
实验二:直线的生成算法绘制
实验目的:
实现C语言编写图形程序。学会了解VC++的基本应用同时了解TC图形环境配置,学习简单的图形画法,并比较画法的优劣,尝试在计算机实现,得到图形,验证比较图形。
实验内容:
直线的生成算法:DDA和Bresenham算法
// DDA算法生成直线
void CMyView:: OnDdaline()
{
CDC* pDC=GetDC();//获得设备指针
int xa=100,ya=300,xb=300,yb=200,c=RGB(255,0,0);//定义直线的两端点,直线颜色
int x,y;
float dx, dy, k;
dx=(float)(xb-xa), dy=(float)(yb-ya);
k=dy/dx, y=ya;
if(abs(k)<1)
{
for (x=xa;x<=xb;x++)
{pDC->SetPixel (x,int(y+0.5),c);
y=y+k;}
}
if(abs(k)>=1)
{
for (y=ya;y<=yb;y++)
{pDC->SetPixel (int(x+0.5),y,c);
x=x+1/k;}
}
ReleaseDC(pDC);
}
说明:
(1)以上代码理论上通过定义直线的两端点,可得到任意端点之间的一直线,但由于一般屏幕坐标采用右手系坐标,屏幕上只有正的x, y值,屏幕坐标与窗口坐标之间转换知识请参考第3章。
(2)注意上述程序考虑到当k 1的情形x每增加1,y最多增加1;当k>1时,y每增加1,x相应增加1/k。在这个算法中,y与k用浮点数表示,而且每一步都要对y进行四舍五入后取整。
//Bresenham算法生成直线
void CMyView::OnBresenhamline()
{
CDC* pDC=GetDC();
int x1=100, y1=200, x2=350, y2=100,c=RGB(0,0,255);
int i,s1,s2,interchange;
float x,y,deltax,deltay,f,temp;
x=x1;
y=y1;
deltax=abs(x2-x1);
deltay=abs(y2-y1);
if(x2-x1>=0) s1=1; else s1=-1;
if(y2-y1>=0) s2=1; else s2=-1;
if(deltay>deltax){
temp=deltax;
deltax=deltay;
deltay=temp;
interchange=1;
}
else interchange=0;
f=2*deltay-deltax;
pDC->SetPixel(x,y,c);
for(i=1;i<=deltax;i++){
if(f>=0){
if(interchange==1) x+=s1;
else y+=s2;
pDC->SetPixel(x,y,c);
f=f-2*deltax;
}
else{
if(interchange==1) y+=s2;
else x+=s1;
f=f+2*deltay;
}
}
}
说明:
(1)以上程序已经考虑到所有象限直线的生成。
(2)Bresenham算法的优点如下:
①不必计算直线的斜率,因此不做除法。
②不用浮点数,只用整数。
③只做整数加减运算和乘2运算,而乘2运算可以用移位操作实现。
④ Bresenham算法的运算速度很快。
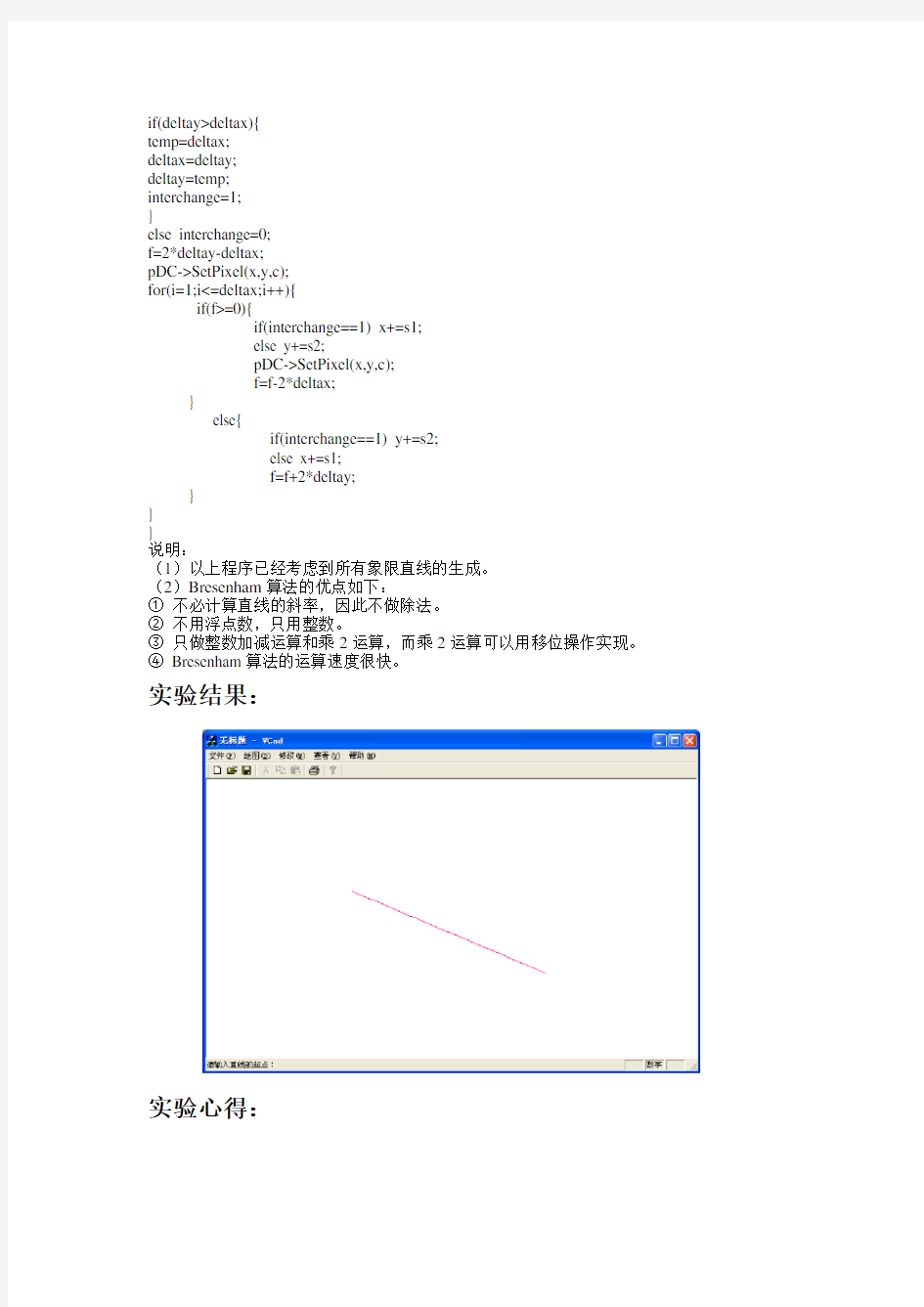
实验结果:
实验心得:
通过这个程序的开发,我比较深刻的理解了DDA算法的思想,由于开始我并没参考任何DDA算法,只是在课堂上听到一些,故这个DDA算法可能与网上大多数不大一样。
此外,由于见了璐恺同学的作品,感到深深内疚,原来那个程序实在是没有认真对待,故在原有程序基础上,增添了一些实用的功能,特别是实现了保存BMP文件的功能。下面重点总结BMP文件生成类开发的心得:
1.通过这个实验,我查阅了相关书籍和网上资料,比较弄明白了BMP文件的完整结构,也弄清了一些细节问题,比如每行字节扫描数必为4的整数(即与DWORD对齐),RGB在BMP文件中的表达等。
2.尽管我实现了BMP文件生成,但是由一些字段还是不大明白,主要是压缩部分biCompression,故我这里设置为0,不压缩。此外垂直水平象素值(即biXPelsPerMeter和biYPelsPerMeter)也不大明白指的是什么,参照资料干脆设置为0。索引色biClrUsed及其重要程度biClrImportant我还是不大明白有什么用途,不过这些应该可以在网上找到答案。
3.在写这部分功能时,我始终用Debug工具查看每个字节的值,试图分析出它们的含义,事实证明这种方法还是有效的。
4.这个实验我还发现,有些参考书上说的接在BITMAPINFOHEADER(同样在BITMAPINFO中)后面的RGBQUAD(色彩表,同样包含在BITMAPINFO 中)并没有用上,但是有些资料上却说有,不过相应的bfOffBits必须设置为0x3E,我发现有写BMP图片确实有这样的值,但是我这个程序设置为bfOffBits =0x36,而且没有色彩表。估计这个可能是版本问题?
5.由于生成BMP过程是采集客户区每个象素的值,所以必须每点扫描,速度真的很慢,这个问题还没有解决。
算法设计与分析实验报告 贪心算法 班级:2013156 学号:201315614 姓名:张春阳哈夫曼编码 代码 #include printf("\n"); for(i=0;i 算法设计与分析基础 实验报告 应用数学学院 二零一六年六月 实验一插入排序算法 一、实验性质设计 二、实验学时14学时 三、实验目的 1、掌握插入排序的方法和原理。 2、掌握java语言实现该算法的一般流程。 四、实验内容 1、数组的输入。 2、输入、输出的异常处理。 3、插入排序的算法流程。 4、运行结果的输出。 五、实验报告 Ⅰ、算法原理 从左到右扫描有序的子数组,直到遇到一个大于(或小于)等于A[n-1]的元素,然后就把A[n-1]插在该元素的前面(或后面)。 插入排序基于递归思想。 Ⅱ、书中源代码 算法InsertionSort(A[0..n-1]) //用插入排序对给定数组A[0..n-1]排序 //输入:n个可排序元素构成的一个数组A[0..n-1] //输出:非降序排列的数组A[0..n-1] for i ←1 to n-1 do v ← A[i] j ← i-1 while j ≥0and A[j] > v do A[j+1] ← A[j] j ← j-1 A[j+1] ← v Ⅲ、Java算法代码: import java.util.*; public class Charu { public static void main(String[] args) { int n = 5; int a[] = new int[n]; int s = a.length; int i = 0, j = 0, v = 0; System.out.println("请输入若干个数字:"); Scanner sc = new Scanner(System.in); try { while (i < s) { a[i] = sc.nextInt(); i++; } for (i = 1; i 实验名 称 作业调度 实验内容1、设计可用于该实验的作业控制块; 2、动态或静态创建多个作业; 3、模拟先来先服务调度算法和短作业优先调度算法。 3、调度所创建的作业并显示调度结果(要求至少显示出各作业的到达时间,服务时间,开始时间,完成时间,周转时间和带权周转时间); 3、比较两种调度算法的优劣。 实验原理一、作业 作业(Job)是系统为完成一个用户的计算任务(或一次事物处理)所做的工作总和,它由程序、数据和作业说明书三部分组成,系统根据该说明书来对程序的运行进行控制。在批处理系统中,是以作业为基本单位从外存调入内存的。 二、作业控制块J C B(J o b C o nt r o l Bl o ck) 作业控制块JCB是记录与该作业有关的各种信息的登记表。为了管理和调度作业,在多道批处理系统中为每个作业设置了一个作业控制块,如同进程控制块是进程在系统中存在的标志一样,它是作业在系统中存在的标志,其中保存了系统对作业进行管理和调度所需的全部信息。在JCB中所包含的内容因系统而异,通常应包含的内容有:作业标识、用户名称、用户帐户、作业类型(CPU 繁忙型、I/O 繁忙型、批量型、终端型)、作业状态、调度信息(优先级、作业已运行时间)、资源需求(预计运行时间、要求内存大小、要求I/O设备的类型和数量等)、进入系统时间、开始处理时间、作业完成时间、作业退出时间、资源使用情况等。 三、作业调度 作业调度的主要功能是根据作业控制块中的信息,审查系统能否满足用户作业的资源需求,以及按照一定的算法,从外存的后备队列中选取某些作业调入内存,并为它们创建进程、分配必要的资源。然后再将新创建的进程插入就绪队列,准备执行。 四、选择调度算法的准则 1).面向用户的准则 (1) 周转时间短。通常把周转时间的长短作为评价批处理系统的性能、选择作业调度方式与算法的重要准则之一。所谓周转时间,是指从作业被提交给系统开始,到作业完成为止的这段时间间隔(称 CAD / CAM 技术实验报告 实验三贝齐尔(Bezier)曲线曲面的生成方法 实验类型:综合型 一、目的与任务 目的:通过学生上机,了解贝齐尔(Bezier)曲线德卡斯特里奥的递推算法和贝齐尔(Bezier)曲线的几何作图法。 任务:熟悉线框建模、表面建模的基本方法。 二、内容、要求与安排方式 1、实验内容与要求: 贝齐尔(Bezier)曲线曲面的德卡斯特里奥的递推算法P(t)=∑Bi,n(t)Q(i)和几何作图法; 要求用熟悉的编程语言编制、调试和运行程序,并打印程序清单和输出结果。 2、实验安排方式:课外编写好程序清单,按自然班统一安排上机。 三、实验步骤 1、熟悉贝齐尔(Bezier)的贝齐尔基函数和贝齐尔的性质 2、贝齐尔(Bezier)曲线的德卡斯特里奥的递推算法; 3、贝齐尔(Bezier)曲线的几何作图法; 4、贝齐尔(Bezier)曲线的德卡斯特里奥的递推算法; 5、贝齐尔(Bezier)曲线的几何作图法。 6、对几何作图法绘制出图,对德卡斯特里奥的递推算法编出程序。 四、实验要求 1.在规定的时间内完成上机任务。 2.必须实验前进行复习和预习实验内容。 3.在熟悉命令过程中,注意相似命令在操作中的区别。 4.指定图形完成后,需经指导教师认可后,方可关闭计算机。 5.完成实验报告一份。 五、试验具体内容 1,Bezier 曲线的描述 在空间给定n + 1 个点P0 ,P1 ,P2 , ?,Pn ,称下列参数曲线为n 次的Bezier 曲线。 P(t) = 6n t = 0 PiJ i ,n (t) , 0 ≤t ≤1 其中J i ,n (t) 是Bernstein 基函数,即 B i ,n (t) = n !/i !(n - i) *t(1-t); i = 0 , ??,n 一般称折线P0P1P2 ?Pn 为曲线P(t) 的控制多边形;称点P0 ,P1 ,P2 , ?,Pn 为P(t) 的控制顶点。在空间曲线的情况下,曲线P(t) = (x(t) ,y(t) ,z (t) ) 和控制顶点Pi = (Xi ,Yi ,Zi) 的关系用分量写出即为: X(t) = 6n i = 0 XiJ i ,n (t) Y(t) = 6 n i = 0 YiJ i ,n (t) Z(t) = 6n i = 0 ZiJ i ,n (t) 当t 在区间[0 ,1 ] 上变动时,就产生了Bezier 曲线。若只考虑x和y ,就是平面上的Bezier 曲线。以三次Bezier 曲线为例,它可用矩阵形式表示如下: P(t) = [t3 t2 t 1] - 1 3 - 3 1 3 - 6 3 0 - 3 3 0 0 1 0 0 0 Q(0) Q(1) Q(2) Q(3) 0 ≤t ≤1 2, Bezier 曲线的性质 Bezier 曲线具有以下性质: 当t = 0 时,P(0) = P0 ,故P0 决定曲线的起点,当t = 1 时,P(1) = Pn ,故Pn 决定曲线的终点。Bezier 曲线的起点、终点与相应的特征多边形的起点、终点重合。Bezier 曲线P(t) 在P0 点与边P0P1 相切,在Pn点与边Pn- 1Pn 相切。Bezier 曲线P(t) 位于其控制顶点P0 ,P1 ,P2 ,?,Pn 的凸包之内。 Bezier 曲线P(t) 具有几何不变性。 Bezier 曲线P(t) 具有变差缩减性。 3, Bezier曲线的de Casteljau算法 Paul de Casteljau 发现了一个Bezier 曲线非常有趣的特性,任何的Bezier 曲线都能很容易地分成两个同样阶次的Bezier 曲线。 实验报告一 课程C++ 实验名称简单算法设计第 1 页专业_数学与应用数学_ __ 班级__ 双师一班学号105012011056 姓名陈萌 实验日期:2013 年 3 月9 日报告退发(订正、重做) 一、实验目的 1. 理解算法设计与分析的基本概念,理解解决问题的算法设计与实现过程; 2. 掌握简单问题的算法设计与分析,能设计比较高效的算法; 3. 熟悉C/C++语言等的集成开发环境,掌握简单程序设计与实现的能力。 二、实验内容 (一)相等元素问题 1.问题描述 元素唯一性问题:给出一个整数集合,假定这些整数存储在数组A[1…n]中,确定它们中是否存在两个相等的元素。请设计出一个有效算法来解决这个问题,你的算法的时间复杂性是多少? 2. 具体要求(若在ACM平台上提交程序,必须按此要求)――平台上1767题 输入:输入的第一行是一个正整数m,表示测试例个数。接下来几行是m个测试例的数据,每个测试例的数据由两行组成,其中第一行为一个正整数n (n<=500),表示整数序列的长度,第二行给出整数序列,整数之间用一个空格隔开。 输出:对于每个测试例输出一行,若该组测试例中存在两个相等的元素则输出”Yes”,否则,输出”No”。每个测试例的输出数据用一行表示。 3. 测试数据 输入:3 10 9 71 25 64 38 52 5 31 19 45 16 26 35 17 92 53 24 6 57 21 12 34 2 17 86 75 33 20 15 87 32 7 84 35 26 45 78 96 52 22 37 65 9 43 21 3 33 91 输出:No Yes No (二) 整数集合分解 1.问题描述 设计算法把一个n个元素的整数集合(n为偶数)分成两个子集S1和S2,使得:每个新的集合中含有n/2个元素,且S1中的所有元素的和与S2中的所有元素的和的差最大。 2. 具体要求(若在ACM平台上提交程序,必须按此要求)――平台上1768题 输入的第一行是一个正整数m,表示测试例个数。接下来几行是m个测试例的数据,每个测试例的数据由两行组成,其中第一行为一个正整数n (n为偶数,且n<=500),表示原整数集合的长度,第二行给出这n个整数序列,整数之间用一个空格隔开。 输出:对于每个测试例输出两行,分别表示新生成的整数集合。其中,第一行是元素和比较小的整数集合,第二行是元素和比较大的整数集合,整数之间用一个空格隔开。两个测 《数据结构》实验报告排序实验题目: 输入十个数,从插入排序,快速排序,选择排序三类算法中各选一种编程实现。 实验所使用的数据结构内容及编程思路: 1. 插入排序:直接插入排序的基本操作是,将一个记录到已排好序的有序表中,从而得到一个新的,记录增一得有序表。 一般情况下,第i 趟直接插入排序的操作为:在含有i-1 个记录的有序子序列r[1..i-1 ]中插入一个记录r[i ]后,变成含有i 个记录的有序子序列r[1..i ];并且,和顺序查找类似,为了在查找插入位置的过程中避免数组下标出界,在r [0]处设置哨兵。在自i-1 起往前搜索的过程中,可以同时后移记录。整个排序过程为进行n-1 趟插入,即:先将序列中的第一个记录看成是一个有序的子序列,然后从第2 个记录起逐个进行插入,直至整个序列变成按关键字非递减有序序列为止。 2. 快速排序:基本思想是,通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。 假设待排序的序列为{L.r[s] ,L.r[s+1],…L.r[t]}, 首先任意选取一个记录 (通常可选第一个记录L.r[s])作为枢轴(或支点)(PiVOt ),然后按下述原则重新排列其余记录:将所有关键字较它小的记录都安置在它的位置之前,将所有关键字较大的记录都安置在它的位置之后。由此可以该“枢轴”记录最后所罗的位置i 作为界线,将序列{L.r[s] ,… ,L.r[t]} 分割成两个子序列{L.r[i+1],L.[i+2], …,L.r[t]}。这个过程称为一趟快速排序,或一次划分。 一趟快速排序的具体做法是:附设两个指针lOw 和high ,他们的初值分别为lOw 和high ,设枢轴记录的关键字为PiVOtkey ,则首先从high 所指位置起向前搜索找到第一个关键字小于PiVOtkey 的记录和枢轴记录互相交换,然后从lOw 所指位置起向后搜索,找到第一个关键字大于PiVOtkey 的记录和枢轴记录互相 交换,重复这两不直至low=high 为止。 具体实现上述算法是,每交换一对记录需进行3 次记录移动(赋值)的操作。而实际上, 实验报告 计算机图形学实验报告——C字曲线算法 计算机图形学实验报告——C字曲线算法 1)算法原理介绍 实验环境:Microsoft Visual C++ C字线算法原理:C曲线由控制多边形通过一系列割角变换生成,具有连续性。C 曲线容易在计算机上快速产生, 用于计算机图形的实时处理。实验中还应用了C 曲线的凸包性、保凸性、局部无依赖性等性质。本实验程中GetMaxX()函数得到屏幕上的X方向上的最大值;GetMaxY()数得到屏幕上的Y方向上的最大值; c(n,300,150,MaxX-300,150)函数画出C字样图形。 2)程序设计文档说明 一、课程设计目的 在掌握图形学的基本原理、算法和实现技术基础上,通过编程实践学会基本的图形软件开发技术。 1.了解Visual C++ 2005绘图的基本概念 2.了解Visual C++2005绘图环境 3.了解Visual C++2005绘图环境 4. 掌握用Visual C++ 2005绘图的基本命令 二、课程设计内容 仿照Windows的附件程序“画图”, 用C++语言编制一个具有交互式绘制和编辑多种图元功能的程序“C字曲线算法”,实现以下功能对应的设计内容: (1) 能够以交互方式在图形绘制区绘制直线(折线); (2)设置C字曲线的迭代次数,分析不同迭代次数的变化情况; (3)通过帮助文档了解和使用函数。 三、实验步骤 1.新建MFC应用程序 1.1新建工程。运行VC++6.0,新建一个MFC AppWizard[exe]工程,并命名,选择保存 路径,确定。 1.2选择应用程序的类型,选择“单文档”,则可以通过菜单打开对话框 2.建立单文档应用程序,在其中调用对话框 2.1 查看工程资源 在单击完成之后,即建立了一个工程,在工程的左侧资源视图可以看到MFC向导为该程序提供的一些资源。 分别如下所示: 《算法设计》实习报告 班级 XXXX 名 XX 学号 XXXXXXX 1.给出Dijkstra算法的思想,并用C或C++实现,并分析该算法的复杂度。对下 图所示的有向网,试利用Dijkstra算法求出从源点1到其他顶点的最短路径。 实习报告的内容: <一>解决问题和算法思想 这个问题即为单源最短路问题。解决单源最短路径的基本思想是把图中所有结点分为两组,每一个结点对应一个距离值。设置两个结点的集合S和T,集合S中存放已找到最短路径的结点,集合T存放当前还未找到最短路径的结点。初始状态时,集合S只包含源点,设为V0,然后不断从集合T中选择到源点V0路径长度最短的结点u加入到集合S中,集合S每加入一个新的结点u都要修改从源点V0到集合T中剩余结点的当前最短路径长度值,集合T中各结点的新的当前路径最短路径,为原来的最短路径与从源点过结点u到达该结点的路径长度中的较小者。此过程不断重复,直到集合T中的结点全部加入到集合S中为止。 <二>调试通过的源程序 (1)顺序表打包文件:seqlist.h typedef struct { datatype list[maxsize]; int size; }seqlist; void listinitiate(seqlist *l) { l->size=0; } int listlength(seqlist l) { return l.size; } int listinsert(seqlist *l,int i,datatype x) { int j; if(l->size>=maxsize) { printf("it is too full!\n"); return 0; } else if(i<0||i>l->size) { printf("error!\n"); return 0; } else { for(j=l->size;j>i;j--) l->list[j]=l->list[j-1]; l->list[i]=x; l->size++; return 1; } } int listdelete(seqlist *l,int i,datatype *x) { int j; if(l->size<=0) { printf("it is empty!\n"); return 0; } else if(i<0||i>l->size-1) { printf("error!\n"); return 0; } else { *x=l->list[i]; for(j=i+1;j<=l->size-1;j++) l->list[j-1]=l->list[j]; l->size--; return 1; } } int listget(seqlist l,int i,datatype *x) { if(i<0||i>=l.size-1) { printf("error!\n"); return 0; } else { *x=l.list[i]; return 1; } } (2)邻接矩阵打包文件:adjmgraph.h 《排序问题求解》实验报告 一、算法的基本思想 1、直接插入排序算法思想 直接插入排序的基本思想是将一个记录插入到已排好序的序列中,从而得到一个新的,记录数增1 的有序序列。 直接插入排序算法的伪代码称为InsertionSort,它的参数是一个数组A[1..n],包含了n 个待排序的数。用伪代码表示直接插入排序算法如下: InsertionSort (A) for i←2 to n do key←A[i] //key 表示待插入数 //Insert A[i] into the sorted sequence A[1..i-1] j←i-1 while j>0 and A[j]>key do A[j+1]←A[j] j←j-1 A[j+1]←key 2、快速排序算法思想 快速排序算法的基本思想是,通过一趟排序将待排序序列分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可对这两部分记录继续进行排序,以达到整个序列有序。 假设待排序序列为数组A[1..n],首先选取第一个数A[0],作为枢轴(pivot),然后按照下述原则重新排列其余数:将所有比A[0]大的数都排在它的位置之前,将所有比A[0] 小的数都排在它的位置之后,由此以A[0]最后所在的位置i 作为分界线,将数组A[1..n]分成两个子数组A[1..i-1]和A[i+1..n]。这个过程称作一趟快速排序。通过递归调用快速排序,对子数组A[1..i-1]和A[i+1..n]排序。 一趟快速排序算法的伪代码称为Partition,它的参数是一个数组A[1..n]和两个指针low、high,设枢轴为pivotkey,则首先从high 所指位置起向前搜索,找到第一个小于pivotkey 的数,并将其移到低端,然后从low 所指位置起向后搜索,找到第一个大于pivotkey 的数,并将其移到高端,重复这两步直至low=high。最后,将枢轴移到正确的位置上。用伪代码表示一趟快速排序算法如下: Partition ( A, low, high) A[0]←A[low] //用数组的第一个记录做枢轴记录 privotkey←A[low] //枢轴记录关键字 while low Voronoi图生成算法的实现、 对比及演示实验报告 C组 张哲 2012212882 唐磊 2012212861 陈帅 2012212906 1. 实验内容 对Voronoi图的生成算法进行实现、对比及演示。 2. 数据结构 采用DCEL结构(下面所列代码去除了函数、只留下成员变量,具体见源码中basic_types.h 文件): class Site { public: Point p; private: double x_, y_; //coordinates of this site Face* incFace_; //the face that this site belongs to }; class Vertex { public: Point p; private: double x_, y_; //coordinates of v Halfedge* incEdge_; //pionter to any outgoing incident halfedge }; class Face { private: Site* site_; //the site of this face Halfedge* incEdge_; //any incident halfedge }; class Halfedge { public: bool hasDraw; private: Halfedge* twinEdge_; //pointer to twin halfedge Vertex* oriVertex_; //pointer to origin vertex Face* incFace_; //pointer to left incident face Halfedge* prevEdge_; //pointer to CCW previous halfedge Halfedge* nextEdge_; //pointer to CCW next halfedge Point* midPoint_; //the midpoint of the two sites of this halfedge Vector* direction_; //the direction of this halfedge }; 3. 算法描述 3.1 增量法 3.1.1 增量法概述 每次向voronoi图中增加一个点,寻找与这个点最近的site,从这个site开始计算新加入的点所统治的区域的边界,删除旧的边并更新DCEL结构,直到所有点都加入到图中为止。 本科实验报告 课程名称:算法设计与分析 实验项目:递归与分治算法 实验地点:计算机系实验楼110 专业班级:物联网1601 学号:2016002105 学生:俞梦真 指导教师:郝晓丽 2018年05月04 日 实验一递归与分治算法 1.1 实验目的与要求 1.进一步熟悉C/C++语言的集成开发环境; 2.通过本实验加深对递归与分治策略的理解和运用。 1.2 实验课时 2学时 1.3 实验原理 分治(Divide-and-Conquer)的思想:一个规模为n的复杂问题的求解,可以划分成若干个规模小于n的子问题,再将子问题的解合并成原问题的解。 需要注意的是,分治法使用递归的思想。划分后的每一个子问题与原问题的性质相同,可用相同的求解方法。最后,当子问题规模足够小时,可以直接求解,然后逆求原问题的解。 1.4 实验题目 1.上机题目:格雷码构造问题 Gray码是一个长度为2n的序列。序列无相同元素,每个元素都是长度为n的串,相邻元素恰好只有一位不同。试设计一个算法对任意n构造相应的Gray码(分治、减治、变治皆可)。 对于给定的正整数n,格雷码为满足如下条件的一个编码序列。 (1)序列由2n个编码组成,每个编码都是长度为n的二进制位串。 (2)序列中无相同的编码。 (3)序列中位置相邻的两个编码恰有一位不同。 2.设计思想: 根据格雷码的性质,找到他的规律,可发现,1位是0 1。两位是00 01 11 10。三位是000 001 011 010 110 111 101 100。n位是前n-1位的2倍个。N-1个位前面加0,N-2为倒转再前面再加1。 3.代码设计: 【一】需求分析 课程题目是排序算法的实现,课程设计一共要设计八种排序算法。这八种算法共包括:堆排序,归并排序,希尔排序,冒泡排序,快速排序,基数排序,折半插入排序,直接插入排序。 为了运行时的方便,将八种排序方法进行编号,其中1为堆排序,2为归并排序,3为希尔排序,4为冒泡排序,5为快速排序,6为基数排序,7为折半插入排序8为直接插入排序。 【二】概要设计 1.堆排序 ⑴算法思想:堆排序只需要一个记录大小的辅助空间,每个待排序的记录仅占有一个存储空间。将序列所存储的元素A[N]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的元素均不大于(或不小于)其左右孩子(若存在)结点的元素。算法的平均时间复杂度为O(N log N)。 ⑵程序实现及核心代码的注释: for(j=2*i+1; j<=m; j=j*2+1) { if(j temp=su[i]; su[i]=su[0]; su[0]=temp; head(0,i-1); } cout<<"排序之后的数组为:"< 实验二作业调度 一. 实验题目 1、编写并调试一个单道处理系统的作业等待模拟程序。 作业调度算法:分别采用先来先服务(FCFS,最短作业优先(SJF)、响应 比高者优先(HRN的调度算法。 (1)先来先服务算法:按照作业提交给系统的先后顺序来挑选作业, 先提交的先被挑选。 (2)最短作业优先算法:是以进入系统的作业所提出的“执行时间”为标准, 总是优先选取执行时间最短的作业。 (3)响应比高者优先算法:是在每次调度前都要计算所有被选作业(在后备队列中)的响应比,然后选择响应比最高的作业执行。 2、编写并调度一个多道程序系统的作业调度模拟程序。 作业调度算法:采用基于先来先服务的调度算法。可以参考课本中的方法进 行设计。 对于多道程序系统,要假定系统中具有的各种资源及数量、调度作业时必须考虑到每个作业的资源要求。 二. 实验目的: 本实验要求用高级语言(C语言实验环境)编写和调试一个或多个作业调度的模拟程序,了解作业调度在操作系统中的作用,以加深对作业调度算法的理解 三. 实验过程 < 一>单道处理系统作业调度 1)单道处理程序作业调度实验的源程序: zuoye.c 执行程序: zuoye.exe 2)实验分析: 1、由于在单道批处理系统中,作业一投入运行,它就占有计算机的一切资 源直到作业完成为止,因此调度作业时不必考虑它所需要的资源是否得到 满足,它所占用的CPU时限等因素。 2、每个作业由一个作业控制块JCB表示,JCB可以包含如下信息:作业名、 提交时间、所需的运行时间、所需的资源、作业状态、链指针等等。作业 的状态可以是等待W(Wait)、运行R(Run)和完成F(Finish)三种状态之一 每个作业的最初状态总是等待W 3、对每种调度算法都要求打印每个作业幵始运行时刻、完成时刻、周转时 间、带权周转时间,以及这组作业的平均周转时间及带权平均周转时间 3) 流程图: .最短作业优先算法 三.高响应比算法 图一.先来先服务流程图 4) 源程序: #in elude 算法设计与分析课程实验项目目录 学生:学号: *实验项目类型:演示性、验证性、综合性、设计性实验。 *此表由学生按顺序填写。 本科实验报告专用纸 课程名称算法设计与分析成绩评定 实验项目名称蛮力法指导教师 实验项目编号实验项目类型设计实验地点机房 学生学号 学院信息科学技术学院数学系信息与计算科学专业级 实验时间2012年3月1 日~6月30日温度24℃ 1.实验目的和要求: 熟悉蛮力法的设计思想。 2.实验原理和主要容: 实验原理:蛮力法常直接基于问题的描述和所涉及的概念解决问题。 实验容:以下题目任选其一 1).为蛮力字符串匹配写一段可视化程序。 2).写一个程序,实现凸包问题的蛮力算法。 3).最著名的算式谜题是由大名鼎鼎的英国谜人 H.E.Dudeney(1857-1930)给出的: S END +MORE MONEY . 这里有两个前提假设: 第一,字母和十进制数字之间一一对应,也就是每个字母只代表一个数字,而且不同的字母代表不同的数字;第二,数字0不出现在任何数的最左边。求解一个字母算术意味着找到每个字母代表的是哪个数字。请注意,解可能并不是唯一的,不同人的解可能并不相同。3.实验结果及分析: (将程序和实验结果粘贴,程序能够注释清楚更好。) 该算法程序代码如下: #include "stdafx.h" #include "time.h" int main(int argc, char* argv[]) { int x[100],y[100]; int a,b,c,i,j,k,l,m,n=0,p,t1[100],num; int xsat[100],ysat[100]; printf("请输入点的个数:\n"); scanf("%d",&num); getchar(); clock_t start,end; start=clock(); printf("请输入各点坐标:\n"); for(l=0;l 《排序问题求解》实验报告 一、算法得基本思想 1、直接插入排序算法思想 直接插入排序得基本思想就是将一个记录插入到已排好序得序列中,从而得到一个新得, 记录数增 1 得有序序列。 直接插入排序算法得伪代码称为InsertionSort,它得参数就是一个数组A[1、、n],包含了n 个待排序得数。用伪代码表示直接插入排序算法如下: InsertionSort (A) for i←2 ton do key←A[i]//key 表示待插入数 //Insert A[i] into thesortedsequence A[1、、i-1] j←i-1 while j>0 andA[j]>key do A[j+1]←A[j] j←j-1 A[j+1]←key 2、快速排序算法思想 快速排序算法得基本思想就是,通过一趟排序将待排序序列分割成独立得两部分,其中一 部分记录得关键字均比另一部分记录得关键字小,则可对这两部分记录继续进行排序,以达 到整个序列有序。 假设待排序序列为数组A[1、、n],首先选取第一个数A[0],作为枢轴(pivot),然后按照下述原则重新排列其余数:将所有比A[0]大得数都排在它得位置之前,将所有比 A[0]小得数都排在它得位置之后,由此以A[0]最后所在得位置i 作为分界线,将数组 A[1、、n]分成两个子数组A[1、、i-1]与A[i+1、、n]。这个过程称作一趟快速排序。通过递归调用快速排序,对子数组A[1、、i-1]与A[i+1、、n]排序。 一趟快速排序算法得伪代码称为Partition,它得参数就是一个数组A[1、、n]与两个指针low、high,设枢轴为pivotkey,则首先从high所指位置起向前搜索,找到第一个小于pivotkey得数,并将其移到低端,然后从low 所指位置起向后搜索,找到第一个大于pivotkey 得数,并将其移到高端,重复这两步直至low=high。最后,将枢轴移到正确得位置上。用伪代码表示一趟快速排序算法如下: Partition ( A,low,high) A[0]←A[low] //用数组得第一个记录做枢轴记录 privotkey←A[low] //枢轴记录关键字 while low<high //从表得两端交替地向中间扫描 while low 先来先服务FCFS和短作业优先SJF进程调度算法 1、实验目的 通过这次实验,加深对进程概念的理解,进一步掌握进程状态的转变、进程调度的策略及对系统性能的评价方法。 2、需求分析 (1) 输入的形式和输入值的范围 输入值:进程个数Num 范围:0 说明本程序中用到的所有抽象数据类型的定义、主程序的流程以及各程序模块之间的层次(调用)关系。 4、详细设计 5、调试分析 (1)调试过程中遇到的问题以及解决方法,设计与实现的回顾讨论和分析 ○1开始的时候没有判断进程是否到达,导致短进程优先算法运行结果错误,后来加上了判断语句后就解决了改问题。 ○2 基本完成的设计所要实现的功能,总的来说,FCFS编写容易,SJF 需要先找到已经到达的进程,再从已经到达的进程里找到进程服务时间最短的进程,再进行计算。 (2)算法的改进设想 改进:即使用户输入的进程到达时间没有先后顺序也能准确的计算出结果。(就是再加个循环,判断各个进程的到达时间先后,组成一个有序的序列) (3)经验和体会 通过本次实验,深入理解了先来先服务和短进程优先进程调度算法的思想,培养了自己的动手能力,通过实践加深了记忆。 6、用户使用说明 (1)输入进程个数Num 算法设计与分析课程实验项目目录 学生姓名:学号: *实验项目类型:演示性、验证性、综合性、设计性实验。 *此表由学生按顺序填写。 本科实验报告专用纸 课程名称算法设计与分析成绩评定 实验项目名称蛮力法指导教师 实验项目编号 201 实验项目类型设计实验地点机房 学生姓名学号 学院信息科学技术学院数学系信息与计算科学专业级 实验时间 2012年 3月 1 日~6月30日温度24℃ 1.实验目的和要求: 熟悉蛮力法的设计思想。 2.实验原理和主要内容: 实验原理:蛮力法常直接基于问题的描述和所涉及的概念解决问题。 实验内容:以下题目任选其一 1).为蛮力字符串匹配写一段可视化程序。 2).写一个程序,实现凸包问题的蛮力算法。 3).最著名的算式谜题是由大名鼎鼎的英国谜人给出的: S END +MORE MONEY . 这 里有两个前提假设:第一,字母和十进制数字之间一一对应,也就是每个字母只代表一个数字,而且不同的字母代表不同的数字;第二,数字0不出现在任何数的最左边。求解一个字母算术意味着找到每个字母代表的是哪个数字。请注意,解可能并不是唯一的,不同人的解可能并不相同。 3.实验结果及分析: (将程序和实验结果粘贴,程序能够注释清楚更好。) 本科实验报告专用纸(附页) 该算法程序代码如下: #include "" #include "" int main(int argc, char* argv[]) { int x[100],y[100]; int a,b,c,i,j,k,l,m,n=0,p,t1[100],num; int xsat[100],ysat[100]; printf("请输入点的个数:\n"); scanf("%d",&num); getchar(); clock_t start,end; start=clock(); printf("请输入各点坐标:\n"); for(l=0;l插入排序算法实验报告
作业调度_实验报告
cad cam实验报告 贝齐尔(Bezier)曲线曲面的生成方法
算法设计实验报告一(简单算法设计)
《数据结构》实验报告——排序.docx
计算机图形学实验报告(原创)
算法设计实验报告
算法排序问题实验报告
Voronoi图生成算法的实现、对比及演示实验报告
算法设计与分析实验报告
各种排序实验报告
作业调度实验报告
《算法设计与分析》实验报告
算法排序问题实验报告
先来先服务FCFS和短作业优先SJF进程调度算法_实验报告材料
算法设计与分析实验报告
相关主题
文本预览