
零售促销(神经网络/C&RT)
此示例使用数据来说明零售产品线和促销对销售的影响。(此数据纯为虚构。)此示例的目的在于预测未来促销活动的影响。与条件监视示例类似,数据挖掘过程包括探索、数据准备、训练和检验阶段。
此示例使用名称为 goods.str、goodsplot.str 和 goodslearn.str 的流,这些流流引用名称为 GOODS1n 和 GOODS2n 的数据文件。可以从任何 Clementine Client 安装软件的 Demos 目录下找到这些文件,也可以通过从 Windows 的开始菜单下选择 Start > [All] Programs > SPSS Clementine 11.1 > Demos 来访问这些文件。goods.str 和 goodsplot.str 文件在 Base_Module 文件夹中,goodslearn.str 文件则在Classification_Module 目录中。
每条记录含有:
? Class.模型类型。
? Cost.单价。
? Promotion.特定促销上所花费金额的指数。
? Before.促销之前的收入。
? After.促销之后的收入。
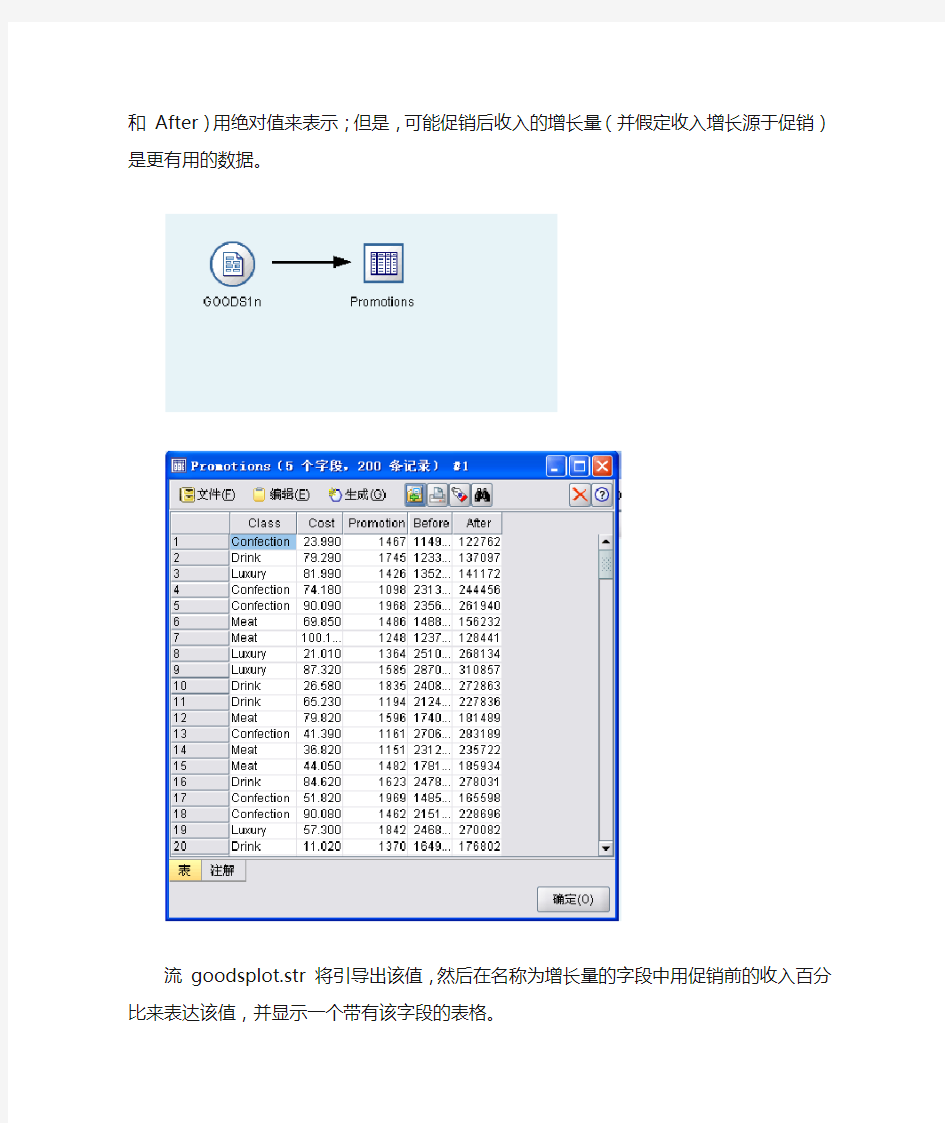
流 goods.str 含有一个用于在表格中显示数据的简单流。两个收入字段(即Before 和 After)用绝对值来表示;但是,可能促销后收入的增长量(并假定收入增长源于促销)是更有用的数据。
流 goodsplot.str 将引导出该值,然后在名称为增长量的字段中用促销前的收入百分比来表达该值,并显示一个带有该字段的表格。
另外,流将显示一个增长量的直方图和一个以促销费用为参照的增长量的散点图,产品的各个类别的散点图将叠放在一起。
散点图显示对于每类产品,收入增长量和促销费用之间存在几乎线性的关系。因此,决策树或神经网络似乎可以合理和准确地预测其他可用字段上的收入增长量。
流 goodslearn.str 将训练神经网络和决策树,以对收入增长量做出预测。
执行模型节点和生成实际模型之后,即可检验学习过程的效果。检验方法如下:将“类型”节点和新“分析”节点之间的决策树和网络串联起来,接着将输入(数据)文件更改为 GOODS2n,然后执行“分析”节点。按照此节点的输出数据,
特别是按照预测的增长量与正确答案之间的线性相关进行判断,可以发现已训练系统对收入增长量的预测成功率颇高。
进一步的探索应该集中在那些与已训练系统的预测有较大差别的案例上;通过收入的预测增长量与真实增长量的对比图,可标识出这些案例。可使用 Clementine 的迭代图来选择图上的离群值,而依据离群值的属性,通过调整数据说明和学习过程,提高预测的准确性将成为可能。
深度神经网络及目标检测学习笔记 https://youtu.be/MPU2HistivI 上面是一段实时目标识别的演示,计算机在视频流上标注出物体的类别,包括人、汽车、自行车、狗、背包、领带、椅子等。 今天的计算机视觉技术已经可以在图片、视频中识别出大量类别的物体,甚至可以初步理解图片或者视频中的内容,在这方面,人工智能已经达到了3岁儿童的智力水平。这是一个很了不起的成就,毕竟人工智能用了几十年的时间,就走完了人类几十万年的进化之路,并且还在加速发展。 道路总是曲折的,也是有迹可循的。在尝试了其它方法之后,计算机视觉在仿生学里找到了正确的道路(至少目前看是正确的)。通过研究人类的视觉原理,计算机利用深度神经网络(Deep Neural Network,NN)实现了对图片的识别,包 括文字识别、物体分类、图像理解等。在这个过程中,神经元和神经网络模型、大数据技术的发展,以及处理器(尤其是GPU)强大的算力,给人工智能技术 的发展提供了很大的支持。 本文是一篇学习笔记,以深度优先的思路,记录了对深度学习(Deep Learning)的简单梳理,主要针对计算机视觉应用领域。 一、神经网络 1.1 神经元和神经网络 神经元是生物学概念,用数学描述就是:对多个输入进行加权求和,并经过激活函数进行非线性输出。 由多个神经元作为输入节点,则构成了简单的单层神经网络(感知器),可以进行线性分类。两层神经网络则可以完成复杂一些的工作,比如解决异或问题,而且具有非常好的非线性分类效果。而多层(两层以上)神经网络,就是所谓的深度神经网络。 神经网络的工作原理就是神经元的计算,一层一层的加权求和、激活,最终输出结果。深度神经网络中的参数太多(可达亿级),必须靠大量数据的训练来“这是苹在父母一遍遍的重复中学习训练的过程就好像是刚出生的婴儿,设置。.果”、“那是汽车”。有人说,人工智能很傻嘛,到现在还不如三岁小孩。其实可以换个角度想:刚出生婴儿就好像是一个裸机,这是经过几十万年的进化才形成的,然后经过几年的学习,就会认识图片和文字了;而深度学习这个“裸机”用了几十年就被设计出来,并且经过几个小时的“学习”,就可以达到这个水平了。 1.2 BP算法 神经网络的训练就是它的参数不断变化收敛的过程。像父母教婴儿识图认字一样,给神经网络看一张图并告诉它这是苹果,它就把所有参数做一些调整,使得它的计算结果比之前更接近“苹果”这个结果。经过上百万张图片的训练,它就可以达到和人差不多的识别能力,可以认出一定种类的物体。这个过程是通过反向传播(Back Propagation,BP)算法来实现的。 建议仔细看一下BP算法的计算原理,以及跟踪一个简单的神经网络来体会训练的过程。
[关闭] 零基础入门深度学习(5) - 循环神经网络 机器学习深度学习入门 无论即将到来的是大数据时代还是人工智能时代,亦或是传统行业使用人工智能在云上处理大数据的时代,作为一个有理想有追求的程序员,不懂深度学习(Deep Learning)这个超热的技术,会不会感觉马上就out了?现在救命稻草来了,《零基础入门深度学习》系列文章旨在讲帮助爱编程的你从零基础达到入门级水平。零基础意味着你不需要太多的数学知识,只要会写程序就行了,没错,这是专门为程序员写的文章。虽然文中会有很多公式你也许看不懂,但同时也会有更多的代码,程序员的你一定能看懂的(我周围是一群狂热的Clean Code程序员,所以我写的代码也不会很差)。 文章列表 零基础入门深度学习(1) - 感知器 零基础入门深度学习(2) - 线性单元和梯度下降 零基础入门深度学习(3) - 神经网络和反向传播算法 零基础入门深度学习(4) - 卷积神经网络 零基础入门深度学习(5) - 循环神经网络 零基础入门深度学习(6) - 长短时记忆网络(LSTM) 零基础入门深度学习(7) - 递归神经网络 往期回顾 在前面的文章系列文章中,我们介绍了全连接神经网络和卷积神经网络,以及它们的训练和使用。他们都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列;当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。这时,就需要用到深度学习领域中另一类非常重要神经网络:循环神经网络(Recurrent Neural Network)。RNN种类很多,也比较绕脑子。不过读者不用担心,本文将一如既往的对复杂的东西剥茧抽丝,帮助您理解RNNs以及它的训练算法,并动手实现一个循环神经网络。 语言模型 RNN是在自然语言处理领域中最先被用起来的,比如,RNN可以为语言模型来建模。那么,什么是语言模型呢? 我们可以和电脑玩一个游戏,我们写出一个句子前面的一些词,然后,让电脑帮我们写下接下来的一个词。比如下面这句:我昨天上学迟到了,老师批评了____。 我们给电脑展示了这句话前面这些词,然后,让电脑写下接下来的一个词。在这个例子中,接下来的这个词最有可能是『我』,而不太可能是『小明』,甚至是『吃饭』。 语言模型就是这样的东西:给定一个一句话前面的部分,预测接下来最有可能的一个词是什么。 语言模型是对一种语言的特征进行建模,它有很多很多用处。比如在语音转文本(STT)的应用中,声学模型输出的结果,往往是若干个可能的候选词,这时候就需要语言模型来从这些候选词中选择一个最可能的。当然,它同样也可以用在图像到文本的识别中(OCR)。 使用RNN之前,语言模型主要是采用N-Gram。N可以是一个自然数,比如2或者3。它的含义是,假设一个词出现的概率只与前面N个词相关。我
第九章神经网络与遗传算法习题参考解答 9.1练习题 9.1 何谓人工神经网络?它有哪些特征? 9.2 生物神经元由哪几部分构成?每一部分的作用是什么?它有哪些特性? 9.3 什么是人工神经元?它有哪些连接方式? 9.4 B-P算法的网络结构是什么?简述B-P算法的学习过程。 9.5 什么是网络的稳定性? Hopfield网络模型分为哪两类?两者的区别是什么? 9.6 有教师学习与无教师学习的区别是什么? 请分析说明。 9.7 Hopfield模型与B-P模型的网络结构有何异同? 9.8 简述简单遗传算法的基本原理和一般过程,说明个体选择的常用策略,以及遗传操作“交叉”和“变异”所起的作用。 9.9 遗传算法有哪些特点?在应用遗传算法时要解决的最关键问题有哪些? 9.2习题参考解答 9.1 答: (略) 9.2 答: 生物神经元主要由三部分构成:细胞体、轴突和树突。 每一部分的作用是:(a)细胞体是神经元的新陈代谢中心,同时还用于接收并处理从其他神经元传递过来的信息。(b)轴突的作用相当于神经元的输出电缆,它通过尾部分出的许多神经末梢以及梢端的突触向其他神经元输出神经冲动。(c)树突的相当于神经元的输入端,用于接收从四面八方传来的神经冲动。 神经元的功能特性包括:(a)时空整合功能。(b)神经元的动态极化性。(c)兴奋与抑制状态。(d)结构的可塑性。(e)脉冲与电位信号的转换。(f)突触延期和不应期。(g)学习、遗忘和疲劳。 9.3 答: (略) 9.4 答: B-P算法的网络结构是一个前向多层网络。网络中不仅含有输入节点和输出节点,而且含有一层或多层隐(层)节点,网络中各处理单元间的连接如图6.16所示。当有信息向网络输入时,信息首先由输入层传递到隐层节点,经特性函数(人工神经元)作用后,再
吴恩达深度学习课程:神经网络和深度学习[中英文字幕+ppt课件] 内容简介 吴恩达(Andrew Ng)相信大家都不陌生了。2017年8 月8 日,吴恩达在他自己创办的在线教育平台Coursera 上线了他的人工智能专项课程(Deep Learning Specialization)。此课程广受好评,通过视频讲解、作业与测验等让更多的人对人工智能有了了解与启蒙,国外媒体报道称:吴恩达这次深度学习课程是迄今为止,最全面、系统和容易获取的深度学习课程,堪称普通人的人工智能第一课。 关注微信公众号datayx 然后回复“深度学习”即可获取。 第一周深度学习概论: 学习驱动神经网络兴起的主要技术趋势,了解现今深度学习在哪里应用、如何应用。 1.1 欢迎来到深度学习工程师微专业 1.2 什么是神经网络? 1.3 用神经网络进行监督学习 1.4 为什么深度学习会兴起? 1.5 关于这门课
1.6 课程资源 第二周神经网络基础: 学习如何用神经网络的思维模式提出机器学习问题、如何使用向量化加速你的模型。 2.1 二分分类 2.2 logistic 回归 2.3 logistic 回归损失函数 2.4 梯度下降法 2.5 导数 2.6 更多导数的例子 2.7 计算图 2.8 计算图的导数计算 2.9 logistic 回归中的梯度下降法 2.10 m 个样本的梯度下降 2.11 向量化 2.12 向量化的更多例子 2.13 向量化logistic 回归 2.14 向量化logistic 回归的梯度输出 2.15 Python 中的广播 2.16 关于python / numpy 向量的说明 2.17 Jupyter / Ipython 笔记本的快速指南 2.18 (选修)logistic 损失函数的解释 第三周浅层神经网络:
深度神经网络全面概述从基本概念到实际模型和硬件基础 深度神经网络(DNN)所代表的人工智能技术被认为是这一次技术变革的基石(之一)。近日,由IEEE Fellow Joel Emer 领导的一个团队发布了一篇题为《深度神经网络的有效处理:教程和调研(Efficient Processing of Deep Neural Networks: A Tutorial and Survey)》的综述论文,从算法、模型、硬件和架构等多个角度对深度神经网络进行了较为全面的梳理和总结。鉴于该论文的篇幅较长,机器之心在此文中提炼了原论文的主干和部分重要内容。 目前,包括计算机视觉、语音识别和机器人在内的诸多人工智能应用已广泛使用了深度神经网络(deep neural networks,DNN)。DNN 在很多人工智能任务之中表现出了当前最佳的准确度,但同时也存在着计算复杂度高的问题。因此,那些能帮助DNN 高效处理并提升效率和吞吐量,同时又无损于表现准确度或不会增加硬件成本的技术是在人工智能系统之中广泛部署DNN 的关键。 论文地址:https://https://www.doczj.com/doc/e2180302.html,/pdf/1703.09039.pdf 本文旨在提供一个关于实现DNN 的有效处理(efficient processing)的目标的最新进展的全面性教程和调查。特别地,本文还给出了一个DNN 综述——讨论了支持DNN 的多种平台和架构,并强调了最新的有效处理的技术的关键趋势,这些技术或者只是通过改善硬件设计或者同时改善硬件设计和网络算法以降低DNN 计算成本。本文也会对帮助研究者和从业者快速上手DNN 设计的开发资源做一个总结,并凸显重要的基准指标和设计考量以评估数量快速增长的DNN 硬件设计,还包括学界和产业界共同推荐的算法联合设计。 读者将从本文中了解到以下概念:理解DNN 的关键设计考量;通过基准和对比指标评估不同的DNN 硬件实现;理解不同架构和平台之间的权衡;评估不同DNN 有效处理技术的设计有效性;理解最新的实现趋势和机遇。 一、导语 深度神经网络(DNN)目前是许多人工智能应用的基础[1]。由于DNN 在语音识别[2] 和图像识别[3] 上的突破性应用,使用DNN 的应用量有了爆炸性的增长。这些DNN 被部署到了从自动驾驶汽车[4]、癌症检测[5] 到复杂游戏[6] 等各种应用中。在这许多领域中,DNN 能够超越人类的准确率。而DNN 的出众表现源于它能使用统计学习方法从原始感官数据中提取高层特征,在大量的数据中获得输入空间的有效表征。这与之前使用手动提取特征或专家设计规则的方法不同。 然而DNN 获得出众准确率的代价是高计算复杂性成本。虽然通用计算引擎(尤其是GPU),已经成为许多DNN 处理的砥柱,但提供对DNN 计算更专门化的加速方法也越来越热门。本文的目标是提供对DNN、理解DNN 行为的各种工具、有效加速计算的各项技术的概述。 该论文的结构如下:
对如下的BP 神经网络,学习系数1=η,各点的阈值0=θ。作用函数为: ? ? ?<≥=111 )(x x x x f 。 输入样本0,121==x x ,输出节点z 的期望输出为1,对于第k 次学习得到的权值分别为1)(,1)(,1)(,2)(,2)(,0)(2122211211======k T k T k w k w k w k w ,求第k 次和1+k 次学习得到的输出节点值)(k z 和)1(+k z (写出计算公式和计算过程)。 y 2 )(11=k w 1)(22=k 102 计算如下: 1. 第k 次训练的正向过程如下: 1 )0()0210()()(12 1 11==?+?==-=∑=f f net f x w f y j j j θ ) ()(i j i j ij i net f x w f y =-=∑θ
2 )2()0112()()(22 1 22==?+?==∑==f f net f x w f y j j j 3 )3()2111()()(2 1 ==?+?==∑==f f net f y T f z l i i i 2)31(2 12 =-=E 2. 第k 次训练的反向过程如下: 212)3()31()(')(''-=?-=?-=-=f net f z z l l δ li l l i i T net f ∑=δδ)('' 1)2(01)2()0(')(''111=?-?=?-?==f T net f l δδ 2 1)2(11)2()2(')(''222-=?-?=?-?==f T net f l δδ 1 1)2(11)()()1(11111-=?-?+=+=?+=+y k T T k T k T l ηδ 3 2)2(11)()()1(22222-=?-?+=+=?+=+y k T T k T k T l ηδ 1010')()()1(111111 1111=??+=+=?+=+x k W W k W k W ηδ ) ()(l i l i li l net f y T f O =-=∑θ
深度神经网络及目标检测学习笔记 https://youtu.be/MPU2HistivI 上面是一段实时目标识别的演示,计算机在视频流上标注出物体的类别,包括人、汽车、自行车、狗、背包、领带、椅子等。 今天的计算机视觉技术已经可以在图片、视频中识别出大量类别的物体,甚至可以初步理解图片或者视频中的内容,在这方面,人工智能已经达到了3岁儿童的智力水平。这是一个很了不起的成就,毕竟人工智能用了几十年的时间,就走完了人类几十万年的进化之路,并且还在加速发展。 道路总是曲折的,也是有迹可循的。在尝试了其它方法之后,计算机视觉在仿生学里找到了正确的道路(至少目前看是正确的)。通过研究人类的视觉原理,计算机利用深度神经网络(DeepNeural Network,NN)实现了对图片的识别,包括文字识别、物体分类、图像理解等。在这个过程中,神经元和神经网络模型、大数据技术的发展,以及处理器(尤其是GPU)强大的算力,给人工智能技术的发展提供了很大的支持。 本文是一篇学习笔记,以深度优先的思路,记录了对深度学习(Deep Learning)的简单梳理,主要针对计算机视觉应用领域。 一、神经网络 1.1 神经元和神经网络 神经元是生物学概念,用数学描述就是:对多个输入进行加权求和,并经过激活函数进行非线性输出。 由多个神经元作为输入节点,则构成了简单的单层神经网络(感知器),可以进行线性分类。两层神经网络则可以完成复杂一些的工作,比如解决异或问题,而且具有非常好的非线性分类效果。而多层(两层以上)神经网络,就是所谓的深度神经网络。 神经网络的工作原理就是神经元的计算,一层一层的加权求和、激活,最终输出结果。深度神经网络中的参数太多(可达亿级),必须靠大量数据的训练来设置。训练的过程就好像是刚出生的婴儿,在父母一遍遍的重复中学习“这是苹
机器学习的定义 从广义上来说,机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。但从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。 机器学习的范围 其实,机器学习跟模式识别,统计学习,数据挖掘,计算机视觉,语音识别,自然语言处理等领域有着很深的联系。 从范围上来说,机器学习跟模式识别,统计学习,数据挖掘是类似的,同时,机器学习与其他领域的处理技术的结合,形成了计算机视觉、语音识别、自然语言处理等交叉学科。因此,一般说数据挖掘时,可以等同于说机器学习。同时,我们平常所说的机器学习应用,应该是通用的,不仅仅模式识别 模式识别=机器学习。两者的主要区别在于前者是从工业界发展起来的概念,后者则主要源自计算机学科。在著名的《Pattern Recognition And Machine Learning》这本书中,Christopher M. Bishop在开头是这样说的“模式识别源自工业界,而机器学习来自于计算机学科。不过,它们中的活动可以被视为同一个领域的两个方面,同时在过去的10年间,它们都有了长足的发展”。 数据挖掘 数据挖掘=机器学习+数据库。这几年数据挖掘的概念实在是太耳熟能详。几乎等同于炒作。但凡说数据挖掘都会吹嘘数据挖掘如何如何,例如从数据中挖出金子,以及将废弃的数据转化为价值等等。但是,我尽管可能会挖出金子,但我也可能挖的是“石头”啊。这个说法的意思是,数据挖掘仅仅是一种思考方式,告诉我们应该尝试从数据中挖掘出知识,但不是每个数据都能挖掘出金子的,所以不要神话它。一个系统绝对不会因为上了一个数据挖掘模块就变得无所不能(这是IBM最喜欢吹嘘的),恰恰相反,一个拥有数据挖掘思维的人员才是关键,而且他还必须对数据有深刻的认识,这样才可能从数据中导出模式指引业务的改善。大部分数据挖掘中的算法是机器学习的算法在数据库中的优化。 统计学习 统计学习近似等于机器学习。统计学习是个与机器学习高度重叠的学科。因为机器学习中的大多数方法来自统计学,甚至可以认为,统计学的发展促进机器学习的繁荣昌盛。例如著名的支持向量机算法,就是源自统计学科。但是在某种程度上两者是有分别的,这个分别在于:统计学习者重点关注的是统计模型的发展与优化,偏数学,而机器学习者更关注的是能够解决问题,偏实践,因此机器学习研究者会重点研究学习算法在计算机上执行的效率与准确性的提升。 计算机视觉 计算机视觉=图像处理+机器学习。图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责从图像中识别出相关的模式。计算机视觉相关的应用非常的多,例如百度识图、手写字符识别、车牌识别等等应用。这个领域是应用前景非常火热的,同时也是研究的热门方向。随着机器学习的新领域深
实验算法BP神经网络实验 【实验名称】 BP神经网络实验 【实验要求】 掌握BP神经网络模型应用过程,根据模型要求进行数据预处理,建模,评价与应用; 【背景描述】 神经网络:是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,是目前应用最广泛的神经网络。其基本组成单元是感知器神经元。 【知识准备】 了解BP神经网络模型的使用场景,数据标准。掌握Python/TensorFlow数据处理一般方法。了解keras神经网络模型搭建,训练以及应用方法 【实验设备】 Windows或Linux操作系统的计算机。部署TensorFlow,Python。本实验提供centos6.8环境。 【实验说明】 采用UCI机器学习库中的wine数据集作为算法数据,把数据集随机划分为训练集和测试集,分别对模型进行训练和测试。 【实验环境】 Pyrhon3.X,实验在命令行python中进行,或者把代码写在py脚本,由于本次为实验,以学习模型为主,所以在命令行中逐步执行代码,以便更加清晰地了解整个建模流程。 【实验步骤】 第一步:启动python: 1
命令行中键入python。 第二步:导入用到的包,并读取数据: (1).导入所需第三方包 import pandas as pd import numpy as np from keras.models import Sequential from https://www.doczj.com/doc/e2180302.html,yers import Dense import keras (2).导入数据源,数据源地址:/opt/algorithm/BPNet/wine.txt df_wine = pd.read_csv("/opt/algorithm/BPNet/wine.txt", header=None).sample(frac=1) (3).查看数据 df_wine.head() 1
1、什么是人工智能?人工智能有哪些研究领域?何时创建该学科,创始人是谁? (1)AI(Artificial Intelligence)是利用计算机技术、传感器技术、自动控制技术、仿生技术、电子技术以及其他技术仿制人类智能机制的学科(或技术),再具体地讲就是利用这些技术仿制出一些具有人类智慧(能)特点的机器或系统 (2)人工智能的研究领域主要有专家系统、机器学习、模式识别、自然语言理解、自动定力证明、自动程序设计、机器人学、博弈、智能决策支持系统、人工神经网络等(3)人工智能于1956年夏季,由麦卡锡,明斯基、洛切斯特、香农等发起创建 2、产生式系统的由哪三部分组成?各部分的功能是什么? 课本29页 (1)产生式系统由综合数据库、产生式规则和控制系统三部分组成 (2)综合数据库用于存放当前信息,包括初始事实和中间结果; 产生式规则用于存放相关知识; 控制系统用于规则的解释或执行程序。 3、设有三枚硬币,其初始状态为(反,正,反),允许每次翻转一个硬币(只翻一个硬币,必须翻一个硬币)。必须连翻三次。用知识的状态空间表示法求出到达状态(反,反,反)的通路。画出状态空间图。 课本51页 问题求解过程如下: (1)构建状态 用数组表示的话,显然每一硬币需占一维空间,则用三维数组状态变量表示这个知识:Q=(q1 , q2 , q3) 取q=0 表示钱币的正面; q=1 表示钱币的反面 构成的问题状态空间显然为: Q0=(0,0,0),Q1=(0,0,1),Q2=(0,1,0), Q3=(0,1,1), Q4=(1,0,0),Q5=(1,0,1),Q6=(1,1,0),Q7=(1,1,1) (2)引入操作 f1:把q1翻一面。 f2:把q2翻一面。 f3:把q3翻一面。 显然:F={f1,f2,f3} 目标状态:(找到的答案)Qg=(0,0,0)或(1,1,1) (3)画出状态图
学习方式 根据数据类型的不同,对一个问题的建模有不同的方式。在机器学习或者人工智能领域,人们首先会考虑算法的学习方式。在机器学习领域,有几种主要的学习方式。将算法按照学习方式分类是一个不错的想法,这样可以让人们在建模和算法选择的时候考虑能根据输入数据来选择最合适的算法来获得最好的结果。 监督式学习: 在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。监督式学习的常见应用场景如分类问题和回归问题。常见算法有逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network) 非监督式学习:
在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法以及k-Means算法。 半监督式学习: 在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)等。 强化学习:
1、在神经网络模型VggNet中,使用两个级联的卷积核大小为3×3,stride=1的卷积层代替了一个5×5的卷积层,如果将stride设置 为2,则此时感受野为 A.7×7 B.9×9 C.5×5 D.8×8 正确答案:A 2、 上图是具有四个隐藏层的神经网络,该网络使用sigmoid函数作为 激活函数,训练过程出现了梯度消失问题。从图中可以判断出四个 隐藏层的先后顺序(靠近输入端的为先,靠近输出端的为后)分别 为 A.DBCA B.ABCD
D.DCBA 正确答案:D 3、在网络训练时,loss在最初几个epoch没有下降,可能原因是 A.学习率过低 B.以下都有可能 C.正则参数过高 D.陷入局部最小值 正确答案:B 4、假设有一个三分类问题,某个样本的标签为(1,0,0),模型的预测结果为(0.5,0.4,0.1),则交叉熵损失值(取自然对数结果)约等于
B.0.7 C.0.8 D.0.5 正确答案:B 5、 IoU是物体检测、语义分割领域中的结果评测指标之一,上图中A 框是物体的真实标记框,面积为8。B框是网络的检测结果,面积为7。两个框的重合区域面积为2。则IoU的值为 A.2/8 B.2/13 C.2/7 D.2/15 正确答案:B
6、Gram矩阵是深度学习领域常用的一种表示相关性的方法,在风格迁移任务中就使用风格Gram矩阵来表示图像的风格特征,以下关于风格Gram矩阵的论述正确的是 A.风格Gram矩阵的大小与输入特征图的通道数、宽、高都不相关 B.风格Gram矩阵的大小只与输入特征图的通道数相关 C.风格Gram矩阵的大小与输入特征图的通道数、宽、高都相关 D.风格Gram矩阵的大小只与输入特征图的宽、高有关 正确答案:B 7、现使用YOLO网络进行目标检测,待检测的物体种类为20种,输入图像被划分成7*7个格子,每个格子生成2个候选框,则YOLO网络最终的全连接层输出维度为 A.1078 B.980 C.1470 D.1960 正确答案:C 二、多选题 1、池化层在卷积神经网络中扮演了重要的角色,下列关于池化层的论述正确的有 A.池化操作具有平移不变性
机器学习中有一个重要的算法,那就是人工神经网络算法,听到这个名称相信大家能够想到 人体中的神经。其实这种算法和人工神经有一点点相似。当然,这种算法能够解决很多的问题,因此在机器学习中有着很高的地位。下面我们就给大家介绍一下关于人工神经网络算法 的知识。 1.神经网络的来源 我们听到神经网络的时候也时候近一段时间,其实神经网络出现有了一段时间了。神经网络 的诞生起源于对大脑工作机理的研究。早期生物界学者们使用神经网络来模拟大脑。机器学 习的学者们使用神经网络进行机器学习的实验,发现在视觉与语音的识别上效果都相当好。 在BP算法诞生以后,神经网络的发展进入了一个热潮。 2.神经网络的原理 那么神经网络的学习机理是什么?简单来说,就是分解与整合。一个复杂的图像变成了大量 的细节进入神经元,神经元处理以后再进行整合,最后得出了看到的是正确的结论。这就是 大脑视觉识别的机理,也是神经网络工作的机理。所以可以看出神经网络有很明显的优点。 3.神经网络的逻辑架构 让我们看一个简单的神经网络的逻辑架构。在这个网络中,分成输入层,隐藏层,和输出层。输入层负责接收信号,隐藏层负责对数据的分解与处理,最后的结果被整合到输出层。每层
中的一个圆代表一个处理单元,可以认为是模拟了一个神经元,若干个处理单元组成了一个层,若干个层再组成了一个网络,也就是”神经网络”。在神经网络中,每个处理单元事实上 就是一个逻辑回归模型,逻辑回归模型接收上层的输入,把模型的预测结果作为输出传输到 下一个层次。通过这样的过程,神经网络可以完成非常复杂的非线性分类。 4.神经网络的应用。 图像识别领域是神经网络中的一个著名应用,这个程序是一个基于多个隐层构建的神经网络。通过这个程序可以识别多种手写数字,并且达到很高的识别精度与拥有较好的鲁棒性。可以 看出,随着层次的不断深入,越深的层次处理的细节越低。但是进入90年代,神经网络的发展进入了一个瓶颈期。其主要原因是尽管有BP算法的加速,神经网络的训练过程仍然很困难。因此90年代后期支持向量机算法取代了神经网络的地位。 在这篇文章中我们大家介绍了关于神经网络的相关知识,具体的内容就是神经网络的起源、 神经网络的原理、神经网络的逻辑架构和神经网络的应用,相信大家看到这里对神经网络知 识有了一定的了解,希望这篇文章能够帮助到大家。
上海大学《人工智能》网络课课后习题答案 育才新工科-人工智能简介 1【判断题】《人工智能》课程为理工类通选课,本课程给予学生的主要是思想而不是知识。 对 图灵是谁? 1【单选题】图灵曾协助军方破解()的著名密码系统Enigma 。 A 英国 B 、美国 C 、德国 D 、日本 2【判断题】电影《模仿游戏》是纪念图灵诞生 90周年而拍摄的电影。X 3【判断题】图灵使用博弈论的方法破解了 Enigma 。对 为什么图灵很灵? 1【单选题】1937年,图灵在发表的论文()中,首次提出图灵机的概念。 A 《左右周期性的等价》B 《论可计算数及其在判定问题中的应用》 C 《可计算性与入可定义性》 D 《论高斯误差函数》 2【单选题】1950年,图灵在他的论文()中,提出了关于机器思维的问题。 A 、《论数字计算在决断难题中的应用》 B 《论可计算数及其在判定问题中的应用》 C 《可计算性与入可定义性》 D 《计算和智能》 3【判断题】存在一种人类认为的可计算系统与图灵计算不等价。 X 4【判断题】图灵测试是指测试者与被测试者(一个人和一台机器)隔开的情况下,通过一些装 置(如键盘)向被测试者随意提问。如果测试者不能确定出被测试者是人还是机器,那么这台机 器 就通过了测试,并被认为具有人类智能。对 为什么图灵不灵? 1【单选题】以下叙述不正确的是()。 A 图灵测试混淆了智能和人类的关系 B 机器智能的机制必须与人类智能相同 C 机器智能可以完全在特定的领域中超越人类智能 D 机器智能可以有人类智能的创造力 2【单选题】在政府报告中,()的报告使用“机器智能”这个词汇。 A 中国B 英国C 德国D 美国 3【多选题】机器智能可以有自己的“人格”体现主要表现在 1【单选题】以下关于未来人类智能与机器智能共融的二元世界叙述不正确的是 A 人类智能与机器智能具有平等性 B 、机器智能是模仿人类智能 C 人类智能与机器智能均具有群智行 D 人工智能与机器智能均具有发展性、合作性 2【单选题】机器通过人类发现的问题空间的数据,进行机器学习,具有在人类发现的问题空间 中求解的能力,并且求解的过程与结果可以被人类智能(),此为机器智能的产生。C ()0 A 模型间的对抗一智能进化的方式 B 、机器智能的协作一机器智能的社会组织 C 机器智能是社会的实际生产者 D 机器智能可以有人类智能的创造力 4【判断题】图灵测试存在的潜台词是机器智能的极限可以超越人的智能 ,机器智能可以不与 人的智能可比拟。X 人类智能与机器智能如何共融及未来 ()。B
可用于自动驾驶的神经网络及深度学习 高级辅助驾驶系统(ADAS)可提供解决方案,用以满足驾乘人员对道路安全及出行体验的更高要求。诸如车道偏离警告、自动刹车及泊车辅助等系统广泛应用于当前的车型,甚至是功能更为强大的车道保持、塞车辅助及自适应巡航控制等系统的配套使用也让未来的全自动驾驶车辆成为现实。 作者:来源:电子产品世界|2017-02-27 13:55 收藏 分享 高级辅助驾驶系统(ADAS)可提供解决方案,用以满足驾乘人员对道路安全及出行体验的更高要求。诸如车道偏离警告、自动刹车及泊车辅助等系统广泛应用于当前的车型,甚至是功能更为强大的车道保持、塞车辅助及自适应巡航控制等系统的配套使用也让未来的全自动驾驶车辆成为现实。 如今,车辆的很多系统使用的都是机器视觉。机器视觉采用传统信号处理技术来检测识别物体。对于正热衷于进一步提高拓展ADAS功能的汽车制造业而言,深度学习神经网络开辟了令人兴奋的研究途径。为了实现从诸如高速公路全程自动驾驶仪的短时辅助模式到专职无人驾驶旅行的自动驾驶,汽车制造业一直在寻求让响应速度更快、识别准确度更高的方法,而深度学习技术无疑为其指明了道路。 以知名品牌为首的汽车制造业正在深度学习神经网络技术上进行投资,并向先进的计算企业、硅谷等技术引擎及学术界看齐。在中国,百度一直在此技术上保持领先。百度计划在2019 年将全自动汽车投入商用,并加大全自动汽车的批量生产力度,使其在2021 年可广泛投入使用。汽车制造业及技术领军者之间的密切合作是嵌入式系统神经网络发展的催化剂。这类神经网络需要满足汽车应用环境对系统大小、成本及功耗的要求。 1轻型嵌入式神经网络 卷积式神经网络(CNN)的应用可分为三个阶段:训练、转化及CNN在生产就绪解决方案中的执行。要想获得一个高性价比、针对大规模车辆应用的高效结果,必须在每阶段使用最为有利的系统。 训练往往在线下通过基于CPU的系统、图形处理器(GPU)或现场可编程门阵列(FPGA)来完成。由于计算功能强大且设计人员对其很熟悉,这些是用于神经网络训练的最为理想的系统。 在训练阶段,开发商利用诸如Caffe(Convolution Architecture For Feature Extraction,卷积神经网络架构)等的框架对CNN 进行训练及优化。参考图像数据库用于确定网络中神经元的最佳权重参数。训练结束即可采用传统方法在CPU、GPU 或FPGA上生成网络及原型,尤其是执行浮点运算以确保最高的精确度。 作为一种车载使用解决方案,这种方法有一些明显的缺点。运算效率低及成本高使其无法在大批量量产系统中使用。 CEVA已经推出了另一种解决方案。这种解决方案可降低浮点运算的工作负荷,并在汽车应用可接受的功耗水平上获得实时的处理性能表现。随着全自动驾驶所需的计算技术的进一步发展,对关键功能进行加速的策略才能保证这些系统得到广泛应用。 利用被称为CDNN的框架对网络生成策略进行改进。经过改进的策略采用在高功耗浮点计算平台上(利用诸如Caffe的传统网络生成器)开发的受训网络结构和权重,并将其转化为基于定点运算,结构紧凑的轻型的定制网络模型。接下来,此模型会在一个基于专门优化的成像和视觉DSP芯片的低功耗嵌入式平台上运行。图1显示了轻型嵌入式神经网络的生成
上海大学《人工智能》网络课课后习题答案 1.1育才新工科-人工智能简介 1【判断题】《人工智能》课程为理工类通选课,本课程给予学生的主要是思想而不是知识。对 1.2图灵是谁? 1【单选题】图灵曾协助军方破解()的著名密码系统Enigma。 A、英国 B、美国 C、德国 D、日本 2【判断题】电影《模仿游戏》是纪念图灵诞生90周年而拍摄的电影。X 3【判断题】图灵使用博弈论的方法破解了Enigma。对 1.3为什么图灵很灵? 1【单选题】1937年,图灵在发表的论文()中,首次提出图灵机的概念。 A、《左右周期性的等价》 B、《论可计算数及其在判定问题中的应用》 C、《可计算性与λ可定义性》 D、《论高斯误差函数》 2【单选题】1950年,图灵在他的论文()中,提出了关于机器思维的问题。 A、《论数字计算在决断难题中的应用》 B、《论可计算数及其在判定问题中的应用》 C、《可计算性与λ可定义性》 D、《计算和智能》 3【判断题】存在一种人类认为的可计算系统与图灵计算不等价。X 4【判断题】图灵测试是指测试者与被测试者(一个人和一台机器)隔开的情况下,通过一些装置(如键盘)向被测试者随意提问。如果测试者不能确定出被测试者是人还是机器,那么这台机器就通过了测试,并被认为具有人类智能。对 1.4为什么图灵不灵? 1【单选题】以下叙述不正确的是()。 A、图灵测试混淆了智能和人类的关系 B、机器智能的机制必须与人类智能相同
C、机器智能可以完全在特定的领域中超越人类智能 D、机器智能可以有人类智能的创造力2【单选题】在政府报告中,()的报告使用“机器智能”这个词汇。 A、中国 B、英国 C、德国 D、美国 3【多选题】机器智能可以有自己的“人格”体现主要表现在()。 A、模型间的对抗—智能进化的方式 B、机器智能的协作—机器智能的社会组织 C、机器智能是社会的实际生产者 D、机器智能可以有人类智能的创造力 4【判断题】图灵测试存在的潜台词是机器智能的极限可以超越人的智能,机器智能可以不与人的智能可比拟。X 1.5人类智能与机器智能如何共融及未来 1【单选题】以下关于未来人类智能与机器智能共融的二元世界叙述不正确的是()。B A、人类智能与机器智能具有平等性 B、机器智能是模仿人类智能 C、人类智能与机器智能均具有群智行 D、人工智能与机器智能均具有发展性、合作性 2【单选题】机器通过人类发现的问题空间的数据,进行机器学习,具有在人类发现的问题空间中求解的能力,并且求解的过程与结果可以被人类智能(),此为机器智能的产生。C A、采纳 B、参考 C、理解 D、相同 3【判断题】人类智能可以和机器智能相互融合。对 4【判断题】机器智能的创造是指机器通过求解人类智能发现的问题空间中的问题积累数据与求解方法,通过机器学习,独立发现新的问题空间。X 1.6人工智能界定与科学 1【单选题】在最初的图灵测试中,如果有超过()的测试者不能确定出被测试者是人还是机器,则这台机器就通过了测试,并认为具有人类智能。 A、0.2 B、0.3 C、0.4 D、0.5 2【单选题】()不属于图灵测试中包含的三个未曾言明的预设前提。
CDA数据分析研究院出品,转载需授权 深度学习是机器学习的一个子领域,研究的算法灵感来自于大脑的结构和功能,称为人工神经网络。 如果你现在刚刚开始进入深度学习领域,或者你曾经有过一些神经网络的经验,你可能会感到困惑。因为我知道我刚开始的时候有很多的困惑,我的许多同事和朋友也是这样。因为他们在20世纪90年代和21世纪初就已经学习和使用神经网络了。 该领域的领导者和专家对深度学习的观点都有自己的见解,这些具体而细微的观点为深度学习的内容提供了很多依据。 在这篇文章中,您将通过听取该领域的一系列专家和领导者的意见,来了解什么是深度学习以及它的内容。 来让我们一探究竟吧。 深度学习是一种大型的神经网络 Coursera的Andrew Ng和百度研究的首席科学家正式创立了Google Brain,最终导致了大量Google服务中的深度学习技术的产品化。 他已经说了很多关于深度学习的内容并且也写了很多,这是一个很好的开始。 在深度学习的早期讨论中,Andrew描述了传统人工神经网络背景下的深度学习。在2013年的题为“ 深度学习,自学习和无监督特征学习”的演讲中“他将深度学习的理念描述为: 这是我在大脑中模拟的对深度学习的希望: - 使学习算法更好,更容易使用。 - 在机器学习和人工智能方面取得革命性进展。 我相信这是我们迈向真正人工智能的最好机会
后来他的评论变得更加细致入微了。 Andrew认为的深度学习的核心是我们现在拥有足够快的计算机和足够多的数据来实际训练大型神经网络。在2015年ExtractConf大会上,当他的题目“科学家应该了解深度学习的数据”讨论到为什么现在是深度学习起飞的时候,他评论道: 我们现在拥有的非常大的神经网络......以及我们可以访问的大量数据 他还评论了一个重要的观点,那就是一切都与规模有关。当我们构建更大的神经网络并用越来越多的数据训练它们时,它们的性能会不断提高。这通常与其他在性能上达到稳定水平的机器学习技术不同。 对于大多数旧时代的学习算法来说......性能将达到稳定水平。......深度学习......是第一类算法......是可以扩展的。...当你给它们提供更多的数据时,它的性能会不断提高 他在幻灯片中提供了一个漂亮的卡通片: 最后,他清楚地指出,我们在实践中看到的深度学习的好处来自有监督的学习。从2015年的ExtractConf演讲中,他评论道: 如今的深度学习几乎所有价值都是通过有监督的学习或从有标记的数据中学习 在2014年的早些时候,在接受斯坦福大学的题为“深度学习”的演讲时,他也发出了类似的评论。 深度学习疯狂发展的一个原因是它非常擅长监督学习
1. 自联想神经网络与深度网络 自联想神经网络是很古老的神经网络模型,简单的说,它就是三层BP网络,只不过它的输出等于输入。很多时候我们并不要求输出精确的等于输入,而是允许一定的误差存在。所以,我们说,输出是对输入的一种重构。其网络结构可以很简单的表示如下: 如果我们在上述网络中不使用sigmoid函数,而使用线性函数,这就是PCA模型。中间网络节点个数就是PCA模型中的主分量个数。不用担心学习算法会收敛到局部最优,因为线性BP网络有唯一的极小值。
在深度学习的术语中,上述结构被称作自编码神经网络。从历史的角度看,自编码神经网络是几十年前的事情,没有什么新奇的地方。 既然自联想神经网络能够实现对输入数据的重构,如果这个网络结构已经训练好了,那么其中间层,就可以看过是对原始输入数据的某种特征表示。如果我们把它的第三层去掉,这样就是一个两层的网络。如果,我们把这个学习到特征再用同样的方法创建一个自联想的三层BP网络,如上图所示。换言之,第二次创建的三层自联想网络的输入是上一个网络的中间层的输出。用同样的训练算法,对第二个自联想网络进行学习。那么,第二个自联想网络的中间层是对其输入的某种特征表示。如果我们按照这种方法,依次创建很多这样的由自联想网络组成的网络结构,这就是深度神经网络,如下图所示:
注意,上图中组成深度网络的最后一层是级联了一个softmax分类器。 深度神经网络在每一层是对最原始输入数据在不同概念的粒度表示,也就是不同级别的特征描述。 这种层叠多个自联想网络的方法,最早被Hinton想到了。 从上面的描述中,可以看出,深度网络是分层训练的,包括最后一层的分类器也是单独训练的,最后一层分类器可以换成任何一种分类器,例如SVM,HMM等。上面的每一层单独训练使用的都是BP算法。相信这一思路,Hinton早就实验过了。 2. DBN神经网络模型 使用BP算法单独训练每一层的时候,我们发现,必须丢掉网络的第三层,才能级联自联想神经网络。然而,有一种更好的神经网络模型,这就是受限玻尔兹曼机。使用层叠波尔兹曼机组成深度神经网络的方法,在深度学习里被称作深度信念网络DBN,这是目前非