第九章查找-欢迎光临青岛科技大学信息科学技术学院
- 格式:docx
- 大小:64.87 KB
- 文档页数:7


青岛科技大学信息科学技术学院C语言程序设计实验指导书目录实验1 C语言入门及选择结构 0实验1.1 Visual C++6。
0开发环境 0实验1.2 C程序快速入门 (7)实验1.3算术运算与赋值运算 (11)实验1。
4逻辑运算及if语句 (17)实验1.5 switch选择结构 (23)实验2循环结构及数组(共8学时) (27)实验2.1 循环结构(2学时) (27)循环结构程序设计补充 (32)实验2.2数组一:一维数组 (36)实验2。
3数组二:二维数组 (43)实验2.4数组三:字符数组 (45)实验3:函数与自定义数据类型 (49)实验3。
1函数一:函数的定义、调用和声明 (49)实验3。
2函数二:函数的参数传递2 (55)实验3。
3函数三:函数的嵌套和递归2 (57)实验3.4 自定义数据类型(2学时) (59)实验4:指针(共6学时) (61)实验4。
1指针一:指针的定义及运算 (61)实验4。
2指针二:指向数组的指针 (67)实验4.3指针三:用指针操作字符串2 (71)实验1 C 语言入门及选择结构实验1.1 Visual C++6.0开发环境一、实验目的1。
熟悉C 语言的系统环境,掌握在集成环境中编辑、编译、连接和运行C 语言程序的方法。
2. 掌握C 语言源程序的结构特点与书写规范. 二、实验学时数2学时三、实验步骤及任务(一) VC++6。
0集成环境(1)运行VC++6。
0a.双击桌面上的VC++6。
0快捷方式,运行VC++6。
0。
b 。
双击"C :\Microsoft Visual Studio\Common\MSDev98\Bin\MSDEV 。
EXE",运行VC++6.0. (2)认识VC++6。
0标题栏的左侧显示当前的文件名,右侧有最小化,最大化和关闭三个按钮。
菜单栏包含了开发环境中几乎所有的命令,其中一些常用的命令还被排列在工具栏中。
工具栏上的按钮提出和一些菜单命令相对应,提供了经常使用的命令的一种快捷方式。

LM-UNet:横向MLP用于增强U-Net的医学图像分割邱海韬;史操【期刊名称】《计算机系统应用》【年(卷),期】2024(33)5【摘要】卷积神经网络(CNN)作为医学图像分割领域中U-Net基线网络的重要组成部分,其主要作用是处理局部特征信息之间的关系.而Transformer是一种能够有效强化特征信息之间的远距离依赖关系的视觉模型.目前的研究表明,结合Transformer和CNN可以在一定程度上提高医学图像分割的准确性.但是,由于医学图像的标注数据较少,而且训练Transformer模型需要大量数据,这使得Transformer模型面临耗时长和参数量大的挑战.基于这些考虑,本文在UNeXt模型的基础上,结合多尺度混合MLP和CNN,提出了一种新型的基于混合MLP的医学图像分割模型——LM-UNet.这种模型能够有效地增强局部与全局信息之间的联系,并加强特征信息间的融合.在多个数据集上的实验表明,LM-UNet模型在皮肤数据集上的分割性能明显提升,平均Dice系数达到92.58%,平均IoU系数达到86.52%,分别比UNeXt模型提高了3%和3.5%.在软骨和乳腺数据集上的分割效果也有显著提升,平均Dice系数分别比UNeXt提高了2.5%和1.0%.因此,LM-UNet 模型不仅提高了医学图像分割的准确性,还增强了其泛化能力.【总页数】8页(P110-117)【作者】邱海韬;史操【作者单位】青岛科技大学信息科学技术学院【正文语种】中文【中图分类】TP3【相关文献】1.特征重加权U-Net超声图像分割的骨结构重建与增强现实显示2.用于肺部肿瘤图像分割的跨模态多编码混合注意力U-Net3.融合边缘增强注意力机制和U-Net 网络的医学图像分割4.基于U-Net网络的医学图像分割研究综述5.改进U-Net 的多级边缘增强医学图像分割网络因版权原因,仅展示原文概要,查看原文内容请购买。


强化内涵突出特色系统建设全面提高本科教学水平与人才培养质量——青岛科技大学2012年本科教学质量报告中国青岛二〇一二年十二月目 录第一部分第一部分 学校概况………………………………………………… (1) 第二部分第二部分 本科人才培养基本情况…………………………………(4) 2.1人才培养理念及人才培养理念及目标目标......................................................(4) 2.2本科专业设置...............................................................(4) 2.3 2012年本科生源质量 (6)第三部分 师资与教学条件................................................(7) 3.1 师资数量师资数量与与结构.........................................................(7) 3.2 教学条件..................................................................(8) 第四部分 本科教学质量内涵建设与成效 (10)4.1 专业建设成效显著专业建设成效显著,,人才培养模式不断创新.....................(10) 4.2 大力推进大力推进师德教风建设师德教风建设 ...............................................(11) 4.3 构建了本科教学质量自我评估系统 ................................(12) 4.4 不断不断健全健全健全完善完善完善教学质量监教学质量监教学质量监控与保障体系控与保障体系............................(14) 4.5 重心下移重心下移,,丰富丰富完善完善完善二级学院本科教学考核二级学院本科教学考核.....................(15) 4.6 优质课程资源群收效显著优质课程资源群收效显著,教材建设教材建设教材建设取得突破取得突破..................(16) 4.7 体育课程建设成效突出体育课程建设成效突出,,高水平运动队成绩优异高水平运动队成绩优异 ............(17) 4.8 教学研究扎实开展教学研究扎实开展,,本科教学工程成绩显著 (17)第五部分 本科教学效果 (19)5.1 课堂课堂、、实验实验、、实习教学效果优良 (19)5.2 各类学科竞赛屡创佳绩................................................(19) 5.3 毕业及就业情况毕业及就业情况好好 (20)第六部分 办学特色 (22)6.1 学科特色 .............................................................(22) 6.2 人才培养人才培养特色特色 ........................................................(23) 6.3 政产学研政产学研合作特色合作特色.................................................. (23) 6.4 国际化国际化教育特色教育特色 (25)第七部分 今后工作重点……………………………………… (27) 7.1 牢固树立以提高质量为核心的教育发展观牢固树立以提高质量为核心的教育发展观,,进一步强化教学工作进一步强化教学工作中心地位............................................................ (27) 7.2 进一步加强高水平师资队伍建设....................................(27) 7.3 坚持坚持走内涵发展走内涵发展走内涵发展、、特色发展之路特色发展之路,,创建省级特色名校 (27)第一部分学校概况青岛科技大学位于美丽的海滨城市青岛,是山东省重点建设的大学,是一所以工为主,理、工、文、经、管、医、法、艺等学科协调发展,以材料学、化学工程、应用化学、机械工程、自动化、信息与计算机为特色学科的多科性大学。

基于多层次的海洋生物分类
赵东;程远志
【期刊名称】《计算机系统应用》
【年(卷),期】2024(33)4
【摘要】本文提出了一种多层次海洋生物分类方法.海洋生物种类繁多,且同门类生物具有较强的类间相似性,而不同门类生物具有较大的差异.我们利用物种间的相似性,帮助网络学习生物先验知识,设计出了一种多层次分类方法.设计了C-MBConv 模块,并结合多层次分类方法改进了EfficientNetV2网络架构,改进后的网络架构称为CMEfficientNetV2.我们的实验表明CM-EfficientNetV2比原网络EfficientNetV2有着更高的准确率,在南麂列岛潮间带海洋生物数据集上准确率提高了1.5%,在CIFAR-100上准确率提高了2%.
【总页数】9页(P226-234)
【作者】赵东;程远志
【作者单位】青岛科技大学信息科学技术学院;哈尔滨工业大学计算机科学与技术学院
【正文语种】中文
【中图分类】TP3
【相关文献】
1.基于多层次分类策略的非特定人人脸表情分类识别
2.基于卷积神经网络的海洋生物图像分类方法研究
3.基于多层次特征的高分影像海岸带地物分类
因版权原因,仅展示原文概要,查看原文内容请购买。

青岛科技大学研究生院官网|青岛科技大学研究生院:山东青岛科
技大学2021考研调剂信息
专业代码
专业名称
085216
化学工程(专业学位)
085235
制药工程(专业学位)
085238
生物工程(专业学位)
085204
材料工程(专业学位)
085201
机械工程(专业学位)
085204
材料工程(专业学位)
085206
动力工程(专业学位)
085210
控制工程(专业学位)
085216
化学工程(专业学位)
085238
生物工程(专业学位)
085204
材料工程(专业学位)
085239
项目管理(专业学位)
125100
工商管理硕士(专业学位)
085224
安全工程(专业学位)
085211
计算机技术(专业学位)
085212
软件工程(专业学位)
感谢您的阅读,祝您生活愉快。

JM模型中UMHexagonS改进算法
刘云;孟岩;孙芳
【期刊名称】《系统仿真学报》
【年(卷),期】2009(0)S1
【摘要】H.264是由ISO/IEC和ITU-T共同发布的较新的视频编解码标准,而JM
模型是JVT官方发布的H.264标准测试模型。
在H.264编码标准中,运动估计是最重要而最耗时的过程,对于多预测模式、多参考帧,更细化的运动矢量来说更是如此。
在JM模型中,可选的运动估计方法有三种,通过对JM10.2源码中的UMHexagonS算法进行分析,改进宏块中绝对误差和计算步骤,在保证视频序列信
噪比的前提下减少运动估计的耗时。
实验结果表明该方法对视频序列处理耗时平均减少达5%~15%,而信噪比衰减不超过0.3%。
【总页数】3页(P149-150)
【作者】刘云;孟岩;孙芳
【作者单位】青岛科技大学信息科学技术学院
【正文语种】中文
【中图分类】TN919.81
【相关文献】
1.H.264 JM模型中运动估计算法及改进方案
2.JM模型中UMHexagonS算法及
改进方案3.H.264JM模型中丢包算法的研究及改进4.H.264JM模型中UMHexagonS算法优化5.基于JM模型的UMHexagonS算法的改进
因版权原因,仅展示原文概要,查看原文内容请购买。

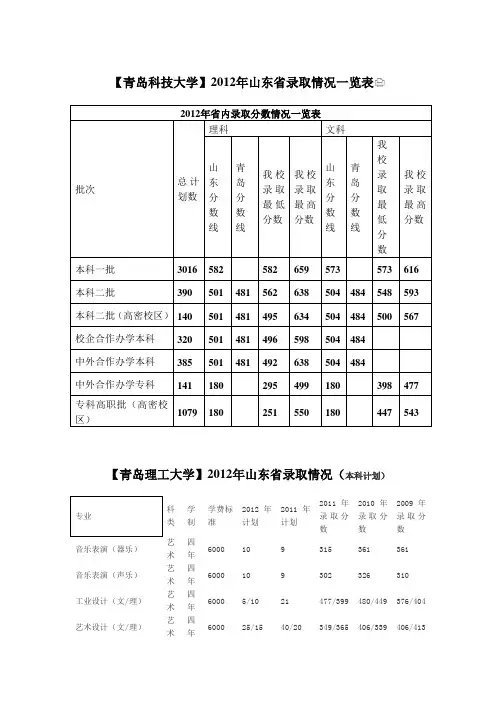
【青岛科技大学】2012年山东省录取情况一览表2012年省内录取分数情况一览表批次总计划数理科文科山东分数线青岛分数线我校录取最低分数我校录取最高分数山东分数线青岛分数线我校录取最低分数我校录取最高分数本科一批3016582582659573573616本科二批390501481562638504484548593本科二批(高密校区)140501481495634504484500567校企合作办学本科320501481496598504484中外合作办学本科385501481492638504484中外合作办学专科141180295499180398477专科高职批(高密校区)1079180251550180447543【青岛理工大学】2012年山东省录取情况(本科计划)专业科类学制学费标准2012年计划2011年计划2011年录取分数2010年录取分数2009年录取分数音乐表演(器乐)艺术四年6000109315361361音乐表演(声乐)艺术四年6000109302326310工业设计(文/理)艺术四年60005/1021477/399480/449376/404艺术设计(文/理)艺术四年600025/1540/20349/365406/339406/413绘画(文/理)艺术四年60005/515314/411399/373302/293服装设计与工程(文/理)艺术四年600016/418296/373324/377308/369会计学文史四年3740*53*40574601595财务管理文史四年3400*24*10571598595国际经济与贸易文史四年3740*89*85570601587国际商务文史四年3400*24*25570590595市场营销文史四年3400*2834570593595朝鲜语文史四年48002021539596582汉语言文学文史四年34002422520——英语文史四年48005054512597583日语文史四年48004755500597584社会工作文史四年34005351495596582广告学文史四年34005349494596582建筑学理工五年3960*62*63596605600土木工程理工四年3960*191*214591602598景观建筑设计理工四年3600*14*4590594592城市规划理工五年3960*28*27589598594工程造价理工四年3960*48*47587601598会计学理工四年3740*34*55586605585机械设计制造及其自动化理工四年3960*153*162586599599财务管理理工四年3600*15*26585603585经济学理工四年3600*27*28582596593材料科学与工程理工四年3960*21*25581593592电力工程与管理理工四年3600*30【山东科技大学】2012年山东省本科录取情况统计表省码省市科类计划录取一志愿征集志愿投档最高投档最低录取分数平均最低控制线3 7 山东省本一文科446 446 301 145 618 573 573 595.1 573理科4304 4504 4504 631 582 582 588.2 582 艺术艺设文40 40 40 543 407407/256432.35300/180广告学40 41 41 547 466 475 492 300工设文20 20 20 539 486 494 507.8 300工设理20 20 20 563 470 487509.75300 音乐学文30 28 28 476 308308/116名357.75300 音乐学理10 11 11 497 316316/20名405.6 300 本二文科180 181 181 575 508 522 542.5 484理科620 726 726 618 517 520 553.6 481 中外本科文科140 140 51 89 559 496 496 520.6 484理科340 340 121 219 594 495 495 531.6 481 软件外包理科120 104 42 62 593 496 496 541.6 481 金融外包文科80 80 80 577 496 500 521.6 484理科40 56 56 607 495 495 521 481 煤炭定向理科550 459 459 596 497 520 548.3 481 中外专科文科180 180 180 500 217 224 388.8 180理科120 120 120 500 237 241 403.8 180 本二(泰山科文科196 196 11 185 555 486 486 501 484理科344 344 62 282 586 486 486 504 481技学院)专科(泰山科技学院)文科412 319 230 89 494 189 189 358 180 理科838 760 606 154 517 183 183 384 180注:东营、烟台、威海、日照、莱芜、聊城执行省属线;淄博、枣庄、济宁、潍坊、泰安、临沂、德州、滨州、菏泽执行市属线。

青岛科技大学教务处文件教字〔2006〕17号关于公布2006届本科毕业生校级优秀学士学位论文的通知各院、部,有关单位:2006届本科生毕业答辩工作圆满完成,在各院(部)认真评选、推荐的基础上,经审议,确定以下111篇论文为2006届本科毕业生校级优秀学士学位论文,现予以公布:所在院系 学生姓名所在班级 论文题目指导教师宫超坤 高材023 纳米导电聚苯胺膜的制备以及其电致变色性能的应用 吴其晔 李阳 高材021 聚乳酸的合成与结构贺继东 燕晓飞高材026 聚烯烃弹性体POE 交联补强性能的研究 邱桂学 王璐 高材025 含氯聚合物的原子转移自由基接枝改性冯莺 刘建世 高材024 不同发泡剂对氯化聚乙烯(CPE)硫化胶发泡特性的影响 杜爱华 王洪振 高材024 EVM/TPU 共混物的制备及相溶性研究 史新妍 高分子学院王鹏 包装021 高全同聚丁烯-1的性能研究 赵永仙 司崇殿 化艺04C 射流流化床射深度的研究 郭庆杰 徐占杰 化工024 烷基磷酸酯在废纸脱墨中的应用 叶庆国 李磊 制药023 来曲唑片剂药学研究刘均洪 陈瑶药剂021 节杆菌(Anthrobacter Pascens DMDC12)SOD 酶的分离纯化及酶学性质研究张永勤 赵帅 制药024 新药α-萘乙酸原料药质量研究及稳定性试验 刘均洪 李志文 化工04C DMC/AM 共聚反应规律的研究刘福胜 李娟 化工023 负载型非晶态合金催化剂的制备表征与应用 吕志国 孙玮 药剂021 枸橼酸钾亲水凝胶骨架缓释丸处方设计与工艺研究 王洪光 化工学院戴吉顺制药04A溶菌酶的固定化研究张永勤刘小飞 制药021 地衣芽孢杆菌发酵条件的优化 于建生 刘永钊 生物022 耐碱耐热木聚糖酶生产菌的筛选 石琰璟 卢世昌 化工021 纳滤膜荷电特性研究 李红海孟祥磊 药剂021 阿昔洛韦微丸的制备和包衣 王洪光 叶伟亮 生物021 集胞藻PCC6803表达载体的构建 张久明 焦杰颖 药剂022 广藿香油的超声提取工艺研究 赵文英 黄淑燕 生物023 质粒转化大肠杆菌菌株的转化效率比较李凤梅 赵晓非 材料化学021 咪唑啉型表面活性剂的界面性能及其在纳米材料制备中的应用 周晓东 王沛 应用化学024 三氟化硼乙醚体系中聚(9-芴酮)的电化学制备与表征 聂广明 翟自芹 材料化学022 溶剂热法制备纳米材料的研究 傅 洵 曹国锐 材料化学021 新型吡咯类化合物的合成李 明 滕菲 材料化学022 瓶梗青霉属次级代谢产物化学成分的研究 钟惠民 化学院桑运东应用化学022 含氟聚合物微凝胶和乳液的合成及涂膜性能 古国华 王明帅 材物022 微纳米氧化锌的合成与形貌崔作林 陶颖镭 材物022 乙烯-醋酸乙烯酯共聚物/纳米TiO 2复合体系的流变行为研究 王兆波 于建华 无机022 纳米二氧化钛复合薄膜的制备及光催化性能的研究王志义 材料学院许新光 无机022 IIB-VIA 半导体化合物/聚乙烯吡咯烷酮纳米复合材料的制备研究 敬承斌 姜雪皎 环境023 黏土对PAC、Al 2(SO 4)3、AlCl 3混凝沉降给水处理后残留Al(Ⅲ)形态影响赵春禄 王新柱安全022 室内火灾烟气的产生和蔓延规律初步分析 李葳 李娜 安全022 地下隧道起火原因分析李葳 刘智勇 环境022 水热合成纳米二氧化钛光催化剂初探赵春禄 刘俊 环境学024 电聚合2.6-吡啶二甲酸膜的电化学DNA 传感器的研制及纳米金在其中的应用李桂村 环境学院刘伟 安全021液化石油气储藏库火灾危险性分析及安全对策李葳 郑传义 计算机024 在线即时客服系统服务端设计与实现杜军威 李伟 计算机04A 计算机控制技术教学网站——多媒体仿真模块设计 胡乃平 轩永盛计算机04E 门禁控制系统杨爱光 曲伟 计算机04F 基于ARM 的嵌入式Web Server 的设计——HTTP 协议的实现 马兴录 赵健国 计算机04G 利用USB 接口实现数据通讯 胡刚 贺常迪 计算机024 招生数据处理系统万玉 秦鹏云 计算机022 基本模型机实验的多媒体系统设计 朱光前 杜国伟 计算机04C 永成食品管理系统解本巨 信息学院康磊计算机024 虚拟现实漫游系统——科大校园漫游(南)丁玉忠宋仕龙 计算机021 一种组合加密算法的研究与实现 唐松生 曲明 计算机04A 基于WEB 架构的防伪系统设计与实现 宋波 谷明 计算机04D 货代企业信息管理系统 曹丛华 胡树 信息023 局域网监控系统的设计与实现 李丽萍 崔鸿璐 信息04A 汽车牌照的定位算法研究 刘云 丁锐 信息021 信息科学技术学院网站建设 刘云 赵艳丽 信息04A 图像增强算法的研究 刘云 杨波 信息022 公交车查询系统 秦玉华 吴昊 信息024 电子邮件的保密和认证 于工 王 霞 国贸02.2 商业银行操作风险的度量与管理张同功 邹宗玲 工程02.1 公交车中栏杆和拉环的人因工程分析与设计刘广珠 尹筱洁 市营02.1 浅谈港中旅国际(山东)旅行社有限公司国内旅游市场的服务营销刘志远 郭华蕊 工管02.1 多媒体教学效果影响因素的调查分析与综合评价 董华 康云龙 国贸02.4 对我国外贸依存度的探析 张立海 张雅东 市营02.1 关于大学生就业问题的调查与思考 徐倩 杜柳松 财务02.2 我国环境会计的现状及发展对策研究 解秀玉 丁媛工管02.2 喀纳斯自然保护区生态旅游开发与管理 李利 李坤育 财务02.1 我国上市公司盈余管理浅析——以钢铁行业为例 刘树艳 朱宏霞 工程02.1 基于3C 的全球供应链网络与B2B 电子商务的融合孙在东 陈 静 国贸02.1 经济全球化条件下跨国公司的国际避税行为及我国的反避税措施 陈岩 张现斌 市营04A 韩进物流进军中国青岛市场的精细化营销战略 袁晓莉 汪 晶财务02.2财务预警体系在财务管理中的应用和评析 张占贞 王昭文菁 市营04A 青岛科技大学品牌战略发展问题的思考 徐倩 张 波 国贸02.3 借鉴国外先进经验,完善中国环境税制陈岩 张庆梅 工程02.1 眼睛正常视线与电脑电子屏的夹角对电脑工作人员视觉疲劳与影响刘广珠 经管学院苏里宁 财务02.2 Excel 在财务管理中的若干应用王玉英 贺兵权 艺术022 《环境与建筑空间设计——杭州余杭双溪茶沙龙设计》 张声远 曹铮 艺术04A 《光教堂——圣之洗礼教堂设计》王滨 艺术学院孙怡村 艺术04B 《聆听自然的呐喊——解读本次公益招帖创作工程》 滕学祥 冯伟 广告04C 浅议对联广告张福芝 传播学院王中伟 广告023 广告是人的意识的延伸—麦克卢汉广告观之解读 杨明 冷涛田 装控021 筒式搅拌器搅拌性能研究 杨洪顺 廖 静 装控021 球形洗衣机创新设计 陈建国 段继来 装控021 固定管板式换热器的工程设计骆晓玲 机电学院邓莲花金属022ZnO/Ag 纳米复合抗菌剂催化性能的研究李镇江王林杰 金属022 盘销式摩擦磨损实验机机电系统的设计 刘春廷 宫明 金属021 盐浴氮碳共渗工艺的研究赵程 张洪霞 机自04B 半钢子午线轮胎成型机帘布导开装置的设计唐跃 刘卓雷 机自04C 高速铁路智能化单车箱悬挂系统的三维造型及主要部件的设计计算常德功 吴娟 机自04B 吊壁式高压输电线检测机器人付平 周末 机自022 内胎接头机压合机构设计及三维动态仿真 周桂莲 杜康 机自024抽油烟机用同步齿形带传动德设计樊智敏 纪宗江 自动化021 锥形量热仪系统设计李进 聂善坤 自动化04A 基于多角度立体视觉的角点特征重建 于镭 曾帆 自动化022 风力发电机组的微机监控与保护系统的设计 孟祥忠 宋蓓 测控022功放测试系统的软件设计童刚 张典自动化04E 水箱式拉丝机控制系统的研制(软件部分)于飞 徐伟科 自动化022 基于单神经元自适应PID 调节器的直流双闭环调速系统设计 赵彤 苏丽亚 自动化04B 基于ETR100嵌入式主板的飞梭绣花控制器 陈为 辛月顺 测控021帆船姿态记录仪的设计周以琳 吴本展 自动化04A 轮胎平衡试验机打标装置控制系统设计 张彦军 王万丽 自动化021 尿素合成塔的温度串级控制系统的设计 戚淑芬 盖萌萌 测控023汽车四轮定位检测装置设计与算法研究单宝明 宁通 自动化026 轮胎硫化生产监控管理系统的研究与应用 刘川来 自动化学院牟聪自动化026 基于频率抽样的带通和带阻滤波器设计 刘军 黄罡 信计021 期权市场中期权模拟定价的探讨 梁希泉 数理学院王付华 信计022 时间测度上动力方程的振动性李博 陈玉平 英语023 A Comparison Between Wordsworth's and Taoist View of Nature 罗苏娜 李兆群英语021 Linguistic Characteristics of English Newspapers in China: A Case Study of China Daily任素贞 王娟 英语023 A Cognitive Perspective of Synaesthesia张煜 范婷婷 英语023 On the Translation of Publicity-oriented Literature of Enterprises------Principle and Strategies康宁 赵铭 英语04A The Functions of Script Formation in Language Evolution 杨晓梅 外国语学院徐飞英语04ACognition and Image Preservation in English-Chinese Translation in a Broad Sense王灏教 务 处二○○六年九月五日。
面向医学影像报告生成的门归一化编解码网络
谭立玮;张淑军;韩琪;郭淇;王鸿雁
【期刊名称】《智能系统学报》
【年(卷),期】2024(19)2
【摘要】医学影像报告的自动生成可以减轻医生的工作强度,减少误诊或漏诊的情况发生。
由于医学影像的独特性,通常病灶比较小,与正常区域灰度差异难以分辨,导致文本生成时关键词的缺失,报告不够准确。
对此提出一种面向医学影像报告生成的门归一化编解码网络,通过门控通道变换单元优化视觉特征提取,加强特征间的差异,自动筛选关键特征;提出门归一化算法,沿通道维度整合上下文信息,在浅层网络激活、深层网络抑制通道间神经元活性,过滤无效特征,使文本和视觉语义充分交互,提高报告生成质量。
在2种广泛使用的基准数据集IU X-Ray和MIMIC-CXR上的试验结果表明,模型能够取得先进的性能,生成的影像报告也具有更好的视觉语义一致性。
【总页数】9页(P411-419)
【作者】谭立玮;张淑军;韩琪;郭淇;王鸿雁
【作者单位】青岛科技大学信息科学技术学院;青岛科技大学数据科学学院;青岛市干部保健服务中心
【正文语种】中文
【中图分类】TP391.4;R445
【相关文献】
1.基于谱归一化生成对抗网络的目标SAR图像仿真方法
2.基于谱归一化条件生成对抗网络的图像修复算法
3.一种基于谱归一化的两阶段堆叠结构生成对抗网络的文本生成图像模型
4.基于残差编解码-生成对抗网络的正弦图修复的稀疏角度锥束CT图像重建
5.基于域无关循环生成对抗网络的跨模态医学影像生成
因版权原因,仅展示原文概要,查看原文内容请购买。
现代电子技术Modern Electronics TechniqueJan. 2024Vol. 47 No. 22024年1月15日第47卷第2期0 引 言目前,烟草收购的大部分评价标准都是针对烟草的成熟度、油分、厚薄、色泽等综合外观因素,进而对烟叶进行人工评级。
但评级过程中大多通过个人的感觉来评价,容易产生一定的评级偏差,导致烟草收购工程量大、工作效率低下,所以亟需一种更加精确、快捷的检验评价方法对烟草的品质进行有效的把控。
近红外光谱(NIRS )技术是一种绿色环保、无损分析技术[1],广泛应用于医学、食品、环境、烟草等领域的质检分析[2]。
依托于近红外光谱分析技术,可以在光谱中寻找到与烟叶等级数据的相关关系,以此进行烟叶的分DOI :10.16652/j.issn.1004‐373x.2024.02.030引用格式:孙祥洪,罗智勇.基于一维残差卷积的烟叶分级方法研究[J].现代电子技术,2024,47(2):165‐170.基于一维残差卷积的烟叶分级方法研究孙祥洪1, 罗智勇2(1.江西中烟工业有限责任公司 技术中心, 江西 南昌 330096;2.青岛科技大学 信息科学技术学院, 山东 青岛 266061)摘 要: 在烟叶分级过程中,由于人为主观性、分级标准不一致等因素导致分级结果不一致。
针对以上问题,提出一种一维残差卷积的烟叶等级分类模型。
首先,改进VGG16网络,将方形矩阵卷积核和池化窗口改为适应于一维光谱数据的向量卷积核和池化窗口。
然后,利用BasicBlock 残差模块替换多层卷积叠加的结构,对光谱数据进行更深层的提取,防止梯度消失问题。
最后,在卷积层后面接入BN 层模块,通过归一化的方式,防止卷积计算后由于数据分布分散而导致的网络效率降低问题。
选取B2V 、B1F 、C4F 、C1L 和X2L 等5种不同等级的烟叶样本的近红外光谱数据进行实验。
结果表明,所提方法对5种等级烟叶训练集和测试集的平均分类准确率分别为98.0%和97.3%,明显高于其他方法。
优秀毕业生简介范文优秀毕业生简介范文戴**,男,1990年6月出生,技师层次计算机软件工程专业,2012年12月毕业,在校期间担任信息科学系学生会主席、班长。
在校期间积极参加学院、系部组织的各项活动,丰富了大学生活、开阔了眼界,锻炼了自己的工作协调、组织管理等能力,学习成绩优异,在2009-2010学年和2010-2011学年综合测评名列班级第一,并两次获得“学院一等奖学金”,在“学院纪念“12·9 运动演讲比赛”上获得“三等奖”,并利用业余时间广泛涉猎知识,参加了全国计算机三级等考试和自学考试,综合素质得到提升。
张**,男,1990年4月出生,两年制高级技工多媒体与平面设计专业,2012年07月毕业,在校期间担任信息科学系学生会组织部部长、班长。
在校期间积极参加团委、院学生会举办的业余团培训班,使自身的政治敏锐性与政治觉悟有所提高。
工作上,认真负责,踏实肯干,不怕吃苦,有协作精神,认真听取大家的意见,积极配合辅导员,创造一个老师与同学的交流平台,切实起到了沟通老师和同学们的桥梁纽带作用,经过不懈的努力使班级获得学院2010-2011学年“先进班集体”称号,学习刻苦认真成绩优异,年终综合测评名列前茅,荣获2010-2011学年院“一等奖学金”、“三好学生” 、“优秀学生干部”等称号。
韩**,女,1990年4月出生,技师层次网络与通信技术专业,2012年12月毕业,在校期间担任信息科学系学生会组织部部长。
在校期间积极参加学院组织的团党课学习,树立了正确的人生观和价值观,同时积极参加院、系组织的各项活动,组织参与过学院团干部培训、章丘红十字会为“玉树地震”募捐等活动,使自己的工作沟通和协调能力得到了提高;在学习中系统全面地学习了本专业理论基础知识的同时,报考了青岛科技大学专科电子商务专业,并取得了良好成绩,并顺利通过了全国高新人才办公应用考核,通过以上的努力得到了师生的认可,并在2009-2010学年荣获院“三等综合奖学金”;2010年6月在信息科学系校园歌手大奖赛中获得“优秀奖”; 2010-2011学年被评为“优秀学生干部”,并连续两年被评为“优秀团员”荣誉称号。
第九章查找 本章中介绍下列主要内容: 静态查找表及查找算法:顺序查找、折半查找 动态查找表及查找算法:二叉排序树 哈希表及查找算法
第一节基本概念 查找表 用于查找的数据元素集合称为查找表。查找表由同一类型的数据元素(或记录)构成。 静态查找表 若只对查找表进行如下两种操作: (1)在查找表中查看某个特定的数据元素是否在查找表中, (2)检索某个特定元素的各种属性, 则称这类查找表为静态查找表。静态查找表在查找过程中查找表本身 不发生变化。对静态查找表进行的查找操作称为静态查找。 动态查找表 若在查找过程中可以将查找表中不存在的数据元素插入,或者从查找表中删除某个数据元素, 则称这类查找表为动态查找表。动态查找表在查找过程中查找表可能会发生变化。对动态查找表进行的查 找操作称为动态查找。 关键字是数据元素中的某个数据项。唯一能标识数据元素(或记录)的关键字,即每个元素的关键字值互 不相同,我们称这种关键字为主关键字;若查找表中某些元素的关键字值相同, 称这种关键字为次关键字。 例如,银行帐户中的帐号是主关键字,而姓名是次关键字。 查找在数据元素集合中查找满足某种条件的数据元素的过程称为查找。最简单且最常用的查找条件是 ”关 键字值等于某个给定值”,在查找表搜索关键字等于给定值的数据元素 (或记录)。若表中存在这样的记录, 则称查找成功,此时的查找结果应给岀找到记录的全部信息或指示找到记录的存储位置;若表中不存在关 键字等于给定值的记录,则称查找不成功,此时查找的结果可以给岀一个空记录或空指针。若按主关键字 查找,查找结果是唯一的;若按次关键字查找,结果可能是多个记录,即结果可能不唯一。 查找表的存储结构查找表是一种非常灵活的数据结构,对于不同的存储结构, 其查找方法不同。为了提高 查找速度,有时会采用一些特殊的存储结构。本章将介绍以线性结构、树型结构及哈希表结构为存储结构 的各种查找算法。 查找算法的时间效率 查找过程的主要操作是关键字的比较, 所以通常以”平均比较次数”来衡量查找算法的 时间效率。
第二节静态查找 正如本章第一节所述:静态查找是指在静态查找表上进行的查找操作,在查找表中查找满足条件的数据元 素的存储位置或各种属性。本节将讨论以线性结构表示的静态查找表及相应的查找算法。 1. 顺序查找 1.1顺序查找的基本思想 顺序查找是一种最简单的查找方法。其基本思想是将查找表作为一个线性表,可以是顺序表,也可以是链 表,依次用查找条件中给定的值与查找表中数据元素的关键字值进行比较,若某个记录的关键字值与给定 值相等,则查找成功,返回该记录的存储位置,反之,若直到最后一个记录,其关键字值与给定值均不相 等,则查找失败,返回查找失败标志。 1.2 顺序表的顺序查找 下面是顺序表的类型定义: #define MAX_NUM 100 // 用于定义表的长度 typedef struct elemtype{ keytype key; anytype otherelem; }Se_List[MAX_NUM],Se_Elem; 假设在查找表中,数据元素个数为 n ( n下面我们给出顺序查找的完整算法。 int seq_search (Se_List a , keytype k) {// 在顺序表中查找关键字值等于 k 的记录, // 若查找成功,返回该记录的位置下标序号,否则返回 0 i=1; while (i<=n && a[i].key != k) i++; if (i<=n) retrun i; else return 0; } 改进算法: int seq_search2 (Se_List a , keytype k) { // 设置了监视哨的顺序表查找,查找关键字值等于指定值 k 的记录, // 若查找成功,返回记录存放位置的下标值,否则返回 0 i=n ; a[0].key=k ; while ( a[i].key != k) i--; return ( i ) ; } 1.3 链表的顺序查找 链表的顺序查找是指将查找表作为线性表并以链式存储结构存储,用顺序查找方法查找与指定关键字值相 等的记录。 链表的类型定义如下所示: typedef struct linklist { keytype key; // 结点的关键字类型 anytype otherelem; // 结点的其他成分 struct linklist *next; // 指向链表结点的指针 }Link_Linklist,*Link; 将查找表中的数据元素用这种结构的结点表示,并以指向头结点的指针标识。 对链表实现顺寻查找就是在有头结点的链式查找表中查找关键字值等于给定值的记录,若查找成功,返回 指向相应结点的指针,否则返回空指针。 Link_Linklist *link_search (Link h , keytype k) {//link 为带头结点链表的头指针,查找关键字值等于 k 的记录, // 查找成功,返回指向找到的结点的指针,查找失败返回空指针 p=h->next; while ((p!=NULL) && (p->key!=k)) p=p->next;
return p; } 顺序查找算法简单,对表的结构无任何要求;但是执行效率较低,尤其当 n较大时,不宜采用这种查找方 法。 2. 折半查找 2.1折半查找的基本思想 折半查找要求查找表用顺序存储结构存放且各数据元素按关键字有序(升序或隆序)排列,也就是说折半 查找只适用于对有序顺序表进行查找。 折半查找的基本思想是:首先以整个查找表作为查找范围,用查找条件中给定值 k与中间位置结点的关键 字比较,若相等,则查找成功,否则,根据比较结果缩小查找范围,如果 k的值小于关键字的值,根据查 找表的有序性可知查找的数据元素只有可能在表的前半部分,即在左半部分子表中,所以继续对左子表进 行折半查找;若k的值大于中间结点的关键字值,则可以判定查找的数据元素只有可能在表的后半部分, 即在右半部分子表中,所以应该继续对右子表进行折半查找。每进行一次折半查找,要么查找成功,结束 查找,要么将查找范围缩小一半,如此重复,直到查找成功或查找范围缩小为空即查找失败为止。 2.2折半查找过程示例
假设待查有序(升序)顺序表中数据元素的关键宁序列为也圾77忿47乱兄
2.3折半查找算法 假设查找表存放在数组 a的a[1]~a[n]中,且升序,查找关键字值为 k。 折半查找的主要步骤为: (1) 置初始查找范围:low=1,high=n;
(2) 求查找范围中间项: mid=(low+high)/2
(3) 将指定的关键字值 k与中间项a[mid].key 比较 若相等,查找成功,找到的数据元素为此时 mid指向的位置; 若小于,查找范围的低端数据元素指针 low不变,高端数据元素指针 high更新为mid-1;
若大于,查找范围的高端数据元素指针 high不变,低端数据元素指针 low更新为mid+1;
(4) 重复步骤(2)、( 3)直到查找成功或查找范围空(low>high ),即查找失败为止。 (5) 如果查找成功,返回找到元素的存放位置,即当前的中间项位置指针 mid;否则返回查找失败标志。 折半查找的完整算法如下: int bin_search (Se_List a, keytype k) { low=1; high=n; // 置初始查找范围的低、高端指针 while (low<=high) { mid=(low+high)/2; // 计算中间项位置 if (k==a[mid].key) break; // 找到,结束循环 else if (k< a[mid].key) high=mid-1; // 给定值 k 小 else low=mid+1; // 给定值 k 大 }
if (low<=high) return mid ; // 查找成功 else return 0 ; // 查找失败 } 第三节动态查找 1•二叉排序树 二叉排序树是一种常用的动态查找表,下面首先给岀它的非递归形式。 二叉排序树是一棵二叉树,它或者为空,或者具有如下性质: (1) 任一非终端结点若有左孩子,则该结点的关键字值大于其左孩子结点的关键字值。 (2) 任一非终端结点若有右孩子,则该结点的关键字值小于其右孩子结点的关键字值。 二叉排序树也可以用递归的形式定义,即二叉排序树是一棵树,它或者为空,或者具有如下性质: (1) 若它的左子树非空,则其左子树所有结点的关键字值均小于其根结点的关键字值。 (2) 若它的右子树非空,则其右子树所有结点的关键字值均大于其根结点的关键字值。 (3) 它的左右子树都是二叉排序树。 例如,由关键字值序列(62,15,68,46,65,12,57,79,35 )构成的一棵二叉排序树如图 7-4所示
如果对上述二叉排序树进行中根遍历可以得到一个关键字有序序列( 12, 15, 35,46, 57,62,65,68,79 ), 这是二叉排序树的一个重要特征,也正是由此将其称为 "二叉排序树"。 2•二叉排序树的查找 二叉排序树的结构定义中可看到:一棵非空二叉排序树中根结点的关键字值大于其左子树上所有结点的关 键字值,而小于其右子树上所有结点的关键字值,所以在二叉排序树中查找一个关键字值为 k的结点的基 本思想是:用给定值k与根结点关键字值比较, 如果k小于根结点的值,则要找的结点只可能在左子树中, 所以继续在左子树中查找,否则将继续在右子树中查找,依此方法,查找下去,至直查找成功或查找失败 为止。二叉排序树查找的过程描述如下: (1 )若二叉树为空树,则查找失败, (2) 将给定值k与根结点的关键字值比较,若相等,则查找成功, (3) 若根结点的关键字值小于给定值 k,则在左子树中继续搜索, (4) 否则,在右子树中继续查找。 假定二叉排序树的链式存储结构的类型定义如下: typedef struct linklist { keytype key; anytype otherelem; struct linklist *lchild ; struct linklist *rchild;
}Bin_Sort_Tree_Linklist,*Bin_Sort_Tree ; 二叉排序树查找过程的描述是一个递归过程,若用链式存储结构存储,其查找操作的递归算法如下所示: