Collocational Translation Memory Extraction Based on Statistical and Linguistic Information
- 格式:pdf
- 大小:202.21 KB
- 文档页数:18

收稿日期:2018 08 22;修回日期:2018 10 24 基金项目:国家自然科学基金资助项目(U1703133);中科院西部之光项目(2017 XBQNXZ A 005);中国科学院青年创新促进会的资助项目(2017472);新疆维吾尔自治区重大科技专项项目(2016A03007 3);新疆维吾尔自治区高层次人才引进工程项目(Y839031201) 作者简介:潘一荣(1992 ),女,天津人,博士研究生,主要研究方向为自然语言处理、机器翻译;李晓(1957 ),男(通信作者),博导,研究员,硕士,主要研究方向为多语种信息处理、信息系统研究与开发(xiaoli@ms.xjb.ac.cn);杨雅婷(1985 ),女,副研究员,硕导,博士,主要研究方向为多语种信息处理技术;董瑞(1985 ),男,助理研究员,博士研究生,主要研究方向为多语种信息处理.面向汉维机器翻译的双语关联度优化模型潘一荣1,2,3,李 晓1,3 ,杨雅婷1,3,董 瑞1,3(1.中国科学院新疆理化技术研究所,乌鲁木齐830011;2.中国科学院大学,北京100049;3.新疆民族语音语言信息处理实验室,乌鲁木齐830011)摘 要:针对汉语—维吾尔语的统计机器翻译系统中存在的语义无关性问题,提出基于神经网络机器翻译方法的双语关联度优化模型。
该模型利用注意力机制捕获词对齐信息,引入双语短语间的语义相关性和内部词汇匹配度,预测双语短语的生成概率并将其作为双语关联度,以优化统计翻译模型中的短语翻译得分。
在第十一届全国机器翻译研讨会(CWMT2015)汉维公开机器翻译数据集上的实验结果表明,与基线系统相比,在使用较小规模的训练数据和词汇表的条件下,所提方法可以同时有效地提高短语级别和句子级别的机器翻译任务性能,分别获得最高2.49和0.59的BLEU值提升。
关键词:维吾尔语;神经网络机器翻译;注意力机制;词对齐;生成概率中图分类号:TP391 文献标志码:A 文章编号:1001 3695(2020)03 019 0726 05doi:10.19734/j.issn.1001 3695.2018.08.0625BilingualrelatednessoptimizationmodelforChinese UyghurmachinetranslationPanYirong1,2,3,LiXiao1,3 ,YangYating1,3,DongRui1,3(1.XinjiangTechnicalInstituteofPhysics&Chemistry,ChineseAcademyofSciences,Urumqi830011,China;2.UniversityofChineseAcademyofSciences,Beijing100049,China;3.XinjiangLaboratoryofMinoritySpeech&LanguageInformationProcessing,Urumqi830011,China)Abstract:FocusedontheissueofsemanticindependenceinChinese Uyghurstatisticalmachinetranslationsystem,thispaperproposedabilingualrelatednessoptimizationmodelbasedonneuralmachinetranslationmethod.Themodelutilizedtheatten tionmechanismtocapturewordalignmentinformationaswellasintroducedbilingualphrasesemanticrelevanceandinnerwordcorrelationtopredicttheconditionalprobabilityofbilingualphrasepair.Andittooktheprobabilityasbilingualrelatednesstooptimizethephrasetranslationscoresinstatisticaltranslationmodel.Experimentalresultsonthe11thChinaWorkshoponMachineTranslation(CWMT2015)Chinese Uyghurpublicmachinetranslationdatasetsshowthattheproposedapproachcanachieveobviousimprovementsbothinthephrase levelandthesentence levelmachinetranslationtasks,whichoutperformsthebaselinesystemwitharelativesmall scaletrainingdataandvocabulary.ThehighestBLEUpointoftheproposedalgorithmgains2.49and0.59respectively.Keywords:Uyghur;neuralnetworkmachinetranslation;attentionmechanism;wordalignment;conditionalprobability0 引言在基于短语的统计机器翻译(statisticalmachinetranslation,SMT)[1]系统中,翻译模型对从平行语料库中抽取的双语短语进行建模,主要包括短语翻译概率、词汇化权重等参数,这些参数作为特征函数并结合对数线性方法,以此训练机器翻译系统,从而获取最优权重分布,在解码时以搜索最有可能的翻译选项,实现双语转换过程。

语料库语言学与ChatGPT在外语研究中的应用语料库语言学和ChatGPT作为自然语言处理领域的两个热点技术,近年来在外语研究中得到广泛应用。
语料库语言学指的是利用大规模语料库进行语言分析、建模和识别的方法。
通过对海量语料库的挖掘和分析,可以得到丰富的语言知识和规律,为自然语言处理提供数据支持。
在外语研究中,语料库语言学可以帮助语言教师和学习者了解外语的语法、词汇、句式等特点,促进外语学习和教学的有效性和效率。
ChatGPT是一种基于深度学习的语言生成模型,使用具有上下文关联性的预训练方式,可生成类人的自然语言文本。
在外语研究中,ChatGPT 可以用于外语写作辅助、机器翻译、对话生成等领域。
通过ChatGPT模型的生成能力,可以更加准确地理解人类语言,实现更自然、更流畅的语言交流。
综上所述,在外语研究中,语料库语言学和ChatGPT技术的结合可以实现对外语语法、词汇、句式等特征的深入挖掘和分析,并且可以生成类人的自然语言文本,有望为外语教学、机器翻译等领域带来更多的创新和突破。
一、语料库语言学与ChatGPT的重要性(一)语料库语言学的重要性1、为语言研究提供大量、真实的语言样本语料库语言学是一种通过收集和整理现实生活中的语料库来研究自然语言的方法。
语料库是指存储大量语言材料的电子化数据库,包括书籍、报纸、杂志、广播、网络等不同类型的语料。
这些语料可以反映语言使用的场景和情境,具有很高的代表性和真实性。
因此,借助语料库语言学方法进行研究,可以使语言研究者在不同领域深入了解语言的实际使用情况和变化规律。
2、帮助语言教学与学习语料库语言学对外语教学与学习也有很大的帮助。
借助语料库,语言教师可以更好地了解不同语境中的语言使用情况,为课程设计提供可靠的实证基础。
学生则可以通过分析语料库中的语言实例,更准确地掌握语言的用法、结构和特点,提高语言应用能力。
(二)ChatGPT的重要性1、提高自然语言处理技术的水平ChatGPT是一种基于神经网络的自然语言处理技术,可以实现计算机对人类语言的理解和生成。

Chapter 6 Language Processing in Mind6.1 Introduction1. Language is a mirror of the mind in a deep and significant sense.2. Language is a product of human intelligence, created a new in each individual byoperation that lie far beyond the reach of will or consciousness.3. Psycholinguistics “proper” can perhaps be glossed as the storage, comprehension,production and acquisition of language in any medium (spoken or written).4. Psycholinguistics is concerned primarily with investigating the psychological reality oflinguistic structures.5. The differences between psycholinguistics and psychology of language.Psycholinguistics can be defined as the storage, comprehension, production and acquisition of language in any medium (spoken or written). It is concerned primarily with investigating the psychological reality of linguistic structures.On the other hand, the psychology of language deals with more general topics such as the extent to which language shapes thought, and from the psychology of communication, includes non-verbal communication such as gestures and facial expressions.6. Cognitive psycholinguistics: Cognitive psycholinguistics is concerned above all withmaking inferences about the content of the human mind.7. Experimental psycholinguistics: Experimental psycholinguistics is mainly concernedwith empirical matters, such as speed of response to a particular word.6.1.1 Evidence1. Linguists tend to favor descriptions of spontaneous speech as their mainsource of evidence, whereas psychologists mostly prefer experimental studies.2. The subjects of psycholinguistic investigation are normal adults and childrenon the one hand, and aphasics----people with speech disorders-----on the other.The primary assumption with regard to aphasic patient that a breakdown insome part of language could lead to an understanding of which componentsmight be independent of others.6.1.2 Current issues1. Modular theory: Modular theory assumes that the mind is structured intoseparate modules or components, each governed by its own principles andoperating independently of others.2. Cohort theory: The cohort theory hypothesizes that auditory word recognitionbegins with the formation of a group of words at the perception of the initialsound and proceeds sound by sound with the cohort of words decreasing asmore sounds are perceived. This theory can be expanded to deal with writtenmaterials as well. Several experiments have supported this view of wordrecognition. One obvious prediction of this model is that if the beginningsound or letter is missing, recognition will be much more difficult, perhapseven impossible. For example: Gray tie------ great eye; a name-----an aim;an ice man-----a nice man; I scream-----ice cream; See Mable----seem able;well fare----welfare; lookout------look out ; decade-----Deck Eight;Layman------laymen; persistent turn------persist and turn3. Psychological reality: The reality of grammar, etc. as a purported account ofstructures represented in the mind of a speaker. Often opposed, in discussionof the merits of alternative grammars, to criteria of simplicity, elegance, andinternal consistency.4. The three major strands of psycholinguistic research:(1) Comprehension: How do people use their knowledge of language, andhow do they understand what they hear or read?(2) Production: How do they produce messages that others can understand inturn?(3) Acquisition: How language is represented in the mind and how languageis acquired?6.2 Language comprehension6.2.1 Word recognition1. An initial step in understanding any message is the recognition of words.2. One of the most important factors that effects word recognition is howfrequently the word is used in a given context.3. Frequency effect: describes the additional ease with which a word is accesseddue to its more frequent usage in the language.4. Recency effect: describe the additional ease with which a word is accesseddue to its repeated occurrence in the discourse or context.5. Another factor that is involved in word recognition is Context.6. Semantic association network represents the relationships between varioussemantically related words. Word recognition is thought to be faster whenother members of the association network are provided in the discourse.6.2.2 Lexical ambiguity1. lexical ambiguity: ambiguity explained by reference to lexical meanings: e.g.that of I saw a bat, where a bat might refer to an animal or, among others,stable tennis bat.2. There are two main theories:(1) All the meanings associated with the word are accessed, and(2) only one meaning is accessed initially. e.g.a. After taking the right turn at the intersection….“right” is ambiguous: correct vs. rightwardb. After taking the left turn at the intersection…“left” is unambiguous6.2.3 Syntactic processing1. Once a word has been dentified , it is used to construct a syntactic structure.2. As always, there are cinokucatuibs due to the ambiguity of individual wordsand to the different possible ways that words can be fit into phrases.Sometimes there is no way to determine which structure and meaning asentence has.e.g. The cop saw the spy with the binoculars. “with the binoculars” isambiguity(1) the cop employed binoculars in order to see the spy.(2) it specifies “the spy has binoculars.”3. Some ambiguities are due to the ambiguous category of some of the words inthe sentence.e.g. the desert trains, trains (培训;列车)the desert trains man to be hardly. 沙漠使人坚韧。

2021.04科学技术创新基于语言学资源的汉-英机器翻译金鹏张春祥冯禹瑄贾永刚王淇桢(哈尔滨理工大学软件与微电子学院,黑龙江哈尔滨150080)1概述在机器翻译系统中翻译知识是重要的知识源,能够完成源语言到目标语言的转换任务。
目前,从语料库中学习翻译知识已经占到了主流地位。
基于语料库的机器翻译可以分为两种形式:基于统计的翻译系统和基于实例的翻译系统。
1.1统计机器翻译(St at i s t i cal M achi ne Tr ans l at i on ,SM T ),又称数据驱动的翻译,是一种采用统计学习技术来获取知识的方法。
这种方法将翻译知识表示为模型参数,利用双语语料来优化模型参数。
统计机器翻译主要包括基于信源信道模型的统计翻译、基于平行概率语法的统计翻译和基于最大熵的统计翻译[1]。
1.2基于实例的机器翻译(Exam pl e-Bas ed M achi ne Tr ans l at i on ,EBM T ),其基本原理是:把双语语料看作翻译知识库,通过实例的查询和相似度计算来实现知识的查找和匹配。
类比源语言与翻译实例,通过组合相近的实例片断来生成目标语译文。
实例的查询和相似度计算本身就是一个知识获取的过程。
这种方法不通过深层次的分析,仅使用已有的经验知识,通过类比原理来进行翻译[2]。
本文对汉英双语语料进行词汇对齐,根据词链从中抽取汉英对译片断对。
同时,给出了基于对译片断对的机器翻译框架,对输入的汉语句子进行翻译转换。
2汉-英对译片断对获取对译片断对也就是人们常说的翻译等价对。
翻译等价对获取不但是机器翻译课题中的一个重要环节,而且也是自然语言处理中亟待解决的问题。
在处理像汉-英这样具有异构语法体系的语言对时,现行的对译片断对抽取方法会遇到很多问题。
对以下汉-英双语句对,其对译片断对的抽取过程如下所示:汉语句子:这是收据和零钱英语句子:H er e i s t he r ecei pt and your change 词汇对齐结果如图1所示:图1汉英句对的词汇对齐结果对译片断对:这是<->H er e i s 收据<->t he r ecei pt 和<->and 零钱<->your change在实际应用中,对译片断对是很复杂的。


统计机器翻译介绍1. 引言统计机器翻译(Statistical Machine Translation,简称SMT)是一种利用统计模型来进行自动翻译的方法。
它与传统的基于规则的机器翻译方法相比,更加准确且适用于多种语言对之间的翻译任务。
本文将介绍统计机器翻译的基本原理、模型构建、训练和评估等方面的内容。
2. 统计机器翻译原理统计机器翻译的基本原理是基于大规模的双语平行语料库进行训练和建模。
通常,平行语料库是指同时包含源语言和目标语言的句子对。
统计机器翻译的目标是通过学习这些句子对之间的概率分布,来推测源语言句子对应的目标语言句子。
3. 统计机器翻译模型统计机器翻译模型主要由两个部分组成:语言模型和翻译模型。
3.1 语言模型语言模型是生成目标语言句子的模型,它通过学习目标语言的概率分布来生成合理的句子。
常用的语言模型有n-gram模型和神经网络语言模型。
其中,n-gram 模型基于n个连续的词的概率进行建模,而神经网络语言模型则利用深度神经网络来学习词之间的语义关系。
3.2 翻译模型翻译模型是从源语言到目标语言的翻译模型,它通过学习源语言和目标语言之间的对应关系来进行翻译。
常用的翻译模型有基于短语的模型和基于句法的模型。
其中,基于短语的模型将源语言和目标语言划分为一些短语,并学习它们之间的翻译概率;而基于句法的模型则通过学习源语言和目标语言的句法结构信息来进行翻译。
4. 统计机器翻译训练统计机器翻译的训练过程主要包括对语言模型和翻译模型的参数进行估计。
4.1 语言模型训练语言模型的训练是通过利用大规模的目标语言语料库,根据句子的出现概率来估计模型的参数。
常用的训练方法有最大似然估计和最大熵模型。
4.2 翻译模型训练翻译模型的训练是通过利用双语平行语料库,根据源语言和目标语言之间的对应关系来估计模型的参数。
常用的训练方法有最大似然估计和最小错误率训练。
5. 统计机器翻译评估统计机器翻译的评估主要通过与人工翻译结果进行比较来进行。


同声传译中译语产出的认知心理模式研究*南京工业大学南京师范大学胡元江南京师范大学马广惠提要:本研究探讨原语意义转化为译者语信后译语产出过程的认知心理模式。
该模式基于简约性和概括性在Kormos(2006)双语言语产出认知心理蓝图的基础上,在主加工器上将语信来源表征为显性,并标注为原语意义构件,形式构成器中的构件调整为Levelt(1989)的语法编码和语音编码,将辅助成分的情景记忆调整为原语和译语情景记忆,将二语陈述性规则调整为译语陈述性规则。
译语产出遵循递增处理原则,各阶段自主处理和并行运作。
该模型能充分体现译语从概念形成器、形式构成器再到发音器的认知心理过程和描述译语从意义代码、言语代码到生理、语音代码的转换过程。
关键词:同声传译;概念形成器;形式构成器;发音器1.引言国际口译研究开始于20世纪中期,虽然历史不长,但已经形成了一些颇具影响的学派,如释意派和实证派等,且各派都有自己的研究取向和范式,理论研究成果也相当丰富。
国内的口译研究起步较晚,至20世纪90年代后才逐渐兴起,自2008年始国内学者亦在国际口译界开始崭露头角(张吉良,2011)。
但目前口译研究的重点仍集中于对口译客体的分析,而且无论对于口译主体还是客体的研究都处于比较表层的阶段(刘绍龙,2008)。
虽然口译有同声传译和交替传译之分,但在西方,同声传译研究可以说是口译研究最主要的动力,甚至可以说西方口译研究史就是同声传译研究史(武光军,2006)。
同声传译模式研究可分为两类,一类是研究口译全景图的完整加工过程模型,另一类是侧重某一阶段的局部模型。
第一类以Gerver(1976)的同传过程模型、Moser (1978)的同传假设模型和Gile(1995)基于口译工作方式的同传模式为代表。
第二类以Lambert (1983)的加工深度模型、Dillinger(1989)的同传成分加工研究和Daro&Fabbro(1994)的同传记忆系统研究为代表。

基于翻译日志的统计机器翻译模型剪枝
刘凯;吕雅娟;姜文斌;刘群
【期刊名称】《北京大学学报:自然科学版》
【年(卷),期】2014()1
【摘要】提出一种基于翻译日志的统计机器翻译模型的剪枝方法。
该方法利用翻译规则在翻译日志中的命中频数对机器翻译规则进行过滤,保留当前机器翻译模型所需的最小规则表。
实验表明,该方法能够在仅保留原有模型1%~3%翻译规则的前提下达到原有模型的翻译效果。
【总页数】6页(P167-172)
【关键词】统计机器翻译;模型剪枝;翻译日志
【作者】刘凯;吕雅娟;姜文斌;刘群
【作者单位】中国科学院大学计算技术研究所,智能信息处理重点实验室,北京100190;Dublin City University(DCU),Dublin 9
【正文语种】中文
【中图分类】TP391
【相关文献】
1.基于主题模型和统计机器翻译方法的中文格律诗自动生成 [J], 蒋锐滢;崔磊;何晶;周明;潘志庚
2.基于神经网络的统计机器翻译的预调序模型 [J], 杨南;李沐
3.基于领域自适应方法的统计机器翻译模型的优化研究 [J], 杨玲
4.基于领域自适应方法的统计机器翻译模型的优化研究 [J], 杨玲
5.基于选择偏向性的统计机器翻译模型 [J], 唐海庆;熊德意
因版权原因,仅展示原文概要,查看原文内容请购买。
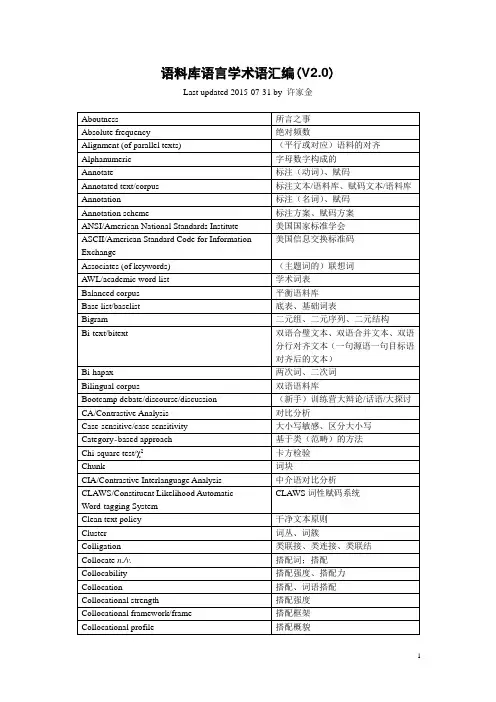

基于双语对齐口语语料的翻译词典的自动生成
陈博兴;杜利民
【期刊名称】《计算机学报》
【年(卷),期】2003(026)003
【摘要】提出了一个基于英汉双语口语对齐语料库的翻译词典的自动生成算法.首先利用释义词典过滤双语文本,得到"过滤词典",继而通过统计共现概率,计算出所有词对的相互关联值,并且生成"汉英(英汉)相互关联值表",对于每个源语词汇选取相互关联值最大的若干项目标语作为候选词对,分别赋予信任值1,然后统计每个候选词对的信任值作为翻译词典的分级标准,得到4个不同级别的词典,其中"过滤词典+4级词典"在召回率为93.5%的情况下,正确率达到93.389%.
【总页数】6页(P275-280)
【作者】陈博兴;杜利民
【作者单位】中国科学院声学研究所语音交互技术研究中心,北京,100080;中国科学院声学研究所语音交互技术研究中心,北京,100080
【正文语种】中文
【中图分类】TP18
【相关文献】
1.统计机器翻译中双语语料的过滤及词对齐的改进 [J], 梁华参;赵铁军
2.统计机器翻译中双语语料的过滤及词对齐的改进 [J], 梁华参;赵铁军;
3.面向小词典的高效英汉双语语料对齐算法 [J], 熊伟;陈蓉;刘佳;徐淼;于中华
4.基于统计和词典方法相结合的韩汉双语语料库名词短语对齐 [J], 凌天斌;毕玉德
5.汉文-维吾尔文双语语料库中基于词典译文的句子对齐方法研究 [J], 热西旦·塔依;吐尔根·依布拉音
因版权原因,仅展示原文概要,查看原文内容请购买。
Computational Linguistics and Chinese Language Processing Vol. 10, No. 3, September 2005, pp. 329-346 329 © The Association for Computational Linguistics and Chinese Language Processing
[Received January 31, 2005; Revised August 24, 2005; Accepted August 26, 2005] Collocational Translation Memory Extraction Based on Statistical and Linguistic Information
Thomas C. Chuang∗, Jia-Yan Jian+, Yu-Chia Chang+ and Jason S. Chang+
Abstract In this paper, we propose a new method for extracting bilingual collocations from a parallel corpus to provide phrasal translation memories. The method integrates statistical and linguistic information to achieve effective extraction of bilingual collocations. The linguistic information includes parts of speech, chunks, and clauses. The method involves first obtaining an extended list of English collocations from a very large monolingual corpus, then identifying the collocations in a parallel corpus, and finally extracting translation equivalents of the collocations based on word alignment information. Experimental results indicate that phrasal translation memories can be effectively used for computer assisted language learning (CALL) and computer assisted translation (CAT).
Keywords: Bilingual Collocation Extraction, Collocational Translation Memory, Collocational Concordancer
1. Introduction Example-based machine translation (EBMT) has been proposed as an alternative approach to automatic translation. Translations of examples range from two-word to multi-word, translations, with or without syntactic or semantic structures [Nagao 1984; Kitano 1993; Smadja 1993; Lin 1998; Andrimanankasian et al. 1999; Carl 1999; Brown 2000; Pearce 2001; Seretan et al. 2003]. In the approach, text and translations are preprocessed and stored in a translation memory, which serves as an archive of existing translations that the MT system can reuse. A number of proposed applications for machine translation and computer assisted translation systems use translation examples found in bilingual corpora; these methods include
∗ Department of Computer Science and Information Engineering, Vanung University, No. 1, Vanung
Road, Jhongli, Taoyuan, Taiwan E-mail: tomchuang@msa.vnu.edu.tw + Department of Computer Science, National Tsing Hua University, 101, Kuangfu Road, Hsinchu,
Taiwan 330 Thomas C. Chuang et al.
[Transit 2005], [Deja–Vu 2005], [TransSearch 2005], and [TOTALrecall 2005]. Statistical methods have been proposed for automatic acquisition of bilingual collocations [Smadja et al. 1996; Gao et al. 2002; Wu and Zhou 2003] from parallel bilingual corpora [Kupiec 1993; Smadja et al. 1996; Echizen-ya et al. 2003] or from two comparable monolingual corpora [Lu and Zhou 2004]. These bilingual collocations, if acquired in quantity, can enable a machine translation system to produce more native-speaker like translations. However, parallel corpora of substantial size are harder than monolingual corpora to come by. Therefore, in small- to mid-size parallel texts, collocations may not have high enough counts for a statistical method to reliably extract them. Consider the example of extracting verb-noun collocations for the noun “influence” from 50,000 bilingual sentences (SMEC-50000) in the Sinorama Mandarin-English Corpus (SMEC)1. Some useful bilingual collocations in SMEC have very low occurrence counts. For
instance, the bilingual collocation “use influence; 發揮 影響力” appears only once in SM-50000 (see Example 1). Such collocations may not be extracted by the methods proposed in the literature.
(1) These circumstances make it unlikely that APEC will be able to avoid reform. In Lai's analysis, the implosion of the Asian economies last year demonstrates their interconnectedness. Therefore, in order to place its own existence on a more secure foundation, Taiwan should carefully observe changes in APEC and use its influence to make the organization into a vehicle driving regional consolidation. 他分析,亞洲國家近年來經濟危機持續不去,證明瞭彼此的連動性,因此台灣應該注意觀察APEC的轉變,發揮意見的影響力,以使APEC能夠成為區域整合的火車頭,為我國創造更大的生存利基。
A good way of extracting such bilingual collocation might be to first extract “use influence” as a collocation in a large, separate, monolingual corpus, and then identify its instances and translations in the given parallel corpus (e.g., the Sinorama Mandarin-English Corpus). At present, it is not difficult to obtain a much larger monolingual corpus (e.g., the British National Corpus) that contains enough instances of “use influence” such that extraction of such a collocation type is mostly effective. Example (2) shows one of the 60 instances of