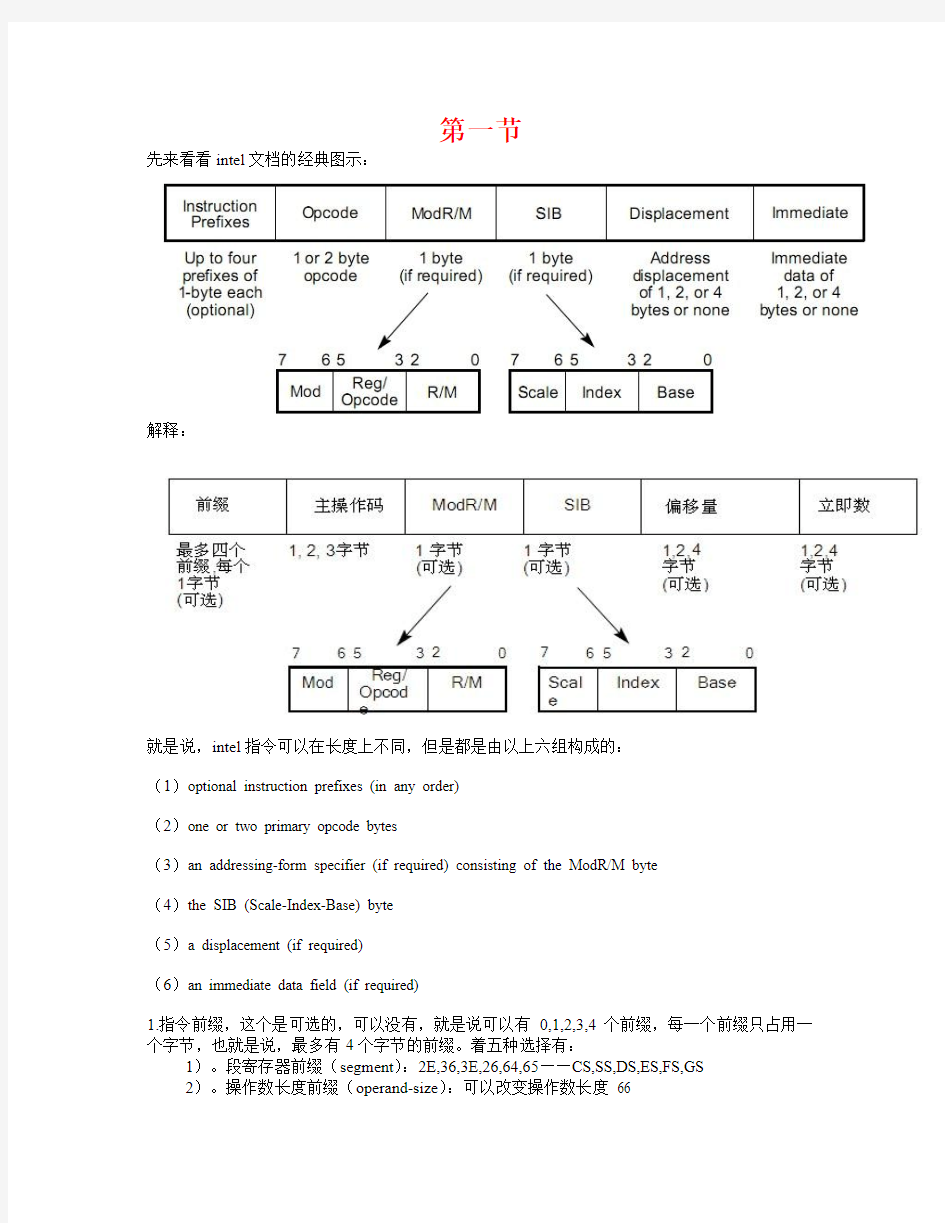

第一节
先来看看intel文档的经典图示:
解释:
就是说,intel指令可以在长度上不同,但是都是由以上六组构成的:
(1)optional instruction prefixes (in any order)
(2)one or two primary opcode bytes
(3)an addressing-form specifier (if required) consisting of the ModR/M byte
(4)the SIB (Scale-Index-Base) byte
(5)a displacement (if required)
(6)an immediate data field (if required)
1.指令前缀,这个是可选的,可以没有,就是说可以有0,1,2,3,4个前缀,每一个前缀只占用一个字节,也就是说,最多有4个字节的前缀。着五种选择有:
1)。段寄存器前缀(segment):2E,36,3E,26,64,65——CS,SS,DS,ES,FS,GS
2)。操作数长度前缀(operand-size):可以改变操作数长度66
3)。地址长度前缀(address-size):可以改变地址长度67
4)。重复前缀(rep/repne):F3 F2
5)。总线加锁前缀(LOCK):控制处理器总线F0
这样的五种,下面作出详细的说明:
1)例子:
8B00 MOV EAX,DWORD PTR DS:[EAX]
2E:8B00 MOV EAX,DWORD PTR CS:[EAX]
36:8B00 MOV EAX,DWORD PTR SS:[EAX]
可以看到默认情况下是使用了DS的
2)操作数前缀,允许一个程序在16/32位操作数长度之间转换,默认下市32位的,就是说,如果加前缀66H,就会转换成16位的指令:
89 C0 MOV EAX,EAX
66 89 C0 MOV AX,AX
3)地址长度前缀,也是和2)一样的,表示16/32位的寻址方式,在win32下编程一般是不用管的:
8B00 MOV EAX,DWORD PTR DS:[EAX]——32bit寻址模式
67:8B00 MOV EAX,DWORD PTR DS:[BX+SI]——16bit寻址模式
4)重复前缀,将会重复操作字符串的每一个元素。
只有MOVS,CMPS,SCAS,LODS,STOS,INS,OUTS等字符串操作或I/O指令才能使用这些前缀,举例子:
AD LODS DWORD PTR DS:[ESI]
F3 AD REP LODS DWORD PTR DS:[ESI]
F2 AD REPNE LODS DWORD PTR DS:[ESI]
5)。总线加锁,这一部分目前还没有涉及,但是如果想知道intel的所有秘密来反汇编,就需要仔细的了解了,还有病毒什么的。。。。(不明)
总之,prefix主要起了三个作用:调整、加强、附加,要彻底了解x86 prefix,必须清楚了解3个很重要的上下文环境:缺省operand-size和缺省addess-size环境,编译器上下文环境以及当前执行上下文环境。
2.操作码,opcode就是这儿了,这个就是解码的关键部分了,从字长上分为:
1)首先是1字节操作码:
2)然后是双字节操作码:
3)最后是三字节操作码:
之所以说这儿是核心,是因为Opcode、ModRM以及SIB,这三者的已经是紧密结合,无论分开谁单独来讲都不能透切的了解x86的指令编码体系,这三部分就是对于一般看见的诸如:MOV EAX,ECX
这样的汇编代码进行恢复的关键要素了!通过查找相对应的表,再对这三个部分综合分析,就可以从机器码中得到确切的汇编代码了。
这个部分有四个表格:
One-byte Opcode Map: (00H —FFH)
Two-byte Opcode Map: 00H —FFH (First Byte is 0FH)
Three-byte Opcode Map: 00H —FFH (First Two Bytes are 0F 38H)
Three-byte Opcode Map: 00H —FFH (First two Bytes are 0F 3AH)
但是三字节的表格还没有填满,说明intel以后还会有新的指令添加,而且一般而言三字节指令也是基本不会涉及的。
还需要注意的有,标记有1A上标的指令需要把ModR/M中的第3,4,5位作为opcode extension使用,在查表的时候需要仔细的注意了,同时也说明了Opcode、ModRM以及SIB这三个部分紧密的联系!
(再有就是opcode表的分组了,现在还是不是很清楚这个作用!第三节中会详细的讲解。)
3.ModR/M,这个是告诉处理器哪一个寄存器或者内存地址被使用了,只有一个字节。许多涉及内存操作数的指令都有一个紧挨着主操作码的寻址格式说明字节,这就是ModR/M字节,ModR/M字节包含3个域信息(在一个字节中的不同位):
1)mod域与r/m域组合有32个可能的值:8个寄存器和24个寻址模式。
其中的mod只有2位:6-7
R/m位有三个:0-2
所以组合有5位,2^5=32
2)reg/opcode域确定寄存器号或者附加的3位操作码。reg/opcode域的用途由主操作码确定。在其中的:3-5位。
这个字段被认为是代码扩展字段或者作为寄存器字段,处理器知道哪一个右侧编码相对于这个字段:
——如果为代码扩展字段(code extension),有的指令需要一个操作数,而有的需要两个操作数
——如果是寄存器字段
3)r/m域确定一个寄存器为操作数或者和mod域一起编码寻址模式。有时候有些指令使用特定的mod域和r/m域组合来表示操作码信息。
所以这一部分的内容就需要仔细的加以区分了,详细情况完了补充一下:
这个部分有2个表格需要仔细的参考:
16-Bit Addressing Forms with the ModR/M Byte
32-Bit Addressing Forms with the ModR/M Byte
一般而言,现在X86编程只需要32位的这个图表了。
4.SIB字节,Scale-Index-Base,他的作用是在ModRM 无法提供更多内存寻址方式时,使用SIB 进行协助寻址,对base+index*scale+disp这种寻址模式下的内存操作数寻址提供补充定义。
一般的格式是:Scale*Index+Base,也是有一个字节,分不同的位来起作用:
7——6——5—4—3——2——1——0
Scale index base
就是说:0-2是base,3-5是index,6-7是scale
Scale被认为是index寄存器的乘数
<1>00:2^0=1 < = > *1
<2>01:2^1=2 < = > *2
<3>10:2^2=4 < = > *4
<4>11:2^3=8 < = > *8
Index是一个寄存器(除了ESP),如果索引寄存器是ESP就会被忽略,scale也就被忽略了Base是基础寄存器(base register)
这个部分也有1个图表需要参考:
32-Bit Addressing Forms with the SIB Byte
5.偏移量
6.立即数
以上就是一个基本的intel指令的格式要求了,具体的内容还有待于进一步的完善,自己学一些就写一些了,难度还是有的,所以需要分阶段的学习了20110124凌晨
学习完成第二课,回过头来补充资料完成,于20110124凌晨
第二节
20110124中午继续
现在来看看一个例子:
在当前32位机器,32位系统下,有如下汇编指令:
mov word ptr es:[eax + ecx * 8 + 0x11223344], 0x12345678
分析这条汇编码:
这是一条mov指令,目标操作数是mem,源操作数是imme,
注意:我特地将操作数的大小定为是word(2个字节),而不是dword,源操作数故意定为0x12345678,这个dword大小的立即。
对应的机器编码是:26 66 c7 84 c8 44 33 22 11 78 56
现在,我对这个机器码略为解释一下:
26:在指令序列里是:prefix部分,作用是调整内存操作数的段选择子
66:在指令序列里是:prefix 部分,作用是调整操作数的缺省大小
C7:在指令序列里是:Opcode部分,是mov指令是操作码
84:在指令序列里是:ModRM值,定义操作数的属性
C8:在指令序列里:SIB值定义内存操作数的属性
44332211:在指令序列里是:displacement值
7856:在指令序列里是:immediate值
疑问:optional instruction prefixes (in any order)就像官方文档的说明一样,是可以任何顺序的吗?这个是可以的,前缀是不区分顺序的!
现在来看一看编码序列:
如图,这个编码序列分为Legacy Prefix、REX prefix、Opcode、ModRM、SIB、Displacement以及Immediate 7个部分。这个顺序就是实现反汇编引擎的核心了!
实际上,将功能组别,我将这个指令序列分为4个部分,分别为:Prefix、Opcode、ModRM/SIB、Disp/Imme,解释如下:
●Prefix(前缀):
AMD推出x86扩展64位技术时,增加了一个用于扩展访问64位数据的REX prefix,而x86的prefix 是Legacy prefix。
在x86模式下,REX prefix是无效的。但是,在x64的64位下Legacy prefix 是有效的。
●Opcode(操作码):
大多数通用指令Opcode是单字节,最多是2字节,但是对有些Float指令和SSEx midea指令来说是3个字节的。
●ModRM/SIB:
ModRM字节实际意义为:mod-reg-rm,按2-3-3比例划分字节,SIB 意即:Sacle-Index-Base 也是按2-3-3比例划分字节。
这两个字节用来修饰指令操作数。
●Disp/Imme:
Displacement最大可为8个字节64位,当然8个字节的displacment只有在x64平台下才会有,displacement也可理解为offset。同样immediate最大可为8个字节,同样在x64下台才会有的。需要注意的一点是:displacement 和immediate都是符号数(single),在32位下,小于32位被符号扩展至32位,在64位下,小于64位会被符号扩展64位。
下面分析一个机器码反汇编的例子来仔细研究一下intel的反汇编核心内容,opcode。
例子:26 c7 84 c8 44 33 22 11 78 56 34 12
分析这个机器码序列,如下:
(1) 26是prefix,这是segment-override prefix,指明是ES段选择子
(2) c7是Opcode,表明这个指令是mov reg/mem, imme
(3) 84是ModRm,即:10-000-100。
(4) c8 是SIB,即:11-001-000
(5) 44332211 是disp,是32位displacement值
(6) 78563412 是imme,是32位immediate值
我们先按照字面意思翻译就是:
mov dword ptr es:[eax + ecx * 8 + 0x11223344], 0x12345678
可是这样还是有问题的,虽然指令对了,但是我们还没有理解这其中的细节信息!
所以这里有一个问题,就是opcode的属性是什么啊?
首先来仔细看看Opcode属性的关键字:
(1)寻址方式关键字:
A Direct address. The instruction has no ModR/M byte; the address of the operand is en-
coded in the instruction; and no base register, index register, or scaling factor can be
applied (for example, far JMP (EA)).
C The reg field of the ModR/M byte selects a control register (for example, MOV (0F20, 0F22)).
D The reg field of the ModR/M byte selects a debug register (for example,
MOV (0F21,0F23)).
E A ModR/M byte follows the opcode and specifies the operand. The operand is either a
general-purpose register or a memory address. If it is a memory address, the address is
computed from a segment register and any of the following values: a base register, an
index register, a scaling factor, a displacement.
F EFLAGS Register.
G The reg field of the ModR/M byte selects a general register (for example, AX (000)).
I Immediate data. The operand value is encoded in subsequent bytes of the instruction.
J The instruction contains a relative offset to be added to the instruction pointer register
(for example, JMP (0E9), LOOP).
M The ModR/M byte may refer only to memory (for example, BOUND, LES, LDS, LSS, LFS, LGS, CMPXCHG8B).
O The instruction has no ModR/M byte; the offset of the operand is coded as a word or
double word (depending on address size attribute) in the instruction. No base register,
index register, or scaling factor can be applied (for example, MOV (A0–A3)).
P The reg field of the ModR/M byte selects a packed quadword MMX?technology reg-
Ister.
Q A ModR/M byte follows the opcode and specifies the operand. The operand is either
an MMX?technology register or a memory address. If it is a memory address, the ad-
dress is computed from a segment register and any of the following values: a base reg-
ister, an index register, a scaling factor, and a displacement.
R The mod field of the ModR/M byte may refer only to a general register (for example,
MOV (0F20-0F24, 0F26)).
S The reg field of the ModR/M byte selects a segment register (for example, MOV
(8C,8E)).
T The reg field of the ModR/M byte selects a test register (for example, MOV
(0F24,0F26)).
V The reg field of the ModR/M byte selects a packed SIMD floating-point register.
W An ModR/M byte follows the opcode and specifies the operand. The operand is either
a SIMD floating-point register or a memory address. If it is a memory address, the ad-
dress is computed from a segment register and any of the following values: a base reg-
ister, an index register, a scaling factor, and a displacement.
X Memory addressed by the DS:SI register pair (for example, MOVS, CMPS, OUTS, or
LODS).
Y Memory addressed by the ES:DI register pair (for example, MOVS, CMPS, INS,
STOS, or SCAS).
(2)操作类型关键字:
a Two one-word operands in memory or two double-word operands in memory, depending on operand-size attribute (used only by the BOUND instruction).
b Byte, regardless of operand-size attribute.
c Byte or word, depending on operand-size attribute.
d Doubleword, regardless of operand-siz
e attribute.
dq Double-quadword, regardless of operand-size attribute.
p 32-bit or 48-bit pointer, depending on operand-size attribute.
pi Quadword MMX?technology register (e.g. mm0)
ps 128-bit packed FP single-precision data.
q Quadword, regardless of operand-size attribute.
s 6-byte pseudo-descriptor.
Ss Scalar element of a 128-bit packed FP single-precision data.
si Doubleword integer register (e.g., eax)
v Word or doubleword, depending on operand-size attribute.
w Word, regardless of operand-size attribute.
综上就是opcode解码的关键字,现在举例如下:
还是看C7这个机器码,查表one-byte opcode map有:
可以看到这个属于Grp 11(1a)类型,有Ev,Iv属性,由以上的属性说明关键字可知:
E A ModR/M byte follows the opcode and specifies the operand. The operand is either a
general-purpose register or a memory address. If it is a memory address, the address is
computed from a segment register and any of the following values: a base register, an
index register, a scaling factor, a displacement.
I Immediate data. The operand value is encoded in subsequent bytes of the instruction.
v Word or doubleword, depending on operand-size attribute.
自己翻译就是:
Ev:是一个在opcode后的ModR/M由操作数大小决定的关键字,或者双字,该操作字指定了一般目的的寄存器或者内存地址,如果指定的是内存地址,那么这个地址是由段寄存器和他之后的基地址寄存器,索引寄存器,比例因子或者displacement值所计算出来。
Iv:是一个立即数数据,其大小是由操作数大小决定为关键字,或者双字。
也就是说,C7这个指令,对应的就是mov ModR/M,Immediate 这个汇编指令了,现在从opcode出发继续看例子中的机器码26 c7 84 c8 44 33 22 11 78 56 34 12,自己现在翻译就是:前缀26:ES(1字节),段寄存器
核心opcode C7:mov ModR/M,Immediate(1字节)
ModR/M:84就是10-000-100(233划分1字节)
SIB:11-001-000(233划分1字节)
Displacement,可理解为offset,最大4个字节:44332211(4字节)——11223344
Immediate:78563412(4字节,按低位到高位排列)——12345678
既然opcode的属性确定了寻址方式,那么接下来就是:
查表32-bit addressing forms with the ModR/M byte表来找ModR/M结构可以得到:
可以得到是EAX
查表32-bit addressing forms with the SIB byte表来找SIB结构可以得到:
可以得到是ECX*8
然后因为目标操作是内存地址,即opcode决定了这个地址是由段寄存器和他之后的基地址寄存器和displacement值所计算出来,就是说:
EAX+ECX*8+11223344
最后就是由操作数决定长度的一个立即数,因为操作数是12345678
综上所分析,机器码26 c7 84 c8 44 33 22 11 78 56 34 12翻译成为汇编语言就是:
mov es:[eax + ecx * 8 + 0x11223344], 0x12345678
这儿又出现了一个问题:SIB不是必须的,那么是什么导出了SIB吗?
总结如下:
首先我们从一句汇编代码的机器码得出了编码序列,并且对于序列的每一个部分进行了划分,分出了一般指令的六个组成部分(不一定全部都有);
然后就对于每一个组成部分做出了解释,而这个解释的关键就在于intel文档的:one-byte opcode map,32-bit addressing forms with the ModR/M byte和32-bit addressing forms with the SIB byte的这三个表,通过查表就可以确定一个opcode的具体含义;
最后,对照表就可以写出相应的汇编代码了!
兴奋吧,终于开始要走上学些intel指令格式的道路了,但是距离自己写反汇编引擎还有很长的路要走啊!于20110124晚,23:16
第三节
既然通过以上两个可以看出关键的部分就在于查表,那么今天就来看看怎么样才能充分的都读懂intel给我们的这些表格了,呵呵
首先看看官方的文档中对于opcode的说明:
Use the opcode tables in this chapter to interpret IA-32 and Intel 64 architecture
object code. Instructions are divided into encoding groups:
?1-byte, 2-byte and 3-byte opcode encodings are used to encode integer, system,
MMX technology, SSE/SSE2/SSE3/SSSE3/SSE4, and VMX instructions. Maps for
these instructions are given in Table A-2 through Table A-6.
?Escape opcodes (in the format: ESC character, opcode, ModR/M byte) are used
for floating-point instructions. The maps for these instructions are provided in
Table A-7 through Table A-22.
简单的翻译就是:
指令按不同的编码分为几组:
(1)1,2,3字节的opcode用于整型编码,操作系统,MMX技术,
SSE/SSE2/SSE3/SSSE3/SSE4技术,,以及VMX instructions(虚拟机指令)技术。这些指令的地图在表2到6中。
(2)Escape 指令用于浮点指令集,在表7到22中。
可以看见,表格的情况也是很复杂的,怎么样从关键的信息出发来找表格的突破点呐?
(1)表格中行指标是除去前缀(2,3字节opcode)之后的高4位字节,列指标是低4位字节:(2)有些1,2字节的opcode会使用ModR/M字节的第3-5位作为opcode的扩展:这个地方就穿插讲解一下ModR/M字节的功能了:
如图可见,整个ModR/M字节分为三部分:MOD,REG/OPCODE和R/M
1)其中的MOD是寻址模式,由两位组成,有四种寻址模式,但是从总体上说,只有两种寻址模式:内存寻址模式和寄存器寻址模式:
<1>mod = 11,寄存器寻址模式,这儿的ModRM的寻址方式的定位是定位2
个操作数寻址方式的这种模式,所以在只有1个寄存器时,寻址方式会直接嵌入在
opcode中;
<2>mod = 00,定义register间接寻址,没有displacement值;
<3>mod = 01,定义[register + disp8],有8位displacemnet 偏移值;
<4>mod = 10,定义[register + disp32],有32位displacement偏移值。
总体上就是这样的寻址模式。
然后由最后的R/M来决定实际的操作数,如图就是其中的一部分表格:
2)REG/Opcode:由三个位组成:
<1>作为reg值:000-111对应RAX、RCX、RDX、RBX、RSP、RBP、RSI以
及RDI(其中的R表示任意位数情况下可能的情况,比如:EAX(32),AX(16),AL
(8)等),究竟最终使用的是32位还是16位的寄存器,则由操作码字节以及操作数
尺寸属性决定=>在介绍指令前缀的时候已经介绍了Intel如何识别8位,16位和32
位操作对象的,这里对寄存器的识别也用的是同样的方式,如图:
<2>作为opcode扩展值:reg域的另一含义是对Opcode的补充,对分为一组
Opcode的进行选择(就是所标记的Group属性),共有16中分组,这里就是(2)
中所关注的部分了:
在opcode的操作数具有group属性的时候才会需要MorD//M中3-5位配合!也就是说:
(a)指令的操作对象中没有寄存器,只有内存和立即数;
(b)指令操作的对象中的寄存器是默认已知的。
这两种情况才会使用扩展的三位来对于opcode补充!
所以:从解码的代码实现的角度来说,我们读到了对应的Opcode,但是要确定其对应的操作,还需要接着再读取ModR/M中的Opcode部分,两个部分结合起来才能得到正确的指令编码。这个也就是不同反汇编引擎的主要区别!
现在看看这个group的具体含义,先来看看group的表式怎么查看的:
首先是从opcode表中出发:
看看这个0x80编码的opcode,没有显示任何的指令,只是写了:
Immediate Grp 1(1A)
表示是立即数,属于group1的1A部分(看下面的图)
既然是属于group属性,那么就需要配合ModR/M来确定具体的操作指令是什么了:查表:Opcode Extensions for One- and Two-byte Opcodes by Group Number
从以上的这两个表就可以确定具体的操作指令,然后综合这个指令的属性:
Eb,Ib
就可以根据后面的ModR/M来最终知道是什么样的一个汇编指令了。
这个就是怎么查opcode表的一般方法了,呵呵,到这儿,我们已经基本上完成了对于intel指令的解析的基本知识的学习,总结一下:
首先我们从指令的顺序出发,先看了prefix;
然后继续查表,找到opcode对应的操作码,接下来就是查看这个操作码的属性:是否属于某一组,如果是,通过组找到具体的操作码;不是就继续看这个操作码的属性,是一个还是两个,来确定寻址方式,看是否需要依赖于ModR/M;
然后是根据ModR/M看是否需要使用SIB来扩展内存寻址方式,如果需要则根据SIB来确定这种寻址方式;
再然后就是,继续读机器码,根据前面opcode,ModR/M,SIB,将最后的DIS和IMM放入解码;
至此,机器码的反汇编就完成了。
第四节
在这一节中我将整合前面的三节内容来完成一个完整思路的反汇编引擎的设计思路。
由于前面的知识是一边学习一边记录的,所以整个思路看起来比较乱,但是从初学的角度说,这样有层次的学习是比较适合逐步理解的,可是最后能够总结精华并且加以应用才是我们的最终目的,所以在这一节中就会综合前面的知识,通过画框架的形式来总结内容,然后通过看egogg 大大的文章和反汇编源代码来最终理解opcode!
现在开始吧!
51单片机汇编指令集 一、数据传送类指令(7种助记符) MOV(英文为Move):对内部数据寄存器RAM和特殊功能寄存器SFR的数据进行传送; MOVC(Move Code)读取程序存储器数据表格的数据传送; MOVX (Move External RAM) 对外部RAM的数据传送; XCH (Exchange) 字节交换; XCHD (Exchange low-order Digit) 低半字节交换; PUSH (Push onto Stack) 入栈; POP (Pop from Stack) 出栈; 二、算术运算类指令(8种助记符) ADD(Addition) 加法; ADDC(Add with Carry) 带进位加法; SUBB(Subtract with Borrow) 带借位减法; DA(Decimal Adjust) 十进制调整; INC(Increment) 加1; DEC(Decrement) 减1; MUL(Multiplication、Multiply) 乘法; DIV(Division、Divide) 除法; 三、逻辑运算类指令(10种助记符) ANL(AND Logic) 逻辑与; ORL(OR Logic) 逻辑或; XRL(Exclusive-OR Logic) 逻辑异或; CLR(Clear) 清零; CPL(Complement) 取反; RL(Rotate left) 循环左移; RLC(Rotate Left throught the Carry flag) 带进位循环左移; RR(Rotate Right) 循环右移; RRC (Rotate Right throught the Carry flag) 带进位循环右移; SWAP (Swap) 低4位与高4位交换; 四、控制转移类指令(17种助记符) ACALL(Absolute subroutine Call)子程序绝对调用; LCALL(Long subroutine Call)子程序长调用; RET(Return from subroutine)子程序返回; RETI(Return from Interruption)中断返回; SJMP(Short Jump)短转移; AJMP(Absolute Jump)绝对转移; LJMP(Long Jump)长转移; CJNE (Compare Jump if Not Equal)比较不相等则转移;
第一章基础知识: 一.机器码:1.计算机只认识0,1两种状态。而机器码只能由0,1组成。故机器码相当难认,故产生了汇编语言。 2.其中汇编由三类指令形成:汇编指令(有机器码对应),伪指令,其他符号(编译的时候有用)。 每一总CPU都有自己的指令集;注意学习的侧重点。 二.存储器:1.存储单元中数据和指令没任何差别。 2.存储单元:Eg:128个储存单元(0~127)128byte。 线: 1.地址总线:寻址用,参数(宽度)为N根,则可以寻到2^N个内存单元。 据总线:传送数据用,参数为N根,一次可以传送N/8个存储单元。 3.控制总线:cpu对元器件的控制能力。越多控制力越强。 四.内存地址空间:1.由地址总线决定大小。 2.主板:cpu和核心器件(或接口卡)用地址总线,数据总线,控制总 线连接起来。 3.接口卡:由于cpu不能直接控制外设,需通过接口卡间接控制。
4.各类存储器芯片:RAM,BIOS(主板,各芯片)的ROM,接卡槽的 RAM CPU在操控他们的时候,把他们都当作内存来对待,把他们总的看作一个由 若干个存储单元组成的逻辑存储器,即我们所说的内存地址空间。 自己的一点理解:CPU对内存的操作是一样的,但是在cpu,内存,芯片之间的硬件本身所牵扯的线是不同的。所以一些地址的功能是对应一些芯片的。 第二章寄存器 引入:CPU中含有运算器,寄存器,控制器(由内部总线连接)。而寄存器是可以用来指令读写的部件。8086有14个寄存器(都是16位,2个存储空间)。 一.通用寄存器(ax,bx,cx,dx),16位,可以分为高低位 注意1.范围:16位的2^16-1,8位的2^8-1 2.进行数据传送或运算时要注意位数对应,否则会报错 二.字:1. 1个字==2个字节。 2. 在寄存器中的存储:0x高位字节低位字节;单元认定的是低单元 数制,16进制h,2进制b
DSP汇编指令总结 一、寻址方式: 1、立即寻址: 短立即寻址(单指令字) 长立即数寻址(双指令字) 第一指令字 第二指令字 16位常数=16384=4000h 2、直接寻址 ARU 辅助寄存器更新代码,决定当前辅助寄存器是否和如何进行增或减。N规定是否改变ARP值,(N=0,不变)
4.3.1、算术逻辑指令(28条) 4.3.1.1、加法指令(4条); 4.3.1.2、减法指令(5条); 4.3.1.3、乘法指令(2条); 4.3.1.4、乘加与乘减指令(6条); 4.3.1.5、其它算数指令(3条); 4.3.1.6、移位和循环移位指令(4条); 4.3.1.7、逻辑运算指令(4条); 4.3.2、寄存器操作指令(35条) 4.3.2.1、累加器操作指令(6条) 4.3.2.2、临时寄存器指令(5条) 4.3.2.3、乘积寄存器指令(6条) 4.3.2.4、辅助寄存器指令(5条) 4.3.2.5、状态寄存器指令(9条) 4.3.2.6、堆栈操作指令(4条) 4.3.3、存储器与I/O操作指令(8条)4.3.3.1、数据移动指令(4条) 4.3.3.2、程序存储器读写指令(2条) 4.3.3.3、I/O操作指令(2条) 4.3.4、程序控制指令(15条) 4.3.4.1、程序分支或调用指令(7条) 4.3.4.2、中断指令(3条) 4.3.4.3、返回指令(2条) 4.3.4.4、其它控制指令(3条)
4.3.1、算术逻辑指令(28条) 4.3.1.1、加法指令(4条); ▲ADD ▲ADDC(带进位加法指令) ▲ADDS(抑制符号扩展加法指令) ▲ADDT(移位次数由TREG指定的加法指令) 4.3.1.2、减法指令(5条); ★SUB(带移位的减法指令) ★SUBB(带借位的减法指令) ★SUBC(条件减法指令) ★SUBS(减法指令) ★SUBT(带移位的减法指令,TREG决定移位次数)4.3.1.3、乘法指令(2条); ★MPY(带符号乘法指令) ★MPYU(无符号乘法指令) 4.3.1.4、乘加与乘减指令(6条); ★MAC(累加前次积并乘)(字数2,周期3) ★MAC(累加前次积并乘) ★MPYA(累加-乘指令) ★MPYS(减-乘指令) ★SQRA(累加平方值指令) ★SQRS(累减并平方指令) 4.3.1.5、其它算数指令(3条); ★ABS(累加器取绝对值指令) ★NEG(累加器取补码指令) ★NORM(累加器规格化指令) 返回 4.3.1.6、移位和循环移位指令(4条); ▲ SFL(累加器内容左移指令) ▲ SFR(累加器内容右移指令) ▲ROL(累加器内容循环左移指令) ▲ROR(累加器内容循环右移指令) 返回 4.3.1.7、逻辑运算指令(4条); ▲ AND(逻辑与指令) ▲ OR(逻辑或指令) ▲ XOR(逻辑异或指令) ▲ CMPL(累加器取反指令) 返回 4.3.2、寄存器操作指令(35条) 4.3.2.1、累加器操作指令(6条)
汇编语言指令表文档编制序号:[KKIDT-LLE0828-LLETD298-POI08]
伪指令 1、定位伪指令 ORG m 2、定义字节伪指令 DB X1,X2,X3,…,Xn 3、字定义伪指令 DW Y1,Y2,Y3,…,Yn 4、汇编结束伪指令 END 寻址方式 MCS-51单片机有五种寻址方式: 1、寄存器寻址 2、寄存器间接寻址 3、直接寻址 4、立即数寻址 5、基寄存器加变址寄存器间接寻址 6、相对寻址 7、位寻址 数据传送指令 一、以累加器A为目的操作数的指令(4条) MOV A,Rn ;(Rn)→A n=0~7 MOV A,direct ;( direct )→A MOV A,@Ri ;((Ri))→A i=0~1 MOV A,#data ; data →A 二、以Rn为目的操作数的指令(3条) MOV Rn ,A;(A)→ Rn MOV Rn ,direct;( direct )→ Rn MOV Rn ,#data; data → Rn 三、以直接寻址的单元为目的操作数的指令(5条) MOV direct,A;(A)→direct MOV direct,Rn;(Rn)→direct MOV direct,direct ;(源direct)→目的direct MOV direct,@Ri;((Ri))→direct MOV direct,#data; data→direct 四、以寄存器间接寻址的单元为目的操作数的指令(3条) MOV @Ri,A;(A)→(Ri) MOV @Ri,direct;(direct)→(Ri) MOV @Ri,#data; data→(Ri) 五、十六位数据传送指令(1条) MOV DPTR,#data16;dataH→DPH,dataL →DPL
《汇编语言》段总结 我们可以可以将一段内存定义为一个段,用一个段地址指示段,用偏移地址访问段内的单元。这完全是我们自己的安排。 “段地址”这个名称中包含着“段”的概念。这种那个说法可能对一些学习者产生了误导【呵呵,曾经有一段时间真的误导了我,有时我禁不住在想为什么会被误导,那是因为我没有真懂。】,使人误以为内存被划分了一个一个的段,每一个段有一个段地址。如果我们在一开始形成了这种认识,将影响以后对汇编语言的深入理解和灵活应用。 其实,内存并没有分段,段的划分来自于CPU,由于8086CPU用“基础地址(段地址x16)+偏移地址=物理地址”的方式给出内存单元的物理地址,使得我们可以用分段的方式来管理内存。 这就好比水杯,水杯并没有给自己刻度,刻度的划分来自于人类。 我们为什么进行这样的安排?因为这可使得我们可以用分段的方式来管理内存,即为了方便、有序的管理内存。 这就是人类的伟大之处,一个没有生命的东西,如果我们给它一个设定,并对这个设定赋予思想,这个被我们设定的没有生命的东西就会以生命的形式存在。 我们可以用一个段存放数据,将它定义为“数据段”; 我们可以用一个段存放代码,将它定义为“代码段”; 我们可以用一个段当作栈,将它定义为“栈段”; 我们可以这样安排。但若要让CPU按照我们的安排来访问这些段,就要: 对于数据段,将它的段地址放在DS中,用mov、add、sub等访问内存单元的指令时,CPU就将我们定义的数据段中的内容当作数据来访问; 对于代码段,将它的段地址放在CS中,将段中第一条指令的偏移地址放在IP中,这样CPU就将执行我们定义的代码段中的指令; 对于栈段,将它的段地址放在SS中,将栈顶单元的偏移地址放在SP中,这样CPU在需要进行栈操作的时候,比如执行push、pop指令等,就将我们定义的栈段当作栈空间来使用。 其实,CS相当于一个指挥部,负责勘探,作战计划的制定、部署等。即任意时刻,CPU将CS:IP指向的内容当作指令执行。 而DS就相当于一个中转部,负责将CS制定出的计划传达,比如作战人员、物质等。 SS就相当于最终的实际的执行者,因为战场在内存中,SS接收到DS传送的CS制定出的计划,及作战人员、物质等开始作战。 总结:CPU相当于一个作战机构,而内存相当于战地。CS、DS及SS用的是望远镜原理,但这个望远镜带有照相功能,其实质是数字记位法。 可见,不管我们如何安排,CPU将内存中的某段内容当作代码,是因CS:IP指向了那里;CPU将某段内存当作栈,是因为SS:SP指向了那里。 我们一定要清楚,什么是我们的安排,以及如何让CPU按我们的安排行事。要非常清楚CPU的工作机理,才能控制CPU按照我们的安排运行的时候做到游刃有余。
MOV指令为双操作数指令,两个操作数中必须有一个是寄存器. MOV DST , SRC // Byte / Word 执行操作: dst = src 1.目的数可以是通用寄存器, 存储单元和段寄存器(但不允许用CS段寄存器). 2.立即数不能直接送段寄存器 3.不允许在两个存储单元直接传送数据 4.不允许在两个段寄存器间直接传送信息 PUSH入栈指令及POP出栈指令: 堆栈操作是以“后进先出”的方式进行数据操作. PUSH SRC //Word 入栈的操作数除不允许用立即数外,可以为通用寄存器,段寄存器(全部)和存储器. 入栈时高位字节先入栈,低位字节后入栈. POP DST //Word 出栈操作数除不允许用立即数和CS段寄存器外, 可以为通用寄存器,段寄存器和存储器. 执行POP SS指令后,堆栈区在存储区的位置要改变. 执行POP SP 指令后,栈顶的位置要改变. XCHG(eXCHanG)交换指令: 将两操作数值交换. XCHG OPR1, OPR2 //Byte/Word 执行操作: Tmp=OPR1 OPR1=OPR2 OPR2=Tmp 1.必须有一个操作数是在寄存器中 2.不能与段寄存器交换数据 3.存储器与存储器之间不能交换数据. XLAT(TRANSLATE)换码指令: 把一种代码转换为另一种代码. XLAT (OPR 可选) //Byte 执行操作: AL=(BX+AL) 指令执行时只使用预先已存入BX中的表格首地址,执行后,AL中内容则是所要转换的代码. LEA(Load Effective Address) 有效地址传送寄存器指令 LEA REG , SRC //指令把源操作数SRC的有效地址送到指定的寄存器中. 执行操作: REG = EAsrc 注: SRC只能是各种寻址方式的存储器操作数,REG只能是16位寄存器 MOV BX , OFFSET OPER_ONE 等价于LEA BX , OPER_ONE MOV SP , [BX] //将BX间接寻址的相继的二个存储单元的内容送入SP中 LEA SP , [BX] //将BX的内容作为存储器有效地址送入SP中 LDS(Load DS with pointer)指针送寄存器和DS指令 LDS REG , SRC //常指定SI寄存器。 执行操作: REG=(SRC), DS=(SRC+2) //将SRC指出的前二个存储单元的内容送入指令中指定的寄存器中,后二个存储单元送入DS段寄存器中。
指令集概述 指令操作数说明操作标志 # 时钟数 算数和逻辑指令 ADD Rd, Rr 无进位加法Rd ← Rd + Rr Z,C,N,V,H 1 ADC Rd, Rr 带进位加法Rd ← Rd + Rr + C Z,C,N,V,H 1 ADIW Rdl,K 立即数与字相加Rdh:Rdl ← Rdh:Rdl + K Z,C,N,V,S 2 SUB Rd, Rr 无进位减法Rd ← Rd - Rr Z,C,N,V,H 1 SUBI Rd, K 减立即数Rd ← Rd - K Z,C,N,V,H 1 SBC Rd, Rr 带进位减法Rd ← Rd - Rr - C Z,C,N,V,H 1 SBCI Rd, K 带进位减立即数Rd ← Rd - K - C Z,C,N,V,H 1 SBIW Rdl,K 从字中减立即数Rdh:Rdl ← Rdh:Rdl - K Z,C,N,V,S 2 AND Rd, Rr 逻辑与Rd ← Rd ? Rr Z,N,V 1 ANDI Rd, K 与立即数的逻辑与操作Rd ← Rd ? K Z,N,V 1 OR Rd, Rr 逻辑或Rd ← Rd v Rr Z,N,V 1 ORI Rd, K 与立即数的逻辑或操作Rd ← Rd v K Z,N,V 1 EOR Rd, Rr 异或Rd ← Rd ⊕ Rr Z,N,V 1 COM Rd 1 的补码Rd ← 0xFF ? Rd Z,C,N,V 1 NEG Rd 2 的补码Rd ← 0x00 ? Rd Z,C,N,V,H 1 SBR Rd,K 设置寄存器的位Rd ← Rd v K Z,N,V 1
CBR Rd,K 寄存器位清零Rd ← Rd ? (0xFF - K Z,N,V 1 INC Rd 加一操作Rd ← Rd + 1 Z,N,V 1 DEC Rd 减一操作Rd ← Rd ? 1 Z,N,V 1 TST Rd 测试是否为零或负Rd ← Rd ? Rd Z,N,V 1 CLR Rd 寄存器清零Rd ← Rd ⊕ Rd Z,N,V 1 SER Rd 寄存器置位Rd ← 0xFF None 1 MUL Rd, Rr 无符号数乘法R1:R0 ← Rd x Rr Z,C 2 MULS Rd, Rr 有符号数乘法R1:R0 ← Rd x Rr Z,C 2 MULSU Rd, Rr 有符号数与无符号数乘法 R1:R0 ← Rd x Rr Z,C 2 FMUL Rd, Rr 无符号小数乘法R1:R0 ← (Rd x Rr << 1 Z,C 2 FMULS Rd, Rr 有符号小数乘法R1:R0 ← (Rd x Rr << 1 Z,C 2 FMULSU Rd, Rr 有符号小数与无符号小数乘法R1:R0 ← (Rd x Rr << 1 Z,C 2跳转指令 RJMP k 相对跳转PC ← PC + k + 1 无 2 IJMP 间接跳转到(Z PC ← Z 无 2 RCALL k 相对子程序调用PC ← PC + k + 1 无 3 ICALL 间接调用(Z PC ← Z 无 3 RET 子程序返回PC ← STACK 无 4 RETI 中断返回PC ← STACK I 4
第一讲 第三章 指令系统--寻址方式 回顾: 8086/8088的内部结构和寄存器,地址分段的概念,8086/8088的工作过 程。 重点和纲要:指令系统--寻址方式。有关寻址的概念;6种基本的寻址方式及 有效地址的计算。 教学方法、实施步骤 时间分配 教学手段 回 顾 5”×2 板书 计算机 投影仪 多媒体课件等 讲 授 40” ×2 提 问 3” ×2 小 结 2” ×2 讲授内容: 3.1 8086/8088寻址方式 首先,简单讲述一下指令的一般格式: 操作码 操作数 …… 操作数 计算机中的指令由操作码字段和操作数字段组成。 操作码:指计算机所要执行的操作,或称为指出操作类型,是一种助记符。 操作数:指在指令执行操作的过程中所需要的操作数。该字段除可以是操作数本身外,也可以是操作数地址或是地址的一部分,还可以是指向操作数地址的指针或其它有关操作数的信息。 寻址方式就是指令中用于说明操作数所在地址的方法,或者说是寻找操作数有效地址的方法。8086/8088的基本寻址方式有六种。 1.立即寻址 所提供的操作数直接包含在指令中。它紧跟在操作码的后面,与操作码一起放在代码段区域中。如图所示。 例如:MOV AX ,3000H 立即数可以是8位的,也可以是16位的。若
是16位的,则存储时低位在前,高位在后。 立即寻址主要用来给寄存器或存储器赋初值。 2.直接寻址 操作数地址的16位偏移量直接包含在指令中。它与操作码—起存放在代码段区域,操作数一般在数据段区域中,它的地址为数据段寄存器DS加上这16位地址偏移量。如图2-2所示。 例如: MOV AX,DS:[2000H]; 图2-2 (对DS来讲可以省略成 MOV AX,[2000H],系统默认为数据段)这种寻址方法是以数据段的地址为基础,可在多达64KB的范围内寻找操作数。 8086/8088中允许段超越,即还允许操作数在以代码段、堆栈段或附加段为基准的区域中。此时只要在指令中指明是段超越的,则16位地址偏移量可以与CS或SS或ES相加,作为操作数的地址。 MOV AX,[2000H] ;数据段 MOV BX,ES:[3000H] ;段超越,操作数在附加段 即绝对地址=(ES)*16+3000H 3.寄存器寻址 操作数包含在CPU的内部寄存器中,如寄存器AX、BX、CX、DX等。 例如:MOV DS,AX MOV AL,BH 4.寄存器间接寻址 操作数是在存储器中,但是,操作数地址的16位偏移量包含在以下四个寄存器SI、DI、BP、BX之一中。可以分成两种情况:
汇编语言的所有指令数据传送指令集 MOV 功能: 把源操作数送给目的操作数 语法: MOV 目的操作数,源操作数 格式: MOV r1,r2 MOV r,m MOV m,r MOV r,data XCHG 功能: 交换两个操作数的数据 语法: XCHG 格式: XCHG r1,r2 XCHG m,r XCHG r,m PUSH,POP 功能: 把操作数压入或取出堆栈 语法: PUSH 操作数POP 操作数 格式: PUSH r PUSH M PUSH data POP r POP m PUSHF,POPF,PUSHA,POPA 功能: 堆栈指令群 格式: PUSHF POPF PUSHA POPA LEA,LDS,LES 功能: 取地址至寄存器 语法: LEA r,m LDS r,m LES r,m XLAT(XLATB) 功能: 查表指令 语法: XLAT XLAT m 算数运算指令 ADD,ADC 功能: 加法指令 语法: ADD OP1,OP2 ADC OP1,OP2 格式: ADD r1,r2 ADD r,m ADD m,r ADD r,data 影响标志: C,P,A,Z,S,O SUB,SBB 功能:减法指令 语法: SUB OP1,OP2 SBB OP1,OP2 格式: SUB r1,r2 SUB r,m SUB m,r SUB r,data SUB m,data 影响标志: C,P,A,Z,S,O
INC,DEC 功能: 把OP的值加一或减一 语法: INC OP DEC OP 格式: INC r/m DEC r/m 影响标志: P,A,Z,S,O NEG 功能: 将OP的符号反相(取二进制补码) 语法: NEG OP 格式: NEG r/m 影响标志: C,P,A,Z,S,O MUL,IMUL 功能: 乘法指令 语法: MUL OP IMUL OP 格式: MUL r/m IMUL r/m 影响标志: C,P,A,Z,S,O(仅IMUL会影响S标志) DIV,IDIV 功能:除法指令 语法: DIV OP IDIV OP 格式: DIV r/m IDIV r/m CBW,CWD 功能: 有符号数扩展指令 语法: CBW CWD AAA,AAS,AAM,AAD 功能: 非压BCD码运算调整指令 语法: AAA AAS AAM AAD 影响标志: A,C(AAA,AAS) S,Z,P(AAM,AAD) DAA,DAS 功能: 压缩BCD码调整指令 语法: DAA DAS 影响标志: C,P,A,Z,S 位运算指令集 AND,OR,XOR,NOT,TEST 功能: 执行BIT与BIT之间的逻辑运算 语法: AND r/m,r/m/data OR r/m,r/m/data XOR r/m,r/m/data TEST r/m,r/m/data NOT r/m 影响标志: C,O,P,Z,S(其中C与O两个标志会被设为0) NOT指令不影响任何标志位 SHR,SHL,SAR,SAL 功能: 移位指令 语法: SHR r/m,data/CL SHL r/m,data/CL SAR r/m,data/CL SAL r/m,data/CL
汇编语言程序设计资料简汇 通用寄存器 8位通用寄存器8个:AL、AH、BL、BH、CL、CH、DL、DH。 16位通用寄存器8个:AX、BX、CX、DX、SI、DI、BP、SP。 AL与AH、BL与BH、CL与CH、DL与DH分别对应于AX、BX、CX和DX的低8位与高8位。专用寄存器 指令指针:IP(16位)。 标志寄存器:没有助记符(FLAGS 16位)。 段寄存器 段寄存器:CS、DS、ES、SS。 内存分段:80x86采用分段内存管理机制,主要包括下列几种类型的段: ?代码段:用来存放程序的指令序列。 ?数据段:用来存放程序的数据。 ?堆栈段:作为堆栈使用的内存区域,用来存放过程返回地址、过程参数等。 物理地址与逻辑地址 ?物理地址:内存单元的实际地址,也就是出现在地址总线上的地址。 ?逻辑地址:或称分段地址。 ?段地址与偏移地址都是16位。 ?系统采用下列方法将逻辑地址自动转换为20位的物理地址: 物理地址= 段地址×16 + 偏移地址 ?每个内存单元具有唯一的物理地址,但可由不同的逻辑地址描述。 与数据有关的寻址方式 立即寻址方式 立即寻址方式所提供的操作数紧跟在操作码的后面,与操作码一起放在指令代码段中。立即数可以是8位数或16位数。如果是16位数,则低位字节存放在低地址中,高位字节存放在高地址中。 例:MOV AL,18 指令执行后,(AL)= 12H 寄存器寻址方式 在寄存器寻址方式中,操作数包含于CPU的内部寄存器之中。这种寻址方式大都用于寄存器之间的数据传输。 例3:MOV AX,BX 如指令执行前(AX)= 6789H,(BX)= 0000H;则指令执行后,(AX)= 0000H,(BX)保持不变。 直接寻址方式 直接寻址方式是操作数地址的16位偏移量直接包含在指令中,和指令操作码一起放在代码段,而操作数则在数据段中。操作数的地址是数据段寄存器DS中的内容左移4位后,加上指令给定的16位地址偏移量。直接寻址方式适合于处理单个数据变量。 寄存器间接寻址方式 在寄存器间接寻址方式中,操作数在存储器中。操作数的有效地址由变址寄存器SI、DI或基址寄存器BX、BP提供。 如果指令中指定的寄存器是BX、SI、DI,则用DS寄存器的内容作为段地址。 如指令中用BP寄存器,则操作数的段地址在SS中,即堆栈段。
MCS-51汇编语言指令集 符号定义表 符号 含义 Rn R0~R7寄存器n=0~7 Direct 直接地址,内部数据区的地址RAM(00H~7FH) SFR(80H~FFH) B,ACC,PSW,IP,P3,IE,P2,SCON,P1,TCON,P0 @Ri 间接地址Ri=R0或R1 8051/31RAM地址(00H~7FH) 8052/32RAM地址(00H~FFH) #data 8位常数 #data16 16位常数 Addr16 16位的目标地址 Addr11 11位的目标地址 Rel 相关地址 bit 内部数据RAM(20H~2FH),特殊功能寄存器的直接地址的位 2指令介绍 指令 字节 周期 动作说明 算数运算指令 1.ADD A,Rn 1 1 将累加器与寄存器的内容相加,结果存回累加器 2.ADD A,direct 2 1 将累加器与直接地址的内容相加,结果存回累加器 3.ADD A,@Ri 1
将累加器与间接地址的内容相加,结果存回累加器4.ADD A,#data 2 1 将累加器与常数相加,结果存回累加器 5.ADDC A,Rn 1 1 将累加器与寄存器的内容及进位C相加,结果存回累加器6.ADDC A,direct 2 1 将累加器与直接地址的内容及进位C相加,结果存回累加器7.ADDC A,@Ri 1 1 将累加器与间接地址的内容及进位C相加,结果存回累加器8.ADDC A,#data 2 1 将累加器与常数及进位C相加,结果存回累加器 9.SUBB A,Rn 1 1 将累加器的值减去寄存器的值减借位C,结果存回累加器10.SUBB A,direct 2 1 将累加器的值减直接地址的值减借位C,结果存回累加器11.SUBB A,@Ri 1 1 将累加器的值减间接地址的值减借位C,结果存回累加器12.SUBB A,0data 2 1 将累加器的值减常数值减借位C,结果存回累加器 13.INC A 1 1 将累加器的值加1 14.INC Rn 1
PIC8位单片机汇编语言常用指令的识读(上) 各大类单片机的指令系统是没有通用性的,它是由单片机生产厂家规定的,所以用户必须遵循厂家规定的标准,才能达到应用单片机的目的。 PIC 8位单片机共有三个级别,有相对应的指令集。基本级PIC系列芯片共有指令33条,每条指令是12位字长;中级PIC系列芯片共有指令35条,每条指令是14位字长;高级PIC 系列芯片共有指令58条,每条指令是16位字长。其指令向下兼容。 在这里笔者介绍PIC 8位单片机汇编语言指令的组成及指令中符号的功能,以供初学者阅读相关书籍和资料时快速入门。 一、PIC汇编语言指令格式 PIC系列微控制器汇编语言指令与MCS-51系列单片机汇编语言一样,每条汇编语言指令由4个部分组成,其书写格式如下: 标号操作码助记符操作数1,操作数2;注释 指令格式说明如下:指令的4个部分之间由空格作隔离符,空格可以是1格或多格,以保证交叉汇编时,PC机能识别指令。 1 标号与MCS-51系列单片机功能相同,标号代表指令的符号地址。在程序汇编时,已赋以指令存储器地址的具体数值。汇编语言中采用符号地址(即标号)是便于查看、修改,尤其是便于指令转移地址的表示。标号是指令格式中的可选项,只有在被其它语句引用时才需派上标号。在无标号的情况下,指令助记符前面必须保留一个或一个以上的空格再写指令助记符。指令助记符不能占用标号的位置,否则该助记符会被汇编程序作标号误处理。 书写标号时,规定第一字符必须是字母或半角下划线“—”,它后面可以跟英文和数字字符、冒号(:)制符表等,并可任意组合。再有标号不能用操作码助记符和寄存器的代号表示。标号也可以单独占一行。 2 操作码助记符该字段是指令的必选项。该项可以是指令助记符,也可以由伪指令及宏命令组成,其作用是在交叉汇编时,“指令操作码助记符”与“操作码表”进行逐一比较,找出其相应的机器码一一代之。 3 操作数由操作数的数据值或以符号表示的数据或地址值组成。若操作数有两个,则两个操作数之间用逗号(,)分开。当操作数是常数时,常数可以是二进制、八进制、十进制或十六进制数。还可以是被定义过的标号、字符串和ASCⅡ码等。具体表示时,规定在二进制数前冠以字母“B”,例如B10011100;八进制数前冠以字母“O”,例如O257;十进制数前冠以字母“D”,例如D122;十六进制数前冠以“H”,例如H2F。在这里PIC 8位单片机默认进制是十六进制,在十六进制数之前加上Ox,如H2F可以写成Ox2F。 指令的操作数项也是可选项。 PIC系列与MCS-51系列8位单片机一样,存在寻址方法,即操作数的来源或去向问题。因PIC系列微控制器采用了精简指令集(RISC)结构体系,其寻址方式和指令都既少而又简单。其寻址方式根据操作数来源的不同,可分为立即数寻址、直接寻址、寄存器间接寻址和位寻址四种。所以PIC系列单片机指令中的操作数常常出现有关寄存器符号。有关的寻址实例,均可在本文的后面找到。 4 注释用来对程序作些说明,便于人们阅读程序。注释开始之前用分号(;)与其它部分相隔。当汇编程序检测到分号时,其后面的字符不再处理。值得注意:在用到子程序时应说明程序的入口条件、出口条件以及该程序应完成的功能和作用。 二、清零指令(共4条) 1 寄存器清零指令 实例:CLRW;寄存器W被清零 说明:该条指令很简单,其中W为PIC单片机的工作寄存器,相当于MCS-51系列单片机中的累加器A,CLR是英语Clear的缩写字母。 2 看门狗定时器清零指令。 实例:CLRWDT;看门狗定时器清零(若已赋值,同时清预分频器)
附录 附录A 常用80x86指令速查表 指令按助记符字母顺序排列,缩写、符号约定如下: (1) 指令中,dst, src表示目的操作数和源操作数。仅一个操作数时,个别处也表示为opr。 (2) imm表示立即数,8/16/32位立即数记作:imm8/imm16/imm32。 (3) reg表示通用寄存器,8/16/32位通用寄存器记作:reg8/reg16/reg32。 (4) mem表示内存操作数,8/16/32等内存操作数记作:mem8/mem16/mem32等。 (5) seg表示段寄存器,CS, DS, SS, ES, FS, GS。 (6) acc表示累加器,8/16/32累加器对应AL/AX/EAX。 (7)OF, SF, ZF, AF, PF, CF分别表示为O, S, Z, A, P, C,相应位置为:字母,根据结果状态设置;?,状态不确定;-,状态不变;1,置1;0,清0;例如:0 S Z ? P -表示:OF清0,AF不确定,CF不变,其它根据结果设置。若该栏空白,则表示无关。 (8)寄存器符号诸如(E)CX, (E)SI, (E)DI, (E)SP, (E)BP和(E)IP等,表示在16地址模式下使用16位寄存器(如CX),或在32地址模式下使用32位寄存器(如ECX)。 (9)周期数表示指令执行所需的CPU时钟周期个数,即执行时间为:周期数/主频(秒)。 (10)诸如(386+)是表示该指令只能用于80386及以后微处理器上。
·252·
附录 ·253·
·254·
附录 ·255·
·256·
汇编语言指令集 一、数据传输指令 1. 通用数据传送指令. MOV(MOVe) 传送字或字节. MOVS(MOVe String) 串传送指令 MOVSX先符号扩展,再传送. MOVZX先零扩展,再传送. PUSH把字压入堆栈. POP把字弹出堆栈. PUSHA把AX,CX,DX,BX,SP,BP,SI,DI依次压入堆栈. POPA把DI,SI,BP,SP,BX,DX,CX,AX依次弹出堆栈. PUSHAD把EAX,ECX,EDX,EBX,ESP,EBP,ESI,EDI依次压入堆栈. POPAD把EDI,ESI,EBP,ESP,EBX,EDX,ECX,EAX依次弹出堆栈. BSWAP 交换32位寄存器里字节的顺序 XCHG (eXCHanG)交换字或字节.( 至少有一个操作数为寄存器,段寄存器不可作为操作数) CMPXCHG比较并交换操作数.( 第二个操作数必须为累加器AL/AX/EAX ) XADD先交换再累加.( 结果在第一个操作数里) XLAT(TRANSLATE) 字节查表转换. ── BX 指向一张256 字节的表的起点, AL 为表的索引值(0-255,即0-FFH); 返回AL 为查表结果. ( [BX+AL]->AL ) 2. 输入输出端口传送指令. IN I/O端口输入. ( 语法: IN 累加器, {端口号│DX} ) OUT I/O端口输出. ( 语法: OUT {端口号│DX},累加器) 输入输出端口由立即方式指定时, 其范围是0-255; 由寄存器DX 指定时,其范围是0-65535. 3. 目的地址传送指令. LEA (Load Effective Address)装入有效地址. 例: LEA DX,string ;把偏移地址存到DX. LDS (Load DS with pointer)传送目标指针,把指针内容装入DS. 例: LDS SI,string ;把段地址:偏移地址存到DS:SI. LES (Load ES with pointer)传送目标指针,把指针内容装入ES. 例: LES DI,string ;把段地址:偏移地址存到ES:DI. LFS 传送目标指针,把指针内容装入FS. 例: LFS DI,string ;把段地址:偏移地址存到FS:DI. LGS 传送目标指针,把指针内容装入GS. 例: LGS DI,string ;把段地址:偏移地址存到GS:DI. LSS 传送目标指针,把指针内容装入SS. 例: LSS DI,string ;把段地址:偏移地址存到SS:DI. 4. 标志传送指令. LAHF (Load AH with Flags)标志寄存器传送,把标志装入AH. SAHF (Store AH into Flgs)标志寄存器传送,把AH内容装入标志寄存器. PUSHF (PUSH the Flags)标志入栈. POPF (POP the Flags)标志出栈.
8086/8088指令系统记忆表 数据寄存器分为: AH&AL=AX(accumulator):累加寄存器,常用于运算;在乘除等指令中指定用来存放操作数,另外,所有的I/O指令都使用这一寄存器与外界设备传送数据. BH&BL=BX(base):基址寄存器,常用于地址索引; CH&CL=CX(count):计数寄存器,常用于计数;常用于保存计算值,如在移位指令,循环(loop)和串处理指令中用作隐含的计数器. DH&DL=DX(data):数据寄存器,常用于数据传递。他们的特点是,这4个16位的寄存器可以分为高8位:AH,BH,CH,DH.以及低八位:AL,BL,CL,DL。这2组8位寄存器可以分别寻址,并单独使用。 另一组是指针寄存器和变址寄存器,包括: SP(Stack Pointer):堆栈指针,与SS配合使用,可指向目前的堆栈位置; BP(Base Pointer):基址指针寄存器,可用作SS的一个相对基址位置; SI(Source Index):源变址寄存器可用来存放相对于DS段之源变址指针; DI(Destination Index):目的变址寄存器,可用来存放相对于ES段之目的变址指针。 指令指针IP(Instruction Pointer) 标志寄存器FR(Flag Register) OF(overflow flag) DF(direction flag) CF(carrier flag) PF(parity flag) AF(auxiliary flag) ZF(zero flag) SF(sign flag) IF(interrupt flag) TF(trap flag) 段寄存器(Segment Register) 为了运用所有的内存空间,8086设定了四个段寄存器,专门用来保存段地址: CS(Code Segment):代码段寄存器; DS(Data Segment):数据段寄存器; SS(Stack Segment):堆栈段寄存器;
ORG 0000H NOP ;空操作指令 AJMP L0003 ;绝对转移指令 L0003: LJMP L0006 ;长调用指令 L0006: RR A ;累加器A内容右移(先置A为88H) INC A ; 累加器A 内容加1 INC 01H ;直接地址(字节01H)内容加1 INC @R0 ; R0的内容(为地址) 的内容即间接RAM加1 ;(设R0=02H,02H=03H,单步执行后02H=04H) INC @R1 ; R1的内容(为地址) 的内容即间接RAM加1 ;(设R1=02H,02H=03H,单步执行后02H=04H) INC R0 ; R0的内容加1 (设R0为00H,单步执行后查R0内容为多少) INC R1 ; R1的内容加1(设R1为01H,单步执行后查R1内容为多少) INC R2 ; R2的内容加1 (设R2为02H,单步执行后查R2内容为多少) INC R3 ; R3的内容加1(设R3为03H,单步执行后查R3内容为多少) INC R4 ; R4的内容加1(设R4为04H,单步执行后查R4内容为多少) INC R5 ; R5的内容加1(设R5为05H,单步执行后查R5内容为多少) INC R6 ; R6的内容加1(设R6为06H,单步执行后查R6内容为多少) INC R7 ; R7的内容加1(设R7为07H,单步执行后查R7内容为多少) JBC 20H,L0017; 如果位(如20H,即24H的0位)为1,则转移并清0该位L0017: ACALL S0019 ;绝对调用 S0019: LCALL S001C ;长调用 S001C: RRC A ;累加器A的内容带进位位右移(设A=11H,C=0 ;单步执行后查A和C内容为多少) DEC A ;A的内容减1 DEC 01H ;直接地址(01H)内容减1 DEC @R0 ;R0间址减1,即R0的内容为地址,该地址的内容减1 DEC @R1 ; R1间址减1 DEC R0 ; R0内容减1 DEC R1 ; R1内容减1 DEC R2 ; R2内容减1 DEC R3 ; R3内容减1 DEC R4 ; R4内容减1 DEC R5 ; R5内容减1 DEC R6 ; R6内容减1 DEC R7 ; R7内容减1 JB 20H,L002D;如果位(20H,即24H的0位)为1则转移 L002D: AJMP L0017 ;绝对转移 RET ;子程序返回指令 RL A ;A左移 ADD A,#01H ;A的内容与立即数(01H)相加 ADD A,01H ; A的内容与直接地址(01H内容)相加 ADD A,@R0 ; A的内容与寄存器R0的间址内容相加 ADD A,@R1 ; A的内容与寄存器R1的间址内容相加
汇编学习心得 08网工(一)班李锐 0804031002 在大三接触汇编语言之前,我们在计算机组成原理课程中就已经有所了解了,但也只是略微明白一些如jmp,mov这样的指令,极度缺乏系统性的学习。 在接触这门课程后,感到汇编语言并不是很容易就可以弄懂的。相比较以前学过的高级语言如C、C++等,电脑等于在迁就人的思维方式,但学汇编,人却必须要去迁就电脑的思维方式,要设身处地地用电脑的角度去思考问题,这就是我们学习汇编语言时遇到的最大的障碍。 另外,在C语言中不到10个语句构成的程序,用汇编语言却要好几十行甚至上百行。这不得不让我们对汇编产生一种恐惧感。事实上,这是完全不必要的。一旦对它的原理掌握后,编写程序就容易多了。另外,学习汇编语言能让我们更加了解计算机内部的组织结构,对我们计算机专业的学生来说,学习汇编也是提升综合能力的关键环节。 汇编的学习不仅仅是学习其语法,而更多的是学习计算机基本的体系结构。其中遇到很多新的概念,名字。如寄存器、中断、寻址方式等。这些概念在刚接触汇编这门课的时候难以理解,但在之后的学习中通过老师的讲解,自己亲手编程的方式也就渐渐清晰明了。 我们在学习之前都需要明确什么是汇编语言。计算机能够直接识别的数据是由二进制数0和1组成的代码。机器指令就是用二进制代码组成的指令,一条机器指令控制计算机完成一个基本操作。为了克服机器语言的缺点,人们采用助记符表示机器指令的操作码,用变量代替操作数的存放地址等,这样就形成了汇编语言。 经过一个学期的学习,我也慢慢摸出了汇编学习的规律。 首先,学习这门语言时如果能联系上以前学过的其他高级语言的知识,则会起到良好的效果。例如C语言程序的运行逻辑结构有顺序(按语句依次执行)、分支结构(IF...THEN...ELSE...),循环结构(FOR...NEXT)三种结构,也通过C 语言了解并掌握了什么是子程序,什么是调用。事实上,汇编语言中有关程序结构,子程序等等的知识都是跟C语言十分相似的,只是在编程时用到的语言不同:汇编语言完全面向机器,需要指明数据在寄存器、内存中的流向。 第二,学习汇编语言,首要问题是学习80X86指令系统。如果能将指令系统中的各个助记符、格式等都能完全掌握并灵活运用,大部分工作就已经完成了。指令系统确定了CPU所能完成的功能,是用汇编语言进行程序设计的最基本部分。如果不熟悉汇编指令的功能及其有关规定,那肯定不能灵活使用汇编语言。 指令的种类十分繁杂,但其格式却是统一的。 其中方括号中的内容为可选项。指令助记符决定了指令的功能,对应一条二进制编码的机器指令。指令的操作数个数由该指令确定,可以没有操作数,也可以有