
第五章贝叶斯统计
5.1 简介
到目前为止,我们已经知道了大量的不同的概率模型,并且我们前面已经讨论了如何用它们去拟合数据等等。前面我们讨论了如何利用各种先验知识,计算MAP参数来估计θ=argmax p(θ|D)。同样的,对于某种特定的请况,我们讨论了如何计算后验的全概率p(θ|D)和后验的预测概率密度p(x|D)。当然在以后的章节我们会讨论一般请况下的算法。
5.2 总结后验分布
后验分布总结关于未知变量θ的一切数值。在这一部分,我们讨论简单的数,这些数是可以通过一个概率分布得到的,比如通过一个后验概率分布得到的数。与全面联接相比,这些统计汇总常常是比较容易理解和可视化。
5.2.1最大后验估计
通过计算后验的均值、中值、或者模型可以轻松地得到未知参数的点估计。在5.7节,我们将讨
论如何利用决策理论从这些模型中做出选择。典型的后验概率均值或者中值是估计真实值的恰当选择,并且后验边缘分布向量最适合离散数值。然而,由于简化了优化问题,算法更加高效,后验概率模型,又名最大后验概率估计成为最受欢迎的模型。另外,通过对先验知识的取对数来正
则化后,最大后验概率可能被非贝叶斯方法解释(详情参考6.5节)。
最大后验概率估计模型在计算方面该方法虽然很诱人,但是他有很多缺点,下面简答介绍一下。在这一章我们将更加全面的学习贝叶斯方法。
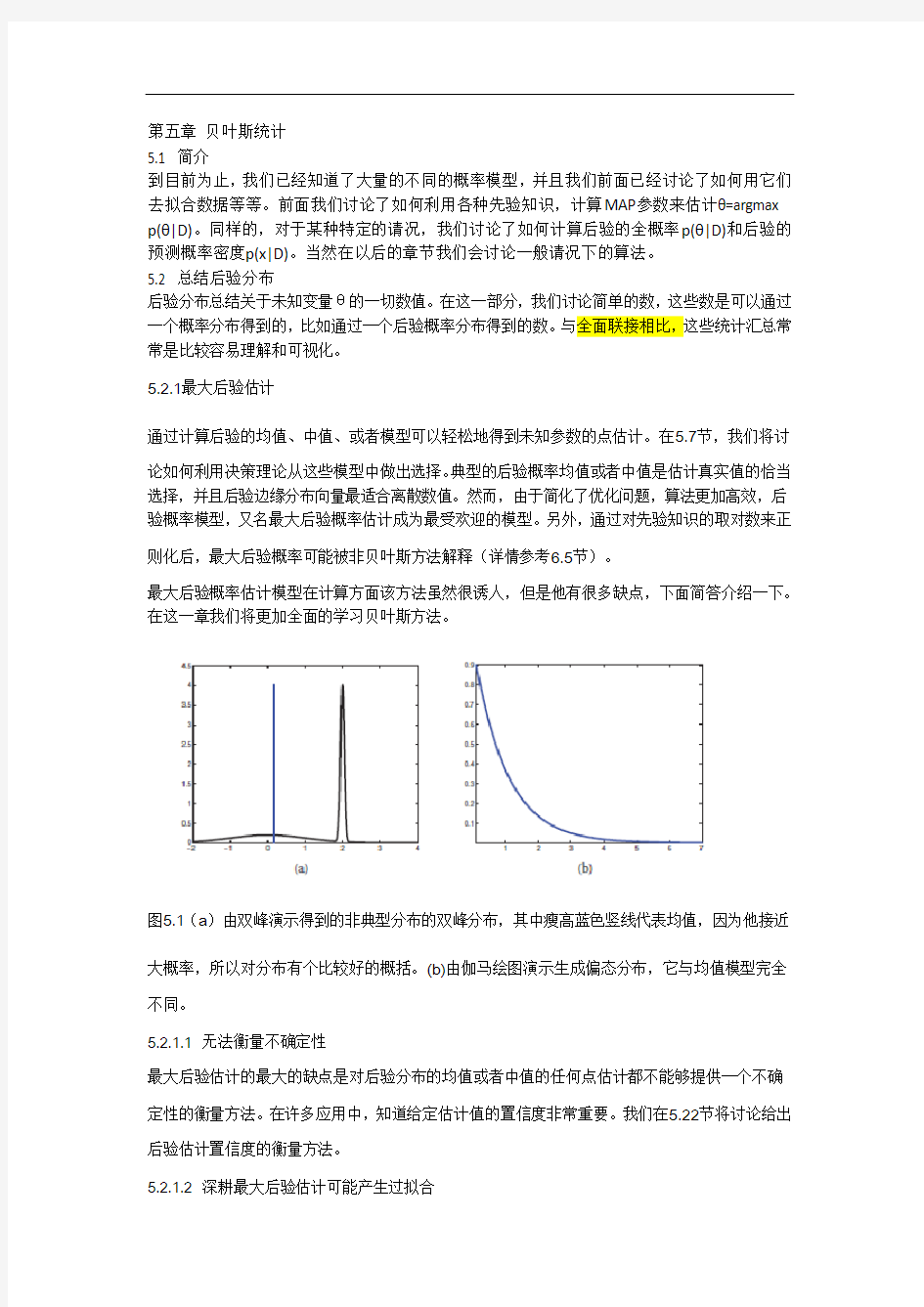
图5.1(a)由双峰演示得到的非典型分布的双峰分布,其中瘦高蓝色竖线代表均值,因为他接近
大概率,所以对分布有个比较好的概括。(b)由伽马绘图演示生成偏态分布,它与均值模型完全不同。
5.2.1.1 无法衡量不确定性
最大后验估计的最大的缺点是对后验分布的均值或者中值的任何点估计都不能够提供一个不确定性的衡量方法。在许多应用中,知道给定估计值的置信度非常重要。我们在5.22节将讨论给出后验估计置信度的衡量方法。
5.2.1.2 深耕最大后验估计可能产生过拟合
在机器学习中,相比于解释模型的参数,我们能够得到精确预测结果。然而,如果我们不能衡量参数的不确定性,那么可能过分信任预测的分布。在第三章我们介绍了几个例子,之后还有更多
这样的例子。预测中的过度自信对于我们的风险规避很成问题;在随后的5.7节我们将详细介绍。
5.2.1.3 模型是一个非典型的点
由于现实模型常常是一个区别于均值或者中值的非典型分布,所以选择一个模型来概括后验分布
的效果往往很差。对于一个一维连续空间图5.1(a)中很好的说明了这一点。该模型的一个根本问题在于它是一个0-1的测量值,而中值和均值是在空间体积上的考虑。图5.1(b)给出了另一个例子:图中模型结果是0.但是均值非零。这样的偏态分布经常在推断方差参数时出现,尤其是
在分层模型中。在这样的例子中,最大后验估计(最大似然估计例外)明显的是一个非常不好的估计方法。
假如模型不是一个很好的选择项,那么我们应该如何概括后验概率呢?在5.7节中讨论的决策理
论将会解答这一疑问。其基本思想是指定一个损失函数,如果你对真实的θ的估计是?θ那么损
失函数为L(θ, ?θ) 。如果我们使用0-1损失L(θ, ?θ) = I(θ = ?θ),那么最优估计便是后验模型。0-1
损失意味着,如果没有估计错误那么就是正确的,否则就是错误的。再这样的损失函数下没有所
谓的“部分可信”!对于连续变量,我们偏好用误差平方来表征损失函数即:L(θ, ?θ) = (θ??θ)2。对应的最优估计是后验均值,详细参见5.7节。或者,我们可以使用一个更可靠地损失函数:L(θ, ?θ) = |θ??θ|,他考虑的是后验的中位数(中值)。
5.2.1.4最大后验估计不是做改变的重新参数化
最大后验估计的一个更加微妙的是其结果依赖于概率模型的参数。从一个表达形式转化为另一个等效的表达形式,例如测量单位的变化(长度的度量,我们可以用厘米也可以用英尺),其结果会变化,这是我们不希望看到的。
为了更好地理解这一问题,假定我们要计算X的后验,如果我们定义y= f(x),其中y的分布为公式(2.87),为方便描述抄写如下公式5.1:
|Dx/dy|项我们成为雅可比(Jacobian),他通过f来衡量单位体积大小的变化。则X的最大后验估计为?x = argmaxx px(x)。通常情况下,f(x)不是y=argmaxypy(y).举个例子来说:x~N(6,1),y=f(x),
利用蒙特卡洛仿真能够得到y的分布(见2.7.1节)。其结果如图5.2.我们看到原始的高斯分布已经被非线性的S曲线乘方。特别的指出的是,我们看到转化后的分布模型不完全等同于原始模型的形式。
图5.2 在非线性转换下的密度转化形式示例。注意转化后的分布函数与原始分布的区别。以练习1.4为例(bishop 2006b)。图形由方差的贝叶斯变化生成。
为了了解最大后验估计中如何产生这一问题的,考虑如下例子。伯努利分布是典型的均值μ参数化模型,所以,p(y = 1|μ) = μ, 其中,y ∈{0, 1}。在每个单元间隔,假定我们有一个统一的先验:pμ(μ) = 1 I(0 ≤μ≤1)。如果这里没有数据,那么最大后验估计仅仅是前验知识的模型,他们可以是在0 、1之间的任意值。现在,我们开始介绍参数化的不同能够在这一任意区间挑选出不同的点。
首先,则新的先验为:
因此,最大后验估计依赖于参数化。因为似然度是一个函数而不是概率密度,所以最大似然估计与参数无关。贝叶斯推断也不受参数化的影响,因为贝叶斯推断在整合参数空间的时候已经考虑了度量方面变化。
解决上述问题的一个方法是最优化下面的目标函数:
I(θ)是与P有关的费舍尔信息矩阵(参见6.2.2节)。这个估计参数是独立的,原因参见(Jermyn 2005;。不幸运的是,优化方程常常很复杂,这很大限度上降低了该方法的吸引力。
5.2.2 置信区间
除了点估计,我们经常想得到可信度的度量。一个标准的可信度度量形式是数据theta的后验分布的宽度。我们可以利用置信区间100(1 ?α)%度量,就是说,在C = ( l, u),区域中包括1 –α的后验概率的量。
这里可能有许多这样的区间,所以我们选择区域是(1?α)/2,位于分布尾端的区间,并把他称为置信区间。
图5.3(a)中心区域和(b)HPD区域的beta(3,9)检验。置信区间是(0.06,0.52)和HPD是(0.04,0.48)。上图是在图3.6的基础上,利用betaHPD生成的。
如果后验是已知的函数形式,我们可以利用l= F?1(α/2) and u = F?1(1?α/2),计算后验分布的中心区间,F为后验分布的累计密度曲线。例如,如果后验是高斯分布,
5.2.2.1 后验密度最高的区域
中心区间的存在的一个问题是很有可能这里有一个点它的概率密度很高但是不在置信区间。图5.3中处于左侧置信区间外的点比刚刚好处于右侧区间的点的概率密度高很多。
这便促使了一个替代变量,称之为最高的后验概率密度或者最高的后验概率密度区间。这被定义为(一组)最可能的点,这是总的概率的100(1-α)%。更正式的,我们发现概率分布函数阈值P为:
并且定义HPD区域为:
在ld,最大概率密度区间有时候被称作最高密度区间或者HDI。例如,图5.3(b)表明BETA的95%的HDI是(0.04,0.48)。我们看到这个区间比置信区间狭窄,但即使这样,他依然包含了总量的95%;而且,区间内的每一点都比区间外的概率密度高。
对于单峰分布,最大密度区间将是包含总量95%的最狭窄的区间。为了看到这个,想想“充水”的反过程,直到全部的95%显示出来,只剩下5%被淹没在水下。在Id情况下,方便计算使用简单的算法:用最小的宽度简单的搜索满足包含总量的95%的区间。如果我们知道累计分布曲线的,这个可以通过数值最优化来实现。或者如果我们有大量样本(从betaHPD图形表示),通过搜索排序的数据点。
如果后验是多峰的分布,最大概率密度区间可能不是一个连续的区域:例如见图5.4(b)。
然而,总结概括多峰后验经常是很难的。
5.2.3 不同比例的推断
有时候我们有多个参数,并且想利用这些参数计算出一些函数的后验概率分布。例如,假如你要从亚马逊上买东西,并且有两个售货商提供相同的价格。售货商1有90的正面评论,10个反面评论。售货商2有两条正面评论0条负面评论。那你想要买谁的?
表面上看,我们应该选择销售商2,但是我们不能非常确信销售商2一定比1好,因为他的评论太
少了。在这一方面,我们构筑贝叶斯方法来分析这个问题。相似的方法可以用来比较不同设置下的群体比例或比率。
假定theta1和theta2是可靠度未知的两个销售商。因为我们不了解他们更多的信息,我们赋予他们统一的先验分布θi ~ Beta(1, 1). 后验概率是p(θ1|D1)= eta(91, 11) 和p(θ2|D2) = Beta(3, 1).
我们想要计算p(θ1 > θ2|D). 为方便起见,定义δ= θ1 ?θ2为比率方面的不同(另外,我们不妨想)利用数值积分,我们可以计算期望值:
我们发现p(δ > 0|D) = 0.710,这表明你应该从销售商1哪里买。代码参见amazonsellerDemo。一个简单的解决方法是利用蒙特卡洛采样得到近似的后验概率。这是容易的,因为theta1和theta2在后验概率分布中是相互独立的,并且两者都有beta分布,这样就可以利用标准方法来采样。p(θi|Di)的分布如图5.5(b)。通过计算theta1大于theta2的部分能够得到一个p(δ > 0|D)的近似值;结果是0.718,非常接近真实值。
图5.5(a)确切的后验概率分布p(θi|Di). (b)蒙特卡洛近似p(δ|D). 我们运用核密度估计得到一个平滑曲线。垂直线围住的是中间95%的区间。
5.3 贝叶斯模型选择
在图1.18中,我们知道使用过高的多项式导致过拟合,使用过低的多项式又导致欠拟合的发生。相似的,在图7.8(a)中,我们知道使用太小的正则化参数导致过拟合,使用太大的参数又导致
欠拟合。通常情况,当面对一系列不同复杂性的模型时(相似的参数化分布),怎样才能选择一个最好的呢?这样一个难题称为模型选择问题。
一个方法是利用交叉验证的方法去估计所有候选模型的泛化误差,然后挑选一个看起来最好的。然而,这需要对每个模型拟合K次,其中,K是训练集交叉验证的次数。一个更加高效的方法是计算关于模型的后验概率分布
通过上式,我们可以容易的计算出最大后验估计模型,称为贝叶斯模型选择。
如果我们在模型中使用了统一的先验,p(m) ∝1,这相当于挑选模型中的最大值
对于模型M,这个数被称为边际似然度,集成的似然度或者证据。在5.3.2中将要详细的介绍如何操作这个积分。但是首先我们要给出这个值的直观解释。