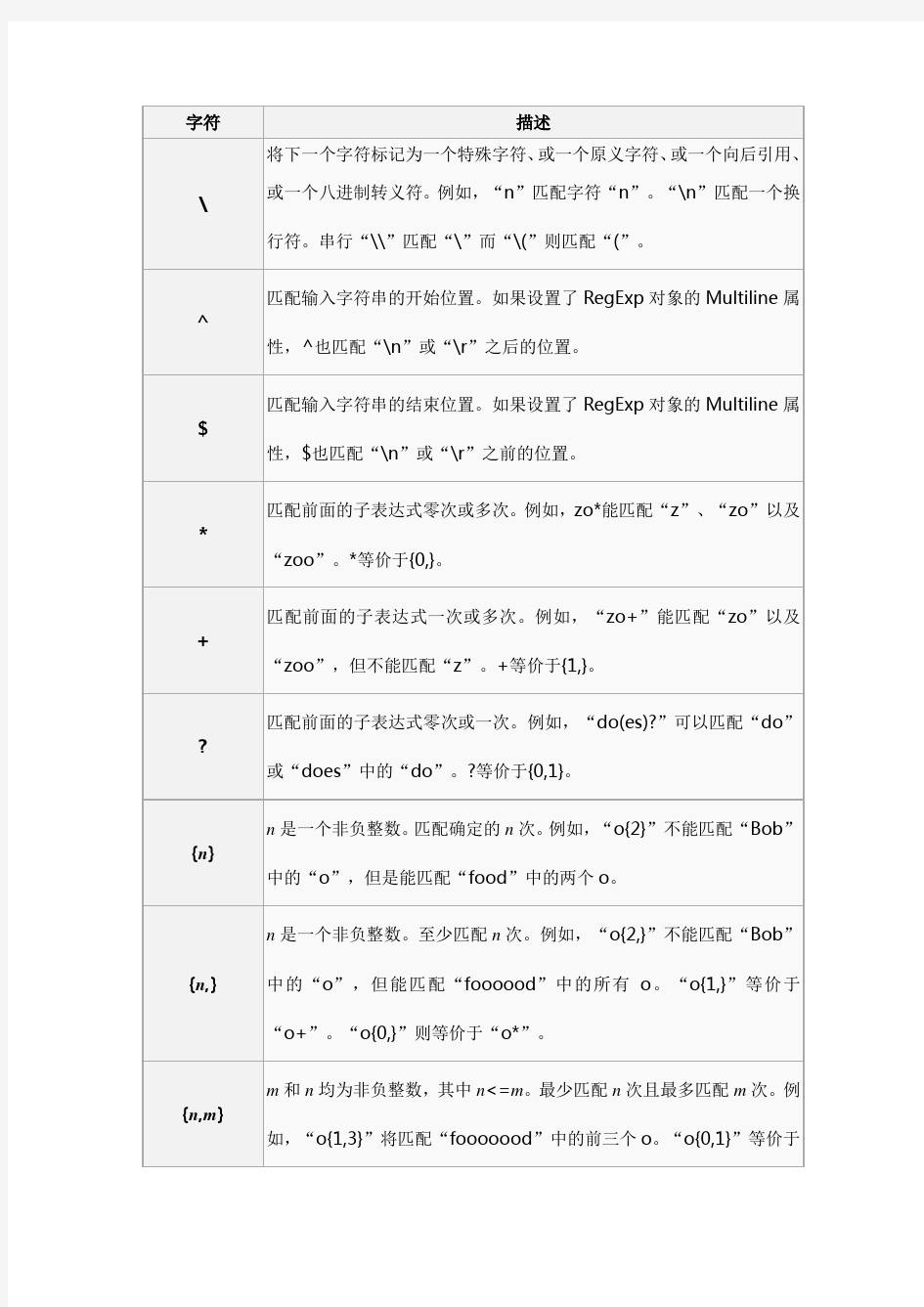

字符描述
\ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,“n”匹配字符“n”。“\n”匹配一个换行符。串行“\\”匹配“\”而“\(”则匹配“(”。
^
匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属
性,^也匹配“\n”或“\r”之后的位置。
$
匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属
性,$也匹配“\n”或“\r”之前的位置。
*
匹配前面的子表达式零次或多次。例如,zo*能匹配“z”、“zo”以及
“zoo”。*等价于{0,}。
+
匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及
“zoo”,但不能匹配“z”。+等价于{1,}。
?
匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”
或“does”中的“do”。?等价于{0,1}。
{n}
n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”
中的“o”,但是能匹配“food”中的两个o。
{n,} n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。
{n,m}
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例
如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于
“o?”。请注意在逗号和两个数之间不能有空格。
? 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,
匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串
“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。
.
匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字
符,请使用像“(.|\n)”的模式。
(pattern) 匹配pattern并获取这一匹配的子字符串。该子字符串用于向后引用。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“\(”或“\)”。
(?:pattern) 匹配pattern但不获取匹配的子字符串,也就是说这是一个非获取匹配,不存储匹配的子字符串用于向后引用。这在使用或字符“(|)”来组合一个模式的各个部分是很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。
(?=pattern) 正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串。
这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预
查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?!pattern) 正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的
“Windows”,但不能匹配“Windows2000”中的“Windows”。
预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始
(?<=pattern) 反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。
(?
x|y
匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”
则匹配“zood”或“food”。
[xyz] 字符集合(character class)。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。特殊字符仅有反斜线\保持特殊含义,用于转义字符。其它特殊字符如星号、加号、各种括号等均作为普通字符。脱字符^如果出现在首位则表示负值字符集合;如果出现在字符串中间就仅作为普通字符。连字符- 如果出现在字符串中间表示字符范围描述;如果如果出现在首位则仅作为普通字符。
[^xyz]
排除型(negate)字符集合。匹配未列出的任意字符。例如,“[^abc]”
可以匹配“plain”中的“plin”。
[a-z]
字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”
到“z”范围内的任意小写字母字符。
[^a-z] 排除型的字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。
\b 匹配一个单词边界,也就是指单词和空格间的位置。例如,“er\b”可
以匹配“never”中的“er”,但不能匹配“verb”中的“er”。
\B
匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配
“never”中的“er”。
\cx
匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。
x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。\d 匹配一个数字字符。等价于[0-9]。
\D 匹配一个非数字字符。等价于[^0-9]。
\f 匹配一个换页符。等价于\x0c和\cL。
\n 匹配一个换行符。等价于\x0a和\cJ。
\r 匹配一个回车符。等价于\x0d和\cM。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。\S 匹配任何非空白字符。等价于[^ \f\n\r\t\v]。
\t 匹配一个制表符。等价于\x09和\cI。
\v 匹配一个垂直制表符。等价于\x0b和\cK。
\w 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”。
\W 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。
\x n 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。.
\num向后引用(back-reference)一个子字符串(substring),该子字符串
与正则表达式的第num个用括号围起来的子表达式(subexpression)匹配。其中num是从1开始的正整数,其上限可能是99。例如:“(.)\1”匹配两个连续的相同字符。
\n 标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。
\nm 标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n 为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m 均为八进制数字(0-7),则\nm将匹配八进制转义值nm。
\nml
如果n为八进制数字(0-3),且m和l均为八进制数字(0-7),则匹配
八进制转义值nm l。
\u n
匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,
\u00A9匹配版权符号(?)。
常用的正则表达式
C#中经常会用到一些正则表达式,今天小编为大家收集整理了30个常用的C#正则表达式,希望对大家有所帮助!
1、整数"^-?\d+$"
2、正整数"^[0-9][1-9][0-9]$"
3、负整数"^-[0-9][1-9][0-9]$"
4、非负整数(正整数+ 0): "^\d+$"
5、非正整数(负整数+ 0)"^((-\d+)|(0+))$"
6、非负浮点数(正浮点数+ 0) "^\d+(.\d+)?$"
7、非正浮点数(负浮点数+ 0) "^((-\d+(.\d+)?)|(0+(.0+)?))$"
8、正浮点数"^(([0-9]+.[0-9][1-9][0-9])|([0-9][1-9][0-9].[0-9]+)|([0-9][1-9][0-9]))$"
9、负浮点数"^(-(([0-9]+.[0-9][1-9][0-9])|([0-9][1-9][0-9].[0-9]+)|([0-9][1-9][0-9])))$"
10、浮点数"^(-?\d+)(.\d+)?$"
11、由26个英文字母组成的字符串"^[A-Za-z]+$"
12、由26个英文字母的小写组成的字符串"^[a-z]+$"
13、由26个英文字母的大写组成的字符串"^[A-Z]+$"
14、由数字和26个英文字母组成的字符串"^[A-Za-z0-9]+$"
15、由数字、26个英文字母或者下划线组成的字符串"^\w+$"
16、email地址"^[\w-]+(.[\w-]+)*@[\w-]+(.[\w-]+)+$"
17、url "^[a-zA-z]+://(\w+(-\w+))(.(\w+(-\w+)))(\?\S)?$"
18、月/日/年/^((0([1-9]{1}))|(1[1|2]))/((0-2)|(3[0|1]))/(d{2}|d{4})$/
19、年-月-日/^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-((0-2)|(3[0|1]))$/
20、Email "^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3}) (]?)$"
21、电话号码"(d+-)?(d{4}-?d{7}|d{3}-?d{8}|^d{7,8})(-d+)?"
22、IP地址"^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0 -5]).(d{1,2}|1dd|2[0-4]d|25[0-5])$"
23、YYYY-MM-DD基本上把闰年和2月等的情况都考虑进去了
^((((1[6-9]|[2-9]\d)\d{2})-(0?[13578]|1[02])-(0?[1-9]|[12]\d|3[01]))|(((1[6-9]|[2-9]\d)\ d{2})-(0?[13456789]|1[012])-(0?[1-9]|[12]\d|30))|(((1[6-9]|[2-9]\d)\d{2})-0?2-(0?[1-9] |1\d|2[0-8]))|(((1[6-9]|[2-9]\d)(0[48]|[2468][048]|[13579][26])|((16|[2468][048]|[357 9][26])00))-0?2-29-))$
24、图片src[^>]*[^/].(?:jpg|bmp|gif)(?:\"|\')
25、匹配空行的正则表达式:\n[\s| ]*\r
26、匹配中文^([\u4e00-\u9fa5]+|[a-zA-Z0-9]+)$
27、匹配双字节字符(包括汉字在内):[^\x00-\xff]
28、匹配HTML标记的正则表达式:/<(.)>.<\/\1>|<(.*) \/>/
29、匹配首尾空格的正则表达式:(^\s)|(\s$)(像vbscript那样的trim函数)
30、匹配html中的A标签"\
"^\d+$" //非负整数(正整数+ 0)
"^[0-9]*[1-9][0-9]*$" //正整数
"^((-\d+)|(0+))$" //非正整数(负整数+ 0)
"^-[0-9]*[1-9][0-9]*$" //负整数
"^-?\d+$" //整数
"^\d+(\.\d+)?$" //非负浮点数(正浮点数+ 0)
"^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮点数
"^((-\d+(\.\d+)?)|(0+(\.0+)?))$" //非正浮点数(负浮点数+ 0)
"^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$" //负浮点数
"^(-?\d+)(\.\d+)?$" //浮点数
"^[A-Za-z]+$" //由26个英文字母组成的字符串
"^[A-Z]+$" //由26个英文字母的大写组成的字符串
"^[a-z]+$" //由26个英文字母的小写组成的字符串
"^[A-Za-z0-9]+$" //由数字和26个英文字母组成的字符串
"^\w+$" //由数字、26个英文字母或者下划线组成的字符串
"^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$" //email地址
"^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$" //url
/^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日
/^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年
"^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3 })(]?)$" //Emil
"(d+-)?(d{4}-?d{7}|d{3}-?d{8}|^d{7,8})(-d+)?" //电话号码
"^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[ 0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5])$" //IP地址
YYYY-MM-DD基本上把闰年和2月等的情况都考虑进去了
^((((1[6-9]|[2-9]\d)\d{2})-(0?[13578]|1[02])-(0?[1-9]|[12]\d|3[01]))|(((1[6-9]|[2-9]\d )\d{2})-(0?[13456789]|1[012])-(0?[1-9]|[12]\d|30))|(((1[6-9]|[2-9]\d)\d{2})-0?2-(0?[1 -9]|1\d|2[0-8]))|(((1[6-9]|[2-9]\d)(0[48]|[2468][048]|[13579][26])|((16|[2468][048]|[3 579][26])00))-0?2-29-))$
C# 中的常用正则表达式总结 - 基本知识
这是我发了不少时间整理的C#的正则表达式,新手朋友注意一定要手册一下哦,这样可以节省很多写代码的时间,为新手朋友整理发布。
只能输入数字:"^[0-9]*$"。
只能输入n位的数字:"^d{n}$"。
只能输入至少n位的数字:"^d{n,}$"。
只能输入m~n位的数字:。"^d{m,n}$"
只能输入零和非零开头的数字:"^(0|[1-9][0-9]*)$"。
只能输入有两位小数的正实数:"^[0-9]+(.[0-9]{2})?$"。
只能输入有1~3位小数的正实数:"^[0-9]+(.[0-9]{1,3})?$"。
只能输入非零的正整数:"^+?[1-9][0-9]*$"。
只能输入非零的负整数:"^-[1-9][]0-9"*$。
只能输入长度为3的字符:"^.{3}$"。
只能输入由26个英文字母组成的字符串:"^[A-Za-z]+$"。
只能输入由26个大写英文字母组成的字符串:"^[A-Z]+$"。
只能输入由26个小写英文字母组成的字符串:"^[a-z]+$"。
只能输入由数字和26个英文字母组成的字符串:"^[A-Za-z0-9]+$"。
只能输入由数字、26个英文字母或者下划线组成的字符串:"^w+$"。
验证用户密码:"^[a-zA-Z]w{5,17}$"正确格式为:以字母开头,长度在6~18之间,只能包含字符、数字和下划线。
验证是否含有^%&’,;=?$"等字符:"[^%&’,;=?$x22]+"。
只能输入汉字:"^[u4e00-u9fa5]{0,}$"
验证Email地址:"^w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*$"。
验证InternetURL:"^http://([w-]+.)+[w-]+(/[w-./?%&=]*)?$"。
C# 中的常用正则表达式总结 - 验证电话身份证
验证电话号码:"^((d{3,4}-)|d{3.4}-)?d{7,8}$"正确格式为:"XXX-XXXXXXX"、"XXX X-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX"。
验证身份证号(15位或18位数字):"^d{15}|d{18}$"。
验证一年的12个月:"^(0?[1-9]|1[0-2])$"正确格式为:"01"~"09"和"1"~"12"。
验证一个月的31天:"^((0?[1-9])|((1|2)[0-9])|30|31)$"正确格式为;"01"~"09"和" 1"~"31"。
利用正则表达式限制网页表单里的文本框输入内容:
用正则表达式限制只能输入中文:OnKeyUp="value=value.replace(/[^u4E00-u9FA5]/ g,’’)"
用正则表达式限制只能输入全角字符:
用正则表达式限制只能输入数字:onkeyup="value=value.replace(/[^d]/g,’’) "on beforepaste="clipboardData.setData(’text’,clipboardData.getData(’text’).rep lace(/[^d]/g,’’))"
用正则表达式限制只能输入数字和英文:onkeyup="value=value.replace(/[W]/g,’’) "onbeforepaste="clipboardData.setData(’text’,clipboardData.getData(’text’). replace(/[^d]/g,’’))"
C# 中的常用正则表达式总结 - 代码片断
得用正则表达式从URL地址中提取文件名的javascript程序,如下结果为page1
以下是引用片段:
s="https://www.doczj.com/doc/eb5540803.html,/page1.htm"
s=s.replace(/(.*/){0,}([^.]+).*/ig,"$2")
alert(s)
匹配双字节字符(包括汉字在内):[^x00-xff]
应用:计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
以下是引用片段:
String.prototype.len=function(){returnthis.replace([^x00-xff]/g,"aa").lengt h;}
匹配空行的正则表达式: [s| ]*
匹配HTML标记的正则表达式:/<(.*)>.*|<(.*) />/
匹配首尾空格的正则表达式:(^s*)|(s*$)
以下是引用片段:
String.prototype.trim=function()
{
returnthis.replace(/(^s*)|(s*$)/g,"");
}
利用正则表达式分解和转换IP地址:
下面是利用正则表达式匹配IP地址,并将IP地址转换成对应数值的Javascript程序:以下是引用片段:
functionIP2V(ip)
{
re=/(d+).(d+).(d+).(d+)/g//匹配IP地址的正则表达式
if(re.test(ip))
{
return RegExp.$1*Math.pow(255,3))+RegExp.$2*Math.pow(255,2))+RegExp.$3*255+R egExp.$4*1
}
else
{
thrownewError("NotavalidIPaddress!")
}
}
不过上面的程序如果不用正则表达式,而直接用split函数来分解可能更简单,程序如下:
以下是引用片段:
varip="10.100.20.168"
ip=ip.split(".")
alert("IP值是:"+(ip[0]*255*255*255+ip[1]*255*255+ip[2]*255+ip[3]*1))
C#正则表达式
图片src[^>]*[^/].(?:jpg|bmp|gif)(?:\"|\')
中文^([\u4e00-\u9fa5]+|[a-zA-Z0-9]+)$
网址"\
匹配中文字符的正则表达式:[\u4e00-\u9fa5]
匹配双字节字符(包括汉字在内):[^\x00-\xff]
匹配空行的正则表达式:\n[\s| ]*\r
匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/
匹配首尾空格的正则表达式:(^\s*)|(\s*$)(像vbscript那样的trim函数)
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配网址URL的正则表达式:http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
---------------------------------------------------------------------------
以下是例子:
利用正则表达式限制网页表单里的文本框输入内容:
用正则表达式限制只能输入中文:onkeyup="value=value.replace(/[^\u4E00-\u9FA5]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\u4 E00-\u9FA5]/g,''))"
1.用正则表达式限制只能输入全角字符:
onkeyup="value=value.replace(/[^\uFF00-\uFFFF]/g,'')"
onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\uFF
00-\uFFFF]/g,''))"
2.用正则表达式限制只能输入数字:onkeyup="value=value.replace(/[^\d]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d] /g,''))"
3.用正则表达式限制只能输入数字和英文:onkeyup="value=value.replace(/[\W]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^\d] /g,''))"
4.计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
String.prototype.len=function(){return this.replace([^\x00-\xff]/g,"aa").length;}
5.javascript中没有像vbscript那样的trim函数,我们就可以利用这个表达式来实现,如下:
String.prototype.trim = function()
{
return this.replace(/(^\s*)|(\s*$)/g, "");
}
利用正则表达式分解和转换IP地址:
6.下面是利用正则表达式匹配IP地址,并将IP地址转换成对应数值的Javascript程序:
function IP2V(ip)
{
re=/(\d+)\.(\d+)\.(\d+)\.(\d+)/g //匹配IP地址的正则表达式
if(re.test(ip))
{
return
RegExp.$1*Math.pow(255,3))+RegExp.$2*Math.pow(255,2))+RegExp.$3*255+RegExp.$4 *1
}
else
{
throw new Error("不是一个正确的IP地址!")
}
}
不过上面的程序如果不用正则表达式,而直接用split函数来分解可能更简单,程序如下:
var ip="10.100.20.168"
ip=ip.split(".")
alert("IP值是:"+(ip[0]*255*255*255+ip[1]*255*255+ip[2]*255+ip[3]*1)) (?<=>)[^>]*(?=<)
JS正则表达式大全 JS正则表达式大全【1】 正则表达式中的特殊字符【留着以后查用】字符含意 \ 做为转意,即通常在"\"后面的字符不按原来意义解释,如/b/匹配字符"b",当b前面加了反斜杆后/\b/,转意为匹配一个单词的边界。 -或- 对正则表达式功能字符的还原,如"*"匹配它前面元字符0次或多次,/a*/将匹配a,aa,aaa,加了"\"后,/a\*/将只匹配"a*"。 ^ 匹配一个输入或一行的开头,/^a/匹配"an A",而不匹配"An a" $ 匹配一个输入或一行的结尾,/a$/匹配"An a",而不匹配"an A" * 匹配前面元字符0次或多次,/ba*/将匹配b,ba,baa,baaa + 匹配前面元字符1次或多次,/ba*/将匹配ba,baa,baaa ? 匹配前面元字符0次或1次,/ba*/将匹配b,ba (x) 匹配x保存x在名为$1...$9的变量中 x|y 匹配x或y {n} 精确匹配n次 {n,} 匹配n次以上 {n,m} 匹配n-m次 [xyz] 字符集(character set),匹配这个集合中的任一一个字符(或元字符) [^xyz] 不匹配这个集合中的任何一个字符 [\b] 匹配一个退格符 \b 匹配一个单词的边界 \B 匹配一个单词的非边界 \cX 这儿,X是一个控制符,/\cM/匹配Ctrl-M \d 匹配一个字数字符,/\d/ = /[0-9]/ \D 匹配一个非字数字符,/\D/ = /[^0-9]/ \n 匹配一个换行符 \r 匹配一个回车符 \s 匹配一个空白字符,包括\n,\r,\f,\t,\v等 \S 匹配一个非空白字符,等于/[^\n\f\r\t\v]/ \t 匹配一个制表符 \v 匹配一个重直制表符 \w 匹配一个可以组成单词的字符(alphanumeric,这是我的意译,含数字),包括下划线,如[\w]匹配
正则表达式基础知识 一个正则表达式就是由普通字符(例如字符a 到z)以及特殊字符(称为元字符)组成的文字模式。该模式描述在查找文字主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。如:
下面看几个例子: "^The":表示所有以"The"开始的字符串("There","The cat"等); "of despair$":表示所以以"of despair"结尾的字符串; "^abc$":表示开始和结尾都是"abc"的字符串——呵呵,只有"abc"自己了;"notice":表示任何包含"notice"的字符串。 '*','+'和'?'这三个符号,表示一个或一序列字符重复出现的次数。它们分别表示“没有或更多”,“一次或更多”还有“没有或一次”。下面是几个例子: "ab*":表示一个字符串有一个a后面跟着零个或若干个b。("a", "ab", "abbb",……);"ab+":表示一个字符串有一个a后面跟着至少一个b或者更多; "ab?":表示一个字符串有一个a后面跟着零个或者一个b; "a?b+$":表示在字符串的末尾有零个或一个a跟着一个或几个b。 也可以使用范围,用大括号括起,用以表示重复次数的范围。 "ab{2}":表示一个字符串有一个a跟着2个b("abb"); "ab{2,}":表示一个字符串有一个a跟着至少2个b; "ab{3,5}":表示一个字符串有一个a跟着3到5个b。
请注意,你必须指定范围的下限(如:"{0,2}"而不是"{,2}")。 还有,你可能注意到了,'*','+'和'?'相当于"{0,}","{1,}"和"{0,1}"。 还有一个'|',表示“或”操作: "hi|hello":表示一个字符串里有"hi"或者"hello"; "(b|cd)ef":表示"bef"或"cdef"; "(a|b)*c":表示一串"a""b"混合的字符串后面跟一个"c"; '.'可以替代任何字符: "a.[0-9]":表示一个字符串有一个"a"后面跟着一个任意字符和一个数字; "^.{3}$":表示有任意三个字符的字符串(长度为3个字符); 方括号表示某些字符允许在一个字符串中的某一特定位置出现: "[ab]":表示一个字符串有一个"a"或"b"(相当于"a|b"); "[a-d]":表示一个字符串包含小写的'a'到'd'中的一个(相当于"a|b|c|d"或者"[abcd]");"^[a-zA-Z]":表示一个以字母开头的字符串; "[0-9]%":表示一个百分号前有一位的数字; "[0-9]+":表示一个以上的数字; ",[a-zA-Z0-9]$":表示一个字符串以一个逗号后面跟着一个字母或数字结束。 你也可以在方括号里用'^'表示不希望出现的字符,'^'应在方括号里的第一位。(如:"%[^a-zA-Z]%"表 示两个百分号中不应该出现字母)。 为了逐字表达,必须在"^.$()|*+?{\"这些字符前加上转移字符'\'。 请注意在方括号中,不需要转义字符。
正则表达式中常用符号 符号含义举例或说明 .任何字符或非字符 2.4匹配204, 214, 2t4, 2 4, 2.4, 2-4 *重复0次或更多BA*匹配B,BA,BAA,BAAA等 .* 某个字符重复0次或更多R.* 表示R后面有0个过多个字符,不同类副词 的赋码包括RR,RG,PGQ,RGQV等, 所以R.*表示, 不分类笼统地指所有副词, 类似的所有名词 N.*,所有形容词J.* +重复1次或多次A+匹配A,AA,AAA等 ?有或者无BA?匹配B和BA .*?任何字符串 |或者(|号在回车键上面)(analyze|analyse) 检索analyse 或者 analyze [ ] 方括号中的任意字符或单词[abc]匹配a、b或c [abc]+匹配 [ ]* n个单词。 () 组合,使得括号中的部分可以当作 一个符号处理 act(ing)可以匹配act和acting (cat|dog),把dog 和cat 两个词一块检索出来, ([pos="R.*"][pos="J.*"]) 前面一个词的词性为副词, 后面一个词的词性为形容词,把副词和形容词作 为一个整体检索 {} { }表示选择范围,{0,3}表示0~3个 范围内[pos="J.*"]{0,2} 表示其前的形容词有0个,1个或者2个 [ ] {0,}中,[ ]表示任意单词,{0,2}表示这个单词有0个,1个,或者无穷个,后面一个数字不写表示无穷个。 & 和,并且
段首标记, “however|However”表示句首为However或 however 开头的句子 !不等于[word!=","] "which"表示which 前没有逗号 [pos!="JJ.*|N.*|I.*"] 词性不是形容词、名词、介词 的词 N.*名词、V.* 动词、J.*形容词、R.* 副词、AT.* 冠词、I.* 介词、P.*代词 VB.*表示be动词、VH*有动词、VV.*实意动词及其各种变形、VM*情态动词
1. 平时做网站经常要用正则表达式,下面是一些讲解和例子,仅供大家参考和修改使用: 2. "^\d+$"//非负整数(正整数+ 0) 3. "^[0-9]*[1-9][0-9]*$"//正整数 4. "^((-\d+)|(0+))$"//非正整数(负整数+ 0) 5. "^-[0-9]*[1-9][0-9]*$"//负整数 6. "^-?\d+$"//整数 7. "^\d+(\.\d+)?$"//非负浮点数(正浮点数+ 0) 8. "^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$"//正浮点数 9. "^((-\d+(\.\d+)?)|(0+(\.0+)?))$"//非正浮点数(负浮点数+ 0) 10. "^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$"//负浮点数 11. "^(-?\d+)(\.\d+)?$"//浮点数 12. "^[A-Za-z]+$"//由26个英文字母组成的字符串 13. "^[A-Z]+$"//由26个英文字母的大写组成的字符串 14. "^[a-z]+$"//由26个英文字母的小写组成的字符串 15. "^[A-Za-z0-9]+$"//由数字和26个英文字母组成的字符串 16. "^\w+$"//由数字、26个英文字母或者下划线组成的字符串 17. "^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$"//email地址 18. "^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$"//url 19. /^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日 20. /^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年 21. "^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$" //Emil 22. /^((\+?[0-9]{2,4}\-[0-9]{3,4}\-)|([0-9]{3,4}\-))?([0-9]{7,8})(\-[0-9]+)?$/ //电话号码 23. "^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}| 1dd|2[0-4]d|25[0-5])$" //IP地址 24. 25. 匹配中文字符的正则表达式:[\u4e00-\u9fa5] 26. 匹配双字节字符(包括汉字在内):[^\x00-\xff] 27. 匹配空行的正则表达式:\n[\s| ]*\r 28. 匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/ 29. 匹配首尾空格的正则表达式:(^\s*)|(\s*$) 30. 匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* 31. 匹配网址URL的正则表达式:^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$ 32. 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$ 33. 匹配国内电话号码:(\d{3}-|\d{4}-)?(\d{8}|\d{7})? 34. 匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$ 35. 36. 37. 元字符及其在正则表达式上下文中的行为:
本文由我司收集整编,推荐下载,如有疑问,请与我司联系 在正则表达式中使用OR 运算符 How can I use OR in a Java regex? I tried the following, but it’s returning null instead of the text. 如何在Java 正则表达式中使用OR?我尝试了以下,但它返回null 而不是文本。 Pattern reg = Patternpile(“\\*+|#+ (.+?)”);Matcher matcher = reg.matcher(“*kdkdk”); \\ “#aksdasd”matcher.find();System.out.println(matcher.group(1)); 3 The regex syntax for searching for X or Y is (X|Y). The parentheses are required if you have anything else in the pattern. You were searching for one of these patterns: 用于搜索X 或Y 的正则表达式语法是(X | Y)。如果模式中还有其他任何内容, 则必须使用括号。您正在搜索以下模式之一: a literal * repeated one or more times 文字*重复一次或多次 OR 要么 a literal # repeated one or more times, followed by a space, followed by one or more of any character, matching a minimum number of times 文字#重复一次或多次,后跟一个空格,后跟一个或多个任何字符,匹配最少次 数 This pattern matches * using the first part of the OR, but since that subpattern defines no capture groups, matcher.group(1) will be null. If you printed matcher.group(0), you would get * as the output. 此模式使用OR 的第一部分匹配*,但由于该子模式不定义捕获组,因此 matcher.group(1)将为null。如果你打印matcher.group(0),你会得到*作为输 出。 If you want to capture the first character to the right of a space on a line that starts with either “*”or “#”repeated some number of times, followed by a space and at least one
Java代码 1.Java中在某个字符串中查询某个字符或者某个子字串Java代码
Java代码 3.对字符串的分割 Java代码 如果用正则表达式分割就如上所示,一般我们都会使用下面更简单的方法:Java代码 4.字符串的替换/删除 Java代码 如果要把字符串中的@都给删除,只用要空字符串替换就可以了: Java代码
注:对Pattern类的说明: 1.public final class java.util.regex.Pattern是正则表达式编译后的表达法。 下面的语句将创建一个Pattern对象并赋值给句柄pat:Pattern pat = https://www.doczj.com/doc/eb5540803.html,pile(regEx); 有趣的是,Pattern类是final类,而且它的构造器是private。也许有人告诉你一些设计模式的东西,或者你自己查有关资料。这里的结论是:Pattern类不能被继承,我们不能通过new创建Pattern类的对象。 因此在Pattern类中,提供了2个重载的静态方法,其返回值是Pattern对象(的引用)。如:Java代码 1.public static Pattern compile(String regex) { 2.return new Pattern(regex, 0); 3.} 当然,我们可以声明Pattern类的句柄,如Pattern pat = null; 2.pat.matcher(str)表示以用Pattern去生成一个字符串str的匹配器,它的返回值是一个Matcher类的引用。 我们可以简单的使用如下方法:boolean rs = https://www.doczj.com/doc/eb5540803.html,pile(regEx).matcher(str).find();
JAVA中正则表达式使用介绍 一、什么是正则表达式 正则表达式是一种可以用于模式匹配和替换的强有力的工具。我们可以在几乎所有的基于UNIX系统的工具中找到正则表达式的身影,例如,vi编辑器,Perl或PHP脚本语言,以及awk或sed shell程序等。此外,象JavaScript这种客户端的脚本语言也提供了对正则表达式的支持。 正则表达式可以让用户通过使用一系列的特殊字符构建匹配模式,进行信息的验证。 此外,它还能够高效地创建、比较和修改字符串,以及迅速地分析大量文本和数据以搜索、移除和替换文本。 例如: 二、基础知识 1.1开始、结束符号(它们同时也属于定位符) 我们先从简单的开始。假设你要写一个正则表达式规则,你会用到^和$符号,他们分别是行首符、行尾符。 例如:/^\d+[0-9]?\d+$/ 1.2句点符号 假设你在玩英文拼字游戏,想要找出三个字母的单词,而且这些单词必须以“t”字母开头,以“n”字母结束。另外,假设有一本英文字典,你可以用正则表达式搜索它的全部内容。要构造出这个正则表达式,你可以使用一个通配符——句点符号“.”。这样,完整的表达式就是“t.n”,它匹配“tan”、“ten”、“tin”和“ton”,还匹配“t#n”、“tpn”甚至“t n”,还有其他许多无意义的组合。这是因为句点符号匹配所有字符,包括空格、Tab字符甚至换行符: 1.3方括号符号 为了解决句点符号匹配范围过于广泛这一问题,你可以在方括号(“[]”)里面指定看来有意义的字符。此时,只有方括号里面指定的字符才参与匹配。也就是说,正则表达式“t[aeio]n”只匹配“tan”、“Ten”、“tin”和“ton”。但“Toon”不匹配,因为在方括号之内你只能匹配单个字符: 1.4“或”符号
C#正则表达式之Regex类用法详解 正则表达式的本质是使用一系列特殊字符模式,来表示某一类字符串,正则表达式无疑是处理文本最有力的工具,而.NET提供的Regex类实现了验证正则表达式的方法。 Regex类表示不可变(只读)的正则表达式。它还包含各种静态方法,允许在不显式创建其他类的实例的情况下使用其他正则表达式类。 正则表达式基础概述 什么是正则表达式 在编写字符串的处理程序时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。 通常,我们在使用WINDOWS查找文件时,会使用通配符(*和?)。如果你想查找某个目录下的所有Word文档时,你就可以使用*.doc进行查找,在这里,*就被解释为任意字符串。和通配符类似,正则表达式也是用来进行文本匹配的工具,只不过比起通配符,它能更精确地描述你的需求——当然,代价就是更复杂。 一、C#正则表达式符号模式
说明: 由于在正则表达式中“\”、“?”、“*”、“^”、“$”、“+”、“(”、“)”、“|”、“{”、“[”等字符已经具有一定特殊意义,如果需要用它们的原始意义,则应该对它进行转义,例如希望在字符串中至少有一个“\”,那么正则表达式应该这么写:\\+。
二、在C#中,要使用正则表达式类,请在源文件开头处添加以下语句: 复制代码代码如下: using Syst https://www.doczj.com/doc/eb5540803.html, ressions; 三、RegEx类常用的方法 1、静态Match方法 使用静态Match方法,可以得到源中第一个匹配模式的连续子串。 静态的Match方法有2个重载,分别是 Regex.Match(string input,string pattern); Regex.Match(string input,string pattern,RegexOptions options); 第一种重载的参数表示:输入、模式 第二种重载的参数表示:输入、模式、RegexOptions枚举的“按位或”组合。 RegexOptions枚举的有效值是: Complied表示编译此模式 CultureInvariant表示不考虑文化背景 ECMAScript表示符合ECMAScript,这个值只能和IgnoreCase、Multiline、Complied连用ExplicitCapture表示只保存显式命名的组 IgnoreCase表示不区分输入的大小写 Ign https://www.doczj.com/doc/eb5540803.html, pace表示去掉模式中的非转义空白,并启用由#标记的注释Multiline表示多行模式,改变元字符^和$的含义,它们可以匹配行的开头和结尾 None表示无设置,此枚举项没有意义 RightToLeft表示从右向左扫描、匹配,这时,静态的Match方法返回从右向左的第一个匹配Singleline表示单行模式,改变元字符.的意义,它可以匹配换行符
一、正则表达式 除非您以前使用过正则表达式,否则您可能不熟悉此术语。但是,毫无疑问,您已经使用过不涉及脚本的某些正则表达式概念。 正则表达式示例 例如,您很可能使用? 和* 通配符来查找硬盘上的文件。通配符匹配文件名中的单个字符,而* 通配符匹配零个或多个字符。像data?.dat 这样的模式将查找下列文件: data1.dat data2.dat datax.dat dataN.dat 使用* 字符代替? 字符扩大了找到的文件的数量。data*.dat 匹配下列所有文件: data.dat data1.dat data2.dat data12.dat datax.dat dataXYZ.dat 尽管这种搜索方法很有用,但它还是有限的。和* 通配符的能力引入了正则表达式所依赖的概念,但正则表达式功能更强大,而且更加灵活。
二、正则表达式语法 正则表达式是一种文本模式,包括普通字符(例如,a 到z 之间的字母)和特殊字符(称为“元字符”)。模式描述在搜索文本时要匹配的一个或多个字符串。 正则表达式示例 下表包含了元字符的完整列表以及它们在正则表达式上下文中的行为:
三、生成正则表达式 正则表达式的结构与算术表达式的结构类似。即,各种元字符和运算符可以将小的表达式组合起来,创建大的表达式。 分隔符 通过在一对分隔符之间放置表达式模式的各种组件,就可以构建正则表达式。对于JScript,分隔符是正斜杠(/) 字符。例如: /expression/ 在上面的示例中,正则表达式模式(expression) 存储在RegExp对象的Pattern属性中。正则表达式的组件可以是单个字符、字符集、字符的范围、在几个字符之间选择或者所有这些组件的任何组合。 四、优先级顺序 正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。 运算符 下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
1.平时做网站经常要用正则表达式,下面是一些讲解和例子,仅供大家参考和修改使用: 2."^\d+$" //非负整数(正整数 + 0) 3."^[0-9]*[1-9][0-9]*$" //正整数 4."^((-\d+)|(0+))$" //非正整数(负整数 + 0) 5."^-[0-9]*[1-9][0-9]*$" //负整数 6."^-?\d+$" //整数 7."^\d+(\.\d+)?$" //非负浮点数(正浮点数 + 0) 8."^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮点数 9."^((-\d+(\.\d+)?)|(0+(\.0+)?))$" //非正浮点数(负浮点数 + 0) 10."^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$" //负浮点数 11."^(-?\d+)(\.\d+)?$" //浮点数 12."^[A-Za-z]+$" //由26个英文字母组成的字符串 13."^[A-Z]+$" //由26个英文字母的大写组成的字符串 14."^[a-z]+$" //由26个英文字母的小写组成的字符串 15."^[A-Za-z0-9]+$" //由数字和26个英文字母组成的字符串 16."^\w+$" //由数字、26个英文字母或者下划线组成的字符串 17."^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$" //email地址 18."^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$" //url 19./^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年- 月-日 20./^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/ 年 21."^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1, 3})(]?)$" //Emil 22./^((\+?[0-9]{2,4}\-[0-9]{3,4}\-)|([0-9]{3,4}\-))?([0-9]{7,8})(\-[0-9]+)?$/ / /电话号码
/b 代表着单词的开头或结尾,也就是单词的分界处.如果要精确地查找hi这个单词的话,我们应该使用/bhi/b. .是另一个元字符,匹配除了换行符以外的任意字符,*同样是元字符,它指定*前边的内容可以重复任意次以使整个表达式得到匹配。 .*连在一起就意味着任意数量的不包含换行的字符。 /d是一个新的元字符,匹配任意的数字,0/d/d‐/d/d/d/d/d/d/d/d也就是中国的电话号码.为了避免那么多烦人的重复,我们也可以这样写这个表达式:0/d{2}‐/d{8}。 /s匹配任意的空白符,包括空格,制表符(Tab),换行符,中文全角空格等。/w匹配字母或数字或下划线或汉字。 /b/w{6}/b 匹配刚好6个字母/数字的单词。 字符转义:使用/来取消这些字符的特殊意义。因此,你应该使用/.和/*。当然,要查找/本身,你也得用//。 代码 说明 . 匹配除换行符以外的任意字符 /w 匹配字母或数字或下划线或汉字 /s 匹配任意的空白符 /d 匹配数字 /b 匹配单词的开始或结束 ^ 匹配字符串的开始 $ 匹配字符串的结束 重复: 常用的限定符 代码/语法 说明 * 重复零次或更多次 + 重复一次或更多次 ? 重复零次或一次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次 要想查找数字,字母或数字,你只需要在中括号里列出它们就行了,像[aeiou]就匹配任何一个元音字母,[.?!]匹配标点符号(.或?或!)
常用的反义代码 代码/语法 说明 /W 匹配任意不是字母,数字,下划线,汉字的字符 /S 匹配任意不是空白符的字符 /D 匹配任意非数字的字符 /B 匹配不是单词开头或结束的位置 [^x] 匹配除了x以外的任意字符 [^aeiou] 匹配除了aeiou这几个字母以外的任意字符 替换: 正则表达式里的替换指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用|把不同的规则分隔开。 0/d{2}‐/d{8}|0/d{3}‐/d{7}这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010‐12345678),一种是4位区号,7位本地号(0376‐2233445)。 /(0/d{2}/)[‐ ]?/d{8}|0/d{2}[‐ ]?/d{8}这个表达式匹配3位区号的电话号码,其中区号可以用小括号括起来,也可以不用,区号与本地号间可以用连字号或空格间隔,也可以没有间隔。你可以试试用替换|把这个表达式扩展成也支持4位区号的。 /d{5}‐/d{4}|/d{5}这个表达式用于匹配美国的邮政编码。美国邮编的规则是5位数字,或者用连字号间隔的9位数字。之所以要给出这个例子是因为它能说明一个问题:使用替换时,顺序是很重要的。如果你把它改成/d{5}|/d{5}‐/d{4}的话,那么就只会匹配5位的邮编(以及9位邮编的前5位)。原因是匹配替换时,将会从左到右地测试每个分枝条件,如果满足了某个分枝的话,就不会去管其它的替换条件了。 分组: 如果想要重复一个字符串又该怎么办?你可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了。 (/d{1,3}/.){3}/d{1,3}是一个简单的IP地址匹配表达式。要理解这个表达式,请按下列顺序分析它:/d{1,3}匹配1到3位的数字,(/d{1,3}/.}{3}匹配三位数字加上一个英文句号(这个整体也就是这个分组)重复3次,最后再加上一个一到三位的数字(/d{1,3})。不幸的是,它也将匹配256.300.888.999这种不可能存在的IP地址(IP地址中每个数字都不能大于255)。如果能使用算术比较的话,或许能简单地解决这个问题,但是正则表达式中并不提供关于数学的任何功能,所以只能使用冗长的分组,选择,字符类来描述一个正确的IP地址:((2[0‐4]/d|25[0‐5]|[01]?/d/d?)/.){3}(2[0‐4]/d|25[0‐5]|[01]?/d/d?)。 后向引用: 后向引用用于重复搜索前面某个分组匹配的文本。例如,/1代表分组1匹配的文本。难以理解?请看示例: /b(/w+)/b/s+/1/b可以用来匹配重复的单词,像go go, kitty kitty。首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(/b(/w+)/b),然后是1个或几个空白符(/s+,最后是前面匹配的那个单词(/1)。
[23:39:35] 王尧说:"^\d+$"//非负整数(正整数+ 0) "^[0-9]*[1-9][0-9]*$"//正整数 "^((-\d+)|(0+))$"//非正整数(负整数+ 0) "^-[0-9]*[1-9][0-9]*$"//负整数 "^-?\d+$"//整数 "^\d+(\.\d+)?$"//非负浮点数(正浮点数+ 0) "^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$"//正浮点数 "^((-\d+(\.\d+)?)|(0+(\.0+)?))$"//非正浮点数(负浮点数+ 0) "^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$"//负浮点数 "^(-?\d+)(\.\d+)?$"//浮点数 "^[A-Za-z]+$"//由26个英文字母组成的字符串 "^[A-Z]+$"//由26个英文字母的大写组成的字符串 "^[a-z]+$"//由26个英文字母的小写组成的字符串 "^[A-Za-z0-9]+$"//由数字和26个英文字母组成的字符串 "^\w+$"//由数字、26个英文字母或者下划线组成的字符串 "^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$"//email地址 "^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$"//url /^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ //年-月-日 /^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ //月/日/年 ^(\w+((-\w+)|(\.\w+))*)\+\w+((-\w+)|(\.\w+))*\@[A-Za-z0-9]+((\.|-)[A-Za-z0-9]+)*\.[A-Za-z0-9]+$ //Emil "(d+-)?(d{4}-?d{7}|d{3}-?d{8}|^d{7,8})(-d+)?" //电话号码 "^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1, 2}|1dd|2[0-4]d|25[0-5])$" //IP地址 匹配中文字符的正则表达式:[\u4e00-\u9fa5] 匹配双字节字符(包括汉字在内):[^\x00-\xff] 匹配空行的正则表达式:\n[\s| ]*\r 匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/ 匹配首尾空格的正则表达式:(^\s*)|(\s*$) 匹配Email地址的正则表达式:^(\w+((-\w+)|(\.\w+))*)\+\w+((-\w+)|(\.\w+))*\@[A-Za-z0-9]+((\.|-)[A-Za-z0-9]+)*\.[A-Za-z0-9]+$ 匹配网址URL的正则表达式:^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$ 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$ 匹配国内电话号码:(\d{3}-|\d{4}-)?(\d{8}|\d{7})? 匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$ 漢字 Private Ps_KanjiRegex As String = "\u00A0-\u303F\u3200-\u33CF\u4E00-\uFF60\uFFA0-\uFFE5" ''入力可能漢字のコード(正規表現チェック用)
ID正则表达式用法及介绍 [复制链接] 本帖最后由漫步云中于2011-2-18 11:23 编辑 ID正则表达式用处很广,正则表达比较复杂的东西,只有不断用到,摸索,就能得心应手! 例1: 如果要把蓝色数据要替换成这右边的[?],有什么比较快捷的方法吗,也就是把左边蓝色底文字的数字全都替换成右边的[?],就用到正则表达式: 用查找替换。选中整列后用Grep 查找 .+ 替换为[?],见下图:
例2 如果把下面对话的人名统一修改格式,英文的加蓝加粗。中文的加蓝变粗宋。因为整本书有几百个不一样的人名,如果用替换的话也是一个大工程,用GREP可以做到:(也可以用嵌套样式) GREP 代码查找参考如下: 代码:^.+?(:|:)
替换如图: 1. grep简介 egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符,fgrep就是fixed grep 或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到屏幕,不影响原文件内容。 grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。 2. grep正则表达式元字符集(基本集)^ 锚定行的开始如:'^grep'匹配所有以grep开头的行。 $ 锚定行的结束如:'grep$'匹配所有以grep结尾的行。 . 匹配一个非换行符的字符如:'gr.p'匹配gr后接一个任意字符,然后是p。 * 匹配零个或多个先前字符如:'*grep'匹配所有一个或多个空格后紧跟grep的行。 .*一起用代表任意字符。 [] 匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。 [^] 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-F和H-Z的一个字母开头,紧跟rep的行。 \(..\) 标记匹配字符,如'\(love\)',love被标记为1。 \< 锚定单词的开始,如:'\
正则表达式语法 正则表达式是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”)。模式描述在搜索文本时要匹配的一个或多个字符串。 正则表达式示例
常用正则表达式: 整数或者小数:^[0-9]+\.{0,1}[0-9]{0,2}$只能输入数字:"^[0-9]*$"。 只能输入n位的数字:"^\d{n}$"。 只能输入至少n位的数字:"^\d{n,}$"。 只能输入m~n位的数字:。"^\d{m,n}$"
只能输入零和非零开头的数字:"^(0|[1-9][0-9]*)$"。 只能输入有两位小数的正实数:"^[0-9]+(.[0-9]{2})?$"。 只能输入有1~3位小数的正实数:"^[0-9]+(.[0-9]{1,3})?$"。 只能输入非零的正整数:"^\+?[1-9][0-9]*$"。 只能输入非零的负整数:"^\-[1-9][]0-9"*$。 只能输入长度为3的字符:"^.{3}$"。 只能输入由26个英文字母组成的字符串:"^[A-Za-z]+$"。 只能输入由26个大写英文字母组成的字符串:"^[A-Z]+$"。 只能输入由26个小写英文字母组成的字符串:"^[a-z]+$"。 只能输入由数字和26个英文字母组成的字符串:"^[A-Za-z0-9]+$"。 只能输入由数字、26个英文字母或者下划线组成的字符串:"^\w+$"。 验证用户密码:"^[a-zA-Z]\w{5,17}$"正确格式为:以字母开头,长度在6~18之间,只能包含字符、数字和下划线。 验证是否含有^%&',;=?$\"等字符:"[^%&',;=?$\x22]+"。 只能输入汉字:"^[\u4e00-\u9fa5]{0,}$" 验证Email地址:"^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([- .]\w+)*$"。 验证InternetURL:"^http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?$"。 验证电话号码:"^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$"正确格式为:"XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX"。 验证11位的手机号:/^1[3|5][0-9]\d{4,8}$/ 验证身份证号(15位或18位数字):"^\d{15}|\d{18}$"。 验证一年的12个月:"^(0?[1-9]|1[0-2])$"正确格式为:"01"~"09"和"1"~"12"。 验证一个月的31天:"^((0?[1-9])|((1|2)[0-9])|30|31)$"正确格式为;"01"~"09"和"1"~"31"。匹配中文字符的正则表达式: [\u4e00-\u9fa5]
1. [……] : 匹配括号中的任何一个字符. [^……] : 匹配不在括号中的任何一个字符. \w : 匹配任何一个字符(a~z , A~Z , 0~9). \W : 匹配任何一个空白字符. \s : 匹配任何一个非空白字符. \S : 与任何非单词字符匹配. \d : 匹配任何一个数字. \D : 匹配任何一个非数字. [\b] : 匹配一个退格键字母. {n,m} : 最少匹配前面表达式n次,最大为m次. {n,} : 最少匹配前面表达式n次. {n} : 恰好匹配前面表达式为n次. ? : 匹配前面表达式0或1 次{0,1} + : 至少匹配前面表达式1 次{1,} * : 至少匹配前面表达式0次{0,} | : 匹配前面表达式或后面表达式. (…) : 在单元中组合项目. ^ : 匹配字符串的开头. $ : 匹配字符串的结尾. \b : 匹配字符边界. \B : 匹配非字符边界的某个位置.
2.举几个常用的正则表达式: (1)验证电子邮件. \w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* 或 \S+@\S+\ .\S+ (2) 验证网址: HTTP://\S+\ .\S+ : 验证网址为大写字母 . http://\S+\ . \S + : 验证网址为小写字母. (3) 验证邮政编码: \d{6} (4) 其他 [0-9] : 表示0~9 十个数字. \d* : 表示任意个数字. \d{3,4}-\d{7,8} : 表示中国大陆的固定电话号码. \d{2}-\d{5} : 验证由两位数字. 一个连字符再加5位数字组成的ID号. <\s*(\S+)(\s[^>]*)?>[\s\S]*<\s*\/\1\s*> : 匹配HTML标记.
正则表达式语法大全 \xn 匹配n,其中n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配"A"。'\x041' 则等价于'\x04' & "1"。正则表达式中可以使用ASCII 编码。. \num 匹配num,其中num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。 \n 标识一个八进制转义值或一个向后引用。如果\n 之前至少n 个获取的子表达式,则n 为向后引用。否则,如果n 为八进制数字(0-7),则n 为一个八进制转义值。 \nm 标识一个八进制转义值或一个向后引用。如果\nm 之前至少有nm 个获得子表达式,则nm 为向后引用。如果\nm 之前至少有n 个获取,则n 为一个后跟文字m 的向后引用。如果前面的条件都不满足,若n 和m 均为八进制数字(0-7),则\nm 将匹配八进制转义值nm。 \nml 如果n 为八进制数字(0-3),且m 和l 均为八进制数字(0-7),则匹配八进制转义值nml。 \un 匹配n,其中n 是一个用四个十六进制数字表示的Unicode 字符。例如,\u00A9 匹配版权符号(?)。 由26个英文字母组成的字符串"^[A-Za-z]+$" 由26个英文字母的大写组成的字符串"^[A-Z]+$" 由26个英文字母的小写组成的字符串"^[a-z]+$" 由数字和26个英文字母组成的字符串"^[A-Za-z0-9]+$" 由数字、26个英文字母或者下划线组成的字符串"^\w+$" email地址"^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$" url"^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$" 手机号正则表达式/^13\d{9}$/gi public static bool IsValidMobileNo(string MobileNo) { conststringregPattern= @"^(130|131|132|133|134|135|136|137|138|139)\d{8}$"; return Regex.IsMatch(MobileNo, regPattern);