无约束优化设计实验报告
力学系型号:联想y470
CPU:i5-2450M
内存:2GB
系统:win7-64位
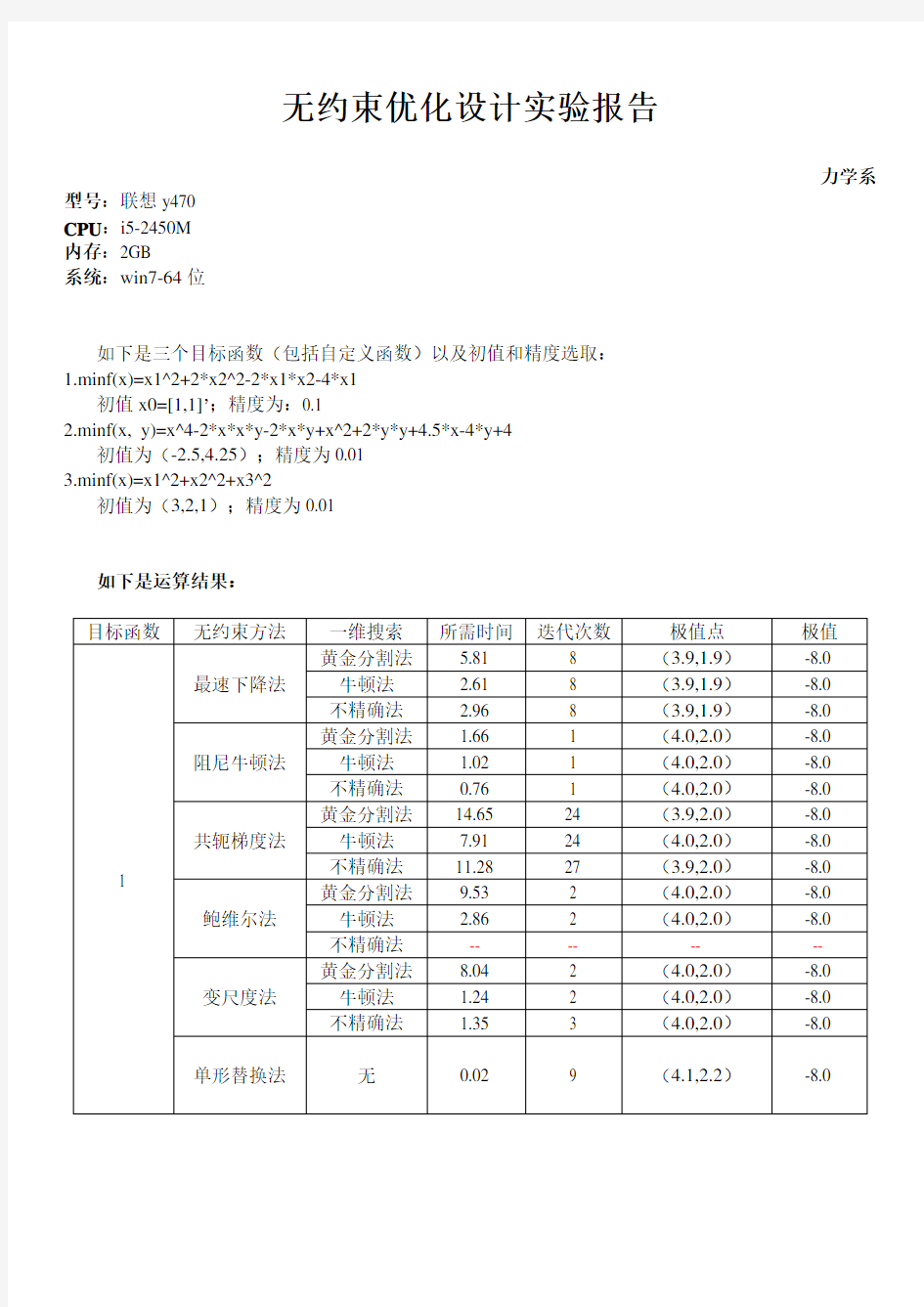
如下是三个目标函数(包括自定义函数)以及初值和精度选取:
1.minf(x)=x1^2+2*x2^2-2*x1*x2-4*x1
初值x0=[1,1]’;精度为:0.1
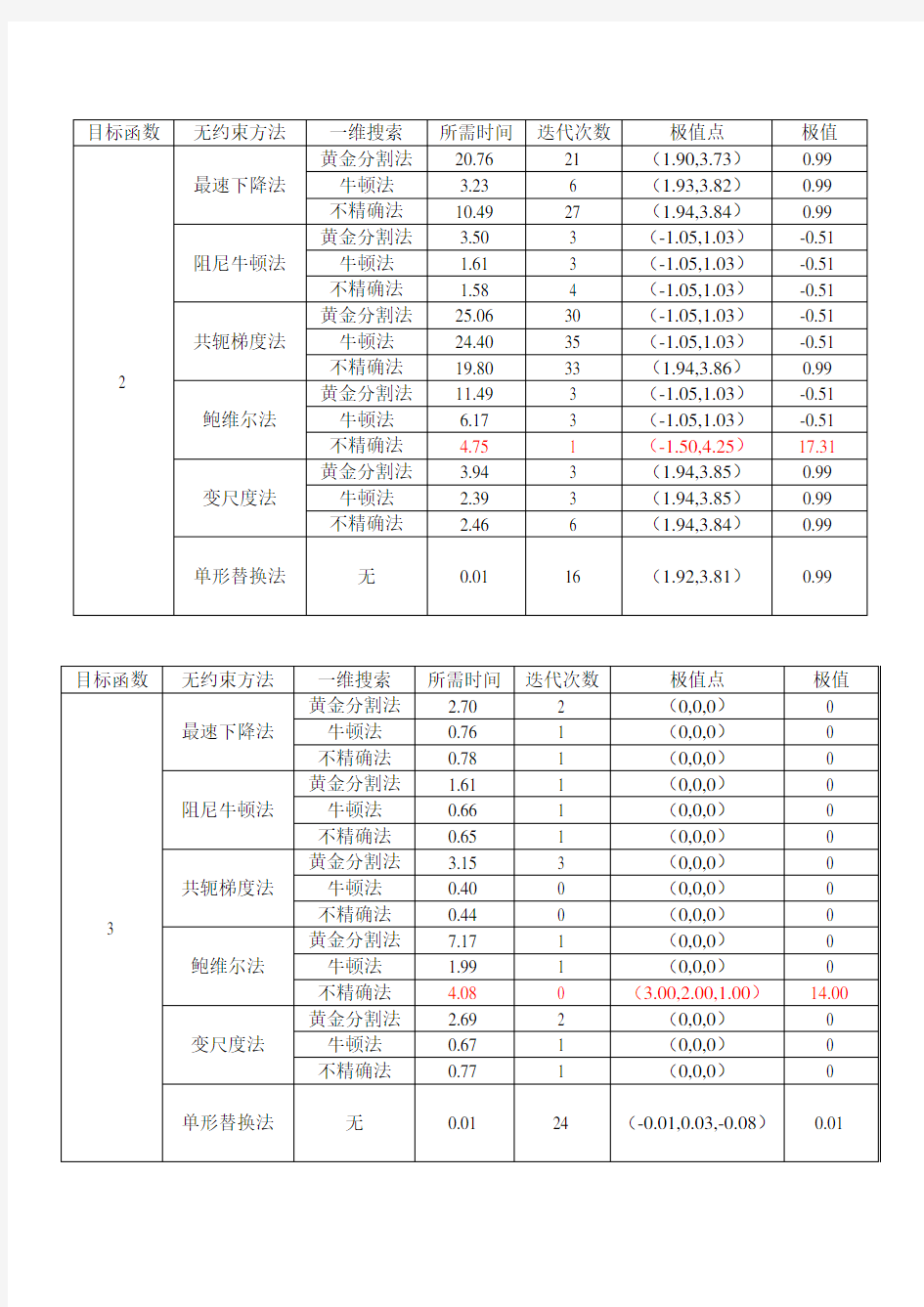
2.minf(x,y)=x^4-2*x*x*y-2*x*y+x^2+2*y*y+4.5*x-4*y+4
初值为(-2.5,4.25);精度为0.01
3.minf(x)=x1^2+x2^2+x3^2
初值为(3,2,1);精度为0.01
如下是运算结果:
总结及比较:
根据上面三个函数的表格可以看出:首先,从迭代时间来看,三种一维搜索方法中黄金分割法所用时间最久,牛顿法和不精确法所用时间较少,这两种方法相比较而言牛顿法所用时间更少一些。而六种无约束方法中,由于单形替代法不需要使用一维搜索方法,故迭代时间最少,紧接着在使用一维搜索的五种方法中以阻尼牛顿法迭代时间相对较少,共轭梯度法迭代时间最久;然后,从迭代次数来看,共轭梯度法往往需要较多的迭代次数,从而所需时间也最久;接着,从计算结果的精度来看,阻尼牛顿法的结果精度最高,而单形替换法的精度最低;最后,从编程来看,在编好一维搜索方法的情况下,最速下降法和阻尼牛顿法编程简单容易,而共轭梯度法、变尺度法和单形替代法需要两重循环实现,鲍威尔法和单形替换法则需要编程者对矩阵的操作能力有较高的要求,故编程较难。
同时,从上面的结果也可以发现,鲍威尔法在使用不精确的一维搜索方法时,对函数1无法收敛,对函数2、3收敛到错误的结果,所以鲍威尔法是依赖于精确的一维搜索过程的,而其他几个则不依赖于精确一维搜索过程。精确的一维搜索方法通常需要花费很大的工作量,特别是当迭代点远离问题的解时,精确的求解一个一维子问题通常不是十分有效率的。因此,只要保证目标函数值在每一步都有满意的下降,使用不是非常精确的一维搜索,就可以大大节省工作量。
在分析函数2的计算结果时,可以发现存在两个收敛结果,当然这两个结果都是极值,因为函数2是二元四次函数,存在多个极值。故为了验证正确性,自己曾将初始点(-2.5,4.25)调成(2.5,4.25),分别代入程序中计算,计算结果都收敛于极值为0.99的这个点上。所以,在存在多个极值点的情况下结果是和初始点的选取有关。
对于单形替换法,这种方法不需要一维搜索最佳步长,故没有一维搜索方法反复地计算最佳步长的计算时间,程序运行效率快。但它的收敛条件不好选择,通过查找文献资料总结出以下三个收敛条件:1.利用最坏点函数值与最好点函数值之差判别;2.利用相邻两次函数值差值的绝对值判别;3.利用各点的函数值与最好点函数值之差的均方根判别。为了保证程序的执行可靠性,这三种常用的方法中自己选择了判别3,即:
综上所述,阻尼牛顿法是无约束方法中最有效的方法。不仅编程简单,而且迭代次数较少,运行时间较短,结果的精度也较高。
在程序的运行方面,分别设置了可变的函数选择、无约束方法选择、一维搜索方法选择、起始点、精度这五个输入,故可以在命令窗口运行主程序main,再根据提示要求分别输入这五个参数的所需值,就可以得到运行结果。
程序如下:
1、主函数
clear;
global k;
k=0;
disp('1.f(x)=x1^2+2*x2^2-2*x1*x2-4*x1');
disp('2.f(x,y)=x^4-2*x*x*y-2*x*y+x^2+2*y*y+4.5*x-4*y+4');
disp('3.f(x)=x1^2+x2^2+x3^2');
while 1
n0=input('请输入上面所想选择函数的编号(1、2、3):');
if n0==1||n0==2||n0==3
break;
end
disp('此次输入无效.');
end
disp(' ');
disp('1.最速下降法');
disp('2.阻尼牛顿法');
disp('3.共轭梯度法');
disp('4.鲍威尔法');
disp('5.变尺度法');
disp('6.单纯形法');
while 1
m0=input('请输入上面所想选择无约束方法的编号(1、2、3、4、5、6):'); if m0==1||m0==2||m0==3||m0==4||m0==5||m0==6
break;
end
disp('此次输入无效.');
end
disp(' ');
disp('1.黄金分割法');
disp('2.牛顿法');
disp('3.不精确一维搜索法');
while 1
m1=input('请输入上面所想选择一维搜索方法的编号(1、2、3):');
if m1==1||m1==2||m1==3
break;
end
disp('此次输入无效.');
end
disp(' ');
s=input('请输入用空格隔开的初始值坐标向量(如:1.1 2.0):','s');
x=str2num(s);
x=x';
disp(' ');
while 1
e=input('请输入精度(建议0.1或0.01):');
if e>0
break;
end
disp('此次输入无效.');
end
disp(' ');
disp('~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~');
[xx,yy]=fmins(m0,m1,n0,x,e);
fprintf('迭代次数为:%8.0f\n', k);
disp('所求极值点的坐标向量为:');
fprintf(' %16.5f\n', xx);
fprintf('所求函数的极值为:%16.5f\n', yy);
2、外部多维的调用函数
function [xx,yy]=fmins(m0,m1,n0,x,e)
%UNTITLED 此处显示有关此函数的摘要% 此处显示详细说明
if m0==1
tic;[xx,yy]=zuisu(m1,n0,x,e);toc;
elseif m0==2
tic;[xx,yy]=zuni(m1,n0,x,e);toc;
elseif m0==3
tic;[xx,yy]=gonge(m1,n0,x,e);toc;
elseif m0==4
tic;[xx,yy]=powell(m1,n0,x,e);toc; elseif m0==5
tic;[xx,yy]=bianchi(m1,n0,x,e);toc;
elseif m0==6
tic;[xx,yy]=danxing(n0,x,e);toc;
end
end
3、最速法
function [xx,yy]=zuisu(m1,n0,x,e)
%UNTITLED2 此处显示有关此函数的摘要% 此处显示详细说明
global k;
[g,ss]=gra(n0);
while 1
d=-double(subs(g,ss,x));
a=fmin(m1,n0,x,d,e);
x1=x+a*d;
if norm(x1-x) break; end x=x1; k=k+1; end xx=x1; yy=f0(n0,xx); end 4、阻尼法 function [xx,yy]=zuni(m1,n0,x,e) %UNTITLED 此处显示有关此函数的摘要% 此处显示详细说明 global k; [g,ss]=gra(n0); h=jacobian(g',ss); while 1 d=-double(subs(h,ss,x)^(-1)*subs(g,ss,x)); a=fmin(m1,n0,x,d,e); x1=x+a*d; if norm(x1-x) break; end x=x1; k=k+1; end xx=x1; yy=f0(n0,xx); end 5、共轭梯度法 function [xx,yy]=gonge(m1,n0,x,e) %UNTITLED2 此处显示有关此函数的摘要% 此处显示详细说明 global k; if n0==1 n=2; elseif n0==2 n=4; elseif n0==3 n=2; end [g,ss]=gra(n0); while 1 kk=0; d=-double(subs(g,ss,x)); while 1 a=fmin(m1,n0,x,d,e); x1=x+a*d; gx=double(subs(g,ss,x)); gx1=double(subs(g,ss,x1)); if norm(gx1) break; elseifkk==n break; end beta=norm(gx1)^2/norm(gx)^2; d=-gx+beta*d; x=x1; k=k+1; kk=kk+1; end if norm(gx1) break; end x=x1; k=k+1; end xx=x1; yy=f0(n0,xx); end 6、鲍威尔法 function [xx,yy]=powell(m1,n0,x,e) %UNTITLED3 此处显示有关此函数的摘要 % 此处显示详细说明 global k; if n0==1 n=2; elseif n0==2 n=2; elseif n0==3 n=3; end d=zeros(n,n+1); xk=zeros(n,n+1); deta=zeros(n,1); for j=1:n d(j,j)=1; end while 1 xt=x; for i=1:n a=fmin(m1,n0,xt,d(:,i),e); xk(:,i)=xt+a*d(:,i); deta(i)=f0(n0,xt)-f0(n0,xk(:,i)); xt=xk(:,i); end xt=x; xk(:,n+1)=2*xk(:,n)-x; ff0=f0(n0,x); ff2=f0(n0,xk(:,n)); ff3=f0(n0,xk(:,n+1)); md=max(deta); m=find(deta==md); if (ff3 a=fmin(m1,n0,xk(:,n),d(:,n+1),e); x=xk(:,n)+a*d(:,n+1); for i=m:n d(:,i)=d(:,i+1); end else if ff2 x=xk(:,n); else x=xk(:,n+1); end end if norm(x-xt) break; end k=k+1; end xx=x; yy=f0(n0,xx); end 7、变尺度法 function [xx,yy]=bianchi(m1,n0,x,e) %UNTITLED 此处显示有关此函数的摘要% 此处显示详细说明 global k; if n0==1 n=2; elseif n0==2 n=2; elseif n0==3 n=3; end [g,ss]=gra(n0); while 1 gx=double(subs(g,ss,x)); h=eye(n); kk=0; while 1 d=-h*gx; a=fmin(m1,n0,x,d,e); xk=x+a*d; if norm(xk-x) break; end ifkk==n break; end gxk=double(subs(g,ss,xk)); yk=gxk-gx; sk=xk-x; h=h+(sk*sk')/(sk'*yk)-((h*yk)*yk'*h)/(yk'*h*yk); x=xk; gx=gxk; kk=kk+1; k=k+1; end if norm(xk-x) break; end x=xk; k=k+1; end xx=xk; yy=f0(n0,xx); end 8、单形替换法 function [xx,yy]=danxing(n0,x,e) %UNTITLED 此处显示有关此函数的摘要 % 此处显示详细说明 global k; if n0==1 n=2; elseif n0==2 n=2; elseif n0==3 n=3; end f=zeros(n+5,1); xk=zeros(n,n+5); h=2*eye(n); xk(:,1)=x; for i=1:n xk(:,i+1)=x+h(:,i); end while 1 for i=1:n+1 f(i)=f0(n0,xk(:,i)); end while 1 f(n+2)=nan; f(n+3)=nan; f(n+4)=nan; f(n+5)=nan; fl=min(f); xll=find(f==fl); xl=xll(1); fh=max(f); xhh=find(f==fh); xh=xhh(1); fff=f; fff(xh)=[]; fg=max(fff); fz=0; for i=1:n+1 fz=fz+(f(i)-f(xl))^2; end fz=sqrt(fz/n); iffz break; end xkk=xk(:,1); for i=1:n xkk=xkk+xk(:,i+1); end xk(:,n+2)=(xkk-xk(:,xh))/n; xk(:,n+3)=2*xk(:,n+2)-xk(:,xh); f(n+3)=f0(n0,xk(:,n+3)); if f(n+3) xk(:,n+4)=xk(:,n+2)+2*(xk(:,n+3)-xk(:,n+2)); f(n+4)=f0(n0,xk(:,n+4)); if f(n+4) xk(:,xh)=xk(:,n+4); f(xh)=f(n+4); else xk(:,xh)=xk(:,n+3); f(xh)=f(n+3); end else if f(n+3) xk(:,xh)=xk(:,n+3); f(xh)=f(n+3); else if f(n+3)>=fh xk(:,n+3)=xk(:,xh); end xk(:,n+5)=xk(:,n+2)+0.5*(xk(:,n+3)-xk(:,n+2)); f(n+5)=f0(n0,xk(:,n+5)); if f(n+5) xk(:,xh)=xk(:,n+5); f(xh)=f(n+5); else for i=1:n+1 xk(:,i)=(xk(:,i)+xk(:,xl))/2; end break; end end end k=k+1; end iffz break; end k=k+1; end xx=xk(:,xl); yy=f0(n0,xx); end 9、内部循环一维调用函数 function xx=fmin(m1,n0,x,d,e) x0=0;%初始步长默认为0 [amin,amax]=range1(n0,x,d,x0); if m1==1 xx=gold(n0,x,d,amin,amax,e); elseif m1==2 xx=newton(n0,x,d,amax,e); elseif m1==3 xx=wolfe(n0,x,d); end end 10、一维搜索确定区间函数 function [amin,amax] = range1(n0,x,d,x0) %UNTITLED5 此处显示有关此函数的摘要% 此处显示详细说明 h=1; a1=x0;y1=f_1(n0,x,d,a1); a2=a1+h;y2=f_1(n0,x,d,a2); if y2>y1 h=-h; a3=a1;y3=y1; a1=a2; a2=a3;y2=y3; end a3=a2+h;y3=f_1(n0,x,d,a3); while y3 h=h*2; a1=a2; a2=a3;y2=y3; a3=a2+h;y3=f_1(n0,x,d,a3); end amin=min(a1,a3); amax=max(a1,a3); end 11、黄金一维法 function xx=gold(no,x,d,amin,amax,e) %UNTITLED6 此处显示有关此函数的摘要% 此处显示详细说明 a1=amax-0.618*(amax-amin); y1=f_1(no,x,d,a1); a2=amin+0.618*(amax-amin); y2=f_1(no,x,d,a2); while abs(amax-amin)>=e if y1>=y2 amin=a1; a1=a2; y1=y2; a2=amin+0.618*(amax-amin); y2=f_1(no,x,d,a2); else amax=a2; a2=a1; y2=y1; a1=amax-0.618*(amax-amin); y1=f_1(no,x,d,a1); end end xx=(amax+amin)/2; end 12、牛顿一维法 function xx=newton(n0,x,d,amax,e) %UNTITLED9 此处显示有关此函数的摘要% 此处显示详细说明 syms s; z=x+s*d; if n0==1 a=z(1); b=z(2); f=a^2+2*b^2-2*a*b-4*a; elseif n0==2 a=z(1); b=z(2); f=a^4-2*a*a*b-2*a*b+a*a+2*b*b+4.5*a-4*b+4; elseif n0==3 a=z(1); b=z(2); c=z(3); f=a*a+b*b+c*c; end x0=amax; while(1) if subs(diff(diff(f,s),s),x0)==0 break; end x0 = x0-double(subs(diff(f,s),x0)/subs(diff(diff(f,s),s),x0)); if abs(double(subs(diff(f,s),x0))) break; end end xx=x0; end 13、不精确一维搜索法 functionalf=wolfe(n0,x,d) if n0==1 syms a b; f=a^2+2*b^2-2*a*b-4*a; g=gradient(f); xx=[a;b]; elseif n0==2 syms a b; f=a^4-2*a*a*b-2*a*b+a*a+2*b*b+4.5*a-4*b+4; g=gradient(f); xx=[a;b]; elseif n0==3 syms a b c; f=a*a+b*b+c*c; g=gradient(f); xx=[a;b;c]; end u=0.1; q=0.4; aa=0; bb=inf; alf=1; fx=double(subs(f,xx,x)); gx=double(subs(g,xx,x)); while 1 xk=x+alf*d; h=-u*alf*gx'*d; whilefx-double(subs(f,xx,xk))< h bb=alf; alf=(alf+aa)/2; h=-u*alf*gx'*d; xk=x+alf*d; end gk=double(subs(g,xx,xk)); ifgk'*d < q*gx'*d aa=alf; alf=min(2*alf,(alf+bb)/2); else break; end end 14、求导函数 function [g,ss]=gra(n0) %UNTITLED 此处显示有关此函数的摘要 % 此处显示详细说明 if n0==1 syms a b; f=a^2+2*b^2-2*a*b-4*a; g=gradient(f); ss=[a;b]; elseif n0==2 syms a b; f=a^4-2*a*a*b-2*a*b+a*a+2*b*b+4.5*a-4*b+4; g=gradient(f); ss=[a;b]; elseif n0==3 syms a b c; f=a*a+b*b+c*c; g=gradient(f); ss=[a;b;c]; end end 15、f0函数 functionyy=f0(n0,xx) %UNTITLED2 此处显示有关此函数的摘要 % 此处显示详细说明 if n0==1 a=xx(1); b=xx(2); yy=a^2+2*b^2-2*a*b-4*a; elseif n0==2 a=xx(1); b=xx(2); yy=a^4-2*a*a*b-2*a*b+a*a+2*b*b+4.5*a-4*b+4; elseif n0==3 a=xx(1); b=xx(2); c=xx(3); yy=a*a+b*b+c*c; end end 16、f_1函数 functionyy=f_1(n0,x,d,xx) syms s; z=x+s*d; if n0==1 a=z(1); b=z(2); f=a^2+2*b^2-2*a*b-4*a; elseif n0==2 a=z(1); b=z(2); f=a^4-2*a*a*b-2*a*b+a*a+2*b*b+4.5*a-4*b+4; elseif n0==3 a=z(1); b=z(2); c=z(3); f=a*a+b*b+c*c; end yy=double(subs(f,s,xx)); end 软件技术实验报告 学号2009300186 姓名赵佶男班级010109卓 越 大作业机房管理系统 课题基本目标要求: 1)可在系统中由系统管理员按班级指定时间进行上机课时安排,安排上机不得与其他已安排机时冲突。 2)在指定上机课时段,除了上机班级学生可以登录外,其余无关学生一律不得登录,除非系统管理员授权。预定上机时间结束时,自动 提前5分钟提示,待真正结束时即自动锁屏。 3)除上机课时安排以外,可以在机动时间段接受学生凭个人一卡通上机,且上机实施计时自动收费(即扣除学生一卡通上因上机而应缴 纳的上机服务费) 4)在接受零散学生付费上机时,可自动为其分配空闲机器并授权使用,在分配机器时应考虑机器的使用情况分布均匀,即每次分配机器是 前一时段未曾使用的机器,当学生一卡通上的余额,不足以支付1 小时上机服务费时,应提示其下机充值,并实施锁屏。 实验步骤: 首先,根据大作业的要求,我建立了机器表,流水表,学生基本情况表,上课表,以及一卡通表五个数据库表。机器表用来按照使用情况,选择空闲时间最长的机器。流水表用来记录现在机器以及人员使用的情况,是个 动态表,用来方便的取用和修改数据。学生基本情况表用来存放学生的学号,密码,班级等基本情况,以实现学生上课登录和自由登录。上课表存放各个班级的上课下课时间,以实现排课功能。一卡通表记录了每个学生一卡通内的金额,用来帮助实现上下机的扣费,以及余额不够支付一小时时间情况下得强制下机。 然后,我进行了窗体的设计。经过筛选优化,我设计了五个窗体,分别是主选择窗体,注册窗体,登录窗体,上课安排窗体,实时计费和下机窗体。 主选择窗体可以用来进行上课登录、学生自由登录、管理员登录和机器的推荐。注册窗体是用来进行学生登录密码的注册。登录窗体限制学生的学号和密码必须匹配才能登录。上课安排窗体可以输入班号、上下课时间并选择星期值。实时计费和下机窗体用来扣费并方便学生随时下机。 接下来,要按照要求进行代码的编写。 A)可在系统中由系统管理员按班级指定时间进行上机课时安排,安排上机不得与其他已安排机时冲突。 此功能我在排课窗体下用select选择出全体班级的上下课以及星期值,并将管理员希望的上下课时间转换为时间类型数值,进行循环比较,用do until 语句逐个比较,使得上下课时间点都不得在其他班级的上课时间段内。如果时间不冲突,就实施修改数据库的功能,并更新保存。 B)在指定上机课时段,除了上机班级学生可以登录外,其余无关学生一律不得登录,除非系统管理员授权。预定上机时间结束时,自动提前5分钟提示,待真正结束时即自动锁屏。 在主选择窗体内有上课登录按钮和自由登录按钮。点击上课登录,输入学 武汉纺织大学《最新数据 库管理系统》课程实验报告 班级: _______姓名:实验时间:年月日指导教师:_______ 一、实验目的 1、通过实验,使学生全面了解最新数据库管理系统的基本内容、基本原理。 2、牢固掌握SQL SERVER的功能操作和Transact-SQL语言。 3、紧密联系实际,学会分析,解决实际问题。学生通过小组项目设计,能够运用最新数据库管理系统于管理信息系统、企业资源计划、供应链管理系统、客户关系管理系统、电子商务系统、决策支持系统、智能信息系统中等。 二、实验内容 1.导入实验用示例数据库: f:\教学库.mdf f:\教学库_log.ldf f:\仓库库存.mdf f:\仓库库存_log.ldf 1.1 将数据库导入 在SqlServer 2005 导入已有的数据库(*.mdf)文件,在SQL Server Management Studio 里连接上数据库后,选择新建查询,然后执行语句 EXEC sp_attach_db @dbname = '教学库', @filename1 = 'f:\教学库.mdf', @filename2 = 'f:\教学库_log.ldf' go use [教学库] EXEC sp_changedbowner 'sa' go EXEC sp_attach_db @dbname = '仓库库存', @filename1 = 'f:\仓库库存.mdf', @filename2 = 'f:\仓库库存_log.ldf' go use [仓库库存] EXEC sp_changedbowner 'sa' go 1.2 可能出现问题 附加数据库出现“无法打开物理文件"X.mdf"。操作系统错误5:"5(拒绝访问。)"。(Microsoft SQL Server,错误: 5120)”。 解决:找到要附加的.mdf文件-->右键-->属性-->安全-->选择当前用户-->编辑-->完全控制。对.log文件进行相同的处理。 2.删除创建的数据库,使用T-SQL语句再次创建该数据库,主文件和日志文件的文件名同上,要求:仓库库存_data最大尺寸为无限大,增长速度为20%,日志文件初始大小为2MB,最大尺寸为5MB,增长速度为1MB。 CREATE DATABASE仓库库存 (NAME = '仓库库存_data', FILENAME = 'F:\仓库库存_data.MDF' , SIZE = 10MB, FILEGROWTH = 20%) LOG ON (NAME ='仓库库存_log', FILENAME = 'F:\仓库库存_log. LDF', SIZE = 2MB, MAXSIZE = 5MB, FILEGROWTH = 1MB) 2.1 在数据库“仓库库存”中完成下列操作。 (1)创建“商品”表,表结构如表1: 学生实验报告册 (理工类) 课程名称:大型数据库技术专业班级:12计算机科学与技术(1)学生学号:学生姓名: 所属院部:计算机工程学院指导教师:陈爱萍 2014——20 15学年第2 学期 金陵科技学院教务处制 实验报告书写要求 实验报告原则上要求学生手写,要求书写工整。若因课程特点需打印的,要遵照以下字体、字号、间距等的具体要求。纸张一律采用A4的纸张。 实验报告书写说明 实验报告中一至四项内容为必填项,包括实验目的和要求;实验仪器和设备;实验内容与过程;实验结果与分析。各院部可根据学科特点和实验具体要求增加项目。 填写注意事项 (1)细致观察,及时、准确、如实记录。 (2)准确说明,层次清晰。 (3)尽量采用专用术语来说明事物。 (4)外文、符号、公式要准确,应使用统一规定的名词和符号。 (5)应独立完成实验报告的书写,严禁抄袭、复印,一经发现,以零分论处。 实验报告批改说明 实验报告的批改要及时、认真、仔细,一律用红色笔批改。实验报告的批改成绩采用百分制,具体评分标准由各院部自行制定。 实验报告装订要求 实验批改完毕后,任课老师将每门课程的每个实验项目的实验报告以自然班为单位、按学号升序排列,装订成册,并附上一份该门课程的实验大纲。 实验项目名称:Oracle数据库安装与配置实验学时: 1 同组学生姓名:实验地点:1316 实验日期:2015/3/27 实验成绩: 批改教师:陈爱萍批改时间: 实验1:Oracle数据库安装与配置 一、实验目的和要求 (1)掌握Oracle数据库服务器的安装与配置。 (2)了解如何检查安装后的数据库服务器产品,验证安装是否成功。 (3)掌握Oracle数据库服务器安装过程中出现的问题的解决方法。 (4)完成Oracle 11g数据库客户端网路服务名的配置。 (5)检查安装后的数据库服务器产品可用性。 (6)解决Oracle数据库服务器安装过程中出现的问题。 二、实验设备、环境 设备:奔腾Ⅳ或奔腾Ⅳ以上计算机 环境:WINDOWS 7、ORACLE 11g中文版 三、实验步骤 (1)从Oracle官方网站下载与操作系统匹配的Oracle 11g数据库服务器和客户机安装程序。 (2)解压Oracle 11g数据库服务器安装程序,进行数据库服务器软件的安装。 口腔鳞癌组织中肿瘤转移相关基因1(MTA1) 一、选择原因及应用 口腔鳞癌组织中肿瘤转移相关基因1(MTA1)在蛋白和mRNA的表达水平,揭示其与口腔鳞癌(OSCC)发生、发展的关系。方法采用免疫组织化学法和原位杂交技术检测46例OSCC标本、15例口腔黏膜白斑与20例正常口腔黏膜标本中MTAl 基因的表达水平,并分析其与OSCC临床病理学参数的关系。结果MTA1蛋白和MTA1mRNA在OSCC组织中的表达水平显著高于口腔黏膜白斑和正常口腔黏膜(P 〈0.05),口腔黏膜白斑中MTA1蛋白和MTA1mRNA表达水平显著高于口腔正常黏膜(P〈0.01),MTA1蛋白和MTA1mRNA表达与肿瘤浸润深度和淋巴结转移密切相关(P〈0.05)。结论MTA1基因在蛋白和mRNA的表达水平在OSCC发生、发展及浸润转移过程中起一定促进作用,有望成为判断OSCC预后及选择治疗方案的一个新肿瘤标志物。 二、2查阅NCBI得到MTA1相关信息并获得目的基因PREDICTED: Gorilla gorilla gorilla metastasis associated 1 (MTA1), mRNA NCBI Reference Sequence: XM_004055801.1 FASTA Graphics LOCUS XM_004055801 2872 bp mRNA linear PRI 03-DEC-2012 DEFINITION PREDICTED: Gorilla gorilla gorilla metastasis associated 1 (MTA1), mRNA. ACCESSION XM_004055801 VERSION XM_004055801.1 GI:426378238 KEYWORDS . SOURCE Gorilla gorilla gorilla (western lowland gorilla) ORGANISM Gorilla gorilla gorilla Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Euarchontoglires; Primates; Haplorrhini; Catarrhini; Hominidae; Gorilla. COMMENT MODEL REFSEQ: This record is predicted by automated computational 黑龙江大学 “数据库系统原理课程设计”总结报告 学院软件学院 年级2014级 专业软件工程 学号20143983 姓名陆芝浩 报告日期2016.11.9 成绩 黑龙江大学软件学院 1、开发环境 操作系统:Windows7 编程语言环境:VC++6.0 2、DBMS系统架构 3、DBMS主要功能模块 1、实现SQL语句中的Create Table建表语句,建立相应的数据库表,并生成相应的数据字典文件和数据文件。 2、实现alter table表模式的修改功能: ①能够为已建立的表添加属性。 ②能够从已建立的表中删除属性。 3、实现drop table删除表功能。 4、实现create index创建索引的功能。 5、实现drop index删除索引的功能。 6、实现insert可以向已经创建的表插入元组。 7、实现delete从已经创建的表中删除元组。 8、实现update修改表中的数据。 9、实现SELECT语句,包括: 实现单表全属性查询。 实现单表单属性查询。 实现多表的连接全属性查询。 实现多表的连接和选择条件的全属性查询。 实现多表的连接的单属性查询。 实现多表的连接和选择的单属性查询。 实现单表的选择的单属性查询。 实现单表的选择的全属性查询。 10、利用启发式关系代数优化算法进行查询优化。 11、建立访问权限,根据数据字典(DD)实现对数据库的安全性检查和完整性约束的机制。 3.1 SQL语言的词法和语法分析 (1)功能介绍 通过编译原理的知识对输入的SQL语句进行词法分析,将SQL语句拆分为若干个单词,对其进行语法分析,确定输入的SQL语句的含义. (2)相关理论 利用编译原理的相关知识,对输入的SQL语句进行模仿SQL语言的词法及语法结构的分析。 UML 建模大作业实验报告 组号:选题名:E-store 网上书店系统小组成员 .1.需求模型 从用户角度描述系统功能的用例 登录 (from Use Case View) .J 八. 修改 (from Use Case View) 个人信息维护 (from Use Case View) 从系统管理员角度描述系统功能的用例 (from Use Case View) 补充 注册 选购 (from Use Case View) * II f (from Use Case View) f 令查看 图书浏览 (from Use Case View) II 7 ------- 亠 '收藏夹维护 (from Use Case View) ' (from Use Case View) 游客 会员 (from Use Case View) (from Use Case View) 购物车管理 添加 I (from Use Case View), (from Use Case View) 图书查询 (from Use Case View) ■订单维护 (from Use Case View) 删除 (from Use Case View) 结账 (from Use Case View) 订单状态查询 (from Use Case View) 缺书登记 (from Use Case View) 一 一' 意见反馈 (from Use Case View) ■分配权限 管理员(from Use Case View) 添加人员(from Use Case View) (from Use Case View) 后台用户管理 ---- 弋 (from Use Case View) ■ > ^,X**(from Use Case View) (from Use Case View) 折扣管理 Z I 身份验证 (from Use Case View) ? 、 销售管理 (from Use Case View) 二d ____ - \图书管理 \ h - ■■■ ■ (from Use Case View) .辿—-- 网站用户管理 V (from Use Case View) 订货管理 (from Use Case View) 查看人员 (from Use Case View) 查看意见反馈 (from Use Case View) 2.分析模型 2.1.架构模型 (from Use Case View) r梟—_ ■<- ■- V 删除 '■ (from Use Case View) 辽二询 (from Use Case View) / 统计 (from Use Case View) 订货通知 (from Use Case View) ,沖后台数据库 (from Use Case View) / (from Use Case View) 服务商 (from Use Case View) Chapter 19 Homologous and Site-Specific Recombination 1. Please explain why most of engineering E. coli cell strain for protein over-expression has the genetic type of RecA- ? (3 points)请解释为什么对于蛋白过度表达的大多数工程大肠杆菌细胞株具有遗传型的RecA- 答:大肠杆菌中的RecA蛋白是第一个被发现的DNA链转移蛋白,这类蛋白质在重组中起着核心作用,促进单链DNA片段与同源双链DNA片段发生链置换。如果某质粒可能携带可作为大肠杆菌重组系统的底物的DNA重复序列,那就应该考虑换用重组缺陷型菌株的可能性。用携带有recA基因突变的菌株就几乎没有重组的可能性,这就保证了质粒的稳定。 2. Please read Invitrogen catalog, and explain how a single Gateway entry plasmid can be applied for multiple different applications. Detail description is expected. (7 points) 答:Gateway技术是一项基因克隆和表达的新技术,在构建好一个入门克隆后不再需要使 用限制性内切酶和连接酶。可以直接转移目的基因到Gateway兼容的各种表达载体。由于 重组时DNA片段的阅读框和方向保持不变,因而不必再对新的表达克隆进行测序。这样, 在使用每一种新的表达系统时,将会节省更多时间。目的基因克隆进入门载体后,可以同 时转移目的基因到多个目的载体。 Gateway技术基于已深入研究的λ噬菌体位点特异重组系统(attB x attP →attL x attR)(图一)。BP和LR两个反应就构成了Gateway技术。 BP反应是利用一个attB DNA 片段或表达克隆和一个attP供体载体(Donor vector)之间的重组反应,创建一个入门克隆。LR反应是一个attL入门克隆和一个attR目的载体之间的重组反应。LR反应用来在平行的反应中转移目的序列到一个或更多个目的载体。Gateway表达克隆仅需两步(图二): 1 创建入门克隆,通过PCR或者传统的克隆方法将目的基因克隆进入门载体。 一、需要实现得功能 1、1录入学生基本信息得功能 学生基本信息主要包括:学号、姓名、性别、年龄、出生地、专业、班级、总学分,在插入时,如果数据库则已经存在该学号,则不能再插入该学号。 1、2修改学生基本信息得功能 在管理员模式下,只要在表格中选中某个学生,就可以对该学生信息进行修改。 1、3查询学生基本信息得功能 可使用“姓名”对已存有得学生资料进行查询。 1、4删除学生基本信息得功能 在管理员模式下,只要选择表格中得某个学生,就可以删除该学生. 1、5用户登陆 用不同得登录权限可以进入不同得后台界面,从而实现权限操作。 1、6用户登陆信息设置 可以修改用户登陆密码 二、设计得目得 课程设计就是学习完该课程后进行得一次较全面得综合练习。其目得在于通过实践加深学生对面向对象程序设计得理论、方法与基础知识得理解,掌握使用Java语言进行面向对象设计得基本思路与方法;加强学生研发、调试程序得能力;培养学生分析、解决问题得能力;提高学生得科技论文写作能力。 三、总体设计 3、1功能图 3、2 Use Case图 3、3系统执行流程图 3、4、数据库设计 主要就是E-R 图与数据库二维表得设计 3、4、1数据库E-R 模型 3、4、2数据库关系模型—-二维表 学生表(s tu dent ) 字段 数据类型 说明 st uId nvarc har(30) 学号 s tuName n varchar(30) 姓名 st uSe x nva rchar(30) 性别 stuAg e i nt 年龄 s tuJg nvar char (30) 籍贯 stuZy n var cha r(30) 专业 cl as sId nvarch ar(30) 班号 stuSour se numeric(5,2) 总学分 学号 姓名 性别 年龄 出生地 专业 班级 总学分 登陆用户管理 账号 密码 职位 学 生 武汉轻工大学 经济与管理学院实验报告 实验课程名称大型数据库管理 实验起止日期2019.11.5至2019.12.10 实验指导教师程红莉 实验学生姓名学生班级学号物流管理1702 实 验 评 语 实验 评分 教师 签名 年月日 实验项目名称数据完整性实验日期2019.12.10 学生姓名班级学号物流管理1702 一、预习报告(请阐述本次实验的目的及意义) 1.熟悉通过SQL对数据进行完整性控制。 2.完成书本上习题的上机练习。 二、实验方案(请说明本次实验的步骤和进程) 1.用Constraint和Check建立完整性约束条件 教材164页例[7] Student表的ssex 只允许取‘男’或‘女’ create table student1 (sno char(9) primary key, sname char(8) not null, sex char(2) check(sex in('男','女')), sage smallint, sdept char(20) ); 教材164页例[8] create table sc1 (sno char(9), cno char(4), grade smallint check(grade>=0 and grade<=100), primary key(sno,cno), foreign key(sno)references student1(sno), foreign key(cno)references course(cno) ); 教材164页例[7]、例[8](给学生表的性别增加约束条件,即只允许“男”或“女”。可用语句: alter table student add constraint course1 check(sex in('男','女')) alter table sc add constraint course2 check (score>=0 and score<=100) go 学生实验报告 实验课名称: C++程序设计 实验项目名称:综合大作业——学生成绩管理系统专业名称:电子信息工程 班级: 学号: 学生: 同组成员: 教师: 2011 年 6 月 23 日 题目:学生成绩管理系统 一、实验目的: (1)对C++语法、基础知识进行综合的复习。 (2)对C++语法、基础知识和编程技巧进行综合运用,编写具有一定综合应用价值的稍大一些的程序。培养学生分析和解决实际问题的能力,增强学生的自信心,提高学生学习专业课程的兴趣。 (3)熟悉掌握C++的语法和面向对象程序设计方法。 (4)培养学生的逻辑思维能力,编程能力和程序调试能力以及工程项目分析和管理能力。 二、设计任务与要求: (1)只能使用/C++语言,源程序要有适当的注释,使程序容易阅读。 (2)至少采用文本菜单界面(如果能采用图形菜单界面更好)。 (3)要求划分功能模块,各个功能分别使用函数来完成。 三、系统需求分析: 1.需求分析: 为了解决学生成绩管理过程中的一些简单问题,方便对学生成绩的管理 (录入,输出,查找,增加,删除,修改。) 系统功能分析: (1):学生成绩的基本信息:学号、、性别、C++成绩、数学成绩、英语成绩、 总分。 (2):具有录入信息、输出信息、查找信息、增加信息、删除信息、修改信息、 排序等功能。 2.系统功能模块(要求介绍各功能) (1)录入信息(Input):录入学生的信息。 (2)输出信息(Print):输出新录入的学生信息。 (3)查找信息(Find):查找已录入的学生信息。 (4)增加信息(Add):增加学生信息。 (5)删除信息(Remove):在查找到所要删除的学生成绩信息后进行删除并输出删除后其余信息。 (6)修改信息(Modify):在查到所要修改的学生信息后重新输入新的学生信息从而进行修改,然后输出修改后的所有信息。 (7)排序(Sort):按照学生学号进行排序。 3.模块功能框架图 分子生物学科大重点 知识点 名词解释 基因gene:能够表达和产生蛋白质和RNA的DNA序列,是决定遗传性状的功能单位 基因组genome:细胞或生物体的一套完整单倍体的遗传物质的总和 基因组文库(genomic library):由基因组DNA所制成的基因文库 基因文库(Gene library)是来自某生物的不同DNA序列的总集这些序列都已被克隆进了载体以便于纯化贮存与分析。 cDNA文库(cDNA library):用来自表达目的基因的细胞或组织的mRNA作为来源构建的文库。cDNA 文库不同于基因组文库,被克隆DNA是从cRNA反转录来源的DNA。cDNA组成特点是其中不含有内含子和其他调控序列。 Sd序列(Shine-Dalgarno sequence):原核生物mRNA起始密码子上游8-13个核苷酸处的保守序列,可与核糖体小亚基中的16srRNA的3'-端附近的互补序列配对,称为核糖体结合位点,又叫sd序列。多聚核糖体(Polyribosomes):在蛋白质合成过程中,同一条mRNA分子能够同多个核糖体结合,同时合成若干条蛋白质多肽链,结合在同一条mRNA上的核糖体就称为多聚核糖体。 tRNA负载(tRNA charging): The amino acid is joind to the tRNA by aminoacyl-tRNA synthetases to bacome charged tRNA. This process is called tRNA charging. 操纵子(Operon):是原核生物基因表达的单位,它包括被协同调节的基因和被调节基因的产物所识别的调控原件, 在细菌中,为一个代谢途经所需要的几种酶的结构基因,可沿DNA直线排列在一起,并受一个共同的启动基因和操纵基因的控制,把这样的启动基因、操纵基因和结构基因可以看做一个单位,称为操纵子。 启动子(Promoter): DNA上的一个特定位点,RNA聚合酶在此和DNA结合,并由此开始转录过程。基因表达(Gene expression):是指生物基因组中结构基因所携带的遗传信息经过转录、翻译等一系列过程,合成特定的蛋白质,进而发挥其特定的生物学功能和生物学效应的全过程。 目录 第一章、需求分析 (2) 1 、需求概述 (2) 2 、功能简介 (2) 第二章、概念结构设计 (3) 1、在员工实体内的E-R图 (3) 2、部门实体内的E-R图 (3) 3、在工资实体内的E-R图 (3) 第三章、逻辑结构设计 (4) 第四章、物理结构设计 (4) 第五章、数据库的实施和维护 (5) 一、数据库的创建 (5) 二、表格的建立 (5) 1、建立Employsse表插入数据并设计相关的完整性约束 (5) 2、建立departments表插入数据并设计相关的完整性约束 (7) 3、建立 salary表插入数据并设计相关的完整性约束 (8) 三、建立视图 (9) 四、建立触发器 (10) 五、建立自定义函数 (12) 六、建立存储过程 (13) 第六章、总结 (14) 第一章、需求分析 1 、需求概述 针对现代化公司管理情况,员工管理工作是公司运行中的一个重环节,是整个公司管理的核心和基础。它的内容对于公司的决策者和管理者来说都至关重要,所以公司管理系统应该能够为用户提供充足的信息和快捷的查询手段。但一直以来人们使用传统人工的方式管理文件工籍,这种管理方式存在着许多缺点,如:效率低、保密性差,另外时间一长,将产生大量的文件和数据,这对于查找、更新和维护都带来了不少的困难。 公司员工管理系统借助于计算机强大的处理能力,大大减轻了管理人员的工作量,并提高了处理的准确性。 能够进行数据库的数据定义、数据操纵、数据控制等处理功能,进行联机处理的相应时间要短。 具体功能包括:系统应该提供员工数据的插入、删除、更新、查询;员工基本信息查询的功能。 2 、功能简介 员工管理系统它可以有效的管理员工信息情况。具体功能有以下几个方面。基本信息的添加,修改,删除和查询。学生信息管理包括添加、查看学生列表等功能。 2013-2014学年第一学期《数据库原理》 课程实验报告 学号: 20112723 学生姓名:林苾湲 班级:软件工程2011-2 教师:陶宏才 辅导老师:张建华刘宝菊 2013年12月 实验一:表及约束的创建1.1 实验目的与内容 目的:创建数据表、添加和删除列、实现所创建表的完整性约束。 内容:11-2、11-26~33。 报告:以11-31作为实验一的报告。 1.2 实验代码及结果 1.2.1 实验代码 (1)CREATE TABLE orderdetail20112723 ( Order_no char(6) PRIMARY KEY CONSTRAINT Order_no_constraint20112723 CHECK(Order_no LIKE'[A-Z][A-Z][0-9][0-9]'), Cust_no char(6) NOT NULL, P_no char(6) NOT NULL, Order_total int NOT NULL, Order_date datetime NOT NULL, CONSTRAINT person_contr20112723 FOREIGN KEY (P_no) REFERENCES person20112723(P_no) ON DELETE CASCADE ON UPDATE CASCADE, CONSTRAINT customer_contr20112723 FOREIGN KEY (Cust_no) REFERENCES customer20112723(Cust_no) ON DELETE CASCADE ON UPDATE CASCADE, ) (2)ALTER TABLE salary20112723 ADD CONSTRAINT Pno_FK20112723 FOREIGN KEY(P_no) REFERENCES person20112723(P_no) 1.2.2 实验结果 (1) 中南大学大型数据库实验报告 课程名称大型数据库技术指导教师 姓名 学号 专业班级 《大型数据库技术》实验三 1.写一个PROC程序,查询并显示表Agents的所有记录。要求定义一个数组类型的宿主变量,一次性把所有记录从服务器端传送到客户端,然后逐行显示。 Java代码如下: public void selectAgents() throws Exception { Connection conn = this.getConnection(); Statement stmnt = conn.createStatement(); ResultSet set = stmnt.executeQuery("select * from Agents"); System.out.println("查询结果如下:\n"); while (set.next()) { String id = set.getString("AID"); String name = set.getString("ANAME"); String city = set.getString("CITY"); int percent = set.getInt("PERCENT"); System.out.println("aid:"+ id + " aname:"+ name + " city:" + city + " percent:" + percent); } set.close(); stmnt.close(); conn.close(); } 测试代码: public static void main(String[] args) throws Exception { String url = "jdbc:oracle:thin:@localhost:1521:ORCL"; String user = "jelly"; String pwd = "csusoft"; DBOpers db = new DBOpers(url, user, pwd); db.selectAgents(); } 测试结果: 2.写一个PROC程序,根据用户输入的城市,查询并逐行显示该城市所有顾客的编号、名称和折扣。如果该城市中不存在任何顾客,则调用一个错误处理函数,函数中显示错误信息:“该城市中不存在顾客”。 Java代码如下: 数字图像处理综合实验报告 车牌识别技术(LPR) 组长:__ ******_____ 组员:___ _****** _ ___ _******_____ ____ _*******___ 指导老师:___ *******_____ *****学院****学院 2010年6月10日 实验五车牌识别技术(LPR) 一、实验目的 1、了解车牌识别系统的实现,及车牌识别系统的应用; 2、了解并掌握车牌识别系统如何实现。 二、实验内容 1、车牌识别系统的图像预处理、 2、车牌定位、 3、字符分割 4、字符识别 三、实验原理 车辆牌照识别(LPR)系统是一个专用的计算机视觉系统,它能够自动地摄取车辆图像和识别车牌号码,可应用在公路自动收费、停车场管理、失窃车辆侦察、门卫系统、智能交通系统等不同场合。LPR系统的广泛应用将有助于加快我国交通管理自动化的进程。 1、预处理 摄像时的光照条件,牌照的整洁程度,摄像机的状态(焦距,角度和镜头的光学畸变),以及车速的不稳定等因素都会不同程度的影响图像效果,出现图像模糊,歪斜或缺损,车牌字符边界模糊不清,细节不清,笔画断开,粗细不均等现象,从而影响车牌区域的分割与字符识别的工作,所以识别之前要进行预处理。预处理的包括: 1)消除模糊—— 用逆滤波处理消除匀速运动造成的图像运动模糊 2)图像去噪。 通常得到的汽车图像会有一些污点,椒盐噪声,应用中值滤波 3)图像增强 自然光照度的昼夜变化会引起图像对比度的不足,所以必须图像增强,可以采用灰度拉伸,直方图均衡等 通过以上处理,提高了图像的质量,强化了图像区域。 2、车牌定位 自然环境下,汽车图像背景复杂、光照不均匀,如何在自然背景中准确地确定牌照区域是整个识别过程的关键。首先对采集到的视频图像进行大范围相关搜索,找到符合汽车牌照特征的若干区域作为候选区,然后对这些侯选区域做进一步分析、评判,最后选定一个最佳的区域作为牌照区域,并将其从图象中分割出来。 ? 图像的灰度化 ? 图像灰度拉伸 ? 对图像进行边缘检测 采用Sobel 算子经行边缘检测 该算子包含两组3*3的矩阵,分别为横向及纵向,将之与图像作平面卷积,即可分别得出横向及纵向的亮度差分近似值。如果以A 代表原始图像,Gx 及Gy 分别代表经横向及纵向边缘检测的图像,其公式如下: A Gx *]101202101?????+-+-+-?????= and A *121000121Gy ?? ?? ? ---+++?????= 图像的每一个像素的横向及纵向梯度近似值可用以下的公式结合,来计算梯度的大小。 2 y 2 x G G G += 然后可用以下公式计算梯度方向。 ??? ? ??=x y G G arctan θ 在以上例子中,如果以上的角度θ等于零,即代表图像该处拥有纵向边缘,左方较右方暗。 ? 对其进行二值化 ? 纹理分析法 行扫描行法是利用了车牌的连续特性。车牌区域有连续7个字符,而且字符与字符之间的距离在一定范围内。定义从目标到背景或者从背景到目标为一个跳变。牌照区域相对于其它非车牌区域跳变多,而且间距在定范围内和跳变次数大于一定次数,并且连续满足上述要求的行要达到一定的数目。 从下到上的顺序扫描,对图像的每一行进行从左向右的扫描,碰到跳变点记录下当前位置,如果某行连续20个跳变点以上,并且前一个跳变点和后一个跳变点的距离在30个像素内,就记录下起始点和终止点位置,如果连续有10行以上这样的跳变点,我们就认为该区域就是车牌预选区域。 3、字符分割: 完成牌照区域的定位后,再将牌照区域分割成单个字符,然后进行识别。字符分割一般采用垂直投影法。由于字符在垂直方向上的投影必然在字符间或字符内的间隙处取得局部最小值的附近,并且这个位置应满足牌照的字符书写格式、字符、尺寸限制和一些其他条件。利用垂直投影法对复杂环境下的汽车图像中的字符分割有较好的效果。 ? 车牌区域灰度二值化 附件1: 《面向对象程序设计》 大作业 题学专班姓目 院 业 级 名 学生成绩管理系统 文法学院 教育学 教育学1201 杨欣 指导教师鄢红国 2013 年12 月20 日学号:0121213640126 目录 一二三四五六七八十设计目的 (1) 大作业的内容 (2) 大作业的要求与数据 (3) 大作业应完成的工作 (4) 总体设计(包含几大功能模块) (5) 详细设计(各功能模块的具体实现算法——流程图) (6) 调试分析(包含各模块的测试用例,及测试结果) (7) 总结 (8) 参考资料 (9) 一二 大作业的目的 《面向对象程序设计》是一门实践性很强的课程,通过大作业不仅可以全方位检验学生知识掌握程度和综合能力,而且还可以进一步加深、巩固所学课程的基本理论知识,理论联系实际,进一步培养自己综合分析问题和解决问题的能力。更好地掌握运用C++语言独立地编写、调试应用程序和进行其它相关设计的技能。 大作业的内容 对图书信息(包括编号、书名、总入库数量、当前库存量、已借出本数等) 进行管理,包括图书信息的输入、输出、查询、删除、排序、统计、退出.将图书的信息进行记录,信息内容包含:(1)图书的编号(2)图书的书名(3)图书的库存量。假设,现收集到了一个图书馆的所有图书信息,要求用C语言编写一个简单的图书管理系统,可进行录入、查询、修改和浏览等功能。学习相关开发工具和应用软件,熟悉系统建设过程。 三大作业的要求与数据 1、用C语言实现系统; 2、对图书信息(包括编号、书名、总入库数量、当前库存量、已借出本数)进行管理,包括图书信息的输入、输出、查询、删除、排序、统计、退出. 3、图书信息包括:其内容较多,为了简化讨论,要求设计的管理系统能够 完成以下功能: (1)每一条记录包括一本图书的编号、书名、库存量 (2)图书信息录入功能:(图书信息用文件保存,可以一次完成若干条记录 的输入。) (3)图书信息显示浏览功能:完成全部图书记录的显示。 (4)查询功能:完成按书名查找图书记录,并显示。 (5)图书信息的删除:按编号进行图书某图书的库存量. (6)借书登记系统:可以输入读者编号和所借书号来借书。 (7)还书管理系统:可以输入读者编号和所借书号来还书。 (8)、应提供一个界面来调用各个功能,调用界面和各个功能的操作界面应 尽可能清晰美观! 中国科学技术大学 细胞生物学试题 一.名词解释(4/40) 1.脂质体 2.吞噬作用 3.磷脂转位因子 4. 微管骨架装备 5.原初反应 6.核基质 7.细 胞周期 8.细胞决定 9.细胞编程死亡 10. 细胞通信 二.填空(3/30) 1.用于透射电镜观察的生物样品应具备几 点特殊要求:1)________2)________3)____ ________ 2.通道蛋白参与细胞质膜的_________运输. 3.线粒体增殖是通过__________进行的,且 不同步于________. 4.叶绿体的电子传递体和光合磷酸化酶系统,定位于叶绿体的_________. 5.根据DNA复性动力学的研究,真核生物DN A序列可分为3种类型:1)______2)_______ 3)_____. 6.染色体要确保在细胞世代种的稳定性起 码应具备3个结构要素,那就是___________ ______. 7.减数分裂过程中,第一次分裂后期是____ _染色体分离,而第二次分裂后期是____染 色体分离. 8.细胞分化是由于基因选择性表达的差异 造成的.而基因表达的差异又是由于______ __造成的. 9.生长因子受体和胞外生长因子选择性结 合是通过受体的_________作用,把信号传 递到胞内. 10.促使细胞融合的试剂是_____,促使细胞 骨架中微管解聚的试剂是_____,促使细胞 排核的试剂是_____. 三.问答题(10/30) 1.简述细胞内结构区室化的生物学意义. 2.简述染色体骨架-发射环四级结构模型. 3.酵母细胞中SPF如何调节G1期进入S期, MPF如何调节G2期进入M期? 1. 细胞倍增与细胞周期 2. G0期和G1期 3. P34cdc2&CDK2 4. SPF&MPF 5. Cyclin 6. Ubiquitin 7. Cdc25&Weel gene 8. Thr161,Thr14,Tyr15 9. 细胞分裂极性 10. 卵列 问答题 1. 在酵母细胞周其中如何调节G1到S,G2到M的运转? 2. P53和Rb在镇喝多细胞生物中的作用是什么? 练习二 名词解释 1. 细胞膜受体 2. G蛋白 3. 第二信号 4. 双信号系统 5. 接头蛋白 6. NFKB/IKB 7. Ca++泵ATP酶 8. CaM 9. 信号反馈系统 10. 蛋白激酶与磷酸酶 问答题 1. 试比较生长因子受体酪氨酸激酶通讯途径与肌醇磷脂通讯途径的特点 2. Ca-CaM通讯与cAMP通讯有何联系? 名词解释 1. 细胞全能性 2. 细胞决定 3. 细胞分化 4. 顶体反应 5. 皮层反应 6. 调整发育与镶嵌发育 7. 克隆 8. 干细胞 9. 染色质重组 10. 基因差异表达 问答题 1. 是从发育和遗传的两个角度分析细胞分化的原因 2. 果蝇圆盘实验说明什么?你认为是什么机 xxxx大学《数据库管理系统》课程实验报告 班级: _______姓名:实验时间:年月日指导教师:_______ 一、实验目的 1、通过实验,使学生全面了解最新数据库管理系统的基本内容、基本原理。 2、牢固掌握SQL SERVER的功能操作和Transact-SQL语言。 3、紧密联系实际,学会分析,解决实际问题。学生通过小组项目设计,能够运用最新数据库管理系统于管理信息系统、企业资源计划、供应链管理系统、客户关系管理系统、电子商务系统、决策支持系统、智能信息系统中等。 二、实验内容 1.导入实验用示例数据库: f:\教学库.mdf f:\教学库_log.ldf f:\仓库库存.mdf f:\仓库库存_log.ldf 1.1 将数据库导入 在SqlServer 2005 导入已有的数据库(*.mdf)文件,在SQL Server Management Studio 里连接上数据库后,选择新建查询,然后执行语句 EXEC sp_attach_db @dbname = '教学库', @ = 'f:\教学库.mdf', @ = 'f:\教学库_log.ldf' go use [教学库] EXEC sp_changedbowner 'sa' go EXEC sp_attach_db @dbname = '仓库库存', @ = 'f:\仓库库存.mdf', @ = 'f:\仓库库存_log.ldf' go use [仓库库存] EXEC sp_changedbowner 'sa' go 1.2 可能出现问题 附加数据库出现“无法打开物理文件"X.mdf"。操作系统错误5:"5(拒绝访问。)"。(Microsoft SQL Server,错误: 5120)”。 解决:找到要附加的.mdf文件-->右键-->属性-->安全-->选择当前用户-->编辑-->完全控制。对.log文件进行相同的处理。 2.删除创建的数据库,使用T-SQL语句再次创建该数据库,主文件和日志文件的文件名同上,要求:仓库库存_data最大尺寸为无限大,增长速度为20%,日志文件初始大小为2MB,最大尺寸为5MB,增长速度为1MB。 CREATE DATABASE仓库库存 (NAME = '仓库库存_data', = 'F:\仓库库存_data.MDF' , SIZE = 10MB, = 20%) LOG ON (NAME ='仓库库存_log', = 'F:\仓库库存_log. LDF', SIZE = 2MB, MAXSIZE = 5MB, = 1MB) 2.1 在数据库“仓库库存”中完成下列操作。 (1)创建“商品”表,表结构如表1: (2)创建“仓库”表,表结构如表2: 表2 仓库表
相关主题
文本预览