迭代显示查询结果集
- 格式:doc
- 大小:194.00 KB
- 文档页数:12

oracle中游标的用法游标是Oracle数据库中一种重要的数据类型,用于处理查询结果集中的数据。
使用游标可以方便地遍历查询结果,进行数据处理和操作。
下面是关于Oracle中游标的用法的参考内容。
一、游标的定义与声明在Oracle数据库中,游标可以在PL/SQL块中使用,用于与查询结果进行交互。
游标的使用分为显示游标和隐式游标两种方式:1. 显示游标:显示游标需要先定义游标类型,然后声明游标变量,并使用OPEN、FETCH和CLOSE等操作进行操作。
示例代码如下:```sql-- 定义游标类型TYPE cursor_type IS REF CURSOR;-- 声明游标变量cursor_var cursor_type;-- 打开游标OPEN cursor_var FOR SELECT * FROM table_name;-- 循环获取游标数据LOOPFETCH cursor_var INTO variable1, variable2...;EXIT WHEN cursor_var%NOTFOUND;-- 对游标数据进行处理END LOOP;-- 关闭游标CLOSE cursor_var;```2. 隐式游标:隐式游标由Oracle自动管理,不需要程序员定义和声明,系统会自动为每一个SELECT语句分配一个隐式游标。
隐式游标无法手动控制游标操作,只能通过向结果集添加条件来限制查询结果。
示例代码如下:```sql-- 查询结果会被自动赋值给隐式游标SELECT * FROM table_name;-- 循环处理查询结果LOOP-- 对查询结果进行处理-- 退出循环条件END LOOP;```二、游标的属性和操作1. 游标属性:(1) %FOUND:如果游标指向的结果集中有数据,则返回真;否则返回假。
(2) %NOTFOUND:如果游标指向的结果集中没有数据,则返回真;否则返回假。
(3) %ROWCOUNT:返回游标当前处理的行数。

如何实现历史查询和关键字查询1.判定数据库创建成功与否?if(!(mysql = mysql_init(NULL))){printf("MySQL_init wrong!\n");//如果数据库创建不成功提示错误信息mysql_close(mysql);//关闭数据库exit(0);}//连接到数据库if(!mysql_real_connect(mysql,"localhost","root",NULL,"qqchat",0,NULL,0)){printf("Connect wrong!\n");mysql_close(mysql);exit(0);}2.如何将通信消息插入数据库中?void Inserts(GtkWidget* widget,GtkWidget *window){if(!(mysql = mysql_init(NULL))){printf("MySQL_init wrong!\n");//如果数据库创建不成功提示错误信息mysql_close(mysql);//关闭数据库exit(0);}//连接到数据库if(!mysql_real_connect(mysql,"localhost","root",NULL,"chat",0,NULL,0)){printf("Connect wrong!\n");mysql_close(mysql);exit(0);}memset(query,0,sizeof(char)*256);//分配一个char数据类型的空间,初始化为0sprintf(query,"insert into history values (now(),'%s')",sbuf); //将sbuf中的内容和系统当前时间插入到表名为history的数据表中,并且将这些内容都写入query内存空间中//执行查询if(mysql_query(mysql,query)){printf("History record failed!\n");mysql_close(mysql);exit(0);}3历史查询void History(GtkWidget* widget,gpointer data){GtkTextIteriter;//判断数据库能否初始化if(!(mysql = mysql_init(NULL))){printf("MySQL_init wrong!\n");mysql_close(mysql);exit(0);}//连接到数据库if(!mysql_real_connect(mysql,"localhost","root",NULL,"chat",0,NULL,0)){printf("Connect wrong!\n");mysql_close(mysql);exit(0);}memset(query,0,sizeof(char)*256);//分配一个char数据类型的空间,初始化为0gtk_text_buffer_get_end_iter(buffer,&iter);将buffer的内容写入迭代器gtk_text_buffer_insert(buffer,&iter,"-------the history messages-------\n",-1);//在迭代器中显示--------the history messages--------strcpy(query,"select * from history where TIME>=CURRENT_TIMESTAMP-INTERVAL 5 MINUTE");//将5分钟以内的历史记录查询出来,并且将内容复制给query//执行查询if(mysql_query(mysql,query)){printf("History inquire failed!\n");mysql_close(mysql);exit(0);}res = mysql_store_result(mysql); //查询完把结果集放在res中rows = mysql_num_rows(res);//查询结果集中的行数,并赋值给rowsif(rows == 0){printf("Return NULL");mysql_free_result(res);mysql_close(mysql);exit(0);}for(count = 0;count <rows;count ++){row = mysql_fetch_row(res);//从结果集中取得一行数据并作为数组返回。

resultset用法ResultSet是java.sql包中的一个接口,用于表示数据库查询的结果集。
它提供了各种方法来访问和操作查询结果,以及获取结果集中的数据。
ResultSet的用法主要包括以下几个方面:1. 创建ResultSet对象:要使用ResultSet对象,必须首先创建一个Statement对象,通过它执行SQL查询语句。
例如:```Statement statement = connection.createStatement(;ResultSet resultSet = statement.executeQuery("SELECT * FROM user");```这里的connection是一个已经建立好的数据库连接,executeQuery方法用于执行查询语句,并返回ResultSet对象。
2. 遍历ResultSet对象:一旦获取到ResultSet对象,就可以使用它提供的方法访问查询结果。
最常用的方法是next(,用于将游标移动到结果集的下一行。
例如:```while (resultSet.next()//处理当前行数据```在循环中使用next(方法,每次迭代都会将游标移动到下一行。
可以在循环体内使用getXXX(方法获取当前行的具体数据,其中XXX代表字段的数据类型。
例如:```String name = resultSet.getString("name");int age = resultSet.getInt("age");```3.获取数据:ResultSet提供了多个getXXX(方法来访问不同类型的数据。
常用的方法包括getString、getInt、getDouble等。
这些方法需要提供一个列名或列索引作为参数,用于指定要获取的数据所在的列。
例如:```String name = resultSet.getString("name");int age = resultSet.getInt(2);```在这个例子中,getString方法通过列名获取数据,getInt方法通过列索引获取数据。

sqlserver里的递归写法在SQL Server中,递归是一种非常有用的技术,它允许我们在查询中使用自引用的表达式。
递归查询通常用于处理具有分层结构的数据,例如组织结构、文件系统等。
SQL Server提供了两种递归查询的方法:使用公用表表达式(CTE)和使用递归函数。
1.使用公用表表达式(CTE):公用表表达式是一个临时的查询结果集,它在查询中可重用,类似于临时表。
CTE用于定义一个递归查询的初始结果集和递归查询的递归部分。
在使用CTE的递归查询中,我们需要定义两个部分:初始查询和递归查询。
初始查询用于获取初始结果集,而递归查询用于在每次迭代中生成新的结果集。
以下是一个使用CTE的递归查询的示例,通过查询一个员工表的组织结构来说明:```WITH EmployeeCTE (EmployeeID, Name, ManagerID, Level) AS(--初始查询SELECT EmployeeID, Name, ManagerID, 0FROM EmployeeWHERE ManagerID IS NULLUNION ALL--递归查询SELECT e.EmployeeID, , e.ManagerID, c.Level + 1 FROM Employee eINNER JOIN EmployeeCTE c ON e.ManagerID = c.EmployeeID )--最终结果SELECT EmployeeID, Name, ManagerID, LevelFROM EmployeeCTE```在这个示例中,首先定义了一个CTE(EmployeeCTE),并在其中执行了初始查询。
初始查询选择了所有没有上级经理的员工(即根节点)作为初始结果集。
然后,使用UNION ALL和递归查询定义了CTE的递归部分。
递归查询加入了Employee表,并根据每个员工的ManagerID与上一次迭代的结果进行连接。
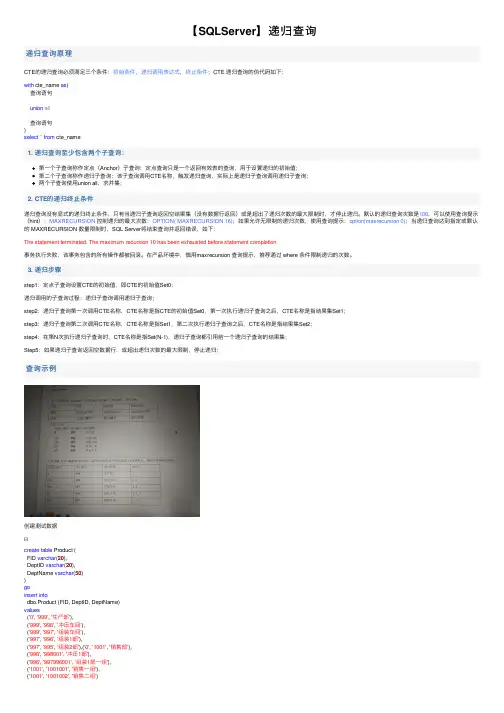
【SQLServer】递归查询递归查询原理CTE的递归查询必须满⾜三个条件:初始条件,递归调⽤表达式,终⽌条件;CTE 递归查询的伪代码如下:with cte_name as(查询语句union all查询语句)select*from cte_name1. 递归查询⾄少包含两个⼦查询:第⼀个⼦查询称作定点(Anchor)⼦查询:定点查询只是⼀个返回有效表的查询,⽤于设置递归的初始值;第⼆个⼦查询称作递归⼦查询:该⼦查询调⽤CTE名称,触发递归查询,实际上是递归⼦查询调⽤递归⼦查询;两个⼦查询使⽤union all,求并集;2. CTE的递归终⽌条件递归查询没有显式的递归终⽌条件,只有当递归⼦查询返回空结果集(没有数据⾏返回)或是超出了递归次数的最⼤限制时,才停⽌递归。
默认的递归查询次数是100,可以使⽤查询提⽰(hint):MAXRECURSION 控制递归的最⼤次数:OPTION( MAXRECURSION 16);如果允许⽆限制的递归次数,使⽤查询提⽰:option(maxrecursion 0);当递归查询达到指定或默认的 MAXRECURSION 数量限制时,SQL Server将结束查询并返回错误,如下:The statement terminated. The maximum recursion 10 has been exhausted before statement completion.事务执⾏失败,该事务包含的所有操作都被回滚。
在产品环境中,慎⽤maxrecursion 查询提⽰,推荐通过 where 条件限制递归的次数。
3. 递归步骤step1:定点⼦查询设置CTE的初始值,即CTE的初始值Set0;递归调⽤的⼦查询过程:递归⼦查询调⽤递归⼦查询;step2:递归⼦查询第⼀次调⽤CTE名称,CTE名称是指CTE的初始值Set0,第⼀次执⾏递归⼦查询之后,CTE名称是指结果集Set1;step3:递归⼦查询第⼆次调⽤CTE名称,CTE名称是指Set1,第⼆次执⾏递归⼦查询之后,CTE名称是指结果集Set2;step4:在第N次执⾏递归⼦查询时,CTE名称是指Set(N-1),递归⼦查询都引⽤前⼀个递归⼦查询的结果集;Step5:如果递归⼦查询返回空数据⾏,或超出递归次数的最⼤限制,停⽌递归;查询⽰例创建测试数据create table Product (FID varchar(20),DeptID varchar(20),DeptName varchar(50))goinsert intodbo.Product (FID, DeptID, DeptName)values('0', '999', '⽣产部'),('999', '998', '冲压车间'),('999', '997', '组装车间'),('997', '996', '组装1部'),('997', '995', '组装2部'),('0', '1001', '销售部'),('998', '998001', '冲压1部'),('996', '997996001', '组装1部⼀组'),('1001', '1001001', '销售⼀组'),('1001', '1001002', '销售⼆组')View Code;with cte as(select FID, DeptID, DeptName, cast(DeptName as varchar(max)) as ReportPath, cast(row_number() over(order by FID) as varchar(max)) as LevelNum from dbo.Productwhere FID=0union allselect B.FID, B.DeptID, B.DeptName, B.DeptName+'-->'+A.ReportPath as ReportPath, LevelNum+'.'+cast(row_number() over(order by B.FID) as varchar(max)) as LevelNum from cte A inner join dbo.Product B on A.DeptID=B.FID)select*from cte order by cte.LevelNumstep1:查询FID=0,作为root node,这是递归查询的起始点。

mysql cursor底层原理MySQL是一种广泛使用的关系型数据库管理系统,而Cursor是MySQL中用于对查询结果集进行迭代处理的一种机制。
本文将介绍MySQL Cursor的底层原理,包括Cursor的定义、实现和使用。
1. Cursor的定义:Cursor是一种数据库对象,用于从查询结果集中提取一行数据,并将光标指向下一行数据。
通过Cursor,我们可以逐行处理查询结果集,而不是一次性将所有数据加载到内存中。
这对于大型数据集非常有用,可以提高性能和降低内存消耗。
2. Cursor的实现:在MySQL中,Cursor是由服务器端实现的。
当执行一个查询时,MySQL会在服务器内部创建一个Cursor对象,并将查询结果集保存在服务器的临时存储区中。
当我们使用Cursor进行迭代处理时,MySQL会从临时存储区中取出一行数据,返回给客户端,并将光标指向下一行。
3. Cursor的使用:使用Cursor需要经过以下步骤:- 声明Cursor:在MySQL中,我们可以使用DECLARE语句声明一个Cursor对象。
例如,DECLARE cursor_name CURSOR FOR SELECT_statement。
这将创建一个名为cursor_name的Cursor对象,并将其与一个SELECT语句关联起来。
- 打开Cursor:使用OPEN语句打开Cursor,例如,OPEN cursor_name。
这将使Cursor准备好从结果集中获取数据。
- 读取数据:使用FETCH语句从Cursor中读取一行数据。
例如,FETCHcursor_name INTO variables。
FETCH语句将返回一行数据,并将数据存储在指定的变量中。
- 处理数据:在读取到数据后,我们可以对数据进行处理,执行相应的业务逻辑。
- 关闭Cursor:使用CLOSE语句关闭Cursor,例如,CLOSE cursor_name。
多线程并发执⾏任务,取结果归集。
终极总结:Future、FutureTask、Comple。
开启线程执⾏任务,不管是使⽤Runnable(⽆返回值不⽀持上报异常)还是Callable(有返回值⽀持上报异常)接⼝,都可以轻松实现。
那么如果是开启线程池并需要获取结果归集的情况下,如何实现,以及优劣,⽼司机直接看总结即可。
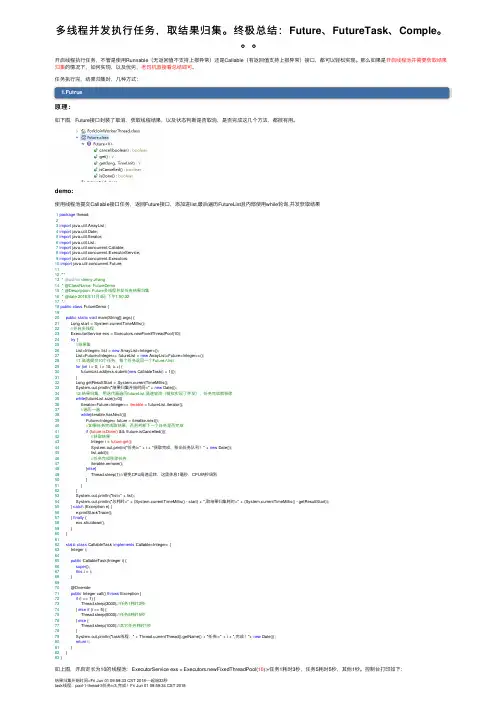
任务执⾏完,结果归集时,⼏种⽅式:1.Futrue原理:如下图,Future接⼝封装了取消,获取线程结果,以及状态判断是否取消,是否完成这⼏个⽅法,都很有⽤。
demo:使⽤线程池提交Callable接⼝任务,返回Future接⼝,添加进list,最后遍历FutureList且内部使⽤while轮询,并发获取结果1package thread;23import java.util.ArrayList;4import java.util.Date;5import java.util.Iterator;6import java.util.List;7import java.util.concurrent.Callable;8import java.util.concurrent.ExecutorService;9import java.util.concurrent.Executors;10import java.util.concurrent.Future;1112/**13 * @author denny.zhang14 * @ClassName: FutureDemo15 * @Description: Future多线程并发任务结果归集16 * @date 2016年11⽉4⽇下午1:50:3217*/18public class FutureDemo {1920public static void main(String[] args) {21 Long start = System.currentTimeMillis();22//开启多线程23 ExecutorService exs = Executors.newFixedThreadPool(10);24try {25//结果集26 List<Integer> list = new ArrayList<Integer>();27 List<Future<Integer>> futureList = new ArrayList<Future<Integer>>();28//1.⾼速提交10个任务,每个任务返回⼀个Future⼊list29for (int i = 0; i < 10; i++) {30 futureList.add(exs.submit(new CallableTask(i + 1)));31 }32 Long getResultStart = System.currentTimeMillis();33 System.out.println("结果归集开始时间=" + new Date());34//2.结果归集,⽤迭代器遍历futureList,⾼速轮询(模拟实现了并发),任务完成就移除35while(futureList.size()>0){36 Iterator<Future<Integer>> iterable = futureList.iterator();37//遍历⼀遍38while(iterable.hasNext()){39 Future<Integer> future = iterable.next();40//如果任务完成取结果,否则判断下⼀个任务是否完成41if (future.isDone() && !future.isCancelled()){42//获取结果43 Integer i = future.get();44 System.out.println("任务i=" + i + "获取完成,移出任务队列!" + new Date());45 list.add(i);46//任务完成移除任务47 iterable.remove();48 }else{49 Thread.sleep(1);//避免CPU⾼速运转,这⾥休息1毫秒,CPU纳秒级别50 }51 }52 }53 System.out.println("list=" + list);54 System.out.println("总耗时=" + (System.currentTimeMillis() - start) + ",取结果归集耗时=" + (System.currentTimeMillis() - getResultStart));55 } catch (Exception e) {56 e.printStackTrace();57 } finally {58 exs.shutdown();59 }60 }6162static class CallableTask implements Callable<Integer> {63 Integer i;6465public CallableTask(Integer i) {66super();67this.i = i;68 }6970 @Override71public Integer call() throws Exception {72if (i == 1) {73 Thread.sleep(3000);//任务1耗时3秒74 } else if (i == 5) {75 Thread.sleep(5000);//任务5耗时5秒76 } else {77 Thread.sleep(1000);//其它任务耗时1秒78 }79 System.out.println("task线程:" + Thread.currentThread().getName() + "任务i=" + i + ",完成!"+ new Date());80return i;81 }82 }83 }如上图,开启定长为10的线程池:ExecutorService exs = Executors.newFixedThreadPool(10);+任务1耗时3秒,任务5耗时5秒,其他1秒。

在SQL中,通常使用循环语句来处理一系列的数据或者执行一组特定的操作。
然而,SQL语言本身并不直接支持像其他编程语言那样的传统循环结构(例如for、while 等),而是提供了一些其他的方式来处理数据集合。
以下是几种常见的在SQL中处理循环的方法:
1. 使用游标(Cursor):游标是指向结果集的指针,可以遍历结果集中的每一行。
你可以使用DECLARE、OPEN、FETCH和CLOSE等命令来定义、打开、获取和关闭游标。
然后通过循环,使用FETCH命令逐个获取结果集中的数据行,并对其进行处理。
2. 使用临时表:你可以创建一个临时表,将需要处理的数据存储在其中,然后使用循
环语句(例如WHILE)来迭代临时表中的每一行。
在每次迭代中,你可以选择处理当
前行的数据,并更新临时表中的状态。
3. 使用递归查询(Recursive Queries):某些数据库系统支持递归查询,允许你以递归
的方式处理数据。
你可以定义一个递归查询,该查询在每次迭代中使用前一次迭代的
结果作为输入,并生成新的结果,直到满足终止条件。
需要注意的是,在使用循环或迭代的任何方法时,都要谨慎处理数据集合的大小和性
能问题,以避免不必要的性能影响。
在大多数情况下,尽量使用SQL的集合操作和批
量处理功能,而不是显式的循环结构。

mysql5.6递归查询语句“mysql5.6递归查询语句”的主题下,我将为您逐步解答,并撰写一篇3000-6000字的文章。
第一步:什么是递归查询语句?递归查询语句是指在数据库中使用递归算法进行查询的一种操作方法。
递归算法是一种自带迭代的方法,它通过在每次迭代中引用先前的结果,逐渐构建出最终的查询结果。
在MySQL 5.6及之后的版本中,引入了递归查询的功能,使得对于一些具有复杂结构的数据,可以更加方便地进行查询和处理。
第二步:如何使用递归查询语句?在MySQL 5.6中,我们可以使用“WITH RECURSIVE”子句来构建递归查询语句。
这个子句允许我们在查询过程中引用先前的结果集,以便进行下一次迭代。
具体的语法如下所示:WITH RECURSIVE <recursive_table_name> (col1, col2, ..., coln) AS ( 初始查询SELECT ... FROM ... WHERE ...UNION递归查询SELECT ... FROM ... INNER JOIN <recursive_table_name> ON ...)SELECT * FROM <recursive_table_name>;在上述语法中,我们首先需要指定递归表的名称以及每一列的名称。
然后,在“初始查询”中,我们可以执行一个普通的SELECT查询语句,以获取初始的结果集。
接着,在“递归查询”中,我们使用JOIN操作来引用先前的结果集,并构建下一次迭代的结果集。
最后,在最外层的SELECT语句中,我们可以使用递归表的名称来获取最终的查询结果。
第三步:如何实践递归查询语句?为了更好地理解和实践递归查询语句,我们将以一个示例来说明。
假设我们有一个名为“departments”的表,它包含了公司的组织结构,每一行代表一个部门,并且每一行都包含了该部门下属的直接下级部门的ID。

Java ResultSet 获取每行数据的方法本文介绍了在 Java 中使用 ResultSet 获取每行数据的几种方法,包括使用 getXXX 方法、使用泛型方法以及使用迭代器方法。
下面是本店铺为大家精心编写的3篇《Java ResultSet 获取每行数据的方法》,供大家借鉴与参考,希望对大家有所帮助。
《Java ResultSet 获取每行数据的方法》篇1在 Java 中,当执行 SQL 查询时,通常会使用 ResultSet 对象来返回查询结果。
ResultSet 对象代表查询结果集,其中每一行代表一个元组。
要获取每行数据,可以使用 ResultSet 的 getXXX 方法、泛型方法或迭代器方法。
1. 使用 getXXX 方法getXXX 方法是 ResultSet 中最常用的方法之一,可以用来获取每一行中的特定列的值。
例如,要获取结果集中第一行第一列的值,可以使用以下代码:```ResultSet rs = stmt.executeQuery("SELECT * FROMtable_name");rs.next(); // 移动到第一行String columnValue = rs.getString("column_name");```在上面的代码中,stmt 是 Connection 对象的实例,用于执行SQL 查询。
executeQuery 方法返回一个 ResultSet 对象,然后使用rs.next() 方法移动到第一行,并使用 rs.getString 方法获取第一列的值。
2. 使用泛型方法Java 中的泛型方法可以定义一个模板,用于处理不同类型的数据。
在获取 ResultSet 中的每行数据时,可以使用泛型方法来简化代码。
例如,以下是一个获取 ResultSet 中每一行所有列的值的泛型方法:```<T> List<T> getRows(ResultSet rs, Class<T> clazz) throws SQLException {List<T> rowValues = new ArrayList<>();while (rs.next()) {T row = clazz.newInstance();for (int i = 1; i <= rs.getMetaData().getColumnCount(); i++) {String columnName = rs.getMetaData().getColumnName(i);row.setValue(columnName, rs.getObject(columnName));}rowValues.add(row);}return rowValues;}```在上面的代码中,getRows 方法接受一个 ResultSet 对象和一个 Class 对象作为参数,并返回一个包含每一行所有列值的 List 对象。

kettle 循环遍历结果集作为参数传入转换在数据处理和ETL(Extract, Transform, Load)的领域中,Kettle是一款非常强大的开源工具。
它可以帮助我们轻松地完成数据抽取、转换和加载的任务。
其中一个非常有用的功能是使用循环遍历结果集作为参数传入转换。
在本文中,我将深入探讨这个主题,并提供一些实际的例子来帮助你更好地理解。
1. 什么是Kettle?Kettle,即Pentaho Data Integration(PDI),是一款面向企业级的ETL工具。
它允许开发人员通过可视化和图形化编程方式来构建ETL 流程。
Kettle提供了一系列强大的转换步骤和作业,可以用于数据提取、转换和加载。
2. 循环遍历结果集的概念循环遍历结果集是指在Kettle中,可以通过设置循环步骤来遍历一个结果集,并将结果集中的每一行作为参数传递给下一个转换。
这个功能非常有用,可以帮助我们处理大量数据或需要迭代处理的情况。
3. 如何在Kettle中循环遍历结果集作为参数传入转换要在Kettle中实现循环遍历结果集作为参数传入转换,可以使用两个关键步骤:「获取数据」和「循环」。
步骤1:获取数据在Kettle中,可以使用「获取数据」步骤从数据库或其他数据源中获取数据。
我们可以定义一个SQL查询,将查询结果作为结果集传递给下一个步骤。
步骤2:循环在「循环」步骤中,我们可以定义循环条件和循环元素。
这里的循环元素即为步骤1中获取的结果集。
我们可以使用内部变量来引用结果集中的每一行。
在每次循环中,Kettle会自动将结果集中的下一行作为参数传递给下一个转换。
4. 实际应用示例为了更好地理解如何在Kettle中循环遍历结果集作为参数传入转换,让我们看一个具体的示例。
假设我们有一个数据库表「employees」,其中包含每个员工的尊称和薪水信息。
我们需要为每个员工计算出其年终奖的金额,并将结果插入到另一个表「bonus」中。
MyBatis SelectList用法1. 简介MyBatis是一个开源的持久层框架,它可以帮助Java程序开发者在数据库操作中实现对象关系映射(ORM)和动态SQL查询。
其中,selectList是MyBatis中一个常用的查询方法,用于返回一个列表结果集。
本文将深入探讨MyBatis的selectList用法,以帮助读者更好地理解并使用该方法。
2. selectList方法参数在开始使用selectList方法之前,我们首先需要了解其参数的含义和作用。
下面是selectList方法的参数列表:2.1 statementstatement参数指定了需要执行的数据库操作语句的唯一标识符。
该标识符在MyBatis的配置文件(例如mybatis-config.xml)中进行定义,并通过命名空间(namespace)和标识符(id)来唯一确定。
例如:<select id="getUserList" parameterType="int" resultType="User">SELECT * FROM user WHERE age > #{age}</select>上述示例中,getUserList就是数据库操作语句的唯一标识符。
2.2 parameter(可选)parameter参数用于向SQL语句中传递参数。
可以是一个基本类型、一个JavaBean对象或一个Map对象。
如果SQL语句中没有需要参数化的部分,可以不传递该参数。
例如:List<User> users = sqlSession.selectList("getUserList", 18);上述示例中,18是作为参数传递给SQL语句的。
2.3 rowBounds(可选)rowBounds参数用于分页查询或限制返回结果集的大小。
sql select for循环用法在SQL语句中,并没有像编程语言中的for循环一样的语法来迭代数据或执行多次查询。
SQL是一种声明式语言,主要用于描述需要从数据库中检索的数据。
然而,可以通过使用条件语句(如IF-ELSE或CASE),以及使用子查询、联接和聚合函数等技术来实现类似于循环的操作。
以下是一些常用的方法:1.使用条件语句:可以使用CASE语句来实现根据不同条件执行不同的查询操作。
例如,可以根据条件来选择不同的WHERE子句或选择不同的列。
2.使用子查询:可以使用子查询来迭代数据。
例如,可以将查询嵌套在另一个查询中,通过逐步筛选的方式来获取所需的结果。
3.使用联接:可以使用JOIN语句将多个表连接起来,然后使用WHERE子句来筛选结果。
这种方式可以实现根据条件获取相关的数据。
需要注意的是,SQL是一种集合操作语言,更适合处理大量的数据集,而不是通过循环来操作单个数据项。
因此,推荐使用SQL的集合操作特性来处理数据,以提高性能和效率。
拓展:除了以上提到的方法,不同的数据库管理系统可能还提供了一些特定的扩展语法来处理类似于循环的操作。
例如,MySQL提供了存储过程和游标(Cursor)来实现循环。
存储过程是一种预编译并存储在数据库中的一系列SQL语句,可以通过调用存储过程来执行其中的逻辑。
而游标可以用于遍历查询结果集。
另外,一些数据库管理系统也支持使用编程语言(如Python、Java)来编写存储过程或扩展SQL语法,从而实现更复杂的逻辑操作。
总之,虽然SQL本身没有内置的for循环语法,但通过使用条件语句、子查询、联接和数据库管理系统提供的特定扩展,可以实现类似循环的操作。
同时,也建议在使用SQL时,尽可能地使用集合操作特性,以获得更好的性能和效率。
sql语句中for的用法SQL语句中for的用法1. for循环•在SQL语句中,可以使用for循环来迭代遍历数据或执行一系列操作。
FOR loop_counter IN lower_limit..upper_limit LOOP-- 执行的操作END LOOP;在上述语法中,loop_counter是用来记录当前循环迭代次数的变量,lower_limit和upper_limit是循环的上下界。
在每次循环迭代时,都会执行一系列的操作。
2. 示例:使用for循环插入数据•在以下示例中,我们使用for循环向表中插入一些示例数据。
CREATE TABLE students (id INT,name VARCHAR(50));FOR i IN 1..10 LOOPINSERT INTO students (id, name) VALUES (i, 'Student '|| i);END LOOP;在上述示例中,我们创建了一个名为students的表,包括id和name字段。
然后使用for循环从1到10循环迭代,向表中插入了10条记录,其中name字段的值为”Student “加上迭代次数i。
3. for循环中的条件判断•在for循环中也可以使用一个条件来决定是否继续迭代。
FOR i IN REVERSE 10..1 LOOPIF i > 5 THENINSERT INTO students (id, name) VALUES (i, 'Studen t ' || i);END IF;END LOOP;在上述示例中,我们使用了REVERSE关键字来让循环倒序迭代。
在每次迭代时,我们使用条件判断来判断迭代次数i是否大于5,如果满足条件,则向students表中插入一条记录。
4. for循环中的游标•在for循环中,还可以使用游标来迭代遍历查询结果集。
FOR student_rec IN (SELECT * FROM students) LOOP-- 执行的操作END LOOP;在上述示例中,我们使用SELECT语句来查询students表中的所有记录,并将结果集赋值给游标student_rec。
迭代器的基本使用方法一、迭代器是什么呢?嘿呀,宝子们!迭代器就像是一个超级小助手呢。
它可以让咱们在处理数据集合的时候,特别方便地一个一个地去访问里面的元素。
比如说,你有一堆小糖果(就把这堆糖果想象成一个数据集合啦),迭代器就像是你的小手,每次拿一颗糖来看看(也就是访问一个元素)。
二、迭代器的创建在很多编程语言里呀,创建迭代器的方法不太一样呢。
就拿Python来说吧,有些数据类型本身就可以直接当迭代器用,像列表呀、元组呀这些。
你就可以直接用for循环去迭代它们。
比如说,有个列表list1 = [1, 2, 3],你就可以直接写个for i in list1:,然后在这个循环里就可以对每个元素i做各种有趣的操作啦,像打印出来呀,或者进行一些计算啥的。
还有一些时候呢,你可能需要自己定义一个迭代器类。
这时候就有点像自己动手做一个小工具啦。
你得定义一些特殊的方法,像__iter__和__next__方法。
__iter__方法呢,就是告诉程序这个东西是个迭代器,就像给它贴上一个小标签说“我是迭代器哦”。
而__next__方法呢,就是定义每次迭代的时候怎么得到下一个元素啦。
三、迭代器的使用场景1. 数据处理在处理大量数据的时候,迭代器可太有用啦。
比如说你有一个超级大的文件,里面有好多好多行的数据,你要是一下子把整个文件都读进内存里,可能你的电脑就会累得“气喘吁吁”的。
但是呢,如果你用迭代器,就可以一行一行地读数据,这样就不会占用太多内存啦。
就好像你从一个大仓库里搬东西,一次拿一点,而不是一下子想把整个仓库都搬走。
2. 遍历复杂数据结构有时候咱们会遇到一些复杂的数据结构,像嵌套的列表或者树结构之类的。
迭代器就可以像个小探险家一样,一层一层地去访问里面的元素。
比如说有个嵌套的列表list2 = [[1, 2], [3, 4], [5, 6]],你可以用迭代器轻松地访问到每个子列表里面的元素呢。
四、迭代器的优点迭代器最大的优点就是节省内存啦。
entityframework例子Entity Framework 示例Entity Framework(EF)是一种对象关系映射(ORM)框架,用于与数据库进行交互并操作数据。
它简化了开发人员与数据库之间的通信和数据操作流程。
在这个示例中,我将介绍如何使用 Entity Framework 进行一个简单的数据库操作操作,包括创建一个数据模型、插入数据、查询数据和更新数据。
首先,我们需要创建一个新的控制台应用程序,并在项目中添加 Entity Framework NuGet 包作为依赖项。
然后,我们需要定义一个数据模型,可以使用 Code First 或 Database First 方法来创建。
在这个示例中,我们将使用 Code First 方法来创建数据模型。
我们可以创建一个名为 "Customer" 的实体类,包含一些属性,例如 Id、FirstName 和 LastName。
我们还可以在类中添加数据注解,定义一些约束和验证规则。
接下来,我们需要创建一个 DbContext 类,扩展自 EntityFramework 的DbContext 基类。
在该类中,我们可以定义数据集(DbSet)属性,以映射到数据库中的表。
通过运行迁移命令,我们可以将数据模型映射到数据库中并创建相应的表。
迁移是一种自动化的数据库更新和模式演化过程。
现在,我们已准备就绪,可以开始操作数据了。
示例中的第一个任务是插入一条新的客户记录。
我们可以实例化 DbContext 类,并使用该实例插入一条新的客户记录。
通过访问 DbSet 属性,我们可以使用 LINQ 查询语法或方法来执行各种查询操作。
示例中的第二个任务是查询客户数据并显示在控制台中。
我们可以使用DbContext 类中的 DbSet 属性,执行查询操作,并迭代结果集并打印每个客户的信息。
示例中的最后一个任务是修改客户数据。
我们可以查询 DbContext 中的客户实体,并对其进行更改,然后保存更改。
1 迭代显示查询结果集 对于查询结果集合,在JSP页面上用迭代输出标签进行显示,语句是: //"studentList"为要迭代输出的集合 //id属性为集合中的当前元素命名
当元素是由多字段组成时,语句是:
2
【例struts-iterator】 项目的程序结构: 3 一、数据库结构定义:
二、student表中的数据: 4 三、web.xml(主要部分): Struts2-cleanup org.apache.struts2.dispatcher.ActionContextCleanUp
Struts2-cleanup /*
Struts2 org.apache.struts2.dispatcher.FilterDispatcher
Struts2 /*
index.jsp
四、struts.xml(主要部分): value="false" />
QuerySuccess.jsp QueryError.jsp
5
五、index.jsp(首页): <%@ page language="java" contentType="text/html;charset=UTF-8"%> <%@ taglib prefix="s" uri="/struts-tags"%> 学生信息查询
学生信息查询
六、Action代码: package com.action;
import java.sql.SQLException; import java.util.ArrayList; import java.util.List; import com.business.*; import com.opensymphony.xwork2.ActionSupport;
public class QueryAction extends ActionSupport { private String classes; private DbQuery dbquery; private List studentList;
public List getStudentList() { return studentList; }
public void setStudentList(List studentList) { this.studentList = studentList; } 6
public String getClasses() { return classes; }
public void setClasses(String classes) { this.classes = classes; }
public String execute() throws Exception { studentList = new ArrayList(); try { dbquery =new DbQuery(); studentList = dbquery.queryStudent(getClasses()); return "success"; }catch(SQLException e) { return "input"; } } }
七、值JavaBean代码(对应数据库中的字段): package com.business;
public class Student { private String number; private String classes; private String name; private String sex; private String telephone; private String resume; public String getNumber() { return number; } public void setNumber(String number) { this.number = number; } public String getClasses() { return classes; 7
} public void setClasses(String classes) { this.classes = classes; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } public String getTelephone() { return telephone; } public void setTelephone(String telephone) { this.telephone = telephone; } public String getResume() { return resume; } public void setResume(String resume) { this.resume = resume; } }
八、查询业务代码: package com.business;
import java.sql.*; import java.util.ArrayList; import java.util.List; import com.dbconn.DbConn2005;
public class DbQuery { private DbConn2005 dbconn; private Connection conn; private PreparedStatement prestmt;