对象的继承关系在数据库中的实现方式和PowerDesigner设计
在面向对象的编程中,使用对象的继承是一个非常普遍的做法,但是在关系数据库管理系统RDBMS中,使用的是外键表示实体(表)之间的关系,那么对于继承关系,该怎么在RDBMS中表示呢?一般来说有3种实现方式:
Concrete Table Inheritance(具体表继承)
Single Table Inheritance(单表继承)
Class Table Inheritance(类表继承)
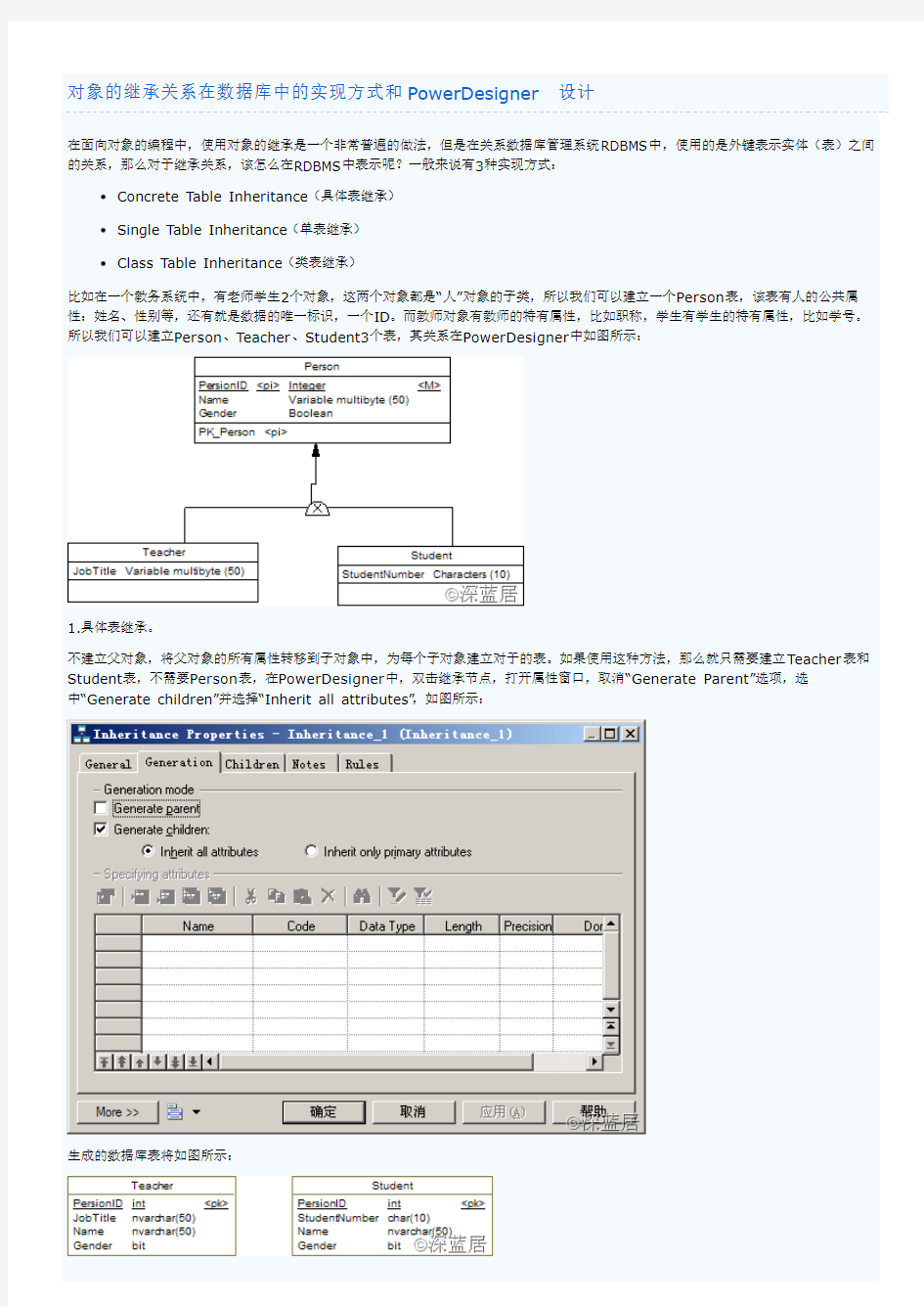
比如在一个教务系统中,有老师学生2个对象,这两个对象都是“人”对象的子类,所以我们可以建立一个Person表,该表有人的公共属性:姓名、性别等,还有就是数据的唯一标识,一个ID。而教师对象有教师的特有属性,比如职称,学生有学生的特有属性,比如学号。所以我们可以建立Person、Teacher、Student3个表,其关系在PowerDesigner中如图所示:
1.具体表继承。
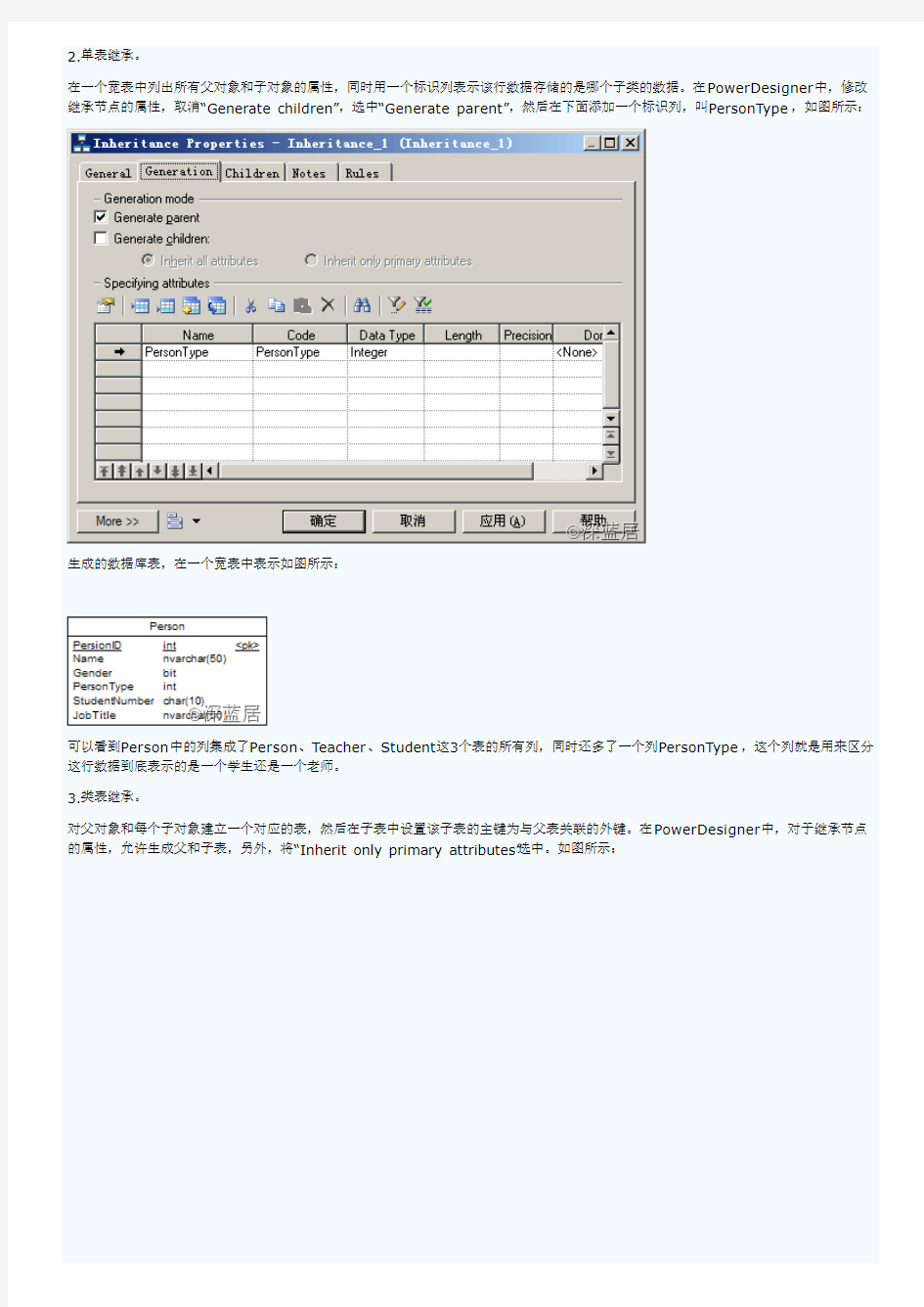
不建立父对象,将父对象的所有属性转移到子对象中,为每个子对象建立对于的表。如果使用这种方法,那么就只需要建立Teacher表和Student表,不需要Person表,在PowerDesigner中,双击继承节点,打开属性窗口,取消“Generate Parent”选项,选
中“Generate children”并选择“Inherit all attributes”,如图所示:
生成的数据库表将如图所示:
2.单表继承。
在一个宽表中列出所有父对象和子对象的属性,同时用一个标识列表示该行数据存储的是哪个子类的数据。在PowerDesigner中,修改继承节点的属性,取消“Generate children”,选中“Generate parent”,然后在下面添加一个标识列,叫PersonType,如图所示:
生成的数据库表,在一个宽表中表示如图所示:
可以看到Person中的列集成了Person、Teacher、Student这3个表的所有列,同时还多了一个列PersonType,这个列就是用来区分这行数据到底表示的是一个学生还是一个老师。
3.类表继承。
对父对象和每个子对象建立一个对应的表,然后在子表中设置该子表的主键为与父表关联的外键。在PowerDesigner中,对于继承节点的属性,允许生成父和子表,另外,将“Inherit only primary attributes”选中。如图所示:
生成的数据库表如图所示:
这里可以看到,Teacher的主键和Student的主键同时又是该表的外键,连接到Person表。
PS:如果使用NHibernate进行编程,那么可以参考这篇文章,介绍了NHibernate对这三种继承的配置方法。如果使用Entity Framework进行编程,那么可以参考这篇文章。
数据库的设计理论 第一节,关系模式的设计问题 一概念: 1. 关系模型:用二维表来表示实体集,用外键来表示实体间的联系,这样的数据模型,叫做关系数据模型。 关系模型包含内涵和外延两个方面: 外延:就是关系或实例、或当前值。它与时间有关,随时间的变化而变化。(主要是由于元组的插入、删除、修改等操作引起的) 内涵:内涵是与时间独立的,它包括关系属性、以及域的一些定义和说明。还有数据的各种完整性约束。 数据的完整性约束分为静态约束和动态约束。 静态约束包括数据之间的联系(称为数据依赖),主键的设计和各种限制。 动态约束主要定义如插入、删除和修改等操作的影响。 通常我们称内涵为关系模式。 2. 关系模式:是对一个关系的描述,二维表的表头那一行称为关系模式,又称为表的框架或记录类型。 关系模式的定义包括:模式名、属性名、值域名和模式的主键。关系模式仅仅是对数据特征的描述。 关系模式的一般形式为R ( U , D , DOM , F ) R 是关系名。 U 是全部属性的集合。 D 是属性域的集合。 DOM 是U 和D 之间的映射关系,关系运算的安全限制。 F 是属性间的各种约束关系,也称为数据依赖。
关系模式可以表示为: 关系模式(属性名1,属性名2 ,……,属性名n ) 示例:学生(学号,姓名,年龄,性别,籍贯)。 当且仅当U 上的一个关系r 满足 F 时,r 就称为关系模式R(U,F)上的一个关系,R是关系的型,r 是关系的值,每个值称为R 的一个关系。 关系数据库模式: 一个数据库是由多个关系构成的。 一个关系数据库对应多个不同的关系模式,关系数据库模式是一个数据库中所有的关系模式的集合。它规定了数据库的全局逻辑结构。 关系数据库模式可以表示为: S = { Ri < Ui , Di , DOM , Fi > | i = 1,2,…, n } 3. 关系子模式 关系子模式是用户所用到的那部分数据的描述。 外模式是关系子模式的集合。 4. 存储模式 存储模式及内模式。 关系数据库理论的主要内容: (1)数据依赖。数据依赖起着核心的作用。 (2)范式。 (3)模式的设计方法。 如何设计一个合理的数据库模式: (1)与实际问题相结合。 泛关系模式:把现实问题的所有属性组成一个关系模式 泛关系:泛关系模式的实例称为泛关系。 泛关系模式中存在的问题: a 数据冗余 b 更新异常, c 插入异常 d 删除异常。
关系型数据库设计原理 1.为E-R图中的每个实体建立一张表。 2.为每张表定义一个主键(如果需要,可以向表添加一个没有实际意义的字段作为该表的主键) 3.增加外键表示一对多关系。 4.建立新表表示多对多关系。 5.为字段选择合适的数据类型。 6.定义约束条件(如果需要)。 7.评价关系的质量,并进行必要的改进 数据库是存储数据库对象的容器。MySQL数据库的管理主要包括数据库的创建、选择当前操作的数据库、显示数据库结构以及删除数据库等操作。成功创建choose数据库后,数据库根目录下会自动创建数据库目录。使用MySQL命令show databases;即可查看MySQL服务实例上所有的数据库使用MySQL命令show create database choose;可以查看choose数据库的相关信息(例如MySQL版本ID号、默认字符集等信息)执行“use choose;”命令后,后续的MySQL命令以及SQL语句将自动操作choose数据库中所有数据库对象。删除student 数据库,使用SQL语句 drop database student 表是数据库中最为重要的数据库对象MyISAM和InnoDB存储引擎设置默认的存储引擎创建数据库表显示表结构表记录的管理 MySQL提供了插件式(Pluggable)的存储引擎,存储引擎是基于表的,同一个数据库,不同的表,存储引擎可以不同。甚至同一个数据库表,在不同的场合可以应用不同的存储引擎。 表记录的插入表记录的修改表记录的删除MySQL特殊字符序列 向数据库表插入记录时,可以使用insert语句向表中插入一条或者多条记录,也可以使用insert….select语句向表中插入另一个表的结果集。 本章详细讲解select语句检索表记录的方法, select语句概述使用where子句过滤结果集使用order by子句对结果集排序使用聚合函数汇总结果集使用group by子句对记录分组统计合并结果集子查询选课系统综合查询 使用正则表达式模糊查询全文检索 视图与表有很多相似的地方,视图也是由若干个字段以及若干条记录构成,视图也可以作为select语句的数据源。甚至在某些特定条件下,可以通过视图对表进行更新操作。视图中保存的仅仅是一条select语句,视图中的源数据都来自于数据库表,数据库表称为基本表或者基表,视图称为虚表。 1.使操作变得简单 2.避免数据冗余 3.增强数据安全性 4.提高数据的逻辑独立性 如果某个视图不再使用,可以使用drop view语句将该视图删除视图分为普通视图与检查视图。通过检查视图更新基表数据时,只有满足检查条件的更新语句才能成功执行
关系数据库逻辑设计(一) (总分:116.98,做题时间:90分钟) 一、选择题(总题数:37,分数:37.00) 1.数据库逻辑设计的依据不包括______。 A) 概念模型 B) 安全性要求 C) 数据约束 D) 功能模型 (分数:1.00) A. B. C. D. √ 解析:[解析] 数据库逻辑设计的依据是数据库概念设计的结果,包括概念数据模型、数据处理要求、数据约束、安全性要求及DBMS的相关信息,因此本题答案为D。 2.以下关于数据库逻辑设计叙述错误的是______。 A) 数据库逻辑设计是面向机器世界的 B) 这个阶段将按照数据库管理系统支持的数据模型来组织和存储数据 C) 目标是得到实际的数据库管理系统可处理的数据库模式,并做到数据结构合理 D) 包括定义和描述数据库的局部逻辑结构、数据之间的关系、数据完整性及安全性要求等 (分数:1.00) A. B. C. D. √ 解析:[解析] 数据库逻辑设计包括定义和描述数据库的全局逻辑结构、数据之间的关系、数据完整性及安全性要求等。因此本题答案为D。 3.在关系数据库设计中,设计关系模式是数据库设计中哪个阶段的任务______。 A) 逻辑设计阶段 B) 概念设计阶段 C) 物理设计阶段 D) 需求分析阶段 (分数:1.00) A. √ B. C. D. 解析:[解析] 关系数据模型是常用的逻辑数据模型,所以设计关系模式是数据库设计中逻辑设计阶段的任务,因此本题答案为A。 4.对于关系的主码必须满足的条件,有下列说法: Ⅰ.一个关系中的主码属性或属性组能函数决定该关系中的所有其他属性 Ⅱ.一个关系中的主码属性不能与其他关系中的主码属性重名 Ⅲ.在一个关系中,一个主码属性的任一真子集都不能函数决定其他属性
关系型数据库和非关系 型数据库 集团标准化办公室:[VV986T-J682P28-JP266L8-68PNN]
关系型数据库和非关系型数据库 自1970年,埃德加·科德提出关系模型之后,关系数据库便开始出现,经过了40多年的演化,如今的关系型数据库具备了强大的存储、维护、查询数据的能力。但在关系数据库日益强大的时候,人们发现,在这个信息爆炸的“大数据”时代,关系型数据库遇到了性能方面的瓶颈,面对一个表中上亿条的数据,SQL语句在大数据的查询方面效率欠佳。我们应该知道,往往添加了越多的约束的技术,在一定程度上定会拖延其效率。 在1998年,CarloStrozzi提出NOSQL的概念,指的是他开发的一个没有SQL功能,轻量级的,开源的关系型数据库。注意,这个定义跟我们现在对NoSQL的定义有很大的区别,它确确实实字如其名,指的就是“没有SQL”的数据库。但是NoSQL的发展慢慢偏离了初衷,CarloStrozzi也发觉,其实我们要的不是"nosql",而应该是"norelational",也就是我们现在常说的非关系型数据库了。 在关系型数据库中,导致性能欠佳的最主要因素是多表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询。为了保证数据库的ACID特性,我们必须尽量按照其要求的范式进行设计,关系型数据库中的表都是存储一些格式化的数据结构,每个元组字段的组成都一样,即使不是每个元组都需要所有的字段,但数据库会为每个元组分配所有的字段,这样的结构可以便于表与表之间进行连接等操作,但从另一个角度来说它也是关系型数据库性能瓶颈的一个因素。 非关系型数据库提出另一种理念,他以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。使用这种方式,用户可以根据需要去添加自己需要的字段,这样,为了获取用户的不同信息,不需要像关系型数据库中,要对多表进行关联查询。仅需要根据id取出相应的value就可以完成查询。但非关系型数据库由于很少的约束,他也不能够提供想SQL所提供的where这种对于字段属性值情况的查询。并且难以体现设计的完整性。他只适合存储一些较为简单的数据,对于需要进行较复杂查询的数据,SQL数据库显得更为合适。 目前出现的NoSQL(NotonlySQL,非关系型数据库)有不下于25种,除了Dynamo、Bigtable以外还有很多,比如Amazon的SimpleDB、微软公司的AzureTable、Facebook使用的Cassandra、类Bigtable的Hypertable、Hadoop的HBase、MongoDB、CouchDB、Redis以及Yahoo!的PNUTS等等。这些NoSQL各有特色,是基于不同应用场景而开发的,而其中以MongoDB和Redis最为被大家追捧。 以下是MongoDB的一些情况: MongoDB是基于文档的存储的(而非表),是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json 的bjson格式,因此可以存储比较复杂的数据类型。模式自由(schema-free),意味着对于存储在MongoDB数据库中的文件,我们不需要知道它的任何结构定义。如果需要的话,你完全可以把不同结构的文件存储在同一个数据库里。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数 据库单表查询的绝大部分功能,而且还支持对数据建立索引。 Mongo主要解决的是海量数据的访问效率问题。因为Mongo主要是支持海量数据存储的,所以Mongo还自带了一个出色的分布式文件系统GridFS,可以支持海量的数据存储。由于Mongo可以支持复杂的数据结构,而且带有强大的数据查询功能,因此非常受到欢迎。 关系型数据库的特点 1.关系型数据库
第四章关系数据库设计理论练习题 一、选择题 1、关系规范化中的删除操作异常是指①A,插入操作异常是指②D A、不该删除的数据被删除. B、不该插入的数据被插入; C、应该删除的数据未被删除; D、应该插入的数据未被插入. 2、关系数据库规范化是为解决关系数据库中()问题而引入的。 A、插入异常、删除异常和数据冗余; B、提高查询速度; C、减少数据操作的复杂性; D、保证数据的安全性和完整性。 3、假设关系模式R(A,B)属于3NF,下列说法中()是正确的。 A、R一定消除了插入和删除异常; B、R仍可能存在一定的插入和删除异常; C、R一定属于BCNF; D、A和C都是. 4、关系模式的分解 A、唯一 B、不唯一. 5、设有关系W(工号,姓名,工种,定额),将其规范化到第三范式正确的答案是() A、W1(工号,姓名),W2(工种,定额); B、W1(工号,工种,定额),W2(工号,姓名); C、W1(工号,姓名,工种),W2(工种,定额); D、以上都不对. 6、设学生关系模式为:学生(学号,姓名,年龄,性别,平均成绩,专业),则该关系模式的主键是() A、姓名; B、学号,姓名; C、学号; D、学号,姓名,年龄. 7根据数据库规范化理论,下面命题中正确的是() A、若R∈2NF,则R∈3NF B、若R∈1NF,则R不属于BCNF C、若R∈3NF,则R∈BCNF D、若R∈BCNF,则R∈3NF 8、关系数据库设计理论中,起核心作用的是 A、范式; B、模式设计; C、函数依赖; D、数据完整性. 9、设计性能较优的关系模设称为规范化,规范化的主要理论依据是() A、关系规范化理论; B、关系运算理论;
目录 一Codd的RDBMS12法则——RDBMS的起源 二关系型数据库设计阶段 三设计原则 四命名规则 数据库设计,一个软件项目成功的基石。很多从业人员都认为,数据库设计其实不那么重要。现实中的情景也相当雷同,开发人员的数量是数据库设计人员的数倍。多数人使用数据库中的一部分,所以也会把数据库设计想的如此简单。其实不然,数据库设计也是门学问。 从笔者的经历看来,笔者更赞成在项目早期由开发者进行数据库设计(后期调优需要DBA)。根据笔者的项目经验,一个精通OOP和ORM的开发者,设计的数据库往往更为合理,更能适应需求的变化,如果追其原因,笔者个人猜测是因为数据库的规范化,与OO的部分思想雷同(如内聚)。而DBA,设计的数据库的优势是能将DBMS的能力发挥到极致,能够使用SQL和DBMS实现很多程序实现的逻辑,与开发者相比,DBA优化过的数据库更为高效和稳定。如标题所示,本文旨在分享一名开发者的数据库设计经验,并不涉及复杂的SQL语句或DBMS使用,因此也不会局限到某种DBMS产品上。真切地希望这篇文章对开发者能有所帮助,也希望读者能帮助笔者查漏补缺。 一 Codd的RDBMS12法则——RDBMS的起源 Edgar Frank Codd(埃德加·弗兰克·科德)被誉为“关系数据库之父”,并因为在数据库管理系统的理论和实践方面的杰出贡献于1981年获图灵奖。在1985年,Codd 博士发布了12条规则,这些规则简明的定义出一个关系型数据库的理念,它们被作为所有关系数据库系统的设计指导性方针。 1. 信息法则关系数据库中的所有信息都用唯一的一种方式表示——表中的值。 2. 保证访问法则依靠表名、主键值和列名的组合,保证能访问每个数据项。 3. 空值的系统化处理支持空值(NULL),以系统化的方式处理空值,空值不依赖于数据类型。 4. 基于关系模型的动态联机目录数据库的描述应该是自描述的,在逻辑级别上和普通数据采用同样 的表示方式,即数据库必须含有描述该数据库结构的系统表或者数据库描述信息应该包含在用 户可以访问的表中。 5. 统一的数据子语言法则一个关系数据库系统可以支持几种语言和多种终端使用方式,但必须至少 有一种语言,它的语句能够一某种定义良好的语法表示为字符串,并能全面地支持以下所有规 则:数据定义、视图定义、数据操作、约束、授权以及事务。(这种语言就是SQL) 6. 视图更新法则所有理论上可以更新的视图也可以由系统更新。 7. 高级的插入、更新和删除操作把一个基础关系或派生关系作为单个操作对象处理的能力不仅适应 于数据的检索,还适用于数据的插入、修改个删除,即在插入、修改和删除操作中数据行被视 作集合。 8. 数据的物理独立性不管数据库的数据在存储表示或访问方式上怎么变化,应用程序和终端活动都 保持着逻辑上的不变性。 9. 数据的逻辑独立性当对表做了理论上不会损害信息的改变时,应用程序和终端活动都会保持逻辑 上的不变性。 10. 数据完整性的独立性专用于某个关系型数据库的完整性约束必须可以用关系数据库子语言定 义,而且可以存储在数据目录中,而非程序中。
1关系数据库中,主键的正确描述是(D )。 (A) 创建唯一的索引,允许空值(B) 允许有多个主键的 (C) 只允许以表中第一字段建立(D) 为标识表中唯一的实体 2以下不适合创建非聚集索引的情况是(A )。 (A) 表中包含大量重复的列值(B) 带WHERE子句的查询 (C) 经常需要进行联接和分组操作的列(D) 表中包含大量非重复的列值 3使用视图的作用有4个,下列哪一个是错误的(A )。 (A) 导入数据(B) 定制操作 (C) 简化操作(D) 安全性 4叙述A:当视图被撤消,不会对基表造成任何影响。叙述B:不能改变作为计算结果的列。关于对以上叙述中,正确的是(C )。 (A) 叙述A错误,叙述B正确(B) 叙述A正确,叙述B错误 (C) 都正确(D) 都是错误的 5语句:select 10%7 的执行结果是(D )。 (A) 7 (B) 1 (C) 70 (D) 3 6下列关于关联的叙述正确的是( D)。 (A) 已创建关联的两个表中的关联字段数据 可能完全不同(B) 可在两个表的不同数据类型的同名字段 间创建关联 (C) 可在两个表的不同数据类型的字段间创 建关联(D) 可在两个表的相同数据类型的不同名称 的字段间创建关联 7用UNION合并两个SELECT查询的结果时,下列叙述中错误的是()。 (A) 两个SELECT语句必须输出同样的列数(B) 将来自不同查询的数据组合起来 (C) 两个表各相应列的数据类型必须相同(D) 被组合的每个查询都可以使用ORDER B Y子句 8查询所有目前年龄在24岁以上(不含24岁)的学生信息(学号、姓名、年龄),正确的命令是()。 (A) SELECT 学号,姓名,年龄=YEAR(GETDA TE())-YEAR(出生日期) FROM 学生 WHE RE YEAR(GETDATE())-YEAR(出生日 期)>24 (B) SELECT 学号,姓名,YEAR(GETDATE())- YEAR(出生日期) 年龄 FROM 学生 WHE RE YEAR(GETDATE())-YEAR(出生日 期)>24
目录 一 Codd的RDBMS12法则——RDBMS的起源 二关系型数据库设计阶段 三设计原则 四命名规则 数据库设计,一个软件项目成功的基石。很多从业人员都认为,数据库设计其实不那么重要。现实中的情景也相当雷同,开发人员的数量是数据库设计人员的数倍。多数人使用数据库中的一部分,所以也会把数据库设计想的如此简单。其实不然,数据库设计也是门学问。 从笔者的经历看来,笔者更赞成在项目早期由开发者进行数据库设计(后期调优需要DBA)。根据笔者的项目经验,一个精通OOP和ORM的开发者,设计的数据库往往更为合理,更能适应需求的变化,如果追其原因,笔者个人猜测是因为数据库的规范化,与OO的部分思想雷同(如内聚)。而DBA,设计的数据库的优势是能将DBMS的能力发挥到极致,能够使用SQL和DBMS实现很多程序实现的逻辑,与开发者相比,DBA优化过的数据库更为高效和稳定。如标题所示,本文旨在分享一名开发者的数据库设计经验,并不涉及复杂的SQL语句或DBMS使用,因此也不会局限到某种DBMS产品上。真切地希望这篇文章对开发者能有所帮助,也希望读者能帮助笔者查漏补缺。 一?Codd的RDBMS12法则——RDBMS的起源 Edgar Frank Codd(埃德加·弗兰克·科德)被誉为“关系数据库之父”,并因为在数据库管理系统的理论和实践方面的杰出贡献于1981年获图灵奖。在1985年,Codd 博士发布了12条规则,这些规则简明的定义出一个关系型数据库的理念,它们被作为所有关系数据库系统的设计指导性方针。 1.信息法则?关系数据库中的所有信息都用唯一的一种方式表示——表中的值。 2.保证访问法则?依靠表名、主键值和列名的组合,保证能访问每个数据项。 3.空值的系统化处理?支持空值(NULL),以系统化的方式处理空值,空值不依赖于数据类型。 4.基于关系模型的动态联机目录?数据库的描述应该是自描述的,在逻辑级别上和普通数据采用同样 的表示方式,即数据库必须含有描述该数据库结构的系统表或者数据库描述信息应该包含在用 户可以访问的表中。 5.统一的数据子语言法则?一个关系数据库系统可以支持几种语言和多种终端使用方式,但必须至少 有一种语言,它的语句能够一某种定义良好的语法表示为字符串,并能全面地支持以下所有规 则:数据定义、视图定义、数据操作、约束、授权以及事务。(这种语言就是SQL) 6.视图更新法则?所有理论上可以更新的视图也可以由系统更新。 7.高级的插入、更新和删除操作?把一个基础关系或派生关系作为单个操作对象处理的能力不仅适应 于数据的检索,还适用于数据的插入、修改个删除,即在插入、修改和删除操作中数据行被视 作集合。 8.数据的物理独立性?不管数据库的数据在存储表示或访问方式上怎么变化,应用程序和终端活动都 保持着逻辑上的不变性。 9.数据的逻辑独立性?当对表做了理论上不会损害信息的改变时,应用程序和终端活动都会保持逻辑 上的不变性。 10.数据完整性的独立性?专用于某个关系型数据库的完整性约束必须可以用关系数据库子语言定 义,而且可以存储在数据目录中,而非程序中。
一,关系型数据库 关系型数据库,是指采用了关系模型来组织数据的数据库。 简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。 关系模型中常用的概念: ?关系:可以理解为一张二维表,每个关系都具有一个关系名,就是通常说的表名?元组:可以理解为二维表中的一行,在数据库中经常被称为记录 ?属性:可以理解为二维表中的一列,在数据库中经常被称为字段 ?域:属性的取值范围,也就是数据库中某一列的取值限制 ?关键字:一组可以唯一标识元组的属性,数据库中常称为主键,由一个或多个列组成 ?关系模式:指对关系的描述。其格式为:关系名(属性1,属性2, ... ... ,属性N),在数据库中成为表结构 关系型数据库的优点: ?容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解 ?使用方便:通用的SQL语言使得操作关系型数据库非常方便 ?易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率 二,范式,英文名称是 Normal Form,它是英国人 E.F.Codd(关系数据库的老祖宗)在上个世纪70年代提出关系数据库模型后总结出来的,范式是关系数据库理论的基础,也是我们在设计数据库结构过程中所要遵循的规则和指导方法,以下就是对这三个范式的基本介绍: 第一范式(1NF): 数据表中的每一列(字段),必须是不可拆分的最小单元,也就是确保每一列的原子性。
通俗解释:一个字段只存储一项信息 例如: userInfo: '山东省烟台市 1318162008' 依照第一范式必须拆分成: userInfo: '山东省烟台市' userTel: '1318162008'两个字段 第二范式(2NF): 满足1NF后要求表中的所有列,都必需依赖于主键,而不能有任何一列与主键没有关系(一个表只描述一件事情)。 通俗解释:任意一个字段都只依赖表中的同一个字段 例如: 订单表只能描述订单相关的信息,所以所有的字段都必须与订单ID相关。 产品表只能描述产品相关的信息,所以所有的字段都必须与产品ID相关。 因此在同一张表中不能同时出现订单信息与产品信息。 第三范式(3NF):第三范式(3NF):满足2NF后,要求:表中的每一列都要与主键直接相关,而不是间接相关(表中的每一列只能依赖于主键) 例如:订单表中需要有客户相关信息,在分离出客户表之后,订单表中只需要有一个用户ID即可,而不能有其他的客户信息,因为其他的用户信息是直接关联于用户ID,而不是关联于订单ID。 注意事项: 1.第二范式与第三范式的本质区别:在于有没有分出两张表。 第二范式是说一张表中包含了多种不同实体的属性,那么必须要分成多张表,第三范式是要求已经分好了多张表的话,一张表中只能有另一张标的ID,而不能有其他任何信息,(其他任何信息,一律用主键在另一张表中查询)。 2.必须先满足第一范式才能满足第二范式,必须同时满足第一第二范式才能满足第三范式。
图书销售 建立某中小型书店图书销售管理信息系统的数据库。 1. 基本需求分析 1)组织结构 对组织结构的分析有助于分析业务范围与业务流程。书店的组织结构如图三所示。 图三书店组织结构简图 其中,书库是保存图书的地方;购书/服务部负责采购计划、读者服务、图书预订等业务;售书部负责图书的销售。财务部负责资金管理;人事部负责员工管理与业务考核。 2)业务分析 对于信息处理系统来说,划分系统边界很重要,即哪些功能由计算机来完成,哪些工作在计算机外完成。这些要通过业务分析确定。同时,业务流程中涉及的相关数据也通过业务分析得到归类和明确。在业务分析的基础上,确定数据流图和数据字典。 本系统主要包含以下业务内容。 ①进书业务。事先采购员根据订书单采购图书。然后将图书入库,同时登记相应的图书入库数据。 本项业务涉及的数据单据和表格有:进书单(包括进书单编号、日期、金额、经手人等)和进书单细目(一个进书单可能有若干种图书。进书单的细目数据包括每种图书的信息、定价、进价或折扣,数量),以及书库账本(图书信息、库存数量、价格等)。 ②售书业务。售书员根据读者所购图书填写售书单(如图四所示)。同时,修改库存信息。
本项业务涉及和产生的数据表格有:售书单(包括售书单编号、售书日期、金额、员工)、售书细目(一个售书单可能有若干种图书。售书细目包括该次售书的书籍编号、售出数量、折扣、售出价格等),以及书库账本。 图四售书单样式 ③图书查询服务业务。根据读者要求,提供本书店特定的图书及库存信息。 本项业务涉及的主要数据是书库账本。 ④综合管理业务。包括进书信息、销售信息、库存信息的查询、汇总和报表输出。 本项业务涉及所有的进书数据、销售数据和库存数据等。 3)处理的数据 上面的分析将本系统的业务归纳为4项。在业务分析的基础上,应该画出系统的数据流图。整个系统的分层数据流图将揭示一个系统内全部的数据项、数据结构、数据存储以及对数据的加工处理功能。在此基础上就可以建立系统的数据字典。本书不讨论数据流图和完整的数据字典规范等内容,仅对最后建立数据库所需要的数据进行分析说明。 在上述4项业务中涉及到的业务数据包括:进书数据、库存数据、销售数据。在这些数据中又涉及到图书数据、员工数据等,而图书数据与出版社有关,员工与部门有关。 因此,将所有数据进行归类分析,书店销售管理信息系统要处理的数据应该包括:
第4章关系数据库设计理论 选择题答案: (1) A (2) B (3) B (4) A (5) D (6) B (7) C (8) B (9) B (10) C (11) D (12) A (13) D (14) D (15) B (16) B (17) D (20) C (21) C (23) A (26) B (27) B (28) B (29) B (30) B (31) D (33) B B D 一、选择题: 1. 为了设计出性能较优的关系模式,必须进行规范化,规范化主要的理论依据是()。 A. 关系规范化理论 B. 关系代数理论C.数理逻辑 D. 关系运算理论 2. 规范化理论是关系数据库进行逻辑设计的理论依据,根据这个理论,关系数据库中的关系必须满足:每一个属性都是()。 A. 长度不变的 B. 不可分解的 C.互相关联的 D. 互不相关的 3. 已知关系模式R(A,B,C,D,E)及其上的函数相关性集合F={A→D,B→C ,E→A },该关系模式的候选关键字是()。 A.AB B. BE C.CD D. DE 4. 设学生关系S(SNO,SNAME,SSEX,SAGE,SDPART)的主键为SNO,学生选课关系SC(SNO,CNO,SCORE)的主键为SNO和CNO, 则关系R(SNO,CNO,SSEX,SAGE,SDPART,SCORE)的主键为SNO和CNO,其满足()。 A. 1NF B.2NF C. 3NF D. BCNF 5. 设有关系模式W(C,P,S,G,T,R),其中各属性的含义是:C表示课程,P表示教师,S表示学生,G表示成绩,T表示时间,R表示教室,根据语义有如下数据依赖集:D={ C→P,(S,C)→G,(T,R)→C,(T,P)→R,(T,S)→R },关系模式W的一个关键字是()。 A. (S,C) B. (T,R) C. (T,P) D. (T,S) 6. 关系模式中,满足2NF的模式()。 A. 可能是1NF B. 必定是1NF C. 必定是3NF D. 必定是BCNF 7. 关系模式R中的属性全是主属性,则R的最高范式必定是()。 A. 1NF B. 2NF C. 3NF D. BCNF 8. 消除了部分函数依赖的1NF的关系模式,必定是()。 A. 1NF B. 2NF C. 3NF D. BCNF 9. 如果A->B ,那么属性A和属性B的联系是()。 A. 一对多 B. 多对一C.多对多 D. 以上都不是 10. 关系模式的候选关键字可以有1个或多个,而主关键字有()。 A. 多个 B. 0个 C. 1个 D. 1个或多个 11. 候选关键字的属性可以有()。 A. 多个 B. 0个 C. 1个 D. 1个或多个 12. 关系模式的任何属性()。 A. 不可再分 B. 可以再分 C. 命名在关系模式上可以不唯一 D. 以上都不是 13. 设有关系模式W(C,P,S,G,T,R),其中各属性的含义是:C表示课程,P表示教师,S表示学生,G表示成绩,T表示时间,R表示教室,根据语义有如下数据依赖集:D={ C→P,(S,C)→G,(T,R)→C,(T,P)→R,(T,S)→R },若将关系模式W分解为三个关系
数据库中表之间的关系 表关系(一对一,一对多,多对多) 收藏 可以在数据库图表中的表之间创建关系,以显示一个表中的列与另一个表中的列是如何相链接的。 在一个关系型数据库中,利用关系可以避免多余的数据。例如,如果设计一个可以跟踪图书信息的数据库,您需要创建一个名为 titles 的表,它用来存储有关每本书的信息,例如书名、出版日期和出版社。您也可能保存有关出版社的信息,诸如出版社的电话、地址和邮政编码。如果您打算在 titles 表中保存所有这些信息,那么对于某出版社出版的每本书都会重复该出版社的电话号码。 更好的方法是将有关出版社的信息在单独的表,publishers,中只保存一次。然后可以在 titles 表中放置一个引用出版社表中某项的指针。 为了确保您的数据同步,可以实施 titles 和 publishers 之间的参照完整性。参照完整性关系可以帮助确保一个表中的信息与另一个表中的信息相匹配。例如,titles 表中的每个书名必须与 publishers 表中的一个特定出版社相关。如果在数据库中没有一个出版社的信息,那么该出版社的书名也不能添加到这个数据库中。 为了更好地理解表关系,请参阅: 定义表关系 实施参照完整性 定义表关系 关系的确立需要通过匹配键列中的数据(通常是两表中同名的列)。在大多数情况下,该关系会将一个表中的主键(它为每行提供了唯一标识)与另一个表的外部键中的某项相匹配。例如,通过创建 titles 表中的 title_id(主键)与 sales 表中的 title_id 列(外部键)之间的关系,则销售额就与售出的特定书名相关联了。 表之间有三种关系。所创建关系的类型取决于相关列是如何定义的。 一对多关系 多对多关系
数据库设计实例 数据库设计是数据库应用系统设计的一个组成部分,其核心是针对于特定的应用环境,设计合理的数据模型,创建数据库及其应用系统,使之能够有效地存储和处理数据,以满足用户的应用需求。从实用角度出发,数据库设计可分为如下几个步骤: 第一步:创建概念数据模型 ◆确定实体和关系 ◆确定属性 ◆规化数据 第二步:生成物理数据模型 第三步:验证设计 为便于学习者理解和掌握,下面结合具体的实例来讲解和展示数据库设计的详细过程。假定我们要开发一个小型的ERP系统,以管理公司部资源,其应用业务场景描述如下: v512工作室由IT业界专业人士组成,在提供高端IT培训业务的同时,还自主制作并免费发布大量公益性学习资源,工作室以公司形式运营,目前共拥有18名员工,这些员工分属于4个部门,且员工之间存在上下级管理关系。计划将来根据业务的发展设立更多的部门,聘用更多的员工。为保证质量,工作室对其成员的各项专业技能进行了级别评定。 8.5.1 确定实体和关系 1. 确定高级别的活动 要确定本ERP系统数据库设计中的实体和实体间关系,首先应明确要基于该数据库执行的高级别活动,这里所谓的高级别活动是指从用户的视角出发,确定本数据库设计中系统所涉及到的业务活动。比如,存储和维护员工的个人信息等。 在前述的应用业务场景中,v512工作室需要考虑的高级别活动包括: -聘用新员工 -解雇现有员工 -维护员工的个人信息 -增设新部门 -裁撤现有部门 -维护部门信息 -维护工作室业务相关的技能信息 -维护各员工的业务技能掌握情况 2. 确定实体 接下来要确定的是,针对上述的高级别活动需要记录和维护有关哪些事物的信息,这些事物将被转换为实体。其中,员工相关信息可抽象为“Employee”实体、部门相关信息可抽象为“Department”实体、技能相关信息抽象为“Skill”实体,为规和方便起见,这些实体均采用英文命名,并尽量在名称中体现其含义。 3. 确定关系 进一步对上述高级活动进行分析,以确定实体间存在何种关系。具体包括: -Employee-Department实体之间存在隶属关系 员工必须且只能隶属于某一个特定的部门,一个部门可以包含0~多名员工,此为一对多关系。 这种从两个方向上对同一个关系的细化描述被称为关系的角色,每个关系都对应两种角色。
简析关系型数据库系统的设计方法 1系统总体设计 面向关系数据库的关键字查询系统主要有五部分组成,首先要分析输入的关键字,有几个关键字组成;然后调用全文索引,查看这些关键字所属,是表名、属性名还是属性值;接下来查询数据库的模式图,从而得到几种可能的元组连接树;最后将相应元组连接树转化成SQ L 语句查询关系数据库,生成查询结果,以二维表格形式显示。 2数据库设计 本系统为面向关系数据库的关键字查询系统,在实验中本文选取了M D B数据集,为了进行实验,将数据集整理为以下七个表数据结构。实验数据集(电影信息数据库):Actor(演员表),Consume(设计师),Director(导演信息),Busness股资),Edito r(编辑),Color(颜色信息),Keyw ord(关键词)。 3数据库索引设计 在关系型数据库中,例如0 racl,DB2,SQ L Server和M ySQ L等都提供了对关键字查询的扩展,可以为数据库的表属性建立全文索引,这为实现关系数据库的关键字查询提供了基础。已有多个关系数据库的关键字查询系统被开发出来,BANKS ,D ISCO VER,IR-style,SEKKER 等等。然而在已有的系统中,多数系统仅仅支持数据库中文本属性的查询,却忽略了对数据库中元数据的处理。如果用户给定的查询关键字是数据库中的元数据,则有些系统就不能够满足用户的查询需求,
或者查询结果不够精确,返回大量与查询不相关的结果。SEKKER虽然提出了支持数字属性和元数据的查询,但是却在查询语言上做了限定,只能通过给定的查询语言格式进行查询,所以系统的灵活性不高。 4数据库模式图的构建 在关系数据库中,关键字是通过主外键进行连接的,因此关系数据库采用的数据模型,即为基于模式图建模。模式图的节点对应数据库中的关系,边表示关系间的主外键约束。 模式图(Schem a Graph,GS)是将关系数据库的模式信息定义为模式图GS(V,E),其中V表示模式图中的节点,与数据库中的关系一一对应,E表示模式图中的边,将具有主外码约束相对应的关系连接起来,关系R;和关系R中的主外键关系对应模式图一条边R -R, 本文数据库对应的数据库模式图如图 3所示。 5关键字检索设计 关键字检索技术主要是,通过分析用户输入的关键字所属类型来确定元组连接树,从而转换成相应的SQ L语句来查询关系数据库。如果用户输入的关键字都是表名,则将几个表自然连接后输出即可;若用户输入的关键字有表名、属性名,那么将属性列加到表中输出就是用户所检索的内容;若用户输入的关键字中有属性值,则将属性值对应属性与表或属性列连接,根据属性值对应元组来显示查询结果。由此可见,对于相同的关键字,如果它不止一种所属值,那么它就会对应不同的SQ L语句。
数据库课程设计报告 教学管理系统 数据库设计 课程设计题目教学管理系统学院软件学院 班级软件技术四班年级2013级 姓名彭超李新徐彤(2014 年11月)
用5行左右的文字对系统进行简要介绍 对教学管理信息统一规范整理,实现各种信息的自动管理。为便于信息的查询,找出各种信息的关联性,根据各种需求设计出合理的报表。 减轻教学日常信息管理的负担,方便学生、教师查询信息和学校对所有信息的管理。以简单便捷的操作获取详尽的信息。 一、数据需求分析 某学校设计学生教学管理系统。学生实体包括学号、姓名、性别、生日、民族、籍贯、简历、登记照,每名学生选择一个主修专业,专业包括专业编号、名称和类别,一个专业属于一个学院,一个学院可以有若干个专业。学院信息要存储学院号、学院名、院长。教学管理还要管理课程表和学生成绩。课程表包括课程号、课程名、学分,每门课程由一个学院开设。学生选修的每门课程获得一个成绩。另外,为了管理教师教学安排,教师包括编号、姓名、年龄、职称,一个教师只能属于一个学院,一名教师可以上若干门课程,一门课程可以有多名老师来上,每个教师所上的每门课都有一个课堂号和课时数。 本系统数据字典如下: 数据项表
数据流 数据流表 二、概念结构设计 1.首先确定系统中的实体 从以上数据需求可以看出,系统共包括5个实体:学生、专业、学院、教师、课程。
2.再确定系统中实体间的关系 根据数据需求描述推出:专业与学生是1对多关系;学生与课程是多对多关系;课程与老师是多对多关系;课程与学院是多对1关系;学院与专业是1对多关系;学院与教师是1对多关系。 3.转化成E-R图 图1 实体-属性图 图2 教学管理ER图 三、逻辑结构设计
关系型数据库和非关系型数据库 自1970年,埃德加·科德提出关系模型之后,关系数据库便开始出现,经过了40多年的演化,如今的关系型数据库具备了强大的存储、维护、查询数据的能力。但在关系数据库日益强大的时候,人们发现,在这个信息爆炸的“大数据”时代,关系型数据库遇到了性能方面的瓶颈,面对一个表中上亿条的数据,SQL语句在大数据的查询方面效率欠佳。我们应该知道,往往添加了越多的约束的技术,在一定程度上定会拖延其效率。 在1998年,Carlo Strozzi提出NOSQL的概念,指的是他开发的一个没有SQL功能,轻量级的,开源的关系型数据库。注意,这个定义跟我们现在对NoSQL的定义有很大的区别,它确确实实字如其名,指的就是“没有SQL”的数据库。但是NoSQL的发展慢慢偏离了初衷,CarloStrozzi也发觉,其实我们要的不是"nosql",而应该是"norelational",也就是我们现在常说的非关系型数据库了。 在关系型数据库中,导致性能欠佳的最主要因素是多表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询。为了保证数据库的ACID特性,我们必须尽量按照其要求的范式进行设计,关系型数据库中的表都是存储一些格式化的数据结构,每个元组字段的组成都一样,即使不是每个元组都需要所有的字段,但数据库会为每个元组分配所有的字段,这样的结构可以便于表与表之间进行连接等操作,但从另一个角度来说它也是关系型数据库性能瓶颈的一个因素。 非关系型数据库提出另一种理念,他以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。使用这种方式,用户可以根据需要去添加自己需要的字段,这样,为了获取用户的不同信息,不需要像关系型数据库中,要对多表进行关联查询。仅需要根据id取出相应的value就可以完成查询。但非关系型数据库由于很少的约束,他也不能够提供想SQL所提供的where这种对于字段属性值情况的查询。并且难以体现设计的完整性。他只适合存储一些较为简单的数据,对于需要进行较复杂查询的数据,SQL数据库显得更为合适。 目前出现的NoSQL(Not only SQL,非关系型数据库)有不下于25种,除了Dynamo、Bigtable以外还有很多,比如Amazon的SimpleDB、微软公司的AzureTable、Facebook使用的Cassandra、类Bigtable的Hypertable、Hadoop的HBase、MongoDB、CouchDB、Redis以及Yahoo!的PNUTS等等。这些NoSQL各有特色,是基于不同应用场景而开发的,而其中以MongoDB和Redis最为被大家追捧。 以下是MongoDB的一些情况: MongoDB是基于文档的存储的(而非表),是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型。模式自由(schema-free),意味着对于存储在MongoDB数据库中的文件,我们不需要知道它的任何结构定义。如果需要的话,你完全可以把不同结构的文件存储在同一个数据库里。Mongo最大的特点是他支持的查询语言非常强大,
114801班 数据库综合题设计实例 一、问题描述:某集团公司拥有多个大型连锁商场,公司需要构建一个数据库系统以方便管理其业务运作活动 ? 需求分析结果: ? 1、商场需要记录的信息包括:商场编号(编号唯一)、商场名称、地址和联系电话; ? 2、每个商场包含有不同的部门,部门需要记录的信息包括:部门编号(编号唯一)、 部门名称、位置分布和联系电话; ? 3、每个部门雇佣多名员工处理日常事务,每个员工只能隶属于一个部门,员工需 要记录的信息包括:员工编号(编号唯一)、姓名、岗位、电话号码和工资; ? 4、每个部门的员工中有一名是经理,每个经理只能管理一个部门,系统需要记录 每个经理的任职时间。 1、E-R 图 2、关系模式 ? 商场(商场编号,商场名称,地址,联系电话) ? 部门(部门编号,部门名称,位置分布,联系电话,商场编号) – 外键:商场编号 ? 员工(员工编号,员工姓名,岗位,电话号码,工资,部门编号) – 外键:部门编号 ? 经理(员工编号,任职时间) – 外键:员工编号 ? 为使商场有紧急任务时能联系到轮休的员工,要求每位员工必须登记且只能登记一 位紧急联系人的姓名和联系电话,不同的员工可以登记相同的紧急联系人,则在E-R 图中还需添加的实体是什么?该实体和图中的员工存在什么样的联系(联系类型)。给出该实体的关系模式。 ? 紧急联系人,1:n 商场 经理 部门 员工 联系1 联系2 联系3 联系4 1 m n 1 m 1 1 1
? 紧急联系人(员工编号,姓名,联系电话) 二、问题描述:某公司拟开发一多用户电子邮件客户端系统,部分功能的初步需求分析结果如下: ? (1)邮件客户端系统支持多个用户,用户的信息主要包括用户名和用户密码,且 系统的用户名不可重复。 ? (2)邮件帐号信息包括邮件地址及其相应的密码,一个用户可以拥有多个邮件地 址。 ? (3)一个用户可以拥有一个地址簿,地址簿信息包括联系人编号、姓名、电话、 单位地址、邮件地址1、邮件地址2、邮件地址3等信息。地址簿中的一个联系人只能属于一个用户,且联系人编号唯一标识一个联系人。 ? (4)一个邮件帐号可以含有多封邮件,一封邮件可以含有多个附件。邮件主要包 括邮件号、发件人地址、收件人地址、邮件状态、邮件主题、邮件内容、发送时间、接收时间。其中邮件号在整个系统内唯一标识一封邮件,邮件状态有已接收、待发送、已发送和已删除4种,分别表示邮件是属于收件箱、发件箱、已发送箱和废件箱。一封邮件可以发给多个用户。附件信息主要包括附件号、附件文件名、附件大小。一个附件只属于一封邮件,附件号仅在一封邮件内唯一。 2、E-R 图 3、关系模式 ? 用户(用户名,用户密码) ? 地址簿(用户名,联系人编号,姓名,电话,单位地址,邮件地址1,邮件地址2, 邮件地址3) – 外键:用户名 ? 邮件帐号(邮件地址,邮件密码,用户名) – 外键:用户名 ? 邮件(邮件号,发件人地址,收件人地址,邮件状态,邮件主题,邮件内容,发送 时间,接收时间) – 外键:发件人地址,收件人地址 ? 附件(邮件号,附件号,附件文件名,附件大小) – 外键:邮件号 地址簿 邮件帐 邮 件 附 件 用 户 拥有1 拥有2 属于 包含 1 1 1 m 1 1 m m