排队模型(matlab代码)
- 格式:doc
- 大小:42.50 KB
- 文档页数:5



M/M/C排队模型及其应用摘要:将随机服务系统中M/M/C排队模型应用到理发服务行业中。
通过对某理发店进行调查,以10min为一个调查单位调查顾客到达数,统计了72个调查单位的数据,又随机调查了113名顾客服务时间,得到了单位时间内到达的顾客数n和为每位顾客服务的时间t,然后利用 2拟合检验,得到单位时间的顾客到达舒服从泊松分布,服务时间服从负指数分布,从而建立起M/M/C等待制排队模型,通过计算和分析M/M/C排队模型的主要指标,得到理发店宜招聘的最佳理发师数目。
排队论主要对由于受随机因素的影响而出现排队系统进行研究,它广泛应用于通信、交通与运输、生产与服务、公共服务事业以及管理运筹等一切服务系统。
在具体应用方面,把排队理论直接应用到实际生活方面也有不少的文献。
另外,排队论和其他学科知识结合起来也有不少应用。
我们可以从现实生活中去的数据资料,基于排队系统基本知识和M/M/C排队模型基本理论和统计学有关知识,通过分析研究,得出一些结论,为实际问题的解决提供参考资料,从而拓宽了该模型的应用领域,并对其他模型的系统应用也有一定的启示作用。
1 M/M/C排队模型定义若顾客的到达间隔服从参数为λ的负指数分布,到达的人数服从泊松分布,每位顾客的服务时间服从参数为μ的负指数分布,且顾客的到达时间与服务时间独立,系统有C个服务台,称这样的排队模型为M/M/C排队模型。
M/M/C排队模型也可以对应分为标准的M/M/C模型、系统容量有限的M/M/C模型和顾客源有限的M/M/C模型3种。
假定顾客到达服从参数为λ的泊松分布,每个顾客所需的服务时间服从参数为μ的指数分布,顾客到达后若有空闲的服务台就按到达的先后顺序接受服务,若所有的服务台均被占用时,顾客则排成一队等候。
令N(t)=i表示时刻t系统中恰有i位顾客,系统的状态集合为{0,1,2,…}。
可证{ N(t),t>0}为生灭过程,而且有:.....2C 1,C n C ...,21n n {....,21n nn,μ,,μ,,,++=====μλλ由此可见,服务台增加了,服务效率提高了。

M/G/1型排队系统分析与仿真一、排队系统排队论(queuing theory), 或称随机服务系统理论, 是通过对服务对象到来及服务时间的统计研究,得出这些数量指标(等待时间、排队长度、忙期长短等)的统计规律,然后根据这些规律来改进服务系统的结构或重新组织被服务对象,使得服务系统既能满足服务对象的需要,又能使机构的费用最经济或某些指标最优。
它是数学运筹学的分支学科。
也是研究服务系统中排队现象随机规律的学科。
广泛应用于计算机网络, 生产, 运输, 库存等各项资源共享的随机服务系统。
排队论研究的内容有3个方面:统计推断,根据资料建立模型;系统的性态,即和排队有关的数量指标的概率规律性;系统的优化问题。
其目的是正确设计和有效运行各个服务系统,使之发挥最佳效益。
一般的排队过程为:顾客由顾客源出发,到达服务机构(服务台、服务员)前,按排队规则排队等待接受服务,服务机构按服务规则给顾客服务,顾客接受完服务后就离开。
排队过程的一般过程可用下图表示。
我们所说的排队系统就是指图中虚线所包括的部分。
排队系统又称服务系统。
服务系统由服务机构和服务对象(顾客)构成。
服务对象到来的时刻和对他服务的时间(即占用服务系统的时间)都是随机的。
描述一个排队系统一般需要分析其三个组成部分:输入过程、排队规则和服务机构。
输入过程输入过程考察的是顾客到达服务系统的规律。
它可以用一定时间内顾客到达数或前后两个顾客相继到达的间隔时间来描述,一般分为确定型和随机型两种。
例如,在生产线上加工的零件按规定的间隔时间依次到达加工地点,定期运行的班车、班机等都属于确定型输入。
随机型的输入是指在时间t内顾客到达数n(t)服从一定的随机分布。
如服从泊松分布,则在时间t内到达n个顾客的概率为或相继到达的顾客的间隔时间T 服从负指数分布,即式中λ为单位时间顾客期望到达数,称为平均到达率;1/λ为平均间隔时间。
在排队论中,讨论的输入过程主要是随机型的。
排队规则排队规则分为等待制、损失制和混合制三种。
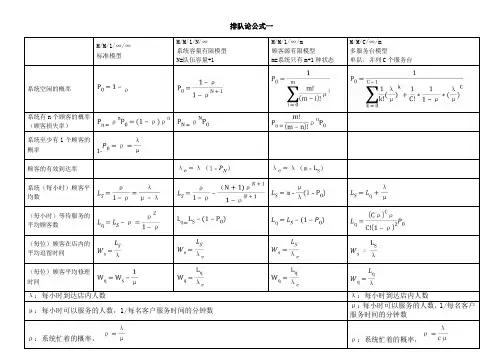
M/M/1/∞/∞标准模型M/M/1/N/∞
系统容量有限模型
N=队伍容量+1
M/M/1/∞/m
顾客源有限模型
m=系统只有m+1种状态
M/M/C/∞/m
多服务台模型
单队,并列C个服务台
系统空闲的概率ρ
系统有n个顾客的概率
(顾客损失率)
系统至少有1个顾客的
概率1-
顾客的有效到达率
系统(每小时)顾客平
均数
(每小时)等待服务的
平均顾客数
=
(每位)顾客在店内的
平均逗留时间
(每位)顾客平均修理
时间
λ:每小时到达店内人数λ:每小时到达店内人数
μ:每小时可以服务的人数,1/每名客户服务时间的分钟数μ:每小时可以服务的人数,1/每名客户服务时间的分钟数
ρ:系统忙着的概率,ρ:系统忙着的概率,
M/G/1/∞/∞M/D/1/N/∞M//1/∞/m 系统(每小时)顾客平均数
(每小时)等待服务的平均
顾客数
(每位)顾客在店内的平均
逗留时间
(每位)顾客平均修理时间
λ:每小时到达店内人数
μ:每小时可以服务的人数,1/每名客户服务时间的分钟数E(v):服务时间v的期望
D(v):方差
ρ:系统忙着的概率,λ:每小时到达店内人数
μ:每小时可以服务的人数,1/每名客户服务时间的分钟数
:服务时间v的期望
D(v):方差
ρ:系统忙着的概率,。


现代物业・新建设 2012年第11卷第10期高校食堂排队模型的研究李欣 肖芳园 杨牡丹(湖南工程学院管理学院,湖南 湘潭 411104)摘 要:在国内大多数高校中,学生食堂是学生就餐的主要场所,显而易见,食堂排队问题是一个无法回避的现实问题。
虽然增加窗口数量可以减少学生排队就餐的时间,但同时也增加了食堂的运营成本。
因此,如何在两者之间进行权衡,确定最佳的窗口数量,对学生和食堂来说都至关重要。
针对高校食堂排队问题进行研究,讨论建立简单的排队模型的基本思路。
关键词:高校食堂;排队;模型中图分类号:G647 文献标识码:A 文章编号:1671-8089(2012)10-0037-03一、食堂就餐排队模型探究的必要性(一)从生活细节着手,构建和谐校园食堂是学生就餐的场所,根据调查,在校学生选择在食堂就餐的比例高达80%以上,因此,如何确定最佳的窗口数量,让学生在最短时间内打到饭菜的同时又兼顾食堂的利益,是摆在眼前的一个非常现实的问题。
学生食堂的存在和发展状况不仅关系到在校学生的生活问题,而且在某种程度上也关系到学生们的身体健康和学习状况。
本研究通过构建一个简单的食堂排队模型,来解决学生就餐时排队等候时间过长的问题,从学生生活细节着手,为在校学生创造一个文明、和谐的就餐环境,有益于构建和谐校园。
(二)降低食堂管理成本,实现资源优化配置食堂既是学校的硬件设施之一,又是学校管理的重要组成部分。
通过对食堂排队模型的探究,得出食堂需要开设的窗口数量,有助于学校加强对食堂的管理,为进一步加强和改善食堂监管工作提供了依据。
此外,通过排队模型得出最佳窗口数量,避免窗口开设过少致使学生排队等候时间过长以及开设窗口过多导致人力的浪费。
因此,排队模型的建立与实现可以有效地降低食堂的管理成本,帮助实现资源的优化配置。
(三)响应国家政策,建设资源节约型社会国家主席胡锦涛在党的第十六届五中全会上强调要加快建设资源节约型社会,指出这是从我国国情出发的一项重大决策。

龙源期刊网
带优先权与不耐烦顾客排队模型的模拟仿真作者:秦海林刘建民
来源:《现代电子技术》2012年第20期
摘要:考虑一个有两类顾客到达的单服务台的排队系统。
两类顾客的到达过程均为泊松过程,第一类顾客较第二类顾客具有强占优先权,且第二类顾客由于第一类顾客的到达而变得不耐烦,其“耐性时间”服从负指数分布。
两类顾客的服务时间服从相同参数的负指数分布,服务规则是强占优先服务,在高负荷条件下用Matlab编程对此排队系统进行模拟仿真,为处理此类排队问题提供了一个新方法。
关键词:泊松过程;强占优先权;高负荷条件;系统模拟仿真
中图分类号:TN911-34; O226文献标识码:A。

排队模型之港口系统本文通过排队论和蒙特卡洛方法解决了生产系统的效率问题,通过对工具到达时间和服务时间的计算机拟合,将基本模型确定在//1M M排队模型,通过对此基本模型的分析和改进,在概率论相关理论的基础之上使用计算机模拟仿真(蒙特卡洛法)对生产系统的整个运行过程进行模拟,得出最后的结论。
好。
关键词:问题提出:一个带有船只卸货设备的小港口,任何时间仅能为一艘船只卸货。
船只进港是为了卸货,响铃两艘船到达的时间间隔在15分钟到145分钟变化。
一艘船只卸货的时间有所卸货物的类型决定,在15分钟到90分钟之间变化。
那么,每艘船只在港口的平均时间和最长时间是多少?若一艘船只的等待时间是从到达到开始卸货的时间,每艘船只的平均等待时间和最长等待时间是多少?卸货设备空闲时间的百分比是多少?船只排队最长的长度是多少?问题分析:排队论:排队论(Queuing Theory) ,是研究系统随机聚散现象和随机服务系统工作过程的数学理论和方法,又称随机服务系统理论,为运筹学的一个分支。
本题研究的是生产系统的效率问题,可以将磨损的工具认为顾客,将打磨机当做服务系统。
【1】M M:较为经典的一种排队论模式,按照前面的Kendall记号定义,//1前面的M代表顾客(工具)到达时间服从泊松分布,后面的M则表示服务时间服从负指数分布,1为仅有一个打磨机。
蒙特卡洛方法:蒙特卡洛法蒙特卡洛(Monte Carlo)方法,或称计算机随机模拟方法,是一种基于“随机数”的计算方法。
这一方法源于美国在第一次世界大战进研制原子弹的“曼哈顿计划”。
该计划的主持人之一、数学家冯·诺伊曼用驰名世界的赌城—摩纳哥的Monte Carlo—来命名这种方法,为它蒙上了一层神秘色彩。
(2)排队论研究的基本问题1.排队系统的统计推断:即判断一个给定的排队系统符合于哪种模型,以便根据排队理论进行研究。
2.系统性态问题:即研究各种排队系统的概率规律性,主要研究队长分布、等待时间分布和忙期分布等统计指标,包括了瞬态和稳态两种情形。

体检排队问题摘要本文讨论的是如何安排顾客的体检顺序,以提高设备利用率、降低顾客等待时间的问题。
本文的创新之处在于利用计算机编程模拟排队模型,结合调查得到的资料,直接利用编程模拟产生了每个人的体检顺序及其相应的时间,使得解答更加周密、全面,而且模拟时只需要输入原始数据即可得到相应的结果,操作简便易行,故而具备较强的实用性。
本文依据顾客的到达人数的随机性,建立了以体检时间最小为目标函数的微分模型,即排队模型,又巧妙地将对原目标函数的求解转化为求每个项目当前排队人数问题,从而运用微分、利用MA TLAB 软件编程对个人的体检顺序做出定性的分析,并代入数据予以检验。
问题一,根据建立的模型,利用MATLA B软件插值拟合体检人员到达率与时间的关系)(t ϕ,再根据到达率,计算出t ∆时间内的到达人数)(t P ∆。
最后,计算出当前每个项目的等待时间()i j i A t S ⨯,通过比较得出等待时间较少的体检顺序。
问题二,利用问题一的模型,本文设计出一组较为合理的数据来验证上述结论。
问题三,我们将团体体检分为将团体视为一个整体,将团体的各队员全部分开情况予以讨论。
经过模型计算,得到团队体检顺序的较优值,其结果见正文。
关键词:插值拟合、M AT LAB 、体检项目、贪心算法一、问题重述某城市的体检中心每天有许多人前去体检,全部体检项目包括:抽血、内科、外科、B超、五官科、胸透、身高、体重、…等等。
每个人的体检项目可能各不相同,假设每个体检项目的服务时间是确定的,并且只有1个医生值班,每次只能为1个客户服务。
为提高设备利用率、降低客人的等待时间,中心请你帮助完成如下任务:1.请你为某个新来的客人安排他的体检顺序,使其完成需要的全部检查的时间尽量少(在各个体检项目处都可能有人排队等待);2.设计1组数据来验证上述结论。
3.接待团体客人时,如何安排每个人的体检顺序,使得体检中心能尽快完成任务,设计1组数据来验证该结论。

LINGO函数有了前几节的基础知识,再加上本节的内容,你就能够借助于LINGO建立并求解复杂的优化模型了。
LINGO有9种类型的函数:1.1.基本运算符:包括算术运算符、逻辑运算符和关系运算符2.2.数学函数:三角函数和常规的数学函数3.3.金融函数:LINGO提供的两种金融函数4.4.概率函数:LINGO提供了大量概率相关的函数5.5.变量界定函数:这类函数用来定义变量的取值范围6.6.集操作函数:这类函数为对集的操作提供帮助7.7.集循环函数:遍历集的元素,执行一定的操作的函数8.8.数据输入输出函数:这类函数允许模型和外部数据源相联系,进行数据的输入输出9.9.辅助函数:各种杂类函数4.1基本运算符这些运算符是非常基本的,甚至可以不认为它们是一类函数。
事实上,在LINGO中它们是非常重要的。
4.1.1算术运算符算术运算符是针对数值进行操作的。
LINGO提供了5种二元运算符:^乘方﹡乘/除﹢加﹣减LINGO唯一的一元算术运算符是取反函数“﹣”。
这些运算符的优先级由高到底为:高﹣(取反)^﹡/低﹢﹣运算符的运算次序为从左到右按优先级高低来执行。
运算的次序可以用圆括号“()”来改变。
例4.1算术运算符示例。
2﹣5/3,(2﹢4)/5等等。
4.1.2逻辑运算符在LINGO中,逻辑运算符主要用于集循环函数的条件表达式中,来控制在函数中哪些集成员被包含,哪些被排斥。
在创建稀疏集时用在成员资格过滤器中。
LINGO具有9种逻辑运算符:#not#否定该操作数的逻辑值,#not#是一个一元运算符#eq#若两个运算数相等,则为true;否则为flase#ne# 若两个运算符不相等,则为true;否则为flase#gt# 若左边的运算符严格大于右边的运算符,则为true;否则为flase#ge#若左边的运算符大于或等于右边的运算符,则为true;否则为flase#lt#若左边的运算符严格小于右边的运算符,则为true;否则为flase#le#若左边的运算符小于或等于右边的运算符,则为true;否则为flase#and#仅当两个参数都为true时,结果为true;否则为flase#or# 仅当两个参数都为false时,结果为false;否则为true这些运算符的优先级由高到低为:高#not##eq# #ne# #gt# #ge# #lt# #le#低#and# #or#例4.2逻辑运算符示例2 #gt#3 #and#4 #gt# 2,其结果为假(0)。
【关键字】问题本科毕业设计论文设计(论文)题目 ______食堂窗口设置问题的研究______指导教师姓名___________ 丁晓东__________________学生姓名 _____________林挺挺________________学生学号 __________0110_____________院系_______理学院_________专业____数学与应用数学_____班级_______应数1103_______食堂窗口设置问题的研究i学生姓名:林挺挺指导教师:丁晓东浙江工业大学理学院摘要本文针对食堂窗口设置问题,首先对统计数据利用matlab编程和spss两种软件进行泊松分布检验。
通过求均值处理并剔除误差较大的数据后可得到所有数据都符合泊松分布。
然后基于排队论理论,结合层次分析法的思想,建立了食堂人流模型,并且借鉴等待制排队模型(M/M/C模型)提出本题的四个窗口合理性分析模型。
此外,由于所给数据的局限性,还考虑了“食堂开设窗口好坏”的评价模型,给出合理评价准则。
并在此基础上分析了各时段的原始人流量数据所对应的最佳应当开放的窗口数,以此来预测之后各时间段的窗口最佳开放数量。
关键词:排队论泊松分布层次分析法Research on the problem of setting up the dining room windowStudent: Lin Tingting Advisor: Dr. Ding XiaodongCollege of of TechnologyAbstractThis thesis is aimed at the problem of setting up the dining room window. Firstly,the statistical data is tested by MATLAB and SPSS two softwares. After the mean processing and deleting the error of the large data, we can find that all the data is in the Poisson distribution. Then based on queuing theory, combinediiwith the idea of analytic hierarchy process (AHP), established the flow model of the canteen, and reference wait queuing model (M / M / C) put forward the four window analyses the rationality of the model. In addition, because of the limitations of the data, the evaluation model of the open window is considered, and the reasonable evaluation criteria is given. Based on this, the best open window number is analyzed, which can predict the best open number of windows for each time period..The key word: Queuing theory Poisson distribution Analytic hierarchy process目录iAbstract ............................................ 错误!未定义书签。
Matlabyalmip⼯具编写⾃动驾驶模型预测控制(MPC)代码⽬录前⾔在⽆⼈驾驶的运动控制中,模型预测控制(MPC)算法得到了⼴泛使⽤,龚建伟的《⽆⼈驾驶车辆模型预测控制》⼀书对MPC算法进⾏了细致的讲解,并提供了代码,⾮常值得参考和学习。
但书中各系数矩阵的推导对于初学者来说极难理解,代码结构也过于复杂,改动代码容易报错。
采⽤yalmip⼯具可以很⼤程度简化代码,利于初学者对应理解MPC公式与代码,代码修改起来也⾮常容易。
⼀、yalmip简介yalmip是由Lofberg开发的⼀种免费的优化求解⼯具。
它是⼀个建模⼯具,甚⾄可以称为⼀种“语⾔”,通过这种“语⾔”来描述模型,然后再调⽤其他求解器(如quadprog、gurobi、fmincon等)来求解模型。
其最⼤特⾊在于集成许多外部的优化求解器,形成⼀种统⼀的建模求解语⾔,提供了Matlab的调⽤API,减少学习者学习成本。
⼆、车辆模型1.车辆运动学模型2.离散化3.线性化这⾥使⽤针对状态轨迹的线性化⽅法(《⽆⼈驾驶车辆模型预测控制》(第⼆版)第五章代码所使⽤的⽅法),与第三、四章的存在参考系统的性线化⽅法略有不同,本质上区别不⼤,具体可以参考《⽆⼈驾驶车辆模型预测控制》(第⼀版)的介绍。
若使⽤较复杂的模型,可借助jacobian函数求解雅可⽐矩阵A,B三、MPC 优化问题定义程序⽬标是对轨迹进⾏跟踪,设计成本函数第⼀项:状态量与参考轨迹误差的平⽅,第⼆项:控制量的平⽅。
约束依次为初始状态约束,车辆运动学模型,控制量约束,控制增量约束。
优化问题如下所⽰:四、Matlab 代码本⽂编写的代码主要为了对标《⽆⼈驾驶车辆模型预测控制》(第⼆版)第四章的代码,主体参照S函数形式编写,便于结合Carsim 使⽤。
以下主要介绍yalmip编写的MPC计算函数:1.函数输⼊1syms x y phi delta v L T 2%x :横坐标;y :纵坐标;phi:航向⾓;delta :前轮偏⾓;3%v :速度;L :轴距;T :离散时间4kesi=[v*cos(phi);v*sin(phi);v*tan(delta)/L]*T+[x;y;phi];%离散化⽅程5X=[x,y,phi];%状态量6u=[v,delta];%控制量7A=jacobian(kesi,X)8B=jacobian(kesi,u)A,B:模型(系统)矩阵;Q,R:权重矩阵;N:控制步长;kesi:当前状态量和控制量;state_k1:下⼀时刻状态量;umin,umax,delta_min,delta_max:控制量和控制增量约束矩阵;Ref: 参考轨迹;MPC_solver:求解器。
传染病传播模型(SIS)Matlab代码function spreadingability=sir(A,beta,mu)for i=1:length(A)for N=1:50%随机次数InitialState=zeros(length(A),1);InitialState(i)=1;time=5;%传播时间I(N,:)=sire(A,InitialState,beta,mu,time);endspreadingability(i,1)=mean(mean(I));%节点i的传播能⼒endendfunction I=sire(A,InitialState,beta,mu,time)%******************************% A邻接矩阵% InitialState初始感染状态% beta感染率% mu恢复率% time传播时间%*****************************Infected=InitialState;recover=[];Infected_temp=zeros(size(Infected));for t=1:1:time %⼀共进⾏时长time的演化%%%若i是易感节点, 则对i以⼀定概率进⾏传染x1=find(Infected==0);a1=rand(size(x1));b1=beta*(A(x1,:)*Infected);%已经被感染的节点以⼀定概率去感染其他节点xx1=setdiff(find(a1<b1),recover);Infected_temp(x1(xx1))=1;%不是recover的节点以⼀定概率被感染xx2=setdiff(find(a1>=b1),recover);Infected_temp(x1(xx2))=0;%对不是recover且没被感染的其他节点保留易感状态%%%若i是染病节点, 则对i以⼀定概率进⾏移除(recover)x2=find(Infected==1); %如果是已经被感染的节点a2=rand(size(x2));xx3=find(a2<mu);%对染病节点以⼀定概率进⾏recoverrecover=[recover;xx3];%更新被recover节点;xx4=find(a2>=mu);Infected_temp(x2(xx4))=1;%余下未被recover的节点仍保留感染能⼒Infected=Infected_temp;I(t)=sum(Infected); %记录每个时间步的染病节点数量endend susceptible-infected-recovered(SIR)传染病模型常⽤来计算节点影响⼒标准测量。
function out=MMSmteam(s,m,mu1,mu2,T)%M/M/S/m排队模型%s——修理工个数%m——机器源数%T——时间终止点%mu1——机器离开-到达时间服从指数分布%mu2——修理时间服从指数分布%事件表:% p_s——修理工空闲概率% arrive_time——机器到达事件% leave_time——机器离开事件%mintime——事件表中的最近事件%current_time——当前时间%L——队长%tt——时间序列%LL——队长序列%c——机器到达时间序列%b——修理开始时间序列%e——机器离开时间序列%a_count——到达机器数%b_count——修理机器数%e_count——损失机器数%初始化arrive_time=exprnd(mu1,1,m);arrive_time=sort(arrive_time);leave_time=[];current_time=0;L=0;LL=[L];tt=[current_time];c=[];b=[];e=[];a_count=0;%循环while min([arrive_time,leave_time])<Tcurrent_time=min([arrive_time,leave_time]);tt=[tt,current_time]; %记录时间序列if current_time==min(arrive_time) %机器到达子过程arrive_time(1)=[]; % 从事件表中抹去机器到达事件a_count=a_count+1; %累加到达机器数if L<s %有空闲修理工L=L+1; %更新队长c=[c,current_time];%记录机器到达时间序列b=[b,current_time];%记录修理开始时间序列leave_time=[leave_time,current_time+exprnd(mu2)];%产生新的机器离开事件leave_time=sort(leave_time);%离开事件表排序else %无空闲修理工L=L+1; %更新队长c=[c,current_time];%记录机器到达时间序列endelse %机器离开子过程leave_time(1)=[];%从事件表中抹去机器离开事件arrive_time=[arrive_time,current_time+exprnd(mu1)];arrive_time=sort(arrive_time);%到达事件表排序e=[e,current_time];%记录机器离开时间序列if L>s %有机器等待L=L-1; %更新队长b=[b,current_time];%记录修理开始时间序列leave_time=[leave_time,current_time+exprnd(mu2)];%产生新的机器离开事件leave_time=sort(leave_time);%离开事件表排序else %无机器等待L=L-1; %更新队长endendLL=[LL,L]; %记录队长序列endWs=sum(e-c(1:length(e)))/length(e);Wq=sum(b-c(1:length(b)))/length(b);Wb=sum(e-b(1:length(e)))/length(e);Ls=sum(diff([tt,T]).*LL)/T;Lq=sum(diff([tt,T]).*max(LL-s,0))/T;p_s=1.0/(factorial(m)/factorial(m).*(mu2/mu1)^0+factorial(m)/factorial(m-1).*(mu2/mu1)^1+fact orial(m-2)/factorial(m-1).*(mu2/mu1)^2+factorial(m)/factorial(m-2).*(mu2/mu1)^2+factorial(m)/ factorial(m-4).*(mu2/mu1)^4+factorial(m)/factorial(m-5).*(mu2/mu1)^5);fprintf('修理工空闲概率:%d\n',p_s)%修理工空闲概率fprintf('到达机器数:%d\n',a_count)%到达机器数fprintf('平均逗留时间:%f\n',sum(e-c(1:length(e)))/length(e))%平均逗留时间fprintf('平均等待时间:%f\n',sum(b-c(1:length(b)))/length(b))%平均等待时间fprintf('平均修理时间:%f\n',sum(e-b(1:length(e)))/length(e))%平均修理时间fprintf('平均队长:%f\n',sum(diff([tt,T]).*LL)/T)%平均队长fprintf('平均等待队长:%f\n',sum(diff([tt,T]).*max(LL-s,0))/T)%平均等待队长for i=0:mp(i+1)=sum((LL==i).*diff([tt,T]))/T;%队长为i的概率fprintf('队长为%d的概率:%f\n',i,p(i+1));fprintf('机器不能马上得到修理的概率:%f\n',1-sum(p(1:s)))%机器不能马上得到修理的概率out=[Ws,Wq,Wb,Ls,Lq,p];function out=MMSkteam(s,k,mu1,mu2,T)%多服务台%s——服务台个数%k——最大顾客等待数%T——时间终止点%mu1——到达时间间隔服从指数分布%mu2——服务时间服从指数分布%事件表:% arrive_time——顾客到达事件% leave_time——顾客离开事件%mintime——事件表中的最近事件%current_time——当前时间%L——队长%tt——时间序列%LL——队长序列%c——顾客到达时间序列%b——服务开始时间序列%e——顾客离开时间序列%a_count——到达顾客数%b_count——服务顾客数%e_count——损失顾客数%初始化arrive_time=exprnd(mu1);leave_time=[];current_time=0;L=0;LL=[L];tt=[current_time];c=[];b=[];e=[];a_count=0;b_count=0;e_count=0;while min([arrive_time,leave_time])<Tcurrent_time=min([arrive_time,leave_time]);tt=[tt,current_time]; %记录时间序列if current_time==arrive_time %顾客到达子过程arrive_time=arrive_time+exprnd(mu1); % 刷新顾客到达事件a_count=a_count+1; %累加到达顾客数if L<s %有空闲服务台L=L+1; %更新队长b_count=b_count+1;%累加服务顾客数c=[c,current_time];%记录顾客到达时间序列b=[b,current_time];%记录服务开始时间序列leave_time=[leave_time,current_time+exprnd(mu2)];%产生新的顾客离开事件leave_time=sort(leave_time);%离开事件表排序elseif L<s+k %有空闲等待位L=L+1; %更新队长b_count=b_count+1;%累加服务顾客数c=[c,current_time];%记录顾客到达时间序列else %顾客损失e_count=e_count+1;%累加损失顾客数endelse %顾客离开子过程leave_time(1)=[];%从事件表中抹去顾客离开事件e=[e,current_time];%记录顾客离开时间序列if L>s %有顾客等待L=L-1; %更新队长b=[b,current_time];%记录服务开始时间序列leave_time=[leave_time,current_time+exprnd(mu2)];leave_time=sort(leave_time);%离开事件表排序else %无顾客等待L=L-1; %更新队长endendLL=[LL,L]; %记录队长序列endWs=sum(e-c(1:length(e)))/length(e);Wq=sum(b-c(1:length(b)))/length(b);Wb=sum(e-b(1:length(e)))/length(e);Ls=sum(diff([tt,T]).*LL)/T;Lq=sum(diff([tt,T]).*max(LL-s,0))/T;fprintf('到达顾客数:%d\n',a_count)%到达顾客数fprintf('服务顾客数:%d\n',b_count)%服务顾客数fprintf('损失顾客数:%d\n',e_count)%损失顾客数fprintf('平均逗留时间:%f\n',Ws)%平均逗留时间fprintf('平均等待时间:%f\n',Wq)%平均等待时间fprintf('平均服务时间:%f\n',Wb)%平均服务时间fprintf('平均队长:%f\n',Ls)%平均队长fprintf('平均等待队长:%f\n',Lq)%平均等待队长if k~=inffor i=0:s+kp(i+1)=sum((LL==i).*diff([tt,T]))/T;%队长为i的概率fprintf('队长为%d的概率:%f\n',i,p(i+1));endelsefor i=0:3*sp(i+1)=sum((LL==i).*diff([tt,T]))/T;%队长为i的概率fprintf('队长为%d的概率:%f\n',i,p(i+1));endendfprintf('顾客不能马上得到服务的概率:%f\n',1-sum(p(1:s)))%顾客不能马上得到服务的概率out=[Ws,Wq,Wb,Ls,Lq,p];。