
★结构方程模型要点
一、结构方程模型的模型构成
1、变量
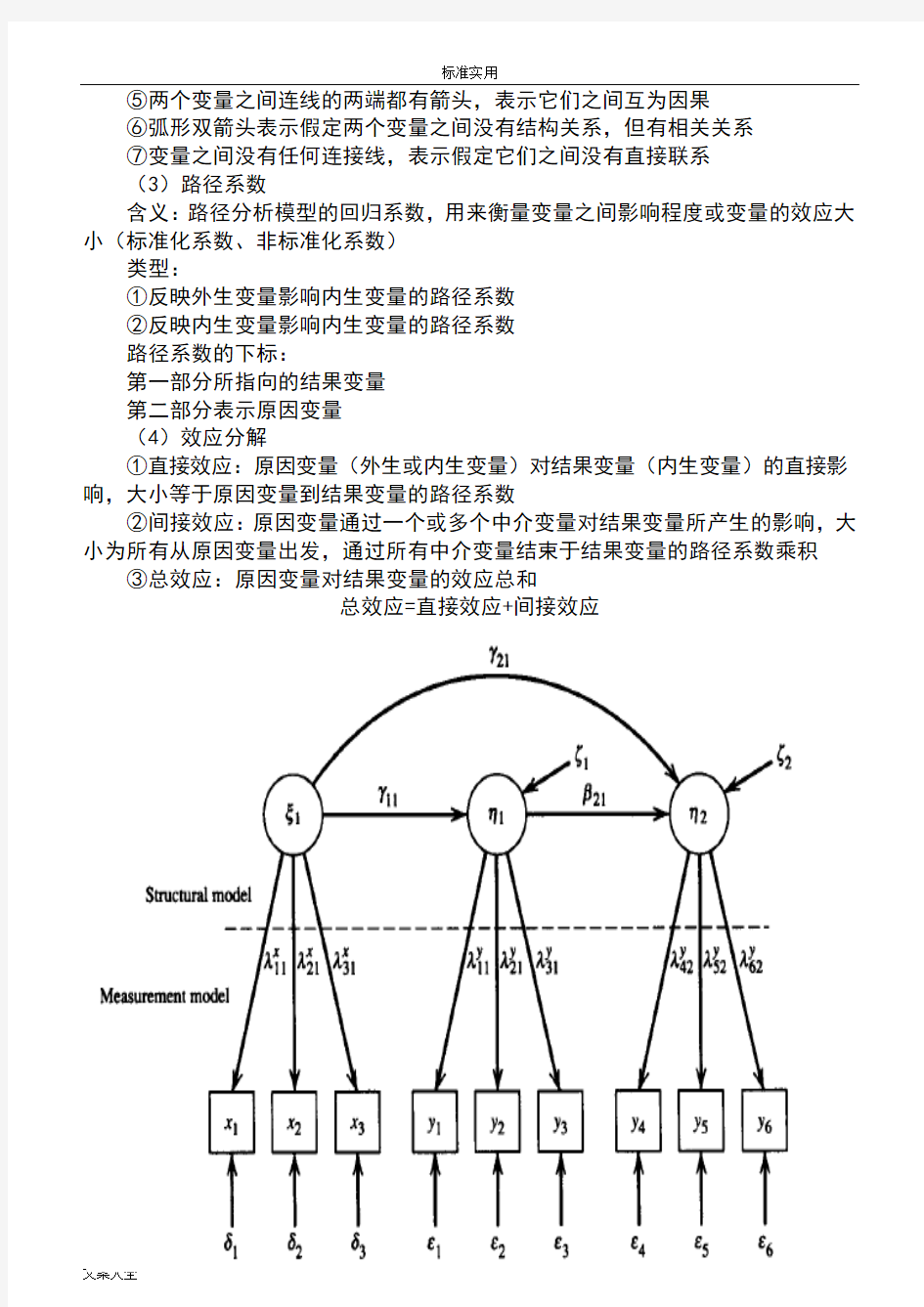
观测变量:能够观测到的变量(路径图中以长方形表示)
潜在变量:难以直接观测到的抽象概念,由观测变量推估出来的变量(路径图中以椭圆形表示)
内生变量:模型总会受到任何一个其他变量影响的变量(因变量;路径图会受
外生变量:模型中不受任何其他变量影响但影响其他变量的变量(自变量;路
中介变量:当内生变量同时做因变量和自变量时,表示该变量不仅被其他变量影响,还可能对其他变量产生影响。
内生潜在变量:潜变量作为内生变量
内生观测变量:内生潜在变量的观测变量
外生潜在变量:潜变量作为外生变量
外生观测变量:外生潜在变量的观测变量
中介潜变量:潜变量作为中介变量
中介观测变量:中介潜在变量的观测变量
2、参数(“未知”和“估计”)
潜在变量自身:总体的平均数或方差
变量之间关系:因素载荷,路径系数,协方差
参数类型:自由参数、固定参数
自由参数:参数大小必须通过统计程序加以估计
固定参数:模型拟合过程中无须估计
(1)为潜在变量设定的测量尺度
①将潜在变量下的各观测变量的残差项方差设置为1
②将潜在变量下的各观测变量的因子负荷固定为1
(2)为提高模型识别度人为设定
限定参数:多样本间比较(半自由参数)
3、路径图
(1)含义:路径分析的最有用的一个工具,用图形形式表示变量之间的各种线性关系,包括直接的和间接的关系。
(2)常用记号:
①矩形框表示观测变量
②圆或椭圆表示潜在变量
③小的圆或椭圆,或无任何框,表示方程或测量的误差
单向箭头指向指标或观测变量,表示测量误差
单向箭头指向因子或潜在变量,表示内生变量未能被外生潜在变量解释的部分,是方程的误差
④单向箭头连接的两个变量表示假定有因果关系,箭头由原因(外生)变量指向结果(内生)变量
⑤两个变量之间连线的两端都有箭头,表示它们之间互为因果
⑥弧形双箭头表示假定两个变量之间没有结构关系,但有相关关系
⑦变量之间没有任何连接线,表示假定它们之间没有直接联系
(3)路径系数
含义:路径分析模型的回归系数,用来衡量变量之间影响程度或变量的效应大小(标准化系数、非标准化系数)
类型:
①反映外生变量影响内生变量的路径系数
②反映内生变量影响内生变量的路径系数
路径系数的下标:
第一部分所指向的结果变量
第二部分表示原因变量
(4)效应分解
①直接效应:原因变量(外生或内生变量)对结果变量(内生变量)的直接影响,大小等于原因变量到结果变量的路径系数
②间接效应:原因变量通过一个或多个中介变量对结果变量所产生的影响,大小为所有从原因变量出发,通过所有中介变量结束于结果变量的路径系数乘积
③总效应:原因变量对结果变量的效应总和
总效应=直接效应+间接效应
4、矩阵方程式
(1)和(2)是测量模型方程,(3)是结构模型方程 测量模型:反映潜在变量和观测变量之间的关系 结构模型:反映潜在变量之间因果关系 5
x x ξδ=∧+ (1)
y y ηε=∧+ (2) B ηηξζ=+Γ+ (3)
三、模型修正
1、参考标准
模型所得结果是适当的;
所得模型的实际意义、模型变量间的实际意义和所得参数与实际假设的关系是合理的;
参考多个不同的整体拟合指数;
2、修正原则
①省俭原则
两个模型拟合度差别不大的情况下,应取两个模型中较简单的模型;
拟合度差别很大,应采取拟合更好的模型,暂不考虑模型的简洁性;
最后采用的模型应是用较少参数但符合实际意义,且能较好拟合数据的模型。
②等同模式
等同模式:用不同的方法表示各个潜在变量之间的关系,能得出基本相同的结果,参数个数相同,拟合程度相同的模式。
实际意义、多次验证
3、模型修正方向
①模型扩展方面(放松一些路径系数,提高拟合度)
修正指数MI=χ12-χm2
MI【Modification Indices(M.I.)】反映的是一个固定或限制参数被恢复自由时,卡方值可能减少的最小的量。如果MI变化很小,则修正没有意义;通常认为MI>4,模型修正才有意义。(显著水平为0.05时,临界值为3.84)
②模型简约方面(删除或限制一些路径系数,使模型变简洁)
临界比率CR=χ2/df
CR通过自由度调整卡方值,以供选择参数不是过多,又能满足一定拟合度的模型,寻找CR比率最小者
单个参数调整设为0
两个变量之间路径系数关系进行调整,设为相等
4、模型修正内容
(1)测量模型修正
添加或删除因子载荷
添加或删除因子之间的协方差
添加或删除测量误差的协方差
(2)结构模型修正
增加或减少潜在变量数目
添加或删减路径系数
添加或删除残差项的协方差
四、验证性因子分析(CFA)
1、验证性因子分析
一阶验证性因子分析
2、路径分析
非递归模型
自我效能对于学业表现的模型衍生相关:(轨迹法则) 1
直接效应:自我效能 学业表现=0.29
2 间接效应:自我效能 成就动机 学业表现=0.1
3 3 相关间接效应:
自我效能 社会期待 学业表现=0.13*0.16=0.02
自我效能 社会期待 成就动机 学业表现=0.13*0.02*0.21=0.000546 衍生相关为0.29+0.13+0.02+0.00=0.44
五、SPSS 与Amos
一般的研究论文的数据分析部分少不了对样本的描述、对变量进行探索性因子分析(EFA ),然后再利用多变量分析技术或SEM 进行数据分析,最后提出研究结论(验证假说),提出建议。基于这样的了解,我们来看SPSS 与Amos 所发挥的功能:
路径分析参数估计图
利用amos,所得到的值是显著性(p值),我们要用显著性和我们所设的显著水平α值做比较,如果显著性大于α值,未达到显著水平,则接受虚无假说;如果显著性小于α值,达到显著水平,则拒绝虚无假说(即发现有统计上的显著性)。在统计检验时,本书所设定的显著性水平皆是0.05(α=0.05)
七、拟合度
AMOS是以卡方统计量来进行检验的,一般以卡方值p大于0.05判断模型是否具有良好的拟合度。但是卡方统计量容易受到样本大小的影响,因此还要参考其他
PA-VO的路径分析有两种应用模型:递归与非递归。
递归与非递归模型可以从两个角度来判别:1.变量之间有无回溯关系 2.残差之间是否具有残差相关。
九、直接效果与间接效果
直接效果是某一变量对另一变量的直接影响。
间接效果是某一变量通过某一中介变量对另一变量的直接影响。
总效果等于直接效果加上间接效果。
通常:如果直接效果大于间接效果,表示中介变量不发挥作用,可以忽略;如果直接效果小于间接效果,表示中介变量具有影响力,要重视中介变量
結 構方程程模型型及其應 新增資 應用 資料
目錄 內容 頁數 引言 2 I. 第9.1版的改動 3 - 4 II. 章節內的新增資料 第一章 5 第三章 6 – 8 第十二章 9 – 10 第十四章 11 – 17 III. 附录內的新增資料 19 1
引言 自2005,為方便普通話及廣東話的學生,修習香港中文大學我所任教的結構方程課程,我製做了一個含有2種方言的網上課程,其後我亦將整個課程放在個人網頁(https://www.doczj.com/doc/d55674686.html,)免費讓公眾使用。 網上課程更精簡地解釋重點,尤其是對本書最艱深的部份(第三、四章),幫助最大。學員先看綱上課程,再參考書本內容,必感事半功倍。 主要参考文獻: du Toit, S., du Toit, M., Mels, G., & Cheng, Y. (n.d.). LISREL for Windows: SIMPLIS syntax files. Lincolnwood, IL: Scientific Software International, Inc. (available https://www.doczj.com/doc/d55674686.html,/lisrel/techdocs/SIMPLISSyntax.pdf) J?reskog, K.G. & S?rbom, D. (1999). LISREL 8: User’s Reference Guide. Lincolnwood, IL: Scientific Software International, Inc. J?reskog, K.G. & S?rbom, D. (1999). Structural Equation Modeling with the SIMPLIS Command Language. Lincolnwood, IL: Scientific Software International, Inc. Scientific Software International (SSI) (2012). LISREL 9.1 Release Notes. Lincolnwood, IL: The Author. (available from https://www.doczj.com/doc/d55674686.html,/lisrel/LISREL_9.1_Release_Notes.pdf) 2
法经济学研究方法的新思路——基于结构方程模型的简介 结构方程模型在社会科学领域得到越 来越多的重视和应用,与传统的研究手段相比,它有显而易见的优点。以法经济学中公司理论的经理人报酬研究为例,可以很好地反映出各因素之间的关系和影响路径,这就为公司法经济学分析中的公司治理理论提 供了更为清楚的结构关系。 关键词:法经济学;结构方程模型;路径分析 Abstract: SEM has been given more thought than ever in the researches of social science as it has some unipue advantages compared with the traditional methods. With regard to the compensation for manager from the perspective of corporate theory in law economics,the paper expounds the
intervelationship of those elements involved that clearly represent the structural relationship of corporate governance. Key words:law and economics;SEM;route analysis 结构方程模型作为一种多元统计技术,产生后迅速得到了普遍的应用。20世纪70 年代初一些学者将因子分析、路径分析等统计方法整合,提出结构方程模型的初步概念。随后Joreskog与其合作者进一步发展了矩 阵模型的分析技术来处理共变结构的分析 问题,提出测量模型与结构模型的概念,促成SEM的发展。结构方程模型为实际上即一种验证一个或多个自变量于一个或多个因 变量之间一组相互关系的多元分析程式, 其中自变量和因变量既可是连续的,也可是离散的。另外,在学术活动方面,根据Hershberger研究 1994 至 2001 年间的相关发现,到了 2003 年,不论在刊登结构方程模型相关论文的期刊数、期刊论文的数量、结构方程模型所延伸出来的多变量分析技
1数据格式转换 因为Mplus只能打开ASCII格式的文件(.dat和.txt文件),所以常规的SPSS数据库的数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式。另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。这两类并没 有明显特异的使用条件。 2打开mplus程序,建立新文件,即点击"new”。当然,新打开Mplus程序也会默认这个
TITLE: example 3.2然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。命令为: DATA: FILE IS C:\Users\dell\Desktop\MPLUS结构方程模型教程数据库.dat; 这里面需要注意的是:DATA: FILE IS (或者DATA: FILE=是固定句式,是必要的。之后 “C:\Users\dell\Desktop\MPLUS结构方程模型教程数据库.dat”这是DAT文件的保存路径。一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA: FILE I黴据库.dat;但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。 另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)° 3.3写出数据库中所有的变量名称以及本次分析需要的变量名称。这需要按照spss数据库中变量名称顺序来写。 VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4; USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4; 当然这是最基本繁琐的写法,可以直接写为: VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4; USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4; 不同变量间有空格。 因为我们本次分析需要纳入该数据库所有变量,所以上下两行变量是一样的,否则需要哪些 变量,在USEVARIABLE里面纳入哪些变量。 3.4分析方法 因为MPLUS中针对连续型变量的结构方程模型的默认分析方法是最小二乘法即ML,所以 如果使用的方法是这个,那么分析方法语句可以不写,当然也可以写,即ANALYSIS: ESTIMATOR = ML; 如果采用其他方法,需要写出来,例如ANALYSIS:ESTIMATOR = MLR;或者ANALYSIS: ESTIMATOR = WLSMV;
结构方程模型的应用及分析策略 侯杰泰成子娟 (香港中文大学教育学院东北师范大学教育学院,130024) 摘要:差不多所有心理、教育、社会等概念,均难以直接准确测量,结构方程(SEM,Structural Equation Modelling)提供一个处理测量误差的方法,采用多个指标去反映潜在变量,也令估计整个模型因子间关系,较传统回归方法更为准确合理。本文主要用一系列有关学习动机的虚拟例子,指出每个问题的主要分析策略,以展示SEM在教育及心理学可以应用的研究范畴。文内探讨的方法包括:验证性因素、高阶因子、路径及因果分析、多时段(multiwave)设计、单形模型(Simple Model)、及多组比较等。 关键词结构方程验证性因素分析路径及因果分析高阶因子多组比较 结构方程(SEM,Structural Equation Modelling)、协方差结构模型(Covariance Structure Modelling、LISREL)等类似名词已渐流行,并成为一种十分重要的数据分析技巧;在大学高等学位研究课程,它是多变量分析(multivariate analysis)的重要课题;比较重要的社会、教育、心理期刊,也早已特开专栏介绍(如:候,1994;Connell & Tanaka,1987;Joreskog & Sorbom,1982);可见SEM在统计学中所建立的声望及崇高地位是无容置疑的。本文主要用一系列有关学习动机的虚拟例子,来指出每个问题的主要分析策略,以展示结构方程模型在教育及心理学可以应用的研究范畴。 一、结构方程:优点及拟合概念 1.数学模式 很多社会、心理等变项,均不能准确地及直接地量度,这包括智力、社会阶层、学习动机等,我们只好退而求其次,用一些外项指标(observable indicators),去反映这些潜伏变项。例如:我们以学生父母教育程度、父母职业及其收入(共六个变项),作为学生家庭社经地位(潜伏变项)的指标,我们又以学生中、英、数三科成绩(外显变项),作为学业成就(潜伏变项)的指标。 简单来说SEM可分测量(measurement)及潜伏变项(latent variable)两部分。测量部分就是求出六个社经指标与社经地位(或三科成绩与学业成就)(即外显指标与潜伏变项之间)的关系:而潜伏变项部分则指社经地位与学业成就(即潜伏变项与潜伏变项间)的关系。 指标(外显变项)含有随机(或系统)性的量度上误差,但潜伏变项则不含这些部份。SEM可用以下矩阵方程表示(Bollen,1989;Joreskog & Sorbom,1993): η=βη+Γξ+ζ
福州大学孙文、贺江娴、詹俊杰 目录 一、选题的意义 (3) (一)幸福的基本内涵 (3) (二)幸福指数成为热点话题 (3) 二、幸福指数指标体系的建立 (4) 三、幸福指数调查方案的设计 (6) (一)调查研究的主要内容 (6) (二)定义目标总体 (6) (三)问卷设计 (6) (四)抽样调查的组织形式和抽样方法的选择 (7) (五)样本量的确定 (7) (六)调查的时间和地点 (7) 四、调查问卷整体统计描述 (7) (一)调查问卷预试的基本分析 (8) 1.问卷的项目分析 (8) 2.问卷的因素分析——结构效度 (10) 3.信度检验 (11) (二)调查数据的基本信息 (12) 1.性别与婚姻 (12) 2.从事行业 (12) 4.所在地区分布 (13) 5.家庭收入情况 (14) 五、实证研究 (14) (一)结构方程模型的初步建立 (14) (二)结构方程模型的修正 (16) 六、结论与建议 (18) (一)结论 (18) (二)建议 (19) (三)注意 (21) 参考文献 (22) 附录 (23) 1.问卷 (23) 2.初始模型的部分运算结果 (26)
摘要:在地方“两会”的热议和媒体宣传推动下,“幸福指数”在今年全国“两会”上迅速升温。虽然各方对幸福有着许多不同的解读,却都离不开对“民生”问题的思考。文章通过网络调查(人大经济论坛)所获得的473份调查问卷,结合马斯洛的需求层次理论,把影响幸福指数的因素由低到高分为生理需求、安全需求、情感需求、尊重需求、自我实现五个层次,运用结构方程模型来对幸福指数进行构建。最后,根据路径图的结果分析,提出了相关的建议。 关键词:幸福指数;结构方程模型;人大经济论坛 Abstract:As the local "two sessions" hot discussing and media promoting, "Happiness index" got rapid warming in national "two sessions" this year. Although everybody has each interpretation to “what is happiness?”, not without thinking "the people livelihood". We got 473 questionnaires by surveying to all registered members on https://www.doczj.com/doc/d55674686.html,, With The Demand Theory of Maslow, we divide the factors that affecting "Happiness index" into five levels from low to high: the physiological demand, the safety demand, the emotional demand, the respect demand and the self-realization demand, and then use the structural equation models(SEM) to build the happiness index. Lastly, according to the analysis results of the road map, put forwarding relevant proposals. Keywords: The happiness index;SEM; https://www.doczj.com/doc/d55674686.html,
《结构方程模型及其应用》 内容简介 侯杰泰,香港中文大学教育心理系教授、系主任。主要研究方向为学习动机,应用统计和香港语文政策。曾多次在北京、上海、南京、长春、广州等地举办的地区或全国性结构方程分析研习班上讲学。 在社会、心理、教育、经济、管理、市场等研究的数据分析中,当今称得上前沿的几个统计方法中,应用最广、研究最多的恐怕非结构方程分析莫属。它包含了方差分析、回归分析、路径分析和因子分析,弥补了传统回归分析和因子分析的不足,可以分析多因多果的联系、潜变量的关系,还可以处理多水平数据和纵向数据,是非常重要的多元数据分析工具。 本书是国内第一本系统介绍结构方程模型和LISREL的著作。阐述了结构方程分析(包括验证性因子分析)的基本概念、统计原理、在社会科学研究中的应用、常用模型及其LISREL程序、输出结果的解释和模型评价。《结构方程模型及其应用》还讨论了一些与结构方程模型有关的专题,是一本由初级至中上程度的结构方程分析著作,可作为有关专业高年级本科生和研究生的教科书及应用工作者的参考书。 目录 序 第一部分结构方程模型入门 第一章引言
一、描述数据 二、具体例子展示准确与简洁的考虑 三、探索性与验证性因子分析比较 第二章结构方程模型简介 一、结构方程模型的重要性 二、结构方程模型的结构 三、结构方程模型的优点 四、结构方程模型包含的统计方法 五、路径图的图标规则 六、结构方程分析软件包 七、LISIREL操作入门 第二部分结构方程模型应用 第三章应用示范I:验证性因子分析和全模型 一、验证性因子分析 二、多质多法模型 三、全模型 四、高阶因子分析 第四章应用示范II:单纯形和多组模型 一、单纯形模型 二、多组验证性因子分析 三、多组分析:均值结构模型 四、回归模型
★作业(全模型3):结构方 程模型和路径分析的区别-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
★数据分析的类型 1、以变量为中心的分析(R研究):探索性因子分析、验证性因子分析、回归分析、结构方程模型分析等 2、以人为中心的分析(S研究):聚类分析、判别分析等 ★因子载荷 因子载荷a(ij)的统计意义就是第i个变量与第j个公共因子的相关系数,即表示X(i)依赖F(j)的份量(比重)。统计学术语称作权,心理学家将它叫做载荷,即表示第i个变量在第j个公共因子上的负荷,它反映了第i个变量在第j个公共因子上的相对重要性。 在因子分析中,通常只选其中m个(m Amos 模型设定操作 在使用 AMOS 进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图, 并确定潜变量与可测变量的名称,以避免不必要的返工。 1.绘制潜变量 使用建模区域绘制模型中的潜变量,在潜变量上点击右键选择Object Properties,为潜变量命名。 2.为潜变量设置可测变量及相应的残差变量 使用绘制。在可测变量上点击右键选择对应的是数据的变量名,在残差变量上右键选择Object Properties为可测变量命名。其中 Object Properties为残差变量命名。 Variable Name 3.配置数据文件,读入数据 File—— Data Files—— File Name—— OK。 4.模型拟合 View—— Analysis Properties—— Estimation—— Maximum Likelihood 。 5.标准化系数 Analysis Properties—— Output—— Standardized Estimates——因子载荷标准化系数。 6.参数估计结果 Analyze—— Calculate Estimates。红色框架部分是模型运算基本结果信息,点击 View the Output Path Diagram查看参数估计结果图。 7.模型评价 点击查看 AMOS 路径系数或载荷系数以及拟合指标评价。 路径系数 /载荷系数的显著性 模型评价首先需要对路径系数或载荷系数进行统计显著性检验。 模型拟合指数 模型拟合指数是考察理论结构模型对数据拟合程度的统计指标。拟合指数的作用是考察理论模型与数据的适配程度,并不能作为判断模型是否成立的唯一依据。拟合优度高的模型只能作为参考,还需要根据所研究问题的背景知识进行模型合理性讨论。 ★结构方程模型要点 一、结构方程模型的模型构成 1、变量 观测变量:能够观测到的变量(路径图中以长方形表示) 潜在变量:难以直接观测到的抽象概念,由观测变量推估出来的变量(路径图中以椭圆形表示) 生变量:模型总会受到任何一个其他变量影响的变量(因变量;路径图会受到任何一个其他变量以单箭头指涉的变量) 外生变量:模型中不受任何其他变量影响但影响其他变量的变量(自变量;路 中介变量:当生变量同时做因变量和自变量时,表示该变量不仅被其他变量影响,还可能对其他变量产生影响。 生潜在变量:潜变量作为生变量 生观测变量:生潜在变量的观测变量 外生潜在变量:潜变量作为外生变量 外生观测变量:外生潜在变量的观测变量 中介潜变量:潜变量作为中介变量 中介观测变量:中介潜在变量的观测变量 2、参数(“未知”和“估计”) 潜在变量自身:总体的平均数或方差 变量之间关系:因素载荷,路径系数,协方差 参数类型:自由参数、固定参数 自由参数:参数大小必须通过统计程序加以估计 固定参数:模型拟合过程中无须估计 (1)为潜在变量设定的测量尺度 ①将潜在变量下的各观测变量的残差项方差设置为1 ②将潜在变量下的各观测变量的因子负荷固定为1 (2)为提高模型识别度人为设定 限定参数:多样本间比较(半自由参数) 3、路径图 (1)含义:路径分析的最有用的一个工具,用图形形式表示变量之间的各种线性关系,包括直接的和间接的关系。 (2)常用记号: ①矩形框表示观测变量 ②圆或椭圆表示潜在变量 ③小的圆或椭圆,或无任何框,表示方程或测量的误差 单向箭头指向指标或观测变量,表示测量误差 单向箭头指向因子或潜在变量,表示生变量未能被外生潜在变量解释的部分,是方程的误差 ④单向箭头连接的两个变量表示假定有因果关系,箭头由原因(外生)变量指 基于结构方程模型的校园安全管理的初步研究 Based on the preliminary research on the structural equation model of campus safety management 辽宁科技大学控制科学与工程胡勇富剑华檀立欣宁晨旭李龙 摘要:在线性系统理论的研究领域中,随着数学工具和系统描述方法的发展,已经形成了不同的分支.这些分支是将线性系统状态空间描述方法和代数理论结合起来,研究了线性系统结构方程模型建立的方法,在社会科学以及经济、市场、管理等研究领域有广泛的应用,例如行为安全管理方面的研究,本文就校园交通安全问题做了研究,这些是传统的统计方法不能很好解决的问题。20世纪80年代以来,随着结构方程模型的迅速发展,为了进一步研究校园安全管理因素,对其关键要素、构成的因果关系进行研究,建立了关于校园安全管理的结构方程模型。关键字:行为安全管理、校园安全管理、结构方程模型、状态空间描述。Abstract: In the field of study of linear system theory, with the development of mathematical tools and adopted system description methods, different branches. have been formed The branches combine the linear system state space description method and the algebra theory and study the establishment method of linear system structure equation model. In the social sciences and research fields, such as economy, market, management ,which have a wide range of applications, as the behavior safety management research, these traditional statistical methods can't l solve the problem very well. Since the 1980’s, with the rapid development of structural equation model, it makes up for the deficiency of the traditional statistical methods and establishes structural equation model about safety management factors. In order to study further on safety culture, we use the structural equation model (SEM) on the key elements of safety culture and study composition of causal relationship Keywords:behavior safety management、safety culture、structural equation mode、state space description 结构方程这几年热度不减,有必要研究一下它的R语言实现过程,今天先复习一下结构方程的相关理论,参考吉林大学余翠林的ppt 一、为什么使用SEM? 1、回归分析有几方面的限制: (1)不允许有多个因变量或输出变量 (2)中间变量不能包含在与预测因子一样的单一模型中 (3)预测因子假设为没有测量误差 (4)预测因子间的多重共线性会妨碍结果解释 (5)结构方程模型不受这些方面的限制 2、SEM的优点: (1)SEM程序同时提供总体模型检验和独立参数估计检验; (2)回归系数,均值和方差同时被比较,即使多个组间交叉; (3)验证性因子分析模型能净化误差,使得潜变量间的关联估计较少地被测量误差污染; (4)拟合非标准模型的能力,包括灵活处理追踪数据,带自相关误差结构的数据库(时间序列分析),和带非正态分布变量和缺失数据的数据库。 3、结构方程模型最为显著的两个特点是: (1)评价多维的和相互关联的关系; (2)能够发现这些关系中没有察觉到的概念关系,而且能够在评价的过程中解释测量误差。 同时具有联系信息技术吸纳能力: SEM能够反映模型中要素之间的相互影响; 吸纳能力概念作为一个重要的模型要素,难以直接度量,结构方程模型技术能够更为充分地体现其蕴含的要素信息和影响作用。 二、SEM的基本思想与方法 SEM是基于变量的协方差矩阵来分析变量之间关系的一种统计方法,实际上是一般线性模型的拓展,包括因子模型与结构模型,体现了传统路径分析与因子分析的完美结合。SEM一般使用最大似然法估计模型(Maxi-Likeliheod,ML) 分析结构方程的路径系数等估计值,因为ML法使得研究者能够基于数据分析的结果对模型进行修正。 第27卷第2期2005年4月 宁波大学学报(教育科学版) JOURNAL OF N I N G BO UN I V ERSI TY (E DUCATI O NAL SC I E NCE ) Vol .27NO.2 Ap r . 2005 结构方程模型(SE M )的原理及操作 孙连荣 (宁波大学师范学院,浙江宁波315211) 摘要:结构方程模型(SE M )是应用线性方程系统表示观测变量与潜在变量之间及潜在变量之间关系的一种统计方法。当前,SE M 及相应的L I SRE L 软件已成为心理学等社会学科中广泛应用的一种分析思想和技术。文章简要介绍了SE M 的特点、原理及L I SRE L 的操作方法。关键词:结构方程模型(SE M );L I S RE L;吻合指数操作程序 中图分类号:B841.2 文献标识码:A 文章编号:1008-0627(2005)02-0031-05 收稿日期:2004-06-27 作者简介:孙连荣,宁波大学师范学院助教,硕士。 科学研究的目的,是通过探讨变量之间的因果关系来揭示客观事物发展、变化的规律及特点,在具体操作层面上,一般是使用一定的统计技术处理并计算各种观测数据的结果来反映因果关系。在心理科学的研究中,实验的方法一直都是揭示心理过程及现象的主流范式。[1] 但由于实验法过分强调控制而使研究结果的真实性和外推力受到局限,尤其是当面对成因复杂的人的行为以及人的许多高级心理现象时,多数情况下都很难对它们进行直接测量或客观标定。事实上,人们一直都在寻求以非实验的方法获取因果关系,以 及通过考察人的外部表现(观测指标)来了解其实质特性(潜在变量或心理概念)的技术,而结构方程模型正是这种思想的产物。上个世纪70年代中期,瑞典统计学家、心理测量学家Karlg .Joreskog 提出了结构方程模型(Structural Equati on Modeling,简称SE M )。根据该方法的不同属性,统计学家们以不同的术语命名,如根据数据结构将其称为“协方差结构分析”;根据其功能,称之为“因果建模(Casual Modeling )”[2,3]等;并开发了相应的L I SRE L (L inear Structural Relati ons:线性结构关系)统计软件。目前,几经完善L I SRE L8.30版本已成为一种重要的统计分析技术,在心理学、社会学、管理学等社会学科的研究中得到了广泛的应用。本文将对SE M 的特点、原理及L I SRE L 的操作方法做一简要的介绍。 1 S E M 的特点 结构方程模型是在已有的理论基础上,应用与之相应的线性方程系统表示该理论的一种统计分析方法。相对于相关、回归分析、路径分析等研究变量间关系的统计方法来说,SE M 从两个方面完善了这些常用方法的不足。第一,针对探索性因素分析假设限制过多的缺点,完善变量结构的探讨。与探索性因素分析相比,结构方程模型既可以假定相关、不相关的潜在因素,从而更符合心理学实际;同时也可以确定某些观察变量只受特定潜在变量影响,而不是受所有潜在变量影响,使结构更清晰;还能在对每个潜在因素进行多方法测量(采用多方法-多特质模型,简称MMM T )时,可排除测量方法的误差。除此之外,最重要的是它不需要假定所有特定变量的误差无相关,而是指定那些两者之间存在相关的特定性变量误差。第二,在考虑测量误差的前提下建立变量间的因果关系。这一步以统计的思路区分了观测(外显)变量和潜在(内隐)变量,进而通过观测外在表现推测潜在概念。这样,研究便能在探讨变量间直接影响、间接影响和总效应以及表达中介变量作用的同时,用潜在变量代替路径分析中的单一外显变量,并考虑变量的测量误差,从而使研究结果更精确。概括来讲,SE M 具有以下特点[4]: (1)可同时考虑及处理多个因变量(endogenous/dependent variable ); (2)允许自变量和因变量(exogenous and endoge 2nous )项目含有测量误差; (3)允许潜伏变量由多个外显指标变量构成(这一 点与因素分析类似),并可同时估计指标变量的信度及效度; (4)可采用比传统方法更有弹性的测量模式(measure ment model )。在传统方法中,项目更多的依 附于单一因子,而在SE M 中,某一指标变量可从属于两个潜伏因子; (5)可构建潜伏变量之间的关系,并估计模式与数 AMOS结构方程模型修正经典案例 第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解 释四个步骤。下面以一个研究实例作为说明,使用 Amos7 软件1进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。 一、模型构建的思路 本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据2进行分析,并对文中提出的模型进行拟合、修正和解释。 二、潜变量和可测变量的设定 本文在继承 ASCI 模型核心概念的基础上,对模型作了一些改进,在模型中 增加超市形象。它包括顾客对超市总体形象及与其他超市相比的知名度。它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。 模型中共包含七个因素 (潜变量 ):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素 是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍, 2000)。 表 7-1设计的结构路径图和基本路径假设 设计的结构路径图基本路径假设 超市形象 顾客抱怨质量期望 感知价值 顾客满意 质量感知 顾客忠诚超市形象对质量期望有路径影响 质量期望对质量感知有路径影响 质量感知对感知价格有路径影响 质量期望对感知价格有路径影响 感知价格对顾客满意有路径影响 顾客满意对顾客忠诚有路径影响 超市形象对顾客满意有路径影响 超市形象对顾客忠诚有路径影响 2.1 、顾客满意模型中各因素的具体范畴 1本案例是在Amos7 中完成的。 2见 spss数据文件“处理后的数据 .sav”。 Amos模型设定操作 在使用AMOS进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图,并确定潜变量与可测变量的名称,以避免不必要的返工。 1.绘制潜变量 使用建模区域绘制模型中的潜变量,在潜变量上点击右键选择Object Properties,为潜变量命名。 2.为潜变量设置可测变量及相应的残差变量 使用绘制。在可测变量上点击右键选择Object Properties为可测变量命名。其中Variable Name 对应的是数据的变量名,在残差变量上右键选择Object Properties为残差变量命名。 3.配置数据文件,读入数据 , File——Data Files——File Name——OK。 4.模型拟合 View——Analysis Properties——Estimation——Maximum Likelihood。 5.标准化系数 Analysis Properties——Output——Standardized Estimates——因子载荷标准化系数。 6.参数估计结果 @ Analyze——Calculate Estimates。红色框架部分是模型运算基本结果信息,点击View the Output Path Diagram查看参数估计结果图。 7.模型评价 点击查看AMOS路径系数或载荷系数以及拟合指标评价。 路径系数/载荷系数的显著性 模型评价首先需要对路径系数或载荷系数进行统计显著性检验。 模型拟合指数 模型拟合指数是考察理论结构模型对数据拟合程度的统计指标。拟合指数的作用是考察理论模型与数据的适配程度,并不能作为判断模型是否成立的唯一依据。拟合优度高的模型只能作为参考,还 AMOS输出解读 惠顿研究 惠顿数据文件在各种结构方程模型中被当作经典案例,包括AMOS 和LISREL。本文以惠顿的社会疏离感追踪研究为例详细解释AMOS的输出结果。AMOS同样能处理与时间有关的自相关回归。 惠顿研究涉及三个潜变量,每个潜变量由两个观测变量确定。67疏离感由67无力感(在1967年无力感量表上的得分)和67无价值感(在1967年无价值感量表上的得分)确定。71疏离感的处理方式相同,使用1971年对应的两个量表的得分。第三个潜变量,SES(社会经济地位)是由教育(上学年数)和SEI (邓肯的社会经济指数)确定。 步骤 解读 解读步骤 导入数据 数据。。 1.导入 数据 AMOS在文件ex06-a.amw中提供惠顿数据文件。使用File/Open,选择这个文件。在图形模式中,文件显示如下。虽然这里是预定义模式,图形模式允许你给变量添加椭圆,方形,箭头等元素建立新模型 2.模型识别 模型识别。。 潜变量的方差和与它关联的回归系数取决于变量的测量单位,但刚开始谁知道呢。比如说要估计误差的回归系数同时也估计误差的方差,就好像说“我买了10块钱的黄瓜,然后你就推测有几根黄瓜,每根黄瓜多少钱”,这是不可能实现的,因为没有足够的信息。如何告诉你“我买了10块钱的黄瓜,有5根”,你便可以推出每根黄瓜2块钱。对潜变量,必须给它们指定一个数值,要么是与潜变量有关的回归系数,要么是它的方差。对误差项的处理也是一样。一旦做完这些处理,其它系数在模型中就可以被估计。在这里我们把与误差项关联的路径设为1,再从潜变量指向观测变量的路径中选一条把它设为1。这样就给每个潜变量设置了测量尺度,如果没有这个测量尺度,模型是不确定的。有了这些约束,模型就可以识别了。 注释:设置的数值可以是1,也可以是其它数,这些数对回归系数没有影响,但对误差有影响,在标准化的情况下,误差项的路径系数平方等于它的测量方差。 模型。。 3.解释 解释模型 模型 模型设置完毕后,在图形模式中点击工具栏中计算估计 计算估计按钮运 计算估计 浏览文本按钮。输出如下。蓝色字体用于注解,不行分析。点击浏览文本 浏览文本 是AMOS输出的一部分。 Title Title Example 6, Model A: Exploratory analysis Stability of alienation, mediated by ses. Correlations, standard deviations and means from Wheaton et al. (1977). 以上是标题,全是英文,自己翻译去吧,没有什么价值,一堆垃圾。 Notes for Group (Group number 1) Notes for Group (Group number 1) The model is recursive. Sample size = 932 ★数据分析的类型 1、以变量为中心的分析(R研究):探索性因子分析、验证性因子分析、回归分析、结构方程模型分析等 2、以人为中心的分析(S研究):聚类分析、判别分析等 ★因子载荷 因子载荷a(ij)的统计意义就是第i个变量与第j个公共因子的相关系数,即表示X(i)依赖F(j)的份量(比重)。统计学术语称作权,心理学家将它叫做载荷,即表示第i个变量在第j个公共因子上的负荷,它反映了第i个变量在第j个公共因子上的相对重要性。 在因子分析中,通常只选其中m个(m 1什么是结构方程模型? 结构方程模型是应用线性方程表示观测变量与潜变量之间,以及潜在变量之间关系的一种多元统计方法,其实质是一种广义的一般线性模型。 ?結構方程模式(Structural Equation Models,簡稱SEM),早期稱為線性結構方程模式(Linear Structural Relationships,簡稱LISREL)或稱為共變數結構分析(Covariance Structure Analysis)。 ?主要目的在於考驗潛在變項(Latent variables)與外顯變項(Manifest variable, 又稱觀察變項)之關係,此種關係猶如古典測驗理論中真分數(true score)與實得分數(observed score)之關係。它結合了因素分析(factor analysis)與路徑分析(path analysis),包涵測量與結構模式。 ? 1.1介绍潜在变量与观察变量的概念 ?(1)很多社会、心理研究中所涉及到的变量,都不能准确、直接地测量,这种变量称为潜变量,如工作自主权、工作满意度等。 ?(2)这时,只能退而求其次,用一些外显指标,去间接测量这些潜变量。如用工作方式选择、工作目标调整作为工作自主权(潜变量)的指标,以目前工作满意度、工作兴趣、工作乐趣、工作厌恶程度(外显指标)作为工作满意度的指标。 ?(3)传统的统计分析方法不能妥善处理这些潜变量,而结构方程模型则能同时处理潜变量及其指标。 (4)书上第7页 观测变量:能够观测到的变量(路径图中以长方形表示) 潜在变量:难以直接观测到的抽象概念,由测量变量推估出来的变量(路 径图中以椭圆形表示) 内生变量:模型总会受到任何一个其他变量影响的变量(因变量;路径图 会受到任何一个其他变量以单箭头指涉的变量 外生变量:模型中不受任何其他变量影响但影响其他变量的变量(自变量; 路径图中会指向任何一个其他变量,但不受任何变量以单箭头指涉的变量) 中介变量:当内生变量同时做因变量和自变量时,表示该变量不仅被其他 变量影响,还可能对其他变量产生影响。 内生潜在变量:潜变量作为内生变量 外生观测变量:外生潜在变量的观测变量 外生潜在变量:潜变量作为外生变量 外生观测变量:外生潜在变量的观测变量 中介潜变量:潜变量作为中介变量 中介观测变量:中介潜在变量的观测变量 1.2介绍测量模型与结构模型的概念(书上第9页) 有的说每个观察变量最好有10 个样本,有的说200 到500 之间比较好。在SEM中,与一般的研究方法相同,样本量越大越好,但是在SEM中,绝对指标卡方容易受到样本量的影响,样本越大,越容易达到显著水平。 在结构方程建模中,在观察变量到潜在变量的路径系数中,必须规定一条为 1 做标准求的其他路径系数和潜变量的值。潜变量之间就不用规定为 1 了。 内衍变量和观察变量都要有一个误差量e。 指标变量包括观察变量和误差变量 如何让绘图区变宽:可以在view 里面的 interface properties 中点击 landscape 在进入模型检验之前,首先检验是否出现违反估计: 负的误差方差存在 标准化系数超过或太接近1(通常以0.95 ) 验证性因素分析 信度:建构信度 等于标准化因素负荷量和的平方/ (标准化因素负荷量和的平方+(1-标准化因素负荷量的平 方 )的和) 收敛效度:平均方差抽取量:是指可以直显示被潜在构念所解释的变异量有多少是来自测量 误差的,平均方差变异量越大,来自于测量误差越少,即因子对于观察数据的变异解释越大, 一般是平均方差抽取量要大于0.5,是一种收敛效度的指标。 等于标准化因素负荷量的平方之和/ 题目数目 验证性因素分析基本模型适配度检验摘要表: 是否没有负的误差变异量e1 e2e3 因素负荷量(潜在变量与观察变量之间的标准化系数)是否介于0.5 到 0.95 之间Variances 是否没有很大的标准误 (路径系数的标准误 ) 整体模型适配度检验摘要表: 绝对适配度指数 卡方值, p 大于 0.05,说明数据本身的协方差矩阵和模型的协方差矩阵是匹配的。 RMR 值小于 0.05, RMSEA小于 0.08(小于 0.05 优良,若是小于0.08 良好) GFI 大于 0.90,适配优度 AGFI 大于 0.90(调整后的适配度) 增值适配度指数 NFI 大于 0.90 RFI 大于 0.90 IFI 大于 0.90 TLI(也称为 NNFI) 大于 0.90 CFI大于 0.90 简约适配度指数: PGFI 大于 0.50 PNFI 大于 0.50 PCFI大于 0.50 CN 大于 200 卡方自由度比小于 2.0,或者小于 3.0 AIC 理论模型值小于独立模型值且二者同时小于饱和模型值 CAIC同 AIC 验证性因素分析的内在质量参数表AMOS结构方程模型分析
★结构方程模型要点
基于结构方程模型的校园安全
结构方程模型基础知识
结构方程模型_SEM_的原理及操作
AMOS结构方程模型修正经典案例
AMOS 结构方程模型分析
AMOS结构方程模型解读
★作业(全模型3):结构方程模型和路径分析的区别
1什么是结构方程模型
结构方程模型+验证性因素分析过程指标
相关主题
文本预览