11.5 一家物流公司的管理人员想研究货物的运输距离和运输时间的关系,为此,他抽出了公司最近10个卡车运货记录的随机样本,得到运送距离(单位:km)和运送时间(单位:天)的数据如下:
要求:
(1)绘制运送距离和运送时间的散点图,判断二者之间的关系形态:
(2)计算线性相关系数,说明两个变量之间的关系强度。
(3)利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。
解:(1)
可能存在线性关系。
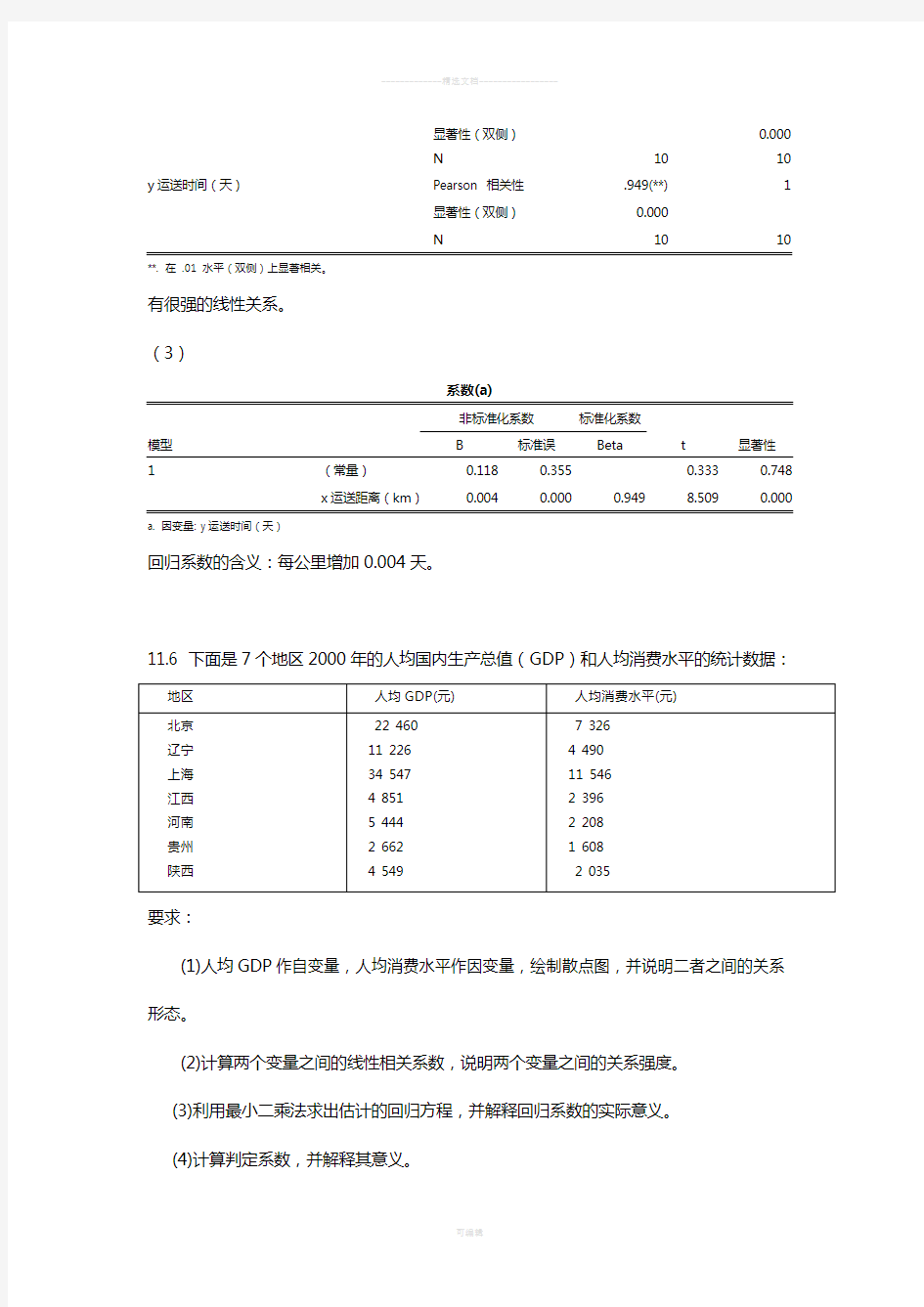
(2)
x运送距离(km)y运送时间(天)x运送距离(km)Pearson 相关性1.949(**)
显著性(双侧)0.000
N1010 y运送时间(天)Pearson 相关性.949(**)1
显著性(双侧)0.000
N1010 **. 在 .01 水平(双侧)上显著相关。
有很强的线性关系。
(3)
模型非标准化系数标准化系数
t显著性B标准误Beta
1(常量)0.1180.3550.3330.748
x运送距离(km)0.0040.0000.9498.5090.000 a. 因变量: y运送时间(天)
回归系数的含义:每公里增加0.004天。
11.6 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据:
要求:
(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(a=0.05)。
(6)如果某地区的人均GDP为5 000元,预测其人均消费水平。
(7)求人均GDP为5 000元时,人均消费水平95%的置信区间和预测区间。
解:(1)
可能存在线性关系。
(2)相关系数:
人均GDP(元)人均消费水平(元)人均GDP(元)Pearson 相关性1.998(**)
显著性(双侧)0.000
N77人均消费水平(元)Pearson 相关性.998(**)1
显著性(双侧)0.000
**. 在 .01 水平(双侧)上显著相关。
有很强的线性关系。
(3)回归方程:
模型非标准化系数标准化系数
t显著性B标准误Beta
1(常量)734.693139.540 5.2650.003
a. 因变量: 人均消费水平(元)
回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
(4)
1.998(a)0.9960.996247.303
a. 预测变量:(常量), 人均GDP(元)。
人均GDP对人均消费的影响达到99.6%。
(5)F检验:
模型平方和df均方F显1回归81,444,968.680181,444,968.6801,331.692
残差305,795.034561,159.007
合计81,750,763.7146
a. 预测变量:(常量), 人均GDP(元)。
b. 因变量: 人均消费水平(元)
回归系数的检验:t检验
模型非标准化系数标准化系数
t显著性B标准误Beta
1(常量)734.693139.540 5.2650.003
人均GDP(元)0.3090.0080.99836.4920.000 a. 因变量: 人均消费水平(元)
(6)
某地区的人均GDP为5 000元,预测其人均消费水平为2278.10657元。
(7)
人均GDP为5 000元时,人均消费水平95%的置信区间为[1990.74915,2565.46399],预测区间为[1580.46315,2975.74999]。
11.9 某汽车生产商欲了解广告费用(x)对销售量(y)的影响,收集了过去12年的有关数据。通过计算得到下面的有关结果:
方差分析表
参数估计表
要求:
(1)完成上面的方差分析表。
(2)汽车销售量的变差中有多少是由于广告费用的变动引起的?
(3)销售量与广告费用之间的相关系数是多少?
(4)写出估计的回归方程并解释回归系数的实际意义。
(5)检验线性关系的显著性(a=0.05)。
解:(2)R 2=0.9756,汽车销售量的变差中有97.56%是由于广告费用的变动引起的。 (3)r=0.9877。
(4)回归系数的意义:广告费用每增加一个单位,汽车销量就增加1.42个单位。 (5)回归系数的检验:p=2.17E —09<α,回归系数不等于0,显著。 回归直线的检验:p=2.17E —09<α,回归直线显著。
11.11 从20的样本中得到的有关回归结果是:SSR=60,SSE=40。要检验x 与y 之间的线性关系是否显著,即检验假设:01:0H β=。 (1)线性关系检验的统计量F 值是多少? (2)给定显著性水平a =0.05,F a 是多少? (3)是拒绝原假设还是不拒绝原假设?
(4)假定x 与y 之间是负相关,计算相关系数r 。 (5)检验x 与y 之间的线性关系是否显著?
解:(1)SSR 的自由度为k=1;SSE 的自由度为n-k-1=18;
因此:F=1SSR k SSE n k --=60
14018
=27 (2)()1,18F α=()0.051,18F =4.41 (3)拒绝原假设,线性关系显著。 (4)
,由于是负相关,因此r=-0.7746
(5)从F 检验看线性关系显著。
11.15 随机抽取7家超市,得到其广告费支出和销售额数据如下:
要求:
(1)用广告费支出作自变量x,销售额作因变量y,求出估计的回归方程。
(2)检验广告费支出与销售额之间的线性关系是否显著(a=0.05)。
(3)绘制关于x的残差图,你觉得关于误差项 的假定被满足了吗?
(4)你是选用这个模型,还是另寻找一个更好的模型?
解:(1)
模型非标准化系数标准化系数
t显著性B标准误Beta
1(常量)29.399 4.807 6.1160.002
广告费支出(万元) 1.5470.4630.831 3.3390.021 a. 因变量: 销售额(万元)
(2)回归直线的F检验:
模型平方和df均方F显著性1回归691.7231691.72311.147.021(a)
残差310.277562.055
合计1,002.0006
a. 预测变量:(常量), 广告费支出(万元)。
b. 因变量: 销售额(万元)显著。
回归系数的t检验:
模型非标准化系数标准化系数
t显著性B标准误Beta
1(常量)29.399 4.807 6.1160.002
广告费支出(万元) 1.5470.4630.831 3.3390.021 a. 因变量: 销售额(万元)
显著。
(3)未标准化残差图:
标准化残差图:
学生氏标准化残差图:
看到残差不全相等。
(4)应考虑其他模型。可考虑对数曲线模型:y=b0+b1ln(x)=22.471+11.576ln(x)。
第七章 相关与回归分析 一、本章学习要点 (一)相关分析就是研究两个或两个以上变量之间相关程度大小以及用一定函数来表达现象相互关系的方法。现象之间的相互关系可以分为两种,一种是函数关系,一种是相关关系。函数关系是一种完全确定性的依存关系,相关关系是一种不完全确定的依存关系。相关关系是相关分析的研究对象,而函数关系则是相关分析的工具。 相关按其程度不同,可分为完全相关、不完全相关和不相关。其中不完全相关关系是相关分析的主要对象;相关按方向不同,可分为正相关和负相关;相关按其形式不同,可分为线性相关和非线性相关;相关按影响因素多少不同,可分为单相关和复相关。 (二)判断现象之间是否存在相关关系及其程度,可以根据对客观现象的定性认识作出,也可以通过编制相关表、绘制相关图的方式来作出,而最精确的方式是计算相关系数。 相关系数是测定变量之间相关密切程度和相关方向的代表性指标。相关系数用符号“γ”表示,其特点表现在:参与相关分析的两个变量是对等的,不分自变量和因变量,因此相关系数只有一个;相关系数有正负号反映相关系数的方向,正号反映正相关,负号反映负相关;计算相关系数的两个变量都是随机变量。 相关系数的取值区间是[-1,+1],不同取值有不同的含义。当1||=γ时,x 与y 的变量为完全相关,即函数关系;当1||0<<γ时,表示x 与y 存在一定的线性相关,||γ的数值越大,越接近于1,表示相关程度越高;反之,越接近于0,相关程度越低,通常判别标准是:3.0||<γ称为微弱相关,5.0||3.0<<γ称为低度相关,8.0||5.0<<γ称为显著相关,1||8.0<<γ称为高度相关;当0||=γ时,表示y 的变化与x 无关,即不相关;当0>γ时,表示x 与y 为线性正相关,当0<γ时,表示x 与y 为线性负相关。 皮尔逊积距相关系数计算的基本公式是: ∑∑∑∑∑∑∑---= =] )(][)([22222y y n x x n y x xy n y x xy σσσγ 斯皮尔曼等级相关系数和肯特尔等级相关系数是测量两个等级变量(定序测度)之间相 关密切程度的常用指标。 (三)回归分析是对具有相关关系的两个或两个以上变量之间数量变化的一般关系进行测定,确定一个相应的数学表达式,以便从一个已知量来推测另一个未知量,为估计预测提供一个重要的方法。回归分析按自变量的个数分,有一元回归和多元回归,按回归线的形状分,有线性回归和非线性回归。与相关分析相比,回归分析的特点是:两个变量是不对等的,必须区分自变量和因变量;因变量是随机的,自变量是可以控制的量;对于一个没有因果关系的两变量,可以求得两个回归方程,一个是y 倚x 的回归方程,一个是x 倚y 的回归方程。 简单线性回归方程式为:bx a y c +=,式中c y 是y 的估计值,a 代表直线在y 轴上的截距,b 表示直线的斜率,又称为回归系数。回归系数的涵义是,当自变量x 每增加一个单位时,因变量y 的平均增加值。当b 的符号为正时,表示两个变量是正相关,当b 的符号为负时,表示两个变量是负相关。a 、b 都是待定参数,可以用最小平方法求得。求解a 、b 的公式为: ∑∑∑∑∑--= 2 2)(x x n y x xy n b ; n x b n y a ∑∑-= 回归估计标准误差是衡量因变量的估计值与观测值之间的平均误差大小的指标。利用此 指标可以说明回归方程的代表性。其计算公式为: 2 ) (2 --= ∑n y y S c yx 或2 2 ---= ∑∑∑n xy b y a y S yx 回归估计标准误和相关系数之间具有以下关系:
第10章 简单线性回归分析 思考与练习参考答案 一、最佳选择题 1.如果两样本的相关系数21r r =,样本量21n n =,那么( D )。 A. 回归系数21b b = B .回归系数12b b < C. 回归系数21b b > D .t 统计量11r b t t = E. 以上均错 2.如果相关系数r =1,则一定有( C )。 A .总SS =残差SS B .残差SS =回归 SS C .总SS =回归SS D .总SS >回归SS E. 回归MS =残差MS 3.记ρ为总体相关系数,r 为样本相关系数,b 为样本回归系数,下列( D )正确。 A .ρ=0时,r =0 B .|r |>0时,b >0 C .r >0时,b <0 D .r <0时,b <0 E. |r |=1时,b =1 4.如果相关系数r =0,则一定有( D )。 A .简单线性回归的截距等于0 B .简单线性回归的截距等于Y 或X C .简单线性回归的残差SS 等于0 D .简单线性回归的残差SS 等于SS 总 E .简单线性回归的总SS 等于0 5.用最小二乘法确定直线回归方程的含义是( B )。 A .各观测点距直线的纵向距离相等 B .各观测点距直线的纵向距离平方和最小 C .各观测点距直线的垂直距离相等 D .各观测点距直线的垂直距离平方和最小
E .各观测点距直线的纵向距离等于零 二、思考题 1.简述简单线性回归分析的基本步骤。 答:① 绘制散点图,考察是否有线性趋势及可疑的异常点;② 估计回归系数;③ 对总体回归系数或回归方程进行假设检验;④ 列出回归方程,绘制回归直线;⑤ 统计应用。 2.简述线性回归分析与线性相关的区别与联系。 答:区别: (1)资料要求上,进行直线回归分析的两变量,若X 为可精确测量和严格控制的变量,则对应于每个X 的Y 值要求服从正态分布;若X 、Y 都是随机变量,则要求X 、Y 服从双变量正态分布。直线相关分析只适用于双变量正态分布资料。 (2)应用上,说明两变量线性依存的数量关系用回归(定量分析),说明两变量的相关关系用相关(定性分析)。 (3)两个系数的意义不同。r 说明具有直线关系的两变量间相互关系的方向与密切程度,b 表示X 每变化一个单位所导致Y 的平均变化量。 (4)两个系数的取值范围不同:-1≤r ≤1,∞<<∞-b 。 (5)两个系数的单位不同:r 没有单位,b 有单位。 联系: (1)对同一双变量资料,回归系数b 与相关系数r 的正负号一致。b >0时,r >0,均表示两变量X 、Y 同向变化;b <0时,r <0,均表示两变量X 、Y 反向变化。 (2)回归系数b 与相关系数r 的假设检验等价,即对同一双变量资料,r b t t =。由于相关系数r 的假设检验较回归系数b 的假设检验简单,故在实际应用中常以r 的假设检验代替b 的假设检验。 (3)用回归解释相关:由于决定系数2 R =SS 回 /SS 总 ,当总平方和固定时,回归平方 和的大小决定了相关的密切程度。回归平方和越接近总平方和,则2 R 越接近1,说明引入相关的效果越好。例如当r =0.20,n =100时,可按检验水准0.05拒绝H 0,接受H 1,认为两变量有相关关系。但2 R =(0.20)2=0.04,表示回归平方和在总平方和中仅占4%,说明
第十一章一元线性回归 11.1从某一行业中随机抽取12家企业,所得产量与生产费用的数据如下: 要求: (1)绘制产量与生产费用的散点图,判断二者之间的关系形态。 (2)计算产量与生产费用之间的线性相关系数。 (3)对相关系数的显著性进行检验(α = 0.05),并说明二者之间的关系强度。 解:(1)利用Excel的散点图绘制功能,绘制的散点图如下: 从散点图的形态可知,产量与生产费用之间存在正的线性相关。 (2)利用Excel的数据分析中的相关系数功能,得到产量与生产费用的线性相关系数r = 0.920232。 (3)计算t统计量,得到t = 7.435453,在α = 0.05的显著性水平下,临界值为2.6337,统计量远大于临界值,拒绝原假设,产量与生产费用之间存在显著
的正线性相关关系。r大于0.8,高度相关。 11.2 学生在期末考试之前用于复习的时间(单位:h)和考试分数(单位:分)之间是否有关系?为研究这一问题,以为研究者抽取了由8名学生构成的一个随机样本,得到的数据如下: 要求: (1)绘制复习时间和考试分数的散点图,判断二者之间的关系形态。 (2)计算相关系数,说明两个变量之间的关系强度。 解:(1)利用Excel的散点图绘制功能,绘制的散点图如下: 从散点图的形态来看,考试分数与复习时间之间似乎存在正的线性相关关系。 (2)r = 0.862109,大于0.8,高度相关。 11.3根据一组数据建立的线性回归方程为?100.5 =-。 y x
要求: ?β的意义。 (1)解释截距 ?β意义。 (2)解释斜率 1 (3)计算当x = 6时的E(y)。 解:(1)在回归模型中,一般不能对截距项赋予意义。 ?β的意义为:当x增加1时,y减小0.5。 (2)斜率 1 (3)当x = 6时,E(y) = 10 – 0.5 * 6 = 7。 11.4 设SSR = 36,SSE = 4,n = 18。 要求: (1)计算判定系数R2并解释其意义。 (2)计算估计标准误差s e并解释其意义。 解:SST = SSR+SSE = 36+4 = 40, R2 = SSR / SST = 36 /40 = 0.9,意义为自变量可解释因变量变异的90%,自因变量与自变量之间存在很高的线性相关关系。 s== 0.5,这是随机项的标准误差的估计值。 (2) e 11.5一家物流公司的管理人员想研究货物的运送距离和运送时间的关系,因此,他抽出了公司最近10辆卡车运货记录的随机样本,得到运送距离(单位:km)和运送时间(单位:天)的数据如下:
(一) 填空题 1、 现象之间的相关关系按相关的程度分有________相关、________相关和_______ 相关;按相关的方向分有________相关和________相关;按相关的形式分有-________相关和________相关;按影响因素的多少分有________相关和-________相关。 2、 对现象之间变量关系的研究中,对于变量之间相互关系密切程度的研究,称为 _______;研究变量之间关系的方程式,根据给定的变量数值以推断另一变量的可能值,则称为_______。 3、 完全相关即是________关系,其相关系数为________。 4、 在相关分析中,要求两个变量都是_______;在回归分析中,要求自变量是 _______,因变量是_______。 5、 person 相关系数是在________相关条件下用来说明两个变量相关________的统 计分析指标。 6、 相关系数的变动范围介于_______与_______之间,其绝对值愈接近于_______, 两个变量之间线性相关程度愈高;愈接近于_______,两个变量之间线性相关程度愈低。当_______时表示两变量正相关;_______时表示两变量负相关。 7、 当变量x 值增加,变量y 值也增加,这是________相关关系;当变量x 值减少, 变量y 值也减少,这是________相关关系。 8、 在判断现象之间的相关关系紧密程度时,主要用_______进行一般性判断,用_______进行数量上的说明。 9、 在回归分析中,两变量不是对等的关系,其中因变量是_______变量,自变量是 _______量。 10、 已知13600))((=----∑y y x x ,14400)(2=--∑x x ,14900)(2=-∑-y y ,那么,x 和y 的相关系数r 是_______。 11、 用来说明回归方程代表性大小的统计分析指标是________指标。 12、 已知1502=xy σ,18=x σ,11=y σ,那么变量x 和y 的相关系数r 是_______。 13、 回归方程bx a y c +=中的参数b 是________,估计特定参数常用的方法是 _________。 14、 若商品销售额和零售价格的相关系数为-0.95,商品销售额和居民人均收入的相关系数为0.85,据此可以认为,销售额对零售价格具有_______相关关系,销售额与人均收入具有_______相关关系,且前者的相关程度_______后者的相关程度。 15、 当变量x 按一定数额变动时,变量y 也按一定数额变动,这时变量x 与y 之间存在着_________关系。 16、 在直线回归分析中,因变量y 的总变差可以分解为_______和_______,用公式表示,即_____________________。 17、 一个回归方程只能作一种推算,即给出_________的数值,估计_________的可能值。 18、 如估计标准误差愈小,则根据回归直线方程计算的估计值就_______ 19、 已知直线回归方程bx a y c +=中,5.17=b ;又知30=n ,∑=13500y ,
所属章节: 第五章相关分析与回归分析 1■在线性相关中,若两个变量的变动方向相反,一个变量的数值增加,另一个变量数值随之减少,或一个变量的数值减少,另一个变量的数值随之增加,则称为()。 答案: 负相关。干扰项: 正相关。干扰项: 完全相关。干扰项: 非线性相关。 提示与解答: 本题的正确答案为: 负相关。 2■在线性相关中,若两个变量的变动方向相同,一个变量的数值增加,另一个变量数值随之增加,或一个变量的数值减少,另一个变量的数值随之减少,则称为()。 答案: 正相关。干扰项: 负相关。干扰项: 完全相关。干扰项: 非线性相关。 提示与解答:
本题的正确答案为: 正相关。 3■下面的xx中哪一个是错误的()。 答案: 相关系数不会取负值。干扰项: 相关系数是度量两个变量之间线性关系强度的统计量。干扰项: 相关系数是一个随机变量。干扰项: 相关系数的绝对值不会大于1。 提示与解答: 本题的正确答案为: 相关系数不会取负值。 4■下面的xx中哪一个是错误的()。 答案: 回归分析中回归系数的显著性检验的原假设是: 所检验的回归系数的真值不为0。 干扰项: 相关系数显著性检验的原假设是: 总体中两个变量不存在相关关系。 干扰项: 回归分析中回归系数的显著性检验的原假设是:
所检验的回归系数的真值为0。 干扰项: 回归分析中多元线性回归方程的整体显著性检验的原假设是: 自变量前的偏回归系数的真值同时为0。 提示与解答: 本题的正确答案为: 回归分析中回归系数的显著性检验的原假设是: 所检验的回归系数的真值不为0。 5■根据你的判断,下面的相关系数值哪一个是错误的()。 答案: 1.25。干扰项:-0.86。干扰项: 0.78。干扰项:0。 提示与解答: 本题的正确答案为: 1.25。 6■下面关于相关系数的陈述中哪一个是错误的()。 答案: 数值越大说明两个变量之间的关系越强,数值越小说明两个变量之间的关系越弱。 干扰项:
第11章 多重线性回归分析 思考与练习参考答案 一、 最佳选择题 1. 逐步回归分析中,若增加自变量的个数,则( D )。 A. 回归平方和与残差平方和均增大 B. 回归平方和与残差平方和均减小 C. 总平方和与回归平方和均增大 D. 回归平方和增大,残差平方和减小 E. 总平方和与回归平方和均减小 2. 下面关于自变量筛选的统计学标准中错误的是( E )。 A. 残差平方和(残差SS )缩小 B. 确定系数(2 R )增大 C. 残差的均方(残差MS )缩小 D. 调整确定系数(2 ad R )增大 E. p C 统计量增大 3. 多重线性回归分析中,能直接反映自变量解释因变量变异百分比的指标为 ( C )。 A. 复相关系数 B. 简单相关系数 C.确定系数 D. 偏回归系数 E. 偏相关系数 4. 多重线性回归分析中的共线性是指( E )。 A.Y 关于各个自变量的回归系数相同 B.Y 关于各个自变量的回归系数与截距都相同 C.Y 变量与各个自变量的相关系数相同 D.Y 与自变量间有较高的复相关 E. 自变量间有较高的相关性 5. 多重线性回归分析中,若对某一自变量的值加上一个不为零的常数K ,则有( D )。 A. 截距和该偏回归系数值均不变 B. 该偏回归系数值为原有偏回归系数值的K 倍 C. 该偏回归系数值会改变,但无规律 D. 截距改变,但所有偏回归系数值均不改变 E. 所有偏回归系数值均不会改变 二、思考题 1. 多重线性回归分析的用途有哪些? 答:多重线性回归在生物医学研究中有广泛的应用,归纳起来,可以包括以下几个方面:定量地建立一个反应变量与多个解释变量之间的线性关系,筛选危险因素,通过较易测量的变量估计不易测量的变量,通过解释变量预测反应变量,通过反应变量控制解释变量。
第十章 直线相关与回归 一、教学大纲要求 (一) 掌握内容 ⒈ 直线相关与回归的基本概念。 ⒉ 相关系数与回归系数的意义及计算。 ⒊ 相关系数与回归系数相互的区别与联系。 (二)熟悉内容 ⒈ 相关系数与回归系数的假设检验。 ⒉ 直线回归方程的应用。 ⒊ 秩相关与秩回归的意义。 (三)了解内容 曲线直线化。 二、 学内容精要 (一) 直线回归 1. 基本概念 直线回归(linear regression)建立一个描述应变量依自变量变化而变化的直线方程,并要求各点与该直线纵向距离的平方和为最小。直线回归是回归分析中最基本、最简单的一种,故又称简单回归(simple regression )。 直线回归方程bX a Y +=?中,a 、b 是决定直线的两个系数,见表10-1。 表10-1 直线回归方程a 、b 两系数对比 a b 含义 回归直线在Y 轴上的截距(intercept )。 表示X 为零时,Y 的平均水平的估计值。 回归系数(regression coefficient ),即直线的斜率。表示X 每变化一个单位时,Y 的平均变化量的估计值。 系数>0 a >0表示直线与纵轴的交点在原点的上方 b >0,表示直线从左下方走向右上方,即Y 随X 增大而增大 系数<0 a <0表示直线与纵轴的交点在原点的下方 b <0,表示直线从左上方走向右下方,即Y 随X 增大而减小 系数=0 a =0表示回归直线通过原点 b =0,表示直线与X 轴平行,即Y 不随X 的变化而变化 计算公式 X b Y a -= XX XY l l X X Y Y X X b =---= ∑∑2 )())(( 2. 样本回归系数b 的假设检验 (1)方差分析; (2)t 检验。
第11章多重线性回归分析 案例辨析及参考答案 案例11-1预测人体吸入氧气的效率。为了解和预测人体吸入氧气的效率,某人收集了31名中年男 性的健康调查资料。一共调查了 7个指标,分别是吸氧效率(Y , %)、年龄(X1,岁)、体重(X2, kg )、 跑1.5 km所需时间(X3, min )、休息时的心跳频率(X4,次/min )、跑步时的心跳频率(X5,次/min) 和最高心跳频率(X6,次/min )(教材表11-9)。试用多重线性回归方法建立预测人体吸氧效率的模型。 教材表11 -9 吸氧效率调查数据 Y X1 X2X3 X4 X5 X6 Y X1 X2X3 X4 X5 X6 44.609 44 89.47 11.37 62 178 182 40.836 51 69.63 10.95 57 168 172 45.313 40 75.07 10.07 62 185 185 46.672 51 77.91 10.00 48 162 168 54.297 44 85.84 8.65 45 156 168 46.774 48 91.63 10.25 48 162 164 59.571 42 68.15 8.17 40 166 172 50.388 49 73.37 10.08 67 168 168 49.874 38 89.02 9.22 55 178 180 39.407 57 73.37 12.63 58 174 176 44.811 47 77.45 11.63 58 176 176 46.080 54 79.38 11.17 62 156 165 45.681 40 75.98 11.95 70 176 180 45.441 56 76.32 9.63 48 164 166 49.091 43 81.19 10.85 64 162 170 54.625 50 70.87 8.92 48 146 155 39.442 44 81.42 13.08 63 174 176 45.118 51 67.25 11.08 48 172 172 60.055 38 81.87 8.63 48 170 186 39.203 54 91.63 12.88 44 168 172 50.541 44 73.03 10.13 45 168 168 45.790 51 73.71 10.47 59 186 188 37.388 45 87.66 14.03 56 186 192 50.545 57 59.08 9.93 49 148 155 44.754 45 66.45 11.12 51 176 176 48.673 49 76.32 9.40 56 186 188 47.273 47 79.15 10.60 47 162 164 47.920 48 61.24 11.50 52 170 176 51.855 54 83.12 10.33 50 166 170 47.467 52 82.78 10.50 53 170 172 49.156 49 81.42 8.95 44 180 185 资料来自:张家放主编?医用多元统计方法?武汉:华中科技大学出版社,2002。 该研究员采用后退法对自变量进行筛选,最后得到结果如教材表11-10所示。 教材表11-10 多重线性回归模型的参数估计 Table 11-10 Parameter estimati on of regressi on model Variable Un sta ndardized Coefficie nts Stan dardized Coefficie nts t P B Std. Error In tercept 100.079 11.577 8.644 0.000 X1 -0.213 0.091 -0.214 -2.337 0.027 X3 -2.768 0.331 -0.721 -8.354 0.000 X5 -0.339 0.116 -0.653 -2.939 0.007 X6 0.255 0.132 0.439 1.936 0.064
第十章 logitic 回归 本章导读: Logitic 回归模型是离散选择模型之一,属于多重变数分析范畴,是社会学、生物统计学、临床、数量心理学、市场营销、会计与财务等实证分析的常用方法。 10.1 logit 模型和原理 Logistic 回归分析是对因变量为定性变量的回归分析。它是一种非线性模型。其基本特点是:因变量必须是二分类变量,若令因变量为y ,则常用y=1表示“yes ”,y=0表示“no ”。 [在发放股利与不发放股利的研究中,分别表示发放和不发放股利的公司]。自变量可以为虚拟变量也可以为连续变量。从模型的角度出发,不妨把事件发生的情况定义为y=1,事件未发生的情况定义为0,这样取值为0、1的因变量可以写作: ???===事情未发生 事情发生01y 我们可以采用多种方法对取值为0、1的因变量进行分析。通常以P 表示事件发生的概率(事件未发生的概率为1-P ),并把P 看作自变量x 的线性函数。由于y 是0-1型Bernoulli 分布,因此有如下分布: P=P (y=1|x ):自变量为x 时y=1的概率,即发放现金股利公司的概率 1-P=P (y=0|x ):自变量为x 时y=0的概率,即不发放现金股利公司的概率 事件发生和不发生的概率比成为发生比,即相对风险,表现为P P odds -= 1.因为是以 对数形式出现的,故该发生比为对数发生比(log odds ),表现为)1ln(P P odds -=。对数发生比也是事件发生概率P 的一个特定函数,通过logistic 转换,该函数可以写成logistic 回归的logit 模型: )1(log )(log P P P it e -= Logit 一方面表达出它是事件发生概率P 的转换单位;另一方面,它作为回归的因变量就可以自己与自变量之间的依存关系保持传统回归模式。 根据离散型随即变量期望值的定义,可得: E(y)=1(P)+0(1-P)=P 进而得到x P y E 10)(ββ+== 因此,从以上分析可以看出,当因变量的取值为0、1时,均值x y E 10)(ββ+=总是代表给定自变量时y=1的概率。虽然这是从简单线性回归分析而得,但也适合复杂的多元回归函数情况。 k k x x x itP y E ββββ++++==Λ22110log )( β0为常数项,β1,β2,…,βk 分别为k 个自变量的回归系数。 因此,logistic 模型为:
第七章 相关分析与回归分析 例1、有10个同类企业的固定资产和总产值资料如下: 根据以上资料计算(1)协方差和相关系数;(2)建立以总产值为因变量的一元线性回归方程;(3)当固定资产改变200万元时,总产值平均改变多少?(4)当固定资产为1300万元时,总产值为多少? 解:计算表如下: (1)协方差——用以说明两指标之间的相关方向。 2 2) )((n y x xy n n y y x x xy ∑∑∑∑- = - -= σ
35.126400100 9801 6525765915610>=?-?= 计算得到的协方差为正数,说明固定资产和总产值之间存在正相关关系。 (2)相关系数用以说明两指标之间的相关方向和相关的密切程度。 ∑∑∑ ∑∑∑∑--- = ] )(][) ([2 2 2 2 y y n x x n y x xy n r 95 .0) 980110866577 10()6525566853910(9801 65257659156102 2 =-??-??-?= 计算得到的相关系数为0.95,表示两指标为高度正相关。 (3) 2 2 26525 56685391098016525765915610) (-??-?= --= ∑∑∑∑∑x x n y x xy n b 90 .014109765 126400354257562556685390 6395152576591560== --= 85 .39210 65259.010 9801=? -= -=x b y a 回归直线方程为: x y 9.085.392?+= (4)当固定资产改变200万元时,总产值平均改变多少? x y ?=?9.0,180 2009.0|200=?=?=?x y 万元 当固定资产改变200万元时,总产值平均增加180万元。 (5)当固定资产为1300万元时,总产值为多少? 85 .156213009.085.392|1300=?+==x y 万元 当固定资产为1300万元时,总产值为1562.85万元。 例2、试根据下列资产总值和平均每昼夜原料加工量资料计算相关系数。
第八章相关与回归分析 一、本章重点 1.相关系数的概念及相关系数的种类。事物之间的依存关系,可以分为函数关系和相关关系。相关关系又有单向因果关系和互为因果关系;单相关和复相关;线性相关和非线性相关;不相关、不完全相关和完全相关;正相关和负相关等类型。 2.相关分析,着重掌握如何画相关表、相关图,如何测定相关系数、测定系数以及进行相关系数的推断。相关表和相关图是变量间相关关系的生动表示,对于未分组资料和分组资料计算相关系数的方法是不同的,一元线性回归中相关系数和测定系数有着密切的关系,得到样本相关系数后还要对总体相关系数进行科学推断。 3.回归分析,着重掌握一元回归的基本原理方法,一元回归是线性回归的基础,多元线性回归和非线性回归都是以此为基础的。用最小平方法估计回归参数,回归参数的性质和显著性检验,随机项方差的估计,回归方程的显著性检验,利用回归方程进行预测是回归分析的主要内容。 4.应用相关与回归分析应注意的问题。相关与回归分析都有它们的应用范围,必须知道在什么情况下能用,什么情况下不能用。相关分析和回归分析必须以定性分析为前提,否则可能会闹出笑话,在进行预测时选取的样本要尽量分散,以减少预测误差,在进行预测时只有在现有条件不变的情况下才能进行,如果条件发生了变化,原来的方程也就失去了效用。 二、难点释疑 本章难点在于计算公式多,不容易记忆,所以更要注重计算的练习。为了掌握基本计算的内容,起码应认真理解书上的例题,做完本指导书上的全部计算题。初学者可能会感到本章公式多且复杂,难于记忆,其实只要抓住Lxx、Lxy、Lyy 这三个记号,记住它们的展开式,几个主要的公式就不难记忆了。如果能自己把这些公式推证一下,搞清其关系,那就更容易记住了。 三、练习题 (一)填空题 1事物之间的依存关系,根据其相互依存和制约的程度不同,可以分为()和()两种。 2.相关关系按相关关系的情况可分为()和();按自变量的多少分()和();按相关的表现形式分()和();按相关关系的
第七章 相关回归分析 皮尔逊线性相关系数计算的基本公式: (简捷法) ])(][)([(积差法)22222∑∑∑∑∑∑∑--- ==y y n x x n y x xy n s s s y x xy γ 简单线性回归方程式为:bx a y c +=, 式中c y 是y 的估计值,a 代表直线在y 轴上的截距,b 表示直线的斜率,又称为回归系数。回归系数的涵义是,当自变量x 每增加一个单位时,因变量y 的平均增加值。 当b 的符号为正时,表示两个变量是正相关,当b 的符号为负时,表示两个变量是负相关。a 、b 都是待定参数,可以用最小平方法求得。 求解a 、b 的公式为: ∑∑∑∑∑--=22) (x x n y x xy n b ; n x b n y a ∑∑-= 相关系数与回归系数之间具有以下的关系: x y s s r b = (一) 填空题 1.在相关关系中,把具有因果关系相互联系的两个变量中起影响作用的变量称为_______,把另一个说明观察结果的变量称为________。 2.现象之间的相关关系按相关的程度分有________相关、________相关、________相关和_______相关;按相关的方向分有________相关和______ _相关;按影响因素的多少分有________相关和________相关。 3.对现象之间变量关系的研究中,对于变量之间相互关系密切程度的研究,称为_______;研究变量之间关系的方程式,根据给定的变量数值以推断另一变量的可能值,则称为_______。 4.完全相关即是________关系,其相关系数为________。 5.相关系数的变动范围介于_______与_______之间,其绝对值愈接近于_______,两个变量之间线性相关程度愈高;愈接近于_______,两个变量之间线性相关程度愈低。当_______时表示两变量正相关;_______时表示两变量负相关。 6.当变量x 值增加,变量y 值也增加,这是________相关关系;当变量x 值减少,变量y 值也减少,这是________相关关系。 7.已知13600))((=----∑y y x x ,14400)(2=--∑x x ,14900)(2 =-∑-y y ,那么,x 和y 的相关系数r 是_______。 8.已知1502=xy s ,18=x s ,11=y s ,那么变量x 和y 的相关系数r 是_______。 9.已知直线回归方程bx a y c +=中,5.17=b ;又知30=n , ∑=13500y ,12=- x , 则可知_______=a 。
第十章多元线性回归与曲线拟合―― Regression菜单详解(上) 回归分析是处理两个及两个以上变量间线性依存关系的统计方法。在医学领域中,此类问题很普遍,如人头发中某种金属元素的含量与血液中该元素的含量有关系,人的体表面积与身高、体重有关系;等等。回归分析就是用于说明这种依存变化的数学关系。 §10.1Linear过程 10.1.1 简单操作入门 调用此过程可完成二元或多元的线性回归分析。在多元线性回归分析中,用户还可根据需要,选用不同筛选自变量的方法(如:逐步法、向前法、向后法,等)。 例10.1:请分析在数据集Fat surfactant.sav中变量fat对变量spovl的大小有无影响? 显然,在这里spovl是连续性变量,而fat是分类变量,我们可用用单因素方差分析来解决这个问题。但此处我们要采用和方差分析等价的分析方法--回归分析来解决它。 回归分析和方差分析都可以被归入广义线性模型中,因此他们在模型的定义、计算方法等许多方面都非常近似,下面大家很快就会看到。 这里spovl是模型中的因变量,根据回归模型的要求,它必须是正态分布的变量才可以,我们可以用直方图来大致看一下,可以看到基本服从正态,因此不再检验其正态性,继续往下做。 10.1.1.1 界面详解 在菜单中选择Regression==>liner,系统弹出线性回归对话框如下:
除了大家熟悉的内容以外,里面还出现了一些特色菜,让我们来一一品尝。 【Dependent框】 用于选入回归分析的应变量。 【Block按钮组】 由Previous和Next两个按钮组成,用于将下面Independent框中选入的自变量分组。由于多元回归分析中自变量的选入方式有前进、后退、逐步等方法,如果对不同的自变量选入的方法不同,则用该按钮组将自变量分组选入即可。下面的例子会讲解其用法。 【Independent框】 用于选入回归分析的自变量。 【Method下拉列表】 用于选择对自变量的选入方法,有Enter(强行进入法)、Stepwise(逐步法)、Remove(强制剔除法)、Backward(向后法)、Forward(向前法)五种。该选项对当前Independent框中的所有变量均有效。
第十一章分类资料的回归分析 ――Regression菜单详解(下) (医学统计之星:张文彤) 在很久很久以前,地球上还是一个阴森恐怖的黑暗时代,大地上恐龙横行,我们的老祖先--类人猿惊恐的睁大了双眼,围坐在仅剩的火堆旁,担心着无边的黑暗中不知何时会出现的妖魔鬼怪,没有电视可看,没有网可上... 我是疯了,还是在说梦话?都不是,类人猿自然不会有机会和恐龙同时代,只不过是我开机准备写这一部分的时候,心里忽然想到,在10年前,国内的统计学应用上还是卡方检验横行,分层的M-H卡方简直就是超级武器,在流行病学中称王称霸,更有那些1:M的配对卡方,N:M的配对卡方,含失访数据的N:M 配对卡方之类的,简直象恐龙一般,搞得我头都大了。其实恐龙我还能讲出十多种来,可上面这些东西我现在还没彻底弄明白,好在社会进步迅速,没等这些恐龙完全统制地球,Logistic模型就已经飞速进化到了现代人的阶段,各种各样的Logistic模型不断地在蚕食着恐龙爷爷们的领地,也许还象贪吃的人类一样贪婪的享用着恐龙的身体。好,这是好事,这里不能讲动物保护,现在我们就远离那些恐龙,来看看现代白领的生活方式。 特别声明:我上面的话并非有贬低流行病学的意思,实际上我一直都在做流行病学,我这样写只是想说明近些年来统计方法的普及速度之快而已。 据我一位学数学的师兄讲,Logistic模型和卡方在原理上是不一样的,在公 式推演上也不可能划等号,只是一般来说两者的检验结果会非常接近而已,多数情况下可忽略其不同。 §10.3 Binary Logistic过程 所谓Logistic模型,或者说Logistic回归模型,就是人们想为两分类的应变量作一个回归方程出来,可概率的取值在0~1之间,回归方程的应变量取值可是在实数集中,直接做会出现0~1范围之外的不可能结果,因此就有人耍小聪明,将率做了一个Logit变换,这样取值区间就变成了整个实数集,作出来的结果就不会有问题了,从而该方法就被叫做了Logistic回归。 随着模型的发展,Logistic家族也变得人丁兴旺起来,除了最早的两分类Logistic外,还有配对Logistic模型,多分类Logistic模型、随机效应的Logistic模型等。由于SPSS的能力所限,对话框只能完成其中的两分类和多分类模型,下面我们就介绍一下最重要和最基本的两分类模型。
第七章 相关分析与回归分析 (3)当固定资产改变200万元时,总产值平均改变多少?(4)当固定资产为1300万元时,总产值为多少? (1)协方差——用以说明两指标之间的相关方向。 2 2))((n y x xy n n y y x x xy ∑∑∑∑-= --=σ 035.126400100 9801 6525765915610>=?-?= 计算得到的协方差为正数,说明固定资产和总产值之间存在正相关关系。 (2)相关系数用以说明两指标之间的相关方向和相关的密切程度。 ∑∑∑∑∑∑∑---= ] )(][)([2222y y n x x n y x xy n r
95.0) 98011086657710()6525566853910(9801 65257659156102 2 =-??-??-?= 计算得到的相关系数为0.95,表示两指标为高度正相关。 (3) 2 226525 5668539109801 6525765915610)(-??-?=--= ∑∑∑∑∑x x n y x xy n b 90.014109765 12640035 42575625566853906395152576591560==--= 85.39210 6525 9.0109801=?-= -=x b y a 回归直线方程为: x y 9.085.392?+= (4)当固定资产改变200万元时,总产值平均改变多少? x y ?=?9.0,1802009.0|200=?=?=?x y 万元 当固定资产改变200万元时,总产值平均增加180万元。 (5)当固定资产为1300万元时,总产值为多少? 85.156213009.085.392|1300=?+==x y 万元 当固定资产为1300万元时,总产值为1562.85万元。 例2、试根据下列资产总值和平均每昼夜原料加工量资料计算相关系数。 解:【分析】本题中“企业数”应看成资产总值和平均每昼夜原料加工量两变量的次数,在计算相关系数的过程,要进行“加权”。
第十一章 一元线性回归 一、填空题 1、对回归系数的显著性检验,通常采用的是 检验。 2、若回归方程的判定系数R 2=0.81,则两个变量x 与y 之间的相关系数r 为_________________。 3、若变量x 与y 之间的相关系数r=0.8,则回归方程的判定系数R 2为____________。 4、对于直线趋势方程bx a y c +=,已知 ∑=,0x ∑=130xy ,n=9,1692=∑x , a=b ,则趋势 方程中的b=______。 5、回归直线方程bx a y c +=中的参数b 是_____________。估计待定参数a 和 b 常用的方法是-_________________。 6、相关系数的取值范围_______________。 7、在回归分析中,描述因变量y 如何依赖于自变量x 和误差项的方程称为 。 8、在回归分析中,根据样本数据求出的方程称为 。 9、在回归模型εββ++=x y 10中的ε反映的是 。 10、在回归分析中,F 检验主要用来检验 。 11、说明回归方程拟合优度检验的统计量称为 。 二、单选题 1、年劳动生产率(x :千元)和工人工资(y :元)之间的回归方程为1070y x =+,这意味着年劳动生产率没提高1千元,工人工资平均( ) A 、 增加70元 B 、 减少70元 C 、增加80元 D 、 减少80元 2、两变量具有线形相关,其相关系数r=-0.9,则两变量之间( )。 A 、强相关 B 、弱相关 C 、不相关 D 、负的弱相关关系 3、变量的线性相关关系为0,表明两变量之间( )。 A 、完全相关 B 、无关系 C 、不完全相关 D 、不存在线性关系 4、相关关系与函数关系之间的联系体现在( )。 A 、相关关系普遍存在,函数关系是相关关系的特例 B 、函数关系普遍存在,相关关系是函数关系的特例 C 、相关关系与函数关系是两种完全独立的现象 D 、相关关系与函数关系没有区别 5、已知x 和y 两变量之间存在线形关系,且δx =10, δy =8, δxy 2=-7,n=100,则x 和y 存在着( )。 A 、显著正相关 B 、低度正相关 C 、显著负相关 D 、低度负相关 6、对某地区前5年粮食产量进行直线趋势估计为:80.5 5.5y t =+? 这5年的时间代码分别是:-2,-1,0,1,2,据此预测今年的粮食产量是( )。 A 、107 B 、102.5 C 、108 D 、113.5 7、两变量的线性相关关系为-1,表明两变量之间( )。 A 、完全相关 B 、无关系 C 、不完全相关 D 、不存在线性关系 8、已知x 和y 两变量之间存在线形关系,且δx =10, δy =8, δxy 2 =-7,n=100,则x 和y 存在着( )。 A 、显著正相关 B 、低度正相关 C 、显著负相关 D 、低度负相关
第七章相关与回归分析习题 一、填空题 1、客观现象之间的数量联系有两种不同的类型:一种函数关系;另一种是相关关系。 2、现象之间是否存在相关关系是进行相关与回归分析的基础,其主要测定方法是计算相关系数。 3、若估计标准误差愈小,则根据直线回归方程计算的估计值就越能代表实际值。 4、对某实验结果做线性回归分析,得到形如y=a+bx的方程,现对回归系数b做显著性检验,该假设检验中原假设为 H0:b=0 ,备择假设为 H1:b≠0 ,若拒绝原假设,则认为 x 对y有显著的影响。 二、选择题 单选题: 1、相关分析对资料的要求是((1)) (1)两变量均为随机的(2)两变量都不是随机的 (3)自变量是随机的,因变量不是随机的 (4)因变量是随机的,自变量不是随机的 2、回归方程Y=a+bx中的回归系数b说明自变量变动一个单位时,因变量((4)) (1)变动a+b个单位(2)变动1/b个单位 (3)变动b个单位(4)平均变动b个单位 3、相关系数r的取值范围((2)) (1)-∞
相关主题
文本预览