
https://www.doczj.com/doc/ed1379382.html,
如何快速获取网站源码
网站源码,又称为源代码,源程序,指的是未编译的文本代码或一个网站的全部源码文件,是一系列人类可读的计算机语言指令。我们所看到的网页的样子,都是由浏览器或者服务器翻译后展示的样子,实际上它是由一大堆的源代码组成的。
我们在使用八爪鱼采集器采集网页数据时,有时候需要查看网站源码来手写xpath去精准定位我们想要采集的数据,那么如何快速获取网站源码呢?下面就为大家介绍几种快速获取网站源码的方法。
获取网页源码有以下几种方式:
一、通过浏览器获取
下载并打开谷歌、搜狐等浏览器,在网页空白处,点击鼠标右键并选择“查看网页源码”,然后将显示出来的源码复制下来即可。
二、通过八爪鱼采集器采集
八爪鱼采集器有自定义抓取方式的功能,可通过此功能抓取网页源码。
1、采集整个网页源码
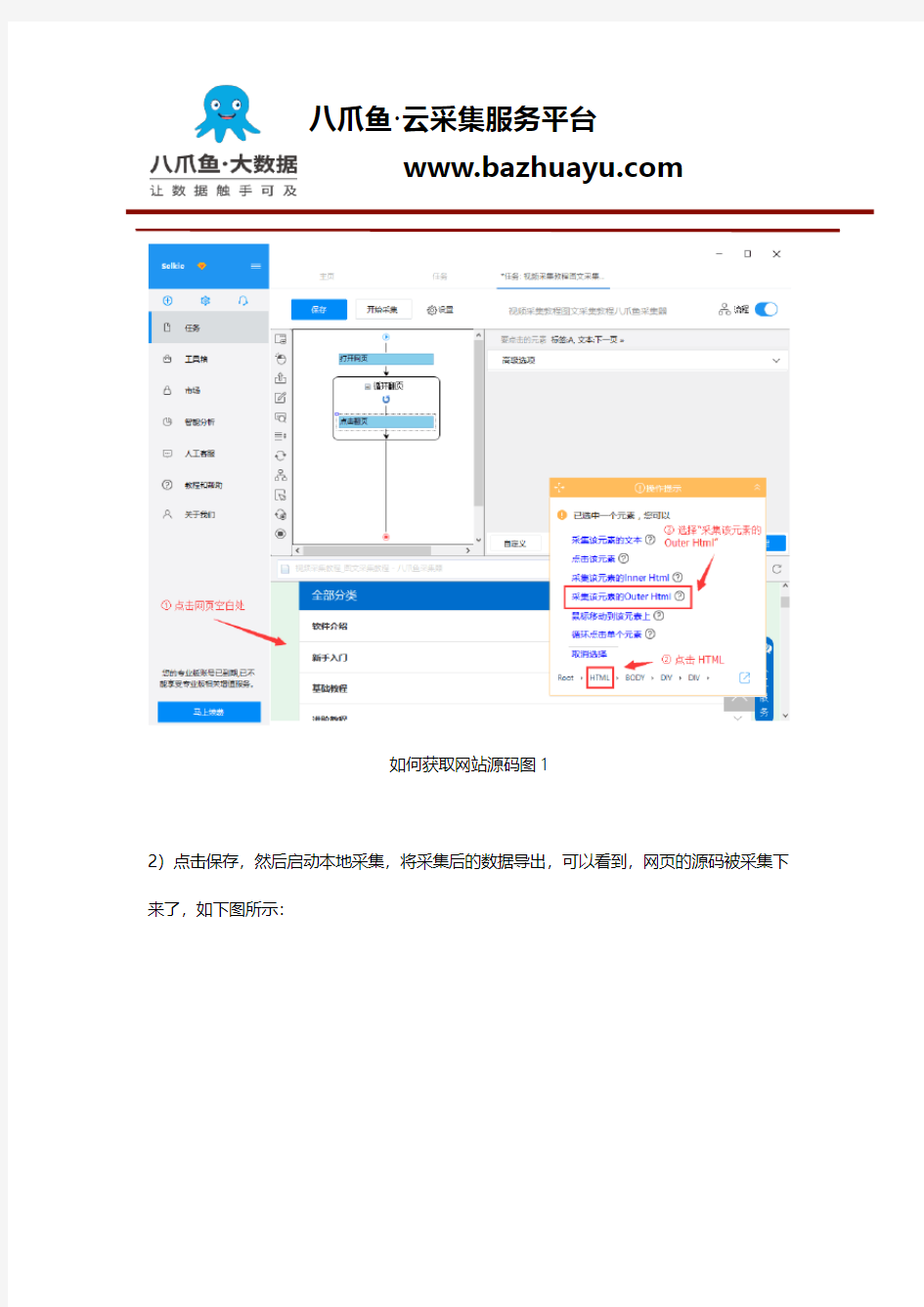
1)在八爪鱼中打开目标网页,点击网页空白处,在操作提示框中,先点击一下“HTML”,然后选择“采集该元素的Outer Html”,如下图所示:
https://www.doczj.com/doc/ed1379382.html,
如何获取网站源码图1
2)点击保存,然后启动本地采集,将采集后的数据导出,可以看到,网页的源码被采集下来了,如下图所示:
https://www.doczj.com/doc/ed1379382.html,
如何获取网站源码图2
注意:①以上只是一个提取网页源码的简单示例,其他操作步骤,请参考八爪鱼新手入门教程
②网页源码导出过程中,可能出现因太长而被excel截断的情况,导出到数据库可避免被截断。
2、采集网页上某个元素的源码
可通过“抓取这个元素的OuterHtml,InnerHtml”选项,抓取网页源码。打开八爪鱼,找到提取数据步骤,选择:自定义抓取方式-从页面中提取数据-抓取这个元素的OuterHtml
https://www.doczj.com/doc/ed1379382.html, (包含当前元素的网页源代码,带格式的文本和图片)
如何获取网站源码图3
相关采集教程:
xpath应用示例—视频教程:
https://www.doczj.com/doc/ed1379382.html,/tutorial/videotutorial/xpathyinyong xpath抓取网页文字:
https://www.doczj.com/doc/ed1379382.html,/tutorial/gnd/xpath
https://www.doczj.com/doc/ed1379382.html,
xpath入门教程1,以采集黄页88企业信息举例:
https://www.doczj.com/doc/ed1379382.html,/tutorial/xpathrm1
xpath入门语法以及教程2:
https://www.doczj.com/doc/ed1379382.html,/tutorial/xpathrm2
系统学习xpath—视频教程:
https://www.doczj.com/doc/ed1379382.html,/tutorial/xitongxpath
网页数据采集相对XPATH使用教程:
https://www.doczj.com/doc/ed1379382.html,/tutorial/xdxpath-7
八爪鱼采集器——相对xpath应用——视频教程:
https://www.doczj.com/doc/ed1379382.html,/tutorial/xiangduixpath
xpath工具使用方法—视频教程:
https://www.doczj.com/doc/ed1379382.html,/tutorial/xpathgongju
XPath调试工具:
https://www.doczj.com/doc/ed1379382.html,/tutorial/xpathgj
电商爬虫:
https://www.doczj.com/doc/ed1379382.html,/tutorial/hottutorial/dianshang
https://www.doczj.com/doc/ed1379382.html,