
§2.3 第7课时 平均数及其估计
学习目标
(1)理解为什么能用样本数据的平均值估计总体的水平;
(2)初步了解如何运用数学知识和方法进行统计研究,提高统计的准确性和科学性; (3)掌握从实际问题中提取数据,利用样本数据计算其平均值,并对总体水平作出估计的
方法. 学习重点
掌握从实际问题中提取数据,利用样本数据计算其平均值,并对总体水平作出估计的 方法. 学习难点
能应用相关知识解决简单的实际问题. 活动过程
活动一:问题情境 1.情境:
某校高一(1)班同学在老师的布置下,用单摆进行测试,以检查重力加速度.全班同学两人一组,在相同条件下进行测试,得到下列实验数据(单位:2/s m )
9.62 9.54 9.78 9.94 10.01 9.66 9.88 9.68 10.32 9.76 9.45 9.99 9.81 9.56 9.78 9.72 9.93 9.94 9.65 9.79 9.42 9.68 9.70 9.84 9.90 2.问题:
怎样利用这些数据对重力加速度进行估计? 活动二:问题探求
我们常用算术平均数∑=n
i i a n 1
1(其中),2,1(n i a i ,?=为n 个实验数据)作为重力加速
度的“最理想”的近似值,它的依据是什么呢?
处理实验数据的原则是使这个近似值与实验数据之间的离差最小.设这个近似值为x ,那么它与n 个实验值),,2,1(n i a i ?=的离差分别为1a x -,2a x -,3a x -,…,n a x -.由于上述离差有正有负,故不宜直接相加.可以考虑离差的平方和,即
22221)()()(n a x a x a x -+?+-+-
=2
2221212)(2n
n a a a x a a a nx ?+++?++-, 所以当n
a a a x n
?++=
21时,离差的平方和最小,
故可用n
a a a n
?++21作为表示这个物理量的理想近似值.
活动三:建构知识
1.平均数最能代表一个样本数据的集中趋势,也就是说它与样本数据的离差最小;
2.数据12,,,n a a a ?的平均数或均值,一般记为n
a a a a n
?++=
21__
(""a a 读作平均);
3.若取值为12,,,n x x x ?的频率分别为12,,,n p p p ?,则其平均数为
1122n n x x p x p x p =+++….
4.平均数的性质: 若123
,,,n x x x x 的平均数为x ,则12,,n ax b ax b ax b +++的平均数
是_____________.
四、知识运用 1.例题:
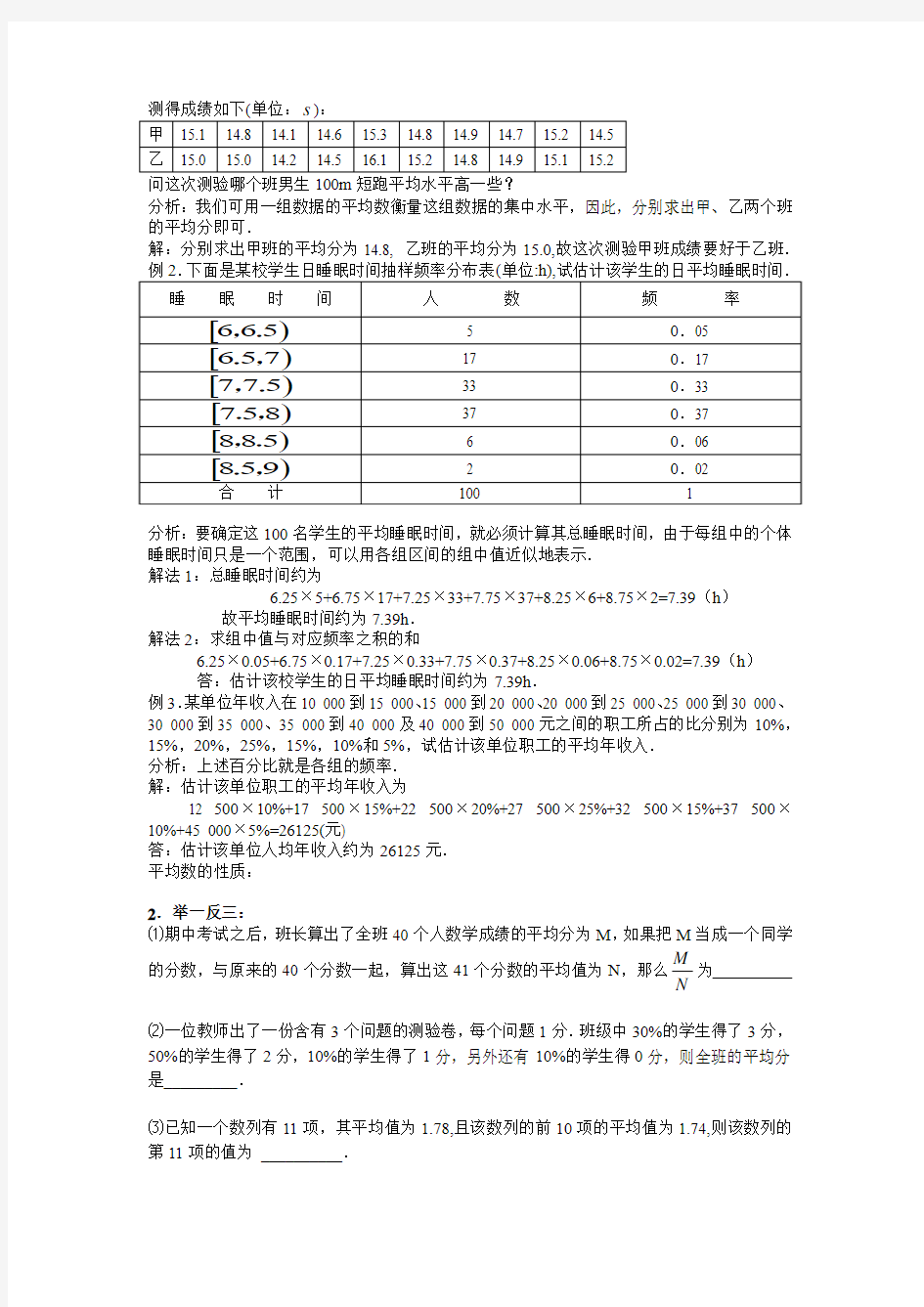
例1.某校在一次学生身体素质调查中,在甲、乙两班中随机抽10名男生测验100m 短跑,
测得成绩如下(单位:):
问这次测验哪个班男生100m短跑平均水平高一些?
分析:我们可用一组数据的平均数衡量这组数据的集中水平,因此,分别求出甲、乙两个班的平均分即可.
解:分别求出甲班的平均分为14.8, 乙班的平均分为15.0,故这次测验甲班成绩要好于乙班.
分析:要确定这100名学生的平均睡眠时间,就必须计算其总睡眠时间,由于每组中的个体睡眠时间只是一个范围,可以用各组区间的组中值近似地表示.
解法1:总睡眠时间约为
6.25×5+6.75×17+
7.25×33+7.75×37+
8.25×6+8.75×2=7.39(h)
故平均睡眠时间约为7.39h.
解法2:求组中值与对应频率之积的和
6.25×0.05+6.75×0.17+
7.25×0.33+7.75×0.37+
8.25×0.06+8.75×0.02=7.39(h)
答:估计该校学生的日平均睡眠时间约为7.39h.
例3.某单位年收入在10 000到15 000、15 000到20 000、20 000到25 000、25 000到30 000、30 000到35 000、35 000到40 000及40 000到50 000元之间的职工所占的比分别为10%,15%,20%,25%,15%,10%和5%,试估计该单位职工的平均年收入.
分析:上述百分比就是各组的频率.
解:估计该单位职工的平均年收入为
12 500×10%+17 500×15%+22 500×20%+27 500×25%+32 500×15%+37 500×10%+45 000×5%=26125(元)
答:估计该单位人均年收入约为26125元.
平均数的性质:
2.举一反三:
⑴期中考试之后,班长算出了全班40个人数学成绩的平均分为M,如果把M当成一个同学
的分数,与原来的40个分数一起,算出这41个分数的平均值为N,那么M
N
为
⑵一位教师出了一份含有3个问题的测验卷,每个问题1分.班级中30%的学生得了3分,50%的学生得了2分,10%的学生得了1分,另外还有10%的学生得0分,则全班的平均分是_________.
⑶已知一个数列有11项,其平均值为1.78,且该数列的前10项的平均值为1.74,则该数列的第11项的值为__________.
从上表中,估计该校毕业生起始月薪平均值是______________.
活动五、回顾小结:
1.能根据实际问题的需要合理地选取样本,从样本数据中提取基本的数字特征(平均数),会用样本的基本数字特征估计总体的基本数字特征;
2.平均数对数据有“取齐”的作用,代表一组数据的平均水平;
考点39 均值与方差在生活中运用解析版 1.设1 02 a << ,随机变量X 的分布列是: 则当()D X 最大时的a 的值是( ) A . 14 B . 316 C . 15 D . 325 2.随机变量X 的分布列如表所示,若1 ()3 E X = ,则(32)D X -=( ) A . 9 B . 3 C .5 D .7 3.已知1 02a << ,102 b <<,随机变量X 的分布列是: 若()3 E X = ,则a =________,()D X =________. 4.如下为简化的计划生育模型:每个家庭允许生男孩最多一个,即某一胎若为男孩,则不能再生下一胎,而女孩可以多个.为方便起见,此处约定每个家庭最多可生育3个小孩,即若第一胎或前两胎为女孩,则继续生,但若第三胎还是女孩,则不能再生了.设每一胎生男生女等可能,且各次生育相互独立.依据每个家庭最多生育一个男孩的政策以及我们对生育女孩的约定,令X 为某一家庭所生的女孩数,Y 为此家庭所生的男孩数.
(1)求X ,Y 的分布列,并比较它们数学期望的大小; (2)求概率()() P X D X >,其中()D X 为X 的方差. 5.某投资公司在2020年年初准备将1000万元投资到“低碳”项目上,现有两个项目供选择: 项目一:新能源汽车.据市场调研,投资到该项目上,到年底可能获利40%,也可能亏损10%,且这两种情况发生的概率分别为 35和25 ; 项目二:通信设备据市场调研,投资到该项目上,到年底可能获利50%,可能损失30%,也可能不赔不赚,且这三种情况发生的概率分别为35,13和1 15 .针对以上两个投资项目,请你为投资公司选择一个合理的项目,并说明理由. 6.某超市计划在九月订购一种时令水果,每天进货量相同,进货成本每个8元,售价每个12元(统一按个销售).当天未售出的水果,以每个4元的价格当天全部卖给水果罐头厂根据往年销售经验,每天需求量与当天最高气温(单位:C )有关.如果最高气温不低于30,需求量为500个;如果最高气温位于区间[)25,30,需求量为350个;如果最高气温低于25,需求量为200个.为了确定九月份的订购计划,统计了前三年九月份各天的最高气温数据,得下面的频数分布表: 以最高气温位于各区间的频率代替最高气温位于该区间的概率. (1)求九月份这种水果一天的需求量X (单位:个)的分布列. (2)设九月份一天销售这种水果的利润为Y (单位:元).当九月份这种水果一天的进货量n (单位:个)为多少时,Y 的数学期望达到最大值?
平均数、众数、中位数、极差、方差、标准差 说明6个基本统计量(平均数、众数、中位数、极差、方差、标准差)的内涵,学生学习过程中可能产生的困难及主要原因、应对策略. 首先,结合简单实例认真把握这6个基本统计量的内涵。 一、平均数、众数、中位数是刻画一组数据的“平均水平”的数据代表。(八上《第八章数据的代表》)平均数分算术平均数和加权平均数,算术平均数是指n个数据的和的平均值,学生理解与计算都不成问题,只要注意细心运算就是其中的取标准值后的简便算法也都是在小学早已熟练的(公式: x=1/n(x1+x2+x3+……+xn);而加权平均数是一组数据里的各个数据乘各自的“权”之后的平均数。此处理解“权”的概念可能产生很大困难,因为“权”的理解的确不易,若是照搬教材直接给出其定义,学生会迷惑成团,再进行应用更是不可思议。所以应对措施:讲好、用好加权平均数就要先举例、后分析、再给出定义,比如:某同学的一次考试各科成绩如下:语文110、数学105、英语106、物理95、化学90、政治86、历史98、地理66、生物89,你可以先让学生算算各科的平均数,再按中考计分法将语、数、英各取120%,物、化、政各取100%,史、地、生各取40%后的平均值算出,两个结果一比较,学生就会很容易发现不同的原因是加入了所谓的“权”,这样,不仅通俗易懂,而且对“权”内涵的理解和应用就不再困难。众数是一组数据中出现次数最多的数。其内涵很好理解和掌握,就是结合实际应用也顺理成章,如商店老板进货号多大的男鞋好?那当然是“众数”(调查数据最多的号)所代表的。 中位数顾名思义是一组数据中间位置的数,但考虑一组数可能有偶数个或奇数个,所以要注意强调取中位数的方法。教材上给出的内涵很好:一般地,n个数据按大小顺序排列,处于最中间位置的一个数据(或最中间两个数据的平均数)叫做这组数据的中位数。如一组数据1.5,1.5,1.6,1.65,1.7,1.7,1.75,1.8的中位数
教学过程 一、课堂导入 “离散型随机变量的分步列,均值和方差”在“排列与组合”知识的延伸,在本讲的学习中,同学们将通过具体实例理解随机变量及其分布列、均值和方差的概念,认识随机变量及其分布对于刻画随机现象的重要性.要求同学们会用随机变量表达简单的随机事件,会用分布列来计算这类事件的概率,计算简单离散型随机变量的均值、方差,并能解决一些实际问题.在高考中,这部分知识通常有一道解答题,占12─14分左右,主要考查学生的逻辑推理能力和运算能力,凸显数学的应用价值.
二、 复习预习 1.判断下面结论是否正确(请在括号中打“√”或“×”) (1)随机变量的均值是常数,样本的平均值是随机变量,它不确定. ( ) (2)随机变量的方差和标准差都反映了随机变量取值偏离均值的平均程度,方差或标准差越小,则偏离变量平均程度越小. ( ) (3)正态分布中的参数μ和σ完全确定了正态分布,参数μ是正态分布的期望,σ是正态分布的标准差. ( ) (4)一个随机变量如果是众多的、互不相干的、不分主次的偶然因素作用结果之和,它就服从或近似服从正态分布. ( ) 2.设随机变量ξ的分布列为P (ξ=k )=1 5(k =2,4,6,8,10),则D (ξ)等于 ( ) A .5 B .8 C .10 D .16 3.设随机变量ξ服从正态分布N (3,4),若P (ξ<2a -3)=P (ξ>a +2),则a 等于 ( ) A .3 B.5 3 C .5 D.73 4.有一批产品,其中有12件正品和4件次品,有放回地任取3件,若X 表示取到次品的件数,则D (X )=________.
方差分析公式 (20PP-06-2611:03:09) 转载▼ 标签: 分类:统计方法 杂谈 方差分析 方差分析(analPsisofvarianee ,简写为ANOV或ANOV A可用于两个或两个以 上样本均数的比较。应用时要求各样本是相互独立的随机样本;各样本来自正态 分布总体且各总体方差相等。方差分析的基本思想是按实验设计和分析目的把全部观察值之间的总变异分为两部分或更多部分,然后再作分析。常用的设计有完 全随机设计和随机区组设计的多个样本均数的比较。 一、完全随机设计的多个样本均数的比较 又称单因素方差分析。把总变异分解为组间(处理间)变异和组内变异(误差)两部分。目的是推断k个样本所分别代表的卩1,卩2,……卩k是否相等,以便比较多个处理的差别有无统计学意义。其计算公式见表19-6. 表19-6完全随机设计的多个样本均数比较的方差分析公式 GC=(艺G) 2/N=艺ni , k为处理组数 方差分析计算的统计量为F,按表19-7所示关系作判断。 例19.9某湖水不同季节氯化物含量测量值如表19-8,问不同季节氯化物含量有 无差别? 表19-8某湖水不同季节氯化物含量(mg/L)
SS 加刖=丄 和 ' 10619.265^ 170 HO:湖水四个季节氯化物含量的总体均数相等,即 卩仁卩2=卩3=卩4 H1:四个总体均数不等或不全相等 a =0.05 先作表19-8下半部分的基础计算。 C=(艺 G ) 2/N= (588.4) 2/32=10819.205 SS 总=艺 G2-C=11100.84-10819.205=281.635 V 总=N-仁31 (工吋 “ 1 广_ (】6二口尸斗/」期.匸尸千 K .IT N "一 - ? r . —I b K V 组间=k-1=4-1=3 SS 组内=SS 总-SS 组间=281.635-141.107=140.465 V 组内=N-k=32-4=28 MS 组间二SS 组间 /v 组间=141.107/3=47.057
平均值(Mean)、方差(Variance)、标准差(Standard Deviation) 对于一维数据的分析,最常见的就是计算平均值(Mean)、方差(Variance)和标准差(Standard Deviation)。 平均值 平均值的概念很简单:所有数据之和除以数据点的个数,以此表示数据集的平均大小;其数学定义为: 以下面10个点的CPU使用率数据为例,其平均值为。 14 31 16 19 26 14 14 14 11 13 方差、标准差 方差这一概念的目的是为了表示数据集中数据点的离散程度;其数学定义为: 标准差与方差一样,表示的也是数据点的离散程度;其在数学上定义为方差的平方根: 为什么使用标准差 与方差相比,使用标准差来表示数据点的离散程度有3个好处: 表示离散程度的数字与样本数据点的数量级一致,更适合对数据样本形成感性认知。依然以上述10个点的CPU使用率数据为例,其方差约为41,而标准差则为;两者相比较,标准差更适合人理解。 表示离散程度的数字单位与样本数据的单位一致,更方便做后续的分析运算。 在样本数据大致符合正态分布的情况下,标准差具有方便估算的特性:%的数据点落在平均值前后1个标准差的范围内、95%的数据点落在平均值前后2个标准差的范围内,而99%的数据点将会落在平均值前后3个标准差的范围内。 贝赛尔修正 在上面的方差公式和标准差公式中,存在一个值为N的分母,其作用为将计算得到的累积偏差进行平均,从而消除数据集大小对计算数据离散程度所产生的影响。不过,使用N 所计算得到的方差及标准差只能用来表示该数据集本身(population)的离散程度;如果数据集是某个更大的研究对象的样本(sample),那么在计算该研究对象的离散程度时,就需要对上述方差公式和标准差公式进行贝塞尔修正,将N替换为N-1: 经过贝塞尔修正后的方差公式: 经过贝塞尔修正后的标准差公式:
离散型随机变量的均值与方差 【教学引入】复习分布列、三种常见分布列。说明分布列全面刻画了随机变量取值的统计规律。提出问题:如何从分布列中获取随机变量取值的总体水平(平均取值)、离散程度(区分度)等信息? 【案例探究】销售由a.b.c 三种糖果混合的混合糖,如何进行合理定价? ① 当a,b,c 价格相同,比例相同时; ② ②当a,b,c 价格不同,比例相同时; ③ ③当a,b,c 价格不同,比例也不同时。 对于①②,只需求三种糖价格的算术平均值即可,对于③,习惯的算术平均显然是不合理的。 设a,b,c 三种糖价格分别为18元/kg, 24元/kg, 36元/kg,混合比例为3:2:1,则易得合理价格为 23366 1 243118212336242183=?+?+?=++?+?+?x x x x x x (元/kg).此价格称为三种价格的 加权平均。 【权的含义】设三种糖每颗质量、外观完全相同,从混合糖中任取一颗,分别求取到a 、b 、c 的概率。 设三种糖的颗数分别为3m,2m,m ,属古典概型,用古典概型概率计算公式计算得概率分别为6 1,31,21。 权是各种糖的质量与总质量之比,其统计意义是随机变量X 等于相应值的概率。 【合理价格的统计意义】用X 表示从总体中任取一颗糖,所抽到的糖的价格,则X 有三种可 能的取值,?? ? ??=c b a X 如果取出的是如果取出的是如果取出的是,36,24,18,其分布列为: =18×P (X=18)+24×P (X=24)+36×P (X=36),是以概率为权重的每种糖果的单位价格的加权平均(即随机变量X 的均值)。 【离散型随机变量的均值(数学期望)】 ∑==n i i i p x EX 1.反映随机变量取值的平均水平。
方差概念及计算公式 一.方差的概念与计算公式 例1两人的5次测验成绩如下: X:50,100,100,60,50 E(X )=72;Y:73,70,75,72,70 E(Y )=72。 平均成绩相同,但X不稳定,对平均值的偏离大。方差描述随机变量对于数学期望的偏离程度。 单个偏离是 消除符号影响 方差即偏离平方的均值,记为D(X ): 直接计算公式分离散型和连续型,具体为: 这里是一个数。推导另一种计算公式 得到:“方差等于平方的均值减去均值的平方”,即 , 其中
分别为离散型和连续型计算公式。称为标准差或均方差,方差描述波动程度。 二.方差的性质 1.设C为常数,则D(C) = 0(常数无波动); 2.D(CX )=C2D(X ) (常数平方提取); 证: 特别地D(-X ) = D(X ), D(-2X ) = 4D(X )(方差无负值) 3.若X、Y相互独立,则 证:记 则 前面两项恰为D(X )和D(Y ),第三项展开后为 当X、Y 相互独立时, , 故第三项为零。 特别地 独立前提的逐项求和,可推广到有限项。 三.常用分布的方差 1.两点分布
2.二项分布 X ~ B( n, p ) 引入随机变量X i(第i次试验中A出现的次数,服从两点分布) , 3.泊松分布(推导略) 4.均匀分布 另一计算过程为 5.指数分布(推导略) 6.正态分布(推导略) ~ 正态分布的后一参数反映它与均值的偏离程度,即波动程度(随机波动),这与图形的特征是相符的。 例2求上节例2的方差。 解根据上节例2给出的分布律,计算得到
求均方差。均方差的公式如下:(xi为第i个元素)。 S = ((x1-x的平均值)^2 + (x2-x的平均值)^2+(x3-x的平均值)^2+...+(xn-x的平均值)^2)/n)的平方根 大数定律表表明:事件发生的频率依概率收敛于事件的概率p,这个定理以严格的数学形式表达了频率的稳定性。就是说当n很大时,事件发生的频率于概率有较大偏差的可能性很小。由实际推断原理,在实际应用中,当试验次数很大时,便可以用事件发生的频率来代替事件的概率。 用matlab或c语言编写求导程序 已知电容电压uc,电容值 求电流i 公式为i=c(duc/dt) 怎样用matlab或c语言求解
方差(Variance) [编辑] 什么是方差 方差和标准差是测度数据变异程度的最重要、最常用的指标。 方差是各个数据与其算术平均数的离差平方和的平均数,通常以σ2表示。方差的计量单位和量纲不便于从经济意义上进行解释,所以实际统计工作中多用方差的算术平方根——标准差来测度统计数据的差异程度。 标准差又称均方差,一般用σ表示。方差和标准差的计算也分为简单平均法和加权平均法,另外,对于总体数据和样本数据,公式略有不同。 [编辑] 方差的计算公式 设总体方差为σ2,对于未经分组整理的原始数据,方差的计算公式为: 对于分组数据,方差的计算公式为: 方差的平方根即为标准差,其相应的计算公式为: 未分组数据: 分组数据: [编辑]
样本方差和标准差 样本方差与总体方差在计算上的区别是:总体方差是用数据个数或总频数去除离差平方和,而样本方差则是用样本数据个数或总频数减1去除离差平方和,其中样本数据个数减1即n-1 称为自由度。设样本方差为,根据未分组数据和分组数据计算样本方差的公式分别为: 未分组数据: 分组数据: 未分组数据: 分组数据: 例:考察一台机器的生产能力,利用抽样程序来检验生产出来的产品质量,假设搜集的数据如下: 根据该行业通用法则:如果一个样本中的14个数据项的方差大于0.005,则该机器必须关闭待修。问此时的机器是否必须关闭? 解:根据已知数据,计算
因此,该机器工作正常。 方差和标准差也是根据全部数据计算的,它反映了每个数据与其均值相比平均相差的数值,因此它能准确地反映出数据的离散程度。方差和标准差是实际中应用最广泛的离散程度测度值。 ?函数VAR假设其参数是样本总体中的一个样本。如果数据为整个样本总体,则应使用函数VARP来计算方差。 ?参数可以是数字或者是包含数字的名称、数组或引用。 ?逻辑值和直接键入到参数列表中代表数字的文本被计算在内。 ?如果参数是一个数组或引用,则只计算其中的数字。数组或引用中的空白单元格、逻辑值、文本或错误值将被忽略。 ?如果参数为错误值或为不能转换为数字的文本,将会导致错误。 ?如果要使计算包含引用中的逻辑值和代表数字的文本,请使用VARA 函数。 ?函数VAR 的计算公式如下: 其中x 为样本平均值AVERAGE(number1,number2,…),n 为样本大小。 示例 假设有10 件工具在制造过程中是由同一台机器制造出来的,并取样为随机样本进行抗断强度检验。 如果将示例复制到一个空白工作表中,可能会更容易理解该示例。 STDEV(number1,number2,...) Number1,number2,...为对应于总体样本的 1 到255 个参数。也可以不使用这种用逗号分隔参数的形式,而用单个数组或对数组的引用。 注解 ?函数STDEV 假设其参数是总体中的样本。如果数据代表全部样本总体,则应该使用函数STDEVP来计算标准偏差。 ?此处标准偏差的计算使用“n-1”方法。
一、百度百科上方差是这样定义的: (variance)是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是各个数据分别与其平均数之差的平方的和的平均数。在许多实际问题中,研究方差即偏离程度有着重要意义。 看这么一段文字可能有些绕,那就先从公式入手, 对于一组随机变量或者统计数据,其期望值我们由E(X)表示,即随机变量或统计数据的均值, 然后对各个数据与均值的差的平方求和,最后对它们再求期望值就得到了方差公式。 这个公式描述了随机变量或统计数据与均值的偏离程度。 二、方差与标准差之间的关系就比较简单了
根号里的内容就是我们刚提到的 那么问题来了,既然有了方差来描述变量与均值的偏离程度,那又搞出来个标准差干什么呢 发现没有,方差与我们要处理的数据的量纲是不一致的,虽然能很好的描述数据与均值的偏离程度,但是处理结果是不符合我们的直观思维的。 举个例子:一个班级里有60个学生,平均成绩是70分,标准差是9,方差是81,成绩服从正态分布,那么我们通过方差不能直观的确定班级学生与均值到底偏离了多少分,通过标准差我们就很直观的得到学生成绩分布在[61,79]范围的概率为,即约等于下图中的%*2 三、均方差、均方误差又是什么
标准差(Standard Deviation),中文环境中又常称均方差,但不同于均方误差(mean squared error,均方误差是各数据偏离真实值的距离平方和的平均数,也即误差平方和的平均数,计算公式形式上接近方差,它的开方叫均方根误差,均方根误差才和标准差形式上接近),标准差是离均差平方和平均后的方根,用σ表示。标准差是方差的算术平方根。 从上面定义我们可以得到以下几点: 1、均方差就是标准差,标准差就是均方差 2、均方误差不同于均方误差 3、均方误差是各数据偏离真实值的距离平方和的平均数 举个例子:我们要测量房间里的温度,很遗憾我们的温度计精度不高,所以就需要测量5次,得到一组数据[x1,x2,x3,x4,x5],假设温度的真实值是x,数据与真实值的误差 e=x-xi 那么均方误差MSE= 总的来说,均方差是数据序列与均值的关系,而均方误差是数据序列与真实值之间的关系,所以我们只需要搞清楚真实值和均值之间的关系就行了。
均值、方差和协方差的定义和基本性质 1 数学期望(均值)的定义和性质 定义:设离散型随机变量X 的分布律为 {}, 1,2,k k P X x p k === 若级数 1k k k x p ∞=∑ 绝对收敛,则称级数1k k k x p ∞=∑的和为随机变量X 的数学期望,记为()E X 。即 ()1k k k E X x p ∞==∑。 设连续型随机变量X 的概率密度为()f x ,若积分 ()xf x dx ∞?∞? 绝对收敛,则称积分 ()xf x dx ∞?∞?的值为随机变量X 的数学期望,记为()E X 。即 ()()E X xf x dx ∞ ?∞=? 数学期望简称期望,又称为均值。 性质:下面给出数学期望的几个重要的性质 (1)设C 是常数,则有()E C C =; (2)设X 是一个随机变量,C 是常数,则有()()E CX CE X =; (3)设X 和Y 是两个随机变量,则有()()()E X Y E X E Y +=+,这一性质可以推 广至任意有限个随机变量之和的情况; (4)设X 和Y 是相互独立的随机变量,则有()()()E XY E X E Y =。 2 方差的定义和性质 定义:设X 是一个随机变量,若(){}2E X E X ?????存在,则称(){}2E X E X ?????为X
的方差,记为()D X 或()Var X ,即 性质:下面给出方差的几个重要性质 (1)设C 是常数,则有()0D C =; (2)设X 是一个随机变量,C 是常数,则有 ()()2D CX C D X =,()()D X C D X +=; (3)设X 和Y 是两个随机变量,则有 ()()()()()()(){}2D X Y D X D Y E X E X Y E Y +=++?? 特别地,若X 和Y 相互独立,则有()()()D X Y D X D Y +=+ (4)()0D X =的充分必要条件是以概率1取常数()E X ,即(){}1P X E X ==。 3 协方差的定义和性质 定义:量()(){} E X E X Y E Y ??????????称为随机变量X 与Y 的协方差。记为(),Cov X Y ,即 ()()(){},Cov X Y E X E X Y E Y =?????????? 性质:下面给出协方差的几个重要性质 (1)()(),,Cov X Y Cov Y X = (2)()(),Cov X X D X = (3)()()()(),Cov X Y E XY E X E Y =? (4)()(),,,,Cov aX bY abCov X Y a b =是常数 (5)()()()1212,,,Cov X X Y Cov X Y Cov X Y +=+ 参考文献 [1]概率论与数理统计(第四版),浙江大学
计算全距、平均差、方差和标准差 一、全距 R(range) 全距是一组数据中的最大值(maximum)与该组数据中最小值(minimum)之差,又称极差。 R=Xmax-Xmin 一般用于研究的预备阶段,用它检查数据的分布范围,以便确定如何进行统计分析 原始数据计算公式 三、四分位差(Quartile) 四分位差是第一个四分位数与第三个四分位数之差计算公式为 Q=Q 3-Q 1 四、方差与标准差 方差:又称为变异数、均方,是每个数据与该组数据平均数之差乘方后的均值,是表示一组数据离散程度的统计指标。 样本的方差用表示,总体的方差用表示。 标准差是方差的算术平方根。一般样本的标准差用 S 表示,总体的标准差用表示。 标准差和方差是描述数据离散程度的最常用的差异量。 分组数据方差与标准差的计算公式 方差与标准差的性质 ?方差是对一组数据中各种变异的总和的测量,具有可加性和可分解性特点。 ?标准差是一组数据方差的算术平方根,它不可以进行代数计算,但有以下特性: 总体方差、标准差或者方差、标准才差的合成 ?方差具有可加性的特点。当已知几个小组数据的方差或标准差时,可
以计算几个小组联合在一起的总的方差或标准差。 ?需要注意的是,只有在应用同一种观测手段,测量的是同一种特质,只是样本不同的数据时,才能计算合成方差或标准差。 方差和标准差的优点: 方差与标准差是表示一组数据离散程度的最好指标,其值越大,离散程度越大。 应用方差和标准差表示一组数据的离散程度,须注意必须是同一类数据(即同一种测量工具的测量结果),而且被比较样本的水平比较接近。 优点: ?反应灵敏。每个数据发生变化,方差与标准差也随之变化 ?有一定计算公式的严密确定 ?容易计算 ?受抽样变动的影响小 ?简单明了 ?方差具有可加性(区分变异源,组间/组内) 五、差异系数(coefficient of variation) 差异系数指标准差与其算术平均数的百分比,它是没有单位的相对数。用CV表示。 何种情况下运用差异系数: ?两个或两个以上样本所测特质不同,即所使用的观测工具不同,如何比较两者的离散程度? ?即使使用同一种观测量具,但样本水平相差较大,如何比较其离散程度? 差异系数的作用 ?比较不同单位资料的差异程度 ?比较单位相同而平均数相差较大的两组资料的差异程度 ?可判断特殊差异情况
#include { Sum+=*(score+i); } return Sum/n; } int main(void) { double *score,sum=0; int n,i=0; double wc; cout<<"请输入仪器误差:"; cin>>wc; cout<<"请输入项数:"; cin>>n; score=new double[n]; input(score,n); for(;i cout< 经常要用到,系统整理了一下。 1、均值 Matlab函数:mean >>X=[1,2,3] >>mean(X)=2 如果X是一个矩阵,则其均值是一个向量组。 mean(X,1)为列向量的均值,mean(X,2)为行向量的均值。>>X=[1 2 3 4 5 6] >>mean(X,1)=[2.5, 3.5, 4.5] >>mean(X,2)=[2 5] 若要求整个矩阵的均值,则为mean(mean(X))。 >>mean(mean(X))=3.5 也可使用mean2函数: >>mean2(X)=3.5 median,求一组数据的中值,用法与mean相同。 >>X=[1,2,9] >>mean(X)=4 >>median(X)=2 2、方差 均方差: Matlab 函数:var 要注意的是var函数所采用公式中,分母不是,而是。这是因为var函数实际上求的并不是方差,而是误差理论中“有限次测量数据的标准偏差的估计值”。 >>X=[1,2,3,4] >>var(X)=1.6667 >> sum((X(1,:)-mean(X)).^2)/length(X)=1.2500 >> sum((X(1,:)-mean(X)).^2)/(length(X)-1)=1.6667 var没有求矩阵的方差功能,可使用std先求均方差,再平方得到方差。 std,均方差,std(X,0,1)求列向量方差,std(X,0,2)求行向量方差。 >>X=[1 2 3 4] >>std(X,0,1)=1.4142 1.4142 >>std(X,0,2)=0.7071 0.7071 若要求整个矩阵所有元素的均方差,则要使用std2函数: >>std2(X)=1.2910 方差计算公式的证明 (1)用新数据法求平均数 当所给的数据都在某一常数a的上下波动时,一般选用简化公式:=+a.其中,常数a通常取接近这组数据平均数的较“整”的数,=-a,=-a,…,=-a ○1 =(+)是新数据的平均数(通常把,,…,,叫做原数据, ,,…,,叫做新数据)。证明: 把○1左边的数据相加,把○1右边的数据相加,得到一个等式: +=-a+-a+…+-a +=++…+-na =—a 即○2 亦即=+a (2)方差的基本公式 方差的基本公式由方差的概念而来。方差的概念是:在一组数据,,,中,各数据与他们的平均数的差的平方的平均数,叫做这组数据的方差。通常用“” 表示,即: =[+] (3) 方差的简化计算公式 =[++…+)-n] 也可写成=[++…+)]- 此公式的记忆方法是:方差等于原数据平方的平均数减去平均数的平方。 证明: =[+] =[++++…++] =[++…+)-2++…++n] =[++…+)-2n =[++…+)-2n =[++…+)-n] =++…+)-………………..(I) 根据○1,有=+a,=+a,…=+a,和=+a(详见(1)的证明) 代入简化公式(I),则有: =[()+()+…()- =[(++…+)+2a(++…+)+n]-(+2a+) =(++…+)+2a+-2a- =(++…+)+ 2a+ =(++…+)…………………….(II) 此公式的记忆方法是:方差等于新数据平方的平均数减去新数据平均数的平方。 由方差的基本公式,经恒等变形后,产生了简化公式(I);由简化公式(I)进行等 量代替产生了简化公式(II).因此,基本公式和简化公式(I)(II)所计算出的方 差都相同。基本公式和简化公式(I)按原数据,,…,计算方差;简化公 式(II)按新数据,,…,计算方差,计算出的方差相同。 (4) 用新数据法计算方差 原数据,,…,的方差与新数据=-a,=-a,…,=-a的方差相等。也就 是说,根据方差的基本公式,求得的,,…,的方差就等于原数据 ,,…,的方差。 证明: 把○1式里的每一个式子的两边,减去○2式的两边(左边-左边,右边-右边)有: -=(-a)-(-a)=- -=(-a)-(-a)=- ………… -=(-a)-(-a)=- 再把以上每一个新生成等式左右两边平方,即有左2=右2: ()=() ()=() ………… ()=() 最后把这些式子的左边加左边,右边加右边,其和分别除以n,即有:[()+()+…+()]=[+] 这就是根据方差的基本公式,求得的,,…,的方差就等于原数据 ,,…,的方差。 随机变量的均值与方差 一、填空题 1.已知离散型随机变量X 的概率分布为 则其方差V (X )=解析 由0.5+m +0.2=1得m =0.3,∴E (X )=1×0.5+3×0.3+5×0.2=2.4,∴V (X )=(1-2.4)2×0.5+(3-2.4)2×0.3+(5-2.4)2×0.2=2.44. 答案 2.44 2.(优质试题·西安调研)某种种子每粒发芽的概率都为0.9,现播种了1 000粒,对于没有发芽的种子,每粒需再补种2粒,补种的种子数记为X ,则X 的数学期望为________. 解析 设没有发芽的种子有ξ粒,则ξ~B (1 000,0.1),且X =2ξ,∴E (X )=E (2ξ)=2E (ξ)=2×1 000×0.1=200. 答案 200 3.已知随机变量X 服从二项分布,且E (X )=2.4,V (X )=1.44,则二项分布的参数n ,p 的值分别为________. 解析 由二项分布X ~B (n ,p )及E (X )=np ,V (X )=np ·(1-p )得2.4=np ,且1.44=np (1-p ),解得n =6,p =0.4. 答案 6,0.4 4.随机变量ξ的取值为0,1,2.若P (ξ=0)=1 5,E (ξ)=1,则V (ξ)=________. 解析 设P (ξ=1)=a ,P (ξ=2)=b , 则????? 15+a +b =1,a +2b =1, 解得????? a =3 5,b =1 5, 所以V(ξ)=(0-1)2×1 5+(1-1) 2× 3 5+(2-1) 2× 1 5= 2 5. 答案2 5 5.已知随机变量X+η=8,若X~B(10,0.6),则E(η),V(η)分别是________.解析由已知随机变量X+η=8,所以有η=8-X.因此,求得E(η)=8-E(X)=8-10×0.6=2,V(η)=(-1)2V(X)=10×0.6×0.4=2.4. 答案 2.4 6.口袋中有5只球,编号分别为1,2,3,4,5,从中任取3只球,以X表示取出的球的最大号码,则X的数学期望E(X)的值是________. 解析由题意知,X可以取3,4,5,P(X=3)=1 C35= 1 10, P(X=4)=C23 C35= 3 10,P(X=5)= C24 C35= 6 10= 3 5, 所以E(X)=3×1 10+4× 3 10+5× 3 5=4.5. 答案 4.5 7.(优质试题·扬州期末)已知X的概率分布为 设Y=2X+1,则 解析由概率分布的性质,a=1-1 2- 1 6= 1 3, ∴E(X)=-1×1 2+0× 1 6+1× 1 3=- 1 6, 因此E(Y)=E(2X+1)=2E(X)+1=2 3. 答案2 3 8.(优质试题·合肥模拟)某科技创新大赛设有一、二、三等奖(参与活动的都有奖)且相应奖项获奖的概率是以a为首项,2为公比的等比数列,相应的奖金分 方差计算公式的变形及应用 江苏 庄亿农 我们知道,对于一组数据x 1、x 2、…x n ,若其平均数为x ,则其方差可用公式 S 2=21)[(1 x x n -+22)(x x -+…+2)(x x n -]计算出来.我们可以对其作如下变形: 2s =n 1[( x 21+2x -2 x 1x )+( x 22+2x -2 x 2x )+…+( x 2n +2x -2 x n x )]=n 1[ (x 21+x 22+…+ x 2n )+n 2x -2x ( x 1+ x 2+…+ x n )]= n 1[ (x 21+x 22+…+ x 2n )+ n 2x -2n 2x ]=n 1[ (x 21+x 22+…+ x 2n )-n 2x ]=n 1[ (x 21+x 22+…+ x 2n )-n 1(x 1+x 2+…+ x n )2],即2s =n 1[ (x 21+x 22+…+ x 2n )-n 1(x 1+x 2+…+ x n )2].显然当x 1=x 2=…=x n 时,2s =0. 这个变形公式很有用处,在解决有些问题中,巧妙地利用这个变形公式,可化繁为简,具有事半功倍之效. 一、判断三角形形状 例1 若△ABC 的三边a 、b 、c ,满足b+c=8,bc=a 2-12a+52,试判断△ABC 的形状. 解析:因为b+c=8,所以(b+c)2=64,所以b 2+c 2=64-2bc .因为bc=a 2-12a+52,所以b 2+c 2=64-2(a 2-12a+52)=-2a 2+24a -40.由方差变形公式知,b 、c 的方差为2s = 21[(b 2+c 2)-21(b+c)2]= 21[(-2a 2+24a -40)-2 1×64]=-a 2+12a -36=-(a -6)2.因为2s ≥0,则-(a -6)2≥0,即 (a -6)2≤0,而(a -6)2≥0,所以(a -6)2=0,所以a -6=0,所以a=6.所以2s =0, 所以b=c .又b+c=8,所以b=c=4.所以△ABC 是等腰三角形. 二、解方程组 例2 解方程组?? ???+==+22493z xy y x . 解析:两个方程,三个未知数,一般情况下是求不出具体的未知数的值的.若考虑利用方差变形公式,则能解决问题. 因为x+y=3,所以(x+y)2=9,所以x 2+y 2=9-2xy .因为xy= 4 9+2z 2,所以x 2+y 2=9-2(49+2z 2)=29-4z 2.由方差变形公式知,x 、y 的方差为2s =21[ (x 2+y 2)-21(x+y)2]=21[2 9-4z 2-21×9]=-2z 2.因为2s ≥0,-2z 2≥0,则2z 2≤0,而z 2≥0,所以z=0.所以2s =0,所以 平均数众数中位数极差 方差标准差 Document serial number【NL89WT-NY98YT-NC8CB-NNUUT-NUT108】 平均数、众数、中位数、极差、方差、标准差说明6个基本统计量(平均数、众数、中位数、极差、方差、标准差)的内涵,学生学习过程中可能产生的困难及主要原因、应对策略. 首先,结合简单实例认真把握这6个基本统计量的内涵。 一、平均数、众数、中位数是刻画一组数据的“平均水平”的数据代表。(八上《第八章数据的代表》) 平均数分算术平均数和加权平均数,算术平均数是指n个数据的和的平均值,学生理解与计算都不成问题,只要注意细心运算就是其中的取标准值后的简便算法也都是在小学早已熟练的(公式: x=1/n(x1+x2+x3+……+xn);而加权平均数是一组数据里的各个数据乘各自的“权”之后的平均数。此处理解“权”的概念可能产生很大困难,因为“权”的理解的确不易,若是照搬教材直接给出其定义,学生会迷惑成团,再进行应用更是不可思议。所以应对措施:讲好、用好加权平均数就要先举例、后分析、再给出定义,比如:某同学的一次考试各科成绩如下:语文110、数学105、英语106、物理95、化学90、政治86、历史98、地理66、生物89,你可以先让学生算算各科的平均数,再按中考计分法将语、数、英各取120%,物、化、政各取100%,史、地、生各取40%后的平均值算出,两个结果一比较,学生就会很容易发现不同的原因是加入了所谓的“权”,这样,不仅通俗易懂,而且对“权”内涵的理解和应用就不再困难。 众数是一组数据中出现次数最多的数。其内涵很好理解和掌握,就是结合实际应用也顺理成章,如商店老板进货号多大的男鞋好那当然是“众数”(调查数据最多的号)所代表的。 学案68 离散型随机变量的均值与方差 导学目标:1.理解取有限个值的离散型随机变量均值、方差的概念.2.能计算简单离散型随机变量的均值、方差,并能解决一些实际问题. 自主梳理 1.离散型随机变量的均值与方差 若离散型随机变量X 的分布列为 (1)均值 称E (X )=____________________________________为随机变量X 的均值或___________,它反映了离散型随机变量取值的____________. (2)方差 称D (X )=__________________________为随机变量X 的方差,它刻画了随机变量X 与其均值E (X )的______________,其________________________为随机变量X 的标准差. 2.均值与方差的性质 (1)E (aX +b )=____________. (2)D (aX +b )=____________.(a ,b 为实数) 3.两点分布与二项分布的均值、方差 (1)若X 服从两点分布,则E (X )=____,D (X )=_____________________________. (2)若X ~B (n ,p ),则E (X )=______,D (X )=____________. 自我检测 1.若随机变量X A.118 B.19 C.209 D.920 2.(2011·菏泽调研)已知随机变量X 服从二项分布,且E (X )=2.4,D (X )=1.44,则二项分布的参数n ,p 的值为( ) A .n =4,p =0.6 B .n =6,p =0.4 C .n =8,p =0.3 D .n =24,p =0.1 3.(2010·全国)某种种子每粒发芽的概率都为0.9,现播种了1000粒,对于没有发芽的种子,每粒需要再补种2粒,补种的种子数记为X ,则X 的数学期望为( ) A .100 B .200 C .300 D .400 4.(2011·浙江)某毕业生参加人才招聘会,分别向甲、乙、丙三个公司投递了个人简历.假 定该毕业生得到甲公司面试的概率为23 ,得到乙、丙两公司面试的概率均为p ,且三个公司是否让其面试是相互独立的,记X 为该毕业生得到面试的公司个数.若P (X =0)=112 ,则随机变量X 的数学期望E (X )=________. 5.(2011·杭州月考)其中a ,b ,c 成等差数列.若E (ξ)=13,则D (ξ)=________. 方差分析公式 (2012-06-26 11:03:09) 转载▼ 标签: 分类:统计方法 杂谈 方差分析 方差分析(analysis of variance,简写为ANOV或ANOVA)可用于两个或两个以上样本均数的比较。应用时要求各样本是相互独立的随机样本;各样本来自正态分布总体且各总体方差相等。方差分析的基本思想是按实验设计和分析目的把全部观察值之间的总变异分为两部分或更多部分,然后再作分析。常用的设计有完全随机设计和随机区组设计的多个样本均数的比较。 一、完全随机设计的多个样本均数的比较 又称单因素方差分析。把总变异分解为组间(处理间)变异和组内变异(误差)两部分。目的是推断k个样本所分别代表的μ1,μ2,……μk是否相等,以便比较多个处理的差别有无统计学意义。其计算公式见表19-6. 表19-6 完全随机设计的多个样本均数比较的方差分析公式变异来源离均差平方和SS 自由度v 均方MS F 总ΣX2-C* N-1 组间(处理组间)k-1 SS组间/v组间MS组间/MS组间 组内(误差)SS总-SS组间N-k SS组内/v组内 *C=(ΣX)2/N=Σni,k为处理组数 表19-7 F值、P值与统计结论 αF值P值统计结论 0.05 <F0.05(v1.V2)>0.05 不拒绝H0,差别无统计学意义 0.05 ≥F0.05(v1.V2)≤0.05 拒绝H0,接受H1,差别有统计学意义 0.01 ≥F0.01(v1.V2)≤0.01 拒绝H0,接受H1,差别有高度统计学意义 方差分析计算的统计量为F,按表19-7所示关系作判断。 例19.9 某湖水不同季节氯化物含量测量值如表19-8,问不同季节氯化物含量有无差别? 表19-8 某湖水不同季节氯化物含量(mg/L ) X ij 春 夏 秋 冬 22.6 19.1 18.9 19.0 22.8 22.8 13.6 16.9 21.0 24.5 17.2 17.6 16.9 18.0 15.1 14.8 20.0 15.2 16.6 13.1 21.9 18.4 14.2 16.9 21.5 20.1 16.7 16.2 21.2 21.2 19.6 14.8 ΣX ij j 167.9 159.3 131.9 129.3 588.4(ΣX ) n i 8 8 8 8 32(N ) X i 20.99 19.91 16.49 16.16 ΣX 2 ijj 3548.51 3231.95 2206.27 2114.11 11100.84(ΣX 2 ) H0:湖水四个季节氯化物含量的总体均数相等,即μ1=μ2=μ3=μ4 H1:四个总体均数不等或不全相等 α=0.05 先作表19-8下半部分的基础计算。 C= (Σx )2/N=(588.4)2/32=10819.205 SS 总=Σx2-C=11100.84-10819.205=281.635 V 总=N-1=31 V 组间=k-1=4-1=3 SS 组内=SS 总-SS 组间=281.635-141.107=140.465 V 组内=N-k=32-4=28MATLAB求均值和方差
方差计算公式的证明
随机变量的均值与方差
方差计算公式的变形及应用
平均数众数中位数极差方差标准差
均值与方差
方差分析公式
相关主题
文本预览