确定有穷自动机的最小化问题探讨
- 格式:doc
- 大小:222.50 KB
- 文档页数:6
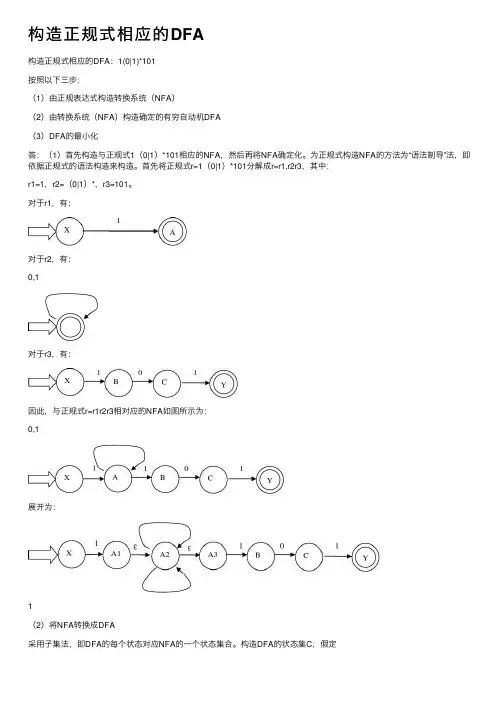
构造正规式相应的DFA
构造正规式相应的DFA:1(0|1)*101
按照以下三步:
(1)由正规表达式构造转换系统(NFA)
(2)由转换系统(NFA)构造确定的有穷⾃动机DFA
(3)DFA的最⼩化
答:(1)⾸先构造与正规式1(0|1)*101相应的NFA,然后再将NFA确定化。
为正规式构造NFA的⽅法为“语法制导”法,即依据正规式的语法构造来构造。
⾸先将正规式r=1(0|1)*101分解成r=r1,r2r3,其中:
r1=1,r2=(0|1)*,r3=101。
对于r1,有:
对于r2,有:
0,1
对于r3,有:
因此,与正规式r=r1r2r3相对应的NFA如图所⽰为:
0,1
展开为:
1
(2)将NFA转换成DFA
采⽤⼦集法,即DFA的每个状态对应NFA的⼀个状态集合。
构造DFA的状态集C,假定
DFA的状态转换图
1
(3)化简DFA:分割法,把DFA的状态集分成⼀些不想交的⼦集,使得不同的两⼦集的状态是可区别的,同⼀⼦集的状态是等价的。
⾸先,将状态分成两个⼦集:⼀个由终态组成,⼀个由⾮态组成:{T0,T1,T2,T3,T4} {T5}
{T0,T1,T2,T3} {T4} {T5}
{ T0,T1,T2} {T3} {T4} {T5}
{T0} {T1,T2} {T3} {T4} {T5}
在等价状态⼦集{T1,T2}中选状态T2做代表,消去其他状态T1,把从消去状态T1射出和
射⼊的弧都引到代表状态T2上,得到化简后的DFA:。


第三章习题参考解答3.1 构造自动机A,使得①②③当从左至右读入二进制数时,它能识别出读入的奇数;④它识别字母表{a, b}上的符号串,但符号串不能含两个相邻的a,也不含两个相邻的b;⑤它能接受字母表{0, 1}上的符号串,这些符号串由任意的1、0和随后的任意的11、00对组成。
⑥它能识别形式如±dd*⋅ d*E ±dd的实数,其中,d∈{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}。
3.2 构造下列正规表达式的DFSA:① xy*∣yx*y∣xyx;② 00∣(01)*∣11;③ 01((10∣01)*(11∣00))*01;④ a(ab*∣ba*)*b。
3.3 消除图3.24所示自动机的空移。
bεq1q2q3aba,bqaq6q4q5abεεε图3.24 含空移的自动机3.4 将图3.25所示NDFSA确定化和最小化。
xyqq1q2q4q3xyxyx,yx图3.25 待确定化的NDFSA3.5 设e、e1、e2是字母表∑上的正规表达式,试证明① e∣e=e;② {{e}}={e};③ {e}=ε∣e{e};④ {e1 e2} e1= e1{e2 e1};⑤ {e1∣e2}={{e1}{e2}}={{e1}∣{e2}}。
3.6 构造下面文法G[Z]的自动机,指明该自动机是不是确定的,并写出它相应的语言: G[Z]:Z→A0A→A0∣Z1∣03.7 设NDFSA M=({x, y},{a, b},f, x, {y}), 其中,f(x, a)={x, y}, f(x, b)={y}, f(y, a)=∅, f(y, b)={x, y}。
试对此NDFSA确定化。
3.8 设文法G[〈单词〉]:〈单词〉→〈标识符〉∣〈无符号整数〉〈标识符〉→〈字母〉∣〈标识符〉〈字母〉∣〈标识符〉〈数字〉〈无符号整数〉→〈数字〉∣〈无符号整数〉〈数字〉〈字母〉→a∣b〈数字〉→1∣2试写出相应的有限自动机和状态图。

DFA(确定的有穷自动机)的化简1. 实验内容输入一个DFA M,输出一个与之等价的最小化的DFA M’,设计并实现将NFA确定化为DFA的子集构造算法,输入非确定有限(穷)状态自动机,输出确定化的有限(穷)状态自动机编写一个程序,将一个非确定有限自动机转换为确定有限自动机。
2. 实验设计分析2.1 实验设计思路首先输入边集找到状态与边的关系,然后输入终结点,这样一个没有简化的NFA图就表示出来了,然后利用求闭包的方式求move集合,画出状态转化图,重命名后进行集合划分,再次重新画出状态转换矩阵,输出简化后的DFA。
2.2 实验算法(1)构造具有两个组的状态集合的初始划分I:接受状态组 F 和非接受状态组Non-F。
(2)对I采用下面所述的过程来构造新的划分I-new.For I 中每个组G doBegin当且仅当对任意输入符号a,状态s和读入a后转换到I的同一组中;/*最坏情况下,一个状态就可能成为一个组*/用所有新形成的小组集代替I-new中的G;end(3)如果I-new=I,令I-final=I,再执行第(4)步,否则令I=I=new,重复步骤(2)。
(4)在划分I-final的每个状态组中选一个状态作为该组的代表。
这些代表构成了化简后的DFA M'状态。
令s是一个代表状态,而且假设:在DFA M 中,输入为a时有从s到t转换。
令t所在组的代表是r,那么在M’中有一个从s到r的转换,标记为a。
令包含s0的状态组的代表是M’的开始状态,并令M’的接受状态是那些属于F的状态所在组的代表。
注意,I-final的每个组或者仅含F中的状态,或者不含F中的状态。
(5)如果M’含有死状态(即一个对所有输入符号都有刀自身的转换的非接受状态d),则从M’中去掉它;删除从开始状态不可到达的状态;取消从任何其他状态到死状态的转换。
2.3 实验流程1. 输入NFA各边信息(起点条件[空为*] 终点),以#结束2. 输入终态3. 求e-clouse闭包,将结点移入相应的闭包集合,并重新排序4. 输出状态转换矩阵,转换成DFA并重命名5. 执行DFA最简化6. 重命名DFA,输出最简化DFA状态转换矩阵2.4 实验的基本技术设计方案实验中含有一些数据结构的知识,假设I是NFA M状态集K的一个子集(即I∈K),则定义ε-closure(I)为:若Q∈I,则Q∈ε-closure(I);若Q∈I,则从Q出发经过任意条ε弧而能到达的任何状态Q’,则Q’∈ε-closure(I)。


有穷自动机状态极小化方法及正则语言判定优化王晓峰【摘要】引入了等价性原则,定义等价关系的商集合∑*/~B,通过对商集合的有限性判断,来判定正则语言,大大简化了正则语言判定的步骤,并在有穷自动机的状态集上引入了等价关系,对等价状态进行压缩,构造出与其等价的最小有穷自动机,同时降低了有穷自动机状态的复杂性.【期刊名称】《广西民族大学学报(自然科学版)》【年(卷),期】2008(014)003【总页数】4页(P81-84)【关键词】自动机;正则语言;等价关系;终结一致;商集合【作者】王晓峰【作者单位】贵州大学,计算机科学与技术学院,贵州,贵阳,550025【正文语种】中文【中图分类】TP3010 引言自动机理论是计算机科学研究的重要分支之一,在编译技术,遗传算法,模式识别,密码学,人工智能等方面有着广泛的应用,几乎所有的有限状态系统都可以用有穷自动机来描述[1].自动机给出了一种计算模型,可以用来识别语言,控制过程等[2].本文引入了等价关系,通过等价类,构造出极小化有穷自动机,降低了自动机的复杂性和存储空间.同时,在等价关系上引入了商集合Σ*/~B的有关概念,通过Σ*/~B的有限性,证明一个语言是否为正则语言(正则语言的代数判定定理).这个定理在某些方面比泵引理更为方便,简化了判定正则语言的步骤.最后,通过举例,说明使用泵引理和代数判定定理判定正则语言的方法,并给出了他们的优劣点.1 基本概念定义1[3]:形如M=(Q, Σ,δ ,q0 ,F ) 的一个五元组称为一台确定性的有穷自动机(DFA)[4],其中:Q是一个有穷集,称为状态集;Σ是一个有穷集,称为字母表;δ是一个函数,称为状态转移函数;δ:Q×Σ→ Q;q0是起始状态,q0∈Q;F是终结状态集,F ⊆Q;这里通过δ诱导出δ*:Q×Σ*→ Q,若ω∈Σ*,则δ*(q,ω)=p,表示经过|ω|步到达状态p.由δ归纳定义δ*如下:δ*(q,λ)=q;δ*(q,ωa)=δ(δ*(q,ω),a).定义2[5]:(1)设M是一台DFA,定义:L(M)={ω∈Σ*|δ*(q0,ω)∈F}表示为M 所接受的语言;(2)B⊆Σ* ,若存在一台DFA的M,使L(M)=B,称B是DFA可接受的语言,称B为正则语言;定义3[6](语言的等价):设M1和M2为两台DFA,若L(M1)=L(M2),则称M1与M2等价,即M1识别的语言与M2识别的语言是一致的.记|M1|为M1中的状态数,若|M1|≤|M2|,且M1与M2等价,称M1比M2简单.定义4:对于所有的ω∈Σ*,如果δ*(p,ω)∈F意味着δ*(q,ω)∈F或者δ*(p,ω)∉F意味着δ*(q,ω)∉F,称这样的p和q为终结一致;反之,若存在符号串ω∈Σ*使得δ*(p,ω)∈F且δ*(q,ω)∉F,或者,反之亦然,那么状态p和q不是终结一致的,称ω是p和q不是终结一致的证据.在Q上引入二元关系R:(p,q)∈R⟺p与q终结一致.可以验证R是一个等价关系. 引理1:对于给定的DFA,M=(Q, Σ,δ,q0 ,F ),Q上的终结一致关系R是等价关系;记(p,q)∈R为p~q;若pq,即存在ω∈Σ*,使得p与q关于ω不是终结一致的.引理2(泵引理):[7](判定正则语言的必要条件) 设L是无穷的正则语言.那么一定存在某个正整数m,满足,任意w∈L,|w|≥m,可以分解成w=xyz,其中:|xy|≤m,|y|≥1,对于所有的i=0,1,2,…,满足wi=xyiz也属于L.2 有穷自动机中的状态压缩(极小化)问题我们已经知道,自动机是一个五元组, M=(Q, Σ,δ,q0 ,F ),一台自动机假如可以停机,那么它必须从起始状态q0出发经过一系列中间状态(Q中的状态),最后到达结束状态(F中的状态)[8].在实现过程中,一般情况下,中间状态越少,所用步数也就越少.因此,能否采用一种算法(方式)将一台已知的自动机当中的“冗余状态”归并掉,从而减少中间状态,进而提高效率.根据定义4及引理1,我们可以实现自动机的最小化,也就是说,对于任意给出的自动机,我们可以构造出与之等价的状态数最少的自动机,而且这个自动机是唯一的.下面我们通过例子来说明具体的构造过程.例1:有穷自动机M=<Q,Σ,δ,q0,F>,其中Q={A,B,C,D,E,F,G,H},Σ={0,1},q0=A,F={C},如图1所示.图1 有穷自动机构造终结等价关系的算法-填表法:p,q∈Q,若p~q,则在表中对应的栏打√;若pq,则在表中对应的栏打×;具体构造如下:状态A和B,则存在ω=“01”,使得δ*(A,ω)∈F且δ*(B,ω)∉F,根据引理1,有AB,故在A和B所对应的栏打×;状态A和C,则存在ω=“1”,使得δ*(A,ω)∉F且δ*(C,ω)∈F,所以有AC,故在A和C所对应的栏打×;状态A和D,则存在ω=“0”,使得δ*(A,ω)∉F且δ*(D,ω)∈F,所以有AD,故在A和D所对应的栏打×;状态A和E,则对ω∈Σ*,使得定义4成立,根据引理1,有A~E,故在A和E所对应的栏打√;同理,有AF, AG, AH, BC, BD, BE, BF, BG, B~H, CD, CE, CF, CG, CH, DE, D~F, DG, DH, EF, EG, EH, FG, FH, GH,所以对应的终结一致等价表如图2所示:图2 终结一致等价图根据表1,把终结一致的状态进行归并,作为新的状态,即:{A,E},{B,H},{D,F},{C},{G}为新的状态,根据新的状态,画出对应的有穷自动机如图3所示:图3 新状态下的有穷自动机可以验证,图3和图1所对应的有穷自动机是等价的;那么图3是不是极小的,唯一的与图1等价的有穷自动机呢?回答是肯定的.证明:10(极小性) 假设图3不是图1的极小化有穷自动机,那么根据定义4及引理1,在图3中一定存在终结一致的状态,根据极小化的构造过程,将其归并;事实上,在图3中,归并任何两个状态,将导致与图1所表示的有穷自动机不等价;故图3是图1所对应的极小化有穷自动机;20(唯一性) 假设极小化有穷自动机是不唯一的,根据上述极小化有穷自动机的构造过程,也就是说至少还存在状态对{p,q},在存在某个串ω的情况下,使得δ*(p,ω)和δ*(q,ω)恰有一个被接受,即状态p和q不是终结一致的,但根据上述构造过程,不可能出现这种情况,因为,上述构造过程实质上是一个满射,不会漏掉不是终结一致的状态p和q.那么这种情况可能出现在图3中,根据引理1,终结一致关系R是等价关系,则必然导致图3中的某个状态归并,这与图3是极小化有穷自动机相矛盾;所以图3是唯一的;证毕.3 正则语言的代数判定方法定义5[9]:已知B⊆Σ*,由B定义Σ*上的一个二元关系~B,对x,y∈Σ*;x~By⟺∀z∈Σ*,xz与yz是B一致的;即:∀z∈Σ*,xz∈B且yz∈B或xz∉B且yz∉B,x与y是B一致的.可以验证,~B是Σ*上的一个等价关系.定义6 (商集合):Σ*/~B={[x]|x∈Σ*},其中[x]表示x所在的等价类对应的状态. 定理1(正则语言的代数判定定理):给定B⊆Σ*,由B诱导出等价关系~B,则B 是正则语言⟺Σ*/~B有限.证明:(⟺)假定B是正则语言,则存在一台有穷自动机M=(Q, Σ,δ ,q0 ,F ),不妨假定M是一台极小化自动机,对每一个q∈Q,定义xq∈Σ*,δ*(q0,xq)=q;记Q={q1,q2,…,qn},对应定义xq1,xq2,…,xqn;由于B=L(M),对于任何x∈Σ*,若δ*(q0,x)=q,则x~Bxq;即:∀x∈Σ*,存在qi∈Q,使得x~Bxqi,由n有限,则Σ*/~B有限,即:|Σ*/~B|≤n;(⟺)设有一台DFA M=(Q, Σ,δ ,q0 ,F ),Σ*/~B有限,令Q=Σ*/~B,q0=[ε],F={[x]| x∈B},δ([x],a)=[xa];证毕.例如:B={0,00,000,…}=0*,Σ*={0,1}*;由定义5可知:[ε]={ε,0,00,000,…}=0*,[1]={1,10,11,…};只有两个等价类[ε]和[1].有穷自动机的转换图如图4所示.故:B是正则语言.图4 有穷自动机的转换图我们知道,判断一个语言是正则语言,可以通过正则表达式、自动机或泵引理来判定;我们只给出无穷语言的泵引理,尽管有穷语言也是正则语言,但是因为泵自动生成无穷集合,所以不能按照上面引理,抽出相应的符号串,这个引理对于有穷语言依然成立,但是没什么意义.泵引理中的m要比最长的符号串的长度还大,所以不能够抽出符号串.泵引理是判定正则语言的必要条件,因此使用时,一般先作出假设,即某个语言是正则语言,然后验证满足引理的条件,但使用泵引理是很讲究技巧性的,使用起来往往是不容易的,并且在有些方面也存在不足.为此我们利用自动机中的等价性原则,得出了正则语言的代数判定定理,即通过商集合Σ*/~B的有限性来判定是否为正则语言,使用此定理在某些方面比泵引理更为方便.下面我们通过举例来说明使用正则语言的代数判定定理来判定正则语言:例2:对于语言A={0n1n|n>0},判断其是否是正则语言.证明:10 我们使用泵引理:假设A是正则语言,那么泵引理一定成立.我们不知道m的值,但是不论它取什么值,我们都可以取n=m.因此,子串y一定仅包含a.假设|y|=k.那么,根据泵引理,取i=0获得的符号串就是w0=am-kbm,显然,这个符号串不属于A.这与泵引理矛盾,因此,假设不成立,A不是正则语言.20 我们使用代数判定定理:假设m,n是正整数,当m<n时,0m1n∉A或者是含有子串10的串也不属于A.根据定义5、定义6及定理1,所有这样的串属于~B的同一个等价类;同时我们注意到,对于0m和0n,当m≠n时,它们不在同一个关于~B的等价类中,这样我们得到关于~B的无穷多个等价类,因此Σ*/~B无限.所以,语言A不是正则语言.证毕.例3:证明语言L={anbl|n≠l}不是正则语言.证明:10 我们使用泵引理:假设A是正则语言,那么泵引理一定成立.这里我们需要灵活的使用泵引理,选择具有n=l+1或n=l+2的符号串都不行,因为总会找到一种分解方式,使我们无法抽出不属于该语言的符号串.我们必须更有创造力才行.我们令n=m!,l=(m+1)!.如果选出长度k<n的y,我们抽取i次,得到具有m!+(i-1)k=(m+1)!,就可以推出和泵引理矛盾的结论.这个等式总是有可能成立的,因为并且k≤m.等式右侧是整数,因此我们成功的推出和泵引理相矛盾;由此,我们看出,使用泵引理是需要一定技巧的,这给我们的使用带来困难.20 我们使用代数判定定理:注意到,根据定义5、定义6及定理1,an和am,当m≠n时,它们不在同一个关于~B的等价类中,这样我们得到关于~B的无穷多个等价类,因此Σ*/~B无限.所以,语言L不是正则语言.证毕.通过上面的例子可以看出,使用正则语言的代数判定定理比使用泵引理更为简单.4 结语综上所述,我们通过定义等价关系,对有穷自动机的状态进行压缩,构造出与之等价的极小化有穷自动机,提出了一整套构造极小化自动机的方法.同时,引入了商集合Σ*/~B的概念,通过Σ*/~B的有限性,来判定一个语言是否是正则语言,这将大大简化了我们判定正则语言的步骤.下一步的任务是,我们争取总结出上下文无关语言的相关理论,形成一套比较完整的有关形式化语言判定的理论体系. [参考文献]【相关文献】[1]韩光辉.有限自动机的最小化理论[J].江汉大学学报, 2005,33(4): 14-16.[2]秦永彬,许道云. 有穷自动机中的等价性与等价归并算法[J].济南大学学报, 2006,(4).[3]Peter Linz. An Introduction to Formal Languages and Automata[M]. China Machine Press,2004.[4]Rabin M O,Scott D.Finite automata and their decision problems[J].IBM J Res Develop,1959,3:114-125.[5]Michael Sipser. Introduction to the Theory of Computation Second Edition[M].China Machine Press,2007.[6]SYu, G Rozenberg,A Salomaa.Handbook of Formal Languages[J].SpringerBerlin,1997(1):41-110.[7]叶瑞芬,沈百英.关于正则语言的泵引理[J].华东理工大学学报,1994,20(5):654-656.[8]John E.Hopcroft Rajeev Movwani Jeffrey D.Ullman. Introduction to Automata Theory,Languages,and Computation[M].China Machine Press,2007.[9]蒋宗礼,姜守旭.形式语言与自动机[M].北京:清华大学出版社,2003.。




编译原理第3章内容简介学习目标第3章有穷自动机3.1 有穷自动机的形式定义3.1 有穷自动机的形式定义DFA的表示举例——状态转换表DFA的表示举例——状态转换图 3.13.1 FA的形式定义有穷自动机识别的符号串举例DFA A3.1 有穷自动机的形式定义 3.1 有穷自动机的形式定义NFA举例 3.13.1用NFA识别符号串yFA的构造FA的构造举例—1FA的构造举例—2FA的构造举例—3请构造一个有穷自动机FA的构造举例—4 3.1请构造一个有穷自动机FA的等价性举例3.2 NFA到DFA的转换 3.2 NFA到DFA的转换—NFA确定化3.2 NFA到DFA的转换3.2 NFA到DFA的转换—NFA确定化——ε闭包状态子集I的ε闭包——举例状态子集I的状态子集I的ε闭包——举例状态子集I的——Ia 子集3.2 NFA到DFA的转换Ia子集——举例Ia子集——举例 3.2 NFA到DFA的转换NFA到DFA的转换——子集法NFA=(Q NFA到DFA的转换——举例1aNFA到DFA的转换——举例2NFA DFA DFA NFA DFA DFADFA化简举例1DFA化简——注意NFA到最小化DFA的转换——举例33.3 正规文法与FA3.3 正规文法与FAFA⇒右线性正规文法FA⇒右线性正规文法——举例1y3.4 正规表达式RE与FA 正规表达式与有穷自动机3.4 RE与FA——RE的性质 3.4 RE与FA—RE⇒FARE⇒FA举例1RE⇒FA举例23.4 RE与FA——FA⇒RE FA⇒REFA⇒RE FA⇒RE举例FA⇒RE举例正规文法到正规表达式正规文法到正规表达式DFA的程序实现DFADFA的程序实现DFA DFA的程序实现lDFA的程序实现l第3章内容小结第3章内容小结参考文献。
dfa最小化例题假设有一个DFA(确定性有限状态自动机),其状态转移表如下: | | 0 | 1 || ---- | ---- | ---- || A | B | C || B | D | E || C | E | F || D | A | B || E | C | D || F | D | E |现在需要对该DFA进行最小化处理,即将其转化成最小的DFA。
最小化DFA的过程可以分为以下几个步骤:1. 状态划分:将DFA中的状态划分成等价类。
2. 构建新的状态转移表:将等价类作为新的状态,构建新的状态转移表。
3. 确定新的接受状态:如果原来的接受状态在同一个等价类中,那么在新的DFA中它们也是接受状态。
根据这个步骤,我们可以进行如下的最小化处理:1. 首先,将所有状态分成两类:接受状态和非接受状态。
在本例中,接受状态为F,非接受状态为A、B、C、D、E。
2. 接下来,将接受状态和非接受状态分别划分成等价类。
对于本例,由于DFA中的状态之间的转移关系比较复杂,这里不再给出详细的划分过程。
划分后得到的等价类如下:{A, C, E}、{B, D, F}3. 根据等价类构建新的状态转移表:| | 0 | 1 || ---- | --------- | --------- || {A, C, E} | {B, D, F} | {B, D, F} || {B, D, F} | {A, C, E} | {C, E} |4. 确定新的接受状态:由于原来的接受状态F在等价类{B, D, F}中,因此在新的DFA中,{B, D, F}为唯一的接受状态。
通过以上步骤,我们得到了最小化的DFA。
新的DFA中只有两个状态{A, C, E}和{B, D, F},比原来的DFA中的状态数少了一半。
矩阵模型方法在有限自动机极小化的应用【摘要】矩阵模型方法在有限自动机极小化中具有重要的应用价值。
通过介绍矩阵模型方法和有限自动机的极小化概念,可以更好地理解基于矩阵模型方法的极小化算法。
结合实际案例分析,展示了矩阵模型方法在有限自动机极小化中的实际应用效果。
虽然矩阵模型方法具有一定的优势,但也存在局限性。
未来研究可以进一步完善该方法,在实际应用中发挥更大的作用。
研究结果表明,矩阵模型方法在有限自动机极小化领域具有实用性,并为未来研究提供了新的方向。
【关键词】矩阵模型方法、有限自动机、极小化、算法、应用案例、优势、局限性、实用性、未来研究方向、总结、研究背景、研究目的、研究意义1. 引言1.1 研究背景有限自动机是计算机科学中重要的概念,广泛应用于编译器设计、自然语言处理、人工智能等领域。
在实际应用中,有限自动机的状态数量可能非常庞大,给系统的设计和性能带来挑战。
为了简化和优化有限自动机,有限自动机的极小化成为一项重要的研究课题。
传统的有限自动机极小化算法通常基于状态等价性划分或遍历算法,这些算法在处理复杂的有限自动机时效率低下,并且难以处理状态空间较大的情况。
研究如何利用新的方法来加速有限自动机的极小化过程是亟待解决的问题。
1.2 研究目的有限自动机是一种数学模型,用于描述和分析各种计算和控制问题。
有限自动机的极小化是对给定有限自动机进行精简,去除冗余状态和转移,提高自动机的效率和可读性。
研究的目的是通过矩阵模型方法来实现有限自动机的极小化,探讨其在自动机理论和实际应用中的作用。
通过探究矩阵模型方法在有限自动机极小化中的应用,可以更好地理解自动机的结构和行为,为自动机设计和优化提供新的思路和方法。
研究还可以为其他领域的算法设计和系统优化提供启示,拓展矩阵模型方法在实际问题中的应用范围。
1.3 研究意义研究矩阵模型方法在有限自动机极小化中的应用具有重要的理论和实际意义。
通过研究矩阵模型方法,可以深入理解有限自动机的结构和性质,拓展自动机理论的研究领域。
确定有穷自动机的最小化问题探讨
本文针对DFA最小化时可能遇到的各种情形,给出最小化的通用算法,并通过具体实例加以验证。
此算法有利于学生对编译原理课程中DFA最小化的学习和理解,同时让学生进一步了解此知识点在其他问题求解中的应用。
关键词:有穷自动机(FA);确定有穷自动机(DFA);最小化
1引言
词法分析是编译程序的第一阶段,其实质是从描述单词构成的工具——正规表达式,向识别单词的工具——确定有限自动机(DFA)的等价转化。
此过程包括正规表达式到非确定有限自动机(NFA)的转化、NFA到确定有限自动机(DFA)的转化和DFA的最小化(化简)三个环节。
DFA最小化是转化的最后一步,也是有限自动机应用及实现方面的重要研究问题之一。
它揭示了状态之间的内在联系,既方便DFA存储实现,又可以提高自动识别单词的效率。
本文在分析DFA最小化理论的基础上,针对转化过程中可能出现的各种情形,给出求DFA M的最小化DFA M′的一种通用算法,并给出实例加以验证。
2DFA最小化理论分析
已知一确定有限自动机DFAM,s和t是M的任意两个不同的状态。
DFA最小化问题涉及到以下几个重要概念:
1) DFA的最小化定义:是指构造一个与DFA M等价且状态个数最少的DFA M′,即等价最小DFAM′,有L(M)=L(M′)。
2) 等价状态:若从状态s出发能读出某个字α而停于终态,从状态t出发也能读出同一个字α而停于终态;反之,若从t 出发能读出某个字α而停于终态,则从s出发也能读出同一个字α而停于终态,则称s和t为等价状态。
如图1 中的状态6和状态7均只能读出若干b而停于终态。
也可以定义为,若分别以s和t为始点,到达终态所识别字的字集相等,则称s和t为等价状态。
如图1,以状态6为始点所识别的字集为b*,而以7为始点所识别的字集为bb*,即b*,所以6和7状态为等价状态。
3) 可区别状态:简言之,如果DFA M中的两个状态s、t不等价,则称s和
t是可区别状态。
即:以s和t为始点,到达终态所识别字的字集不相等。
DFA M化简时的可区别状态可分为以下三种情形:
●非终态和终态是可区别的。
因为,终态识别的字集中一定有ε字而DFA M 中的非初态识别的字集中不可能有ε字。
●对同一个字w,s和t两个状态,一个到达终态,另一个到达非终态,则s 和t可区别。
如状态1和状态3是可区别的,因为状态3遇b字符而到达终态6,即能识别字b,而状态1遇b字符而到达非终态2,即能识别以b开头的部分字,但不能识别b字。
●s和t两个状态,一个有a字符后继(a∈Σ),另一个无a字符后继,则s和t可区别。
如状态2和状态5是可区别的,因为状态2有b字符后继,能识别以b开头的部分字,而状态5没有b字符后继,不可识别以b开头的任何字。
3上述概念中,等价状态和可区别状态是DFA最小化的两个重要依据。
3DFA最小化求解算法改进
确定有穷自动机的化简方法很多,文中以”分割法”介绍DFA的化简:一个DFA M最小化过程是在把M的状态集分割成一些不相交的子集,使得任何不同的两子集的状态都是可区别的,而同一子集的中的任何两个状态都是等价的。
最后,让每个子集选出一个代表,同时消除其他等价状态或者为每一个子集重新命
名。
那么给定DFA M,如何形成初始划分、进一步划分形成最少状态数的等价DFA M′?如何解决DFA最小化过程中可能遇到的各种情形?下面介绍一种通用算法。
3.1DFA状态转换矩阵的扩展
一个DFA可以表示成一张状态转换矩阵。
上图DFA的状态转换矩阵如下表1。
其中的许多ø元素,表示当前状态没有以对应字符为弧的后继状态。
按照此转换矩阵,由某一状态集求其对应字符的后继状态集是很方便的,例如I={1,2,3,4,5},其对应字符的后继状态集为I ={1,2,3,4,5}a={3,4, ø},I={1,2,3,4,5}b={2,6,7,ø}。
通常在教科书上,初始划分一般分为两个子集:终态组和非终态组。
然后对形成的每个子集再进一步划分。
但对后继状态集中的{ø}算法要特殊处理,因为它不属于任何已划分子集。
现用一种通用算法解决DFA化简过程中的所有情形:设想在DFA M状态转换中有一个出错状态e,该状态为非终止状态,对于每个状态,若没有对应字符为弧的后继状态,均引一条弧到达出错状态e,并在弧上标注对应字符。
扩展后的DFA M如图2所示,其所对应的状态转换矩阵如表2。
3.2 DFA最小化求解算法
依据可区别状态的定义,可知出错状态{e}可区别于终态集和非终态集,因为出错状态e识别的字集为空集。
因此,可以将初始划分为三个状态集(或子集)。
改进的DFA最小化算法如下:
已知:DFA M=(K,∑,f,k0,kt),求最小状态DFA M′
(1)(1) 构造状态的初始化划分∏:
终态kt、非终态K-kt、、出错状态e 三个子集
(2)(2) 对∏施用过程PP构造新划分∏new
(3)(3) 如果∏new==∏,则令∏final=∏并继续步骤(4)
否则,∏=∏new,重复(2)
(4) 为∏final中的每一子集选一代表,这些构成M′的状态。
若k是一代表且
f(k,a)=t,令p是t组的代表,则M′中有一转换f′(k,a)=p。
(5) 删除其他等价状态和出错状态。
过程PP:构造新的划分∏new
①对∏每一个状态集G进行下述工作:
将G划分为子集。
G的两个状态s和t分在同一子集的充要条件是:对所有的输入符号a,状态s和t的a转换都是∏的同一子集中的状态。
②形成的所有子集成为∏new的状态子集。
下面以图1所示的DFA M,利用上述算法将其最小化:
首先将M的状态分成3个子集:一个由终态(可接受态)组成,一个由非终态组成,一个出错状态组成,即初始划分P0为:P0=({1,2,3,4,5},{6,7},{e}),显然一个子集中的任何状态与另外两子集中的任何状态不等价。
现在观察第一个子集{1,2,3,4,5},在读入输入符号a后,状态1、2和5分别转换为第一个子集中所含的状态3和4,而3和4分别转换为第三个子集中所含的状态e,这就意味着{1,2,5}中的状态和{3,4}中的任何状态在读入a 后到达了不等价的状态,因此{1,2,5}中的任何状态与{3,4}中的任何状态都是可区别的,因此得到了新的划分P1如下:
P1=({1,2,5},{3,4},{6,7},{e})
下面试图在P1中寻找一个子集和一个输入符号使得这个子集中的状态可区别,P1中的子集{1,2,5}对应输入符号b将其再分割,而得到划分P2=({1,2},{3,4},{5},{6,7},{e})。
经过考察,P2不能再划分了。
令1代表{1,2}消去2,令3代表{3,4},消去4,令6代表{6,7},消去7,再消去e,我们便得到了图3的DFA M′,即为图1 DFA M的最小化。
4 结束语
目前有限自动机理论已广泛应用于计算理论、编译技术、模式识别、人工智能等领域,几乎所有的有限状态系统都可以用FA来描述。
DFA的最小化是有限自动机应用及实现方面的重要问题之一,比起原来的有穷自动机,化简了的有穷
自动机具有较少的状态,便于其存储实现,提高自动识别单词的效率。
本文通过具体实例对DFA的最小化进行了详细的讨论,并针对化简中遇到的各种情形,给出了一种通用、方便的求解算法,可以帮助学生对编译原理课程中有穷自动机的相关概念有更深入理解,并能针对不同情形完成DFA的最小化。
参考文献
[1] 张幸儿. 编译程序构造实践[M]. 北京:科学出版社,2005.
[2] 吕映芝. 编译原理[M]. 北京:清华大学出版社.
[3] 冯雁. 编译原理与技术[M]. 浙江大学出版社,2003.
[4] 刘坚. 编译原理基础[M]. 西安电子科技大学出版社,2002.
[5] 朱征宇等. 有限自动机研究的矩阵模型方法[J]. 计算机科学,2001,28(4):46-48.。