
全球语言使用概况统计
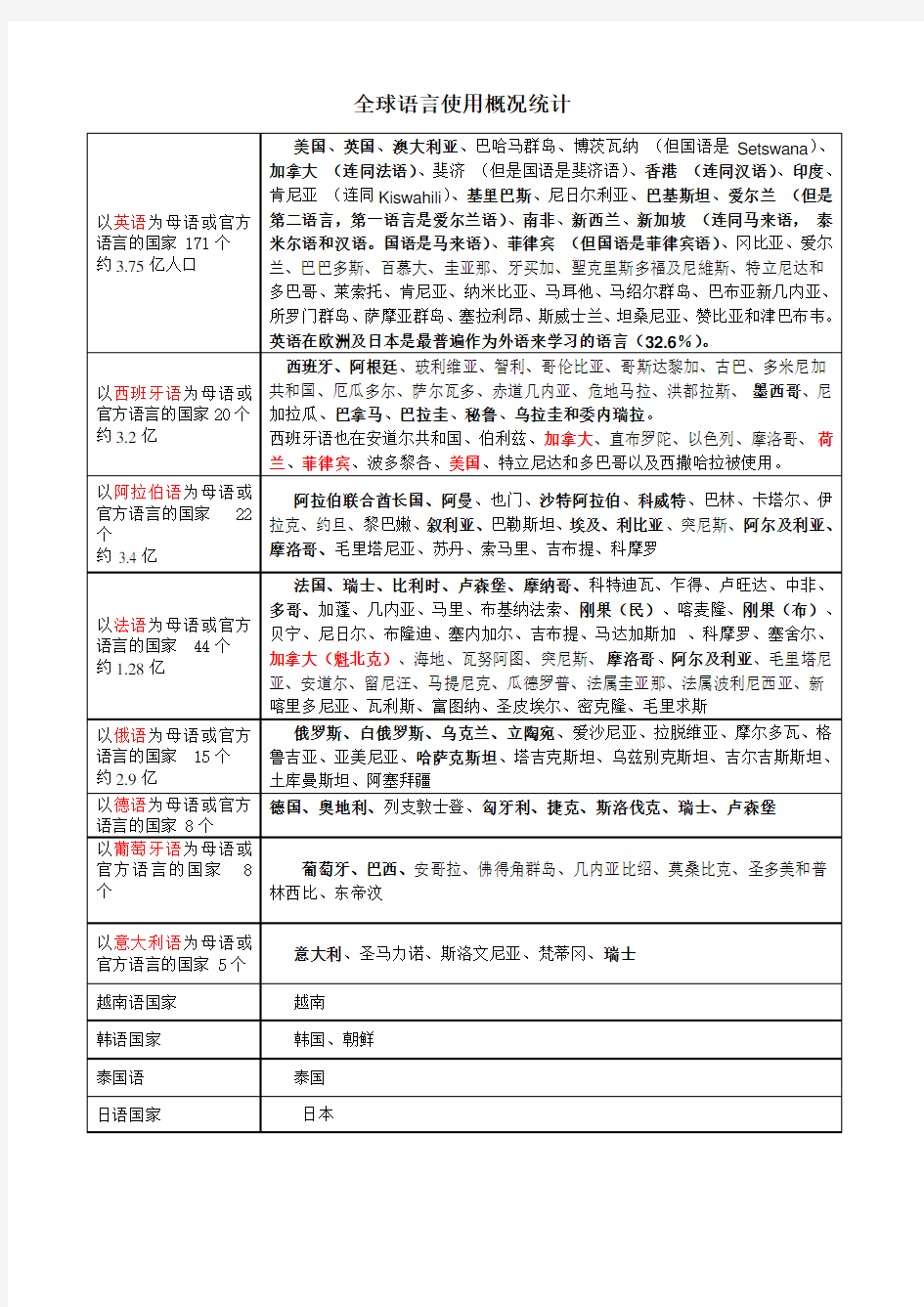
西班牙语、阿拉伯语、法语、俄语、德语、意大利语
西班牙语
西班牙语像汉语一样也是世界上的大语种,是联合国五大工作语言之一.世界上有21个国家把西班牙语作为官方语言,除了欧洲的西班牙之外,拉丁美洲的绝大部分国家(除了讲葡萄牙语的巴西等)都讲西班牙语,非洲的赤道几内亚和菲律宾也把西班牙语作为官方语言.就使用人数而言,世界上有3亿2000万人讲西班牙语(包括美国讲西班牙语的2500万人),仅次于汉语和英语,居世界第三位.
西班牙语是非盟,欧盟和联合国的官方语言。使用西班牙语作为官方语言的国家有:阿根廷、玻利维亚、智利、哥伦比亚、哥斯达黎加、古巴、多米尼加共和国、厄瓜多尔、萨尔瓦多、赤道几内亚、危地马拉、洪都拉斯、墨西哥、尼加拉瓜、巴拿马、巴拉圭、秘鲁、西班牙、乌拉圭和委内瑞拉。
西班牙语也在安道尔共和国、伯利兹、加拿大、直布罗陀、以色列、摩洛哥、荷兰、菲律宾、波多黎各、美国、特立尼达和多巴哥以及西撒哈拉被使用。
阿拉伯语
阿拉伯语即阿拉伯民族的语言,属於闪含语系闪语族,主要通行於中东和北非地区,现为27个亚非国家及4个国际组织的官方语言。以阿拉伯语作为母语的人数超过二亿一千万人,同时阿拉伯语为全世界穆斯林的宗教语言。阿拉伯语因分布广阔,因此各个地区都有其方言,而「标准」阿拉伯语则是以回教经典《古兰经》为准。
国家:
埃及苏丹阿尔及利亚摩洛哥伊拉克沙乌地阿拉伯也门叙利亚查德突尼斯索马利亚以色列利比亚约旦厄利垂亚阿联黎巴嫩茅利塔尼亚科威特阿曼卡达吉布地巴林葛摩
地区:
巴勒斯坦索马利兰邦特兰西撒国
法语
法文是下列国家的第一语言:法国(六千万人使用,包括瓜德罗普岛、马提尼克岛和圣皮埃尔和密克隆)加拿大(6,700,000使用者,特别是魁北克、新不伦瑞克)比利时(4,000,000使用者,瓦龙语是Langue d'O?l语的一种方言,与比利时法语有显着的差异)瑞士(跟德文(German),意大利文(Italian)和罗曼文四文共行) 摩纳哥法属圭亚那(Guyane fran?aise)海地
同时法文也是下列国家的主要第二语言:阿尔及利亚、黎巴嫩、毛里裘斯、摩洛哥、新喀里多尼亚、留尼旺和突尼西亚。
它在下列国家是官方语言,也是学校唯一使用的语言:科摩罗、刚果共和国、法属玻利尼西亚、加蓬和马里。
它在下列国家是官方语言,但是没有当地语那么常用:贝宁、布基纳法索、布隆迪、喀麦隆、中非共和国、乍得、科特迪瓦、畿内亚、马达加斯加、尼日尔、卢旺达、塞内加尔、塞舌尔、多哥、瓦努阿图和刚果民主共和国。
它在安道尔和卢森堡也是一种普遍的语言。
7.1 概述 自然语言是指人类语言集团的本族语,如汉语、英语、日语等,以及人类用与交流的非发声语言,如手语、旗语等。自然语言是相对于人造语言而言的。人造语言是指世界语或计算机的各种程序设计语言。 众所周知,语言是思维的载体,是人际交流的最重要工具。 在人类历史上以语言文字形式记载和流传的知识占到知识总量的80%以上。就计算机的应用而言,据统计用于数学计算的仅占10%,用于过程控制的不到5%,其余85%左右都是用于语言文字的信息处理。在信息化社会中,语言信息处理的技术水平和每年所处理的信息总量已成为衡量一个国家现代化水平的重要标志之一。 在社会发展需求下,自然语言理解作为语言信息处理技术的一个高层次的重要方向,一直是人工智能界所关注的核心课题之一。显然,如果计算机能够理解自然语言,人-机间的信息交流能够以人们所熟悉的本族语言来进行,那将是计算技术的一项重大突破。另一方面,由于创造和使用自然语言是人类高度智能的表现,因此对自然语言理解的研究也有助于揭开人类智能的奥秘,深化我们对语言能力和思维本质的认识。 那么什么叫"自然语言理解"?正如什么是"智能"一样,对于"理解"这个术语也存在着各式各样的认识。在人工智能界,或者语言信息处理领域中,人们普遍认为可以采用著名的图灵
(Turing)试验来判断计算机是否"理解"了某种自然语言。 相比较人工智能其它领域,自然语言理解是难度大,进展小的。至今为止未能达到很高的水平。 Turing提出的智能实验,参加者是计算机、被实验的人以及主持实验的人。由主持人提出问题,计算机和被实验的人来回答,被实验者在回答问题时尽可能的向主持人表示他是"真正"的人,计算机也尽可能逼真的模仿人的思维。如果主持人通过听取对问题的回答分辨不出哪个是人的回答,哪个是机器的回答时,便可认为被试验的计算机是有智能的了。有人对这样设计的实验提出了疑义,他们认为这种实验只反映了结果的比较而没有涉及思维的过程,而且也没明确此人是个孩子还是有良好素质的成年人参加了实验。当一个计算机系统能给出有关问题的正确答案或有用的建议、而解决问题所用的概念和推理与人相当、还能解释推理过程时,便可说这样的计算机系统是有智能的了。 本章将讨论自然语言理解的概念、发展简史以及系统组成与模型等;然后,逐一研究语言的自动分析、句子的自动理解、语言的自动生成和机器翻译等重要问题。 7.1.1 自然语言理解 怎样判断一个机器对人类的自然语言是理解了?没有通用的答案。通常我们同样可以用"图灵"实验来得到结论。判断"自然语言理解"的主要方面有如右页所示: ·问题应答:机器能正确的回答输入文本的有关问题。
世界各国语言一览表 Afghanistan 阿富汗Pashto 普什图语,Afghan Persian 波斯语,Dari 达 利语 Albania 阿尔巴尼亚Albanian 阿尔巴尼亚语 Algeria 阿尔及利亚Arabic 阿拉伯语,French 法语 Andorra 安道尔Catalan 加泰罗尼亚语,French 法语,Spanish 西 班牙语 Angola 安哥拉Portuguese 葡萄牙语 Antigua and Barbuda 安地卡(与巴布 达) English 英语 Argentina 阿根廷Spanish 西班牙语 Armenia 亚美尼亚Armenian 亚美尼亚语 Australia 澳大利亚English 英语 Austria 奥地利German 德语 Azerbaijan 阿塞拜疆Azerbaijani 阿塞拜疆语 Bahamas 巴哈马English 英语 Bahrain 巴林Arabic 阿拉伯语 Bangladesh 孟加拉国Bengali 孟加拉国语 Barbados 巴巴多斯English 英语 Belarus 白俄罗斯Belarusian 白俄罗斯语,Russian 俄语 Belgium 比利时French 法语,Dutch 荷兰语,German 德语Belize 伯利兹English 英语,Spanish 西班牙语 Benin 贝宁French 法语 Bhutan 不丹Dzongkha 宗卡语(不丹语) Bolivia 玻利维亚Spanish 西班牙语 Bosnia and Herzegovina 波斯尼亚和黑塞 哥维那 Bosnian 波斯尼亚语,Serbian 塞尔维亚语, Croatian 克罗地亚语 Botswana 博茨瓦纳English 英语,Setswana 博茨瓦纳语Brazil 巴西Portuguese 葡萄牙语 Brunei 文莱Malay 马来语,English 英语Bulgaria 保加利亚Bulgarian 保加利亚语 Burkina Faso 布基纳法索French 法语
浅谈自然语言处理 摘要 主要阐述了自然语言处理的定义,发展历史,并对其研究内容,以及目前相关领域的应用加以讨论。最后对自然语言处理的未来发展趋势做简单的介绍。 关键词 自然语言处理 Abstract The definition and the development history of Natural Language Processing(NLP) are explained,the research content and the applications in interrelated areas of NLP are discussed.And the develop direction of NLP in the future are simply introduced. Key Words: Natural Language Processing(NLP)
0.引言 早在计算机还未出现之前,英国数学家A.M.Turing便已经预见到未来计算机将会对自然语言处理研究提出新的问题。他指出,在未来我们可以“教机器英语并且说英语。”同时他觉得“这个过程可以仿效教小孩子说话的那种办法进行”。这便是最早关于自然语言处理概念的设想。 人类的逻辑思维以语言为形式,人类的多种智能都与语言有着密切的联系。所以用自然语言与计算机进行通信是计算机出现以来人们一直所追求的目标。 1.什么是然语言处理 美国计算机科学家Bill Manaris(马纳瑞斯)在1999年出版的《计算机进展》(Advances Computers)第47卷的《从人—机交互的角度看自然语言处理》一文中,曾经给自然与然处理提出了如下定义:“自然语言处理可以定义为研究在人与人交际中的语言问题的一门学科。自然语言处理要研制表示语言能力(linguistic competence)和语言应用(linguistic performance)的模型,建立计算框架来实现这样的语言模型,提出相应的方法来不断地完善这样的语言模型,根据这样的语言模型设计各种实用系统,并探讨这些实用系统的评测技术。”这个定义被广泛的接受,它比较全面的地表达了计算机对自然语言的研究和处理。 简单来说,自然语言处理就是一门研究能实现人鱼计算机之间用自然语言处理进行有效的通信与方法的一门学科,它是计算机科学领域与人工智能领域中的一个重要方向。普遍认为它主要是应用计算机技术,通过可计算的方法对自然语言处理的各级语言单位(字,词,语句,篇章等)进行转换,传输,存储,分析等加工处理的学科,是一门融合了语言学,计算机学,数学等学科于一体的交叉性学科。 互联网技术的发展,极大地推动了信息处理技术的发展,也为信息处理技术不断提出新的需求,语言作为信息的载体,语言处理技术已经日益成为全球信息化和我国社会及经济发展的重要支撑技术。
从语言学到深度学习nlp一文概述自然语言处理 自然语言处理(NLP)近来因为人类语言的计算表征和分析而获得越来越多的关注。它已经应用于许多如机器翻译、垃圾邮件检测、信息提取、自动摘要、医疗和问答系统等领域。本论文从历史和发展的角度讨论不同层次的NLP 和自然语言生成(NLG)的不同部分,以呈现NLP 应用的各种最新技术和当前的趋势与挑战。 1 前言 自然语言处理(NLP)是人工智能和语言学的一部分,它致力于使用计算机理解人类语言中的句子或词语。NLP 以降低用户工作量并满足使用自然语言进行人机交互的愿望为目的。因为用户可能不熟悉机器语言,所以NLP 就能帮助这样的用户使用自然语言和机器交流。 语言可以被定义为一组规则或符号。我们会组合符号并用来传递信息或广播信息。NLP 基本上可以分为两个部分,即自然语言理解和自然语言生成,它们演化为理解和生成文本的任务(图1)。 图1:NLP 的粗分类 语言学是语言的科学,它包括代表声音的音系学(Phonology)、代表构词法的词态学(Morphology)、代表语句结构的句法学(Syntax)、代表理解的语义句法学(Semantics
syntax)和语用学(Pragmatics)。 NLP 的研究任务如自动摘要、指代消解(Co-Reference Resolution)、语篇分析、机器翻译、语素切分(Morphological Segmentation)、命名实体识别、光学字符识别和词性标注等。自动摘要即对一组文本的详细信息以一种特定的格式生成 一个摘要。指代消解指的是用句子或更大的一组文本确定哪些词指代的是相同对象。语篇分析指识别连接文本的语篇结构,而机器翻译则指两种或多种语言之间的自动翻译。词素切分表示将词汇分割为词素,并识别词素的类别。命名实体识别(NER)描述了一串文本,并确定哪一个名词指代专有名词。光学字符识别(OCR)给出了打印版文档(如PDF)中间的文字信息。词性标注描述了一个句子及其每个单词的词性。虽然这些NLP 任务看起来彼此不同,但实际上它们经常多个任务协同处理。 2 NLP 的层级 语言的层级是表达NLP 的最具解释性的方法,能通过实现内容规划(Content Planning)、语句规划(Sentence Planning)与表层实现(Surface Realization)三个阶段,帮助NLP 生成文本(图2)。 图2:NLP 架构的阶段 语言学是涉及到语言、语境和各种语言形式的学科。与NLP 相关的重要术语包括:
本文写给语言狂,以助其理智地选择学习新语种。 比较指标: 难度:共分5个级别。判断标准以母语为汉语的学习者为标准。学习新语种的难度取决于你所操母语本身的难度。我所采取的衡量标准或许有局限性,但我尽量保持相对误差最小。本文假设读者对英语已经有一定程度的了解。 普及度:以世界各国人口学习该语种的大致人数为标准,不以操此语种的绝对人口为标准。 GDP(以十亿美刀计):操此语种的所有国家生产总值之和。这是选择学习某种语言的重要参考标准。 国家数:以此语言作为官方语言的国家的个数。 人数(以百万计):以此语言为母语的大致人数。 英语: 难度:★★★|普及度:★★★★★|GDP:14129|国家:12|人数:618 无论是在科学、商业,还是国际贸易等领域,英语都是无可争异的语言之王。是学习外语的第一选择,有了英语,你能够看懂世界上大部分报纸、杂志、电影、网站等等,这是一个广阔的世界。 西班牙语: 难度:★★|普及度:★★★★|GDP:3198|国家:25|人数:376 简单、易学、有用,而且富于逻辑性的语言。去西班牙语国家旅行的
时候能给你带来很大方便。很多浪漫的音乐和电影也都用西班牙语,是泡马子必备的语种。 法语: 难度:★★★★|普及度:★★★★|GDP:2223|国家:17|人数:213 精巧、别致、浪漫,这些词通常用来形容法语,但并不是很容易学习的语言。当然,法语带给你的体验也不一样,文学、哲学、建筑、美食,即使不在法国,你也可以享受到,前提是得懂得法语。泡妞必备。俄语: 难度:★★★★|普及度:★★★|GDP:548|国家:8|人数:167 无论是对英语国家的人还是以东方语系为母语的人来说,俄语都算是比较难学的语言。学会她的好处是去大部分独联体国家都很方便,而且网上有很多免费有趣的俄语资料。 德语: 难度:★★★★★|普及度:★★★|GDP:2850|国家:3|人数:91 一种重要的欧洲语言,极其难学。德语中蕴藏着巨大的文化宝库。 意大利语: 难度:★★★|普及度:★★★|GDP:1490|国家:2|人数:58 已被证明的有着最唯美发音的语言。艺术狂热爱好者的必备语言。当你学习意大利语时,你很容易就爱上她,并且爱上意大利这个国家。如果你掌握了一种罗曼语系的语言,那么,你一定得学一下意大利语,
联合国公布世界上最难学的十大语言汉语居榜首 发音优美的语言 在国际语言学界,日语,意大利语和西班牙语,是三个公认的发音优美的语言,其中,日语更是排在第一位。在语言学上,评价一种语言的发音是否优美,有一个公认的标准,那就是辅音数量和元音数量的比例,比较合适,最好是一比一,比如“さくら”,它的发音是 [s]a[k]ua(我故意把辅音放在方括号中),您看,一个辅音带一个元音,正好是一比一,很规范,这样的语言,发音就好听。相反,您看这个英语(论坛)单词 script,它的发音是[skr]i[pt],五个辅音带一个元音,这样的语言,发音就难听。英语和汉语不是最好听,如果你在投票上看到汉语得票最多,那正常,我们都是中国人,都会为自己的母语投上一票,外国人就不会这么认为了。 其实,联合国教科文组织公布的世界十大难学语言中,汉语名列榜首。想想我们都学会了世界上最难的语言了,你还怕别的吗? 世界上最难学的十大语言排行(联合国公布) NO.1-汉语(中国) NO.2-希腊语(希腊) NO.3-阿拉伯语(阿拉伯)
NO.4-冰岛语(冰岛) NO.5-日语(日本) NO.6-芬兰语(芬兰) NO.7-德语(德国) NO.8-挪威语(挪威) NO.9-丹麦语(丹麦) NO.10-法语(法国) 当一个人听不懂另一个人在说啥的时候,他会怎么发牢骚呢?各国群众纷纷表示: 英语:“It is Greek to me!”(“简直就是希腊语!”) 南非语:“Dis Grieks vir my!”(又是希腊语) 拉丁语:“Graecum est; non potestlegi.”(还是希腊语) 葡萄牙语:“E grego para mim.”(继续希腊语) 波兰语:“To jest dla mnie greka!”(仍然希腊语) 但是波兰语也有另一种说法:“To jest dla mnie chinszczyzna!”(汉语) 荷兰语:“Dat is Latijns voor mij!”(拉丁语,这是最常用的一种说法,另外倒霉的还有汉语和西班牙语) 那么被大量群众围观的希腊语又是怎么来表示这个意思的呢? 希腊语:“μουφαινεταικινεζικο”(“听着就跟汉语似的”) 然后汉语开始惨遭围观: 希伯来语:“Nishma c’moh sinit!”(“它听起来像汉语!”)
Χρονια∏ολλα!! Сднемрождения!! Hro'nia Polla'!! Gratulerer med dagen!! VSE NAJBOLJSE!! Van Harte Gefeliciteerd met jeverj aardag!! WSZYSTKIEGO NAJLEPSZEGO OKAZJIURODZIN!! Selamat Ulang Tahun!! Maligayang Kaarawan!! iFeliz CumpleaRos!! Alles Gute Zum Geburtstag!! buon compleanno!! Eed Milad Sa`id!! Tillykke med fodselsdagen!! Hyvaa Syntymapaivaa!! Yom Huledet Sameach!! Til Hamingju Med Afmaelid!! Isteneltessen!! Hau'olilahanau!! Fortuna dies natalis!! Сре?ан ро?ендан!! feliz aniversario!! Janmadinada V andanegalu!! La Multi Ani!! Hongera!! Grattis pa fodelsedagen!! Poranda Naal Valthukal !! Janmadina Subhaa Kaankshalu !! Suk-san Wan-gerd !! Dogum gunun kutlu olsun !! Saal Girra Mubarak Ho !! Chu'c Mu+`ng Sinh Nha^.t !! Pen-blwydd Hapus !! Felichan Naskightagon!! BANJIHA INENGGI SAYIN!! banxike inenggi sayin!! VsenejlepsikTvymnarozeninam!! tu hurhan kvnei mubarei!! ???????!! お诞生日おめでとございます!! Bon Anniversaire!! Appy birthday, mate!! Happy Birthday!! 生日快乐!!
课程编号:S0300010Q 课程名称:自然语言处理 开课院系:计算机科学与技术学院任课教师:关毅刘秉权 先修课程:概率论与数理统计适用学科范围:计算机科学与技术 学时:40 学分:2 开课学期:秋季开课形式:课堂讲授 课程目的和基本要求: 本课程属于计算机科学与技术学科硕士研究生学科专业课。计算机自然语言处理是用计算机通过可计算的方法对自然语言的各级语言单位进行转换、传输、存贮、分析等加工处理的科学。是一门与语言学、计算机科学、数学、心理学、信息论、声学相联系的交叉性学科。通过本课程的学习,使学生掌握自然语言(特别是中文语言)处理技术(特别是基于统计的语言处理技术)的基本概念、基本原理和主要方法,了解当前国际国内语言处理技术的发展概貌,接触语言处理技术的前沿课题,具备运用基本原理和主要方法解决科研工作中出现的实际问题的能力。为学生开展相关领域(如网络信息处理、机器翻译、语音识别)的研究奠定基础。 课程主要内容: 本课程全面阐述了自然语言处理技术的基本原理、实用方法和主要应用,在课程内容的安排上,既借鉴了国外学者在计算语言学领域里的最新成就,又阐明了中文语言处理技术的特殊规律,还包括了授课人的实践经验和体会。 1 自然语言处理技术概论(2学时) 自然语言处理技术理性主义和经验主义的技术路线;自然语言处理技术的发展概况及主要困难;本学科主要科目;本课程的重点与难点。 2 自然语言处理技术的数学基础(4学时) 基于统计的自然语言处理技术的数学基础:概率论和信息论的基本概念及其在语言处理技术中的应用。如何处理文本文件和二进制文件,包括如何对文本形式的语料文件进行属性标注;如何处理成批的文件等实践内容 3 自然语言处理技术的语言学基础(4学时) 汉语的基本特点;汉语的语法功能分类体系;汉语句法分析的特殊性;基于规则的语言处理方法。ASCII字符集、ASCII扩展集、汉字字符集、汉字编码等基础知识。 4 分词与频度统计(4学时) 中文分词技术的发展概貌;主要的分词算法;中文分词技术的主要难点:切分歧义的基本概念与处理方法和未登录词的处理方法;中外人名、地名、机构名的自
世界语言使用人数排名前三十的语言 语言人口排名 排名语言名称所属语系主要国家人口 1 汉语(普通话)汉藏语系中国8.85亿 2 西班牙语印欧语系西班牙3.32亿 3 英语印欧语系英国3.22亿 4 孟加拉语印欧语系孟加拉国1.89亿 5 印地语印欧语系印度1.82亿 6 俄语印欧语系俄罗斯1.7亿 6 葡萄牙语印欧语系葡萄牙1.7亿 8 日语不明日本1.25亿 9 (标准)德语印欧语系德国9.8千万 10 汉语(吴方言)汉藏语系中国7.7千万 11 爪哇语南岛语系印度尼西亚7.5千万 12 朝鲜语不明韩国7.5千万 13 法语印欧语系法国7.2千万 14 越南语南亚语系越南6.76千万 15 泰卢固语达罗毗荼语系印度6.6千万 16 汉语(粤方言)汉藏语系中国6.6千万 17 马拉提语印欧语系印度6.48千万 18 泰米尔语达罗毗荼语系印度6.3千万 19 土耳其语阿尔泰语系土耳其5.9千万 20 乌尔都语印欧语系巴基斯坦5.8千万 21 汉语(闽南方言)汉藏语系中国4.9千万 22 汉语(晋方言)汉藏语系中国4.5千万 23 波兰语印欧语系波兰4.4千万 23 古吉拉特语印欧语系印度4.4千万 25 阿拉bo语(埃及方言)阿非罗–亚细亚语系埃及4.25千万 26 乌克兰语印欧语系乌克兰4.1千万 27 意大利语印欧语系意大利3.7千万 28 汉语(湘方言)汉藏语系中国3.6千万 29 马拉雅拉姆语达罗毗荼语系印度 3.4千万 30 汉语(客家方言)汉藏语系中国3.4千万 此外乌尔都语、斯瓦希里语、豪萨语、马来语都超过了5000万人使用等也都是 1. 汉语(官话)8.85亿 2. 西班牙语 3.32亿 3. 英语 3.22亿 4. 孟加拉语 1.89亿 5. 印地语 1.82亿 6. 葡萄牙语 1.81亿
岗位说明书系列 自然语言处理工程师岗位 工作职责 (标准、完整、实用、可修改)
编号:FS-QG-78290自然语言处理工程师岗位工作职责Job Responsibilities of Natural Language Processing Engineer 说明:为规划化、统一化进行岗位管理,使岗位管理人员有章可循,提高工作效率与明确责任制,特此编写。 简介:自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。自然语言处理(NLP)是计算机科学,人工智能,语言学关注计算机和人类(自然)语言之间的相互作用的领域。 自然语言处理工程师职位描述(模板一) 岗位职责:
1.负责自然语言处理基础模块开发及应用,优化属性预测分类器; 2.从半结构化或非结构化数据中抽取结构化信息,建立并完善特定领域知识图谱; 3.研发知识表示、知识图谱、知识管理和知识工程相关模型及算法; 4.负责调研最前沿的人工智能技术,追踪并实验最新NLP前沿技术,参与搭建和实现相关模型。 任职要求: 1.计算机及相关专业本科以上学历; 2.熟悉自然语言处理方向常用技术,如分词、词性标注、命名实体识别,关系抽取,句法分析等; 3.熟悉信息抽取相关的算法和逻辑; 4.熟悉知识图谱的构建,熟悉图数据库,拥有知识图谱相关的开发经验优先; 5.熟悉大数据系统架构和开发框架,对深度学习和自然语言处理有深入的研究和实践的优先。自然语言处理工程师职位描述(模板二)
内容大概分为:自然语言处理的简介、关键技术、流程及应用。 首先,介绍一下什么是自然语言处理(也叫自然语言理解): 语言学家刘涌泉在《大百科全书》(2002)中对自然语言处理的定义为:“自然语言处理是人工智能领域的主要内容,即利用电子计算机等工具对人类所特有的语言信息(包括口语信息和文字信息)进行各种加工,并建立各种类型的人-机-人系统,自然语言理解是其核心,其中包括语音和语符的自动识别以及语音的自动合成。” 从微观上讲,自然语言理解是指从自然语言到机器(计算机系统)内部之间的一种映射。 从宏观上看,自然语言理解是指机器能够执行人类所期望的某些语言功能。这些功能包括: ①回答有关提问;计算机正确地回答用自然语言输入的有关问题 ②提取材料摘要;机器能产生输入文本的摘要 ③同词语叙述;机器能用不同的词语和句型来复述输入的自然语言信息 ④不同语言翻译。机器能把一种语言翻译成另外一种语言 自然语言处理的关键技术 自然语言处理的关键技术包括:词法分析、句法分析、语义分析、语用分析和语句分析。 1.词法分析 词法分析的主要目的是从句子中切分出单词,找出词汇的各个词素,并确定其词义。 词法分析包括词形和词汇两个方面。一般来讲,词形主要表现在对单词的前缀、后缀等的分析,而词汇则表现在对整个词汇系统的控制。在中文全文检索系统中,词法分析主要表现在对汉语信息进行词语切分,即汉语自动分词技术。通过这种技术能够比较准确的分析用户输入信息的特征,从而完成准确的搜索过程。它是中文全文检索技术的重要发展方向。 不同的语言对词法分析有不同的要求,例如英语和汉语就有较大的差距 汉语中的每个字就是一个词素,所以要找出各个词素是相当容易的,但要切分出各个词就非常难。 如”我们研究所有东西“,可以是“我们——研究所——有——东西”也可是“我们——研究——所有——东西”。
自然语言处理的应用及发展趋势 摘要本文主要阐述了自然语言处理的研究内容,以及对目前相关领域的应用加以讨论。自然语言处理的研究内容主要有四大块[1-2]:语言学方向、数据处理方向、人工智能和认知科学方向、语言工程方向。最后对自然语言处理的未来发展趋势做简单的介绍。 关键词自然语言处理应用发展趋势 一.自然语言处理的研究内容 自然语言处理的范围涉及众多方面,如语音的自动识别与合成,机器翻译,自然语言理解,人机对话,信息检索,文本分类,自动文摘,等等。我们认为,这些部门可以归纳为如下四个大的方向: (1)语言学方向 本方向是把自然语言处理作为语言学的分时来研究,它之研究语言及语言处理与计算相关的方面,而不管其在计算机上的具体实现。这个方向最重要的研究领域是语法形式化理论和数学理论。 (2)数据处理方向 是把自然语言处理作为开发语言研究相关程序以及语言数据处理的学科来研究。这一方向早起的研究有属于数据库的建设、各种机器可读的电子词典的开发,近些年来则有大规模的语料库的涌现。 (3)人工智能和认知科学方向 在这个方向中,自然语言处理被作为在计算机上实现自然语言能力的学科来研究,探索自然语言理解的只能机制和认知机制。这一方向的研究与人工智能以及认知科学关系密切。 (4)语言工程方向 主要是把自然语言处理作为面向实践的、工程化的语言软件开发来研究,这一方向的研究一般称为“人类语言技术”或者“语言工程”。 二.自然语言处理的应用 以上所提及的自然语言处理的四大研究方向基本上涵盖了当今自然语言处理研究的内容,更加细致的说,自然语言处理可以进一步细化为以下13项研究内容,也即为自然语言处理的应用方向,这13个应用方向分别是[3]:口语输入、
世界语言排名 根据“世界观察”组织及美国“夏季语言学研究所”的估计,全世界最通行的语言是中国的普通话,其次是西班牙语,使用人数达33200万人,英语第三名,全世界能说英语者有32200万人,接着是阿拉伯语,使用者有22000万,然后是孟加拉语,18900万人使用。 至于语言的发源地,全球6800种语言当中,有32%源自亚洲,30%源自非洲,19%源自太平洋诸岛,15%源自美洲。源自欧洲的只有4%,但其中的英语和西班牙语经过殖民手段,已经成为世界第二和第三大语言。巴布亚新几内亚有832种语言,是全球语言最“丰富”的国家,其次是印尼(731种)、阿尔及利亚(515种)、印度(400种)。墨西哥、喀麦隆、澳大利亚各有约300种,巴西有234种,也算是语言繁复的国家。 语言最繁复的地方应属新几内亚岛,这个巴布亚新几内亚和印尼的伊利安加雅州重叠的地带,人口只占全球的0.1%,语言总数却是全球的六分之一。人少语多的另一个地方是太平洋上的万那杜群岛,那儿只有19万人,语言却超过100种。 少人讲的语言很可能灭绝。“世界观察组织”指出,全球6800种语言当中,有90%面临消失的危险。该组织说,语言虽然有那么多种,但其中一半,使用的人不超过2500人,这种语言最可能消失。在加拿大,土著居民语言有50多种,但只有三种??克里族、伊奴族和欧吉卜威族的语言算是“安全”无虞的语言,其他都可能因为通晓
人数太少而被淘汰。天灾、人祸和强势语言如俄语和英语的传布,加上有些政府禁用某些语言,都是造成许多弱势语言遭到淘汰命运的原因。 加拿大萨斯卡其万省印第安语言教授沃芬格雷说,每种语言都表现出一种世界观、处世观,你丧失一种语言的时候,就丧失了一种知识基础,一种世界观,这只会让我们更贫乏。 第二外语学法语——最有潜力的选择! 英语以其简单实用使用广泛的特性和国内教育机构大力推广,以绝对的优势占据着第一外语的位置,现在不是讲究业余充电和终身学习吗,所以经常有朋友会问,第二外语应该学什么语,德语、法语、日语、俄语还是西班牙语。 “喜欢什么语就学什么语”以前我一直是这样即简单又深刻的来“蒙”网友的,但工作一段时间后,可以很负责任的对网友说:“第二外语学法语是最有潜力的选择!”。 德语就目前而言,也比较受欢迎,但据说是比较难听,而且讲德语的国家不多。另外德国偏爱工科的学生,而学语言的基本都是文科出身,如果不仅仅是出于个人爱好,学德语之前,的确应该斟酌一下。 日语,就我个人而言,是不怎么喜欢的。可能是经常上网的缘故,日语给人的感觉怎么都象乱码,而且中日之间的关系很敏感,你大街满口日语给小日本做翻译,很容易引路人反感。当然,不可否认,日文歌曲的旋律是相当不错的。 俄语目前最好是不要学的,一句话,就业形式不好,用的机会不
自然语言处理中的卷积神经网络的详细资料介绍和应用 1、传统的自然语言处理模型 1)传统的词袋模型或者连续词袋模型(CBOW)都可以通过构建一个全连接的神经网络对句子进行情感标签的分类,但是这样存在一个问题,我们通过激活函数可以让某些结点激活(例如一个句子里”not”,”hate”这样的较强的特征词),但是由于在这样网络构建里,句子中词语的顺序被忽略,也许同样两个句子都出现了not和hate但是一个句子(I do not hate this movie)表示的是good的情感,另一个句子(I hate this movie and will not choose it)表示的是bad的情感。其实很重要的一点是在刚才上述模型中我们无法捕获像not hate 这样由连续两个词所构成的关键特征的词的含义。 2)在语言模型里n-gram模型是可以用来解决上面的问题的,想法其实就是将连续的两个词作为一个整体纳入到模型中,这样确实能够解决我们刚才提出的问题,加入bi-gram,tri-gram可以让我们捕捉到例如“don’t love”,“not the best”。但是新的问题又来了,如果我们使用多元模型,实际训练时的参数是一个非常大的问题,因为假设你有20000个词,加入bi-gram实际上你就要有400000000个词,这样参数训练显然是爆炸的。另外一点,相似的词语在这样的模型中不能共享例如参数权重等,这样就会导致相似词无法获得交互信息。 2、自然语言处理中的卷积神经网络 在图像中卷积核通常是对图像的一小块区域进行计算,而在文本中,一句话所构成的词向量作为输入。每一行代表一个词的词向量,所以在处理文本时,卷积核通常覆盖上下几行的词,所以此时卷积核的宽度与输入的宽度相同,通过这样的方式,我们就能够捕捉到多个连续词之间的特征(只要通过设置卷积核的尺寸,卷积核的宽度一般和词向量的长度一致,长度可以去1,2,3这类的值,当取3时就会将3个连续词的特征表示出来),并且能够在同一类特征计算时中共享权重。如下图所示 如上图所示,不同长度的卷积核,会获得不同长度的输出值,但在之后的池化中又会得到
世界十大语言排名 10、印地语 印度的官方语言是英语和印地语,但是印度南方人并不讲印地语,北印度5亿多人讲印地语。可以说讲印地语的人口不少,但国际影响甚微,勉强可以挤入前10,若整个印度10几亿人口全都讲印地语,这种语言还能往前排一些。 图-印地语范围 9、日语 最近20年,日语的影响力一直在下降,原因是日本的经济一直不好。但是作为一个面积并不大的岛国,能排到这个位置已经实属不易。日本有亿人口,但是日本之外,除了日本侨民,几乎没有人讲日语,这是日语的悲哀,也是岛国的先天不足。日本历史上侵略过许多国家,特别是朝鲜和韩国,是被日本侵略的重灾区,可是日本竟然没有从语言上同化任何一个国家,也是比较奇怪的事情。 图-日本 8、德语 将德语作为母语的国家,有欧洲的德国、奥地利,人口约有1亿。其他如瑞士、比利时等国也有相当部分德语人口,英国法国等也有少量讲德语的人。德语跟日语最大不同,是德国是陆地国家,德语在德国和奥地利之外的其他西欧国家,也有一定市场。德国在欧盟,是绝对的领袖地位。放眼
西欧,如果德国的经济政治排第二,那谁也不敢称第一。德文亏就亏在德国是二战的战败国,德国在海外的许多权益被无限压缩,以至现在欧洲之外说德文的人很少。 图-德语范围 7、阿拉伯语 阿拉伯语相对德语和日语来说,第一大优势是人口多,有约亿人。第二大优势是地域大,在西亚和北非,包括沙特阿拉伯、伊拉克、埃及、摩纳哥等20多个国家。另外,从财富的角度看,阿拉伯地区石油多,富豪也多,经济总量也大。阿拉伯地区的不足是,制造业和科技水平不如德国和日本,不过这不影响阿拉伯语的地位,因为排名更靠前的语言中,科技水平也有并不高的。 图-阿拉伯语范围 6、俄罗斯语 俄罗斯语,大致是前苏联15个国家使用,人口约3亿。俄罗斯语最大特点是占地广,前苏联2000多万平方公里,中国加美国再加日本都没这么大。如果前苏联国家经济再强一点,俄罗斯语还可获得更高排名。 图-俄罗斯语范围 5、葡萄牙语 全球超过2亿人口将葡萄牙语定位官方语言,大多是葡萄牙以前的殖民地。这其中包括巴西这个新兴的大国,也包
汉语在世界语言中的10大优势 1使用人口最多全世界60亿人口,200多个国家和地区,2500多个民族,现已查明的语言有5651种。使用人口最多的语言有:汉语、英语、印地语、西班牙语、阿拉伯语、德语、俄语、法语、孟加拉语、葡萄牙语等。据联合国统计,全世界16亿人使用汉语,占世界总人口的25%。联合国新公布的六大语言是:1 英语,2 汉语,3 德语,4 法语,5 俄语,6 西班牙语。2汉字稳定,历史悠久,文化传承力强汉字是延续五千年的文字。尽管汉语因语音的差别形成众多方言,但都不影响人与人之间的书面汉字的理解。汉语是相对收敛、稳定的语言。这使祖先智慧与文明得以传承与发展。现在的中国学生,可以琅琅上口地读2000年前的诗人屈原的楚词。英语是发散易变、不稳定的语言。英文400年前才统一了拼写,英语毕业生读300前莎士比亚的原著仍困难重重。3汉字用字少(常用字3500个),组词力强,信息量大现在,英语词汇量已突破100万,普通人一辈子也记不完。据《纽约时报》统计,英语每年还有1~2万新词产生。而英语的新词汇与原有词汇关联很小,上百万的英语单词就是这样出来的。而汉语,不必造新字,仅靠现有汉字组新词即可。而所有英语词汇和新词都可用3500个汉字来组词表达。汉字组词能力太强大,还可触类旁通,记忆量大减。著名学者
季羡林说:“汉语是世界语言里最简练的一个语种。同样表达一个意思,如果英语要60秒,汉语5秒就够了。”在英语国家,没有20000个字别想读报,没有30000字别想读《时代》周刊。大学毕业10年的职业人士一般要懂80000字。而我国汉字扫盲标准是1500字。理工科的大学生一般掌握3500汉字,搞科研没问题。至于读书看报小学毕业就能做到。一般人2000汉字看书写字都能搞定。真庆幸,我们生在中国而不是美国。一句话:做中国人---爽!想想看,美国人学习了3~5万单词,他能享受的信息还很有限,每年还要面对上万新词。中国人学习三四千汉字,就可享受几乎全部信息。最好的语言是不学而知、学少而知多。什么是智慧?这就是智慧。4汉语词汇极丰富,易表达汉语词汇非常丰富。譬如“看”就有很多种表达:看,观,望,瞧,瞅,瞟,瞥,瞄,阅,窥,乜斜,了望,俯瞰,仰望,瞻仰,等等,还有瞪、白、横(如横了他一眼)等等。另外,观赏,欣赏,侦察,审查,查阅等等,都含有看的意思。比如"死"的表达,用词选择余地更大,褒贬分明,该用什么词用什么词。历史上天子皇帝死了曰“崩”,皇后或大官死了曰“薨”,常用的有:死,亡,殁,去世,逝世,老了,走了,去了,不在了,与世长辞,长眠不醒,牺牲,就义,成仁,光荣了,倒毙,离开人间,离我而去,永远不回来了,停止了思想,心脏停止了跳动,驾鹤西去,归西了,上西天了,见马克思了,凉了,硬
2017年自然语言处理NLP技术应用前景分析报告 (此文档为word格式,可任意修改编辑!) 2017年10月
正文目录 一、NLP技术研究不断突破,商业化落地未来可期 (4) 二、应用需求不断深化呾拓展,NLP市场将持续快速发展 (5) (一)应用场景丰富,NLP有望在多领域实现商业化 (5) 1、教育领域 (6) 2、医疗领域 (7) 3、金融领域 (8) 4、政务领域 (9) 5、智能设备领域 (9) (二)NLP市场持续快速发展,2025年全球市场将超220亿美元 (10) 三、主要公司分析 (11) (一)拓尔思 (11) (二)华宇软件 (13) 四、风险提示 (14) 图表目录
图1:Google以机器学习为背景的语音识别系统英文领域的字准确率 (5) 图2:NLP在多个使用场景呾行业领域都的广泛应用 (6) 图3:智慧医疗领域NLP应用 (8) 图4:2016-2025年全球NLP市场规模及预测 (11) 图5:2011-2017年中国智能语音产业规模 (11)
一、NLP技术研究不断突破,商业化落地未来可期 自然语言处理作为人工智能发展最早、且率先商业化的技术,是未来人机交于的趋势,在大多数智能产品中,NLP 技术都是不可戒缺的。近几年来随着深度学习技术的突破,技术能力大幅提升,带动了一波产业热潮。 目前的应用中,DNN、RNN/LSTM呾CNN是语音识别中比较主流的方向。过去的一年中,语音识别取得了很大的突破,IBM、微软、Google、百度等多家机构相继推出了自己的Deep CNN模型,提升了语音识别的准确率。根据Mary Meeker年度于联网报告,Google以机器学习为背景的语音识别系统,2017年3月已经获得英文领域95%的字准确率,逼近人类语音识别的准确率;2017年8月,微软的语音对话研究小组在Switchboard语音识别任务中,将错误率从去年的5.9%再一次降低到5.1%,达到目前最先进水平。在中文语音识别率方面,百度、搜狗,科大讯飞等主流平台识别准确率均在97%以上。此外,NLP对二浅层次的特征提取、分类等问题已经比较成熟,而深层次的语义理解正是如今研究的重要方向。NLP领域技术的不断突破,为语音技术的落地提供了可能。
世界十大语言排名 到底中文在世界约2000种语言(一说有6000种,但95%以上的世界人口讲的语言不到100种)中到底排名第几?口说无凭,有研究为证,而研究的第一步就是要建立评价语言地位的体系。 瑞士社会家者George Weber提出了这样的语言评价体系: 具体来说,评价语言地位需要按这6条标准加权评分综合考虑: 1. 以该语言为第一语言(母语)人数:最高得分4 2. 以该语言为第二语言的人数: 最高得分6 3. 使用该语言国家的经济实力: 最高得分8 4. 科学、外交中该语言的重要性:最高得分8 5. 使用该语言的国家数和人口数:最高得分7 6. 该语言的社会、文学地位:最高得分4分(如果是联合国工作语言加1分) 按照这个评分标准,我们不难想象,虽然以中文作为母语这一项我们占尽优势,但是其他几项却未必乐观。我们先看第一项指标:第一语言人数。这项指标看似简单,但要给出准确的数字也不容易,有时甚至是有争议的。举例来说,如果要把汉语各个方言都看作同一种语言(中文)的话,那么欧洲国家同一语系的语言是否也应该算同一种语言呢?George Weber先生对中文采用了宽松的认定标准,把汉语各方言认作是同一种语言。 按母语人口排序的前10名是: (1)中文(占世界总人口20.7%); (2)英语(6.2%); (3)西班牙语(5.6%); (4)印地、乌尔都语(4.7%); (5)阿拉伯语(3.8%);
(6)孟加拉语(3.5%); (7)巴西葡萄牙语(3.0%); (8)俄语(3.0%); (9)日语(2.3%); (10)德语(1.8%)。 值得注意的是法语连前10名都没有进,仅排在第13位(1.4%),险胜排在第14位的韩语。 再看第二项指标:有多少人以该语言为第二语言?这下,中文从第一落到了第7,而法语则咸鱼翻身成了第一:(1)法语(约1亿8千万);(2)英语(约1亿5千万);(3)俄语(约1亿2千万);(4)葡萄牙语(约3000万);(5)阿拉伯语(约2400万);(6)西班牙语(约2200万);(7)中文(约2100万);(8)德语(约2000万);(9)日语(约1000万);(10)印地语。当然括号中的数字只是大致的估算,不是也不可能是科学统计,但先后顺序大致是不错的。 George Weber先生对其他4项指标也做了估算,限于篇幅不一一叙述,他最后排出了世界语言的前十名: 根据上面那6个指标,所做出的排名 第一名:英语37分 第二名:法语23分 第三名:西班牙语20分 第四名:俄语16分 第五名:阿拉伯语14分 第六名:汉语普通话13分 第七名:德语12分 第八名:日语10分
自然语言处理NLP论文1.引言 做为人工智能(AI)的一个研究主题,自然语言处理(NLP)已经在一些系统中得到应用。人类使用自然语言(如汉语、英语)进行交流是一种智能活动。AI研究者们一直在尝试形式化处理自然语言所需要的过程机制,如把自然语言概念化为一种知识库系统以处理人与计算机的自然语言对话,并建立计算机软件来模型化这个处理过程。一种比较成熟和有效的方法并不使用显式的领域模型而是利用关键字或模式(Pattern)来处理自然语言。这种方法利用预先设计的结构存储有限的语言学和领域知识,输入的自然语言句子由预定义的含有指示已知对象或关系的关键字或模式的软件来扫描处理。这种方法也即做为一种自然语言接口与数据库系统或专家系统等进行连接,以检索其中的信息。通过学习国外相关应用案例,分析一个英语自然语言处理的模型系统,从而研究并实现基于WEB与汉语自然语言处理的地理信息查询系统模型。 2.基于英语自然语言处理的系统模型Geobase 2.1 Geobase模型简介 Geobase是针对一个地理信息系统的查询而研制的,其中用自然语言英语来查询地理信息数据库(Visual Prolog可装入的一个文本文件)。通过输入查询的英语句子,Geobase
分析并转换这些英语句子为Visual Prolog能够理解的形式,然后给出查询的答案。Geobase把数据库看做是由联系而联接起来的实体联系网络。实体是存储在数据库中的数据项,联系是联接查询句子中实体的词或词组,如句子Cities in the state California,这里的两个实体Cities和state 是由联系in 联接的,词the在这里被忽略,而California被看做是state 实体的一个实例。Geobase通过将用户的查询与实体联系网络进行匹配来分析查询句子。如查询句子:which rivers run through states that border the state with the capital Austin? 首先忽略某些词:which、that、the、?,其结果查询句子为:rivers run through states border state with capital Austin,其次找出实体与联系的内部名,实体可能有同义词、复数,联系也有同义词并可能由几个词组成等,经过转换后,查询句子为:river in state border state with capital Aaustin,通过查找state with capital Austin的state,Geobase再找出与这个state相邻接的所有的states,最后找出run through(由assoc("in",["run","through"])转义为in)states的rivers。2.2 数据库及实体联系网络 数据库谓词举例如下: state(Name,Abbreviation,Capitol,Area,Admit,Population,City,C ity,City,City) city(State,Abbreviation,Name,Population)