建立远程登陆db2连接步骤
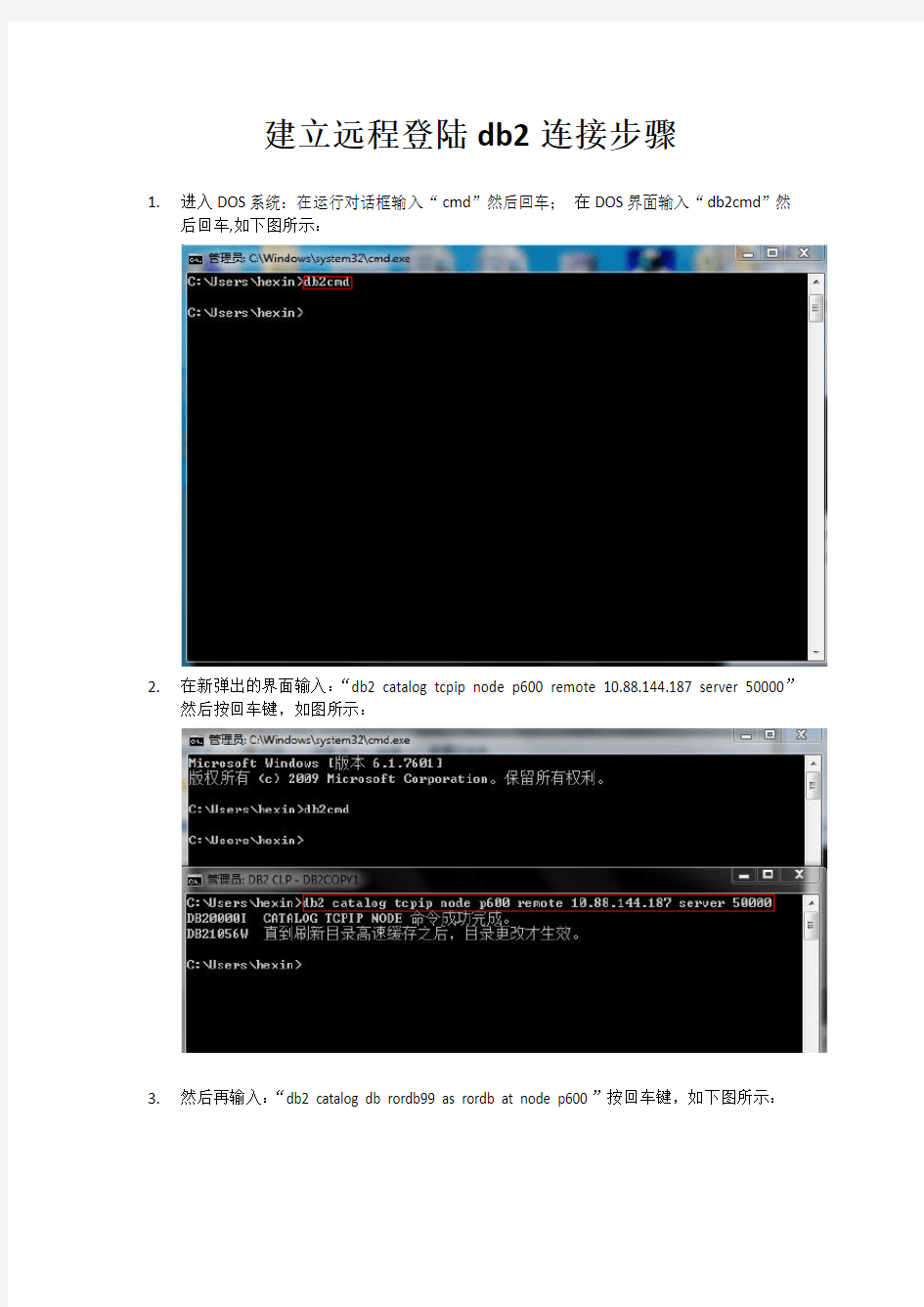
1.进入DOS系统:在运行对话框输入“cmd”然后回车;在DOS界面输入“db2cmd”然
后回车,如下图所示:
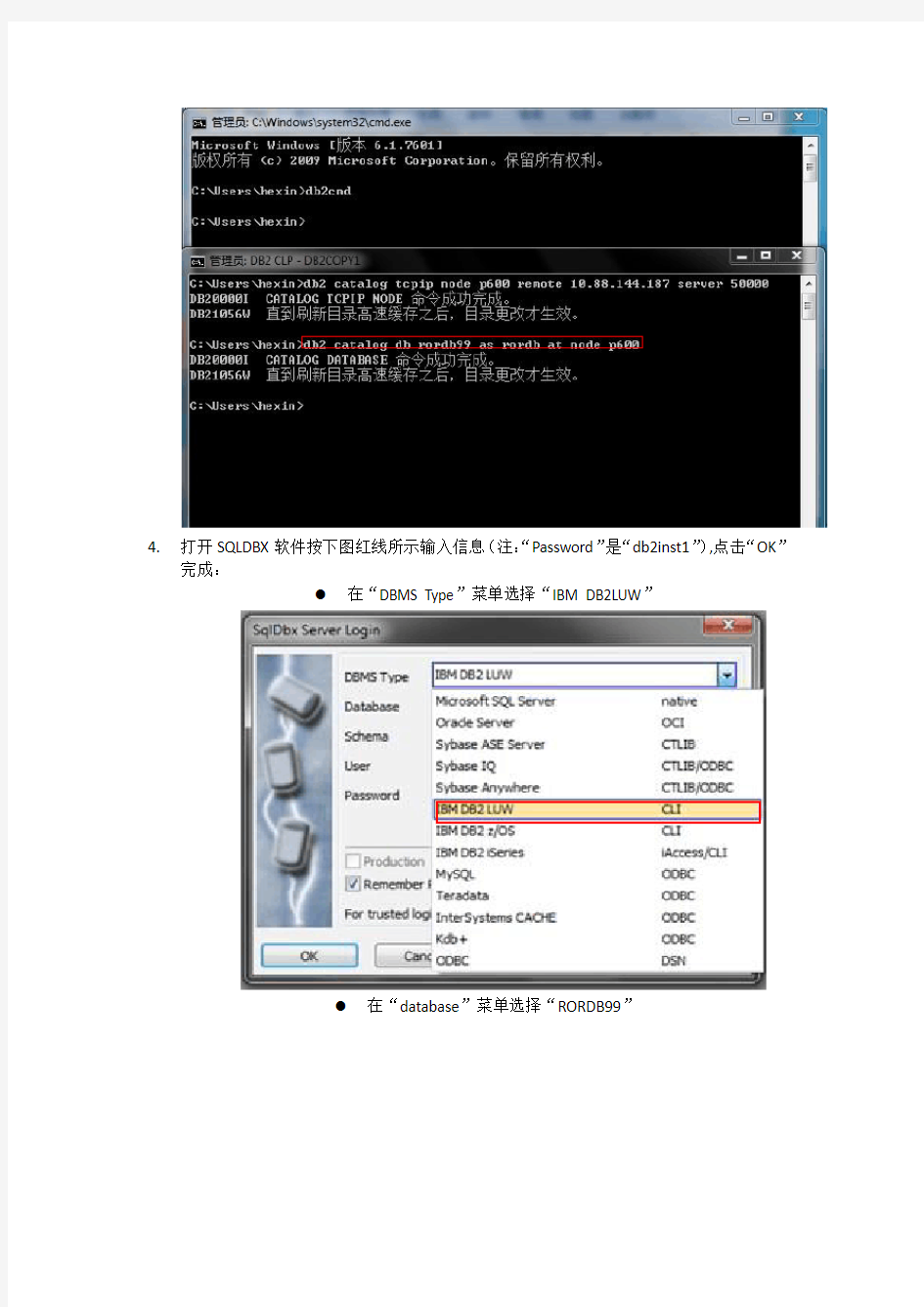
2.在新弹出的界面输入:“db2 catalog tcpip node p600 remote 10.88.144.187 server 50000”
然后按回车键,如图所示:
3.然后再输入:“db2 catalog db rordb99 as rordb at node p600”按回车键,如下图所示:
4.打开SQLDBX软件按下图红线所示输入信息(注:“Password”是“db2inst1”),点击“OK”
完成:
●在“DBMS Type”菜单选择“IBM DB2LUW”
●在“database”菜单选择“RORDB99”
在“Schema”,“User”,“Password”输入框输入“rordb99”,“db2inst1”,“db2inst1”
DB2 SQLJ 存储过程开发宝典,第 2 部分 简介: 在第 1 部分,我们已经介绍了 SQLJ 存储过程的基本知识,如何逐步完成开发和调试。现在,我们将总结说明在运行 SQLJ 存储过程时,经常遇到的错误,并对这些错误产生的原因进行分析,并给出相应的修正方法。此外,在开发过程中,有一些值得考虑或者需要进一步说明的问题,我们也将他们罗列出来,予以探讨。 引言 在第 1 部分,我们已经介绍了 SQLJ 存储过程的基本知识,如何逐步完成开发和调试。现在,我们将总结说明在运行 SQLJ 存储过程时,经常遇到的错误,并对这些错误产生的原因进行分析,并给出相应的修正方法。此外,在开发过程中,有一些值得考虑或者需要进一步说明的问题,我们也将他们罗列出来,予以探讨。 常见错误总结 由于程序代码本身、运行环境、参数配置等原因,SQLJ 存储过程在被调用时,可能会发生各种错误。对这些错误进行分析,明确其产生的原因,找到相应的应对措施,并加以归纳总结,对我们提高开发水平、保证产品质量和提高工作效率等方面具有重要的意义。这些信息对于 SQLJ 应用开发的初学者尤为重要,能够直接的帮助他们解决开发实际工作中遇到的问题,表 1 列出了常见的 SQLJ 存储过程运行错误,原因以及相应措施。 表 1. 常见错误 错误 原因 措施 SQL4306N Java 存储过程或用户定义的函数 名称(特定名称 特定名称)不能调用 Java 方法 方法,特征符为 字符串 DB2 通过 JAR 包名、类名、方法名和签名(Signature )无法找到创建存储过程时指定的被调用的方法。可能是引用的类不存在、jar 包没有安装、方法声明的参数列表与数据库期望的参数列表不匹配或者不是“public”实例方法 1.查看 Java 代码中的方法名和类名,检查存储过程 DDL 中 Java 方法名、类名和 jar 包名是否有误; 2.检查 jar/calss 文件是否在指定位置,如 sqllib/function 目录下; 3.检查存储过程 DDL 中的方法参数列表是否与 Java 代码匹配(使用 javap – s class_id 可以查看类中方法的签名),并且 Java 代码中该方法是 public 的。 SQL4304N Java 存储过程或用户定义的函数 名称(特定名称 特定名称)不能装入 Java 类 类,原因码为 原因码。 1. RC=1:在 CLASSPATH 上找不到该类。往往可能是我们在 DDL 发生了拼写错误; 2. RC=2:该类未实现必需的接口 COM.ibm.db2.app.StoredProc 或缺少 public 访问权标志。如果是 PARAMETER STYLE DB2GENERAL 的存储过程,那么要求被调用 Java 类是 public 的并继承了接口 COM.ibm.db2.app.StoredProc 。 1.检查 Java 代码中的类 / 方法名和存储过程 DDL 中 Java 类 / 方法名是否一致; 2.检查 jar/calss 文件是否在 CLASSPATH 中,如 sqllib/function 目录下; 3.检查是否 DDL 指定了 PARAMETER STYLE DB2GENERAL 而 Java 代码类是否是 public 并继承 接口 COM.ibm.db2.app.StoredProc 。 SQL4302N 过程或用户定义的函数 名称(特定名称 特定名称)由于异常 字符串 而 存储过程由于异常而异常终止。通常可能是查询返回是空的 数据集,或是 SQL 中使用“select into :hostvar”但是实际查 询返回多条数据,或 Java 运行中出现空指针异常等。 检查 db2diag.log 诊断日志,找到错误,修正 Java 代码。
1.1 SQL过程的结构 命名规则: 1、清洗过程名称命名: PROC_业务主题_目标表(PROC_JY_KJYRLJB 交易主题的卡交易日类聚表) 2、函数名称命名: PROC_业务主题_函数名(PROC_JY_GETYWZL 交易主题取得卡业务种类函数) 3、变量命名: VAR_变量描述(VAR_YWZL 业务种类变量) 4、游标命名: CUR_游标描述(CUR_KJYB 对卡交易表进行游标处理) 语法: CREATE PROCEDURE 过程名称 (参数列表 DYNAMIC RESULT SETS 结果集数量 是否允许SQL LANGUAGE SQL BEGIN SQL 过程体
END 范例“资产负债.sql ”中 第1行:Create Procedure admin.BalanceSheetDayly定义了过程名称 参数列表为Out ProcState varchar(100 其定义SQL 过程从客户应用获取,或返回客户应用的0个或多个参数,参数列表使用逗号侵害各个参数 参数类型有三种: l IN 从客户应用检索值。其不能够在SQL 过程体中修改 l OUT 向客户应用返回值 l INOUT 从客户应用检索值,并返回值 省略了结果集数量的定义,default 为0。即表示不返回结果集。 省略了是否允许SQL 的说明。其值指出了存储过程是否会使用SQL 语句,如果使用,其类型如何: l NO SQL 不能够执行任何SQL 语句 l COTAINS SQL 可以执行不会读取SQL 数据,也不会修改SQL 数据的SQL 语句 l READS SQL DATA 可以包含不会修改SQL 数据的SQL 语句 l MODIFIES SQL DATA 可以执行任何SQL 语句,除了不能够在存储过程中支持的语句以外。
本文将为您介绍一个DB2存储过程使用动态游标的例子,如果您对动态游标的使用感兴趣的话,不妨一看,对您学习DB2的使用会有所帮助。 CREATE PROCEDURE data_wtptest( IN in_taskid_timestamp varchar(30), OUT o_err_no int, OUT o_err_msg varchar(1024)) LANGUAGE SQL P1: BEGIN ATOMIC --声明开始 --临时变量出错变量 DECLARE SQLCODE integer default 0; DECLARE SQLStmt varchar(1024) default ''; DECLARE r_code integer default 0; DECLARE state varchar(1024) default 'AAA';--记录程序当前所作工作 DECLARE at_end int DEFAULT 0; DECLARE t_destnetid int default 0; DECLARE t_recvid varchar(30) default ''; DECLARE SP_Name varchar(50) default 'data_wtptest'; --声明放游标的值 --声明动态游标存储变量 DECLARE stmt1 STATEMENT; DECLARE c1 CURSOR FOR stmt1; --声明出错处理 DECLARE EXIT HANDLER FOR SQLEXCEPTION begin set r_code=SQLCODE; set o_err_no=1; set o_err_msg='处理['||state||']出错,'||'错误代码SQLCODE:['||CHAR(r_code) || '].'; insert into fcc_sp_log(object,name,value) values(SP_Name,in_taskid_timestamp,o_err_msg); end; DECLARE continue HANDLER for not found begin
db2回滚处理问题 DB2处理器对于存储过程来说,有着不可替代的作用。在DB2中,SQL存储过程可以利用DB2处理器(Condition Handler)来处理存储过程运行过程中的SQL错误(SQLERROR)、SQL警告(SQLWARNING)和没有数据(NOT FOUND)三种常见情况以及你自己定义的触发,你可以使用包括退出(EXIT)、继续(CONTINUE)和撤销(UNDO)在内的三种处理器。 在SQL存储过程运行过程中,如果出现了SQLERROR、SQLWARNING和NOT FOUND 三种情况,SQL存储过程将会自动将执行SQL语句后的SQLCODE和SQLSTATE存储在你事先定义好的变量SQLCODE和SQLSTATE中,并触发你在存储过程中定义的处理器。 在SQL存储过程处理错误,您需要做如下两步:声明SQLCODE和SQLSTATE 变量、定义处理器。在SQL存储过程中,您通过下列语句声明SQLCODE和SQLSTATE 变量: DECLARE SQLCODE INTEGER DEFAULT 0; DECLARE SQLSTATE CHAR(5) DEFAULT ‘00000’; 当存储过程执行时,DB2会自动将该SQL语句的返回码付给这两个变量,你可以在调试程序的时候,将这两个值插入到调试表中,或者利用处理器将这两个值返回给调用者。这样可以方便SQL存储过程的调试。注意:当你在SQL存储过程中存取SQLCODE和SQLSTATE时,DB2会自动将SQLCODE和SQLSTATE置为零。 可以通过下列语句定义DB2处理器: DECLARE handler-type HANDLER FOR condition SQL-procedure-statement 其中handler-type可以是如下几种: CONTINUE:SQL存储过程在执行完处理器中的SQL语句后,继续执行出错SQL 语句后边的SQL语句。 EXIT: SQL存储过程在执行完处理器中的SQL语句后,退出存储过程的执行。 UNDO:这种处理器仅限于原子动作(ATOMIC)复合SQL语句,SQL存储过程将会回滚包含该处理器的复合SQL语句,并在执行完该处理器中的SQL语句后,继续执行原子动作(ATOMIC)复合SQL语句后面的SQL语句。 包括如下三种常见情况: SQLEXCEPTION:在SQL执行过程中返回任何负值。 SQLWARNING:在SQL执行过程中出现警告(SQLWARN0为‘W’),或者是任何不是+100的正的SQL返回值,相应的SQLSTATE以‘01’开始。 NOT FOUND:SQL返回值为+100或者SQLSTATE以‘02’开始。 当然你也可以使用DECLARE语句为特定的SQLSATE定义你自己的。
Db2 存储过程学习总结 ●在命令窗口执行存储过程,可以方便看出存储过程在哪一行出现错误,方便修改。 ●db2 存储过程常用语句格式 ----定义 DECLARE CC VARCHAR(4000); DECLARE SQLSTR VARCHAR(4000); DECLARE st STATEMENT; DECLARE CUR CURSOR WITH RETURN TO CLIENT FOR CC; ----执行动态SQL不返回 PREPARE st FROM SQLSTR; EXECUTE st; ----执行动态SQL返回 PREPARE CC FROM SQLSTR; OPEN CUR; ----判断是否为空,使用值替代 COALESCE(判断对象,替代值)
----定义临时表 DECLARE GLOBAL TEMPORARY TABLE SESSION.TempResultTable ( Organization int, OrganizationName varchar(100), AnimalTypeName varchar(20), ProcessType int, OperatorName varchar(100), OperateCount int ) WITH REPLACE -- 如果存在此临时表,则替换 NOT LOGGED; DB2 9.x临时表使用总结 1). DB2的临时表需要用命令Declare Temporary Table来创建,并且需要创建在用户临时表空间上; 2). DB2在数据库创建时,缺省并不创建用户临时表空间,如果需要使用临时表,则需要用户在创建临时表之前创建用户临时表空间; 3). 临时表的模式为SESSION,SESSION即基于会话的,且在会话之间是隔离的。当会话结束时,临时表的数据被删除,临时表被隐式卸下。对临时表的定义不会在SYSCAT.TABLES中出现 .; 4). 缺省情况下,在Commit命令执行时,DB2临时表中的所有记录将被删除; 这可以通过创建临时表时指定不同的参数来控制; 5). 运行ROLLBACK命令时,用户临时表将被删除; 下面是DB2临时表定义的一个示例: DECLARE GLOBAL TEMPORARY TABLE results ( RECID VARCHAR(32) , --id XXLY VARCHAR(100), --信息来源 LXDH VARCHAR(32 ), --信息来源联系电话 FKRQ DATE --反馈时间 ) ON COMMIT PRESERVE ROWS WITH REPLACE NOT LOGGED; ----字符串函数
DB2存储过程简单例子 客户在进行短信服务这个业务申请时,需要填写一些基本信息,然后根据这些信息判断这个用户是否已经存在于业务系统中。因为网上服务和业务系统两个项目物理隔离,而且网上数据库保存的客户信息不全,所以判断需要把数据交换到业务系统,在业务系统中判断。 解决方式是通过存储过程,以前也了解过存储过程,但没使用到项目中。不过经过一番努力最后还是完成了,期间遇到了一些困难,特写此文让对DB2存储过程还不熟悉的童鞋避免一些无谓的错误。 DROP PROCEDURE "PLName" @ CREATE PROCEDURE "PLName"(--存储过程名字 IN IN_ID BIGINT , --以下全是输入参数 IN IN_ENTNAME VARCHAR(200) , IN IN_REGNO VARCHAR(50), IN IN_PASSWORD VARCHAR(20), IN IN_LEREP VARCHAR(300), IN IN_CERTYPE CHARACTER(1), IN IN_CERNO VARCHAR(50), IN IN_LINKMAN VARCHAR(50), IN IN_SEX CHARACTER(1), IN IN_MOBTEL VARCHAR(30), IN IN_REQDATE TIMESTAMP, IN IN_REMITEM VARCHAR(300), IN IN_STATE CHARACTER(1), IN IN_TIMESTAMP TIMESTAMP ) BEGIN declare V_RESULT BIGINT; --声明变量 DELETE FROM TableNameA WHERE ID = IN_ID;
文档编号:ETL-11-T-2008 DB2 SQL及存储过程编写规范 当前版本:V1.0 版本日期:2009年08月15日
文件信息 修订记录 文件审核/审批 此文件需如下审核 文档分发 此文档将分发至如下个人或机构
1引言 1.1 目的 本标准是针对IBM DB2数据库SQL编写设计而起草的开发规范;同时,也作为各项目ETL组评审ETL任务开发质量的标准之一。 本标准将作为项目规范开发系列之一,并且需要在项目实施工作中不断改进和完善,保障规范能够真正的提高质量和效率。 引言 1.2 总则 整个系统中ETL开发的编码,包括基于封装的程序包中的代码,在对象的命名和使用、程序的注释和排版,都应当注重规范 在编码的过程中,应时刻牢记优化的重要性,对重要程序块或程序包需要注明其逻辑结构。在必要的时候,还应进行代码评审 本规范适用各IBM DB2数据库和项目ETL开发的程序包 应用于系统基于数据库的ETL模块开发并对应用集市相关开发提供参考与指导1.3 预期读者 项目管理人员 软件设计人员 软件编程人员 质量控制人员 软件维护人员
1.4 术语和定义 描述术语 本文档采用以下的术语描述: 规范:编程时强制必须遵守的原则标准:量化的规范。 说明:对此规则或建议进行必要的说明和解释。 示例:对此规则或建议给出适当的例子。 编码术语 编码(Coding) 关键字(Keyword) 函数(Function) 存储过程(Procedure) 变量(Variable) 游标(Cursor) ETL(Extraction、Translation、Loading) 2编码规范 2.1 命名规范 对象命名不能超过30个英文字母,前缀和单词之间用下划线分隔,尽量不采用汉语拼音,使用英文单词或公认单词缩写,单词缩写可通过去掉“元音” 形成。 所有数据库对象(表、视图、存储过程)、关键字和系统函数、数据类型大写;自定义变量、游标小写。 命名的组成只能使用26个英文字母、下划线或阿拉伯数字,不能使用汉字。 名称具有复数意义时,使用名词的正确的复数形式 当一个SQL 语句中涉及到多个表时,始终使用表名别名来限定字段名。这使其他人阅读起来更清楚,避免了含义模糊的引用。 一般情况下,列名称不应包含表名或者表名的任何形式,列名不允许使用统
DB2存储过程-基础详解 2010-12-20 来源:网络 简介 DB2 SQL Procedural Language(SQL PL)是SQL Persistent Stored Module 语言标准的一个子集。该标准结合了SQL 访问数据的方便性和编程语言的流控制。通过SQL PL 当前的语句集合和语言特性,可以用SQL 开发综合的、高级的程序,例如函数、存储过程和触发器。这样便可以将业务逻辑封装到易于维护的数据库对象中,从而提高数据库应用程序的性能。 SQL PL 支持本地和全局变量,包括声明和赋值,还支持条件语句和迭代语句、控制语句的转移、错误管理语句以及返回结果集的方法。这些话题将在本教程中讨论。 变量声明 SQL 过程允许使用本地变量赋予和获取SQL 值,以支持所有SQL 逻辑。在SQL 过程中,在代码中使用本地变量之前要先进行声明。 清单 1 中的图演示了变量声明的语法: 清单 1. 变量声明的语法 .-,-----------------. V | |--DECLARE----SQL-variable-name-+-------------------------------> .-DEFAULT NULL------. >--+-data-type--+-------------------+-+-------------------------| | '-DEFAULT--constant-' | SQL-variable-name 定义本地变量的名称。该名称不能与其他变量或参数名称相同,也不能与列名相同。 图 1 显示了受支持的DB2 数据类型:
DB2 存储过程开发最佳实践 COALESCE函数会依次检查输入的参数,返回第一个不是NULL的参数,只有当传入COALESCE函数的所有的参数都是NULL的时候,函数才会返回NULL。例如, COALESCE(piName,''),如果变量piName为NULL,那么函数会返回'',否则就会返回piName本身的值。 下面的例子展示了如何对参数进行检查何初始化。 Person表用来存储个人的基本信息,其定义如下: 表1: Person 下面是用于向表Person插入数据的存储过程的参数预处理部分代码:
表Person中num、name和age都是非空字段。对于name字段,多个空格我们也认为是空值,所以在进行判断前我们调用RTRIM和COALESCE对其进行处理,然后使用 piName = '',对其进行非空判断;对于Rank 字段,我们希望如果用户输入的NULL,我们把它设置成"0",对其我们也使用COALESCE进行初始化;对于"Age"和"Num" 我们直接使用 IS NULL进行非空判断就可以了。 如果输入参数没有通过非空判断,我们就对输出参数poGenStatus设置一个确定的值(例子中为 34100)告知调用者:输入参数错误。 下面是对参数初始化规则的一个总结,供大家参考: 1. 输入参数为字符类型,且允许为空的,可以使用COALESCE(inputParameter,'')把NULL转换成''; 2. 输入类型为整型,且允许为空的,可以使用COALESCE(inputParameter,0),把空转换成0; 3. 输入参数为字符类型,且是非空非空格的,可以使用COALESCE(inputParameter,'')把NULL转换成'',然后判断函数返回值是否为''; 4. 输入类型为整型,且是非空的,不需要使用COALESCE函数,直接使用IS NULL进行非空判断。 最佳实践 3:正确设定游标的返回类型 前面我们已经讨论了如何声明存储过程的返回结果集。这里我们讨论一下结果集返回类型的问题。结果集的返回类型有两种:调用者(CALLER) 和客户应用(CLIENT)。首先我们看一下声明这两种游标的例子:
1 限制结果表大小 Select * from tabname fetch first 5 rows only; 2 cast用法 Select * from tabnameA where coln = cast( ‘TR01’ as tabnameB) CAST(salary AS DOUBLE) 类型转换 3 连接 内连接selet a.col,b.col from tab a,tab b where a.t1=b.t1; 外连接: 左连接:select a.col,b.col from tab a left join tab b on a.t1=b.t1 (left outer join) 右连接: 4 输出排序 Order by col DESC 降序排列 缺省为升序 5 限制输出结果,与order共用 Select * from tabA order by col desc fetch first 5 rows only 6 substr函数 Substr(col,1,2); col为char或varchar型 7 列函数 可以参照数据库中FUNCTIONS中的说明 用Quest Centeral查看,以下是常用的 Max 、avg、count… DB2中的VARCHAR转换为INTEGER的函数为CAST() DB2中的INTEGER转换为VARCHAR的函数为CHAR() DB2中的VARCHAR转换为DATE的函数为DATE() DB2中的DATE转换为VARCHAR的函数为CHAR() char(col,iso) 输出yyyy-mm-dd YEAR() 返回date数值的年部分 Month()返回date数值的月部分 HOUR() 返回一个数值的小时部分SELECT HOUR('18:34:23')FROM SECOND() 返回一个数值的秒部分 RTRIM()删除字符串尾部的空格 Ltrim()删除字符串左边的空格 Replace(col,exp1,exp2)替换col中exp1为exp2 MOD(EXP1,EXP2) 返回EXP1除以EXP2的余数 DOUBLE()如果参数是一个数字表达式,返回与其相对应的浮点数,如果参数是字符串表达式,则返回该数的字符串表达式.
DB2存储过程语法 语法: CREATE PROCEDURE
IBM DB2数据库基础 基本命令集合 1. 建立数据库DB2_GCB CREATE DATABASE DB2_GCB ON G: ALIAS DB2_GCB USING CODESET GBK TERRITORY CN COLLATE USING SYSTEM DFT_EXTENT_SZ 32 2. 连接数据库 connect to sample1 user db2admin using 8301206 3. 建立别名 create alias db2admin.tables for sysstat.tables; CREATE ALIAS DB2ADMIN.VIEWS FOR SYSCAT.VIEWS create alias db2admin.columns for syscat.columns; create alias guest.columns for syscat.columns; 4. 建立表 create table zjt_tables as (select * from tables) definition only; create table zjt_views as (select * from views) definition only; 5. 插入记录 insert into zjt_tables select * from tables; insert into zjt_views select * from views;
6. 建立视图 create view V_zjt_tables as select tabschema,tabname from zjt_tables; 7. 建立触发器 CREATE TRIGGER zjt_tables_del AFTER DELETE ON zjt_tables REFERENCING OLD AS O FOR EACH ROW MODE DB2SQL Insert into zjt_tables1 values(substr(o.tabschema,1,8),substr(o.tabname,1,10)) 8. 建立唯一性索引 CREATE UNIQUE INDEX I_ztables_tabname ON zjt_tables(tabname); 9. 查看表 select tabname from tables where tabname='ZJT_TABLES'; 10. 查看列 select SUBSTR(COLNAME,1,20) as 列名,TYPENAME as 类型,LENGTH as 长度 from columns where tabname='ZJT_TABLES'; 11. 查看表结构 db2 describe table user1.department db2 describe select * from user.tables
DB2存储过程编写规范 版本号:1.0 修订记录:
目录 第一章.前言 (3) 一.编写目的 (3) 二.编写背景 (4) 三.适用范围 (4) 第二章.程序结构 (5) 一.整体结构 (5) 二.程序说明 (6) 三.变量定义 (7) 四.异常错误处理 (7) 五.程序正文 (9) 第三章.命名规范 (10) 一.存储过程命名 (10) 二.参数命名 (10) 三.变量命名 (11) 四.临时表命名 (11) 第四章.书写格式 (12) 一.表达范式 (12) 二.段落缩进 (12) 三.段落间隔 (12) 四.程序注释 (13) 第五章.注意事项 (13)
一.固定的输出参数 (13) 二.临时表的使用 (14) 三.数据的插入 (14) 四.where 条件 (14) 五.count 的使用 (15) 六.全表删除 (15) 七.MERGE(UPSERT)的使用 (15) 第六章.附录A (15) 第一章.前言 一.编写目的 为了提高开发效率和程序的可读性,降低程序编写过程的出错率和重复劳动性,保持程序编写风格的一致性和连贯性,特定此规范。
二.编写背景 目前数据库工具有很多种,考虑到数据仓库开发的实用性,数据仓库开发工具选择了DB2。 三.适用范围 本规范适用于招商银行信息技术部开发人员以及运行管理人员,从事DB2存储过程开发的相关技术人必须按照此规范编写存储过程。
第二章.程序结构 一.整体结构 创建DB2存储过程必须按如下标准格式书写: DROP PROCEDURE 模式名.过程名@ CREATE PROCEDURE 模式名.过程名 ( IN|OUT 输入|输出变量名输入|输出变量类型 [ , ... ] ) SPECIFIC模式名.过程名 LANGUAGE SQL /* 程序说明*/ BEGIN <程序体> END@ 其中: 1)模式名是用来指定该存储过程属于哪个模式下的,默认为编译该过程的登录用户名,但为了过程的统一管理以及各系统间的相互区分,必须要指定一个模式名,模式名由过程所属项目设计中统一制
教你深入了解IBM DB2的通信与连接过程 本文详细描述了DB2? Universal Database?(DB2 UDB)代理的工作原理以及连接集中器的特性,并对DB2 连接上常见的问题及代理的优化作了详细的分析。希望通过本文让用户能够了解DB2 的连接机制和客户端与服务器端的交互作用,可以解决在实际的商业环境中遇到的性能问题。 简介 DB2 的代理(agent) 是位于DB2 服务器中的服务于应用程序请求的一些进程或线程。当有外部应用程序连接至DB2 实例提出访问请求时,DB2 的代理就会被激活去应答这些请求。一般DB2 的代理被称为工作代理,工作代理大概有三种类型:空闲代理、活动的协调代理、子代理。 ◆空闲代理:指的是没有任何任务的代理。这种代理不服务于任何远程连接也不服务于本地连接,处于一种备用或待命状态。 ◆活动的协调代理:指的是处于工作状态的代理,每一个外部应用程序产生的数据库活动连接的都有一个活动协调代理来为它服务。 ◆子代理:指的是接受协调代理分发出来的工作的下一级代理。在DB2 V95 以前,只有在多分区环境(MPP) 或节点内并行环境(SMP) 下才存在子代理,在DB2 V95 中所有环境中都可能存在子代理。 在DB2 服务器中有一个代理池,当实例刚启动后这里便有一些代理(其数量取决于实例参数NUM_INITAGENTS)。在没有任何数据库连接时,它们处于待命状态,就是空闲代理。而当有外部程序连接至数据库时,这些代理开始得到命令去服务于这些新建的连接,这时它们就变成了活动的协调代理。这些协调代理再将请求逐步细分,分配给下一级代理即子代理去处理。如果当前的代理都已经在工作了,同时又来了新的请求,数据库管理器会产生一个新的代理去应答。当事务处理完毕而且数据库连接断开后,协调代理要么返回代理池变回空闲代理,要么就自动消失了(取决于实例参数NUM_POOLAGENTS)。这就是一个代理的生命周期。 相关的配置参数 通过执行DB2 get dbm cfg 可以看到以下几个和代理相关的实例参数:MAXAGENTS,NUM_POOLAGENTS,NUM_INITAGENTS,MAX_COORDAGENTS,MAX_CONNECTIONS,MAXCAGENTS。下面对它们做一下简要介绍: ◆MAXAGENTS:这个参数为当前实例中全部代理的数量,包括协调代理,空闲代理和子代理之和。不过这个参数在DB2 V95 中已经不再使用了。 ◆NUM_POOLAGENTS:这个参数用来控制代理池中的空闲代理的数量。当活动的代理完成工作返回代理池变成空闲代理时,如果数量超过了这个参数,那么这个代理就会自动消失了。注意:在连接集中器激活的情况下,代理池中的空闲代理数目在某一时刻可能会超过NUM_POOLAGENTS 的大小,以应对突发的高密度连接。 ◆NUM_INITAGENTS:这个参数就是前面提到的在实例刚刚启动时便生成的一些空闲
LINUX下定时执行含有DB2存储过程的SHELL脚本 最近项目要求将某些表中的数据转移到历史数据表中,并将成功转移后的数据在生产系统中删除,并且要求每天凌晨1:00定时执行脚本。这是我第一次写这样的脚本程序,现将整个编写过程或步骤记录如下,希望能对有类似需求的人所有帮助,由于本人也是刚接触DB2数据库和shell脚本,错误之处还请见谅。测试服务器的操作系统是Redhat,数据库产品:DB2(10.1版本),转移数据是在DB2存储过程中实现的,下面分几个步骤进行叙述。 一、编写DB2存储过程 1》编写存储过程 具体代码见表格1,将其中的代码形成一个sql文件,文件名为dataHandle.sql CREATE OR REPLACE PROCEDURE test_schema.dataHandle(in t_Id INT)--in表示输入参数 RESULT SETS 1 --返回结果为1个 LANGUAGE SQL P1: BEGIN ATOMIC --ATOMIC为了使P1和END P1之间形成一个事务,要么同时成功,要么同时失败 declare tIdINT; --声明变量 set tId=t_Id; --赋值变量 IF tId> 0 THEN --判断 insert into TEST_SCHEMA.TEST_HISTORY(t_Id,t_name)
select t_Id,t_name from TEST_SCHEMA.TM_ASM_FLTSCH where where t_Id=tId; --转移数据 delete from TEST_SCHEMA.TM_ASM_FLTSCH where t_Id=tId; --删除数据 END IF; END P1 @ --@这里是必须的 表1 2》部署存储过程到指定数据库 a)连接数据库 切换到数据库用户下执行命令:db2 connect to Dbname 或者不切换用户执行命令:db2 connect to Dbname user Username using ****** b)部署1》中写好的存储过程 执行命令:db2 -td@ -vf dataHandle.sql 或者使用datastudio进行部署,具体流程如下:
db2 backup db DBNAME online compress include logs 脱机备份 db2 force applications all Db2 backup db DBNAMEE compress 查看表空间 db2 list tablespace show detail //显示很多信息。 High water mark 曾经达到过的占用率 80%左右,要扩表空间或者清理数据 查看表状态 db2 load query table TABNAME 查看归档日志目录 db2 get db cfg for DBNAME|grep LOGARCHMETH1 数据库重整 Runstats ,reorgchk,计算是否需要重整 db2 diag。log文件,看中间是否有异常 Cd 演示 1,增加表空间(文件系统,裸设备) 2,查看表空间 3,循环日志变归档日志 4,脱机备份数据库 5,联机备份数据库 6,归档日志 7,load 数据 8,扩表空间
很多操作都要先关闭数据库,然后再开启,连接后再操作 3: Db2 updte db cfg for sample using Db2stop 停数据库 Db2start 启数据库 Db2 connect to sample 连接到数据库sample Db2 “import from test.del of del insert into DBNAME”从本地的DEL文件中导入数据中Db2 prune logfile prior to dddddd.log 日志 1: Db2 “alter Tablespace dms_dat4k extend //扩展表空间 Db2 termiate //写到当前目录。 空闲时备份 Db2 backup db Db2 list utilities show detail 查看备份信息 Db2 “export to staff.del of del select * from test ”//导出或者备份
db2编程使用技巧一(转帖) 1 DB2编程 1.1 建存储过程时CREATE 后一定不要用TAB键3 1.2 使用临时表3 1.3 从数据表中取指定前几条记录3 1.4 游标的使用4 注意commit和rollback 4 游标的两种定义方式4 修改游标的当前记录的方法5 1.5 类似DECODE的转码操作5 1.6 类似CHARINDEX查找字符在字串中的位置5 1.7 类似DATEDIF计算两个日期的相差天数5 1.8 写UDF的例子5 1.9 创建含IDENTITY值(即自动生成的ID)的表6 1.10 预防字段空值的处理6 1.11 取得处理的记录数6 1.12 从存储过程返回结果集(游标)的用法6 1.13 类型转换函数8 1.14 存储过程的互相调用8 1.15 C存储过程参数注意8 1.16 存储过程FENCE及UNFENCE 8 1.17 SP错误处理用法9 1.18 IMPORT用法9 1.19 VALUES的使用9 1.20 给SELECT 语句指定隔离级别10 1.21 ATOMIC及NOT ATOMIC区别10 2 DB2编程性能注意10 2.1 大数据的导表10 2.2 SQL语句尽量写复杂SQL 10 2.3 SQL SP及C SP的选择10 2.4 查询的优化(HASH及RR_TO_RS) 11 2.5 避免使用COUNT(*) 及EXISTS的方法11 3 DB2表及SP管理12 3.1 看存储过程文本12 3.2 看表结构12 3.3 查看各表对SP的影响(被哪些SP使用) 12 3.4 查看SP使用了哪些表12 3.5 查看FUNCTION被哪些SP使用12 3.6 修改表结构12 4 DB2系统管理13 4.1 DB2安装13
DB2在Win7下安装及建库流程 安装流程 安装步骤 db2exc_972_WIN_x86.exe文件,双击运行即可。安装时它会把安装文件解压到系统临时文件夹,然后再运行,其实这就是一个压缩包,可以用360解压工具解压出来,除了一张图片无法解压外其他正常,以后安装时直接从解压出来的文件运行,可以省点时间,建议解压。双击setup.exe进入安装启动板,选择安装新产品 初始界面如下 下一步,接受许可
的,所以这里直接下一步 响应文件,这是用来自动安装的。有时,你需要将DB2 客户端安装到多台机器上,又或者需要将DB2 数据库服务器嵌入到应用程序,并在安装这个应用程序同时安装DB2 数据库服务器。这些情况下,DB2 的自动安装是一个理想的方法。DB2 利用响应文件来进行自动安 装,响应文件是一个文本文件,它保存了安装所需的信息。这里直接下一步
选择安装文件夹 用户帐户配置,新手只用填入密码和确认密码,其他不变,下一步。对于了解的人,可以输入一个存在的用户,这个用户将会使用DB2 的实例和其它服务。这个用户必须是windows 中本地管理员(Local Administrator)组的一员,且密码是登陆操作系统时用的密码。如果您输入的用户ID 不存在,这个用户ID 就会被创建,并成为一个本地管理员,即新建一个系统管理员。如果用户不属于任何的一个域,请将域(domain)留空。Windows 中,默认创建 的用户名是db2admin。这里,我选择使用当前登陆的系统用户帐户(最好是管理员大叔)
配置实例,可以做一些相应的配置,例如,是否开机启动服务、端口号(默认端口可能会是:50000,50001,50002),这里直接下一步。 点击完成开始安装
关于DB2游标的一些要点 文章分类:数据库 游标一般用来迭代结果集中的行 为了在一个过程中处理一个游标的结果,需要做以下事情: 在存储过程块的开头部分 DECLARE 游标。 打开该游标。 将游标的结果取出到之前已声明的本地变量中(隐式游标处理除外,在下面的 FOR 语句中将对此加以解释)。 关闭该游标。(注意:如果现在不关闭游标,当过程终止时将隐式地关闭游标)。 注:游标的申明如果放在中间段,要用”begin。。。end;”.段分割标志分割开; 游标使用的步骤如下: 1、说明游标。说明游标的时候并不执行select语句。 declare <游标名> cursor for