数据库生成脚本
- 格式:doc
- 大小:340.00 KB
- 文档页数:11

自动生成数据库表的方法全文共四篇示例,供读者参考第一篇示例:自动生成数据库表的方法在软件开发中扮演着重要的角色,它能够极大地简化开发流程,提高开发效率。
通过自动生成数据库表,开发人员可以避免手动创建数据库表的繁琐过程,同时保证表结构的一致性和准确性。
本文将介绍几种常见的自动生成数据库表的方法。
一、使用ORM框架ORM(对象关系映射)是一种编程技术,它将数据库表映射为对象,开发人员可以通过操作对象来操作数据库表。
ORM框架会根据对象定义自动生成数据库表。
常见的ORM框架有Hibernate、MyBatis 等。
通过ORM框架,开发人员可以通过注解或配置文件定义实体类和对象之间的映射关系,然后自动生成数据库表。
在Hibernate中,可以通过在实体类中添加注解来定义数据库表的字段和约束,然后通过Hibernate工具自动生成对应的数据库表。
开发人员只需关注对象的定义,不用关心数据库表的创建和维护。
这样可以减少开发人员的工作量,并确保数据库表的结构和实体类的一致性。
二、使用数据库建模工具数据库建模工具是一种专门用于设计数据库结构的工具,它可以帮助开发人员创建数据库表,并生成相应的SQL语句。
常见的数据库建模工具有Visual Paradigm、ERwin等。
通过数据库建模工具,开发人员可以使用图形界面设计数据库表的结构,然后生成对应的数据库脚本。
三、使用代码生成器代码生成器是一种自动化工具,可以根据模板和配置文件快速生成代码。
开发人员可以通过代码生成器定义实体类的属性、字段和关联关系,然后生成相应的数据库表和CRUD操作代码。
常见的代码生成器有MyBatis Generator、JFinalCodeGenerator等。
总结第二篇示例:在软件开发过程中,数据库是非常重要的一环,它负责存储和管理应用程序的数据。
在设计和开发数据库时,最基础也是最重要的一步就是创建数据库表。
数据库表是数据库中的一个重要组成部分,它是存储数据的基本单位,用于存储实体的属性以及实体之间的关系。

使用Lombok和Groovy结合,自动从数据库表生成实体类和对应的Groovy文件,通常涉及到几个步骤。
这里是一个简化的流程和示例:1. 设置环境:确保你的项目已经添加了Lombok和Groovy的依赖。
使用一个数据库,如MySQL、PostgreSQL等。
2. 工具选择:你可以选择使用工具如dbreverse或dbtoaster来从数据库表生成实体类。
如果你想使用Groovy脚本,你可以手动编写一个脚本来读取数据库表结构并生成Groovy文件。
3. 手动编写Groovy脚本:以下是一个简化的示例,展示如何使用Groovy从数据库表生成实体类和对应的Groovy 文件:groovyimport groovy.sql.Sqldef dbUrl = 'jdbc:mysql:3306/mydb'def dbUser = 'root'def dbPassword = 'password'def driver = 'com.mysql.cj.jdbc.Driver'def sql = Sql.newInstance(dbUrl, dbUser, dbPassword, driver)def tables = sql.execute('SHOW TABLES')tables.each { tableName ->def columns = sql.execute("SELECT FROM ${tableName}")columns.each { column ->def property = column.columnNamedef type = column.dataType.toLowerCase()println """@ToString@Builderpublic class ${tableName.capitalize()} {private ${type} ${property};// getters and setters...}}}这个脚本会为数据库中的每个表生成一个实体类。

批量导出建表语句在数据库管理中,经常会遇到需要将某个数据库中的所有表的建表语句导出到一个文件中的情况。
这时候,我们就需要使用一些工具来完成这个任务。
下面介绍两种常用的方法:方法一:使用SQL Server Management Studio1. 打开SQL Server Management Studio,连接到需要导出建表语句的数据库。
2. 在对象资源管理器中,右键单击该数据库的名称,选择“生成脚本”。
3. 在“生成脚本向导”中,选择要导出建表语句的表,然后选择“高级”。
4. 在“高级脚本选项”中,将“建表语句”选项设置为“是”,然后点击“确定”。
5. 点击“下一步”,然后在“选择输出选项”中,选择将脚本输出到一个文件或剪贴板中。
如果选择输出到文件中,还可以设置文件的路径和名称。
6. 点击“下一步”,然后在“生成脚本”页面上,点击“完成”按钮,即可将所选表的建表语句导出到指定的文件中。
方法二:使用命令行工具1. 打开命令提示符,输入以下命令:sqlcmd -S <服务器名称> -d <数据库名称> -E -Q 'EXECsp_MSforeachtable 'PRINT ''CREATE TABLE ?''; PRINT ''GO'';''其中,“<服务器名称>”是数据库所在的服务器名称,“<数据库名称>”是要导出建表语句的数据库名称。
2. 执行命令后,会将所有表的建表语句输出到命令提示符窗口中。
如果需要将输出保存到文件中,可以将命令改为以下形式:sqlcmd -S <服务器名称> -d <数据库名称> -E -Q 'EXECsp_MSforeachtable 'PRINT ''CREATE TABLE ?''; PRINT ''GO'';'' > <输出文件名称>其中,“<输出文件名称>”是要保存输出的文件名称和路径。
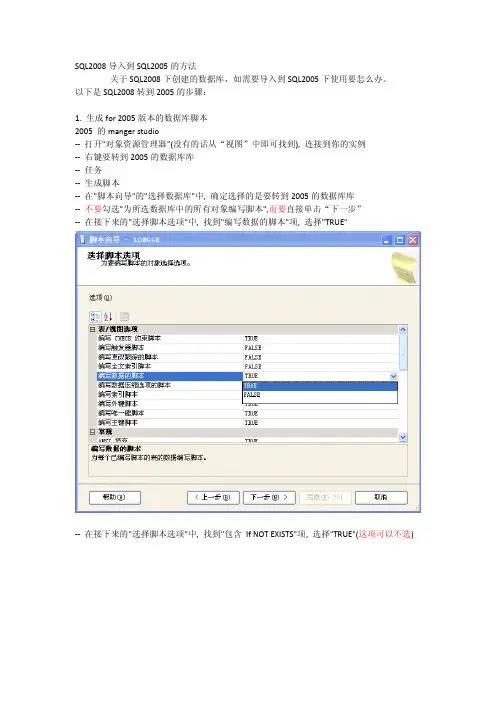
SQL2008导入到SQL2005的方法关于SQL2008下创建的数据库,如需要导入到SQL2005下使用要怎么办。
以下是SQL2008转到2005的步骤:1.生成for2005版本的数据库脚本2005的manger studio--打开"对象资源管理器"(没有的话从“视图”中即可找到),连接到你的实例--右键要转到2005的数据库库--任务--生成脚本--在"脚本向导"的"选择数据库"中,确定选择的是要转到2005的数据库库--不要勾选"为所选数据库中的所有对象编写脚本",而要直接单击“下一步”--在接下来的"选择脚本选项"中,找到"编写数据的脚本"项,选择"TRUE"--在接下来的"选择脚本选项"中,找到"包含If NOT EXISTS"项,选择"TRUE"(这项可以不选)--在接下来的"选择脚本选项"中,找到"为服务器版本编写脚本"项,选择"SQL Server2005"--其他选项根据需要设置--在接下来的”选择对象类型”中,选择”表”(根据需要可以全选)--在接下来的”选择表”中,全选(或者根据需要选择)--在接下来的”输出选项”中,选择将脚本保存到“新建查询窗口(W)”(或者根据需要选择)--最后把脚本保存到一个.sql脚本文件2.在sql2005中创建表--在sql2005中新建一个数据库(注意,新的数据库一定要与由上面所生成的.sql脚本文件所使用的数据库名字相同)--在sql2005中打开所生成的.sql脚本文件(或者直接将其拖动到sql2005中即可打开)--执行上面生成的脚本即可创建数据表并且在数据表中自动填充数据。

sqlserver数据库导出表⾥所有数据成insert语句有时候,我们想把数据库的某张表⾥的所有数据导⼊到另外⼀个数据库或另外⼀台计算机上的数据库,对于sql server有这样的⼀种⽅法下⾯我以sql server 2008 R2,数据库是Northwind数据库为例,⽬标:把Northwind数据库的Orders表导出成insert语句。
第⼀步:选择Northwind数据库,右键-任务-⽣成脚本:第⼆步:在弹出的“⽣成和发布脚本”的简介窗⼝,按“下⼀步”按钮:第三步:在“选择对象”窗⼝,选中“选择特定数据库对象”,展开表,勾选要⽣成insert语句的表,我这⾥选的是order表,按“下⼀步”按钮:第四步:在弹出的“设置脚本编写选项”窗⼝,按“⾼级”按钮,在弹出的“⾼级脚本编写选项”中下拉下拉条⾄底部,设置“要编写脚本的数据类型”为“仅限数据”(“仅限数据”是只导出数据为insert语句,如果是导出表结构的话选择“仅限架构”,选择“架构和数据”则架构和insert语句都⽣成),按“确定”按钮:第五步:在“设置脚本编写选项”窗⼝,“指定如何保存或发布脚本”的“输出类型”选中“将脚本保存到特定位置”,勾选“保存到⽂件”,则可以指定⼀个保存的路径,保存为.sql⽂件,勾选“保存到新建查询窗⼝”,则会新打开⼀个查询窗⼝,把所有insert 语句放到新查询窗⼝:第六步:在“设置脚本编写选项”窗⼝,按“下⼀步”按钮,弹出:第七步:在“摘要”窗⼝,按“下⼀步”按钮:第⼋步:在“保存或发布脚本”窗⼝,按“完成”按钮:最终会⾃动新建⼀个查询窗⼝,order表⾥的所有数据都转换成insert语句。
=====================================================================================将表⾥的数据批量⽣成INSERT语句的存储过程增强版有时候,我们需要将某个表⾥的数据全部或者根据查询条件导出来,迁移到另⼀个相同结构的库中⽬前SQL Server⾥⾯是没有相关的⼯具根据查询条件来⽣成INSERT语句的,只有借助第三⽅⼯具(third party tools)这种脚本⽹上也有很多,但是⽹上的脚本还是⽋缺⼀些规范和功能,例如:我只想导出特定查询条件的数据,⽹上的脚本都是导出全表数据如果表很⼤,对性能会有很⼤影响这⾥有⼀个存储过程(适⽤于SQLServer2005 或以上版本)-- =============================================-- Author: <桦仔>-- Blog: </lyhabc/>-- Create date: <2014/10/18>-- Description: <根据查询条件导出表数据的insert脚本>-- =============================================CREATE PROCEDURE[InsertGenerator](@tableName NVARCHAR(100),-- the table name@whereClause NVARCHAR(MAX),--col1=1@includeIdentity INT-- include identity column(1:yes,0:no))AS--of an INSERT DML statement.DECLARE@string NVARCHAR(MAX) --for storing the first half of INSERT statementDECLARE@stringData NVARCHAR(MAX) --for storing the data (VALUES) related statementDECLARE@dataType NVARCHAR(20) --data types returned for respective columnsDECLARE@schemaName NVARCHAR(20) --schema name returned from sys.schemasDECLARE@schemaNameCount int--shema countDECLARE@QueryString NVARCHAR(MAX) -- provide for the whole query,DECLARE@identity INT--identity column(1:yes,0:no)set@QueryString=''--如果有多个schema,选择其中⼀个schemaSELECT@schemaNameCount=COUNT(*)FROM sys.tables tINNER JOIN sys.schemas s ON t.schema_id = s.schema_idWHERE =@tableNameWHILE(@schemaNameCount>0)BEGIN--如果有多个schema,依次指定select@schemaName= namefrom(SELECT ROW_NUMBER() over(order by s.schema_id) RowID,FROM sys.tables tINNER JOIN sys.schemas s ON t.schema_id = s.schema_idWHERE =@tableName) as vwhere RowID=@schemaNameCount--Declare a cursor to retrieve column specific information--for the specified tableDECLARE cursCol CURSOR FAST_FORWARDFORSELECTclmns.[name]AS[column_name],usrt.[name]AS[data_type],CAST(COLUMNPROPERTY(clmns.id, clmns.[name], N'IsIdentity') AS int) AS[Identity]FROM dbo.sysobjects AS tbl WITH (NOLOCK)INNER JOIN dbo.syscolumns AS clmns WITH (NOLOCK) ON clmns.id=tbl.idLEFT JOIN dbo.systypes AS usrt WITH (NOLOCK) ON usrt.xusertype = clmns.xusertypeLEFT JOIN dbo.sysusers AS sclmns WITH (NOLOCK) ON sclmns.uid = usrt.uidLEFT JOIN dbo.systypes AS baset WITH (NOLOCK) ON baset.xusertype = clmns.xtype and baset.xusertype = baset.xtype LEFT JOIN dbo.syscomments AS defaults WITH (NOLOCK) ON defaults.id = clmns.cdefaultLEFT JOIN dbo.syscomments AS cdef WITH (NOLOCK) ON cdef.id = clmns.id AND cdef.number= clmns.colidWHERE (tbl.[type]='U') AND (tbl.[name]=@tableName AND SCHEMA_NAME(tbl.uid)=@schemaName) AND CAST(COLUMNPROPERTY(clmns.id, clmns.[name], N'IsIdentity') AS int)=@includeIdentity ORDER BY tbl.[name], clmns.colorderOPEN cursColSET@string='INSERT INTO ['+@schemaName+'].['+@tableName+']('SET@stringData=''DECLARE@colName NVARCHAR(500)FETCH NEXT FROM cursCol INTO@colName, @dataType,@identityPRINT@schemaNamePRINT@colNameIF@@fetch_status<>0BEGINPRINT'Table '+@tableName+' not found, processing skipped.'CLOSE curscolDEALLOCATE curscolRETURNENDWHILE@@FETCH_STATUS=0BEGINIF@dataType IN ( 'varchar', 'char', 'nchar', 'nvarchar' )BEGINSET@stringData=@stringData+'''''''''+isnull('+@colName+','''')+'''''',''+'ENDELSEIF@dataType IN ( 'text', 'ntext' ) --if the datatype--is text or something elseBEGINSET@stringData=@stringData+'''''''''+isnull(cast('+@colName+' as nvarchar(max)),'''')+'''''',''+'END--from varchar implicitlyBEGINSET@stringData=@stringData+'''convert(money,''''''+isnull(cast('+@colName+' as nvarchar(max)),''0.0000'')+''''''),''+'ENDELSEIF@dataType='datetime'BEGIN-- SET @stringData = @stringData-- + '''convert(datetime,''''''+--isnull(cast(' + @colName + ' as nvarchar(max)),''null'')+''''''),''+'SET@stringData=@stringData+'COALESCE(''''''''+CONVERT(varchar(max),'+@colName+',120)+'''''''',''NULL'')+'',''+'ENDELSEIF@dataType='image'BEGINSET@stringData=@stringData+'''''''''+isnull(cast(convert(varbinary,'+@colName+')as varchar(6)),''0'')+'''''',''+'ENDELSE--presuming the data type is int,bit,numeric,decimalBEGINSET@stringData=@stringData+'''''''''+isnull(cast('+@colName+' as nvarchar(max)),''0'')+'''''',''+'ENDSET@string=@string+'['+@colName+']'+','FETCH NEXT FROM cursCol INTO@colName, @dataType,@identityEND--After both of the clauses are built, the VALUES clause contains a trailing comma which needs to be replaced with a single quote. The prefixed clause will only face removal of the trailing comma. DECLARE@Query NVARCHAR(MAX) -- provide for the whole query,-- you may increase the sizePRINT@whereClauseIF ( @whereClause IS NOT NULLAND@whereClause<>'')BEGINPRINT'stringData:'+@stringDataSET@query='SELECT '''+SUBSTRING(@string, 0, LEN(@string))+') VALUES(''+ '+SUBSTRING(@stringData, 0,LEN(@stringData) -2)+'''+'')''FROM '+@schemaName+'.'+@tableName+' WHERE '+@whereClausePRINT@query-- EXEC sp_executesql @query --load and run the built query--Eventually, close and de-allocate the cursor created for columns information.ENDELSEBEGINSET@query='SELECT '''+SUBSTRING(@string, 0, LEN(@string))+') VALUES(''+ '+SUBSTRING(@stringData, 0,LEN(@stringData) -2)+'''+'')''FROM '+@schemaName+'.'+@tableNameENDCLOSE cursColDEALLOCATE cursColSET@schemaNameCount=@schemaNameCount-1IF(@schemaNameCount=0)BEGINSET@QueryString=@QueryString+@queryENDELSEBEGINSET@QueryString=@QueryString+@query+' UNION ALL 'END--SET @QueryString=REPLACE(@QueryString,'convert(datetime,''NULL'')',NULL)PRINT CONVERT(VARCHAR(MAX),@schemaNameCount)+'---'+@QueryStringEND--PRINT @QueryStringEXEC sp_executesql @QueryString--load and run the built query--Eventually, close and de-allocate the cursor created for columns information.这⾥要声明⼀下,如果你有多个schema,并且每个schema下⾯都有同⼀张表,那么脚本只会⽣成其中⼀个schema下⾯的表insert脚本⽐如我现在有三个schema,下⾯都有customer这个表CREATE SCHEMA testCREATE TABLE test.[customer](city int,region int)CREATE SCHEMA test1CREATE TABLE test1.[customer](city int,region int)在执⾏脚本的时候他只会⽣成dbo这个schema下⾯的表insert脚本INSERT INTO[dbo].[customer]([city],[region]) VALUES('1','2')这个脚本有⼀个缺陷⽆论你的表的字段是什麽数据类型,导出来的时候只能是字符表结构CREATE TABLE[dbo].[customer](city int,region int)导出来的insert脚本INSERT INTO[dbo].[customer]([city],[region]) VALUES('1','2')我这⾥演⽰⼀下怎麽⽤有两种⽅式1、导全表数据InsertGenerator 'customer', null或InsertGenerator 'customer', ''2、根据查询条件导数据InsertGenerator 'customer', 'city=3'或者InsertGenerator 'customer', 'city=3 and region=8'点击⼀下,选择全部然后复制新建⼀个查询窗⼝,然后粘贴其实SQLServer的技巧有很多最后,⼤家可以看⼀下代码,⾮常简单,如果要⽀持SQLServer2000,只要改⼀下代码就可以了补充:创建⼀张测试表CREATE TABLE testinsert (id INT,name VARCHAR(100),cash MONEY,dtime DATETIME) INSERT INTO[dbo].[testinsert]( [id], [name], [cash], [dtime] )VALUES ( 1, -- id - int'nihao', -- name - varchar(100)8.8, -- cash - moneyGETDATE() -- dtime - datetime)SELECT*FROM[dbo].[testinsert]测试InsertGenerator 'testinsert' ,''InsertGenerator 'testinsert' ,'name=''nihao'''InsertGenerator 'testinsert' ,'name=''nihao'' and cash=8.8'datetime类型会有⼀些问题⽣成的结果会⾃动帮你转换INSERT INTO[dbo].[testinsert]([id],[name],[cash],[dtime]) VALUES('1','nihao',convert(money,'8.80'),convert(datetime,'02 8 2015 5:17PM'))群⾥的⼈共享的另⼀个脚本IF OBJECT_ID('spGenInsertSQL','P') IS NOT NULLDROP PROC spGenInsertSQLGOCREATE proc spGenInsertSQL (@tablename varchar(256),@number BIGINT,@whereClause NVARCHAR(MAX))asbegindeclare@sql varchar(8000)declare@sqlValues varchar(8000)set@sql=' ('set@sqlValues='values (''+'select@sqlValues=@sqlValues+ cols +' + '','' + ' ,@sql=@sql+'['+ name +'],'from(select casewhen xtype in (48,52,56,59,60,62,104,106,108,122,127)then'case when '+ name +' is null then ''NULL'' else '+'cast('+ name +' as varchar)'+' end'when xtype in (58,61,40,41,42)then'case when '+ name +' is null then ''NULL'' else '+''''''''' + '+'cast('+ name +' as varchar)'+'+'''''''''+' end'when xtype in (167)then'case when '+ name +' is null then ''NULL'' else '+''''''''' + '+'replace('+ name+','''''''','''''''''''')'+'+'''''''''+' end'when xtype in (231)then'case when '+ name +' is null then ''NULL'' else '+'''N'''''' + '+'replace('+ name+','''''''','''''''''''')'+'+'''''''''+' end'when xtype in (175)then'case when '+ name +' is null then ''NULL'' else '+''''''''' + '+'cast(replace('+ name+','''''''','''''''''''') as Char('+cast(length as varchar) +'))+'''''''''+' end' when xtype in (239)then'case when '+ name +' is null then ''NULL'' else '+'''N'''''' + '+'cast(replace('+ name+','''''''','''''''''''') as Char('+cast(length as varchar) +'))+'''''''''+' end' else'''NULL'''end as Cols,namefrom syscolumnswhere id =object_id(@tablename)) TIF (@number!=0AND@number IS NOT NULL)BEGINset@sql='select top '+CAST(@number AS VARCHAR(6000))+'''INSERT INTO ['+@tablename+']'+left(@sql,len(@sql)-1)+') '+left(@sqlValues,len(@sqlValues)-4) +')'' from '+@tablename print@sqlENDELSEBEGINset@sql='select ''INSERT INTO ['+@tablename+']'+left(@sql,len(@sql)-1)+') '+left(@sqlValues,len(@sqlValues)-4) +')'' from '+@tablenameprint@sqlENDPRINT@whereClauseIF ( @whereClause IS NOT NULL AND@whereClause<>'')BEGINset@sql=@sql+' where '+@whereClauseprint@sqlENDexec (@sql)endGOView Code调⽤⽰例--⾮dbo默认架构需注意--⽀持数据类型:bigint,int, bit,char,datetime,date,time,decimal,money, nvarchar(50),tinyint, nvarchar(max),varchar(max),datetime2--调⽤⽰例如果top⾏或者where条件为空,只需要把参数填上nullspGenInsertSQL 'customer'--表名, 2--top ⾏数, 'city=3 and didian=''⼤连'''--where 条件--导出全表 where条件为空spGenInsertSQL 'customer'--表名, null--top ⾏数,null--where 条件INSERT INTO[Department] ([DepartmentID],[Name],[GroupName],[Company],[ModifiedDate]) values (1,N'售后部',N'销售组',N'中国你好有限公司XX分公司','05 5 2015 5:58PM') INSERT INTO[Department] ([DepartmentID],[Name],[GroupName],[Company],[ModifiedDate]) values (2,N'售后部',N'销售组',N'中国你好有限公司XX分公司','05 5 2015 5:58PM')。

ORACLEAWR报告生成和分析ORACLEAWR(Automatic Workload Repository)是Oracle数据库中的一个功能,用于收集和存储数据库的性能统计信息。
通过AWR报告,可以分析数据库的性能瓶颈,并提供相关的建议和推荐的解决方案。
下面将对AWR报告的生成和分析进行详细介绍。
AWR报告的生成AWR报告主要由两个组件生成:一是Statspack/SNAP工具(用于收集性能数据),二是AWR报告生成脚本(用于生成AWR报告)。
1. Statspack/SNAP工具Statspack/SNAP工具是Oracle数据库中用于收集数据库性能统计信息的功能。
可以通过以下步骤使用Statspack/SNAP工具收集性能数据:- 创建Statspack/SNAP用户:在数据库中创建一个新用户,用于存储性能统计信息。
- 安装Statspack/SNAP工具:将Statspack/SNAP工具的SQL脚本导入数据库中。
- 创建收集任务:使用Statspack/SNAP工具创建收集任务,指定收集的时间间隔。
- 收集性能数据:定期运行Statspack/SNAP任务,收集数据库的性能统计信息。
2.AWR报告生成脚本AWR报告生成脚本是一个PL/SQL脚本,用于生成AWR报告。
可以通过以下步骤生成AWR报告:-运行AWR报告生成脚本:将AWR报告生成脚本导入数据库中,并运行该脚本。
-指定时间范围:在运行AWR报告生成脚本时,可以指定要分析的时间范围。
- 生成AWR报告:AWR报告生成脚本会从Statspack/SNAP工具导出的数据中提取所需的性能统计信息,并生成AWR报告。
AWR报告的分析生成AWR报告后,可以使用AWR报告进行性能分析。
AWR报告提供了丰富的性能统计信息,可以帮助我们定位和解决数据库性能问题。
1.数据库总览AWR报告的第一部分提供了数据库的总体性能概览,包括数据库版本、实例名称、开始和结束时间等。

YONYOU NC 6.5数据库参考脚本及临时表空间配置
2015年12月
版权所有(c) 2015用友网络科技股份有限公司
目录
YONYOU NC 6.5 数据库参考脚本及临时表空间配置 (1)
目录 (2)
1SQLSERVER参考脚本 (3)
2ORACLE参考脚本 (5)
3DB2参考脚本 (6)
1SQLServer参考脚本
NC应用数据库是SQL Server数据库时,NC使用tempdb数据库作临时表数据库,不需要另建。
对于tempdb 数据库,用户可以根据实际应用存储位置;对其大小要求,预调整到10000M,文件增长设置为自动增长,
2Oracle参考脚本
用户创建ORACLE数据库最高权限的脚本如下。
可以根据需求,修改参数大小。
酌情创建所需目录。
5
3DB2参考脚本
需要特别注意,本版支持的是DB2V10版本,在建库时,务必检查以下参数设置是否正确
7。

1、打开命令行窗口#db2cmd2、打开控制中心# db2cmd db2cc3、打开命令编辑器db2cmd db2ce=====操作数据库命令=====4、启动数据库实例#db2start5、停止数据库实例#db2stop如果你不能停止数据库由于激活的连接,在运行db2stop前执行db2 force application all 就可以了/db2stop force6、创建数据库(1)、#db2 create db [dbname](2)、#db2 –tvf <文件路径>7、连接到数据库#db2 connect to [dbname] user [username] using [password]8、断开数据库连接#db2 connect reset9、列出所有数据库#db2 list db directory10、列出所有激活的数据库#db2 list active databases11、列出所有数据库配置#db2 get db cfg12、删除数据库#db2 drop database [dbname](执行此操作要小心)如果不能删除,断开所有数据库连接或者重启db2=========操作数据表命令==========13、列出所有用户表#db2 list tables14、列出所有系统表#db2 list tables for system15、列出所有表#db2 list tables for all16、列出系统表#db2 list tables for system17、列出用户表#db2 list tables for user18、列出特定用户表#db2 list tables for schema [user]19、创建一个与数据库中某个表(t2)结构相同的新表(t1)#db2 create table t1 like t220、将一个表t1的数据导入到另一个表t2#db2 "insert into t1 select * from t2"21、查询表#db2 "select * from table name where ..."22、显示表结构#db2 describe table tablename23、修改列#db2 alter table [tablename] alter column [columname] set data type varchar(24)======脚本文件操作命令=======24、执行脚本文件#db2 -tvf scripts.sql25、帮助命令* 查看命令帮助#db2 ? db2start* 查看错误码信息#db2 ? 22001* memo: 详细命令请使用"db2 ? <command>"进行查看。

数据采集脚本操作方法数据采集脚本是指通过自动化脚本的方式,从网站、API或其他数据源中提取所需的数据,并将其保存到本地或其他数据库中。
数据采集脚本的操作方法如下所示:1. 确定数据源:首先需要确定需要从哪个网站、API或其他数据源中采集数据。
可以根据需求选择合适的数据源,并获取相关的访问权限或API密钥。
2. 了解数据结构:在开始编写数据采集脚本之前,需要了解所需数据的结构。
这包括数据的类型、字段、格式等信息。
可以通过查看网站的源代码或API文档来获取这些信息。
3. 选择合适的编程语言:数据采集脚本可以使用多种编程语言来实现,如Python、Java、JavaScript等。
根据个人的编程能力和需求,选择合适的编程语言来编写脚本。
4. 安装必要的工具和库:根据选择的编程语言,安装相应的开发工具和库。
例如,对于Python,可以使用pip安装所需的第三方库,如Requests、BeautifulSoup、Selenium等。
5. 编写脚本:根据数据源和数据结构的了解,开始编写数据采集脚本。
脚本的主要任务是通过网络请求获取数据,解析数据并保存到本地或其他数据库中。
- 网络请求:根据数据源的要求,使用合适的网络请求方法(如GET、POST 等)向数据源发送请求,并获取返回的数据。
可以使用现成的网络请求库,如Requests。
- 数据解析:对于网页数据,可以使用HTML解析库,如BeautifulSoup,来解析网页的结构,提取所需的数据。
对于API返回的数据,可以直接使用JSON 解析库,如json或者pandas。
- 数据保存:根据需求,选择合适的方式来保存数据。
可以将数据保存到本地文件中,如CSV、Excel等格式。
也可以将数据存储到数据库中,如MySQL、MongoDB等。
6. 定时运行:如果需要定时采集数据,可以使用操作系统的定时任务功能或者第三方调度工具,如crontab、Airflow等,来定时运行数据采集脚本。

数据库数据字典引言概述:数据库数据字典是数据库管理系统中的一个重要组成部份,它记录了数据库中的各个表、字段以及相关的约束、索引等信息。
数据库数据字典不仅对数据库管理员和开辟人员有重要的参考价值,也对项目组成员和系统维护人员提供了便利。
本文将详细介绍数据库数据字典的定义、作用、组成部份、创建方法以及使用注意事项。
一、定义1.1 数据库数据字典的概念数据库数据字典是指记录了数据库中各个表、字段以及相关约束、索引等信息的文档或者文件。
它是数据库管理系统的一部份,用于描述和记录数据库的结构和内容。
1.2 数据库数据字典的作用数据库数据字典具有以下几个重要的作用:1.2.1 数据库设计参考:数据库数据字典可以作为数据库设计的参考依据,匡助开辟人员理清数据库的结构和关系,提高数据库设计的准确性和规范性。
1.2.2 数据库文档说明:数据库数据字典可以作为数据库的文档说明,记录了数据库的结构和内容,方便项目组成员和系统维护人员理解和使用数据库。
1.2.3 数据库维护依据:数据库数据字典可以作为数据库维护的依据,记录了数据库的各个表、字段以及相关约束、索引等信息,方便进行数据库的维护和优化。
1.3 数据库数据字典的组成部份数据库数据字典普通包括以下几个主要部份:1.3.1 表信息:记录了数据库中的各个表的名称、描述、创建时间等信息。
1.3.2 字段信息:记录了每一个表中的字段名称、数据类型、长度、约束等信息。
1.3.3 约束信息:记录了每一个表中的主键、外键、惟一约束等信息。
1.3.4 索引信息:记录了每一个表中的索引名称、字段、类型等信息。
1.3.5 视图信息:记录了数据库中的各个视图的名称、定义、创建时间等信息。
二、创建数据库数据字典的方法2.1 手工创建手工创建数据库数据字典是最常见的方法之一,可以通过文档或者电子表格等工具,逐个记录数据库中的表、字段、约束、索引等信息。
这种方法相对简单,但需要手动维护,容易出错。
windows应用场景下自动备份指定数据库的批处理脚本在Windows应用场景下,自动备份指定数据库是一个常见的需求。
通过批处理脚本编写,可以方便地实现数据库备份的自动化。
下面是一份适用于Windows应用场景的自动备份脚本示例:```bat@echo offsetlocalREM 配置数据库信息set "DB_SERVER=127.0.0.1"set "DB_NAME=example_db"set "DB_USERNAME=example_user"set "DB_PASSWORD=example_password"REM 配置备份信息set "BACKUP_FOLDER=C:\backup"set "BACKUP_FILE_NAME=%DB_NAME%_%date:/=-%_%time::=-%.bak"REM 创建备份文件夹(如果不存在)if not exist "%BACKUP_FOLDER%" (mkdir "%BACKUP_FOLDER%")REM 使用SQLCMD备份数据库sqlcmd -S %DB_SERVER% -d %DB_NAME% -U %DB_USERNAME% -P %DB_PASSWORD% -Q "BACKUP DATABASE [%DB_NAME%] TO DISK = N'%BACKUP_FOLDER%\%BACKUP_FILE_NAME%' WITH NOFORMAT, NOINIT, SKIP, STATS=10"REM 检查备份是否成功if %errorlevel% neq 0 (echo 备份失败,请检查数据库配置和备份文件夹路径。
) else (echo 备份成功,备份文件保存在 %BACKUP_FOLDER%\%BACKUP_FILE_NAME%。
方法如下:
选择“生成脚本”, 出现下图:
选择“下一步”
选择要操作的数据库PB2K,然后点击“下一步”
选择“下一步”
选择你需要的,这儿我选择了“存储过程、表、用户自定义函数和视图”,然后
点击“下一步”
选择你需要的存储过程,这儿我“全选”,然后点击“下一步”
选择需要的表,这儿“全选”,然后“下一步”
选择需要的自定义函数,这儿“全选”,然后“下一步”
选择需要的视图,这儿“全选”,然后“下一步”
选择脚本模式“将脚本保存到文件”,然后选择保存路径,点击“完成”
再点击“完成”即可。
等完成以后,到保存路径下即可看到XXX.sql文件,这时只需要重新建一个新的
数据库,然后在该数据库下执行该SQL文件内的命令。这样一来,所有的表、视
图、存储过程和函数就都自定建立了。