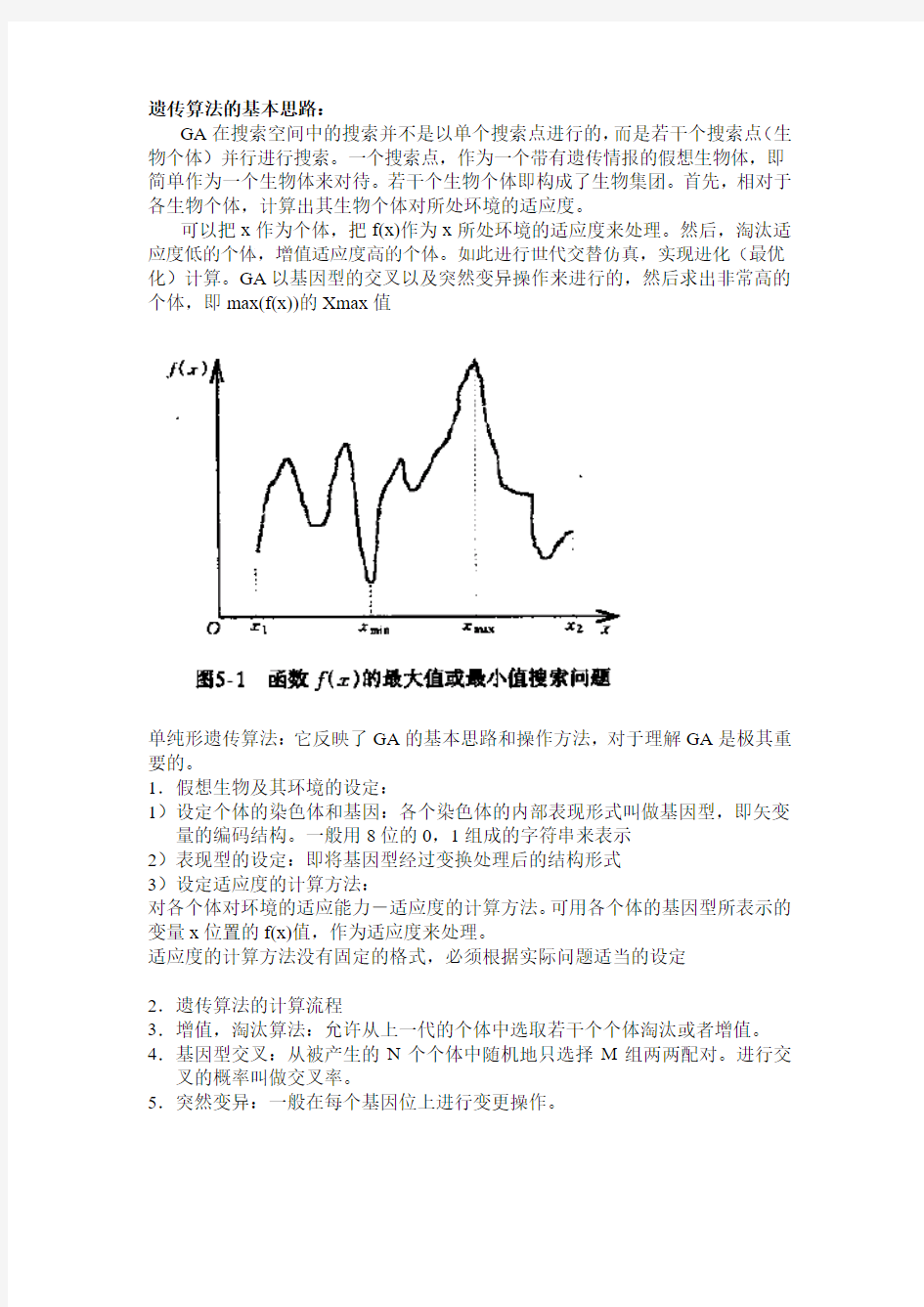
遗传算法的基本思路:
GA在搜索空间中的搜索并不是以单个搜索点进行的,而是若干个搜索点(生物个体)并行进行搜索。一个搜索点,作为一个带有遗传情报的假想生物体,即简单作为一个生物体来对待。若干个生物个体即构成了生物集团。首先,相对于各生物个体,计算出其生物个体对所处环境的适应度。
可以把x作为个体,把f(x)作为x所处环境的适应度来处理。然后,淘汰适应度低的个体,增值适应度高的个体。如此进行世代交替仿真,实现进化(最优化)计算。GA以基因型的交叉以及突然变异操作来进行的,然后求出非常高的个体,即max(f(x))的Xmax值
单纯形遗传算法:它反映了GA的基本思路和操作方法,对于理解GA是极其重要的。
1.假想生物及其环境的设定:
1)设定个体的染色体和基因:各个染色体的内部表现形式叫做基因型,即矢变量的编码结构。一般用8位的0,1组成的字符串来表示
2)表现型的设定:即将基因型经过变换处理后的结构形式
3)设定适应度的计算方法:
对各个体对环境的适应能力-适应度的计算方法。可用各个体的基因型所表示的变量x位置的f(x)值,作为适应度来处理。
适应度的计算方法没有固定的格式,必须根据实际问题适当的设定
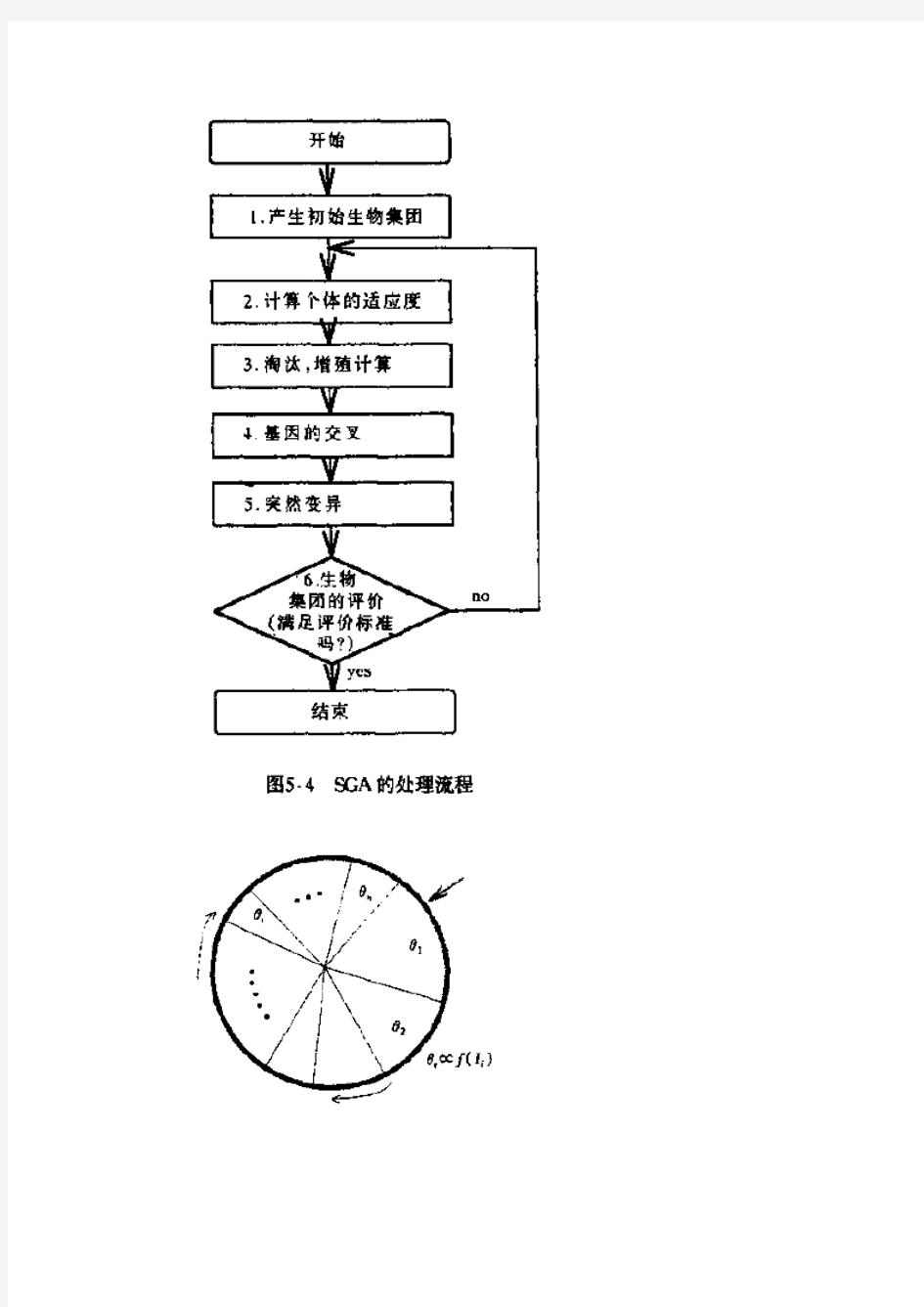
2.遗传算法的计算流程
3.增值,淘汰算法:允许从上一代的个体中选取若干个个体淘汰或者增值。4.基因型交叉:从被产生的N个个体中随机地只选择M组两两配对。进行交叉的概率叫做交叉率。
5.突然变异:一般在每个基因位上进行变更操作。
神经网络应用:
神经网络称为人工神经网络,一般简称神经网络。主要应用于信息处理,模式识别,智能控制等领域。
专家系统支持下的优化设计
什么是专家系统呢?专家系统是人工智能技术的一个分支,是模拟专家用知识和经验解决诊断或设计问题的软件系统。它一般由五个部分组成:人机界画(通常以菜单形式构成)、解释部分、推理部分、知识获取部分、知识库和知识表达方式。
CIPS (Computer Integrated Manufacturing System )优化模型: 1 CIPS 的概念模型
CIPS 的概念模型(图1)是把信息处理、物料平衡以及决策这三方面有机地结合起来,实现管理控制一体化.复合信息是对企业内部和外部的各种信息进行采集、分类、分析,并建立相应的信息管理系统,为决策层提供必要的信息,从而指导生产.物料平衡强调了过程工业中减少能耗提高产品收串的特点,它包含了生产系统中各个自动化孤岛
2.CIPS 的优化模型
炼油厂编制年度和月度生产计划,大多数都采用线性规划优化方法,优化模型中的变量和约束方程数以干计,且有些方面表达的还不尽如人意.针对练油厂的持点.建立了如图2所示的CIPS 综合多级优化模型:油品凋合优化模型、装置优比生产模型等子级优化模型也都包含了自变量、因变量、约束方程、目标函数等优化要素.一方面这些子优化模型是具有一定独立性的优化问题;另一方面,子级模型与整体之间、子级与子级之间存在着各种相互制约和相互影响的关系,而这正是各级子优化模型间存在锅台的主要原因.综合多级优化模型中各子模型间相互影响的关系可由输入信息流和输出信息流来描述,其中的重要内容之一是相互间变量与约束条件之间的影响关系.约束条件分为自约束和它约束两类,它约束条件是于模型间招合的信息载体.例如汽油质量和数量的
约束条件在总体目标优化、生产系统优化、油品调合优化、装置优化、产品储运优化等模型中,或者为自约束,或者为它约束条件,在各个模型中的信息含量也有较大差异.因此,有效地处理优化模型间相关信息是提高多级优化效率的关键.故提出如下多级优化的求解策略“采用专家系统技术解决各级优化问题中的时序特性和不确定性因素,利电神经网络技术配合建棋,将瓤Ps 优化问题转化为一个确定性的公式化的优化问题:5I ,然后用成熟的线性规划方法求解.b
.如
果菜子模型的它约束条件是同级或上级子模型的约束条件,则可直接将该类它约束条件加入该子模型的约束集中.cl如果菜子模型的它约束条件是下级子模型的约束条件,则可将这些它约束条件以合适的罚项形式与模型的原目标函数构成新的目标函数.d.采用暂时删除策略先不考虑那些较弱的相关约束条件,随着综合多级优化迭代过程的进行再逐渐加入这些相关约束条件.e.如果综合多级优化的一些子级优化模型没有目标函数,这时应将子模型的相关它约束条件以罚函数的形式作为目标函数.
图2 CIPS优化模型
二、广义优化的理论框架
1.工程优化的发展历程:
2.广义优化的范畴:
传统优化往往只适用于简单零部件,广义优化把对象由此扩展到复杂零部件、整机、系列产品和组合产品的整体优化,可统称为全系统优化。传统优化往往只侧重于某种或某一方面性能的优化,处理不同类性能时一般分先后而优之。广义优化把优化准则由某方面性能扩展到各方面性能,要实现技术性、经济性和社会性的综合评估和优化。仅技术性能而百,追求实现目的性能和约束性能、使用性能和结构性能的综合优化;就结构优化而盲,则追求静态性能与动态性能的
组合优化,因此可统称为全性能优化,见图2。
3.传统优化与广义优化的比较:
实验六 遗传算法与优化设计 一、实验目的 1. 了解遗传算法的基本原理和基本操作(选择、交叉、变异); 2. 学习使用Matlab 中的遗传算法工具箱(gatool)来解决优化设计问题; 二、实验原理及遗传算法工具箱介绍 1. 一个优化设计例子 图1所示是用于传输微波信号的微带线(电极)的横截面结构示意图,上下两根黑条分别 代表上电极和下电极,一般下电极接地,上电极接输入信号,电极之间是介质(如空气,陶瓷等)。微带电极的结构参数如图所示,W 、t 分别是上电极的宽度和厚度,D 是上下电极间距。当微波信号在微带线中传输时,由于趋肤效应,微带线中的电流集中在电极的表面,会产生较大的欧姆损耗。根据微带传输线理论,高频工作状态下(假定信号频率1GHz ),电极的欧姆损耗可以写成(简单起见,不考虑电极厚度造成电极宽度的增加): 图1 微带线横截面结构以及场分布示意图 {} 28.6821ln 5020.942ln 20.942S W R W D D D t D W D D W W t D W W D e D D παπππ=+++-+++?????? ? ??? ??????????? ??????? (1) 其中πρμ0=S R 为金属的表面电阻率,为电阻率。可见电极的结构参数影响着电极损
耗,通过合理设计这些参数可以使电极的欧姆损耗做到最小,这就是所谓的最优化问题或者称为规划设计问题。此处设计变量有3个:W 、D 、t ,它们组成决策向量[W, D ,t ] T ,待优化函数(,,)W D t α称为目标函数。 上述优化设计问题可以抽象为数学描述: ()()min .. 0,1,2,...,j f X s t g X j p ????≤=? (2) 其中()T n x x x X ,...,,21=是决策向量,x 1,…,x n 为n 个设计变量。这是一个单目标的数学规划问题:在一组针对决策变量的约束条件()0,1,...,j g X j p ≤=下,使目标函数最小化(有时 也可能是最大化,此时在目标函数()X f 前添个负号即可)。满足约束条件的解X 称为可行解,所有满足条件的X 组成问题的可行解空间。 2. 遗传算法基本原理和基本操作 遗传算法(Genetic Algorithm, GA)是一种非常实用、高效、鲁棒性强的优化技术,广 泛应用于工程技术的各个领域(如函数优化、机器学习、图像处理、生产调度等)。遗传算法是模拟生物在自然环境中的遗传和进化过程而形成的一种自适应全局优化算法。按照达尔文的进化论,生物在进化过程中“物竞天择”,对自然环境适应度高的物种被保留下来,适应度差的物种而被淘汰。物种通过遗传将这些好的性状复制给下一代,同时也通过种间的交配(交叉)和变异不断产生新的物种以适应环境的变化。从总体水平上看,生物在进化过程中子代总要比其父代优良,因此生物的进化过程其实就是一个不断产生优良物种的过程,这和优化设计问题具有惊人的相似性,从而使得生物的遗传和进化能够被用于实际的优化设计问题。 按照生物学知识,遗传信息基因(Gene)的载体是染色体(Chromosome),染色体中 一定数量的基因按照一定的规律排列(即编码),遗传基因在染色体中的排列位置称为基因
yj1.m :简单一元函数优化实例,利用遗传算法计算下面函数的最大值 0.2)*10sin()(+=x x x f π,∈x [-1, 2] 选择二进制编码,种群中个体数目为40,每个种群的长度为20,使用代沟为0.9, 最大遗传代数为25 译码矩阵结构:?????????? ??????? ???? ?=ubin lbin scale code ub lb len FieldD 译码矩阵说明: len – 包含在Chrom 中的每个子串的长度,注意sum(len)=length(Chrom); lb 、ub – 行向量,分别指明每个变量使用的上界和下界; code – 二进制行向量,指明子串是怎样编码的,code(i)=1为标准二进制编码, code(i)=0则为格雷编码; scale – 二进制行向量,指明每个子串是否使用对数或算术刻度,scale(i)=0为算术 刻度,scale(i)=1则为对数刻度; lbin 、ubin – 二进制行向量,指明表示范围中是否包含每个边界,选择lbin=0或 ubin=0,表示从范围中去掉边界;lbin=1或ubin=1则表示范围中包含边界; 注:增加第22行:variable=bs2rv(Chrom, FieldD);否则提示第26行plot(variable(I), Y, 'bo'); 中variable(I)越界 yj2.m :目标函数是De Jong 函数,是一个连续、凸起的单峰函数,它的M 文件objfun1包含在GA 工具箱软件中,De Jong 函数的表达式为: ∑ == n i i x x f 1 2 )(, 512512≤≤-i x 这里n 是定义问题维数的一个值,本例中选取n=20,求解 )(min x f ,程序主要变量: NIND (个体的数量):=40; MAXGEN (最大遗传代数):=500; NV AR (变量维数):=20; PRECI (每个变量使用多少位来表示):=20; GGAP (代沟):=0.9 注:函数objfun1.m 中switch 改为switch1,否则提示出错,因为switch 为matlab 保留字,下同! yj3.m :多元多峰函数的优化实例,Shubert 函数表达式如下,求)(min x f 【shubert.m 】
遗传算法入门到掌握 读完这个讲义,你将基本掌握遗传算法,要有耐心看完。 想了很久,应该用一个怎么样的例子带领大家走进遗传算法的神奇世界呢?遗传算法的有趣应用很多,诸如寻路问题,8数码问题,囚犯困境,动作控制,找圆心问题(这是一个国外网友的建议:在一个不规则的多边形中,寻找一个包含在该多边形内的最大圆圈的圆心。),TSP问题(在以后的章节里面将做详细介绍。),生产调度问题,人工生命模拟等。直到最后看到一个非常有趣的比喻,觉得由此引出的袋鼠跳问题(暂且这么叫它吧),既有趣直观又直达遗传算法的本质,确实非常适合作为初学者入门的例子。这一章将告诉读者,我们怎么让袋鼠跳到珠穆朗玛峰上去(如果它没有过早被冻坏的话)。 问题的提出与解决方案 让我们先来考虑考虑下面这个问题的解决办法。 已知一元函数: 图2-1 现在要求在既定的区间内找出函数的最大值。函数图像如图2-1所示。 极大值、最大值、局部最优解、全局最优解
在解决上面提出的问题之前我们有必要先澄清几个以后将常常会碰到的概念:极大值、最大值、局部最优解、全局最优解。学过高中数学的人都知道极大值在一个小邻域里面左边的函数值递增,右边的函数值递减,在图2.1里面的表现就是一个“山峰”。当然,在图上有很多个“山峰”,所以这个函数有很多个极大值。而对于一个函数来说,最大值就是在所有极大值当中,最大的那个。所以极大值具有局部性,而最大值则具有全局性。 因为遗传算法中每一条染色体,对应着遗传算法的一个解决方案,一般我们用适应性函数(fitness function)来衡量这个解决方案的优劣。所以从一个基因组到其解的适应度形成一个映射。所以也可以把遗传算法的过程看作是一个在多元函数里面求最优解的过程。在这个多维曲面里面也有数不清的“山峰”,而这些最优解所对应的就是局部最优解。而其中也会有一个“山峰”的海拔最高的,那么这个就是全局最优解。而遗传算法的任务就是尽量爬到最高峰,而不是陷落在一些小山峰。(另外,值得注意的是遗传算法不一定要找“最高的山峰”,如果问题的适应度评价越小越好的话,那么全局最优解就是函数的最小值,对应的,遗传算法所要找的就是“最深的谷底”)如果至今你还不太理解的话,那么你先往下看。本章的示例程序将会非常形象的表现出这个情景。 “袋鼠跳”问题 既然我们把函数曲线理解成一个一个山峰和山谷组成的山脉。那么我们可以设想所得到的每一个解就是一只袋鼠,我们希望它们不断的向着更高处跳去,直到跳到最高的山峰(尽管袋鼠本身不见得愿意那么做)。所以求最大值的过程就转化成一个“袋鼠跳”的过程。下面介绍介绍“袋鼠跳”的几种方式。 爬山法、模拟退火和遗传算法 解决寻找最大值问题的几种常见的算法: 1. 爬山法(最速上升爬山法): 从搜索空间中随机产生邻近的点,从中选择对应解最优的个体,替换原来的个体,不断重复上述过程。因为只对“邻近”的点作比较,所以目光比较“短浅”,常常只能收敛到离开初始位置比较近的局部最优解上面。对于存在很多局部最优点的问题,通过一个简单的迭代找出全局最优解的机会非常渺茫。(在爬山法中,袋鼠最有希望到达最靠近它出发点的山顶,但不能保证该山顶是珠穆朗玛峰,或者是一个非常高的山峰。因为一路上它只顾上坡,没有下坡。) 2. 模拟退火: 这个方法来自金属热加工过程的启发。在金属热加工过程中,当金属的温度超过它的熔点(Melting Point)时,原子就会激烈地随机运动。与所有的其它的物理系统相类似,原子的这种运动趋向于寻找其能量的极小状态。在这个能量的变
附录 Machining fixture locating and clamping position optimization using genetic algorithms Necmettin Kaya* Department of Mechanical Engineering, Uludag University, Go¨ru¨kle, Bursa 16059, Turkey Received 8 July 2004; accepted 26 May 2005 Available online 6 September 2005 Abstract Deformation of the workpiece may cause dimensional problems in machining. Supports and locators are used in order to reduce the error caused by elastic deformation of the workpiece. The optimization of support, locator and clamp locations is a critical problem to minimize the geometric error in workpiece machining. In this paper, the application of genetic algorithms (GAs) to the fixture layout optimization is presented to handle fixture layout optimization problem. A genetic algorithm based approach is developed to optimise fixture layout through integrating a finite element code running in batch mode to compute the objective function values for each generation. Case studies are given to illustrate the application of proposed approach. Chromosome library approach is used to decrease the total solution time. Developed GA keeps track of previously analyzed designs; therefore the numbers of function evaluations are decreased about 93%. The results of this approach show that the fixture layout optimization problems are multi-modal problems. Optimized designs do not have any apparent similarities although they provide very similar performances. Keywords: Fixture design; Genetic algorithms; Optimization 1. Introduction Fixtures are used to locate and constrain a workpiece during a machining operation, minimizing workpiece and fixture tooling deflections due to clamping and cutting forces are critical to ensuring accuracy of the machining operation. Traditionally, machining fixtures are designed and manufactured through trial-and-error, which prove to be both expensive and time-consuming to the manufacturing process. To ensure a workpiece is manufactured according to specified dimensions and tolerances, it must be appropriately located and clamped, making it imperative to develop tools that will eliminate costly and time-consuming trial-and-error designs. Proper
matlab自带优化工具箱遗传算法中文解释 problem setup and results设置与结果 problem fitness function适应度函数 number of variable变量数 constraints约束 linear inequalities线性不等式,A*x<=b形式,其中A是矩阵,b是向量 linear equalities线性等式,A*x=b形式,其中A是矩阵,b是向量 bounds定义域,lower下限,upper上限,列向量形式,每一个位置对应一个变量 nonlinear constraint function非线性约束,用户定义,非线性等式必须写成c=0形式,不等式必须写成c<=0形式 integer variable indices整型变量标记约束,使用该项时Aeq和beq必须为空,所有非线性约束函数必须返回一个空值,种群类型必须是实数编码 run solver and view results求解 use random states from previous run使用前次的状态运行,完全重复前次运行的过程和结果 population population type编码类型 double vector实数编码,采用双精度 bitstring二进制编码对于生成函数和变异函数,只能选用uniform和custom,对于杂交函数,只能使用 scattered singlepoint,twopoint或custom不能使用hybrid function和nonlinear constraint function custom 自定义 population size:种群大小 creation function:生成函数,产生初始种群 constraint dependent:约束相关,无约束时为uniform,有约束时为feasible population uniform:均匀分布 feasible population :自适应种群,生成能够满足约束的种群 initial population:初始种群,不指定则使用creation function生成,可以指定少于种群数量的种群,由creation function完成剩余的 initial scores:初始值,如果不指定,则有计算机计算适应度函数作为初始值,对于整型约束不可用,使用向量表示 initial range:初始范围,使用向量矩阵表示,第一行表示范围的下限,第二行表示上限 fitness scaling:适应度尺度 rank:等级。将适应度排序,然后编号 proportional:按比例 top:按比例选取种群中最高适应度的个体,这些个体有等比例的机会繁衍,其余的个体被淘汰 shift linear:线性转换
使用遗传算法求解函数最大值 题目 使用遗传算法求解函数 在及y的最大值。 解答 算法 使用遗传算法进行求解,篇末所附源代码中带有算法的详细注释。算法中涉及不同的参数,参数的取值需要根据实际情况进行设定,下面运行时将给出不同参数的结果对比。 定义整体算法的结束条件为,当种群进化次数达到maxGeneration时停止,此时种群中的最优解即作为算法的最终输出。 设种群规模为N,首先是随机产生N个个体,实验中定义了类型Chromosome表示一个个体,并且在默认构造函数中即进行了随机的操作。 然后程序进行若干次的迭代,在每次迭代过程中,进行选择、交叉及变异三个操作。 一选择操作 首先计算当前每个个体的适应度函数值,这里的适应度函数即为所要求的优化函数,然后归一化求得每个个体选中的概率,然后用轮盘赌的方法以允许重复的方式选择选择N个个体,即为选择之后的群体。
但实验时发现结果不好,经过仔细研究之后发现,这里在x、y取某些值的时候,目标函数计算出来的适应值可能会出现负值,这时如果按照把每个个体的适应值除以适应值的总和的进行归一化的话会出现问题,因为个体可能出现负值,总和也可能出现负值,如果归一化的时候除以了一个负值,选择时就会选择一些不良的个体,对实验结果造成影响。对于这个问题,我把适应度函数定为目标函数的函数值加一个正数,保证得到的适应值为正数,然后再进行一般的归一化和选择的操作。实验结果表明,之前的实验结果很不稳定,修正后的结果比较稳定,趋于最大值。 二交叉操作 首先是根据交叉概率probCross选择要交叉的个体进行交叉。
这里根据交叉参数crossnum进行多点交叉,首先随机生成交叉点位置,允许交叉点重合,两个重合的交叉点效果互相抵消,相当于没有交叉点,然后根据交叉点进行交叉操作,得到新的个体。 三变异操作 首先是根据变异概率probMutation选择要变异的个体。 变异时先随机生成变异的位置,然后把改位的01值翻转。
蚁群算法蚂蚁算法中英文对照外文翻译文献(文档含英文原文和中文翻译)
翻译: 蚁群算法 起源 蚁群算法(ant colony optimization, ACO),又称蚂蚁算法,是一种用来在图中寻找优化路径的机率型算法。它由Marco Dorigo于1992年在他的博士论文中提出,其灵感来源于蚂蚁在寻找食物过程中发现路径的行为。蚁群算法是一种模拟进化算法,初步的研究表明该算法具有许多优良的性质.针对PID 控制器参数优化设计问题,将蚁群算法设计的结果与遗传算法设计的结果进行了比较,数值仿真结果表明,蚁群算法具有一种新的模拟进化优化方法的有效性和应用价值。 原理 各个蚂蚁在没有事先告诉他们食物在什么地方的前提下开始寻找食物。当一只找到食物以后,它会向环境释放一种信息素,吸引其他的蚂蚁过来,这样越来越多的蚂蚁会找到食物!有些蚂蚁并没有象其它蚂蚁一样总重复同样的路,他们会另辟蹊径,如果令开辟的道路比原来的其他道路更短,那么,渐渐地更多的蚂蚁被吸引到这条较短的路上来。最后,经过一段时间运行,可能会出现一条最短的路径被大多数蚂蚁重复着。 为什么小小的蚂蚁能够找到食物?他们具有智能么?设想,如果我们要为蚂蚁设计一个人工智能的程序,那么这个程序要多么复杂呢?首先,你要让蚂蚁能够避开障碍物,就必须根据适当的地形给它编进指令让他们能够巧妙的避开障碍物,其次,要让蚂蚁找到食物,就需要让他们遍历空间上的所有点;再次,如果要让蚂蚁找到最短的路径,那么需要计算所有可能的路径并且比
较它们的大小,而且更重要的是,你要小心翼翼的编程,因为程序的错误也许会让你前功尽弃。这是多么不可思议的程序!太复杂了,恐怕没人能够完成这样繁琐冗余的程序。 然而,事实并没有你想得那么复杂,上面这个程序每个蚂蚁的核心程序编码不过100多行!为什么这么简单的程序会让蚂蚁干这样复杂的事情?答案是:简单规则的涌现。事实上,每只蚂蚁并不是像我们想象的需要知道整个世界的信息,他们其实只关心很小范围内的眼前信息,而且根据这些局部信息利用几条简单的规则进行决策,这样在蚁群这个集体里,复杂性的行为就会凸现出来。这就是人工生命、复杂性科学解释的规律!那么,这些简单规则是什么呢? 1、范围: 蚂蚁观察到的范围是一个方格世界,蚂蚁有一个参数为速度半径(一般是3),那么它能观察到的范围就是3*3个方格世界,并且能移动的距离也在这个范围之内。 2、环境: 蚂蚁所在的环境是一个虚拟的世界,其中有障碍物,有别的蚂蚁,还有信息素,信息素有两种,一种是找到食物的蚂蚁洒下的食物信息素,一种是找到窝的蚂蚁洒下的窝的信息素。每个蚂蚁都仅仅能感知它范围内的环境信息。环境以一定的速率让信息素消失。 3、觅食规则: 在每只蚂蚁能感知的范围内寻找是否有食物,如果有就直接过去。否则看是否有信息素,并且比较在能感知的范围内哪一点的信息素最多,这样,它就朝信息素多的地方走,并且每只蚂蚁都会以小概率犯错误,从而并不是往信
用遗传算法优化BP神经网络的 Matlab编程实例 由于BP网络的权值优化是一个无约束优化问题,而且权值要采用实数编码,所以直接利用Matlab遗传算法工具箱。以下贴出的代码是为一个19输入变量,1个输出变量情况下的非线性回归而设计的,如果要应用于其它情况,只需改动编解码函数即可。 程序一:GA训练BP权值的主函数 function net=GABPNET(XX,YY) %-------------------------------------------------------------------------- % % 使用遗传算法对BP网络权值阈值进行优化,再用BP算法训练网络 %-------------------------------------------------------------------------- %数据归一化预处理 nntwarn off XX=premnmx(XX); YY=premnmx(YY); %创建网络 net=newff(minmax(XX),[19,25,1],{'tansig','tan sig','purelin'},'trainlm'); %下面使用遗传算法对网络进行优化 P=XX; T=YY; R=size(P,1); S2=size(T,1); S1=25;%隐含层节点数 S=R*S1+S1*S2+S1+S2;%遗传算法编码长度 aa=ones(S,1)*[-1,1]; popu=50;%种群规模 initPpp=initializega(popu,aa,'gabpEval');%初始化种群 gen=100;%遗传代数 %下面调用gaot工具箱,其中目标函数定义为gabpEval [x,endPop,bPop,trace]=ga(aa,'gabpEval',[],ini tPpp,[1e-6 1 1],'maxGenTerm',gen,... 'normGeomSelect',[],['arithXover'],[2],'n onUnifMutation',[2 gen 3]); %绘收敛曲线图 figure(1) plot(trace(:,1),1./trace(:,3),'r-'); hold on plot(trace(:,1),1./trace(:,2),'b-'); xlabel('Generation'); ylabel('Sum-Squared Error'); figure(2) plot(trace(:,1),trace(:,3),'r-'); hold on plot(trace(:,1),trace(:,2),'b-'); xlabel('Generation'); ylabel('Fittness'); %下面将初步得到的权值矩阵赋给尚未开始训练的BP 网络 [W1,B1,W2,B2,P,T,A1,A2,SE,val]=gadecod(x); {2,1}=W1; {3,2}=W2; {2,1}=B1; {3,1}=B2; XX=P; YY=T; %设置训练参数 %训练网络 net=train(net,XX,YY); 程序二:适应值函数 function [sol, val] = gabpEval(sol,options) % val - the fittness of this individual % sol - the individual, returned to allow for Lamarckian evolution % options - [current_generation] load data2 nntwarn off XX=premnmx(XX); YY=premnmx(YY); P=XX; T=YY; R=size(P,1); S2=size(T,1); S1=25;%隐含层节点数 S=R*S1+S1*S2+S1+S2;%遗传算法编码长度 for i=1:S, x(i)=sol(i);
Using Genetic Algorithms for Dynamic Scheduling
Ana Madureira * Carlos Ramos * Sílvio do Carmo Silva ? anamadur@dei.isep.ipp.pt,, csr@dei.isep.ipp.pt, scarmo@dps.uminho.pt
1
Institute of Engineering Polytechnic of Porto, GECAD - Knowledge Engineering and Decision Support Research Group, Dept. of Computer Science Rua de S?o Tomé, 4200 Porto-Portugal Phone: +351 228340500 Fax: +351 228321159
2 Minho University, Dept. of Production and Systems 4710-057, Braga -– Portugal, Phone: +351 253604745
Abstract
In most practical environments, scheduling is an ongoing reactive process where the presence of real time information continually forces reconsideration and revision of pre-established schedules. Scheduling algorithms that achieve good or near optimal solutions and can efficiently adapt them to perturbations are, in most cases, preferable to those that achieve optimal ones but that cannot implement such an adaptation. This reality, motivated us to concentrate on tools, which could deal with such dynamic, disturbed scheduling problems, both for single and multi-machine manufacturing settings, even though, due to the complexity of these problems, optimal solutions may not be possible to find. We decided to address the problem drawing upon the potential of Genetic Algorithms to deal with such complex situations. We decided to address the problem drawing upon the potential of Genetic Algorithms to deal with such complex situations. Since in a sense natural evolution is a process of continuous adaptation, it seems appropriate to consider Genetic Algorithms as good candidates for dynamic scheduling problems. This paper is concerned with vertical oriented detailed scheduling of Extended Job-Shop on dynamic environments. It addresses the scheduling of tasks, either simple or complex products, comprehending the parts fabrication and their multistage assembly into complex products. Key Words: Dynamic Scheduling, Population Dynamic Adaptation, Regenerating Mechanism, Genetic Algorithms.
1. INTRODUCTION
Research on the theory and practice of scheduling has been pursued for many years. Theoretical scheduling problems concerned with searching for optimal schedules subject to a limited number of constraints have adopted a variety of techniques including branch-and-bound and dynamic programming. From the point of view of combinatorial optimization the question of how to sequence and schedule jobs in a dynamic environment looks rather complex and is known to be NP-hard. For literature on this subject, see for example, Baker (1974), French (1982), Blazewicz et al. (2001), Pinedo (2001) and Brucker (2001). In generic terms, the scheduling process can be defined as the assignment of time-constrained jobs to timeconstrained resources within a pre-defined time framework, which represents the complete time horizon of the schedule. An admissible schedule will have to satisfy a set of hard and soft constraints imposed on jobs and resources. So, a scheduling problems can be seen as a decision making process for operations starting and resources to be used. A variety of characteristics and constraints related with jobs and production system, such as operation processing times, release and due dates, precedence constraints and resource availability, can affect scheduling decisions. If all jobs are known before processing starts a scheduling problem is said to be static, while, to classify a problem as dynamic it is sufficient that job release times are not fixed at a single point in time, i.e. jobs arrive to the system at different times. Scheduling problems can also be classified as either deterministic, when processing times and all other parameters are known and fixed, or as non-deterministic, when some or all parameters are uncertain (French, 1982). Most of the known work on scheduling deals with optimisation of scheduling problems in static environments, whereas, due to several sorts of random occurrences and perturbations, real world scheduling problems are usually of dynamic nature. Due to their dynamic nature, real scheduling problems have additional complexity in relation to static ones. However, in many situations, both static and dynamic problems, even for apparently simple cases, are hard to
摘要 随着科学技术和社会信息技术的不断提高,计算机科学的日渐成熟,其强大的功能已为人们深刻认识,它在人类社会的各个领域发挥着越来越重要的作用,给人们的生活带来了极大的便利,成为推动社会发展的首要技术动力。排课是学校教学管理中十分重要、又相当复杂的工作之一。解决好教学工作中的排课问题对整个教学计划的进行,有着十分重要的意义。首先对排课的已有算法作了相关的调查研究,决定采用遗传算法。通过设计实现基于遗传算法的自动排课系统,研究了遗传算法在排课系统中的应用。 关键词:遗传算法、自动排课、Java。
Abstract Along with science technical and community information technical increases continuously, calculator science is gradually mature, its mighty function has behaved deep cognition, and it has entered the human social each realm erupts to flick the more and more important function, bringing our life biggest of convenience. Curriculum arrangement is an important and complicated working in school,so solving the problem is of great importance for teaching programming.Investigated and studied the algorithm existed, determine that adoptgenetic algorithm. ThroughDesign Implementation theAuto CourseArrangementManagement System Base onGenetic Algorithm, researched the application of genetic algorithmin theCourseArrangementManagement System. Keywords: Genetic Algorithm Auto Course Arrangement ManagementJava.
What is a genetic algorithm? ●Methods of representation ●Methods of selection ●Methods of change ●Other problem-solving techniques Concisely stated, a genetic algorithm (or GA for short) is a programming technique that mimics biological evolution as a problem-solving strategy. Given a specific problem to solve, the input to the GA is a set of potential solutions to that problem, encoded in some fashion, and a metric called a fitness function that allows each candidate to be quantitatively evaluated. These candidates may be solutions already known to work, with the aim of the GA being to improve them, but more often they are generated at random. The GA then evaluates each candidate according to the fitness function. In a pool of randomly generated candidates, of course, most will not work at all, and these will be deleted. However, purely by chance, a few may hold promise - they may show activity, even if only weak and imperfect activity, toward solving the problem. These promising candidates are kept and allowed to reproduce. Multiple copies are made of them, but the copies are not perfect; random changes are introduced during the copying process. These digital offspring then go on to the next generation, forming a new pool of candidate solutions, and are subjected to a second round of fitness evaluation. Those candidate solutions which were worsened, or made no better, by the changes to their code are again deleted; but again, purely by chance, the random variations introduced into the population may have improved some individuals, making them into better, more complete or more efficient solutions to the problem at hand. Again these winning individuals are selected and copied over into the next generation with random changes, and the process repeats. The expectation is that the average fitness of the population will increase each round, and so by repeating this process for hundreds or thousands of rounds, very good solutions to the problem can be discovered. As astonishing and counterintuitive as it may seem to some, genetic algorithms have proven to be an enormously powerful and successful problem-solving strategy, dramatically demonstrating