Bridging Centrality Identifying Bridging Nodes In Scale-free Networks
- 格式:pdf
- 大小:279.14 KB
- 文档页数:8

cytohubbamcc算法迭代公式CytoHubba算法是一种用于蛋白质相互作用网络的节点中心性分析工具,能够帮助研究者从全局的角度评估网络节点的重要性。
其中,McC (Maximal Clique Centrality)算法是CytoHubba算法中的一种迭代公式,用于计算节点的最大团中心性。
在介绍McC算法之前,我们先来了解一下最大团(Maximal Clique)的定义。
在一个图中,最大团是一个完全连接的子图,其中的每个节点都与其他所有节点相连。
最大团中的每个节点都是强相关的,这意味着它们在其中一种程度上相互依赖。
最大团中心性则是用来衡量最大团的重要性。
McC算法的计算过程如下:1.对于给定的蛋白质相互作用网络,首先确定网络中的所有最大团。
2. 对于每个最大团,计算其节点的度中心性(Degree Centrality)。
节点的度中心性是指节点与其他节点的连接数,用来度量节点在网络中的交互程度。
度中心性可以通过计算节点的度(即与其他节点直接相连的边数)来获得。
3.在计算各个最大团的度中心性后,将度中心性的平均值赋予每个节点。
4.重复执行上述过程,直到网络中所有节点的度中心性不再发生变化。
McC算法的迭代公式如下:度中心性(v)=(1-d)+d*∑[(1/,C,)*∑(度中心性/C中的节点数)]其中,v表示节点的度中心性,d是一个介于0和1之间的阻尼系数(用于控制信息传递的速度),C表示一个最大团,C,表示最大团中节点的数量。
通过不断迭代这个公式,McC算法可以得到更准确的节点度中心性值。
一个节点的度中心性越高,说明它在最大团中的重要性越大。
McC算法的优点是能够在整个网络中获取节点的最大团中心性,而不仅仅是在特定的子图或团中。
这种全局的分析可以帮助研究者更好地了解节点之间的相互关系和网络的整体结构。
同时,迭代过程也可以提高度中心性的准确性。
总而言之,McC算法是CytoHubba算法中的一种迭代公式,用于计算蛋白质相互作用网络中节点的最大团中心性。

复杂网络中关键节点的识别方法研究引言:随着互联网的快速发展,复杂网络已成为重要的研究领域。
在复杂网络中,节点的重要性不同,有些节点对网络的稳定性和功能起着至关重要的作用,我们称这些节点为关键节点。
识别并理解复杂网络中的关键节点对于网络管理、灾难应对和信息传输优化等方面具有重要意义。
本文将研究复杂网络中关键节点的识别方法,包括基于网络拓扑性质、结构层次和动态演化的方法。
一、基于网络拓扑性质的关键节点识别方法1.1 度中心性度中心性是一种常用的关键节点识别方法,它基于节点的度来衡量节点在网络中的重要性。
具有较高度的节点往往是关键节点,因为它们在网络中具有更多的联系和控制能力。
然而,度中心性只考虑了节点的连接数,忽略了节点的位置和影响力,因此准确性受到一定限制。
1.2 中介中心性中介中心性是另一种依据节点在网络中作为中间人的作用来衡量节点的重要性的方法。
在复杂网络中,拥有较高中介中心性的节点往往在信息传递和通信方面起着至关重要的作用。
通过计算节点在最短路径中的出现次数,可以识别中介节点,进而找到关键节点。
然而,该方法也存在计算复杂度较高的问题,并且无法准确衡量节点的重要性。
1.3 特征向量中心性特征向量中心性是一种综合考虑节点的邻居节点的信息来计算节点重要性的方法。
它利用矩阵运算的方法,将节点的邻居节点与其本身权衡结合起来,计算节点的特征向量,从中可以得到节点的重要性指标。
特征向量中心性在识别复杂网络中的关键节点方面具有较高的准确性和鲁棒性。
二、基于结构层次的关键节点识别方法2.1 社区结构复杂网络中常常存在分布式的社区结构,即节点之间存在着紧密的连接,而社区之间的连接较少。
识别复杂网络中的关键节点可以通过分析社区的结构。
具有较高连接度的节点常常位于社区之间,因此可以被认为是关键节点。
通过社区的划分和节点的连接度等指标,可以准确识别关键节点。
2.2 共享益中心性共享益中心性是一种新近提出的方法,通过考虑节点在网络上所连接的路线各自的贡献来表示节点的重要性。


大规模复杂网络中的节点关键度分析方法研究随着互联网的发展,复杂网络已经成为了现代社会不可或缺的组成部分,它们包括了很多知名的网络结构,例如社交网络、交通网络、电力网络、物流网络等等。
在这些复杂网络中,节点的重要性尤为重要,因为它们承担着网络中的重要任务。
节点重要性指的是节点在网络中对整个网络的影响力大小,通常是从度、介数、紧密度三个方面来衡量的。
度是指节点所连接的边数,介数是指节点在网络中的最短路径数,紧密度是指节点到其他节点的平均距离。
在网络分析中,关键节点是指从全局来看对整个网络具有重要影响的节点,是节点重要性的衍生。
一旦关键节点受到破坏,网络会遭受巨大的损失,从而导致网络结构的崩溃。
如何分析大规模复杂网络的节点关键度?现今,有许多研究着眼于如何快速准确地在大规模复杂网络中发现关键节点。
这些研究不仅在理论方面有着基础的突破,而且在实践中也具有重要意义。
以下为几种基于网络结构特征的节点关键度分析方法:1.度中心性分析法度中心性分析法,顾名思义,基于节点度来分析节点重要性。
节点的度越高,其在整个网络中所占的地位越重要,其责任也愈重。
因此,在分析网络中的节点时,可以考虑节点的度数,并将高度中心性的节点称为“关键节点”。
2.介数中心性分析法介数中心性分析法是指在网络中,能够将其连接分隔成为更小的部分的节点具有高度中心性。
对于每个节点,在网络中求出到其他节点的最短距离,术语为介数。
节点介数越高,说明其在整个网络中所占的地位越重要。
因此,介数中心性分析法也是非常常用的一种方法。
3.紧密度中心性分析法紧密度中心性分析法是另一种公认的衡量节点重要性的方法。
从节点的角度来看,紧密度中心度意味着该节点的邻居节点往往非常相互联系。
因此,紧密度中心性分析法可以通过计算每个节点的平均距离来判断节点的重要性。
紧密度越高,则说明节点所占的地位越重要。
4.介于中心性分析法介于中心性是介数和紧密度之间的平均值。
在网络中,交互次数众多,节点与其他节点高度相互联系时,介于中心性增大,节点的重要性也增加。


Home Search Collections Journals About Contact us My IOPscienceMapping Koch curves into scale-free small-world networksThis article has been downloaded from IOPscience. Please scroll down to see the full text article.2010 J. Phys. A: Math. Theor. 43 395101(/1751-8121/43/39/395101)View the table of contents for this issue, or go to the journal homepage for moreDownload details:IP Address: 219.220.208.31The article was downloaded on 21/10/2010 at 07:26Please note that terms and conditions apply.IOP P UBLISHING J OURNAL OF P HYSICS A:M ATHEMATICAL AND T HEORETICAL J.Phys.A:Math.Theor.43(2010)395101(16pp)doi:10.1088/1751-8113/43/39/395101Mapping Koch curves into scale-free small-world networksZhongzhi Zhang1,2,Shuyang Gao1,2,Lichao Chen3,Shuigeng Zhou1,2,Hongjuan Zhang2,4and Jihong Guan51School of Computer Science,Fudan University,Shanghai200433,People’s Republic of China2Shanghai Key Lab of Intelligent Information Processing,Fudan University,Shanghai200433,People’s Republic of China3Electrical Engineering Department,University of California,Los Angeles,CA90024,USA4Department of Mathematics,College of Science,Shanghai University,Shanghai200444,People’s Republic of China5Department of Computer Science and Technology,Tongji University,4800Cao’an Road,Shanghai201804,People’s Republic of ChinaE-mail:zhangzz@,sgzhou@ and jhguan@Received8June2010,infinal form7July2010Published1September2010Online at /JPhysA/43/395101AbstractThe class of Koch fractals is one of the most interesting families of fractals,andthe study of complex networks is a central issue in the scientific community.In this paper,inspired by the famous Koch fractals,we propose a mappingtechnique converting Koch fractals into a family of deterministic networkscalled Koch networks.This novel class of networks incorporates somekey properties characterizing a majority of real-life networked systems—apower-law distribution with exponent in the range between2and3,a highclustering coefficient,a small diameter and average path length and degreecorrelations.Besides,we enumerate the exact numbers of spanning trees,spanning forests and connected spanning subgraphs in the networks.All thesefeatures are obtained exactly according to the proposed generation algorithm ofthe networks considered.The network representation approach could be usedto investigate the complexity of some real-world systems from the perspectiveof complex networks.PACS numbers:89.75.Hc,05.10.−a,89.75.Fb,61.43.Hv(Somefigures in this article are in colour only in the electronic version)1.IntroductionThe past decade has witnessed a great deal of activity devoted to complex networks by the scientific community,since many systems in the real world can be described and characterized 1751-8113/10/395101+16$30.00©2010IOP Publishing Ltd Printed in the UK&the USA1by complex networks[1–4].Prompted by the computerization of data acquisition and the increased computing power of computers,researchers have done a lot of empirical studies on diverse real networked systems,unveiling the presence of some generic properties of various natural and manmade networks:power-law degree distribution P(k)∼k−γwith the characteristic exponentγin the range between2and3[5],small-world effect including a large clustering coefficient and small average distance[6],and degree correlations[7,8].The empirical studies have inspired researchers to construct network models with the aim to reproduce or explain the striking common features of real-life systems[1,2].In addition to the seminal Watts–Strogatz’s(WS)small-world network model[6]and Barab´a si–Albert’s (BA)scale-free network model[5],a considerable number of models and mechanisms have been developed to mimic real-world systems,including initial attractiveness[9],aging and cost[10],fitness model[11],duplication[12],weight or traffic driven evolution[13,14], geographical constraint[15],accelerating growth[16,17],coevolution[18]and visibility graph[19],to list a few.Although significant progress has been made in thefield of network modeling and has led to a significant improvement in our understanding of complex systems,it is still a fundamental task and of current interest to construct models mimicking real networks and reproducing their generic properties from different angles[20].In this paper,enlightened by the famous class of Koch fractals,we propose a family of deterministic mathematical networks,called Koch networks,which integrates the observed properties of real networks in a single framework.We derive analytically exact scaling laws for degree distribution,clustering coefficient,diameter,average distance or average path length (APL),degree correlations,even for spanning trees,spanning forests and connected spanning subgraphs.The obtained precise results show that Koch networks have rich topological features:they obey a power-law degree distribution with the exponent lies between2and3; they have a large clustering coefficient and their diameter and APL grow logarithmically with the total number of nodes;and they may be either disassortative or uncorrelated.This work unfolds an alternative perspective in the study of complex networks.Instead of searching generation mechanisms for real networks,we explore deterministic mathematical networks that exhibit some typical properties of real-world systems.As the classical Koch fractals are important for the understanding of geometrical fractals in real systems[21],we believe that Koch networks could provide valuable insights into real-world systems.work constructionIn order to define the networks,wefirst introduce a classical fractal—Koch curve,which was proposed by von Koch[22].The Koch curve,denoted as S1(t)after t generations,can be constructed in a recursive way.To produce this well-known fractal,we begin with an equilateral triangle and let this initial configuration be S1(0).In thefirst generation,we perform the following operations:firstly,we trisect each side of the initial equilateral triangle; secondly,on the middle segment of each side,we construct new equilateral triangles whose interiors lie external to the region enclosed by the base triangle;thirdly,we remove the three middle segments of the base triangle,upon which new triangles were established.Thus,we get S1(1).In the second generation,for each line segment in S1(1),we repeat the above procedure of three operations to obtain S1(2).This process is then repeated for successive generations. As t tends to infinite,the Koch curve is obtained,and its Hausdorff dimension is d f=2ln2ln3 [23].Figure1depicts the structure of S1(2).The Koch curve can be easily generalized to other dimensions by introducing a parameter m(a positive integer)[23,24].The generalization after t generations is denoted by S m(t),which is constructed as follows[23]:start with an equilateral triangle as the initial configuration 2Figure1.Thefirst two generations of the construction for the Koch curve.S m(0).In thefirst generation,we perform the following operations similar to those described in the last paragraph:partition each side of the initial triangle into2m+1segments,which are consecutively numbered1,2,...,2m,2m+1from one endpoint of the side to the other; construct a new small equilateral triangle on each even-numbered segment so that the interiors of the new triangles lie in the exterior of the base triangle;remove the segments upon which triangles were constructed.In this way we obtain S m(1).Analogously,we can get S m(t) from S m(t−1)by repeating recursively the procedure of the above three operations for each existing line segment in generation t−1.In the infinite t limit,the Hausdorff dimension ofthe generalized Koch curves d f=ln(4m+1)ln(2m+1)[23].Figure2shows the structure of S2(2).The generalized Koch curves can be used as a basis of a new class of networks: sides(excluding those deleted)of the triangles of the Koch curves constructed at arbitrary generations are mapped to nodes,which are connected to one another if their corresponding sides in the Koch curves are in contact.For uniformity,the three sides of the initial equilateral triangle of S m(0)also correspond to three different nodes.We shall call the resultant networks Koch networks.Note that after establishing each side of a triangle constructed at a given generation of the Koch curves,although some segments of it will be removed at subsequent steps,we look at its remaining segments as a whole and map it to only one node.Figures3 and4show two networks corresponding to S1(2)and S2(2),respectively.Obviously,Koch networks have an infinite number of nodes.But in what follows we shall generally consider the network characteristics after afinite number of generations in the development of complete Koch networks.From our analytical results,we can quickly obtain the characteristics of the complete networks by taking the limit of large t.However,the numerical results are necessarily limited to networks withfinite order(number of all nodes).3.Generation algorithmAccording to the construction process of the generalized Koch curves and the proposed method of mapping from Koch curves to Koch networks,we can introduce an iterative algorithm with3Figure2.Thefirst two generations of the construction for the generalized Koch curve in the caseof m=2.Figure3.The network derived from S1(2).ease to create Koch networks,denoted by K m,t after t generation evolutions.The algorithm is as follows:initially(t=0),K m,0consists of three nodes forming a triangle.For t 1, K m,t is obtained from K m,t−1by adding m groups of nodes for each of the three nodes of every existing triangle in K m,t−1.Each node group has two nodes.These two new nodes and their‘mother’nodes are linked to one another shaping a new triangle.In other words,to obtain K m,t from K m,t−1,we replace each of the existing triangles of K m,t−1by the connected clusters on the rightmost side offigure5.Figures3and4illustrate the growing process of the networks for two particular cases of m=1and m=2,respectively.Note that in the peculiar case of m=1,the networks under consideration reduce to the one previously studied in[25].Let us compute the order and size(number of all edges)of the Koch networks K m,t.To this end,wefirst consider the total number of triangles L (t)that exist at step t.By construction 4Figure4.The network corresponding to S2(2).Figure5.Iterative construction method for the Koch networks.(seefigure5),this quantity increases by a factor of3m+1,i.e.L (t)=(3m+1)L (t−1). Considering L (0)=1,we have L (t)=(3m+1)t.Denote L v(t)and L e(t)as the numbers of nodes and edges created at step t,respectively.Note that each triangle in K m,t−1 will give rise to6m new nodes and9m new edges at step t;then one can easily obtain L v(t)=6m L (t−1)=6m(3m+1)t−1and L e(t)=9m L (t−1)=9m(3m+1)t−1,both of which hold for arbitrary t>0.Then,the total numbers of nodes N t and edges E t present at step t areN t=tt i=0L v(t i)=2(3m+1)t+1(1)andE t=tt i=0L e(t i)=3(3m+1)t,(2)respectively.Thus,the average degree isk =2E tN t =6(3m+1)t2(3m+1)t+1,(3)5which is approximately3for large t,showing that Koch networks are sparse as most real-life networks[1–4].4.Topological propertiesNow we study some relevant characteristics of the Koch networks K m,t,focusing on degree distribution,clustering coefficient,diameter,average distance,degree correlations,spanning trees,spanning forests and connected spanning subgraphs.We emphasize that this is the first analytical study for counting spanning trees,spanning forests and connected spanning subgraphs in scale-free networks.4.1.Degree distributionLet k i(t)be the degree of node i at time t.When node i enters the network at step t i(t i 0), it has a degree of2,namely k i(t i)=2.To determine k i(t),wefirst consider the number of triangles involving node i at step t that is denoted by L (i,t).These triangles will give rise to new nodes linked to node i at step t+1.Then at step t i,L (i,t i)=1.By construction, for any triangle involving node i at a given step,it will lead to m new triangles passing by node i at a next step.Thus,L (i,t)=(m+1)L (i,t−1).Considering the initial condition L (i,t i)=1,we have L (i,t)=(m+1)t−t i.On the other hand,each triangle passing by node i contains two links connected to i;therefore,we have k i(t)=2L (i,t).Then we obtaink i(t)=2L (i,t)=2(m+1)t−t i.(4) In this way,at time t the degree of the arbitrary node i of Koch networks has been computed explicitly.From equation(4),it is easy to see that at each step the degree of a node increases m times,i.e.k i(t)=(m+1)k i(t−1).(5) Equation(4)shows that the degree spectrum of Koch networks is discrete.Thus,we can get the degree distribution P(k)of the Koch networks via the cumulative degree distribution [3]given byP cum(k)=1N tτ t iL v(τ)=2×(3m+1)t i+12×(3m+1)+1.(6)Substituting t i=t−ln(k2)ln(m+1)in this expression givesP cum(k)=2×(3m+1)t×k2−ln(3m+1)ln(m+1)+12×(3m+1)t+1.(7)In the infinite t limit,we obtainP cum(k)=2ln(3m+1)ln(m+1)×k−ln(3m+1)ln(m+1).(8) So the degree distribution follows a power-law form P(k)∼k−γwith the exponentγ=1+ln(3m+1)ln(m+1)belonging to the interval[2,3].When m increases from1to infinite,γdecreases from3to2.It should be stressed that the exponent of degree distribution of most real scale-free networks also lies in the same range between2and3.6Figure6.Semilogarithmic plot of the average clustering coefficient C t versus the networkorder N t.4.2.Clustering coefficientBy definition,the clustering coefficient[6]of a node i with degree k i is the ratio between thenumber of triangles e i that actually exist among the k i neighbors of node i and the maximumpossible number of triangles involving i,k i(k i−1)/2,namely C i=2e i/[k i(k i−1)].For Koch networks,we can obtain the exact expression of the clustering coefficient C(k)for asingle node with degree k.By construction,for any given node having a degree k,there are juste=k2triangles connected with this node;see also equation(4).Hence there is a one-to-onecorresponding relation between the clustering coefficient of a node and its degree:for a node of degree k,C(k)=1k−1,(9)which shows a power-law scaling C(k)∼k−1in the large limit of k,in agreement with the behavior observed in a variety of real-life systems[26].After t step growth,the average clustering coefficient C t of the whole network K m,t, defined as the mean of Cis over all nodes in the network,is given byC t=1N ttr=01G r−1×L v(r),(10)where the sum runs over all the nodes of all generations and G r is the degree of those nodes created at step r,which is given by equation(4).In the limit of large N t,equation(10) converges to a nonzero value C,as reported infigure6.For m=1,2and3,C is0.82008, 0.88271and0.91316,respectively.As m approaches infinite,C converges to1.Thus,C increases with m:when m grows from1to infinite,C increases form0.82008to1.Therefore, for the full range of m,the the average clustering coefficient of Koch networks is very high.74.3.DiameterMost real networks are small-world,i.e.their average distance grows logarithmically with network order or slower.Here the average distance means the minimum number of edges connecting a pair of nodes,averaged over all node pairs.For a general network,it is not easy to derive a closed formula for its average distance.However,the whole family of Koch networks has a self-similar structure,allowing for analytically calculating the average distance,which approximately increases as a logarithmic function of the network order.We leave the detailed exact derivation about the average distance to the next subsection.Here we provide the exact result of the diameter of K m,t denoted by Diam(K m,t)for all parameters m,which is defined as the maximum of the shortest distances between all pairs of nodes.Small diameter is consistent with the concept of small-world.The obtained diameter also scales logarithmically with the network order.The computation details are presented as follows.Clearly,at step t=0,Diam(K m,0)is equal to1.At each step t 1,we call newly created nodes at this step as active nodes.Since all active nodes are attached to those nodes existing in K m,t−1,so one can easily see that the maximum distance between any active node and those nodes in K m,t−1is not more than Diam(K m,t−1)+1and that the maximum distance between any pair of active nodes is at most Diam(K m,t−1)+2.Thus,at any step,the diameter of the network increases by2at most.Then we get2(t+1)as the diameter of Diam(K m,t). Equation(1)indicates that the logarithm of the order of Diam(K m,t)is proportional to t in the large limit t.Thus the diameter Diam(K m,t)grows logarithmically with the network order, showing that the Koch networks are small-world.4.4.Average path lengthUsing a method similar to but different from those in the literature[27,28],we now study analytically the average path length d t of the Koch networks K m,t.It follows thatd t=D tot(t)N t(N t−1)/2,(11)where D tot(t)is the total distance between all couples of nodes,i.e.D tot(t)=i∈K m,t,j∈K m,t,i=jd ij(t),(12)where d ij(t)is the shortest distance between nodes i and j in the networks K m,t.Note that Koch networks have a self-similar structure,which allows us to address D tot(t) analytically.This self-similar structure is obvious from an equivalent network construction method:to obtain K m,t,one can make3m+1copies of K m,t−1and join them at the hubs (namely nodes with largest degree).As shown infigure7,the network K m,t+1may be obtained by the juxtaposition of3m+1copies of K m,t,which are labeled as K1m,t,K2m,t,...,K3m m,t,andK3m+1m,t ,respectively.We continue by exhibiting the procedure of the determination of the total distance and present the recurrence formula,which allows us to obtain D tot(t+1)of the t+1generation from D tot(t)of the t generation.From the obvious self-similar structure of Koch networks,it is easy to see that the total distance D tot(t+1)satisfies the recursion relationD tot(t+1)=(3m+1)D tot(t)+ t,(13) 8Figure7.Second construction method of Koch networks that highlights self-similarity.Thegraph after t+1construction steps,K m,t+1,consists of3m+1copies of K m,t denoted as Kθm,t(θ=1,2,3,...,3m,3m+1),which are connected to one another as above.where t is the sum over all shortest paths whose endpoints are not in the same Kθm,t branch. The solution of equation(13)isD tot(t)=(3m+1)t−1D tot(1)+t−1τ=1(3m+1)t−τ−1 τ.(14)All the paths contributing to t must go through at least one of the three edge nodes(i.e.the gray nodes X,Y and Z infigure7)at which the different Kθm,t branches are connected.The analytical expression for t,called the length of crossing paths,is found below.Let α,βt be the sum of the lengths of all shortest paths with endpoints in Kαm,t and Kβm,t. Based on whether or not two branches are adjacent,we sort the crossing path length α,βt into two classes:if Kαm,t and Kβm,t meet at an edge node, α,βt rules out the paths where either endpoint is that shared edge node.For example,each path contributed to 1,2t should not end at node X.If Kαm,t and Kβm,t do not meet, α,βt excludes the paths where either endpoint is any edge node.For instance,each path contributed to 2,m+2tshould not end at node X or Y.We can easily compute that the numbers of the two types of crossing paths are3m2+3m2and3m2,respectively.On the other hand,any two crossing paths belonging to the same class have identical length.Thus,the total sum t is given byt=3m2+3m21,2t+3m2 2,m+2t.(15)In order to determine 1,2t and 2,m+2t,we defines t=i∈K m,t,i=Xd iX(t).(16)Considering the self-similar network structure,we can easily know that at time t+1,the quantity s t+1evolves recursively ass t+1=(m+1)s t+2m[s t+(N t−1)]=(3m+1)s t+4m(3m+1)t.(17)9Using s0=2,we haves t=(4mt+6m+2)(3m+1)t−1.(18) Having obtained s t,the next step is to compute the quantities 1,2t and 2,m+2tgiven by 1,2t=i∈K1m,t,j∈K2m,ti,j=Xd ij(t+1)=i∈K1m,t,j∈K2m,ti,j=X[d iX(t+1)+d jX(t+1)]=(N t−1)i∈K1m,ti=X d iX(t+1)+(N t−1)j∈K2m,tj=Xd jX(t+1)=2(N t−1)i∈K1m,ti=Xd iX(t+1)=2(N t−1)s t,(19) and2,m+2t =i∈K2m,t,i=Xj∈K m+2m,t,j=Yd ij(t+1)=i∈K2m,t,i=Xj∈K m+2m,t,j=Y[d iX(t+1)+d XY(t+1)+d jY(t+1)]=2(N t−1)s t+(N t−1)2,(20)where d XY(t+1)=1has been used.Substituting equations(19)and(20)into equation(15), we obtaint=(9m2+3m)(N t−1)s t+3m2(N t−1)2=12m(2mt+4m+1)(3m+1)2t.(21) Inserting equations(21)for τinto equation(14),and using D tot(1)=48m2+21m+3,we can exactly obtain the expression for D tot(t)asD tot(t)=(3m+1)t−13[3m+5+(24mt+24m+4)(3m+1)t].(22)By inserting equation(22)into equation(11),one can obtain the analytical expression for d t:d t=3m+5+(24mt+24m+4)(3m+1)t3(3m+1)[2(3m+1)t+1],(23)which approximates4mt3m+1in the infinite t,implying that the APL shows a logarithmic scalingwith network order.This again shows that the Koch networks exhibit a small-world behavior. We have checked our analytic result for d t given in equation(23)against numerical calculations for different m and various t.In all the cases we obtain complete agreement between our theoretical formula and the results of numerical investigation,seefigure8.10Figure8.Average path length d t versus network order N t on a semi-log scale.The solid lines areguides to the eyes.4.5.Degree correlationsDegree correlation is a particularly interesting subject in thefield of network science[7,8, 29–32]because it can give rise to some interesting network structure effects.An interesting quantity related to degree correlations is the average degree of the nearest neighbors for nodes with degree k,denoted as k nn(k),which is a function of the node degree k[30,31].When k nn(k)increases with k,it means that nodes have a tendency to connect to the nodes with a similar or larger degree.In this case the network is defined as assortative[7,8].In contrast, if k nn(k)is decreasing with k,which implies that the nodes of large degree are likely to have near neighbors with small degree,then the network is said to be disassortative.If correlations are absent,k nn(k)=const.We can exactly calculate k nn(k)for Koch networks using equations(4)and(5)to work out how many links are made at a particular step to nodes with a particular degree.By construction,we have the following expression:k nn(k)=1L v(t i)k(t i,t)ti=t i−1ti=0m L v(t i)k(t i,t i−1)k(t i,t)+ti=tti=t i+1m L v(t i)k(t i,t i−1)k(t i,t)+1(24)for k=2(m+1)t−t i.Here thefirst sum on the right-hand side accounts for the links made tonodes with a larger degree(i.e.ti <t i)when the node was generated at t i.The second sumdescribes the links made to the current smallest degree nodes at each step ti >t i.The last term1accounts for the link connected to the simultaneously emerging node.In order to compute equation(24),we distinguish two cases according to the parameter m:m=1and m 2.When m=1,we havek nn(k)=t+2.(25)11Thus,in the case of m=1,the networks show the absence of correlations in the full range of t.From equations(25)and(1)we can easily see that for large t,k nn(k)is approximately a logarithmic function of the network order N t,namely k nn(k)∼ln N t,exhibiting a similar behavior as that of the BA model[31]and the two-dimensional random Apollonian network [32].When m 2,equation(24)is simplified tok nn(k)=3m+1)m−1(m+1)23m+1t i−m+3m−1+2mm+1(t−t i).(26)Thus after the initial step k nn(k)grows linearly with time.Writing equation(26)in terms of k,it is straightforward to obtaink nn(k)=3m+1m−1(m+1)23m+1tk2−ln[(m+1)23m+1]ln(m+1)−m+3m−1+2mm+1lnk2ln(m+1).(27)Therefore,k nn(k)is approximately a power-law function of k with negative exponent,which shows that the networks are disassortative.Note that k nn(k)of the Internet exhibits a similar power-law dependence on the degree k nn(k)∼k−ω,withω=0.5[30].4.6.Spanning trees,spanning forests and connected spanning subgraphsSpanning trees,spanning forests and connected spanning subgraphs are important quantities of networks,and the enumeration of these interesting quantities in networks is a fundamental issue[33–37].However,explicitly determining the numbers of these quantities in networks is a theoretical challenge[38].Fortunately,the peculiar construction of Koch networks makes it possible to derive exactly the three variables.4.6.1.Spanning trees.By definition,a spanning tree of any connected network is a minimal set of edges that connect every node.The problem of spanning trees is closely related to various aspects of networks,such as reliability[39,40],optimal synchronization[41]and random walks[42].Thus,it is of great interest to determine the exact number of spanning trees[43].In what follows we will examine the number of spanning trees in Koch networks.Note that in the Koch networks K m,t there are L (t)=(3m+1)t triangles,but there are no cycles of length more than3.For each of L (t)=(3m+1)t triangles,to assure that its three nodes are in one tree,only two edges of it must be present.Obviously,there are three possibilities for this.Thus,the total number of spanning trees in K m,t,denoted by N ST(t),isN ST(t)=3L (t)=3(3m+1)t.(28) We proceed to represent N ST(t)as a function of the network order N t,with the aim to provide the relation governing the two quantities.From equation(1),we have(3m+1)t=N t−12. This expression allows one to write N ST(t)in terms of N t asN ST(t)=3(N t−1)/2.(29)Thus,the number of spanning trees in K m,t increases exponentially with the network order N t,which means that there exists a constant E ST,called as the entropy of spanning trees, describing this exponential growth[34]:E ST=limN t→∞ln N ST(t)N t=12ln3.(30)In addition to the above analytical computation,according to the previously known result [44],one can also obtain numerically but exactly the number of spanning trees,N ST(t),by 12computing the nonzero eigenvalues of the Laplacian matrix associated with the networks K m,t asN ST(t)=1N ti=N t−1i=1λi(t),(31)whereλi(t)(i=1,2,...,N t−1)are the N t−1nonzero eigenvalues of the Laplacian matrix, denoted by L t,for the networks K m,t,which is defined as follows:its non-diagonal element l ij(t)(i=j)is−1(or0)if nodes i and j are(or not)directly linked to each other,while the diagonal entry l ii(t)is exactly the degree of node i.Using equation(31),we have calculated directly the number of spanning trees in the networks K m,t,and the results from equation(31)are fully consistent with those obtained from equation(28),showing that our analytical formula is right.It should be stressed that although expression(31)seems compact,it is involved in the computation of the eigenvalues of a matrix of order N t×N t,which makes heavy demands on time and computational resources. Thus,it is not acceptable for large networks.In particular,by virtue of the eigenvalue method it is difficult and even impossible to obtain the entropy E ST.Our analytical computation can get around the two difficulties,but is only applicable to peculiar networks.4.6.2.Spanning forests.To define spanning forests,wefirst recall the definition for a spanning subgraph.A spanning subgraph of a network is a subgraph having the same node as of the network but having partial or all edges of the original graph.A spanning forest of a network is a spanning graph of it that is a disjoint union of trees(here an isolated node is consider as a tree),i.e.a spanning graph without any cycle.The enumeration of spanning forests is very interesting since it corresponds to the partition function of the q-state Potts model[45]in the limit of q→0.For a general network,it is very hard to count the number of its spanning subgraphs.But below we will show that for the Koch networks K m,t,the number of spanning subgraphs,N SF(t),can be obtained explicitly.Analogous to the enumeration of spanning trees,for each triangle in K m,t,to guarantee the absence of cycle among its three nodes,at least one edge must be removed.And there are total seven possibilities for deleting the edges of a triangle.Then the number of spanning forests in K m,t isN SF(t)=7L (t)=7(3m+1)t,(32) which can be rewritten as a function of the network order N t asN SF(t)=7(N t−1)/2.(33) Therefore,N SF(t)also grows exponentially in N t,which allows for defining the entropy of the spanning forests of Koch networks as the limiting value[46]:E SF=limN t→∞ln N SF(t)N t=12ln7.(34)Thus,we have obtained the rigorous results for the number of spanning forests in Koch networks and its entropy.4.6.3.Connected spanning subgraphs.As the name suggests,a connected spanning subgraph of a connected network is a spanning subgraph of the network,which remains connected.By applying a method similar to that given above,we can compute the number of connected spanning subgraphs in the Koch networks K m,t,which is denoted by N CSS(t).For any triangle in K m,t,to ensure the connectedness of its three nodes,at most one edge can be13。

ucinet中核心与边缘的划分标准UCINET是一个用于社会网络分析的计算机软件,可以对社会网络中的成员进行分类和分析。
在UCINET中,对网络中的成员进行核心与边缘的划分主要有以下几个标准:1.度中心性(Degree centrality):度中心性是指一个节点在网络中的连接数。
在UCINET中,可以通过计算每个节点的度中心性来判断节点的核心性。
度中心性越高的节点,表示其在网络中的连接数越多,其在网络中的地位越重要,也更有可能属于核心节点。
2.集团中心性(Closeness centrality):集团中心性是指一个节点与其他节点之间的平均距离。
在UCINET 中,可以通过计算每个节点的集团中心性来判断节点的核心性。
集团中心性越高的节点,表示其与其他节点的距离越近,其在网络中的地位越重要,也更有可能属于核心节点。
3.介数中心性(Betweenness centrality):介数中心性是指一个节点在网络中所有最短路径中出现的次数。
在UCINET中,可以通过计算每个节点的介数中心性来判断节点的核心性。
介数中心性越高的节点,表示其在网络中扮演了更多的桥梁角色,其在网络中的地位越重要,也更有可能属于核心节点。
4.特征向量中心性(Eigenvector centrality):特征向量中心性是指一个节点在网络中的链接数和邻居节点的连接情况。
在UCINET中,可以通过计算每个节点的特征向量中心性来判断节点的核心性。
特征向量中心性越高的节点,表示其在网络中的链接数越多,且其邻居节点的链接数也越多,其在网络中的地位越重要,也更有可能属于核心节点。
除了以上几个常见的划分标准外,UCINET还提供了一些其他的分析方法,如社会网络聚类、社会网络分析、中心节点分析等,这些方法可以对UCINET中的网络进行更深入的分析和划分。
总之,UCINET中的核心与边缘的划分标准主要包括度中心性、集团中心性、介数中心性和特征向量中心性等。

改进无标度网络模型研究孙立晟;何东之【摘要】Based on complex networks theory, this paper studies construction algorithm of the scale-free networks. On the basic of the original BA scale-free networks model, the network model adds internal side edges and reconnection mechanism so that it has not only a scale-free property but also a small-world property of the real social networks. The network's nodes are added initially attractive at the same time, and this paper obtains an improved scale-free networks' model.Finally, the improved scale-free networksmodel is vertified by mean-field methods theoretically and data simulation.%基于复杂网络理论知识研究了无标度网络的构造算法,并在原有的BA无标度网络模型的基础上,通过加入内部边和重连边机制使该网络模型不但具有无标度特性而且具有现实社会网络的小世界特性,同时给网络的节点加入初始引力,得出了一种改进的无标度网络模型。
最后,不仅从理论上通过平均场方法验证了改进模型,而且通过数据仿真验证该模型。
【期刊名称】《电子设计工程》【年(卷),期】2016(024)006【总页数】4页(P115-117,120)【关键词】复杂网络;无标度网络;改进无标度网络;平均场方法【作者】孙立晟;何东之【作者单位】北京工业大学嵌入式软件与系统研究所,北京 100022;北京工业大学嵌入式软件与系统研究所,北京 100022【正文语种】中文【中图分类】TN919现在越来越多的研究者通过复杂网络[1]中的小世界网络[2]模型或无标度网络[3]模型来研究社会网路,而社会网络同时具有小世界特性和无标度特性。

实验一网络中心性---生物网络中的关键基因识别计算机学院一、实验内容1.问题描述关键基因在生物体存活、生殖以及疾病过程中都扮演着重要角色,构建关键基因的预测工具对系统生物学研究具有重要意义。
由于关键基因通常在生物网络中位于拓扑结构上的中心位置,因此大量的计算工具都是通过量化基因在生物网络中的拓扑中心性来有效预测潜在的关键基因。
2.实验数据模式生物Saccharomyces cerevisiae(Yeast)具有目前较为完整的蛋白质相互作用网络(PPI)数据以及实验验证的关键基因金标准。
Yeast的PPI网络具有5049个蛋白质以及它们之间的24714个物理相互作用关系;已知的关键基因个数1165个。
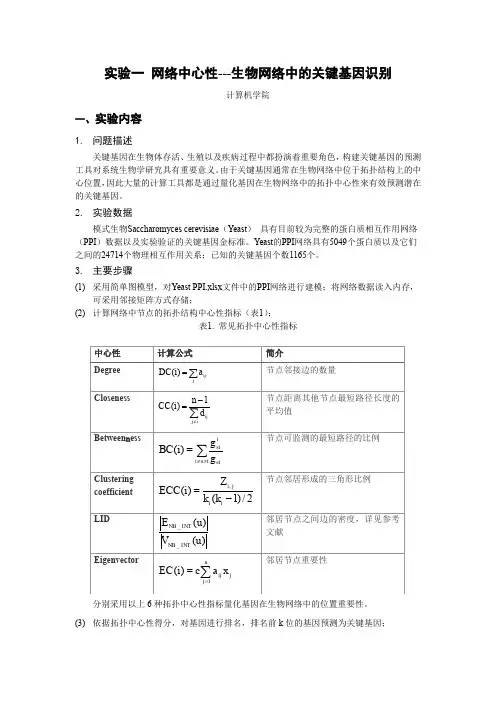
3.主要步骤(1)采用简单图模型,对Yeast PPI.xlsx文件中的PPI网络进行建模;将网络数据读入内存,可采用邻接矩阵方式存储;(2)计算网络中节点的拓扑结构中心性指标(表1);表1. 常见拓扑中心性指标分别采用以上6种拓扑中心性指标量化基因在生物网络中的位置重要性。
(3)依据拓扑中心性得分,对基因进行排名,排名前k位的基因预测为关键基因;(4) 结果的比较分析:比较6种不同拓扑指标的预测结果。
随着参数k 的不断增大,计算在不同k 值下预测结果的准确率。
二、分析及设计1. 数据预处理首先对拿到的xlxs 格式表格进行预处理,将其转换为csv 合适,以更方便编程使用。
2. 计算网络中节点的拓扑结构中心性指标 (1) Degree 度,节点邻接边的数量,即边集合{a}中包含某个节点的边的个数,由于边的值是0,1,所以degree 公式为:其中i 为待求得某个节点,j 为与i 连接的某个节点,ij a 为节点间的边且有:1 , 0 ij if i j are connecteda otherwise⎧=⎨⎩ (2) Closeness 紧密中心性,定义了单个节点的紧密程度,是节点距离其他节点最短路径长度的平均值。

社交网络分析算法的使用教程社交网络分析(Social Network Analysis,SNA)是一种研究人际关系的方法,通过分析个体之间的连接和关联,揭示社交网络中的模式和结构。
在社交媒体时代,社交网络分析算法成为了研究网络社会学、营销学以及信息传播的重要工具。
本文将介绍几种常用的社交网络分析算法及其使用教程。
一、度中心性算法(Degree Centrality)度中心性算法是最简单也是最常用的社交网络分析算法之一,用于计算每个节点在网络中有多少条边与之连接。
该算法可以用来评估一个节点的重要性和影响力。
具体计算方法如下:1. 首先,将网络数据导入社交网络分析工具(如Gephi、Cytoscape等)中。
2. 在工具中选择度中心性算法,并点击运行。
3. 程序会计算每个节点的度中心性,并将结果显示在节点上或作为节点的属性。
4. 分析结果,找出具有较高度中心性的节点,这些节点在网络中起到重要的枢纽作用。
二、介数中心性算法(Betweenness Centrality)介数中心性算法用于衡量节点在网络中的中介地位,即节点在连接其他节点之间的最短路径中扮演的角色。
该算法可以用来识别那些在信息传播、资源传输中起到关键作用的节点。
具体计算方法如下:1. 在社交网络分析工具中导入网络数据。
2. 在工具中选择介数中心性算法,并点击运行。
3. 工具会计算每个节点的介数中心性,并在节点上显示结果。
4. 根据分析结果,找出介数中心性较高的节点,这些节点在信息传播和资源传输中扮演着重要的桥梁角色。
三、聚集系数算法(Clustering Coefficient)聚集系数算法用于衡量节点邻居之间的相互连接程度,用来判断网络中的群组和社区结构。
该算法可以帮助我们理解社交网络中的小世界现象和群体行为。
具体计算方法如下:1. 将网络数据导入社交网络分析工具中。
2. 在工具中选择聚集系数算法,并运行。
3. 工具会计算每个节点的聚集系数,并在节点上显示结果。
(一)行动者结点中心度(P109)在一个社会网络中各个行动者跟其他行动者的联系密切程度是不同的,因而其所处的位置也不同,这种情况可用社群图中的结点度数的差异来测量。
在无向图中,某点的结点数是指跟它相连的线条数,可表示为:此式是根据绝对数计算的中心度,结点数最大的行动者即为中心。
另外一种方式是根据相对数计算的中心度,是指某结点的结点度与连线总数之比。
故P t点的中心度为:或者表示为:式中N指网络规模,其任一结点的最大度数是N一1。
相对数中心度为标准化形式,便于进行比较,可以分析不同网络中行动者结点中心度的差异。
例如,结点数同样都是20的一个结点,在一个有100个结点的图中和有30个结点的图中,其中心地位是不一样的(相对中心度分别为20/100一0.2,20/30=0.67)。
所以,相对中心度被看作是一个更为标准化的测量。
在有向图中,也可以根据结点度来计算其结点的中心度,同样有绝对数和相对数之分。
跟无向图不同的是,由绝对数计算的中心度分为两个方面:一是对应内结点度确定的是内中心度(in—centrality),二是对应外结点度确定的是外中心度(out—centrality)。
根据相对数计算有向图的中心度时,根据其基本定义,需要同时计算某一结点的内结点度和外结点度,然后再与连线总数求比。
其公式为:在以结点度数为基础对结点中心度进行测量时,应注意以下两点:第一,这种测量依据的主要是直接关系,没有考虑间接关系。
但实际上也可以进一步扩大到间接关系。
这就涉及了“邻居”(neighbourhood)概念——与某一特定结点相连接的点。
此概念包含与远距离点之间的关系。
例如,对某一结点的地方中心度测量依据直接关系(距离为1),也可根据距离为2或大2的关系来测量。
但要考虑多大的距离,这要视一个图的密度等因素而定,主要应考虑距离相对较小的那些间接点。
第二,对行动者结点中心度进行测量时,没有涉及整个网络是否有独一无二的“中心”点这个问题,下面的群体中心势测量将涉及这两点。
特征向量中心度计算摘要:一、特征向量中心度计算的背景与意义1.中心度在图论中的重要性2.特征向量中心度的提出二、特征向量中心度的计算方法1.特征向量的概念2.特征向量中心度的定义3.计算方法详解三、特征向量中心度计算的应用实例1.网络社区发现2.社交网络分析3.生物信息学正文:特征向量中心度计算是一种在图论中衡量节点重要性的方法,具有广泛的应用价值。
在复杂网络研究中,中心度是一个重要的概念,它可以帮助我们识别出网络中的核心节点,从而更好地理解网络的结构和功能。
特征向量中心度作为一种中心度度量方法,因其独特的性质和高效的计算方法,逐渐成为研究的热点。
特征向量中心度的计算方法主要基于特征向量的概念。
在图论中,特征向量是指在网络中传播的一种信息或影响力,它可以沿着网络中的边传播,并受到各个节点的特征值的影响。
特征向量中心度就是通过计算特征向量在各个节点上的投影来衡量节点的重要性。
具体来说,特征向量中心度等于特征向量在节点上的投影的平方和除以投影向量的模长的平方。
在实际应用中,特征向量中心度计算可以帮助我们更好地理解网络的结构和功能。
例如,在网络社区发现中,特征向量中心度可以用来识别网络中的社区结构,从而揭示出网络中隐藏的子群体。
在社交网络分析中,特征向量中心度可以用来衡量社交网络中用户的影响力,帮助我们识别出网络中的关键节点,从而更好地理解信息的传播过程。
在生物信息学中,特征向量中心度可以用来分析基因表达数据的聚类结构,帮助我们揭示基因之间的功能关联。
总之,特征向量中心度计算作为一种高效的中心度度量方法,在图论、网络科学等领域具有广泛的应用价值。
复杂网络中的节点重要性评估研究随着互联网的迅速发展以及人类社会更加复杂多元化,一些复杂网络问题也日益凸显。
如何通过对网络中不同节点的重要性评估,优化网络的布局以及提高网络的安全性等问题引起了广泛的关注。
本文将针对这些问题,探讨当前复杂网络中的节点重要性评估研究。
一、复杂网络与节点重要性复杂网络是由大量互联的节点组成的网络,节点之间通常会通过不同的边、链接进行联系。
在复杂网络中,节点的重要性评估是指判断某个节点对整个网络的运行、性能等方面有多大的影响。
而确定节点的重要性则可以对网络结构及安全性做出相应的调整。
节点重要性评估可以分为多种方法,其中最常见的是基于节点度数的度中心性指标。
度中心性是衡量一个节点与其他节点的链接数目,即节点的度数。
在网络中,度数越大则代表节点的连通性越强,可以通过增加节点度数来达到改善网络性能的目的。
二、其他节点重要性评估方法除了度中心性外,还有一些其他的节点重要性评估指标。
例如介数中心性、特征向量中心性、聚类系数等。
介数中心性指标衡量的是节点在网络中能够连接其他节点的数量,可以用于判断节点在信息传输方面的跳数,主要基于节点间短路长度的计算方式。
特征向量中心性则是通过节点与其他节点之间的关联来评估节点影响力的大小。
聚类系数则是指节点的密集程度,即节点周围节点之间形成的连接数量,可以用于度量节点的影响力和稳定性。
三、评估方法的限制与挑战尽管这些节点重要性评估方法被广泛采用,并且表现出了良好的效果。
但是,这些方法也存在一些限制和挑战。
例如,在节点度数评估中,只考虑了节点数量的因素,忽略了节点的位置和链路质量。
因此,节点的度数并不是评估节点重要性的完整因素,这也就导致了这种度数方法并不完全可靠。
在介数中心性的评估中,可能会被一些受限制的节点影响,导致结果出现偏差。
针对这些局限性,需要我们同时采用多种节点重要性评估方法,以确保正确性和准确性。
四、节点重要性评估的应用在不同的领域中,节点重要性评估方法被广泛应用,例如社会网络、交通网络、金融网络等。
2021年2月第2期Vol. 42 No. 2 2021小型微 型计算 机系统Journal of Chinese Computer Systems利用网络表征学习辨识复杂网络节点影响力杨旭华,熊帅(浙江工业大学计算机科学与技术学院,杭州310023)E-mail : xhyang@ zjut. edu. cn摘要:发现复杂网络中最具影响力的节点,有助于分析和控制网络中的信息传播,具有重要的理论意义和实用价值.传统的确定节点影响力的方法大多基于网络的邻接矩阵、拓扑结构等,普遍存在数据维度高和数据稀疏的问题,基于网络表征学习,本 文提出了一种局部中心性指标来辨识网络中高影响节点(NLC),首先采用DeepWalk 算法,把高维网络中餉节点映射为一个低维空间的向量表示,并计算局部节点对之间的欧氏距离;接着根据网络的拓扑结构,计算每个节点在信息的传播过程中,对所在 局部的影响力大小,用以识别高影响力节点.在八个真实网络中,以SIR 和SI 传播模型作为评价手段,将NLC 算法和度中心性、接近中心性、介数中心性、邻居核中心性、半局部中心性做了对比,结果表明NLC 算法具有良好的识别高影响力传播节点飴 性能.关键词:节点影响力;网络表征学习;局部节点中心性;复杂网络中图分类号:TP301文献标识码:A 文章编号:1000-1220(2021)02-0418-06Identiflcation of Node Influence Using Network Representation Learning in Complex NetworkYANG Xu-hua,XIONG Shuai(Computer Science and Technology College,Zhejiang University of Technology ,Hangzhou 310023 .China)Abstract : Finding the most influential propagation nodes in complex networks is helpful to analyze and control the propagation of in formation in the network , which is of great theoretical significance and practical value. Most of the traditional methods for determining the influence of nodes are based on the adjacency matrix and topology of the network , and the problems of high data dimension and da ta sparsity are common. Based on Network Representation Learning , this paper proposes an algorithm to identify the high influence propagation nodes of the network ( NLC). Firstly ,the deepwalk algorithm is used to map the nodes in a high-dimensional network intoa vector representation of a low-dimensional space and calculate the euclidean distance between local node pairs. Then ,according to thetopology of the network,the influence of each node on the local area during the propagation of information is calculated to identify the high-influence nodes. In eight real networks , SIR and SI propagation models are used as evaluation methods , comparing the NLC algo rithm with degree centrality , closeness centrality , betweeness centrality , neighborhood coreness , and semi-local centrality , the resultsshow that NLC algorithm has good performance in identifying high-influence propagation nodes.Key words : node influence ; network representation learning ; node local centrality ; complex network1引言真实世界中的许多系统都可以抽象为复杂网络,比如社 交网络、交通网络、电力网络、通信网络、人物关系网络、流行病传播网络等.辨识网络中有影响力的传播节点,涉及到网络 的结构和功能等属性,包括度分布,平均距离,连通性,信息传 播,鲁棒性等3〕,在实际应用中,能够控制信息在网络中的 传播⑷、做高效的新闻推广⑸、避免电网中故障的传播⑷、分 析蛋白质之间的相互作用⑺等.如何有效辨识网络中节点传播影响力的大小,研究者们 已经有了不少研究成果,这些方法总体上可以分为两种类型: 基于局部信息和基于全局信息的判断节点中心性的方法.基 于局部信息的方法,例如:度中心性⑻把节点连接的边的数量作为衡量的指标;邻居核中心性⑼把节点的一级邻居、二级邻居和三级邻居节点个数之和当做判断影响力大小的指 标;K-shell 分解方法31,是一种基于节点局部拓扑结构的方 法丄iu 等人认为许多真实网络由于局部的紧密连接而存在类核结构,导致许多节点的值不能真实的反映节点在网络中的影响力,他们通过删除冗余边的策略,提高了 K-shell 值 的准确性;郑文萍等人衡量节点在网络连通性中的作用, 通过节点所连边对局部网络连通性的影响来反映该节点在网 络连通性方面的重要性;Chen 等人口结合度中心性和全局信息,提出了一种半局部中心性方法,实验表现与紧密中心性相同,但计算复杂度较低;李维娜等人,基于网络的局部社 团结构和节点度的分布情况,提出了一种重要节点挖掘算法SG-CPMini n &基于网络全局信息的方法往往能获得比基于局部信息的算法更高的精确度,但计算复杂度比较高.例如介数中心收稿日期:2020-02-24 收修改稿日期;2020-04-14 基金项目:国家自然科学基金项目(61773348)资助;浙江省自然科学基金项目 (LY17F030016)资助.作者简介:杨旭华,男,1971年生,博士,教授,CCF 会员,研究方向为机器学习、复杂网络、智能交通;熊0巾,男,1994年生,硕士研究生,研究方向为机器学习、复杂网络.2期杨旭华等:利用网络表征学习辨识复杂网络节点影响力419性和接近中心性:冏,都是基于全局路径的方法,考虑网络中任意节点对之间的路径.谷歌公司提出的PageRank"",通过考虑邻居节点的数量和质量,再进行全局的迭代计算来确定节点的重要性.吕琳環等人提出一种类似于PageRank的算法,在网络中增加了一个背景节点与所有节点进行双向连接,使新的网络成为强连通网络,称作LeaderRank").王斌等人(切考虑网络的结构及属性信息,提出节点信任度的概念,同时将节点信任度引入到PageRank算法中,构建了一种关键节点识别算法TPR(Trust-PageRank);Lu等人画提出了一种基于信息扩散特性,将节点的局部属性与全局属性相结合的WeiboRank(WR)算法,在微博社交网络数据上表现良好.上述辨识方法,都是建立在传统的网络表示方法之上的,普遍依赖于网络的邻接矩阵和拓扑结构,具有维度高和数据稀疏的特点,计算复杂度高,在大型网络使用中计算代价比较高.随着网络表征学习技术在自然语言处理等领域的发展和广泛应用,研究者们转而探索如何将网络中的节点表示为低维且稠密的向量,提岀了诸多方法.DeepWalk是网络表征学习的先驱0),将词表示学习算法word2vec[22]应用在随机游走序列上,从而生成了节点的低维度表示向量.Lineal针对一阶相似度和二阶相似度,提出了一种边采样算法优化目标函数,进而得到节点的向量表示.N o de2vec[241通过改变随机游走序列生成的方式扩展了DeepWalk算法,将宽度优先搜索和深度优先搜索引入了随机游走序列的生成过程,综合考虑了网络的局部信息和全局信息来表示节点•CANE1251假设每个节点的表示向量由文本表示向量及结构表示向量构成,其中,文本表示向量的生成过程与边上的邻居相关,再利用卷积神经网络和注意力机制对一条边上两个节点的文本信息进行编码,得到节点的表示向量■SDNE1261使用深层神经网络对节点表示间的非线性进行建模,把模型分为两个部分:一个是由Laplace矩阵监督的建模第1级相似度的模块,另一个是由无监督的深层自编码器对第2级相似度关系进行建模,将深层自编码器的中间层输岀作为节点的向量表示.这些算法从不同的角度,采用不同的优化方法,把高维和稀疏的网络映射到低维和稠密的向量空间,保留网络的原有结构,具有计算复杂度低和准确度高等特点.在本文中,我们基于网络表征学习提出了一种辨识网络节点影响力的方法.采用网络表征学习DeepWalk算法把高维的复杂网络映射到低维的向量空间,把网络节点映射为欧式空间中低维的向量表示,然后结合网络拓扑信息提出节点的局部中心性,作为判断节点影响力大小的指标.2基于网络表征学习的节点局部中心性节点在网络中传播信息时,与其局部的拓扑结构有很大的关系.已有研究表明:节点的K-shell值越大,周围的拓扑结构越紧密,节点向周围区域传播信息的效率越高〔勿,同时,信息传递的强度随着节点间距离的增大而迅速衰减皿),由此,提出一种基于网络表征学习和局部中心性确定任意节点i的影响力指标:NLC(i)=Z心X e-')Ti-X/2(J)其中,Ks,■表示节点i的K-shell值必”分别表示节点ij用DeepWalk网络表征方法映射到低维欧式空间的向量,比-X」表示两个向量之间的欧氏距离,r(i)表示i节点的三级邻域,即i节点的一级邻居、二级邻居以及三级邻居节点的集合j节点属于r(i)集合.网络中节点间的距离,本文没有采用网络的最短路径距离,因为会存在如下的问题,如图1所示,i节点在传播它自身的信息时,首先会影响它的一级邻居节点,比如节点k和节点j,当节点A和/被感染后,由于j节点有更多的连接到外部区域的邻居节点(图1中灰色节点),尽管同样是节点i的一级邻居节点J比k在传播i节点信息的过程中贡献更大【切,所以,信息在网络中的传播,除了距离以外,还与网络的结构密切相关,最短路径距离的长度不能准确的表示信息在传播过程中的衰减,还要根据网络的拓扑结构,对所求节点的邻域节点做进一步的划分.因为网络表征学习方法不但可以把高维网络映射到低维的向量表示,而且可以同时保持网络的结构,节点间的距离用低维向量间的欧式距离替代后,不仅考虑了最短路径距离,而且包含了图1一个有8个节戌和节点周围的拓扑结构信息,能够9务边的网络更准确的描述信息在网络传播过Fig.1Nitwork with eight程中的衰减因此在本文中,我们....选择应用DeepWalk方法,把网nodes and nine edges络节点映射到低维的向量表示,然后用节点相应的低维向量来计算节点之间的距离.具体地,基于DeepWalk方法,将网络空间映射到欧式空间,把每一个节点表示为一个低维稠密的向量,将具有N个节点的网络G转化为欧氏空间的N个r维向量,一个网络节点及其连边信息对应一个向量,其中任意节点i的向量表示为:Xi=(x.l,X.2,X.3,…,x.,),i=1,2,3,,N,在本文中,『取N/23实验和分析3.1数据集为了评估所提出的方法的性能,我们在8个真实世界的网络中进行了实验,这8个网络都是无向网络,也不考虑权重,它们分别是常见形容词和名词的邻接网络adjnoun f30]、科学家合作网络netscience、Ca-GrQc和hep-th[31H]、新西兰宽吻海豚社会网络dolphin1341、小型的facebook社交网络、爵士音乐人合作网络Jazz匈、美国政治图书网络polbooks1371,表1给出了8个真实数据集的拓扑属性参数.其中,N和E分别表示网络的节点数和边数,〈&〉表示网络的平均度,在本文中,考虑到现实世界中网络的度分布往往存在“重尾效应”,令0”=<*>/<*2>[381,表示SIR模型传播的阈值,c表示网络的平均聚类系数.3.2评价方法和指标3.2.1SIR疾病传播模型SIR属于动态传播算法,结果准确性好但计算复杂度高,420小型微型计算机系统2021年本文提出的NLC算法及其他静态指标方法计算复杂度低,我们用SIR疾病模型做为基准参照模型去评价不同的判断节点影响力静态指标方法性能的优劣(列.在SIR模型中,如果需要判定一个节点在网络中的传播影响力,则把这个节点设定为网络中唯一的感染节点(Infected),其他节点标记为易感节表1数据集Table1Data setsNetwork N E〈k〉cdolphin62159 5.130.1470.27polbooks1054418.40.0840.488Jazz198274227.700.0260.617adj n oun1124257.5890.0730.1728 netscience15892742 3.4510.1440.6378 facebook40398823443.6910.0090.6055 Ca-GrQc524214496 5.5310.05930.5296 hep-th836115751 3.7680.1150.4420点(Susceptible),在每个时间步,每个感染态节点会以概率0(0=1.50*)感染其易感邻居节点,0”表示SIR模型传播的阈值,然后以概率“(在本文中,我们设置“=1)从疾病中恢复,变成移除态(Recovered),移除态节点不会再被感染.这个过程不断迭代直到网络中没有感染节点为止,r时刻网络中移除态和感染态节点的总数量,记为F(r),F(r),作为评价r时刻该节点传播影响力大小的指标,F(r)越大,该节点影响力越大. 3.2.2SI疾病传播模型在该模型中,节点一旦被感染,状态从S变为I之后不能恢复,其他条件和SIR模型相同,在本文中,易感状态节点被感染的概率为苹".如果在相同的时间步的条件下,一个节点感染的网络节点越多,则说明该节点感染能力越强,影响力越大.3.2.3肯德尔系数不同的方法都可以按照所计算的传播能力,对网络中所有节点从高到低排序,针对不同的感染率0,我们用肯德尔系数7去评价不同的静态指标方法得到的排序列表和SIR动态传播模型生成的排序列表之间的联系I切,t是一个在[-1, 1]之间的一个数,7■越大,两个序列吻合度越高,T被定义为:2(M-NJN(N-1)(2)N c表示两个排序列表相协调元素的数量,M表示二者不协调元素的数量,N表示网络节点总数.3.3数值仿真首先,对八个真实网络的每一个节点在本网络内赋予唯一的编号,比如网络1有N个节点,则网络节点的编号应该是1,2,……,N.3.3.1比较NLC和5种知名中心性方法识别的Top-10高影响力节点的准确性在表2中,我们以SIR模型计算出来的Top-10节点为基准,在4个真实网络上,用NLC方法,度中心性(DC)、接近中心性(CC)、介数中心性(BC)、邻居核中心性(Cnc)、半局部中心性(CL)分别计算ToplO节点,比较不同方法的准确性,考虑到网络的规模和时间复杂度,本文令『=10[41].具体计算方法为:以dolphin网络为例,首先用SIR模型在t=10时刻,计算得到F(10)数值最大的Top-10节点做为基准,然后用NLC方法算出Top-10节点,如果两组节点有9个相同,则NLC算法的准确率为90%.表26种中心性算法和SIR模型对排名前10节点的识别结果Table2Six algorithms and SIR modelsto identify thetop-10nodes网络dolphin算法(准确率)排序DC(70%)BC(60%)cc(60%)Cnc CL(80%)(80%)NLC(90%)F(10) 1153737151515152382414638383834641383846412143438213434214155281521413746618182303046377212184151342830552952525130958523422125110258958173052网络adj n oun算法(准确率)排序DC(70%)BC(60%)CC Cnc CL(70%)(80%)(80%)NLC(80%)F(10) 11818181818181823333352334444525252352452524444444444510510281051051051056108010525512851725105105125101082828272826252592622510552655102292619325160网络polbooks算法(准确率)排序DC(80%)BC(60%)CC Cnc CL(40%)(70%)(90%)NLC(90%)F(10) 193131999921350591313131334108858531734851350473410573731073747346677777743110317744153148585831597367676774912954112745104183248741212网络netscience算法(准确率)排序DC(30%)BC(30%)CC Cnc(20%)(40%)CL(0%)NLC(80%)F(10) 134797934143034552351512823514313556337951715163143255344552827575564656335529521730291714332821336143035152914143413354714317573554143513475781432302132120214361351359631337602951437562762102172041124220143854562在表2中,比较其它5种方法,本文提出的NLC算法在4个数据集中都取得了最高的准确率.接下来,我们比较了各种2期杨旭华等:利用网络表征学习辨识复杂网络节点影响力421静态指标算法与SIR模型得到的Top-10节点排序列表的吻合程度,在小型网络polbooks和adjnoun中,6种中心性算法都有较高的准确率,CL算法和NLC算法有相同的准确率,但NLC得到的序列与SIR模型给出的序列更吻合;在dolphin 和netscience网络中,NLC算法不仅有最高的准确率,而且给出的排序序列与SIR模型给出的序列更吻合;就整体而言,NLC与SIR模型得到的序列保持良好的吻合度.其中实验结果取1000次实验的平均值,最佳准确率用黑体字标出,F(10)表示SIR模型在第10时间步的结果.3.3.2比较NLC与5种知名中心性方法在SIR模型下餉肯德尔系数分别用各种静态指标算法与SIR模型对一个网络中所有节点的影响力排序,然后比较各种静态指标算法得到的节点排序列表和SIR模型得到列表的吻合程度,我们用肯德尔系如图2所示,针对不同的感染率B,使用NLC和5种知名中心性方法计算出网络中所有节点的影响力大小排序列表,与SIR模型生成的排序列表做对比,得到肯德尔系数T.在adjnoun网络中,BC算法表现最差,CL和Cnc算法表现基本相同,NLC算法表现最好;在polbooks网络中,CC和BC 表现最差,NLC、CL、Cnc表现良好;在netscience网络中,表现最差的还是BC算法,CC和CL算法也表现不佳,当B< 0.04.NLC算法表现最好,总体表现良好;在facebook网络中,CC表现最差,当p>0.04,NLC表现最好;在hep-th网络中,当B<0.04时,NLC算法表现最好,当p>0.04,NLC算法在6种方法中排名第二;dolphin网络中,当B在0到0.04以及0.07到0.1这两个区间时,NLC算法表现最好,优于其它算法;在Jazz和Ca-Grtjc网络中,BC算法表现最差,当B >0.03时,NLC算法表现最好;综上所述,NLC在肯德尔系数表示这个吻合程度.0.80数上表现最佳.netscienceinounb0.70l0.60.650.60NLC CC BC DC CL Cnc00.020.04 0.06 0.080.100.020.040.060.080.103NLC CC BC DC CL Cnc图2NLC,8,BC,DC,CL,Cnc算法的肯德尔系数,取1000实验的平均值.横坐标表示节点被感染的概率,纵坐标表示肯德尔系数Fig.2Kendall correlation coefficient of NLC,CC,BC,DC,CL,Cnc algorithm which are taken as the average value of1000 experiments.The horizontal ordinate represents the probability of the node being infected,and the longitudinalordinate represents the Kendall correlation coefficient3.3.3比较NLC和CL、Cnc方法■所选Top-10节点的平均感染能力在8种不同的网络中.NLC算法性能均排前列;BC和CC 算法不仅计算量大,而且表现差;Cnc算法和CL算法,在不同的数据集中,表现极不稳定,在有些数据集中表现较好,在有些数据集中甚至差于BC和CC算法.为进一步比较NLC.CL以及Cnc算法的性能,我们使用SI模型检验3种算法性能.首先用一个算法选出Top-10节点,然后用Top-10节点在第r个时间步之内感染的节点总数与网络节点总数的比值的平均值I(t)诰(3)422小型微型计算机系统2021年做为该算法的性能指标•在式(3)中,n表示网络节点总数,%,表示Top-10节点中第i个节点第1到第r步感染的节点总数.在相同的时间步和感染概率的情况下,哪一种方法选出的Top-10节点感染的节点越多,可以认为该算法表现越好.具体实验结果如图3所示,可以看到,NLC算法在4个网络中都取得了最佳性能.在dolphin网络中,NLC算法表现最好,Cnc算法性能最差;在netscience网络中,当时间步大于15后,NLC算法感染的节点比另外两种算法明显增多,达到 稳定的时间也比另外两种算法早,所选Top-10节点表现最好Ca-GrQc网络中,时间步小于10时,3种算法表现相近,大于10后,NLC算法表现最好,且NLC算法在第33个时间步就达到稳定;在hep-th网络中,Cnc算法表现最差,在第42个时间步才达到稳定,NLC算法表现最好.(d)©图3Top-10节点的感染能力和时间步的关系曲线,取1000次实验的平均值.横坐标表示时间步,纵坐标表示第t个时间步内Top-10节点在SI模型中感染的节点数的平均值与网络节点总数的比值Fig.3Relationship curve of infection ability and time step of Top-10node.The results are taken the average of1000experiments, the horizontal ordinate represents the time step,and the longitudinal ordinate represents the ratio of the average number of nodes infected by Top-10nodes in the SI model to the total number of network nodes within the t time step4总结和分析在本文中,我们基于网络表征学习方法,结合节点的拓扑结构和邻域信息,提出了一种节点局部中心性指标来识别节点影响力的方法•该方法提出网络中的节点的影响力由拓扑结构决定,同时随着距离的增加而衰减•在8个真实网络中,通过和5种知名的中心性方法相比较,在计算Top-10节点、Top-10节点的感染能力和肯德尔系数等方面,NLC算法取得了良好的辨识效果,在分析和控制复杂网络中的信息传播过程中具有广阔的应用前景.References:[1]Albert R,Barabasi A L.Statistical mechanics of complex networks[J].Review of Modem Phy s ics,2001,74(1):47-97.[2]Boccaletti S,Latora V,Moreno Y,et plex networks:structure and dynamics[J].Complex Systems and Complexity Science, 2006,424(4-5):175-308.[3]Newman M E J.The structure and function of complex networks[J].Siam Review,2003,45(2):167-256.[4]Wells C R,Galvani A P.Coupled disease-behavior dynamics oncomplex networks:a reviewf J].Physics of Life Reviews,2015,62(15):55-56.[5]Medo M,Zhang Y C,Zhou T.Adaptive model for recommendationof news[J].Europhysics Letters,2009,88(3):42-51.[6]Albert Reka,Albert Istvdn,Nakarado G L.Structural vulnerabilityof the North American power grid[J].Physical Review E,2(X)4,69(2):59-73.[7]Li Min,Meng Xiang-mao.The construction,analysis,and applications of dynamic protein-protein interaction networks[J].Journal of Computer Research and Development,2017,54(6):1281-1299.[8]Bonacich P F.Factoring and weighting approaches to status scoresand clique identification[J].Journal of Mathematical Sociology, 1972,2(1):113-120.[9]Bae J,Kim S.Identifying and ranking influential spreaders in complex networks by neighborhood coreness[J].Physica a Statistical Mechanics&Its Applications,2014,395(4):549-559.[10]Dorogovtsev S N,Goltsev A V,Mendes J F F.K-core organizationof complex networks[J].Physical Review Letters, 2006,96(4):40601.1-40601.4.[11]Liu Y,Tang M,Zhou T,et al.Improving the accuracy of the k-shell method by removing redundant links:from a perspective of spreading dynamics[J].Scientific Reports,2015,5(2):33~46. [12]Zheng Wen-ping,Wu Zhi-kang,Yang Gui.A novel algorithm for i2期杨旭华等:利用网络表征学习辨识复杂网络节点影响力423dentifying critical nodes in networks based on local centrality[J].Journal of Computer Rresearch and Development,2019,56(9):1872-1880.[13]Chen D,Lii L,Shang M S,et al.Identifying influential nodes incomplex networksf J].Physica a Statistical Mechanics&Its Applications,2012,391(4):1777-1787.[14]Li Wei-na,Ren Jia-dong.Key node mining in complex softwarenetwork[J].Journal of Chinese Computer Systems,2018,39(9):2022-2028.[15]Freeman L C.A set of measures of centrality based on betweenness[J].Sociometry,1977,40(1):35-41.[16]Sabidussi G.The centrality index of a graph[J].Psychometrika,1966,31(4):581-603.[17]Brin S,Page L.The anatomy of a large-scale hypertextual websearch engine[J].Computer Networks&Isdn Systems,1998,30(2):16-34.[18]Lii L,Zhang Y C,Yeung C H,et al.Leaders in social networks,thedelicious case[J].Pios One,2011,23(6):1-13.[19]Wang Bin,Wang Ya-yun,Sheng Jin-fang,et al.Identifying influential nodes of complex networks based on trust-value[J].Journal of Chinese Computer Sy s tems,2019,40(11):2337-2342.[20]Jing L,Wanggen W.Identification of key nodes in microblog net-works[J].Etri Journal,2016,38(1):52-61.[21]Perozzi B,Al-Rfou R,Skiena S.Deepwlk:online learning of socialrepresentations[C]//ACM Sigkdd International Conference on Knowledge Discovery&Data Mining,2014.[22]Mikolov T,Sutskever I,Chen K,et al.Distributed representationsof words and phrases and their compositionality[J].Advances in Neural Information Processing Systems,2013,26(2):3111-3119.[23]Jian T,Meng Q,Wang M,et al.LINE:large-scale information network embedding[C]//24th International Conference on World Wide Web,WWW2015,2015.[24]Aditya Grover J L.node2vec:scalable feature learning for networks[CJ//ACM Sigkdd International Conference on Knowledge Discovery&Data Mining,2016.[25]Tu C C,Liu H,Liu Z Y,et al.CANE:context-aware network embedding for relation modeling[C]//Proceedings of the55th Annual Meeting of the Association for Computational Linguistics,Van-couve,2017:1722-1731.[26]Wang D,Cui P,Zhu W.Structural deep network embedding]C]//Proceedings of the22n d ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,San Francisco,2016:1225-1234[27]Kitsak M,Gallos L K,Havlin S,et al.Identification of influentialspreaders in complex networks[J].Nature Phy s ics,2010,6(11):888-893.[28]Ma L L,Ma C,Zhang H F,et al.Identifying influential spreaders incomplex networks based on gravity formula[J].Physica a Statistical Mechanics&Its Applications,2016,451(3):205-212.[29]Liu Y,Tang M,Do Y,et al.Accurate ranking of influential spreaders in networks based on dynamically asymmetric link-impact[J].Physical Review E,2017,96(2):1-1,doi:10.1103/PhysRevE.96.022323.[30]Newman M E J.Finding community structure in networks using theeigenvectors of matrices[J].Physical Review E,2006,74(3):51-66.[31]Newman M E J.The structure of scientific collaboration networks[J].Proceedings of the National Academy of Sciences of the United States of America,2001,98(2):404-409.[32]Leskovec J,Kleinberg J,Faloutsos C.Graph evolution:densifica-tion and shrinking diameters[M].Association for Computing Machinery,ACM,2007.[33]Duncan J Watts,Steven H.Strogatz.Collective dynamics of smallworld networks[J].Nature,1998,393(6684):440-442.[34]Newman M E J,Watts D J,Strogatz S H.Random graph models ofsocial networks[J].Proceedings of the National Academy of Sciences'^,99(Sup):2566-2572.[35]McAuley J,Leskovec J.Learning to discover social circles in egonetworks[C]//Conference and Workshop on Neural Information Processing Systems(NIPS),2012.[36]Maridn Bogufid,Pastor-Satorras R,Albert Diaz-Guilera,et al.Models of social networks based on social distance attachment[J].Physical Review E Statistical Nonlinear&Soft Matter Physics, 2004,70(2):2441.[37]Fatiha Souam,Ali Aitelhadj,Riadh Baba-Ali.Dual modularity optimization for detecting overlapping communities in bipartite networks [J].Knowledge&Information Systems,2014,40(2):455-488. [38]Li Rui-qi,Wang Wei,et al.Review of threshold theoretical analysisabout epidemic spreading dynamics on complex networks[J].Complex Systems and Complexity Science,2016,13(1):l-39. [39]Garas A,Argyrakis P,Rozenblat C,et al.Worldwide spreading ofeconomic crisis[J].New J Phys,2010,12(11):69-73.[40]Kendall M G.A new measure of rank correlation[J].Biometrika,1938,30(1-2):81-93.[41]Wang S,Du Y,Deng Y.A new measure of identifying influentialnodes:efficiency centrality[J].Communications in Nonlinear Science and Numerical Simulation,2017,47(6):151-163.附中文参考文献:[7]李敏,孟祥茂•动态蛋白质网络的构建、分析及应用研究进展[J].计算机研究与发展,2017,54(6):1281-1299.[12]郑文萍,吴志康,杨贵•一种基于局部中心性的网络关键节点识别算法[J]•计算机研究与发展,2019,56(9):1872-1880. [14]李维娜,任家东•复杂软件群体网络社团中关键节点挖掘算法[J].小型微型计算机系统,2018,39(9):2022-202&[19]王斌,王亚云,盛津芳,等•基于节点信任度的复杂网络关键节点识别[J]•小型微型计算机系统,2019,40(11):2337-2342.。
ucinet核心度公式UCINet核心度公式是一种用于分析网络中节点重要性的指标。
UCINet是一种广泛使用的社会网络分析软件,它提供了多个核心度指标,帮助研究人员理解和评估网络中各个节点的中心性。
UCINet核心度公式的计算基于节点在网络中的连接情况。
以下是UCINet中几种常用的核心度公式:1. 度中心性(Degree Centrality):度中心性衡量了节点与其他节点之间的连接数量。
度中心性越高,表示节点在网络中具有更多的连接。
例如,若某个节点的度中心性为10,说明该节点与其他节点均有10条连接。
2. 接近中心性(Closeness Centrality):接近中心性衡量了节点与其他节点之间的距离。
距离是节点之间路径的长度,接近中心性越高表示节点与其他节点之间的距离越短。
若某个节点的接近中心性为0.5,说明该节点与其他节点的平均距离为2。
3. 中介中心性(Betweenness Centrality):中介中心性衡量了节点在网络中作为信息传递的桥梁的程度。
中介中心性越高,表示节点在信息传递中扮演着更重要的角色。
例如,如果某个节点的中介中心性为0.3,说明该节点在网络中的信息传递中有30%的比例经过它。
4. 特征向量中心性(Eigenvector Centrality):特征向量中心性结合了节点自身的重要性和邻居节点的重要性。
节点与重要节点的连接会使得该节点的特征向量中心性提高。
如果一个节点连接到多个重要节点,那么它的特征向量中心性将更高。
UCINet核心度公式的计算可以帮助研究人员了解网络中节点的重要性和影响力。
这些指标可以被应用于各种领域,如社交网络分析、组织网络分析等。
准确理解和运用UCINet核心度公式将有助于深入研究网络中节点的角色和影响,并为进一步分析和决策提供支持。
几种典型网络的节点分析在网络分析中,节点是指网络的单个元素或实体,可以是个人、组织、网站、文档等。
网络节点的分析是指通过对节点的属性和关系进行研究,揭示网络中节点的特征和功能。
下面介绍几种典型的网络节点分析方法。
1.节点中心性分析节点的中心性是衡量节点在网络中的重要程度或影响力的指标。
常用的节点中心性分析方法有度中心性、接近中心性、中介中心性、特征向量中心性等。
-度中心性:节点的度中心性是指节点在网络中的连接数或邻居数。
具有较高度中心性的节点通常是网络中的核心节点,可以从全局的角度很好地控制或传播信息。
-中介中心性:节点的中介中心性是指节点的重要性程度,即在网络中充当桥梁或传递信息的角色。
具有较高中介中心性的节点是网络中的关键节点,对信息传播和资源流动具有重要影响。
-特征向量中心性:节点的特征向量中心性是指节点作为连接到其他中心节点的中间节点的重要程度。
通过计算节点与其他中心节点的关系,可以有效地评估节点的特征向量中心性。
2.节点影响分析节点影响分析是指通过研究节点的属性和关系,揭示节点在网络中的影响力和传播能力。
常用的节点影响分析方法有布局分析、社区发现和信息传播分析等。
-布局分析:布局分析是通过可视化节点在网络中的位置和布局,来研究节点之间的关系和连接方式。
布局分析可以帮助我们理解节点之间的相对位置和影响力,从而更好地揭示网络的结构和功能。
-社区发现:社区发现是指通过划分节点集合成不同的社区,研究节点在网络中的聚集程度和相似性。
社区发现可以帮助我们发现网络中存在的隐藏结构和隐含关系,从而更好地理解节点之间的相互作用和影响。
-信息传播分析:信息传播分析是指通过研究节点的传播行为和模式,来研究节点在网络中的传播能力和影响力。
信息传播分析可以帮助我们预测节点的传播效果和影响范围,为信息传播和广告宣传等提供决策依据。
3.节点演化分析节点演化分析是指通过跟踪节点的变化和演化过程,研究节点在网络中的发展和演变规律。
BridgingCentrality:IdentifyingBridgingNodesInScale-freeNetworks∗
WoochangHwang†Young-raeCho†AidongZhang†MuraliRamanathan††
†DepartmentofComputerScienceandEngineering,StateUniversityofNewYorkatBuffalo,USA††DepartmentofPharmaceutical
Sciences,StateUniversityofNewYorkatBuffalo,USA
Email:{whwang2,ycho8,azhang}@cse.buffalo.edu,murali@acsu.buffalo.edu
ABSTRACTSeveralcentralitymeasureswereintroducedtoidentifyes-sentialcomponentsandcomputecomponents’importanceinnetworks.Majorityofthesecentralitymeasuresaredom-inatedbycomponents’degreeduetotheirnatureoflookingatnetworks’topology.Weproposeanovelessentialcom-ponentidentificationmodel,bridgingcentrality,basedoninformationflowandtopologicallocalityinscale-freenet-works.Bridgingcentralityprovidesanentirelynewwayofscrutinizingnetworkstructuresandmeasuringcompo-nents’importance.Weapplybridgingcentralityonrealworldnetworks,includingonesimulatednetwork,twobio-logicalnetworks,twosocialnetworks,andonewebnetwork,andshowthatthenodesdistinguishedbybridgingcentralityarewelllocatedontheconnectingpositionsbetweenhighlyconnectedregionsthroughanalyzingtheclusteringcoeffi-cientandaveragepathlengthofthosenetworks.Bridgingcentralitycandiscriminatebridgingnodes,thenodeswithmoreinformationflowedthroughthemandlocationsbe-tweenhighlyconnectedregions,whileothercentralitymea-surescannot.
CategoriesandSubjectDescriptors[NetworkAnalysis]:Networkmetrics,Networkcompo-nentimportancemetrics,Essentialcomponentanalysis
GeneralTermsDegree,shortestpath,betweenness,clusteringcoefficient,averagepathlength,singleton
Keywords∗ThisresearchispartlysupportedbyNSFgrantsDBI-
0234895,IIS-0308001andNIHgrant1P20GM067650-01A1.Allopinions,findings,conclusionsandrecommen-dationsinthispaperarethoseoftheauthorsanddonotnecessarilyreflecttheviewsofthefundingagencies.
KDD’06August20-23,2006,Philadelphia,PA,USA
Scale-freenetwork,centrality,bridgingnode,bridgingcoef-ficient,bridgingcentrality,modularity,robusteness,pathsprotection
1.INTRODUCTIONManyrealworldsystems,e.g.,internet,WorldWideWeb(WWW),socialsystems,biologicalsystems,etc.,canbede-scribedascomplexnetworks,whicharestructuredasasetofnodesandasetofedgesconnectingthenodes.Scale-freenetwork[4]isthemostpopularandemergingformofnet-workintheserealworldnetworksystems.Mostoftheserealworldnetworkshavebeenprovedtofollowsometopo-logicalstatisticalfeatures,i.e.,featuresofscale-freenetwork,suchaspowerlawdegreedistribution,smallworldproperty,andhighmodularity[2,3,4,5].Powerlawdegreedistri-butiondepictstheprobabilityoffindingahighlyconnectednodedecreasesexponentiallywithitsowndegree,whichisthenumberofedgesincidentonthenode.Inotherwords,therearemanylowdegreenodes,andonlyasmallnumberofnodeshavehighdegree.Thesecondphenomenon,smallworldproperty,describesthattheaveragedistancebetweennodesinanetworkisrelativelyshorterthanothernetworktypes,e.g.,randomnetworksofthesamesize.Namely,anynodecanbereachedwithinsmallnumberofconsec-utiveedgesfromanodeinanetwork.Amodulereferstoadenselyconnected,functionallyorphysically,groupofnodesinanetwork.Forthelastdistinctandthemostinterestingproperty,theserealworldnetworkshavehighmodularitywhichindicatesthathighclusteringisoneofdominatingcharacteristicsofthesenetworks.
Overthepastfewyears,empiricalandtheoreticalstudiesofnetworkshavebeenoneofthemostpopularsubjectsofrecentresearchesinmanyareasincludingtechnological,so-cial,andbiologicalfields.Networktheorieshavebeenap-pliedwithgoodsuccesstotheserealworldsystems,andmanycentralityindices,measurementsoftheimportanceofthecomponentsinanetwork,havebeenintroduced[6,9,10,16,7,18].Whilethesecentralityindiceshaveprovedthattheymadeoutstandingachievementsintheanalysisandunderstandingoftherolesofnodesinanetwork,ma-jorityoftheseexistingcentralityindicesfocusesonlyontheextenthowmuchnodesarewelllocatedoncentralpositionsorplaycentralrolesfromthestandpointoftopologyandinformationflow.Theseexistingcentralitymeasurescannothelpbeingconsiderablydominatedbynodes’degreeduetotheirnatureofcomputingcomponents’importance.Eventhoughtheseapproachesareverygoodatidentifyingcen-tralcomponents,i.e.,centralcomponentsfromanycentral-ityviewpoint,ofanetworkorofamodule,theyconcentrateonlyoncentralcomponentsandoverlookanotheressentialtopologicalaspectinnetworks.Inthisresearch,wemovethefocusofthenetworkanaly-sisfromthedirectionsofidentifyingcentralnodestoan-otherentirelynew,fresh,andimportantdirection.Fromourdeeperobservationofthehighmodularitypropertyofscale-freenetworks,weclaimthatthereshouldbe“bridg-ing”nodesthatarelocatedbetweenmodules,andwefoundthatthereexist“bridging”nodesinrealworldscale-freenet-worksduetotheirhighmodularityphenomenon.So,wealsoclaimthatthesebridgingnodes,whichbridgedenselycon-nectedregions,shouldbeattractiveandimportantessentialcomponentsinanetwork.Weintroduceanovelcentralitymetric,bridgingcentrality,thatsuccessfullyidentifiesthebridgingnodeslocatingbetweendenselyconnectedregions,i.e.modules,usinghighmodularityorhighclusteringprop-ertywhichisoneofthemostimportantpropertyofscale-freenetworks.Experimentsonseveralrealworldnetworksys-temsareperformedtodemonstratetheeffectivenessofourmetric.Bridgingcentralityhasmanypotentialapplicationsinsev-eralareas.First,itcanbeusedtobreakupmodulesinanetworkforclusteringpurpose.Functionalmodulesorphysicalmodulesinbiologicalnetworksorsubcommunitystructuresinsocialandtechnologicalnetworkscanbede-tectedusingthebridgingnodeschosenbybridgingcentral-ity.Second,italsocanbeusedtoidentifythemostcriticalpointsinterruptingtheinformationflowinanetworkfornetworkprotectionandrobustnessimprovementpurposesfornetworks.Third,inbiologicalapplications,thebridgingcentralitycanbeusedtolocatethekeyproteins,whicharetheconnectingnodesamongfunctionalmodules.2.METHOD2.1TerminologyandRepresentationRealworldsystemscanberepresentedusinggraphtheoreticmethods.Theapproachpresentedinthispaperfocusesonundirectedgraphs.AnundirectedgraphG=(V,E)consistsofasetVofnodesorverticesandasetEofedges,E⊆V×V.Anedgee(i,j)connectstwonodesiandj,e(i,j)∈E.TheneighborsN(i)ofnodeiaredefinedtobeasetofdi-rectlyconnectednodestonodei.Thedegreed(i)ofanodeiisthenumberoftheedgesconnectedtonodei.Apathisdefinedasasequenceofnodes(n1,...,nk)suchthatfromeachofitsnodesthereisanedgetothesuccessornode.Thelengthofapathisthenumberofedgesinitsnodese-quence.Ashortestpathbetweentwonodes,iandj,isaminimallengthpathbetweenthem.Thedistancebetweentwonodes,iandj,isthelengthofitsshortestpath.TheclusteringcoefficientCvforanodevistheproportionoflinksbetweenthenodeswithinitsneighbourhooddividedbythenumberoflinksthatcouldpossiblyexistbetweenthem,Cv=2|{e(i,j)}|d(v)(d(v)−1):i,j∈N(v),e(i,j)∈E[19].Inotherwords,|{e(i,j)}|givesthenumberoftrianglesthatgothroughnodev,whereasd(v)(d(v)−1)/2isthetotalnumberoftrianglesthatcouldpassthroughnodev.Thus,clusteringcoefficientofnodevindicateshowtheneighborsofnodevarewellconnectedeachother.Theclusteringcoefficientofagraphistheaverageoftheclusteringcoefficientsofallnodesinthegraph.Theaveragepathlengthofagraphistheaverageoftheshortestpathsbetweenallpairsofnodesinthegraph.