
模式识别
摘要:本文简单介绍了模式识别,主要讲述了模式识别常用的方法:神经网络、模糊诊断、支持向量机、聚类分析的定义及各自有缺点。
关键字:模式识别;神经网络;模糊诊;、支持向量机;聚类分析ABSTRACT:This paper briefly introduced the pattern recognition, mainly tells the story of pattern recognition commonly used method: neural network and fuzzy diagnosis, support vector machine, clustering analysis of the definition and have their own shortcomings.
Key words: Pattern recognition; Neural network; Fuzzy diagnosis; And support vector machine (SVM); Clustering analysis
一、模式识别
我们知道,被识对象都具有一些属性、状态或者特征。而对象之间的差异也就表现在这些特征的差异上。因此可以用对象的特征来表征对象。另一方面,从结构来看,有些被识对象可以看作是由若干基本成分按一定的规则组合而成。因此,可以用一些基本元素的某种组合来刻画对象。
广义地说,存在于时间和空间中可观察的物体,如果我们可以区别它们是否相似,都可以称之为模式。模式所指的不是事物本身,而是从事物获得的信息,能够表征或刻画被识对象类属特征的信息模型成为对象的模式。有了模式,对实体对象的识别就转化为对其模式的识别。识别其实就是分类,即辨识或判别被识对象的类属。
模式识别就是确定一个样本的类别属性(模式类)的过程,即把某一样本归属于多个类型中的某个类型。
模式识别的三大任务:模式采集、特征提取和特征选择、类型判别。
模式识别系统的主要环节:特征提取、特征选择、学习和训练、分类识别。
模式识别的应用如下:
生物学:自动细胞学、染色体特性研究、遗传研究;天文学:天文望远镜图像分析、自动光谱学;经济学:股票交易预测、企业行为分析;医学:心电图分析、脑电图分析、医学图像分析;工程:产品缺陷检测、特征识别、语音识别、自动导航系统、污染分析;军事:航空设想分析、雷达和声纳信号检测和分类、自动目标识别;安全:指纹识别、人脸识别、监视和报警系统。
模式识别常用的方法:神经网络、模糊诊断、支持向量机、聚类分析。
二、模式识别常用的方法
1、聚类分析
聚类分析法是理想的多变量统计技术,主要有分层聚类法和迭代聚类法。聚类分析也称群分析、点群分析,是研究分类的一种多元统计方法。
聚类分析概述:例如,我们可以根据各个银行网点的储蓄量、人力资源状况、营业面积、特色功能、网点级别、所处功能区域等因素情况,将网点分为几个等级,再比较各银行之间不同等级网点数量对比状况。
聚类分析的基本思想:相似的归为一类、模式相似性的度量和聚类算法、无监督分类。即我们所研究的样品(网点)或指标(变量)之间存在程度不同的相似性(亲疏关系——以样品间距离衡量)。于是根据一批样品的多个观测指标,具体找出一些能够度量样品或指标之间相似程度的统计量,以这些统计量为划分类型的依据。把一些相似程度较大的样品(或指标)聚合为一类,把另外一些彼此之间相似程度较大的样品(或指标)又聚合为另一类,直到把所有的样品(或
指标)聚合完毕,这就是分类的基本思想。选择什么特征、选择多少个特征、选择什么样的量纲、选择什么样的距离测度对分类结果都会产生极大影响。
聚类过程遵循的基本步骤:特征选择、近邻测度、聚类准则、聚类算法、结果验证、结果判定。
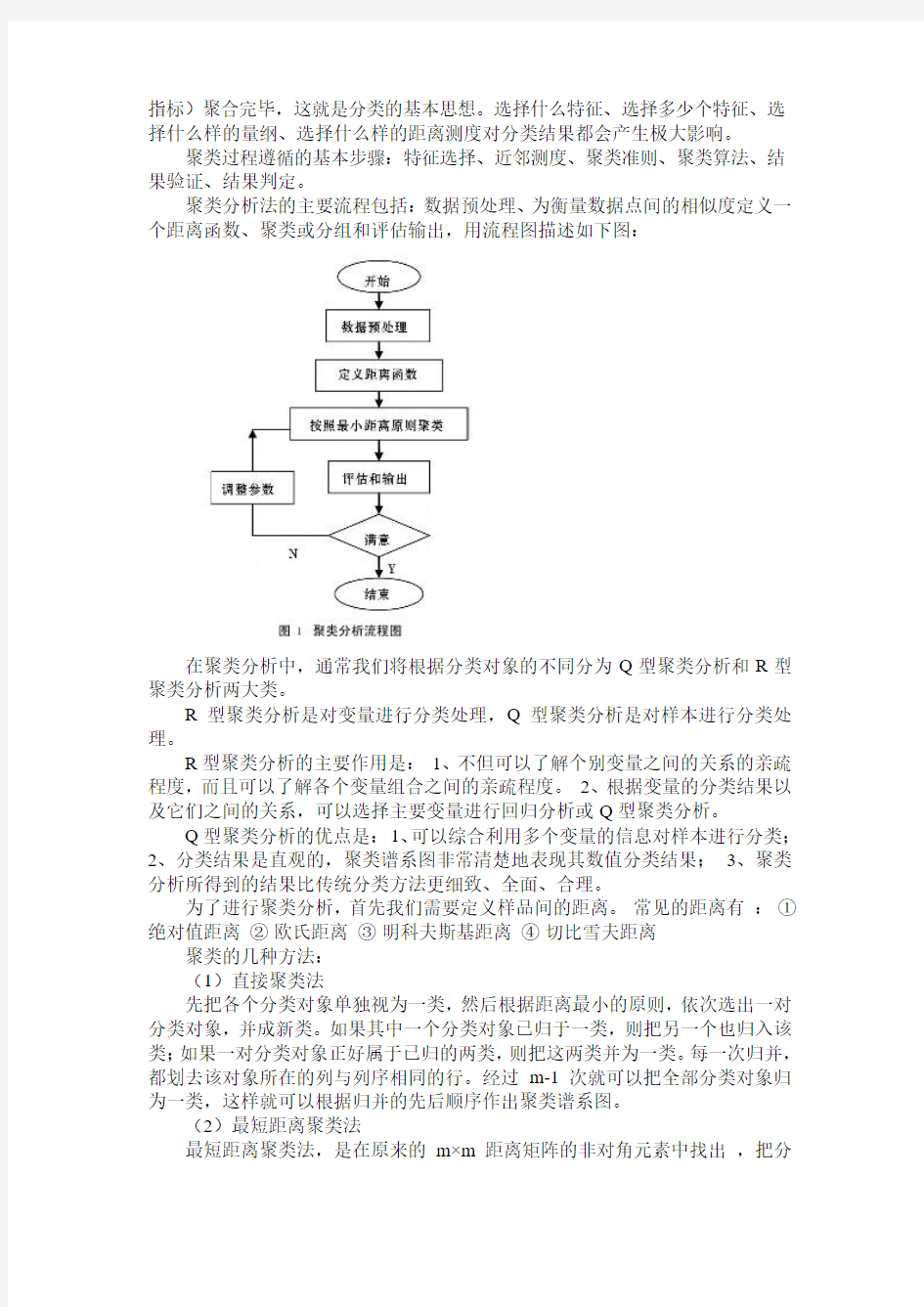
聚类分析法的主要流程包括:数据预处理、为衡量数据点间的相似度定义一个距离函数、聚类或分组和评估输出,用流程图描述如下图:
在聚类分析中,通常我们将根据分类对象的不同分为Q型聚类分析和R型聚类分析两大类。
R型聚类分析是对变量进行分类处理,Q型聚类分析是对样本进行分类处理。
R型聚类分析的主要作用是:1、不但可以了解个别变量之间的关系的亲疏程度,而且可以了解各个变量组合之间的亲疏程度。2、根据变量的分类结果以及它们之间的关系,可以选择主要变量进行回归分析或Q型聚类分析。
Q型聚类分析的优点是:1、可以综合利用多个变量的信息对样本进行分类;
2、分类结果是直观的,聚类谱系图非常清楚地表现其数值分类结果;
3、聚类分析所得到的结果比传统分类方法更细致、全面、合理。
为了进行聚类分析,首先我们需要定义样品间的距离。常见的距离有:①绝对值距离②欧氏距离③明科夫斯基距离④切比雪夫距离
聚类的几种方法:
(1)直接聚类法
先把各个分类对象单独视为一类,然后根据距离最小的原则,依次选出一对分类对象,并成新类。如果其中一个分类对象已归于一类,则把另一个也归入该类;如果一对分类对象正好属于已归的两类,则把这两类并为一类。每一次归并,都划去该对象所在的列与列序相同的行。经过m-1次就可以把全部分类对象归为一类,这样就可以根据归并的先后顺序作出聚类谱系图。
(2)最短距离聚类法
最短距离聚类法,是在原来的m×m距离矩阵的非对角元素中找出,把分
类对象Gp和Gq归并为一新类Gr,然后按计算公式计算原来各类与新类之间的距离,这样就得到一个新的(m-1)阶的距离矩阵;再从新的距离矩阵中选出最小者dij,把Gi和Gj归并成新类;再计算各类与新类的距离,这样一直下去,直至各分类对象被归为一类为止。
(3)最远距离聚类法
最远距离聚类法与最短距离聚类法的区别在于计算原来的类与新类距离时采用的公式不同。最远距离聚类法所用的是最远距离来衡量样本之间的距离。
目标:用某种相似性度量的方法将原始数据组织成有意义的和有用的各种数据集。
聚类应用的四个基本方向:减少数据、假说生成、假说检验、基于分组的预测。
聚类分析是一种非监督学习的方法,解决方案是数据驱动的。
模糊聚类分析技术广泛应用于故障诊断、识别等场合。例如应用在了汽车变速箱齿轮故障诊断中,液体火箭发动机故障仿真数据的聚类识别,得到了该方法应用于该型号液体火箭发动机故障诊断中时的精度并据此说明了其应用与液体火箭发动机故障诊断中的应用价值。
2、神经网络
2.1 神经网络介绍
模式描述方法:以不同活跃度表示的输入节点集(神经元)
模式判定:是一个非线性动态系统。通过对样本的学习建立起记忆,然后将未知模式判决为其最接近的记忆。
理论基础:神经生理学,心理学
主要方法:BP模型、HOP模型、高阶网
主要优点:可处理一些环境信息十分复杂,背景知识不清楚,推理规则不明确的问题。允许样本有较大的缺损、畸变。
主要缺点:模型在不断丰富与完善中,目前能识别的模式类还不够多。
神经网络是受人脑组织的生理学启发而创立的。由一系列互相联系的、相同的单元(神经元)组成。相互间的联系可以在不同的神经元之间传递增强或抑制信号。增强或抑制是通过调整神经元相互间联系的权重系数来实现的。神经网络可以实现监督和非监督学习条件下的分类。
神经网络具有并行处理能力、自学习能力、自适应能力和以任意精度逼近任意非线性函数的特点,是解决非线性、多变量、不确定等复杂控制问题的一条十分有效的途径,它在模式识别、系统辨识、控制等领域都得到了广泛的应用。
神经网络的类型多种多样,它们是从不同角度对生物神经系统不同层次的抽象和模拟。从功能特性和学习特性来分,典型的神经网络模型主要包括感知器神经网络、线性神经网络、BP神经网络、径向基函数神经网络(RBF神经网络)、自组织映射神经网络和反馈神经网络等。
BP神经网络和RBF神经网络在解决非线性系统辨识中蕴藏着巨大的潜力。而RBF神经网络是以函数逼近理论为基础而构造的一类前向网络,且每个隐含层神经元传递函数都构成了拟合平面的一个基函数,它是一种局部逼近网络(即对于输入空间的某一个局部区域只存在少数的神经元用于决定网络的输出),且径向基函数神经网络的学习速度要较BP网络快,这类网络的学习等价于在多维空间中寻找训练数据的最佳似合面。径向基函数神经网络在逼近能力和学习速度等方面均优于BP神经网络。
2.2 神经网络模式识别原理
模式识别主要是研究对象的特征或属性,利用以计算机为中心的机器系统运用一定的分析算法认定对象的类别,系统应使分类识别的结果尽可能地与真实情况相符合。模式识别方法最大的实用性在于“智能”仿真,可以说在平常生活中随处可见,如医疗诊断系统、地球资源探测系统、机器人辅助生产线、公安人员用于破案的指纹识别系统等。模式识别包含由特征和属性所描述的对象的数学模型,这里所提到的特征和属性是指通常意义上的系统的输入/输出数据对。
模式识别系统主要由两个过程组成,即设计过程和实现过程。设计过程是指用一定数量的样本(也称训练集或学习集)进行分类器的设计:实现过程是指用所设计的分类器对待识别的样本进行分类决策。
神经网络以其强大的非线性映射能力,已经在模式识别领域中得到了广泛的应用,能够实现网络仿真,达到很好的识别分类效果,而且运用也是很广泛的。针对不同模型需要我们仔细考虑如何进行特征选择,建立相应的神经网络模型,并对网络优化设计训练,提高网络性能,最终实现识别分类的效果。
模式识别的神经网络方法和传统的方法相比,具有下面几个明显的优点:(1)具有较强的容错性,能够识别带有噪声或变形的输入模式;
(2)具有很强的自适应学习能力;
(3)并行分布式信息存储与处理,识别速度快;
(4)能把识别处理和若干与处理融为一体进行。
神经网络在尾水管故障诊断,柴油机故障诊断,大型回转机械故障诊断,模拟电路故障诊断,核电厂故障诊断,电气故障诊断等等都已经得到广泛的应用。
3、支持向量机
根据统计学习理论,学习机器的实际风险由经验风险值和置信范围值两部分组成。而基于经验风险最小化准则的学习方法只强调了训练样本的经验风险最小误差,没有最小化置信范围值,因此其推广能力较差。
Vapnik 提出的支持向量机(Support Vector Machine, SVM)以训练误差作为优化问题的约束条件,以置信范围值最小化作为优化目标,即SVM是一种基于结构风险最小化准则的学习方法,其推广能力明显优于一些传统的学习方法。
支持向量机是在统计学习理论的基础上发展起来的一种新的机器学习方法,它是建立在统计学习理论的VC维理论和结构风险最小化原则上的,避免了局部极小点(支持向量机算法是一个凸二次优化问题,能够保证找到的极值解就是全局最优解),并能有效地解决过学习问题,具有良好的推广性能和较好的分类精确性(由有限训练样本得到的决策规则对独立的测试集仍能够得到小的误差)。
由于SVM 的求解最后转化成二次规划问题的求解,因此SVM 的解是全局唯一的最优解
SVM在解决小样本、非线性及高维模式识别问题中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中
Joachims 最近采用SVM在Reuters-21578来进行文本分类,并声称它比当前发表的其他方法都好
先考虑二维情况下的线性可分的两类样本(○,×),如图所示,存在很多条可能的分类线能够将训练样本分开。显然分类线a最好,因为它更远离每一类样本,风险小。而其他的分类线离样本较近,只要样本有较小的变化,将会导致错误的分类结果。因此分类线a是代表一个最优的线性分类器。
所谓最优分类线就是要求分类线不但能将两类无误地分开,而且要使两类的分类间隔最大。图中H是最优分类线,H1和H2分别为过各类样本中离分类线最近的点且平行于分类线的直线,H1和H2之间的距离叫做两类的分类空隙或者分类间隔(margin)。
将二维推广到高维,最优分类线就成为最优分类超平面。
设线性可分样本集为(xi,yi),i=1,2,…n,x∈Rd,y∈{+1,-1}是类别号。d维空间中线性判别函数的一般形式为g(x)=w?x+b,则分类超平面方程为:
w?x+b=0
其中,w为分类超平面的法线,是可调的权值向量;b为偏置,决定相对原点的位置。当两类样本是线性可分时,满足条件:
(w?xi)+b≥+1 yi=+1
(w?xi)+b≤-1 yi=-1
超平面(w?xi)+b=+1距离原点的垂直距离为|1|
||||
b
w
-
,而超平面
(w?xi)+b=-1距离原点的垂直距离为|1|
||||
b
w
--
,因此分类间隔就等于
|11|2_||||||||b b w w -++ ,所以使间隔最大等价于使 |||w (或 2|||w )最小。
若要求分类线对所有样本正确分类,则要求它满足:
yi[(w ?xi)+b]-1≥0,i=1,2,…,n
因此满足该条件且使 2|||w 最小的分类超平面就是最优分类超平面。 过两类样本中离分类超平面最近点且平行于最优分类面的超平面的训练样本就是使等号成立的哪些样本,它们叫做支持向量(Support Vectors)。
最优分类超平面问题可以表示成如下约束优化问题
2,,11min ()min ||||min ()22w b w b w w w w Φ==? 其约束条件为
yi[(w ?xi)+b]-1≥0,i=1,2,…,n
定义Lagrange 函数:
[]{}11(,,)()()12n i i i i L w b w w y w x b αα==?-?+-∑
其中,αi>0为Lagrange 系数。分别对w 和b 求偏微分并令它们等于0,
得 11
11(,,)0(,,)00n n i i i i i i i i n
n i i i i i i L w b w y x w y x w L w b y y b αααααα====?=-=?=??==?=?∑∑∑∑
带入原始Lagrange 函数,得
1,11()()2n n
i i j i j i j i i j Q y y x x αααα===-?∑∑
因此,原问题转换为对偶问题:
在约束条件:
10
0,1,2,,n i
i i i y i n αα==≥=∧∑
之下对αi 求解下列函数的最大值:
1,11()()2n n
i i j i j i j i i j Q y y x x αααα===-?∑∑
对偶问题完全是根据训练数据来表达的。所得到的解αi 只有一部分(通常是少部分)不为零,对应的样本就是支持向量。
若 i α+ 为最优解,则
1n i i i i w y x α+
+==∑, 1s s b w x y ++=-?
其中s x 为任一支持向量。最后得到的最优分类函数为:
1()sgn ()sgn ()n i i i i f x w x b y x x b α++
++=????=?+=?+??????∑ 支持向量机的学习算法:
① 给出一组输入样本xi,i=1,2,…,n 及其对应的期望输出yi ∈{+1,-1};
② 在约束条件:10
0,1,2,,n i
i i i y i n αα==≥=∧∑
下求解下面函数的最大值,得到 i α+ ;
1,11()()2n n
i i j i j i j i i j Q y y K x x αααα===-?∑∑
③ 计算:
1n i i i i w y x α+
+==∑, 1s s b w x y ++=-? 其中s x 为一个特定的支持向量;
④ 对于待分类向量x ,选择某一特定类型的核函数K(x,xi),计算:
1()sgn ()sgn ()n i i i i f x w x b y K x x b α++
++=????=?+=?+??????∑ 为+1或-1,决定x 属于哪一类。
SVM 方法的特点
① 非线性映射是SVM 方法的理论基础,SVM 利用内积核函数代替向高维空间的非线性映射;
② 对特征空间划分的最优超平面是SVM 的目标,最大化分类边际的思想是SVM 方法的核心;
③ 支持向量是SVM 的训练结果,在SVM 分类决策中起决定作用的是支持向量。
SVM 是一种有坚实理论基础的新颖的小样本学习方法。它基本上不涉及概率测度及大数定律等,因此不同于现有的统计方法。从本质上看,它避开了从归纳到演绎的传统过程,实现了高效的从训练样本到预报样本的“转导推理”(transductive inference) ,大大简化了通常的分类和回归等问题。
SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性。这种
“鲁棒”性主要体现在:
①增、删非支持向量样本对模型没有影响;
②支持向量样本集具有一定的鲁棒性;
③有些成功的应用中,SVM 方法对核的选取不敏感。
SVM 应用
近年来SVM 方法已经在图像识别、信号处理和基因图谱识别等方面得到了成功的应用,显示了它的优势。
SVM 通过核函数实现到高维空间的非线性映射,所以适合于解决本质上非线性的分类、回归和密度函数估计等问题。
支持向量方法也为样本分析、因子筛选、信息压缩、知识挖掘和数据修复等提供了新工具。
支持向量机的研究:对支持向量机的研究主要集中在对SVM本身性质的研究以及加大支持向量机应用研究的深度和广度两方面。
SVM训练算法:传统的利用标准二次型优化技术解决对偶问题的方法,是SVM训练算法慢及受到训练样本集规模制约的主要原因。
目前已提出了许多解决方法和改进算法,主要是从如何处理大规模样本集的训练问题、提高训练算法收敛速度等方面改进。
主要有:分解方法、修改优化问题法、增量学习法、几何方法等分别讨论。
SVM分类算法:训练好SVM分类器后,得到的支持向量被用来构成决策分类面。对于大规模样本集问题,SVM训练得到的支持向量数目很大,则进行分类决策时的计算代价就是一个值得考虑的问题。
解决方法如:缩减集(Reduced Set) SVM方法,采用缩减集代替支持向量集,缩减集中的向量不是支持向量,数目比支持向量少,但它们在分类决策函数中的形式与支持向量相同。
支持向量机针对小样本情况所表现出来的优良性能引起了众多故障诊断领域研究人员的注意,Poyhonen等对SVM在电机故障诊断方面进行了应用研究,Gao等将SVM用于往复式泵故障诊断;Worden等运用SVM进行球轴承故障分类。Jack将SVM用于滚动轴承的状态检测,并采用遗传算法优化SVM的参数,取得比较好的推广性能。Samanta分别用轴承和齿轮故障诊断比较神经网络和SVM的性能,并采用遗传算法优化各自的参数。Chu等运用SVM进行故障检测和运行模式识别,还有许多的例子,在这里不再详细的进行介绍。这些针对不同故障现象的诊断研究表明:将支持向量机应用在故障诊断方面,其性能优于许多已有的方法。对于小样本,诊断精度高于神经网络方法,对于高维样本,诊断速度比神经网络快。众所周知,故障诊断的瓶颈之一就是故障样本的缺乏,由此可见SVM在机械故障诊断中有很好的应用前景。但是目前大多数还处在实验阶段,真正应用到实际中还需要进一步的研究和现场实践。
4、模糊诊断
人类对模式识别过程的机理目前仍然不是很清楚。对具体事物的识别主要是心理现象,对抽象事物的识别主要是思维现象。当一个人对于具体事物的认识,涉及人与客观事物在人类感官中所引起的刺激之间的关系。当一个人感受到一个模式时,他把此感觉与他从自己过去的经验中得来的一般概念或线索结合起来,并作出归纳性的推理判断。由于客观事物的特征存在不同程度的模糊性,使得经典的识别方法越来越不适应客观实际的要求,模糊识别正是为了满足这一要求而产生起来的。
模式描述方法:模糊集合 A={(μa,a), (μb,b),... (μn,n)}
模式判定:是一种集合运算。用隶属度将模糊集合划分为若干子集, m 类就有m 个子集,然后根据择近原则分类。
理论基础:模糊数学
主要方法:模糊统计法、二元对比排序法、推理法、模糊集运算规则、模糊矩阵
主要优点:由于隶属度函数作为样本与模板间相似程度的度量,故往往能反映整体的与主体的特征,从而允许样本有相当程度的干扰与畸变。
主要缺点:准确合理的隶属度函数往往难以建立,故限制了它的应用。 模糊模式识别已实际应用在选煤厂工序失控原因诊断系统、内燃机失火故障的研究中。
...1m x c x kx k t T ++=÷
模式识别的研究现状与发展趋势 摘要:随着现今社会信息技术的飞速发展, 人工智能的应用越来越广泛, 其中模式识别是人工智能应用的一个方面。而且现今的模式识别的应用也越来越得到大家的重视与支持,在各方面也有重大的进步。模式识别也成为人们身边不可或缺的一部分。关键词:人工智能,技术,模式识别,前景 Abstract:In the modern society with the rapid development of information technology, the application of a rtificial intelligence is more and more extensive, among them pattern recognition is one of the ap ply of artificial intelligence. And now the application of pattern recognition is also more and more to get everyone's attention and support, in various aspects have significant progress. Pattern rec ognition has become an integral part of people around. Keywords: Artificial Intelligence, Technology,Pattern Recognition, prospects 一,引言 如今计算机硬件的高速发展, 以及计算机应用领域的不断开拓, 人们开始要求计算机能够更有效地感知诸如声音、文字、图像、温度、震动等人类赖以发展自身、改造环境所运用的信息资料。但就一般意义来说, 目前一般计算机却无法直接感知它们, 我们常用的键盘、鼠标等外部设备, 对于这些外部世界显得无能为力。虽然摄像机、图文扫描仪、话筒等设备业已解决了上述非电信号的转换, 并与计算机联机, 但由于识别技术不高, 而未能使计算机真正知道采录后的究竟是什么信息。计算机对外部世界感知能力的低下, 成为开拓计算机应用的瓶颈, 也与其高超的运算能力形成强烈的对比。于是, 着眼于拓宽计算机的应用领域, 提高其感知外部信息能力的学科———模式识别, 便得到迅速发展。 人工智能所研究的模式识别是指用计算机代替人类或帮助人类感知模式, 是对人类感知外界功能的模拟, 研究的是计算机模式识别系统, 也就是使一个计算机系统具有模拟人类通过感官接受外界信息、识别和理解周围环境的感知能力。现将人工智能在模式识别方面的一些具体和最新的应用范围遍及遥感、生物医学图象和信号的分析、工业产品的自动无损检验、指纹鉴定、文字和语音识别、机器视觉地圈模式识别等方面。 二,现状 以地图模式识别为例,地图模式识别是由计算机来对地图进行识别与理解, 并借助一定的技术手段, 让计算机研究和分析地图上的各种模式信息, 获取地图要素的质量意义。其计算处理的过程类似于人对地图的阅读。 地图模式识别是近年来在地图制图领域中新兴的一门高新技术, 是信息时代人工智能、模式识别技术在地图制图中的具体应用。由于它是传统地图制图迈向数字地图制图的一座桥梁, 因此,地图模式识别遥感技术、地理信息系统一起, 被称为现代地图制图的三大技术。 目前, 地图模式识别由于具有广泛的应用价值和发展潜力,因而受到了人们的普遍重视。尤其是随着现今的计算机及其外部硬件环境的不断提高, 科技不过发展的情况下,
中国科学技术大学模式识别试题 (2012年春季学期) 姓名:学号:成绩: 一、填空与选择填空(本题答案写在此试卷上,30分) 1、模式识别系统的基本构成单元包括:、 和。 2、统计模式识别中描述模式的方法一般使用;句法模式识别中模式描述方法一般 有、、。 3、聚类分析算法属于;判别域代数界面方程法属于。 (1)无监督分类 (2)有监督分类(3)统计模式识别方法(4)句法模式识别方法 4、若描述模式的特征量为0-1二值特征量,则一般采用进行相似性度量。 (1)距离测度(2)模糊测度(3)相似测度(4)匹配测度 5、下列函数可以作为聚类分析中的准则函数的有。 (1) (4) 6、Fisher线性判别函数的求解过程是将N维特征矢量投影在中进行。 (1)二维空间(2)一维空间(3)N-1维空间 7、下列判别域界面方程法中只适用于线性可分情况的算法有;线性可分、不可分都适用的 有。 (1)感知器算法(2)H-K算法(3)积累位势函数法 8、下列四元组中满足文法定义的有。 (1)({A, B}, {0, 1}, {A→01, A→ 0A1 , A→ 1A0 , B→BA , B→ 0}, A) (2)({A}, {0, 1}, {A→0, A→ 0A}, A) (3)({S}, {a, b}, {S → 00S, S → 11S, S → 00, S → 11}, S) (4)({A}, {0, 1}, {A→01, A→ 0A1, A→ 1A0}, A) 二、(15分)简答及证明题 (1)影响聚类结果的主要因素有那些? (2)证明马氏距离是平移不变的、非奇异线性变换不变的。 (3)画出对样本集 ω1:{(0,0,0)T, (1,0,0)T, (1,0,1)T, (1,1,0)T,} PDF 文件使用 "pdfFactory Pro" 试用版本创建https://www.doczj.com/doc/dd4943047.html,
一、填空与选择填空(本题答案写在此试卷上,30分) 1、模式识别系统的基本构成单元包括:模式采集、特征提取与选择 和模式分类。 2、统计模式识别中描述模式的方法一般使用特真矢量;句法模式识别中模式描述方法一般有串、树、网。 3、聚类分析算法属于(1);判别域代数界面方程法属于(3)。 (1)无监督分类 (2)有监督分类(3)统计模式识别方法(4)句法模式识别方法 4、若描述模式的特征量为0-1二值特征量,则一般采用(4)进行相似性度量。 (1)距离测度(2)模糊测度(3)相似测度(4)匹配测度 5、下列函数可以作为聚类分析中的准则函数的有(1)(3)(4)。 (1)(2) (3) (4) 6、Fisher线性判别函数的求解过程是将N维特征矢量投影在(2)中进行。 (1)二维空间(2)一维空间(3)N-1维空间 7、下列判别域界面方程法中只适用于线性可分情况的算法有(1);线性可分、不可分都适用的有(3)。 (1)感知器算法(2)H-K算法(3)积累位势函数法 8、下列四元组中满足文法定义的有(1)(2)(4)。 (1)({A, B}, {0, 1}, {A→01, A→ 0A1 , A→ 1A0 , B→BA , B→ 0}, A) (2)({A}, {0, 1}, {A→0, A→ 0A}, A) (3)({S}, {a, b}, {S → 00S, S → 11S, S → 00, S → 11}, S) (4)({A}, {0, 1}, {A→01, A→ 0A1, A→ 1A0}, A) 9、影响层次聚类算法结果的主要因素有(计算模式距离的测度、(聚类准则、类间距离门限、预定的 类别数目))。 10、欧式距离具有( 1、2 );马式距离具有(1、2、3、4 )。 (1)平移不变性(2)旋转不变性(3)尺度缩放不变性(4)不受量纲影响的特性 11、线性判别函数的正负和数值大小的几何意义是(正(负)表示样本点位于判别界面法向量指向的 正(负)半空间中;绝对值正比于样本点到判别界面的距离。)。 12、感知器算法1。 (1)只适用于线性可分的情况;(2)线性可分、不可分都适用。
人工智能与模式识别 摘要:信息技术的飞速发展使得人工智能的应用围变得越来越广,而模式识别作为其中的一个重要方面,一直是人工智能研究的重要方向。在介绍人工智能和模式识别的相关知识的同时,对人工智能在模式识别中的应用进行了一定的论述。模式识别是人类的一项基本智能,着20世纪40年代计算机的出现以及50年代人工智能的兴起,模式识别技术有了长足的发展。模式识别与统计学、心理学、语言学、计算机科学、生物学、控制论等都有关系。它与人工智能、图像处理的研究有交叉关系。模式识别的发展潜力巨大。 关键词:模式识别;数字识别;人脸识别中图分类号; Abstract: The rapid development of information technology makes the application of artificial intelligence become more and more widely. Pattern recognition, as one of the important aspects, has always been an important direction of artificial intelligence research. In the introduction of artificial intelligence and pattern recognition related knowledge at the same time, artificial intelligence in pattern recognition applications were discussed.Pattern recognition is a basic human intelligence, the emergence of the 20th century, 40 years of computer and the rise of artificial intelligence in the 1950s, pattern recognition technology has made great progress. Pattern recognition and statistics, psychology,
模式识别 课题:基于支持向量机人工神经网络的水质预测研究专业:电子信息工程
摘要 针对江水浊度序列宽频、非线性、非平稳的特点,将经验模态分解(EMD)和支持向量机(SVM)回归方法引入浊度预测领域,建立了基于EMD2SVM的浊度预测模型.通过EMD分解,将原始非平稳的浊度序列分解为若干固有模态分量(IMF),根据各IMF序列的特点,选择不同的参数对各IMF序列进行预测,最后合成原始序列的预测值.将该方法应用于实际浊度预测,并与径向基神经网络(RBF)预测及单独支持向量机回归预测结果进行比较,仿真结果表明该方法预测精度有明显提高.水质评价实际上是一个监测数据处理与状态估计、识别的过程,提出一种基于支持向量机的方法应用于水质评价,该方法依据决策二叉树多类分类的思想,构建了基于支持向量机的水环境质量状况识别与评价模型。以长江口的实际水质监测数据为例进行了实验分析,并与单因子方法及单个BP神经网络方法进行了比较分析。实验结果表明,运用该模型对长江口的实际水质监测数据进行的综合水质评价效果较好,且具有较高的实用价值。 关键词:浊度;预测;经验模态分解;支持向量;BP神经网络 一.概述 江水浊度受地表径流、温度以及人类活动等的影响,波动明显,在不同的月份有着很大的变化,表现出非平稳、非线性的特点.对其进行分析和预测,对于河流生态评价、航运安全以及以江河水为原水的饮用
水生产具有重要的指导意义.国内外在浊度序列分析方面的研究文献较少,通常都是综合考虑各种水质参数而对浊度进行预测,采用较多的是人工神经网络等非线性模型方法[1,2].这种模型结构复杂,要求原始数据丰富,在实际操作中实现较为困难.此外,对于江水浊度这一具有宽带频谱的小样本混沌时间序列,采用单一的预测方法,将会把原始浊度序列中的各种不同特征信息同质化,势必影响其预测精度.采用经验模态分解(Empirical Mode Decomposition,EMD)将浊度序列分解后分别预测,再进行合成将可能提高其预测精度.不同于小波变换,在对信号进行经验模态分解时不需要先验基底,每一个固有模态函数(In2trinsic Mode Function,IMF)包含的频率成分不仅与采样频率有关,并且还随着信号本身的变化而变化,具有自适应性,能够把局部时间内含有的多个模态的非线性、非平稳信号分解成若干个彼此间影响甚微的基本模态分量,这些分量具有不同的尺度,从而简化系统间特征信息的干涉或耦合[3].支持向量机(Support Vector Ma2chines,SVM)是建立在统计学习理论上的一种机器学习方法,是目前针对小样本统计估计和预测学习的较好方法[4],对统计学习理论的发展起到巨大推动作用并得到广泛应用[5~8].SVM有良好的泛化能力,并解决了模型选择与欠学习、过学习问题及非线性问题,避免了局部最优解,克服了“维数灾难”,且人为设定参数少,便于使用,已成功应用于许多分类、识别和回归问题[5,6,8].根据江水浊度序列的特点,结合EMD和SVM两种方法的不同功能,本文提出了基于EMD2SVM模型的预测方法,用于江水浊度的
·在一个10类的模式识别问题中,有3类单独满足多类情况1,其余的类别满足多类情况2。问该模式识别问题所需判别函数的最少数目是多少? 应该是252142 6 *74132 7=+=+ =++C 其中加一是分别3类 和 7类 ·一个三类问题,其判别函数如下: d1(x)=-x1, d2(x)=x1+x2-1, d3(x)=x1-x2-1 (1)设这些函数是在多类情况1条件下确定的,绘出其判别界面和每一个模式类别的区域。 (2)设为多类情况2,并使:d12(x)= d1(x), d13(x)= d2(x), d23(x)= d3(x)。绘出其判别界面和多类情况2的区域。
(3)设d1(x), d2(x)和d3(x)是在多类情况3的条件下确定的,绘出其判别界面和每类的区域。 ·两类模式,每类包括5个3维不同的模式,且良好分布。如果它们是线性可分的,问权向量至少需要几个系数分量?假如要建立二次的多项式判别函数,又至少需要几个系数分量?(设模式的良好分布不因模式变化而改变。) 如果线性可分,则4个 建立二次的多项式判别函数,则102 5 C 个 ·(1)用感知器算法求下列模式分类的解向量w: ω1: {(0 0 0)T , (1 0 0)T , (1 0 1)T , (1 1 0)T } ω2: {(0 0 1)T , (0 1 1)T , (0 1 0)T , (1 1 1)T } 将属于ω2的训练样本乘以(-1),并写成增广向量的形式。 x ①=(0 0 0 1)T , x ②=(1 0 0 1)T , x ③=(1 0 1 1)T , x ④=(1 1 0 1)T x ⑤=(0 0 -1 -1)T , x ⑥=(0 -1 -1 -1)T , x ⑦=(0 -1 0 -1)T , x ⑧=(-1 -1 -1 -1)T 第一轮迭代:取C=1,w(1)=(0 0 0 0) T 因w T (1) x ① =(0 0 0 0)(0 0 0 1) T =0 ≯0,故w(2)=w(1)+ x ① =(0 0 0 1) 因w T (2) x ② =(0 0 0 1)(1 0 0 1) T =1>0,故w(3)=w(2)=(0 0 0 1)T 因w T (3)x ③=(0 0 0 1)(1 0 1 1)T =1>0,故w(4)=w(3) =(0 0 0 1)T 因w T (4)x ④=(0 0 0 1)(1 1 0 1)T =1>0,故w(5)=w(4)=(0 0 0 1)T 因w T (5)x ⑤=(0 0 0 1)(0 0 -1 -1)T =-1≯0,故w(6)=w(5)+ x ⑤=(0 0 -1 0)T 因w T (6)x ⑥=(0 0 -1 0)(0 -1 -1 -1)T =1>0,故w(7)=w(6)=(0 0 -1 0)T 因w T (7)x ⑦=(0 0 -1 0)(0 -1 0 -1)T =0≯0,故w(8)=w(7)+ x ⑦=(0 -1 -1 -1)T 因w T (8)x ⑧=(0 -1 -1 -1)(-1 -1 -1 -1)T =3>0,故w(9)=w(8) =(0 -1 -1 -1)T 因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第二轮迭代。 第二轮迭代: 因w T (9)x ①=(0 -1 -1 -1)(0 0 0 1)T =-1≯0,故w(10)=w(9)+ x ① =(0 -1 -1 0)T
211大学介绍 (2014-03-21 18:37:56) 转载▼ 我国 211大学 第一档 (财经类):中央财经大学、上海财经大学、对外经济贸易大学、西南财经大学、中南财经政法大学 (专属类):北京外国语大学、上海外国语大学、中国政法大学、中国传媒大学、中央音乐学院、北京体育大学 (理工类):北京邮电大学、华北电力大学、北京交通大学、北京科技大学、南京航空航天大学、西安电子科技大学、华东理工大学、南京理工大学 第二档 (理工类):西南交通大学、哈尔滨工程大学、武汉理工大学、北京化工大学、北京工业大学、河海大学、大连海事大学 (综合类):上海大学、暨南大学、苏州大学 (医药类):天津医科大学、北京中医药大学、中国药科大学 第三档 (综合类):郑州大学、福州大学、安徽大学、南昌大学、西北大学 (理工类):东华大学、长安大学、江南大学、合肥工业大学、河北工业大学、太原理工大学 (师范类):华中师范大学、华南师范大学、西南大学、东北师范大学、陕西师范大学、南京师范大学、湖南师范大学 (专属类):中国石油大学、中国地质大学、中国矿业大学 第四档 (边远类):云南大学、贵州大学、广西大学、海南大学、辽宁大学、内蒙古大学
(边远类):宁夏大学、青海大学、新疆大学、西藏大学、延边大学、石河子大学 (农林类):北京林业大学、华中农业大学、南京农业大学、东北农业大学、东北林业大学、四川农业大学 下面对211大学的分档进行一下简单的说明 一、排名依据 主要依据是2011年所有大学在全国31个省市的理科平均录取分的平均值的排名。 二、最热门的211 在一档211大学中,最热门的几所大学为中央财经大学、上海财经大学、对外经济贸易大学、北京外国语大学、北京邮电大学这五所。他们的录取分数排在前20名,和二档的985大学可以一争天下。 二档985中只有同济大学、南开大学、北京航空航天大学、西安交通大学可以和他们抗衡。 连著名的中山大学、武汉大学、厦门大学、天津大学,哈尔滨工业大学、华中科技大学,东南大学这些老牌的二档985的分数都没有他们高。可见这五所211大学是何等的热门。 三、一档211财经类 1、中央财经大学 号称我国银行家的摇篮,在金融街的校友资源全国第一,主要是政治定位,需要一所高水平的财经类院校在北京首都。中央财经大学最好的专业是金融学院的金融、金融工程、国际金融。 2、上海财经大学 上海财经大学是全国最著名的财经类大学,全国财经院校综合实力前五,经济学实力全国前十。加上地处上海这个金融大都市、全国金融中心,上海财大的未来将更加辉煌。最好的学院是会计学院、金融学院、商学院、经济学院、国际工商管理学院。 会计学院是第一大王牌大院。国际会计班包括ACCA、CGA、美国会计师。 国际会计班的CGA和ACCA比较好,美国会计证书很难考。非国际会计班包括会计学、注册会计师、财务管理。
XXX大学 课程设计报告书 课题名称模式识别 姓名 学号 院、系、部 专业 指导教师 xxxx年 xx 月 xx日
模式识别方法简述 摘要:模式识别(Pattern Recognition)是指对表征事物或现象的各种形式的( 数值的、文字的和逻辑关系的) 信息进行处理和分析, 以对事物或现象进行描述、辨认、分类和解释的过程, 是信息科学和人工智能的重要组成部分。模式识别研究主要集中在两方面, 一是研究生物体( 包括人) 是如何感知对象的,属于认识科学的范畴, 二是在给定的任务下, 如何用计算机实现模式识别的理论和方法。前者是生理学家、心理学家、生物学家和神经生理学家的研究内容, 后者通过数学家、信息学专家和计算机科学工作者近几十年来的努力, 已经取得了系统的研究成果。 关键词:模式识别; 模式识别方法; 统计模式识别; 模板匹配; 神经网络模式识别 模式识别(Pattern Recognition)是人类的一项基本智能,在日常生活中,人们经常在进行“模式识别”。随着2 0 世纪4 0 年代计算机的出现以及5 0 年代人工智能的兴起,人们当然也希望能用计算机来代替或扩展人类的部分脑力劳动。(计算机)模式识别在2 0 世纪6 0 年代初迅速发展并成为一门新学科。 模式识别研究主要集中在两方面, 一是研究生物体( 包括人) 是如何感知对象的,属于认识科学的范畴, 二是在给定的任务下, 如何用计算机实现模式识别的理论和方法。前者是生理学家、心理学家、生物学家和神经生理学家的研究内容, 后者通过数学家、信息学专家和计算机科学工作者近几十年来的努力, 已经取得了系统的研究成果。模式识别与统计学、心理学、语言学、计算机科学、生物学、控制论等都有关系。它与人工智能、图像处理的研究有交叉关系。例如自适应或自组织的模式识别系统包含了人工智能的学习机制;人工智能研究的景物理解、自然语言理解也包含模式识别问题。又如模式识别中的预处理和特征抽取环节应用图像处理的技术;图像处理中的图像分析也应用模式识别的技术。 模式识别是一种借助计算机对信息进行处理、判别的分类过程。判决分类在
Pattern Recognition Lecture0 Introduction Feb. 19th, 2009
?任课教师 –唐珂ketang@https://www.doczj.com/doc/dd4943047.html,; –电话:3600754 ?助教 –林民龙sunnyboy@https://www.doczj.com/doc/dd4943047.html, ?课程主页 https://www.doczj.com/doc/dd4943047.html,/~sunnyboy/pr/
主要内容 ?0.1 课程内容介绍 –课程内容、特点和授课方式 –教材和主要参考书目 ?0.2 课程要求 –考核和评分要求 ?0.3 模式识别导论 –什么是模式识别? –为什么需要模式识别? –模式识别在计算机科学中的地位 –模式识别系统框架 –模式识别研究领域的重要科学问题
0.1 课程内容介绍 ?课程内容: –模式识别系统模型和基本知识; –模式识别算法:贝叶斯方法、判别分析、神经网络、决策树、聚类算法等; –特征分析方法:特征选择、特征提取; –模式识别理论及系统评估方法。 ?课程特点: –介绍各种模式识别方法 –学习结束后,应能大致了解本领域的研究现状,并会用基本的模式识别方法解决自己科研中的相关问题。?学习方式: –课程讲授、平时作业和课堂讨论相结合
0.1 教材和主要参考书目 ?教材: ?Richard.O.Duda, P.E.Hart, D.G.Stork; 《模式分类》,机械工业出版社,2005年。 ?主要参考书目: – A. R. Webb, Statistical Pattern Recognition. John Wiley & Sons, London, (2002). –T. Hastie, R. Tibshirani, J. Friedman. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer, 2001. –边肇祺,张学工;《模式识别》,清华大学出版社,2004年
浅谈人工智能与模式识别的应用 一、引言 随着计算机应用范围不断的拓宽,我们对于计算机具有更加有效的感知“能力”,诸如对声音、文字、图像、温度以及震动等外界信息,这样就可以依靠计算机来对人类的生存环境进行数字化改造。但是从一般的意义上来讲,当前的计算机都无法直接感知这些信息,而只能通过人在键盘、鼠标等外设上的操作才能感知外部信息。虽然摄像仪、图文扫描仪和话筒等相关设备已经部分的解决了非电信号的转换问题,但是仍然存在着识别技术不高,不能确保计算机真正的感知所采录的究竟是什么信息。这直接使得计算机对外部世界的感知能力低下,成为计算机应用发展的瓶颈。这时,能够提高计算机外部感知能力的学科——模式识别应运而生,并得到了快速的发展,同时也成为了未来电子信息产业发展的必然趋势。 人工智能中所提到的模式识别是指采用计算机来代替人类或者是帮助人类来感知外部信息,可以说是一种对人类感知能力的一种仿真模拟。近年来电子产品中也加入了诸多此类的功能:如手机中的指纹识别解锁功能;眼球识别解锁技术;手势拍照功能亦或是机场先进的人耳识别技术等等。这些功能看起来纷繁复杂,但如果需要一个概括的话,可以说这都是模式识别技术给现代生活带来的福分。它探讨的是计算机模式识别系统的建立,通过计算机系统来模拟人类感官对外界信息的识别和感知,从而将非电信号转化为计算机可以识别的电信号。
二、人工智能和模式识别 (一)人工智能。人工智能(Artificial Intelligence),是相对与人的自然智能而言的,它是指采用人工的方法及技术,对人工智能进行模仿、延伸及扩展,进而实现“机器思维”式的人工智能。简而言之,人工智能是一门研究具有智能行为的计算模型,其最终的目的在于建立一个具有感知、推理、学习和联想,甚至是决策能力的计算机系统,快速的解决一些需要专业人才能解决的问题。从本质上来讲,人工智能是一种对人类思维及信息处理过程的模拟和仿真。 (二)模式识别。模式识别,即通过计算机采用数学的知识和方法来研究模式的自动处理及判读,实现人工智能。在这里,我们将周围的环境及客体统统都称之为“模式”,即计算机需要对其周围所有的相关信息进行识别和感知,进而进行信息的处理。在人工智能开发,即智能机器开发过程中的一个关键环节,就是采用计算机来实现模式(包括文字、声音、人物和物体等)的自动识别,其在实现智能的过程中也给人类对自身智能的认识提供了一个途径。在模式识别的过程中,信息处理实际上是机器对周围环境及客体的识别过程,是对人参与智能识别的一个仿真。相对于人而言,光学信息及声学信息是两个重要的信息识别来源和方式,它同时也是人工智能机器在模式识别过程中的两个重要途径。在市场上具有代表性的产品有:光学字符识别系统以及语音识别系统等。 在这里的模式识别,我们可以将之理解成为:根据识别对象具有特征的观察值来将其进行分类的一个过程。采用计算机来进行模式识别,是在上世纪60年代初发展起来的一门新兴学科,但同样也是未来一段实践中发展的必然方向。在生活节奏相当之快的今天人们希望电子产品可以为我们的生活提供更多的便利条件。因此在未来相当一段时间内模式识别技术依然是发展的必然趋势。
2013模式识别练习题 一. 填空题 1、模式识别系统的基本构成单元包括:模式采集、特征的选择和提取和模式分类。 2、统计模式识别中描述模式的方法一般使用特征矢量;句法模式识别中模式描述方法一般有串、树、 网。 3、影响层次聚类算法结果的主要因素有计算模式距离的测度、聚类准则、类间距离阈值、预定的类别数目。 4、线性判别函数的正负和数值大小的几何意义是正负表示样本点位于判别界面法向量指向的正负半空间中, 绝对值正比于样本点与判别界面的距离。 5、感知器算法1 ,H-K算法 2 。 (1)只适用于线性可分的情况;(2)线性可分、不可分都适用。 6、在统计模式分类问题中,聂曼-皮尔逊判决准则主要用于某一种判别错误较另一种判别错误更为重要的情 况;最小最大判别准则主要用于先验概率未知的情况。 7、 。一般在可 8、散度J ij越大,说明ωi类模式与ωj类模式的分布差别越大; 当ωi类模式与ωj类模式的分布相同时,J ij= 0。 二、选择题 1、影响聚类算法结果的主要因素有(B、C、D )。 A.已知类别的样本质量; B.分类准则; C.特征选取; D.模式相似性测度 2、模式识别中,马式距离较之于欧式距离的优点是(C、D)。 A.平移不变性; B.旋转不变性;C尺度不变性;D.考虑了模式的分布 3、影响基本K-均值算法的主要因素有(ABD)。 A.样本输入顺序; B.模式相似性测度; C.聚类准则; D.初始类中心的选取 4、位势函数法的积累势函数K(x)的作用相当于Bayes判决中的(B D)。 A. 先验概率; B. 后验概率; C. 类概率密度; D. 类概率密度与先验概率的乘积 5、在统计模式分类问题中,当先验概率未知时,可以使用(BD)。 A. 最小损失准则; B. 最小最大损失准则; C. 最小误判概率准则; D. N-P判决 6、散度J D是根据(C )构造的可分性判据。 A. 先验概率; B. 后验概率; C. 类概率密度; D. 信息熵; E. 几何距离 7、似然函数的概型已知且为单峰,则可用(ABCDE)估计该似然函数。 A. 矩估计; B. 最大似然估计; C. Bayes估计; D. Bayes学习; E. Parzen窗法 8、KN近邻元法较之Parzen窗法的优点是(B)。 A. 所需样本数较少; B. 稳定性较好; C. 分辨率较高; D. 连续性较好 9、从分类的角度讲,用DKLT做特征提取主要利用了DKLT的性质:(A C )。 A.变换产生的新分量正交或不相关; B.以部分新的分量表示原矢量均方误差最小; C.使变换后的矢量能量 更集中 10、如果以特征向量的相关系数作为模式相似性测度,则影响聚类算法结果的主要因素有(BC)。 A. 已知类别样本质量; B. 分类准则; C. 特征选取; D. 量纲 11、欧式距离具有(A B );马式距离具有(A B C D )。 A. 平移不变性; B. 旋转不变性; C. 尺度缩放不变性; D. 不受量纲影响的特性 12、聚类分析算法属于(A );判别域代数界面方程法属于(C )。 A.无监督分类; B.有监督分类; C.统计模式识别方法; D.句法模式识别方法 13、若描述模式的特征量为0-1二值特征量,则一般采用(D)进行相似性度量。 A. 距离测度; B. 模糊测度; C. 相似测度; D. 匹配测度 14、下列函数可以作为聚类分析中的准则函数的有(ACD)。
武汉理工大学 模式识别及其在图像处理中的应用 学院(系):自动化学院 课程名称:模式识别原理 专业班级:控制科学与工程1603班 任课教师:张素文 学生姓名:王红刚 2017年1月3日
模式识别及其在图像处理中的应用 摘要:随着计算机和人工智能技术的发展,模式识别在图像处理中的应用日益广泛。综述了模式识别在图像处理中特征提取、主要的识别方法(统计决策法、句法识别、模糊识别、神经网络)及其存在的问题, 并且对近年来模式识别的新进展———支持向量机与仿生模式识别做了分析和总结, 最后讨论了模式识别亟待解决的问题并对其发展进行了展望。 关键词:模式识别;图像处理;特征提取;识别方法 Pattern Recognition and Its Application in Image Processing Abstract:With the development of computer and artificial intelli-gence , pattern recognition is w idely used in the image processing in-creasingly .T he feature extraction and the main methods of pattern recognition in the image processing , w hich include statistical deci-sion, structural method , fuzzy method , artificial neural netw ork aresummarized.T he support vector and bionic pattern recognition w hich are the new developments of the pattern recognition are also analyzed .At last, the problems to be solved and development trends are discussed. Key words:pattern recognition ;image processing ;feature extrac-tion;recognition methods
人工智能与模式识别 摘要:模式识别(Pattern Recognition)是人类的一项基本智能,着20世纪40年代计算机的出现以及50年代人工智能的兴起,模式识别技术有了长足的发展。模式识别与统计学、心理学、语言学、计算机科学、生物学、控制论等都有关系。它与人工智能、图像处理的研究有交叉关系。模式识别的发展潜力巨大。 关键词:人工智能模式识别模式识别的方法模式识别的应用模式识别的发展潜力 正文: 模式识别的定义是借助计算机,就人类对外部世界某一特定环境中的客体、过程和现象的识别功能(包括视觉、听觉、触觉、判断等)进行自动模拟的科学技术。随着20世纪40年代计算机的出现以及50年代人工智能的兴起,人们当然也希望能用计算机来代替或扩展人类的部分脑力劳动。(计算机)模式识别在20世纪60年代初迅速发展并成为一门新学科。 模式识别(Pattern Recognition)是指对表征事物或现象的各种形式的(数 值的、文字的和逻辑关系的)信息进行处理和分析,以对事物或现象进行描述、辨认、分类和解释的过程,是信息科学和人工智能的重要组成部分。模式识别又常称作模式分类,从处理问题的性质和解决问题的方法等角度,模式识别分为有监督的分类(Supervised Classification)和无监督的分类(Unsupervised Classification)两种。二者的主要差别在于,各实验样本所属的类别是否预先已知。一般说来,有监督的分类往往需要提供大量已知类别的样本,但在实际问题中,这是存在一定困难的,因此研究无监督的分类就变得十分有必要了。 此外,模式还可分成抽象的和具体的两种形式。前者如意识、思想、议论等,属于概念识别研究的范畴,是人工智能的另一研究分支。我们所指的模式识别主要是对语音波形、地震波、心电图、脑电图、图片、照片、文字、符号、生物传感器等对象的具体模式进行辨识和分类。 模式识别研究主要集中在两方面,一是研究生物体(包括人)是如何感知对象的,属于认识科学的范畴,二是在给定的任务下,如何用计算机实现模式识别的理论和方法。 模式识别与很多学科都有联系,它与统计学、心理学、语言学、计算机科学、生物学、控制论等都有关系。它与人工智能、图像处理的研究有交叉关系。例如自适应或自组织的模式识别系统包含了人工智能的学习机制;人工智能研究的景物理解、自然语言理解也包含模式识别问题。又如模式识别中的预处理和特征抽取环节应用图像处理的技术;图像处理中的图像分析也应用模式识别的技术。 模式识别的方法主要有决策理论方法和句法方法,模式识别方法的选择取决于问题的性质。如果被识别的对象极为复杂,而且包含丰富的结构信息,一般采用句法方法;被识别对象不很复杂或不含明显的结构信息,一般采用决策理论方法。这两种方法不能截然分开,在句法方法中,基元本身就是用决策理论方法抽取的。在应用中,将这两种方法结合起来分别施加于不同的层次,常能收到较好的效果。 模式识别的应用非常广泛,比较典型的有:1 文字识别:在信息技术及计算机技术日益普及的今天,如何将文字方便、快速地输入到计算机中已成为影响人机接口效率的一个重要瓶颈,也关系到计算机能否真正在我过得到普及的应用。
2.1图像模式识别的方法 图像模式识别的方法很多,从图像模式识别提取的特征对象来看,图像识别方法可分为以下几种:基于形状特征的识别技术、基于色彩特征的识别技术以及基于纹理特征的识别技术。其中,基于形状特征的识别方法,其关键是找到图像中对象形状及对此进行描述,形成可视特征矢量,以完成不同图像的分类,常用来表示形状的变量有形状的周长、面积、圆形度、离心率等。基于色彩特征的识别技术主要针对彩色图像,通过色彩直方图具有的简单且随图像的大小、旋转变换不敏感等特点进行分类识别。基于纹理特征的识别方法是通过对图像中非常具有结构规律的特征加以分析或者则是对图像中的色彩强度的分布信息进行统计来完成。 从模式特征选择及判别决策方法的不同可将图像模式识别方法大致归纳为两类:统计模式(决策理论)识别方法和句法(结构)模式识别方法。此外,近些年随着对模式识别技术研究的进一步深入,模糊模式识别方法和神经网络模式识别方法也开始得到广泛的应用。在此将这四种方法进行一下说明。 2.1.1句法模式识别 对于较复杂的模式,如采用统计模式识别的方法,所面临的一个困难就是特征提取的问题,它所要求的特征量十分巨大,要把某一个复杂模式准确分类很困难,从而很自然地就想到这样的一种设计,即努力地把一个复杂模式分化为若干
较简单子模式的组合,而子模式又分为若干基元,通过对基元的识别,进而识别子模式,最终识别该复杂模式。正如英文句子由一些短语,短语又由单词,单词又由字母构成一样。用一组模式基元和它们的组成来描述模式的结构的语言,称为模式描述语言。支配基元组成模式的规则称为文法。当每个基元被识别后,利用句法分析就可以作出整个的模式识别。即以这个句子是否符合某特定文法,以判别它是否属于某一类别。这就是句法模式识别的基本思想。 句法模式识别系统主要由预处理、基元提取、句法分析和文法推断等几部分组成。由预处理分割的模式,经基元提取形成描述模式的基元串(即字符串)。句法分析根据文法推理所推断的文法,判决有序字符串所描述的模式类别,得到判决结果。问题在于句法分析所依据的文法。不同的模式类对应着不同的文法,描述不同的目标。为了得到于模式类相适应的文法,类似于统计模式识别的训练过程,必须事先采集足够多的训练模式样本,经基元提取,把相应的文法推断出来。实际应用还有一定的困难。 2.1.2统计模式识别 统计模式识别是目前最成熟也是应用最广泛的方法,它主要利用贝叶斯决策规则解决最优分类器问题。统计决策理论的基本思想就是在不同的模式类中建立一个决策边界,利用决策函数把一个给定的模式归入相应的模式类中。统计模式识别的基本模型如图2,该模型主要包括两种操作模型:训练和分类,其中训练主要利用己有样本完成对决策边界的划分,并采取了一定的学习机制以保证基于样本的划分是最优的;而分类主要对输入的模式利用其特征和训练得来的决策函数而把模式划分到相应模式类中。 统计模式识别方法以数学上的决策理论为基础建立统计模式识别模型。其基本模型是:对被研究图像进行大量统计分析,找出规律性的认识,并选取出反映图像本质的特征进行分类识别。统计模式识别系统可分为两种运行模式:训练和分类。训练模式中,预处理模块负责将感兴趣的特征从背景中分割出来、去除噪声以及进行其它操作;特征选取模块主要负责找到合适的特征来表示输入模式;分类器负责训练分割特征空间。在分类模式中,被训练好的分类器将输入模式根据测量的特征分配到某个指定的类。统计模式识别组成如图2所示。
模式识别miniproject 实验报告 报告人:李南云 学号:SA16173027 日期:2016.12.23
数据分析 在此简要的说明一下数据情况,给定数据集分为train和test 两个data文件, train.data是11列8285行,意味着有8285个样本,矩阵的最后一列是该列所对应的样本类别。根据统计,train数据前466个样本均为1类,而后7819个样本均为-1类,所以该分类器为二分类问题。MATLAB中用importdata()读取数据,并将样本和其所属类别分开来,样本为trnset,所属类别为trnclass,train数据用于训练分类器。 Test.data是11列2072行,同样也意味着有2072个样本,最后一列为该列所对应样本类别,test数据前117为1类,后1955个数据为-1类。同样读取数据后,分为tstset和tstclass两个矩阵,前者代表2072个样本,后者代表所对应样本的类别,我们需要将train所训练好的分类器应用在tstset样本上,输出分类结果tstclass1,将其与tstclass相比较,计算每个类别的正确率和总的正确率。 算法介绍 本次实验采用了SVM(support vector machines)分类模型,由于数据线性不可分而且在实际问题中数据也大都线性不可分,所以本次试验采取的线性不可分SVM方法,即将数据向高维空间映射,使其变得线性可分。 本实验选取的二分类算法,SVC_C。
下面先以线性分类器为例,来引入SVM算法的一些概念和处理流程,如图1所示,假设C1和C2是需要区分的类别,而在二维平面中它们的样本如图,中间的一条直线就是一个线性分类函数,由图中可以看出,这个线性分类函数可以完全的将两类样本区分开来,我们就称这样的数据是线性可分的,否则则为线性不可分,本实验中所采用的数据在二维空间里分布如图2和图3所示(红色标注分类为1的样本,蓝色标注为分类为-1的样本),明显线性不可分。 图1
模式识别及其在图像处理中的应用 摘要:随着计算机和人工智能技术的发展,模式识别在图像处理中的应用日益广泛。综述了模式识别在图像处理中特征提取、主要的识别方法(统计决策法、句法识别、模糊识别、神经网络)及其存在的问题,并且对近年来模式识别的新进展——支持向量机与仿生模式识别做了分析和总结,最后讨论了模式识别亟待解决的问题并对其发展进行了展望。 关键词:模式识别;图像处理;特征提取;识别方法
模式识别诞生于20世纪20年代,随着计算机的出现和人工智能的发展,模式识别在60年代初迅速发展成一门学科。它所研究的理论和方法在很多学科和领域中得到广泛的重视,推动了人工智能系统的发展,扩大了计算机应用的可能性。图像处理就是模式识别方法的一个重要领域,目前广泛应用的文字识别( MNO)就是模式识别在图像处理中的一个典型应用。 1.模式识别的基本框架 模式识别在不同的文献中给出的定义不同。一般认为,模式是通过对具体的事物进行观测所得到的具有时间与空间分布的信息,模式所属的类别或同一类中模式的总体称为模式类,其中个别具体的模式往往称为样本。模式识别就是研究通过计算机自动地(或者人为进行少量干预)将待识别的模式分配到各个模式类中的技术。模式识别的基本框架如图1所示。 根据有无标准样本,模式识别可分为监督识别方法和非监督识别方法。监督识别方法是在已知训练样本所属类别的条件下设计分类器,通过该分类器对待识样本进行识别的方法。如图1,标准样本集中的样本经过预处理、选择与提取特征后设计分类器,分类器的性能与样本集的大小、分布等有关。待检样本经过预处理、选择与提取特征后进入分类器,得到分类结果或识别结果。非监督模式识别方法是在没有样本所属类别信息的情况下直接根据某种规则进行分类决策。应用于图像处理中的模式识别方法大多为有监督模式识别法,例如人脸检测、车牌识别等。无监督的模式识别方法主要用于图像分割、图像压缩、遥感图像的识别等。