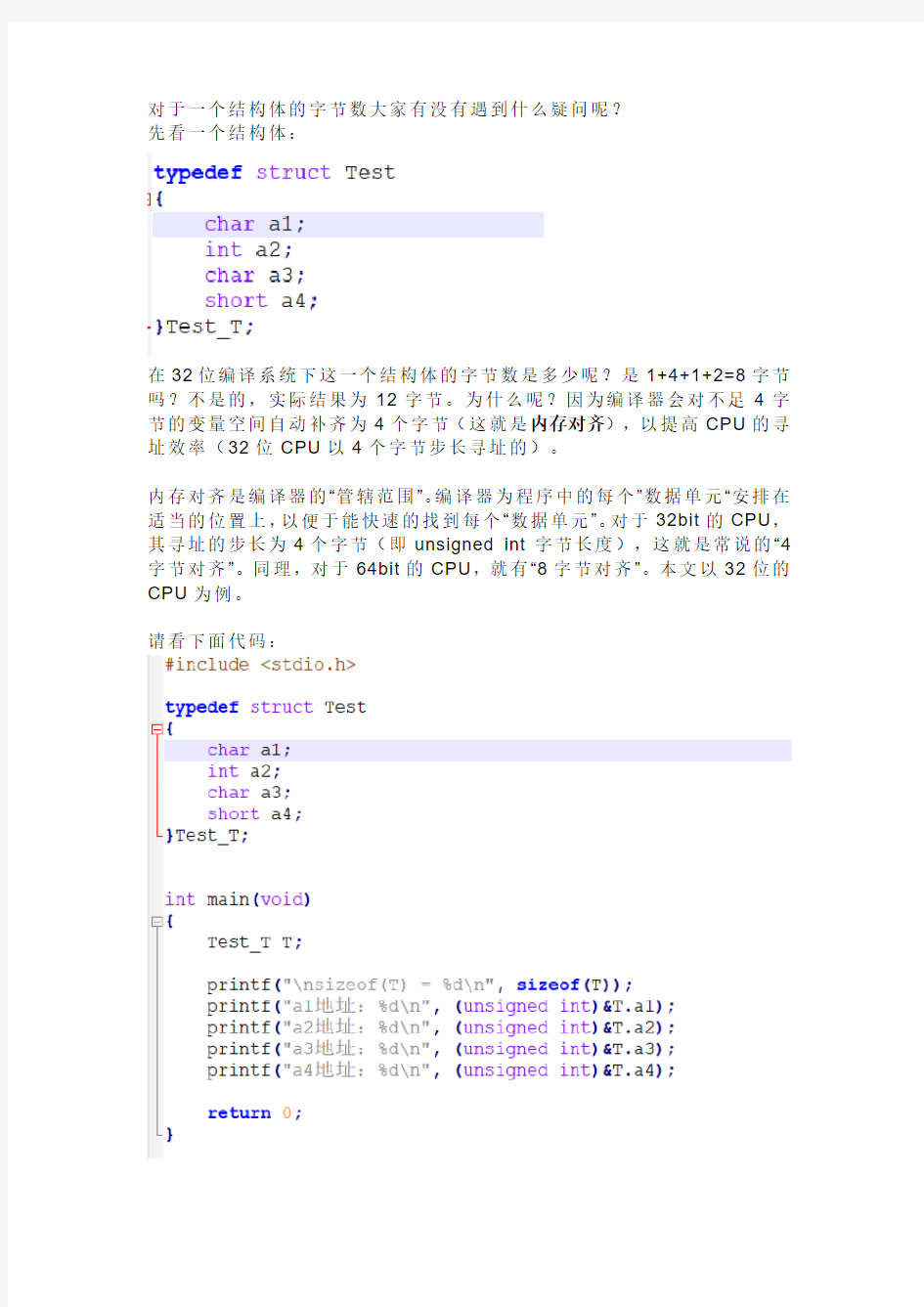

对于一个结构体的字节数大家有没有遇到什么疑问呢?
先看一个结构体:
在32位编译系统下这一个结构体的字节数是多少呢?是1+4+1+2=8字节吗?不是的,实际结果为12字节。为什么呢?因为编译器会对不足4字节的变量空间自动补齐为4个字节(这就是内存对齐),以提高CPU的寻址效率(32位CPU以4个字节步长寻址的)。
内存对齐是编译器的“管辖范围”。编译器为程序中的每个”数据单元“安排在适当的位置上,以便于能快速的找到每个“数据单元”。对于32bit的CPU,其寻址的步长为4个字节(即unsigned int 字节长度),这就是常说的“4字节对齐”。同理,对于64bit的CPU,就有“8字节对齐”。本文以32位的CPU为例。
请看下面代码:
运行结果为:
可见,正好印证了上述的说法,补齐之后结构体成员a1,a2,a3的地址之间正好相差4个字节,a3与a4之间相差两个字节也是因为在其中多留出了1个空白字节。该程序的运行结果可形象地描述为下图:
a1只占用一个字节,为了内存对齐保留了三个空白字节;a3和a4加起来共3字节,为了内存对齐保留了1个空白字节。这就是编译器存储变量时做的见不得人的”手脚“,以方便其雇主——CPU能更快地找到这些变量。
欢迎关注我的公众号(zhengnian-2018)查看更多分享!
1、变量 a 所占的内存字节数是。(假设整型int 为 4 字节) structstu {charname[20]; longintn; intscore[4]; }a; A)28B)30 C)32D)46 C 2、下列程序的输出结果是 A)5B)6 C)7D)8 structabc {inta,b,c;}; main() {structabcs[2]={{1,2,3},{4,5,6}};intt; t=s[0].a+s[1].b; printf("%d\n",t); } B 3、有如下定义 structperson{charname[9];intage;}; structpersoncalss[4]={"Johu",17, "Paul",19, "Mary",18, "Adam",16,}; 根据以上定义,能输出字母M 的语句是________ 。 A)printf("%c\n",class[3].name); B)printf("%c\n",class[3].name[1]); C)printf("%c\n",class[2].name[1]); D)printf("%c\n",class[2].name[0]); D 4、以下程序的输出是________ 。 structst {intx;int*y;}*p; intdt[4]={10,20,30,40}; structstaa[4]={50,&dt[0],60,&dt[0],60,&dt[0],60,dt[0],}; main() {p=aa; printf("%d\n",++(p->x)); } A)10B)11 C)51D)60 C 6、以下程序的输出结果是________ 。 structHAR {intx,y;structHAR*p;}h[2]; main() {inth[0].x=1;h[0].y=2; h[1].x=3;h[1].y=4;
实验九参考程序 实验 9- 1 /**************************************************************** * 实验 9.1 * * ( 1 )为某商店的商品设计合适的结构体 (PRODUCT) 。每一种商品包含编号 (number) 、 * 名称 (name) 、价格 (price) 、折扣 (discount)4 项信息,根据表 9-1 ,为这些信 息选择合适的数据类型。 * (2)建立 2个函数,以实现对商品的操作。 input 函数实现商品的输入; * display 函数显示商品信息。要求这 2个函数都以商品的结构体 (PRODUCT) 指针为 参数。 * (3 )在主函数中为商品键盘定义一个结构体变量 (keyboard) ,利用 input 函数实现键 盘信息的输入; * 定义一个结构体数组 (elec_device[3]) ,利用 input 函数实现冰箱、 空调、电视 信息的输入; * 最后利用 display 函数显示 4 种商品的信息。 * * 表 9-1 #include
对齐方式 为什么会有内存对齐? 在结构中,编译器为结构的每个成员按其自然对界(alignment)条件分配空间;各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同。在缺省情况下,C编译器为每一个变量或数据单元按其自然对界条件分配空间。 字,双字,和四字在自然边界上不需要在内存中对齐。(对字,双字,和四字来说,自然边界分别是偶数地址,可以被4整除的地址,和可以被8整除的地址。)无论如何,为了提高程序的性能,数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;然而,对齐的内存访问仅需要一次访问。 一个字或双字操作数跨越了4字节边界,或者一个四字操作数跨越了8字节边界,被认为是未对齐的,从而需要两次总线周期来访问内存。一个字起始地址是奇数但却没有跨越字边界被认为是对齐的,能够在一个总线周期中被访问。 某些操作双四字的指令需要内存操作数在自然边界上对齐。如果操作数没有对齐,这些指令将会产生一个通用保护异常(#GP)。双四字的自然边界是能够被16整除的地址。其他的操作双四字的指令允许未对齐的访问(不会产生通用保护异常),然而,需要额外的内存总线周期来访问内存中未对齐的数据。 影响结构体的sizeof的因素: 1)不同的系统(如32位或16位系统):不同的系统下int等类型的长度是变化的,如对于16位系统,int的长度(字节)为2,而在32位系统下,int的长度为4;因此如果结构体中有int等类型的成员,在不同的系统中得到的sizeof值是不相同的。 2)编译器设置中的对齐方式:对齐方式的作用常常会让我们对结构体的sizeof 值感到惊讶,编译器默认都是8字节对齐。 对齐: 为了能使CPU对变量进行高效快速的访问,变量的起始地址应该具有某些特性,即所谓的“对齐”。例如对于4字节的int类型变量,其起始地址应位于4字节边界上,即起始地址能够被4整除。变量的对齐规则如下(32位系统)
《高级语言程序设计》实验报告实验序号:8 实验项目名称:结构体
附源程序清单: 1. #include
for(i=1;i<=5;i++) stu[i].aver_score=((stu[i].score[1]+stu[i].score[2]+stu[i].score[3])/3); printf("平均成绩:"); for(i=1;i<6;i++) printf("第%d个同学的平均成绩%f:\n",i,stu[i].aver_score); printf("\n"); }; void max() { int i,k=0; float temp=stu[1].aver_score; for(i=2;i<=5;i++) if(stu[i].aver_score>temp) {temp=stu[i] .aver_score;k=i;}; printf("成绩最好的同学:\n"); printf("%d %s %s %4.2f %4.2f %4.2f %4.2f\n", stu[k].num,stu[k].name,stu[k].classname,stu[k].score[1],stu[k].score[2],stu[k].score[3],stu[k].aver _score); }; void main() { input(); averagescore(); max(); } 2.#include
一个程序本质上都是由BSS 段、data段、text段三个组成的。这种概念在当前的计算机程序设计中是非常重要的一个基本概念,并且在嵌入式系统的设计中也非常重要,牵涉到嵌入式系统执行时的内存大小分配,存储单元占用空间大小的问题。 ●BSS段:在採用段式内存管理的架构中。BSS段(bss segment)一般是指用 来存放程序中未初始化的全局变量的一块内存区域。 BSS是英文Block Started by Symbol的简称。 BSS段属于静态内存分配。 ●数据段:在採用段式内存管理的架构中,数据段(data segment)一般是指 用来存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。 ●代码段:在採用段式内存管理的架构中,代码段(text segment)一般是指 用来存放程序执行代码的一块内存区域。这部分区域的大小在程序执行前就已经确定,而且内存区域属于仅仅读。 在代码段中。也有可能包括一些仅仅读的常数变量,比如字符串常量等。 程序编译后生成的目标文件至少含有这三个段。这三个段的大致结构图例如以下所看到的: 当中.text即为代码段,为仅仅读。.bss段包括程序中未初始化的全局变量和static变量。 data段包括三个部分:heap(堆)、stack(栈)和静态数据区。 ●堆(heap):堆是用于存放进程执行中被动态分配的内存段。它的大小并不 固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时。新分配的内存就被动态加入到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
栈(stack):栈又称堆栈,是用户存放程序暂时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包含static声明的变量。static意味着在数据段中存放变量)。 除此以外,在函数被调用时。其參数也会被压入发起调用的进程栈中。而且待到调用结束后。函数的返回值也会被存放回栈中。 因为栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们能够把堆栈看成一个寄存、交换暂时数据的内存区。 当程序在运行时动态分配空间(C中的malloc函数),所分配的空间就属于heap。其概念与数据结构中“堆”的概念不同。 stack段存放函数内部的变量、參数和返回地址,其在函数被调用时自己主动分配。訪问方式就是标准栈中的LIFO方式。 (由于函数的局部变量存放在此,因此其訪问方式应该是栈指针加偏移的方式,否则若通过push、pop操作来訪问相当麻烦) data段中的静态数据区存放的是程序中已初始化的全局变量、静态变量和常量。 在採用段式内存管理的架构中(比方intel的80x86系统),BSS 段(Block Started by Symbol segment)一般是指用来存放程序中未初始化的全局变量的一块内存区域,一般在初始化时BSS 段部分将会清零。BSS 段属于静态内存分配。即程序一開始就将其清零了。 比方,在C语言之类的程序编译完毕之后,已初始化的全局变量保存在.data 段中,未初始化的全局变量保存在.bss 段中。 text和data段都在可运行文件里(在嵌入式系统里通常是固化在镜像文件里)。由系统从可运行文件里载入;而BSS段不在可运行文件里,由系统初始化。
1.内存字节对齐和小端模式: /* 本程序是关于:编译器内存的字节对齐方式和存储时的小端对齐模式(win7 32bit) #pragma pack(n) 默认为8字节对齐,(即n=8)其中n的取值为1,2,4,8,16,32等 内存字节对齐大小和方式: 1)结构体内变量对齐: 每个变量的对齐字节数大小argAlignsize=min(#pragma pack(n),sizeof(变量)); 方式:结构体的第一个变量的初始偏移地址为0,其它变量的偏移地址(当前变量的起始地址)必须是argAlignsize的整数倍,不够整数倍的补空,不添加任何数据 2)结构体对齐: 结构体的对齐字节数大小strAlignsize=min(#pragma pack(n),sizeof(所有变量中最大字节的变量)) 方式: A.对于单独的结构体来说,结构体本身按照strAlignsize大小来对齐 B.结构体B在结构体A中时,结构体B的起始地址是结构体B的 strAlignsize大小的整数倍 小端对齐模式: 指针指着一个存储空间,存储空间地址由低到高的存储内容为:0x78,0x67,0x33,0x45 若指针为char,则获取的数据为0x78 若指针为short,则获取的数据为0x6778 若指针为long,则获取的数据为0x45336778 */ #include
C语言结构体(struct)常见使用方法 基本定义:结构体,通俗讲就像是打包封装,把一些有共同特征(比如同属于某一类事物的属性,往往是某种业务相关属性的聚合)的变量封装在内部,通过一定方法访问修改内部变量。 结构体定义: 第一种:只有结构体定义 [cpp]view plain copy 1.struct stuff{ 2.char job[20]; 3.int age; 4.float height; 5.}; 第二种:附加该结构体类型的“结构体变量”的初始化的结构体定义 [cpp]view plain copy 1.//直接带变量名Huqinwei 2.struct stuff{ 3.char job[20]; 4.int age; 5.float height; 6.}Huqinwei; 也许初期看不习惯容易困惑,其实这就相当于: [cpp]view plain copy 1.struct stuff{ 2.char job[20]; 3.int age;
4.float height; 5.}; 6.struct stuff Huqinwei; 第三种:如果该结构体你只用一个变量Huqinwei,而不再需要用 [cpp]view plain copy 1.struct stuff yourname; 去定义第二个变量。 那么,附加变量初始化的结构体定义还可进一步简化出第三种: [cpp]view plain copy 1.struct{ 2.char job[20]; 3.int age; 4.float height; 5.}Huqinwei; 把结构体名称去掉,这样更简洁,不过也不能定义其他同结构体变量了——至少我现在没掌握这种方法。 结构体变量及其内部成员变量的定义及访问: 绕口吧?要分清结构体变量和结构体内部成员变量的概念。 就像刚才的第二种提到的,结构体变量的声明可以用: [cpp]view plain copy 1.struct stuff yourname; 其成员变量的定义可以随声明进行: [cpp]view plain copy 1.struct stuff Huqinwei = {"manager",30,185}; 也可以考虑结构体之间的赋值: [cpp]view plain copy
https://www.doczj.com/doc/e418748671.html,/2005/03/25/12365.html 所谓共用体类型是指将不同的数据项组织成一个整体,它们在内存中占用同一段存储单元。其定义形式为: union 共用体名 {成员表列}; 7.5.1 共用体的定义 union data { int a ; float b ; d o u b l e c ; c h a r d ; } obj; 该形式定义了一个共用体数据类型union data ,定义了共用体数据类型变量o b j。共用体 数据类型与结构体在形式上非常相似,但其表示的含义及存储是完全不同的。先让我们看一个小例子。 [例7 - 8 ] union data /*共用体* / { int a; float b; double c; char d; } m m ; struct stud /*结构体* / { int a; float b; double c; char d; } ; m a i n ( ) { struct stud student printf("%d,%d",sizeof(struct stud),sizeof(union data)); } 程序的输出说明结构体类型所占的内存空间为其各成员所占存储空间之和。而形同结构体的
共用体类型实际占用存储空间为其最长的成员所占的存储空间。详细说明如图7 - 6所示。 对共用体的成员的引用与结构体成员的引用相同。但由于共用体各成员共用同一段内存 空间,使用时,根据需要使用其中的某一个成员。从图中特别说明了共用体的特点,方便程序设计人员在同一内存区对不同数据类型的交替使用,增加灵活性,节省内存。 7.5.2 共用体变量的引用 可以引用共用体变量的成员,其用法与结构体完全相同。若定义共用体类型为: union data /*共用体* / { int a; float b; double c; char d; } m m ; 其成员引用为:m m . a , m m . b , m m . c , m m . d 但是要注意的是,不能同时引用四个成员,在某一时刻,只能使用其中之一的成员。 [例7-9] 对共用体变量的使用。 m a i n ( ) { union data { int a; float b; double c; char d; } m m ; m m . a = 6 ; printf("%d\n",mm.a); m m . c = 6 7 . 2 ; p r i n t f ( " % 5 . 1 l f \ n " , m m . c ) ; m m . d = ' W ' ; m m . b = 3 4 . 2 ; p r i n t f ( " % 5 . 1 f , % c \ n " , m m . b , m m . d ) ; }
C语言内存对齐 分类:C/C++2012-04-05 20:54 1070人阅读评论(1) 收藏举报语言c编译器平台oo 首先由一个程序引入话题: 1//环境:vc6 + windows sp2 2//程序1 3 #include 程序的输出结果为: sizeof(st1) is 12 sizeof(st2) is 8 问题出来了,这两个一样的结构体,为什么sizeof的时候大小不一样呢? 本文的主要目的就是解释明白这一问题。 内存对齐,正是因为内存对齐的影响,导致结果不同。 对于大多数的程序员来说,内存对齐基本上是透明的,这是编译器该干的活,编译器为程序中的每个数据单元安排在合适的位置上,从而导致了相同的变量,不同声明顺序的结构体大小的不同。 那么编译器为什么要进行内存对齐呢?程序1中结构体按常理来理解sizeof(st1)和sizeof(st2)结果都应该是7,4(int) + 2(short) + 1(char) = 7 。经过内存对齐后,结构体的空间反而增大了。 在解释内存对齐的作用前,先来看下内存对齐的规则: 1、对于结构的各个成员,第一个成员位于偏移为0的位置,以后每个数据成员的偏移量必须是min(#pragma pack()指定的数,这个数据成员的自身长度) 的倍数。 2、在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行。 #pragma pack(n) 表示设置为n字节对齐。VC6默认8字节对齐 以程序1为例解释对齐的规则: c语言结构体共用体选择 题新 The pony was revised in January 2021 1、变量a所占的内存字节数是________。(假设整型i n t为4字节) struct stu { char name[20]; long int n; int score[4]; } a ; A) 28 B) 30 C) 32 D) 46 C 2、下列程序的输出结果是 A)5 B)6 C)7 D)8 struct abc {int a,b,c;}; main() {struct abc s[2]={{1,2,3},{4,5,6}};int t; t=s[0].a+s[1].b; printf("%d\n",t); } B 3、有如下定义 struct person{ char name[9]; int age;}; struct person calss[4]={ "Johu",17, "Paul",19, "Mary",18, "Adam",16,}; 根据以上定义,能输出字母M的语句是________。 A) printf("%c\n",class[3].name); B) printf("%c\n",class[3].name[1]); C) printf("%c\n",class[2].name[1]); D) printf("%c\n",class[2].name[0]); D 4、以下程序的输出是________。 struct st {int x;int *y;} *p; int dt[4]={10,20,30,40}; struct st aa[4]={50,&dt[0],60,&dt[0],60,&dt[0],60,dt[0],}; main() { p=aa; printf("%d\n",++(p->x)); } A) 10 B) 11 C) 51 D) 60 C 6、以下程序的输出结果是________。 struct HAR c语言中动态内存申请与释放的简单理解 在C里,内存管理是通过专门的函数来实现的。与c++不同,在c++中是通过new、delete函数动态申请、释放内存的。 1、分配内存 malloc 函数 需要包含头文件: #include C语言内存字节对齐规则 在C语言面试和考试中经常会遇到内存字节对齐的问题。今天就来对字节对齐的知识进行小结一下。 首先说说为什么要对齐。为了提高效率,计算机从内存中取数据是按照一个固定长度的。以32位机为例,它每次取32个位,也就是4个字节(每字节8个位,计算机基础知识,别说不知道)。字节对齐有什么好处?以int型数据为例,如果它在内存中存放的位置按4字节对齐,也就是说1个int的数据全部落在计算机一次取数的区间内,那么只需要取一次就可以了。如图a-1。如果不对齐,很不巧,这个int数据刚好跨越了取数的边界,这样就需要取两次才能把这个int的数据全部取到,这样效率也就降低了。 图:a-1 图:a-2 内存对齐是会浪费一些空间的。但是这种空间上得浪费却可以减少取数的时间。这是典型的一种以空间换时间的做法。空间与时间孰优孰略这个每个人都有自己的看法,但是C 语言既然采取了这种以空间换时间的策略,就必然有它的道理。况且,在存储器越来越便宜的今天,这一点点的空间上的浪费就不算什么了。 需要说明的是,字节对齐不同的编译器可能会采用不同的优化策略,以下以GCC为例讲解结构体的对齐. 一、原则: 1.结构体内成员按自身按自身长度自对齐。 自身长度,如char=1,short=2,int=4,double=8,。所谓自对齐,指的是该成员的起始位置的内存地址必须是它自身长度的整数倍。如int只能以0,4,8这类的地址开始 2.结构体的总大小为结构体的有效对齐值的整数倍 结构体的有效对齐值的确定: 1)当未明确指定时,以结构体中最长的成员的长度为其有效值 2)当用#pragma pack(n)指定时,以n和结构体中最长的成员的长度中较小者为其值。 3)当用__attribute__ ((__packed__))指定长度时,强制按照此值为结构体的有效对齐值 二、例子 1) struct AA{ //结构体的有效对齐值为其中最大的成员即int的长度4 char a; int b; char c; }aa 结果,sizeof(aa)=12 何解?首先假设结构体内存起始地址为0,那么地址的分布如下 0 a 1 2 3 4 b 5 b 6 b 7 b 8 c 9 10 11 char的字对齐长度为1,所以可以在任何地址开始,但是,int自对齐长度为4,必须以4的倍数地址开始。所以,尽管1-3空着,但b也只能从4开始。再加上c后,整个结构体的总长度为9,结构体的有效对齐值为其中最大的成员即int的长度4,所以,结构体的大小向上扩展到12,即9-11的地址空着。 2) //结构体的有效对齐值为其中最大的成员即int的长度4 struct AA{ char a; char c; int b; }aa sizeof(aa)=8,为什么呢 0 a 1 c 解析C语言结构体对齐(内存对齐问题) C语言结构体对齐也是老生常谈的话题了。基本上是面试题的必考题。内容虽然很基础,但一不小心就会弄错。写出一个struct,然后sizeof,你会不会经常对结果感到奇怪?sizeof的结果往往都比你声明的变量总长度要大,这是怎么回事呢? 开始学的时候,也被此类问题困扰很久。其实相关的文章很多,感觉说清楚的不多。结构体到底怎样对齐? 有人给对齐原则做过总结,具体在哪里看到现在已记不起来,这里引用一下前人的经验(在没有#pragma pack宏的情况下): 原则1、数据成员对齐规则:结构(struct或联合union)的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小的整数倍开始(比如int在32位机为4字节,则要从4的整数倍地址开始存储)。 原则2、结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储。(struct a里存有struct b,b里有char,int,double等元素,那b应该从8的整数倍开始存储。) 原则3、收尾工作:结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的整数倍,不足的要补齐。 这三个原则具体怎样理解呢?我们看下面几个例子,通过实例来加深理解。 例1:struct { short a1; short a2; short a3; }A; struct{ long a1; short a2; }B; sizeof(A) = 6; 这个很好理解,三个short都为2。 sizeof(B) = 8; 这个比是不是比预想的大2个字节?long为4,short为2,整个为8,因为原则3。 例2:struct A{ int a; char b; short c; }; struct B{ char b; int a; short c; }; sizeof(A) = 8; int为4,char为1,short为2,这里用到了原则1和原则3。 sizeof(B) = 12; 是否超出预想范围?char为1,int为4,short为2,怎么会是12?还是原则1和原则3。 c语言结构体指针初始化 今天来讨论一下C中的内存管理。 记得上周在饭桌上和同事讨论C语言的崛起时,讲到了内存管理方面 我说所有指针使用前都必须初始化,结构体中的成员指针也是一样 有人反驳说,不是吧,以前做二叉树算法时,他的左右孩子指针使用时难道有初始化吗 那时我不知怎么的想不出理由,虽然我还是坚信要初始化的 过了几天这位同事说他试了一下,结构体中的成员指针不经过初始化是可以用(左子树和右子树指针) 那时在忙着整理文档,没在意 今天抽空调了一下,结论是,还是需要初始化的。 而且,不写代码你是不知道原因的(也许是对着电脑久了IQ和记性严重下跌吧) 测试代码如下 1.#include 2.#include 3.#include 4. 5.struct student{ 6.char *name; 7.int score; 8.struct student* next; 9.}stu,*stu1; 10. 11.int main(){ 12. https://www.doczj.com/doc/e418748671.html, = (char*)malloc(sizeof(char)); /*1.结构体成员指针需要初始化*/ 13. strcpy(https://www.doczj.com/doc/e418748671.html,,"Jimy"); 14. stu.score = 99; 15. 16. stu1 = (struct student*)malloc(sizeof(struct student));/*2.结构体指针需要初始化*/ 17. stu1->name = (char*)malloc(sizeof(char));/*3.结构体指针的成员指针同样需要初始化*/ 18. stu.next = stu1; 19. strcpy(stu1->name,"Lucy"); 20. stu1->score = 98; 21. stu1->next = NULL; 22. printf("name %s, score %d \n ",https://www.doczj.com/doc/e418748671.html,, stu.score); 23. printf("name %s, score %d \n ",stu1->name, stu1->score); 24. free(stu1); 25.return 0; 26.} #include #include #include struct student{ char *name; int score; struct student* next; }stu,*stu1; int main(){ https://www.doczj.com/doc/e418748671.html, = (char*)malloc(sizeof(char)); /*1.结构体成员指针需要初始化*/ strcpy(https://www.doczj.com/doc/e418748671.html,,"Jimy"); stu.score = 99; stu1 = (struct student*)malloc(sizeof(struct student));/*2.结构体指针需要初始化*/ stu1->name = (char*)malloc(sizeof(char));/*3.结构体指针的成员指针同样需要初始化*/ stu.next = stu1; strcpy(stu1->name,"Lucy"); stu1->score = 98; stu1->next = NULL; printf("name %s, score %d \n ",https://www.doczj.com/doc/e418748671.html,, stu.score); C语言结构体对齐 C语言结构体对齐也是老生常谈的话题了。基本上是面试题的必考题。内容虽然很基础,但一不小心就会弄错。写出一个struct,然后sizeof,你会不会经常对结果感到奇怪?sizeof的结果往往都比你声明的变量总长度要大,这是怎么回事呢? 开始学的时候,也被此类问题困扰很久。其实相关的文章很多,感觉说清楚的不多。结构体到底怎样对齐? 有人给对齐原则做过总结,具体在哪里看到现在已记不起来,这里引用一下前人的经验(在没有#pragma pack宏的情况下): 原则1、数据成员对齐规则:结构(struct或联合union)的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小的整数倍开始(比如int在32位机为4字节,则要从4的整数倍地址开始存储)。 原则2、结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储。(struct a里存有struct b,b 里有char,int,double等元素,那b应该从8的整数倍开始存储。) 原则3、收尾工作:结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的整数倍,不足的要补齐。 这三个原则具体怎样理解呢?我们看下面几个例子,通过实例来加深理解。 例1:struct { short a1; short a2; short a3; }A; struct{ long a1; short a2; }B; sizeof(A) = 6; 这个很好理解,三个short都为2。 sizeof(B) = 8; 这个比是不是比预想的大2个字节?long为4,short为2, (1)有以下程序段 typedef struct NODE { int num; struct NODE *next; } OLD; 以下叙述中正确的是C A)以上的说明形式非法 B)NODE是一个结构体类型 C)OLD是一个结构体类型 D)OLD是一个结构体变量(2)若有以下说明和定义union dt { int a; char b; double c; }data; 以下叙述中错误的是 C A)data的每个成员起始地址都相同 B)变量data所占内存字节数与成员c所占字节数相等 C)程序段:data.a=5;printf("%f\n",data.c);输出结果为5.000000 D)data可以作为函数的实参(3)设有如下说明 typedef struct ST { long a; int b; char c[2]; } NEW; 则下面叙述中正确的是 C A)以上的说明形式非法 B)ST是一个结构体类型 C)NEW是一个结构体类型 D)NEW是一个结构体变量(4)以下对结构体类型变量td的定义中,错误的是 C A)typedef struct aa { int n; float m; }AA; AA td; B)struct aa { int n; float m; } td; struct aa td; C)struct { int n; float m; }aa; struct aa td; D)struct { int n; float m; }td; (5)设有以下语句 typedef struct S { int g; char h;} T; 则下面叙述中正确的是B A)可用S定义结构体变量 B)可以用T定义结构体变量 C)S是struct类型的变量 D)T是struct S类型的变量(6)设有如下说明 typedef struct { int n; char c; double x;}STD; 则以下选项中,能正确定义结构体数组并赋初值的语句是B A)STD tt[2]={{1,'A',62},{2, 'B',75}}; B) STD tt[2]={1,"A",62},2, "B",75}; C) struct tt[2]={{1,'A'},{2, 'B'}}; D)structtt[2]={{1,"A",62.5},{2, "B",75.0}}; (7)设有以下说明语句 typedef struct { int n; char ch[8]; }PER; 则下面叙述中正确的是B A) PER 是结构体变量名 B) PER是结构体类型名 C) typedef struct 是结构体类型 D)struct 是结构体类型名(8)设有以下说明语句 struct ex { int x ; float y; char z ;} example; 则下面的叙述中不正确的是B A) struct结构体类型的关键字 B)example是结构体类型名 C) x,y,z都是结构体成员名 D) struct ex是结构体类型(9)有如下定义 struct person{char name[9]; int age;}; strict person class[10]={“Johu”, 17, “Paul”, 19 “Mary”, 18, “Adam 16,}; 根据上述定义,能输出字母M的语句是D A) prinft(“%c\n”,class[ 3].mane); B) pfintf(“%c\n”,class[3].name[1]); C) prinft (“%c\n”,class[2].n ame[1]); D) printf(“%^c\n”,class[2].name[0]); (10)变量a 页眉内容 一、选择题 1、定义结构类型时,下列叙述正确的是() A、系统会按成员大小分配每个空间 B、系统会按最大成员大小分配空间 C、系统不会分配空间 D、以上说法均不正确 2、已知结构类型变量x的初始化值为{“20”,30,40,35.5},请问合适的结构定义是() A、Struct s{int no;int x,y,z}; B、Struct s{char no[2];int x,y,z}; C、Struct s{int no;float x,y,z}; D、Struct s{char no[2];float x,y,z}; 3、若程序中有定义struct abc{int x;char y;};abc s1,s2;则会发生的情况是() A、编译时会有错误 B、链接时会有错误 C、运行时会有错误 D、程序没有错误 4、已知学生记录描述为 struct student {int no; char name[20]; char set; struct {int year; int month; int day; }birth;}; struct student s; 设变量s中的“生日”应是“1984年11月11日”,下列对生日的正确赋值方式是( ). A)year=1984; B)birth.year=1984; month=11; birth.month=11; day=11; birth.day=11; C)s.year=1984; D)s.birth.year=1984; s.month=11; s.birth.month=11; s.day=11; s.birth.day=11; 5、当说明一个结构体变量时系统分配给它的内存是( ). A)各成员所需内存量的总和 B)结构中第一个成员所需内存量 C)成员中占内存量最大者所需的容量 D)结构中最后一个成员所需内存量 6、以下对结构体类型变量的定义中不正确的是( ). A)#define STUDENT struct student B)struct student STUDENT {int num; {int num; float age; float age; }std1; }std1; C)struct D)struct {int num; int num; 实验报告 实验课程名称:动态内存分配算法 年12月1日 实验报告 一、实验内容与要求 动态分区分配又称为可变分区分配,它是根据进程的实际需要,动态地为之分配内存空间。在实验中运用了三种基于顺序搜索的动态分区分配算法,分别是1.首次适应算法2.循环首次适应算法3.最佳适应法3.最坏适应法分配主存空间。 二、需求分析 本次实验通过C语言进行编程并调试、运行,显示出动态分区的分配方式,直观的展示了首次适应算法循环首次适应算法、最佳适应算法和最坏适应算法对内存的释放和回收方式之间的区别。 首次适应算法 要求空闲分区链以地址递增的次序链接,在分配内存时,从链首开始顺序查找,直至找到一个大小能满足要求的空闲分区为止,然后在按照作业的大小,从该分区中划出一块内存空间,分配给请求者,余下的空余分区仍留在空链中。 优点:优先利用内存中低址部分的空闲分区,从而保留了高址部分的大空闲区,为以后到达的大作业分配大的内存空间创造了条件。 缺点:低址部分不断被划分,会留下许多难以利用的、很小的空闲分区即碎片。而每次查找又都是从低址部分开始的,这无疑又会增加查找可用空闲分区时的开销。 循环首次适应算法 在为进程分配内存空间时,不是每次都从链首开始查找,而是从上次找到的空闲分区的下一个空闲分区开始查找,直到找到一个能满足要求的空闲分区。 优点:该算法能使内存中的空闲分区分布得更均匀,从而减少了查找空闲分区时的开销。 最佳适应算法 该算法总是把能满足要求、又是最小的空闲分区分配给作业,避免大材小用,该算法要求将所有的空闲分区按其容量以从小到大的顺序形成一空闲分区链。 缺点:每次分配后所切割下来的剩余部分总是最小的,这样,在存储器中会留下许多难以利用的碎片。 最坏适应算法 最坏适应算法选择空闲分区的策略正好与最佳适应算法相反:它在扫描整个空闲分区或链表时,总会挑选一个最大的空闲区,从中切割一部分存储空间给作业使用。该算法要求,将所有的空闲分区,按其容量以大到小的顺序形成一空闲分区链。查找时,只要看第一个分区能否满足作业要求即可。 优点:可使剩下的空闲区不至于太小,产生碎片的可能性最小,对中小作业有利,同时,最坏适应算法查找效率很高。 缺点:导致存储器中缺乏大的空闲分区 三、数据结构 为了实现动态分区分配算法,系统中配置了相应的数据结构,用以描述空闲分区和已分配分区的情况,常用的数据结构有空闲分区表和空闲分区链 流程图c语言结构体共用体选择题新
c语言中动态内存申请与释放的简单理解
C语言内存字节对齐规则20180718
C语言内存对齐
c语言结构体指针初始化===
C语言结构体对齐
二级C语言结构体定义及应用部分练习题(十三)(精)
C语言程序设计 结构体与共用体
动态内存分配(C语言)
相关主题
文本预览