
词法分析实验报告
一、实验目的与要求:
1、了解字符串编码组成的词的内涵,感觉一下字符串编码的方法和解读
2、了解和掌握自动机理论和正规式理论在词法分析程序和控制理论中的应用
二、实验内容:
构造一个自己设计的小语言的词法分析器:
1、这个小语言能说明一些简单的变量
识别诸如begin,end,if,while等保留字;识别非保留字的一般标识符(有下划线、字符、数字,且第一个字符不能是数字)。识别数字序列(整数和小数);识别:=,<=,>=之类的特殊符号以及;,(,)等界符。
2、相关过程(函数):
Scanner()词法扫描程序,提取标识符并填入display表中
3、这个小语言有顺序结构的语句
4、这个小语言能表达分支结构的语句
5、这个小语言能够输出结果
总之这个小语言词法分析器能提供以上所说明到的语法描述的功能……
三、实验步骤:
1、测试评价
(1)、测试1:能说明一些简单的变量,如关键字、一般标识符、界符等;
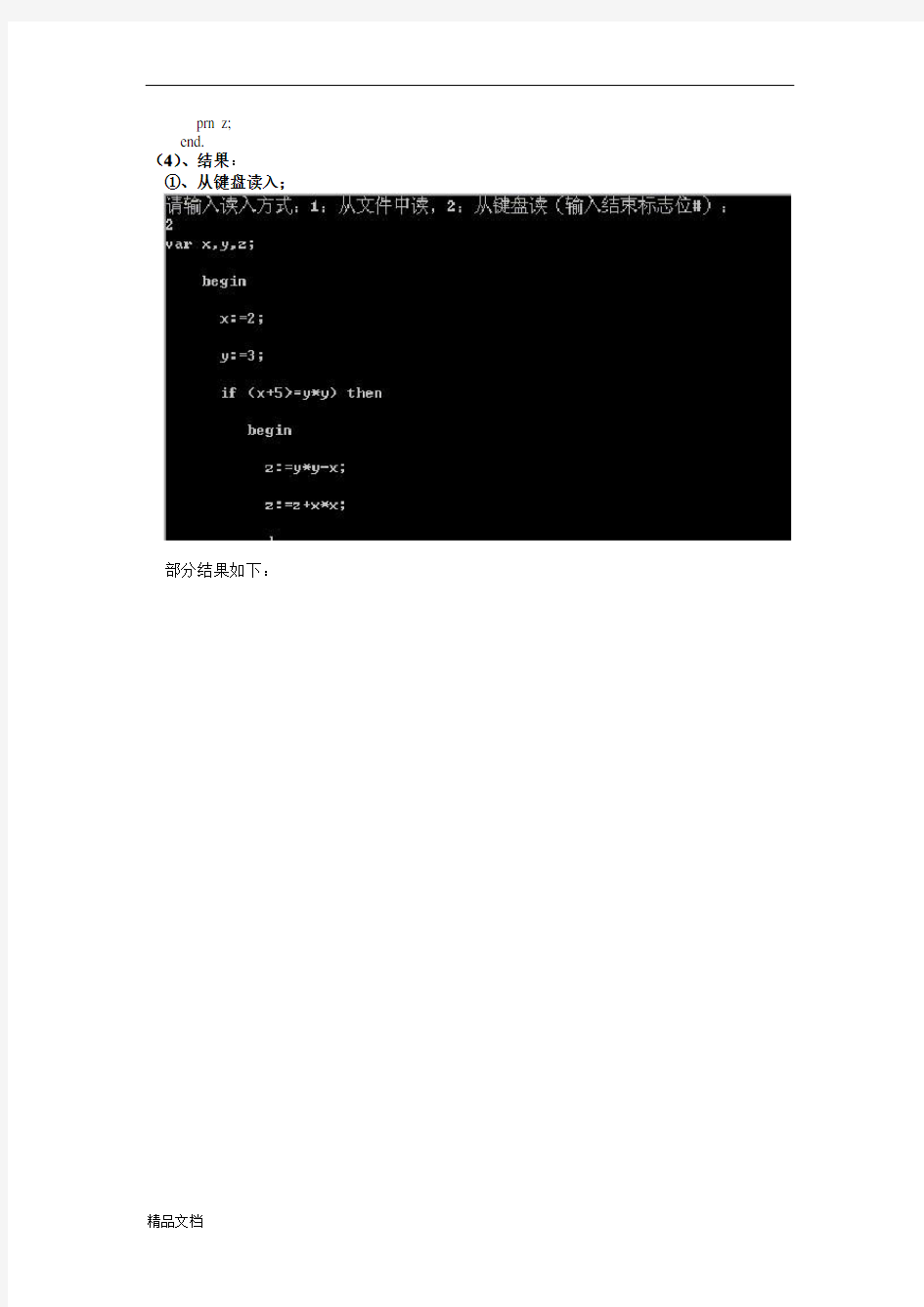
(2)、测试2:能输出结果:单词符号(内码形式)、各种信息表(如符号表、常量表等);(3)、测试程序:
var x,y,z;
begin
x:=2;
y:=3;
if (x+5>=y*y) then
begin
z:=y*y-x;
z:=z+x*x;
end
else
z:=x+y;
prn z;
end.
(4)、结果:
①、从键盘读入;
部分结果如下:
(类型:该标识符所属的类型,如关键字,变量等;下标:该标识符所对应表(如变量标识符表,常量标识符表等)中其相应的位置,下同)
②、从文件读入,输出到文件;
部分结果如下:
其他测试及结果如下:
③、出错处理;
注:若有错误,则只指出错误,不输出各个表;
(5)、评价:
这个小语言程序基本上能完成词法分析阶段的工作,识别诸如begin,if等保留字;识别非保留字的一般标识符(有下划线、字符、数字,且第一个字符不能是数字)。识别数字序列(整数和小数);识别:=,<=,>=之类的特殊符号以及;,(,)等界符。在扫描源程序串的同时,能进行一些简单的处理,如删除空格、tab、换行等无效字符,也进行了一些基本的错误处理,如变量长度的判别等。
遇到的问题:(a)、判别标识符超过规定长度(20)时,未输出处理结果;(b)、整数长度过长输出结果仍为整数类型3;(c)、对于小数如﹒045,被解释为界符和整数;(d)、对以数字开头的一般标识符的处理,如100nuts被解释为整数类型和标识符,未给出错误提示。
如上测试,出现前两个问题时已报错并输出所在行,而后两个问题待解决。
2、对小语言的词法规则(正规式)画出一个确定的有限自动机(见附录2、3)
四、实验的源代码:(见附录1)
五、实验中发现的问题和遇到的困难及解决方法:
由于以前未曾接触过编译原理,在该实验的设计中,的确遇到一定的困难。主要是display表结构的设计,由于语法分析和语义分析还未学习,无法站在全局的角度统筹兼顾,在表结构设计时,不知该往表结构体中添加哪些内容,可以为后续的工作做铺垫,这是刚开始就遇到的最大的困难,也是最难的。
经过分析,我们在现有局限性的基础上,设计出一种折中的表结构,即在表结构中只添加标识符在其相应表中的对应下表,标记符类型码等关键的几处,这样既能唯一确定一标识符,达到该实验的要求,同时又为表保留了很好的扩充性,以达到后续实验的要求。表结构设计好后,其余的工作就是提取字符串和写入display表,在提取单字符还是双字符组成的运算符时有些麻烦,不过利用数据结构的相关知识也是容易做到。
六、总结:
词法分析是构造编译器的起始阶段,也是相应比较简单的一个环节。词法分析的主要任务是:根据构造的状态转换图,从左到右逐个字符地対源程序进行扫描,识别开源程序中具有独立含义的最小语法单位——符号或单词,如变量标识符,关键字,常量,运算符,界符等。
然后将提取出的标识符以内码的形式表示,即用int类型的数字来表示其类型和在display表中的位置,而无须保留原来标识符本身的字符串,这不仅节省了内存空间,也有利于下一阶段的分析工作。
当然,在扫描源程序串的同时,进行一些简单的处理,如删除空格、tab、换行等无效字符,也进行了一些基本的错误处理,如变量长度的判别,有些不合词法规则的标识符判别等。总之,严格说来,词法分析程序只进行和词法分析相关的工作。
七、实验感想:
通过此次实验,让我了解到如何设计、编制并调试词法分析程序,加深对词法分析原理的理解;熟悉了构造词法分析程序的手工方式的相关原理,使用某种高级语言(例如C++语言)直接编写此法分析程序。另外,也让我重新熟悉了C++语言的相关内容,加深了对C++语言的用途的理解。
附录1(代码)
#include
#include
#include
#include
#include
#include
using namespace std;
#define Max 655 //最大代码长度
#define WordMaxNum 256 //变量最大个数
#define DigitNum 256 //常量最大个数
#define MaxKeyWord 32 //关键字数量
#define MaxOptANum 8 //运算符最大个数
#define MaxOptBNum 4 //运算符最大个数
#define MaxEndNum 11 //界符最大个数
typedef struct DisplayTable
{
int Index; //标识符所在表的下标
int type; //标识符的类型
int line; //标识符所在表的行数
char symbol[20]; //标识符所在表的名称
}Table;
int TableNum = 0; //display表的下标
char Word[WordMaxNum][20]; //标识符表
char Digit[WordMaxNum][20]; //数字表
int WordNum = 0; //变量表的下标
int DigNum = 0; //常量表的下标
bool errorFlag = 0; //错误标志
const char* const KeyWord[MaxKeyWord] = {"and", "array", "begin", "case","char"
"constant", "do", "else", "end", "false","for", "if", "input", "integer", "not", "of", "or", "output","packed","procedure", "program", "read", "real","repeat", "set", "then", "to", "type", "until", "var","while", "with","prn"}; //关键字
const char OptA[] = {'+','-','*','/','=','#','<','>'}; // 单目运算
const char *OptB[] = {"<=",">=",":=","<>"}; //双目运算符
const char End[] = {'(', ')' , ',' , ';' , '.' , '[' , ']' , ':' , '{' , '}' , '"'}; // 界符
void error(char str[20],int nLine, int errorType)
{
cout <<" \nError : ";
switch(errorType)
{
case 1:
cout << "第" << nLine-1 <<"行" << str << " 变量的长度超过限制!\n";
errorFlag = 1;
break;
case 2:
cout << "第" << nLine-1 <<"行" << str << " 小数点错误!\n";
errorFlag = 1;
break;
case 3:
cout << "第" << nLine-1 <<"行" << str << " 常量的长度超过限制!\n";
errorFlag = 1;
break;
}
}//error
void Scanner(char ch[],int chLen,Table table[Max],int nLine)
{
int chIndex = 0;
while(chIndex < chLen) //对输入的字符扫描
{
/**************************处理空格和tab ************************/ while(ch[chIndex] == ' ' || ch[chIndex] == 9 ) //忽略空格和tab
{ chIndex ++; }
/***************************处理换行符*************************************/ while(ch[chIndex] == 10) //遇到换行符,行数加1
{ nLine++;chIndex ++;}
/***************************标识符***************************************/ if( isalpha(ch[chIndex])) //以字母、下划线开头
{
char str[256];
int strLen = 0;
while(isalpha(ch[chIndex]) || ch[chIndex] == '_' ) //是字母、下划线
{
str[strLen ++] = ch[chIndex];
chIndex ++;
while(isdigit(ch[chIndex]))//不是第一位,可以为数字
{
str[strLen ++] = ch[chIndex];
chIndex ++;
}
}
str[strLen] = 0; //字符串结束符
if(strlen(str) > 20) //标识符超过规定长度,报错处理
{
error(str,nLine,1);
}
else{ int i;
for(i = 0;i < MaxKeyWord; i++) //与关键字匹配
if(strcmp(str, KeyWord[i]) == 0) //是关键字,写入table表中
{
strcpy(table[TableNum].symbol,str);
table[TableNum].type = 1; //关键字
table[TableNum].line = nLine;
table[TableNum].Index = i;
TableNum ++;
break;
}
if(i >= MaxKeyWord) //不是关键字
{
table[TableNum].Index = WordNum;
strcpy(Word[WordNum++],str);
table[TableNum].type = 2; //变量标识符
strcpy(table[TableNum].symbol,str);
table[TableNum].line = nLine;
TableNum ++;
}
}
}
/**********************************常数***********************/
//else if(isdigit(ch[chIndex])&&ch[chIndex]!='0') //遇到数字
else if(isdigit(ch[chIndex])) //遇到数字
{
int flag = 0;
char str[256];
int strLen = 0;
while(isdigit(ch[chIndex]) || ch[chIndex] == '.') //数字和小数点
{
if(ch[chIndex] == '.') //flag表记小数点的个数,0时为整数,1时为小数,2时出错
flag ++;
str[strLen ++] = ch[chIndex];
chIndex ++;
}
str[strLen] = 0;
if(strlen(str) > 20) //常量标识符超过规定长度20,报错处理{
error(str,nLine,3);
}
if(flag == 0)
{
table[TableNum].type = 3; //整数
}
if(flag == 1)
{
table[TableNum].type = 4; //小数
}
if(flag > 1)
{
error(str,nLine,2);
}
table[TableNum].Index = DigNum;
strcpy(Digit[DigNum ++],str);
strcpy(table[TableNum].symbol,str);
table[TableNum].line = nLine;
TableNum ++;
}
/*******************************运算符************************************/
else
{
int errorFlag; //用来区分是不是无法识别的标识符,0为运算符,1为界符
char str[3];
str[0] = ch[chIndex];
str[1] = ch[chIndex + 1];
str[3] = 0;
for(int i = 0;i < MaxOptBNum;i++)//MaxOptBNum)
if(strcmp(str,OptB[i]) == 0)
{
errorFlag = 0;
table[TableNum].type = 6;
strcpy(table[TableNum].symbol,str);
table[TableNum].line = nLine;
table[TableNum].Index = i;
TableNum ++;
chIndex = chIndex + 2;
break;
}
if(i >= MaxOptBNum)
{
for( int k = 0;k < MaxOptANum; k++)
if(OptA[k] == ch[chIndex])
{
errorFlag = 0;
table[TableNum].type = 5;
table[TableNum].symbol[0] = ch[chIndex];
table[TableNum].symbol[1] = 0;
table[TableNum].line = nLine;
table[TableNum].Index = k;
TableNum ++;
chIndex ++;
break;
}
/*************************界符*****************************************/ for(int j = 0;j < MaxEndNum;j ++)
if(End[j] ==ch[chIndex])
{
errorFlag = 1;
table[TableNum].line = nLine;
table[TableNum].symbol[0] = ch[chIndex];
table[TableNum].symbol[1] = 0;
table[TableNum].Index = j;
table[TableNum].type = 7;
TableNum ++;
chIndex ++;
}
/********************其他无法识别字符*************************************/ if(errorFlag != 0 && errorFlag != 1) //开头的不是字母、数字、运算符、界符
{
char str[256];
int strLen = -1;
str[strLen ++] = ch[chIndex];
chIndex ++;
while(*ch != ' ' || *ch != 9 || ch[chIndex] != 10)//
{
str[strLen ++] = ch[chIndex];
chIndex ++;
}
str[strLen] = 0;
table[TableNum].type = 8;
strcpy(table[TableNum].symbol,str);
table[TableNum].line = nLine;
table[TableNum].Index = -2;
TableNum ++;
}
}
}
}
}
void Trans(double x,int p) //把十进制小数转为16进制{
int i=0; //控制保留的有效位数
while(i { if(x==0) //如果小数部分是0 break; //则退出循环 else { int k=int(x*16); //取整数部分 x=x*16-int(k); //得到小数部分 if(k<=9) cout< else cout< }; i++; }; }; int main() { ifstream in; ofstream out,outVar,outCon; char in_file_name[26],out_file_name[26]; //读入文件和写入文件的名称 char ch[Max]; //存放输入代码的缓冲区 int nLine = 1; //初始化行数 Table *table = new Table[Max]; int choice; cout << "请输入读入方式:1:从文件中读,2:从键盘读(输入结束标志位#):\n"; cin >> choice; switch(choice) { int i; /****************************从文件读取***************************/ case 1: cout<<"Enter the input file name:\n"; cin>>in_file_name; in.open(in_file_name); if(in.fail()) //打开display表读文件失败 { cout<<"Inputput file opening failed.\n"; exit(1); } cout<<"Enter the output file name:\n"; cin>>out_file_name; out.open(out_file_name); outVar.open("变量表.txt"); outCon.open("常量表.txt"); if(out.fail()) //打开display表写文件失败 { cout<<"Output file opening failed.\n"; exit(1); } if(outVar.fail()) //打开变量表写文件失败 { cout<<"VarOutput file opening failed.\n"; exit(1); } if(outCon.fail()) //打开常量表写文件失败 { cout<<"ConstOutput file opening failed.\n"; exit(1); } in.getline(ch,Max,'#'); Scanner(ch, strlen(ch),table,nLine); //调用扫描函数 if(errorFlag == 1) //出错处理 return 0; /*******************************把结果打印到各个表中***********************/ out <<"类型"<<" "<<"下标" < for( i = 0; i < TableNum;i ++)//打印display out<< "(0x" < outCon << "下标" << " " << "常量值" << endl; for(i = 0;i < TableNum;i++) //打印常量表 { if(table[i].type == 3) { long num1; num1 = atoi(table[i].symbol); outCon<< "(0x" < } if(table[i].type == 4) { double num2; num2 = atof(table[i].symbol); outCon<< "(0x" < } } outVar <<"类型"<<" "<< "变量名称" < for( i = 0; i < WordNum;i ++)//打印变量表 outVar<< "(0x" < in.close();//关闭文件 out.close(); outVar.close(); outCon.close(); break; /***********************************从键盘输入****************************/ case 2: cin.getline(ch,Max,'#'); Scanner(ch, strlen(ch),table,nLine); //调用扫描函数 if(errorFlag == 1) return 0; cout << "\nDisplay表: \n"; cout <<"类型"<<" "<<"下标" < for( i = 0; i < TableNum;i ++) cout<< "(0x" < cout << "\n常量表:\n" << "下标" << " " << "常量值" << endl; for(i = 0;i < TableNum;i++) //打印常量表 { if(table[i].type == 3) { long num1; num1 = atoi(table[i].symbol); cout<< "(0x" < } if(table[i].type == 4) { char *num2; float num,num3; num = atof(table[i].symbol); num2 = gcvt(16,strlen(table[i].symbol),table[i].symbol); num3 = num - floor(num); cout << "(0x" << hex << table[i].Index << " , " << num2; Trans(num3,5) ; cout << ")" < } } cout <<"\n变量表:\n类型"<<" "<< "变量名称" < for( i = 0; i < WordNum;i ++)//打印变量表 cout<< "(0x" < break; } return 0; } 附录2:在状态转换图中各个状态表示的种类、种别编码、解释如下表: 附录3:(状态转换图) 空格 换行tab
相关主题
文本预览