Binder深入讲解 底层 内核实现
- 格式:doc
- 大小:451.50 KB
- 文档页数:38

binder源码解析Binder是Android系统中用于进程间通信(IPC)的核心机制。
它提供了一种高效、可靠的方式,让不同进程之间能够进行数据交换和方法调用。
下面我将从多个角度对Binder源码进行解析。
1. Binder架构,Binder架构包含了Binder驱动、Binder服务和Binder代理三个关键组件。
Binder驱动是底层的驱动程序,负责处理进程间通信的底层细节。
Binder服务是运行在服务端的组件,用于注册和管理Binder对象。
Binder代理是运行在客户端的组件,用于与服务端的Binder对象进行通信。
2. Binder驱动,Binder驱动是Linux内核中的一个模块,负责处理进程间通信的底层操作。
它提供了一组系统调用接口,用于注册和注销Binder对象、发送和接收Binder消息等。
Binder驱动使用了C/C++语言编写,源码位于内核源码树的drivers/android/binder目录下。
3. Binder服务,Binder服务是运行在服务端的组件,用于注册和管理Binder对象。
在Binder服务中,每个Binder对象都有一个唯一的标识符(Binder对象的handle)。
当客户端需要与服务端通信时,它可以通过Binder对象的handle来获取对应的Binder代理对象,并通过Binder代理对象进行数据交换和方法调用。
Binder服务的源码位于frameworks/base/core/java/android/os目录下。
4. Binder代理,Binder代理是运行在客户端的组件,用于与服务端的Binder对象进行通信。
在客户端中,通过Binder对象的handle可以获取到对应的Binder代理对象。
通过Binder代理对象,客户端可以向服务端发送请求、接收响应,并进行数据交换和方法调用。
Binder代理的源码位于frameworks/base/core/java/android/os目录下。
![[IT计算机]androidbinder机制](https://uimg.taocdn.com/eb114ac0cf2f0066f5335a8102d276a20029607a.webp)
Android进程间通信-Binder机制目录一.简要介绍和学习计划二.Service Manager成为Binder守护进程之路三.Server和Client获得Service Manager接口之路四.Server启动过程源代码分析五.Client获得Server远程接口过程源代码分析六.应用程序框架层的Java接口源代码分析一、Android进程间通信(IPC)机制Binder 简要介绍和学习计划我们知道,在Android系统中,每一个应用程序都是由一些Activity和Service组成的,一般Service 运行在独立的进程中,而 不同的Activity有可能运行在同一个进程中,也可能运行在不同的进程中。
这很自然地想到,不在同一个进程的Activity和Service是如何 通信的呢?毕竟它们要协作在一起来完成一个完整的应用程序功能。
这就是本文中要介绍的Android系统进程间通信机制Binder了。
我们知道,Android系统是基于Linux内核的,而Linux内核继承和兼容了丰富的Unix系统进程间通信(IPC)机制。
有传统的管道 (Pipe)、信号(Signal)和跟踪(Trace),这三项通信手段只能用于父进程与子进程之间,或者兄弟进程之间;后来又增加了命令管道 (Named Pipe),使得进程间通信不再局限于父子进程或者兄弟进程之间;为了更好地支持商业应用中的事务处理,在AT&T的Unix 系统V中,又增加了 三种称为“System V IPC”的进程间通信机制,分别是报文队列(Message)、共享内存(Share Memory)和信号量(Semaphore);后来BSD Unix对“System V IPC”机制进行了重要的扩充,提供了一种称为插口(Socket)的进程间通信机制。
若想进一步详细了解这些进程间通信机制,建议参考Android学习启动篇一文中提到《Linux内核源代码情景分析》一书。

binder通信实例-回复Binder通信实例在计算机科学领域中,Binder通信是Android操作系统中用于进程间通信的一种机制。
它允许不同应用程序之间共享数据和功能,以实现更强大的功能集成和交互体验。
本文将以Binder通信实例为主题,逐步介绍Binder通信的原理和应用。
首先,我们需要了解Binder通信的基本原理。
Binder是一种轻量级的进程间通信机制,通过它,可以在不同的进程间传输数据和调用远程方法。
Binder机制包含了三个核心组件:Binder驱动程序、Binder服务和Binder 代理。
Binder驱动程序是Binder通信的底层实现,它负责管理Binder通道的创建、销毁和数据传输。
在Android系统启动时,Binder驱动程序会加载并初始化。
它提供了两种类型的Binder通道:Binder本地通道和Binder 远程通道。
Binder服务是一个运行在后台的进程,它提供了需要共享的数据和方法。
Binder服务中的数据和方法可以通过Binder代理暴露给其他应用程序使用。
在Binder通信中,Binder服务相当于服务器端,负责接收和处理来自其他应用程序的请求。
Binder代理是运行在客户端的应用程序组件,它用于与Binder服务进行通信。
Binder代理可以通过Binder服务提供的接口实现数据传输和方法调用。
Binder代理相当于客户端,负责向Binder服务发起请求并接收相应的结果。
接下来,我们将通过一个示例来展示Binder通信的具体应用。
假设我们有两个应用程序:应用程序A和应用程序B。
应用程序A需要获取应用程序B中的某个数据,并对其进行处理。
首先,在应用程序B中创建一个Binder服务,用于管理需要共享的数据和方法。
在Binder服务中,我们定义一个接口,包含获取数据和处理数据的方法。
然后,将该接口暴露给其他应用程序使用。
接着,我们在应用程序A中创建一个Binder代理,用于与应用程序B的Binder服务进行通信。


binder机制原理和dds原理Binder机制原理和DDS原理一、Binder机制原理Binder机制是Android操作系统中用于进程间通信(IPC)的一种机制,它提供了一种轻量级的、高效的跨进程通信方式。
1. Binder机制的基本概念和组成部分:Binder机制主要由以下几个组成部分构成:- Binder驱动:位于Linux内核空间,负责底层的进程间通信。
- Binder服务端:运行在服务端进程中,负责提供服务接口。
- Binder客户端:运行在客户端进程中,负责调用服务端提供的接口。
- Binder代理:位于服务端和客户端之间,负责在服务端和客户端之间传输数据和消息。
2. Binder机制的工作原理:Binder机制的工作原理可以分为以下几个步骤:- 客户端调用:客户端通过Binder代理调用服务端提供的接口方法。
- 进程间通信:Binder代理将调用请求封装成一个Binder消息,并通过Binder驱动将消息发送给服务端。
- 服务端响应:服务端接收到Binder消息后,解析消息并调用相应的接口方法进行处理。
- 返回结果:服务端将处理结果封装成一个Binder消息,并通过Binder驱动将消息发送给客户端。
- 客户端接收:客户端接收到服务端返回的消息后,解析消息并获取处理结果。
3. Binder机制的特点:- 跨进程通信:Binder机制可以实现不同进程之间的通信,可以在不同的应用程序之间进行进程间通信。
- 高效可靠:Binder机制底层使用了共享内存和缓冲区技术,可以高效地传输大量数据,同时具有较低的延迟和较高的可靠性。
- 安全性:Binder机制通过权限验证和身份标识来确保通信的安全性,可以防止恶意程序的攻击。
- 支持多线程:Binder机制支持多线程并发访问,可以在多线程环境下进行并发操作。
二、DDS原理DDS(Data Distribution Service,数据分发服务)是一种用于实时系统中的分布式数据通信的标准,它提供了一种可靠、实时的数据传输机制。

android binder 原理AndroidBinder是一种IPC机制,是 Android 系统中非常重要的一部分。
它使得不同进程之间可以通过接口来进行通信,实现了进程间的数据传输,从而让应用程序之间可以互相协作。
Android Binder 主要由以下两个部分组成:Binder 驱动和Binder 服务。
Binder 驱动是位于内核空间的模块,它负责管理进程间通信的核心逻辑。
Binder 服务则是位于用户空间的进程,它负责提供接口,允许其他进程通过 Binder 驱动来进行通信。
Android Binder 采用面向对象的方式来实现进程间通信。
每个Binder 服务都有一个唯一的标识符,称为 Binder ID。
其他进程可以通过 Binder ID 来访问对应的 Binder 服务。
在 Binder 服务中,会定义一些接口,用于提供数据传输和方法调用的功能。
Binder 服务通过 Binder 驱动来进行注册和管理,当其他进程需要访问该服务时,Binder 驱动会将请求传递给对应的 Binder 服务。
Android Binder 采用了一些特殊的机制来实现进程间通信的安全性和效率。
例如,Binder 驱动会对传输的数据进行序列化和反序列化,以确保数据的正确性和一致性。
此外,Binder 驱动还实现了优化机制,能够对频繁的数据传输进行加速,提高传输效率。
总的来说,Android Binder 是 Android 系统中非常重要的一部分。
它实现了进程间通信的功能,让应用程序之间可以互相协作。
对于 Android 开发者来说,理解 Android Binder 的原理,能够更好地进行应用程序的开发和优化。
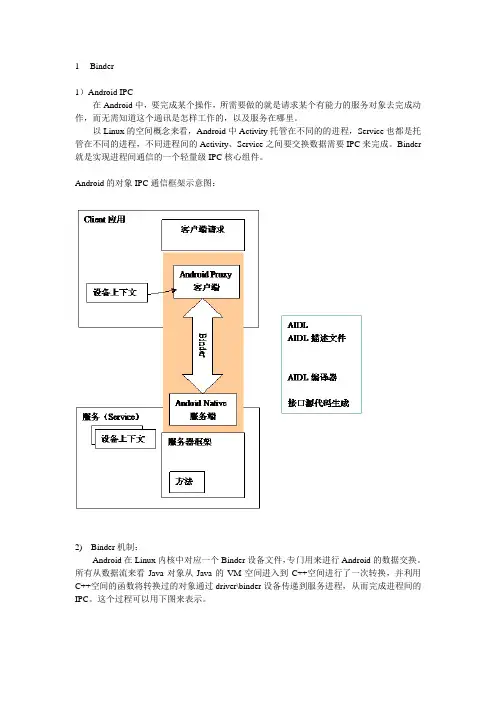
1Binder1)Android IPC在Android中,要完成某个操作,所需要做的就是请求某个有能力的服务对象去完成动作,而无需知道这个通讯是怎样工作的,以及服务在哪里。
以Linux的空间概念来看,Android中Activity托管在不同的的进程,Service也都是托管在不同的进程,不同进程间的Activity、Service之间要交换数据需要IPC来完成。
Binder 就是实现进程间通信的一个轻量级IPC核心组件。
Android的对象IPC通信框架示意图:2) Binder机制:Android在Linux内核中对应一个Binder设备文件,专门用来进行Android的数据交换。
所有从数据流来看Java对象从Java的VM空间进入到C++空间进行了一次转换,并利用C++空间的函数将转换过的对象通过driver\binder设备传递到服务进程,从而完成进程间的IPC。
这个过程可以用下图来表示。
这里数据流有几层转换过程。
(1)从JVM空间传到c++空间,这个是靠JNI使用ENV来完成对象的映射过程。
(2)从c++空间传入内核Binder设备,使用ProcessState类完成工作。
(3)Service从内核中Binder设备读取数据。
2Service1) ServiceManagerAndroid的服务使用方并不需要知道服务在那里,只要通过代理对象完成请求,为了在上层使用统一的接口,在Android引入了ServiceManger这个服务。
所有的服务都是从ServiceManager开始的,只用通过Service Manager获取到某个特定的服务标识构建代理IBinder。
Service Manager作为一个native service,其服务启动在init.rc定义,init程序起来后会进行解析并将其启动起来。
/*****************************************************************************/service servicemanager /system/bin/servicemanageruser systemcriticalonrestart restart zygoteonrestart restart media/*****************************************************************************/Android中Service Manager的源码,其源码位于frameworks\base\cmds\servicemanager\service_manager.c/*****************************************************************************/ #define BINDER_SERVICE_MANAGER ((void*) 0)int main(int argc, char **argv){struct binder_state *bs;void *svcmgr = BINDER_SERVICE_MANAGER;bs = binder_open(128*1024);//调用binder_open打开binder设备(/dev/binder)if (binder_become_context_manager(bs)) {LOGE("cannot become context manager (%s)\n", strerror(errno));return -1;}svcmgr_handle = svcmgr;binder_loop(bs, svcmgr_handler);//进入到循环状态,并提供svcmgr_handler回调函数,等待用户的请求,如getService 和addServicereturn 0;}/*****************************************************************************/在Android中Service Manager是默认的Handle为0,只要设置请求包的目标句柄为0,就是发给Service Manager这个Service的。

Android深入浅出之Binder机制一说明Android系统最常见也是初学者最难搞明白的就是Binder了,很多很多的Service就是通过Binder机制来和客户端通讯交互的。
所以搞明白Binder的话,在很大程度上就能理解程序运行的流程。
我们这里将以MediaService的例子来分析Binder的使用:●ServiceManager,这是Android OS的整个服务的管理程序●MediaService,这个程序里边注册了提供媒体播放的服务程序MediaPlayerService,我们最后只分析这个●MediaPlayerClient,这个是与MediaPlayerService交互的客户端程序下面先讲讲MediaService应用程序。
二 MediaService的诞生MediaService是一个应用程序,虽然Android搞了七七八八的JAVA之类的东西,但是在本质上,它还是一个完整的Linux操作系统,也还没有牛到什么应用程序都是JAVA写。
所以,MS(MediaService)就是一个和普通的C++应用程序一样的东西。
MediaService的源码文件在:framework\base\Media\MediaServer\Main_mediaserver.cpp中。
让我们看看到底是个什么玩意儿!int main(int argc, char** argv){//FT,就这么简单??//获得一个ProcessState实例sp<ProcessState> proc(ProcessState::self());//得到一个ServiceManager对象sp<IServiceManager> sm = defaultServiceManager();MediaPlayerService::instantiate();//初始化MediaPlayerService服务ProcessState::self()->startThreadPool();//看名字,启动Process的线程池?IPCThreadState::self()->joinThreadPool();//将自己加入到刚才的线程池?}其中,我们只分析MediaPlayerService。

Android Binder机制总结1Android组件化思想Android应用的体系结构是基于分布式组件模型。
Android应用中的组件之间是松耦合,具有模块化以及可扩展的特性。
这些组件可以同时运行在同一个进程中,也可以在不同的进程中。
如你编写的应用程序需要显示一个可以滚动的图片列表,如果其它某个应用程序已经开发了具有此功能的组件,并对外发布了此组件以使其它应用程序能够使用此组件,因此你可以直接调用这个组件来显示图片,而不需要重新开发一个具有此功能的组件。
另外一些系统服务如联系人列表、拍照、打电话等公共功能都能够在其它的应用程序中被调用。
2常见的进程通信方式(IPC)IPC是Inter-process communication的缩写形式,主要用于多进程间通信和数据交互。
a) Pipes(管道): Pipes are unidirectional byte-streams that connect the standard output from one process with the standard input of another process.b) Message Queues(消息队列): maintains a queue of messages to which processes can read to and write from, thereby achieving IPC.c) Shared Memory(共享内存): A common memory location which is accessible by all communicating processes. IPC is achieved by writing to and reading from the shared memory location.d) Semaphores(信号量): A semaphore is a shared variable on which processes can signal and wait thereby achieving IPC.e) Signals(信号): A process can send signals to processes with the same uid and gid or in the same process group.f) Sockets: Sockets are bidirectional communication streams. Two processes can communicate with byte-streams by opening the same socket.3Android中进程通信方式Android中的Binder机制源于OpenBinder,它的创造者是Dianne Kyra Hackborn,但是已经不再维护。

binderservice原理BinderService原理BinderService是Android系统中的一个重要组件,它是实现IPC (进程间通信)的关键之一。
在Android系统中,不同的应用程序运行在各自的进程中,为了实现不同应用程序之间的通信,Android引入了Binder机制。
BinderService作为Binder机制的核心,负责处理不同进程间的通信请求。
一、Binder机制简介Binder机制是Android系统中实现IPC的一种方式。
它基于C/S (Client/Server)架构,通过Binder驱动将不同进程中的组件连接起来。
在Binder机制中,服务端通过Binder对象提供服务,客户端通过获取Binder对象的引用来调用服务端的方法。
Binder机制的核心是Binder驱动,它负责进程间通信的底层实现。
二、BinderService的作用BinderService是服务端的一种实现方式,它可以提供一系列的方法供客户端调用。
在BinderService中,我们可以定义一些远程接口,客户端可以通过这些接口来调用服务端的方法。
服务端收到客户端的请求后,会执行相应的方法,并将结果返回给客户端。
三、BinderService的工作原理1. 创建Binder对象:在服务端,我们首先需要创建一个继承自Binder类的对象。
这个对象就是我们要提供给客户端调用的实例。
2. 实现远程接口:在Binder对象中,我们需要实现一些远程接口。
这些接口定义了客户端可以调用的方法。
3. 注册BinderService:在服务端,我们需要将Binder对象注册为BinderService。
这样客户端才能通过Binder对象来调用服务端的方法。
4. 客户端连接服务端:在客户端,我们需要获取服务端的Binder 对象引用。
通过这个引用,客户端可以调用服务端的方法。
5. 客户端调用服务端方法:客户端通过Binder对象引用来调用服务端的方法。
Binder的⼯作机制浅析在Android开发中,Binder主要⽤于Service中,包括AIDL和Messenger,其中Messenger的底层实现就是AIDL,所以我们这⾥通过AIDL来分析⼀下Binder的⼯作机制。
⼀、在Android Studio中建⽴AIDL⾸先,我们需要建⽴⼀个AIDL1.在建⽴了对应的实现Parcelable接⼝的实体类和AIDL接⼝后,⽂件结构如下:2.点击clean Project/reBuild Project,出现如下错误:提⽰⽆法找到Book实体类。
3.解决⽅案这个问题的出现是因为我还没有在build.gradle中对默认的sourceSets进⾏修改,默认情况下他指定的源码⽬录不包括aidl。
加⼊下⾯语句后同步build.gradle,再重建⼯程即可。
在app下的build.gradle添加:系统⾃动⽣成的IBookManager⼆、Binder原理分析通过Structure我们可以看到这个系统⽣成这个接⼝⽂件包括⼀个静态抽象类Stub和两个⽅法getBookList()和addBook(),这两个⽅法很显然就是我们之前在IBookManager.aidl中声明的⽅法,此外它还为这两个⽅法⽤两个int来标⽰,从⽽在onTransact()⽅法中起到标⽰作⽤,如下所⽰:⽽内部类Stub继承⾃Binder,在这个类内部⼜有⼀个代理类Proxy。
接下来看这⼀段代码:这⾥判断了客户端和服务端是否处于同⼀个进程中,如果处于同⼀个进程中,则⽅法调⽤不会⾛跨进程的transact⽅法,⽽如果处于不同的进程中,则需要通过其中的代理⾥proxy来完成。
下⾯展现代理类在这个代理类中的getBookList和addBook⽅法中调⽤transact⽅法来发起RPC(远程过程调⽤)请求,并将当前线程挂起,然后服务端的onTransact⽅法响应并执⾏,当RPC过程返回后,当前线程继续执⾏。
Binder学习——C实现注:基于Android5.1版本,Tiny4412平台。
⼀、学习笔记1.Binder的核⼼是IPC和RPCIPC: (Inter-Process Communication)进程间通信,指⾄少两个进程或线程间传送数据或信号的⼀些技术或⽅法。
RPC: (Remote-Process Communication)远程过程调⽤,类似于调⽤其它进程的函数。
ICP三要素:源:A⽬的:B向ServiceManager注册led服务A向ServiceManager查询led服务得到⼀个handle。
数据:buf[512]RPC:调⽤哪个函数:Server的函数编号传给它什么参数:通过IPC的buf[]进⾏传输(使⽤的是binder驱动)。
返回结果:远端执⾏完返回值2.系统⾃带的C实现的Binder程序:frameworks/native/cmds/servicemanagerservice_manager.c 充当SM的⾓⾊,管理所有的Service,其本⾝也是⼀个服务。
binder.c 封装好的C库bctest.c 半成品,演⽰怎样注册服务3.int svcmgr_publish(struct binder_state *bs, uint32_t target, const char *name, void *ptr)如果两个service的注册函数svcmgr_publish()的最后⼀个参数值相同,那么会报错。
正常情况下kill掉service_manager的时候,所有的service都会收到死亡通知,然后从链表中删除掉。
但是若两个service指定为相同的ptr,那么下次再重启service_manager的时候它会报这个服务已经存在了,由于相同的ptr导致kill掉service_manager时有⼀个并没有收到死亡通知,也就不能从链表中删除。
4.binder应该是个内核线程,binder驱动中创建了⼀个单CPU的⼯作队列# ps | grep binderroot 1073 2 0 0 c00a0668 00000000 S binder5.驱动中数据结构表⽰struct binder_ref : 表⽰引⽤binder_node :表⽰⼀个Servicebinder_proc :表⽰进程binder_thread :表⽰线程的⼀个线程6.handle是进程A(Client)对进程B(Service)提供的服务的引⽤,由handle可以对⽐desc成员找到binder_ref结构,其*node成员指向表⽰某项服务的binder_node结构体,binder_node的proc成员指向表⽰进程的binder_proc结构体,其内部指向对应的进程从⽽找到⽬的进程, 然后把数据给到⽬的进程的todo链表上,然后唤醒⽬的进程。
android binder通信原理Android Binder通信原理Android系统中进程间通信(IPC)是非常重要的。
Binder是Android系统中最常用的IPC机制,Binder通信原理是将客户端与服务端连接起来的一种技术。
Binder是Linux内核中Android的一种IPC机制。
它最早是在2005年由负责Android项目的Google工程师写出的。
Binder在进程间通信方案中发挥着重要作用。
在Android系统中,许多服务都是在后台运行的,因此需要IPC机制来支持它们。
Binder通信机制是非常快速和可靠的,所以它很适合用来处理Android系统中各种进程的通信和交互。
Android系统中的Binder通信原理采用的是基于C++的IPC机制。
在Android系统中,系统的各个组件都通过Binder通信实现数据的传递。
Android组件以进程为单位进行划分,不同的进程之间共享内存。
系统中的各个组件都是由客户端和服务端组成。
Binder通信机制的实现方式是,客户端首先打开一个Binder对象,然后将其传递给服务端。
服务端使用这个传递的Binder对象来与客户端进行通信。
客户端和服务端都是通过Binder对象进行交互的。
在Android系统中,Java层的应用程序使用Binder来与底层的C++或者C语言的服务进行通信,而底层的C++或者C服务则使用IPC机制实现。
Binder通信的主要内容包括:Binder通信流的创建、Binder对象的传递、Binder流数据的传递以及Binder流的销毁。
当客户端和服务端进行Binder通信时,使用的都是Linux的Socket流传输方式。
Binder的Socket流传输是基于Linux内核Socket的,因此它支持自动管理Socket连接,自动构建Socket通信端点,自动管理Socket 连接状态等功能。
在Android系统中,Binder非常重要,它为Android系统提供了高效、可靠和高度安全的进程间通信机制。
android binder机制原理Android Binder机制原理在Android系统中,不同进程间的通信是非常常见的,例如应用程序之间或系统服务之间的通信。
为了保证通信的稳定和效率,Android系统采用了一种名为Binder机制的进程间通信(IPC)方案。
本文将介绍Android Binder机制的原理以及它的工作模式。
一、Android Binder机制的原理Android Binder机制是基于C++语言和Linux内核的,在Binder 机制中最重要的概念是“Binder对象”。
Binder对象是一个可以跨进程使用的对象,它通过进程间共享内存的方式进行通信,以提高性能和效率。
Binder机制通过Binder驱动程序在内核空间和用户空间之间建立虚拟连接。
具体来说,Binder机制的原理是:当一个进程请求访问另一个进程中的对象时,它会通过Binder驱动程序向目标进程发送一个请求消息。
进程B在收到请求消息后,将生成一个Binder对象,并将其返回给进程A。
之后,进程A通过这个Binder对象与进程B进行通信,这样就完成了进程间的通信。
二、Android Binder机制的工作模式1. Binder通信基本框架Android Binder机制的基本框架可以描述如下:(1) Binder驱动程序在内核空间中负责处理进程A和进程B之间的通信。
(2) 进程A通过Binder通信建立一个客户端,与进程B建立连接。
(3) 进程B在客户端连接上创建一个Binder服务对象,以提供服务。
(4) 进程A和进程B基于客户端与服务对象进行通信。
2. Binder服务Binder服务是Android Binder机制的核心,它是一种用于提供跨进程通信服务的对象。
在Binder服务中,最为重要的是“Binder对象”。
每个Binder服务都会生成一个唯一的Binder对象,这个对象代表了这个服务的身份标识。
AndroidBinder机制(超级详尽)1.binder通信概述binder通信是⼀种client-server的通信结构,1.从表⾯上来看,是client通过获得⼀个server的代理接⼝,对server进⾏直接调⽤;2.实际上,代理接⼝中定义的⽅法与server中定义的⽅法是⼀⼀对应的;3.client调⽤某个代理接⼝中的⽅法时,代理接⼝的⽅法会将client传递的参数打包成为Parcel 对象;4.代理接⼝将该Parcel发送给内核中的binder driver.5.server会读取binder driver中的请求数据,如果是发送给⾃⼰的,解包Parcel对象,处理并将结果返回;6.整个的调⽤过程是⼀个同步过程,在server处理的时候,client会block住。
2.service managerService Manager是⼀个linux级的进程,顾名思义,就是service的管理器。
这⾥的service是什么概念呢?这⾥的service的概念和init过程中init.rc中的service是不同,init.rc中的service是都是linux进程,但是这⾥的service它并不⼀定是⼀个进程,也就是说可能⼀个或多个service属于同⼀个linux进程。
在这篇⽂章中不加特殊说明均指android native端的service。
任何service在被使⽤之前,均要向SM(Service Manager)注册,同时客户端需要访问某个service时,应该⾸先向SM查询是否存在该服务。
如果SM存在这个service,那么会将该service 的handle返回给client,handle是每个service的唯⼀标识符。
SM的⼊⼝函数在service_manager.c中,下⾯是SM的代码部分int main(int argc, char **argv){struct binder_state *bs;void *svcmgr = BINDER_SERVICE_MANAGER;bs = binder_open(128*1024);if (binder_become_context_manager(bs)) {LOGE("cannot become context manager (%s)/n", strerror(errno));return -1;}svcmgr_handle = svcmgr;binder_loop(bs, svcmgr_handler);return 0;}这个进程的主要⼯作如下:1.初始化binder,打开/dev/binder设备;在内存中为binder映射128K字节空间;2.指定SM对应的代理binder的handle为0,当client尝试与SM通信时,需要创建⼀个handle为0的代理binder,这⾥的代理binder其实就是第⼀节中描述的那个代理接⼝;3.通知binder driver(BD)使SM成为BD的context manager;4.维护⼀个死循环,在这个死循环中,不停地去读内核中binder driver,查看是否有可读的内容;即是否有对service的操作要求, 如果有,则调⽤svcmgr_handler回调来处理请求的操作。
第一节Android Binder星期四, 06/17/2010 - 00:03 —williamAndroid Binder是一种在Android里广泛使用的一种远程过程调用接口。
从结构上来说Android Binder 系统是一种服务器/客户机模式,包括Binder Server、Binder Client和Android Binder驱动,实际的数据传输就是通过Android Binder驱动来完成的,这里我们就来详细的介绍Android Binder驱动程序。
通常来说,Binder是Android系统中的内部进程通讯(IPC)之一。
在Android系统中共有三种IPC机制,分别是:-标准Linux Kernel IPC接口-标准D-BUS接口-Binder接口尽管Google宣称Binder具有更加简洁、快速,消耗更小内存资源的优点,但并没有证据表明D-BUS就很差。
实际上D-BUS可能会更合适些,或许只是当时Google并没有注意到它吧,或者Google不想使用GPL 协议的D-BUS库。
我们不去探究具体的原因了,你只要清楚Android系统中支持了多个IPC接口,而且大部分程序使用的是我们并不熟悉的Binder接口。
Binder是OpenBinder的Google精简实现,它包括一个Binder驱动程序、一个Binder服务器及Binder 客户端(?)。
这里我们只要介绍内核中的Binder驱动的实现。
对于Android Binder,它也可以称为是Android系统的一种RPC(远程过程调用)机制,因为Binder实现的功能就是在本地“执行”其他服务进程的功能的函数调用。
不管是IPC也好,还是RPC也好,我们所要知道的就是Android Binder的功能是如何实现的。
Openbinder介绍2.1.1 Android Binder协议Android 的Binder机制是基于OpenBinder(/~hackbod/openbinder/docs/html/BinderIPCMechanism.html)来实现的,是一个OpenBinder的Linux实现。
Android Binder的协议定义在binder.h头文件中,Android的通讯就是基于这样的一个协议的。
Binder Type(描述binder type的功能)Android定义了五个(三大类)Binder类型,如下:enum {BINDER_TYPE_BINDER = B_PACK_CHARS('s', 'b', '*', B_TYPE_LARGE),BINDER_TYPE_WEAK_BINDER = B_PACK_CHARS('w', 'b', '*', B_TYPE_LARGE),BINDER_TYPE_HANDLE = B_PACK_CHARS('s', 'h', '*', B_TYPE_LARGE),BINDER_TYPE_WEAK_HANDLE= B_PACK_CHARS('w', 'h', '*', B_TYPE_LARGE),BINDER_TYPE_FD = B_PACK_CHARS('f', 'd', '*', B_TYPE_LARGE),};∙Binder Object进程间传输的数据被称为Binder对象(Binder Object),它是一个flat_binder_object,定义如下:struct flat_binder_object {/* 8 bytes for large_flat_header. */unsigned long type;unsigned long flags;/* 8 bytes of data. */union {void *binder; /* local object */signed long handle; /* remote object */};/* extra data associated with local object */void *cookie;};其中,类型字段描述了Binder 对象的类型,flags描述了传输方式,比如同步、异步等。
enum transaction_flags {TF_ONE_WAY = 0x01, /* this is a one-way call: async, no return */TF_ROOT_OBJECT = 0x04, /* contents are the component's root object */TF_STATUS_CODE = 0x08, /* contents are a 32-bit status code */TF_ACCEPT_FDS = 0x10, /* allow replies with file descriptors */ };传输的数据是一个复用数据联合体,对于BINDER类型,数据就是一个binder本地对象,如果是HANDLE类型,这数据就是一个远程的handle对象。
该如何理解本地binder对象和远程handle 对象呢?其实它们都指向同一个对象,不过是从不同的角度来说。
举例来说,假如A有个对象X,对于A来说,X就是一个本地的binder对象;如果B想访问A的X对象,这对于B来说,X就是一个handle。
因此,从根本上来说handle和binder都指向X。
本地对象还可以带有额外的数据,保存在cookie中。
Binder对象的传递是通过binder_transaction_data来实现的,即Binder对象实际是封装在binder_transaction_data结构体中。
∙binder_transaction_data这个数据结构才是真正要传输的数据。
它的定义如下:struct binder_transaction_data {/* The first two are only used for bcTRANSACTION and brTRANSACTION,* identifying the target and contents of the transaction.*/union {size_t handle; /* target descriptor of command transaction */void *ptr; /* target descriptor of return transaction */} target;void *cookie; /* target object cookie */unsigned int code; /* transaction command *//* General information about the transaction. */unsigned int flags;pid_t sender_pid;uid_t sender_euid;size_t data_size; /* number of bytes of data */size_t offsets_size; /* number of bytes of offsets *//* If this transaction is inline, the data immediately* follows here; otherwise, it ends with a pointer to* the data buffer.*/union {struct {/* transaction data */const void *buffer;/* offsets from buffer to flat_binder_object structs */const void *offsets;} ptr;uint8_t buf[8];} data;};结构体中的数据成员target是一个复合联合体对象,请参考前面的关于binder本地对象及handle 远程对象的描述。
code是一个命令,描述了请求Binder对象执行的操作。
对象的索引和映射Binder中的一个重要概念就是对象的映射和索引。
就是要把对象从一个进程映射到另一个进程中,以实现线程迁移的概念。
前面描述过Binder的一个重要概念是进程/线程迁移,即当一个进程需要同另一个进程通信时,它可以“迁移”远程的进程/线程到本地来执行。
对于调用进程来说,看起来就像是在本地执行一样。
这是Binder与其他IPC机制的不同点或者说是优点。
当然迁移的工作是由Binder 驱动来完成的,而实现的基础和核心就是对象的映射和索引。
Binder中有两种索引,一是本地进程地址空间的一个地址,另一个是一个抽象的32位句柄(HANDLE),它们之间是互斥的:所有的进程本地对象的索引都是本地进程的一个地址(address, ptr, binder),所有的远程进程的对象的索引都是一个句柄(handle)。
对于发送者进程来说,索引就是一个远端对象的一个句柄,当Binder对象数据被发送到远端接收进程时,远端接受进程则会认为索引是一个本地对象地址,因此从第三方的角度来说,尽管名称不同,对于一次Binder调用,两种索引指的是同一个对象,Binder驱动则负责两种索引的映射,这样才能把数据发送给正确的进程。
对于Android的Binder来说,对象的索引和映射是通过binder_node和binder_ref两个核心数据结构来完成的,对于Binder本地对象,对象的Binder地址保存在binder_node->ptr里,对于远程对象,索引就保存在binder_ref->desc里,每一个binder_node都有一个binder_ref对象与之相联系,他们就是是通过ptr和desc来做映射的,如下图:flat_binder_object就是进程间传递的Binder对象,每一个flat_binder_object对象内核都有一个唯一的binder_node对象,这个对象挂接在binder_proc的一颗二叉树上。
对于一个binder_node对象,内核也会有一个唯一的binder_ref对象,可以这么理解,binder_ref的desc 唯一的映射到binder_node的ptr和cookie上,同时也唯一的映射到了flat_binder_object的handler上。