scatter文件的写法
- 格式:pdf
- 大小:1.11 MB
- 文档页数:80

VF常用命令1、打开表命令:USE 表文件名2、关闭表命令:USE 、CLOSE ALL3、记录指针定位命令:GO 数值表达式(绝对移动)、SKIP(相对移动)4、替换(修改)记录命令:REPLACE 字段1 WITH 表达式1,字段2 WITH 表达式2…… [范围][FOR<条件>]5、复制表命令:COPY TO 新文件名[FOR〈条件〉][范围]复制表结构命令:COPY STRU TO 新表文件名[FIEL 〈字段名表〉]6、建立索引命令:INDEX ON 关键字段TO 单索引文件名INDEX ON 关键字段TAG 索引标识名7、查询命令:(1)条件查询:LOCATE FOR 〈条件〉继续查找命令:CONTINUE(2)索引查询:FIND 字符表达式SEEK 表达式继续查找命令:SKIP常用命令:1、设置默认路径命令:SET DEFA TO 盘符:\路径2、关闭表命令:CLOSE TABLE,CLEAR ALL3、记录显示命令:LIST/DISP [范围][FOR 〈条件〉]4、追加记录命令:(1)表尾追加:APPEND [BLANK](2)表中插入:INSERT [BEFORE] [BLANK] P81(3)从其他文件中追加多条记录到当前表:APPEND FROM 文件名[FOR〈条件〉][FIEL <字段名表>]5、删除记录命令:DELE [范围][FOR<条件>]6、彻底删除带标记记录命令:PACK7、取消删除标记命令:RECALL [范围][FOR<条件>]8、物理删除表中所有记录命令:ZAP P849、复制任何类型文件:COPY FILE 〈文件名1〉TO 〈文件名2〉10、将单个记录发送到数组:SCATTER TO 〈数组名〉[FIEL〈字段名表〉]11、将数组中的值发送到当前记录命令:GATHER FROM 数组名12、将表中多条记录传送到数组命令:COPY TO ARRAY 数组名13、将二维数组中的值传送到表中:APPEND FROM ARRAY 数组名14、表的排序命令:SORT ON 〈字段1〉/A|/D,字段2/A|/D to 新表文件名15、打开索引文件命令:SET INDEX TO 索引文件名表P9116、设置主控索引命令:SET ORDER TO 单索引文件名|TAG 索引标识17、更新索引文件命令:REINDEX P9218、关闭索引文件:SET INDEX TO 、CLOSE INDEX、CLOSE ALL、CLEAR ALL、USE19、删除索引标识命令:DELE TAG 索引标识名删除单索引文件命令:DELE FILE 单索引文件名20、表的浏览命令:BROWSE21、记录的过滤命令:SET FILTER TO 条件22、字段的过滤命令:SET FIELDSS TO 字段名表23、表之间的连接命令:JOIN WITH 别名TO 新表文件名FOR 条件24、设置一对多关系命令:SET SKIP TO 别名25、数据库相关命令:打开:OPEN DATA 数据库名新建:CREAT DATA 数据库名P111修改:MODI DATE 数据库名关闭:CLOSE DATA、CLOSE DATA ALL、CLOSE ALL、CLEAR ALL设置当前数据库命令:SET DATA TO 数据库名26、程序相关命令:建立/修改程序:MODI COMMAND 程序文件名运行程序:DO 程序文件名27、内存变量/数组赋值命令:=、STORE P138或28、交互式输入命令:@行,列SAY 表达式GET 变量29、文本输出命令:TEXT〈输出显示内容〉ENDTEXT30、终止程序执行命令:CANCEL、QUIT、RETURN31、清除主屏幕命令:CLEAR32、系统设置命令:(1)设置精确比较命令:SET EXACT ON/OFF (2)设置删除标记命令:SET DELE ON/OFF还有很多,就不再一一列举了。
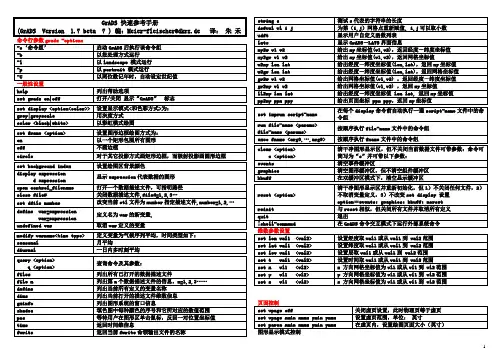
刷机前请确保电脑端驱动已经安装好,怎么安装驱动呢,可能很多人不会手动安装方法,其实联想官方已经提供傻瓜式一键安装程序了,就是内置卡内的“PC套件-驱动”。
第一步:以管理员权限运行文件夹内主程序Flash_tool.exe,打开主程序界面
第二步:点击“加载Scatter”,选择刷机配置文件MT6589_Android_scatter_emmc.txt,如图。
注意:MT65**_Android_scatter_emmc.txt文件必须跟ROM同目录,比如都放在桌面,加载Scatter时需要选择桌面的MT65**_Android_scatter_emmc.txt.
如果是线刷包,Scatter文件就在解压以后的文件夹里,直接选择
即可
第三步:点击“下载”按钮,手机完全关机,数据线连接电脑,开始刷机,在弹出的对话框中点击“是”
(特别说明:如果关机后连接电脑后没有反应请重新安装下电池)
第四步:等待刷机完成,进度条走完以后会弹出绿色圆圈窗口提示刷机成功。
ADS1.2开发环境简介实验⼀ ADS1.2开发环境简介⼀、实验⽬的熟悉ADS1.2 开发环境,学会ARM 仿真器的使⽤。
使⽤ADS 编译、下载、调试并跟踪⼀段已有的程序,了解嵌⼊式开发的基本思想和过程。
超级终端设置及BIOS 功能使⽤。
⼆、实验内容本次实验配置ADS 集成开发环境,新建⼀个简单的⼯程⽂件,并编译这个⼯程⽂件。
学习ARM 仿真器的使⽤和开发环境的设置。
下载已经编译好的⽂件到嵌⼊式控制器中运⾏。
学会在程序中设置断点,观察系统内存和变量,为调试应⽤程序打下基础。
运⾏Windows系统下的超级终端,通过超级终端查看BIOS启动情况。
三、预备知识C 语⾔的基础知识、程序调试的基础知识和⽅法。
四、实验设备及⼯具(包括软件调试⼯具)硬件:ARM 嵌⼊式开发平台、⽤于ARM7TDMI 的JTAG 仿真器、PC 机Pentium100 以上、串⼝线。
软件:PC 机操作系统win98、Win2000 或WinXP、ARM SDT 2.51 或ADS1.2 集成开发环境、仿真器驱动程序、超级终端通讯程序。
五、实验步骤1 配置ADS 集成开发环境(1)运⾏ADS1.2 集成开发环境(CodeWarrior for ARM Developer Suite)。
选择File|New…菜单,在对话框中选择Project,如图1-17 所⽰,新建⼀个⼯程⽂件。
图中⽰例的⼯程名为Exp6.mcp。
点set…按钮可为该⼯程选择路径如图1-18 所⽰,选中CreatFolder 选项后将以图1-17 中的ProjectName 或图1-18 中的⽂件名为名创建⽬录,这样可以将所有与该⼯程相关的⽂件放到该⼯程⽬录下,便于管理⼯程。
(2)在图1-17 中⼯程模板列表中我们选择ARM Executable Image 通⽤模板。
我们随后将⼀步⼀步的把它配置成针对我们ARM3000 开发板的模板44B0 ARM ExecutableImaage,并把它拷贝到ADS1.2 安装⽬录下的Stationery ⽬录中(所有的⼯程模板都在此⽬录下)。


mtk下载工具主要使用FlashTool_V3.1(其实各个版本都差不多),主要用于将编译生成的bin 文件写入目标手机中,该工具不用安装,直接运行,主要用法如下:1 运行Flash_tool.exe 打开软件,2 点击Download Agent 载入MTK_AllInOne_DA.bin 这个文件3 点击Scatter_Loading 载入scat.txt 这个文件4 双击ROM 将项目目录下build文件夹下的bin文件加载进来5 插上手机的下载线,点击option,选择手机的rate速率,和相应的com口(一般会用到com3和com4,可以根据实际情况而定)点击DownLoad,然后轻轻按下手机的开机键,就可以下载选择的bin文件到目标手机中TRACE工具的使用1 注意事项mtk手机默认情况下想要打trace,需要在平台代码中你要打trace的语句中添加如下代码kal_prompt_trace(MOD_MED, "Check err: buffer miss %d\n",g_video_enc_info_ptr->check_buffer_miss_count);kal_prompt_trace(MOD_MED, "Check err: camera miss %d\n",g_video_enc_info_ptr->check_camera_miss_count);用法和c语言的printf函数相似,只不过第一个参数需要写想要打trace的模块的名称,如MOD_MED并且在还需要打开手机,在待机屏幕下输入*#3646633#,进入工程模式,然后进入设备菜单,再进入Set UART à UART Setting将TST Config 设置为UART 1按下确认键后手机会自动关机,经过这样的设置后就可以打trace了2 打开Catcher.exe 点击Config 菜单,选择set database path,会弹出一个set path的对话框到项目文件下的路径tst\database_classb下选择相应的database 文件点击Control,选择mode ,然后选择Logging 模式会弹出logging对话框,然后选择Config à Configure RS232.. 会自动弹出PORT这个对话框,选择相应的端口和速率按下F5 快捷键和目标手机链接,点击Control à Set Filter...选择PS Filter,选择你想显示的trace 模块打开手机,打出相应的trace 信息不同的手机MTK FlashTool 和Catch工具的的使用可能有些不同,但基本使用都差不多。


eps在matlab中的用法在MATLAB中,EPS(矢量图文件格式)是一个常用的文件格式,用于保存图形,尤其适用于发布论文、创建幻灯片和印刷等需求。
本文将介绍如何在MATLAB中使用EPS格式,并提供一些常见的用法。
首先,要在MATLAB中使用EPS格式,需要先将图形绘制出来。
可以使用MATLAB的绘图函数,例如plot、scatter、bar等等,根据需要选择合适的函数。
然后,可以使用一些属性设置来自定义图形,如线条颜色、线型、标签、标题等。
一旦图形绘制完成,可以使用"print"函数将图形保存为EPS文件。
该函数的语法如下:print('filename','-depsc')其中,'filename'是你想要保存的文件名(无需加上.eps后缀),'-depsc'表示将图形保存为EPS格式。
如果需要更高分辨率的输出,可以添加'-r'选项,例如:print('filename','-depsc','-r300')此处的'-r300'表示输出分辨率为300 dpi(每英寸点数),可以根据需求自行调整。
此外,还可以使用"-loose"选项在EPS文件中添加白边,以便在其他应用程序中更好地使用,例如:print('filename','-depsc','-loose')这样可以确保生成的EPS文件在导入其他应用程序时边缘不会被裁剪。
除了使用"print"函数,MATLAB还提供了其他几种方法保存图形为EPS格式。
例如,可以使用"saveas"函数:saveas(gcf,'filename','epsc')其中,gcf表示当前图形的句柄。

试图搞懂MDK程序下载到flash(三)--MDK配置选项Linker、Target、Debug的理解分析在写这一节时,我还是想再重复一下自己写这文章的目的,我的目的就是为了实现将MDK 编写的裸机程序可不可以脱机运行,也就是不用调试的方法,因为调试的话程序默认是在SRAM中运行的,掉电丢失。
而要脱机运行,就得将程序编译后的文件下载到flash中,最好能是nand flash。
如果要下载到nand flash,那么就要编译生成一个bin文件,而不是用axf文件。
那么剩下的问题就是,怎么生成一个完整、正确的bin文件?所以我现在就需要看能否通过编写一个分散加载文件,解决bin文件的地址问题。
生成了bin文件,那么我就可以利用韦东山的方法,利用supervivi的v选项,配合DNW将程序下载到nand flash中并运行!现在咱们就分析一下MDK配置选项,首先解释一下MDK中三种linker之间的区别:1、采用Target对话框中的RAM和ROM地址。
采用此方式,需在Linker选项卡中勾选Use Memory Layout from Target Dialog选项(选中这一项实际上是默认在Target中对Flash和RAM的地址配置,编译链接时会产生一个默认的脚本文件),并且在Target中设置好RAM、ROM地址,图2所示。
MDK会根据Target选项中设定的RAM和ROM地址自动加载生成一个加载文件。
最后链接器会根据此文件中的信息对目标文件进行链接,生成axf镜像文件。
至于ROM和RAM是片内还是片外、容量(Size)多大,就需要根据芯片和开发板来决定了。
2、直接通过Linker选项卡中的R/O Base和R/W Base来设定链接信息。
链接器最后可根据此处指定的地址信息进行链接,链接的文件应该是顺序存放了,最多RO和RW分开。
此时需要注意的是应将Use Memory Layout from Target Diaglog前的勾去掉,且保证Scatter File一栏中未包含分散加载文件,并且要在Misc controls中设定镜像文件的入口点,如:--first 2440init.o(Init) 对于这个括号内的填写依据,我暂时还不懂。

多口下载使用说明(SPMultiPortFlashDownload_V3.1408.00)
------2014/04/12
一、产生CheckSum文件
(1)、先将CheckSum_Gen.exe拷贝到需要下载的bin文件夹的目录下,如下图所示。
(2)、然后再双击运行如下图所示。
(3)、按任意键会退出,同时产生一个Checksum.ini文件,如下图所示:
二、识别端口
(1)、先选择对应的端口数量,再点击右下的“scan”,会弹出对话框,直接点“是”。
图1MX232V00主板照片
(2)、识别过程出现如下图所示。
(3)
(3)、识别完成后如下图所示。
识别端口注意事项:如果不能有效识别端口,则将主板的KCOL0短接到GND,再重复上述操作直至识别出端口。
在下载的时候,则不需要将主板的KCOL0短接到GND。
三、开始下载
(1)、先选择scatter文件。
然后连上手机,点击对应端口后面的“start”按钮。
即开始下载。
下载过程界面如下:
(2)、下载完成后,界面如下:
下载注意事项:在正常下载的时候,请注意不要选择格式化,否则会引起一些参数丢失,可能会导致整机出现异常。
如果有特殊需求,请及时联系!。

VFP常用命令在下一行显示表达式串在当前行显示表达式串@... 将数据按用户设定的格式显示在屏幕上或在打印机上打印ACCEPT 把一个字符串赋给内存变量APPEND 给数据库文件追加记录APPEND FROM 从其它库文件将记录添加到数据库文件中AVERAGE 计算数值表达式的算术平均值BROWSE 全屏幕显示和编辑数据库记录CALL 运行内存中的二进制文件CANCEL 终止程序执行,返回圆点提示符CASE 在多重选择语句中,指定一个条件CHANGE 对数据库中的指定字段和记录进行编辑CLEAR 清洁屏幕,将光标移动到屏幕左上角CLEAR ALL 关闭所有打开的文件,释放所有内存变量,选择1号工作区CLEAR FIELDS 清除用SET FIELDS TO命令建立的字段名表CLEAR GETS 从全屏幕READ中释放任何当前GET语句的变量CLEAR MEMORY 清除当前所有内存变量CLEAR PROGRAM 清除程序缓冲区CLEAR TYPEAHEAD 清除键盘缓冲区CLOSE 关闭指定类型文件CONTINUE 把记录指针指到下一个满足LOCATE命令给定条件的记录,在LOCATE 命令后出现。
无LOCATE则出错COPY TO 将使用的数据库文件复制另一个库文件或文本文件COPY FILE 复制任何类型的文件COPY STRUCTURE EXTENED TO 当前库文件的结构作为记录,建立一个新的库文件COPY STRUCTURE TO 将正在使用的库文件的结构复制到目的库文件中COUNT 计算给定范围内指定记录的个数CREATE 定义一个新数据库文件结构并将其登记到目录中CREATE FROM 根据库结构文件建立一个新的库文件CREATE LABEL 建立并编辑一个标签格式文件CREATE REPORT 建立宾编辑一个报表格式文件DELETE 给指定的记录加上删除标记DELETE FILE 删除一个未打开的文件DIMENSION 定义内存变量数组DIR 或DIRECTORY 列出指定磁盘上的文件目录DISPLAY 显示一个打开的库文件的记录和字段DISPLAY FILES 查阅磁盘上的文件DISPLAY HISTORY 查阅执行过的命令DISPLAY MEMORY 分页显示当前的内存变量DISPLAY STATUS 显示系统状态和系统参数DISPLAY STRUCTURE 显示当前书库文件的结构DO 执行FoxBase程序DO CASE 程序中多重判断开始的标志DO WHILE 程序中一个循环开始的标志EDIT 编辑数据库字段的内容EJECT 使打印机换页的命令,将PROW()函数和PCOL()函数值置为0ELSE 在IF...ENDIF结构中提供另一个条件选择路线ENDCASE 终止多重判断ENDDO 程序中一个循环体结束的标志ENDIF 判断体IF...ENDIF结构结束标志ERASE 从目录中删除指定文件EXIT 在循环体内执行退出循环的命令FIND 将记录指针移动到第一个含有与给定字符串一致的索引关键字的记录上FLUSH 清除所有的磁盘存取缓冲区GATHER FROM 将数组元素的值赋予数据库的当前记录中GO/GOTO 将记录指针移动到指定的记录号HELP 激活帮助菜单,解释FoxBASE+的命令IF 在IF...ENDIF结构中指定判断条件INDEX 根据指定的关键词生成索引文件INPUT 接受键盘键入的一个表达式并赋予指定的内存变量INSERT 在指定的位置插入一个记录JOIN 从两个数据库文件中把指定的记录和字段组合成另一个库文件KEYBOARD 将字符串填入键盘缓冲区LABEL FROM 用指定的标签格式文件打印标签LIST 列出数据库文件的记录和字段LIST FILES 列出磁盘当前目录下的文件LIST HISTORY 列出执行过的命令LIST MEMORY 列出当前内存变量及其值LIST STATUS 列出当前系统状态和系统参数LIST STRUCTURE 列出当前使用的数据库的库结构LOAD 将汇编语言程序从磁盘上调入内存LOCATE 将记录指针移动到对给定条件为真的记录上LOOP 跳过循环体内LOOP与ENDDO之间的所有语句,返回到循环体首行MENU TO 激活一组@...PROMPT命令定义的菜单MODIFY COMMAND 进入FoxBASE+系统的字处理状态,并编辑一个ASCII码文本文件(如果指定文件名以.PRG为后缀,则编辑一个FoxBASE+命令文件)MODIFY FILE 编辑一个一般的ASCII码文本文件MODIFY LABEL 建立并编辑一个标签(.LBL)文件MODIFY REPORT 建立并编辑一个报表格式文件(.FRM)文件MODIFY STRUCTURE 修改当前使用的库文件结构NOTE/* 在命令文件(程序)中插入以行注释(本行不被执行)ON 根据指定条件转移程序执行OTHERWISE 在多重判断(DO CASE)中指定除给定条件外的其它情况PACK 彻底删除加有删除标记的记录PARAMETERS 指定子过程接受主过程传递来的参数所存放的内存变量PRIVATE 定义内存变量的属性为局部性质PROCEDURE 一个子过程开始的标志PUBLIC 定义内存变量为全局性质QUIT 关闭所有文件并退出FoxBASE+READ 激活GET语句,并正是接受在GET语句中输入的数据RECALL 恢复用DELETE加上删除标记的记录REINDEX 重新建立正在使用的原有索引文件RELEASE 清楚当前内存变量和汇编语言子程序RENAME 修改文件名REPLACE 用指定的数据替换数据库字段中原有的内容REPORT FORM 显示数据报表RESTORE FROM 从内存变量文件(.MEM)中恢复内存变量RESTORE SCREEN 装载原来存储过的屏幕映象RESUME 使暂停的程序从暂停的断点继续执行RETRY 从当前执行的子程序返回调用程序,并从原调用行重新执行RETURN 结束子程序,返回调用程序RUN/!在FoxBASE+中执行一个操作系统程序SAVE TO 把当前内存变量及其值存入指定的磁盘文件(.MEM)SAVE SCREEN 将当前屏幕显示内容存储在指定的内存变量中SCATTER 将当前数据库文件中的数据移到指定的数组中SEEK 将记录指针移到第一个含有与指定表达式相符的索引关键字的记录SELECT 选择一个工作区SET 设置FoxBASE+控制参数SET ALTERNATE ON/OFF 设置传送/不传送输出到一个文件中SET ALTERNATE TO 建立一个存放输出的文件SET BELL ON/OFF 设置输入数据时响铃/不响铃SET CARRY ON/OFF 设置最后一个记录复制/不复制到添加的记录中SET CENTURY ON/OFF 设置日期型变量要/不要世纪前缀SET CLEAR ON/OFF 设置屏幕信息能/不能被清除SET COLOR ON/OFF 设置彩色/单色显示SET COLOR TO 设置屏幕显示色彩SET CONFIRM ON/OFF 设置在全屏幕编辑方式中,要求/不要求自动跳到下一个字段SET CONSOLE ON/OFF 设置将输出传送/不传送到屏幕SET DATE 设置日期表达式的格式SET DEBUG ON/OFF 设置传送/不传送ECHO的输出到打印机上SET DECIMALS TO 设置计算结果需要显示的小数位数SET DEFAULT TO 设置默认的驱动器SET DELETED ON/OFF 设置隐藏/显示有删除标记的记录SET DELIMITER TO 为全屏幕显示字段和变量设置定界符SET DELIMITER ON/OFF 选择可选的定界符SET DEVICE TO SCREEN/PRINT 将@...SAY命令的结果传送到屏幕/打印机SET DOHISTORY ON/OFF 设置存/不存命令文件中的命令到历史记录中SET ECHO ON/OFF 命令行回送到屏幕或打印机SET ESCAPE ON/OFF 允许ESCAPE退出/继续命令文件的执行SET EXACT ON/OFF 在字符串的比较中,要求/不要求准确一致SET EXACLUSIVE ON/OFF 设置数据库文件的共享SET FIELDS ON/OFF 设置当前打开的数据库中部分/全部字段为可用SET FIELDS TO 指定打开的数据库中可被访问的字段SET FILTER TO 在操作中将数据库中所有不满足给定条件的记录排除SET FIXED ON/OFF 固定/不固定显示的小数位数SET FORMAT TO 打开指定的格式文件SET FUNCTION 设置F1-F9功能键值SET HEADING ON/OFF 设置LIST或DISPLAY时,显示/不显示字段名SET HELP ON/OFF 确定在出现错误时,是否给用户提示SET HISTORY ON/OFF 决定是/否把命令存储起来以便重新调用SET HISTORY TO 决定显示历史命令的数目SET INDEX TO 打开指定的索引文件SET INTENSITY ON/OFF 对全屏幕操作实行/不实行反转显示SET MARGIN TO 设置打印机左页边SET MEMOWIDTH TO 定义备注型字段输出宽度和REPORT命令隐含宽度SET MENU ON/OFF 确定在全屏幕操作中是否显示菜单SET MESSAGE TO 定义菜单中屏幕底行显示的字符串SET ODOMETER TO 改变TALK命令响应间隔时间SET ORDER TO 指定索引文件列表中的索引文件SET PATH TO 为文件检索指定路径SET PRINT ON/OFF 传送/不传送输出数据到打印机SET PRINTER TO 把打印的数据输送到另一种设备或一个文件中SET PROCEDURE TO 打开指定的过程文件SET RELATION TO 根据一个关键字表达式连接两个数据库文件SET SAFETY ON/OFF 设置保护,在重写文件时提示用户确认SET SCOREBORAD ON/OFF 设置是/否在屏幕的第0行上显示FoxBASE+的状态信息SET STATUS ON/OFF 控制是/否显示状态行SET STEP ON/OFF 每当执行完一条命令后,暂停/不暂停程序的执行SET TALK ON/OFF 是否将命令执行的结果传送到屏幕上SET TYPEAHEAD TO 设置键盘缓冲区的大小SET UNIQUE ON/OFF 在索引文件中出现相同关键字的第一个/所有记录SKIP 以当前记录指针为准,前后移动指针SORT TO 根据数据库文件的一个字段或多个字段产生一个排序的哭文件STORE 赋值语句SUM 计算并显示数据库记录的一个表达式在某范围内的和SUSPEND 暂停(挂起)程序的执行TEXT...ENDTEXT 在屏幕上当前光标位置显示...的文本数据块TOTAL TO 对预先已排序的文件产生一个具有总计的摘要文件TYPE 显示ASCII码文件的内容UNLOCK 解除当前库文件对记录和文件的加锁操作UPDATE 允许对一个数据库进行成批修改USE 带文件名的USE命令打开这个数据库文件。
ADS命令⾏命令介绍1.1.1 armasm1. 命令:armasm [选项] -o ⽬标⽂件源⽂件2. 选项说明-Errors 错误⽂件名 ;指定⼀个错误输出⽂件-I ⽬录[,⽬录] ;指定源⽂件搜索⽬录-PreDefine 预定义宏 ;指定预定义的宏-NOCache ;编译源代码时禁⽌使⽤ Cache 进⾏优化-MaxCache <n> ;编译源代码时使⽤ Cache 进⾏优化-NOWarn ;关闭所有的警告信息-G ;输出调试表-keep ;在⽬标⽂件中保存本地符号表-LIttleend ;⽣成⼩端(Little-endian) ARM 代码-BIgend ;⽣成⼤端(Big-endian) ARM 代码-CPU <target-cpu> ;设⽴⽬标板 ARM 核类型,如: arm920t.-16 ;建⽴ 16 位的 thumb 指令.-32 ;建⽴ 32 位的 ARM 指令.3. 编译⼀个汇编⽂件c:\adsloader>armasm -LIttleend -cpu ARM920T -32 bdinit.s把汇编语⾔编译成⼩端, 32 位, ARM920T CPU.1.1.2 armcc, armcpp1. 命令:armcc [选项] 源⽂件 1 源⽂件 2 ... 源⽂件 n2. 选项说明-c ;编译但是不连接-D ;指定⼀个编译时使⽤的预定义宏常量-E ;仅仅对 C 源⽂件做预处理-g ;产⽣调试信息表-I ;指头⽂件的搜索路径-o<file> ;指定⼀个输出的⽬标⽂件-O[0/1/2] ;指定源代码的优化级别-S ;输出汇编代码来代替⽬标⽂件-CPU <target-cpu> ;设⽴⽬标板 ARM 核类型,如: arm920t.3.编译⼀个 C 程序c:\adsloader>armcc -c -O1 -cpu ARM920T bdisr.c编译不连接, ⼆级优化, ARM920T CPU.1.1.3 armlink1. 命令:armlink [选项] 输⼊⽂件2. 选项说明-partial ;合并⽬标⽂件-Output ⽂件 ;指定输出⽂件名-scatter ⽂件 ;按照指定的⽂件为可执⾏⽂件建⽴内存映射-ro-base 地址值 ;只读代码段的起始地址-rw-base 地址值 ;RW/ZI 段的起始地址3. 把多个⽬标⽂件合并成⼀个⽬标⽂件c:\adsloader>armlink -partial bdmain.o bdport.o bdserial.o bdmmu.o bdisr.o -o bd.o4. 把⼏个⽬标⽂件编译⼀个可执地⽂件c:\adsloader>armlink bd.o bdinit.o -scatter bdscf.scf -o bd.axf1.1.4 fromelf1. 命令:fromelf [选项] 输⼊⽂件2. 选项说明-bin ⼆进制⽂件名 ;产⽣的⼆进制⽂件-elf elf ⽂件名 ;产⽣⼀个 elf ⽂件-text text ⽂件名 ;产⽣ text ⽂件3. 产⽣⼀个可执⾏的⼆进制代码c:\adsloader>fromelf bd.axf b in o bd.bin。
多路下载工具使用方法
1 将压缩包SP_MDT_exe_v3.12**.00.rar 解压,文件列表如下:
2 双击SPMultiPortFlashDownloadProject.exe 出现下图界面(此时端口列表全部
是N/A):
3 关闭下载工具,此时文件列表会多出一个文件 SPMultiPortFlashDownloadProject.ini
4 打开SPMultiPortFlashDownloadProject.ini 文件,里面有端口设置项( 0—15
共16 路)
Channel 需要设置对应的电脑端口。
可设置如下:(Ports端口设置和PreloaderPorts端口设置保持一致)
关闭并保存此文件,此时再打开多路下载工具,界面如下:
5 点击“Scatter file”按钮选中软件bin 档中的Scatter 文件并打开
6 将Option 选项里的“Enable DA download all”勾选,“Enable DA checksum”不勾选。
7 此项无需勾选
8 设置为高速下载和无电池状态,组装厂软件升级时下载类型请务必选择
“Format and Download All,否则容易出现异常。
(非常重要!!!!)
9 勾选有效的COM 口(非N/A)并点击“Start all”按钮
10 1)勾选No battery,然后插入USB 线,按住音量侧键下键/上键(视项目而定),直至出现红色进度条开始下载
2)勾选Battery,然后插入USB线装上电池,无需按键,红色进度条出现开始下载
备注:下载过程中如果有提示安装驱动,自动安装即可。
NXP LPC ARM 必须知道的知识寄存器和工作模式:7种工作模式:fiq/irq/abt/und/sys/usr/svc。
通过"MSR cpsr_c,#0xdx"切换。
上电时进入svc模式。
svc和usr的区别是:svc可以通过"MSR cpsr_c,#0xdx"自由切换到其它任何模式,但是usr 不可以。
各模式下有自己的堆栈。
要在程序启动后依次进入各个模式分别设置自己的堆栈,最后进入usr模式。
好多个寄存器:r0 - r7 (a1 - a4 / v1 - v4),r15(pc) 在所有模式下都可见。
r8(v5),r9(sb,v6),r10(sl,v7),r11(fp,v8),r12(ip) fiq模式下有一组独立的映射。
r13(sp)/R14(lr) 在usr和sys模式下用同一组映射,其它模式下各有自己的映射。
cpsr在所有模式下可见。
spsr在usr和sys模式下没有映射。
cpsr是一个最特殊的寄存器,结构如下:31 30 29 28 27~8 7 6 5 4 3 2 1 0N Z C V 保留 I F T M4 M3 M2 M1 M0其中,N/Z/C/V分别为负/零/进位/溢出的标志位。
在所有模式下都可以进行读操作。
I/F为中断/快中断禁止位,M4~M0是工作模式控制位,它们在USR模式下都不可操作。
T为Thum/ARM模式位,在所有模式下不可直接操作,否则会天下大乱,预取址错误中断可以捕获这种乱局。
只能用BX指令进行Thum/ARM的状态切换。
总之,USR模式很不方便。
在该模式下只可以通过软中断控制I/F位。
cpsr只能够用MSR/MRS 指令来操作。
各工作模式下的spsr: 在由突发事件引起的模式切换发生时,新模式的spsr自动保存cpsr 的值,以备该模式退出时还原cpsr。
在程序的控制下进入某模式时,cpsr不会自动保存到相应的spsr。
龙源期刊网 http://www.qikan.com.cn 嵌入式软件开发的关键技术分析 作者:罗毅 来源:《中国科技博览》2018年第36期
[摘 要]嵌入式系统是以应用为中心、以计算机技术为基础、软件硬件可裁剪、适应应用系统对功能、可靠性、成本、体积、功耗严格要求的专用计算机系统。文章分析了嵌入式软件开发需要考虑的内容,然后分析了嵌入式软件开发中的关键技术,希望能够为相关人员提供一定的借鉴。
[关键词]嵌入式;软件开发;关键技术 中图分类号:TP503 文献标识码:A 文章编号:1009-914X(2018)36-0140-01 引言 现阶段,社会上关于嵌入式软件开发的研究越来越多,嵌入式软件在软件开发中占据的地位也越来越重要。嵌入式软件开发过程中需要用到各种技术,例如c语言、网络协议、嵌入式数据库等,还需要了解linux等系统的功能,分析当前嵌入式软件开发中的关键技术,能够为相关人员的开发提供便利。
1嵌入式软件开发需要考虑的地方 嵌入式软件一般需着重考虑三个方面:性能、安全性和开发效率(包括代码可移植性等)。性能(运行效率)方面,汇编明显是最高的。但汇编在安全性和开发效率方面明显是最低的。所以除非是要求极端高性能的嵌入式平台或者是系统实在是太简单而没办法支持高级语言,使用汇编语言的不多,一般进行初始化时会使用汇编语言。
2嵌入式软件开发中的关键技术 2.1存储器映射 一,在Scatter文件中定位目标外设。通常情况下,外设寄存器的内存映射地址是在源文件或头文件中定义的“硬编码(hard-code)”。但为了增加代码的可移植性,可以在源文件中声明一个映射到外设寄存器的结构,并将这个结构在Scatter文件中定位;
二,在Scatter文件中放置堆和栈。首先是显示放置标号。为了在Scatter文件中放置堆栈,必须在源文件中定义Scatter文件的参照符号。其次,使用链接程序生成符号,该方法需要在目标文件中指定堆和栈的大小,先在一个汇编源文件中为堆和栈定义一个适当大小的区域。使用SPACE命令保留一个清零的存储器块。然后为该区域设置NOINIT属性,避免在链接时被修改。这样避免了显示放置堆栈标号而浪费内存空间; 龙源期刊网 http://www.qikan.com.cn 三,使用Scatter文件的EMPTY属性,该方法使用了Scatter文件执行域的EMPTY属性。该属性使得定义的区域不包括目标数据和代码。在EMPTY属性后制定区域长度。存储器中向上增长的堆,其区域长度一般为正,为了表明栈在存储器中是向下增长的,一般将栈标为负数。
如何在Keil4下通过J-Link下载文件数据到STM32外部的Nor Flash实验目的:把一张320*240像素的图片文件,通过J-Link下载到STM32外部的Nor Flash里去,然后再读到LCD显示屏显示出来。
用LCD转换图片工具把图片搞成一个C文件。
准备烧写算法:声明:图例中用到的地址需要根据你自己的情况作相应调整。
Keil单片机开发平台是根据预先设定好的Flash烧写算法将用户程序烧到单片机的Flash内部的,那么由于这个算法是固定的,我们往往不关心,所以我们对其原理不是很了解,实际上,我们都知道,要将程序烧进去,需要在工程选项中选择对应的单片机型号,如下图所示。
这个过程就是准备Flash的烧写算法,选中了某个单片机型号,就确定了其使用的Flash特征,那么这些算法藏在什么地方呢。
这些算法就藏在Keil安装的根目录下X:\Keil\ARM\Flash目下,该目录下有很多的文件夹,每个文件夹里有对应的工程,每个工程都是某种型号单片机的Flash烧写算法,他们具体的内容不同,但是具有统一的接口,以便被Keil调用。
现在我们要烧写STM32的外部Nor Flash,所以我们要新建一个算法:新建一个文件夹,如Test。
将X:\Keil\ARM\Flash\STM32F10x\下的所有文件拷进Test文件夹来,将X:\Keil\ARM\Flash\SST39x160x\下的FlashPrg.c文件也拷进Test文件夹来并覆盖同名文件,将X:\Keil\ARM\Flash\下的FlashOS.h 文件也拷进Test文件夹来。
如果你使用的Nor Flash不在MDK自带驱动的范围内,那么需要根据FlashPrg.c文件自行编写相关函数。
打开工程文件STM32Fx.uvproj,此时会报一个错误,提示没有选择STM32的Device型号。
这时你根据你的STM32的型号选择相应的就OK了,如下图所示。