。但为了剔除物价的影响,分别对CSJTZC 和CSJTSR 除以物价(用CPI 表示),这里CPI 为城镇居民消费物价指数(以1990年为100%),经过扣除价格因素以后,记 CPI CSJTSR X CPI CSJTZC Y = = 即如下表 回归以后得到的残差为 Dependent Variable: Y Method: Least Squares Date: 10/27/04 Time: 09:39 Sample: 1978 1997 Included observations: 20 Std. Error t-Statistic Prob. Variable Coefficien t C-103.369278.80739-1.3116690.2061 X0.9235510.01603357.603880.0000 3939.341 R-squared0.994605Mean dependent var Adjusted R-squared0.994305S.D. dependent var2124.467 S.E. of regression160.3247Akaike info criterion13.08692 Sum squared resid462671.9Schwarz criterion13.18649 重庆科技学院学生实验报告 五、实验记录与处理(数据、图表、计算等) 一、估计回归方程 工业增加值主要由全社会固定资产投资决定。为了考察全社会固定资产投资对工业 增加值的影响,可使用如下模型:Y i = 1 β β+ i X;其中,X表示全社会固定资产投资, Y表示工业增加值。下表列出了中国1998-2000的全社会固定资产投资X与工业增加值Y的统计数据。 单位:亿元年份固定资产投资X工业增加值Y年份固定资产投资X工业增加值Y 1980910.91996.519915594.58087.1 198********.419928080.110284.5 19821230.42162.3199313072.314143.8 19831430.12375.6199417042.119359.6 19841832.92789199520019.324718.3 19852543.23448.7199622913.529082.6 19863120.63967199724941.132412.1 19873791.74585.8199828406.233387.9 19884753.85777.2199929854.735087.2 19894410.46484200032917.739570.3 199045176858 由此实验结果可知模型估计结果为: Y=668.0114+1.181861X (2.24039)(61.0963) R2=0.994936,R2=0.994669,SE=951.3388,D.W.=1.282353。 二、序列相关性的检验 (1)图示检验法 通过残差与残差滞后一期的散点图可以判断,随机干扰项存在正序列相关性。 (2)回归检验法: 一阶回归检验 t e =0.356978e 1-t +εt 可见该模型存在一阶自相关 (3)D.W 检验法 由普通最小二乘法的估计结果知:D.W.=1.282353。在本例中,在5%的显著性水平下,解释变量个数为2,样本容量为21,查表得DL=1.22,DU=1.42,而D.W.=1.282353,DW 位于下限与上限之间,所以一阶序列相关性不能确定。 三、序列相关的补救 广义差分法估计模型 由D.W.=1.282353,得到一阶自相关系数的估计值ρ=1-DW/2=0.6412 则DY=Y-0.6412*Y(-1), DX=X-0.6412*X(-1);以DY 为因变量,DX 为解释变量,用OLS 法做回归模型,这样就生成了经过广义差分后的模型。 第一节相关分析 1.1协方差 命令:C = cov(X) 当X为行或列向量时,它等于var(X) 样本标准差。 X=1:15;cov(X) ans = 20 >> var(X) ans = 20 当X为矩阵时,此时X的每行为一次观察值,每列为一个变量。cov(X)为协方差矩阵,它是对称矩阵。 例:x=rand(100,3);c=cov(x) c= 0.089672 -0.012641 -0.0055434 -0.012641 0.07928 0.012326 -0.0055434 0.012326 0.082203 c的对角线为:diag(c) ans = 0.0897 0.0793 0.0822 它等于:var(x) ans = 0.0897 0.0793 0.0822 sqrt(diag(cov(x))) ans = 0.2995 0.2816 0.2867 它等于:std(x) ans = 0.2995 0.2816 0.2867 命令:c = cov(x,y) 其中x和y是等长度的列向量(不是行向量),它等于cov([x y])或cov([x,y]) 例:x=[1;4;9];y=[5;8;6]; >> c=cov(x,y) c = 16.3333 1.1667 1.1667 2.3333 >> cov([x,y]) ans = 16.3333 1.1667 1.1667 2.3333 COV(X)、 COV(X,0)[两者相等] 或COV(X,Y)、COV(X,Y,0) [两者相等],它们都是除以n-1,而COV(X,1) or COV(X,Y,1)是除以n x=[1;4;9];y=[5;8;6]; >> cov(x,y,1) ans = 10.8889 0.7778 0.7778 1.5556 它的对角线与var([x y],1) 相等 ans = 10.8889 1.5556 协差阵的代数计算: [n,p] = size(X); X = X - ones(n,1) * mean(X); Y = X'*X/(n-1); Y 为X 的协差阵 1.2 相关系数(一) 命令:r=corrcoef(x) x 为矩阵,此时x 的每行为一次观察值,每列为一个变量。 r 为相关系数矩阵。它称为Pearson 相关系数 例:x=rand(18,3);r=corrcoef(x) r = 1.0000 0.1509 -0.2008 0.1509 1.0000 0.1142 -0.2008 0.1142 1.0000 r 为对称矩阵,主对角阵为1 命令:r=corrcoef(x,y) 其中x 和y 是等长度的列向量(不是行向量),它等于cov([x y])或cov([x,y]),或x 和y 是等长度的行向量,r=corrcoef(x,y)它则等于r=corrcoef(x ’,y ’), r=corrcoef([x ’,y ’]) 例:x=[1;4;9];y=[5;8;6]; corrcoef(x,y) ans = 1.0000 0.1890 0.1890 1.0000 corrcoef([x,y]) ans = 1.0000 0.1890 0.1890 1.0000 C = COV(X) R ij =C(i,j)/SQRT(C(i,i)*C(j,j)) 如:X=[1 2 7 4 ;5 12 7 8;9 17 11 17]; ( )() ( ) ( ) y y x x y y x x 22∑∑∑-?---=r 1.什么是计量经济学?它与经济学、统计学和数学的关系怎样? 答:1、计量经济学是一门运用经济理论和统计技术来分析经济数据的科学和艺术,它以经济理论为指导,以客观事实为依据,运用数学、统计学的方法和计算机技术,研究带有随机影响的经济变量之间的数量关系和规律。2、经济理论、数学和统计学知识是在计量经济学这一领域进行研究的必要前提,这三者中的每一个对于真正理解现代经济生活中的数量关系是必要的,但不充分,只有结合在一起才行。 2计量经济学三个要素是什么? 经济理论、经济数据和统计方法。 3.计量经济学模型的检验包括哪几个方面?其具体含义是什么? 答:(1)经济意义检验,即根据拟定的符号、大小、关系,对参数估计结果的可靠性进行判断(2)统计检验,由数理统计理论决定。包括:拟合优度检验、总体显着性检验。(3)计量经济学检验,由计量经济学理论决定。包括:异方差性检验、序列相关性检验、多重共线性检验。(4)模型预测检验,由模型应用要求决定。包括:稳定性检验:扩大样本重新估计;预测性能检验:对样本外一点进行实际预测。 4.计量经济学方法与一般经济数学方法有什么区别? 答:计量经济学揭示经济活动中各因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各因素之间的理论关系,用确定性的数学方程加以描述。 5.计量经济学模型研究的经济关系有那两个基本特征? 答:一是随机关系,二是因果关系 6.计量经济学研究的对象和核心内容是什么? 答:计量经济学的研究对象是经济现象,是研究经济现象中的具体数量规律。计量经济学的核心内容包括两个方面:一是方法论,即计量经济学方法或者理论计量经济学。二是应用,即应用计量经济学。无论是理论计量经济学还是应用计量经济学,都包括理论、方法和数据三种要素。 7.计量经济学中应用的数据类型怎样?举例解释其中三种数据类型的结构。 答:计量经济模型:WAGE=f(EDU,EXP,GEND,μ) 1)时间序列数据是按时间周期收集的数据,如年度或季度的国民生产总值。 2)横截面数据是在同一时间点手机的不同个体的数据。如世界各国某年国民生产总值。 3)混合数据是兼有时间序列和横截面成分的数据,如1985—2010世界各国GDP数据。 8.建立与应用计量经济学模型的主要步骤有哪些? (1)理论模型的设计(2)样本数据的收集(3)模型参数的估计(4)模型的检验 9.用OLS建立多元线性回归模型,有哪些基本假设? 1、回归模型是线性的,模型设定无误且含有误差项 2、误差项总体均值为零 3、所有解释变量与误差项都不相关 4、误差项互不相关(不存在序列相关性) 5、误差项具有同方差 6、任何一个解释变量都不是其他解释变量的完全线性函数 7、误差项服从正态分布。 10.随机误差项包含哪些因素影响? 所有计量经济学检验方法(全) 计量经济学所有检验方法 一、拟合优度检验 可决系数 TSS RSS TSS ESS R -== 12 TSS 为总离差平方和,ESS 为回归平方和,RSS 为残差平方和 该统计量用来测量样本回归线对样本观测值的拟合优度。 该统计量越接近于1,模型的拟合优度越高。 调整的可决系数 ) 1/() 1/(12---- =n TSS k n RSS R 其中:n-k-1为残差 平方和的自由度,n-1为总体平方和的自由度。将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。 二、方程的显著性检验(F 检验) 方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。 原假设与备择假设: H 0:β1=β2=β3=…βk =0 H 1: βj 不全为0 统计量 ) 1/(/--= k n RSS k ESS F 服从自由度为(k , n-k-1)的F 分布,给定显著性水平α,可得到临界值F α(k,n-k-1),由样本求出统计量F的数值,通过 F>F α(k,n-k-1)或F≤F α (k,n-k-1)来拒绝或接受 原假设H ,以判定原方程总体上的线性关系是否显著成立。 三、变量的显著性检验(t检验) 对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。 原假设与备择假设:H0:β i =0 (i=1,2…k); H1:β i ≠0 给定显著性水平α,可得到临界值t α/2 (n-k-1),由样本求出统计量t的数值,通过 |t|> t α/2(n-k-1) 或|t|≤t α /2 (n-k-1) 来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。 四、参数的置信区间 参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。 1.excel与MATLAB: Excel: 选项——加载项——COM加载项——转到——没有勾选项 2. MATLAB安装目录中寻找toolbox——exlink——点击,启用宏 E:\MATLAB\toolbox\exlink 然后,Excel中就出现MATLAB工具 (注意Excel中的数据:) 3.启动matlab (1)点击start MATLAB (2)senddata to matlab ,并对变量矩阵变量进行命名(注意:选取变量为数值,不包括各变量) (data表中数据进行命名) (空间权重进行命名) (3)导入MATLAB中的两个矩阵变量就可以看见 4.将elhorst和jplv7两个程序文件夹复制到MATLAB安装目录的toolbox文件夹 5.设置路径: 6.输入程序,得出结果 T=30; N=46; W=normw(W1); y=A(:,3); x=A(:,[4,6]); xconstant=ones(N*T,1); [nobs K]=size(x); results=ols(y,[xconstant x]); vnames=strvcat('logcit','intercept','logp','logy'); prt_reg(results,vnames,1); sige=results.sige*((nobs-K)/nobs); loglikols=-nobs/2*log(2*pi*sige)-1/(2*sige)*results.resid'* results.resid % The (robust)LM tests developed by Elhorst LMsarsem_panel(results,W,y,[xconstant x]); % (Robust) LM tests 解释 每一行分别表示: 4.2 序列相关王中昭制作§ 违反了随机扰动项 之间相互独立的假 定,称为序列相关。 ●学习内容: 王中昭制作 ?一、序列相关定义及其类型 ?二、实际经济问题中的序列相关性 ?三、序列相关性的后果 ?四、序列相关性的检验 ?五、序列相关性的修正 王中昭制作 ?1、序列相关(或称自相关)的定义: ?在线性回归模型基本假定4中,我们假设随机扰动项序列的各项之间不相关,如果这一假定不满足,则称之为序列相关。即用符号表示为: j i E Cov j i j i ≠≠=当 0)(),(μμμμ一、序列相关定义及其类型 王中昭制作 ?称为一阶序列相关,即μi =ρμi-1+εi ,,i=1,2,…,n,-1<ρ<1 ?其中ρ称为自协方差系数或者一阶自相关系数。 这是常见的序列相关, 除此之外统称为高阶序列相关。如:μi =ρ1μi-1+ρ2μi-2+εi ,称为二阶序列相关。 1 ,2,1 0)(1-=≠+n i E i i μμ如果仅存在 ●2、类型 王中昭制作 ?1、经济发展的惯性?2、模型设定偏误?3、滞后效应 ?4、对数据的处理可能会导致序列相关? 5、由随机扰动项本身特性所决定 ●二、实际经济问题中的序 列相关性 ●1、经济发展的惯性 王中昭制作 ?大多数经济时间序列都有一个明显的特 点,就是它的惯性。表现在时间序列数据不 同时间的前后关联上。众所周知,GDP、价 格指数、生产、消费、就业和失业等时间序 列都呈现周期循环。相继的观测值很可能是 相互依赖的。这样就导致经济变量的前后期 (或前后若干期)出现相关,从而使随机误 差项相关。 ?这是最常见的序列相关现象。 第五节 多重共线性的诊断与处理 5.1 多重共线性的诊断 数据来源:《计量经济学》于俊年 编著 对外经济贸易大学出版社 2000.6 p208-p209 5.1.1 条件数与病态指数诊断 重共线性。 ,则认为存在严重的多共线性;若或较强的多重,则认为存在中等程度很小;则认为多重共线性程度重共线性。 ,则认为存在严重的多的多重共线性;若或较强 ,则认为存在中等程度度很小;若,则认为多重共线性程阵(不包括常数项) 为自变量的相关系数矩303010,1010001000100100)() ()()(min max 1>≤≤<>≤≤<== ?=-CI CI CI R R CI R R R R R κκκκλλκ 设x 1,x 2,…,x p 是自变量X 1,X 2,…X P ,经过中心化和标准化得到的向量,即: R x x X X X X x T i i i =--= ∑2 )( 记(x 1,x 2,…,x p )为x,设λ为x T x 一个特征值,?为对应的特征向量,其长度为1,若0≈λ,则: 221122110000c X c X c X c x x x x x x x x p p p p T T T T ≈+++?≈+++?≈?≈==?≈= ????λ?λ???λ?? 根据上表,计算如下: x=[149.3, 4.2, 108.1; 161.2, 4.1, 114.8; 171.5, 3.1,123.2; 175.5, 3.1, 126.9; 180.8, 1.1, 132.1; 190.7, 2.2, 137.7; 202.1, 2.1, 146; 212.1, 5.6, 154.1; 226.1,5, 162.3; 231.9, 5.1, 164.3; 239, 0.7, 167.6] 求x 的相关矩阵R 班级:金融学×××班姓名:××学号:×××××××C4.1 voteA=β0+β1log expendA+β2log expendB+β3prtystrA+u 其中,voteA表示候选人A得到的选票百分数,expendA和expendB分别表示候选人A和B的竞选支出,而prtystrA则是对A所在党派势力的一种度量(A所在党派在最近一次总统选举中获得的选票百分比)。 解:(ⅰ)如何解释β1? β1表示当候选人B的竞选支出和候选人A所在党派势力固定不变时,候选人A的竞选支出 (expendA)增加一个百分点时,voteA将增加β1 100。 (ⅱ)用参数表述如下虚拟假设:A的竞选支出提高1% 被B的竞选支出提高1% 所抵消。 虚拟假设为H0∶β1+β2=0 ,该假设意味着A的竞选支出提高x% 被B的竞选支出提高x% 所抵消,voteA保持不变。 (ⅲ)利用VOTE1.RAW中的数据来估计上述模型,并以通常的方式报告结论。A的竞选支出会影响结果吗?B的支出呢?你能用这些结论来检验第(ⅱ)部分中的假设吗? 所以,voteA=45.0789+6.0833log expendA?6.6154log expendB+ 0.1520prtystrA, n=173, R2=0.7926 . 由截图可得:expendA 系数β1的 t 统计量为15.9187,在很小的显著水平上都是显著的,意味着当其他条件不变时,A 的竞选支出增加1%,voteA 将增加0.0608。 同理可得,expendB 系数β2的 t 统计量为-17.4632,在很小的显著水平上都是显著的,意味着当其他条件不变时,B 的竞选支出增加1%,voteA 将增加0.066。 由于A 的竞选支出的系数β1和B 的竞选支出的系数β2符号相反,绝对值差不多,所以近似有虚拟假设“ H 0∶β1+β2=0 ”成立,即第(ⅱ)部分中的假设成立。 (ⅳ)估计一个模型,使之能直接给出检验第(ⅱ)部分中假设所需用的 t 统计量。你有什么结论?(使用双侧对立假设。) 有截图可得:se β 0 =3.9263,se β 1 =0.3821,se β 2 =0.3788,se β 3 =0.0620 . 令θ1=β1+β2,则有:voteA =β0+θ1log expendA + β2[log expendB ?log expendA ]+β3prtystrA +u , 由截图可知:θ1=?0.5321,se θ1 =0.5331, 所以第(ⅱ)部分虚拟假设的 t =?0.53210.5331≈?1, 即 H 0∶β1+β2=0 不能被拒绝。计量经济学 自相关 实验报告
计量经济学(英文)重点知识点考试必备
计量经济学课件:第六章-自相关性
计量经济学序列相关性实验分析
matlab计量经济学 相关分析
计量经济学简答题 经典
所有计量经济学检验方法(全)
六步学会用MATLAB做空间计量回归详细步骤
计量经济学序列相关
第matlab计量经济学多重共线性的诊断与处理
伍德里奇---计量经济学第4章部分计算机习题详解(MATLAB)
相关主题
文本预览